
1. Tổng quan
Trong thế giới giàu dữ liệu ngày nay, việc trích xuất thông tin chi tiết có ý nghĩa từ nội dung không có cấu trúc, đặc biệt là video, là một nhu cầu quan trọng. Hãy tưởng tượng bạn cần phân tích hàng trăm hoặc hàng nghìn URL video, tóm tắt nội dung của chúng, trích xuất các công nghệ chính và thậm chí tạo các cặp câu hỏi và câu trả lời cho tài liệu giáo dục. Việc thực hiện từng bước không chỉ tốn thời gian mà còn không hiệu quả. Đây là điểm nổi bật của các kiến trúc đám mây hiện đại.
Trong phòng thí nghiệm này, chúng ta sẽ tìm hiểu giải pháp không máy chủ, có khả năng mở rộng để xử lý nội dung video bằng bộ dịch vụ mạnh mẽ của Google Cloud: Cloud Run, BigQuery và AI tạo sinh của Google (Gemini). Chúng tôi sẽ trình bày chi tiết hành trình của mình từ việc xử lý một URL duy nhất đến việc điều phối quá trình thực thi song song trên một tập dữ liệu lớn, tất cả đều không cần quản lý các hàng đợi và hoạt động tích hợp thông báo phức tạp.
Thách thức
Chúng tôi được giao nhiệm vụ xử lý một danh mục lớn nội dung video, đặc biệt tập trung vào các buổi thực hành. Mục tiêu là phân tích từng video và tạo một bản tóm tắt có cấu trúc, bao gồm tiêu đề chương, bối cảnh giới thiệu, hướng dẫn từng bước, các công nghệ được sử dụng và các cặp câu hỏi và câu trả lời có liên quan. Đầu ra này cần được lưu trữ hiệu quả để sử dụng sau này trong việc xây dựng tài liệu giáo dục.
Ban đầu, chúng tôi có một dịch vụ Cloud Run đơn giản dựa trên HTTP, có thể xử lý một URL tại một thời điểm. Điều này rất hiệu quả cho việc kiểm thử và phân tích đặc biệt. Tuy nhiên, khi phải đối mặt với danh sách hàng nghìn URL lấy từ BigQuery, những hạn chế của mô hình một yêu cầu, một phản hồi này đã trở nên rõ ràng. Quá trình xử lý tuần tự sẽ mất nhiều ngày, thậm chí là nhiều tuần.
Cơ hội là chuyển đổi một quy trình tuần tự thủ công hoặc chậm thành một quy trình làm việc tự động, song song. Bằng cách tận dụng đám mây, chúng tôi hướng đến mục tiêu:
- Xử lý dữ liệu song song: Giảm đáng kể thời gian xử lý cho các tập dữ liệu lớn.
- Tận dụng các chức năng AI hiện có: Sử dụng sức mạnh của Gemini để phân tích nội dung một cách tinh vi.
- Duy trì kiến trúc không máy chủ: Tránh quản lý máy chủ hoặc cơ sở hạ tầng phức tạp.
- Tập trung hoá dữ liệu: Sử dụng BigQuery làm nguồn dữ liệu duy nhất cho các URL đầu vào và đích đến đáng tin cậy cho kết quả đã xử lý.
- Xây dựng một quy trình mạnh mẽ: Tạo một hệ thống có khả năng phục hồi khi gặp sự cố và có thể dễ dàng quản lý cũng như giám sát.
Mục tiêu
Điều phối quá trình xử lý song song bằng AI với các công việc trên Cloud Run:
Giải pháp của chúng tôi xoay quanh một Cloud Run Job đóng vai trò là trình điều phối. Ứng dụng này đọc một cách thông minh các lô URL từ BigQuery, gửi các URL này đến Dịch vụ Cloud Run hiện có mà chúng tôi đã triển khai (dịch vụ này xử lý hoạt động xử lý bằng AI cho một URL duy nhất), sau đó tổng hợp kết quả để ghi lại vào BigQuery. Phương pháp này cho phép chúng tôi:
- Tách rời việc điều phối khỏi quá trình xử lý: Tác vụ quản lý quy trình công việc, trong khi Dịch vụ riêng biệt tập trung vào tác vụ AI.
- Tận dụng khả năng song song của Cloud Run Job: Tác vụ có thể mở rộng nhiều phiên bản vùng chứa để gọi dịch vụ AI đồng thời.
- Giảm độ phức tạp: Chúng tôi đạt được tính song song bằng cách để tác vụ quản lý trực tiếp các lệnh gọi HTTP đồng thời, giúp đơn giản hoá cấu trúc.
Trường hợp sử dụng
Thông tin chi tiết do AI cung cấp từ các video về phiên Vipassana cho mã
Trường hợp sử dụng cụ thể của chúng tôi là phân tích các video về phiên Google Cloud của phòng thí nghiệm thực hành Code Vipassana. Mục tiêu là tự động tạo tài liệu có cấu trúc (dàn ý chương sách), bao gồm:
- Tiêu đề phân cảnh: Tiêu đề ngắn gọn cho từng phân cảnh trong video
- Bối cảnh giới thiệu: Giải thích mức độ liên quan của video trong một lộ trình học tập rộng hơn
- Nội dung sẽ được xây dựng: Nhiệm vụ hoặc mục tiêu cốt lõi của phiên
- Các công nghệ được sử dụng: Danh sách các dịch vụ đám mây và các công nghệ khác được đề cập
- Hướng dẫn từng bước: Cách thực hiện tác vụ, bao gồm cả đoạn mã
- URL mã nguồn/bản minh hoạ: Đường liên kết được cung cấp trong video
- Đoạn hỏi đáp: Tạo câu hỏi và câu trả lời phù hợp để kiểm tra kiến thức.
Flow

Luồng kiến trúc
Cloud Run là gì? Công việc trên Cloud Run là gì?
Cloud Run
Một nền tảng không máy chủ được quản lý toàn diện, cho phép bạn chạy các vùng chứa không trạng thái. Đây là lựa chọn lý tưởng cho các dịch vụ web, API và vi dịch vụ có thể tự động mở rộng quy mô dựa trên các yêu cầu đến. Bạn cung cấp một hình ảnh vùng chứa và Cloud Run sẽ xử lý phần còn lại, từ việc triển khai và mở rộng quy mô cho đến quản lý cơ sở hạ tầng. Nó có khả năng xử lý các tải đồng bộ, yêu cầu-phản hồi một cách hiệu quả.
Công việc trên Cloud Run
Một dịch vụ bổ sung cho các dịch vụ Cloud Run. Công việc trên Cloud Run được thiết kế cho các tác vụ xử lý hàng loạt cần hoàn tất rồi dừng lại. Chúng phù hợp với việc xử lý dữ liệu, ETL, suy luận hàng loạt bằng học máy và mọi tác vụ liên quan đến việc xử lý một tập dữ liệu thay vì xử lý các yêu cầu trực tiếp. Một tính năng chính là khả năng mở rộng số lượng phiên bản vùng chứa (tác vụ) chạy đồng thời để xử lý một lô công việc và chúng có thể được kích hoạt bởi nhiều nguồn sự kiện hoặc theo cách thủ công.
Điểm khác biệt chính
Dịch vụ Cloud Run dành cho các ứng dụng chạy trong thời gian dài và dựa trên yêu cầu. Công việc trên Cloud Run là để xử lý hàng loạt theo hướng tác vụ, có thời hạn và chạy cho đến khi hoàn tất.
Sản phẩm bạn sẽ tạo ra
Ứng dụng tìm kiếm bán lẻ
Trong quá trình này, bạn sẽ:
- Tạo tập dữ liệu, bảng BigQuery và nhập dữ liệu (Siêu dữ liệu Vipassana)
- Tạo một Cloud Run Functions bằng Python để triển khai chức năng AI tạo sinh (chuyển đổi video thành tệp json phân cảnh sách)
- Tạo một ứng dụng Python cho pipeline dữ liệu đến AI – Đọc từ BigQuery và gọi Điểm cuối của Cloud Run Functions để khai thác thông tin chi tiết, đồng thời ghi ngữ cảnh trở lại BigQuery
- Tạo bản dựng và đóng gói ứng dụng vào vùng chứa
- Định cấu hình một Công việc trên Cloud Run bằng vùng chứa này
- Thực hiện và giám sát công việc
- Kết quả báo cáo
Yêu cầu
2. Trước khi bắt đầu
Tạo dự án
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trong một dự án hay không .
- Bạn sẽ sử dụng Cloud Shell, một môi trường dòng lệnh chạy trong Google Cloud. Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud.

- Sau khi kết nối với Cloud Shell, bạn có thể kiểm tra để đảm bảo rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn.
gcloud config list project
- Nếu bạn chưa đặt dự án, hãy dùng lệnh sau để đặt:
gcloud config set project <YOUR_PROJECT_ID>
- Bật các API bắt buộc: Truy cập vào đường liên kết rồi bật các API.
Ngoài ra, bạn có thể dùng lệnh gcloud cho việc này. Tham khảo tài liệu để biết các lệnh và cách sử dụng gcloud.
3. Thiết lập cơ sở dữ liệu/kho dữ liệu
BigQuery đóng vai trò là nền tảng của quy trình dữ liệu. Tính chất không máy chủ và có khả năng mở rộng cao của BigQuery khiến nó trở thành lựa chọn hoàn hảo cho cả việc lưu trữ dữ liệu đầu vào và lưu trữ kết quả đã xử lý.
- Lưu trữ dữ liệu: BigQuery đóng vai trò là kho dữ liệu của chúng tôi. Nền tảng này lưu trữ danh sách URL video, trạng thái của video (ví dụ: ĐANG CHỜ XỬ LÝ, ĐANG XỬ LÝ, ĐÃ HOÀN TẤT) và ngữ cảnh cuối cùng được tạo. Đây là nguồn thông tin xác thực duy nhất cho biết những video cần được xử lý.
- Đích đến: Đây là nơi lưu trữ thông tin chi tiết do AI tạo, giúp các ứng dụng hạ nguồn hoặc quy trình xem xét thủ công dễ dàng truy vấn. Tập dữ liệu của chúng tôi bao gồm thông tin chi tiết về phiên video, đặc biệt là từ nội dung "Code Vipassana Seasons" (Các mùa của Code Vipassana). Nội dung này thường có các bản minh hoạ kỹ thuật chi tiết.
- Bảng nguồn: Một bảng BigQuery (ví dụ: post_session_labs) chứa các bản ghi như:
- id: Giá trị nhận dạng riêng biệt cho mỗi phiên/hàng.
- url: URL của video (ví dụ: đường liên kết đến YouTube hoặc đường liên kết đến ổ đĩa mà mọi người có thể truy cập).
- status: Một chuỗi cho biết trạng thái xử lý (ví dụ: PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- context: Trường chuỗi để lưu trữ bản tóm tắt do AI tạo.
- Nhập dữ liệu: Trong trường hợp này, dữ liệu được nhập vào BigQuery bằng các tập lệnh INSERT. Đối với quy trình của chúng tôi, BigQuery là điểm xuất phát.
Chuyển đến bảng điều khiển BigQuery, mở một thẻ mới và thực thi các câu lệnh SQL sau:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Nhập dữ liệu
Bây giờ, đã đến lúc thêm một bảng có dữ liệu về cửa hàng. Chuyển đến một thẻ trong BigQuery Studio và thực thi các câu lệnh SQL sau để chèn các bản ghi mẫu:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Tạo hàm thông tin chi tiết về video
Chúng ta phải tạo và triển khai một Hàm Cloud Run để triển khai cốt lõi của chức năng tạo chương sách có cấu trúc từ URL video. Để có thể truy cập vào công cụ này dưới dạng một công cụ hộp độc lập cho điểm cuối, chúng ta vừa tạo và triển khai một Hàm Cloud Run. Ngoài ra, bạn có thể chọn đưa chức năng này vào một hàm riêng trong ứng dụng Python thực tế cho Cloud Run Job:
- Trong bảng điều khiển Google Cloud, hãy chuyển đến trang Cloud Run
- Nhấp vào Viết hàm.
- Trong trường Tên dịch vụ, hãy nhập tên để mô tả hàm của bạn. Tên dịch vụ chỉ được bắt đầu bằng một chữ cái và có tối đa 49 ký tự, bao gồm cả chữ cái, chữ số hoặc dấu gạch ngang. Tên dịch vụ không được kết thúc bằng dấu gạch ngang và phải là tên duy nhất cho mỗi khu vực và dự án. Sau này, bạn không thể thay đổi tên dịch vụ và tên này sẽ hiển thị công khai. ( generate-video-insights**)**
- Trong danh sách Khu vực, hãy sử dụng giá trị mặc định hoặc chọn khu vực mà bạn muốn triển khai hàm. (Chọn us-central1)
- Trong danh sách Runtime (Thời gian chạy), hãy sử dụng giá trị mặc định hoặc chọn một phiên bản thời gian chạy. (Chọn Python 3.11)
- Trong phần Xác thực, hãy chọn "Cho phép truy cập công khai"
- Nhấp vào nút "Tạo"
- Hàm này được tạo và tải bằng một mẫu main.py và requirements.txt
- Thay thế bằng các tệp: main.py và requirements.txt trong kho lưu trữ của dự án này
LƯU Ý QUAN TRỌNG: Trong main.py, hãy nhớ thay thế <<YOUR_PROJECT_ID>> bằng mã dự án của bạn.
- Triển khai và lưu điểm cuối để bạn có thể sử dụng điểm cuối đó trong nguồn cho Cloud Run Job.
Điểm cuối của bạn sẽ có dạng như sau (hoặc tương tự): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
Hàm Cloud Run này có gì?
Gemini 2.5 Flash để xử lý video
Đối với nhiệm vụ cốt lõi là hiểu và tóm tắt nội dung video, chúng tôi đã tận dụng mô hình Gemini 2.5 Flash của Google. Các mô hình Gemini là những mô hình AI đa phương thức mạnh mẽ, có khả năng hiểu và xử lý nhiều loại dữ liệu đầu vào, bao gồm cả văn bản và video (với các tính năng tích hợp cụ thể).
Trong quá trình thiết lập, chúng tôi không trực tiếp cung cấp tệp video cho Gemini. Thay vào đó, chúng tôi đã gửi một câu lệnh dạng văn bản có chứa URL của video và hướng dẫn Gemini cách phân tích nội dung (giả định) của một video tại URL đó. Mặc dù Gemini 2.5 Flash có khả năng nhận dữ liệu đầu vào đa phương thức, nhưng quy trình cụ thể này đã sử dụng một câu lệnh dựa trên văn bản mô tả bản chất của video (một phiên thực hành) và yêu cầu đầu ra JSON có cấu trúc. Tính năng này tận dụng khả năng suy luận nâng cao và khả năng hiểu ngôn ngữ tự nhiên của Gemini để suy luận và tổng hợp thông tin dựa trên bối cảnh của câu lệnh.
Câu lệnh cho Gemini: Hướng dẫn AI
Câu lệnh được soạn thảo kỹ lưỡng là yếu tố quan trọng đối với các mô hình AI. Câu lệnh của chúng tôi được thiết kế để trích xuất thông tin rất cụ thể và cấu trúc thông tin đó thành định dạng JSON, giúp ứng dụng của chúng tôi dễ dàng phân tích cú pháp.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
Câu lệnh này rất cụ thể, hướng dẫn Gemini đóng vai trò là một nhà giáo dục. Yêu cầu về chuỗi JSON đảm bảo đầu ra có cấu trúc mà máy có thể đọc được.
Sau đây là mã để phân tích dữ liệu đầu vào của video và trả về ngữ cảnh của video đó:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
Đoạn mã ở trên minh hoạ chức năng cốt lõi của trường hợp sử dụng này. Ứng dụng này nhận một URL video và sử dụng mô hình Gemini thông qua ứng dụng Vertex AI để phân tích nội dung video và trích xuất thông tin chi tiết có liên quan theo câu lệnh. Sau đó, ngữ cảnh được trích xuất sẽ được trả về để xử lý thêm. Đây là một thao tác đồng bộ, trong đó Cloud Run Job chờ dịch vụ hoàn tất.
6. Phát triển ứng dụng quy trình (Python)
Logic quy trình trung tâm của chúng tôi nằm trong mã nguồn của ứng dụng. Mã nguồn này sẽ được đóng gói vào một Cloud Run Job, giúp điều phối toàn bộ quá trình thực thi song song. Sau đây là thông tin về các phần chính:
Vai trò của trình điều phối trong việc quản lý quy trình công việc và đảm bảo tính toàn vẹn của dữ liệu:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
Đoạn mã ở trên bắt đầu bằng cách tìm nạp một lô URL video có trạng thái "ĐANG CHỜ" từ bảng nguồn BigQuery. Sau đó, hệ thống sẽ cập nhật trạng thái của những URL này thành "ĐANG XỬ LÝ" trong BigQuery để ngăn xử lý trùng lặp.
Xử lý song song bằng ThreadPoolExecutor và gọi Dịch vụ xử lý:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
Phần mã này tận dụng ThreadPoolExecutor để đạt được khả năng xử lý song song các URL video đã tìm nạp. Đối với mỗi URL, mã sẽ gửi một tác vụ để gọi Dịch vụ Cloud Run (Trình xử lý URL) một cách không đồng bộ. Điều này cho phép Cloud Run Job xử lý hiệu quả nhiều video cùng lúc, giúp nâng cao hiệu suất tổng thể của quy trình. Đoạn mã này cũng xử lý các lỗi và thời gian chờ có thể xảy ra từ dịch vụ bộ xử lý.
Đọc và ghi dữ liệu từ BigQuery
Tương tác chính với BigQuery liên quan đến việc tìm nạp các URL đang chờ xử lý, sau đó cập nhật các URL đó bằng kết quả đã xử lý.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Ghi kết quả trở lại BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
Các đoạn mã ở trên tập trung vào hoạt động tương tác dữ liệu giữa Cloud Run Job và BigQuery. Thao tác này truy xuất một lô URL video có trạng thái "ĐANG CHỜ XỬ LÝ" và mã nhận dạng của các URL đó từ bảng nguồn. Sau khi các URL được xử lý, đoạn mã này minh hoạ việc ghi ngữ cảnh và trạng thái đã trích xuất ("COMPLETED" hoặc "FAILED_PROCESSING") trở lại bảng BigQuery đích bằng cách sử dụng truy vấn UPDATE. Đoạn mã này hoàn tất vòng lặp xử lý dữ liệu. Thư viện này cũng bao gồm hàm trợ giúp update_bq_row cho biết cách xác định các tham số của câu lệnh cập nhật.
Thiết lập ứng dụng
Ứng dụng này được cấu trúc dưới dạng một tập lệnh Python duy nhất sẽ được đưa vào vùng chứa. Ứng dụng này tận dụng các thư viện ứng dụng Google Cloud và functions-framework để xác định điểm truy cập.
- Phần phụ thuộc: google-cloud-bigquery, requests
- Cấu hình: Tất cả các chế độ cài đặt quan trọng (dự án/tập dữ liệu/bảng BigQuery, URL của dịch vụ xử lý URL) đều được tải từ các biến môi trường, giúp ứng dụng có tính di động và bảo mật
- Logic cốt lõi: Hàm process_batch_from_bq điều phối toàn bộ quy trình làm việc
- Tích hợp dịch vụ bên ngoài: Hàm call_url_processor_service xử lý thông tin liên lạc với Dịch vụ Cloud Run riêng biệt
- Tương tác với BigQuery: bq_client được dùng để tìm nạp URL và cập nhật kết quả, đồng thời xử lý tham số đúng cách
- Tính song song: concurrent.futures.ThreadPoolExecutor quản lý các lệnh gọi đồng thời đến dịch vụ bên ngoài
- Điểm truy cập: Mã Python có tên main.py đóng vai trò là điểm truy cập khởi động quy trình xử lý hàng loạt.
Hãy thiết lập ứng dụng ngay bây giờ:
- Bạn có thể bắt đầu bằng cách chuyển đến Cloud Shell Terminal và sao chép kho lưu trữ:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Chuyển đến Cloud Shell Editor, nơi bạn có thể thấy thư mục mới tạo video-context-crj
- Xoá những bước sau vì bạn đã hoàn tất các bước đó trong những phần trước:
- Xoá thư mục Cloud_Run_Function
- Chuyển đến thư mục dự án video-context-crj, bạn sẽ thấy cấu trúc dự án như sau:
7. Thiết lập Dockerfile và ảo hoá
Để triển khai logic này dưới dạng một Công việc Cloud Run, chúng ta cần phải tạo vùng chứa cho logic đó. Việc tạo vùng chứa là quá trình đóng gói mã xử lý ứng dụng, các phần phụ thuộc và thời gian chạy của ứng dụng vào một hình ảnh di động.
Hãy nhớ thay thế các phần giữ chỗ (văn bản được bôi đậm) bằng các giá trị của bạn trong Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
Đoạn Dockerfile ở trên xác định hình ảnh cơ sở, cài đặt các phần phụ thuộc, sao chép mã của chúng ta và đặt lệnh chạy ứng dụng bằng functions-framework với hàm mục tiêu chính xác (process_batch_from_bq). Sau đó, hình ảnh này sẽ được chuyển đến Artifact Registry.
Tạo vùng chứa
Để tạo vùng chứa cho ứng dụng này, hãy chuyển đến Cloud Shell Terminal rồi thực thi các lệnh sau (Nhớ thay thế phần giữ chỗ <<YOUR_PROJECT_ID>>):
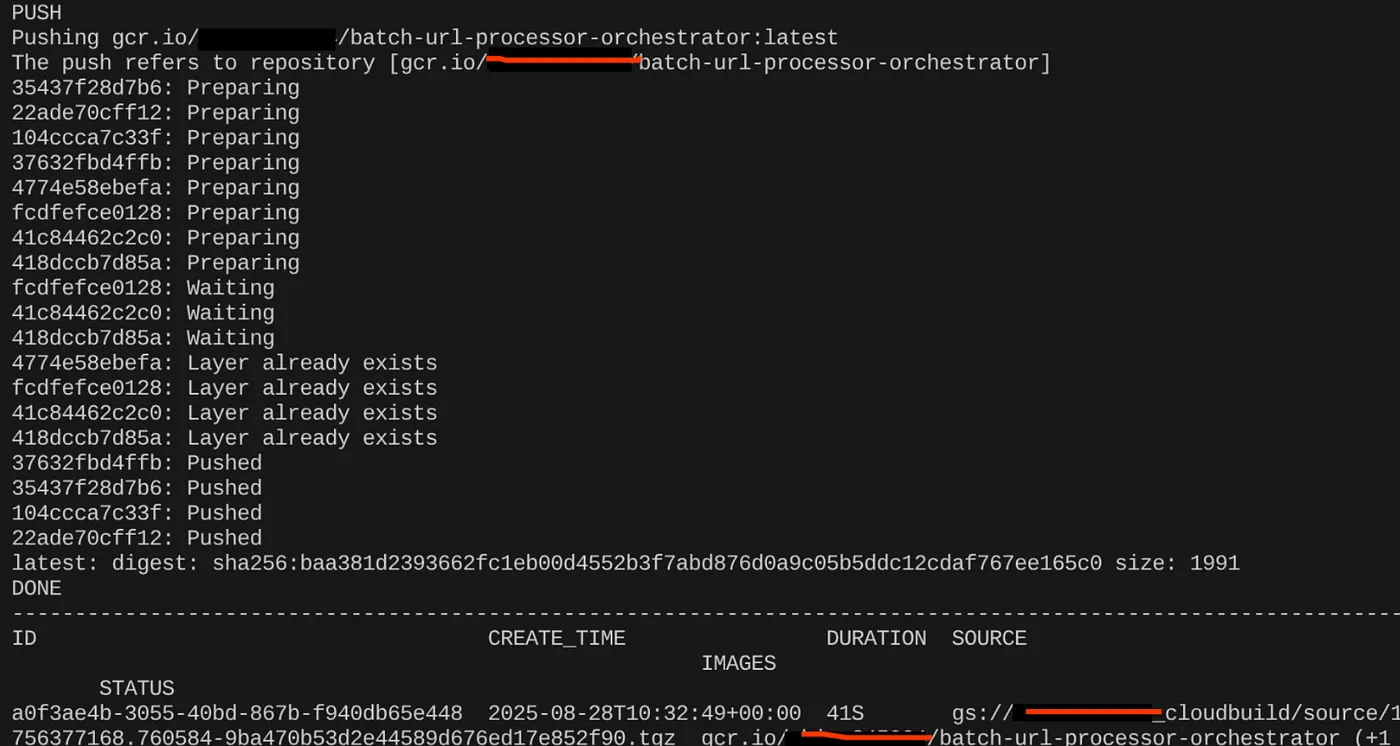
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
Sau khi tạo hình ảnh vùng chứa, bạn sẽ thấy kết quả sau:
Hiện tại, vùng chứa của chúng ta đã được tạo và lưu trong Artifact Registry. Chúng ta có thể chuyển sang bước tiếp theo.
8. Tạo công việc trên Cloud Run
Việc triển khai công việc bao gồm việc tạo hình ảnh vùng chứa rồi tạo tài nguyên Công việc trên Cloud Run.
Chúng ta đã tạo hình ảnh vùng chứa và lưu trữ trong Artifact Registry. Bây giờ, hãy tạo công việc.
- Chuyển đến bảng điều khiển Cloud Run Jobs rồi nhấp vào Deploy Container (Triển khai vùng chứa):

- Chọn hình ảnh vùng chứa mà chúng ta vừa tạo:
- Nhập các thông tin chi tiết khác về cấu hình như sau:

- Đặt năng lực của việc cần làm như sau:
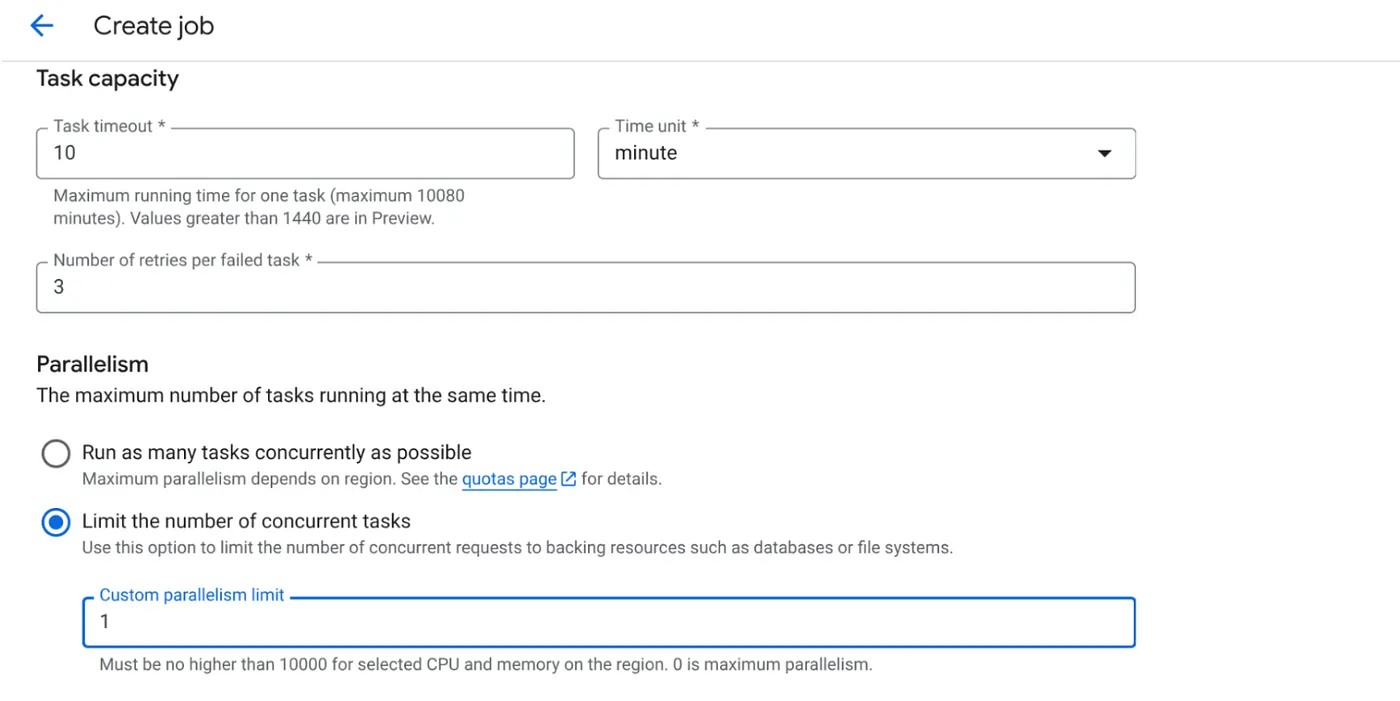
Vì chúng ta có các thao tác ghi cơ sở dữ liệu và thực tế là việc song song hoá (max_instances và mức độ đồng thời của tác vụ) đã được xử lý trong mã, nên chúng ta sẽ đặt số lượng tác vụ đồng thời thành 1. Tuy nhiên, bạn có thể tăng số lượng này theo yêu cầu của mình. Mục tiêu ở đây là các tác vụ sẽ chạy cho đến khi hoàn thành theo cấu hình với mức độ đồng thời được đặt song song.
- Nhấp vào Tạo
Cloud Run Job của bạn sẽ được tạo thành công.
Cách hoạt động
Một phiên bản vùng chứa của công việc sẽ bắt đầu. Thao tác này truy vấn BigQuery để lấy một lô nhỏ (BATCH_SIZE) gồm các URL được đánh dấu là ĐANG CHỜ XỬ LÝ. Thao tác này sẽ cập nhật ngay trạng thái của các URL đã tìm nạp này thành ĐANG XỬ LÝ trong BigQuery để ngăn các phiên bản công việc khác chọn các URL này. Nó tạo một ThreadPoolExecutor và gửi một tác vụ cho mỗi URL trong lô. Mỗi tác vụ gọi hàm call_url_processor_service. Khi các yêu cầu call_url_processor_service hoàn tất (hoặc hết thời gian chờ/thất bại), kết quả của các yêu cầu đó (hoặc ngữ cảnh do AI tạo hoặc thông báo lỗi) sẽ được thu thập, ánh xạ trở lại row_id ban đầu. Sau khi hoàn tất tất cả các tác vụ cho lô, công việc sẽ lặp lại các kết quả đã thu thập và cập nhật các trường ngữ cảnh và trạng thái cho từng hàng tương ứng trong BigQuery. Nếu thành công, phiên bản công việc sẽ thoát một cách gọn gàng. Nếu gặp phải lỗi chưa được xử lý, thì nó sẽ tạo ra một ngoại lệ, có thể kích hoạt Cloud Run Jobs thử lại (tuỳ thuộc vào cấu hình của tác vụ).
Cách các công việc trên Cloud Run phù hợp với việc điều phối
Đây là điểm mạnh thực sự của Công việc trên Cloud Run.
Xử lý hàng loạt không máy chủ: Chúng tôi có cơ sở hạ tầng được quản lý có thể tăng số lượng phiên bản vùng chứa khi cần (tối đa là MAX_INSTANCES) để xử lý dữ liệu đồng thời.
Kiểm soát tính song song: Chúng tôi xác định MAX_INSTANCES (tổng số lượng công việc có thể chạy song song) và TASK_CONCURRENCY (số lượng thao tác mà mỗi phiên bản công việc thực hiện song song). Điều này giúp bạn kiểm soát chi tiết thông lượng và mức sử dụng tài nguyên.
Khả năng chịu lỗi: Nếu một phiên bản công việc gặp lỗi giữa chừng, bạn có thể định cấu hình Cloud Run Jobs để thử lại toàn bộ công việc hoặc các tác vụ cụ thể, đảm bảo rằng quá trình xử lý dữ liệu không bị mất.
Kiến trúc đơn giản: Bằng cách điều phối các lệnh gọi HTTP ngay trong Job và sử dụng BigQuery để quản lý trạng thái, chúng tôi tránh được sự phức tạp khi thiết lập và quản lý Pub/Sub, các chủ đề, gói thuê bao và logic xác nhận của Pub/Sub.
MAX_INSTANCES so với TASK_CONCURRENCY:
MAX_INSTANCES: Tổng số phiên bản công việc có thể chạy đồng thời trong toàn bộ quá trình thực thi công việc. Đây là đòn bẩy song song chính của bạn để xử lý nhiều URL cùng một lúc.
TASK_CONCURRENCY: Số lượng thao tác song song (lệnh gọi đến dịch vụ xử lý) mà một phiên bản duy nhất của công việc sẽ thực hiện. Điều này giúp làm bão hoà CPU/mạng của một phiên bản.
9. Thực thi và giám sát công việc trên Cloud Run
Siêu dữ liệu Video
Trước khi nhấp vào thực thi, hãy xem trạng thái của dữ liệu.
Chuyển đến BigQuery Studio rồi chạy truy vấn sau:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
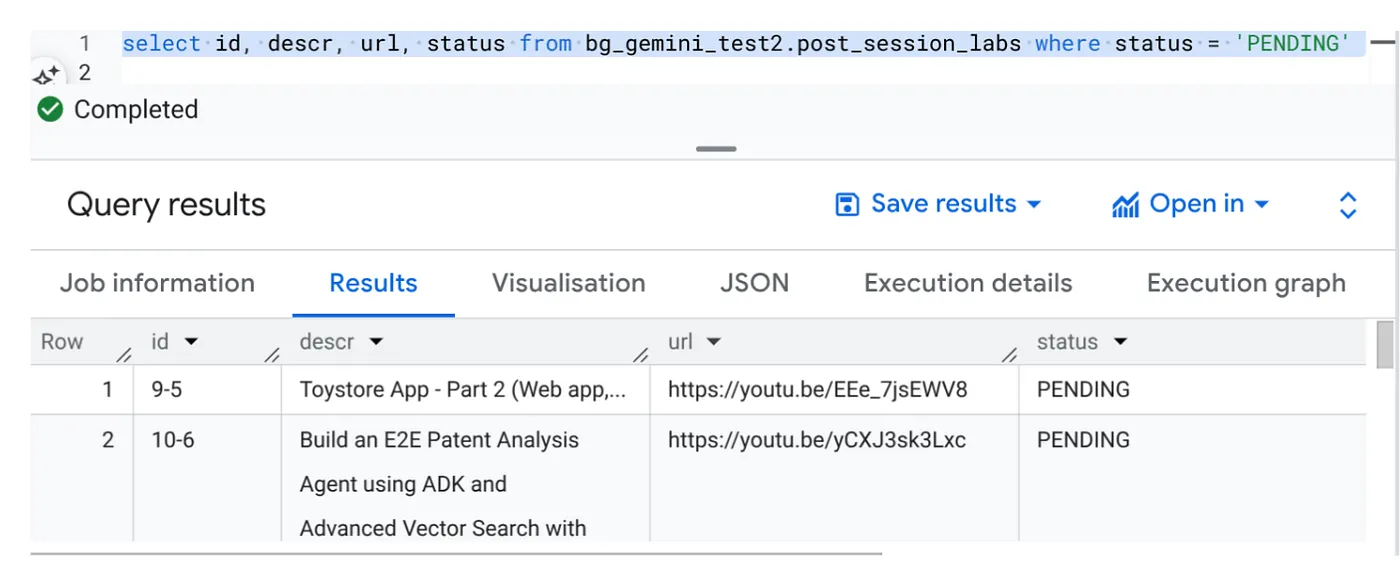
Chúng tôi có một số bản ghi mẫu có URL video và ở trạng thái ĐANG CHỜ. Mục tiêu của chúng tôi là điền thông tin vào trường "bối cảnh" bằng thông tin chi tiết từ video theo định dạng được giải thích trong câu lệnh.
Điều kiện kích hoạt công việc
Hãy tiến hành thực thi công việc bằng cách nhấp vào nút THỰC THI trên công việc trong bảng điều khiển Cloud Run Jobs. Bạn sẽ có thể xem tiến trình và trạng thái của các công việc trong bảng điều khiển:
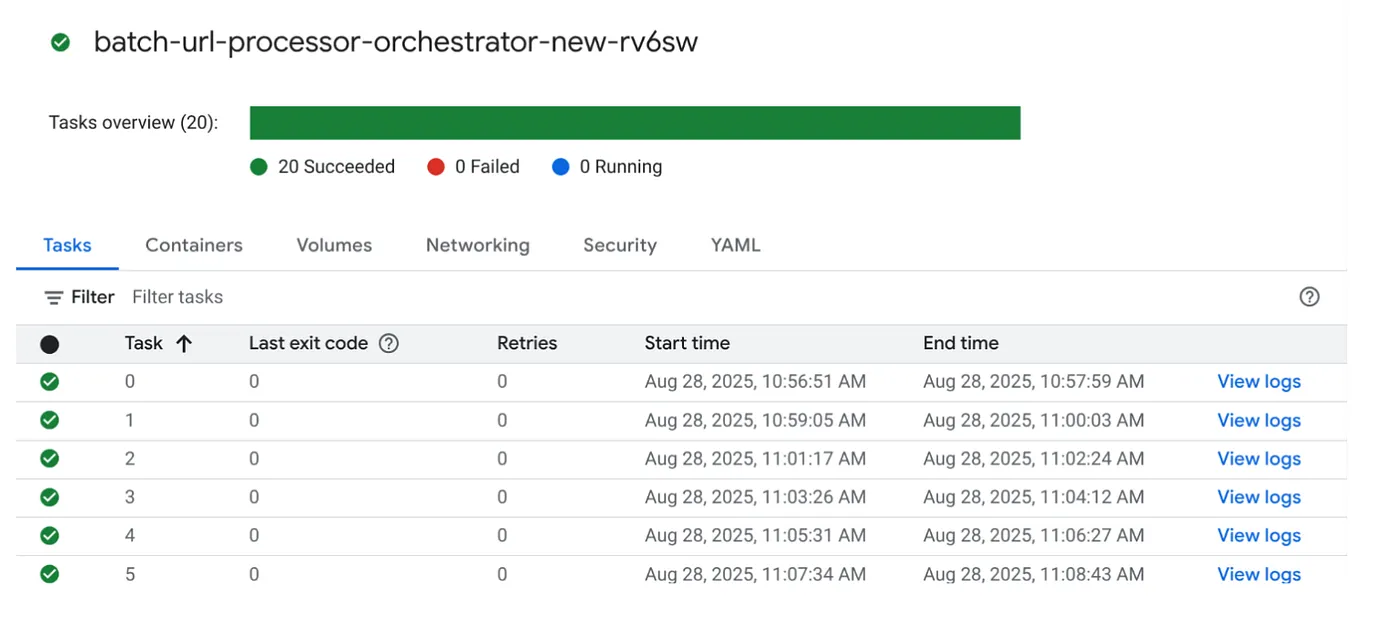
Bạn có thể kiểm tra thẻ LOGS (NHẬT KÝ) trong phần OBSERVABILITY (KHẢ NĂNG QUAN SÁT) để theo dõi các bước và thông tin chi tiết khác về công việc và các tác vụ.
10. Phân tích kết quả
Sau khi hoàn tất, bạn sẽ thấy ngữ cảnh của từng URL video được cập nhật trong bảng:
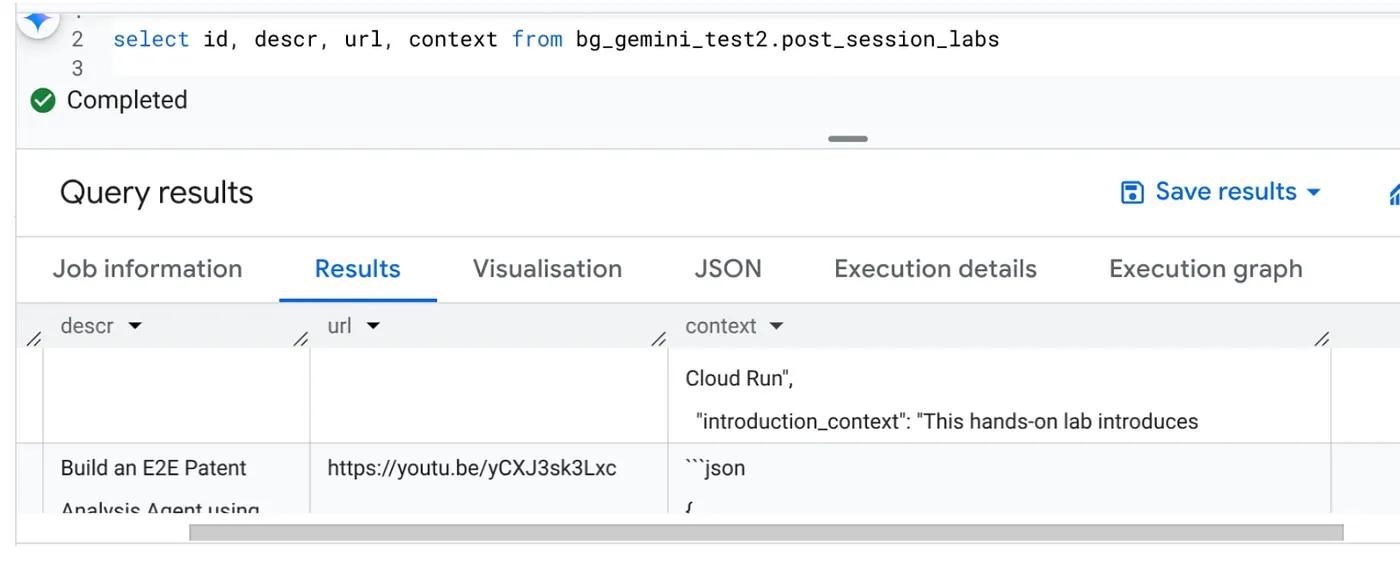
Ngữ cảnh đầu ra (cho một trong các bản ghi)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
Giờ đây, bạn có thể xác thực cấu trúc JSON này cho các trường hợp sử dụng nâng cao hơn của tác nhân.
Tại sao nên dùng phương pháp này?
Cấu trúc này mang lại những lợi thế chiến lược đáng kể:
- Hiệu quả về chi phí: Các dịch vụ không máy chủ có nghĩa là bạn chỉ phải trả tiền cho những gì bạn sử dụng. Các công việc trên Cloud Run sẽ giảm xuống 0 khi không được sử dụng.
- Khả năng mở rộng: Dễ dàng xử lý hàng chục nghìn URL bằng cách điều chỉnh chế độ cài đặt phiên bản và mức độ đồng thời của Cloud Run Job.
- Tính linh hoạt: Chu kỳ phát triển và triển khai nhanh chóng cho logic xử lý hoặc mô hình AI mới bằng cách chỉ cần cập nhật ứng dụng được chứa và dịch vụ của ứng dụng đó.
- Giảm chi phí vận hành: Không cần vá lỗi hoặc quản lý máy chủ; Google xử lý cơ sở hạ tầng.
- Dân chủ hoá AI: Giúp mọi người có thể sử dụng quy trình xử lý bằng AI nâng cao cho các tác vụ hàng loạt mà không cần chuyên môn sâu về hoạt động học máy.
11. Dọn dẹp
Để tránh bị tính phí vào tài khoản Google Cloud của bạn cho các tài nguyên được dùng trong bài đăng này, hãy làm theo các bước sau:
- Trong bảng điều khiển Cloud, hãy chuyển đến trang trình quản lý tài nguyên.
- Trong danh sách dự án, hãy chọn dự án mà bạn muốn xoá, rồi nhấp vào Xoá.
- Trong hộp thoại, hãy nhập mã dự án rồi nhấp vào Tắt để xoá dự án.
12. Xin chúc mừng
Xin chúc mừng! Bằng cách thiết kế giải pháp của chúng tôi dựa trên Cloud Run Jobs và tận dụng sức mạnh của BigQuery để quản lý dữ liệu cũng như Cloud Run Service bên ngoài để xử lý bằng AI, bạn đã xây dựng một hệ thống có khả năng mở rộng cao, tiết kiệm chi phí và dễ bảo trì. Mẫu này tách rời logic xử lý, cho phép thực thi song song mà không cần cơ sở hạ tầng phức tạp, đồng thời rút ngắn đáng kể thời gian để thu thập thông tin chi tiết.
Bạn nên khám phá Công việc trên Cloud Run cho nhu cầu xử lý hàng loạt của riêng mình. Cho dù bạn đang mở rộng quy mô phân tích AI, chạy quy trình ETL hay thực hiện các tác vụ dữ liệu định kỳ, thì phương pháp không máy chủ này đều mang đến một giải pháp mạnh mẽ và hiệu quả. Để tự bắt đầu, hãy xem hướng dẫn này.
Nếu bạn muốn tạo và triển khai tất cả các ứng dụng không máy chủ và có tác nhân, hãy đăng ký tham gia Code Vipassana. Đây là một sự kiện tập trung vào việc tăng tốc các ứng dụng có tác nhân tạo sinh dựa trên dữ liệu!