
1. ภาพรวม
ในโลกที่เต็มไปด้วยข้อมูลในปัจจุบัน การดึงข้อมูลเชิงลึกที่มีความหมายจากเนื้อหาที่ไม่มีโครงสร้าง โดยเฉพาะวิดีโอ เป็นสิ่งจำเป็นอย่างยิ่ง ลองนึกภาพว่าคุณต้องวิเคราะห์ URL ของวิดีโอหลายร้อยหรือหลายพันรายการ สรุปเนื้อหาของวิดีโอเหล่านั้น แยกเทคโนโลยีหลักๆ และแม้แต่สร้างคู่คำถามและคำตอบสำหรับสื่อการเรียนรู้ การทำทีละรายการไม่เพียงแต่จะเสียเวลาเท่านั้น แต่ยังไม่มีประสิทธิภาพอีกด้วย และนี่คือจุดที่สถาปัตยกรรมระบบคลาวด์สมัยใหม่จะเฉิดฉาย
ในแล็บนี้ เราจะแนะนำโซลูชันแบบ Serverless ที่ปรับขนาดได้เพื่อประมวลผลเนื้อหาวิดีโอโดยใช้ชุดบริการที่มีประสิทธิภาพของ Google Cloud ได้แก่ Cloud Run, BigQuery และ Generative AI ของ Google (Gemini) เราจะอธิบายรายละเอียดเส้นทางการเดินทางของเราตั้งแต่การประมวลผล URL เดียวไปจนถึงการประสานงานการดำเนินการแบบขนานในชุดข้อมูลขนาดใหญ่ โดยไม่ต้องมีค่าใช้จ่ายในการจัดการคิวการรับส่งข้อความและการผสานรวมที่ซับซ้อน
ความท้าทาย
เราได้รับมอบหมายให้ประมวลผลแคตตาล็อกเนื้อหาวิดีโอจำนวนมาก โดยมุ่งเน้นไปที่เซสชันแล็บภาคปฏิบัติโดยเฉพาะ เป้าหมายคือการวิเคราะห์วิดีโอแต่ละรายการและสร้างข้อมูลสรุปที่มีโครงสร้าง ซึ่งรวมถึงชื่อตอน บริบทของคำนำ คำสั่งแบบทีละขั้นตอน เทคโนโลยีที่ใช้ และคู่คำถามและคำตอบที่เกี่ยวข้อง เราจึงต้องจัดเก็บเอาต์พุตนี้อย่างมีประสิทธิภาพเพื่อนำไปใช้สร้างสื่อการศึกษาในภายหลัง
ในตอนแรก เรามีบริการ Cloud Run ที่ใช้ HTTP แบบง่ายๆ ซึ่งประมวลผล URL ได้ทีละรายการ ซึ่งเหมาะสําหรับการทดสอบและการวิเคราะห์เฉพาะกิจ อย่างไรก็ตาม เมื่อต้องจัดการกับรายการ URL หลายพันรายการที่มาจาก BigQuery ข้อจำกัดของโมเดลคำขอเดียวและการตอบกลับเดียวนี้ก็เริ่มเห็นได้ชัด การประมวลผลแบบลำดับจะใช้เวลาหลายวันหรือหลายสัปดาห์
โอกาสคือการเปลี่ยนกระบวนการแบบลำดับที่ช้าหรือต้องทำด้วยตนเองให้เป็นเวิร์กโฟลว์แบบคู่ขนานที่ทำงานอัตโนมัติ เรามีเป้าหมายในการใช้ประโยชน์จากระบบคลาวด์ดังนี้
- ประมวลผลข้อมูลแบบขนาน: ลดเวลาประมวลผลชุดข้อมูลขนาดใหญ่ได้อย่างมาก
- ใช้ประโยชน์จากความสามารถของ AI ที่มีอยู่: ใช้ความสามารถของ Gemini เพื่อวิเคราะห์เนื้อหาที่ซับซ้อน
- ดูแลรักษาสถาปัตยกรรมแบบ Serverless: ไม่ต้องจัดการเซิร์ฟเวอร์หรือโครงสร้างพื้นฐานที่ซับซ้อน
- รวมศูนย์ข้อมูล: ใช้ BigQuery เป็นแหล่งข้อมูลเดียวที่เชื่อถือได้สำหรับ URL อินพุตและปลายทางที่เชื่อถือได้สำหรับผลลัพธ์ที่ประมวลผลแล้ว
- สร้างไปป์ไลน์ที่แข็งแกร่ง: สร้างระบบที่ทนทานต่อความล้มเหลวและจัดการและตรวจสอบได้ง่าย
วัตถุประสงค์
การจัดระเบียบการประมวลผล AI แบบขนานด้วย Cloud Run Jobs
โซลูชันของเรามุ่งเน้นที่งาน Cloud Run ซึ่งทำหน้าที่เป็นตัวจัดระเบียบ โดยจะอ่านชุด URL จาก BigQuery อย่างชาญฉลาด ส่ง URL เหล่านี้ไปยังบริการ Cloud Run ที่ใช้งานอยู่ (ซึ่งจัดการการประมวลผลด้วย AI สำหรับ URL เดียว) แล้วรวบรวมผลลัพธ์เพื่อเขียนกลับไปยัง BigQuery แนวทางนี้ช่วยให้เราทำสิ่งต่อไปนี้ได้
- แยกการจัดสรรออกจากกระบวนการ: งานจะจัดการเวิร์กโฟลว์ ในขณะที่บริการแยกต่างหากจะมุ่งเน้นไปที่งาน AI
- ใช้ประโยชน์จากความขนานของงาน Cloud Run: งานสามารถเพิ่มโหนดอินสแตนซ์คอนเทนเนอร์หลายรายการเพื่อเรียกใช้บริการ AI พร้อมกันได้
- ลดความซับซ้อน: เราบรรลุการทำงานแบบคู่ขนานโดยให้งานจัดการการเรียก HTTP พร้อมกันโดยตรง ซึ่งจะช่วยลดความซับซ้อนของสถาปัตยกรรม
กรณีการใช้งาน
ข้อมูลเชิงลึกที่ขับเคลื่อนโดย AI จากวิดีโอเซสชัน Code Vipassana
กรณีการใช้งานเฉพาะของเราคือการวิเคราะห์วิดีโอเซสชัน Google Cloud ของแล็บภาคปฏิบัติ Code Vipassana เป้าหมายคือการสร้างเอกสารประกอบที่มีโครงสร้าง (โครงร่างบทหนังสือ) โดยอัตโนมัติ ซึ่งรวมถึง
- ชื่อส่วนเนื้อหา: ชื่อที่กระชับสำหรับแต่ละส่วนของวิดีโอ
- บริบทการแนะนำ: อธิบายความเกี่ยวข้องของวิดีโอในเส้นทางการเรียนรู้ที่กว้างขึ้น
- สิ่งที่จะสร้าง: งานหรือเป้าหมายหลักของเซสชัน
- เทคโนโลยีที่ใช้: รายการบริการคลาวด์และเทคโนโลยีอื่นๆ ที่กล่าวถึง
- วิธีการทีละขั้นตอน: วิธีการทำงาน รวมถึงข้อมูลโค้ด
- ซอร์สโค้ด/URL ของเดโม: ลิงก์ที่ระบุในวิดีโอ
- ช่วงถามและตอบ: สร้างคำถามและคำตอบที่เกี่ยวข้องสำหรับการตรวจสอบความรู้
Flow

ขั้นตอนของสถาปัตยกรรม
Cloud Run คืออะไร Cloud Run Jobs คืออะไร
Cloud Run
แพลตฟอร์มแบบ Serverless ที่มีการจัดการครบวงจรซึ่งช่วยให้คุณเรียกใช้คอนเทนเนอร์แบบไม่เก็บสถานะได้ เหมาะสำหรับบริการบนเว็บ, API และ Microservice ที่ปรับขนาดโดยอัตโนมัติตามคำขอขาเข้า คุณระบุอิมเมจคอนเทนเนอร์ แล้ว Cloud Run จะจัดการส่วนที่เหลือให้ ตั้งแต่การทำให้ใช้งานได้และการปรับขนาดไปจนถึงการจัดการโครงสร้างพื้นฐาน จึงสามารถจัดการภาระงานแบบซิงโครนัสและภาระงานแบบคำขอ-การตอบกลับได้เป็นอย่างดี
งานใน Cloud Run
ข้อเสนอที่เสริมบริการ Cloud Run Cloud Run Jobs ออกแบบมาสำหรับงานประมวลผลแบบกลุ่มที่ต้องดำเนินการให้เสร็จสมบูรณ์แล้วจึงหยุด ซึ่งเหมาะอย่างยิ่งสำหรับการประมวลผลข้อมูล, ETL, การอนุมานแบบกลุ่มของแมชชีนเลิร์นนิง และงานใดๆ ที่เกี่ยวข้องกับการประมวลผลชุดข้อมูลแทนการตอบคำขอแบบเรียลไทม์ ฟีเจอร์หลักคือความสามารถในการเพิ่มโหนดจำนวนอินสแตนซ์คอนเทนเนอร์ (งาน) ที่ทำงานพร้อมกันเพื่อประมวลผลงานเป็นกลุ่ม และสามารถทริกเกอร์ได้จากแหล่งเหตุการณ์ต่างๆ หรือด้วยตนเอง
ความแตกต่างที่สำคัญ
บริการ Cloud Run เหมาะสำหรับแอปพลิเคชันที่ทำงานเป็นเวลานานและทำงานตามคำขอ งาน Cloud Run เหมาะสำหรับการประมวลผลแบบกลุ่มที่เน้นงานและมีขอบเขตจำกัดซึ่งทำงานจนเสร็จสมบูรณ์
สิ่งที่คุณจะสร้าง
แอปพลิเคชันการค้นหาค้าปลีก
โดยคุณจะต้องดำเนินการต่อไปนี้
- สร้างชุดข้อมูล ตาราง และส่งออกข้อมูล BigQuery (ข้อมูลเมตาของ Code Vipassana)
- สร้างฟังก์ชัน Python Cloud Run เพื่อใช้ฟังก์ชัน Generative AI (แปลงวิดีโอเป็น JSON ของบทในหนังสือ)
- สร้างแอปพลิเคชัน Python สำหรับไปป์ไลน์ข้อมูลไปยัง AI - อ่านจาก BigQuery และเรียกใช้ปลายทางฟังก์ชัน Cloud Run เพื่อรับข้อมูลเชิงลึก แล้วเขียนบริบทกลับไปยัง BigQuery
- สร้างและคอนเทนเนอร์แอปพลิเคชัน
- กำหนดค่า Cloud Run Jobs ด้วยคอนเทนเนอร์นี้
- เรียกใช้และตรวจสอบงาน
- ผลลัพธ์ของรายงาน
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น: ทำตามลิงก์และเปิดใช้ API
หรือจะใช้คำสั่ง gcloud สำหรับการดำเนินการนี้ก็ได้ โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
3. การตั้งค่าฐานข้อมูล/คลังข้อมูล
BigQuery เป็นกระดูกสันหลังของไปป์ไลน์ข้อมูล ลักษณะแบบ Serverless ที่ปรับขนาดได้สูงทำให้เหมาะสำหรับการจัดเก็บข้อมูลอินพุตและจัดเก็บผลลัพธ์ที่ประมวลผลแล้ว
- ที่เก็บข้อมูล: BigQuery ทำหน้าที่เป็นคลังข้อมูลของเรา โดยจะจัดเก็บรายการ URL ของวิดีโอ สถานะของวิดีโอ (เช่น รอดำเนินการ กำลังประมวลผล เสร็จสมบูรณ์) และบริบทสุดท้ายที่สร้างขึ้น ซึ่งเป็นแหล่งข้อมูลที่เชื่อถือได้เพียงแหล่งเดียวสำหรับวิดีโอที่ต้องประมวลผล
- ปลายทาง: เป็นที่ที่จัดเก็บข้อมูลเชิงลึกที่ AI สร้างขึ้น ทำให้สามารถค้นหาข้อมูลดังกล่าวได้อย่างง่ายดายสำหรับแอปพลิเคชันดาวน์สตรีมหรือการตรวจสอบด้วยตนเอง ชุดข้อมูลของเราประกอบด้วยรายละเอียดเซสชันวิดีโอ โดยเฉพาะจากเนื้อหา "Code Vipassana Seasons" ซึ่งมักจะมีการสาธิตทางเทคนิคอย่างละเอียด
- ตารางแหล่งที่มา: ตาราง BigQuery (เช่น post_session_labs) ที่มีระเบียน เช่น
- id: ตัวระบุที่ไม่ซ้ำกันสำหรับแต่ละเซสชัน/แถว
- url: URL ของวิดีโอ (เช่น ลิงก์ YouTube หรือลิงก์ไดรฟ์ที่เข้าถึงได้)
- status: สตริงที่ระบุสถานะการประมวลผล (เช่น PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING)
- context: ฟิลด์สตริงสำหรับจัดเก็บข้อมูลสรุปที่ AI สร้างขึ้น
- การนำเข้าข้อมูล: ในสถานการณ์นี้ ระบบได้นำเข้าข้อมูลไปยัง BigQuery ด้วยสคริปต์ INSERT สำหรับไปป์ไลน์ของเรา BigQuery เป็นจุดเริ่มต้น
ไปที่คอนโซล BigQuery เปิดแท็บใหม่ แล้วเรียกใช้คำสั่ง SQL ต่อไปนี้
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. การนำเข้าข้อมูล
ตอนนี้ได้เวลาเพิ่มตารางที่มีข้อมูลเกี่ยวกับร้านค้าแล้ว ไปที่แท็บใน BigQuery Studio แล้วเรียกใช้คำสั่ง SQL ต่อไปนี้เพื่อแทรกระเบียนตัวอย่าง
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. การสร้างฟังก์ชันข้อมูลเชิงลึกของวิดีโอ
เราต้องสร้างและทำให้ฟังก์ชัน Cloud Run ใช้งานได้เพื่อใช้ฟังก์ชันหลักในการสร้างบทหนังสือที่มีโครงสร้างจาก URL ของวิดีโอ หากต้องการเข้าถึงเครื่องมือนี้ในฐานะกล่องเครื่องมือปลายทางอิสระ เราเพิ่งสร้างและทำให้ฟังก์ชัน Cloud Run ใช้งานได้ หรือคุณจะเลือกใส่ฟังก์ชันนี้เป็นฟังก์ชันแยกต่างหากในแอปพลิเคชัน Python จริงสำหรับ Cloud Run Job ก็ได้
- ในคอนโซล Google Cloud ให้ไปที่หน้า Cloud Run
- คลิกเขียนฟังก์ชัน
- ในช่องชื่อบริการ ให้ป้อนชื่อเพื่ออธิบายฟังก์ชันของคุณ ชื่อบริการต้องขึ้นต้นด้วยตัวอักษรเท่านั้น และมีความยาวไม่เกิน 49 อักขระ ซึ่งรวมถึงตัวอักษร ตัวเลข หรือขีดกลาง ชื่อบริการต้องไม่ลงท้ายด้วยขีดกลาง และต้องไม่ซ้ำกันในแต่ละภูมิภาคและโปรเจ็กต์ ชื่อบริการจะเปลี่ยนในภายหลังไม่ได้และจะแสดงต่อสาธารณะ ( generate-video-insights**)**
- ในรายการภูมิภาค ให้ใช้ค่าเริ่มต้น หรือเลือกภูมิภาคที่คุณต้องการติดตั้งใช้งานฟังก์ชัน (เลือก us-central1)
- ในรายการรันไทม์ ให้ใช้ค่าเริ่มต้นหรือเลือกรุ่นรันไทม์ (เลือก Python 3.11)
- ในส่วนการตรวจสอบสิทธิ์ ให้เลือก "อนุญาตการเข้าถึงแบบสาธารณะ"
- คลิกปุ่ม "สร้าง"
- ระบบจะสร้างฟังก์ชันและโหลดด้วยเทมเพลต main.py และ requirements.txt
- แทนที่ด้วยไฟล์ main.py และ requirements.txt จากที่เก็บของโปรเจ็กต์นี้
หมายเหตุสำคัญ: ใน main.py อย่าลืมแทนที่ <<YOUR_PROJECT_ID>> ด้วยรหัสโปรเจ็กต์ของคุณ
- ทำให้ปลายทางใช้งานได้และบันทึกปลายทางเพื่อให้คุณใช้ปลายทางในแหล่งที่มาสําหรับงาน Cloud Run ได้
ปลายทางควรมีลักษณะดังนี้ (หรือคล้ายกัน): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
ฟังก์ชัน Cloud Run นี้มีอะไรบ้าง
Gemini 2.5 Flash สำหรับการประมวลผลวิดีโอ
สำหรับงานหลักในการทำความเข้าใจและสรุปเนื้อหาวิดีโอ เราใช้ประโยชน์จากโมเดล Gemini 2.5 Flash ของ Google โมเดล Gemini เป็นโมเดล AI ที่ทรงพลังและทำงานได้กับข้อมูลหลายรูปแบบ ซึ่งสามารถทำความเข้าใจและประมวลผลอินพุตประเภทต่างๆ ได้ รวมถึงข้อความและวิดีโอ (เมื่อมีการผสานรวมที่เฉพาะเจาะจง)
ในการตั้งค่าของเรา เราไม่ได้ป้อนไฟล์วิดีโอไปยัง Gemini โดยตรง แต่เราได้ส่งพรอมต์ที่เป็นข้อความซึ่งมี URL ของวิดีโอและสั่งให้ Gemini วิเคราะห์เนื้อหา (สมมติ) ของวิดีโอที่ URL นั้น แม้ว่า Gemini 2.5 Flash จะรองรับอินพุตหลายรูปแบบ แต่ไปป์ไลน์เฉพาะนี้ใช้พรอมต์แบบข้อความที่อธิบายลักษณะของวิดีโอ (เซสชันแล็บภาคปฏิบัติ) และขอเอาต์พุต JSON ที่มีโครงสร้าง ซึ่งจะใช้การให้เหตุผลขั้นสูงและความเข้าใจภาษาธรรมชาติของ Gemini เพื่ออนุมานและสังเคราะห์ข้อมูลตามบริบทของพรอมต์
พรอมต์ Gemini: การชี้นำ AI
พรอมต์ที่สร้างขึ้นอย่างดีมีความสำคัญอย่างยิ่งต่อโมเดล AI พรอมต์ของเราได้รับการออกแบบมาเพื่อดึงข้อมูลที่เฉพาะเจาะจงมากและจัดโครงสร้างเป็นรูปแบบ JSON ซึ่งทำให้แอปพลิเคชันของเราแยกวิเคราะห์ได้ง่าย
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
พรอมต์นี้มีความเฉพาะเจาะจงสูง ซึ่งจะนำทางให้ Gemini ทำหน้าที่เป็นนักการศึกษา คำขอสตริง JSON ช่วยให้มั่นใจได้ว่าเอาต์พุตจะมีโครงสร้างและเครื่องอ่านได้
โค้ดสำหรับการวิเคราะห์อินพุตวิดีโอและแสดงบริบทของวิดีโอมีดังนี้
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
ข้อมูลโค้ดด้านบนแสดงฟังก์ชันหลักของกรณีการใช้งาน โดยจะรับ URL ของวิดีโอและใช้โมเดล Gemini ผ่านไคลเอ็นต์ Vertex AI เพื่อวิเคราะห์เนื้อหาวิดีโอและดึงข้อมูลเชิงลึกที่เกี่ยวข้องตามพรอมต์ จากนั้นระบบจะส่งบริบทที่ดึงออกมากลับมาเพื่อประมวลผลเพิ่มเติม ซึ่งแสดงถึงการดำเนินการแบบซิงโครนัสที่งาน Cloud Run รอให้บริการเสร็จสมบูรณ์
6. การพัฒนาแอปพลิเคชันไปป์ไลน์ (Python)
ตรรกะของไปป์ไลน์ส่วนกลางของเราอยู่ในซอร์สโค้ดของแอปพลิเคชันที่จะนำไปใส่ในคอนเทนเนอร์เป็น Cloud Run Job ซึ่งจะประสานงานการดำเนินการแบบขนานทั้งหมด ส่วนสำคัญมีดังนี้
บทบาทของ Orchestrator ในการจัดการเวิร์กโฟลว์และรับประกันความสมบูรณ์ของข้อมูล
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
ข้อมูลโค้ดด้านบนเริ่มต้นด้วยการดึงข้อมูล URL ของวิดีโอเป็นชุดที่มีสถานะ "รอดำเนินการ" จากตารางแหล่งที่มาของ BigQuery จากนั้นจะอัปเดตสถานะของ URL เหล่านี้เป็น "กำลังประมวลผล" ใน BigQuery เพื่อป้องกันการประมวลผลที่ซ้ำกัน
การประมวลผลแบบขนานด้วย ThreadPoolExecutor และการเรียกใช้บริการโปรเซสเซอร์
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
โค้ดส่วนนี้ใช้ประโยชน์จาก ThreadPoolExecutor เพื่อให้ประมวลผล URL ของวิดีโอที่ดึงมาแบบขนานได้ โดยจะส่งงานเพื่อเรียกใช้บริการ Cloud Run (ตัวประมวลผล URL) แบบไม่พร้อมกันสำหรับแต่ละ URL ซึ่งจะช่วยให้ Cloud Run Job ประมวลผลวิดีโอหลายรายการพร้อมกันได้อย่างมีประสิทธิภาพ ซึ่งจะช่วยเพิ่มประสิทธิภาพของไปป์ไลน์โดยรวม นอกจากนี้ ข้อมูลโค้ดยังจัดการการหมดเวลาและข้อผิดพลาดที่อาจเกิดขึ้นจากบริการโปรเซสเซอร์ด้วย
การอ่านและการเขียนจากและไปยัง BigQuery
การโต้ตอบหลักกับ BigQuery เกี่ยวข้องกับการดึง URL ที่รอดำเนินการ แล้วอัปเดต URL เหล่านั้นด้วยผลลัพธ์ที่ประมวลผลแล้ว
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
เขียนผลลัพธ์กลับไปยัง BigQuery
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
ข้อมูลโค้ดด้านบนมุ่งเน้นที่การโต้ตอบข้อมูลระหว่างงาน Cloud Run กับ BigQuery โดยจะดึงข้อมูล URL ของวิดีโอที่มีสถานะ "รอดำเนินการ" และรหัสของวิดีโอเหล่านั้นจากตารางแหล่งที่มา หลังจากประมวลผล URL แล้ว ข้อมูลโค้ดนี้จะแสดงการเขียนบริบทและสถานะที่แยกออกมา ("COMPLETED" หรือ "FAILED_PROCESSING") กลับไปยังตาราง BigQuery เป้าหมายโดยใช้การค้นหา UPDATE ข้อมูลโค้ดนี้จะทําให้ลูปการประมวลผลข้อมูลเสร็จสมบูรณ์ นอกจากนี้ ยังมีฟังก์ชันตัวช่วย update_bq_row ซึ่งแสดงวิธีกำหนดพารามิเตอร์ของคำสั่งอัปเดต
การตั้งค่าแอปพลิเคชัน
แอปพลิเคชันมีโครงสร้างเป็นสคริปต์ Python เดียวที่จะสร้างเป็นคอนเทนเนอร์ โดยจะใช้ประโยชน์จากไลบรารีของไคลเอ็นต์ Google Cloud และฟังก์ชันเฟรมเวิร์กเพื่อกำหนดจุดแรกเข้า
- การอ้างอิง: google-cloud-bigquery, requests
- การกำหนดค่า: ระบบจะโหลดการตั้งค่าที่สำคัญทั้งหมด (โปรเจ็กต์/ชุดข้อมูล/ตาราง BigQuery, URL ของบริการตัวประมวลผล URL) จากตัวแปรสภาพแวดล้อม ซึ่งทำให้แอปพลิเคชันพกพาได้และปลอดภัย
- ตรรกะหลัก: ฟังก์ชัน process_batch_from_bq จะจัดระเบียบเวิร์กโฟลว์ทั้งหมด
- การผสานรวมบริการภายนอก: ฟังก์ชัน call_url_processor_service จัดการการสื่อสารกับบริการ Cloud Run ที่แยกต่างหาก
- การโต้ตอบกับ BigQuery: ใช้ bq_client เพื่อดึงข้อมูล URL และอัปเดตผลลัพธ์ พร้อมการจัดการพารามิเตอร์ที่เหมาะสม
- Parallelism: concurrent.futures.ThreadPoolExecutor จัดการการเรียกใช้บริการภายนอกพร้อมกัน
- จุดแรกเข้า: โค้ด Python ชื่อ main.py ทำหน้าที่เป็นจุดแรกเข้าที่เริ่มการประมวลผลแบบกลุ่ม
มาตั้งค่าแอปพลิเคชันกันเลย
- คุณเริ่มต้นได้โดยไปที่เทอร์มินัล Cloud Shell และโคลนที่เก็บ
git clone https://github.com/AbiramiSukumaran/video-context-crj
- ไปที่ Cloud Shell Editor ซึ่งคุณจะเห็นโฟลเดอร์ที่สร้างใหม่ video-context-crj
- ลบรายการต่อไปนี้ เนื่องจากขั้นตอนเหล่านั้นเสร็จสมบูรณ์แล้วในส่วนก่อนหน้า
- ลบโฟลเดอร์ Cloud_Run_Function
- ไปที่โฟลเดอร์โปรเจ็กต์ video-context-crj แล้วคุณจะเห็นโครงสร้างโปรเจ็กต์ดังนี้
7. การตั้งค่า Dockerfile และการแปลงเป็นคอนเทนเนอร์
หากต้องการทำให้ตรรกะนี้ใช้งานได้เป็น Cloud Run Job เราต้องสร้างคอนเทนเนอร์ การทำคอนเทนเนอร์คือกระบวนการสร้างแพ็กเกจโค้ดของแอปพลิเคชัน ทรัพยากร Dependency และรันไทม์ลงในอิมเมจแบบพกพา
โปรดตรวจสอบว่าได้แทนที่ตัวยึดตำแหน่ง (ข้อความตัวหนา) ด้วยค่าของคุณใน Dockerfile แล้ว
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
ข้อมูลโค้ด Dockerfile ด้านบนกำหนดอิมเมจพื้นฐาน ติดตั้งการอ้างอิง คัดลอกโค้ด และตั้งค่าคำสั่งเพื่อเรียกใช้แอปพลิเคชันโดยใช้ฟังก์ชันเฟรมเวิร์กที่มีฟังก์ชันเป้าหมายที่ถูกต้อง (process_batch_from_bq) จากนั้นระบบจะพุชอิมเมจนี้ไปยัง Artifact Registry
สร้างคอนเทนเนอร์
หากต้องการสร้างคอนเทนเนอร์ ให้ไปที่เทอร์มินัล Cloud Shell แล้วเรียกใช้คำสั่งต่อไปนี้ (อย่าลืมแทนที่ตัวยึดตำแหน่ง <<YOUR_PROJECT_ID>>)
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
เมื่อสร้างอิมเมจคอนเทนเนอร์แล้ว คุณควรเห็นเอาต์พุตต่อไปนี้
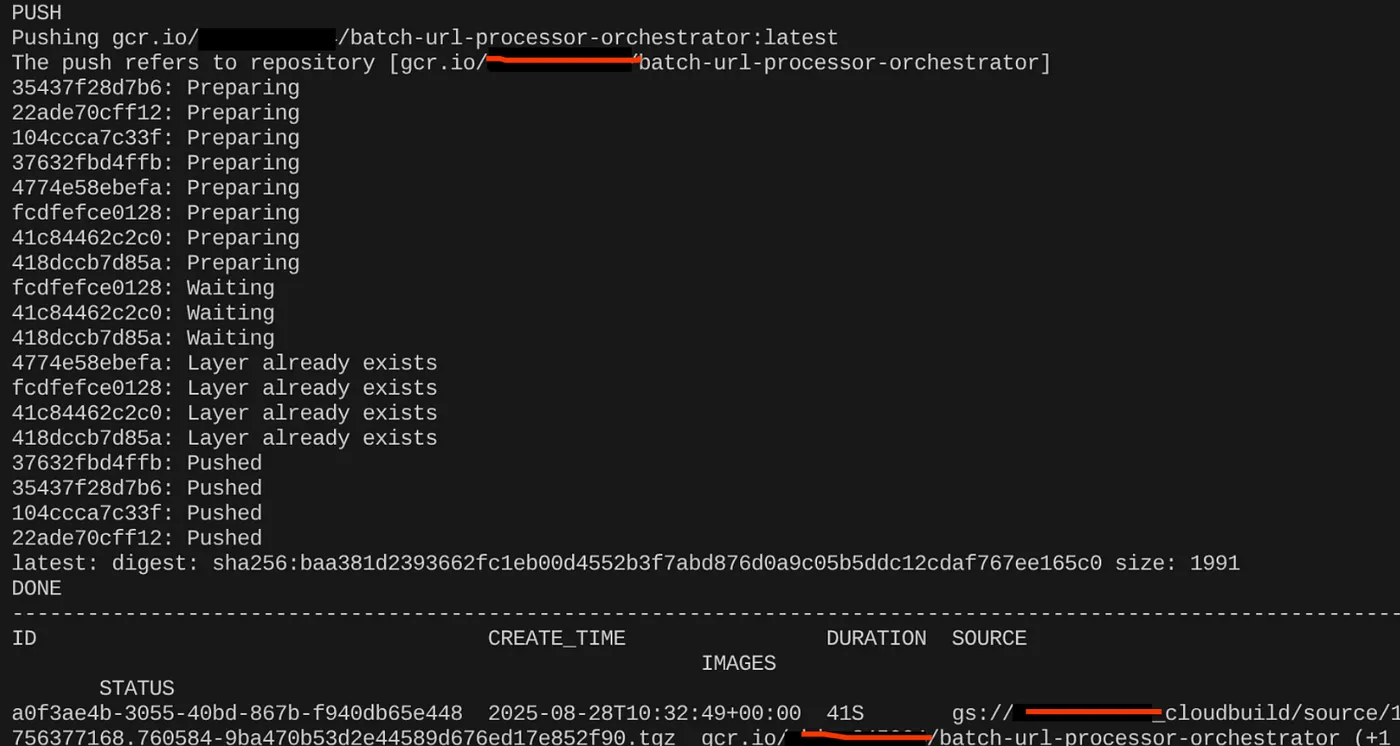
ตอนนี้ระบบได้สร้างและบันทึกคอนเทนเนอร์ไว้ใน Artifact Registry แล้ว เราพร้อมที่จะไปยังขั้นตอนถัดไปแล้ว
8. การสร้างงานใน Cloud Run
การทำให้งานใช้งานได้เกี่ยวข้องกับการสร้างอิมเมจคอนเทนเนอร์ แล้วสร้างทรัพยากร Cloud Run Job
เราได้สร้างอิมเมจคอนเทนเนอร์และจัดเก็บไว้ใน Artifact Registry แล้ว ตอนนี้มาสร้างงานกัน
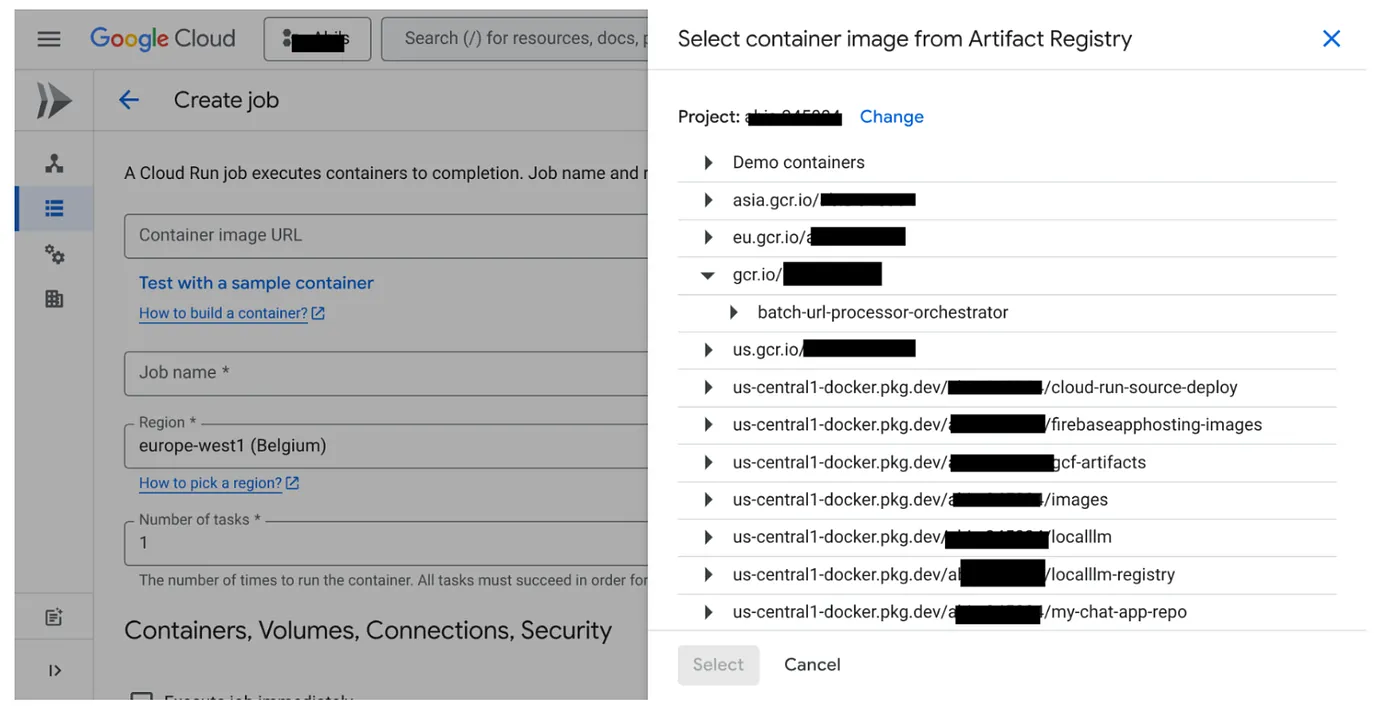
- ไปที่คอนโซล Cloud Run Jobs แล้วคลิก "Deploy Container"

- เลือกอิมเมจคอนเทนเนอร์ที่เราเพิ่งสร้าง
- ป้อนรายละเอียดการกำหนดค่าอื่นๆ ดังนี้

- ตั้งค่าความจุของงานดังนี้
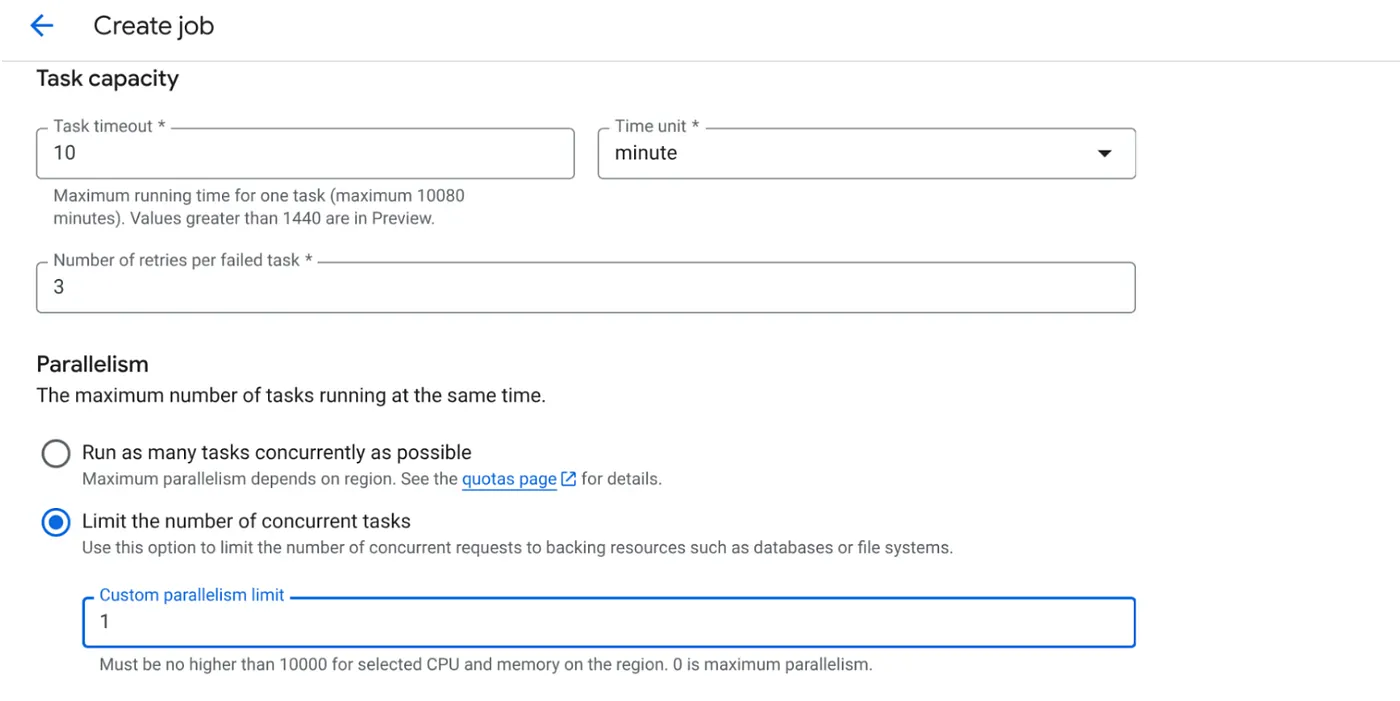
เนื่องจากเรามีการเขียนฐานข้อมูลและข้อเท็จจริงที่ว่าการประมวลผลแบบขนาน (max_instances และ task concurrency) ได้รับการจัดการในโค้ดแล้ว เราจึงจะตั้งค่าจำนวนงานที่ทำงานพร้อมกันเป็น 1 แต่คุณสามารถเพิ่มได้ตามต้องการ เป้าหมายในที่นี้คือ งานจะทำงานจนเสร็จสมบูรณ์ตามการกำหนดค่าโดยมีระดับการเกิดขึ้นพร้อมกันที่ตั้งค่าไว้ในการทำงานแบบคู่ขนาน
- คลิกสร้าง
ระบบจะสร้างงาน Cloud Run ให้คุณเรียบร้อยแล้ว
วิธีการทำงาน
อินสแตนซ์คอนเทนเนอร์ของงานจะเริ่มขึ้น โดยจะค้นหา BigQuery เพื่อรับ URL ชุดเล็ก (BATCH_SIZE) ที่ทำเครื่องหมายเป็น "รอดำเนินการ" โดยจะอัปเดตสถานะของ URL ที่ดึงข้อมูลเหล่านี้เป็น "กำลังประมวลผล" ใน BigQuery ทันทีเพื่อป้องกันไม่ให้อินสแตนซ์ของงานอื่นๆ เลือก URL เหล่านี้ โดยจะสร้าง ThreadPoolExecutor และส่งงานสำหรับแต่ละ URL ในกลุ่ม แต่ละงานจะเรียกฟังก์ชัน call_url_processor_service เมื่อคำขอ call_url_processor_service เสร็จสมบูรณ์ (หรือหมดเวลา/ล้มเหลว) ระบบจะรวบรวมผลลัพธ์ (บริบทที่ AI สร้างขึ้นหรือข้อความแสดงข้อผิดพลาด) และแมปกลับไปยัง row_id เดิม เมื่องานทั้งหมดสำหรับแบตช์เสร็จสิ้นแล้ว งานจะวนซ้ำผลลัพธ์ที่รวบรวมไว้และอัปเดตฟิลด์บริบทและสถานะสำหรับแต่ละแถวที่เกี่ยวข้องใน BigQuery หากสำเร็จ อินสแตนซ์ของงานจะออกอย่างเรียบร้อย หากพบข้อผิดพลาดที่ไม่ได้จัดการ ฟังก์ชันจะยกเว้น ซึ่งอาจทริกเกอร์ให้ Cloud Run Jobs ลองอีกครั้ง (ขึ้นอยู่กับการกำหนดค่างาน)
ตำแหน่งของงานใน Cloud Run: การจัดการเป็นกลุ่ม
นี่คือจุดที่ Cloud Run Jobs โดดเด่นอย่างแท้จริง
การประมวลผลแบบกลุ่มแบบไร้เซิร์ฟเวอร์: เรามีโครงสร้างพื้นฐานที่มีการจัดการซึ่งสามารถเปิดใช้อินสแตนซ์คอนเทนเนอร์ได้มากเท่าที่ต้องการ (สูงสุด MAX_INSTANCES) เพื่อประมวลผลข้อมูลพร้อมกัน
การควบคุมการทำงานแบบขนาน: เรากำหนด MAX_INSTANCES (จำนวนงานที่เรียกใช้แบบขนานได้โดยรวม) และ TASK_CONCURRENCY (จำนวนการดำเนินการที่อินสแตนซ์งานแต่ละรายการดำเนินการแบบขนาน) ซึ่งช่วยให้ควบคุมปริมาณงานและการใช้ทรัพยากรได้อย่างละเอียด
การทนต่อข้อผิดพลาด: หากอินสแตนซ์ของงานล้มเหลวกลางคัน คุณสามารถกำหนดค่างาน Cloud Run ให้ลองทั้งงานหรือเฉพาะงานอีกครั้งได้ เพื่อให้มั่นใจว่าการประมวลผลข้อมูลจะไม่สูญหาย
สถาปัตยกรรมที่เรียบง่าย: การจัดระเบียบการเรียก HTTP ภายในงานโดยตรงและการใช้ BigQuery เพื่อการจัดการสถานะช่วยให้เราหลีกเลี่ยงความซับซ้อนในการตั้งค่าและจัดการ Pub/Sub, หัวข้อ, การสมัครใช้บริการ และตรรกะการรับทราบ
MAX_INSTANCES กับ TASK_CONCURRENCY:
MAX_INSTANCES: จำนวนอินสแตนซ์ของงานทั้งหมดที่สามารถเรียกใช้พร้อมกันในการดำเนินการงานทั้งหมด นี่คือคันโยกหลักในการประมวลผล URL จำนวนมากพร้อมกัน
TASK_CONCURRENCY: จำนวนการดำเนินการแบบขนาน (การเรียกไปยังบริการโปรเซสเซอร์) ที่อินสแตนซ์เดียวของงานจะดำเนินการ ซึ่งจะช่วยเพิ่มการใช้งาน CPU/เครือข่ายของอินสแตนซ์หนึ่ง
9. การเรียกใช้และการตรวจสอบงานใน Cloud Run
ข้อมูลเมตาของวิดีโอ
ก่อนคลิก "ดำเนินการ" มาดูสถานะของข้อมูลกัน
ไปที่ BigQuery Studio แล้วเรียกใช้การค้นหาต่อไปนี้
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
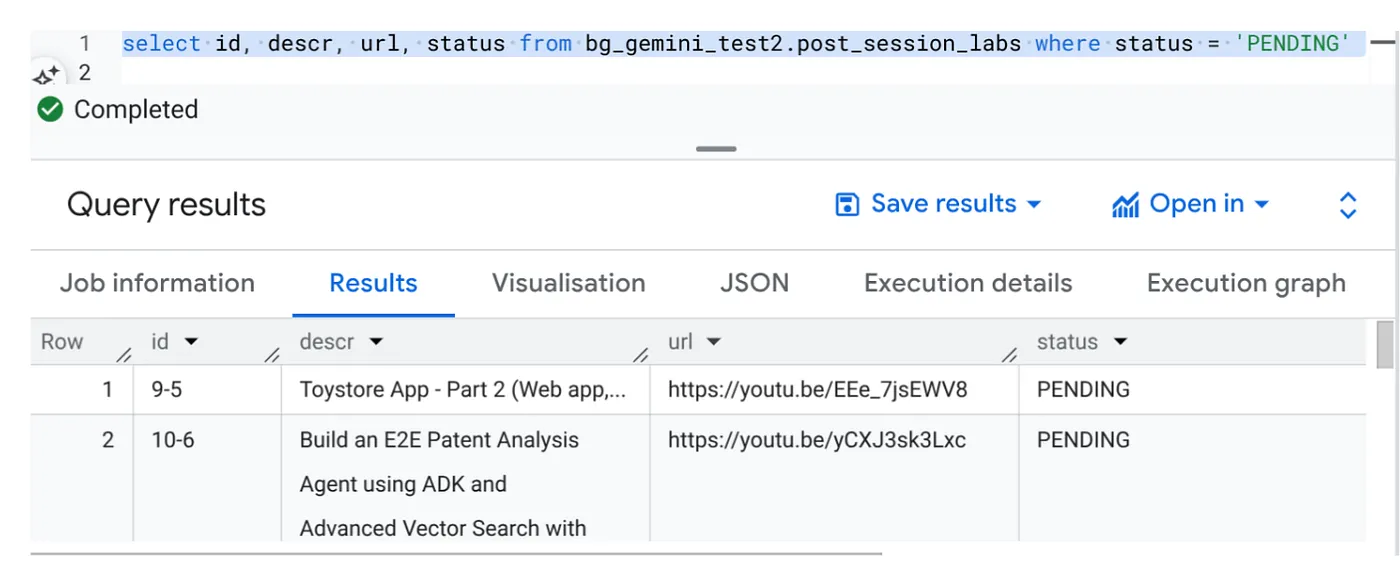
เรามีตัวอย่างระเบียนที่มี URL ของวิดีโอและมีสถานะเป็น "รอดำเนินการ" เป้าหมายของเราคือการป้อนข้อมูลในช่อง "บริบท" ด้วยข้อมูลเชิงลึกจากวิดีโอในรูปแบบที่อธิบายไว้ในพรอมต์
ทริกเกอร์งาน
มาดำเนินการกับงานกันเลยโดยคลิกปุ่ม "EXECUTE" ในงานในคอนโซล Cloud Run Jobs แล้วคุณจะเห็นความคืบหน้าและสถานะของงานในคอนโซล
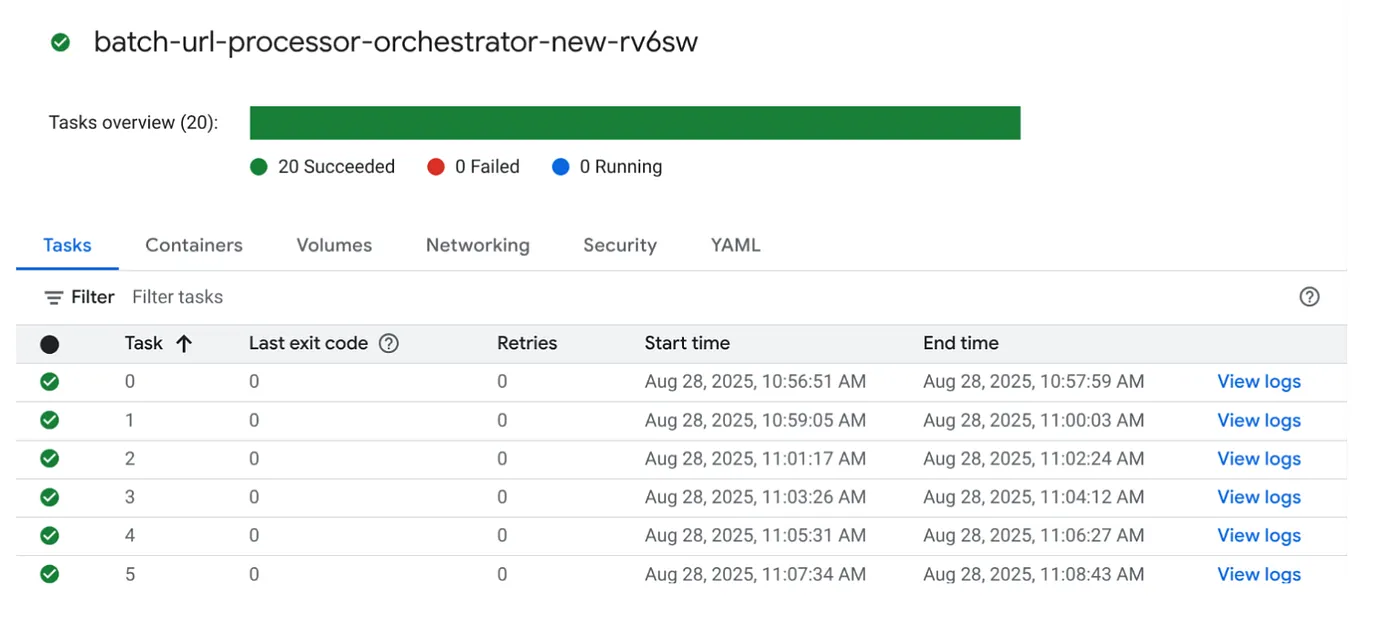
คุณสามารถตรวจสอบแท็ก LOGS ใน OBSERVABILITY เพื่อดูขั้นตอนการตรวจสอบและรายละเอียดอื่นๆ เกี่ยวกับงานและงานต่างๆ
10. การวิเคราะห์ผลลัพธ์
เมื่องานเสร็จสมบูรณ์แล้ว คุณจะเห็นบริบทของ URL วิดีโอแต่ละรายการที่อัปเดตในตาราง
บริบทเอาต์พุต (สำหรับ 1 ในระเบียน)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
ตอนนี้คุณควรตรวจสอบโครงสร้าง JSON นี้ได้แล้วสำหรับกรณีการใช้งานแบบ Agentic ขั้นสูงเพิ่มเติม
เหตุผลที่ใช้วิธีนี้
สถาปัตยกรรมนี้มีข้อได้เปรียบเชิงกลยุทธ์ที่สำคัญ ดังนี้
- ความคุ้มค่า: บริการแบบ Serverless หมายความว่าคุณจะจ่ายค่าบริการตามการใช้งานจริงเท่านั้น งานใน Cloud Run จะลดขนาดลงเป็น 0 เมื่อไม่ได้ใช้งาน
- ความสามารถในการปรับขนาด: จัดการ URL หลายหมื่นรายการได้อย่างง่ายดายโดยการปรับการตั้งค่าอินสแตนซ์งานและความพร้อมกันของ Cloud Run
- ความคล่องตัว: วงจรการพัฒนาและการติดตั้งใช้งานที่รวดเร็วสำหรับตรรกะการประมวลผลหรือโมเดล AI ใหม่ๆ เพียงแค่อัปเดตแอปพลิเคชันที่มีอยู่และบริการของแอปพลิเคชัน
- ลดค่าใช้จ่ายในการดำเนินการ: ไม่ต้องแพตช์หรือจัดการเซิร์ฟเวอร์ Google จะจัดการโครงสร้างพื้นฐานให้
- การทำให้ AI เป็นประชาธิปไตย: ช่วยให้การประมวลผลด้วย AI ขั้นสูงเข้าถึงได้สำหรับงานแบบเป็นชุดโดยไม่ต้องมีความเชี่ยวชาญด้าน ML Ops ในเชิงลึก
11. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าResource Manager
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
12. ขอแสดงความยินดี
ยินดีด้วย การออกแบบโซลูชันของเราโดยใช้ Cloud Run Jobs และใช้ประโยชน์จากความสามารถของ BigQuery ในการจัดการข้อมูลและบริการ Cloud Run ภายนอกสำหรับการประมวลผลด้วย AI ทำให้คุณสร้างระบบที่ปรับขนาดได้สูง คุ้มค่า และดูแลรักษาง่าย รูปแบบนี้จะแยกตรรกะการประมวลผล ช่วยให้ดำเนินการแบบคู่ขนานได้โดยไม่ต้องมีโครงสร้างพื้นฐานที่ซับซ้อน และช่วยเร่งเวลาในการรับข้อมูลเชิงลึกได้อย่างมาก
เราขอแนะนำให้คุณลองใช้ Cloud Run Jobs เพื่อตอบสนองความต้องการในการประมวลผลแบบกลุ่มของคุณเอง ไม่ว่าจะเป็นการปรับขนาดการวิเคราะห์ AI, การเรียกใช้ไปป์ไลน์ ETL หรือการทำงานเกี่ยวกับข้อมูลเป็นระยะ แนวทางแบบ Serverless นี้ก็เป็นโซลูชันที่มีประสิทธิภาพและมีประสิทธิภาพ หากต้องการเริ่มต้นด้วยตนเอง โปรดดูที่นี่
หากคุณสนใจที่จะสร้างและทำให้ใช้งานได้แอปทั้งหมดแบบ Serverless และเป็น Agent โปรดจดทะเบียนเข้าร่วม Code Vipassana ซึ่งมุ่งเน้นการเร่งความเร็วแอปพลิเคชันที่เป็น Agent Generative ที่ขับเคลื่อนด้วยข้อมูล