1. Die Mission

Sie treiben in der Stille eines unbekannten Sektors. Ein gewaltiger **Solarpuls** hat dein Schiff durch einen Riss gerissen und dich in einer Tasche des Universums zurückgelassen, die auf keiner Sternenkarte existiert.
Nach Tagen anstrengender Reparaturen spürst du endlich das Summen der Motoren unter deinen Füßen. Dein Raumschiff wurde repariert. Du hast es sogar geschafft, eine Langstreckenverbindung zum Mutterschiff herzustellen. Sie können starten. Du bist bereit, nach Hause zu gehen. Als du dich darauf vorbereitest, den Sprungantrieb zu aktivieren, durchbricht ein Notsignal das Rauschen. Ihre Sensoren erfassen fünf schwache Wärmesignaturen, die in The Ravine gefangen sind – einem zerklüfteten, durch die Schwerkraft verzerrten Sektor, den Ihr Hauptschiff niemals betreten kann. Das sind andere Entdecker, die denselben Sturm überlebt haben, der dich fast das Leben gekostet hätte. Sie können sie nicht zurücklassen.
Sie wenden sich an Ihren Alpha-Drone Rescue Scout. Dieses kleine, wendige Schiff ist das einzige, das die engen Wände der Schlucht passieren kann. Es gibt jedoch ein Problem: Der Sonnenpuls hat einen vollständigen „System Reset“ der Kernlogik durchgeführt. Die Steuerungssysteme des Scout reagieren nicht. Es ist eingeschaltet, aber der integrierte Computer ist leer und kann keine manuellen Pilotbefehle oder Flugrouten verarbeiten.
Die Herausforderung
Um die Überlebenden zu retten, musst du die beschädigten Schaltkreise des Scout vollständig umgehen. Sie haben eine verzweifelte Option: Erstellen Sie einen KI-Agenten, um eine biometrische neurale Synchronisierung herzustellen. Dieser Agent fungiert als Echtzeit-Brücke, über die Sie den Rescue Scout manuell über Ihre eigenen biologischen Eingaben steuern können. Sie verwenden keinen Joystick oder keine Tastatur, sondern verdrahten Ihre Absicht direkt mit dem Navigationsnetzwerk des Schiffs.
Um den Link zu fixieren, müssen Sie das Synchronisierungsprotokoll vor den optischen Sensoren des Scout durchführen. Der KI-Agent muss Ihre biometrische Signatur durch einen präzisen Handshake in Echtzeit erkennen.
Missionsziele:
- Neural Core einprägen:Definieren Sie einen ADK-Agenten, der multimodale Eingaben erkennen kann.
- Verbindung herstellen:Erstellen Sie eine bidirektionale WebSocket-Pipeline, um visuelle Daten vom Scout an die KI zu streamen.
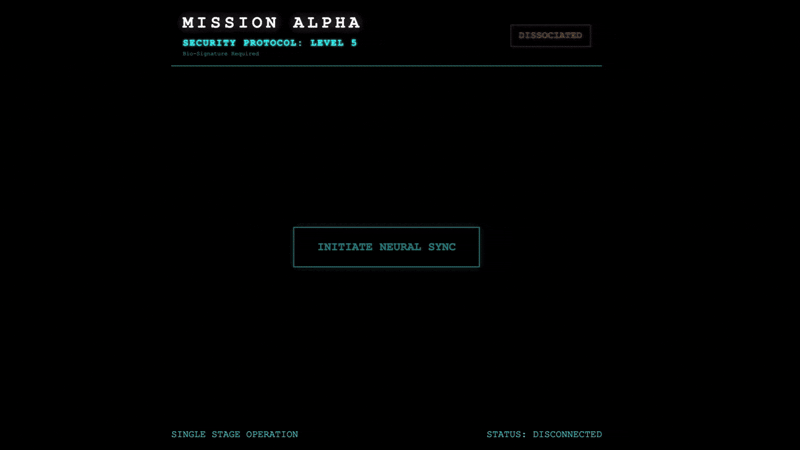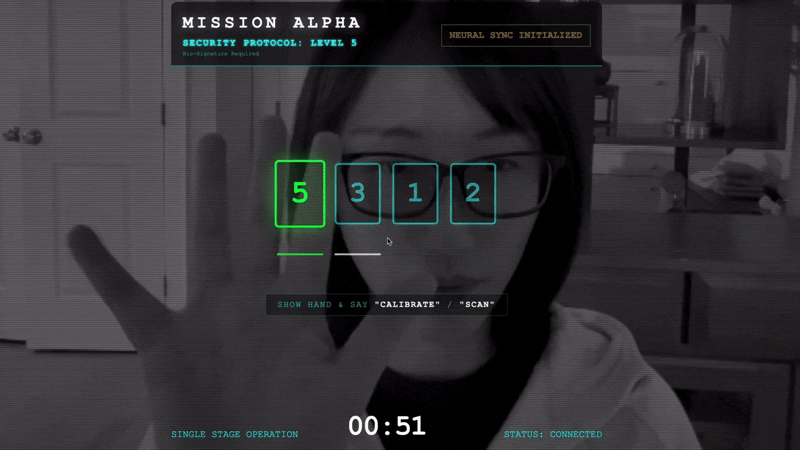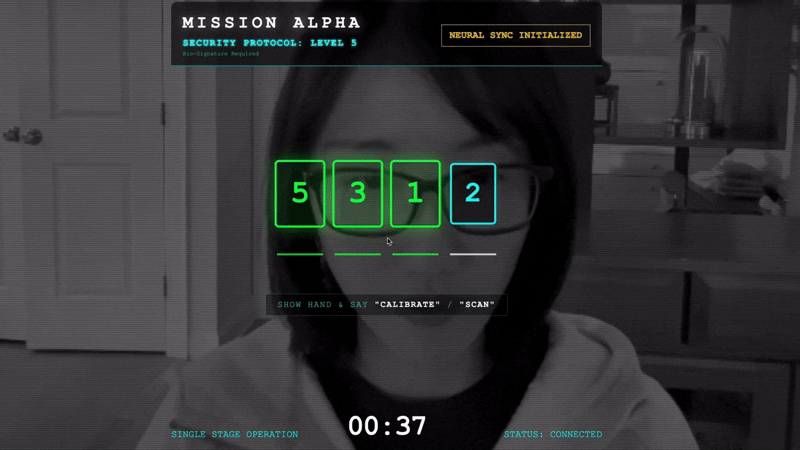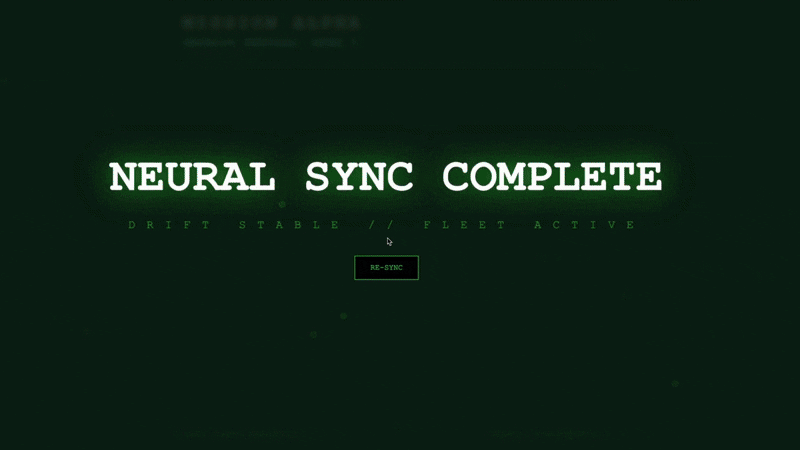
- Handshake initiieren:Stellen Sie sich vor den Sensor und führen Sie die Fingerfolge aus – zeigen Sie die Zahlen 1 bis 5 in der richtigen Reihenfolge.
Bei Erfolg wird die biometrische Synchronisierung aktiviert. Die KI verriegelt die neuronale Verbindung, sodass du die volle manuelle Kontrolle hast, um den Scout zu starten und die Überlebenden nach Hause zu bringen.
Umfang
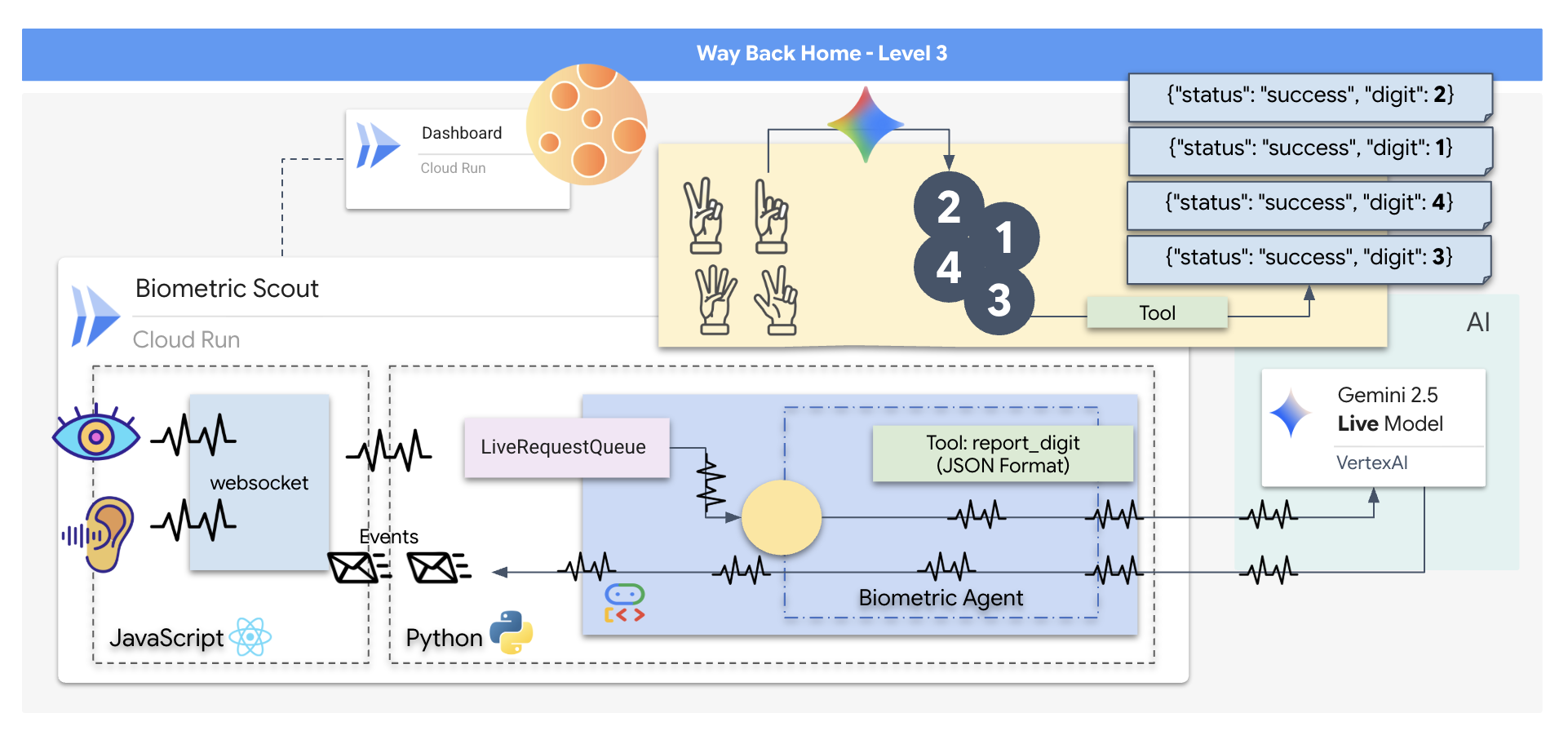
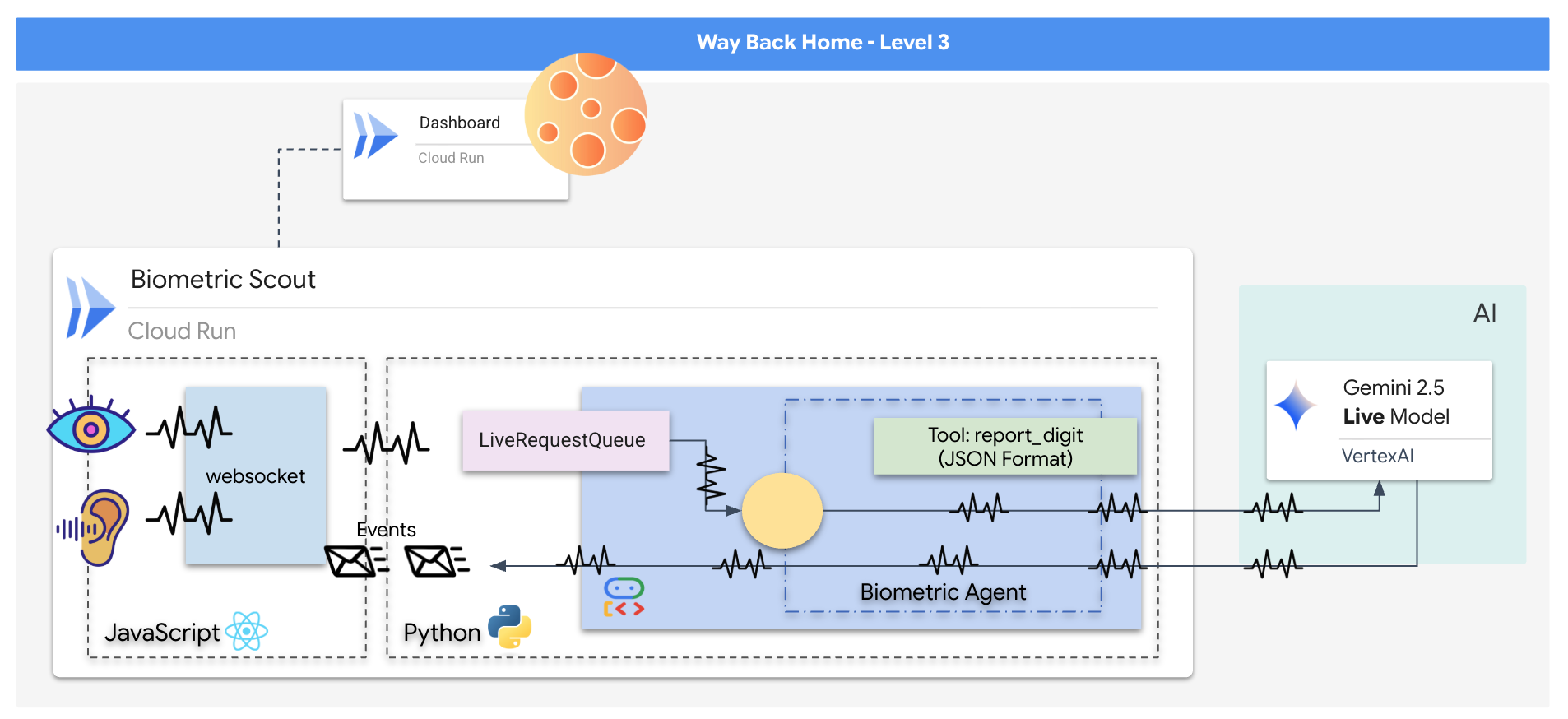
Sie entwickeln eine Anwendung namens „Biometric Neural Sync“, ein KI-basiertes Echtzeitsystem, das als Steuerungsschnittstelle für eine Rettungsdrohne dient. Dieses System besteht aus:
- React-Frontend:Das „Cockpit“ Ihres Schiffs, das Live-Video von Ihrer Webcam und Audio von Ihrem Mikrofon aufnimmt.
- Python-Backend:Ein leistungsstarker Server, der mit FastAPI erstellt wurde und das Agent Development Kit (ADK) von Google verwendet, um die Logik und den Status des LLM zu verwalten.
- Multimodaler KI-Agent:Das „Gehirn“ der Anwendung, das die Gemini Live API über das
google-genaiSDK verwendet, um Video- und Audiostreams gleichzeitig zu verarbeiten und zu analysieren. - Bidirektionale WebSocket-Pipeline:Das „Nervensystem“, das eine persistente Verbindung mit niedriger Latenz zwischen dem Frontend und der KI herstellt und so eine Echtzeitinteraktion ermöglicht.
Lerninhalte
Technologie / Konzept | Beschreibung |
Backend-KI-Agent | Erstellen Sie einen zustandsbehafteten KI-Agenten mit Python und FastAPI. Verwenden Sie das ADK (Agent Development Kit) von Google, um Anweisungen und den Speicher zu verwalten, und das |
Frontend-Benutzeroberfläche | Entwickeln Sie eine dynamische Benutzeroberfläche mit React, um Live-Video und ‑Audio direkt aus dem Browser aufzunehmen und zu streamen. |
Echtzeitkommunikation | Implementieren Sie eine WebSocket-Pipeline für die Vollduplex-Kommunikation mit niedriger Latenz, damit Nutzer und KI gleichzeitig interagieren können. |
Multimodale KI | Mit der Gemini Live API können Sie gleichzeitige Video- und Audiostreams verarbeiten und analysieren. So kann die KI gleichzeitig „sehen“ und „hören“. |
Tool-Aufrufe | Die KI kann bestimmte Python-Funktionen als Reaktion auf visuelle Trigger ausführen und so die Lücke zwischen der Intelligenz des Modells und der realen Welt schließen. |
Full-Stack-Bereitstellung | Containerisieren Sie die gesamte Anwendung (React-Frontend und Python-Backend) mit Docker und stellen Sie sie als skalierbaren, serverlosen Dienst in Google Cloud Run bereit. |
2. Umgebung einrichten
Auf Cloud Shell zugreifen
Zuerst öffnen wir Cloud Shell. Das ist ein browserbasiertes Terminal, in dem das Google Cloud SDK und andere wichtige Tools vorinstalliert sind.
👉 Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“ (das Terminalsymbol oben im Cloud Shell-Bereich), 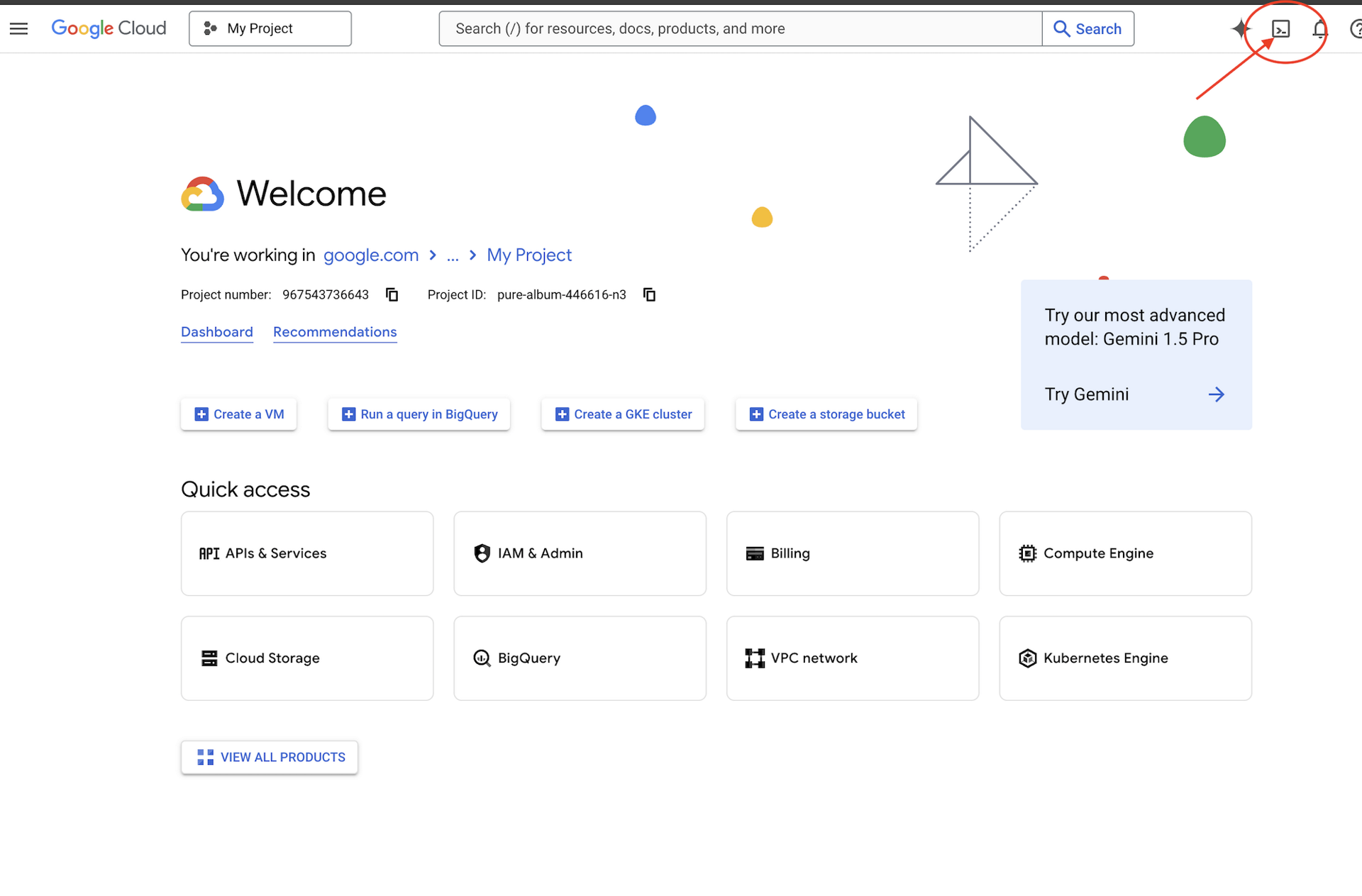 .
.
👉 Klicken Sie auf die Schaltfläche „Editor öffnen“ (sie sieht aus wie ein geöffneter Ordner mit einem Stift). Dadurch wird der Cloud Shell-Code-Editor im Fenster geöffnet. Auf der linken Seite wird ein Datei-Explorer angezeigt. 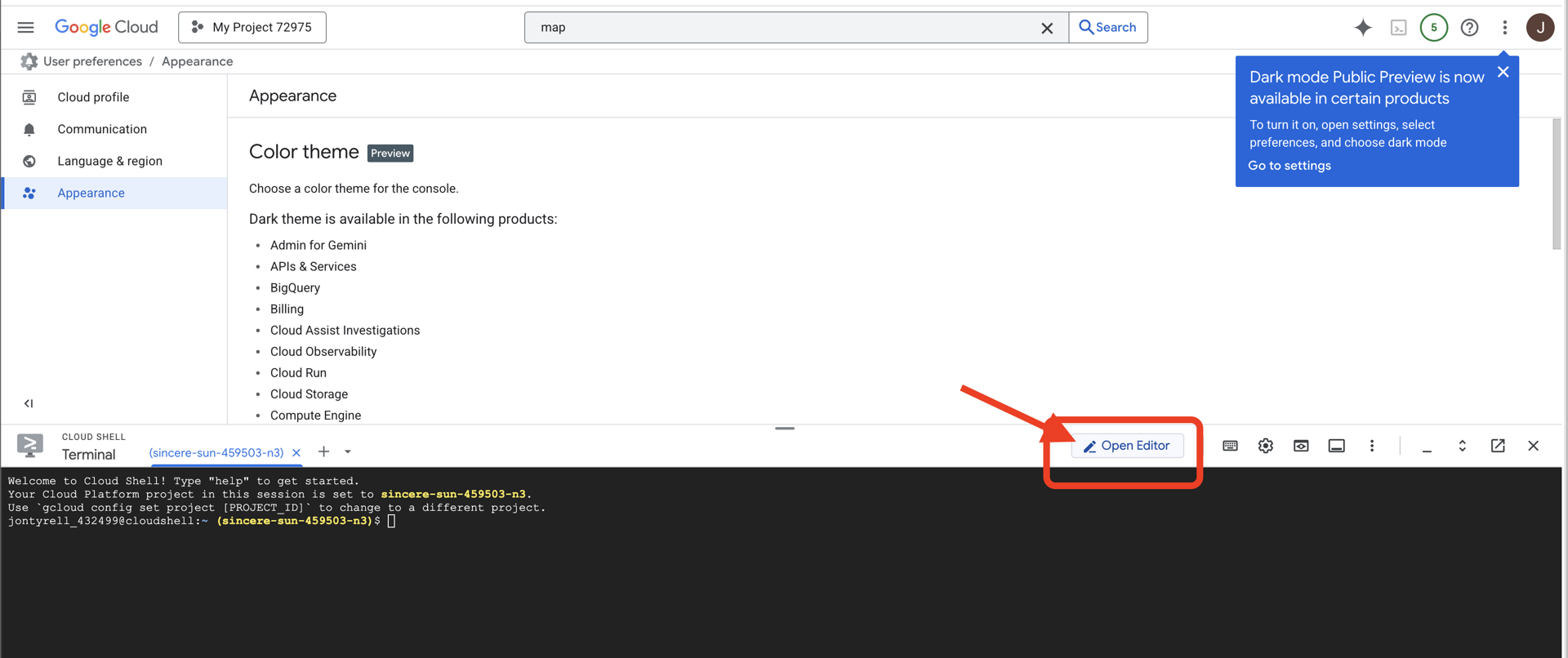
👉 Öffnen Sie das Terminal in der Cloud-IDE.
👉💻 Prüfen Sie im Terminal mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und das Projekt auf Ihre Projekt-ID festgelegt ist:
gcloud auth list
Ihr Konto sollte als (ACTIVE) aufgeführt sein.
Vorbereitung
ℹ️ Stufe 0 ist optional (aber empfohlen)
Sie können diese Mission auch ohne Level 0 abschließen. Wenn Sie sie jedoch zuerst abschließen, wird die Mission noch spannender, da Sie sehen können, wie Ihr Leuchtfeuer auf der globalen Karte aufleuchtet, während Sie Fortschritte machen.
Projekumgebung einrichten
Kehren Sie zu Ihrem Terminal zurück und schließen Sie die Konfiguration ab, indem Sie das aktive Projekt festlegen und die erforderlichen Google Cloud-Dienste (Cloud Run, Vertex AI usw.) aktivieren.
👉💻 Legen Sie in Ihrem Terminal die Projekt-ID fest:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Erforderliche Dienste aktivieren:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
Abhängigkeiten installieren
👉💻 Rufen Sie die Ebene auf und installieren Sie die erforderlichen Python-Pakete:
cd $HOME/way-back-home/level_3
uv sync
Die wichtigsten Abhängigkeiten sind:
Paket | Zweck |
| Leistungsstarkes Web-Framework für die Satellite Station und SSE-Streaming |
| ASGI-Server zum Ausführen der FastAPI-Anwendung erforderlich |
| Das Agent Development Kit, mit dem der Formation Agent erstellt wurde |
| Nativer Client für den Zugriff auf Gemini-Modelle |
| Unterstützung für bidirektionale Kommunikation in Echtzeit |
| Verwaltet Umgebungsvariablen und Konfigurations-Secrets |
Einrichtung überprüfen
Bevor wir uns den Code ansehen, sollten wir prüfen, ob alle Systeme grün sind. Führen Sie das Verifizierungsskript aus, um Ihr Google Cloud-Projekt, Ihre APIs und Ihre Python-Abhängigkeiten zu prüfen.
👉💻 Überprüfungsskript ausführen:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Du solltest eine Reihe von grünen Häkchen (✅) sehen.
- Wenn Rote Kreuze (❌) angezeigt werden, folgen Sie den vorgeschlagenen Korrekturbefehlen in der Ausgabe (z.B.
gcloud services enable ...oderpip install ...). - Hinweis:Eine gelbe Warnung für
.envist vorerst akzeptabel. Wir erstellen diese Datei im nächsten Schritt.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
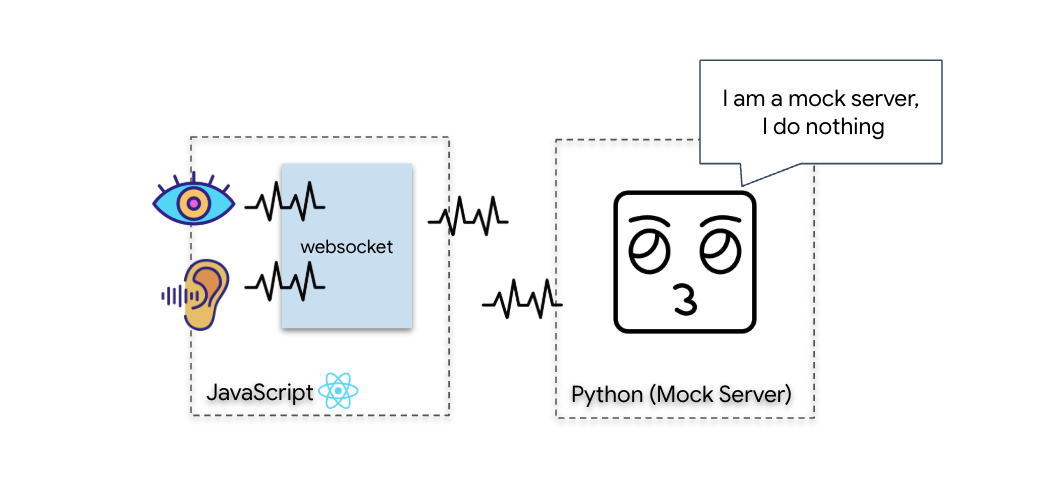
3. Comm-Link kalibrieren (WebSockets)
Bevor wir mit der biometrischen neuronalen Synchronisierung beginnen können, müssen wir die internen Systeme deines Schiffs aktualisieren. Unser Hauptziel ist es, einen hochwertigen Video- und Audiostream aus Ihrem Cockpit aufzunehmen. Dieser Stream liefert die wesentlichen Komponenten für die neuronale Verbindung: die visuelle Identifizierung Ihrer Fingerfolgen und die Schallfrequenz Ihrer Stimme.
Vollduplex und Halbduplex im Vergleich
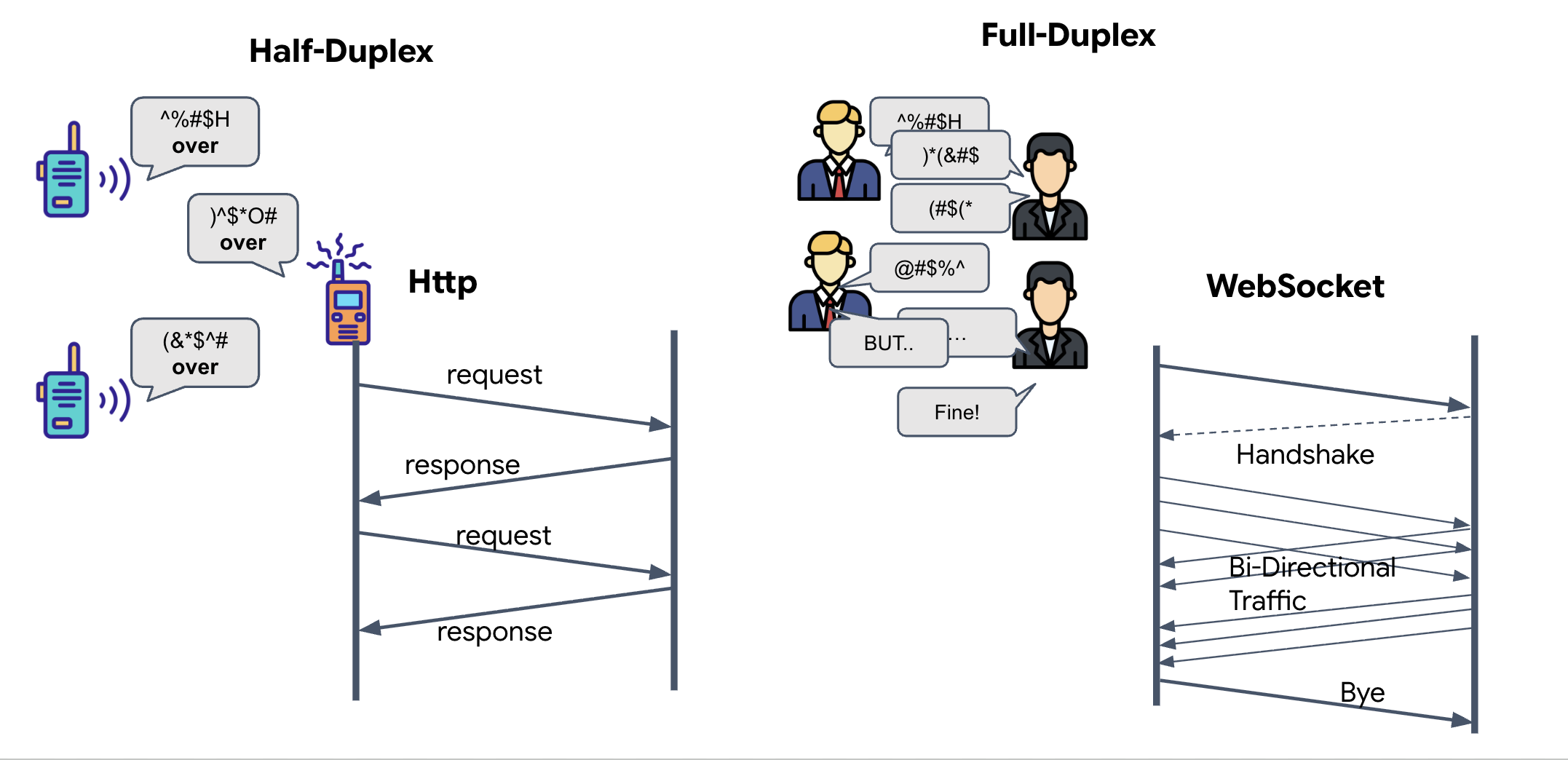
Um zu verstehen, warum wir das für Neural Sync benötigen, müssen Sie den Datenfluss nachvollziehen:
- Halbduplex (Standard-HTTP): Wie ein Walkie-Talkie. Eine Person spricht, sagt „Over“ und dann kann die andere Person sprechen. Sie können nicht gleichzeitig zuhören und sprechen.
- Vollduplex (WebSocket): Ähnlich wie bei einem persönlichen Gespräch. Daten fließen gleichzeitig in beide Richtungen. Während Ihr Browser Videoframes und Audiobeispiele an die KI sendet, kann die KI gleichzeitig Sprachantworten und Tool-Befehle an Sie senden.
Warum Gemini Live Vollduplex benötigt:Die Gemini Live API ist für Unterbrechungen konzipiert. Stellen Sie sich vor, Sie zeigen die Fingerfolge und die KI erkennt, dass Sie es falsch machen. Bei einer Standard-HTTP-Einrichtung müsste die KI warten, bis Sie mit dem Senden Ihrer Daten fertig sind, bevor sie Sie auffordern könnte, den Vorgang zu beenden. Bei WebSockets kann die KI einen Fehler in Frame 1 erkennen und ein „Unterbrechungssignal“ senden, das in Ihrem Cockpit ankommt, während Sie Ihre Hand noch für Frame 2 bewegen.
Was ist ein WebSocket?
Bei einer standardmäßigen galaktischen Übertragung (HTTP) senden Sie eine Anfrage und warten auf eine Antwort – wie beim Senden einer Postkarte. Für Neural Sync sind Postkarten zu langsam. Wir brauchen einen „stromführenden Draht“.
WebSockets beginnen als Standard-Webanfrage (HTTP), werden dann aber auf etwas anderes „aktualisiert“.
- Die Anfrage:Ihr Browser sendet eine Standard-HTTP-Anfrage mit einem speziellen Header an den Server:
Upgrade: websocket. Das bedeutet im Grunde: „Ich möchte keine Postkarten mehr senden und stattdessen einen Live-Anruf starten.“ - Die Antwort:Wenn der KI-Agent (der Server) dies unterstützt, sendet er eine
HTTP 101 Switching Protocols-Antwort zurück. - Die Transformation:In diesem Moment wird die HTTP-Verbindung durch das WebSocket-Protokoll ersetzt, aber der zugrunde liegende TCP/IP-Socket bleibt geöffnet. Die Kommunikationsregeln ändern sich sofort von „Anfrage/Antwort“ zu „Vollduplex-Streaming“.
WebSocket-Hook implementieren
Sehen wir uns den Anschlussblock an, um zu verstehen, wie die Daten fließen.
👀 Öffne $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. Die Standard-Event-Handler für den WebSocket-Lebenszyklus sind bereits eingerichtet. So sieht das Grundgerüst unseres Kommunikationssystems aus:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
Der onMessage-Handler
Konzentrieren Sie sich auf den Block ws.current.onmessage. Das ist der Empfänger. Jedes Mal, wenn der Agent „denkt“ oder „spricht“, kommt hier ein Datenpaket an. Derzeit passiert nichts – das Paket wird abgefangen und verworfen (über den Platzhalter //#REPLACE-HANDLE-MSG).
Wir müssen diese Lücke mit einer Logik füllen, die zwischen folgenden Fällen unterscheiden kann:
- Tool-Aufrufe (functionCall): Die KI erkennt Ihre Handsignale (die „Synchronisierung“).
- Audiodaten (inlineData): Die Stimme der KI, die auf Sie reagiert.
👉✏️ Ersetzen Sie in derselben $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js-Datei //#REPLACE-HANDLE-MSG durch die folgende Logik, um den eingehenden Stream zu verarbeiten:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
So werden Audio und Video in Daten für die Übertragung umgewandelt
Damit die Echtzeitkommunikation über das Internet möglich ist, müssen Audio- und Video-Rohdaten in ein für die Übertragung geeignetes Format umgewandelt werden. Dazu gehören das Erfassen, Codieren und Verpacken der Daten, bevor sie über ein Netzwerk gesendet werden.
Transformation von Audiodaten
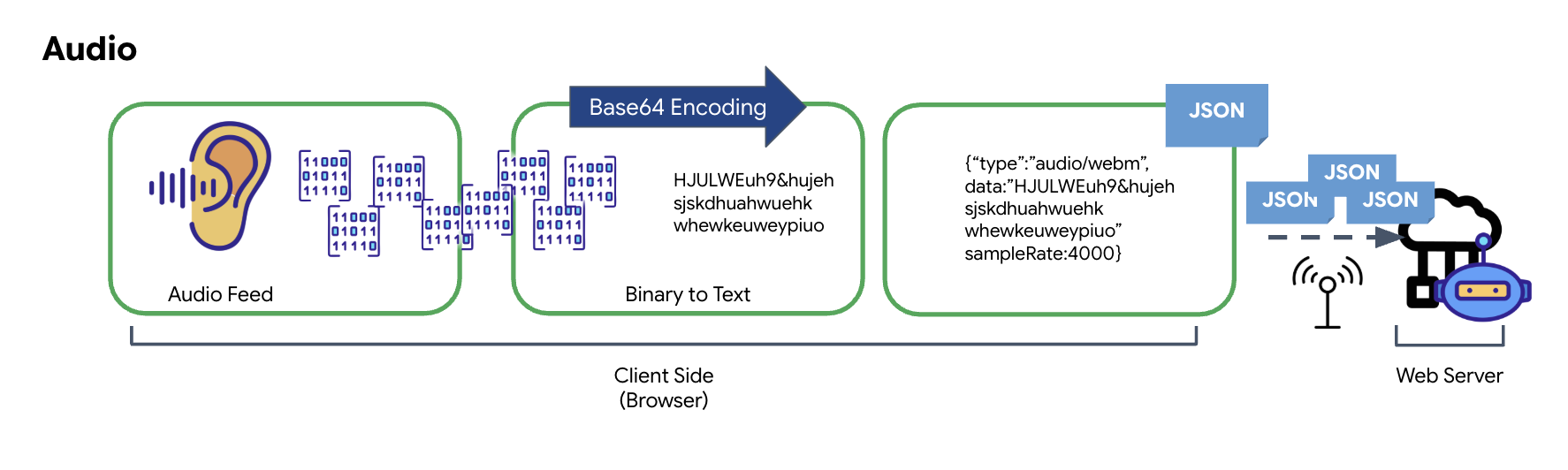
Die Umwandlung von analogem Audio in übertragbare digitale Daten beginnt mit der Erfassung der Schallwellen durch ein Mikrofon. Dieses Rohaudio wird dann über die Web Audio API des Browsers verarbeitet. Da diese Rohdaten in einem Binärformat vorliegen, sind sie nicht direkt mit textbasierten Übertragungsformaten wie JSON kompatibel. Um dieses Problem zu beheben, wird jedes Audiosegment in einen Base64-String codiert. Base64 ist eine Methode, mit der Binärdaten in einem ASCII-Stringformat dargestellt werden, um ihre Integrität während der Übertragung zu gewährleisten.
Dieser codierte String wird dann in ein JSON-Objekt eingebettet. Dieses Objekt bietet ein strukturiertes Format für die Daten, das in der Regel ein Feld „type“ enthält, um es als Audio zu identifizieren, sowie Metadaten wie die Samplerate des Audios. Das gesamte JSON-Objekt wird dann in einen String serialisiert und über eine WebSocket-Verbindung gesendet. So wird dafür gesorgt, dass das Audio auf organisierte und leicht parsierbare Weise übertragen wird.
Videodatentransformation
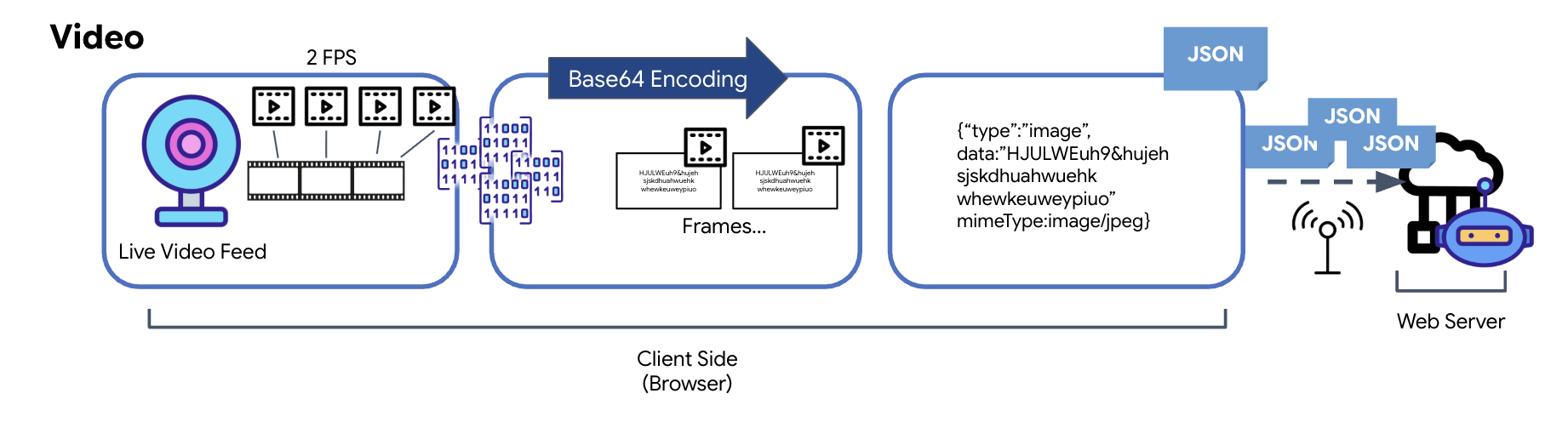
Die Videoübertragung erfolgt durch eine Frame-Capture-Technik. Anstatt einen kontinuierlichen Videostream zu senden, werden in einer wiederkehrenden Schleife in einem festgelegten Intervall, z. B. zwei Frames pro Sekunde, Standbilder aus dem Live-Videofeed erfasst. Dazu wird der aktuelle Frame aus einem HTML-Videoelement auf ein verborgenes Canvas-Element gezeichnet.
Die Methode toDataURL des Canvas wird dann verwendet, um dieses aufgenommene Bild in einen Base64-codierten JPEG-String umzuwandeln. Bei dieser Methode kann die Bildqualität angegeben werden, sodass ein Kompromiss zwischen Bildtreue und Dateigröße möglich ist, um die Leistung zu optimieren. Ähnlich wie bei den Audiodaten wird dieser Base64-String dann in ein JSON-Objekt eingefügt. Dieses Objekt ist in der Regel mit dem Typ „image“ gekennzeichnet und enthält den mimeType, z. B. „image/jpeg“. Dieses JSON-Paket wird dann in einen String umgewandelt und über das WebSocket gesendet, sodass das empfangende Ende das Video durch Anzeigen der Bildfolge rekonstruieren kann.
👉✏️ Ersetzen Sie in derselben Datei $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js //#CAPTURE AUDIO and VIDEO durch Folgendes, um Nutzereingaben zu erfassen:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
Nach dem Speichern kann das Cockpit die digitalen Signale des Kundenservicemitarbeiters in visuelle Dashboard-Updates und Audio umwandeln.
Diagnoseprüfung (Loopback-Test)
Ihr Cockpit ist jetzt live. Alle 500 Millisekunden wird ein visuelles „Paket“ Ihrer Umgebung gesendet. Bevor wir uns mit der Gemini verbinden können, müssen wir überprüfen, ob der Sender Ihres Schiffs funktioniert. Wir führen einen „Loopback-Test“ mit einem lokalen Diagnoseserver durch.
👉💻 Erstellen Sie zuerst die Cockpit-Schnittstelle über das Terminal:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 Starten Sie als Nächstes den Mock-Server:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 Testprotokoll ausführen:
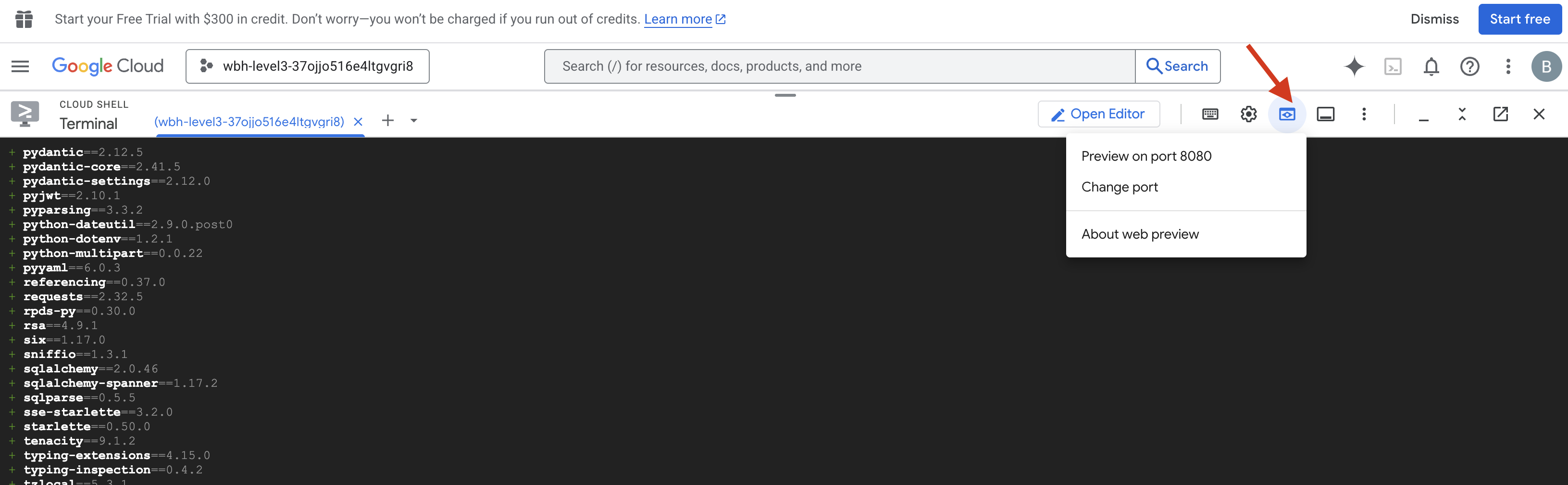
- Vorschau öffnen:Klicken Sie in der Cloud Shell-Symbolleiste auf das Symbol für die Webvorschau. Wählen Sie Port ändern aus, legen Sie 8080 fest und klicken Sie auf Ändern und Vorschau. Ein neuer Browsertab mit der Cockpit-Oberfläche wird geöffnet.
- WICHTIG:Wenn Sie dazu aufgefordert werden, MÜSSEN Sie dem Browser Zugriff auf Ihre Kamera und Ihr Mikrofon gewähren. Ohne diese Eingaben kann die neurale Synchronisierung nicht gestartet werden.
- Klicken Sie in der Benutzeroberfläche auf die Schaltfläche NEURALE SYNCHRONISIERUNG STARTEN.
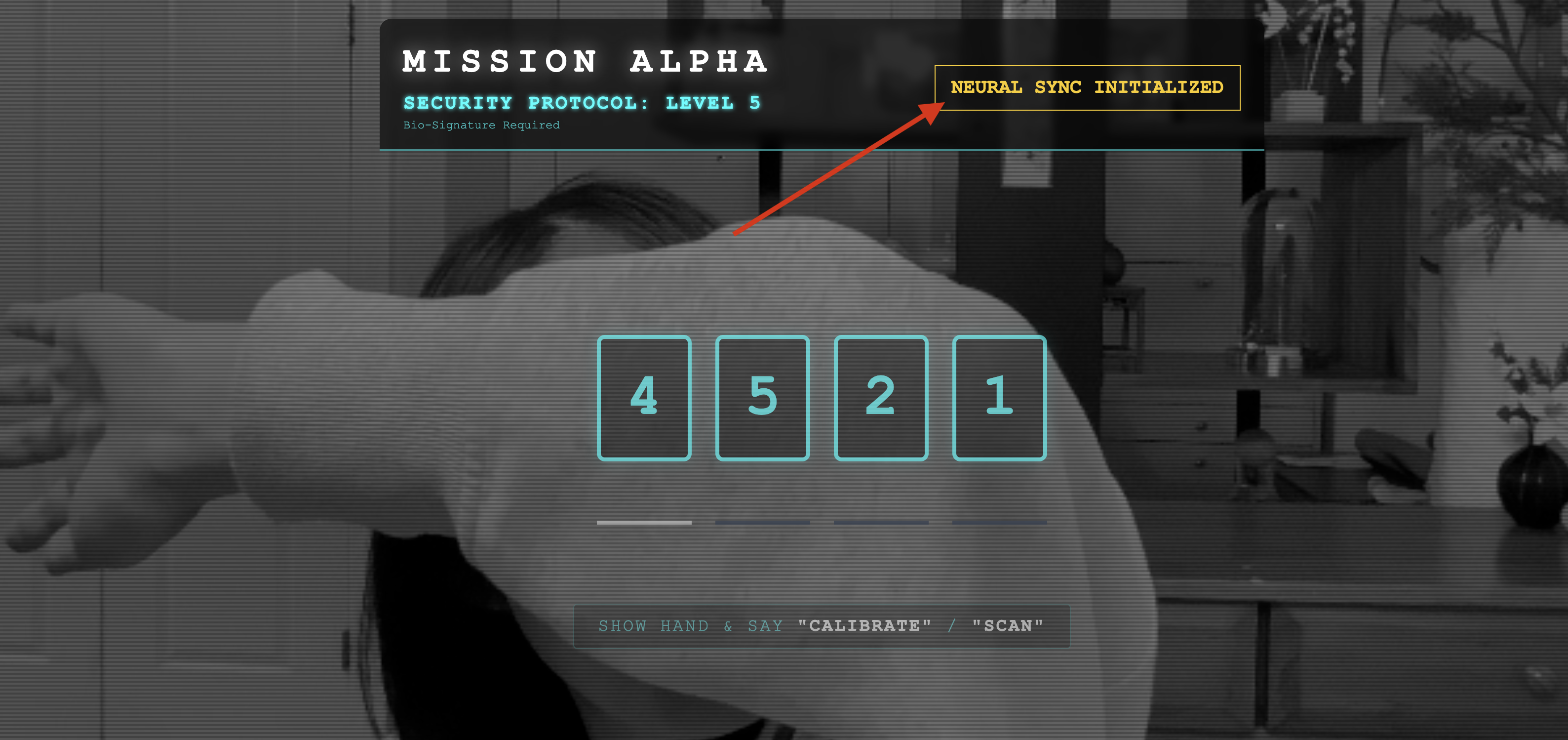
👀 Statusanzeigen prüfen:
- Visuelle Prüfung:Öffnen Sie die Browserkonsole. Rechts oben sollte
NEURAL SYNC INITIALIZEDangezeigt werden. - Audio-Check:Wenn Ihre bidirektionale Audio-Pipeline vollständig betriebsbereit ist, hören Sie eine simulierte Stimme, die bestätigt: „System verbunden!“
Wenn Sie die Audiobestätigung „System verbunden!“ hören, war der Test erfolgreich. Schließen Sie den Tab. Wir müssen die Frequenz jetzt freigeben, um Platz für die echte KI zu schaffen.
👉💻 Drücken Sie in den Terminals für den simulierten Server und das Frontend Ctrl+C. Schließen Sie den Browsertab, auf dem die Benutzeroberfläche ausgeführt wird.
4. Der multimodale Agent
Der Rescue Scout ist einsatzbereit, aber sein „Geist“ ist leer. Wenn du jetzt eine Verbindung herstellst, wird es dich nur anstarren. Es weiß nicht, was ein „Finger“ ist. Um die Überlebenden zu retten, musst du das Biometric Neural Protocol in den Kern des Scouts einprägen.
Der herkömmliche Agent funktioniert wie eine Reihe von Übersetzern. Wenn Sie mit einer herkömmlichen KI sprechen, wandelt ein „Speech-to-Text“-Modell Ihre Stimme in Wörter um, ein „Language Model“ liest diese Wörter und gibt eine Antwort ein und ein „Text-to-Speech“-Modell liest diese Antwort schließlich vor. Dadurch entsteht eine „Latenzlücke“, eine Verzögerung, die bei einer Rettungsmission fatal wäre.
Die Gemini Live API ist ein natives multimodales Modell. Es verarbeitet Roh-Audio-Bytes und Roh-Videoframes direkt und gleichzeitig. Sie „hört“ die Vibrationen Ihrer Stimme und „sieht“ die Pixel Ihrer Handbewegungen in derselben neuronalen Architektur.
Um diese Leistungsfähigkeit zu nutzen, könnten wir die Anwendung erstellen, indem wir das Cockpit direkt mit der Raw Live API verbinden. Unser Ziel ist es jedoch, einen wiederverwendbaren Agenten zu erstellen – eine modulare, robuste Einheit, die schneller zu erstellen ist.
Warum ADK (Agent Development Kit)?
Das Google Agent Development Kit (ADK) ist ein modulares Framework zum Entwickeln und Bereitstellen von KI-Agenten.
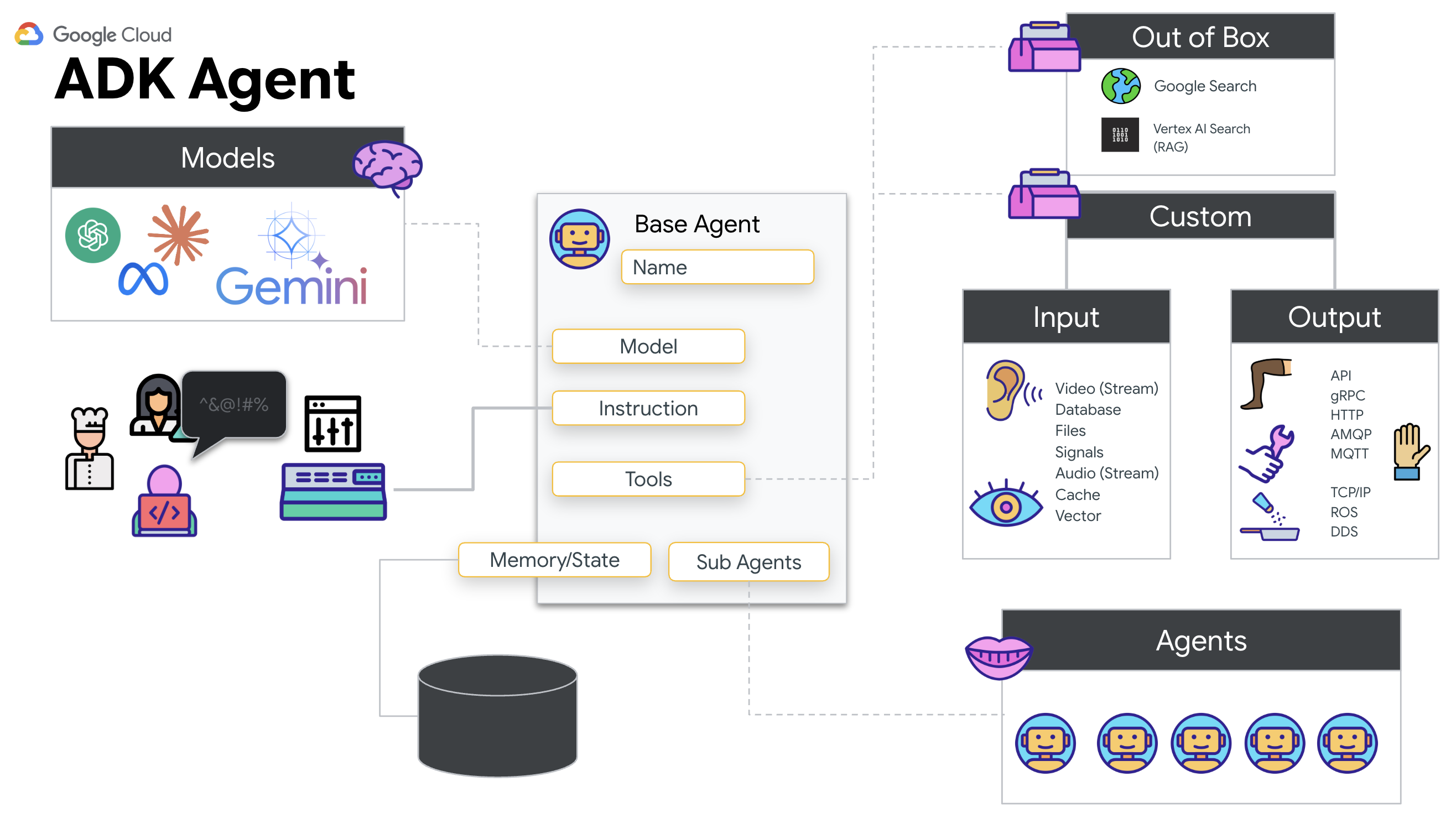
Standard-LLM-Aufrufe sind in der Regel zustandslos. Jede Anfrage ist ein Neustart. Live-Agents, insbesondere wenn sie in den SessionService des ADK integriert sind, ermöglichen robuste, lang andauernde Konversationssitzungen.
- Sitzungspersistenz:ADK-Sitzungen sind persistent und können in Datenbanken (z. B. SQL oder Vertex AI) gespeichert werden. Sie überdauern Serverneustarts und Verbindungsunterbrechungen. Wenn ein Nutzer die Verbindung trennt und später wiederherstellt, werden sein Unterhaltungsverlauf und Kontext vollständig wiederhergestellt. Die kurzlebige Live API-Sitzung wird vom ADK verwaltet und abstrahiert.
- Automatische Wiederverbindung:WebSocket-Verbindungen können wegen Zeitüberschreitung beendet werden (z.B. nach etwa 10 Minuten). Das ADK verarbeitet diese erneuten Verbindungen transparent, wenn
session_resumptioninRunConfigaktiviert ist. In Ihrem Anwendungscode muss keine komplexe Logik für die erneute Verbindung verwaltet werden, was für eine nahtlose Nutzererfahrung sorgt. - Zustandsorientierte Interaktionen:Der KI-Agent merkt sich vorherige Antworten und ermöglicht so Folgefragen, Erläuterungen und komplexe mehrteilige Dialoge, in denen der Kontext entscheidend ist. Das ist grundlegend für Anwendungen wie Kundensupport, interaktive Tutorials oder Szenarien mit Missionskontrolle, in denen Kontinuität unerlässlich ist.
Durch diese Persistenz fühlt sich die Interaktion wie eine fortlaufende Unterhaltung mit einer intelligenten Einheit an und nicht wie eine Reihe isolierter Fragen und Antworten.
Im Wesentlichen geht ein „Live Agent“ mit ADK-Bidi-Streaming über einen einfachen Frage-Antwort-Mechanismus hinaus und bietet eine wirklich interaktive, zustandsbehaftete und unterbrechungsbewusste Konversationsfunktion. Dadurch fühlen sich KI-Interaktionen menschlicher an und sind für komplexe, langwierige Aufgaben deutlich leistungsfähiger.
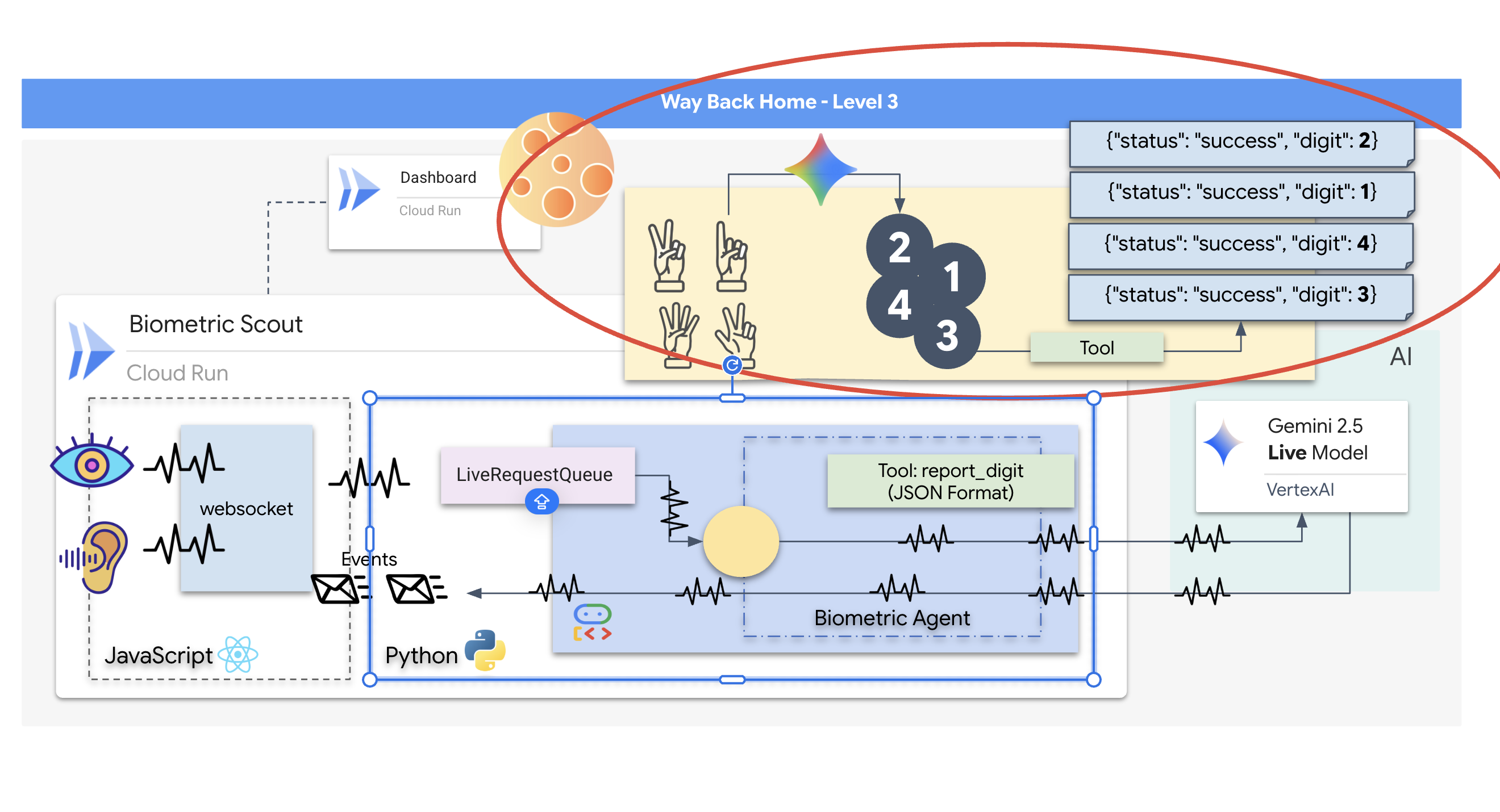
Kundenservicemitarbeiter kontaktieren
Das Erstellen eines Prompts für einen bidirektionalen Echtzeit-Agenten erfordert eine Umstellung der Denkweise. Im Gegensatz zu einem Standard-Chatbot, der auf eine statische Textanfrage wartet, ist ein Live-Kundenservicemitarbeiter „immer aktiv“. Es empfängt einen konstanten Stream von Audio- und Videoframes. Ihr Prompt muss also als Control Loop Script und nicht nur als Persönlichkeitsdefinition fungieren.
So unterscheidet sich ein Live-Kundenservicemitarbeiter-Prompt von einem herkömmlichen Prompt:
- Logik des Zustandsautomaten:Im Prompt muss ein „Verhaltenszyklus“ (Warten → Analysieren → Handeln) definiert werden. Es sind explizite Anweisungen erforderlich, wann der Agent stumm bleiben und wann er sich beteiligen soll, damit er nicht über leere Hintergrundgeräusche hinweg plappert.
- Multimodales Bewusstsein:Dem Agent muss gesagt werden, dass er „Augen“ hat. Sie müssen die KI explizit anweisen, Videoframes im Rahmen des Entscheidungsprozesses zu analysieren.
- Latenz und Kürze:In einem Live-Sprachgespräch wirken lange, prosareiche Absätze unnatürlich und langsam. Der Prompt sorgt für eine kurze und knackige Interaktion.
- Action-First-Architektur:In den Anweisungen wird Tool Calling gegenüber Sprache priorisiert. Der Agent soll die Arbeit (biometrische Daten scannen) vor oder während der verbalen Bestätigung ausführen, nicht erst nach einem langen Monolog.
👉✏️ Öffnen Sie $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py und ersetzen Sie #REPLACE INSTRUCTIONS durch Folgendes:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
HINWEIS: Sie stellen keine Verbindung zu einem Standard-LLM her. Suchen Sie in derselben Datei ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py) nach #REPLACE_MODEL. Wir müssen explizit auf die Vorschauversion dieses Modells abzielen, um die Audiofunktionen in Echtzeit besser zu unterstützen.
👉✏️ Ersetzen Sie den Platzhalter durch:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
Ihr KI-Agent ist jetzt definiert. Es weiß, wer es ist und wie es denken soll. Als Nächstes geben wir ihr die Tools, die sie zum Handeln benötigt.
Toolaufrufe
Die Live API beschränkt sich nicht nur auf den Austausch von Text-, Audio- und Videostreams. Es unterstützt Tool Calling nativ. So werden Agenten von einem passiven Gesprächspartner zu einem aktiven Bediener.
Während einer bidirektionalen Live-Sitzung wird der Kontext vom Modell fortlaufend ausgewertet. Wenn das LLM feststellt, dass eine Aktion ausgeführt werden muss, z. B. „Sensortelemetrie prüfen“ oder „Sicherheitstür entriegeln“. Es wechselt nahtlos von der Konversation zur Ausführung. Der Agent löst die jeweilige Tool-Funktion sofort aus, wartet auf das Ergebnis und integriert die Daten wieder in den Livestream, ohne den Ablauf der Interaktion zu unterbrechen.
👉✏️ Ersetzen Sie in $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py #REPLACE TOOLS durch diese Funktion:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ Registrieren Sie sie dann in der Agent-Definition, indem Sie #TOOL CONFIG ersetzen:
tools=[report_digit],
adk web-Simulator
Bevor wir die Verbindung zum komplexen Schiffscockpit (unserem React-Frontend) herstellen, sollten wir die Logik des Agents isoliert testen. Das ADK enthält eine integrierte Entwicklerkonsole namens adk web, mit der wir Tool Calling überprüfen können, bevor wir die Netzwerkkomplexität erhöhen.
👉💻 Führen Sie im Terminal folgenden Befehl aus:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Klicken Sie in der Cloud Shell-Symbolleiste auf das Symbol für die Webvorschau. Wählen Sie Port ändern aus, legen Sie den Port auf 8000 fest und klicken Sie auf Ändern und Vorschau.
- Berechtigungen erteilen: Erlauben Sie den Zugriff auf Ihre Kamera und Ihr Mikrofon, wenn Sie dazu aufgefordert werden.
- Klicken Sie auf das Kamerasymbol, um die Sitzung zu starten.
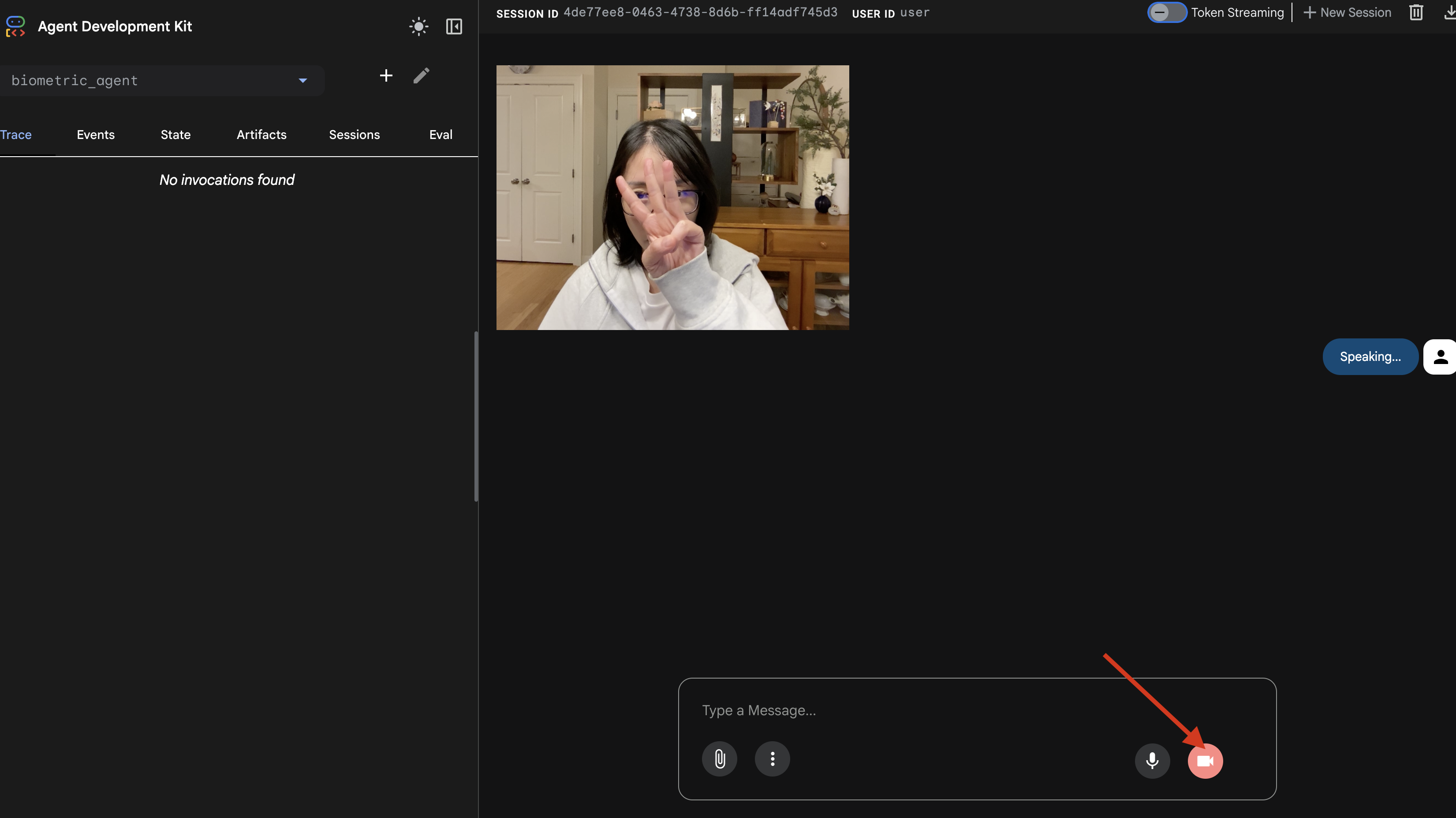
- Der visuelle Test:
- Halten Sie drei Finger deutlich vor die Kamera.
- Sagen Sie „Scannen“.
- Erfolg überprüfen
- :
- Logs:Sehen Sie sich das Terminal an, in dem der
adk web-Befehl ausgeführt wird. Dieses Log muss angezeigt werden:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- Logs:Sehen Sie sich das Terminal an, in dem der
Wenn Sie das Ausführungsprotokoll des Tools sehen, ist Ihr Agent intelligent. Es kann sehen, denken und handeln. Der letzte Schritt ist, es mit dem Hauptschiff zu verbinden.
Klicken Sie in das Terminalfenster und drücken Sie Ctrl+C, um den adk web-Simulator zu beenden.
5. Bidirektionaler Streaming-Ablauf
Der Agent funktioniert. Das Cockpit funktioniert. Jetzt müssen wir sie verbinden.
Der Lebenszyklus von Live-Agents
Beim Streaming in Echtzeit tritt ein Problem mit der „Impedanzanpassung“ auf. Der Client (Browser) überträgt Daten asynchron mit variablen Raten – Netzwerk-Bursts oder schnelle Eingaben –, während das Modell einen regulierten, sequenziellen Eingabestream erfordert. Das Google ADK löst dieses Problem durch den Einsatz von LiveRequestQueue.
Er fungiert als threadsicherer, asynchroner FIFO-Puffer (First-In-First-Out). Der WebSocket-Handler fungiert als Producer und überträgt Roh-Audio-/Video-Chunks in die Warteschlange. Der ADK-Agent fungiert als Consumer und ruft Daten aus der Warteschlange ab, um das Kontextfenster des Modells zu füllen. Durch diese Entkopplung kann die Anwendung weiterhin Nutzereingaben empfangen, auch wenn das Modell eine Antwort generiert oder ein Tool ausführt.
Die Warteschlange dient als multimodaler Multiplexer. In einer realen Umgebung besteht der Upstream-Flow aus verschiedenen, gleichzeitigen Datentypen: rohe PCM-Audiobytes, Videoframes, textbasierte Systemanweisungen und die Ergebnisse von asynchronen Tool-Aufrufen. Die LiveRequestQueue linearisiert diese unterschiedlichen Eingaben in einer einzigen chronologischen Sequenz. Ob das Paket eine Millisekunde Stille, ein hochauflösendes Bild oder eine JSON-Nutzlast aus einer Datenbankabfrage enthält, es wird in der genauen Reihenfolge des Eintreffens serialisiert, sodass das Modell eine konsistente, kausale Zeitachse wahrnimmt.
Diese Architektur ermöglicht die nicht blockierende Steuerung. Da die Erfassungsebene (Producer) von der Verarbeitungsebene (Consumer) entkoppelt ist, bleibt das System auch bei rechenintensiven Modellinferenzen reaktionsfähig. Wenn ein Nutzer die Ausführung eines Tools durch den Agent mit dem Befehl „Stopp!“ unterbricht, wird dieses Audiosignal sofort in die Warteschlange gestellt. Die zugrunde liegende Ereignisschleife verarbeitet dieses Prioritätssignal sofort, sodass das System die Generierung oder Pivot-Aufgaben beenden kann, ohne dass die Benutzeroberfläche einfriert oder Pakete verloren gehen.
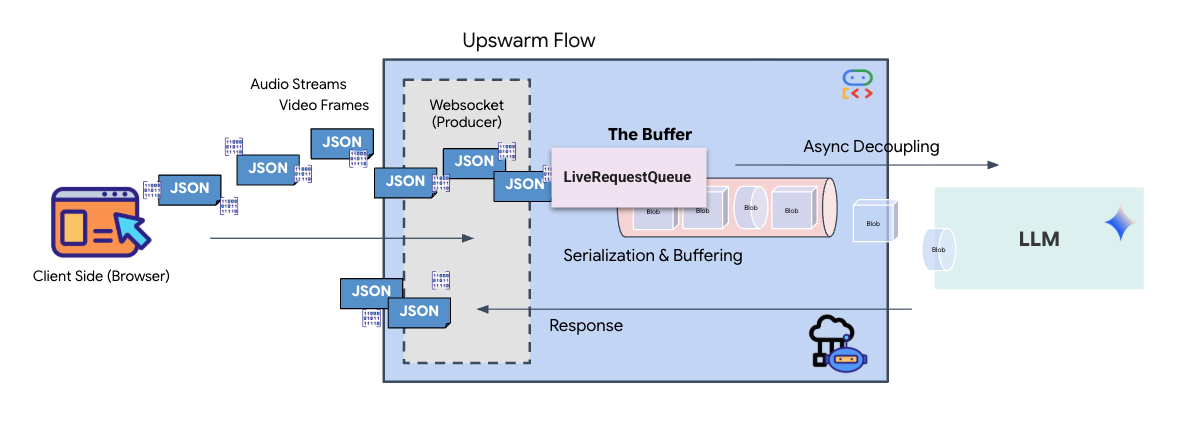
👉💻 Suchen Sie in $HOME/way-back-home/level_3/backend/app/main.py den Kommentar #REPLACE_RUNNER_CONFIG und ersetzen Sie ihn durch den folgenden Code, um das System zu aktivieren:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
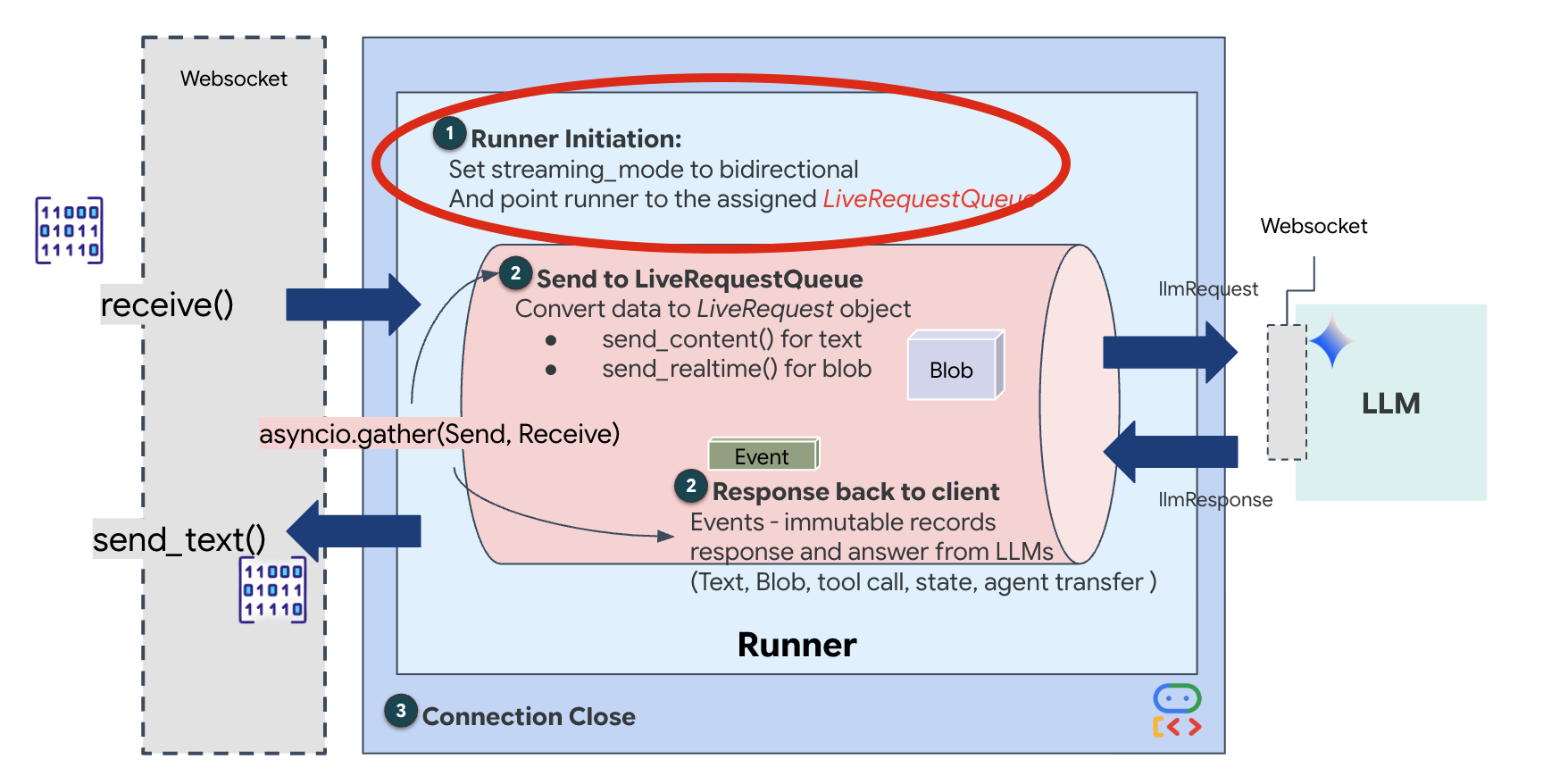
Wenn eine neue WebSocket-Verbindung geöffnet wird, müssen wir konfigurieren, wie die KI interagiert. Hier definieren wir die „Rules of Engagement“.
👉✏️ Ersetzen Sie in $HOME/way-back-home/level_3/backend/app/main.py in der Funktion async def websocket_endpoint den Kommentar #REPLACE_SESSION_INIT durch den folgenden Code:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
Die Laufzeitkonfiguration
StreamingMode.BIDI: Dadurch wird die Verbindung auf bidirektional festgelegt. Im Gegensatz zu „rundenbasierter“ KI, bei der Sie sprechen, aufhören und dann die KI spricht, ermöglicht BIDI eine realistische „Vollduplex“-Unterhaltung. Sie können die KI unterbrechen und die KI kann sprechen, während Sie sich bewegen.AudioTranscriptionConfig: Obwohl das Modell Rohaudio „hört“, benötigen wir (die Entwickler) Logs. Diese Konfiguration weist Gemini an: „Verarbeite das Audio, sende aber auch ein Texttranskript des Gehörten zurück, damit wir Fehler beheben können.“
Ausführungslogik: Nachdem der Runner die Sitzung eingerichtet hat, übergibt er die Steuerung an die Ausführungslogik, die auf dem LiveRequestQueue basiert. Dies ist die wichtigste Komponente für die Echtzeitinteraktion. Durch die Schleife kann der Agent eine Sprachantwort generieren, während in der Warteschlange weiterhin neue Videoframes vom Nutzer eingehen. So wird sichergestellt, dass „Neural Sync“ nie unterbrochen wird.
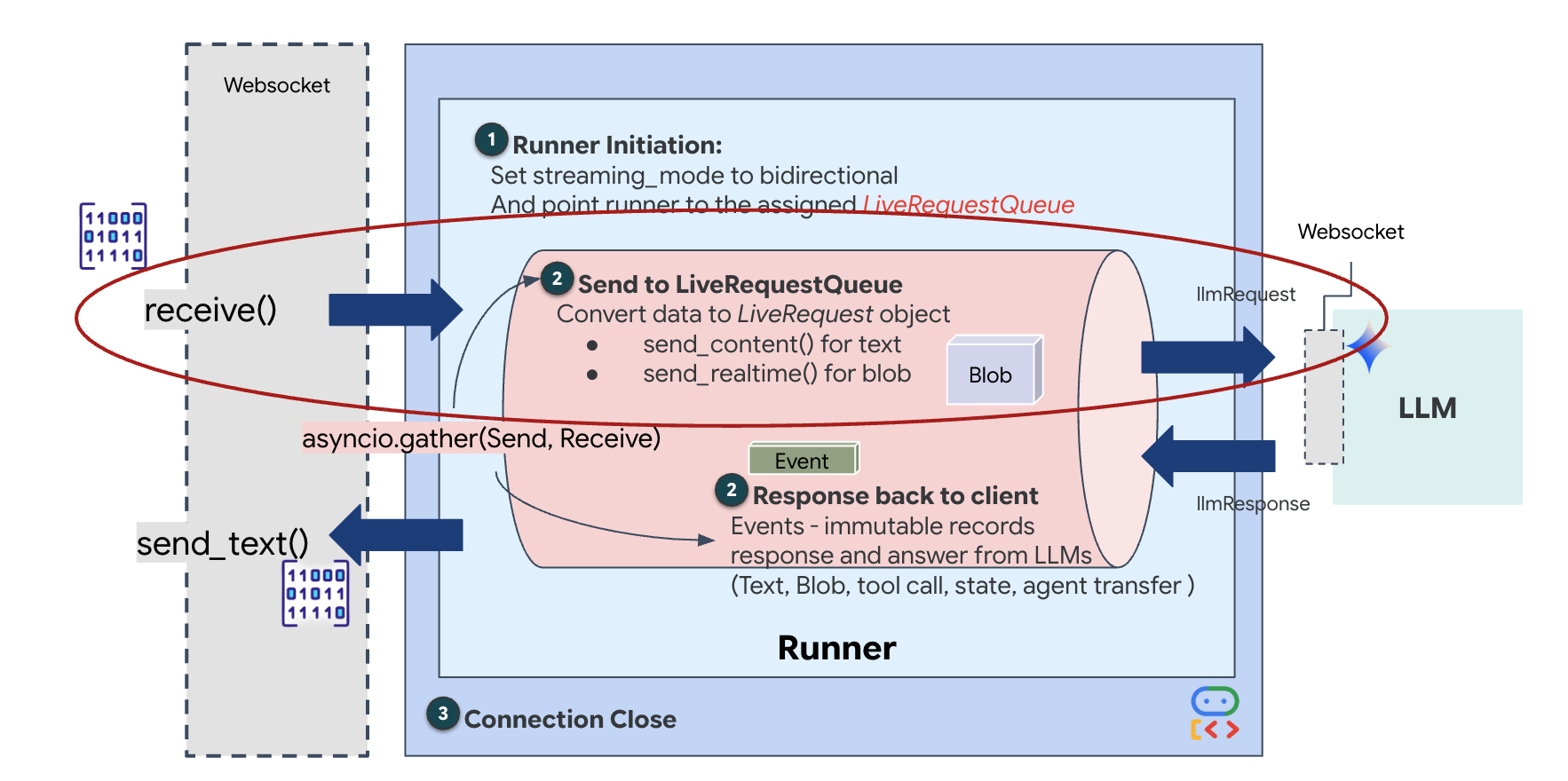
👉✏️ Ersetzen Sie in $HOME/way-back-home/level_3/backend/app/main.py #REPLACE_LIVE_REQUEST, um die Upstream-Aufgabe zu definieren, die Daten an LiveRequestQueue sendet:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
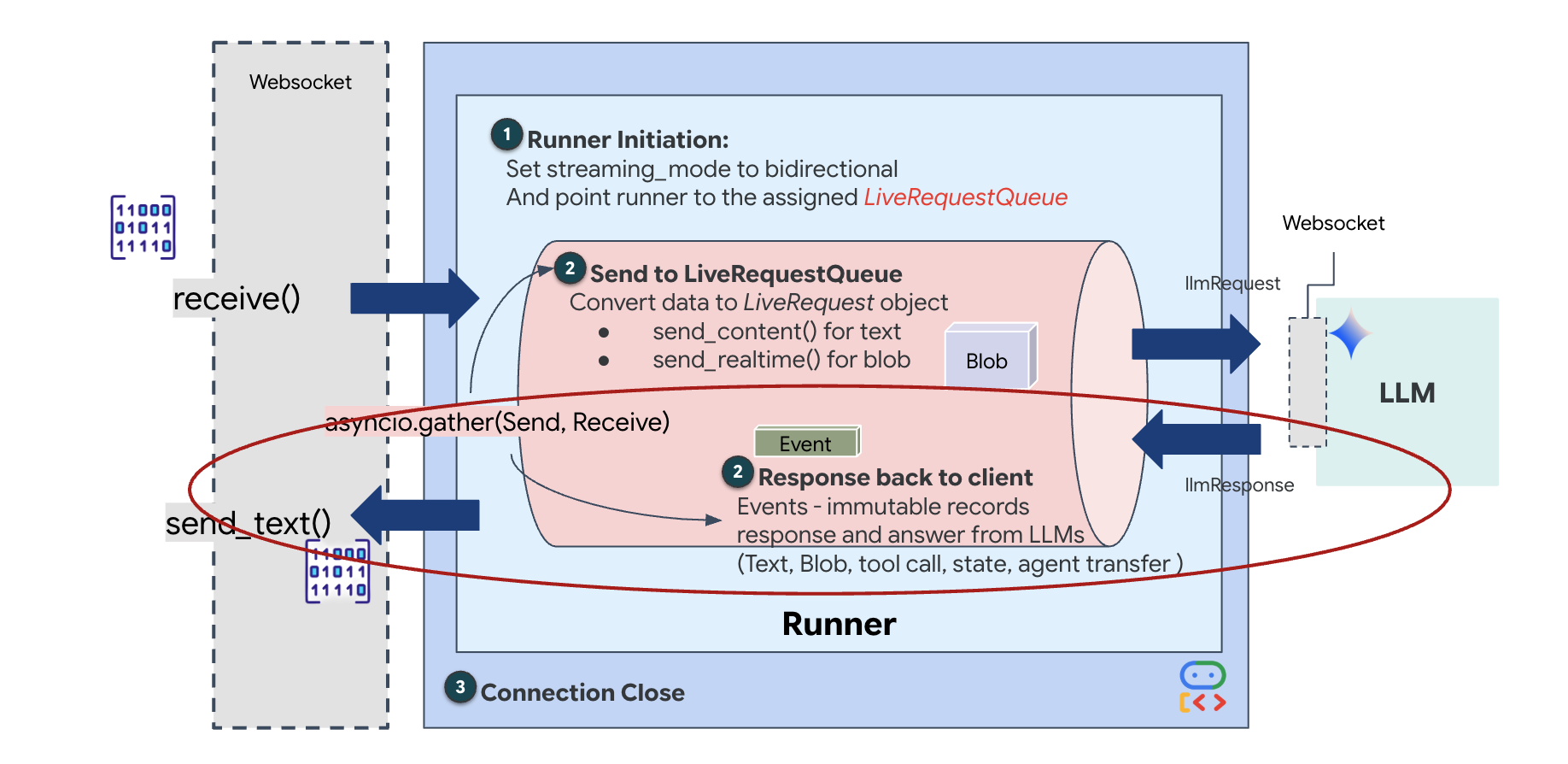
Schließlich müssen wir noch die Antworten der KI verarbeiten. Dazu wird runner.run_live() verwendet, ein Ereignisgenerator, der Ereignisse (Audio, Text oder Tool-Aufrufe) erzeugt, sobald sie eintreten.
👉✏️ Ersetzen Sie in $HOME/way-back-home/level_3/backend/app/main.py #REPLACE_SORT_RESPONSE, um die Downstream-Aufgabe und den Concurrency Manager zu definieren:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
Beachten Sie die Zeile await asyncio.gather(upstream_task(), downstream_task()). Das ist das Wesen von Vollduplex. Wir führen die Zuhör-Aufgabe (Upstream) und die Sprech-Aufgabe (Downstream) gleichzeitig aus. So wird sichergestellt, dass die „Neural Link“-Verbindung Unterbrechungen und gleichzeitigen Datenfluss ermöglicht.
Ihr Backend ist jetzt vollständig programmiert. Das „Gehirn“ (ADK) ist mit dem „Körper“ (WebSocket) verbunden.
Bio-Sync-Ausführung
Der Code ist vollständig. Die Systeme sind grün. Es ist an der Zeit, die Rettung zu starten.
- 👉💻 Backend starten:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 Frontend starten:
- Klicken Sie in der Cloud Shell-Symbolleiste auf das Symbol für die Webvorschau. Wählen Sie Port ändern aus, legen Sie 8080 fest und klicken Sie auf Ändern und Vorschau.
- 👉 Protokoll ausführen:
- Klicken Sie auf NEURALE SYNCHRONISIERUNG STARTEN.
- Kalibrieren:Achten Sie darauf, dass die Kamera Ihre Hand deutlich vor dem Hintergrund erkennen kann.
- Die Synchronisierung:Merken Sie sich den auf dem Bildschirm angezeigten Sicherheitscode (z.B. 3, dann 2, dann 5).
- Signal anpassen:Wenn eine Zahl angezeigt wird, halte genau diese Anzahl von Fingern hoch.
- Ruhig halten:Halten Sie Ihre Hand so lange sichtbar, bis die KI die biometrische Übereinstimmung bestätigt.
- Anpassen:Der Code ist zufällig. Wechsle sofort zur nächsten angezeigten Zahl, bis die Sequenz abgeschlossen ist.

- Wenn du die letzte Zahl in der zufälligen Folge erreicht hast, ist die biometrische Synchronisierung abgeschlossen. Die neuronale Verbindung wird gesperrt. Sie haben die manuelle Kontrolle. Die Motoren der Scout-Fahrzeuge heulen auf und sie stürzen sich in die Schlucht, um die Überlebenden nach Hause zu bringen.
👉💻 Drücken Sie Ctrl+C im Backend-Terminal, um das Programm zu beenden.
6. Für die Produktion bereitstellen (optional)
Sie haben die biometrische Authentifizierung lokal getestet. Jetzt müssen wir den neuronalen Kern des Agenten auf die Mainframes des Schiffs (Cloud Run) hochladen, damit er unabhängig von Ihrer lokalen Konsole arbeiten kann.
👉💻 Führen Sie den folgenden Befehl in Ihrem Cloud Shell-Terminal aus. Dadurch wird das vollständige, mehrstufige Dockerfile in Ihrem Backend-Verzeichnis erstellt.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 Wechseln Sie zum Backend-Verzeichnis und verpacken Sie die Anwendung in ein Container-Image.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 Stellen Sie den Dienst in Cloud Run bereit. Wir fügen die erforderlichen Umgebungsvariablen, insbesondere die Gemini-Konfiguration, direkt in den Startbefehl ein.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
Wenn der Befehl ausgeführt wurde, wird eine Dienst-URL angezeigt, z.B. https://biometric-scout-...run.app. Die Anwendung ist jetzt in der Cloud verfügbar.
👉 Rufen Sie die Seite Google Cloud Run auf und wählen Sie den Dienst „biometric-scout“ aus der Liste aus. 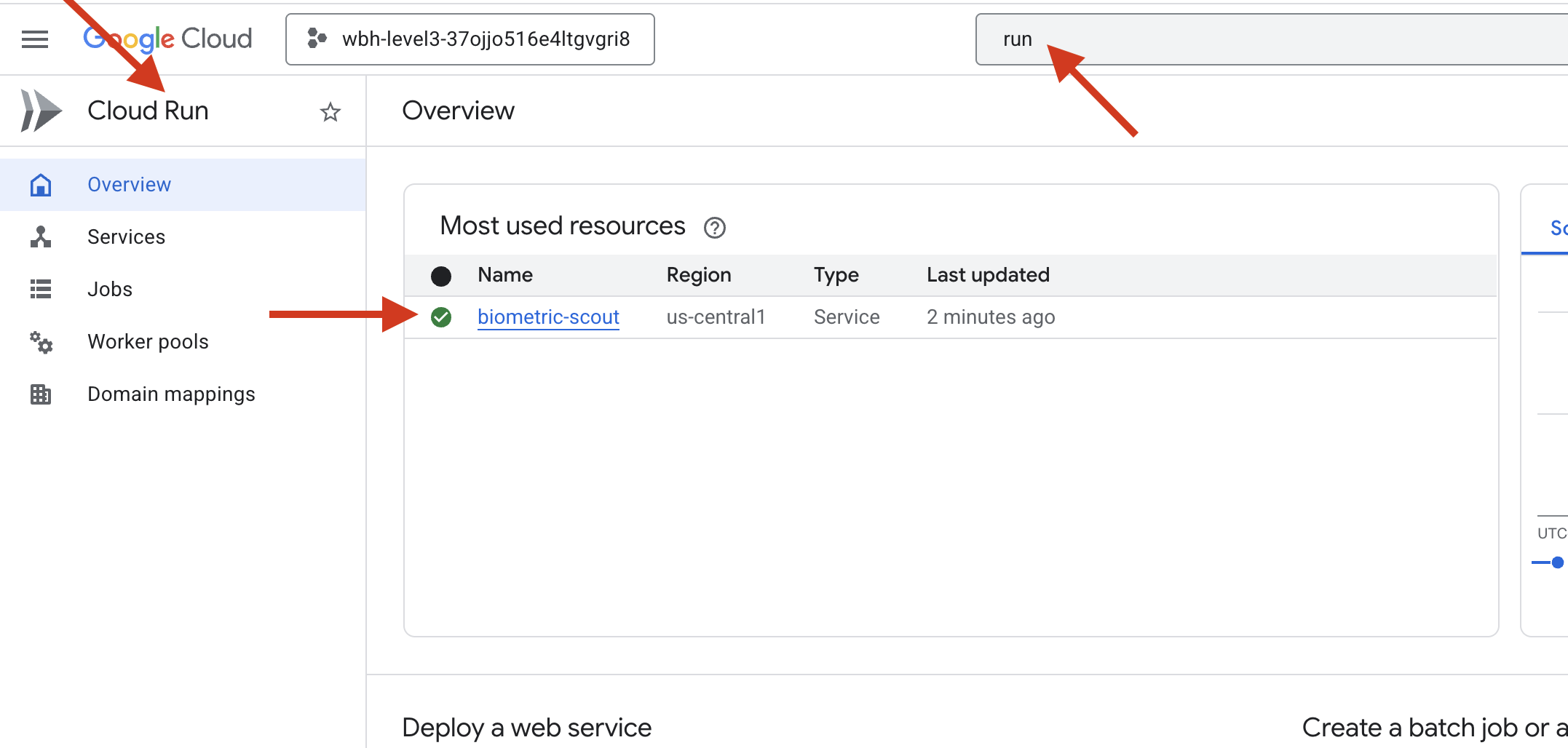
👉 Suchen Sie oben auf der Seite „Dienstdetails“ nach der öffentlichen URL. 
Versuche, in dieser Umgebung die Bio-Synchronisierung durchzuführen. Funktioniert das?
Wenn Sie den fünften Finger strecken, wird die Sequenz von der KI gesperrt. Der Bildschirm blinkt grün: „Biometric Neural Sync: ESTABLISHED.“ (Biometrische neuronale Synchronisierung: HERGESTELLT.)
Mit einem einzigen Gedanken tauchst du den Scout in die Dunkelheit, klammerst dich an die gestrandete Kapsel und ziehst sie heraus, kurz bevor das Gravitationsloch zusammenbricht.

Die Luftschleuse öffnet sich zischend und da sind sie – fünf lebende, atmende Überlebende. Sie stolpern auf das Deck, zerschlagen, aber lebendig, endlich in Sicherheit dank dir.
Dank dir ist die neuronale Verbindung synchronisiert und die Überlebenden wurden gerettet.
Wenn du an Level 0 teilgenommen hast, vergiss nicht, deinen Fortschritt bei der Mission „Auf dem Weg nach Hause“ zu überprüfen.