
1. 개요
오늘날의 데이터가 풍부한 세상에서 비구조화된 콘텐츠, 특히 동영상에서 유의미한 인사이트를 추출하는 것은 매우 중요합니다. 수백 또는 수천 개의 동영상 URL을 분석하고, 콘텐츠를 요약하고, 주요 기술을 추출하고, 교육 자료를 위한 질문과 답변 쌍을 생성해야 한다고 가정해 보겠습니다. 이 작업을 하나씩 수행하는 것은 시간이 오래 걸릴 뿐만 아니라 비효율적입니다. 최신 클라우드 아키텍처가 빛을 발하는 부분입니다.
이 실습에서는 Google Cloud의 강력한 서비스 모음인 Cloud Run, BigQuery, Google의 생성형 AI (Gemini)를 사용하여 동영상 콘텐츠를 처리하는 확장 가능한 서버리스 솔루션을 살펴봅니다. 단일 URL 처리에서 복잡한 메시지 대기열 및 통합 관리 오버헤드 없이 대규모 데이터 세트에서 병렬 실행을 오케스트레이션하는 여정을 자세히 설명합니다.
과제
Google은 실습 세션에 중점을 두고 대규모 동영상 콘텐츠 카탈로그를 처리해야 했습니다. 목표는 각 동영상을 분석하고 챕터 제목, 소개 컨텍스트, 단계별 안내, 사용된 기술, 관련 Q&A 쌍을 포함한 구조화된 요약을 생성하는 것이었습니다. 이 출력은 교육 자료를 만드는 데 나중에 사용할 수 있도록 효율적으로 저장해야 했습니다.
처음에는 한 번에 하나의 URL을 처리할 수 있는 간단한 HTTP 기반 Cloud Run 서비스가 있었습니다. 이 방법은 테스트 및 임시 분석에 적합했습니다. 하지만 BigQuery에서 가져온 수천 개의 URL 목록을 처리할 때는 단일 요청, 단일 응답 모델의 한계가 명확해졌습니다. 순차적으로 처리하는 데는 몇 주가 걸릴 수 있습니다.
기회는 수동 또는 느린 순차적 프로세스를 자동화된 병렬화된 워크플로로 변환하는 것이었습니다. 클라우드를 활용하여 다음과 같은 목표를 달성하고자 했습니다.
- 데이터를 병렬로 처리: 대규모 데이터 세트의 처리 시간을 크게 줄입니다.
- 기존 AI 기능 활용: Gemini의 기능을 활용하여 정교한 콘텐츠 분석을 수행합니다.
- 서버리스 아키텍처 유지: 서버 또는 복잡한 인프라를 관리하지 않습니다.
- 데이터 중앙 집중화: BigQuery를 입력 URL의 단일 정보 소스이자 처리된 결과의 신뢰할 수 있는 대상으로 사용합니다.
- 강력한 파이프라인 구축: 장애에 강하고 쉽게 관리하고 모니터링할 수 있는 시스템을 만듭니다.
목표
Cloud Run 작업을 사용한 병렬 AI 처리 조정:
이 솔루션은 조정자 역할을 하는 Cloud Run 작업을 중심으로 합니다. BigQuery에서 URL 배치를 지능적으로 읽고, 이러한 URL을 기존에 배포된 Cloud Run 서비스 (단일 URL의 AI 처리를 처리함)로 디스패치한 다음, 결과를 집계하여 BigQuery에 다시 씁니다. 이 접근 방식을 사용하면 다음 작업을 할 수 있습니다.
- 처리에서 조정 분리: 작업은 워크플로를 관리하고 별도의 서비스는 AI 작업에 집중합니다.
- Cloud Run 작업의 병렬 처리 활용: 작업은 AI 서비스를 동시에 호출하기 위해 여러 컨테이너 인스턴스를 스케일 아웃할 수 있습니다.
- 복잡성 감소: 작업에서 동시 HTTP 호출을 직접 관리하여 병렬 처리를 달성하고 아키텍처를 간소화합니다.
사용 사례
Code Vipassana 세션 동영상의 AI 기반 인사이트
구체적인 사용 사례는 Code Vipassana 실습의 Google Cloud 세션 동영상을 분석하는 것이었습니다. 목표는 다음을 포함한 구조화된 문서 (책 챕터 개요)를 자동으로 생성하는 것이었습니다.
- 챕터 제목: 각 동영상 세그먼트의 간결한 제목
- 소개 맥락: 더 넓은 학습 과정에서 동영상의 관련성 설명
- 빌드할 항목: 세션의 핵심 작업 또는 목표
- 사용된 기술: 언급된 클라우드 서비스 및 기타 기술 목록
- 단계별 안내: 코드 스니펫을 포함하여 태스크가 수행된 방식
- 소스 코드/데모 URL: 동영상에 제공된 링크
- Q&A 세그먼트: 지식 확인을 위한 관련 질문과 답변을 생성합니다.
Flow

아키텍처 흐름
Cloud Run이란 무엇인가요? Cloud Run 작업이란 무엇인가요?
Cloud Run
스테이트리스(Stateless) 컨테이너를 실행할 수 있는 완전 관리형 서버리스 플랫폼입니다. 수신 요청에 따라 자동으로 확장할 수 있는 웹 서비스, API, 마이크로서비스에 적합합니다. 컨테이너 이미지를 제공하면 Cloud Run에서 배포, 확장, 인프라 관리 등 나머지 작업을 처리합니다. 동기식 요청-응답 워크로드를 처리하는 데 탁월합니다.
Cloud Run 작업
Cloud Run 서비스를 보완하는 제품입니다. Cloud Run 작업은 완료된 후 중지해야 하는 일괄 처리 작업을 위해 설계되었습니다. 데이터 처리, ETL, 머신러닝 일괄 추론, 실시간 요청을 처리하는 대신 데이터 세트를 처리하는 작업에 적합합니다. 주요 기능은 일괄 작업을 처리하기 위해 동시에 실행되는 컨테이너 인스턴스 (작업) 수를 확장할 수 있다는 점이며, 다양한 이벤트 소스에 의해 트리거되거나 수동으로 트리거될 수 있습니다.
주요 차이점
Cloud Run 서비스는 장기 실행 요청 기반 애플리케이션을 위한 것입니다. Cloud Run 작업은 완료될 때까지 실행되는 유한한 작업 중심 일괄 처리를 위한 것입니다.
빌드할 항목
Retail Search 애플리케이션
이 과정에서 다음 작업을 수행합니다.
- BigQuery 데이터 세트, 테이블 만들기 및 데이터 수집 (코드 Vipassana 메타데이터)
- 생성형 AI 기능을 구현하기 위한 Python Cloud Run Functions 만들기 (동영상을 책 챕터 json으로 변환)
- 데이터-AI 파이프라인용 Python 애플리케이션 만들기 - BigQuery에서 읽고, 통계를 위해 Cloud Run 함수 엔드포인트를 호출하고, 컨텍스트를 BigQuery에 다시 쓰기
- 애플리케이션 빌드 및 컨테이너화
- 이 컨테이너로 Cloud Run 작업을 구성합니다.
- 작업 실행 및 모니터링
- 결과 보고
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요 .
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API 사용 설정: 링크를 따라 API를 사용 설정합니다.
또는 gcloud 명령어를 사용할 수 있습니다. gcloud 명령어 및 사용법은 문서를 참조하세요.
3. 데이터베이스/웨어하우스 설정
BigQuery는 데이터 파이프라인의 중추 역할을 했습니다. 서버리스이며 확장성이 뛰어나 입력 데이터를 저장하고 처리된 결과를 보관하는 데 적합합니다.
- 데이터 스토리지: BigQuery가 데이터 웨어하우스 역할을 했습니다. 동영상 URL, 상태 (예: PENDING, PROCESSING, COMPLETED), 최종 생성된 컨텍스트의 목록을 저장합니다. 처리해야 하는 동영상의 단일 정보 소스입니다.
- 대상: AI 생성 통계가 저장되어 다운스트림 애플리케이션에서 쉽게 쿼리하거나 수동으로 검토할 수 있는 위치입니다. 데이터 세트는 동영상 세션 세부정보, 특히 자세한 기술 시연이 자주 포함되는 'Code Vipassana Seasons' 콘텐츠로 구성되었습니다.
- 소스 테이블: 다음과 같은 레코드가 포함된 BigQuery 테이블 (예: post_session_labs)
- id: 각 세션/행의 고유 식별자입니다.
- url: 동영상의 URL (예: YouTube 링크 또는 액세스 가능한 드라이브 링크)입니다.
- status: 처리 상태를 나타내는 문자열입니다 (예: PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- context: AI 생성 요약을 저장하는 문자열 필드입니다.
- 데이터 수집: 이 시나리오에서는 INSERT 스크립트를 사용하여 데이터를 BigQuery로 수집했습니다. 파이프라인의 경우 BigQuery가 시작점이었습니다.
BigQuery 콘솔로 이동하여 새 탭을 열고 다음 SQL 문을 실행합니다.
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. 데이터 수집
이제 매장에 관한 데이터가 포함된 표를 추가할 차례입니다. BigQuery Studio에서 탭으로 이동하고 다음 SQL 문을 실행하여 샘플 레코드를 삽입합니다.
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. 동영상 통계 함수 생성
동영상 URL에서 구조화된 책 챕터를 만드는 기능의 핵심을 구현하려면 Cloud Run 함수를 만들고 배포해야 합니다. 이 도구에 독립적인 엔드포인트 도구 상자로 액세스할 수 있도록 Cloud Run 함수를 만들고 배포했습니다. 또는 Cloud Run 작업의 실제 Python 애플리케이션에 별도의 함수로 포함할 수도 있습니다.
- Google Cloud 콘솔에서 Cloud Run 페이지로 이동합니다.
- 함수 작성을 클릭합니다.
- '서비스 이름' 필드에 함수를 설명하는 이름을 입력합니다. 서비스 이름은 문자로만 시작해야 하고 문자, 숫자, 하이픈을 포함하여 최대 49자까지 포함할 수 있습니다. 서비스 이름은 하이픈으로 끝날 수 없고 리전 및 프로젝트별로 고유해야 합니다. 서비스 이름은 나중에 변경할 수 없으며 공개적으로 표시됩니다. ( generate-video-insights**)**
- '리전' 목록에서 기본값을 사용하거나 함수를 배포하려는 리전을 선택합니다. (us-central1 선택)
- 런타임 목록에서 기본값을 사용하거나 런타임 버전을 선택합니다. (Python 3.11 선택)
- 인증 섹션에서 '공개 액세스 허용'을 선택합니다.
- '만들기' 버튼을 클릭합니다.
- 함수가 생성되고 템플릿 main.py 및 requirements.txt와 함께 로드됩니다.
- 이 프로젝트의 저장소에 있는 main.py 및 requirements.txt 파일로 바꿉니다.
중요: main.py에서 <<YOUR_PROJECT_ID>>를 프로젝트 ID로 바꿔야 합니다.
- Cloud Run 작업의 소스에서 사용할 수 있도록 엔드포인트를 배포하고 저장합니다.
엔드포인트는 다음과 같아야 합니다 (또는 이와 유사해야 함). https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
이 Cloud Run 함수에는 무엇이 있나요?
동영상 처리를 위한 Gemini 2.5 Flash
동영상 콘텐츠를 이해하고 요약하는 핵심 작업에는 Google의 Gemini 2.5 Flash 모델을 활용했습니다. Gemini 모델은 텍스트를 비롯해 특정 통합을 통해 동영상 등 다양한 유형의 입력을 이해하고 처리할 수 있는 강력한 멀티모달 AI 모델입니다.
설정에서 동영상 파일을 Gemini에 직접 피드하지 않았습니다. 대신 동영상 URL을 포함하는 텍스트 프롬프트를 전송하고 해당 URL의 (가상) 동영상 콘텐츠를 분석하는 방법을 Gemini에 안내했습니다. Gemini 2.5 Flash는 멀티모달 입력을 지원하지만 이 특정 파이프라인에서는 동영상의 특성 (실습 세션)을 설명하고 구조화된 JSON 출력을 요청하는 텍스트 기반 프롬프트를 사용했습니다. 이를 통해 Gemini의 고급 추론 및 자연어 이해 기능을 활용하여 프롬프트의 컨텍스트를 기반으로 정보를 추론하고 합성합니다.
Gemini 프롬프트: AI 안내
잘 작성된 프롬프트는 AI 모델에 매우 중요합니다. 프롬프트는 매우 구체적인 정보를 추출하고 이를 JSON 형식으로 구조화하여 애플리케이션에서 쉽게 파싱할 수 있도록 설계되었습니다.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
이 프롬프트는 매우 구체적이며 Gemini가 일종의 교육자 역할을 하도록 안내합니다. JSON 문자열을 요청하면 구조화된 머신 판독 가능 출력이 보장됩니다.
다음은 동영상 입력을 분석하고 컨텍스트를 반환하는 코드입니다.
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
위 스니펫은 사용 사례의 핵심 기능을 보여줍니다. 동영상 URL을 수신하고 Vertex AI 클라이언트를 통해 Gemini 모델을 활용하여 동영상 콘텐츠를 분석하고 프롬프트에 따라 관련 통계를 추출합니다. 추출된 컨텍스트는 추가 처리를 위해 반환됩니다. 이는 Cloud Run 작업이 서비스가 완료될 때까지 기다리는 동기 작업을 나타냅니다.
6. 파이프라인 애플리케이션 개발 (Python)
중앙 파이프라인 로직은 Cloud Run 작업으로 컨테이너화되는 애플리케이션의 소스 코드에 있으며, 이 소스 코드가 전체 병렬 실행을 오케스트레이션합니다. 주요 부분은 다음과 같습니다.
워크플로를 관리하고 데이터 무결성을 보장하는 데 있어 오케스트레이터의 역할은 다음과 같습니다.
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
위 스니펫은 BigQuery 소스 테이블에서 상태가 'PENDING'인 동영상 URL 배치를 가져오는 것으로 시작합니다. 그런 다음 BigQuery에서 이러한 URL의 상태를 'PROCESSING'으로 업데이트하여 중복 처리를 방지합니다.
ThreadPoolExecutor를 사용한 병렬 처리 및 프로세서 서비스 호출:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
이 코드 부분에서는 ThreadPoolExecutor를 활용하여 가져온 동영상 URL의 병렬 처리를 구현합니다. 각 URL에 대해 Cloud Run 서비스 (URL 프로세서)를 비동기적으로 호출하는 작업을 제출합니다. 이를 통해 Cloud Run 작업이 여러 동영상을 동시에 효율적으로 처리하여 전체 파이프라인 성능을 향상할 수 있습니다. 이 스니펫은 프로세서 서비스의 잠재적인 시간 초과 및 오류도 처리합니다.
BigQuery에서 읽기 및 쓰기
BigQuery와의 핵심 상호작용에는 대기 중인 URL을 가져온 다음 처리된 결과로 업데이트하는 작업이 포함됩니다.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
결과를 BigQuery에 다시 작성:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
위 스니펫은 Cloud Run 작업과 BigQuery 간의 데이터 상호작용에 중점을 둡니다. 소스 테이블에서 'PENDING' 동영상 URL과 ID를 일괄적으로 가져옵니다. URL이 처리된 후 이 스니펫은 추출된 컨텍스트와 상태('COMPLETED' 또는 'FAILED_PROCESSING')를 UPDATE 쿼리를 사용하여 타겟 BigQuery 테이블에 다시 쓰는 방법을 보여줍니다. 이 스니펫은 데이터 처리 루프를 완료합니다. 또한 업데이트 문의 매개변수를 정의하는 방법을 보여주는 update_bq_row 도우미 함수도 포함되어 있습니다.
애플리케이션 설정
애플리케이션은 컨테이너화될 단일 Python 스크립트로 구성됩니다. Google Cloud 클라이언트 라이브러리와 functions-framework를 활용하여 진입점을 정의합니다.
- 종속 항목: google-cloud-bigquery, requests
- 구성: 모든 중요 설정 (BigQuery 프로젝트/데이터 세트/테이블, URL 프로세서 서비스 URL)이 환경 변수에서 로드되므로 애플리케이션을 휴대하고 안전하게 사용할 수 있습니다.
- 핵심 로직: process_batch_from_bq 함수는 전체 워크플로를 조정합니다.
- 외부 서비스 통합: call_url_processor_service 함수는 별도의 Cloud Run 서비스와의 통신을 처리합니다.
- BigQuery 상호작용: bq_client는 URL을 가져오고 결과를 업데이트하는 데 사용되며, 적절한 매개변수 처리가 이루어집니다.
- 병렬 처리: concurrent.futures.ThreadPoolExecutor가 외부 서비스에 대한 동시 호출을 관리합니다.
- 진입점: main.py라는 Python 코드는 일괄 처리를 시작하는 진입점 역할을 합니다.
이제 애플리케이션을 설정해 보겠습니다.
- 먼저 Cloud Shell 터미널로 이동하여 저장소를 클론합니다.
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Cloud Shell 편집기로 이동하면 새로 만든 폴더 video-context-crj가 표시됩니다.
- 이전 섹션에서 이미 완료된 단계이므로 다음을 삭제합니다.
- Cloud_Run_Function 폴더 삭제
- video-context-crj 프로젝트 폴더로 이동하면 다음과 같은 프로젝트 구조가 표시됩니다.
7. Dockerfile 설정 및 컨테이너화
이 로직을 Cloud Run 작업으로 배포하려면 컨테이너화해야 합니다. 컨테이너화는 애플리케이션 코드, 종속 항목, 런타임을 휴대용 이미지로 패키징하는 프로세스입니다.
Dockerfile에서 자리표시자 (굵은 텍스트)를 값으로 바꿔야 합니다.
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
위의 Dockerfile 스니펫은 기본 이미지를 정의하고, 종속 항목을 설치하고, 코드를 복사하고, 올바른 타겟 함수 (process_batch_from_bq)를 사용하여 functions-framework로 애플리케이션을 실행하는 명령어를 설정합니다. 그런 다음 이 이미지가 Artifact Registry로 푸시됩니다.
컨테이너화
컨테이너화하려면 Cloud Shell 터미널로 이동하여 다음 명령어를 실행합니다(<<YOUR_PROJECT_ID>> 자리표시자를 바꿔야 함).
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
컨테이너 이미지가 생성되면 다음 출력이 표시됩니다.
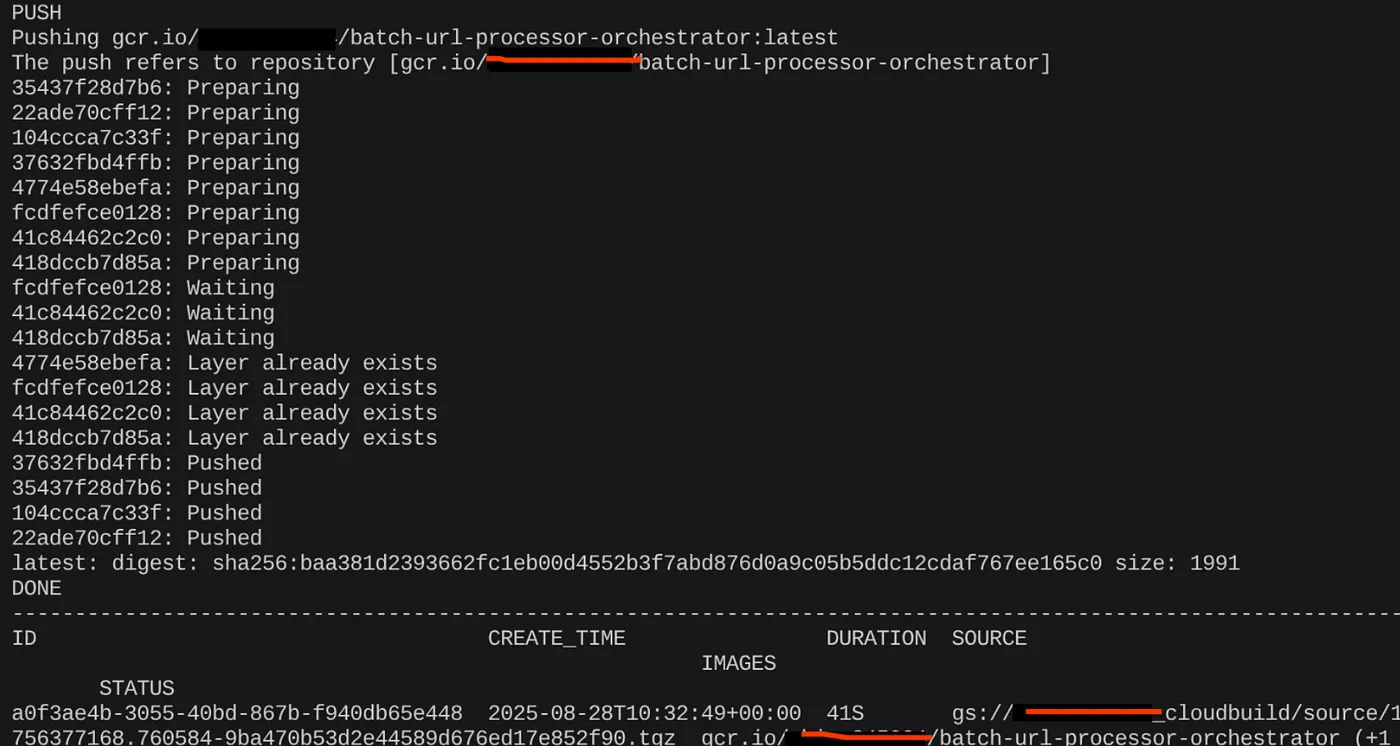
이제 컨테이너가 생성되어 Artifact Registry에 저장되었습니다. 다음 단계로 진행해도 됩니다.
8. Cloud Run 작업 생성
작업을 배포하려면 컨테이너 이미지를 빌드한 다음 Cloud Run 작업 리소스를 만들어야 합니다.
컨테이너 이미지를 이미 만들어 Artifact Registry에 저장했습니다. 이제 작업을 만들어 보겠습니다.
- Cloud Run 작업 콘솔로 이동하여 컨테이너 배포를 클릭합니다.

- 방금 만든 컨테이너 이미지를 선택합니다.
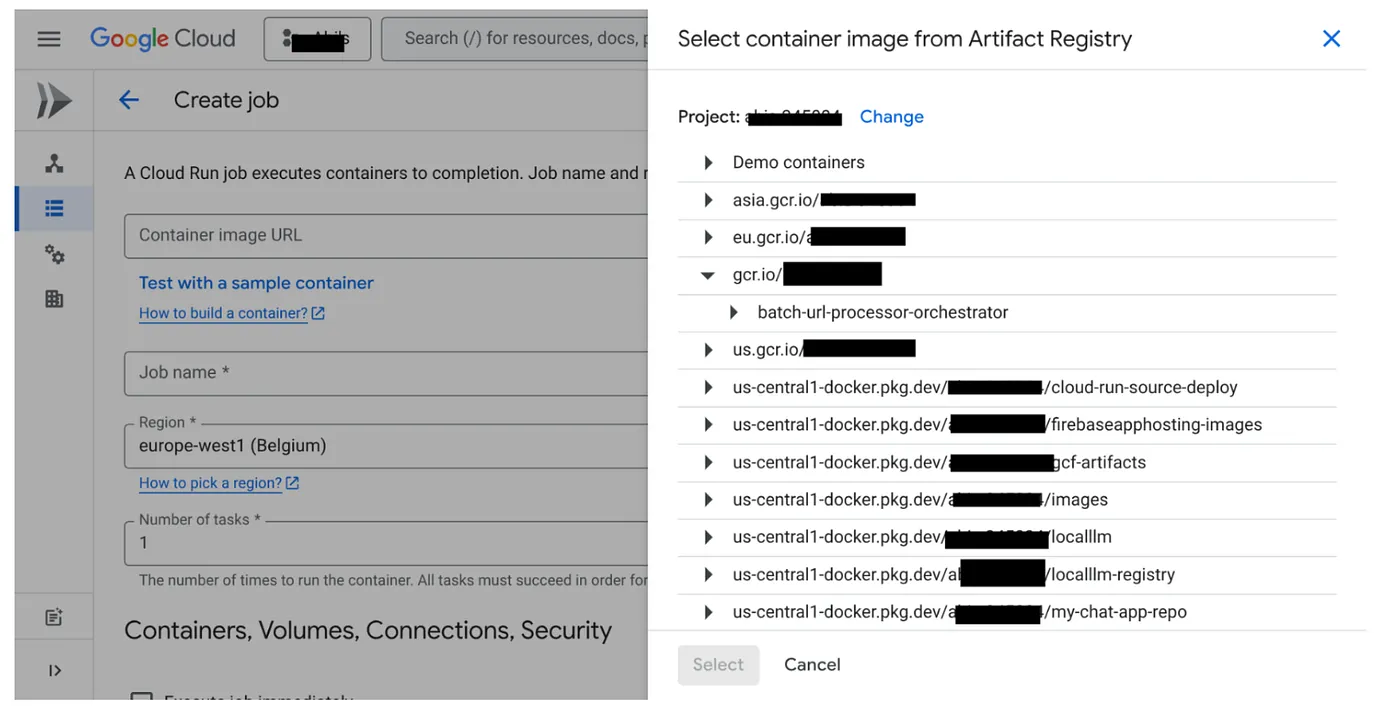
- 다음과 같이 다른 구성 세부정보를 입력합니다.

- 다음과 같이 작업 용량을 설정합니다.
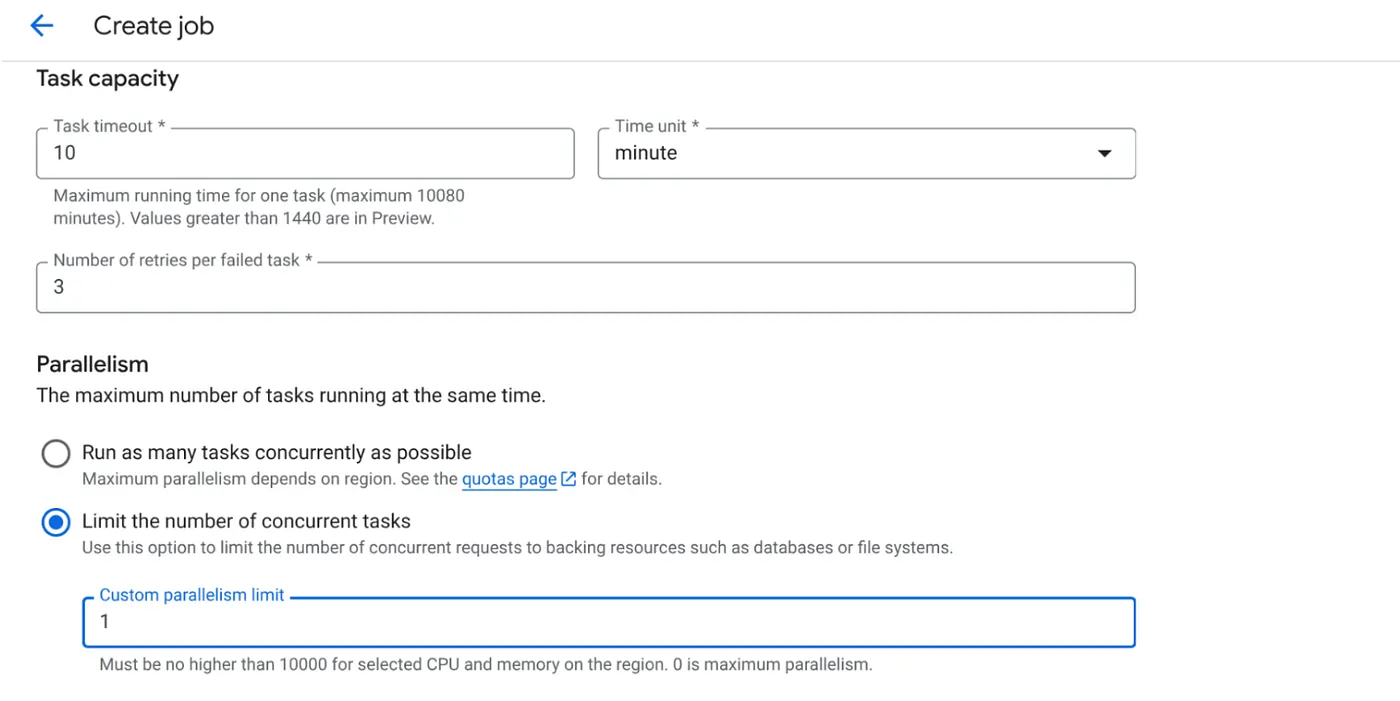
데이터베이스 쓰기가 있고 병렬화 (max_instances 및 작업 동시성)가 이미 코드에서 처리되므로 동시 작업 수를 1로 설정합니다. 하지만 요구사항에 따라 늘려도 됩니다. 여기서 목표는 병렬 처리에서 설정된 동시 실행 수준으로 구성에 따라 작업이 완료될 때까지 실행되는 것입니다.
- 만들기 클릭
Cloud Run 작업이 생성됩니다.
작동 방식
작업의 컨테이너 인스턴스가 시작됩니다. BigQuery를 쿼리하여 PENDING으로 표시된 URL의 작은 배치 (BATCH_SIZE)를 가져옵니다. 다른 작업 인스턴스가 이러한 URL을 선택하지 못하도록 BigQuery에서 가져온 URL의 상태를 즉시 PROCESSING으로 업데이트합니다. ThreadPoolExecutor를 만들고 배치에 있는 각 URL에 대한 작업을 제출합니다. 각 작업은 call_url_processor_service 함수를 호출합니다. call_url_processor_service 요청이 완료되거나 시간 초과/실패되면 결과(AI 생성 컨텍스트 또는 오류 메시지)가 수집되어 원래 row_id에 다시 매핑됩니다. 배치의 모든 작업이 완료되면 작업은 수집된 결과를 반복하고 BigQuery의 각 해당 행에 대한 컨텍스트 및 상태 필드를 업데이트합니다. 성공하면 작업 인스턴스가 깔끔하게 종료됩니다. 처리되지 않은 오류가 발생하면 예외가 발생하여 Cloud Run Jobs에서 재시도를 트리거할 수 있습니다 (작업 구성에 따라 다름).
Cloud Run 작업의 역할: 오케스트레이션
이때 Cloud Run 작업이 진가를 발휘합니다.
서버리스 일괄 처리: 데이터를 동시에 처리하기 위해 필요한 만큼 (최대 MAX_INSTANCES) 컨테이너 인스턴스를 실행할 수 있는 관리형 인프라를 얻습니다.
동시 로드 제어: MAX_INSTANCES (전체적으로 동시에 실행할 수 있는 작업 수)와 TASK_CONCURRENCY (각 작업 인스턴스가 동시에 실행하는 작업 수)를 정의합니다. 이를 통해 처리량과 리소스 사용률을 세밀하게 제어할 수 있습니다.
내결함성: 작업 인스턴스가 중간에 실패하면 데이터 처리가 손실되지 않도록 전체 작업 또는 특정 작업을 재시도하도록 Cloud Run Jobs를 구성할 수 있습니다.
간소화된 아키텍처: 작업 내에서 직접 HTTP 호출을 오케스트레이션하고 상태 관리에 BigQuery를 사용하면 Pub/Sub, 주제, 구독, 승인 로직을 설정하고 관리하는 복잡성을 피할 수 있습니다.
MAX_INSTANCES와 TASK_CONCURRENCY 비교:
MAX_INSTANCES: 전체 작업 실행에서 동시에 실행할 수 있는 작업 인스턴스의 총수입니다. 이는 한 번에 여러 URL을 처리하기 위한 주요 병렬 처리 레버입니다.
TASK_CONCURRENCY: 작업의 단일 인스턴스가 실행할 병렬 작업 (프로세서 서비스 호출)의 수입니다. 이렇게 하면 하나의 인스턴스의 CPU/네트워크가 포화됩니다.
9. Cloud Run 작업 실행 및 모니터링
동영상 메타데이터
실행을 클릭하기 전에 데이터의 상태를 확인해 보겠습니다.
BigQuery Studio로 이동하여 다음 쿼리를 실행합니다.
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
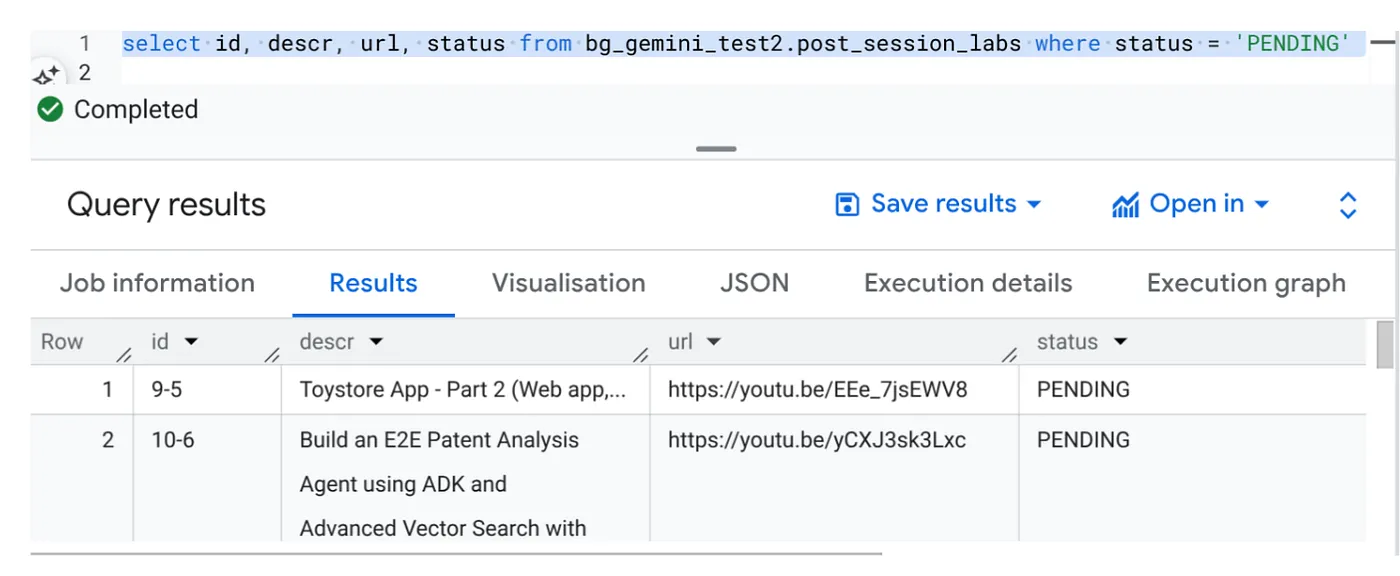
동영상 URL이 있고 상태가 '대기 중'인 샘플 레코드가 몇 개 있습니다. 목표는 프롬프트에 설명된 형식으로 동영상의 유용한 정보를 '컨텍스트' 필드에 입력하는 것입니다.
작업 트리거
Cloud Run 작업 콘솔에서 작업의 실행 버튼을 클릭하여 작업을 실행하면 콘솔에서 작업의 진행 상황과 상태를 확인할 수 있습니다.
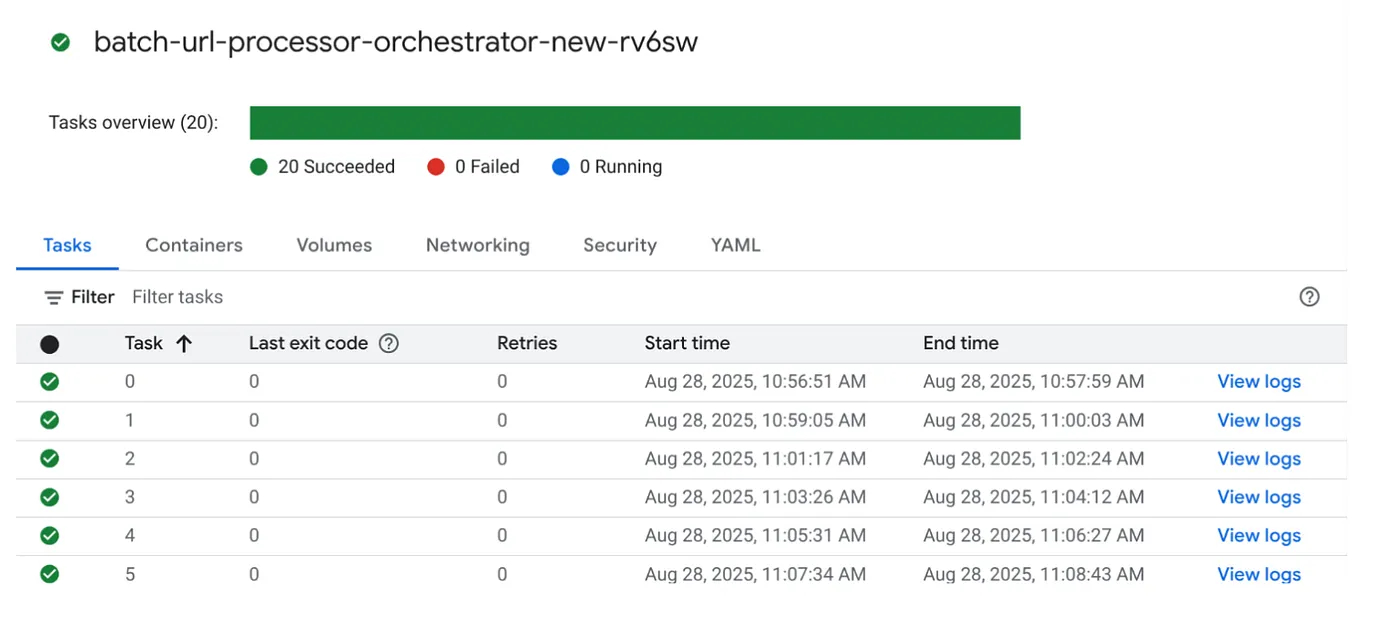
관측 가능성의 로그 태그에서 모니터링 단계와 작업 및 태스크에 관한 기타 세부정보를 확인할 수 있습니다.
10. 결과 분석
작업이 완료되면 표에 각 동영상 URL의 컨텍스트가 업데이트되어 표시됩니다.
출력 컨텍스트 (레코드 중 하나)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
이제 더 고급 에이전트 사용 사례를 위해 이 JSON 구조를 검증할 수 있습니다.
이 접근 방식을 사용하는 이유
이 아키텍처는 다음과 같은 중요한 전략적 이점을 제공합니다.
- 비용 효율성: 서버리스 서비스를 사용하면 사용한 만큼만 지불하면 됩니다. Cloud Run 작업은 사용하지 않을 때 0으로 축소됩니다.
- 확장성: Cloud Run 작업 인스턴스 및 동시 실행 설정을 조정하여 수만 개의 URL을 손쉽게 처리합니다.
- 민첩성: 포함된 애플리케이션과 서비스를 업데이트하기만 하면 새로운 처리 로직이나 AI 모델을 빠르게 개발하고 배포할 수 있습니다.
- 운영 오버헤드 감소: 패치하거나 관리할 서버가 없습니다. Google에서 인프라를 처리합니다.
- AI 대중화: 심층적인 ML Ops 전문 지식 없이도 일괄 작업에 고급 AI 처리를 사용할 수 있습니다.
11. 삭제
이 게시물에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 리소스 관리자 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력하고 종료를 클릭하여 프로젝트를 삭제합니다.
12. 축하합니다
축하합니다. Cloud Run Jobs를 중심으로 솔루션을 설계하고 데이터 관리에는 BigQuery를, AI 처리에는 외부 Cloud Run 서비스를 활용하여 확장성이 뛰어나고 비용 효율적이며 유지관리 가능한 시스템을 구축했습니다. 이 패턴은 처리 로직을 분리하고, 복잡한 인프라 없이 병렬 실행을 지원하며, 통찰력 확보 시간을 크게 단축합니다.
자체 일괄 처리 요구사항에 Cloud Run 작업을 활용해 보시기 바랍니다. AI 분석 확장, ETL 파이프라인 실행, 주기적인 데이터 작업 실행 등 어떤 작업을 수행하든 이 서버리스 방식은 강력하고 효율적인 솔루션을 제공합니다. 직접 시작하려면 여기에서 확인하세요.
모든 앱을 서버리스 및 에이전트 방식으로 빌드하고 배포하는 데 관심이 있다면 데이터 기반 생성형 에이전트 애플리케이션을 가속화하는 데 중점을 둔 Code Vipassana에 등록하세요.