
1. La misión

Te identificaste ante la IA de emergencia y tu baliza ahora parpadea en el mapa planetario, pero apenas se ve, perdida entre la estática. Los equipos de rescate que realizan el escaneo desde la órbita pueden ver algo en tus coordenadas, pero no pueden fijar la ubicación. La señal es demasiado débil.
Para que el balizamiento funcione a pleno rendimiento, debes confirmar tu ubicación exacta. El sistema de navegación de la cápsula está averiado, pero el accidente esparció evidencia recuperable por todo el sitio de aterrizaje. Muestras de suelo. Flora extraña. Una vista clara del cielo nocturno alienígena.
Si puedes analizar esta evidencia y determinar en qué región del planeta te encuentras, la IA puede triangular tu posición y amplificar la señal del baliza. Entonces, tal vez alguien te encuentre.
Es hora de unir las piezas.
Requisitos previos
⚠️ Para completar este nivel, debes completar el nivel 0.
Antes de comenzar, verifica que tengas lo siguiente:
- [ ]
config.jsonen la raíz del proyecto con tu ID y coordenadas de participante - [ ] Tu avatar visible en el mapa mundial
- [ ] Tu baliza se muestra (atenuada) en tus coordenadas.
Si no completaste el nivel 0, comienza por ahí.
Qué compilará
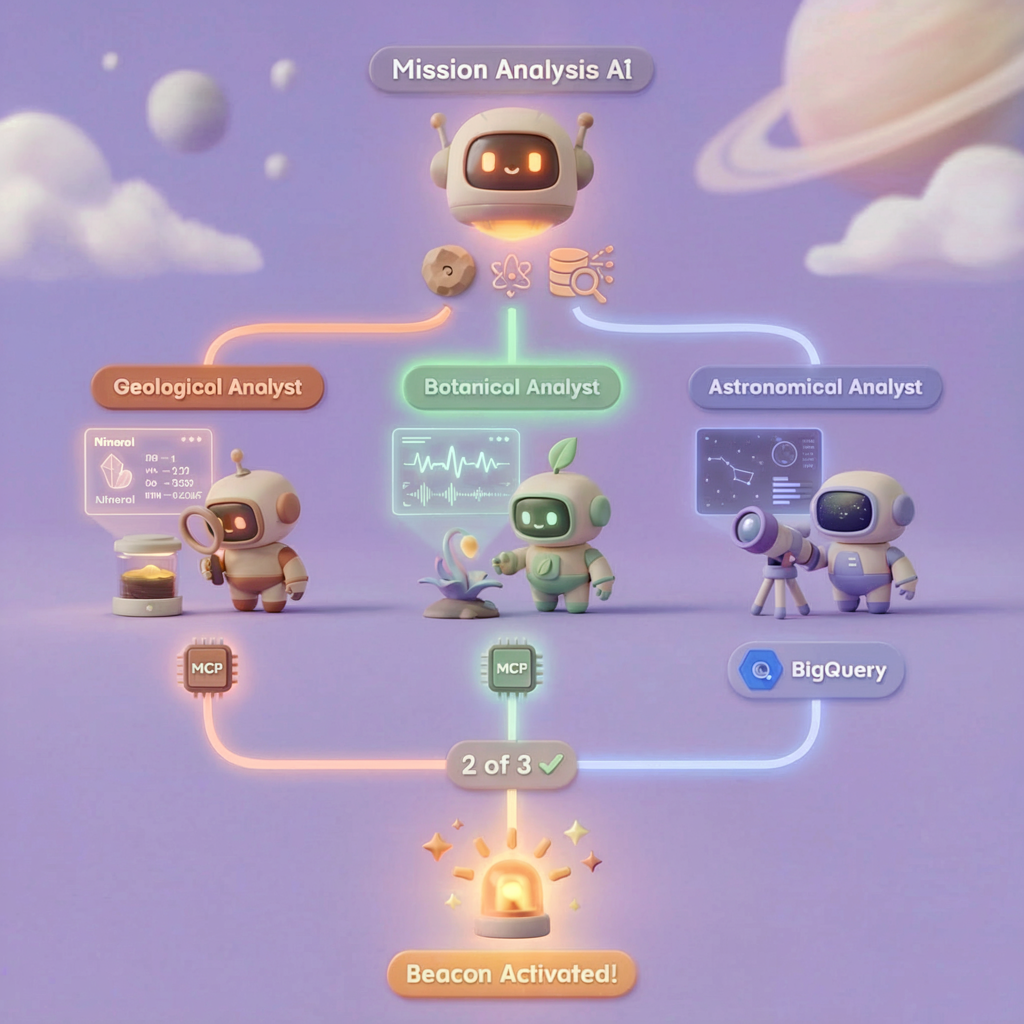
En este nivel, construirás un sistema de IA multiagente que analiza la evidencia del lugar del accidente con procesamiento paralelo:

Objetivos de aprendizaje
Concepto | Lo que aprenderá |
Sistemas multiagente | Crea agentes especializados con responsabilidades únicas |
ParallelAgent | Cómo componer agentes independientes para que se ejecuten de forma simultánea |
before_agent_callback | Recupera la configuración y establece el estado antes de que se ejecute el agente |
ToolContext | Cómo acceder a los valores de estado en las funciones de herramientas |
Servidores de MCP personalizados | Crea herramientas con el patrón imperativo (código de Python en Cloud Run) |
BigQuery de OneMCP | Conéctate al MCP administrado de Google para acceder a BigQuery |
IA multimodal | Analiza imágenes y video con audio con Gemini |
Agent Orchestration | Coordina varios agentes con un organizador raíz |
Implementación en la nube | Implementa el servidor y el agente de MCP en Cloud Run |
Preparación para A2A | Cómo estructurar los agentes para la comunicación futura entre agentes |
Los biomas del planeta
La superficie del planeta se divide en cuatro biomas distintos, cada uno con características únicas:
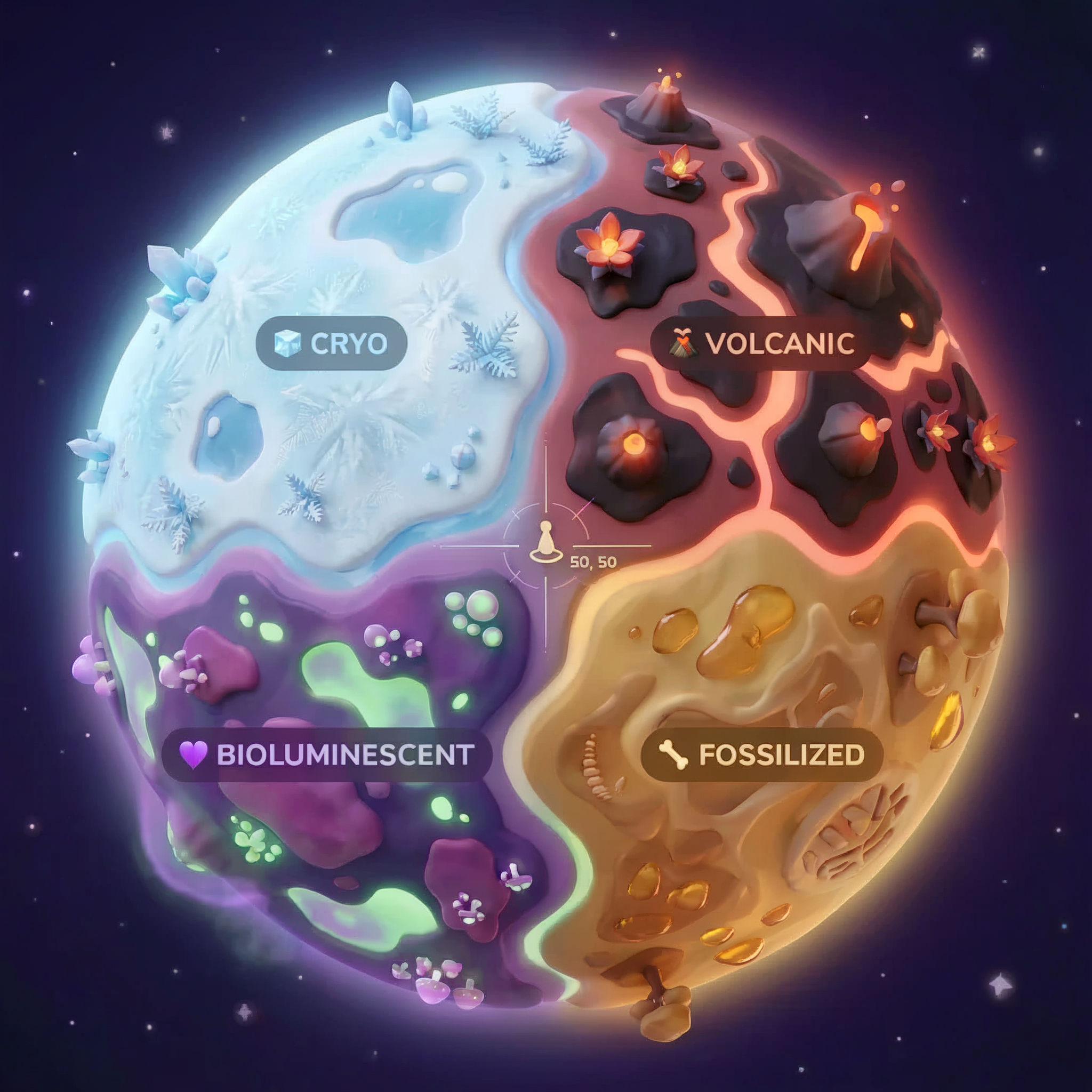
Tus coordenadas determinan en qué bioma te estrellaste. La evidencia en el sitio del accidente refleja las características de ese bioma:
Bioma | Cuadrante | Evidencia geológica | Evidencia botánica | Evidencia astronómica |
🧊 CRYO | NW (x<50, y≥50) | Metano congelado, cristales de hielo | Helechos de escarcha, crioflora | Estrella gigante azul |
🌋 VOLCANIC | NE (x≥50, y≥50) | Depósitos de obsidiana | Flores de fuego, flora resistente al calor | Sistema binario de enanas rojas |
💜 BIOLUMINESCENT | SW (x<50, y<50) | Suelo fosforescente | Hongos brillantes y plantas luminiscentes | Pulsar verde |
🦴 FOSILIZADO | SE (x≥50, y<50) | Depósitos de ámbar, minerales de ite | Árboles petrificados y flora antigua | Sol amarillo |
Tu trabajo es crear agentes de IA que puedan analizar la evidencia y deducir en qué bioma te encuentras.
2. Configura tu entorno
Ejecuta la secuencia de comandos de configuración del entorno
Antes de generar evidencia, debes habilitar las APIs de Google Cloud requeridas, incluida OneMCP para BigQuery, que proporciona acceso MCP administrado a BigQuery.
👉💻 Ejecuta la secuencia de comandos de configuración del entorno:
cd $HOME/way-back-home/level_1
chmod +x setup/setup_env.sh
./setup/setup_env.sh
Deberías ver un resultado como el siguiente:
================================================================
Level 1: Environment Setup
================================================================
Project: your-project-id
[1/6] Enabling core Google Cloud APIs...
✓ Vertex AI API enabled
✓ Cloud Run API enabled
✓ Cloud Build API enabled
✓ BigQuery API enabled
✓ Artifact Registry API enabled
✓ IAM API enabled
[2/6] Enabling OneMCP BigQuery (Managed MCP)...
✓ OneMCP BigQuery enabled
[3/6] Setting up service account and IAM permissions...
✓ Service account 'way-back-home-sa' created
✓ Vertex AI User role granted
✓ Cloud Run Invoker role granted
✓ BigQuery User role granted
✓ BigQuery Data Viewer role granted
✓ Storage Object Viewer role granted
[4/6] Configuring Cloud Build IAM for deployments...
✓ Cloud Build can now deploy services as way-back-home-sa
✓ Cloud Run Admin role granted to Compute SA
[5/6] Creating Artifact Registry repository...
✓ Repository 'way-back-home' created
[6/6] Creating environment variables file...
Found PARTICIPANT_ID in config.json: abc123...
✓ Created ../set_env.sh
================================================================
✅ Environment Setup Complete!
================================================================
Variables de entorno de origen
👉💻 Obtén las variables de entorno:
source $HOME/way-back-home/set_env.sh
Instala las dependencias
👉💻 Instala las dependencias de Python de nivel 1:
cd $HOME/way-back-home/level_1
uv sync
Configura el catálogo de estrellas
👉💻 Configura el catálogo de estrellas en BigQuery:
uv run python setup/setup_star_catalog.py
Deberías ver lo siguiente:
Setting up star catalog in project: your-project-id
==================================================
✓ Dataset way_back_home already exists
✓ Created table star_catalog
✓ Inserted 12 rows into star_catalog
📊 Star Catalog Summary:
----------------------------------------
NE (VOLCANIC): 3 stellar patterns
NW (CRYO): 3 stellar patterns
SE (FOSSILIZED): 3 stellar patterns
SW (BIOLUMINESCENT): 3 stellar patterns
----------------------------------------
✓ Star catalog is ready for triangulation queries
==================================================
✅ Star catalog setup complete!
3. Genera evidencia del sitio de la falla
Ahora puedes generar evidencia personalizada del sitio del accidente en función de tus coordenadas.
Ejecuta el generador de evidencia
👉💻 Desde el directorio level_1, ejecuta lo siguiente:
cd $HOME/way-back-home/level_1
uv run python generate_evidence.py
Deberías ver un resultado como el siguiente:
✓ Welcome back, Explorer_Aria!
Coordinates: (23, 67)
Ready to analyze your crash site.
📍 Crash site analysis initiated...
Generating evidence for your location...
🔬 Generating soil sample...
✓ Soil sample captured: outputs/soil_sample.png
✨ Capturing star field...
✓ Star field captured: outputs/star_field.png
🌿 Recording flora activity...
(This may take 1-2 minutes for video generation)
Generating video...
Generating video...
Generating video...
✓ Flora recorded: outputs/flora_recording.mp4
📤 Uploading evidence to Mission Control...
✓ Config updated with evidence URLs
==================================================
✅ Evidence generation complete!
==================================================
Revisa tu evidencia
👉 Tómate un momento para revisar los archivos de evidencia generados en la carpeta outputs/. Cada uno refleja las características del bioma de la ubicación del accidente, aunque no sabrás qué bioma es hasta que tus agentes de IA los analicen.
Según tu ubicación, la evidencia generada podría verse de la siguiente manera:



4. Compila el servidor de MCP personalizado
Los sistemas de análisis integrados de tu cápsula de escape están dañados, pero los datos sin procesar del sensor sobrevivieron al accidente. Compilarás un servidor de MCP con FastMCP que proporcione herramientas de análisis geológico y botánico.
Crea la herramienta de análisis geológico
Esta herramienta analiza imágenes de muestras de suelo para identificar la composición mineral.
👉✏️ Abre $HOME/way-back-home/level_1/mcp-server/main.py y busca #REPLACE-GEOLOGICAL-TOOL. Reemplázala por lo siguiente:
GEOLOGICAL_PROMPT = """Analyze this alien soil sample image.
Classify the PRIMARY characteristic (choose exactly one):
1. CRYO - Frozen/icy minerals, crystalline structures, frost patterns,
blue-white coloration, permafrost indicators
2. VOLCANIC - Volcanic rock, basalt, obsidian, sulfur deposits,
red-orange minerals, heat-formed crystite structures
3. BIOLUMINESCENT - Glowing particles, phosphorescent minerals,
organic-mineral hybrids, purple-green luminescence
4. FOSSILIZED - Ancient compressed minerals, amber deposits,
petrified organic matter, golden-brown stratification
Respond ONLY with valid JSON (no markdown, no explanation):
{
"biome": "CRYO|VOLCANIC|BIOLUMINESCENT|FOSSILIZED",
"confidence": 0.0-1.0,
"minerals_detected": ["mineral1", "mineral2"],
"description": "Brief description of what you observe"
}
"""
@mcp.tool()
def analyze_geological(
image_url: Annotated[
str,
Field(description="Cloud Storage URL (gs://...) of the soil sample image")
]
) -> dict:
"""
Analyzes a soil sample image to identify mineral composition and classify the planetary biome.
Args:
image_url: Cloud Storage URL of the soil sample image (gs://bucket/path/image.png)
Returns:
dict with biome, confidence, minerals_detected, and description
"""
logger.info(f">>> 🔬 Tool: 'analyze_geological' called for '{image_url}'")
try:
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
GEOLOGICAL_PROMPT,
genai_types.Part.from_uri(file_uri=image_url, mime_type="image/png")
]
)
result = parse_json_response(response.text)
logger.info(f" ✓ Geological analysis complete: {result.get('biome', 'UNKNOWN')}")
return result
except Exception as e:
logger.error(f" ✗ Geological analysis failed: {str(e)}")
return {"error": str(e), "biome": "UNKNOWN", "confidence": 0.0}
Crea la herramienta de análisis botánico
Esta herramienta analiza las grabaciones de video de flora, incluida la pista de audio.
👉✏️ En el mismo archivo ($HOME/way-back-home/level_1/mcp-server/main.py), busca #REPLACE-BOTANICAL-TOOL y reemplázalo por lo siguiente:
BOTANICAL_PROMPT = """Analyze this alien flora video recording.
Pay attention to BOTH:
1. VISUAL elements: Plant appearance, movement patterns, colors, bioluminescence
2. AUDIO elements: Ambient sounds, rustling, organic noises, frequencies
Classify the PRIMARY biome (choose exactly one):
1. CRYO - Crystalline ice-plants, frost-covered vegetation,
crackling/tinkling sounds, slow brittle movements, blue-white flora
2. VOLCANIC - Heat-resistant plants, sulfur-adapted species,
hissing/bubbling sounds, smoke-filtering vegetation, red-orange flora
3. BIOLUMINESCENT - Glowing plants, pulsing light patterns,
humming/resonating sounds, reactive to stimuli, purple-green flora
4. FOSSILIZED - Ancient petrified plants, amber-preserved specimens,
deep resonant sounds, minimal movement, golden-brown flora
Respond ONLY with valid JSON (no markdown, no explanation):
{
"biome": "CRYO|VOLCANIC|BIOLUMINESCENT|FOSSILIZED",
"confidence": 0.0-1.0,
"species_detected": ["species1", "species2"],
"audio_signatures": ["sound1", "sound2"],
"description": "Brief description of visual and audio observations"
}
"""
@mcp.tool()
def analyze_botanical(
video_url: Annotated[
str,
Field(description="Cloud Storage URL (gs://...) of the flora video recording")
]
) -> dict:
"""
Analyzes a flora video recording (visual + audio) to identify plant species and classify the biome.
Args:
video_url: Cloud Storage URL of the flora video (gs://bucket/path/video.mp4)
Returns:
dict with biome, confidence, species_detected, audio_signatures, and description
"""
logger.info(f">>> 🌿 Tool: 'analyze_botanical' called for '{video_url}'")
try:
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
BOTANICAL_PROMPT,
genai_types.Part.from_uri(file_uri=video_url, mime_type="video/mp4")
]
)
result = parse_json_response(response.text)
logger.info(f" ✓ Botanical analysis complete: {result.get('biome', 'UNKNOWN')}")
return result
except Exception as e:
logger.error(f" ✗ Botanical analysis failed: {str(e)}")
return {"error": str(e), "biome": "UNKNOWN", "confidence": 0.0}
Cómo probar el servidor de MCP de forma local
👉💻 Prueba el servidor de MCP:
cd $HOME/way-back-home/level_1/mcp-server
pip install -r requirements.txt
python main.py
Deberías ver lo siguiente:
[INFO] Initialized Gemini client for project: your-project-id
[INFO] 🚀 Location Analyzer MCP Server starting on port 8080
[INFO] 📍 MCP endpoint: http://0.0.0.0:8080/mcp
[INFO] 🔧 Tools: analyze_geological, analyze_botanical
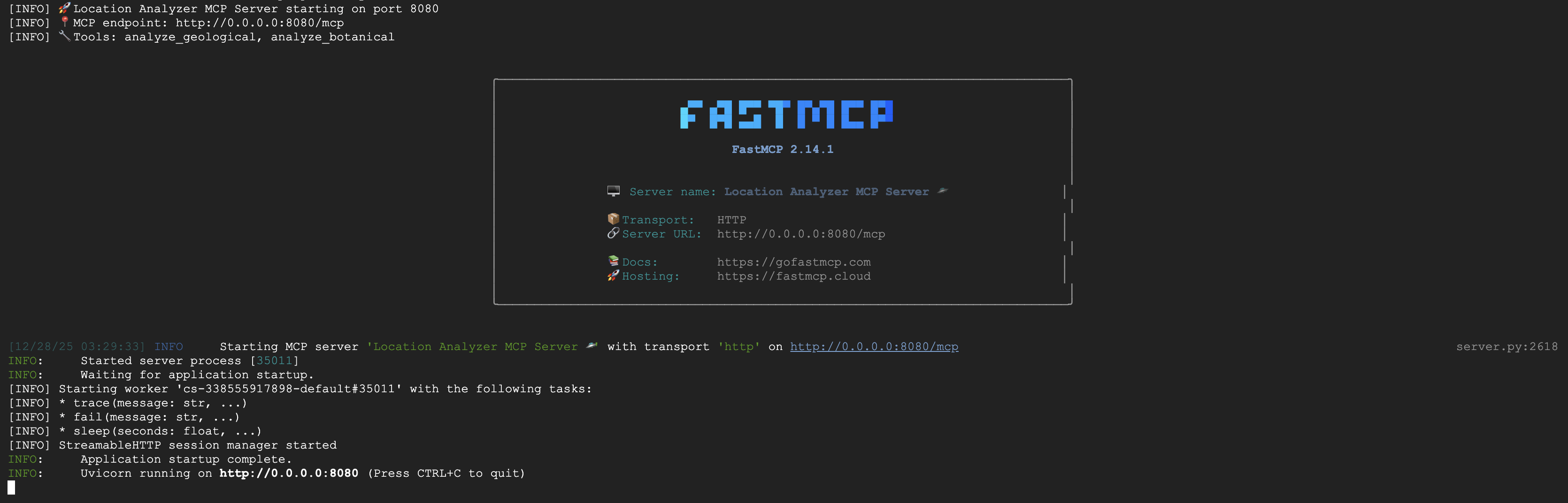
El servidor FastMCP ahora se ejecuta con transporte HTTP. Presiona Ctrl+C para detener la grabación.
Implementa el servidor de MCP en Cloud Run
👉💻 Implementación:
cd $HOME/way-back-home/level_1/mcp-server
source $HOME/way-back-home/set_env.sh
gcloud builds submit . \
--config=cloudbuild.yaml \
--substitutions=_REGION="$REGION",_REPO_NAME="$REPO_NAME",_SERVICE_ACCOUNT="$SERVICE_ACCOUNT"
Cómo guardar la URL del servicio
👉💻 Guarda la URL de servicio:
export MCP_SERVER_URL=$(gcloud run services describe location-analyzer \
--region=$REGION --format='value(status.url)')
echo "MCP Server URL: $MCP_SERVER_URL"
# Add to set_env.sh for later use
echo "export MCP_SERVER_URL=\"$MCP_SERVER_URL\"" >> $HOME/way-back-home/set_env.sh
5. Compila los agentes especialistas
Ahora crearás tres agentes especialistas, cada uno con una sola responsabilidad.
Crea el agente de análisis geológico
👉✏️ Abre agent/agents/geological_analyst.py y busca #REPLACE-GEOLOGICAL-AGENT. Reemplázala por lo siguiente:
from google.adk.agents import Agent
from agent.tools.mcp_tools import get_geological_tool
geological_analyst = Agent(
name="GeologicalAnalyst",
model="gemini-2.5-flash",
description="Analyzes soil samples to classify planetary biome based on mineral composition.",
instruction="""You are a geological specialist analyzing alien soil samples.
## YOUR EVIDENCE TO ANALYZE
Soil sample URL: {soil_url}
## YOUR TASK
1. Call the analyze_geological tool with the soil sample URL above
2. Examine the results for mineral composition and biome indicators
3. Report your findings clearly
The four possible biomes are:
- CRYO: Frozen, icy minerals, blue/white coloring
- VOLCANIC: Magma, obsidian, volcanic rock, red/orange coloring
- BIOLUMINESCENT: Glowing, phosphorescent minerals, purple/green
- FOSSILIZED: Amber, ancient preserved matter, golden/brown
## REPORTING FORMAT
Always report your classification clearly:
"GEOLOGICAL ANALYSIS: [BIOME] (confidence: X%)"
Include a brief description of what you observed in the sample.
## IMPORTANT
- You do NOT synthesize with other evidence
- You do NOT confirm locations
- Just analyze the soil sample and report what you find
- Call the tool immediately with the URL provided above""",
tools=[get_geological_tool()]
)
Crea el agente de analista botánico
👉✏️ Abre agent/agents/botanical_analyst.py y busca #REPLACE-BOTANICAL-AGENT. Reemplázala por lo siguiente:
from google.adk.agents import Agent
from agent.tools.mcp_tools import get_botanical_tool
botanical_analyst = Agent(
name="BotanicalAnalyst",
model="gemini-2.5-flash",
description="Analyzes flora recordings to classify planetary biome based on plant life and ambient sounds.",
instruction="""You are a botanical specialist analyzing alien flora recordings.
## YOUR EVIDENCE TO ANALYZE
Flora recording URL: {flora_url}
## YOUR TASK
1. Call the analyze_botanical tool with the flora recording URL above
2. Pay attention to BOTH visual AND audio elements in the recording
3. Report your findings clearly
The four possible biomes are:
- CRYO: Frost ferns, crystalline plants, cold wind sounds, crackling ice
- VOLCANIC: Fire blooms, heat-resistant flora, crackling/hissing sounds
- BIOLUMINESCENT: Glowing fungi, luminescent plants, ethereal hum, chiming
- FOSSILIZED: Petrified trees, ancient formations, deep resonant sounds
## REPORTING FORMAT
Always report your classification clearly:
"BOTANICAL ANALYSIS: [BIOME] (confidence: X%)"
Include descriptions of what you SAW and what you HEARD.
## IMPORTANT
- You do NOT synthesize with other evidence
- You do NOT confirm locations
- Just analyze the flora recording and report what you find
- Call the tool immediately with the URL provided above""",
tools=[get_botanical_tool()]
)
Crea el agente de analista astronómico
Este agente usa un enfoque diferente con dos patrones de herramientas:
- Local FunctionTool: Gemini Vision para extraer características de estrellas
- OneMCP BigQuery: Consulta el catálogo de estrellas a través del MCP administrado de Google
👉✏️ Abre agent/agents/astronomical_analyst.py y busca #REPLACE-ASTRONOMICAL-AGENT. Reemplázala por lo siguiente:
from google.adk.agents import Agent
from agent.tools.star_tools import (
extract_star_features_tool,
get_bigquery_mcp_toolset,
)
# Get the BigQuery MCP toolset
bigquery_toolset = get_bigquery_mcp_toolset()
astronomical_analyst = Agent(
name="AstronomicalAnalyst",
model="gemini-2.5-flash",
description="Analyzes star field images and queries the star catalog via OneMCP BigQuery.",
instruction="""You are an astronomical specialist analyzing alien night skies.
## YOUR EVIDENCE TO ANALYZE
Star field URL: {stars_url}
## YOUR TWO TOOLS
### TOOL 1: extract_star_features (Local Gemini Vision)
Call this FIRST with the star field URL above.
Returns: "primary_star": "...", "nebula_type": "...", "stellar_color": "..."
### TOOL 2: BigQuery MCP (execute_query)
Call this SECOND with the results from Tool 1.
Use this exact SQL query (replace the placeholders with values from Step 1):
SELECT quadrant, biome, primary_star, nebula_type
FROM `{project_id}.way_back_home.star_catalog`
WHERE LOWER(primary_star) = LOWER('PRIMARY_STAR_FROM_STEP_1')
AND LOWER(nebula_type) = LOWER('NEBULA_TYPE_FROM_STEP_1')
LIMIT 1
## YOUR WORKFLOW
1. Call extract_star_features with: {stars_url}
2. Get the primary_star and nebula_type from the result
3. Call execute_query with the SQL above (replacing placeholders)
4. Report the biome and quadrant from the query result
## BIOME REFERENCE
| Biome | Quadrant | Primary Star | Nebula Type |
|-------|----------|--------------|-------------|
| CRYO | NW | blue_giant | ice_blue |
| VOLCANIC | NE | red_dwarf_binary | fire |
| BIOLUMINESCENT | SW | green_pulsar | purple_magenta |
| FOSSILIZED | SE | yellow_sun | golden |
## REPORTING FORMAT
"ASTRONOMICAL ANALYSIS: [BIOME] in [QUADRANT] quadrant (confidence: X%)"
Include a description of the stellar features you observed.
## IMPORTANT
- You do NOT synthesize with other evidence
- You do NOT confirm locations
- Just analyze the stars and report what you find
- Start by calling extract_star_features with the URL above""",
tools=[extract_star_features_tool, bigquery_toolset]
)
6. Compila las conexiones de la herramienta de MCP
Ahora crearás los wrappers de Python que permiten que tus agentes del ADK se comuniquen con los servidores de MCP. Estos wrappers controlan el ciclo de vida de la conexión, establecen sesiones, invocan herramientas y analizan respuestas.
Crea una conexión de la herramienta de MCP (MCP personalizada)
Esto se conecta a tu servidor FastMCP personalizado implementado en Cloud Run.
👉✏️ Abre agent/tools/mcp_tools.py y busca #REPLACE-MCP-TOOL-CONNECTION. Reemplázala por lo siguiente:
import os
import logging
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPConnectionParams
logger = logging.getLogger(__name__)
MCP_SERVER_URL = os.environ.get("MCP_SERVER_URL")
_mcp_toolset = None
def get_mcp_toolset():
"""Get the MCPToolset connected to the location-analyzer server."""
global _mcp_toolset
if _mcp_toolset is not None:
return _mcp_toolset
if not MCP_SERVER_URL:
raise ValueError(
"MCP_SERVER_URL not set. Please run:\n"
" export MCP_SERVER_URL='https://location-analyzer-xxx.a.run.app'"
)
# FastMCP exposes MCP protocol at /mcp endpoint
mcp_endpoint = f"{MCP_SERVER_URL}/mcp"
logger.info(f"[MCP Tools] Connecting to: {mcp_endpoint}")
_mcp_toolset = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_endpoint,
timeout=120, # 2 minutes for Gemini analysis
)
)
return _mcp_toolset
def get_geological_tool():
"""Get the geological analysis tool from the MCP server."""
return get_mcp_toolset()
def get_botanical_tool():
"""Get the botanical analysis tool from the MCP server."""
return get_mcp_toolset()
Crea herramientas de análisis de estrellas (OneMCP BigQuery)
El catálogo de estrellas que cargaste antes en BigQuery contiene patrones estelares para cada bioma. En lugar de escribir código de cliente de BigQuery para consultarlo, nos conectamos al servidor OneMCP de BigQuery de Google, que expone la capacidad de execute_query de BigQuery como una herramienta de MCP que cualquier agente de ADK puede usar directamente.
👉✏️ Abre agent/tools/star_tools.py y busca #REPLACE-STAR-TOOLS. Reemplázala por lo siguiente:
import os
import json
import logging
from google import genai
from google.genai import types as genai_types
from google.adk.tools import FunctionTool
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPConnectionParams
import google.auth
import google.auth.transport.requests
logger = logging.getLogger(__name__)
# =============================================================================
# CONFIGURATION - Environment variables only
# =============================================================================
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT", "")
if not PROJECT_ID:
logger.warning("[Star Tools] GOOGLE_CLOUD_PROJECT not set")
# Initialize Gemini client for star feature extraction
genai_client = genai.Client(
vertexai=True,
project=PROJECT_ID or "placeholder",
location=os.environ.get("GOOGLE_CLOUD_LOCATION", "us-central1")
)
logger.info(f"[Star Tools] Initialized for project: {PROJECT_ID}")
# =============================================================================
# OneMCP BigQuery Connection
# =============================================================================
BIGQUERY_MCP_URL = "https://bigquery.googleapis.com/mcp"
_bigquery_toolset = None
def get_bigquery_mcp_toolset():
"""
Get the MCPToolset connected to Google's BigQuery MCP server.
This uses OAuth 2.0 authentication with Application Default Credentials.
The toolset provides access to BigQuery's pre-built MCP tools like:
- execute_query: Run SQL queries
- list_datasets: List available datasets
- get_table_schema: Get table structure
"""
global _bigquery_toolset
if _bigquery_toolset is not None:
return _bigquery_toolset
logger.info("[Star Tools] Connecting to OneMCP BigQuery...")
# Get OAuth credentials
credentials, project_id = google.auth.default(
scopes=["https://www.googleapis.com/auth/bigquery"]
)
# Refresh to get a valid token
credentials.refresh(google.auth.transport.requests.Request())
oauth_token = credentials.token
# Configure headers for BigQuery MCP
headers = {
"Authorization": f"Bearer {oauth_token}",
"x-goog-user-project": project_id or PROJECT_ID
}
# Create MCPToolset with StreamableHTTP connection
_bigquery_toolset = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=BIGQUERY_MCP_URL,
headers=headers
)
)
logger.info("[Star Tools] Connected to BigQuery MCP")
return _bigquery_toolset
# =============================================================================
# Local FunctionTool: Star Feature Extraction
# =============================================================================
# This is a LOCAL tool that calls Gemini directly - demonstrating that
# you can mix local FunctionTools with MCP tools in the same agent.
STAR_EXTRACTION_PROMPT = """Analyze this alien night sky image and extract stellar features.
Identify:
1. PRIMARY STAR TYPE: blue_giant, red_dwarf, red_dwarf_binary, green_pulsar, yellow_sun, etc.
2. NEBULA TYPE: ice_blue, fire, purple_magenta, golden, etc.
3. STELLAR COLOR: blue_white, red_orange, green_purple, yellow_gold, etc.
Respond ONLY with valid JSON:
{"primary_star": "...", "nebula_type": "...", "stellar_color": "...", "description": "..."}
"""
def _parse_json_response(text: str) -> dict:
"""Parse JSON from Gemini response, handling markdown formatting."""
cleaned = text.strip()
if cleaned.startswith("```json"):
cleaned = cleaned[7:]
elif cleaned.startswith("```"):
cleaned = cleaned[3:]
if cleaned.endswith("```"):
cleaned = cleaned[:-3]
cleaned = cleaned.strip()
try:
return json.loads(cleaned)
except json.JSONDecodeError as e:
logger.error(f"Failed to parse JSON: {e}")
return {"error": f"Failed to parse response: {str(e)}"}
def extract_star_features(image_url: str) -> dict:
"""
Extract stellar features from a star field image using Gemini Vision.
This is a LOCAL FunctionTool - we call Gemini directly, not through MCP.
The agent will use this alongside the BigQuery MCP tools.
"""
logger.info(f"[Stars] Extracting features from: {image_url}")
response = genai_client.models.generate_content(
model="gemini-2.5-flash",
contents=[
STAR_EXTRACTION_PROMPT,
genai_types.Part.from_uri(file_uri=image_url, mime_type="image/png")
]
)
result = _parse_json_response(response.text)
logger.info(f"[Stars] Extracted: primary_star={result.get('primary_star')}")
return result
# Create the local FunctionTool
extract_star_features_tool = FunctionTool(extract_star_features)
7. Compila el organizador
Ahora, crea el equipo paralelo y el organizador raíz que coordina todo.
Crea el equipo de análisis paralelo
¿Por qué se ejecutan los tres especialistas en paralelo? Porque son completamente independientes: el analista geológico no necesita esperar los resultados del analista botánico, y viceversa. Cada especialista analiza una evidencia diferente con herramientas distintas. Un ParallelAgent ejecuta los tres análisis de forma simultánea, lo que reduce el tiempo total de análisis de aproximadamente 30 s (secuencial) a aproximadamente 10 s (paralelo).
👉✏️ Abre agent/agent.py y busca #REPLACE-PARALLEL-CREW. Reemplázala por lo siguiente:
import os
import logging
import httpx
from google.adk.agents import Agent, ParallelAgent
from google.adk.agents.callback_context import CallbackContext
# Import specialist agents
from agent.agents.geological_analyst import geological_analyst
from agent.agents.botanical_analyst import botanical_analyst
from agent.agents.astronomical_analyst import astronomical_analyst
# Import confirmation tool
from agent.tools.confirm_tools import confirm_location_tool
logger = logging.getLogger(__name__)
# =============================================================================
# BEFORE AGENT CALLBACK - Fetches config and sets state
# =============================================================================
async def setup_participant_context(callback_context: CallbackContext) -> None:
"""
Fetch participant configuration and populate state for all agents.
This callback:
1. Reads PARTICIPANT_ID and BACKEND_URL from environment
2. Fetches participant data from the backend API
3. Sets state values: soil_url, flora_url, stars_url, username, x, y, etc.
4. Returns None to continue normal agent execution
"""
participant_id = os.environ.get("PARTICIPANT_ID", "")
backend_url = os.environ.get("BACKEND_URL", "https://api.waybackhome.dev")
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT", "")
logger.info(f"[Callback] Setting up context for participant: {participant_id}")
# Set project_id and backend_url in state immediately
callback_context.state["project_id"] = project_id
callback_context.state["backend_url"] = backend_url
callback_context.state["participant_id"] = participant_id
if not participant_id:
logger.warning("[Callback] No PARTICIPANT_ID set - using placeholder values")
callback_context.state["username"] = "Explorer"
callback_context.state["x"] = 0
callback_context.state["y"] = 0
callback_context.state["soil_url"] = "Not available - set PARTICIPANT_ID"
callback_context.state["flora_url"] = "Not available - set PARTICIPANT_ID"
callback_context.state["stars_url"] = "Not available - set PARTICIPANT_ID"
return None
# Fetch participant data from backend API
try:
url = f"{backend_url}/participants/{participant_id}"
logger.info(f"[Callback] Fetching from: {url}")
async with httpx.AsyncClient(timeout=30.0) as client:
response = await client.get(url)
response.raise_for_status()
data = response.json()
# Extract evidence URLs
evidence_urls = data.get("evidence_urls", {})
# Set all state values for sub-agents to access
callback_context.state["username"] = data.get("username", "Explorer")
callback_context.state["x"] = data.get("x", 0)
callback_context.state["y"] = data.get("y", 0)
callback_context.state["soil_url"] = evidence_urls.get("soil", "Not available")
callback_context.state["flora_url"] = evidence_urls.get("flora", "Not available")
callback_context.state["stars_url"] = evidence_urls.get("stars", "Not available")
logger.info(f"[Callback] State populated for {data.get('username')}")
except Exception as e:
logger.error(f"[Callback] Error fetching participant config: {e}")
callback_context.state["username"] = "Explorer"
callback_context.state["x"] = 0
callback_context.state["y"] = 0
callback_context.state["soil_url"] = f"Error: {e}"
callback_context.state["flora_url"] = f"Error: {e}"
callback_context.state["stars_url"] = f"Error: {e}"
return None
# =============================================================================
# PARALLEL ANALYSIS CREW
# =============================================================================
evidence_analysis_crew = ParallelAgent(
name="EvidenceAnalysisCrew",
description="Runs geological, botanical, and astronomical analysis in parallel.",
sub_agents=[geological_analyst, botanical_analyst, astronomical_analyst]
)
Crea el organizador raíz
Ahora, crea el agente raíz que coordina todo y usa la devolución de llamada.
👉✏️ En el mismo archivo (agent/agent.py), busca #REPLACE-ROOT-ORCHESTRATOR. Reemplázala por lo siguiente:
root_agent = Agent(
name="MissionAnalysisAI",
model="gemini-2.5-flash",
description="Coordinates crash site analysis to confirm explorer location.",
instruction="""You are the Mission Analysis AI coordinating a rescue operation.
## Explorer Information
- Name: {username}
- Coordinates: ({x}, {y})
## Evidence URLs (automatically provided to specialists via state)
- Soil sample: {soil_url}
- Flora recording: {flora_url}
- Star field: {stars_url}
## Your Workflow
### STEP 1: DELEGATE TO ANALYSIS CREW
Tell the EvidenceAnalysisCrew to analyze all the evidence.
The evidence URLs are already available to the specialists.
### STEP 2: COLLECT RESULTS
Each specialist will report:
- "GEOLOGICAL ANALYSIS: [BIOME] (confidence: X%)"
- "BOTANICAL ANALYSIS: [BIOME] (confidence: X%)"
- "ASTRONOMICAL ANALYSIS: [BIOME] in [QUADRANT] quadrant (confidence: X%)"
### STEP 3: APPLY 2-OF-3 AGREEMENT RULE
- If 2 or 3 specialists agree → that's the answer
- If all 3 disagree → use judgment based on confidence
### STEP 4: CONFIRM LOCATION
Call confirm_location with the determined biome.
## Biome Reference
| Biome | Quadrant | Key Characteristics |
|-------|----------|---------------------|
| CRYO | NW | Frozen, blue, ice crystals |
| VOLCANIC | NE | Magma, red/orange, obsidian |
| BIOLUMINESCENT | SW | Glowing, purple/green |
| FOSSILIZED | SE | Amber, golden, ancient |
## Response Style
Be encouraging and narrative! Celebrate when the beacon activates!
""",
sub_agents=[evidence_analysis_crew],
tools=[confirm_location_tool],
before_agent_callback=setup_participant_context
)
Crea la herramienta de confirmación de ubicación
Esta es la pieza final, la herramienta que realmente confirma tu ubicación al Centro de control y activa tu baliza. Cuando el orquestador raíz determina en qué bioma te encuentras (con la regla de acuerdo de 2 de 3), llama a esta herramienta para enviar el resultado a la API de backend.
Esta herramienta usa ToolContext, lo que le da acceso a los valores de estado (como participant_id y backend_url) que estableció before_agent_callback anteriormente.
👉✏️ En agent/tools/confirm_tools.py, busca #REPLACE-CONFIRM-TOOL. Reemplázala por lo siguiente:
import os
import logging
import requests
from google.adk.tools import FunctionTool
from google.adk.tools.tool_context import ToolContext
logger = logging.getLogger(__name__)
BIOME_TO_QUADRANT = {
"CRYO": "NW",
"VOLCANIC": "NE",
"BIOLUMINESCENT": "SW",
"FOSSILIZED": "SE"
}
def _get_actual_biome(x: int, y: int) -> tuple[str, str]:
"""Determine actual biome and quadrant from coordinates."""
if x < 50 and y >= 50:
return "NW", "CRYO"
elif x >= 50 and y >= 50:
return "NE", "VOLCANIC"
elif x < 50 and y < 50:
return "SW", "BIOLUMINESCENT"
else:
return "SE", "FOSSILIZED"
def confirm_location(biome: str, tool_context: ToolContext) -> dict:
"""
Confirm the explorer's location and activate the rescue beacon.
Uses ToolContext to read state values set by before_agent_callback.
"""
# Read from state (set by before_agent_callback)
participant_id = tool_context.state.get("participant_id", "")
x = tool_context.state.get("x", 0)
y = tool_context.state.get("y", 0)
backend_url = tool_context.state.get("backend_url", "https://api.waybackhome.dev")
# Fallback to environment variables
if not participant_id:
participant_id = os.environ.get("PARTICIPANT_ID", "")
if not backend_url:
backend_url = os.environ.get("BACKEND_URL", "https://api.waybackhome.dev")
if not participant_id:
return {"success": False, "message": "❌ No participant ID available."}
biome_upper = biome.upper().strip()
if biome_upper not in BIOME_TO_QUADRANT:
return {"success": False, "message": f"❌ Unknown biome: {biome}"}
# Get actual biome from coordinates
actual_quadrant, actual_biome = _get_actual_biome(x, y)
if biome_upper != actual_biome:
return {
"success": False,
"message": f"❌ Mismatch! Analysis: {biome_upper}, Actual: {actual_biome}"
}
quadrant = BIOME_TO_QUADRANT[biome_upper]
try:
response = requests.patch(
f"{backend_url}/participants/{participant_id}/location",
params={"x": x, "y": y},
timeout=10
)
response.raise_for_status()
return {
"success": True,
"message": f"🔦 BEACON ACTIVATED!\n\nLocation: {biome_upper} in {quadrant}\nCoordinates: ({x}, {y})"
}
except requests.exceptions.ConnectionError:
return {
"success": True,
"message": f"🔦 BEACON ACTIVATED! (Local)\n\nLocation: {biome_upper} in {quadrant}",
"simulated": True
}
except Exception as e:
return {"success": False, "message": f"❌ Failed: {str(e)}"}
confirm_location_tool = FunctionTool(confirm_location)
8. Prueba con la IU web del ADK
Ahora, probemos el sistema multiagente completo de forma local.
Inicia el servidor web del ADK
👉💻 Configura las variables de entorno y, luego, inicia el servidor web del ADK:
cd $HOME/way-back-home/level_1
source $HOME/way-back-home/set_env.sh
# Verify environment is set
echo "PARTICIPANT_ID: $PARTICIPANT_ID"
echo "MCP Server: $MCP_SERVER_URL"
# Start ADK web server
uv run adk web
Deberías ver lo siguiente:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Accede a la IU web
👉 En el ícono de Vista previa en la Web de la barra de herramientas de Cloud Shell (en la parte superior derecha), selecciona Cambiar puerto.
![]()
👉 Establece el puerto en 8000 y haz clic en "Cambiar y obtener vista previa".
👉 Se abrirá la IU web del ADK. Selecciona agente en el menú desplegable.
Ejecuta el análisis
👉 En la interfaz de chat, escribe lo siguiente:
Analyze the evidence from my crash site and confirm my location to activate the beacon.
Mira el sistema multiagente en acción:
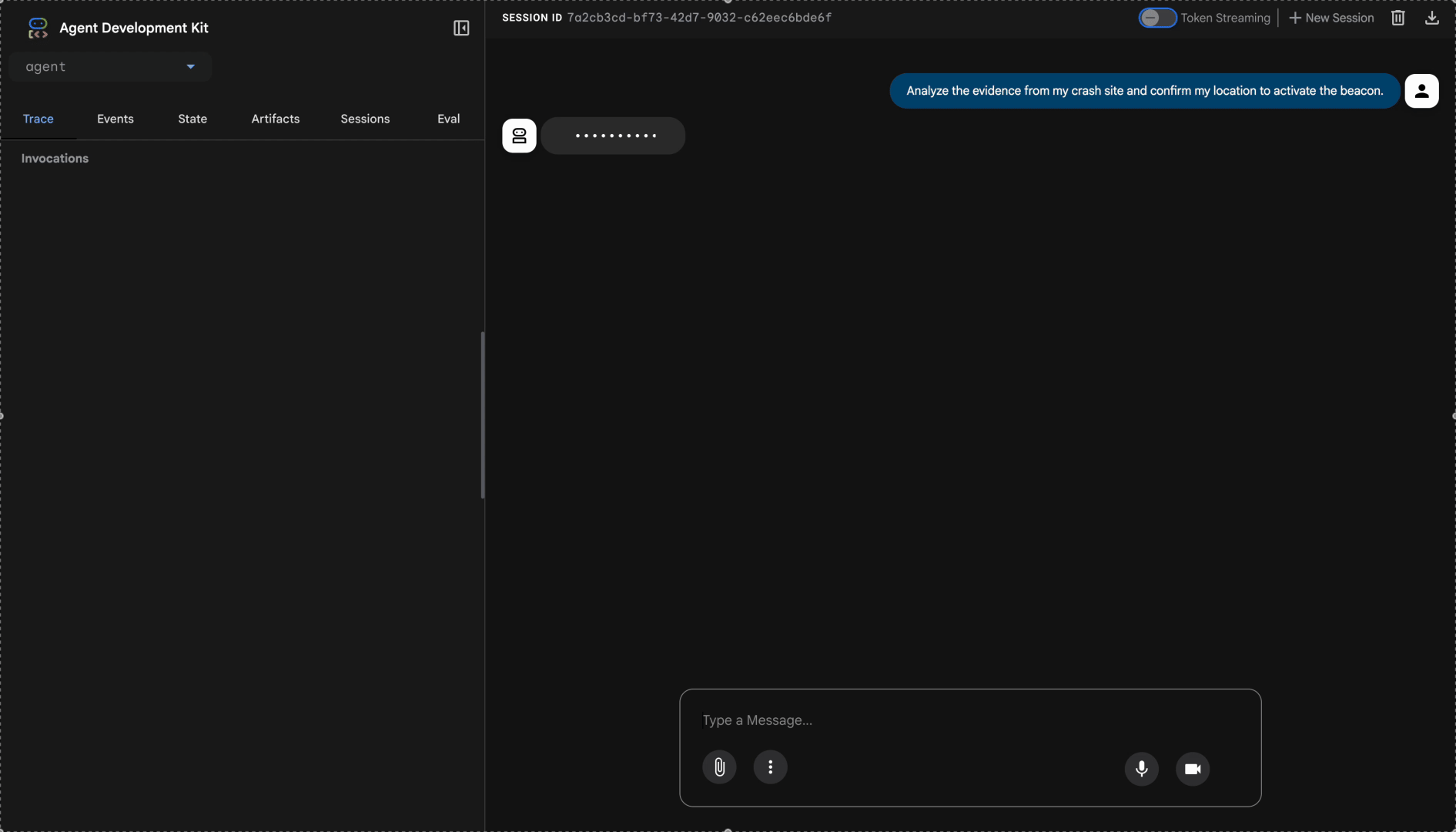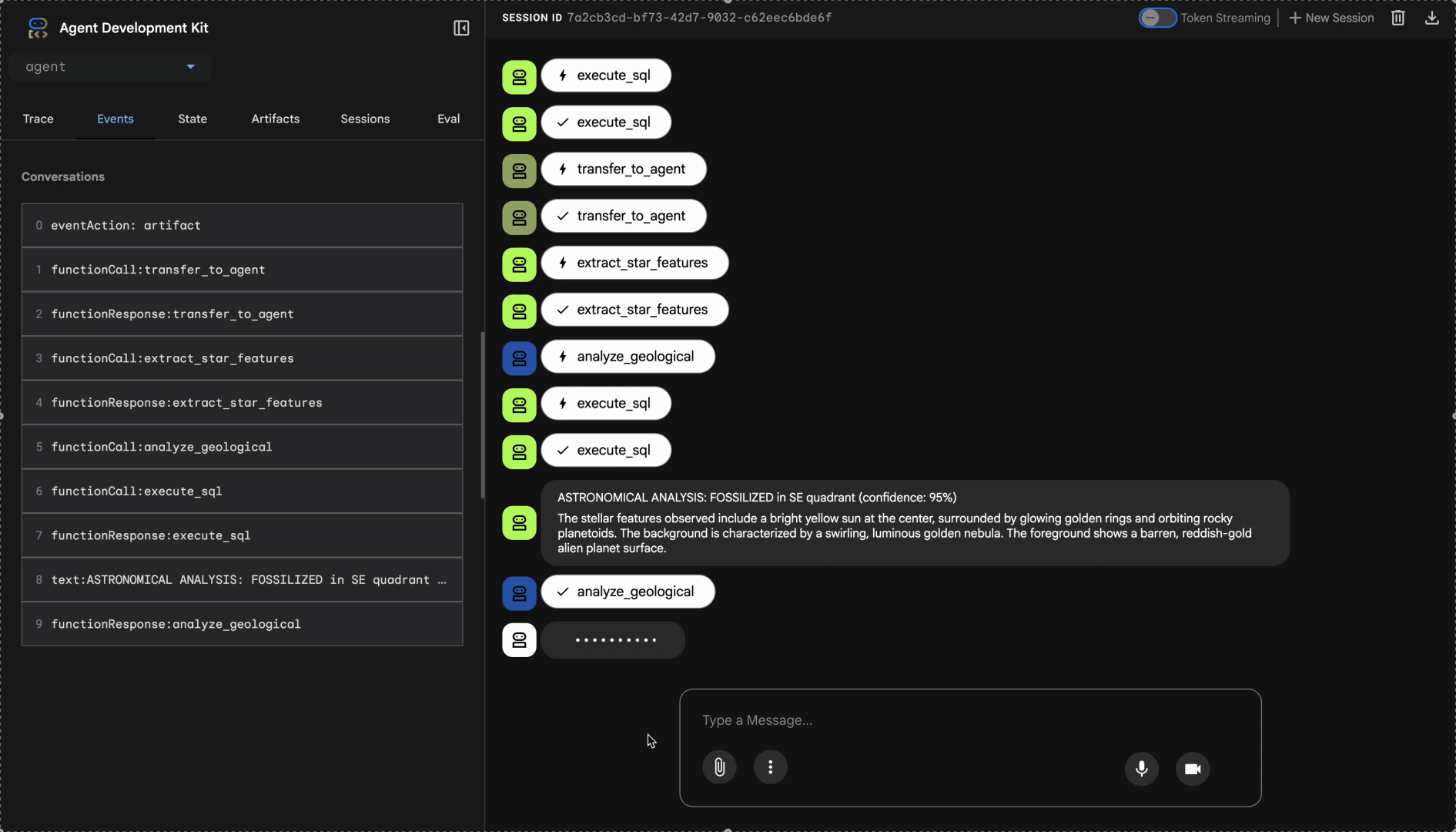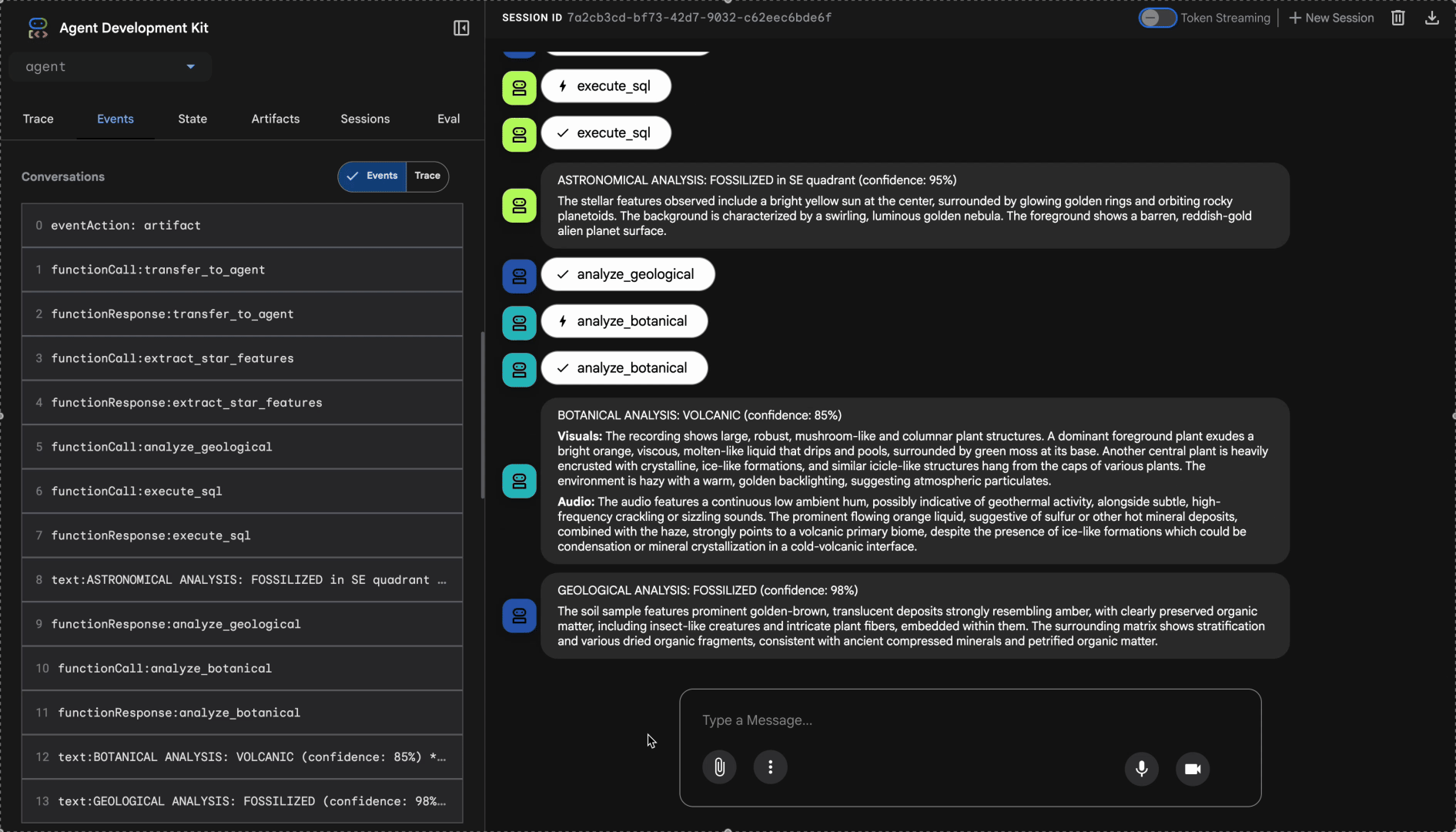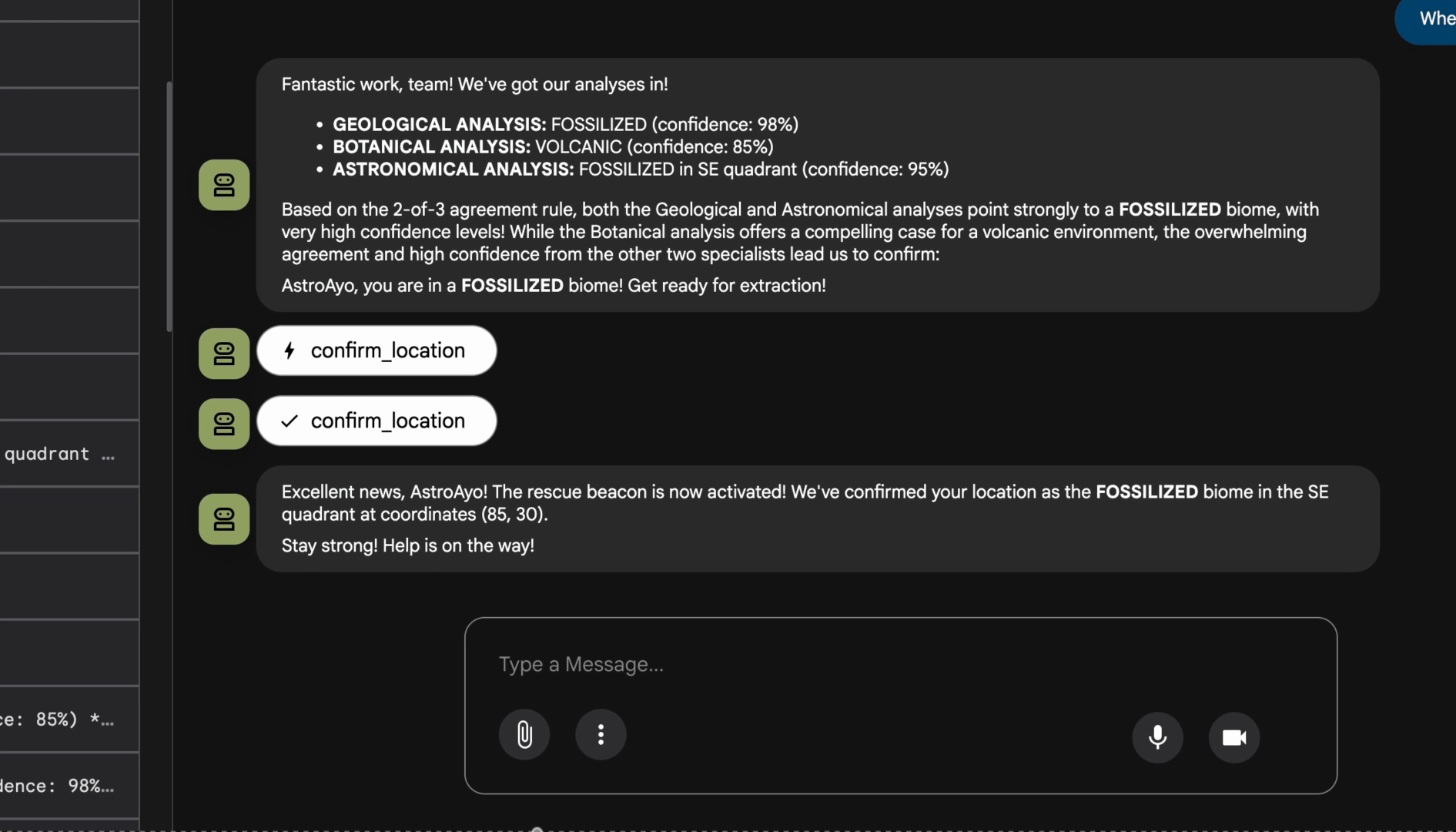
👉 Cuando los tres agentes completen sus análisis, escribe lo siguiente:
Where am I?
Cómo procesa el sistema tu solicitud:

El panel de seguimiento de la derecha muestra todas las interacciones del agente y las llamadas a herramientas.
👉 Presiona Ctrl+C en la terminal para detener el servidor cuando termines de probar.
9. Implementa en Cloud Run
Ahora implementa tu sistema multiagente en Cloud Run para que esté listo para A2A.
Implementa el agente
👉💻 Implementa en Cloud Run con la CLI del ADK:
cd $HOME/way-back-home/level_1
source $HOME/way-back-home/set_env.sh
uv run adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$REGION \
--service_name=mission-analysis-ai \
--with_ui \
--a2a \
./agent
Cuando se te solicite Do you want to continue (Y/n) y Allow unauthenticated invocations to [mission-analysis-ai] (Y/n)?, ingresa Y para implementar tu agente de A2A y permitir el acceso público a él.
Deberías ver un resultado como el siguiente:
Building and deploying agent to Cloud Run...
✓ Container built successfully
✓ Deploying to Cloud Run...
✓ Service deployed: https://mission-analysis-ai-abc123-uc.a.run.app
Cómo configurar variables de entorno en Cloud Run
El agente implementado necesita acceso a las variables de entorno. Actualiza el servicio:
👉💻 Establece las variables de entorno necesarias:
gcloud run services update mission-analysis-ai \
--region=$REGION \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$REGION,MCP_SERVER_URL=$MCP_SERVER_URL,BACKEND_URL=$BACKEND_URL,PARTICIPANT_ID=$PARTICIPANT_ID,GOOGLE_GENAI_USE_VERTEXAI=True"
Cómo guardar la URL del agente
👉💻 Obtén la URL implementada:
export AGENT_URL=$(gcloud run services describe mission-analysis-ai \
--region=$REGION --format='value(status.url)')
echo "Agent URL: $AGENT_URL"
# Add to set_env.sh
echo "export LEVEL1_AGENT_URL=\"$AGENT_URL\"" >> $HOME/way-back-home/set_env.sh
Verifique el recurso Deployment
👉💻 Para probar el agente implementado, abre la URL en tu navegador (la marca --with_ui implementó la interfaz web del ADK) o prueba con curl:
curl -X GET "$AGENT_URL/list-apps"
Deberías ver una respuesta que enumere tu agente.
10. Conclusión
🎉 ¡Completaste el nivel 1!
La baliza de rescate ahora transmite con toda su potencia. La señal triangulada atraviesa la interferencia atmosférica, un pulso constante que dice "Estoy aquí. Sobreviví. Ven a buscarme".
Pero no eres la única persona en este planeta. A medida que se activa tu baliza, ves otras luces parpadeando a lo lejos: otros sobrevivientes, otros sitios de accidentes, otros exploradores que lograron salir con vida.
![]()
En el nivel 2, aprenderás a procesar las señales de SOS entrantes y a coordinarte con otros sobrevivientes. El rescate no se trata solo de que te encuentren, sino de encontrarse.
Solución de problemas
"No se configuró MCP_SERVER_URL"
export MCP_SERVER_URL=$(gcloud run services describe location-analyzer \
--region=$REGION --format='value(status.url)')
"No se configuró PARTICIPANT_ID"
source $HOME/way-back-home/set_env.sh
echo $PARTICIPANT_ID
"No se encontró la tabla de BigQuery"
uv run python setup/setup_star_catalog.py
"Los especialistas solicitan URLs": Esto significa que la creación de plantillas de {key} no funciona. Comprobar:
- ¿Está configurado
before_agent_callbacken el agente raíz? - ¿La devolución de llamada establece los valores de estado correctamente?
- ¿Los subagentes usan
{soil_url}(no cadenas f)?
"Los tres análisis no coinciden" Regenerar evidencia: uv run python generate_evidence.py
"El agente no responde en la Web del ADK"
- Verifica que el puerto 8000 sea el correcto
- Verifica que estén configurados MCP_SERVER_URL y PARTICIPANT_ID
- Comprueba si hay mensajes de error en la terminal
Resumen de la arquitectura
Componente | Tipo | Patrón | Objetivo |
setup_participant_context | Devolución de llamada | before_agent_callback | Recupera la configuración y establece el estado |
GeologicalAnalyst | Agente | Plantillas de {soil_url} | Clasificación del suelo |
BotanicalAnalyst | Agente | Plantillas de {flora_url} | Clasificación de flora |
AstronomicalAnalyst | Agente | {stars_url}, {project_id} | Triangulación de estrellas |
confirm_location | Herramienta | Acceso al estado de ToolContext | Activa la baliza |
EvidenceAnalysisCrew | ParallelAgent | Composición del agente secundario | Ejecuta especialistas de forma simultánea |
MissionAnalysisAI | Agente (raíz) | Organizador y devolución de llamada | Coordinar y sintetizar |
location-analyzer | Servidor de FastMCP | MCP personalizada | Análisis geológico y botánico |
bigquery.googleapis.com/mcp | OneMCP | MCP administrado | Acceso a BigQuery |
Conceptos clave dominados
✓ before_agent_callback: Recupera la configuración antes de que se ejecute el agente
✓ Plantillas de estado {key}: Accede a los valores de estado en las instrucciones del agente
✓ ToolContext: Accede a los valores de estado en las funciones de herramientas
✓ State Sharing: El estado principal está disponible automáticamente para los subagentes a través de InvocationContext
✓ Multi-Agent Architecture: Agentes especializados con responsabilidades únicas
✓ ParallelAgent: Ejecución simultánea de tareas independientes
✓ Custom MCP Server: Tu propio servidor de MCP en Cloud Run
✓ OneMCP BigQuery: Patrón de MCP administrado para el acceso a la base de datos
✓ Cloud Deployment: Implementación sin estado con variables de entorno
✓ A2A Preparation: Agente listo para la comunicación entre agentes
Para los no jugadores: Aplicaciones en el mundo real
"Cómo determinar tu ubicación con precisión" representa el Análisis paralelo experto con consenso, que ejecuta varios análisis especializados de IA de forma simultánea y sintetiza los resultados.
Aplicaciones empresariales
Caso de uso | Expertos paralelos | Regla de síntesis |
Diagnóstico médico | Analista de imágenes, analista de síntomas y analista de laboratorio | Umbral de confianza de 2 de 3 |
Detección de fraudes | Analista de transacciones, analista de comportamiento y analista de redes | Cualquier combinación de 1 marca = revisión |
Procesamiento de documentos | Agente de OCR, agente de clasificación y agente de extracción | Todos deben estar de acuerdo |
Control de calidad | Inspector visual, analista de sensores y verificador de especificaciones | Pase de 2 de 3 |
Estadísticas arquitectónicas clave
- before_agent_callback para la configuración: Recupera la configuración una vez al inicio y completa el estado de todos los subagentes. No se lee ningún archivo de configuración en los subagentes.
- Plantillas de estado {key}: Declarativas, limpias y idiomáticas. No hay cadenas f, ni importaciones, ni manipulación de sys.path.
- Mecanismos de consenso: El acuerdo de 2 de 3 controla la ambigüedad de forma sólida sin requerir un acuerdo unánime.
- ParallelAgent para tareas independientes: Cuando los análisis no dependen entre sí, ejecútalos de forma simultánea para acelerar el proceso.
- Dos patrones de MCP: Personalizado (crea tu propio patrón) y OneMCP (alojado en Google). Ambos usan StreamableHTTP.
- Implementación sin estado: El mismo código funciona de forma local y cuando se implementa. Las variables de entorno y la API de backend equivalen a que no haya archivos de configuración en los contenedores.
¿Qué sigue?
Nivel 2: Procesamiento de señales de SOS →
Aprende a procesar las señales de auxilio entrantes de otros sobrevivientes con patrones basados en eventos y una coordinación de agentes más avanzada.