
1. Panoramica
Nel mondo odierno, ricco di dati, estrarre informazioni significative da contenuti non strutturati, in particolare video, è una necessità importante. Immagina di dover analizzare centinaia o migliaia di URL di video, riassumere i loro contenuti, estrarre le tecnologie chiave e persino generare coppie di domande e risposte per i materiali didattici. Eseguire questa operazione uno alla volta non solo richiede molto tempo, ma è anche inefficiente. È qui che le moderne architetture cloud brillano.
In questo lab, esamineremo la soluzione scalabile e serverless per elaborare i contenuti video utilizzando la potente suite di servizi di Google Cloud: Cloud Run, BigQuery e l'AI generativa di Google (Gemini). Descriveremo il nostro percorso dall'elaborazione di un singolo URL all'orchestrazione dell'esecuzione parallela su un ampio set di dati, il tutto senza il sovraccarico della gestione di complesse code di messaggi e integrazioni.
La sfida
Ci è stato chiesto di elaborare un ampio catalogo di contenuti video, concentrandoci in particolare sulle sessioni di laboratorio pratiche. L'obiettivo era analizzare ogni video e generare un riepilogo strutturato, inclusi i titoli dei capitoli, il contesto dell'introduzione, le istruzioni passo passo, le tecnologie utilizzate e le coppie di domande e risposte pertinenti. Questo output doveva essere archiviato in modo efficiente per essere utilizzato in seguito nella creazione di materiali didattici.
Inizialmente, avevamo un semplice servizio Cloud Run basato su HTTP in grado di elaborare un URL alla volta. Questo approccio ha funzionato bene per i test e le analisi ad hoc. Tuttavia, di fronte a un elenco di migliaia di URL provenienti da BigQuery, i limiti di questo modello di singola richiesta e singola risposta sono diventati evidenti. L'elaborazione sequenziale richiederebbe giorni, se non settimane.
L'opportunità era quella di trasformare un processo manuale o sequenziale lento in un flusso di lavoro automatizzato e parallelizzato. Sfruttando il cloud, il nostro obiettivo era:
- Elabora i dati in parallelo: riduci in modo significativo il tempo di elaborazione per i set di dati di grandi dimensioni.
- Sfrutta le funzionalità AI esistenti: utilizza la potenza di Gemini per un'analisi sofisticata dei contenuti.
- Gestisci l'architettura serverless: evita di gestire server o infrastrutture complesse.
- Centralizza i dati: utilizza BigQuery come unica fonte attendibile per gli URL di input e come destinazione affidabile per i risultati elaborati.
- Crea una pipeline solida: crea un sistema resiliente agli errori e che possa essere gestito e monitorato facilmente.
Obiettivo
Orchestrazione dell'elaborazione parallela dell'AI con Cloud Run Jobs:
La nostra soluzione si basa su un job Cloud Run che funge da orchestratore. Legge in modo intelligente batch di URL da BigQuery, li invia al nostro servizio Cloud Run esistente e di cui è stato eseguito il deployment (che gestisce l'elaborazione con l'AI per un singolo URL) e poi aggrega i risultati per riscriverli in BigQuery. Questo approccio ci consente di:
- Disaccoppia l'orchestrazione dall'elaborazione: il job gestisce il workflow, mentre il servizio separato si concentra sull'attività AI.
- Sfrutta il parallelismo di Cloud Run Job: il job può fare lo scale out di più istanze container per chiamare il servizio AI contemporaneamente.
- Riduzione della complessità: otteniamo il parallelismo facendo in modo che il job gestisca direttamente le chiamate HTTP simultanee, semplificando l'architettura.
Caso d'uso
Approfondimenti basati sull'AI dai video della sessione di Code Vipassana
Il nostro caso d'uso specifico consisteva nell'analizzare i video delle sessioni di Google Cloud dei lab pratici di Code Vipassana. L'obiettivo era generare automaticamente documentazione strutturata (schemi dei capitoli del libro), tra cui:
- Titoli dei capitoli: titoli concisi per ogni segmento del video
- Contesto dell'introduzione: spiegare la pertinenza del video in un percorso di apprendimento più ampio
- Cosa verrà creato: l'attività o l'obiettivo principale della sessione
- Tecnologie utilizzate: un elenco di servizi cloud e altre tecnologie menzionate
- Istruzioni passo passo: come è stata eseguita l'attività, inclusi gli snippet di codice
- URL del codice sorgente/demo: link forniti nel video
- Segmento Domande e risposte: generazione di domande e risposte pertinenti per i controlli delle conoscenze.
Flow

Flusso dell'architettura
Che cos'è Cloud Run? Che cosa sono i job Cloud Run?
Cloud Run
Una piattaforma serverless completamente gestita che ti consente di eseguire container stateless. È ideale per servizi web, API e microservizi che possono essere scalati automaticamente in base alle richieste in entrata. Fornisci un'immagine container e Cloud Run si occupa del resto, dal deployment e dallo scaling alla gestione dell'infrastruttura. È eccellente nella gestione dei carichi di lavoro sincroni di richiesta-risposta.
Job Cloud Run
Un'offerta che integra i servizi Cloud Run. I job Cloud Run sono progettati per le attività di elaborazione batch che devono essere completate e poi interrotte. Sono perfetti per l'elaborazione dei dati, l'ETL, l'inferenza batch di machine learning e qualsiasi attività che comporti l'elaborazione di un set di dati anziché la gestione di richieste live. Una caratteristica fondamentale è la loro capacità di fare lo scale out del numero di istanze container (attività) in esecuzione contemporaneamente per elaborare un batch di lavoro e possono essere attivate da varie origini eventi o manualmente.
Differenza principale
I servizi Cloud Run sono destinati ad applicazioni a lunga esecuzione basate su richieste. I job Cloud Run sono per l'elaborazione batch finita e orientata alle attività che viene eseguita fino al completamento.
Cosa creerai
Un'applicazione Retail Search
Nell'ambito di questo processo, potrai:
- Crea un set di dati, una tabella e importa dati BigQuery (metadati Code Vipassana)
- Crea una funzione Cloud Run Python per implementare la funzionalità di AI generativa (conversione del video in un file JSON del capitolo del libro)
- Crea un'applicazione Python per la pipeline di dati in AI: leggi da BigQuery e richiama l'endpoint Cloud Run Functions per gli approfondimenti e scrivi il contesto in BigQuery
- Crea e containerizza l'applicazione
- Configura un job Cloud Run con questo container
- Esegui e monitora il job
- Risultato del report
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto .
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: segui il link e abilita le API.
In alternativa, puoi utilizzare il comando gcloud. Consulta la documentazione per i comandi e l'utilizzo di gcloud.
3. Configurazione del database/data warehouse
BigQuery ha costituito la spina dorsale della nostra pipeline di dati. La sua natura serverless e altamente scalabile lo rende perfetto sia per archiviare i dati di input sia per ospitare i risultati elaborati.
- Archiviazione dei dati:BigQuery fungeva da data warehouse. Memorizza l'elenco degli URL dei video, il loro stato (ad es. IN ATTESA, IN ELABORAZIONE, COMPLETATO) e il contesto finale generato. È l'unica fonte attendibile per i video che devono essere elaborati.
- Destinazione:è la posizione in cui vengono archiviati gli approfondimenti generati dall'AI, rendendoli facilmente interrogabili per le applicazioni downstream o la revisione manuale. Il nostro set di dati era costituito dai dettagli delle sessioni video, in particolare dei contenuti di "Code Vipassana Seasons", che spesso includono dimostrazioni tecniche dettagliate.
- Tabella di origine:una tabella BigQuery (ad es. post_session_labs) contenente record come:
- id: un identificatore univoco per ogni sessione/riga.
- url: l'URL del video (ad es. un link di YouTube o un link di Drive accessibile).
- stato: una stringa che indica lo stato di elaborazione (ad es. PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- context: un campo stringa per memorizzare il riepilogo creato con l'AI.
- Importazione dei dati: in questo scenario, i dati sono stati importati in BigQuery con script INSERT. Per la nostra pipeline, BigQuery è stato il punto di partenza.
Vai alla console BigQuery, apri una nuova scheda ed esegui le seguenti istruzioni SQL:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Importazione dati
Ora è il momento di aggiungere una tabella con i dati del negozio. Vai a una scheda in BigQuery Studio ed esegui le seguenti istruzioni SQL per inserire i record di esempio:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Creazione della funzione di approfondimenti sui video
Dobbiamo creare ed eseguire il deployment di una funzione Cloud Run per implementare il nucleo della funzionalità, ovvero creare un capitolo strutturato del libro dall'URL del video. Per poter accedere a questo come a un insieme di strumenti per endpoint indipendenti, abbiamo appena creato e implementato una funzione Cloud Run. In alternativa, puoi scegliere di includerlo come funzione separata nell'applicazione Python effettiva per il job Cloud Run:
- Nella console Google Cloud, vai alla pagina Cloud Run.
- Fai clic su Scrivi una funzione.
- Nel campo Nome servizio, inserisci un nome per descrivere la funzione. I nomi dei servizi devono iniziare solo con una lettera e contenere un massimo di 49 caratteri, tra cui lettere, numeri o trattini. I nomi dei servizi non possono terminare con trattini e devono essere univoci per regione e progetto. Il nome del servizio non può essere modificato in seguito ed è visibile pubblicamente. ( generate-video-insights**)**
- Nell'elenco Regione, utilizza il valore predefinito o seleziona la regione in cui vuoi eseguire il deployment della funzione. (Scegli us-central1)
- Nell'elenco Runtime, utilizza il valore predefinito o seleziona una versione del runtime. (Scegli Python 3.11)
- Nella sezione Autenticazione, scegli "Consenti accesso pubblico".
- Fai clic sul pulsante "Crea".
- La funzione viene creata e caricata con un modello main.py e requirements.txt
- Sostituisci il file con i file main.py e requirements.txt dal repository di questo progetto.
NOTA IMPORTANTE: in main.py, ricorda di sostituire <<YOUR_PROJECT_ID>> con il tuo ID progetto.
- Esegui il deployment e salva l'endpoint in modo da poterlo utilizzare nell'origine del job Cloud Run.
Il tuo endpoint dovrebbe avere questo aspetto (o uno simile): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
Che cosa contiene questa funzione Cloud Run?
Gemini 2.5 Flash per l'elaborazione video
Per l'attività principale di comprensione e riepilogo dei contenuti video, abbiamo sfruttato il modello Gemini 2.5 Flash di Google. I modelli Gemini sono potenti modelli di AI multimodali in grado di comprendere ed elaborare vari tipi di input, tra cui testo e, con integrazioni specifiche, video.
Nella nostra configurazione, non abbiamo fornito direttamente il file video a Gemini. Abbiamo invece inviato un prompt testuale che includeva l'URL del video e istruiva Gemini su come analizzare i contenuti (ipotetici) di un video a quell'URL. Sebbene Gemini 2.5 Flash sia in grado di gestire input multimodali, questa pipeline specifica ha utilizzato un prompt basato su testo che descriveva la natura del video (una sessione di laboratorio pratica) e richiedeva un output JSON strutturato. Sfrutta il ragionamento avanzato e la comprensione del linguaggio naturale di Gemini per dedurre e sintetizzare le informazioni in base al contesto del prompt.
Il prompt di Gemini: guidare l'AI
Un prompt ben realizzato è fondamentale per i modelli di AI. Il nostro prompt è stato progettato per estrarre informazioni molto specifiche e strutturarle in formato JSON, in modo che possano essere analizzate facilmente dalla nostra applicazione.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
Questo prompt è molto specifico e guida Gemini ad agire come una sorta di educatore. La richiesta di una stringa JSON garantisce un output strutturato e leggibile dal computer.
Ecco il codice per analizzare l'input video e restituirne il contesto:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
Lo snippet riportato sopra mostra la funzione principale del caso d'uso. Riceve un URL video e utilizza il modello Gemini tramite il client Vertex AI per analizzare i contenuti video ed estrarre insight pertinenti in base al prompt. Il contesto estratto viene quindi restituito per un'ulteriore elaborazione. Rappresenta un'operazione sincrona in cui il job Cloud Run attende il completamento del servizio.
6. Sviluppo di applicazioni pipeline (Python)
La logica della pipeline centrale risiede nel codice sorgente dell'applicazione, che verrà inserito in un container in un job Cloud Run, che coordina l'intera esecuzione parallela. Ecco un'occhiata alle parti principali:
Il ruolo dell'orchestratore nella gestione del flusso di lavoro e nella garanzia dell'integrità dei dati:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
Lo snippet precedente inizia recuperando un batch di URL video con stato "PENDING" dalla tabella di origine BigQuery. Aggiorna quindi lo stato di questi URL su "IN ELABORAZIONE" in BigQuery, impedendo l'elaborazione duplicata.
Elaborazione parallela con ThreadPoolExecutor e chiamata al servizio di elaborazione:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
Questa parte del codice utilizza ThreadPoolExecutor per ottenere l'elaborazione parallela degli URL dei video recuperati. Per ogni URL, invia un'attività per chiamare il servizio Cloud Run (URL Processor) in modo asincrono. In questo modo, il job Cloud Run può elaborare in modo efficiente più video contemporaneamente, migliorando le prestazioni complessive della pipeline. Lo snippet gestisce anche potenziali timeout ed errori del servizio di elaborazione.
Lettura e scrittura da e verso BigQuery
L'interazione principale con BigQuery prevede il recupero degli URL in attesa e il loro aggiornamento con i risultati elaborati.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Scrittura dei risultati in BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
Gli snippet precedenti si concentrano sull'interazione dei dati tra il job Cloud Run e BigQuery. Recupera un batch di URL video "PENDING" e i relativi ID dalla tabella di origine. Dopo l'elaborazione degli URL, questo snippet mostra come scrivere il contesto e lo stato estratti ("COMPLETATO" o "ELABORAZIONE NON RIUSCITA") nella tabella BigQuery di destinazione utilizzando una query UPDATE. Questo snippet completa il ciclo di elaborazione dei dati. Include anche la funzione helper update_bq_row che mostra come definire i parametri dell'istruzione di aggiornamento.
Configurazione dell'applicazione
L'applicazione è strutturata come un singolo script Python che verrà containerizzato. Sfrutta le librerie client di Google Cloud e functions-framework per definire il punto di ingresso.
- Dipendenze: google-cloud-bigquery, requests
- Configurazione: tutte le impostazioni critiche (progetto/set di dati/tabella BigQuery, URL del servizio di elaborazione degli URL) vengono caricate dalle variabili di ambiente, rendendo l'applicazione portatile e sicura
- Logica principale: la funzione process_batch_from_bq orchestra l'intero flusso di lavoro
- Integrazione del servizio esterno: la funzione call_url_processor_service gestisce la comunicazione con il servizio Cloud Run separato
- Interazione con BigQuery: bq_client viene utilizzato per recuperare gli URL e aggiornare i risultati, con la corretta gestione dei parametri
- Parallelismo: concurrent.futures.ThreadPoolExecutor gestisce le chiamate simultanee al servizio esterno
- Entry point: il codice Python denominato main.py funge da entry point che avvia l'elaborazione batch.
Configuriamo ora l'applicazione:
- Puoi iniziare andando al terminale Cloud Shell e clonando il repository:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Vai all'editor di Cloud Shell, dove puoi vedere la cartella appena creata video-context-crj.
- Elimina quanto segue, poiché questi passaggi sono già stati completati nelle sezioni precedenti:
- Elimina la cartella Cloud_Run_Function
- Vai alla cartella del progetto video-context-crj e dovresti visualizzare la struttura del progetto:
7. Configurazione di Dockerfile e containerizzazione
Per eseguire il deployment di questa logica come job Cloud Run, dobbiamo containerizzarla. La containerizzazione è il processo di pacchettizzazione del codice dell'applicazione, delle sue dipendenze e del runtime in un'immagine portabile.
Assicurati di sostituire i segnaposto (testo in grassetto) con i tuoi valori nel Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
Lo snippet Dockerfile riportato sopra definisce l'immagine di base, installa le dipendenze, copia il nostro codice e imposta il comando per eseguire la nostra applicazione utilizzando functions-framework con la funzione di destinazione corretta (process_batch_from_bq). Questa immagine viene poi inviata ad Artifact Registry.
Containerizza
Per containerizzarlo, vai al terminale Cloud Shell ed esegui i seguenti comandi (ricorda di sostituire il segnaposto <<YOUR_PROJECT_ID>>):
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
Una volta creata l'immagine container, dovresti visualizzare l'output:
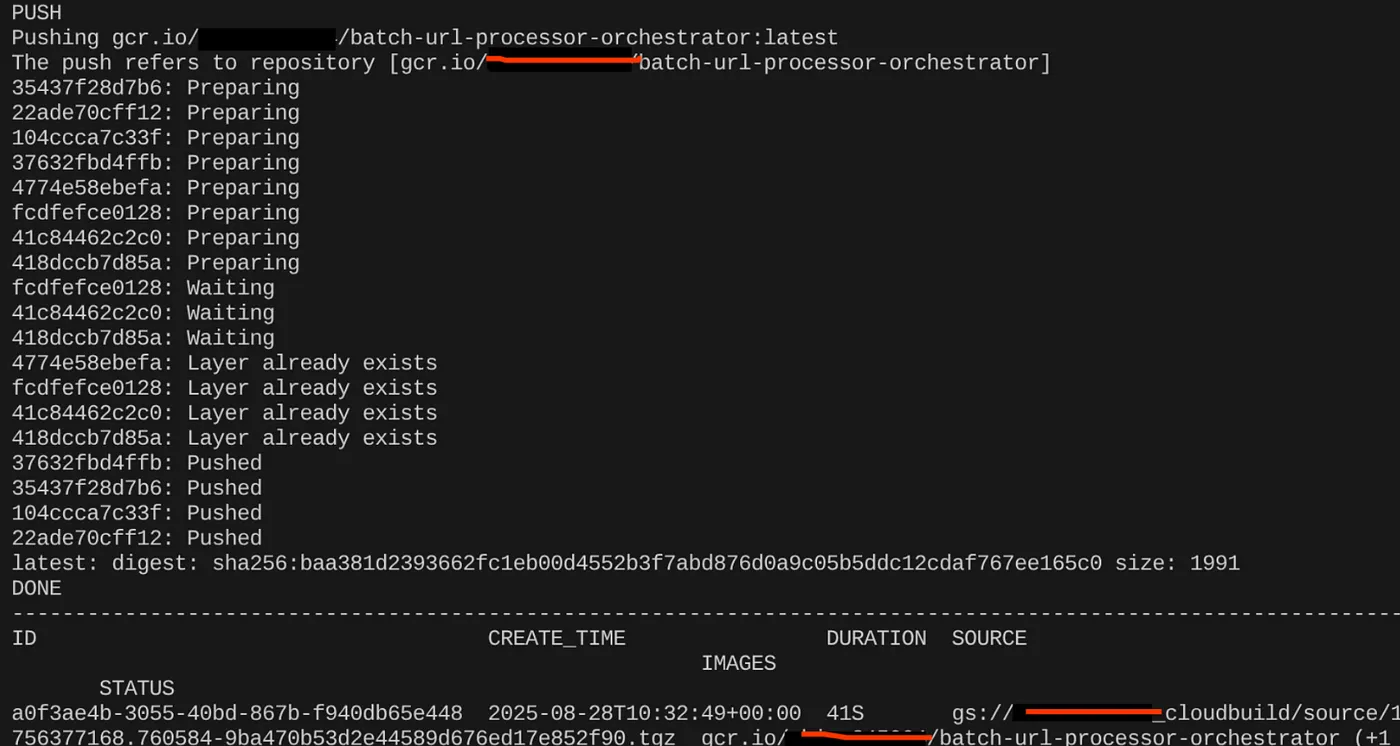
Il nostro container è ora creato e salvato in Artifact Registry. Possiamo passare al passaggio successivo.
8. Creazione di job Cloud Run
Il deployment del job prevede la creazione dell'immagine container e poi la creazione di una risorsa Cloud Run Job.
Abbiamo già creato l'immagine container e l'abbiamo archiviata in Artifact Registry. Ora creiamo il job.
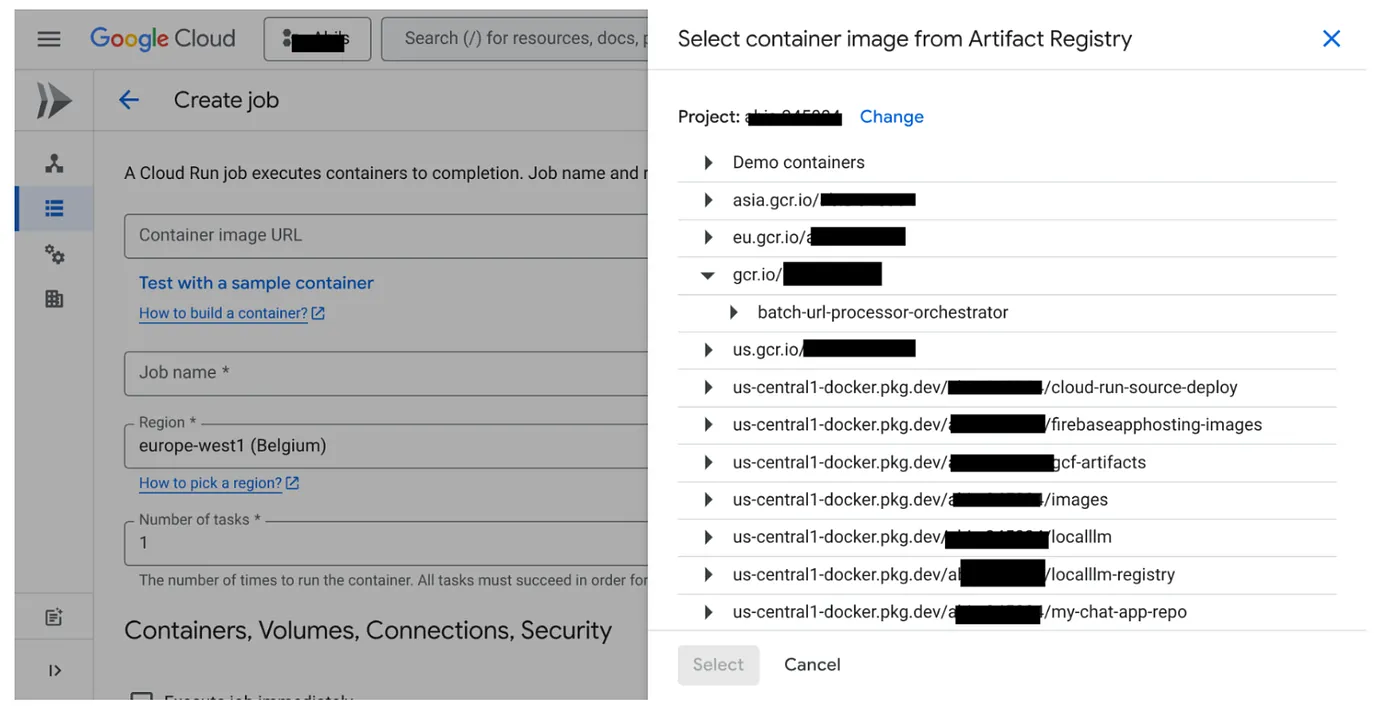
- Vai alla console Cloud Run Jobs e fai clic su Esegui il deployment del container:

- Seleziona l'immagine container appena creata:
- Inserisci gli altri dettagli di configurazione nel seguente modo:

- Imposta la capacità dell'attività come segue:
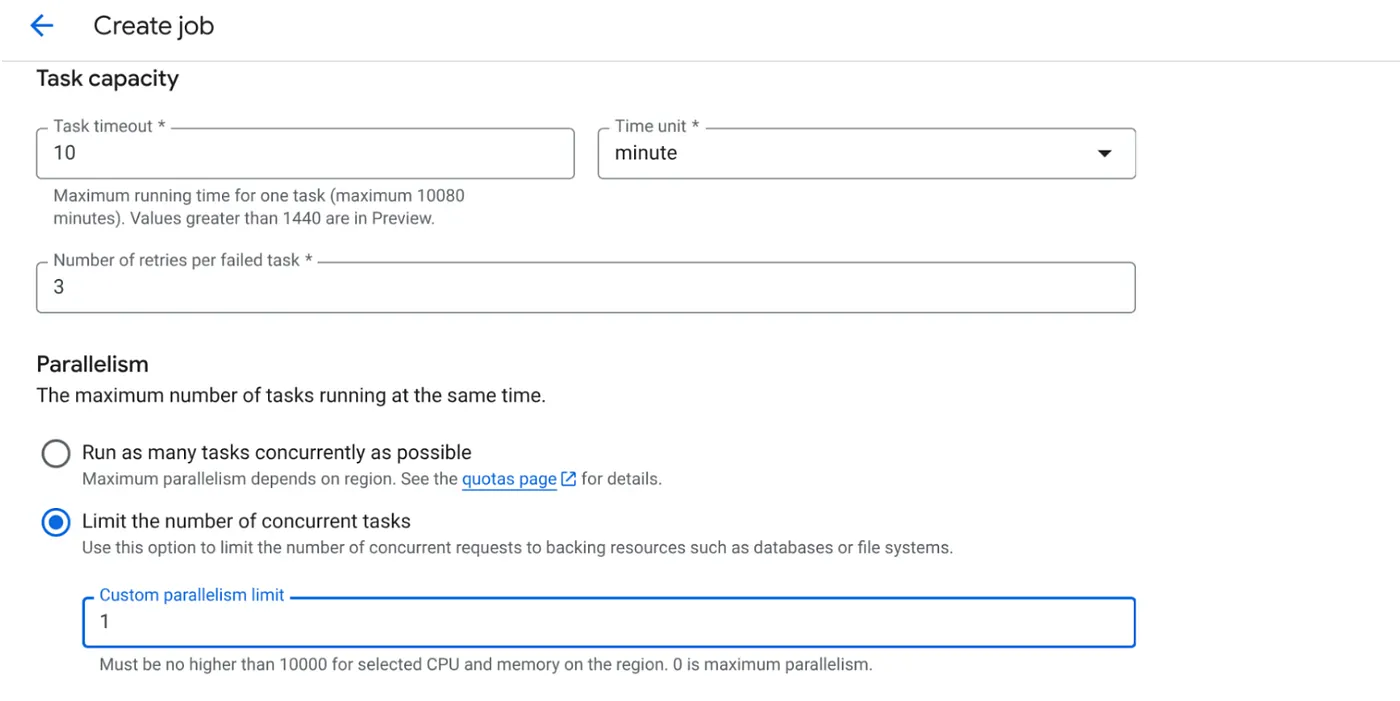
Poiché abbiamo scritture di database e la parallelizzazione (max_instances e concorrenza delle attività) è già gestita nel codice, impostiamo il numero di attività simultanee su 1. ma non esitare ad aumentarlo in base alle tue esigenze. L'obiettivo è che le attività vengano eseguite fino al completamento in base alla configurazione con il livello di concorrenza impostato nel parallelismo.
- Fai clic su Crea
Il job Cloud Run verrà creato correttamente.
Come funziona
Viene avviata un'istanza di container del job. Esegue query su BigQuery per ottenere un piccolo batch (BATCH_SIZE) di URL contrassegnati come PENDING. Aggiorna immediatamente lo stato di questi URL recuperati su PROCESSING in BigQuery per impedire ad altre istanze del job di rilevarli. Crea un ThreadPoolExecutor e invia un'attività per ogni URL nel batch. Ogni attività chiama la funzione call_url_processor_service. Man mano che le richieste call_url_processor_service vengono completate (o scadono/non riescono), i risultati (il contesto generato con l'AI o un messaggio di errore) vengono raccolti e mappati nuovamente al row_id originale. Una volta completate tutte le attività del batch, il job scorre i risultati raccolti e aggiorna i campi di contesto e stato per ogni riga corrispondente in BigQuery. In caso di esito positivo, l'istanza del job viene chiusa correttamente. Se rileva errori non gestiti, genera un'eccezione, che potrebbe attivare un nuovo tentativo da parte di Cloud Run Jobs (a seconda della configurazione del job).
Come si inseriscono i job Cloud Run: orchestrazione
È qui che Cloud Run Jobs si distingue davvero.
Elaborazione batch serverless: otteniamo un'infrastruttura gestita in grado di avviare tutte le istanze container necessarie (fino a MAX_INSTANCES) per elaborare i dati contemporaneamente.
Controllo del parallelismo: definiamo MAX_INSTANCES (il numero di job che possono essere eseguiti in parallelo complessivamente) e TASK_CONCURRENCY (il numero di operazioni che ogni istanza del job esegue in parallelo). Ciò consente un controllo granulare della velocità effettiva e dell'utilizzo delle risorse.
Tolleranza agli errori: se un'istanza del job non va a buon fine a metà, i job Cloud Run possono essere configurati per riprovare l'intero job o attività specifiche, garantendo che l'elaborazione dei dati non venga persa.
Architettura semplificata: orchestrando le chiamate HTTP direttamente all'interno del job e utilizzando BigQuery per la gestione dello stato, evitiamo la complessità della configurazione e della gestione di Pub/Sub, dei relativi argomenti, sottoscrizioni e logica di riconoscimento.
MAX_INSTANCES e TASK_CONCURRENCY:
MAX_INSTANCES::il numero totale di istanze del job che possono essere eseguite contemporaneamente durante l'intera esecuzione del job. Questo è il tuo principale strumento di parallelismo per l'elaborazione di molti URL contemporaneamente.
TASK_CONCURRENCY::il numero di operazioni parallele (chiamate al servizio di elaborazione) che una singola istanza del job eseguirà. In questo modo, la CPU/la rete di un'istanza viene saturata.
9. Esecuzione e monitoraggio del job Cloud Run
Metadati video
Prima di fare clic su Esegui, visualizziamo lo stato dei dati.
Vai a BigQuery Studio ed esegui la seguente query:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
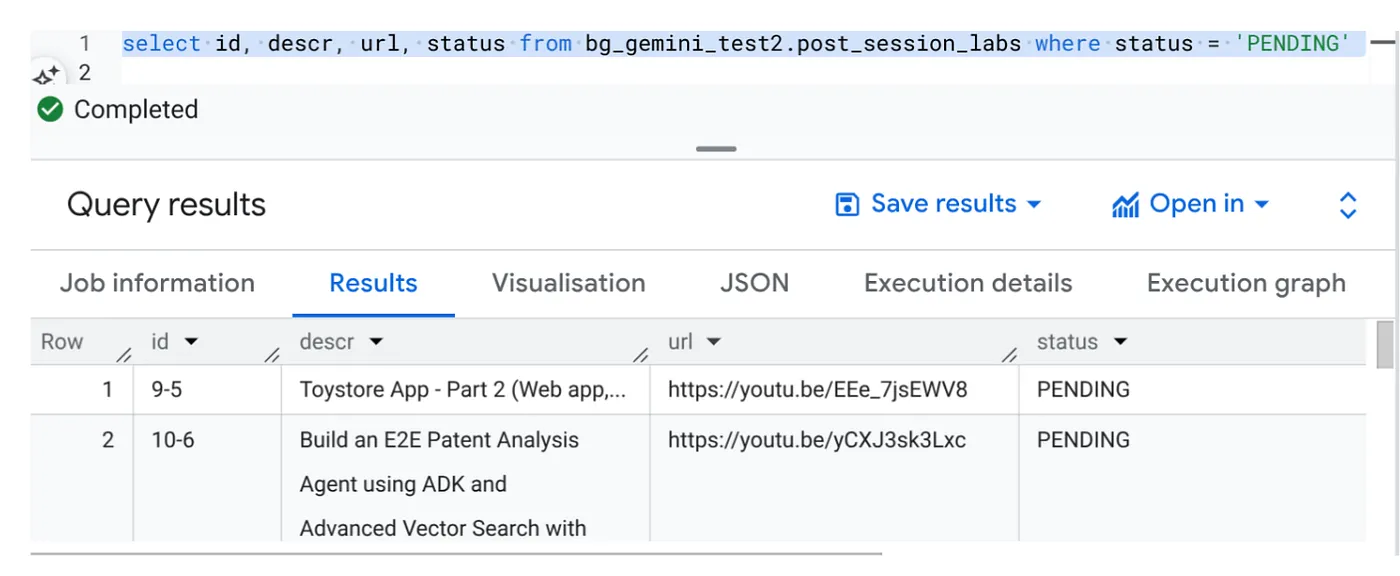
Abbiamo alcuni record di esempio con URL di video e con stato IN ATTESA. Il nostro obiettivo è compilare il campo "Contesto" con approfondimenti sul video nel formato spiegato nel prompt.
Trigger di job
Procediamo con l'esecuzione del job facendo clic sul pulsante EXECUTE (ESEGUI) nel job nella console Cloud Run Jobs. Dovresti essere in grado di visualizzare l'avanzamento e lo stato dei job nella console:
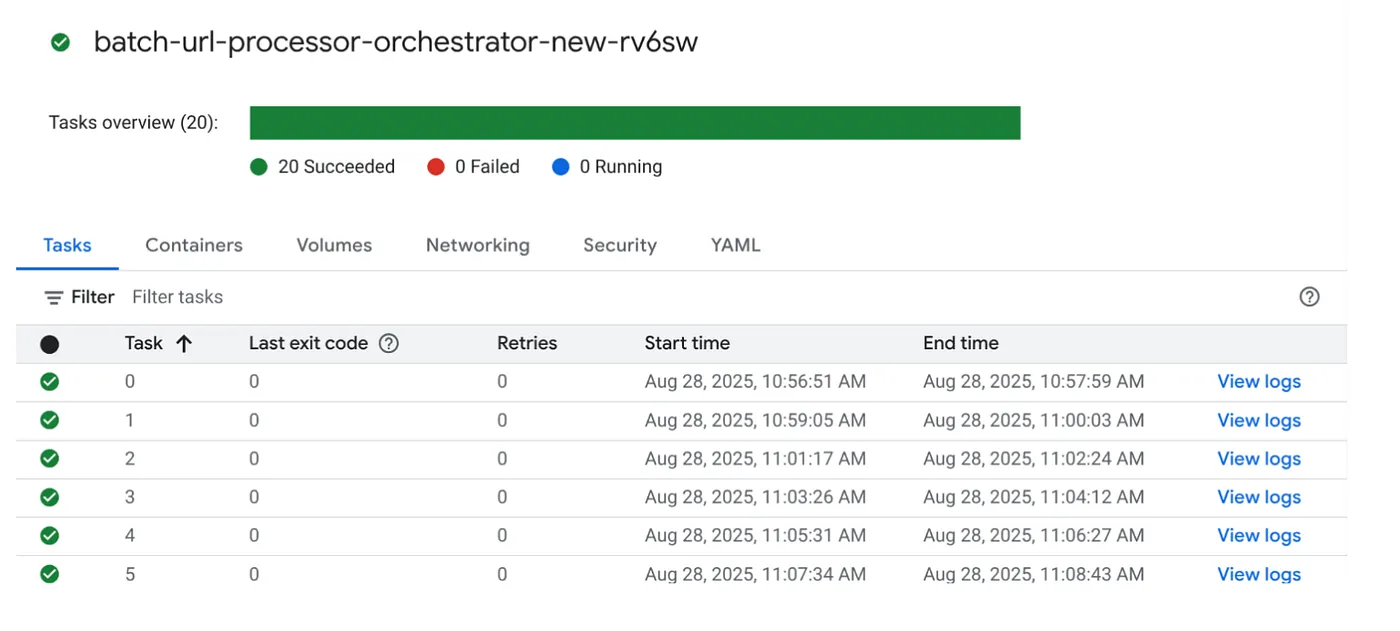
Puoi controllare il tag LOGS in OBSERVABILITY per i passaggi di monitoraggio e altri dettagli sul job e sulle attività.
10. Analisi dei risultati
Una volta completato il job, dovresti vedere il contesto di ogni URL video aggiornato nella tabella:
Contesto dell'output (per uno dei record)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
Ora dovresti essere in grado di convalidare questa struttura JSON per casi d'uso più avanzati.
Perché questo approccio?
Questa architettura offre vantaggi strategici significativi:
- Convenienza: i servizi serverless ti consentono di pagare solo per ciò che utilizzi. I job Cloud Run vengono ridotti a zero quando non sono in uso.
- Scalabilità: gestisce facilmente decine di migliaia di URL modificando le impostazioni di concorrenza e delle istanze di Cloud Run Job.
- Agilità: cicli di sviluppo e deployment rapidi per nuova logica di elaborazione o modelli di AI semplicemente aggiornando l'applicazione contenuta e il relativo servizio.
- Riduzione dell'overhead operativo: nessun server da applicare patch o gestire; Google gestisce l'infrastruttura.
- Democratizzazione dell'AI: rende accessibile l'elaborazione con l'AI avanzata per le attività batch senza competenze approfondite di ML Ops.
11. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo post, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Resource Manager.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
12. Complimenti
Complimenti! Progettando la nostra soluzione intorno a Cloud Run Jobs e sfruttando la potenza di BigQuery per la gestione dei dati e un servizio Cloud Run esterno per elaborare con l'AI, hai creato un sistema altamente scalabile, conveniente e gestibile. Questo pattern disaccoppia la logica di elaborazione, consente l'esecuzione parallela senza infrastrutture complesse e accelera notevolmente il time-to-insight.
Ti invitiamo a esplorare Cloud Run Jobs per le tue esigenze di elaborazione batch. Che si tratti di scalare l'analisi AI, eseguire pipeline ETL o svolgere attività periodiche sui dati, questo approccio serverless offre una soluzione potente ed efficiente. Per iniziare in autonomia, dai un'occhiata a questa pagina.
Se vuoi creare ed eseguire il deployment di tutte le tue app senza server e con agenti, registrati a Code Vipassana, un evento incentrato sull'accelerazione delle applicazioni con agenti generativi basati sui dati.