
1. Ringkasan
Di dunia yang kaya akan data saat ini, mengekstrak insight bermakna dari konten tidak terstruktur, terutama video, adalah kebutuhan yang signifikan. Bayangkan Anda perlu menganalisis ratusan atau ribuan URL video, meringkas kontennya, mengekstrak teknologi utama, dan bahkan membuat pasangan Tanya Jawab untuk materi pendidikan. Melakukannya satu per satu tidak hanya memakan waktu, tetapi juga tidak efisien. Di sinilah arsitektur cloud modern berperan.
Dalam lab ini, kita akan membahas solusi serverless yang skalabel untuk memproses konten video menggunakan rangkaian layanan canggih Google Cloud: Cloud Run, BigQuery, dan AI Generatif Google (Gemini). Kami akan menjelaskan perjalanan kami dari memproses satu URL hingga mengatur eksekusi paralel di seluruh set data besar, semuanya tanpa overhead pengelolaan integrasi dan antrean pesan yang kompleks.
Tantangan
Kami ditugaskan untuk memproses katalog besar konten video, khususnya berfokus pada sesi lab interaktif. Tujuannya adalah menganalisis setiap video dan membuat ringkasan terstruktur, termasuk judul bab, konteks pengantar, petunjuk langkah demi langkah, teknologi yang digunakan, dan pasangan Tanya Jawab yang relevan. Output ini perlu disimpan secara efisien untuk digunakan nanti dalam membuat materi pendidikan.
Awalnya, kami memiliki layanan Cloud Run berbasis HTTP sederhana yang dapat memproses satu URL dalam satu waktu. Cara ini berfungsi dengan baik untuk pengujian dan analisis ad-hoc. Namun, saat menghadapi daftar ribuan URL yang bersumber dari BigQuery, keterbatasan model respons tunggal dan permintaan tunggal ini menjadi jelas. Pemrosesan berurutan akan memakan waktu berhari-hari, bahkan berminggu-minggu.
Peluangnya adalah mengubah proses berurutan yang manual atau lambat menjadi alur kerja otomatis yang diparalelkan. Dengan memanfaatkan cloud, kami bertujuan untuk:
- Memproses data secara paralel: Mengurangi waktu pemrosesan secara signifikan untuk set data besar.
- Memanfaatkan kemampuan AI yang ada: Manfaatkan kecanggihan Gemini untuk analisis konten yang canggih.
- Mempertahankan arsitektur serverless: Hindari pengelolaan server atau infrastruktur yang kompleks.
- Pusatkan data: Gunakan BigQuery sebagai sumber kebenaran tunggal untuk URL input dan tujuan yang andal untuk hasil yang diproses.
- Bangun pipeline yang tangguh: Buat sistem yang tahan terhadap kegagalan dan dapat dikelola serta dipantau dengan mudah.
Tujuan
Mengorkestrasi Pemrosesan AI Paralel dengan Tugas Cloud Run:
Solusi kami berpusat pada Tugas Cloud Run yang bertindak sebagai orkestrator. Secara cerdas, fungsi ini membaca batch URL dari BigQuery, mengirimkan URL ini ke Layanan Cloud Run yang sudah ada dan di-deploy (yang menangani pemrosesan AI untuk satu URL), lalu menggabungkan hasilnya untuk ditulis kembali ke BigQuery. Pendekatan ini memungkinkan kami untuk:
- Memisahkan orkestrasi dari pemrosesan: Tugas mengelola alur kerja, sementara Layanan terpisah berfokus pada tugas AI.
- Memanfaatkan paralelisme Tugas Cloud Run: Tugas dapat menskalakan beberapa instance container untuk memanggil layanan AI secara bersamaan.
- Mengurangi kompleksitas: Kita mencapai paralelisme dengan membuat tugas mengelola panggilan HTTP serentak secara langsung, sehingga menyederhanakan arsitektur.
Kasus Penggunaan
Insight yang Didukung AI dari Video Sesi Vipassana Kode
Kasus penggunaan khusus kami adalah menganalisis video sesi Google Cloud dari lab interaktif Code Vipassana. Tujuannya adalah membuat dokumentasi terstruktur (uraian bab buku) secara otomatis, termasuk:
- Judul Segmen: Judul ringkas untuk setiap segmen video
- Konteks Pengantar: Menjelaskan relevansi video dalam jalur pembelajaran yang lebih luas
- Yang Akan Dibangun: Tugas atau sasaran inti sesi
- Teknologi yang Digunakan: Daftar layanan cloud dan teknologi lain yang disebutkan
- Petunjuk Langkah demi Langkah: Cara tugas dilakukan, termasuk cuplikan kode
- URL Kode Sumber/Demo: Link yang diberikan dalam video
- Segmen Tanya Jawab: Membuat pertanyaan dan jawaban yang relevan untuk pemeriksaan pengetahuan.
Flow

Alur arsitektur
Apa itu Cloud Run? Apa itu Tugas Cloud Run?
Cloud Run
Platform serverless yang terkelola sepenuhnya yang memungkinkan Anda menjalankan container stateless. Layanan ini ideal untuk layanan web, API, dan microservice yang dapat diskalakan secara otomatis berdasarkan permintaan yang masuk. Anda menyediakan image container, dan Cloud Run akan menangani sisanya — mulai dari men-deploy dan menskalakan hingga mengelola infrastruktur. Layanan ini unggul dalam menangani beban kerja permintaan-respons sinkron.
Tugas Cloud Run
Penawaran yang melengkapi layanan Cloud Run. Tugas Cloud Run dirancang untuk tugas pemrosesan batch yang harus diselesaikan lalu dihentikan. VM ini sangat cocok untuk pemrosesan data, ETL, inferensi batch machine learning, dan tugas apa pun yang melibatkan pemrosesan set data, bukan melayani permintaan langsung. Fitur utamanya adalah kemampuannya untuk menskalakan jumlah instance container (tugas) yang berjalan secara bersamaan untuk memproses batch pekerjaan, dan dapat dipicu oleh berbagai sumber peristiwa atau secara manual.
Perbedaan Utama
Layanan Cloud Run ditujukan untuk aplikasi berbasis permintaan yang berjalan lama. Tugas Cloud Run ditujukan untuk pemrosesan batch berorientasi tugas yang terbatas dan berjalan hingga selesai.
Yang akan Anda build
Aplikasi Retail Search
Sebagai bagian dari proses ini, Anda akan:
- Membuat Set Data, tabel, dan memasukkan data BigQuery (Metadata Vipassana Code)
- Buat Fungsi Cloud Run Python untuk menerapkan fungsi AI Generatif (mengonversi video ke json bab buku)
- Membuat aplikasi Python untuk pipeline data ke AI - Membaca dari BigQuery dan memanggil Endpoint Fungsi Cloud Run untuk mendapatkan insight serta menulis kembali konteks ke BigQuery
- Membangun dan Memasukkan aplikasi ke dalam container
- Mengonfigurasi Tugas Cloud Run dengan container ini
- Menjalankan & memantau tugas
- Hasil laporan
Persyaratan
2. Sebelum memulai
Membuat project
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project .
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud. Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda dapat memeriksa bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
- Aktifkan API yang diperlukan: Ikuti link dan aktifkan API.
Atau, Anda dapat menggunakan perintah gcloud untuk melakukannya. Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya.
3. Penyiapan Database/Warehouse
BigQuery berfungsi sebagai tulang punggung pipeline data kami. Sifatnya yang serverless dan sangat skalabel menjadikannya sempurna untuk menyimpan data input dan menampung hasil yang diproses.
- Penyimpanan Data: BigQuery bertindak sebagai data warehouse kami. File ini menyimpan daftar URL video, statusnya (misalnya, PENDING, PROCESSING, COMPLETED), dan konteks akhir yang dihasilkan. Ini adalah satu-satunya sumber tepercaya untuk mengetahui video mana yang perlu diproses.
- Tujuan: Tempat insight yang dihasilkan AI disimpan, sehingga mudah dikueri untuk aplikasi hilir atau peninjauan manual. Set data kami terdiri dari detail sesi video, terutama dari konten "Code Vipassana Seasons", yang sering kali melibatkan demonstrasi teknis yang mendetail.
- Tabel Sumber: Tabel BigQuery (misalnya, post_session_labs) yang berisi rekaman seperti:
- id: ID unik untuk setiap sesi/baris.
- url: URL video (misalnya, link YouTube atau link drive yang dapat diakses).
- status: String yang menunjukkan status pemrosesan (misalnya, PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- konteks: Kolom string untuk menyimpan ringkasan yang dibuat AI.
- Penyerapan Data: Dalam skenario ini, data diserap ke BigQuery dengan skrip INSERT. Untuk pipeline kami, BigQuery adalah titik awalnya.
Buka konsol BigQuery, buka tab baru, lalu jalankan pernyataan SQL berikut:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Penyerapan data
Sekarang saatnya menambahkan tabel dengan data tentang toko. Buka tab di BigQuery Studio dan jalankan pernyataan SQL berikut untuk menyisipkan data contoh:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Pembuatan Fungsi Insight Video
Kita harus membuat dan men-deploy Cloud Run Function untuk menerapkan inti fungsionalitas, yaitu membuat bab buku terstruktur dari URL video. Untuk dapat mengaksesnya sebagai alat kotak endpoint independen, kami baru saja membuat dan men-deploy Cloud Run Function. Atau, Anda dapat memilih untuk menyertakannya sebagai fungsi terpisah dalam aplikasi Python sebenarnya untuk Tugas Cloud Run:
- Di konsol Google Cloud, buka halaman Cloud Run
- Klik Write a function.
- Di kolom Nama layanan, masukkan nama untuk mendeskripsikan fungsi Anda. Nama layanan hanya boleh diawali dengan huruf, dan berisi hingga 49 karakter atau kurang, termasuk huruf, angka, atau tanda hubung. Nama layanan tidak boleh diakhiri dengan tanda hubung, dan harus unik per region dan project. Nama layanan tidak dapat diubah nanti dan akan terlihat secara publik. ( generate-video-insights**)**
- Dalam daftar Region, gunakan nilai default, atau pilih region tempat Anda ingin men-deploy fungsi. (Pilih us-central1)
- Dalam daftar Runtime, gunakan nilai default, atau pilih versi runtime. (Pilih Python 3.11)
- Di bagian Autentikasi, pilih "Izinkan akses publik"
- Klik tombol "Buat"
- Fungsi dibuat dan dimuat dengan template main.py dan requirements.txt
- Ganti dengan file: main.py dan requirements.txt dari repo project ini
CATATAN PENTING: Di main.py, jangan lupa untuk mengganti <<YOUR_PROJECT_ID>> dengan project ID Anda.
- Deploy dan simpan endpoint sehingga Anda dapat menggunakannya di sumber untuk Tugas Cloud Run.
Endpoint Anda akan terlihat seperti ini (atau yang serupa): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
Apa yang ada di Cloud Run Function ini?
Gemini 2.5 Flash untuk Pemrosesan Video
Untuk tugas inti memahami dan meringkas konten video, kami memanfaatkan model Gemini 2.5 Flash Google. Model Gemini adalah model AI multimodal yang canggih dan mampu memahami serta memproses berbagai jenis input, termasuk teks dan, dengan integrasi tertentu, video.
Dalam penyiapan kami, kami tidak langsung memasukkan file video ke Gemini. Sebagai gantinya, kami mengirimkan perintah tekstual yang menyertakan URL video dan menginstruksikan Gemini tentang cara menganalisis konten (hipotetis) video di URL tersebut. Meskipun Gemini 2.5 Flash mampu menerima input multimodal, pipeline khusus ini menggunakan perintah berbasis teks yang menjelaskan sifat video (sesi lab praktik) dan meminta output JSON terstruktur. Fitur ini memanfaatkan kemampuan penalaran tingkat lanjut dan pemahaman bahasa alami Gemini untuk menyimpulkan dan menggabungkan informasi berdasarkan konteks perintah.
Perintah Gemini: Memandu AI
Perintah yang dibuat dengan baik sangat penting untuk model AI. Perintah kami dirancang untuk mengekstrak informasi yang sangat spesifik dan menyusunnya ke dalam format JSON, sehingga mudah diuraikan oleh aplikasi kami.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
Perintah ini sangat spesifik, yang memandu Gemini untuk bertindak sebagai pendidik. Permintaan string JSON memastikan output terstruktur yang dapat dibaca mesin.
Berikut adalah kode untuk menganalisis input video dan menampilkan konteksnya:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
Cuplikan di atas menunjukkan fungsi inti kasus penggunaan. Aplikasi ini menerima URL video dan menggunakan model Gemini melalui klien Vertex AI untuk menganalisis konten video dan mengekstrak insight yang relevan sesuai perintah. Konteks yang diekstrak kemudian ditampilkan untuk diproses lebih lanjut. Tindakan ini mewakili operasi sinkron tempat Tugas Cloud Run menunggu layanan selesai.
6. Pengembangan Aplikasi Pipeline (Python)
Logika pipeline pusat kita berada di kode sumber aplikasi yang akan dikontainerisasi menjadi Job Cloud Run, yang mengatur seluruh eksekusi paralel. Berikut adalah bagian-bagian pentingnya:
Peran orkestrator dalam mengelola alur kerja dan memastikan integritas data:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
Cuplikan di atas dimulai dengan mengambil batch URL video dengan status 'PENDING' dari tabel sumber BigQuery. Kemudian, status URL ini diperbarui menjadi 'PROCESSING' di BigQuery, sehingga mencegah pemrosesan duplikat.
Pemrosesan Paralel dengan ThreadPoolExecutor dan Memanggil Layanan Pemroses:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
Bagian kode ini memanfaatkan ThreadPoolExecutor untuk mencapai pemrosesan paralel URL video yang diambil. Untuk setiap URL, kode ini mengirimkan tugas untuk memanggil Layanan Cloud Run (Pemroses URL) secara asinkron. Hal ini memungkinkan Tugas Cloud Run memproses beberapa video secara bersamaan secara efisien, sehingga meningkatkan performa pipeline secara keseluruhan. Cuplikan ini juga menangani potensi waktu tunggu dan error dari layanan pemroses.
Membaca & Menulis dari & ke BigQuery
Interaksi inti dengan BigQuery melibatkan pengambilan URL yang tertunda, lalu memperbaruinya dengan hasil yang diproses.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Menulis kembali hasil ke BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
Cuplikan di atas berfokus pada interaksi data antara Job Cloud Run dan BigQuery. Langkah ini mengambil batch URL video 'PENDING' dan ID-nya dari tabel sumber. Setelah URL diproses, cuplikan ini menunjukkan cara menulis konteks dan status yang diekstrak (‘SELESAI' atau ‘GAGAL_DIPROSES') kembali ke tabel BigQuery target menggunakan kueri UPDATE. Cuplikan ini melengkapi loop pemrosesan data. Tautan ini juga menyertakan fungsi bantuan update_bq_row yang menunjukkan cara menentukan parameter pernyataan update.
Penyiapan Aplikasi
Aplikasi ini disusun sebagai satu skrip Python yang akan di-containerisasi. Aplikasi ini memanfaatkan library klien Google Cloud dan functions-framework untuk menentukan titik entri.
- Dependensi: google-cloud-bigquery, requests
- Konfigurasi: Semua setelan penting (project/set data/tabel BigQuery, URL layanan pemroses URL) dimuat dari variabel lingkungan, sehingga aplikasi dapat dipindahkan dan aman
- Logika Inti: Fungsi process_batch_from_bq mengatur seluruh alur kerja
- Integrasi Layanan Eksternal: Fungsi call_url_processor_service menangani komunikasi dengan Layanan Cloud Run terpisah
- Interaksi BigQuery: bq_client digunakan untuk mengambil URL dan memperbarui hasil, dengan penanganan parameter yang tepat
- Paralelisme: concurrent.futures.ThreadPoolExecutor mengelola panggilan serentak ke layanan eksternal
- Titik Entri: Kode Python bernama main.py berfungsi sebagai titik entri yang memulai pemrosesan batch.
Mari kita siapkan aplikasi sekarang:
- Anda dapat memulai dengan membuka Terminal Cloud Shell dan meng-clone repositori:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Buka Cloud Shell Editor, tempat Anda dapat melihat folder video-context-crj yang baru dibuat
- Hapus langkah-langkah berikut karena telah diselesaikan di bagian sebelumnya:
- Hapus folder Cloud_Run_Function
- Buka folder project video-context-crj dan Anda akan melihat struktur project:
7. Penyiapan Dockerfile dan Kontainerisasi
Untuk men-deploy logika ini sebagai Tugas Cloud Run, kita perlu membuat container-nya. Containerization adalah proses pengemasan kode aplikasi, dependensi, dan runtime ke dalam image portabel.
Pastikan untuk mengganti placeholder (teks dalam huruf tebal) dengan nilai Anda di Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
Cuplikan Dockerfile di atas menentukan image dasar, menginstal dependensi, menyalin kode, dan menetapkan perintah untuk menjalankan aplikasi menggunakan functions-framework dengan fungsi target yang benar (process_batch_from_bq). Image ini kemudian dikirim ke Artifact Registry.
Membuat container
Untuk membuat container, buka Terminal Cloud Shell dan jalankan perintah berikut (Jangan lupa untuk mengganti placeholder <<YOUR_PROJECT_ID>>):
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
Setelah image container dibuat, Anda akan melihat output:
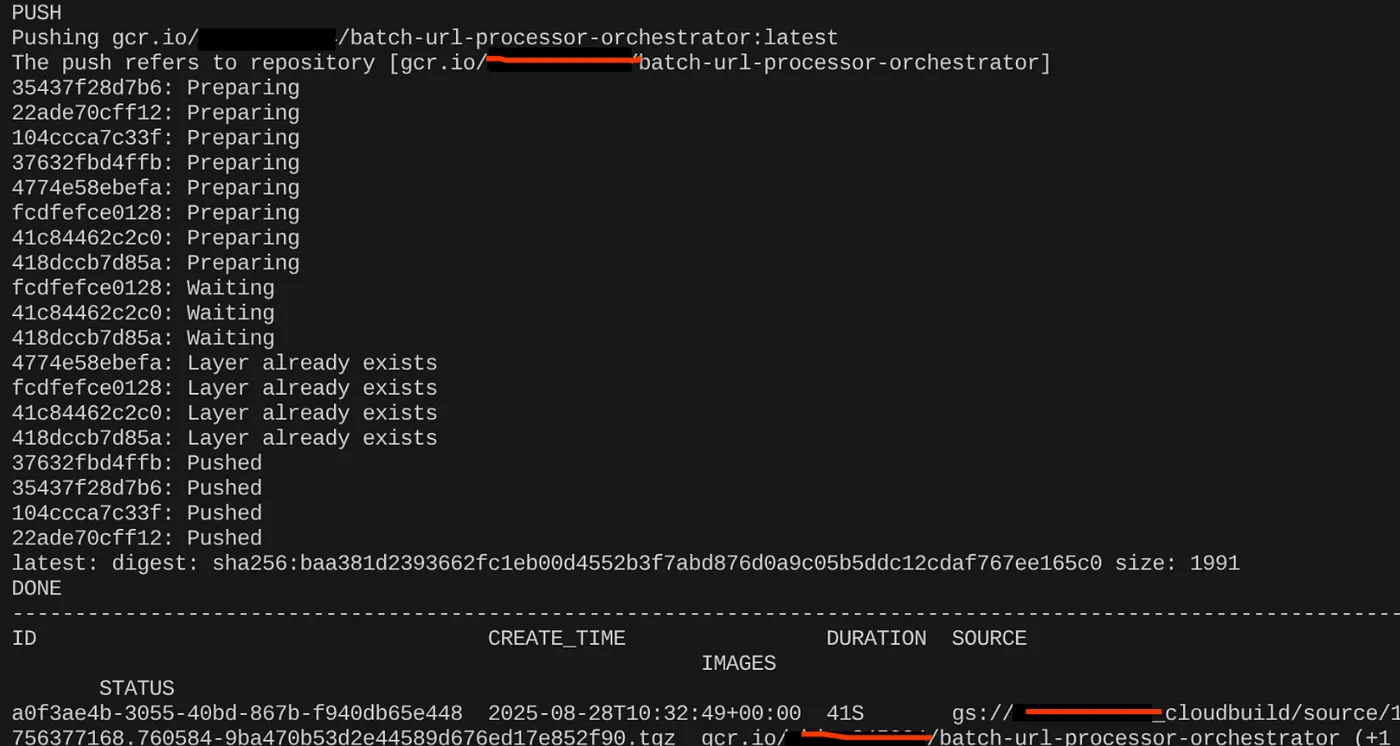
Container kita kini telah dibuat dan disimpan di Artifact Registry. Kita siap melanjutkan ke langkah berikutnya.
8. Pembuatan Tugas Cloud Run
Men-deploy tugas melibatkan pembuatan image container, lalu pembuatan resource Tugas Cloud Run.
Kita telah membuat image container dan menyimpannya di Artifact Registry. Sekarang, mari kita buat tugas.
- Buka konsol Cloud Run Jobs, lalu klik Deploy Container:

- Pilih image container yang baru saja kita buat:
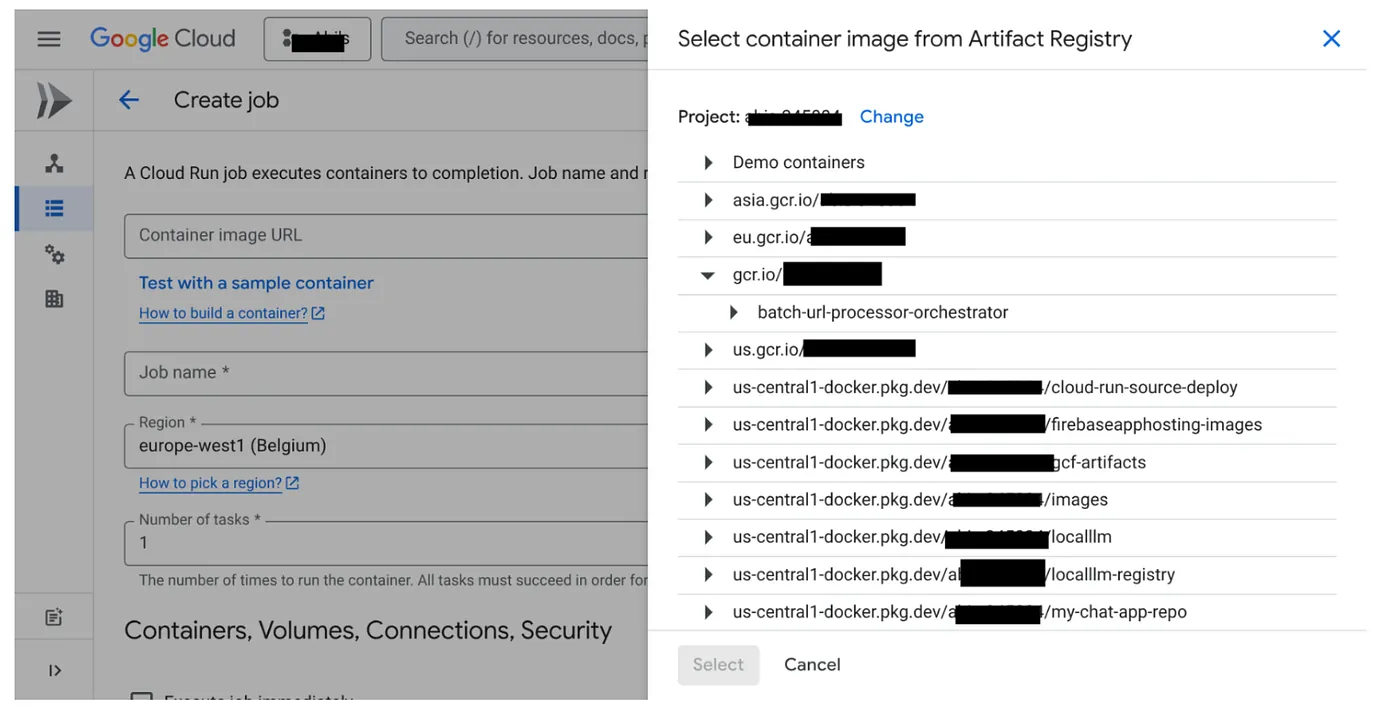
- Masukkan detail konfigurasi lainnya sebagai berikut:

- Tetapkan Kapasitas Tugas sebagai berikut:
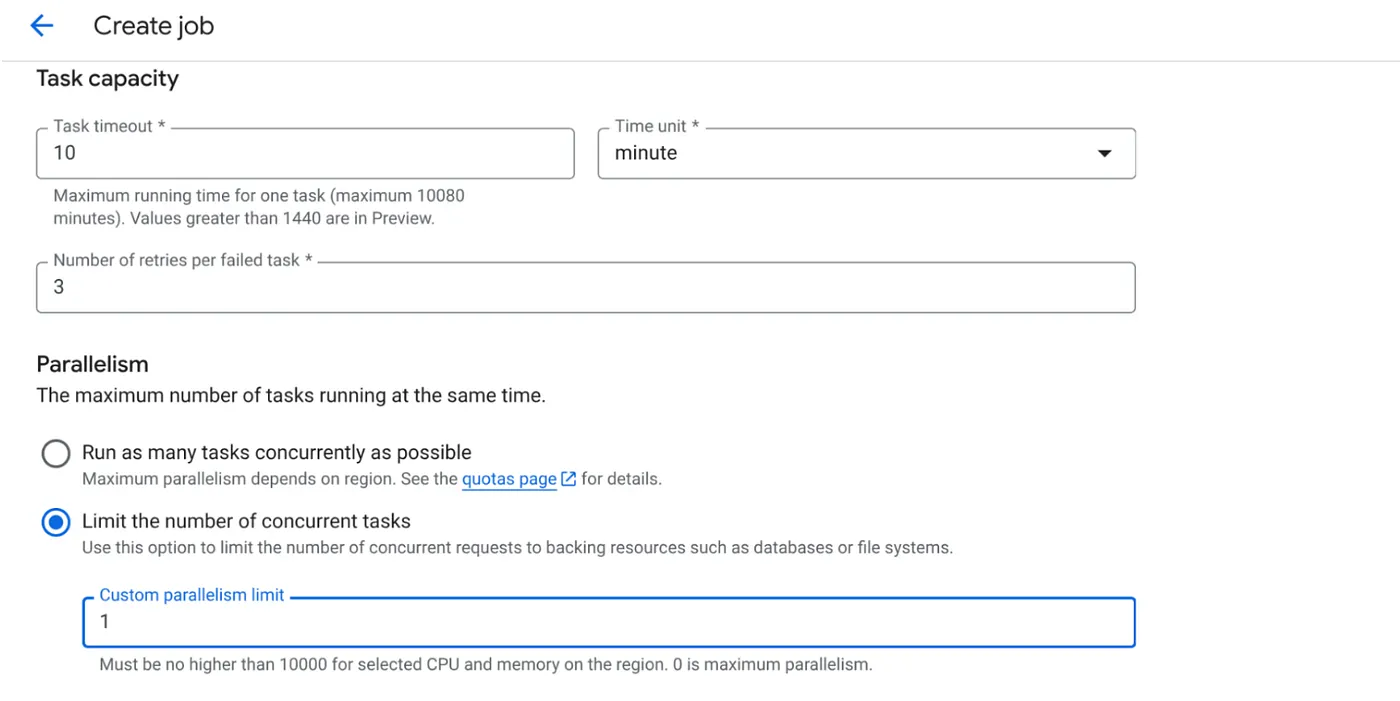
Karena kita memiliki penulisan database dan fakta bahwa paralelisme (max_instances dan konkurensi tugas) sudah ditangani dalam kode, kita akan menetapkan jumlah tugas serentak menjadi 1. Namun, Anda dapat menambahkannya sesuai kebutuhan. Tujuannya di sini adalah agar tugas berjalan hingga selesai sesuai konfigurasi dengan tingkat konkurensi yang ditetapkan dalam paralelisme.
- Klik Buat
Tugas Cloud Run Anda akan berhasil dibuat.
Cara kerjanya
Instance container tugas kita dimulai. Proses ini mengirimkan kueri ke BigQuery untuk mendapatkan batch kecil (BATCH_SIZE) URL yang ditandai sebagai PENDING. Tindakan ini akan segera memperbarui status URL yang diambil ini menjadi PROCESSING di BigQuery untuk mencegah instance tugas lain mengambilnya. Proses ini membuat ThreadPoolExecutor dan mengirimkan tugas untuk setiap URL dalam batch. Setiap tugas memanggil fungsi call_url_processor_service. Saat permintaan call_url_processor_service selesai (atau waktu habis/gagal), hasilnya (baik konteks yang dibuat AI atau pesan error) dikumpulkan, dipetakan kembali ke row_id asli. Setelah semua tugas untuk batch selesai, tugas akan melakukan iterasi melalui hasil yang dikumpulkan dan memperbarui kolom konteks dan status untuk setiap baris yang sesuai di BigQuery. Jika berhasil, instance tugas akan keluar dengan bersih. Jika mengalami error yang tidak tertangani, fungsi ini akan memunculkan pengecualian, yang berpotensi memicu percobaan ulang oleh Tugas Cloud Run (bergantung pada konfigurasi tugas).
Kesesuaian Tugas Cloud Run: Orkestrasi
Di sinilah Tugas Cloud Run benar-benar unggul.
Pemrosesan Batch Serverless: Kita mendapatkan infrastruktur terkelola yang dapat meluncurkan instance container sebanyak yang diperlukan (hingga MAX_INSTANCES) untuk memproses data kita secara bersamaan.
Kontrol Paralelisme: Kita menentukan MAX_INSTANCES (jumlah tugas yang dapat berjalan secara paralel secara keseluruhan) dan TASK_CONCURRENCY (jumlah operasi yang dilakukan setiap instance tugas secara paralel). Hal ini memberikan kontrol terperinci atas throughput dan pemanfaatan resource.
Fault Tolerance: Jika instance tugas gagal di tengah proses, Cloud Run Jobs dapat dikonfigurasi untuk mencoba ulang seluruh tugas atau tugas tertentu, sehingga memastikan pemrosesan data tidak hilang.
Arsitektur yang Disederhanakan: Dengan mengatur panggilan HTTP langsung dalam Tugas dan menggunakan BigQuery untuk pengelolaan status, kita menghindari kompleksitas penyiapan dan pengelolaan Pub/Sub, topik, langganan, dan logika konfirmasinya.
MAX_INSTANCES vs. TASK_CONCURRENCY:
MAX_INSTANCES: Jumlah total instance tugas yang dapat berjalan secara serentak di seluruh eksekusi tugas Anda. Ini adalah tuas paralelisme utama Anda untuk memproses banyak URL sekaligus.
TASK_CONCURRENCY: Jumlah operasi paralel (panggilan ke layanan pemroses) yang akan dilakukan oleh satu instance tugas Anda. Hal ini membantu membebani CPU/jaringan satu instance.
9. Menjalankan & Memantau Tugas Cloud Run
Metadata Video
Sebelum mengklik jalankan, mari kita lihat status data.
Buka BigQuery Studio dan jalankan kueri berikut:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
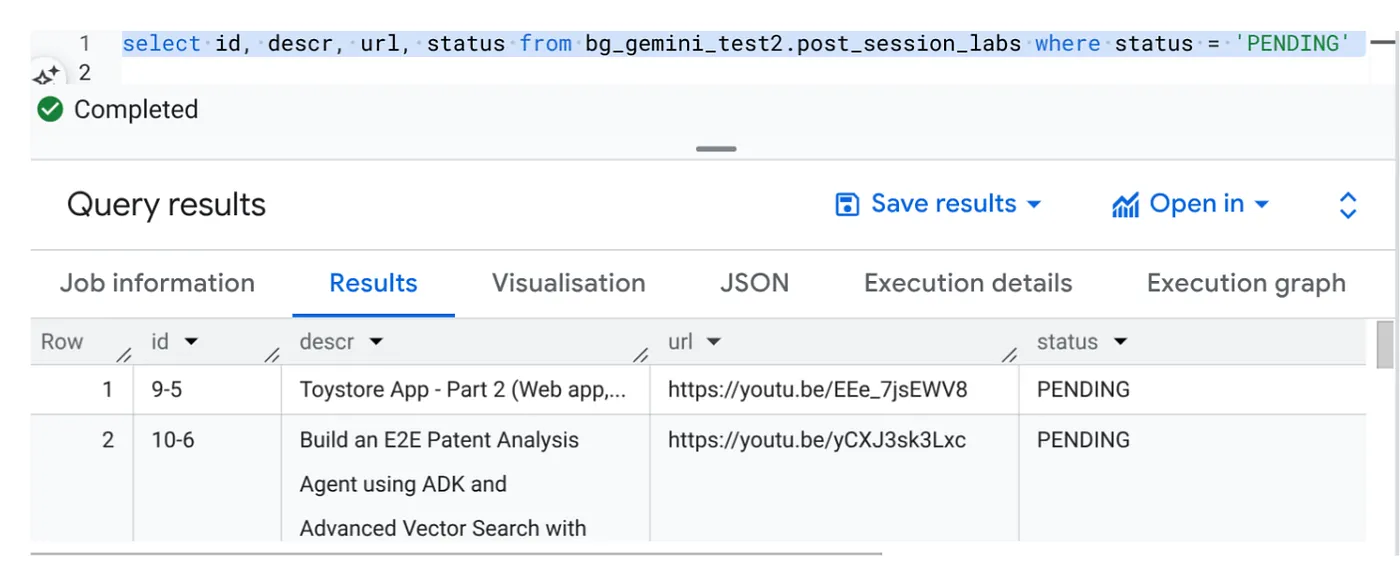
Kami memiliki beberapa contoh data dengan URL video dan dalam status PENDING. Tujuan kami adalah mengisi kolom "konteks" dengan insight dari video dalam format yang dijelaskan dalam perintah.
Pemicu Tugas
Lanjutkan dan jalankan tugas dengan mengklik tombol EXECUTE pada tugas di konsol Cloud Run Jobs dan Anda akan dapat melihat progres dan status tugas di konsol:
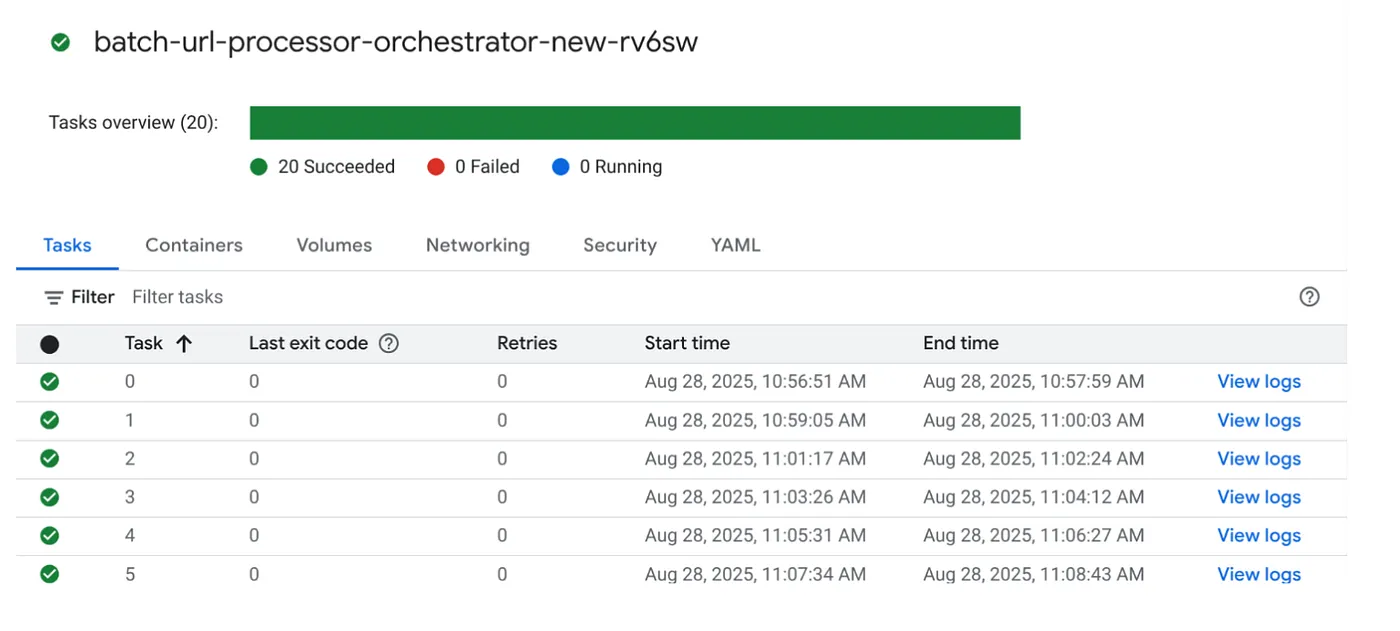
Anda dapat memeriksa tag LOGS di OBSERVABILITY untuk memantau langkah-langkah dan detail lainnya tentang tugas dan sub-tugas.
10. Analisis Hasil
Setelah tugas selesai, Anda akan dapat melihat konteks untuk setiap URL video yang diperbarui dalam tabel:
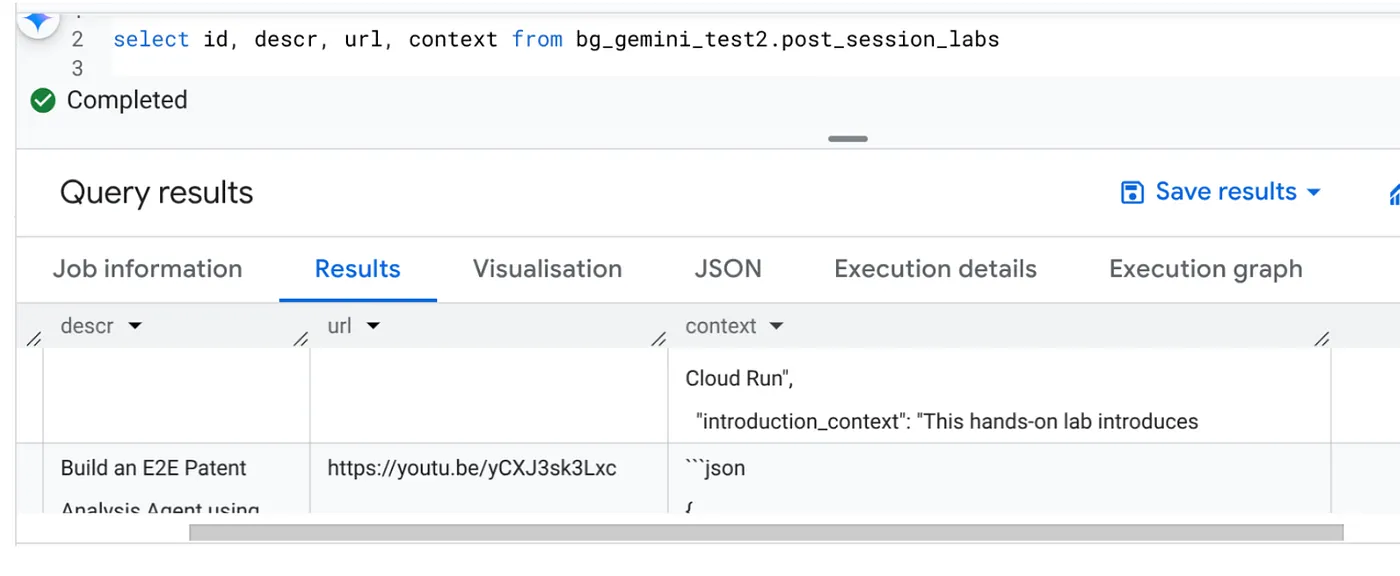
Konteks Output (untuk salah satu catatan)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
Sekarang Anda dapat memvalidasi struktur JSON ini untuk kasus penggunaan agentik yang lebih canggih.
Mengapa pendekatan ini?
Arsitektur ini memberikan keuntungan strategis yang signifikan:
- Efisiensi Biaya: Dengan layanan serverless, Anda hanya membayar sesuai penggunaan. Tugas Cloud Run diturunkan skalanya hingga nol saat tidak digunakan.
- Skalabilitas: Menangani puluhan ribu URL dengan mudah dengan menyesuaikan setelan konkurensi dan instance Tugas Cloud Run.
- Agilitas: Siklus pengembangan dan deployment yang cepat untuk logika pemrosesan atau model AI baru hanya dengan memperbarui aplikasi yang disertakan dan layanannya.
- Mengurangi Overhead Operasional: Tidak ada server yang perlu di-patch atau dikelola; Google menangani infrastruktur.
- Mendemokratisasi AI: Membuat pemrosesan AI tingkat lanjut dapat diakses untuk tugas batch tanpa memerlukan keahlian ML Ops yang mendalam.
11. Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam posting ini, ikuti langkah-langkah berikut:
- Di konsol Google Cloud, buka halaman resource manager.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
12. Selamat
Selamat! Dengan merancang solusi di sekitar Cloud Run Jobs dan memanfaatkan kecanggihan BigQuery untuk pengelolaan data serta Layanan Cloud Run eksternal untuk pemrosesan AI, Anda telah membangun sistem yang sangat skalabel, hemat biaya, dan mudah dikelola. Pola ini memisahkan logika pemrosesan, memungkinkan eksekusi paralel tanpa infrastruktur yang rumit, dan mempercepat waktu untuk mendapatkan insight secara signifikan.
Sebaiknya Anda mempelajari Tugas Cloud Run untuk kebutuhan pemrosesan batch Anda sendiri. Baik untuk menskalakan analisis AI, menjalankan pipeline ETL, atau melakukan tugas data berkala, pendekatan serverless ini menawarkan solusi yang andal dan efisien. Untuk mulai melakukannya sendiri, lihat artikel ini.
Jika Anda ingin membangun dan men-deploy semua aplikasi Anda secara serverless dan agentik, daftar ke Code Vipassana yang berfokus pada percepatan aplikasi agentik generatif berbasis data.