
1. Przegląd
W dzisiejszym świecie, w którym mamy dostęp do ogromnych ilości danych, wyodrębnianie istotnych informacji z nieustrukturyzowanych treści, zwłaszcza z filmów, jest bardzo ważne. Wyobraź sobie, że musisz przeanalizować setki lub tysiące adresów URL filmów, podsumować ich zawartość, wyodrębnić kluczowe technologie, a nawet wygenerować pary pytań i odpowiedzi do materiałów edukacyjnych. Robienie tego po kolei jest nie tylko czasochłonne, ale też nieefektywne. W tym miejscu ujawniają się zalety nowoczesnych architektur chmurowych.
W tym module poznasz skalowalne, bezserwerowe rozwiązanie do przetwarzania treści wideo za pomocą zaawansowanego pakietu usług Google Cloud: Cloud Run, BigQuery i generatywnej AI od Google (Gemini). Opiszemy, jak przeszliśmy od przetwarzania pojedynczego adresu URL do koordynowania równoległego wykonywania operacji na dużym zbiorze danych bez konieczności zarządzania złożonymi kolejkami wiadomości i integracjami.
Wyzwanie
Naszym zadaniem było przetworzenie dużego katalogu treści wideo, ze szczególnym uwzględnieniem praktycznych sesji laboratoryjnych. Celem było przeanalizowanie każdego filmu i wygenerowanie strukturalnego podsumowania, w tym tytułów rozdziałów, kontekstu wprowadzenia, instrukcji krok po kroku, użytych technologii i odpowiednich par pytań i odpowiedzi. Dane wyjściowe musiały być przechowywane w efektywny sposób, aby można było ich później użyć do tworzenia materiałów edukacyjnych.
Początkowo mieliśmy prostą usługę Cloud Run opartą na protokole HTTP, która mogła przetwarzać jeden adres URL naraz. Sprawdzało się to w przypadku testowania i analiz ad hoc. Jednak w przypadku listy tysięcy adresów URL pochodzących z BigQuery ograniczenia tego modelu z pojedynczym żądaniem i pojedynczą odpowiedzią stały się oczywiste. Przetwarzanie sekwencyjne zajęłoby dni, a nawet tygodnie.
Możliwość polegała na przekształceniu ręcznego lub powolnego procesu sekwencyjnego w zautomatyzowany przepływ pracy wykonywany równolegle. Korzystając z chmury, chcieliśmy:
- Przetwarzanie danych równolegle: znacznie skraca czas przetwarzania dużych zbiorów danych.
- Wykorzystaj istniejące funkcje AI: używaj mocy Gemini do zaawansowanej analizy treści.
- Utrzymanie architektury bezserwerowej: unikaj zarządzania serwerami lub złożoną infrastrukturą.
- Centralizacja danych: używaj BigQuery jako jednego źródła informacji o adresach URL wejściowych i niezawodnego miejsca docelowego przetworzonych wyników.
- Zbuduj solidny potok: utwórz system odporny na awarie, którym można łatwo zarządzać i który można łatwo monitorować.
Cel
Orkiestracja przetwarzania równoległego AI za pomocą zadań Cloud Run:
Nasze rozwiązanie opiera się na zadaniu Cloud Run, które pełni rolę koordynatora. Inteligentnie odczytuje partie adresów URL z BigQuery, wysyła je do istniejącej, wdrożonej usługi Cloud Run (która obsługuje przetwarzanie AI dla pojedynczego adresu URL), a następnie agreguje wyniki i zapisuje je z powrotem w BigQuery. Dzięki temu możemy:
- Oddziel orkiestrację od przetwarzania: zadanie zarządza przepływem pracy, a osobna usługa koncentruje się na zadaniu realizowanym z wykorzystaniem AI.
- Skorzystaj z równoległości zadania Cloud Run: zadanie może skalować w poziomie wiele instancji kontenera, aby równocześnie wywoływać usługę AI.
- Zmniejszenie złożoności: równoległość osiągamy dzięki bezpośredniemu zarządzaniu przez zadanie równoczesnymi wywołaniami HTTP, co upraszcza architekturę.
Przypadek użycia
Obserwacje oparte na AI z filmów z sesji Code Vipassana
W naszym przypadku analizowaliśmy filmy z sesji Google Cloud w ramach praktycznych ćwiczeń z Code Vipassana. Celem było automatyczne generowanie ustrukturyzowanej dokumentacji (konspektów rozdziałów książki), w tym:
- Tytuły rozdziałów: zwięzłe tytuły każdego segmentu filmu
- Wprowadzenie: wyjaśnienie, dlaczego film jest istotny w szerszej ścieżce szkoleniowej.
- Co zostanie zbudowane: podstawowe zadanie lub cel sesji
- Użyte technologie: lista usług w chmurze i innych wymienionych technologii.
- Szczegółowe instrukcje: jak wykonano zadanie, w tym fragmenty kodu
- Adresy URL kodu źródłowego lub wersji demonstracyjnej: linki podane w filmie
- Segment pytań i odpowiedzi: generowanie odpowiednich pytań i odpowiedzi do sprawdzania wiedzy.
Flow

Przepływ w architekturze
Co to jest Cloud Run? Czym są zadania Cloud Run?
Cloud Run
W pełni zarządzana platforma bezserwerowa, która umożliwia uruchamianie bezstanowych kontenerów. Jest to idealne rozwiązanie w przypadku usług internetowych, interfejsów API i mikroserwisów, które można automatycznie skalować na podstawie żądań przychodzących. Ty dostarczasz obraz kontenera, a Cloud Run zajmuje się resztą – od wdrażania i skalowania po zarządzanie infrastrukturą. Doskonale radzi sobie z synchronicznymi zbiorami zadań typu żądanie-odpowiedź.
Zadania Cloud Run
Oferta uzupełniająca usługi Cloud Run. Zadania Cloud Run są przeznaczone do zadań przetwarzania wsadowego, które muszą zostać wykonane, a następnie zatrzymane. Świetnie nadają się do przetwarzania danych, ETL, wnioskowania wsadowego w uczeniu maszynowym i wszelkich zadań, które obejmują przetwarzanie zbioru danych, a nie obsługę żądań na żywo. Kluczową cechą jest możliwość skalowania w poziomie liczby instancji kontenerów (zadań) uruchomionych równocześnie w celu przetworzenia partii zadań. Można je wywoływać za pomocą różnych źródeł zdarzeń lub ręcznie.
Kluczowa różnica
Usługi Cloud Run są przeznaczone dla aplikacji działających długo i opartych na żądaniach. Zadania Cloud Run służą do przetwarzania wsadowego o określonym czasie trwania, które jest zorientowane na zadania i działa do ukończenia.
Co utworzysz
Aplikacja do wyszukiwania w handlu detalicznym
W ramach tego procesu:
- Utworzenie zbioru danych i tabeli BigQuery oraz wczytanie danych (metadane Code Vipassana)
- Utwórz funkcję Cloud Run w Pythonie, aby zaimplementować funkcję generatywnej AI (konwertowanie filmu na rozdział książki w formacie JSON).
- Tworzenie aplikacji w Pythonie na potrzeby potoku danych do AI – odczytywanie danych z BigQuery i wywoływanie punktu końcowego funkcji Cloud Run w celu uzyskania statystyk oraz zapisywanie kontekstu z powrotem w BigQuery
- Tworzenie i konteneryzowanie aplikacji
- Konfigurowanie zadań Cloud Run za pomocą tego kontenera
- Wykonywanie i monitorowanie zadania
- Wynik raportu
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności .
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: kliknij link i włącz interfejsy API.
Możesz też użyć polecenia gcloud. Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
3. Konfiguracja bazy danych lub hurtowni
BigQuery stanowiło podstawę naszego potoku danych. Dzięki bezserwerowej i wysoce skalowalnej architekturze idealnie nadaje się do przechowywania danych wejściowych i wyników przetwarzania.
- Przechowywanie danych: BigQuery pełniło funkcję hurtowni danych. Zawiera listę adresów URL filmów, ich stan (np. OCZEKUJĄCY, PRZETWARZANY, ZAKOŃCZONY) i wygenerowany kontekst. Jest to jedyne źródło informacji o tym, które filmy wymagają przetworzenia.
- Miejsce docelowe: to miejsce, w którym są przechowywane wygenerowane przez AI statystyki, dzięki czemu można je łatwo wysyłać do aplikacji podrzędnych lub ręcznie sprawdzać. Nasz zbiór danych zawierał szczegóły sesji wideo, zwłaszcza dotyczące treści „Code Vipassana Seasons”, które często obejmują szczegółowe demonstracje techniczne.
- Tabela źródłowa: tabela BigQuery (np. post_session_labs) zawierająca rekordy takie jak:
- id: unikalny identyfikator każdej sesji lub każdego wiersza.
- url: adres URL filmu (np. link do YouTube lub dostępny link do Dysku).
- status: ciąg znaków wskazujący stan przetwarzania (np. PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- context: pole tekstowe do przechowywania podsumowania wygenerowanego przez AI.
- Pozyskiwanie danych: w tym scenariuszu dane zostały pozyskane do BigQuery za pomocą skryptów INSERT. W naszym potoku BigQuery było punktem początkowym.
Otwórz konsolę BigQuery, otwórz nową kartę i wykonaj te instrukcje SQL:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Pozyskiwanie danych
Teraz dodaj tabelę z danymi o sklepie. Otwórz kartę w BigQuery Studio i wykonaj te instrukcje SQL, aby wstawić przykładowe rekordy:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Tworzenie funkcji statystyk wideo
Musimy utworzyć i wdrożyć funkcję Cloud Run, aby zaimplementować podstawową funkcję, która ma tworzyć uporządkowany rozdział książki na podstawie adresu URL filmu. Aby uzyskać do niego dostęp jako do niezależnego narzędzia punktu końcowego, utworzyliśmy i wdrożyliśmy funkcję Cloud Run. Możesz też uwzględnić tę funkcję jako osobną funkcję w rzeczywistej aplikacji w Pythonie dla zadania Cloud Run:
- W konsoli Google Cloud otwórz stronę Cloud Run.
- Kliknij Napisz funkcję.
- W polu Nazwa usługi wpisz nazwę opisującą funkcję. Nazwy usług muszą zaczynać się od litery i zawierać maksymalnie 49 znaków, w tym litery, cyfry i łączniki. Nazwy usług nie mogą kończyć się myślnikami i muszą być niepowtarzalne w obrębie regionu i projektu. Nazwy usługi nie można później zmienić i jest ona widoczna publicznie. ( generate-video-insights**)**
- Na liście Region (Region) użyj wartości domyślnej lub wybierz region, w którym chcesz wdrożyć funkcję. (Wybierz us-central1)
- Na liście Środowisko wykonawcze pozostaw wartość domyślną lub wybierz wersję środowiska wykonawczego. (Wybierz Python 3.11)
- W sekcji Uwierzytelnianie kliknij „Zezwól na dostęp publiczny”.
- Kliknij przycisk „Utwórz”.
- Funkcja zostanie utworzona i załaduje się z plikami szablonu main.py i requirements.txt.
- Zastąp je plikami main.py i requirements.txt z repozytorium tego projektu.
WAŻNA UWAGA: w pliku main.py pamiętaj, aby zastąpić ciąg znaków <<YOUR_PROJECT_ID>> identyfikatorem projektu.
- Wdróż i zapisz punkt końcowy, aby móc go używać w źródle zadania Cloud Run.
Punkt końcowy powinien wyglądać tak (lub podobnie): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
Co zawiera ta funkcja Cloud Run?
Gemini 2.5 Flash do przetwarzania wideo
Do podstawowego zadania, jakim jest zrozumienie i podsumowanie treści wideo, wykorzystaliśmy model Google Gemini 2.5 Flash. Modele Gemini to zaawansowane, multimodalne modele AI, które potrafią rozumieć i przetwarzać różne rodzaje danych wejściowych, w tym tekst, a w przypadku konkretnych integracji także filmy.
W naszym przypadku nie przekazaliśmy pliku wideo bezpośrednio do Gemini. Zamiast tego wysłaliśmy prompt tekstowy, który zawierał adres URL filmu i instrukcje dla Gemini dotyczące analizy (hipotetycznej) zawartości filmu pod tym adresem URL. Model Gemini 2.5 Flash obsługuje dane wejściowe multimodalne, ale w tym konkretnym potoku użyto prompta tekstowego, który opisywał charakter filmu (praktyczne zajęcia laboratoryjne) i wymagał strukturalnego wyjścia w formacie JSON. Wykorzystuje to zaawansowane wnioskowanie i rozumienie języka naturalnego Gemini, aby wywnioskować i zsyntetyzować informacje na podstawie kontekstu promptu.
Prompt Gemini: wskazówki dla AI
Dobrze sformułowany prompt ma kluczowe znaczenie dla modeli AI. Nasz prompt został zaprojektowany tak, aby wyodrębniać bardzo konkretne informacje i układać je w formacie JSON, co ułatwia ich analizowanie przez naszą aplikację.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
Ten prompt jest bardzo szczegółowy i nakierowuje Gemini na rolę edukatora. Żądanie ciągu JSON zapewnia uporządkowane dane wyjściowe czytelne dla komputera.
Oto kod do analizowania danych wejściowych wideo i zwracania ich kontekstu:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
Powyższy fragment kodu przedstawia podstawową funkcję tego przypadku użycia. Otrzymuje on adres URL filmu i korzysta z modelu Gemini za pomocą klienta Vertex AI, aby analizować treść filmu i wyodrębniać odpowiednie informacje zgodnie z promptem. Wyodrębniony kontekst jest następnie zwracany do dalszego przetwarzania. Jest to operacja synchroniczna, w której zadanie Cloud Run czeka na zakończenie działania usługi.
6. Tworzenie aplikacji potokowych (Python)
Główna logika potoku znajduje się w kodzie źródłowym aplikacji, który zostanie skonteneryzowany w zadaniu Cloud Run, które koordynuje całe równoległe wykonywanie. Oto najważniejsze części:
Rola orkiestratora w zarządzaniu przepływem pracy i zapewnianiu integralności danych:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
Powyższy fragment kodu zaczyna się od pobrania z tabeli źródłowej BigQuery partii adresów URL filmów ze stanem „PENDING”. Następnie aktualizuje stan tych adresów URL na „PROCESSING” w BigQuery, co zapobiega duplikowaniu przetwarzania.
Przetwarzanie równoległe za pomocą klasy ThreadPoolExecutor i wywoływanie usługi procesora:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
Ta część kodu wykorzystuje klasę ThreadPoolExecutor do równoległego przetwarzania pobranych adresów URL filmów. Dla każdego adresu URL przesyła zadanie, aby asynchronicznie wywołać usługę Cloud Run (procesor adresów URL). Dzięki temu zadanie Cloud Run może wydajnie przetwarzać wiele filmów jednocześnie, co zwiększa ogólną wydajność potoku. Fragment kodu obsługuje też potencjalne przekroczenia limitu czasu i błędy usługi procesora.
Odczytywanie i zapisywanie danych z BigQuery
Podstawowa interakcja z BigQuery polega na pobieraniu oczekujących adresów URL, a następnie aktualizowaniu ich przetworzonymi wynikami.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Zapisywanie wyników z powrotem w BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
Powyższe fragmenty kodu koncentrują się na interakcji danych między zadaniem Cloud Run a BigQuery. Pobiera z tabeli źródłowej partię adresów URL filmów o stanie „PENDING” i ich identyfikatorów. Po przetworzeniu adresów URL ten fragment kodu pokazuje, jak zapisać wyodrębniony kontekst i stan („COMPLETED” lub „FAILED_PROCESSING”) z powrotem w docelowej tabeli BigQuery za pomocą zapytania UPDATE. Ten fragment kodu zamyka pętlę przetwarzania danych. Zawiera też funkcję pomocniczą update_bq_row, która pokazuje, jak zdefiniować parametry instrukcji aktualizacji.
Konfiguracja aplikacji
Aplikacja ma postać pojedynczego skryptu w Pythonie, który zostanie umieszczony w kontenerze. Wykorzystuje biblioteki klienta Google Cloud i funkcje-framework do zdefiniowania punktu wejścia.
- Zależności: google-cloud-bigquery, requests
- Konfiguracja: wszystkie krytyczne ustawienia (projekt, zbiór danych i tabela BigQuery, adres URL usługi przetwarzania adresów URL) są wczytywane ze zmiennych środowiskowych, co sprawia, że aplikacja jest przenośna i bezpieczna.
- Logika podstawowa: funkcja process_batch_from_bq zarządza całym przepływem pracy.
- Integracja z usługą zewnętrzną: funkcja call_url_processor_service obsługuje komunikację z osobną usługą Cloud Run.
- Interakcja z BigQuery: bq_client służy do pobierania adresów URL i aktualizowania wyników z odpowiednią obsługą parametrów.
- Równoległość: concurrent.futures.ThreadPoolExecutor zarządza równoczesnymi wywołaniami usługi zewnętrznej.
- Punkt wejścia: kod Pythona o nazwie main.py działa jako punkt wejścia, który rozpoczyna przetwarzanie wsadowe.
Skonfigurujmy teraz aplikację:
- Zacznij od przejścia do terminala Cloud Shell i sklonowania repozytorium:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Otwórz edytor Cloud Shell, w którym zobaczysz nowo utworzony folder video-context-crj.
- Usuń te elementy, ponieważ zostały już wykonane w poprzednich sekcjach:
- Usuń folder Cloud_Run_Function.
- Przejdź do folderu projektu video-context-crj. Powinna się wyświetlić struktura projektu:
7. Konfiguracja pliku Dockerfile i konteneryzacja
Aby wdrożyć tę logikę jako zadanie Cloud Run, musimy ją skonteneryzować. Konteneryzacja to proces pakowania kodu aplikacji, jej zależności i środowiska wykonawczego w przenośny obraz.
W pliku Dockerfile zastąp symbole zastępcze (pogrubiony tekst) swoimi wartościami:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
Fragment pliku Dockerfile powyżej definiuje obraz bazowy, instaluje zależności, kopiuje nasz kod i ustawia polecenie uruchamiające aplikację za pomocą frameworka funkcji z odpowiednią funkcją docelową (process_batch_from_bq). Obraz jest następnie przesyłany do Artifact Registry.
Konteneryzacja
Aby umieścić go w kontenerze, otwórz terminal Cloud Shell i wykonaj te polecenia (pamiętaj, aby zastąpić symbol zastępczy <<YOUR_PROJECT_ID>>):
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
Po utworzeniu obrazu kontenera powinny pojawić się te dane wyjściowe:
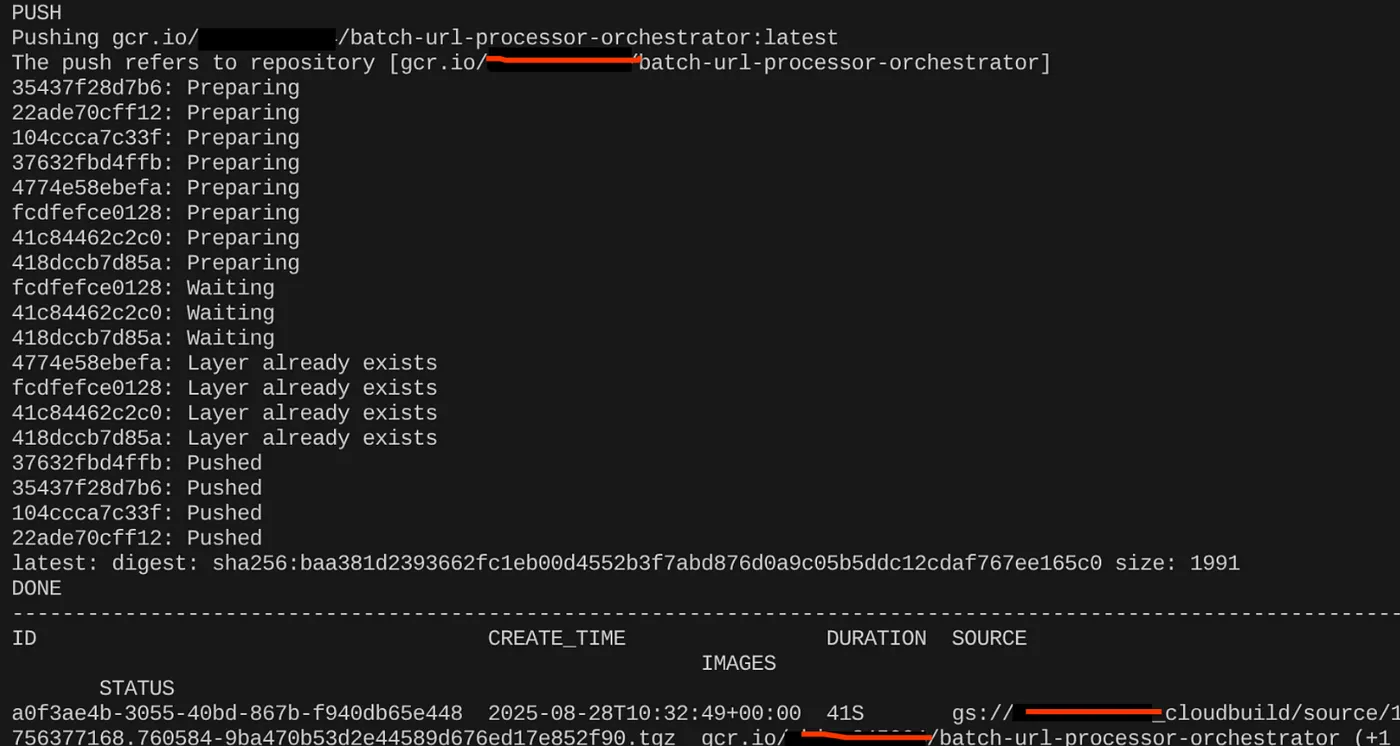
Kontener został utworzony i zapisany w Artifact Registry. Możemy przejść do następnego kroku.
8. Tworzenie zadań Cloud Run
Wdrożenie zadania obejmuje skompilowanie obrazu kontenera, a następnie utworzenie zasobu Cloud Run Job.
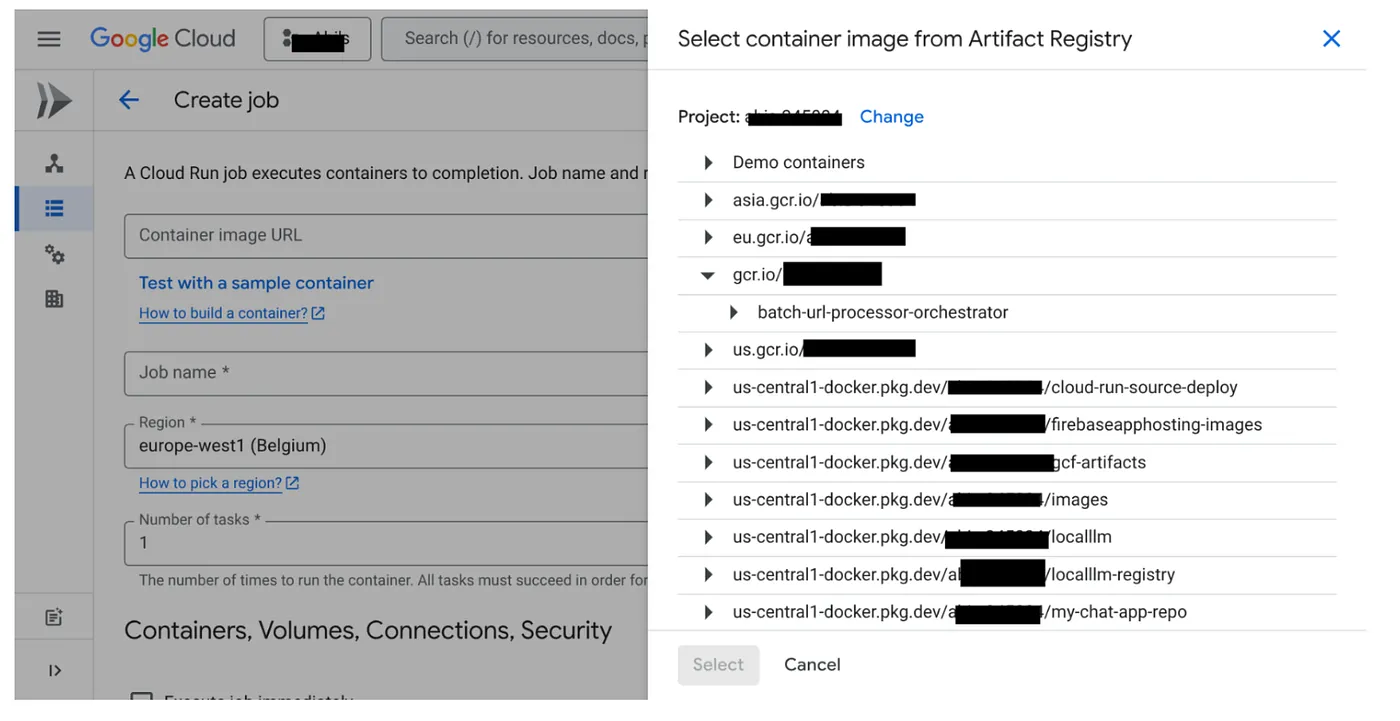
Obraz kontenera został już utworzony i jest przechowywany w Artifact Registry. Teraz utwórzmy zadanie.
- Otwórz konsolę Cloud Run Jobs i kliknij Wdróż kontener:

- Wybierz utworzony obraz kontenera:
- Podaj inne szczegóły konfiguracji:

- Ustaw Parametry działań w ten sposób:
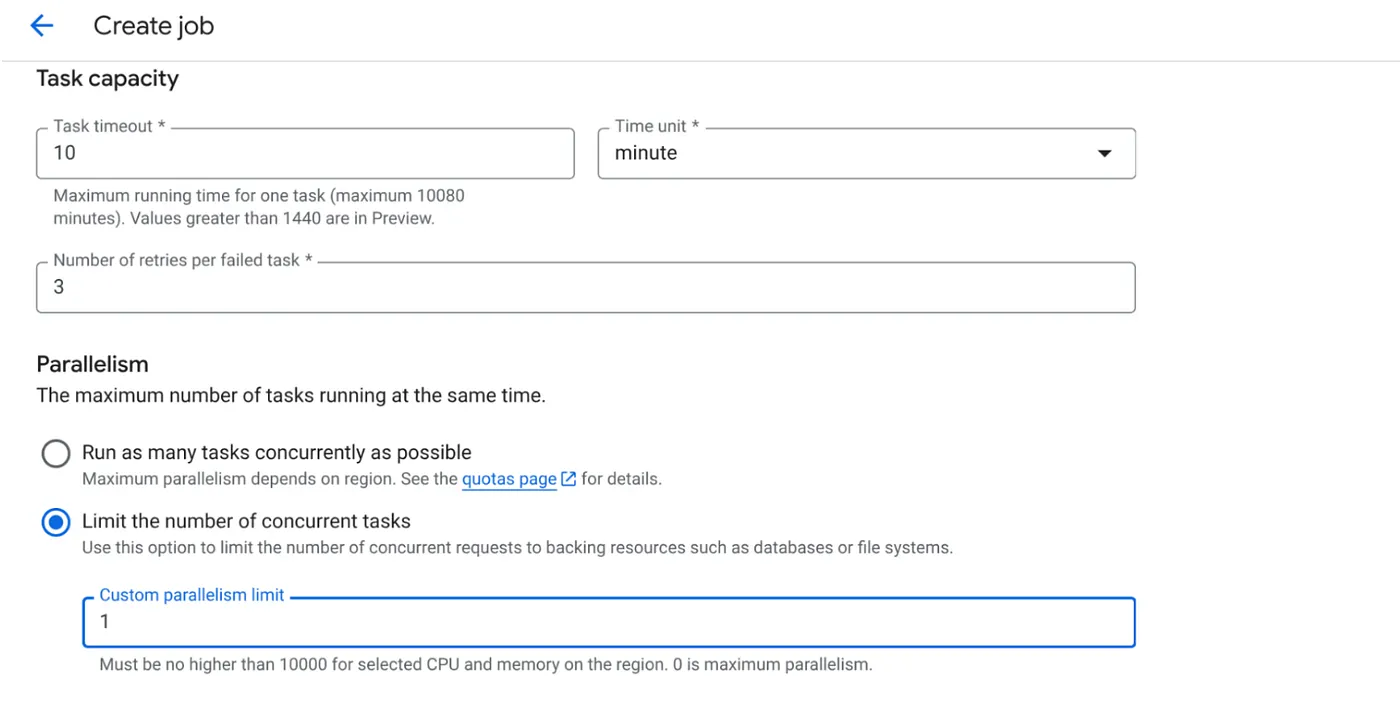
Ponieważ mamy zapisy w bazie danych, a równoległość (max_instances i task concurrency) jest już obsługiwana w kodzie, ustawimy liczbę równoległych zadań na 1. Możesz jednak zwiększyć tę wartość, jeśli zajdzie taka potrzeba. Celem jest wykonanie zadań zgodnie z konfiguracją z poziomem współbieżności ustawionym w równoległości.
- Kliknij Utwórz
Zadanie Cloud Run zostanie utworzone.
Jak to działa
Uruchamia się instancja kontenera zadania. Wysyła zapytanie do BigQuery, aby pobrać małą partię (BATCH_SIZE) adresów URL oznaczonych jako PENDING. Natychmiast aktualizuje stan pobranych adresów URL na PROCESSING w BigQuery, aby zapobiec ich pobraniu przez inne instancje zadania. Tworzy pulę wątków ThreadPoolExecutor i przesyła zadanie dla każdego adresu URL w partii. Każde zadanie wywołuje funkcję call_url_processor_service. Gdy żądania call_url_processor_service zostaną zrealizowane (lub przekroczą limit czasu bądź nie zostaną zrealizowane), ich wyniki (wygenerowany przez AI kontekst lub komunikat o błędzie) są zbierane i mapowane z powrotem na pierwotny identyfikator wiersza. Po zakończeniu wszystkich zadań w partii zadanie iteruje zebrane wyniki i aktualizuje pola kontekstu i stanu w każdym odpowiednim wierszu w BigQuery. Jeśli się powiedzie, instancja zadania zostanie zakończona. Jeśli napotka nieobsłużone błędy, zgłosi wyjątek, co może spowodować ponowienie próby przez Cloud Run Jobs (w zależności od konfiguracji zadania).
Miejsce zadań Cloud Run w orkiestracji
To właśnie w tym przypadku zadania Cloud Run sprawdzają się najlepiej.
Przetwarzanie wsadowe bezserwerowe: otrzymujemy zarządzaną infrastrukturę, która może uruchamiać tyle instancji kontenerów, ile jest potrzebnych (maksymalnie MAX_INSTANCES), aby przetwarzać dane równolegle.
Kontrola równoległości: definiujemy MAX_INSTANCES (ile zadań może być uruchomionych równolegle) i TASK_CONCURRENCY (ile operacji wykonuje równolegle każda instancja zadania). Zapewnia to szczegółową kontrolę nad przepustowością i wykorzystaniem zasobów.
Odporność na błędy: jeśli instancja zadania ulegnie awarii w trakcie wykonywania, zadania Cloud Run można skonfigurować tak, aby ponawiały całe zadanie lub określone zadania, co zapewnia, że przetwarzanie danych nie zostanie utracone.
Uproszczona architektura: dzięki orkiestracji wywołań HTTP bezpośrednio w ramach zadania i używaniu BigQuery do zarządzania stanem unikamy złożoności związanej z konfigurowaniem i zarządzaniem Pub/Sub, jego tematami, subskrypcjami i logiką potwierdzeń.
MAX_INSTANCES a TASK_CONCURRENCY:
MAX_INSTANCES: łączna liczba instancji zadań, które mogą być uruchamiane jednocześnie w ramach całego wykonania zadania. Jest to główny mechanizm równoległości przetwarzania wielu adresów URL jednocześnie.
TASK_CONCURRENCY: liczba równoległych operacji (wywołań usługi procesora), które wykona pojedyncza instancja zadania. Pomaga to w pełnym wykorzystaniu procesora lub sieci jednej instancji.
9. Wykonywanie i monitorowanie zadania Cloud Run
Metadane filmu wideo
Zanim klikniemy „Wykonaj”, sprawdźmy stan danych.
Otwórz BigQuery Studio i uruchom to zapytanie:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
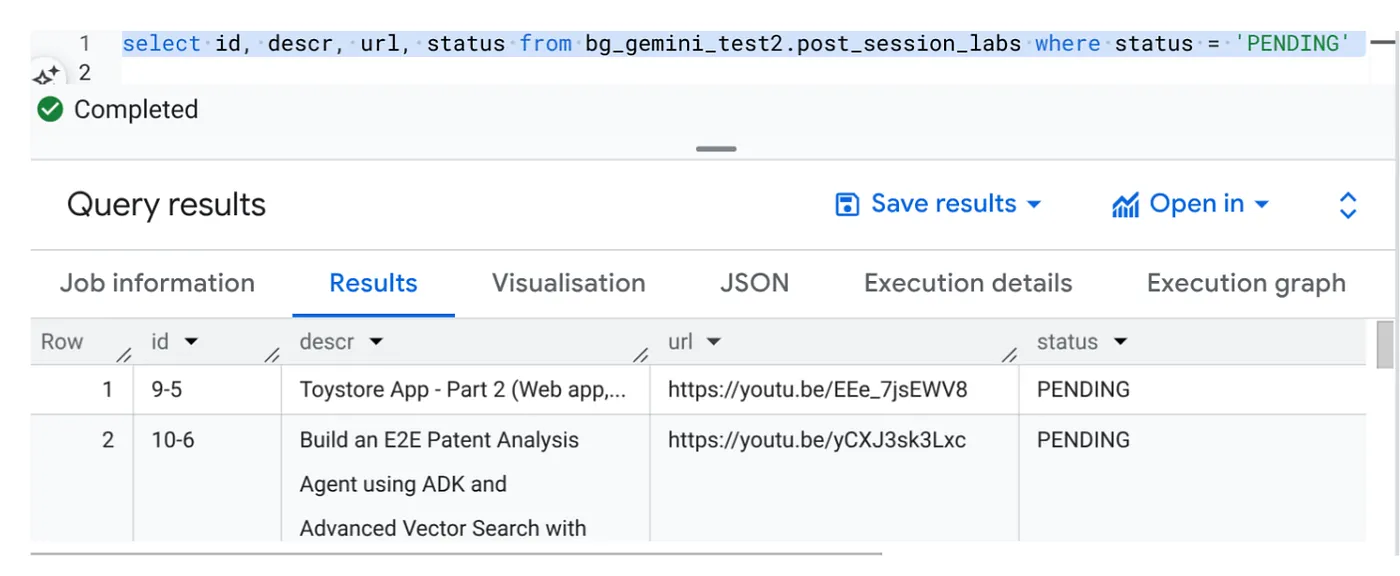
Mamy kilka przykładowych rekordów z adresami URL filmów w stanie OCZEKUJĄCYM. Naszym celem jest wypełnienie pola „context” (kontekst) informacjami z filmu w formacie opisanym w prompcie.
Aktywator zadania
Wykonajmy zadanie, klikając przycisk WYKONAJ w konsoli zadań Cloud Run. W konsoli powinny być widoczne postęp i stan zadań:
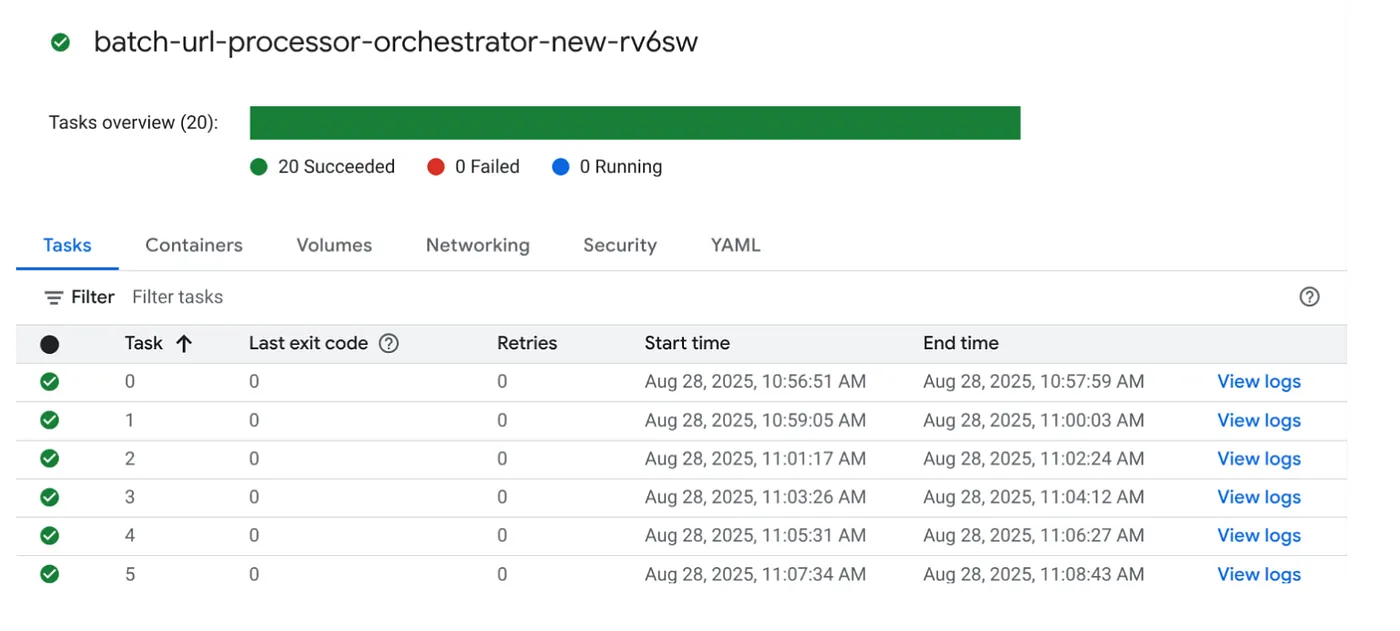
Aby monitorować kroki i sprawdzać inne szczegóły dotyczące zadania i zadań, możesz użyć tagu LOGS w sekcji OBSERWABILITY.
10. Analiza wyników
Po zakończeniu zadania w tabeli powinny być widoczne zaktualizowane konteksty poszczególnych adresów URL filmów:
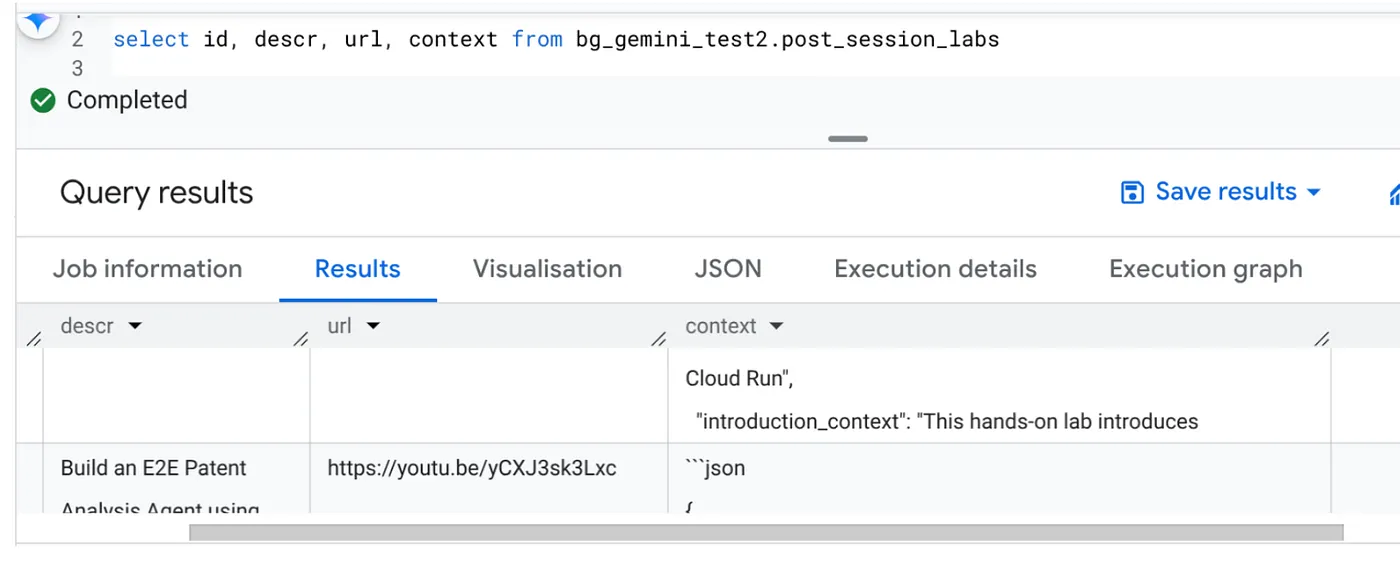
Kontekst wyjściowy (dla jednego z rekordów)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
Możesz teraz sprawdzić poprawność tej struktury JSON w bardziej zaawansowanych przypadkach użycia agentów.
Dlaczego takie podejście?
Ta architektura zapewnia istotne korzyści strategiczne:
- Opłacalność: usługi bezserwerowe oznaczają, że płacisz tylko za to, z czego korzystasz. Zadania Cloud Run są skalowane w dół do zera, gdy nie są używane.
- Skalowalność: bezproblemowa obsługa dziesiątek tysięcy adresów URL dzięki dostosowywaniu ustawień instancji i współbieżności zadania Cloud Run.
- Elastyczność: szybkie cykle tworzenia i wdrażania nowej logiki przetwarzania lub modeli AI przez proste aktualizowanie zawartej aplikacji i jej usługi.
- Mniejsze obciążenie operacyjne: nie trzeba instalować poprawek na serwerach ani nimi zarządzać, ponieważ Google zajmuje się infrastrukturą.
- Demokratyzacja AI: udostępnia zaawansowane przetwarzanie AI do zadań wsadowych bez konieczności posiadania zaawansowanej wiedzy z zakresu ML Ops.
11. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym poście, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Menedżer zasobów.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
12. Gratulacje
Gratulacje! Dzięki zaprojektowaniu rozwiązania opartego na zadaniach Cloud Run i wykorzystaniu możliwości BigQuery do zarządzania danymi oraz zewnętrznej usługi Cloud Run do przetwarzania AI udało Ci się stworzyć wysoce skalowalny, ekonomiczny i łatwy w utrzymaniu system. Ten wzorzec odłącza logikę przetwarzania, umożliwia równoległe wykonywanie zadań bez złożonej infrastruktury i znacznie przyspiesza uzyskiwanie informacji.
Zachęcamy do wypróbowania zadań Cloud Run w celu zaspokojenia własnych potrzeb w zakresie przetwarzania wsadowego. Niezależnie od tego, czy chodzi o skalowanie analizy AI, uruchamianie potoków ETL czy wykonywanie okresowych zadań związanych z danymi, to bezserwerowe podejście zapewnia wydajne i efektywne rozwiązanie. Aby rozpocząć samodzielnie, kliknij tutaj.
Jeśli chcesz tworzyć i wdrażać wszystkie aplikacje bezserwerowo i z użyciem agentów, zarejestruj się na Code Vipassana, czyli szkolenie, które pomoże Ci przyspieszyć tworzenie aplikacji generatywnych opartych na danych.