
1. Обзор
В современном мире, насыщенном данными, извлечение ценной информации из неструктурированного контента, особенно видео, является крайне необходимой задачей. Представьте себе необходимость анализа сотен или тысяч URL-адресов видео, обобщения их содержимого, извлечения ключевых технологий и даже генерации пар вопросов и ответов для образовательных материалов. Выполнение этой работы по одному видео не только отнимает много времени, но и неэффективно. Именно здесь проявляются преимущества современных облачных архитектур.
В этой лабораторной работе мы рассмотрим масштабируемое бессерверное решение для обработки видеоконтента с использованием мощного набора сервисов Google Cloud: Cloud Run, BigQuery и генеративного искусственного интеллекта Google (Gemini). Мы подробно расскажем о нашем пути от обработки одного URL-адреса до организации параллельного выполнения для большого набора данных, и все это без дополнительных затрат на управление сложными очередями сообщений и интеграциями.
Вызов
Перед нами стояла задача обработать большой каталог видеоконтента, уделяя особое внимание практическим лабораторным занятиям. Цель заключалась в анализе каждого видео и создании структурированного резюме, включающего названия глав, вводную информацию, пошаговые инструкции, используемые технологии и соответствующие пары вопросов и ответов. Полученные данные необходимо было эффективно хранить для последующего использования при создании учебных материалов.
Изначально у нас был простой сервис Cloud Run на основе HTTP, который мог обрабатывать по одному URL-адресу за раз. Это хорошо работало для тестирования и анализа в режиме реального времени. Однако, когда мы столкнулись со списком из тысяч URL-адресов, полученных из BigQuery, стали очевидны ограничения этой модели «один запрос — один ответ». Последовательная обработка занимала дни, если не недели.
Задача заключалась в преобразовании ручного или медленного последовательного процесса в автоматизированный, параллельный рабочий процесс. Используя облачные технологии, мы стремились к следующему:
- Параллельная обработка данных: значительно сокращает время обработки больших наборов данных.
- Используйте существующие возможности ИИ: задействуйте возможности Gemini для сложного анализа контента.
- Поддерживайте бессерверную архитектуру: избегайте управления серверами или сложной инфраструктурой.
- Централизация данных: используйте BigQuery в качестве единого источника достоверной информации о входных URL-адресах и надежного места для хранения обработанных результатов.
- Создайте надежный конвейер: разработайте систему, устойчивую к сбоям, которую легко управлять и контролировать.
Цель
Организация параллельной обработки данных в рамках ИИ с помощью заданий, запускаемых в облаке:
Наше решение основано на задании Cloud Run, которое выступает в роли оркестратора. Оно интеллектуально считывает пакеты URL-адресов из BigQuery, перенаправляет эти URL-адреса в нашу существующую развернутую службу Cloud Run (которая обрабатывает данные с помощью ИИ для одного URL-адреса), а затем агрегирует результаты и записывает их обратно в BigQuery. Такой подход позволяет нам:
- Разделение оркестровки и обработки: задача управляет рабочим процессом, а отдельная служба фокусируется на задаче ИИ.
- Используйте параллелизм Cloud Run Job: задача может масштабировать несколько экземпляров контейнеров для одновременного вызова сервиса ИИ.
- Снижение сложности: мы достигаем параллелизма, заставляя задачу напрямую управлять одновременными HTTP-вызовами, что упрощает архитектуру.
Вариант использования
Анализ видеозаписей сессий випассаны на основе кода с использованием искусственного интеллекта
В нашем конкретном случае задача заключалась в анализе видеозаписей практических занятий по Code Vipassana в Google Cloud. Цель состояла в автоматическом создании структурированной документации (планов глав книг), включающей:
- Названия глав: Краткие названия для каждого видеофрагмента.
- Введение. Контекст: Объяснение значимости видео в более широком контексте обучения.
- Что будет создано: основная задача или цель занятия.
- Используемые технологии: список облачных сервисов и других упомянутых технологий.
- Пошаговая инструкция: как выполнялась задача, включая фрагменты кода.
- Ссылки на исходный код/демонстрационные ролики: ссылки указаны в видео.
- Раздел «Вопросы и ответы»: Формирование актуальных вопросов и ответов для проверки знаний.
Поток

Архитектурный поток
Что такое Cloud Run? Что такое задания Cloud Run?
Cloud Run
Полностью управляемая бессерверная платформа, позволяющая запускать контейнеры без сохранения состояния. Она идеально подходит для веб-сервисов, API и микросервисов, которые могут автоматически масштабироваться в зависимости от входящих запросов. Вы предоставляете образ контейнера, а Cloud Run берет на себя все остальное — от развертывания и масштабирования до управления инфраструктурой. Она отлично справляется с синхронными рабочими нагрузками типа «запрос-ответ».
Задания Cloud Run
Предложение, дополняющее сервисы Cloud Run. Задания Cloud Run предназначены для пакетной обработки задач, которые необходимо завершить, а затем остановить. Они идеально подходят для обработки данных, ETL, пакетного вывода в машинном обучении и любых задач, связанных с обработкой набора данных, а не с обработкой запросов в реальном времени. Ключевой особенностью является возможность масштабирования количества одновременно работающих экземпляров контейнеров (задач) для обработки пакета данных, а также возможность запуска заданий различными источниками событий или вручную.
Ключевое отличие
Сервисы Cloud Run предназначены для длительно работающих приложений, управляемых запросами. Задания Cloud Run предназначены для пакетной обработки ограниченного количества задач, выполняемой до завершения.
Что вы построите
Приложение для поиска в розничной торговле
В рамках этого процесса вы будете:
- Создайте набор данных BigQuery, таблицу и загрузите данные (код: Метаданные Випассаны).
- Создайте облачную функцию запуска Python для реализации функциональности генеративного ИИ (преобразование видео в JSON-файл главы книги).
- Создайте приложение на Python для конвейера обработки данных и преобразования их в ИИ: считывайте данные из BigQuery, вызывайте конечную точку Cloud Run Functions для получения аналитических данных и записывайте контекст обратно в BigQuery.
- Соберите и контейнеризируйте приложение.
- Настройте задания Cloud Run с помощью этого контейнера.
- Выполнение и контроль работы
- Сообщить о результате
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API: перейдите по ссылке и включите API.
В качестве альтернативы можно использовать команду gcloud. Для получения информации о командах gcloud и их использовании обратитесь к документации .
3. Настройка базы данных/хранилища
BigQuery послужил основой для нашего конвейера обработки данных. Его бессерверная, масштабируемая архитектура идеально подходит как для хранения входных данных, так и для размещения обработанных результатов.
- Хранение данных: В качестве хранилища данных мы использовали BigQuery. В нем хранится список URL-адресов видео, их статус (например, ОЖИДАНИЕ, ОБРАБОТКА, ЗАВЕРШЕНО) и итоговый сгенерированный контекст. Это единственный источник достоверной информации о том, какие видео нуждаются в обработке.
- Место назначения: Здесь сохраняются данные, полученные с помощью ИИ, что позволяет легко запрашивать их для последующих приложений или для ручного анализа. Наш набор данных состоял из подробностей видеосессий, в частности, из контента "Code Vipassana Seasons", который часто включает в себя подробные технические демонстрации.
- Исходная таблица: таблица BigQuery (например, post_session_labs), содержащая записи следующего вида:
- id: Уникальный идентификатор для каждой сессии/строки.
- url: URL видео (например, ссылка на YouTube или доступная ссылка на Google Диск).
- status: Строка, указывающая на состояние обработки (например, PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- context: Строковое поле для хранения сгенерированного ИИ резюме.
- Загрузка данных: В данном сценарии данные загружались в BigQuery с помощью скриптов INSERT. Для нашего конвейера BigQuery послужил отправной точкой.
Перейдите в консоль BigQuery, откройте новую вкладку и выполните следующие SQL-запросы:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Ввод данных
Теперь пришло время добавить таблицу с данными о магазине. Перейдите на вкладку в BigQuery Studio и выполните следующие SQL-запросы для вставки тестовых записей:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Создание функции анализа видеоконтента.
Нам необходимо создать и развернуть функцию Cloud Run для реализации основной функциональности, а именно создания структурированной главы книги из URL-адреса видео. Чтобы иметь возможность получить к этому доступ как к независимой конечной точке в наборе инструментов, мы только что создали и развернули функцию Cloud Run. В качестве альтернативы вы можете включить это как отдельную функцию в само приложение Python для задания Cloud Run:
- В консоли Google Cloud перейдите на страницу Cloud Run .
- Нажмите «Написать функцию».
- В поле «Название услуги» введите название, описывающее вашу функцию. Названия услуг должны начинаться только с буквы и содержать не более 49 символов, включая буквы, цифры или дефисы. Названия услуг не могут заканчиваться дефисами и должны быть уникальными для каждого региона и проекта. Название услуги нельзя изменить позже, оно является общедоступным. ( generate-video-insights **)**
- В списке регионов используйте значение по умолчанию или выберите регион, в котором вы хотите развернуть свою функцию. (Выберите us-central1)
- В списке «Среда выполнения» используйте значение по умолчанию или выберите версию среды выполнения. (Выберите Python 3.11)
- В разделе «Аутентификация» выберите «Разрешить публичный доступ».
- Нажмите кнопку «Создать».
- Функция создается и загружается с помощью шаблона main.py и requirements.txt.
- Замените это файлами main.py и requirements.txt из репозитория этого проекта.
ВАЖНОЕ ЗАМЕЧАНИЕ: В файле main.py замените <<YOUR_PROJECT_ID>> на идентификатор вашего проекта.
- Разверните и сохраните конечную точку, чтобы использовать ее в качестве источника для задания Cloud Run.
Ваш адрес конечной точки должен выглядеть примерно так (или аналогично): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
Что представляет собой эта функция Cloud Run?
Флеш-память Gemini 2.5 для обработки видео
Для решения основной задачи — понимания и обобщения видеоконтента — мы использовали модель Google Gemini 2.5 Flash. Модели Gemini — это мощные мультимодальные модели искусственного интеллекта, способные понимать и обрабатывать различные типы входных данных, включая текст и, при определенных интеграциях, видео.
В нашей конфигурации мы не передавали видеофайл напрямую в Gemini. Вместо этого мы отправляли текстовое сообщение, содержащее URL-адрес видео, и инструктировали Gemini, как анализировать (гипотетическое) содержимое видео по этому URL-адресу. Хотя Gemini 2.5 Flash способен обрабатывать многомодальный ввод, в этом конкретном случае использовалось текстовое сообщение, описывающее характер видео (практическое занятие) и запрашивающее структурированный вывод в формате JSON. Это позволяет использовать продвинутые аналитические способности Gemini и понимание естественного языка для вывода и синтеза информации на основе контекста сообщения.
Совет Близнецов: Как направлять искусственный интеллект
Грамотно составленный запрос имеет решающее значение для моделей ИИ. Наш запрос был разработан для извлечения очень специфической информации и ее структурирования в формат JSON, что делает его легко обрабатываемым нашим приложением.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
Этот запрос очень конкретен и направляет Gemini в качестве своего рода наставника. Запрос на JSON-строку обеспечивает структурированный, машиночитаемый вывод.
Вот код для анализа видеовхода и возврата его контекста:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
Приведённый выше фрагмент кода демонстрирует основную функцию сценария использования. Он получает URL-адрес видео и использует модель Gemini через клиент Vertex AI для анализа видеоконтента и извлечения соответствующей информации в соответствии с запросом. Извлечённый контекст затем возвращается для дальнейшей обработки. Это представляет собой синхронную операцию, в ходе которой задание Cloud Run Job ожидает завершения работы сервиса.
6. Разработка конвейерных приложений (Python)
Основная логика нашего конвейера обработки данных находится в исходном коде приложения, который будет контейнеризирован в задание Cloud Run, управляющее всем параллельным выполнением. Вот основные компоненты:
Роль координатора в управлении рабочим процессом и обеспечении целостности данных:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
Приведённый выше фрагмент кода начинается с получения из исходной таблицы BigQuery пакета URL-адресов видео со статусом «ОЖИДАНИЕ». Затем он обновляет статус этих URL-адресов в BigQuery до «ОБРАБОТКА», предотвращая повторную обработку.
Параллельная обработка с использованием ThreadPoolExecutor и вызов службы Processor:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
Этот фрагмент кода использует ThreadPoolExecutor для параллельной обработки полученных URL-адресов видео. Для каждого URL-адреса он отправляет задачу на асинхронный вызов службы Cloud Run (обработчика URL-адресов). Это позволяет заданию Cloud Run эффективно обрабатывать несколько видео одновременно, повышая общую производительность конвейера. Фрагмент также обрабатывает возможные тайм-ауты и ошибки от службы обработки.
Чтение и запись данных из и в BigQuery
Основное взаимодействие с BigQuery заключается в получении ожидающих обработки URL-адресов и последующем обновлении их результатами обработки.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Запись результатов обратно в BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
Приведенные выше фрагменты кода демонстрируют взаимодействие данных между заданием Cloud Run Job и BigQuery. Они извлекают из исходной таблицы пакет URL-адресов видео со статусом «PENDING» и их идентификаторы. После обработки URL-адресов этот фрагмент кода показывает запись извлеченного контекста и статуса («COMPLETED» или «FAILED_PROCESSING») обратно в целевую таблицу BigQuery с помощью запроса UPDATE. Этот фрагмент кода завершает цикл обработки данных. Он также включает вспомогательную функцию update_bq_row, которая показывает, как определять параметры оператора UPDATE.
Настройка приложения
Приложение представляет собой единый скрипт на Python, который будет контейнеризирован. Для определения точки входа в него используются клиентские библиотеки Google Cloud и фреймворк функций.
- Зависимости: google-cloud-bigquery, requests
- Конфигурация: Все критически важные параметры (проект/набор данных/таблица BigQuery, URL-адрес службы обработки URL-адресов) загружаются из переменных среды, что делает приложение портативным и безопасным.
- Основная логика: функция process_batch_from_bq координирует весь рабочий процесс.
- Интеграция с внешними сервисами: функция call_url_processor_service обрабатывает взаимодействие с отдельным сервисом Cloud Run Service.
- Взаимодействие с BigQuery: bq_client используется для получения URL-адресов и обновления результатов с корректной обработкой параметров.
- Параллелизм: concurrent.futures.ThreadPoolExecutor управляет одновременными вызовами к внешнему сервису.
- Точка входа: Файл main.py на языке Python служит точкой входа, запускающей пакетную обработку.
Давайте теперь настроим приложение:
- Для начала перейдите в терминал Cloud Shell и клонируйте репозиторий:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Перейдите в редактор Cloud Shell, где вы увидите только что созданную папку video-context-crj.
- Удалите следующие строки, так как эти шаги уже были выполнены в предыдущих разделах:
- Удалите папку Cloud_Run_Function
- Перейдите в папку проекта video-context-crj , и вы увидите структуру проекта:
7. Настройка Dockerfile и контейнеризация
Для развертывания этой логики в качестве задания Cloud Run Job нам необходимо контейнеризировать ее. Контейнеризация — это процесс упаковки кода нашего приложения, его зависимостей и среды выполнения в портативный образ.
Обязательно замените заполнители (текст, выделенный жирным шрифтом) своими значениями в Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
Приведённый выше фрагмент Dockerfile определяет базовый образ, устанавливает зависимости, копирует наш код и задаёт команду для запуска нашего приложения с использованием фреймворка функций с правильной целевой функцией (process_batch_from_bq). Затем этот образ загружается в реестр артефактов.
Контейнеризация
Для контейнеризации перейдите в терминал Cloud Shell и выполните следующие команды (не забудьте заменить заполнитель <<YOUR_PROJECT_ID>>):
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
После создания образа контейнера вы должны увидеть следующий результат:
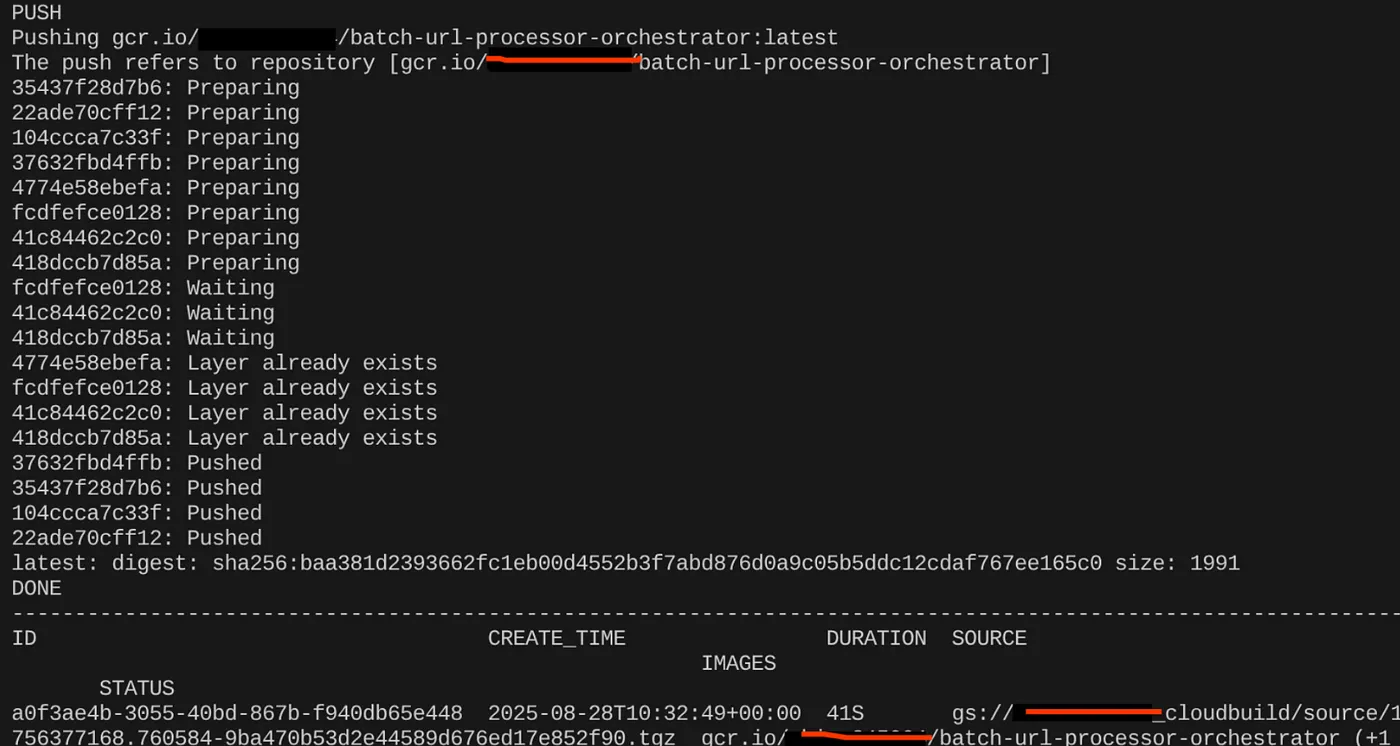
Наш контейнер создан и сохранен в реестре артефактов. Мы готовы перейти к следующему шагу.
8. Создание заданий Cloud Run
Развертывание задания включает в себя создание образа контейнера, а затем создание ресурса Cloud Run Job.
Мы уже создали образ контейнера и сохранили его в реестре артефактов. Теперь давайте создадим задание.
- Перейдите в консоль Cloud Run Jobs и нажмите «Развернуть контейнер»:

- Выберите созданный нами образ контейнера:
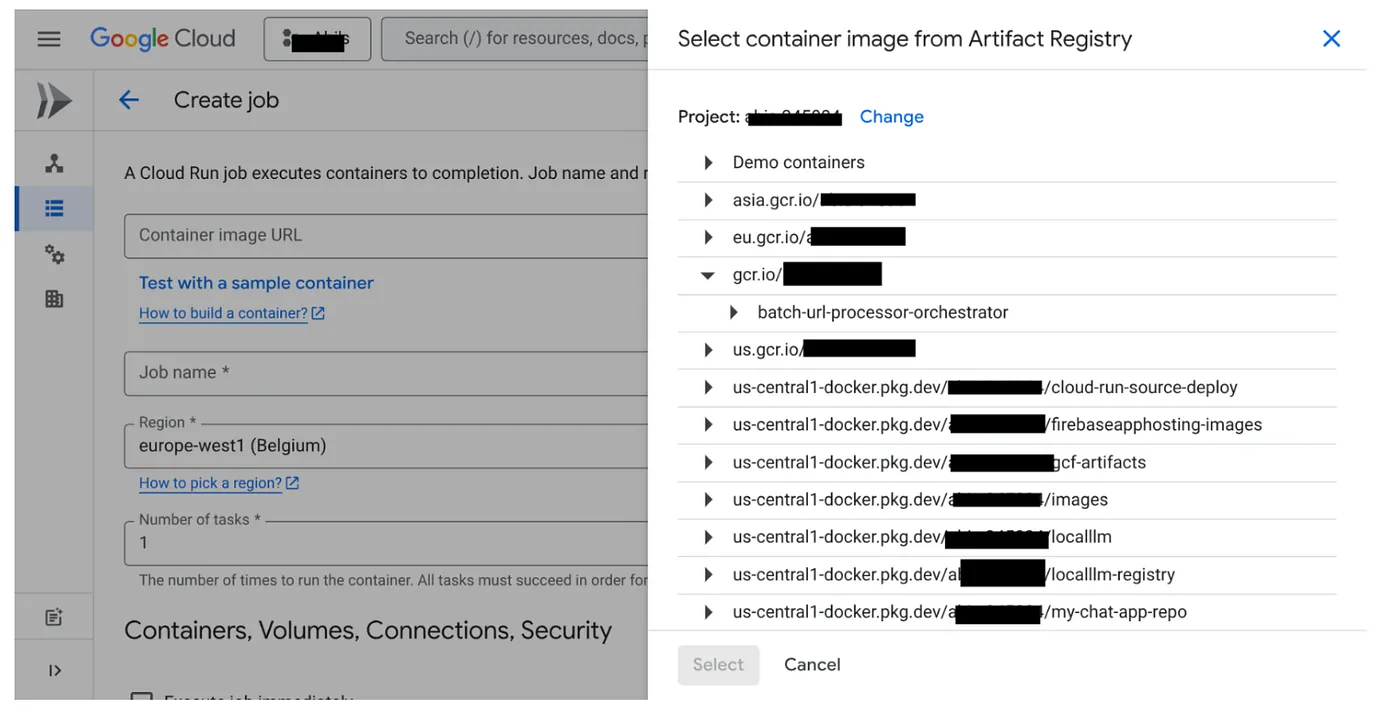
- Остальные параметры конфигурации следует указать следующим образом:

- Установите производительность задачи следующим образом:
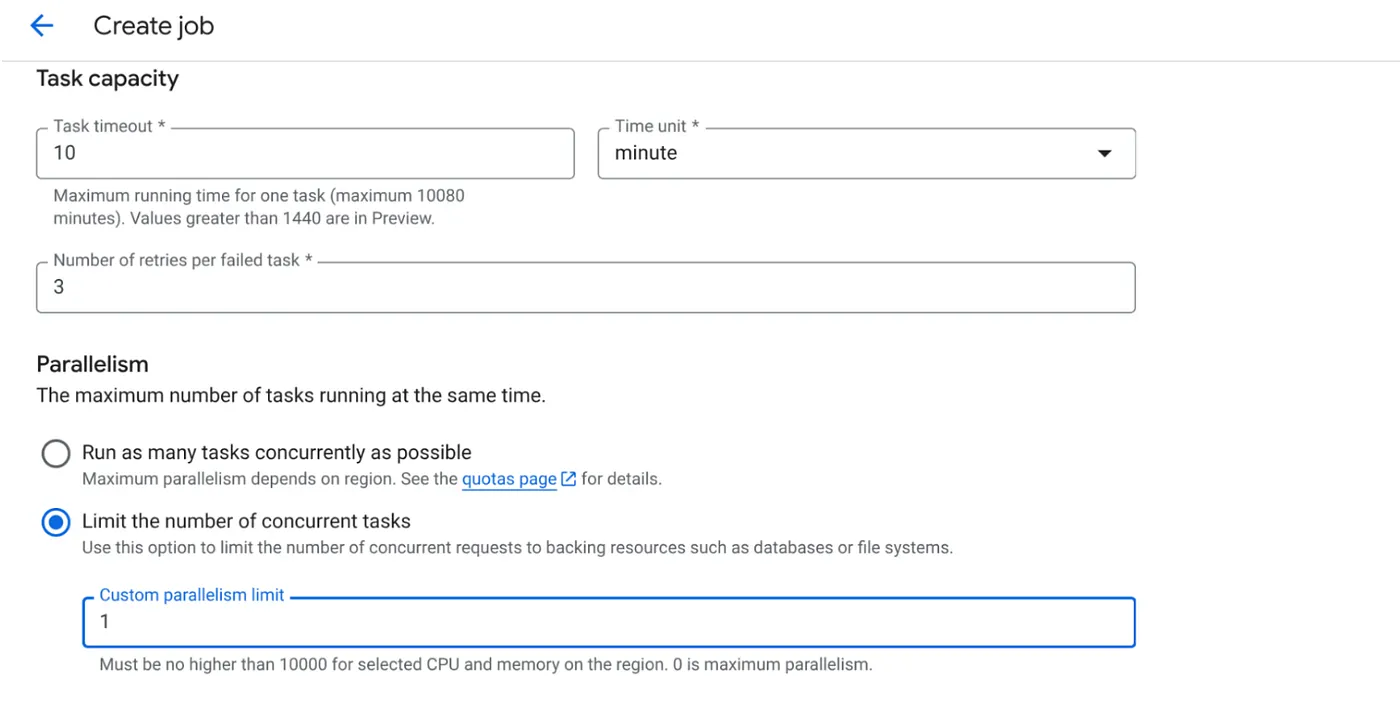
Поскольку у нас есть операции записи в базу данных, и распараллеливание (max_instances и параллелизм задач) уже обрабатывается в коде, мы установим количество параллельно выполняемых задач равным 1. Но вы можете увеличить его в соответствии с вашими потребностями. Цель состоит в том, чтобы задачи выполнялись до завершения в соответствии с конфигурацией и уровнем параллелизма, установленным в параметре parallelism.
- Нажмите «Создать».
Ваше задание Cloud Run будет успешно создано.
Как это работает
Запускается контейнерный экземпляр нашей задачи. Он запрашивает у BigQuery небольшую партию (BATCH_SIZE) URL-адресов, помеченных как PENDING (ожидающие обработки). Он немедленно обновляет статус этих полученных URL-адресов на PROCESSING (обрабатываются) в BigQuery, чтобы предотвратить их обработку другими экземплярами задач. Он создает ThreadPoolExecutor и отправляет задачу для каждого URL-адреса в партии. Каждая задача вызывает функцию call_url_processor_service. По мере завершения запросов call_url_processor_service (или истечения времени ожидания/сбоя), их результаты (либо контекст, сгенерированный ИИ, либо сообщение об ошибке) собираются и сопоставляются с исходным row_id. После завершения всех задач для партии задача проходит по собранным результатам и обновляет поля контекста и статуса для каждой соответствующей строки в BigQuery. В случае успеха экземпляр задачи завершает работу корректно. Если он сталкивается с необработанными ошибками, он генерирует исключение, потенциально инициируя повторную попытку выполнения задач Cloud Run Jobs (в зависимости от конфигурации задачи).
Как вписываются задачи Cloud Run: оркестровка
Именно здесь Cloud Run Jobs проявляет свои лучшие качества.
Пакетная обработка данных без использования серверов: мы получаем управляемую инфраструктуру, которая может запускать столько экземпляров контейнеров, сколько необходимо (до MAX_INSTANCES), для одновременной обработки наших данных.
Управление параллелизмом: Мы определяем MAX_INSTANCES (общее количество заданий, которые могут выполняться параллельно) и TASK_CONCURRENCY (количество операций, выполняемых каждым экземпляром задания параллельно). Это обеспечивает точный контроль над пропускной способностью и использованием ресурсов.
Отказоустойчивость: если выполнение задания прерывается на полпути, Cloud Run Jobs можно настроить на повторный запуск всего задания или отдельных задач, гарантируя, что обработка данных не будет потеряна.
Упрощенная архитектура: организуя HTTP-запросы непосредственно внутри задания и используя BigQuery для управления состоянием, мы избегаем сложностей, связанных с настройкой и управлением системой Pub/Sub, ее темами, подписками и логикой подтверждения.
MAX_INSTANCES против TASK_CONCURRENCY:
MAX_INSTANCES: Общее количество экземпляров заданий, которые могут выполняться одновременно на протяжении всего процесса выполнения задания. Это основной инструмент параллелизма для обработки множества URL-адресов одновременно.
TASK_CONCURRENCY: Количество параллельных операций (вызовов к вашей службе обработки), которые будет выполнять один экземпляр вашей задачи. Это помогает максимально эффективно использовать ресурсы ЦП/сети одного экземпляра.
9. Выполнение и мониторинг задания Cloud Run
Метаданные видео
Прежде чем нажать кнопку «Выполнить», давайте посмотрим на состояние данных.
Перейдите в BigQuery Studio и выполните следующий запрос:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
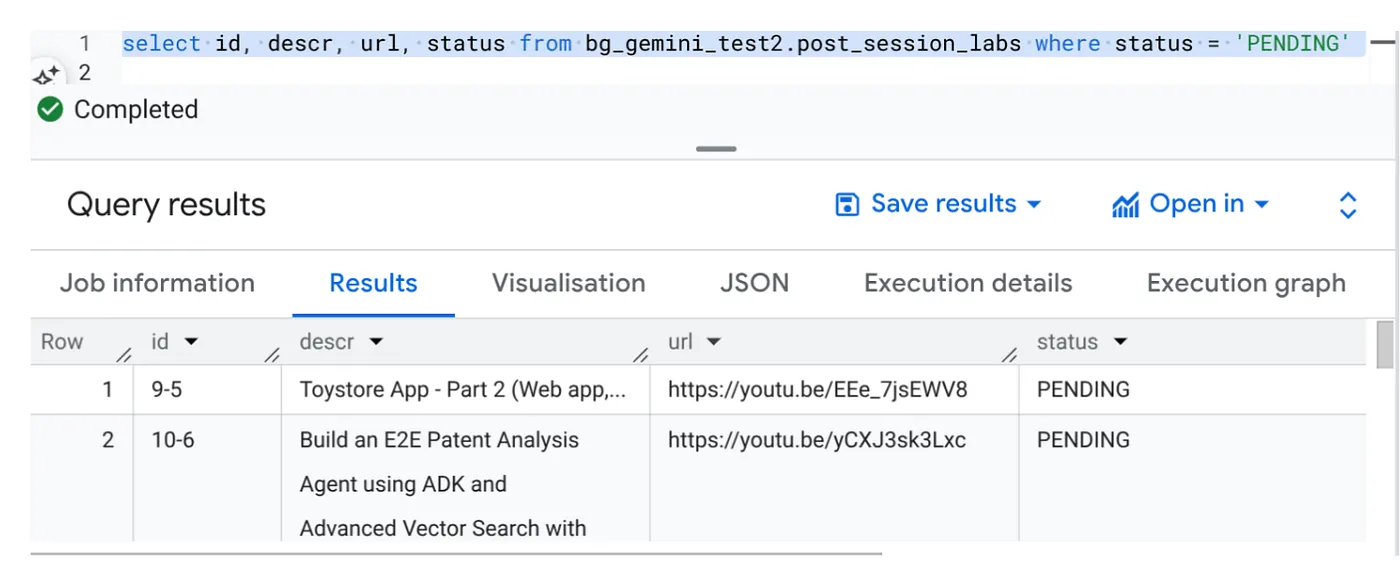
У нас есть несколько примеров записей с URL-адресами видео и статусом «ОЖИДАНИЕ». Наша цель — заполнить поле «контекст» информацией из видео в формате, описанном в задании.
Запуск задания
Давайте запустим задание, нажав кнопку «Выполнить» рядом с заданием в консоли Cloud Run Jobs. Вы сможете увидеть ход выполнения и статус задания в консоли:
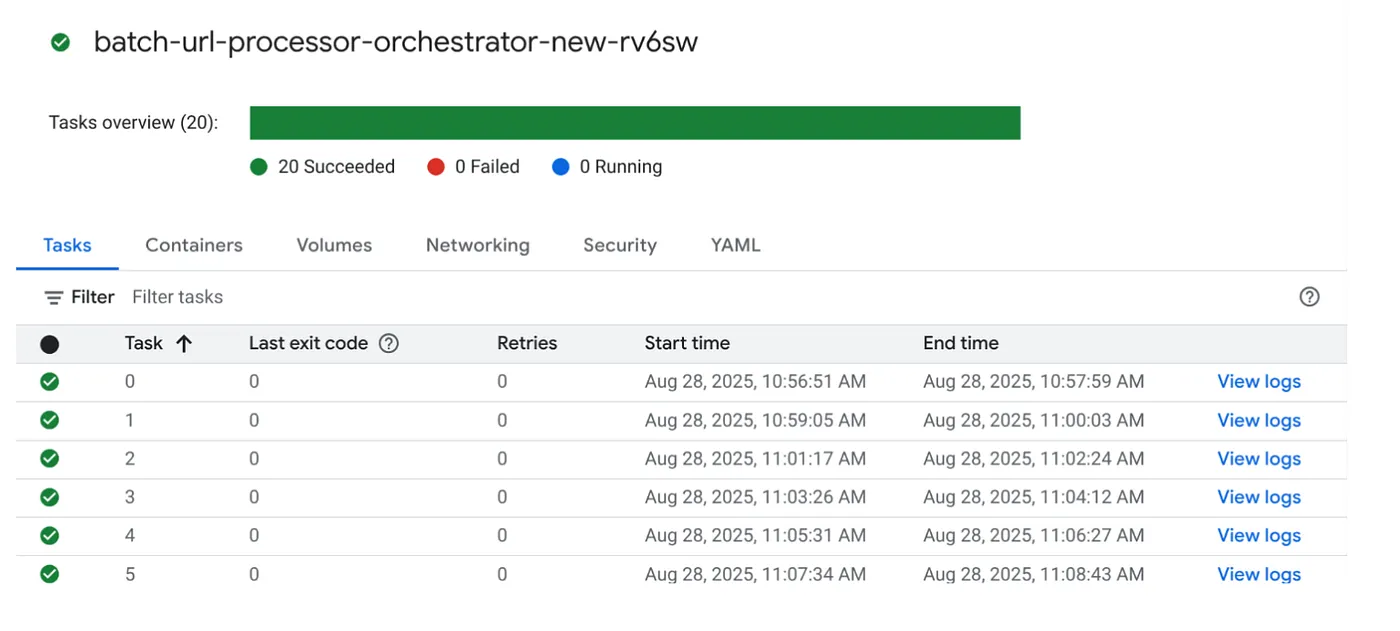
В разделе «Наблюдение» можно проверить тег LOGS, чтобы увидеть этапы мониторинга и другие подробности о задании и задачах.
10. Анализ результатов
После завершения работы вы увидите, что контекст для каждого URL-адреса видео обновился в таблице:
Контекст вывода (для одной из записей)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
Теперь вы сможете проверить эту JSON-структуру для более сложных сценариев использования агентов.
Почему именно такой подход?
Данная архитектура обеспечивает значительные стратегические преимущества:
- Экономическая эффективность: Бессерверные сервисы означают, что вы платите только за то, что используете. Cloud Run Jobs масштабируются до нуля, когда не используются.
- Масштабируемость: Легко обрабатывает десятки тысяч URL-адресов, регулируя параметры экземпляра задания Cloud Run Job и параллельного выполнения.
- Гибкость: Быстрые циклы разработки и развертывания новой логики обработки или моделей ИИ за счет простого обновления содержащегося в нем приложения и его сервиса.
- Снижение эксплуатационных расходов: нет необходимости обновлять или управлять серверами; инфраструктурой занимается Google.
- Демократизация ИИ: делает доступной обработку сложных задач ИИ в пакетном режиме без глубоких знаний в области машинного обучения.
11. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этой статье, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу управления ресурсами .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
12. Поздравляем!
Поздравляем! Построив наше решение на основе Cloud Run Jobs и используя возможности BigQuery для управления данными, а также внешний Cloud Run Service для обработки данных с помощью ИИ, вы создали масштабируемую, экономически эффективную и поддерживаемую систему. Такая модель позволяет разделить логику обработки, обеспечивает параллельное выполнение без сложной инфраструктуры и значительно ускоряет получение аналитических данных.
Мы рекомендуем вам изучить Cloud Run Jobs для решения ваших задач пакетной обработки данных. Независимо от того, масштабируете ли вы анализ с помощью ИИ, запускаете ETL-конвейеры или выполняете периодические задачи обработки данных, этот бессерверный подход предлагает мощное и эффективное решение. Чтобы начать работу самостоятельно, ознакомьтесь с этим материалом .
Если вам интересно создавать и развертывать все свои приложения без использования серверов и с помощью агентов, зарегистрируйтесь на Code Vipassana , посвященный ускорению разработки генеративных агентных приложений, основанных на данных!