
1. Visão geral
No mundo atual, rico em dados, extrair insights significativos de conteúdo não estruturado, especialmente vídeos, é uma necessidade importante. Imagine precisar analisar centenas ou milhares de URLs de vídeo, resumir o conteúdo deles, extrair tecnologias importantes e até gerar pares de perguntas e respostas para materiais educativos. Fazer isso um por um não é apenas demorado, mas também ineficiente. É aqui que as arquiteturas modernas de nuvem se destacam.
Neste laboratório, vamos apresentar a solução escalonável e sem servidor para processar conteúdo de vídeo usando o pacote de serviços avançados do Google Cloud: Cloud Run, BigQuery e IA generativa do Google (Gemini). Vamos detalhar nossa jornada, desde o processamento de um único URL até a organização da execução paralela em um grande conjunto de dados, tudo sem a sobrecarga de gerenciar filas e integrações de mensagens complexas.
O desafio
Nossa tarefa era processar um grande catálogo de conteúdo de vídeo, com foco específico em sessões práticas de laboratório. O objetivo era analisar cada vídeo e gerar um resumo estruturado, incluindo títulos de capítulos, contexto da introdução, instruções detalhadas, tecnologias usadas e pares de perguntas e respostas relevantes. Essa saída precisava ser armazenada de maneira eficiente para uso posterior na criação de materiais educativos.
Inicialmente, tínhamos um serviço simples do Cloud Run baseado em HTTP que podia processar um URL por vez. Isso funcionou bem para testes e análises ad hoc. No entanto, quando confrontado com uma lista de milhares de URLs provenientes do BigQuery, as limitações desse modelo de solicitação única e resposta única ficaram evidentes. O processamento sequencial levaria dias, se não semanas.
A oportunidade era transformar um processo manual ou sequencial lento em um fluxo de trabalho automatizado e paralelizado. Ao aproveitar a nuvem, nosso objetivo era:
- Processar dados em paralelo: reduz significativamente o tempo de processamento de grandes conjuntos de dados.
- Aproveite os recursos de IA atuais: use o poder do Gemini para fazer análises sofisticadas de conteúdo.
- Manter a arquitetura sem servidor: evite gerenciar servidores ou infraestruturas complexas.
- Centralize os dados: use o BigQuery como a única fonte de verdade para URLs de entrada e um destino confiável para resultados processados.
- Crie um pipeline robusto: crie um sistema resiliente a falhas e que possa ser gerenciado e monitorado com facilidade.
Objetivo
Orquestração do processamento paralelo de IA com jobs do Cloud Run:
Nossa solução se concentra em um job do Cloud Run que funciona como um orquestrador. Ele lê de maneira inteligente lotes de URLs do BigQuery, envia esses URLs para nosso serviço do Cloud Run implantado (que processa a IA para um único URL) e agrega os resultados para gravar de volta no BigQuery. Essa abordagem permite que:
- Desvincule a orquestração do processamento: o job gerencia o fluxo de trabalho, enquanto o serviço separado se concentra na tarefa de IA.
- Aproveite o paralelismo do job do Cloud Run: o job pode escalonar horizontalmente várias instâncias de contêiner para chamar o serviço de IA simultaneamente.
- Reduzir a complexidade: alcançamos o paralelismo fazendo com que o job gerencie chamadas HTTP simultâneas diretamente, simplificando a arquitetura.
Caso de uso
Insights com tecnologia de IA dos vídeos da sessão do Code Vipassana
Nosso caso de uso específico foi analisar vídeos de sessões do Google Cloud dos laboratórios práticos do Code Vipassana. O objetivo era gerar automaticamente documentação estruturada (esboços de capítulos de livros), incluindo:
- Títulos dos capítulos: títulos concisos para cada segmento do vídeo
- Contexto da introdução: explicar a relevância do vídeo em um programa de aprendizado mais amplo
- O que será criado: a tarefa ou meta principal da sessão
- Tecnologias usadas: uma lista de serviços de nuvem e outras tecnologias mencionadas
- Instruções detalhadas: como a tarefa foi realizada, incluindo snippets de código
- URLs de código-fonte/demonstração: links fornecidos no vídeo
- Segmento de perguntas e respostas: gerar perguntas e respostas relevantes para testes de conhecimento.
Fluxo

Fluxo da arquitetura
O que é o Cloud Run? O que são jobs do Cloud Run?
Cloud Run
Uma plataforma sem servidor totalmente gerenciada que permite executar contêineres sem estado. É ideal para serviços da Web, APIs e microsserviços que podem ser escalonados automaticamente com base nas solicitações recebidas. Você fornece uma imagem de contêiner, e o Cloud Run cuida do restante, desde a implantação e o escalonamento até o gerenciamento da infraestrutura. Ele é excelente no processamento de cargas de trabalho síncronas de solicitação-resposta.
Jobs do Cloud Run
Uma oferta que complementa os serviços do Cloud Run. Os jobs do Cloud Run são projetados para tarefas de processamento em lote que precisam ser concluídas e depois interrompidas. Eles são perfeitos para processamento de dados, ETL, inferência em lote de machine learning e qualquer tarefa que envolva o processamento de um conjunto de dados em vez de atender a solicitações ativas. Um recurso importante é a capacidade de escalonar horizontalmente o número de instâncias de contêiner (tarefas) em execução simultânea para processar um lote de trabalho. Além disso, elas podem ser acionadas por várias origens de eventos ou manualmente.
Diferença principal
Os serviços do Cloud Run são para aplicativos de longa duração e orientados por solicitações. Os jobs do Cloud Run são para processamento em lote finito e orientado a tarefas que é executado até a conclusão.
O que você vai criar
Um aplicativo de pesquisa de varejo
Como parte disso, você vai:
- Criar um conjunto de dados e uma tabela do BigQuery e ingerir dados (metadados do Code Vipassana)
- Crie uma função do Cloud Run em Python para implementar a funcionalidade de IA generativa (conversão de vídeo em JSON de capítulo de livro).
- Criar um aplicativo Python para o pipeline de dados para IA: ler do BigQuery e invocar o endpoint das funções do Cloud Run para insights e gravar o contexto de volta no BigQuery.
- Criar e conteinerizar o aplicativo
- Configurar um job do Cloud Run com esse contêiner
- Executar e monitorar o job
- Resultado do relatório
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto .
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com o ID do seu projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: siga o link e ative as APIs.
Como alternativa, use o comando gcloud. Consulte a documentação para ver o uso e os comandos gcloud.
3. Configuração de banco de dados/data warehouse
O BigQuery foi a base do nosso pipeline de dados. A natureza sem servidor e altamente escalonável o torna perfeito para armazenar dados de entrada e os resultados processados.
- Armazenamento de dados:o BigQuery atuou como nosso data warehouse. Ele armazena a lista de URLs de vídeo, o status deles (por exemplo, PENDING, PROCESSING, COMPLETED) e o contexto final gerado. É a única fonte de verdade para quais vídeos precisam de processamento.
- Destino:é onde os insights gerados pela IA são mantidos, facilitando a consulta para aplicativos downstream ou revisão manual. Nosso conjunto de dados consistia em detalhes de sessões de vídeo, principalmente do conteúdo "Code Vipassana Seasons", que geralmente envolve demonstrações técnicas detalhadas.
- Tabela de origem:uma tabela do BigQuery (por exemplo, post_session_labs) que contém registros como:
- id: um identificador exclusivo para cada sessão/linha.
- url: o URL do vídeo (por exemplo, um link do YouTube ou do Drive acessível).
- status: uma string que indica o estado de processamento (por exemplo, PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- context: um campo de string para armazenar o resumo gerado com IA.
- Ingestão de dados: neste cenário, os dados foram ingeridos no BigQuery com scripts INSERT. Para nosso pipeline, o BigQuery foi o ponto de partida.
Acesse o console do BigQuery, abra uma nova guia e execute as seguintes instruções SQL:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Ingestão de dados
Agora é hora de adicionar uma tabela com os dados da loja. Acesse uma guia no BigQuery Studio e execute as seguintes instruções SQL para inserir os registros de exemplo:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Criação de função de insights de vídeo
Precisamos criar e implantar uma função do Cloud Run para implementar o núcleo da funcionalidade, que é criar um capítulo de livro estruturado com base no URL do vídeo. Para acessar isso como um conjunto de ferramentas de endpoint independente, acabamos de criar e implantar uma função do Cloud Run. Como alternativa, você pode incluir isso como uma função separada no aplicativo Python real para o job do Cloud Run:
- No console do Google Cloud, acesse a página do Cloud Run.
- Clique em "Escrever uma função".
- No campo "Nome do serviço", insira um nome para descrever sua função. Os nomes de serviços precisam começar com uma letra e conter até 49 caracteres, incluindo letras, números ou hífens. Os nomes de serviço não podem terminar com hífens e precisam ser exclusivos por região e projeto. Não é possível alterar o nome de um serviço depois e ele fica visível publicamente. ( generate-video-insights**)**
- Na lista "Região", use o valor padrão ou selecione a região em que você quer implantar a função. Escolha us-central1
- Na lista "Ambiente de execução", use o valor padrão ou selecione uma versão do ambiente de execução. Escolha Python 3.11
- Na seção "Autenticação", escolha "Permitir acesso público".
- Clique no botão "Criar".
- A função é criada e carregada com um main.py e um requirements.txt de modelo.
- Substitua por estes arquivos: main.py e requirements.txt do repositório deste projeto.
OBSERVAÇÃO IMPORTANTE: em main.py, substitua <<YOUR_PROJECT_ID>> pelo ID do seu projeto.
- Implante e salve o endpoint para usá-lo na origem do job do Cloud Run.
Seu endpoint vai ficar assim (ou algo parecido): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
O que há nesta função do Cloud Run?
Gemini 2.5 Flash para processamento de vídeo
Para a tarefa principal de entender e resumir o conteúdo de vídeo, usamos o modelo Gemini 2.5 Flash do Google. Os modelos do Gemini são modelos de IA multimodais avançados capazes de entender e processar vários tipos de entrada, incluindo texto e, com integrações específicas, vídeo.
Na nossa configuração, não alimentamos o arquivo de vídeo diretamente no Gemini. Em vez disso, enviamos um comando de texto que incluía o URL do vídeo e instruía o Gemini sobre como analisar o conteúdo (hipotético) de um vídeo nesse URL. Embora o Gemini 2.5 Flash seja capaz de receber entradas multimodais, esse pipeline específico usou um comando baseado em texto que descrevia a natureza do vídeo (uma sessão prática de laboratório) e solicitava uma saída JSON estruturada. Isso aproveita o raciocínio avançado e o processamento de linguagem natural do Gemini para inferir e sintetizar informações com base no contexto do comando.
O comando do Gemini: orientando a IA
Um comando bem elaborado é crucial para modelos de IA. Nosso comando foi projetado para extrair informações muito específicas e estruturá-las em um formato JSON, facilitando a análise pelo nosso aplicativo.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
Esse comando é altamente específico, orientando o Gemini a agir como um educador. A solicitação de uma string JSON garante uma saída estruturada e legível por máquina.
Confira o código para analisar a entrada de vídeo e retornar o contexto dela:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
O snippet acima demonstra a função principal do caso de uso. Ele recebe um URL de vídeo e usa o modelo Gemini pela Vertex AI Client para analisar o conteúdo do vídeo e extrair insights relevantes de acordo com o comando. O contexto extraído é retornado para processamento posterior. Isso representa uma operação síncrona em que o job do Cloud Run aguarda a conclusão do serviço.
6. Desenvolvimento de aplicativos de pipeline (Python)
A lógica central do pipeline reside no código-fonte do aplicativo, que será contêinerizado em um job do Cloud Run, que orquestra toda a execução paralela. Confira as principais partes:
A função do orquestrador no gerenciamento do fluxo de trabalho e na garantia da integridade de dados:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
O snippet acima começa buscando um lote de URLs de vídeo com o status "PENDING" na tabela de origem do BigQuery. Em seguida, ele atualiza o status desses URLs para "PROCESSING" no BigQuery, evitando o processamento duplicado.
Processamento paralelo com ThreadPoolExecutor e chamada do serviço de processador:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
Essa parte do código usa o ThreadPoolExecutor para realizar o processamento paralelo dos URLs de vídeo buscados. Para cada URL, ela envia uma tarefa para chamar o serviço do Cloud Run (processador de URL) de forma assíncrona. Isso permite que o job do Cloud Run processe vários vídeos simultaneamente, melhorando a performance geral do pipeline. O snippet também processa possíveis tempos limite e erros do serviço do processador.
Leitura e gravação do BigQuery
A interação principal com o BigQuery envolve buscar URLs pendentes e atualizá-los com resultados processados.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Gravar os resultados de volta no BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
Os snippets acima se concentram na interação de dados entre o job do Cloud Run e o BigQuery. Ele recupera um lote de URLs de vídeo "PENDING" e os IDs correspondentes da tabela de origem. Depois que os URLs são processados, este snippet demonstra como gravar o contexto extraído e o status ("COMPLETED" ou "FAILED_PROCESSING") de volta na tabela do BigQuery de destino usando uma consulta UPDATE. Este snippet conclui o loop de processamento de dados. Ele também inclui a função auxiliar update_bq_row, que mostra como definir parâmetros da instrução de atualização.
Configuração do aplicativo
O aplicativo é estruturado como um único script Python que será conteinerizado. Ele usa as bibliotecas de cliente do Google Cloud e o framework de funções para definir o ponto de entrada.
- Dependências: google-cloud-bigquery, requests
- Configuração: todas as configurações críticas (projeto/conjunto de dados/tabela do BigQuery, URL do serviço de processador de URL) são carregadas de variáveis de ambiente, tornando o aplicativo portátil e seguro.
- Lógica principal: a função "process_batch_from_bq" orquestra todo o fluxo de trabalho.
- Integração de serviços externos: a função call_url_processor_service processa a comunicação com o serviço separado do Cloud Run.
- Interação com o BigQuery: bq_client é usado para buscar URLs e atualizar resultados, com a manipulação adequada de parâmetros.
- Paralelismo: concurrent.futures.ThreadPoolExecutor gerencia chamadas simultâneas para o serviço externo
- Ponto de entrada: o código Python chamado main.py atua como o ponto de entrada que inicia o processamento em lote.
Vamos configurar o aplicativo agora:
- Para começar, navegue até o terminal do Cloud Shell e clone o repositório:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Acesse o editor do Cloud Shell, onde você pode ver a pasta recém-criada video-context-crj.
- Exclua o seguinte, já que essas etapas foram concluídas nas seções anteriores:
- Exclua a pasta Cloud_Run_Function
- Navegue até a pasta do projeto video-context-crj. A estrutura do projeto vai aparecer:
7. Configuração do Dockerfile e contêinerização
Para implantar essa lógica como um job do Cloud Run, precisamos conteinerizá-la. A conteinerização é o processo de empacotar o código do aplicativo, as dependências e o ambiente de execução em uma imagem portátil.
Substitua os marcadores de posição (texto em negrito) pelos seus valores no Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
O snippet de Dockerfile acima define a imagem de base, instala dependências, copia nosso código e define o comando para executar o aplicativo usando o framework de funções com a função de destino correta (process_batch_from_bq). Essa imagem é enviada para o Artifact Registry.
Conteinerizar
Para contêinerizar, acesse o terminal do Cloud Shell e execute os seguintes comandos. Não se esqueça de substituir o marcador de posição <<YOUR_PROJECT_ID>>:
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
Depois que a imagem do contêiner for criada, você vai ver a saída:
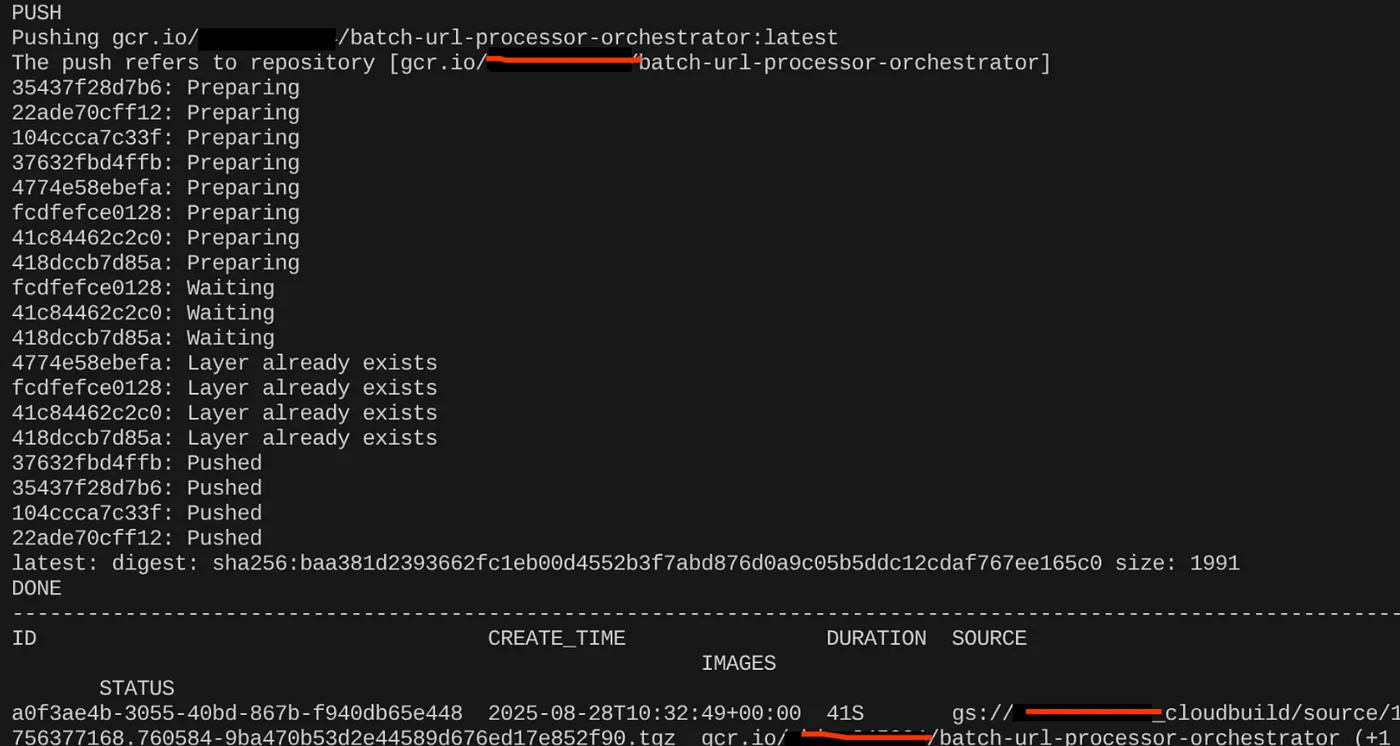
Nosso contêiner foi criado e salvo no Artifact Registry. Podemos seguir para a próxima etapa.
8. Criação de jobs do Cloud Run
A implantação do job envolve a criação da imagem do contêiner e de um recurso de job do Cloud Run.
Já criamos a imagem do contêiner e a armazenamos no Artifact Registry. Agora vamos criar o job.
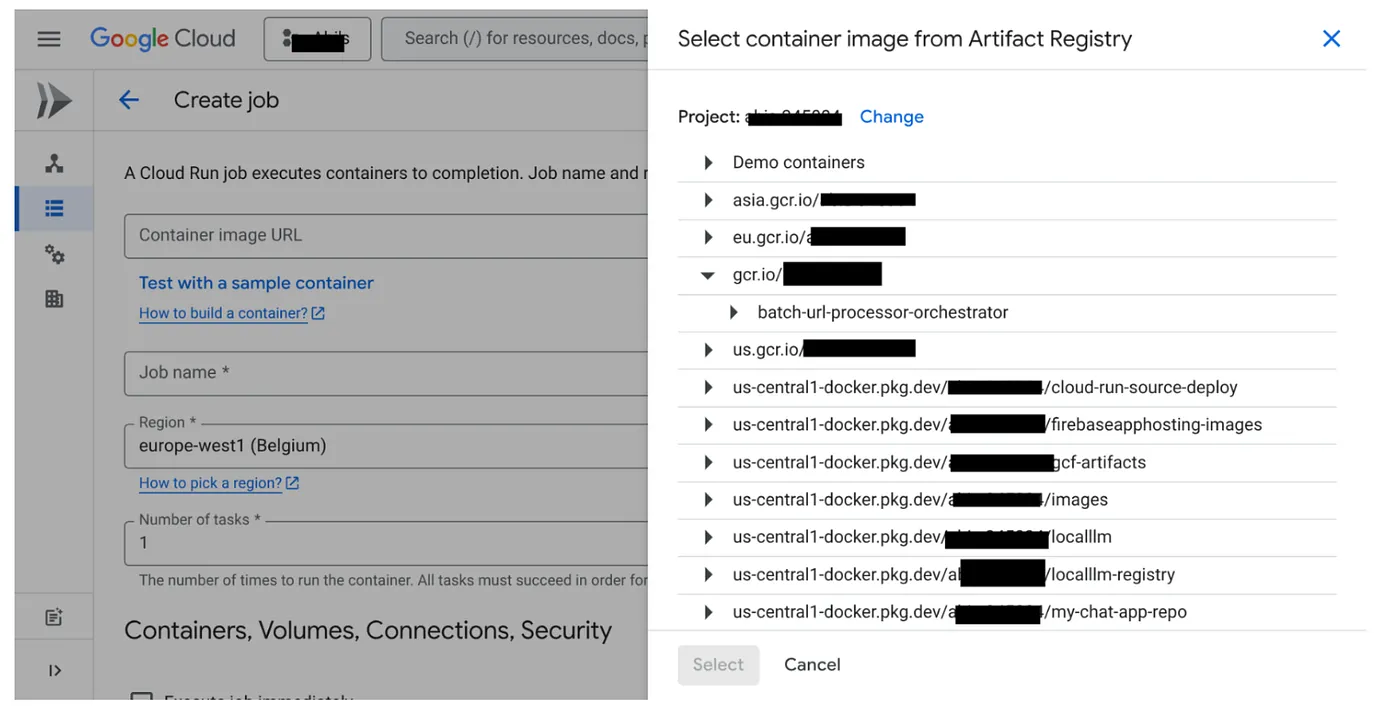
- Acesse o console Jobs do Cloud Run e clique em "Implantar contêiner":

- Selecione a imagem do contêiner que acabamos de criar:
- Insira outros detalhes de configuração da seguinte forma:

- Defina a capacidade da tarefa da seguinte forma:
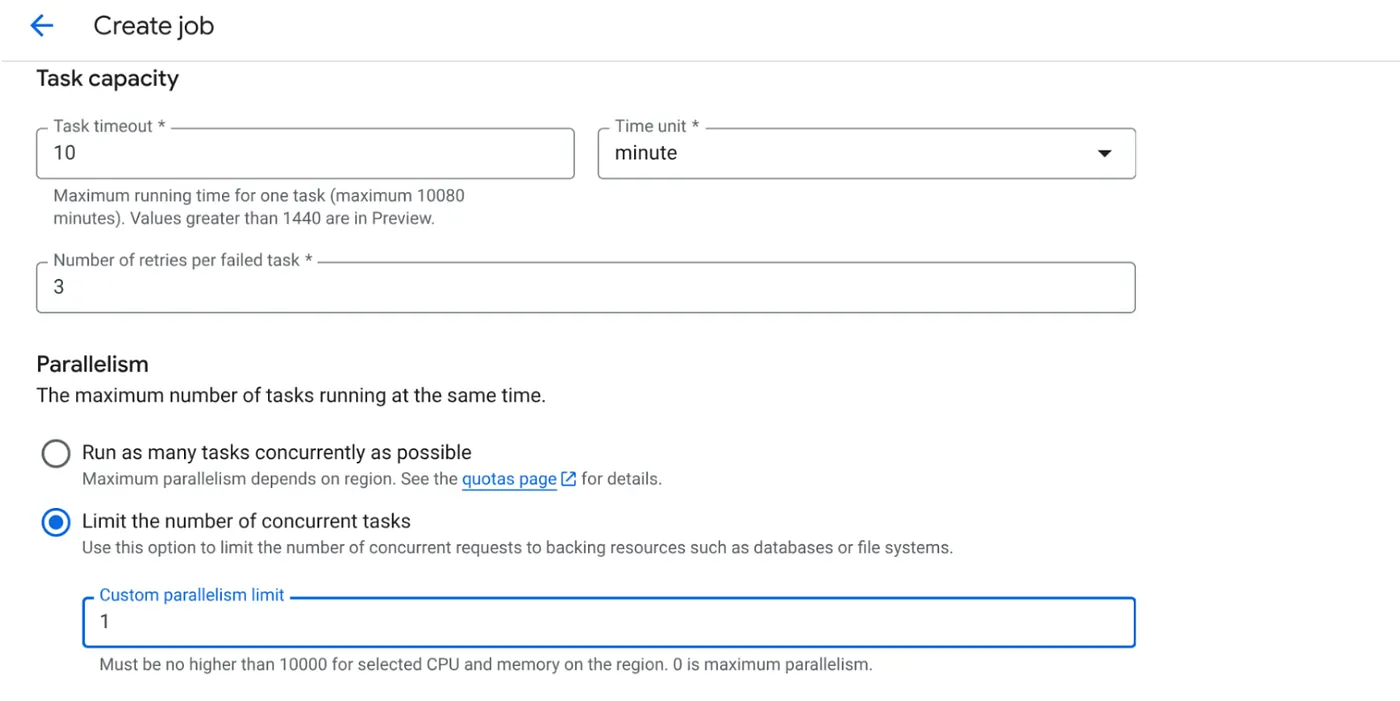
Como temos gravações de banco de dados e o fato de que a paralelização (max_instances e simultaneidade de tarefas) já é processada no código, vamos definir o número de tarefas simultâneas como 1. Mas fique à vontade para aumentar de acordo com sua necessidade. O objetivo aqui é que as tarefas sejam executadas até a conclusão, conforme a configuração com o nível de simultaneidade definido em paralelismo.
- Clique em Criar
O job do Cloud Run será criado.
Como funciona
Uma instância de contêiner do nosso job é iniciada. Ele consulta o BigQuery para receber um pequeno lote (BATCH_SIZE) de URLs marcados como PENDING. Ele atualiza imediatamente o status desses URLs buscados para "PROCESSING" no BigQuery para evitar que outras instâncias de job os selecionem. Ele cria um ThreadPoolExecutor e envia uma tarefa para cada URL no lote. Cada tarefa chama a função call_url_processor_service. À medida que as solicitações call_url_processor_service são concluídas (ou atingem o tempo limite/falham), os resultados delas (o contexto gerado por IA ou uma mensagem de erro) são coletados e mapeados de volta para o row_id original. Quando todas as tarefas do lote são concluídas, o job itera pelos resultados coletados e atualiza os campos de contexto e status de cada linha correspondente no BigQuery. Se for bem-sucedida, a instância do job será encerrada corretamente. Se ele encontrar erros não tratados, vai gerar uma exceção, possivelmente acionando uma nova tentativa pelos jobs do Cloud Run (dependendo da configuração do job).
Como os jobs do Cloud Run se encaixam: orquestração
É aí que os jobs do Cloud Run realmente se destacam.
Processamento em lote sem servidor: temos uma infraestrutura gerenciada que pode criar quantas instâncias de contêiner forem necessárias (até MAX_INSTANCES) para processar nossos dados simultaneamente.
Controle de paralelismo: definimos MAX_INSTANCES (quantos jobs podem ser executados em paralelo no geral) e TASK_CONCURRENCY (quantas operações cada instância de job realiza em paralelo). Isso oferece controle refinado sobre a capacidade de processamento e a utilização de recursos.
Tolerância a falhas: se uma instância de job falhar no meio do processo, os jobs do Cloud Run poderão ser configurados para tentar novamente o job inteiro ou tarefas específicas, garantindo que o processamento de dados não seja perdido.
Arquitetura simplificada: ao orquestrar chamadas HTTP diretamente no job e usar o BigQuery para gerenciamento de estado, evitamos a complexidade de configurar e gerenciar o Pub/Sub, os tópicos, as assinaturas e a lógica de confirmação.
MAX_INSTANCES x TASK_CONCURRENCY:
MAX_INSTANCES::o número total de instâncias de job que podem ser executadas simultaneamente em toda a execução do job. Essa é sua principal alavanca de paralelismo para processar muitos URLs de uma só vez.
TASK_CONCURRENCY::o número de operações paralelas (chamadas ao serviço de processamento) que uma única instância do seu job vai realizar. Isso ajuda a saturar a CPU/rede de uma instância.
9. Executar e monitorar o job do Cloud Run
Metadados do vídeo
Antes de clicar em "Executar", vamos conferir o status dos dados.
Acesse o BigQuery Studio e execute a seguinte consulta:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
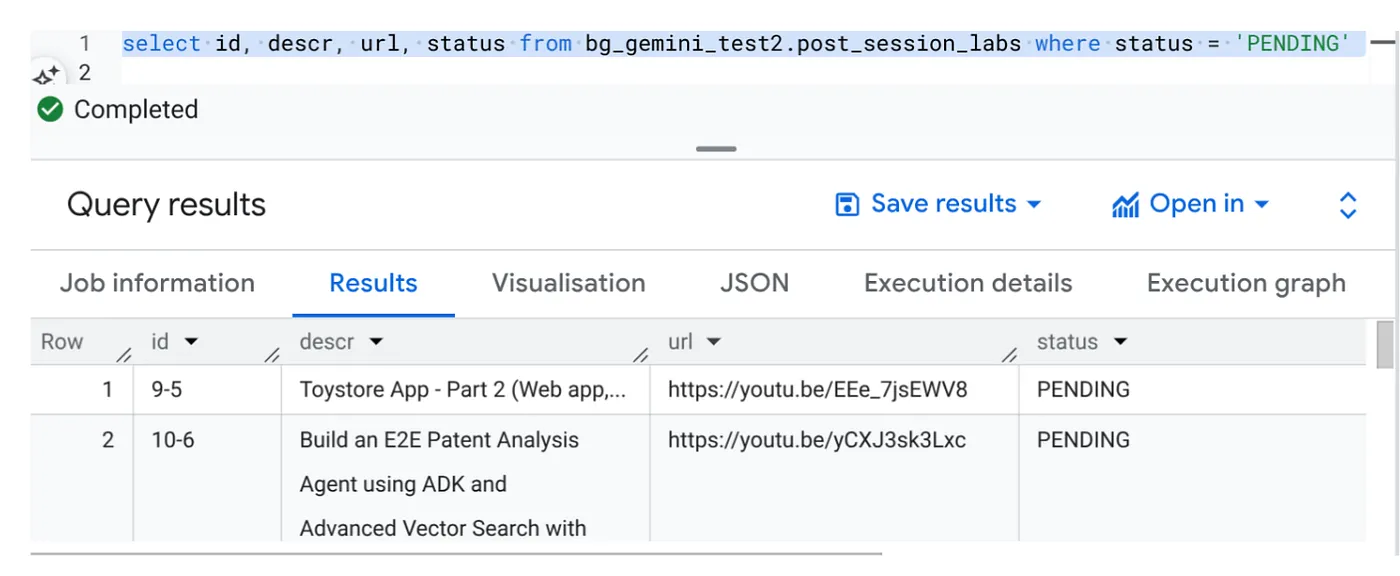
Temos alguns exemplos de registros com URLs de vídeo e status PENDENTE. Nosso objetivo é preencher o campo "contexto" com insights do vídeo no formato explicado no comando.
Acionador de jobs
Clique no botão "EXECUTAR" no job no console de jobs do Cloud Run para executar o job. Assim, você poderá conferir o progresso e o status dos jobs no console:
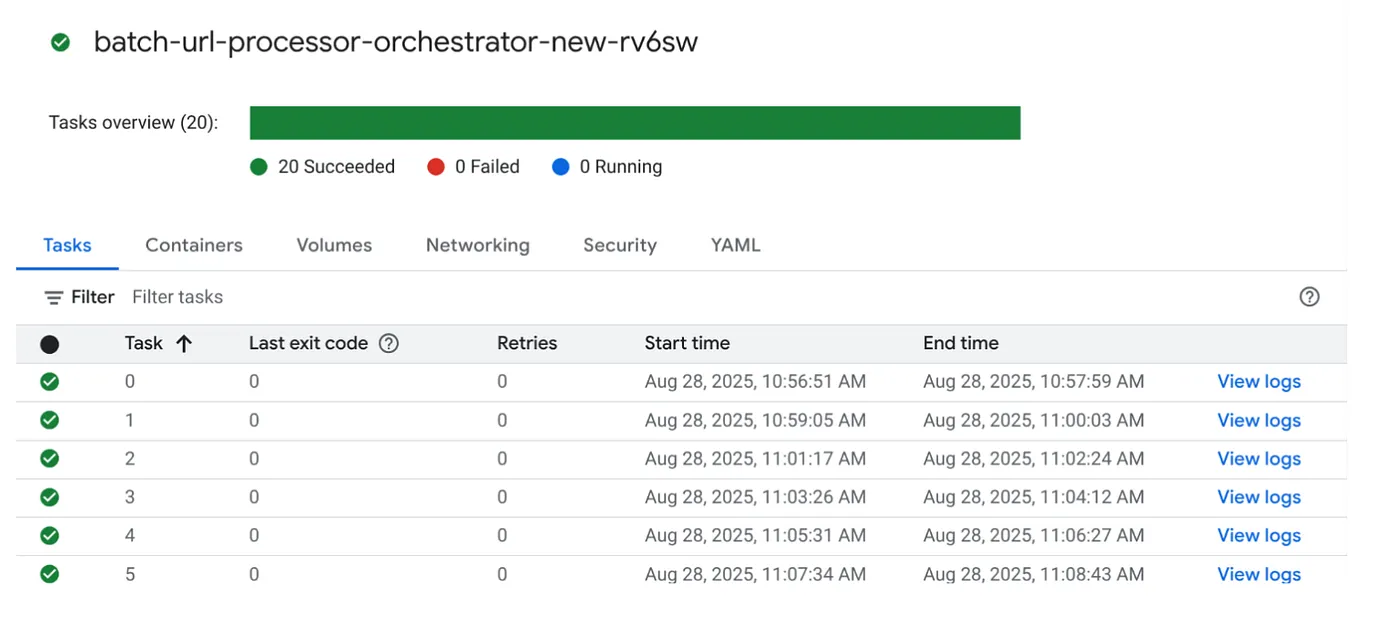
Verifique a tag "LOGS" em "OBSERVABILITY" para etapas de monitoramento e outros detalhes sobre o job e as tarefas.
10. Análise de resultados
Quando o job for concluído, você poderá conferir o contexto de cada URL de vídeo atualizado na tabela:
Contexto de saída (para um dos registros)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
Agora você pode validar essa estrutura JSON para casos de uso de agentes mais avançados.
Por que essa abordagem?
Essa arquitetura oferece vantagens estratégicas significativas:
- Custo-benefício: com os serviços sem servidor, você paga apenas pelo que usa. Os jobs do Cloud Run são reduzidos a zero quando não estão em uso.
- Escalonabilidade: processa sem esforço dezenas de milhares de URLs ajustando as configurações de simultaneidade e instância do job do Cloud Run.
- Agilidade: ciclos rápidos de desenvolvimento e implantação para novas lógicas de processamento ou modelos de IA, basta atualizar o aplicativo contido e o serviço dele.
- Redução da sobrecarga operacional: não há servidores para corrigir ou gerenciar. O Google cuida da infraestrutura.
- Democratização da IA: torna o processamento avançado de IA acessível para tarefas em lote sem exigir experiência em ML Ops.
11. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados nesta postagem, siga estas etapas:
- No console do Google Cloud, acesse a página do Gerenciador de recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
12. Parabéns
Parabéns! Ao arquitetar nossa solução com base em jobs do Cloud Run e aproveitar o poder do BigQuery para gerenciamento de dados e um serviço externo do Cloud Run para processamento de IA, você criou um sistema altamente escalonável, econômico e fácil de manter. Esse padrão desacopla a lógica de processamento, permite a execução paralela sem infraestrutura complexa e acelera significativamente o tempo até a geração de insights.
Recomendamos que você conheça os jobs do Cloud Run para suas próprias necessidades de processamento em lote. Seja para escalonar a análise de IA, executar pipelines de ETL ou realizar tarefas de dados periódicas, essa abordagem sem servidor oferece uma solução eficiente e poderosa. Para começar por conta própria, confira isto.
Se você quer criar e implantar todos os seus apps sem servidor e com agentes, inscreva-se no Code Vipassana, que se concentra em acelerar aplicativos generativos com agentes orientados por dados.