
1. 概要
データが豊富な今日の社会では、非構造化コンテンツ、特に動画から有意義な分析情報を抽出することが非常に重要になっています。数百または数千もの動画 URL を分析し、コンテンツを要約し、主要なテクノロジーを抽出し、教育資料用の Q&A ペアを生成する必要があるとします。これを 1 つずつ行うのは時間がかかるだけでなく、非効率的です。ここで、最新のクラウド アーキテクチャが威力を発揮します。
このラボでは、Google Cloud の強力なサービス スイート(Cloud Run、BigQuery、Google の生成 AI(Gemini))を使用して動画コンテンツを処理する、スケーラブルなサーバーレス ソリューションについて説明します。単一の URL の処理から、複雑なメッセージ キューや統合のオーバーヘッドなしで大規模なデータセットにわたる並列実行のオーケストレーションまで、Google の取り組みについて詳しく説明します。
課題
私たちは、動画コンテンツの大規模なカタログを処理するタスクを任されました。特に、ハンズオンラボ セッションに重点を置いていました。目標は、各動画を分析し、チャプターのタイトル、導入のコンテキスト、手順ガイド、使用されているテクノロジー、関連する Q&A のペアなどを含む構造化された要約を生成することでした。この出力は、教材の作成で後で使用するために効率的に保存する必要がありました。
当初は、一度に 1 つの URL を処理できるシンプルな HTTP ベースの Cloud Run サービスがありました。これはテストやアドホック分析には適していましたが、しかし、BigQuery から取得した数千もの URL のリストに直面したとき、この単一リクエスト、単一レスポンス モデルの限界が明らかになりました。順次処理では、数週間とは言わないまでも数日かかります。
この機会は、手動または遅い順次プロセスを自動化された並列ワークフローに変換することでした。クラウドを活用することで、次のことを目指しました。
- データを並列処理する: 大規模なデータセットの処理時間を大幅に短縮します。
- 既存の AI 機能を活用する: Gemini の機能を活用して、高度なコンテンツ分析を行います。
- サーバーレス アーキテクチャを維持する: サーバーや複雑なインフラストラクチャの管理を回避します。
- データを一元化する: BigQuery を入力 URL の信頼できる唯一の情報源として使用し、処理結果の信頼できる宛先として使用します。
- 堅牢なパイプラインを構築する: 障害に強く、管理とモニタリングが容易なシステムを作成します。
目標
Cloud Run ジョブを使用した並列 AI 処理のオーケストレーション:
このソリューションは、オーケストレーターとして機能する Cloud Run ジョブを中心に展開されます。この関数は、BigQuery から URL のバッチをインテリジェントに読み取り、これらの URL を既存のデプロイ済み Cloud Run サービス(単一の URL の AI 処理を処理する)にディスパッチし、結果を集計して BigQuery に書き戻します。このアプローチにより、次のことが可能になります。
- オーケストレーションと処理を分離する: ジョブはワークフローを管理し、個別のサービスは AI タスクに重点を置きます。
- Cloud Run Job の並列処理を活用する: ジョブは、複数のコンテナ インスタンスをスケールアウトして、AI サービスを同時に呼び出すことができます。
- 複雑さを軽減する: ジョブで同時 HTTP 呼び出しを直接管理することで並列処理を実現し、アーキテクチャを簡素化します。
ユースケース
Code Vipassana セッション動画から得られる AI を活用した分析情報
具体的なユースケースは、Code Vipassana ハンズオンラボの Google Cloud セッションの動画を分析することでした。目標は、次のような構造化されたドキュメント(書籍の章の概要)を自動的に生成することでした。
- チャプターのタイトル: 各動画セグメントの簡潔なタイトル
- 導入のコンテキスト: より広範な学習プログラムにおける動画の関連性を説明する
- 構築するもの: セッションのコアタスクまたは目標
- 使用されたテクノロジー: 言及されたクラウド サービスやその他のテクノロジーのリスト
- 手順ガイド: タスクの実行方法(コード スニペットを含む)
- ソースコード/デモ URL: 動画で提供されているリンク
- Q&A セグメント: 知識チェックに関連する質問と回答を生成します。
フロー

アーキテクチャのフロー
Cloud Run とはCloud Run ジョブとは
Cloud Run
ステートレス コンテナを実行できるフルマネージドのサーバーレス プラットフォーム。受信リクエストに基づいて自動的にスケーリングできるウェブ サービス、API、マイクロサービスに最適です。コンテナ イメージを指定すると、Cloud Run がデプロイ、スケーリング、インフラストラクチャの管理など、残りの処理を行います。同期リクエスト / レスポンス ワークロードの処理に優れています。
Cloud Run ジョブ
Cloud Run サービスを補完するサービス。Cloud Run ジョブは、完了後に停止する必要があるバッチ処理タスク用に設計されています。データ処理、ETL、ML バッチ推論、ライブ リクエストの処理ではなくデータセットの処理を伴うタスクに最適です。主な特徴は、同時に実行されるコンテナ インスタンス(タスク)の数をスケールアウトして、バッチ処理を実行できることです。また、さまざまなイベントソースまたは手動でトリガーできます。
主な違い
Cloud Run サービスは、長時間実行されるリクエスト主導のアプリケーション用です。Cloud Run ジョブは、完了するまで実行される有限のタスク指向のバッチ処理に使用されます。
作成するアプリの概要
小売検索アプリケーション
この一環として、次のことを行います。
- BigQuery データセットとテーブルを作成してデータを取り込む(Code Vipassana メタデータ)
- 生成 AI 機能(動画を本の章の JSON に変換)を実装する Python Cloud Run Functions を作成する
- データから AI パイプライン用の Python アプリケーションを作成する - BigQuery から読み取り、分析のために Cloud Run Functions エンドポイントを呼び出し、コンテキストを BigQuery に書き戻す
- アプリケーションをビルドしてコンテナ化する
- このコンテナを使用して Cloud Run ジョブを構成する
- ジョブを実行してモニタリングする
- レポートの結果
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/video-insights-with-cloud-run-jobs/img/7875ca05ca6f7cab.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にする: リンクにアクセスして、API を有効にします。
または、この操作に gcloud コマンドを使用することもできます。gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
3. データベース/ウェアハウスの設定
BigQuery は、データ パイプラインのバックボーンとして機能しました。サーバーレスでスケーラビリティに優れているため、入力データの保存と処理結果の格納の両方に最適です。
- データ ストレージ: BigQuery はデータ ウェアハウスとして機能しました。動画 URL のリスト、ステータス(PENDING、PROCESSING、COMPLETED など)、最終的に生成されたコンテキストが保存されます。これは、どの動画を処理する必要があるかについての信頼できる唯一の情報源です。
- 宛先: AI 生成の分析情報が保存され、ダウンストリーム アプリケーションや手動レビューで簡単にクエリできるようになります。データセットは、動画セッションの詳細で構成されていました。特に「Code Vipassana Seasons」のコンテンツは、詳細な技術デモを伴うことが多いため、このコンテンツのデータが中心でした。
- ソーステーブル: 次のようなレコードを含む BigQuery テーブル(例: post_session_labs)。
- id: 各セッション/行の一意の識別子。
- url: 動画の URL(YouTube のリンクやアクセス可能なドライブのリンクなど)。
- status: 処理状態を示す文字列(PENDING、PROCESSING、COMPLETED、FAILED_PROCESSING など)。
- context: AI 生成の要約を保存する文字列フィールド。
- データの取り込み: このシナリオでは、INSERT スクリプトを使用して BigQuery にデータを取り込みました。このパイプラインでは、BigQuery が出発点でした。
BigQuery コンソールに移動し、新しいタブを開いて次の SQL ステートメントを実行します。
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. データの取り込み
次に、店舗に関するデータを含むテーブルを追加します。BigQuery Studio のタブに移動し、次の SQL ステートメントを実行してサンプルレコードを挿入します。
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. 動画インサイト機能の作成
動画の URL から構造化された書籍の章を作成する機能の中核を実装するには、Cloud Run 関数を作成してデプロイする必要があります。これを独立したエンドポイント ツールボックス ツールとしてアクセスできるようにするために、Cloud Run 関数を作成してデプロイしました。または、Cloud Run Job の実際の Python アプリケーションに別の関数として含めることもできます。
- Google Cloud コンソールで、Cloud Run ページに移動します。
- [関数を作成] をクリックします。
- [サービス名] フィールドに、関数を表す名前を入力します。サービス名は、先頭を英字にして、49 文字以下の英字、数字、ハイフンで構成します。サービス名はハイフンで終わることはできません。また、リージョンとプロジェクトごとに一意にする必要があります。サービス名は後から変更することはできません。この名前は一般公開されます。( generate-video-insights**)**
- [リージョン] リストで、デフォルト値を使用するか、関数をデプロイするリージョンを選択します。(us-central1 を選択)
- [ランタイム] リストで、デフォルト値を使用するか、ランタイム バージョンを選択します。(Python 3.11 を選択)
- [認証] セクションで、[一般公開アクセスを許可] を選択します。
- [作成] ボタンをクリックします。
- 関数が作成され、テンプレートの main.py と requirements.txt が読み込まれます。
- このプロジェクトのリポジトリにある main.py ファイルと requirements.txt ファイルに置き換えます。
重要な注意事項: main.py で、<<YOUR_PROJECT_ID>> をプロジェクト ID に置き換えてください。
- エンドポイントをデプロイして保存し、Cloud Run ジョブのソースで使用できるようにします。
エンドポイントは次のようになります(または同様の形式になります)。https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
この Cloud Run 関数には何が含まれていますか?
動画処理用の Gemini 2.5 Flash
動画コンテンツの理解と要約というコアタスクには、Google の Gemini 2.5 Flash モデルを活用しました。Gemini モデルは、テキストや(特定の統合により)動画など、さまざまな種類の入力を理解して処理できる強力なマルチモーダル AI モデルです。
この設定では、動画ファイルを Gemini に直接フィードしていません。代わりに、動画の URL を含むテキスト プロンプトを送信し、その URL の動画の(仮説上の)コンテンツを分析する方法を Gemini に指示しました。Gemini 2.5 Flash はマルチモーダル入力に対応していますが、この特定のパイプラインでは、動画の内容(ハンズオン ラボセッション)を説明し、構造化された JSON 出力をリクエストするテキストベースのプロンプトが使用されました。Gemini の高度な推論と自然言語理解を活用して、プロンプトのコンテキストに基づいて情報を推論して合成します。
Gemini プロンプト: AI をガイドする
AI モデルでは、適切に作成されたプロンプトが重要です。このプロンプトは、非常に具体的な情報を抽出し、JSON 形式で構造化するように設計されています。これにより、アプリケーションで簡単に解析できるようになります。
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
このプロンプトは非常に具体的で、Gemini が教育者のように振る舞うように指示しています。JSON 文字列のリクエストにより、構造化されたコンピュータが解読できる出力が保証されます。
動画入力を分析してコンテキストを返すコードは次のとおりです。
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
上記のスニペットは、ユースケースのコア機能を示しています。動画の URL を受け取り、Vertex AI クライアントを介して Gemini モデルを利用して、動画コンテンツを分析し、プロンプトごとに適切な分析情報を抽出します。抽出されたコンテキストは、さらなる処理のために返されます。これは、Cloud Run ジョブがサービスの完了を待機する同期オペレーションを表します。
6. パイプライン アプリケーション開発(Python)
中央パイプライン ロジックは、Cloud Run ジョブにコンテナ化されるアプリケーションのソースコードに存在し、並列実行全体をオーケストレートします。主な部分は次のとおりです。
ワークフローの管理とデータの完全性の確保におけるオーケストレーターの役割:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
上記のスニペットは、BigQuery ソーステーブルから「PENDING」ステータスの動画 URL のバッチを取得することから始まります。その後、BigQuery でこれらの URL のステータスを「PROCESSING」に更新し、重複処理を防ぎます。
ThreadPoolExecutor を使用した並列処理と Processor サービスの呼び出し:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
このコード部分では、ThreadPoolExecutor を利用して、取得した動画 URL の並列処理を実現しています。各 URL に対して、Cloud Run サービス(URL プロセッサ)を非同期で呼び出すタスクを送信します。これにより、Cloud Run Job は複数の動画を同時に効率的に処理し、パイプライン全体のパフォーマンスを向上させることができます。このスニペットは、プロセッサ サービスからのタイムアウトやエラーの可能性も処理します。
BigQuery との間での読み取りと書き込み
BigQuery との主なやり取りは、保留中の URL を取得し、処理された結果で更新することです。
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
結果を BigQuery に書き戻す:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
上記のスニペットは、Cloud Run Job と BigQuery 間のデータ インタラクションに焦点を当てています。ソーステーブルから「PENDING」の動画 URL とその ID のバッチを取得します。URL の処理後、このスニペットは、UPDATE クエリを使用して、抽出されたコンテキストとステータス(「COMPLETED」または「FAILED_PROCESSING」)をターゲット BigQuery テーブルに書き戻す方法を示しています。このスニペットでデータ処理ループが完了します。また、update ステートメントのパラメータを定義する方法を示す update_bq_row ヘルパー関数も含まれています。
アプリケーションのセットアップ
アプリケーションは、コンテナ化される単一の Python スクリプトとして構造化されています。Google Cloud クライアント ライブラリと functions-framework を活用して、エントリ ポイントを定義します。
- 依存関係: google-cloud-bigquery、requests
- 構成: すべての重要な設定(BigQuery プロジェクト/データセット/テーブル、URL プロセッサ サービス URL)は環境変数から読み込まれるため、アプリケーションの移植性とセキュリティが向上します。
- コアロジック: process_batch_from_bq 関数がワークフロー全体をオーケストレートする
- 外部サービス統合: call_url_processor_service 関数は、別の Cloud Run サービスとの通信を処理します。
- BigQuery のインタラクション: bq_client は、URL の取得と結果の更新に使用され、パラメータが適切に処理されます
- 並列処理: concurrent.futures.ThreadPoolExecutor は、外部サービスへの同時呼び出しを管理します
- エントリ ポイント: main.py という名前の Python コードは、バッチ処理を開始するエントリ ポイントとして機能します。
アプリケーションを設定しましょう。
- まず、Cloud Shell ターミナルに移動して、リポジトリのクローンを作成します。
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Cloud Shell エディタに移動します。ここで、新しく作成されたフォルダ video-context-crj を確認できます。
- 次の手順は前のセクションで完了しているため、削除します。
- フォルダ Cloud_Run_Function を削除します。
- プロジェクト フォルダ video-context-crj に移動すると、次のようなプロジェクト構造が表示されます。
7. Dockerfile の設定とコンテナ化
このロジックを Cloud Run ジョブとしてデプロイするには、コンテナ化する必要があります。コンテナ化とは、アプリケーション コード、その依存関係、ランタイムをポータブル イメージにパッケージ化するプロセスです。
Dockerfile でプレースホルダ(太字のテキスト)を自分の値に置き換えてください。
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
上記の Dockerfile スニペットは、ベースイメージを定義し、依存関係をインストールし、コードをコピーし、正しいターゲット関数(process_batch_from_bq)で functions-framework を使用してアプリケーションを実行するコマンドを設定します。このイメージは Artifact Registry に push されます。
コンテナ化
コンテナ化するには、Cloud Shell ターミナルに移動して次のコマンドを実行します(<<YOUR_PROJECT_ID>> プレースホルダを置き換えてください)。
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
コンテナ イメージが作成されると、次の出力が表示されます。
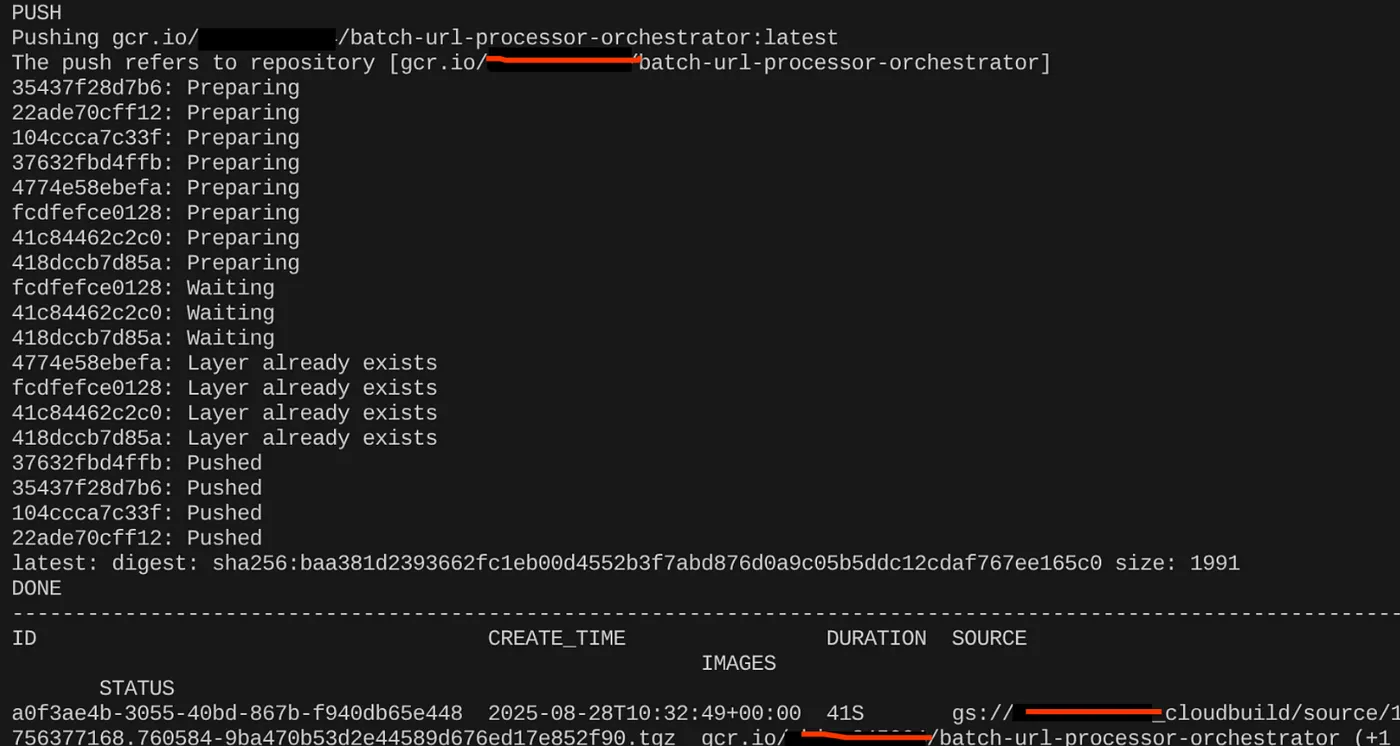
これでコンテナが作成され、Artifact Registry に保存されました。次のステップに進みます。
8. Cloud Run ジョブの作成
ジョブのデプロイには、コンテナ イメージのビルドと Cloud Run Job リソースの作成が含まれます。
コンテナ イメージはすでに作成済みで、Artifact Registry に保存されています。ジョブを作成しましょう。
- Cloud Run Jobs コンソールに移動し、[コンテナをデプロイ] をクリックします。

- 作成したコンテナ イメージを選択します。
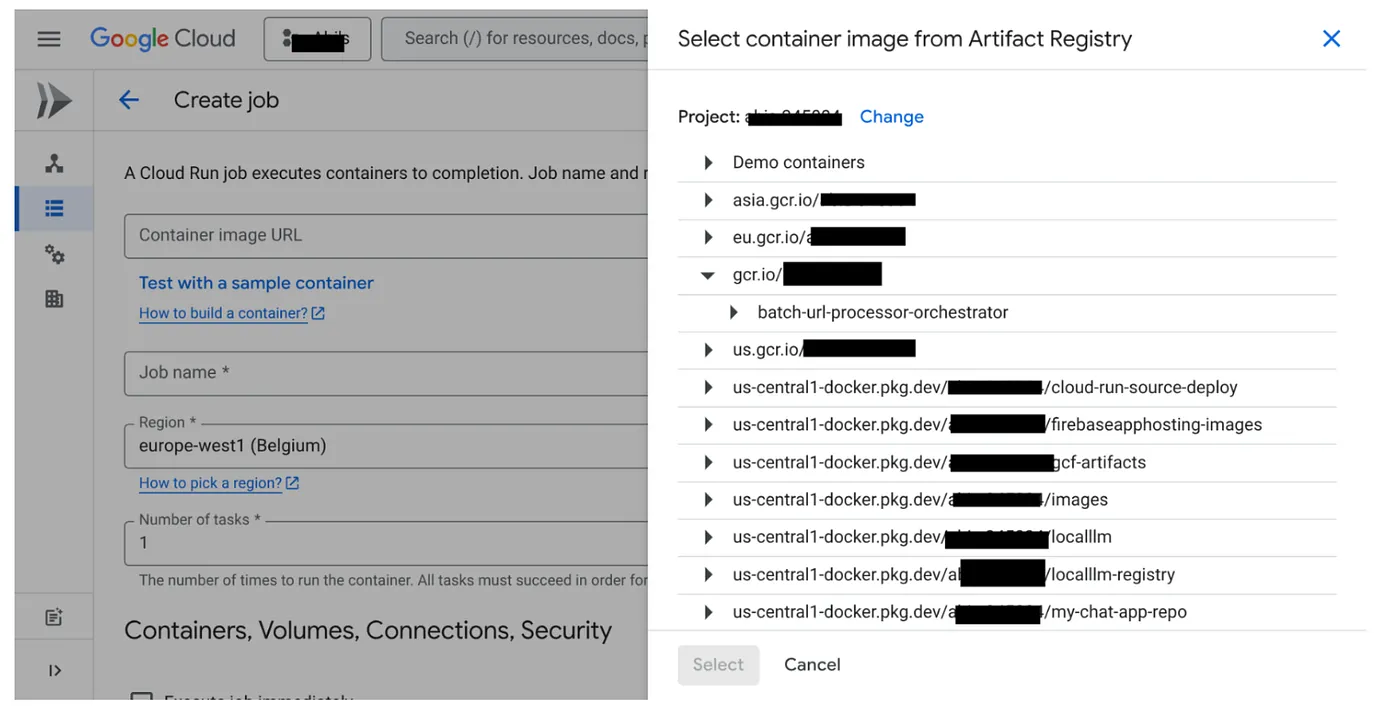
- 次のように、その他の構成の詳細を入力します。

- [タスクの容量] を次のように設定します。
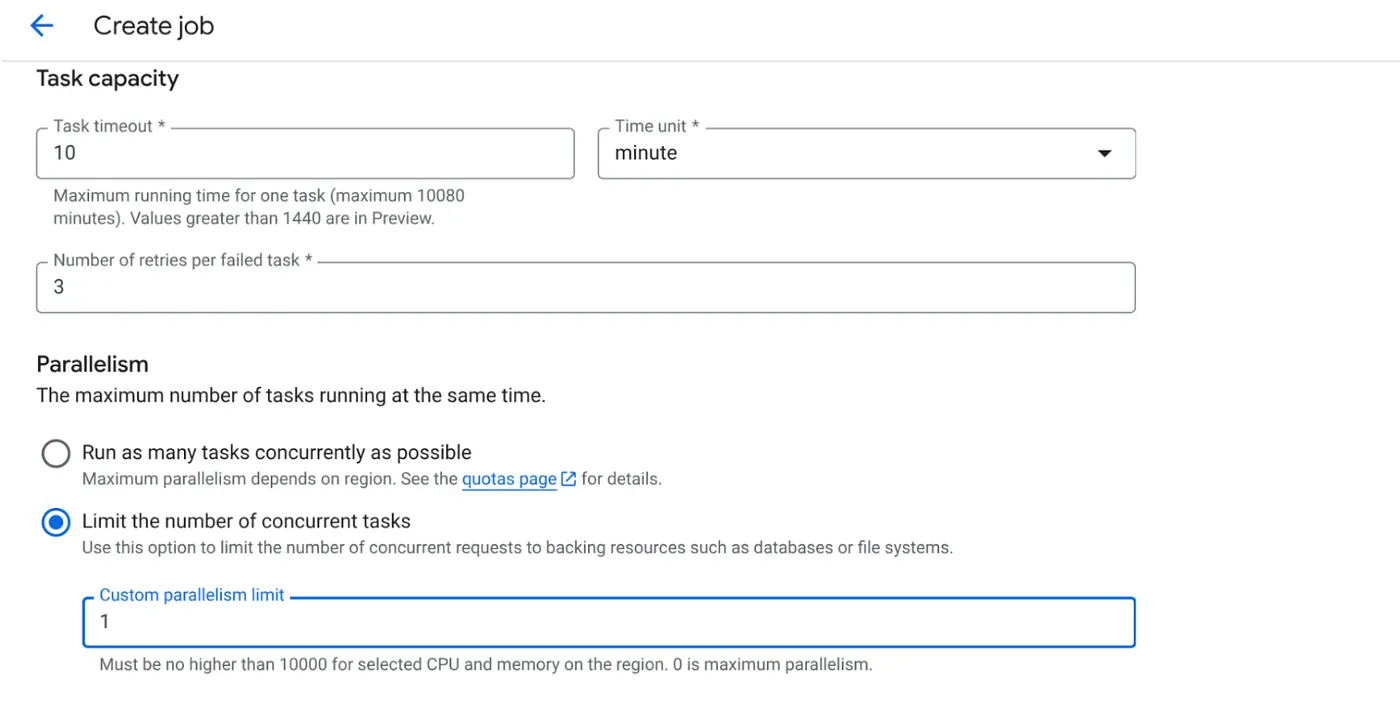
データベース書き込みがあり、並列化(max_instances とタスクの同時実行)がコードで処理されているため、同時実行タスクの数を 1 に設定します。ただし、要件に応じて増やすことは可能です。ここでの目的は、並列処理で設定された同時実行レベルで、構成に従ってタスクが完了まで実行されることです。
- [作成] をクリックする
Cloud Run ジョブが正常に作成されます。
仕組み
ジョブのコンテナ インスタンスが起動します。BigQuery にクエリを送信して、PENDING とマークされた URL の小さなバッチ(BATCH_SIZE)を取得します。取得した URL のステータスを BigQuery で PROCESSING にすぐに更新し、他のジョブ インスタンスがそれらを取得しないようにします。ThreadPoolExecutor を作成し、バッチ内の URL ごとにタスクを送信します。各タスクは call_url_processor_service 関数を呼び出します。call_url_processor_service リクエストが完了(またはタイムアウト/失敗)すると、その結果(AI 生成のコンテキストまたはエラー メッセージ)が収集され、元の row_id にマッピングされます。バッチのすべてのタスクが完了すると、ジョブは収集された結果を反復処理し、BigQuery の対応する各行のコンテキスト フィールドとステータス フィールドを更新します。成功すると、ジョブ インスタンスは正常に終了します。処理されないエラーが発生すると、例外が発生し、Cloud Run Jobs による再試行がトリガーされる可能性があります(ジョブ構成によって異なります)。
Cloud Run ジョブの適合性: オーケストレーション
ここで Cloud Run Jobs が真価を発揮します。
サーバーレス バッチ処理: データを同時に処理するために、必要に応じて(最大 MAX_INSTANCES まで)コンテナ インスタンスをスピンアップできるマネージド インフラストラクチャを取得します。
並列処理の制御: MAX_INSTANCES(全体で並列実行できるジョブの数)と TASK_CONCURRENCY(各ジョブ インスタンスが並列実行するオペレーションの数)を定義します。これにより、スループットとリソース使用率をきめ細かく制御できます。
フォールト トレランス: ジョブ インスタンスが途中で失敗した場合、Cloud Run Jobs はジョブ全体または特定のタスクを再試行するように構成できます。これにより、データ処理が失われることはありません。
アーキテクチャの簡素化: ジョブ内で HTTP 呼び出しを直接オーケストレートし、状態管理に BigQuery を使用することで、Pub/Sub、そのトピック、サブスクリプション、確認応答ロジックの設定と管理の複雑さを回避できます。
MAX_INSTANCES と TASK_CONCURRENCY:
MAX_INSTANCES: ジョブ実行全体で同時に実行できるジョブ インスタンスの合計数。これは、一度に多くの URL を処理するための主な並列処理の手段です。
TASK_CONCURRENCY: ジョブの単一インスタンスが実行する並列オペレーション(プロセッサ サービスへの呼び出し)の数。これにより、1 つのインスタンスの CPU/ネットワークが飽和状態になります。
9. Cloud Run ジョブの実行とモニタリング
動画メタデータ
実行をクリックする前に、データのステータスを確認しましょう。
BigQuery Studio に移動し、次のクエリを実行します。
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
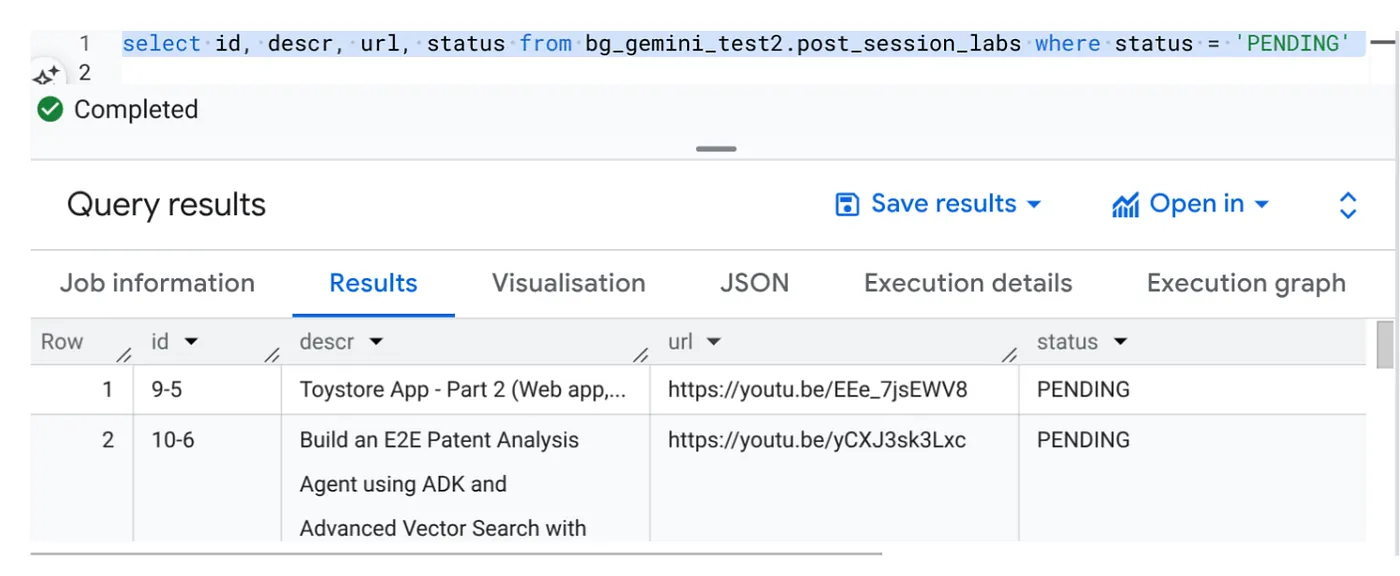
動画 URL が含まれ、ステータスが PENDING のサンプル レコードがいくつかあります。この機能の目的は、プロンプトで説明した形式で動画の分析情報を「コンテキスト」フィールドに入力することです。
ジョブトリガー
Cloud Run ジョブ コンソールのジョブで [実行] ボタンをクリックしてジョブを実行します。コンソールでジョブの進行状況とステータスを確認できます。
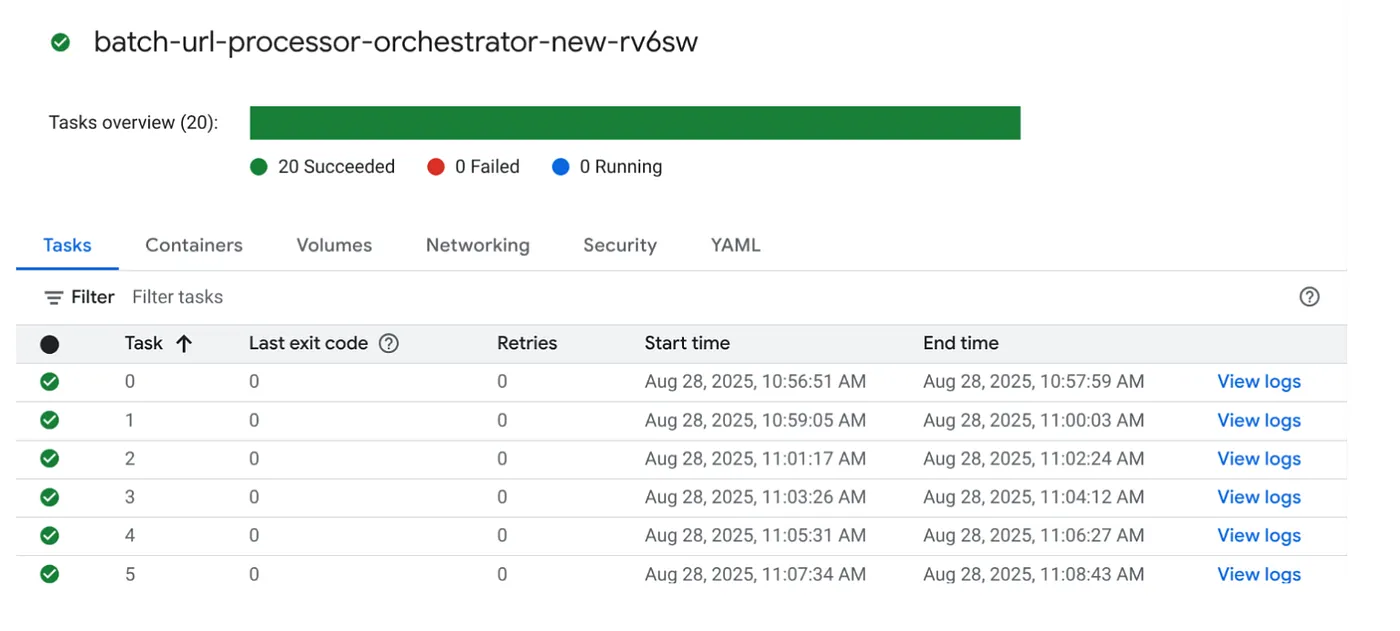
[OBSERVABILITY] の [LOGS] タグで、モニタリング ステップと、ジョブとタスクに関するその他の詳細を確認できます。
10. 結果の分析
ジョブが完了すると、各動画 URL のコンテキストがテーブルで更新されていることを確認できます。
出力コンテキスト(レコードの 1 つ)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
これで、より高度なエージェント ユースケースでこの JSON 構造を検証できるようになりました。
このアプローチを採用した理由
このアーキテクチャには、次のような戦略上の大きな利点があります。
- 費用対効果: サーバーレス サービスでは、使用した分に対してのみ料金が発生します。Cloud Run ジョブは、使用されていない場合はゼロまでスケールダウンします。
- スケーラビリティ: Cloud Run Job のインスタンスと同時実行の設定を調整することで、数万件の URL を簡単に処理できます。
- アジリティ: 含まれるアプリケーションとそのサービスを更新するだけで、新しい処理ロジックや AI モデルの開発とデプロイのサイクルを迅速に行うことができます。
- 運用オーバーヘッドの削減: パッチ適用や管理が必要なサーバーはありません。インフラストラクチャは Google が処理します。
- AI の民主化: 高度な AI 処理をバッチタスクで利用できるようにします。ML Ops の深い専門知識は必要ありません。
11. クリーンアップ
この投稿で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の操作を行います。
- Google Cloud コンソールで、[リソース マネージャー] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
12. 完了
おめでとうございます!Cloud Run ジョブを中心にソリューションを設計し、データ管理に BigQuery の能力を活用し、AI 処理に外部の Cloud Run サービスを活用することで、スケーラビリティが高く、費用対効果が高く、保守しやすいシステムを構築しました。このパターンは、処理ロジックを分離し、複雑なインフラストラクチャなしで並列実行を可能にし、インサイトまでの時間を大幅に短縮します。
独自のバッチ処理のニーズに合わせて Cloud Run ジョブをご検討ください。AI 分析のスケーリング、ETL パイプラインの実行、定期的なデータタスクの実行など、このサーバーレス アプローチは強力で効率的なソリューションを提供します。ご自身で始めるには、こちらをご覧ください。
すべてのアプリをサーバーレスでエージェントベースで構築してデプロイすることにご興味をお持ちの場合は、データドリブン型の生成エージェント アプリケーションの高速化に焦点を当てた Code Vipassana にご登録ください。