
1. 概要
「読み取り専用の Chatbot」の時代は終わりを迎えつつあります。私たちは Agentic Vision の時代に突入しています。
この Codelab では、推測しない AI システムを構築するプラクティスである決定論的 AI エンジニアリングを実装します。標準の AI モデルは、複雑な画像内のアイテムの数を尋ねられると、ハルシネーション(推測)することがよくあります。サプライ チェーンでは、推測は危険です。AI が 12 個のアイテムがあると推測したときに、実際には 15 個のアイテムがある場合、コストのかかるエラーが発生します。
Gemini 3 Flash の新しい思考、行動、観察ループを活用して、自律型サプライ チェーン エージェントを構築します。単に調べるだけでなく、調査も行います。
決定論的アーキテクチャ
まず、「ブラインド」システムと「健忘症」システムから始めます。感覚を 1 つずつ手動で「目覚め」させます。
- The Eyes(Vision Agent): コード実行で Gemini 3 Flash を有効にします。モデルは、トークンを予測して数値を推測するのではなく、Python コード(OpenCV)を記述してピクセルを決定論的にカウントします。
- メモリ(サプライヤー エージェント): ScaNN(Scalable Nearest Neighbors)で AlloyDB AI を有効にします。これにより、エージェントは数ミリ秒で数百万のオプションから部品の正確なサプライヤーを呼び出すことができます。
- ハンドシェイク(A2A プロトコル): 標準化された agent_card.json を使用してエージェント間通信を可能にし、Vision Agent が Supplier Agent に在庫を自律的に注文できるようにします。
作成するアプリの概要
- カメラフィードで「視覚的な計算」を行う Vision Agent。
- 高速ベクトル検索用に AlloyDB ScaNN を使用するサプライヤー エージェント。
- 自律ループを可視化するリアルタイム WebSocket 更新を備えた Control Tower フロントエンド。
学習内容
- ベクトル エンベディングと ScaNN インデックスを使用して AlloyDB を設定する方法。
- Gemini API を使用して gemini-3-flash-preview で Agentic Vision を有効にする方法。
- AlloyDB で <=>(コサイン距離)演算子を使用してベクトル検索を実装する方法。
- AlloyDB Python コネクタを使用してエージェントを AlloyDB に接続する方法。
- 動的エージェント検出に A2A プロトコルを使用する方法。
要件
- ブラウザ(Chrome、Firefox など)
- 課金を有効にした Google Cloud プロジェクト
- Vision Agent の Gemini API キー(Google AI Studio で無料枠を利用可能)。
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/visual-commerce-gemini-3-alloydb/img/91567e2f55467574.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
データベースの設定 [AlloyDB]
まず、データベースをプロビジョニングします。これには約 15 分かかるため、最初に開始します。
- 下のボタンをクリックして、Cloud Shell で AlloyDB 設定ツールを開きます。
- セットアップを実行します。
Sh run.sh
- ウェブ プレビュー(目のアイコン 👁️ → ポート 8080 でプレビュー)を使用して、設定 UI を開きます。
- プロジェクト ID を入力し、リージョン(us-central1 など)を選択して、データベース パスワードを作成します。
⚠️ このパスワードを保存してください。設定スクリプトで求められたときに必要になります。
- [デプロイを開始] をクリックし、クラスタがプロビジョニングされるまで約 15 分待ちます。
コードを取得
AlloyDB のプロビジョニング中(または完了後)に、Cloud Shell で codelab リポジトリを開きます。
⚠️ 重要: ボタンをクリックすると、セキュリティ ダイアログが表示されます。[リポジトリを信頼する] のチェックボックスをオンにして、[確認] をクリックします。
または、手動でクローンを作成します。
git clone https://github.com/MohitBhimrajka/visual-commerce-gemini-3-alloydb.git
cd visual-commerce-gemini-3-alloydb
プロジェクトを設定する
この Cloud Shell ターミナルで、プロジェクトが設定されていることを確認します。
gcloud config set project <YOUR_PROJECT_ID>
AlloyDB でパブリック IP を有効にする
AlloyDB のプロビジョニングが完了したら、パブリック IP を有効にして、Python コネクタが Cloud Shell から接続できるようにします。
- AlloyDB コンソールに移動します。
- クラスタをクリック → プライマリ インスタンスをクリック
- [編集] をクリックします。
- [パブリック IP 接続] までスクロールして、[パブリック IP を有効にする] をオンにします。
- [インスタンスを更新] をクリックします。
💡 注: AlloyDB Python Connector は認証と暗号化を処理するため、承認済み外部ネットワークを追加する必要はありません。
Vertex AI の権限を付与する
AlloyDB サービス アカウントには、エンベディングを生成するための Vertex AI アクセス権が必要です。同じ Cloud Shell ウィンドウで次のコマンドを実行します。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
設定スクリプトを実行する
設定スクリプトを実行します。AlloyDB インスタンスが自動的に検出されます。
sh setup.sh
このスクリプトの処理内容:
- gcloud CLI、認証、プロジェクト、Python 3 を検証します
- 必要な API(AlloyDB、Vertex AI、Compute、Service Networking)を確認して有効にします。
- Gemini API キーのプロンプト
- AlloyDB インスタンスを自動検出し、リージョン、クラスタ、インスタンス名を抽出します。
- データベースのパスワードを要求する
- .env 構成ファイルを生成します
- Python 依存関係をインストールする
3. データベースの設定
アプリケーションの中核となるのは AlloyDB for PostgreSQL です。強力なベクトル機能と ScaNN インデックスを使用して、準リアルタイムのセマンティック検索を実現し、エージェントが数千件のレコードからミリ秒単位で在庫を検索できるようにします。
このセクションでは、AlloyDB Studio からスキーマのプロビジョニング、データのシード、エンベディングの生成を行います。
AlloyDB Studio に接続する
- AlloyDB コンソールで AlloyDB インスタンスに移動します。
- 左側のナビゲーションで [AlloyDB Studio] をクリックします。
- 認証に使用:
- ユーザー名: postgres
- データベース: postgres
- パスワード: クラスタの作成時に設定したパスワード
拡張機能を有効にする
AlloyDB には、ベクトルと AI 用の組み込み拡張機能が用意されています。AlloyDB Studio で次の SQL を実行します。
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann CASCADE;
- google_ml_integration: SQL から Vertex AI を直接呼び出すための ai.embedding() 関数を有効にします。
- vector: 768 次元のベクトル エンベディングを保存してクエリします。
- alloydb_scann: 超高速ベクトル検索用に Google の ScaNN インデックスを有効にします。
在庫テーブルを作成する
DROP TABLE IF EXISTS inventory;
CREATE TABLE inventory (
id SERIAL PRIMARY KEY,
part_name TEXT NOT NULL,
supplier_name TEXT NOT NULL,
description TEXT,
stock_level INT DEFAULT 0,
part_embedding vector(768)
);
part_embedding 列には、text-embedding-005 からの 768 次元のベクトルが保存されます。これがセマンティック検索の基盤となります。
サンプルデータを挿入する
倉庫の在庫アイテムを 20 個挿入します。
INSERT INTO inventory (part_name, supplier_name, description, stock_level) VALUES
('Cardboard Shipping Box Large', 'Packaging Solutions Inc', 'Heavy-duty corrugated cardboard shipping container, 24x18x12 inches', 250),
('Warehouse Storage Container', 'Industrial Supply Co', 'Stackable plastic storage bin with snap-lock lid, blue', 180),
('Product Shipping Boxes', 'Acme Packaging', 'Medium corrugated boxes for warehouse storage, 18x14x10 inches', 320),
('Industrial Widget X-9', 'Acme Corp', 'Heavy-duty industrial coupling for pneumatic systems', 50),
('Precision Bolt M4', 'Global Fasteners Inc', 'Stainless steel M4 allen bolt, 20mm length, grade A2-70', 200),
('Hexagonal Nut M6', 'Metro Supply Co', 'Galvanized steel hex nut M6, DIN 934 standard', 150),
('Phillips Head Screw 3x20', 'Acme Corp', 'Zinc-plated Phillips head wood screw, 3mm x 20mm', 500),
('Wooden Dowel 10mm', 'Craft Materials Ltd', 'Hardwood birch dowel rod, 10mm diameter x 300mm length', 80),
('Rubber Gasket Small', 'SealTech Industries', 'Buna-N rubber gasket, 25mm OD x 15mm ID, oil resistant', 120),
('Spring Tension 5kg', 'Mechanical Parts Co', 'Stainless steel compression spring, 5kg load capacity', 60),
('Bearing 6204', 'Bearings Direct', 'Deep groove ball bearing 6204-2RS, 20x47x14mm sealed', 45),
('Warehouse Shelf Boxes', 'Storage Systems Ltd', 'Standardized warehouse inventory boxes, corrugated, bulk pack', 400),
('Inventory Container Units', 'Supply Chain Pros', 'Modular stackable storage units for warehouse racking', 95),
('Aluminum Extrusion Bar', 'MetalWorks International', 'T-slot aluminum extrusion 20x20mm profile, 1 meter length', 110),
('Cable Tie Pack 200mm', 'ElectroParts Depot', 'Nylon cable ties, 200mm x 4.8mm, UV resistant black, pack of 100', 600),
('Hydraulic Hose 1/2 inch', 'FluidPower Systems', 'High-pressure hydraulic hose, 1/2 inch ID, 3000 PSI rated', 35),
('Safety Goggles Clear', 'WorkSafe Equipment Co', 'ANSI Z87.1 rated clear safety goggles, anti-fog coating', 275),
('Packing Tape Industrial', 'Packaging Solutions Inc', 'Heavy-duty polypropylene packing tape, 48mm x 100m, clear', 450),
('Stainless Steel Sheet 1mm', 'MetalWorks International', '304 stainless steel sheet, 1mm thickness, 300x300mm', 70),
('Silicone Sealant Tube', 'SealTech Industries', 'Industrial-grade RTV silicone sealant, 300ml cartridge, grey', 190);
埋め込み権限を付与する
GRANT EXECUTE ON FUNCTION embedding TO postgres;
ベクトル エンベディングを生成する
AlloyDB の組み込み ai.embedding() 関数を使用して、SQL から Vertex AI の text-embedding-005 モデルを直接呼び出します。Python コードは必要ありません。
UPDATE inventory
SET part_embedding = ai.embedding(
'text-embedding-005',
part_name || '. ' || description
)::vector
WHERE part_embedding IS NULL;
これにより、各パーツの名前と説明の意味論的意味を捉えた 768 次元のベクトルが生成されます。ScaNN インデックスは、これらのエンベディングを使用して高速な類似性検索を行います。[完了するまでに 3 ~ 5 分ほどかかります]
ScaNN インデックスを作成する
SET scann.allow_blocked_operations = true;
CREATE INDEX IF NOT EXISTS idx_inventory_scann
ON inventory USING scann (part_embedding cosine)
WITH (num_leaves=5, quantizer='sq8');
すべてが機能したことを確認する
SELECT part_name, supplier_name, stock_level,
(part_embedding IS NOT NULL) as has_embedding
FROM inventory
ORDER BY id;
20 行が表示され、すべて has_embedding = true になっています。
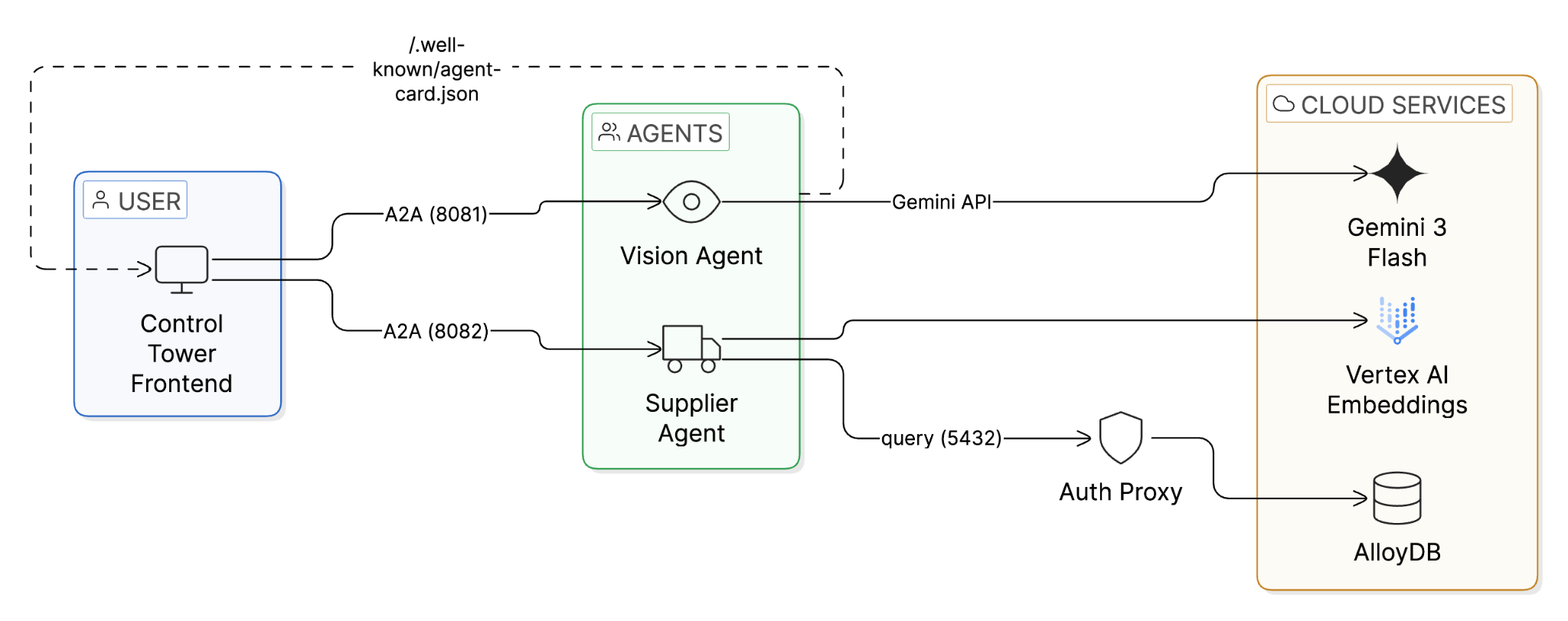
4. アーキテクチャについて
コードを変更する前に、システムの構築方法を理解しましょう。このアーキテクチャは、段階的な「覚醒」パターンに従っています。
エージェント スタック
Vision Agent(agents/vision-agent/)
- agent.py - Gemini 3 Flash のコアロジック。コード実行が有効になっているモデルに画像を送信し、Python(OpenCV)を記述してアイテムを確定的にカウントします。
- agent_executor.py - A2A プロトコル リクエストをエージェント ロジックにブリッジします。
- main.py - /.well-known/agent-card.json を提供し、リクエストを処理する Uvicorn A2A サーバー。
Supplier Agent(agents/supplier-agent/)
- inventory.py - AlloyDB Python コネクタを介して AlloyDB に接続します(Auth Proxy は不要)。ScaNN ベクトル検索を実行する find_supplier() 関数が含まれています。
- agent_executor.py - A2A プロトコルと在庫検索ロジックをブリッジします。
- main.py - エージェント カードとヘルス エンドポイントを備えた Uvicorn A2A サーバー。
Control Tower(frontend/)
- app.py - A2A を介してエージェントを検出する FastAPI + WebSocket サーバー。ビジョン → 検索 → 注文パイプラインをオーケストレートし、リアルタイム更新をブラウザにストリーミングします。
A2A フロー
- Control Tower は各エージェントから /.well-known/agent-card.json を読み取ります
- 機能(スキル、エンドポイント)を検出する - ハードコードされた URL はない
- 画像を Vision Agent に送信 → アイテム数と説明を取得
- 説明をエンベディング クエリとしてサプライヤー エージェントに送信 → 部分一致を取得
- 注文を自律的に行う
AlloyDB 接続
サプライヤー エージェントは、従来の Auth Proxy ではなく AlloyDB Python コネクタを使用します。
from google.cloud.alloydbconnector import Connector
connector = Connector()
conn = connector.connect(
inst_uri, # Full instance URI
"pg8000", # Driver
user="postgres",
password=DB_PASS,
ip_type="PUBLIC", # Cloud Shell uses Public IP
)
これにより、IAM 認証、SSL/TLS、接続ルーティングが自動的に処理されます。後で Cloud Run にデプロイする場合は、VPC アクセス用に ip_type を「PRIVATE」に変更します。
5. ステップ 1: メモリ(サプライヤー エージェント)
サプライヤー エージェントは、AlloyDB ScaNN を使用して数百万個の部品を記憶します。現在、プレースホルダ クエリ(検索内容に関係なく最初に見つかった行を返すアムネシア)が付属しています。
監査: 記憶喪失
この時点でサプライヤー エージェントにクエリを実行すると、ランダムな結果が返されます。類似性の概念はありません。これを解決しましょう。
サプライヤー エージェントを開始する
A2A サーバー(main.py)は agent_executor.py に委任します。これにより、プロトコルが inventory.py のビジネス ロジックにブリッジされます。
pkill -f uvicorn #Kill all uvicorn processes
ステップ 1: エージェント ディレクトリに移動する
cd agents/supplier-agent
ステップ 2: 依存関係をインストールする
pip install -r requirements.txt
ステップ 3: エージェント サーバーを起動する
uvicorn main:app --host 0.0.0.0 --port 8082 > /dev/null 2>&1 &
> /dev/null 2>&1 & は、サーバーをバックグラウンドで実行し、出力を抑制してターミナルを中断しないようにします。
ステップ 4: エージェントが実行されていることを確認する(起動後 2 ~ 3 秒待つ)
curl http://localhost:8082/.well-known/agent-card.json
想定される出力: エージェント構成を含む JSON(エラーなしで返される)
修正: <=> 演算子の実装
agents/supplier-agent/inventory.py を開き、60 ~ 70 行目付近にある find_supplier() 関数を見つけます。プレースホルダが表示されます。
# TODO: Replace this placeholder query with ScaNN vector search
sql = "SELECT part_name, supplier_name FROM inventory LIMIT 1;"
cursor.execute(sql)
この 2 行を次のように置き換えます。
sql = """
SELECT part_name, supplier_name,
part_embedding <=> %s::vector as distance
FROM inventory
ORDER BY part_embedding <=> %s::vector
LIMIT 1;
"""
cursor.execute(sql, (embedding_str, embedding_str))
この機能の用途:
- <=> は、PostgreSQL のコサイン距離演算子です。
- ORDER BY part_embedding <=> %s::vector は、最も近い一致(距離が最小 = 意味的に最も近い)を見つけます。
- %s::vector は、エンベディング配列を PostgreSQL のベクトル型にキャストします。
- ScaNN インデックスは、このクエリを自動的に高速化します。
ステップ 4: ファイルを保存する(Ctrl+S または Cmd+S)
これで、エージェントはランダムな結果を返すのではなく、セマンティック検索を使用するようになります。
確認
A2A 検出とインベントリをテストします。
curl http://localhost:8082/.well-known/agent-card.json

python3 -c "
from inventory import find_supplier
import json
vec = [0.1]*768
r = find_supplier(vec)
if r:
result = {'part': r[0], 'supplier': r[1]}
if len(r) > 2:
result['distance'] = float(r[2]) if r[2] else None
print(json.dumps(result))
else:
print('No result found')
"
期待される結果: agent-card.json がエージェント カードを返します。Python スニペットは、シードされたデータから部品とサプライヤーを返します。
6. ステップ 2: 目(Vision エージェント)
データベースにアクセスできるようになったら、Gemini 3 Flash を使用して目を覚ましましょう。Vision Agent は、コード実行を介して「ビジュアル数学」を実行します。
監査: ハルシネーション
標準のマルチモーダル モデルに「この散らかった画像には箱がいくつありますか?」と質問すると、画像が静的なスナップショットとして処理され、推測が行われます。
- モデルの回答: 「箱が 12 個あります。」
- 実際: 箱は 15 個あります。
- 結果: サプライ チェーンの障害。
解決策: 思考 - 行動 - 観察ループを起動する
コード実行と ThinkingConfig を有効にして、モデルが Python(OpenCV)を記述して確定的にカウントできるようにします。
- agents/vision-agent/agent.py を開きます。
- GenerateContentConfig セクション(68 ~ 78 行目付近)を見つけます。
- thinking_config=types.ThinkingConfig(...) ブロックと tools=[types.Tool(code_execution=...)] の両方のコメントを解除します。
- クライアントは、環境から GEMINI_API_KEY を使用するようにすでに構成されています。
ファイル: agents/vision-agent/agent.py
config = types.GenerateContentConfig(
temperature=0,
# CODELAB STEP 1: Uncomment to enable reasoning
thinking_config=types.ThinkingConfig(
thinking_level="MINIMAL", # Valid: "MINIMAL", "LOW", "MEDIUM", "HIGH"
include_thoughts=False # Set to True for debugging
),
# CODELAB STEP 2: Uncomment to enable code execution
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
)
thinking_level="MINIMAL" なぜですか?
このタスク(コード実行によるアイテムのカウント)では、「MINIMAL」でスクリプトを計画し、カウントを検証するのに十分な推論が提供されます。「HIGH」を使用すると、決定論的タスクの精度が向上することなく、レイテンシが 2 ~ 3 倍になります。費用対効果の最適化 - 推論の深さとタスクの複雑さを一致させます。
費用対効果の最適化は、本番環境の AI エンジニアリングの重要なスキルです。推論の深さとタスクの複雑さを一致させます。
Vision エージェントを起動する
🔄 パスを確認: まだ agents/supplier-agent/ にいる場合は、まず cd ../.. でリポジトリのルートに戻ります。
ステップ 1: Vision エージェント ディレクトリに移動する
cd agents/vision-agent
ステップ 2: 依存関係をインストールする
pip install -r requirements.txt
ステップ 3: ビジョン エージェント サーバーを起動する
uvicorn main:app --host 0.0.0.0 --port 8081 > /dev/null 2>&1 &
> /dev/null 2>&1 & は、サーバーをバックグラウンドで実行し、出力を抑制してターミナルを中断しないようにします。
確認
A2A 検出のテスト:
curl http://localhost:8081/.well-known/agent-card.json
想定される動作: エージェントの名前とスキルを含む JSON。ステップ 8 で、Control Tower UI を使用して実際のビジョン カウントをテストします。

7. ステップ 3: ハンドシェイク(A2A エージェント カード)
エージェントは問題(Vision)を認識し、サプライヤー(Memory)を把握しています。A2A プロトコルにより、動的検出が可能になります。フロントエンドは、各エージェントのカードを読み取ることで、各エージェントとの通信方法を学習します。
A2A と従来の REST API
Aspect | 従来の REST | A2A プロトコル |
エンドポイントの検出 | 構成内のハードコードされた URL | /.well-known/agent-card.json 経由の動的コントロール |
機能の説明 | API ドキュメント(人間向け) | スキル(機械可読) |
インテグレーション | サービスごとの手動コード | セマンティック マッチング: 「在庫検索が必要」→ スキルを検出 |
新しいエージェントが追加されました | すべてのクライアントの構成を更新する | 構成不要 - 自動検出 |
実際のメリット: 従来のマイクロサービスでは、3 番目の「ロジスティクス エージェント」を追加する場合、その URL と API コントラクトで Control Tower のコードを更新する必要があります。A2A を使用すると、Control Tower は自動的に検出され、自然言語のスキル記述を通じてその機能を理解します。
そのため、A2A では、自律型システムのアーキテクチャ パターンであるプラグ アンド プレイ エージェント構成が有効になっています。
エージェント カードを作成する
🔄 パスチェック: まだ agents/vision-agent/ にいる場合は、まず cd ../.. でリポジトリのルートに戻ります。
エージェント カードは agents/supplier-agent/agent_card.json にすでに含まれています。開いて確認します。
{
"name": "Acme Supplier Agent",
"description": "Autonomous fulfillment for industrial parts via AlloyDB ScaNN.",
"version": "1.0.0",
"skills": [{
"id": "search_inventory",
"name": "Search Inventory",
"description": "Searches the warehouse database for semantic matches using AlloyDB ScaNN vector search.",
"tags": ["inventory", "search", "alloydb"],
"examples": ["Find stock for Industrial Widget X-9", "Who supplies ball bearings?"]
}]
}
ユースケースに合わせて、名前、説明、例を自由にカスタマイズしてください。
サプライヤー エージェントを再起動してカードを読み込みます。
ステップ 1: 実行中のエージェントを停止する
pkill -f "uvicorn main:app.*8082"
ステップ 2: エージェント ディレクトリに移動する
cd agents/supplier-agent
ステップ 3: エージェントを再度起動する
uvicorn main:app --host 0.0.0.0 --port 8082 > /dev/null 2>&1 &
> /dev/null 2>&1 & は、サーバーをバックグラウンドで実行し、出力を抑制してターミナルを中断しないようにします。
ステップ 4: 新しいエージェント カードを確認する(開始後 2 ~ 3 秒待つ)
curl http://localhost:8082/.well-known/agent-card.json
想定される出力: 名前、説明、スキルが入力された JSON。

8. ステップ 4: Control Tower
FastAPI と WebSocket を使用して Control Tower フロントエンドを実行します。A2A を介してエージェントを検出し、リアルタイム更新でフルループをオーケストレートします。
すべてのサービスを開始
すべてのサービスを開始する最も簡単な方法:
リポジトリのルートにいることを確認する
pwd # Should end with: visual-commerce-gemini-3-alloydb
次の手順を行ってください。
sh run.sh
この単一のコマンドは次の処理を開始します。
- ポート 8081 の Vision エージェント
- ポート 8082 のサプライヤー エージェント
- ポート 8080 の Control Tower
すべてのサービスが初期化されるまで約 10 秒待ちます。
システムをテストする
Control Tower にアクセスする:
- Cloud Shell ツールバーの [ウェブでプレビュー] ボタン(目のアイコン 👁️)をクリックします。
- [ポート 8080 でプレビュー] を選択します。
- Control Tower ダッシュボードが新しいタブで開きます。
デモを実施する:
- 右上: 接続ステータス(緑色の「ライブ」ドット)、デモモード/自動モードの切り替え、音声コントロール
- 中央: 画像のアップロードと分析の可視化を行うメインのワークフロー キャンバス
- サイドパネル(分析中に表示): ワークフローのタイムライン(左)、進行状況の追跡とコードビューア(右)
オプション 1: クイック スタート(推奨)
- ホームページに、サンプル画像が表示された [クイック スタート] セクションが表示されます。
- サンプル画像をいずれかクリックすると、分析が自動的に開始されます。
- 自律型ワークフローを見る(約 30 ~ 45 秒)
オプション 2: 自分でアップロードする
- 倉庫や棚の画像(PNG、JPG、最大 10 MB)をドラッグ&ドロップするか、クリックして参照します
- [Initiate Autonomous Workflow] をクリックします。
- 4 ステージのパイプラインを観察する
結果:
- エージェントの検出: A2A プロトコルのモーダルに、スキルとエンドポイントを含む Vision エージェントとサプライヤー エージェントのカードが表示されます。
- ビジョン分析: Gemini 3 Flash は、アイテムをカウントするための Python コード(OpenCV)を生成して実行します。進行状況バーにサブステップが表示されます。検出されたアイテムに境界ボックスがオーバーレイ表示されます。結果バッジに「✓ コード検証済み」または「~ 推定」と表示される
- サプライヤー マッチング: AlloyDB ScaNN ベクトル検索のアニメーション。検索語句が表示されます(例: 「工業用金属ボックス」)。一致した部品、サプライヤー、信頼スコアが結果カードに表示される
- 注文完了: 注文 ID、数量、詳細が記載された領収書カード
ヒント: プレゼンテーションの各段階で一時停止するには、デモモードをオン(右上)にしておきます。AUTO モードでは、ワークフローは継続的に実行されます。

What Just Happened
Control Tower は A2A プロトコルを使用して、/.well-known/agent-card.json 経由で両方のエージェントを検出し、ビジョン分析(コード実行による Gemini 3 Flash)をオーケストレートし、ベクトル検索(AlloyDB ScaNN)を実行し、自律的な注文を行いました。これらはすべてリアルタイムの WebSocket 更新で行われました。各エージェントは A2A 標準を介して機能を公開するため、カスタム SDK を使用せずにプラグ アンド プレイで構成できます。詳細: A2A プロトコル
トラブルシューティング
パス関連のエラー:
- コマンド実行時に「No such file or directory」と表示される: リポジトリのルートにいません。
# Check where you are
pwd
# If you're lost, navigate to home and back to repo
cd
cd visual-commerce-gemini-3-alloydb
サービスエラー:
- 「Address already in use」: 前回の実行のプロセスがまだアクティブです。
# Kill all services and restart
pkill -f uvicorn
sh run.sh # Or manually restart individual agents
- サービスが起動しない: ポートが占有されているかどうかを確認します。
# Check which processes are using the ports
lsof -i :8080 # Control Tower
lsof -i :8081 # Vision Agent
lsof -i :8082 # Supplier Agent
- AlloyDB への「接続拒否」: AlloyDB インスタンスでパブリック IP が有効になっていることを確認する
9. 🎁 ボーナス: Cloud Run にデプロイする
省略可 - すべてがローカルで動作します。作成したものを公開 URL で共有する場合は、次の手順を行います。
# From repo root
sh deploy/deploy.sh
結果:
- .env 構成を読み取る
- 名前の入力を求める(デプロイされたアプリに表示される)
- 3 つのサービスすべてを単一の Cloud Run コンテナとしてデプロイする
- AlloyDB アクセス用の IAM ロールを付与する
- 共有可能な URL を出力する
URL を開いたユーザーには、次のようなポップアップが表示されます。
10. クリーンアップ
料金が発生しないようにするには、自動クリーンアップ スクリプトを使用してすべてのリソースを破棄します。
# From repo root
sh deploy/cleanup.sh
この操作を行うと、以下のものが安全に削除されます。
- AlloyDB クラスタ(主な費用要因)
- Cloud Run サービス(デプロイされている場合)
- 関連付けられたサービス アカウント
スクリプトは、削除を行う前に確認を求めます。
11. リファレンスとその他の資料
この Codelab の技術的な主張はすべて、Google Cloud と Google AI の公式ドキュメントで検証されています。
正式なドキュメント
Gemini 3 Flash:
- Code Execution API: https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/code-execution-api
- デベロッパー ガイド: https://ai.google.dev/gemini-api/docs/gemini-3
- モデルのドキュメント: https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-flash
- モデルカード: https://deepmind.google/models/gemini/flash/
AlloyDB AI と ScaNN:
- ScaNN パフォーマンス ベンチマーク: https://cloud.google.com/blog/products/databases/how-scann-for-alloydb-vector-search-compares-to-pgvector-hnsw
- ScaNN インデックスについて: https://cloud.google.com/blog/products/databases/understanding-the-scann-index-in-alloydb
- AlloyDB AI の詳細: https://cloud.google.com/blog/products/databases/alloydb-ais-scann-index-improves-search-on-all-kinds-of-data
- チューニングのベスト プラクティス: https://docs.cloud.google.com/alloydb/docs/ai/best-practices-tuning-scann
- AlloyDB のドキュメント: https://cloud.google.com/alloydb/docs
データベース向け MCP ツールボックス(代替アプローチ):
- MCP ツールボックス: https://mcp-toolbox.dev/documentation/introduction/
料金に関する情報:
- Gemini API の料金: https://ai.google.dev/gemini-api/docs/pricing
- AlloyDB の料金: https://cloud.google.com/alloydb/pricing
- Vertex AI の料金: https://cloud.google.com/vertex-ai/pricing
Verified Performance Claims
機能 | 申請する | ソース |
ScaNN と HNSW(フィルタ付き) | 10 倍高速 | Google Cloud Blog(確認済み) |
ScaNN と HNSW(標準) | 4 倍高速 | Google Cloud Blog(確認済み) |
ScaNN のメモリ使用量 | 3 ~ 4 倍小さい | Google Cloud Blog(確認済み) |
ScaNN インデックスのビルド時間 | 8 倍高速 | Google Cloud Blog(確認済み) |
コード実行のタイムアウト | 最大 30 秒 | Google Cloud ドキュメント(確認済み) |
コード実行ファイル I/O | サポート対象外 | Google Cloud ドキュメント(確認済み) |
Temperature=0 の動作 | 決定論的な出力 | コミュニティ確認済み |
参考情報
Agent-to-Agent(A2A)プロトコル:
- A2A はエージェントの検出と通信を標準化します
/.well-known/agent-card.jsonで配信されるエージェント カード- 自律型エージェントのコラボレーションに関する新しい標準
ScaNN の研究:
- 12 年間の Google Research に基づく
- 数十億規模の Google 検索と YouTube を強化
- 一般提供開始: 2024 年 10 月
- 数百万から数十億のベクトルに適した初の PostgreSQL ベクトル インデックス
12. チャレンジ モード: エージェント スキルをレベルアップする
自律型サプライ チェーンを構築しました。さらに詳しく見ていきましょう。これらの課題では、学習したパターンを新しい問題に適用します。
チャレンジ 1: 画像ベースの検索(マルチモーダル エンベディング)
現在のフロー: Vision エージェントがアイテムをカウント → テキスト クエリを生成 → サプライヤー エージェントがテキストをエンベディング → AlloyDB を検索
課題: テキストを完全にバイパスし、切り抜いた画像をサプライヤー エージェントに直接送信します。
ヒント:
- Vision Agent のコード実行により、棚の画像から個々のアイテムを切り抜くことができる
- Vertex AI の multimodalembedding@001 モデルは画像を直接埋め込むことができます
- テキストではなく画像バイトを受け入れるように inventory.py を変更する
- A2A スキルの説明を「Accepts: image/jpeg or text」と表示するように更新
重要性: 外観が複雑な部品(色のバリエーション、損傷、パッケージの違い)については、画像検索の方が精度が高くなります。
チャレンジ 2: 可観測性 - 透明性による信頼
現在の状態: システムは機能しているが、内部を確認できない
課題: AlloyDB のクエリログを調べて、ベクトル検索が実行されていることを確認します。
手順:
- クエリ分析情報は、AlloyDB でデフォルトで有効になっています。確認するには、次のコマンドを実行します。
gcloud alloydb instances describe INSTANCE_NAME \
--cluster=CLUSTER_NAME \
--region=us-central1 \
--format="value(queryInsightsConfig.queryPlansPerMinute)"
- UI でサプライヤー検索を実行する
- 実行された実際の SQL を表示します。
gcloud logging read \
'resource.type="alloydb.googleapis.com/Instance" AND textPayload:"ORDER BY part_embedding"' \
--limit 5 \
--format=json
想定される出力: 実行時間とともに、ORDER BY part_embedding <=> $1::vector LIMIT 1 クエリが表示されます。
なぜこれが重要なのか: 可観測性により信頼性が高まります。ステークホルダーから「このエージェントはどのように意思決定を行うのですか?」と質問された場合は、出力だけでなくクエリプランも提示できます。
課題 3: マルチエージェントの構成
課題: 倉庫の所在地とアイテムの重量に基づいて送料を計算する 3 番目のエージェント(ロジスティクス エージェント)を追加します。
アーキテクチャ:
- Vision エージェントの出力: アイテム数
- サプライヤー エージェントの出力: サプライヤーの所在地
- ロジスティクス エージェント(新規)の入力: 配送先、重量 → 出力: 送料 + ETA
ヒント: A2A プロトコルを使用すると、これは簡単です。calculate_shipping スキルを含む新しいエージェント カードを作成します。Control Tower はこれを自動的に検出します。
学習するパターン: これは、エージェント指向アーキテクチャの中核です。つまり、小さなコンポーザブルなスペシャリストから構築された複雑なシステムです。
13. まとめ
生成 AI から エージェント型 AI への移行が完了しました。
構築した内容:
- ビジョン: 「推測」を コード実行(API キー経由の Gemini 3 Flash)に置き換えました。
- メモリ: 「遅い検索」を AlloyDB ScaNN(GCP 経由)に置き換えました。
- 対応: 「API 統合」を A2A プロトコルに置き換えました。
ハイブリッド アーキテクチャのメリット:
この Codelab では、ハイブリッド アプローチについて説明しました。
- Vision エージェント: Gemini API(API キー)を使用 - シンプルで無料枠が利用可能、GCP の課金は不要
- サプライヤー エージェント: GCP(Vertex AI + AlloyDB)を使用 - エンタープライズ グレード、コンプライアンス対応
これが自律型経済のアーキテクチャです。コードはそのままお使いいただけます。
次のステップ