
1. Genel Bakış
Günümüzün veri açısından zengin dünyasında, yapılandırılmamış içeriklerden (özellikle videolardan) anlamlı analizler elde etmek büyük bir gerekliliktir. Yüzlerce veya binlerce video URL'sini analiz etmeniz, içeriklerini özetlemeniz, temel teknolojileri çıkarmanız ve hatta eğitim materyalleri için soru-cevap çiftleri oluşturmanız gerektiğini düşünün. Bunu tek tek yapmak hem zaman alır hem de verimli değildir. Modern bulut mimarileri bu noktada öne çıkar.
Bu laboratuvarda, Google Cloud'un güçlü hizmet paketi (Cloud Run, BigQuery ve Google'ın üretken yapay zeka modeli Gemini) kullanılarak video içeriklerinin işlenmesi için ölçeklenebilir ve sunucusuz çözümün nasıl kullanılacağını öğreneceksiniz. Tek bir URL'yi işlemekten karmaşık mesajlaşma kuyruklarını ve entegrasyonları yönetme yükü olmadan büyük bir veri kümesinde paralel yürütmeyi düzenlemeye kadar olan yolculuğumuzu ayrıntılı olarak açıklayacağız.
Hedef
Özellikle uygulamalı laboratuvar oturumlarına odaklanarak büyük bir video içeriği kataloğunu işlememiz gerekiyordu. Amaç, her videoyu analiz edip bölüm başlıkları, giriş bağlamı, adım adım talimatlar, kullanılan teknolojiler ve ilgili soru-cevap çiftleri gibi bilgileri içeren yapılandırılmış bir özet oluşturmaktı. Bu çıktının, eğitim materyalleri oluştururken daha sonra kullanılmak üzere verimli bir şekilde depolanması gerekiyordu.
Başlangıçta, tek seferde bir URL işleyebilen basit bir HTTP tabanlı Cloud Run hizmetimiz vardı. Bu yöntem, test ve geçici analiz için iyi sonuçlar verdi. Ancak BigQuery'den alınan binlerce URL'lik bir liste söz konusu olduğunda bu tek istekli, tek yanıtlı modelin sınırlamaları ortaya çıktı. Sıralı işleme günlerce, hatta haftalarca sürebilir.
Fırsat, manuel veya yavaş sıralı bir süreci otomatikleştirilmiş, paralelleştirilmiş bir iş akışına dönüştürmekti. Buluttan yararlanarak şunları hedefledik:
- Verileri paralel olarak işleme: Büyük veri kümelerinin işleme süresini önemli ölçüde kısaltın.
- Mevcut yapay zeka özelliklerinden yararlanma: Gelişmiş içerik analizi için Gemini'ın gücünden yararlanın.
- Sunucusuz mimariyi koruma: Sunucuları veya karmaşık altyapıları yönetmekten kaçının.
- Verileri merkezileştirme: Giriş URL'leri için tek doğruluk kaynağı ve işlenmiş sonuçlar için güvenilir bir hedef olarak BigQuery'yi kullanın.
- Sağlam bir ardışık düzen oluşturun: Hatalara karşı dayanıklı, kolayca yönetilebilen ve izlenebilen bir sistem oluşturun.
Hedef
Cloud Run işleriyle paralel yapay zeka işlemeyi düzenleme:
Çözümümüz, düzenleyici görevi gören bir Cloud Run işi etrafında şekilleniyor. BigQuery'den URL gruplarını akıllıca okur, bu URL'leri mevcut ve dağıtılmış Cloud Run hizmetimize (tek bir URL için yapay zeka işlemeyi yönetir) gönderir ve sonuçları toplayarak BigQuery'ye geri yazar. Bu yaklaşım sayesinde:
- Düzenlemeyi işleme işleminden ayırma: İş, iş akışını yönetirken ayrı Hizmet, yapay zeka görevine odaklanır.
- Cloud Run Job'un paralelliğinden yararlanma: İş, yapay zeka hizmetini eşzamanlı olarak çağırmak için birden fazla kapsayıcı örneğini ölçeği genişletebilir.
- Karmaşıklığı azaltma: İşin eşzamanlı HTTP çağrılarını doğrudan yönetmesini sağlayarak paralellik elde ederiz ve mimariyi basitleştiririz.
Kullanım Örneği
Code Vipassana oturum videolarından yapay zeka destekli analizler
Bizim özel kullanım alanımız, Code Vipassana uygulamalı laboratuvarlarının Google Cloud oturumlarının videolarını analiz etmekti. Amaç, aşağıdakiler de dahil olmak üzere yapılandırılmış dokümanları (kitap bölümü ana hatları) otomatik olarak oluşturmaktı:
- Bölüm Başlıkları: Her video segmenti için kısa başlıklar
- Giriş Bağlamı: Videonun daha geniş bir öğrenme rotasındaki önemini açıklama
- Ne Oluşturulacak: Oturumun temel görevi veya hedefi
- Kullanılan Teknolojiler: Bulut hizmetlerinin ve bahsedilen diğer teknolojilerin listesi
- Adım Adım Talimatlar: Kod snippet'leri de dahil olmak üzere görevin nasıl gerçekleştirildiği
- Kaynak kodu/demo URL'leri: Videoda sağlanan bağlantılar
- Soru-cevap bölümü: Bilgi kontrolleri için alakalı sorular ve yanıtlar oluşturma.
Flow

Mimari akışı
Cloud Run nedir? Cloud Run işleri nedir?
Cloud Run
Durum bilgisiz container'ları çalıştırmanıza olanak tanıyan, tümüyle yönetilen bir sunucusuz platform. Gelen isteklere göre otomatik olarak ölçeklenebilen web hizmetleri, API'ler ve mikro hizmetler için idealdir. Bir container görüntüsü sağlarsınız ve Cloud Run, dağıtım ve ölçeklendirmeden altyapı yönetimine kadar geri kalan her şeyi halleder. Senkronize, istek-yanıt iş yüklerini işleme konusunda uzmandır.
Cloud Run işleri
Cloud Run hizmetlerini tamamlayan bir teklif. Cloud Run Jobs, tamamlanması ve ardından durması gereken toplu işleme görevleri için tasarlanmıştır. Veri işleme, ETL, makine öğrenimi toplu çıkarımı ve canlı istek sunmak yerine bir veri kümesini işlemeyi içeren tüm görevler için idealdir. Temel özelliklerinden biri, bir iş grubunu işlemek için eşzamanlı olarak çalışan kapsayıcı örneklerinin (görevler) sayısını ölçeği genişletebilmeleridir. Ayrıca çeşitli etkinlik kaynakları tarafından tetiklenebilir veya manuel olarak başlatılabilirler.
Temel Fark
Cloud Run hizmetleri, uzun süren ve isteğe dayalı uygulamalar için kullanılır. Cloud Run işleri, tamamlanana kadar çalışan, sonlu ve göreve yönelik toplu işleme için kullanılır.
Ne oluşturacaksınız?
Perakende Araması Uygulaması
Bu kapsamda şunları yapacaksınız:
- BigQuery veri kümesi ve tablosu oluşturma ve veri alma (Code Vipassana Metadata)
- Üretken yapay zeka işlevini uygulamak için Python Cloud Run işlevleri oluşturun (videoyu kitap bölümü JSON'a dönüştürme)
- Veri-yapay zeka ardışık düzeni için bir Python uygulaması oluşturun: BigQuery'den okuyun, analizler için Cloud Run Functions uç noktasını çağırın ve bağlamı BigQuery'ye geri yazın.
- Uygulamayı oluşturma ve kapsayıcıya alma
- Bu container ile Cloud Run işleri yapılandırma
- İşi yürütme ve izleme
- Rapor sonucu
Şartlar
2. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin .
- Google Cloud'da çalışan bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmından Cloud Shell'i etkinleştir'i tıklayın.

- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
gcloud config set project <YOUR_PROJECT_ID>
- Gerekli API'leri etkinleştirin: Bağlantıyı takip ederek API'leri etkinleştirin.
Alternatif olarak, bu işlem için gcloud komutunu kullanabilirsiniz. gcloud komutları ve kullanımı için belgelere bakın.
3. Veritabanı/Ambar kurulumu
BigQuery, veri işlem hattımızın temelini oluşturdu. Sunucusuz ve yüksek düzeyde ölçeklenebilir yapısı sayesinde hem giriş verilerimizi depolamak hem de işlenmiş sonuçları barındırmak için mükemmeldir.
- Veri Depolama: BigQuery, veri ambarımız olarak kullanıldı. Video URL'lerinin listesini, durumlarını (ör. BEKLEMEDE, İŞLENİYOR, TAMAMLANDI) ve oluşturulan nihai içeriği saklar. Hangi videoların işlenmesi gerektiğiyle ilgili tek doğruluk kaynağıdır.
- Hedef: Yapay zeka tarafından oluşturulan analizlerin kalıcı olarak saklandığı yerdir. Bu sayede, analizler sonraki uygulamalar için kolayca sorgulanabilir veya manuel olarak incelenebilir. Veri setimiz, özellikle ayrıntılı teknik gösterimlerin yer aldığı "Code Vipassana Seasons" içeriğinden elde edilen video oturumu ayrıntılarından oluşuyordu.
- Kaynak Tablo: Aşağıdaki gibi kayıtlar içeren bir BigQuery tablosu (ör. post_session_labs):
- id: Her oturum/satır için benzersiz bir tanımlayıcı.
- url: Videonun URL'si (ör. YouTube bağlantısı veya erişilebilir bir Drive bağlantısı).
- status: İşleme durumunu (ör. PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING) belirten bir dize.
- context: Yapay zekayla üretilen özeti depolamak için kullanılan bir dize alanı.
- Veri Alma: Bu senaryoda veriler, INSERT komut dosyalarıyla BigQuery'ye alınmıştır. BigQuery, işlem hattımız için başlangıç noktasıydı.
BigQuery konsoluna gidin, yeni bir sekme açın ve aşağıdaki SQL ifadelerini çalıştırın:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Veri kullanımı
Şimdi de mağazayla ilgili verilerin bulunduğu bir tablo ekleme zamanı. BigQuery Studio'da bir sekmeye gidin ve örnek kayıtları eklemek için aşağıdaki SQL ifadelerini yürütün:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Video Analizleri İşlevi Oluşturma
Video URL'sinden yapılandırılmış bir kitap bölümü oluşturma işlevinin temelini uygulamak için bir Cloud Run işlevi oluşturup dağıtmamız gerekir. Buna bağımsız bir uç nokta araç kutusu araçları olarak erişebilmek için yeni bir Cloud Run işlevi oluşturup dağıttık. Alternatif olarak, bunu Cloud Run işi için gerçek Python uygulamasında ayrı bir işlev olarak eklemeyi seçebilirsiniz:
- Google Cloud Console'da Cloud Run sayfasına gidin.
- İşlev yaz'ı tıklayın.
- Hizmet adı alanına işlevinizi açıklayan bir ad girin. Hizmet adları yalnızca harfle başlamalı ve harf, sayı ya da kısa çizgi dahil en fazla 49 karakter içermelidir. Hizmet adları tireyle bitemez ve bölge ile proje başına benzersiz olmalıdır. Hizmet adı daha sonra değiştirilemez ve herkese görünür durumdadır. ( generate-video-insights**)**
- Bölge listesinde varsayılan değeri kullanın veya işlevinizi dağıtmak istediğiniz bölgeyi seçin. (us-central1'i seçin)
- Çalışma zamanı listesinde varsayılan değeri kullanın veya bir çalışma zamanı sürümü seçin. (Python 3.11'i seçin)
- Kimlik doğrulama bölümünde "Herkese açık erişime izin ver"i seçin.
- "Oluştur" düğmesini tıklayın.
- İşlev oluşturulur ve şablon main.py ile requirements.txt ile yüklenir.
- Bu dosyayı, projenin deposundaki main.py ve requirements.txt dosyalarıyla değiştirin.
ÖNEMLİ NOT: main.py dosyasında <<YOUR_PROJECT_ID>> kısmını proje kimliğinizle değiştirmeyi unutmayın.
- Uç noktayı dağıtın ve kaydedin. Böylece, Cloud Run işi için kaynağınızda kullanabilirsiniz.
Uç noktanız şu şekilde (veya benzer şekilde) görünmelidir: https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
Bu Cloud Run işlevinde neler var?
Video işleme için Gemini 2.5 Flash
Video içeriklerini anlama ve özetleme gibi temel görevler için Google'ın Gemini 2.5 Flash modelinden yararlandık. Gemini modelleri, metin ve belirli entegrasyonlarla video da dahil olmak üzere çeşitli giriş türlerini anlayıp işleyebilen güçlü ve çok formatlı yapay zeka modelleridir.
Kurulumumuzda video dosyasını doğrudan Gemini'a aktarmadık. Bunun yerine, video URL'sini içeren bir metin istemi gönderdik ve Gemini'a bu URL'deki videonun (varsayımsal) içeriğini nasıl analiz edeceğini anlattık. Gemini 2.5 Flash, çok formatlı giriş yapabilse de bu özel ardışık düzende, videonun niteliğini (uygulamalı laboratuvar oturumu) açıklayan ve yapılandırılmış bir JSON çıkışı isteyen metin tabanlı bir istem kullanıldı. Bu özellik, istemin bağlamına göre bilgileri tahmin etmek ve sentezlemek için Gemini'ın gelişmiş akıl yürütme ve doğal dil anlama özelliklerinden yararlanır.
Gemini İstemleri: Yapay Zekaya Yol Gösterme
İyi hazırlanmış bir istem, yapay zeka modelleri için çok önemlidir. İstemimiz, çok spesifik bilgileri ayıklayıp JSON biçiminde yapılandıracak şekilde tasarlandı. Bu sayede, uygulamamız tarafından kolayca ayrıştırılabiliyor.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
Bu istem son derece spesifik olup Gemini'ı bir tür eğitmen gibi davranmaya yönlendiriyor. JSON dizesi isteği, yapılandırılmış ve makine tarafından okunabilir bir çıkış sağlar.
Video girişini analiz edip bağlamını döndürmek için kullanılan kod aşağıda verilmiştir:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
Yukarıdaki snippet, kullanım alanının temel işlevini gösterir. Bir video URL'si alır ve video içeriğini analiz etmek ve isteme göre alakalı analizler elde etmek için Vertex AI istemcisi aracılığıyla Gemini modelini kullanır. Ardından, çıkarılan bağlam daha fazla işlenmek üzere döndürülür. Bu, Cloud Run işinin hizmetin tamamlanmasını beklediği senkron bir işlemi ifade eder.
6. Ardışık Düzen Uygulaması Geliştirme (Python)
Merkezi ardışık düzen mantığımız, tüm paralel yürütmeyi düzenleyen bir Cloud Run işine kapsülleştirilecek olan uygulamanın kaynak kodunda bulunur. Temel bölümler aşağıda açıklanmıştır:
İş akışını yönetme ve veri bütünlüğünü sağlama konusunda düzenleyicinin rolü:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
Yukarıdaki snippet, BigQuery kaynak tablosundan "PENDING" (Beklemede) durumundaki bir grup video URL'sini getirerek başlıyor. Ardından, bu URL'lerin durumunu BigQuery'de "İŞLENİYOR" olarak güncelleyerek yinelenen işlemeyi önler.
ThreadPoolExecutor ile Paralel İşleme ve İşlemci Hizmetini Çağırma:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
Kodun bu bölümü, getirilen video URL'lerinin paralel olarak işlenmesi için ThreadPoolExecutor'dan yararlanır. Her URL için Cloud Run hizmetini (URL İşleyici) eşzamansız olarak çağırmak üzere bir görev gönderir. Bu sayede Cloud Run işi, birden fazla videoyu aynı anda verimli bir şekilde işleyerek genel ardışık düzen performansını artırabilir. Snippet, işlemci hizmetinden kaynaklanan olası zaman aşımlarını ve hataları da ele alır.
BigQuery'den okuma ve BigQuery'ye yazma
BigQuery ile temel etkileşim, bekleyen URL'leri getirmeyi ve ardından bunları işlenmiş sonuçlarla güncellemeyi içerir.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Sonuçları BigQuery'ye geri yazma:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
Yukarıdaki snippet'ler, Cloud Run işi ile BigQuery arasındaki veri etkileşimine odaklanmaktadır. Kaynak tablodan bir grup "BEKLEMEDE" video URL'si ve bunların kimliklerini alır. URL'ler işlendikten sonra bu snippet, ayıklanan bağlamı ve durumu ("COMPLETED" veya "FAILED_PROCESSING") bir UPDATE sorgusu kullanarak hedef BigQuery tablosuna geri yazmayı gösterir. Bu snippet, veri işleme döngüsünü tamamlar. Ayrıca, güncelleme ifadesinin parametrelerinin nasıl tanımlanacağını gösteren update_bq_row yardımcı işlevini de içerir.
Uygulama Kurulumu
Uygulama, container'a alınacak tek bir Python komut dosyası olarak yapılandırılmıştır. Giriş noktasını tanımlamak için Google Cloud istemci kitaplıklarından ve functions-framework'ten yararlanır.
- Bağımlılıklar: google-cloud-bigquery, requests
- Yapılandırma: Tüm kritik ayarlar (BigQuery projesi/veri kümesi/tablo, URL işleme hizmeti URL'si) ortam değişkenlerinden yüklenir. Bu sayede uygulama taşınabilir ve güvenli hale gelir.
- Temel Mantık: process_batch_from_bq işlevi, iş akışının tamamını düzenler.
- Harici hizmet entegrasyonu: call_url_processor_service işlevi, ayrı Cloud Run hizmetiyle iletişimi yönetir.
- BigQuery Etkileşimi: bq_client, URL'leri getirmek ve sonuçları güncellemek için kullanılır. Parametreler uygun şekilde işlenir.
- Paralellik: concurrent.futures.ThreadPoolExecutor, harici hizmete eşzamanlı çağrıları yönetir.
- Giriş noktası: main.py adlı Python kodu, toplu işlemeyi başlatan giriş noktası olarak işlev görür.
Şimdi uygulamayı ayarlayalım:
- Cloud Shell Terminal'inize gidip depoyu klonlayarak başlayabilirsiniz:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Yeni oluşturulan video-context-crj klasörünü görebileceğiniz Cloud Shell Düzenleyici'ye gidin.
- Aşağıdaki adımları silin. Bu adımlar önceki bölümlerde zaten tamamlanmıştır:
- Cloud_Run_Function klasörünü silin.
- video-context-crj proje klasörüne gidin. Proje yapısını görmelisiniz:
7. Dockerfile Kurulumu ve Kapsayıcı Oluşturma
Bu mantığı Cloud Run işi olarak dağıtmak için kapsüllememiz gerekir. Container mimarisine alma, uygulama kodumuzu, bağımlılıklarını ve çalışma zamanını taşınabilir bir görüntüye paketleme işlemidir.
Yer tutucuları (kalın metin) Dockerfile'daki değerlerinizle değiştirdiğinizden emin olun:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
Yukarıdaki Dockerfile snippet'i temel görüntüyü tanımlar, bağımlılıkları yükler, kodumuzu kopyalar ve doğru hedef işlevle (process_batch_from_bq) functions-framework'ü kullanarak uygulamamızı çalıştıracak komutu ayarlar. Bu görüntü daha sonra Artifact Registry'ye aktarılır.
Container mimarisine alma
Kapsüllemek için Cloud Shell Terminali'ne gidin ve aşağıdaki komutları çalıştırın (<<YOUR_PROJECT_ID>> yer tutucusunu değiştirmeyi unutmayın):
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
Container görüntüsü oluşturulduktan sonra şu çıkışı görürsünüz:
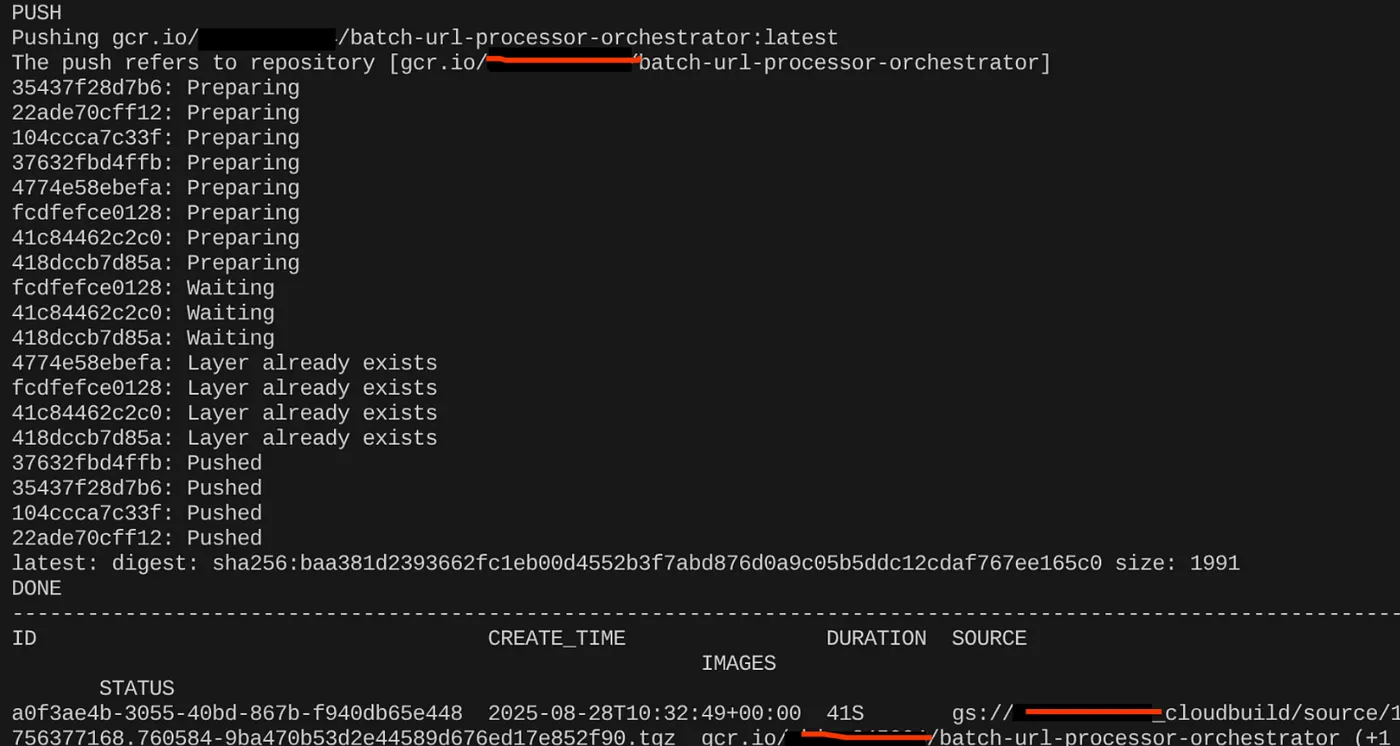
Container'ımız oluşturuldu ve Artifact Registry'ye kaydedildi. Bir sonraki adıma geçebiliriz.
8. Cloud Run işi oluşturma
İşi dağıtmak için önce container görüntüsü oluşturulur, ardından Cloud Run iş kaynağı oluşturulur.
Container görüntüsünü zaten oluşturup Artifact Registry'de depoladık. Şimdi işi oluşturalım.
- Cloud Run Jobs konsoluna gidin ve Container'ı Dağıt'ı tıklayın:

- Yeni oluşturduğumuz container görüntüsünü seçin:
- Diğer yapılandırma ayrıntılarını aşağıdaki gibi girin:

- Görev kapasitesini aşağıdaki gibi ayarlayın:
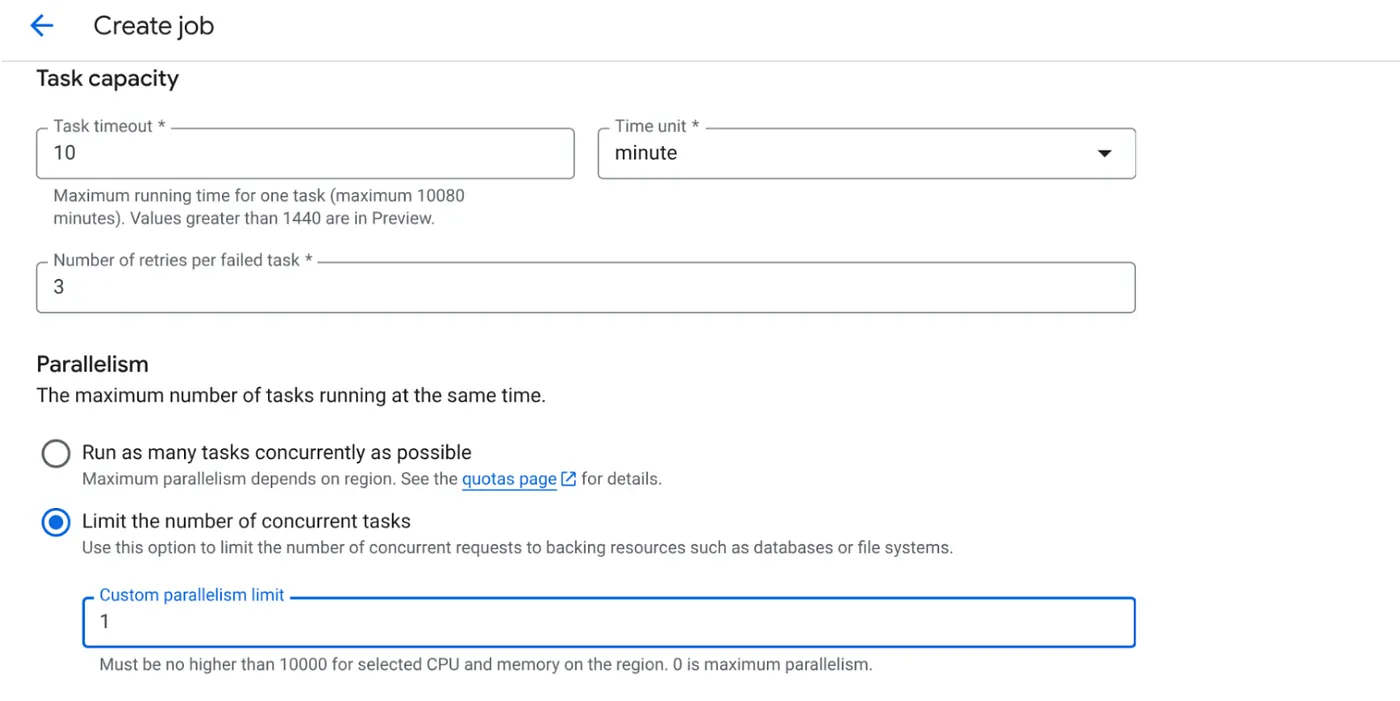
Veritabanı yazma işlemleri yaptığımız ve paralelleştirme (max_instances ve task concurrency) işleminin kodda zaten yapıldığı için eşzamanlı görev sayısını 1 olarak ayarlayacağız. Ancak ihtiyacınıza göre bu değeri artırabilirsiniz. Buradaki amaç, görevlerin eşzamanlılık düzeyinde ayarlanan paralellik ile yapılandırmaya göre tamamlanacak şekilde çalışmasıdır.
- Oluştur'u tıklayın
Cloud Run işiniz başarıyla oluşturulur.
İşleyiş şekli
İşimizin kapsayıcı örneği başlatılır. PENDING olarak işaretlenen URL'lerin küçük bir grubunu (BATCH_SIZE) almak için BigQuery'ye sorgu gönderir. Diğer iş örneklerinin bunları almasını önlemek için bu getirilen URL'lerin durumunu BigQuery'de hemen İŞLENİYOR olarak günceller. ThreadPoolExecutor oluşturur ve gruptaki her URL için bir görev gönderir. Her görev, call_url_processor_service işlevini çağırır. call_url_processor_service istekleri tamamlandıkça (veya zaman aşımına uğradıkça/başarısız oldukça) sonuçları (yapay zeka tarafından oluşturulan bağlam veya hata mesajı) toplanır ve orijinal row_id ile yeniden eşlenir. Toplu işteki tüm görevler tamamlandıktan sonra iş, toplanan sonuçlar arasında yinelenir ve BigQuery'deki her bir satırın bağlam ve durum alanlarını günceller. Başarılı olursa iş örneği temiz bir şekilde çıkar. İşlenmemiş hatalarla karşılaşırsa bir istisna oluşturur ve bu da Cloud Run Jobs tarafından yeniden denemeyi tetikleyebilir (iş yapılandırmasına bağlı olarak).
Cloud Run işlerinin rolü: Düzenleme
Cloud Run işlerinin gerçekten öne çıktığı nokta burasıdır.
Sunucusuz Toplu İşleme: Verilerimizi eşzamanlı olarak işlemek için gerektiği kadar (MAX_INSTANCES'a kadar) kapsayıcı örneği oluşturabilen yönetilen bir altyapı elde ederiz.
Paralellik Kontrolü: MAX_INSTANCES (toplamda kaç işin paralel olarak çalışabileceği) ve TASK_CONCURRENCY (her iş örneğinin kaç işlemi paralel olarak gerçekleştirdiği) tanımlanır. Bu sayede, işleme hızı ve kaynak kullanımı üzerinde ayrıntılı kontrol sağlanır.
Hata Toleransı: Bir iş örneği yarıda başarısız olursa Cloud Run Jobs, işin tamamını veya belirli görevleri yeniden deneyecek şekilde yapılandırılabilir. Böylece veri işlemenin kaybolmaması sağlanır.
Basitleştirilmiş mimari: HTTP çağrılarını doğrudan iş içinde düzenleyerek ve durum yönetimi için BigQuery'yi kullanarak Pub/Sub'ı, konularını, aboneliklerini ve onay mantığını ayarlama ve yönetme karmaşıklığını önleriz.
MAX_INSTANCES ve TASK_CONCURRENCY:
MAX_INSTANCES: İşinizin yürütülmesi sırasında aynı anda çalıştırılabilecek toplam iş örneği sayısı. Bu, aynı anda birçok URL'yi işlemek için kullandığınız temel paralellik koludur.
TASK_CONCURRENCY: İşinizin tek bir örneğinin gerçekleştireceği paralel işlem sayısı (işlemci hizmetinize yapılan çağrılar). Bu, bir örneğin CPU'sunun/ağının doygun hale gelmesine yardımcı olur.
9. Cloud Run işini yürütme ve izleme
Video Meta Verileri
Yürüt'ü tıklamadan önce verilerin durumunu görüntüleyelim.
BigQuery Studio'ya gidin ve aşağıdaki sorguyu çalıştırın:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
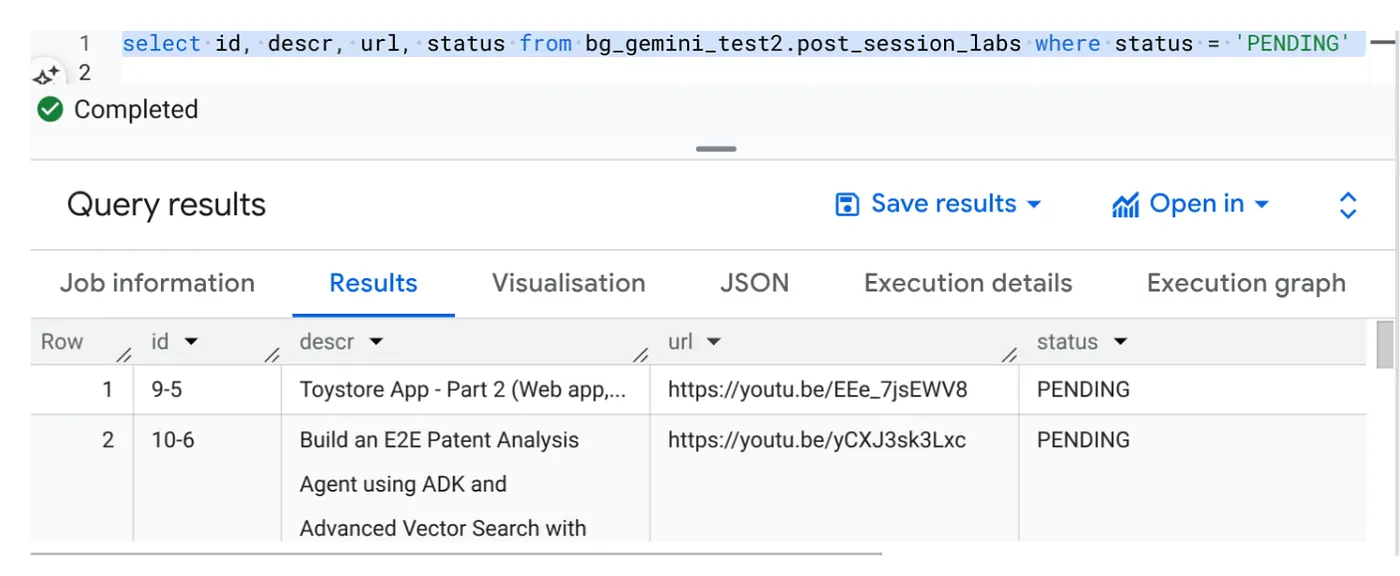
Video URL'leri içeren ve BEKLEMEDE durumunda olan birkaç örnek kaydımız var. Amacımız, "bağlam" alanını istemde açıklanan biçimde videodaki analizlerle doldurmaktır.
İş Tetikleyicisi
Cloud Run Jobs konsolunda işi tıklayıp ÇALIŞTIR düğmesini tıklayarak işi yürütelim. Konsolda işlerin ilerleme durumunu ve durumunu görebilirsiniz:
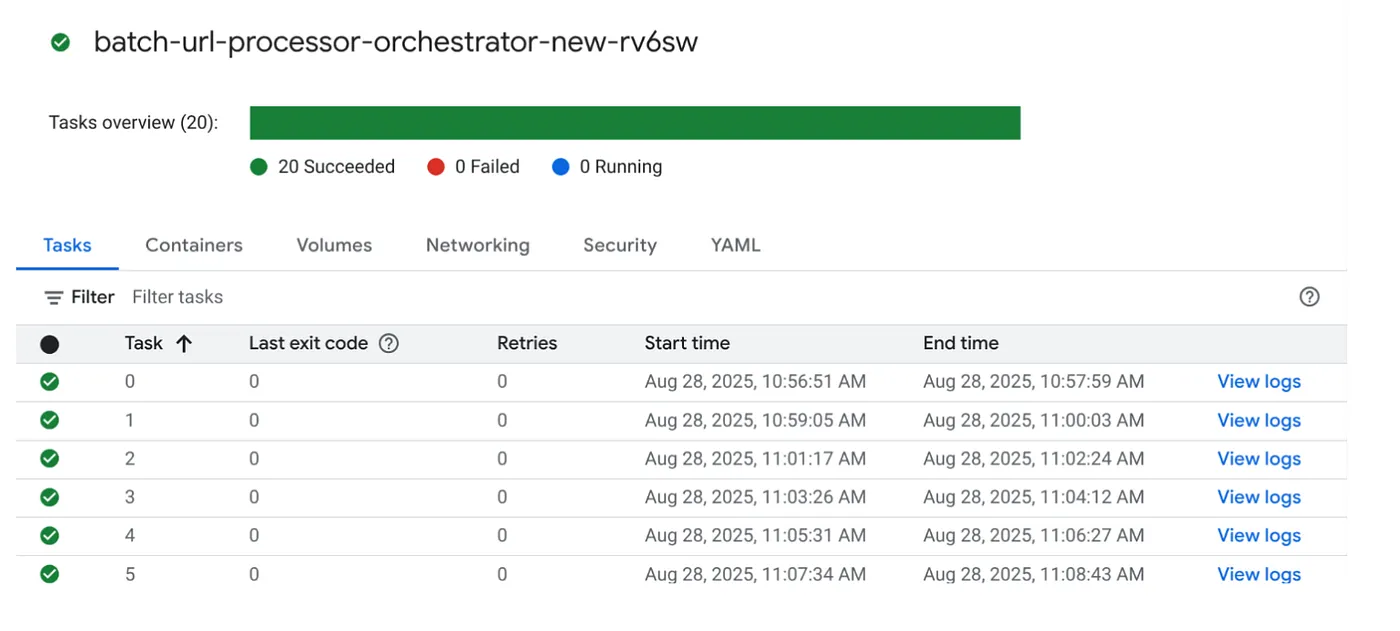
İş ve görevlerle ilgili izleme adımları ve diğer ayrıntılar için OBSERVABILITY'deki LOGS etiketini kontrol edebilirsiniz.
10. Sonuç Analizi
İşlem tamamlandıktan sonra, tablodaki her video URL'sinin güncellenen bağlamını görebilirsiniz:
Çıkış bağlamı (kayıtlardan biri için)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
Artık daha gelişmiş ajan kullanım alanları için bu JSON yapısını doğrulayabilirsiniz.
Neden bu yaklaşım?
Bu mimari önemli stratejik avantajlar sağlar:
- Maliyet etkinliği: Sunucusuz hizmetler sayesinde yalnızca kullandığınız kadar ödersiniz. Cloud Run işleri kullanılmadığında sıfıra ölçeklendirilir.
- Ölçeklenebilirlik: Cloud Run Job örneği ve eşzamanlılık ayarlarını düzenleyerek on binlerce URL'yi kolayca işler.
- Çeviklik: Yeni işleme mantığı veya yapay zeka modelleri için hızlı geliştirme ve dağıtım döngüleri. Bunun için kapsanan uygulamayı ve hizmetini güncellemeniz yeterlidir.
- Daha az yönetim yükü: Yama uygulanacak veya yönetilecek sunucu yoktur. Altyapı Google tarafından yönetilir.
- Yapay zekayı herkes için erişilebilir hale getirme: Derin ML Ops uzmanlığı gerektirmeden toplu görevler için gelişmiş yapay zeka işlemeyi erişilebilir hale getirir.
11. Temizleme
Bu yayında kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız şu adımları uygulayın:
- Google Cloud Console'da Kaynak Yöneticisi sayfasına gidin.
- Proje listesinde silmek istediğiniz projeyi seçin ve Sil'i tıklayın.
- İletişim kutusunda proje kimliğini yazın ve projeyi silmek için Kapat'ı tıklayın.
12. Tebrikler
Tebrikler! Çözümümüzü Cloud Run Jobs etrafında tasarlayarak ve veri yönetimi için BigQuery'nin gücünden, yapay zeka işleme için ise harici bir Cloud Run hizmetinden yararlanarak yüksek düzeyde ölçeklenebilir, uygun maliyetli ve bakımı kolay bir sistem oluşturduk. Bu model, işleme mantığını birbirinden ayırır, karmaşık bir altyapı olmadan paralel yürütmeye olanak tanır ve analiz süresini önemli ölçüde kısaltır.
Kendi toplu işleme ihtiyaçlarınız için Cloud Run Jobs'u keşfetmenizi öneririz. Bu sunucusuz yaklaşım; yapay zeka analizini ölçeklendirme, ETL ardışık düzenlerini çalıştırma veya periyodik veri görevlerini gerçekleştirme gibi işlemler için güçlü ve verimli bir çözüm sunar. Kendi başınıza başlamak için bu sayfaya göz atın.
Tüm uygulamalarınızı sunucusuz ve temsilci tabanlı olarak oluşturup dağıtmak istiyorsanız veri odaklı üretken temsilci tabanlı uygulamaları hızlandırmaya odaklanan Code Vipassana'ya kaydolun.