1. La misión

Estás flotando en el silencio de un sector desconocido. Un enorme **pulso solar** atravesó tu nave por una grieta, lo que te dejó varado en un bolsillo del universo que no existe en ningún mapa estelar.
Después de días de reparaciones agotadoras, finalmente sientes el zumbido de los motores bajo tus pies. Se arregló tu nave espacial. Incluso lograste asegurar una conexión de enlace ascendente de largo alcance con la nave nodriza. Puedes salir. Ya puedes irte a casa. Pero, mientras te preparas para usar la unidad flash, una señal de auxilio atraviesa la estática. Tus sensores detectan cinco leves firmas de calor atrapadas en "El barranco", un sector irregular y distorsionado por la gravedad al que tu nave principal nunca podrá ingresar. Son compañeros exploradores, sobrevivientes de la misma tormenta que casi te quita la vida. No puedes dejarlos atrás.
Te diriges a tu explorador de rescate Alpha-Drone. Esta pequeña y ágil nave es la única capaz de navegar por las estrechas paredes de La Barranca. Pero hay un problema: El pulso solar realizó un "Restablecimiento del sistema" total en su lógica central. Los sistemas de control del Scout no responden. Está encendido, pero su computadora integrada está en blanco, por lo que no puede procesar comandos manuales del piloto ni rutas de vuelo.
El desafío
Para salvar a los sobrevivientes, debes evitar por completo los circuitos dañados del explorador. Tienes una opción desesperada: crear un agente de IA para establecer una sincronización neuronal biométrica. Este agente actuará como un puente en tiempo real, lo que te permitirá controlar el Rescue Scout de forma manual a través de tus propios datos biológicos. No usarás un joystick ni un teclado, sino que conectarás tu intención directamente a la red de navegación de la nave.
Para fijar el vínculo, debes realizar el Protocolo de sincronización frente a los sensores ópticos del Scout. El agente de IA debe reconocer tu firma biológica a través de un intercambio preciso en tiempo real.
Tus objetivos de la misión:
- Imprime el núcleo neuronal: Define un agente de ADK capaz de reconocer entradas multimodales.
- Establece la conexión: Crea una canalización de WebSocket bidireccional para transmitir datos visuales desde Scout a la IA.
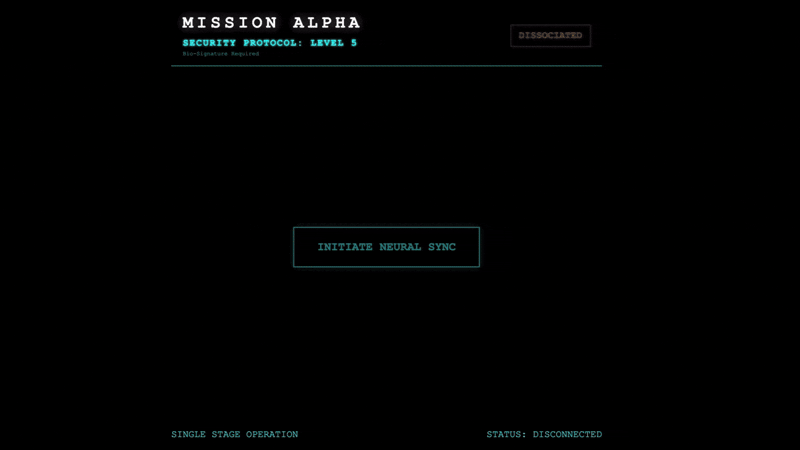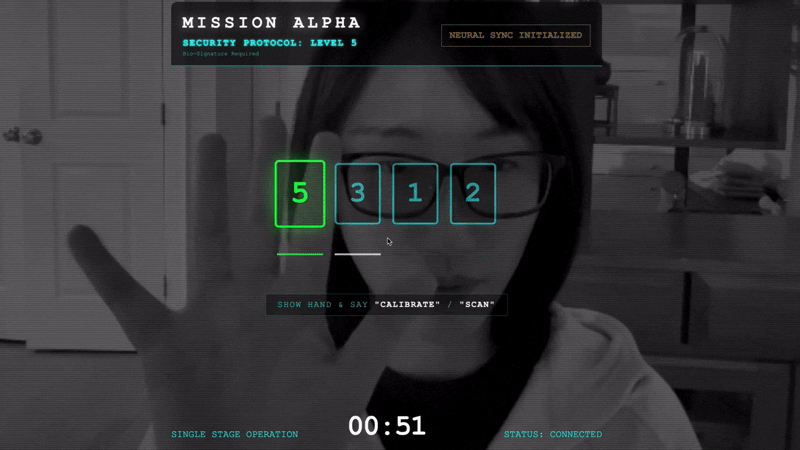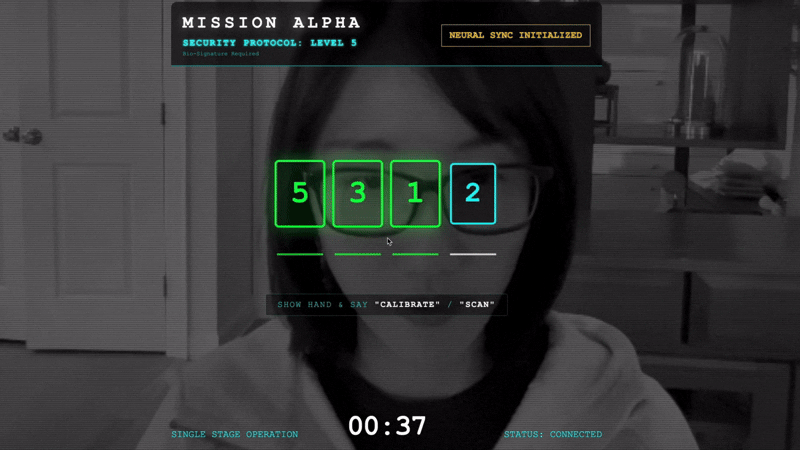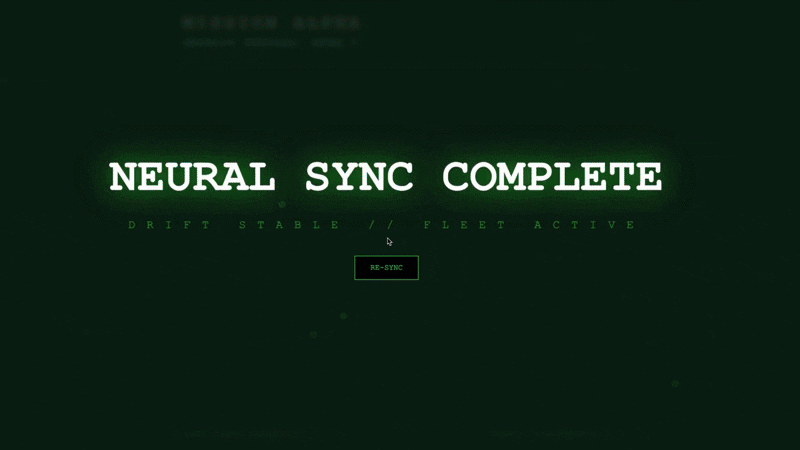
- Inicia el protocolo de enlace: Párate frente al sensor y completa la secuencia de dedos, mostrando del 1 al 5 en orden.
Si se ejecuta correctamente, se activará la "Sincronización biométrica". La IA bloqueará la conexión neuronal, lo que te dará control manual total para lanzar el Scout y llevar a esos sobrevivientes a casa.
Qué compilarás
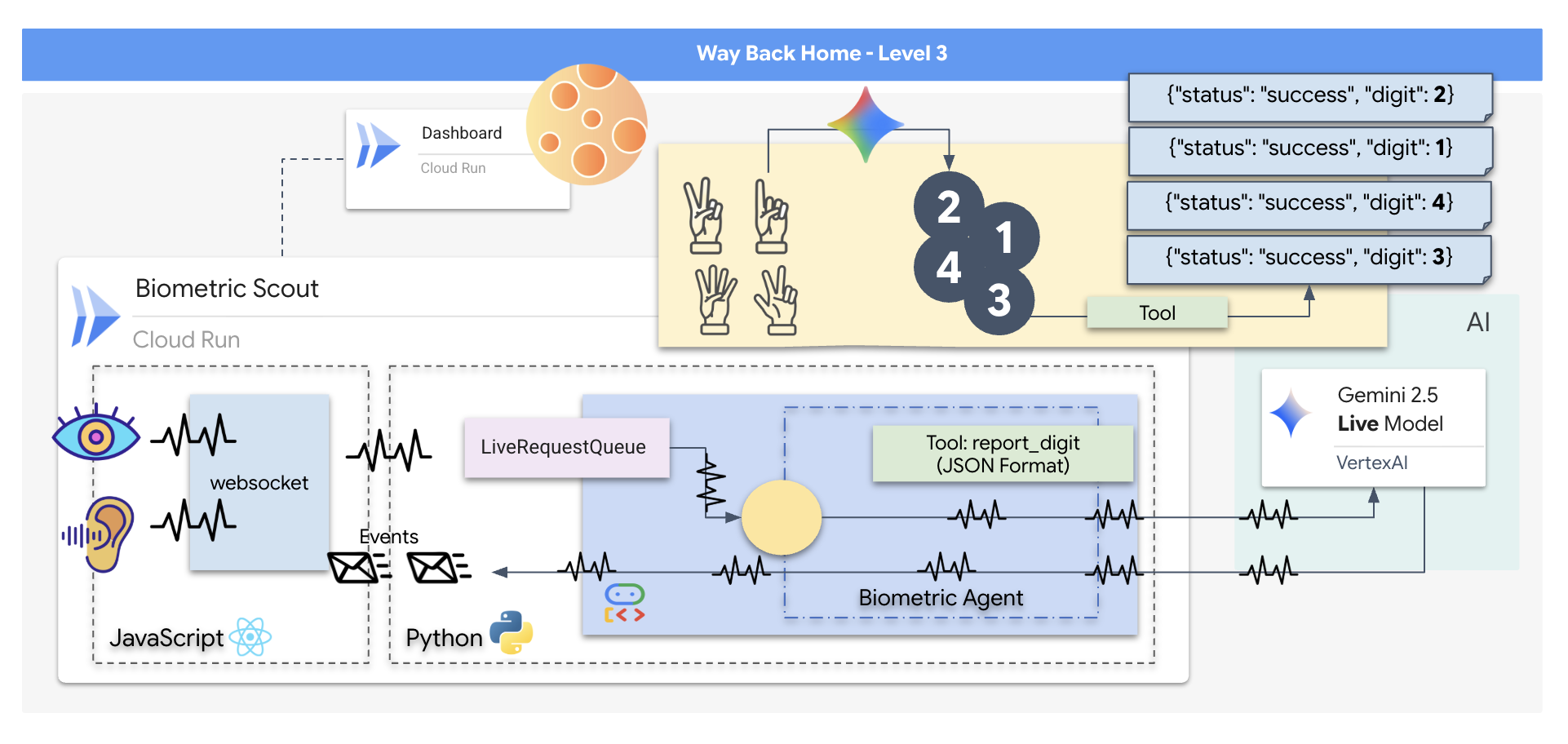
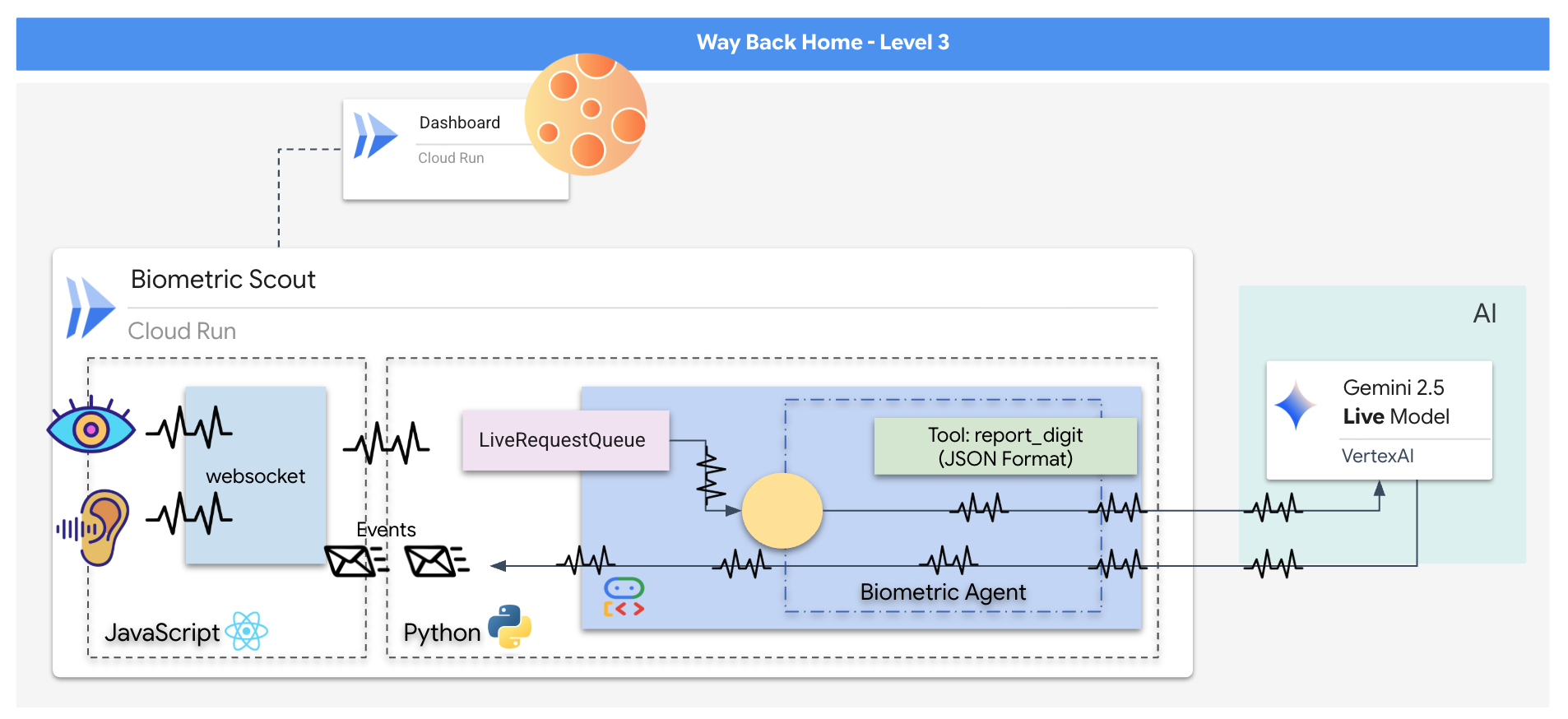
Crearás una aplicación de "Sincronización neuronal biométrica", un sistema potenciado por IA en tiempo real que actúa como interfaz de control para un dron de rescate. Este sistema consta de lo siguiente:
- Un frontend de React: La "cabina" de tu nave, que captura video en vivo de tu cámara web y audio de tu micrófono.
- Un backend de Python: Un servidor de alto rendimiento compilado con FastAPI, que usa el Kit de desarrollo de agentes (ADK) de Google para administrar la lógica y el estado del LLM.
- Un agente de IA multimodal: Es el "cerebro" de la operación, ya que usa la API de Gemini Live a través del SDK de
google-genaipara procesar y comprender transmisiones de audio y video de forma simultánea. - Una canalización de WebSocket bidireccional: El "sistema nervioso" que crea una conexión persistente de baja latencia entre el frontend y la IA, lo que permite la interacción en tiempo real.
Qué aprenderás
Tecnología / Concepto | Descripción |
Agente de IA de backend | Compila un agente de IA con estado con Python y FastAPI. Usa el ADK (Agent Development Kit) de Google para administrar las instrucciones y la memoria, y el SDK de |
IU de frontend | Desarrolla una interfaz de usuario dinámica con React para capturar y transmitir audio y video en vivo directamente desde el navegador. |
Comunicación en tiempo real | Implementa una canalización de WebSocket para la comunicación dúplex completa y de baja latencia, lo que permite que el usuario y la IA interactúen de forma simultánea. |
IA multimodal | Aprovecha la API de Gemini Live para procesar y comprender transmisiones simultáneas de audio y video, lo que permite que la IA "vea" y "escuche" al mismo tiempo. |
Llamadas a herramientas | Permite que la IA ejecute funciones específicas de Python en respuesta a activadores visuales, lo que une la brecha entre la inteligencia del modelo y la acción en el mundo real. |
Implementación de pila completa | Crea un contenedor para toda la aplicación (frontend de React y backend de Python) con Docker y, luego, impleméntala como un servicio escalable y sin servidores en Google Cloud Run. |
2. Configura tu entorno
Accede a Cloud Shell
Primero, abriremos Cloud Shell, que es una terminal basada en el navegador con el SDK de Google Cloud y otras herramientas esenciales preinstaladas.
👉 Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud (es el ícono con forma de terminal en la parte superior del panel de Cloud Shell). 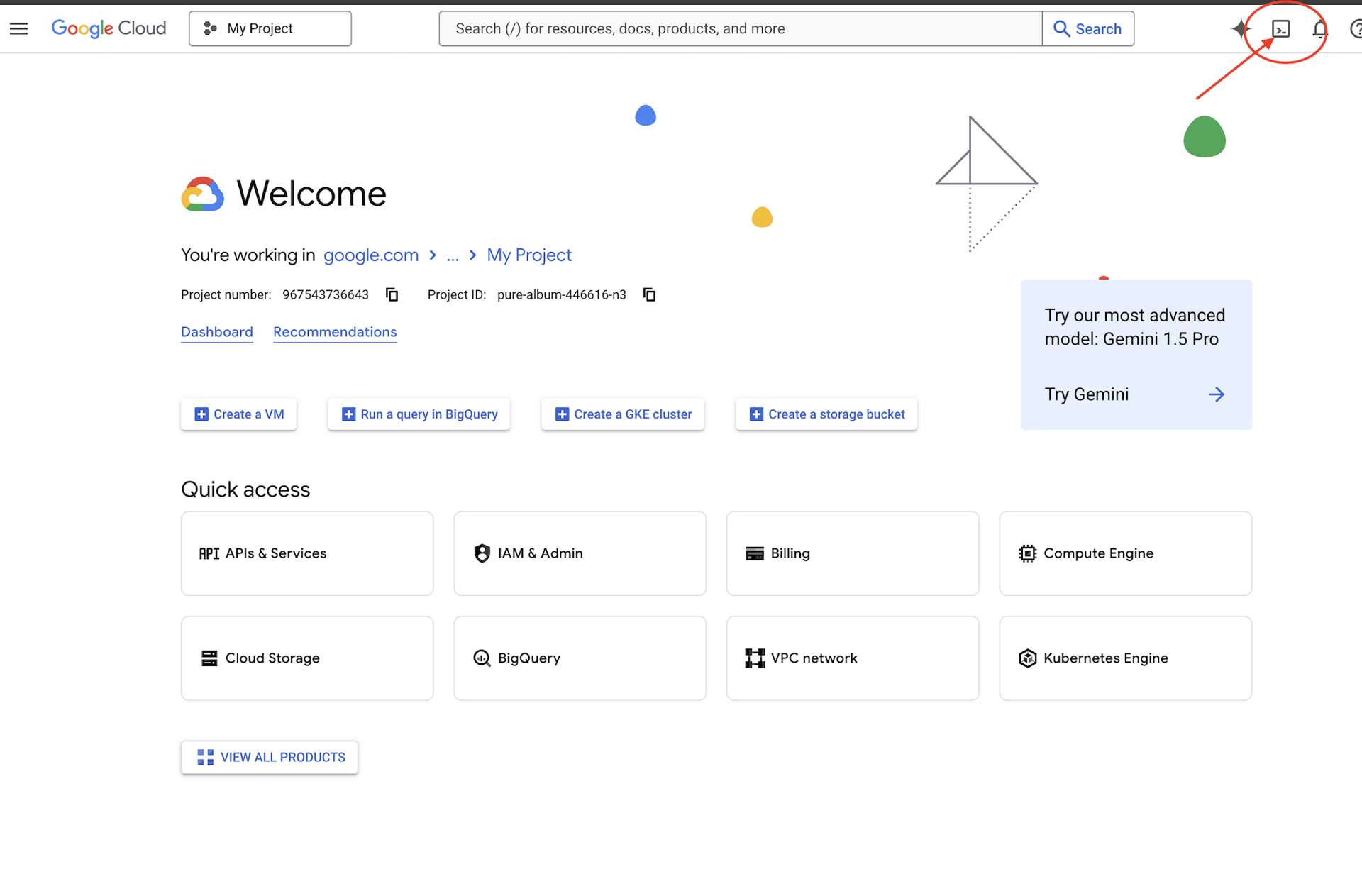
👉 Haz clic en el botón "Abrir editor" (tiene forma de carpeta abierta con un lápiz). Se abrirá el editor de código de Cloud Shell en la ventana. Verás un explorador de archivos en el lado izquierdo. 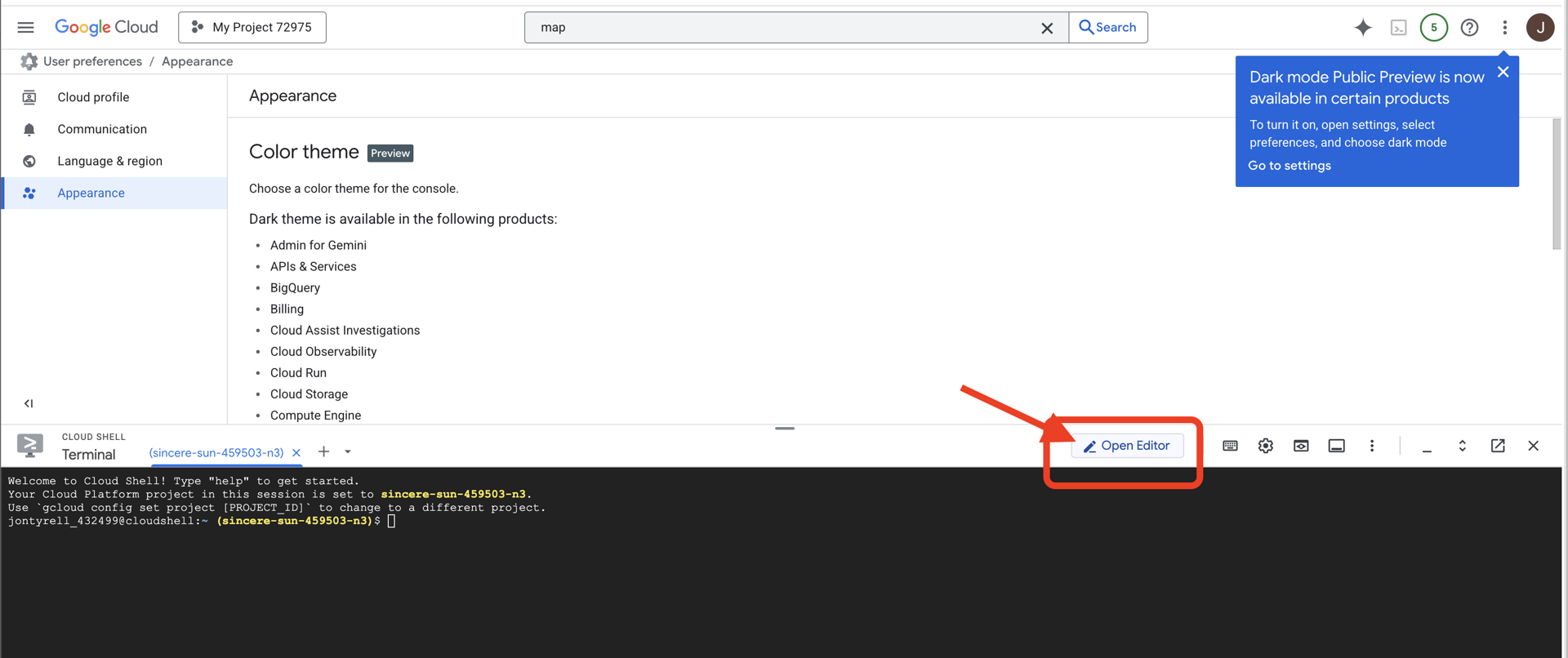
👉Abre la terminal en el IDE de Cloud.
👉💻 En la terminal, verifica que ya te autenticaste y que el proyecto esté configurado con tu ID del proyecto usando el siguiente comando:
gcloud auth list
Deberías ver tu cuenta como (ACTIVE).
Requisitos previos
ℹ️ El nivel 0 es opcional (pero recomendado)
Puedes completar esta misión sin el nivel 0, pero terminarla primero ofrece una experiencia más inmersiva, ya que te permite ver cómo se ilumina tu baliza en el mapa global a medida que avanzas.
Configura el entorno del proyecto
De vuelta en tu terminal, finaliza la configuración estableciendo el proyecto activo y habilitando los servicios de Google Cloud requeridos (Cloud Run, Vertex AI, etcétera).
👉💻 En tu terminal, establece el ID del proyecto:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Habilita los servicios obligatorios:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
Instala las dependencias
👉💻 Navega al nivel y, luego, instala los paquetes de Python necesarios:
cd $HOME/way-back-home/level_3
uv sync
Las dependencias clave son las siguientes:
Paquete | Objetivo |
| Framework web de alto rendimiento para la estación satelital y la transmisión de SSE |
| Servidor ASGI necesario para ejecutar la aplicación de FastAPI |
| El Kit de desarrollo de agentes que se usó para crear el agente de formación |
| Cliente nativo para acceder a los modelos de Gemini |
| Compatibilidad con la comunicación bidireccional en tiempo real |
| Administra las variables de entorno y los secretos de configuración |
Verifica la configuración
Antes de comenzar con el código, asegurémonos de que todos los sistemas funcionen correctamente. Ejecuta la secuencia de comandos de verificación para auditar tu proyecto de Google Cloud, las APIs y las dependencias de Python.
👉💻 Ejecuta la secuencia de comandos de verificación:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Deberías ver una serie de íconos de verificación verdes (✅).
- Si ves cruces rojas (❌), sigue los comandos de corrección sugeridos en el resultado (p.ej.,
gcloud services enable ...opip install ...). - Nota: Por el momento, es aceptable una advertencia amarilla para
.env. Crearemos ese archivo en el siguiente paso.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Calibración de Comm-Link (WebSockets)
Para comenzar la sincronización neuronal biométrica, debemos actualizar los sistemas internos de la nave. Nuestro objetivo principal es capturar un flujo de audio y video de alta fidelidad desde la cabina. Este flujo proporciona los componentes esenciales para la vinculación neuronal: la identificación visual de las secuencias de tus dedos y la frecuencia sónica de tu voz.
Dúplex completo vs. Dúplex medio
Para comprender por qué necesitamos esto para la Sincronización neuronal, debes comprender el flujo de datos:
- Half-Duplex (HTTP estándar): Como un walkie-talkie. Una persona habla, dice "Cambio" y, luego, la otra persona puede hablar. No puedes escuchar y hablar al mismo tiempo.
- Dúplex completo (WebSocket): Como una conversación cara a cara. Los datos fluyen en ambas direcciones de forma simultánea. Mientras tu navegador envía fotogramas de video y muestras de audio hacia arriba a la IA, esta puede enviarte respuestas de voz y comandos de herramientas hacia abajo al mismo tiempo.
Por qué Gemini Live necesita Full-Duplex: La API de Gemini Live se diseñó para "interrupciones". Imagina que estás mostrando la secuencia de dedos y la IA ve que lo estás haciendo mal. En una configuración HTTP estándar, la IA tendría que esperar a que termines de enviar tus datos antes de indicarte que te detengas. Con WebSockets, la IA puede ver un error en el cuadro 1 y enviar una señal de "interrupción" que llega a la cabina mientras aún mueves la mano para el cuadro 2.
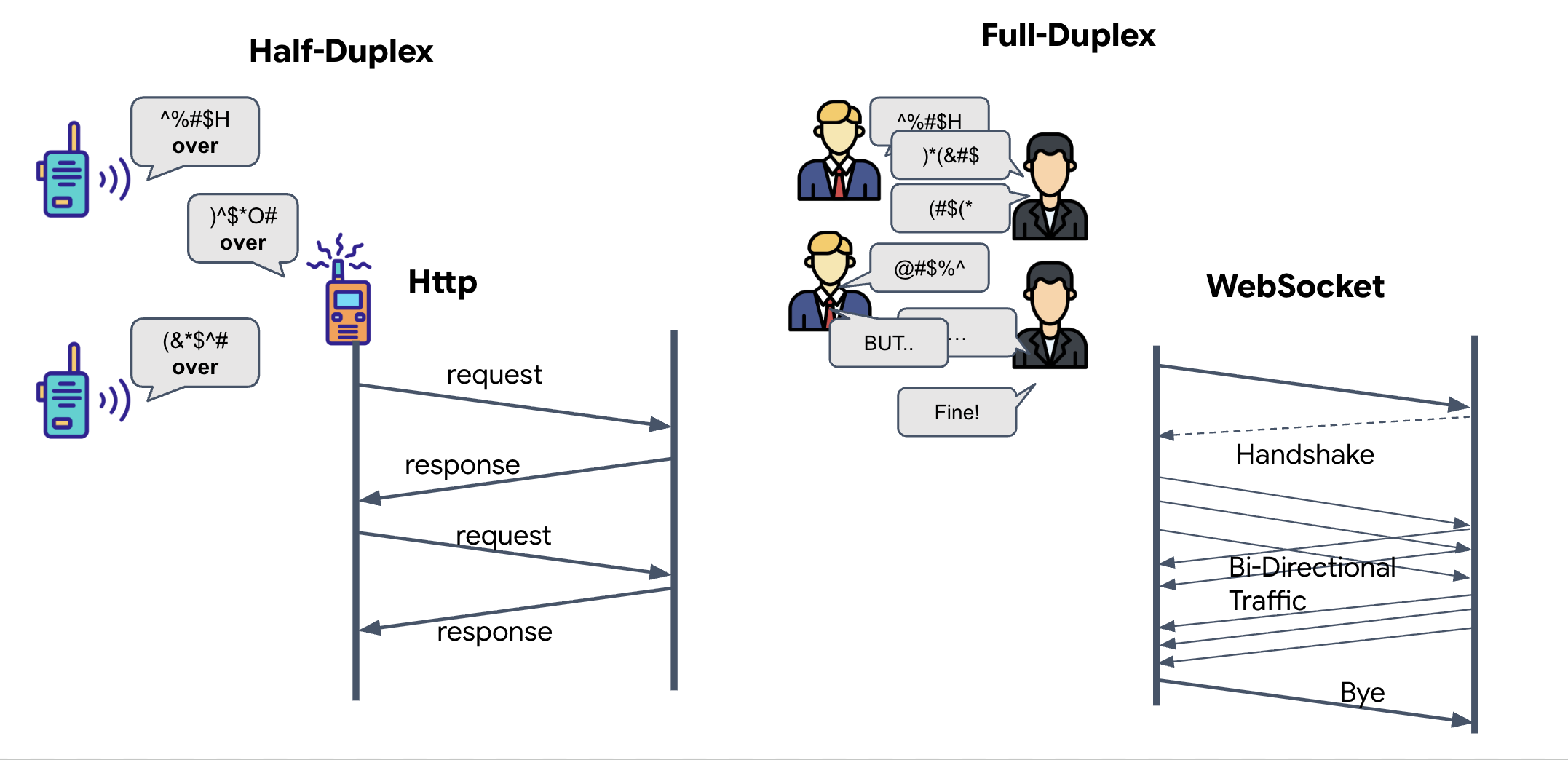
¿Qué es un WebSocket?
En una transmisión galáctica estándar (HTTP), envías una solicitud y esperas una respuesta, como si enviaras una postal. Para una sincronización neuronal, las postales son demasiado lentas. Necesitamos un "cable con corriente".
Los WebSockets comienzan como una solicitud web estándar (HTTP), pero luego se "actualizan" a algo diferente.
- La solicitud: Tu navegador envía una solicitud HTTP estándar al servidor con un encabezado especial:
Upgrade: websocket. Básicamente, le dices: "Quiero dejar de enviar postales y comenzar una llamada telefónica en vivo". - La respuesta: Si el agente de IA (el servidor) admite esta acción, envía una respuesta
HTTP 101 Switching Protocols. - La transformación: En este momento, la conexión HTTP se reemplaza por el protocolo WebSocket, pero el socket TCP/IP subyacente permanece abierto. Las reglas de comunicación cambian instantáneamente de "Solicitud/Respuesta" a "Transmisión Full-Duplex".
Implementa el gancho de WebSocket
Inspeccionemos el bloque de terminal para comprender cómo fluyen los datos.
👀 Abrir $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. Verás que los controladores de eventos de ciclo de vida de WebSocket estándar ya están configurados. Este es el esqueleto de nuestro sistema de comunicación:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
El controlador onMessage
Enfócate en el bloque ws.current.onmessage. Este es el receptor. Cada vez que el agente "piensa" o "habla", llega un paquete de datos aquí. Actualmente, no hace nada: captura el paquete y lo descarta (a través del marcador de posición //#REPLACE-HANDLE-MSG).
Debemos llenar este vacío con lógica que pueda distinguir entre lo siguiente:
- Llamadas a herramientas (functionCall): La IA reconoce tus gestos con las manos (la "sincronización").
- Datos de audio (inlineData): La voz de la IA que te responde.
👉✏️ Ahora, en el mismo archivo $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, reemplaza //#REPLACE-HANDLE-MSG por la siguiente lógica para controlar el flujo entrante:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
Cómo se transforman el audio y el video en datos para la transmisión
Para habilitar la comunicación en tiempo real a través de Internet, el audio y el video sin procesar deben convertirse en un formato adecuado para la transmisión. Esto implica capturar, codificar y empaquetar los datos antes de enviarlos a través de una red.
Transformación de datos de audio
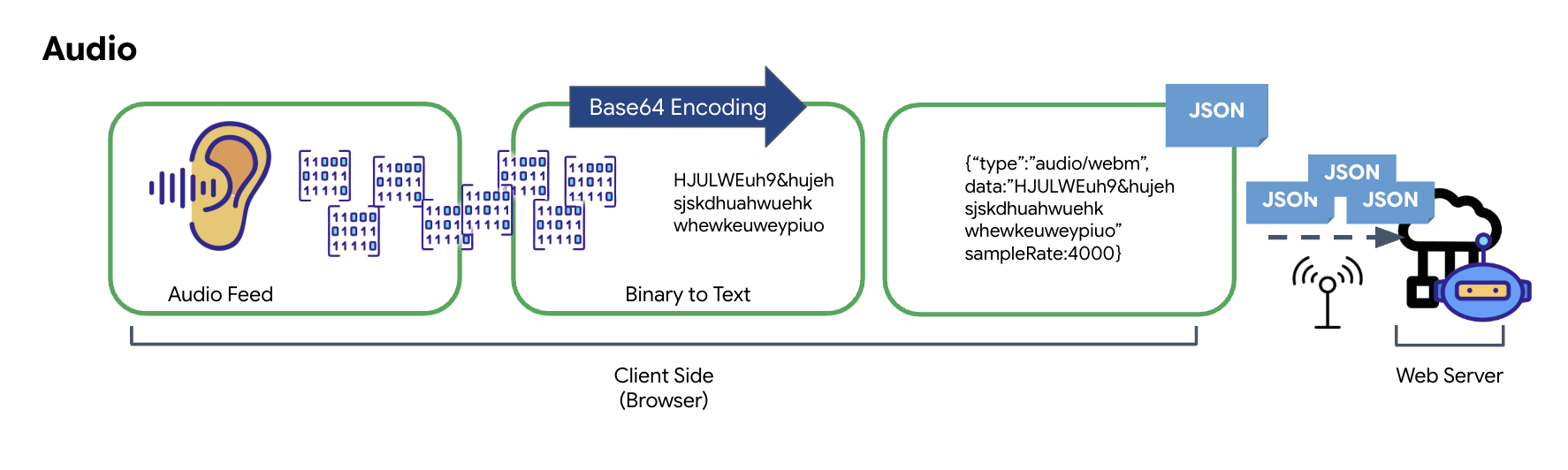
El proceso de convertir el audio analógico en datos digitales transmisibles comienza con la captura de las ondas de sonido a través de un micrófono. Luego, este audio sin procesar se procesa a través de la API de Web Audio del navegador. Como estos datos sin procesar están en formato binario, no son directamente compatibles con los formatos de transmisión basados en texto, como JSON. Para resolver este problema, cada segmento de audio se codifica en una cadena Base64. Base64 es un método que representa datos binarios en un formato de cadena ASCII, lo que garantiza su integridad durante la transmisión.
Luego, esta cadena codificada se incorpora en un objeto JSON. Este objeto proporciona un formato estructurado para los datos, que suele incluir un campo "type" para identificarlo como audio y metadatos, como la frecuencia de muestreo del audio. Luego, todo el objeto JSON se serializa en una cadena y se envía a través de una conexión WebSocket. Este enfoque garantiza que el audio se transmita de una manera bien organizada y fácil de analizar.
Transformación de datos de video
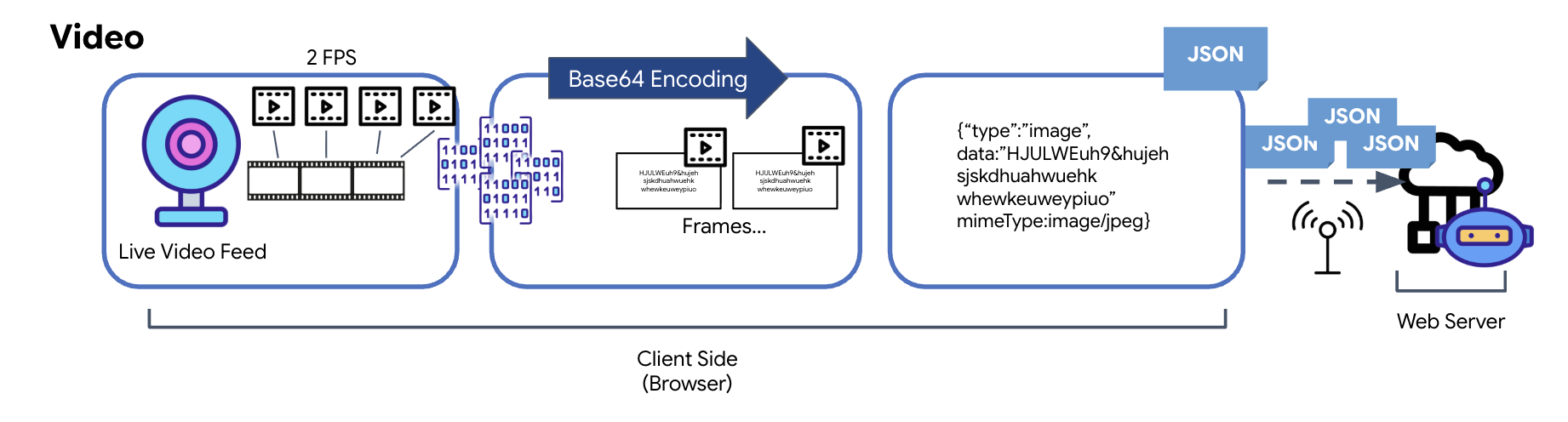
La transmisión de video se logra a través de una técnica de captura de fotogramas. En lugar de enviar una transmisión de video continua, un bucle recurrente captura imágenes estáticas del feed de video en vivo a un intervalo establecido, como dos fotogramas por segundo. Esto se logra dibujando el fotograma actual de un elemento de video HTML en un elemento de lienzo oculto.
Luego, se usa el método toDataURL del lienzo para convertir esta imagen capturada en una cadena JPEG codificada en Base64. Este método incluye una opción para especificar la calidad de la imagen, lo que permite un equilibrio entre la fidelidad de la imagen y el tamaño del archivo para optimizar el rendimiento. Al igual que los datos de audio, esta cadena Base64 se coloca en un objeto JSON. Por lo general, este objeto se etiqueta con un "tipo" de "imagen" y se incluye el mimeType, como "image/jpeg". Luego, este paquete JSON se convierte en una cadena y se envía a través de WebSocket, lo que permite que el extremo receptor reconstruya el video mostrando la secuencia de imágenes.
👉✏️ En el mismo archivo $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, reemplaza //#CAPTURE AUDIO and VIDEO por lo siguiente para capturar la entrada del usuario:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
Una vez guardado, el panel estará listo para traducir los indicadores digitales del agente en actualizaciones visuales del panel y audio.
Prueba de diagnóstico (prueba de bucle invertido)
Tu cabina ya está disponible. Cada 500 ms, se transmite un "paquete" visual de tu entorno. Antes de conectarnos a Gemini, debemos verificar que el transmisor de tu barco funcione. Ejecutaremos una "prueba de bucle" con un servidor de diagnóstico local.
👉💻 Primero, compila la interfaz de Cockpit desde tu terminal:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 A continuación, inicia el servidor de simulación:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 Ejecuta el protocolo de prueba:
- Abre la vista previa: Haz clic en el ícono de vista previa en la Web en la barra de herramientas de Cloud Shell. Selecciona Cambiar puerto, configúralo en 8080 y haz clic en Cambiar y obtener vista previa. Se abrirá una nueva pestaña del navegador en la que se mostrará la interfaz de Cockpit.
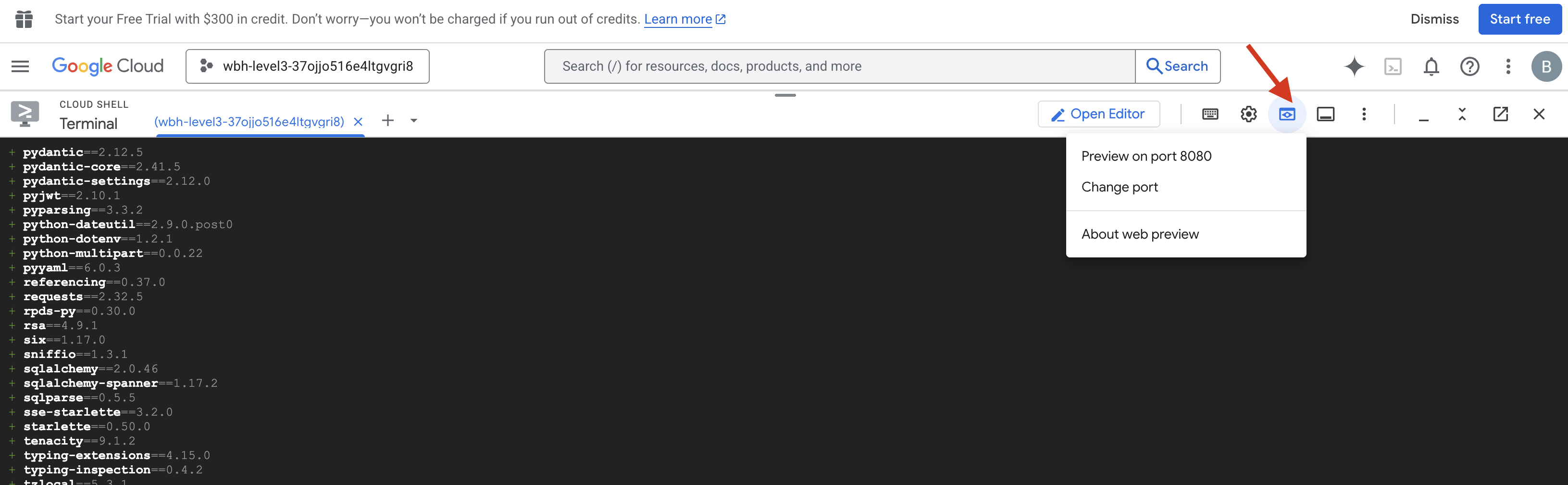
- IMPORTANTE: Cuando se te solicite, DEBES permitir que el navegador acceda a tu cámara y micrófono. Sin estos datos de entrada, no se puede iniciar la sincronización neuronal.
- Haz clic en el botón "INITIATE NEURAL SYNC" en la IU.
👀 Verifica los indicadores de estado:
- Verificación visual: Abre la consola del navegador. Deberías ver
NEURAL SYNC INITIALIZEDen la parte superior derecha. - Verificación de audio: Si tu canalización de audio bidireccional funciona correctamente, escucharás una voz simulada que confirma: "¡Sistema conectado!".
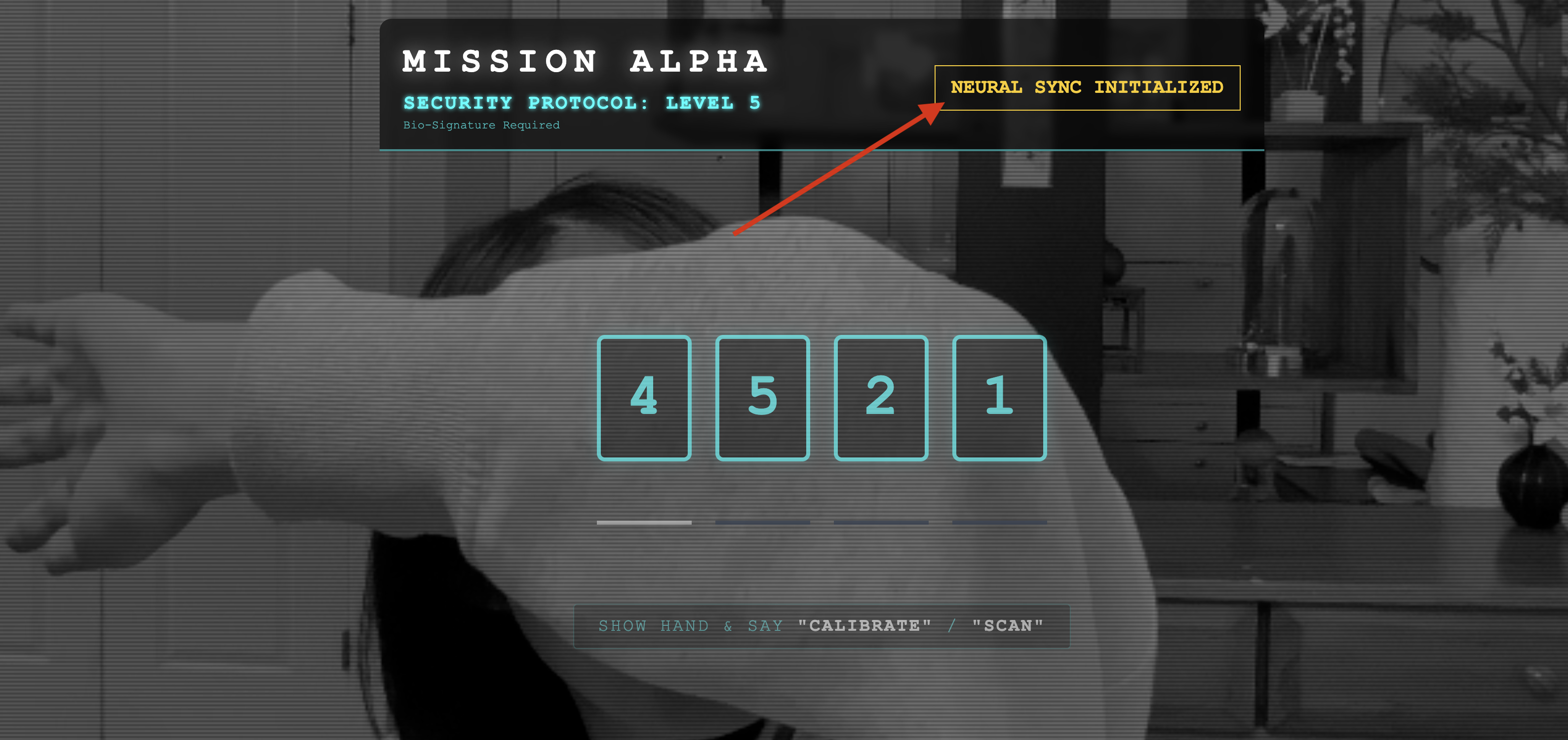
Una vez que escuches la confirmación de audio "¡Sistema conectado!", la prueba se habrá realizado correctamente. Cierra la pestaña. Ahora debemos borrar la frecuencia para dejar espacio a la IA real.
👉💻 Presiona Ctrl+C en las terminales del servidor simulado y del frontend. Cierra la pestaña del navegador en la que se ejecuta la IU.
4. El agente multimodal
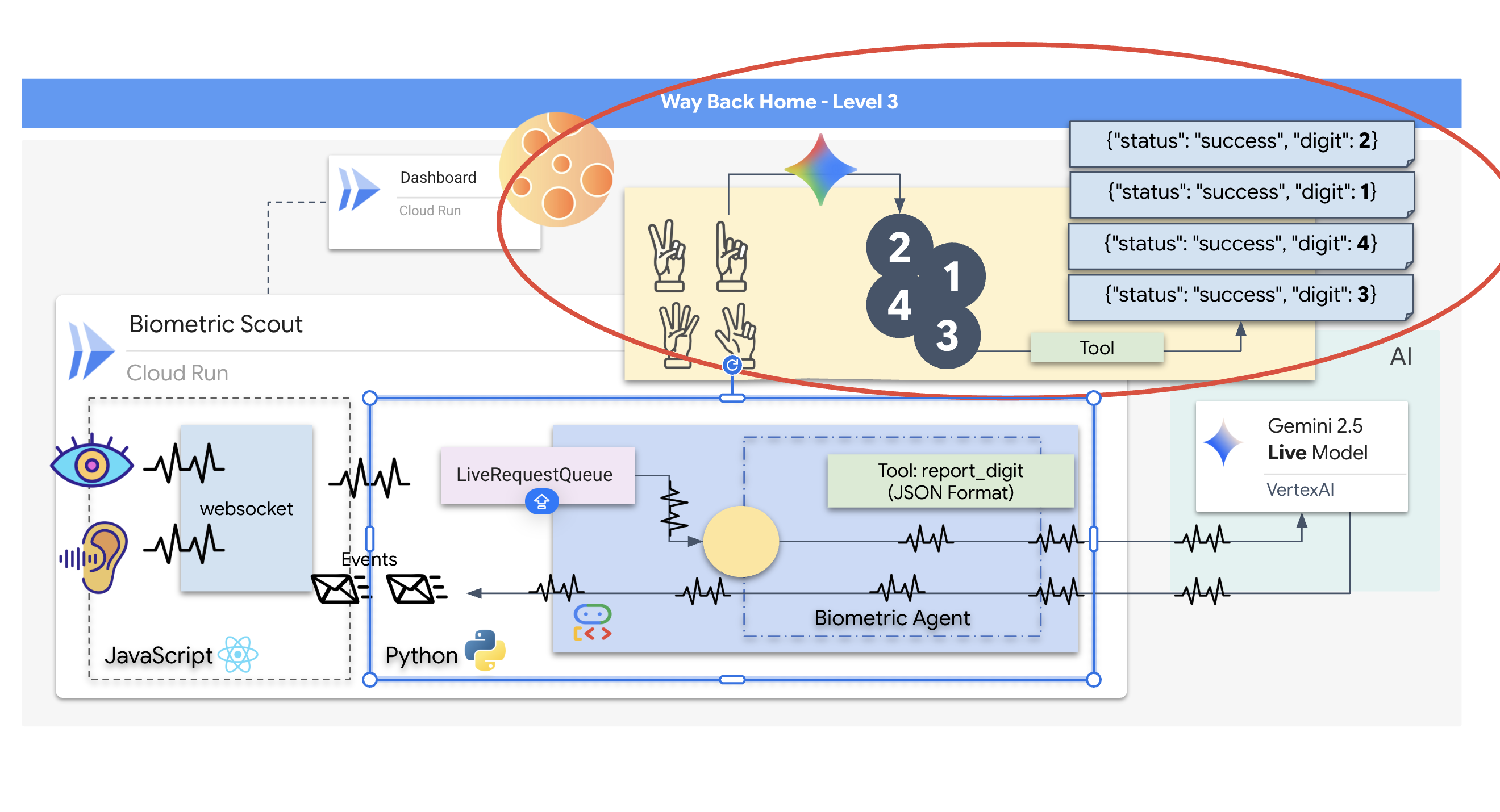
El explorador de rescate está operativo, pero su "mente" está en blanco. Si te conectas ahora, solo te mirará. No sabe qué es un "dedo". Para salvar a los sobrevivientes, debes grabar el Protocolo Neurál Biométrico en el núcleo del Scout.
El agente tradicional funciona como una serie de traductores. Si hablas con una IA de la vieja escuela, un modelo de "Voz a texto" convierte tu voz en palabras, un "Modelo de lenguaje" lee esas palabras y escribe una respuesta, y un modelo de "Texto a voz" finalmente te lee esa respuesta. Esto crea una "brecha de latencia", un retraso que sería fatal en una misión de rescate.
La API de Gemini Live es un modelo multimodal nativo. Procesa bytes de audio y fotogramas de video sin procesar de forma directa y simultánea. "Escucha" la vibración de tu voz y "ve" los píxeles de los gestos con las manos dentro de la misma arquitectura neuronal.
Para aprovechar esta potencia, podríamos compilar la aplicación conectando la cabina directamente a la API de Live sin procesar. Sin embargo, nuestro objetivo es crear un agente reutilizable, una entidad modular y sólida que sea más rápida de compilar.
¿Por qué usar el ADK (Kit de desarrollo de agentes)?
El Kit de desarrollo de agentes (ADK) de Google es un framework modular para desarrollar y, luego, implementar agentes de IA.
Por lo general, las llamadas a LLM estándar no tienen estado, y cada consulta es un nuevo comienzo. Los agentes humanos, en especial cuando se integran con SessionService del ADK, permiten sesiones conversacionales sólidas y de larga duración.
- Persistencia de sesión: Las sesiones del ADK son persistentes y se pueden almacenar en bases de datos (como SQL o Vertex AI), y sobreviven a los reinicios y las desconexiones del servidor. Esto significa que, si un usuario se desconecta y vuelve a conectarse más tarde (incluso días después), se restablecerán por completo su historial y contexto de conversación. El ADK administra y abstrae la sesión efímera de la API de Live.
- Reconexión automática: Las conexiones de WebSocket pueden agotar el tiempo de espera (p.ej., después de ~10 minutos). El ADK controla estas reconexiones de forma transparente cuando
session_resumptionestá habilitado enRunConfig. El código de tu aplicación no necesita administrar una lógica de reconexión compleja, lo que garantiza una experiencia fluida para el usuario. - Interacciones con estado: El agente recuerda los turnos anteriores, lo que permite hacer preguntas de seguimiento, aclaraciones y diálogos complejos de varios turnos en los que el contexto es fundamental. Esto es fundamental para aplicaciones como la asistencia al cliente, los instructivos interactivos o las situaciones de control de misión en las que la continuidad es esencial.
Esta persistencia garantiza que la interacción se sienta como una conversación continua con una entidad inteligente, en lugar de una serie de preguntas y respuestas aisladas.
En esencia, un "agente en vivo" con la transmisión bidireccional del ADK va más allá de un simple mecanismo de respuesta a consultas para ofrecer una experiencia conversacional verdaderamente interactiva, con estado y consciente de las interrupciones, lo que hace que las interacciones con la IA se sientan más humanas y sean significativamente más potentes para tareas complejas y de larga duración.
Indicaciones para un agente humano
Diseñar una instrucción para un agente bidireccional en tiempo real requiere un cambio de mentalidad. A diferencia de un chat bot estándar que espera una consulta de texto estática, un agente en vivo está "siempre activo". Recibe un flujo constante de fotogramas de audio y video, lo que significa que tu instrucción debe actuar como un script de bucle de control en lugar de solo una definición de personalidad.
Así es como una instrucción de Live Agent difiere de una tradicional:
- Lógica de la máquina de estados: La instrucción debe definir un "bucle de comportamiento" (esperar → analizar → actuar). Necesita instrucciones explícitas sobre cuándo permanecer en silencio y cuándo participar, lo que evita que el agente balbucee sobre el ruido de fondo vacío.
- Multimodal Awareness: Se le debe indicar al agente que tiene "ojos". Debes indicarle explícitamente que analice los fotogramas de video como parte de su proceso de razonamiento.
- Latencia y brevedad: En una conversación de voz en vivo, los párrafos largos y cargados de prosa se sienten poco naturales y lentos. La instrucción exige brevedad para que la interacción sea ágil.
- Arquitectura centrada en la acción: Las instrucciones priorizan la llamada a herramientas por sobre el habla. Queremos que el agente "haga" el trabajo (escanear la biometría) antes o mientras confirma verbalmente, no después de un monólogo largo.
👉✏️ Abre $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py y reemplaza #REPLACE INSTRUCTIONS por lo siguiente:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
NOTA: No te estás conectando a un LLM estándar. En el mismo archivo ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py), busca #REPLACE_MODEL. Debemos segmentar de forma explícita la versión preliminar de este modelo para admitir mejor las capacidades de audio en tiempo real.
👉✏️ Reemplaza el marcador de posición por lo siguiente:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
Ya se definió tu agente. Sabe quién es y cómo pensar. Luego, le proporcionamos las herramientas para actuar.
Llamadas a herramientas
La API de Live no se limita solo al intercambio de transmisiones de texto, audio y video. Admite de forma nativa la llamada a herramientas. Esto convierte a los agentes de conversadores pasivos en operadores activos.
Durante una sesión bidireccional en vivo, el modelo evalúa constantemente el contexto. Si el LLM detecta la necesidad de realizar una acción, ya sea "verificar la telemetría del sensor" o "destrabar una puerta segura". Cambia sin problemas de la conversación a la ejecución. El agente activa la función de herramienta específica de inmediato, espera el resultado y vuelve a integrar esos datos en la transmisión en vivo, todo sin interrumpir el flujo de la interacción.
👉✏️ En $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py, reemplaza #REPLACE TOOLS por esta función:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ Luego, regístralo en la definición de Agent reemplazando #TOOL CONFIG:
tools=[report_digit],
El simulador adk web
Antes de conectar esto a la cabina de la nave compleja (nuestro frontend de React), debemos probar la lógica del agente de forma aislada. El ADK incluye una consola para desarrolladores integrada llamada adk web que nos permite verificar la Llamada a herramientas antes de agregar complejidad de red.
👉💻 En tu terminal, ejecuta lo siguiente:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Haz clic en el ícono de vista previa en la Web en la barra de herramientas de Cloud Shell. Selecciona Cambiar puerto, configúralo en 8000 y haz clic en Cambiar y obtener vista previa.
- Otorga permisos: Permite el acceso a la cámara y al micrófono cuando se te solicite.
- Para iniciar la sesión, haz clic en el ícono de la cámara.
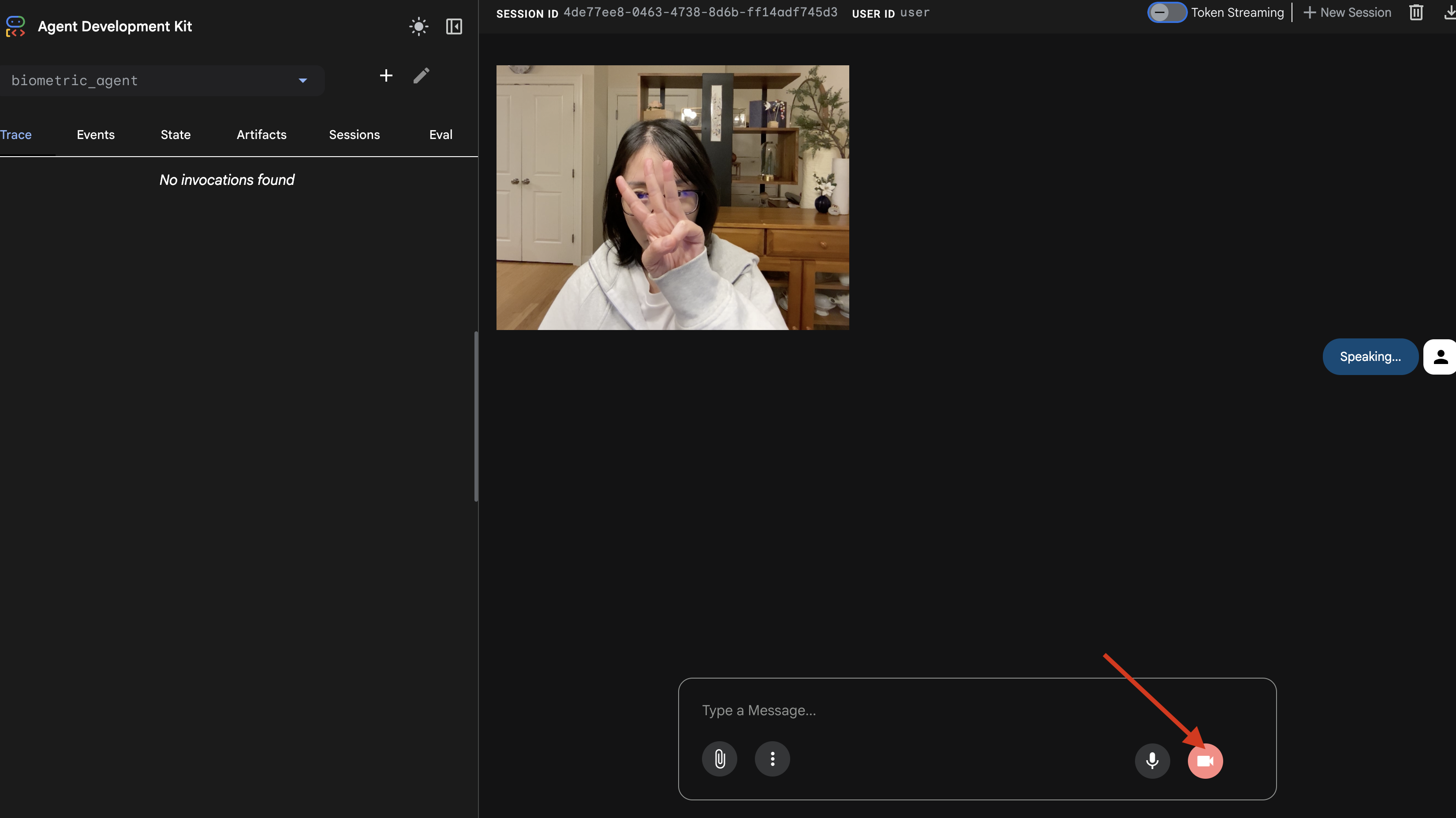
- La prueba visual:
- Sostén 3 dedos claramente frente a la cámara.
- Di "Escanear".
- Verifica el éxito:
- Registros: Observa la terminal que ejecuta el comando
adk web. Deberías ver este registro:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- Registros: Observa la terminal que ejecuta el comando
Si ves el registro de ejecución de la herramienta, significa que tu agente es inteligente. Puede ver, pensar y actuar. El último paso es conectarlo a la nave principal.
Haz clic en la ventana de la terminal y presiona Ctrl+C para detener el simulador de adk web.
5. Flujo de transmisión bidireccional
El agente funciona. Cockpit funciona. Ahora debemos conectarlos.
Ciclo de vida del agente en vivo
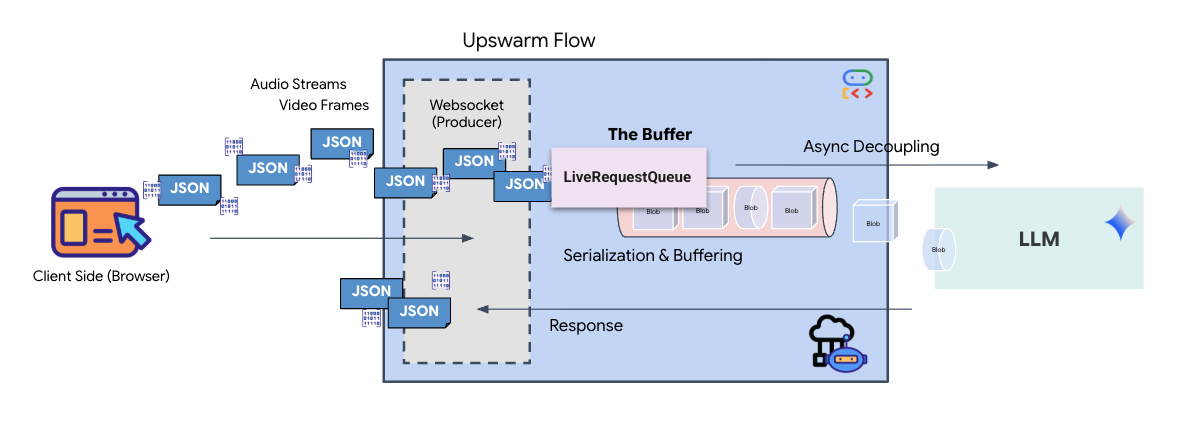
La transmisión en tiempo real introduce un problema de "desajuste de impedancia". El cliente (navegador) envía datos de forma asíncrona a velocidades variables (ráfagas de red o entradas rápidas), mientras que el modelo requiere un flujo de entrada secuencial y regulado. El ADK de Google resuelve este problema con el uso de LiveRequestQueue.
Actúa como un búfer asíncrono de primero en entrar, primero en salir (FIFO) seguro para subprocesos. El controlador de WebSocket actúa como productor y envía fragmentos de audio o video sin procesar a la cola. El agente del ADK actúa como consumidor y extrae datos de la cola para alimentar la ventana de contexto del modelo. Este desacoplamiento permite que la aplicación siga recibiendo entradas del usuario incluso mientras el modelo genera una respuesta o ejecuta una herramienta.
La cola funciona como un multiplexor multimodal. En un entorno real, el flujo ascendente consta de tipos de datos distintos y simultáneos: bytes de audio PCM sin procesar, fotogramas de video, instrucciones del sistema basadas en texto y los resultados de las llamadas a herramientas asíncronas. LiveRequestQueue linealiza estas entradas dispares en una sola secuencia cronológica. Ya sea que el paquete contenga un milisegundo de silencio, una imagen de alta resolución o una carga útil JSON de una consulta de base de datos, se serializa en el orden exacto de llegada, lo que garantiza que el modelo perciba una línea de tiempo causal y coherente.
Esta arquitectura habilita el control sin bloqueo. Dado que la capa de transferencia (productor) está desacoplada de la capa de procesamiento (consumidor), el sistema sigue respondiendo incluso durante la inferencia de modelos que requieren mucha capacidad de procesamiento. Si un usuario interrumpe con un comando "Detener" mientras el agente ejecuta una herramienta, ese indicador de audio se pone en cola de inmediato. El bucle de eventos subyacente procesa este indicador de prioridad de inmediato, lo que permite que el sistema detenga la generación o cambie las tareas sin que la IU se congele ni se pierdan paquetes.
👉💻 En $HOME/way-back-home/level_3/backend/app/main.py, busca el comentario #REPLACE_RUNNER_CONFIG y reemplázalo por el siguiente código para poner el sistema en línea:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
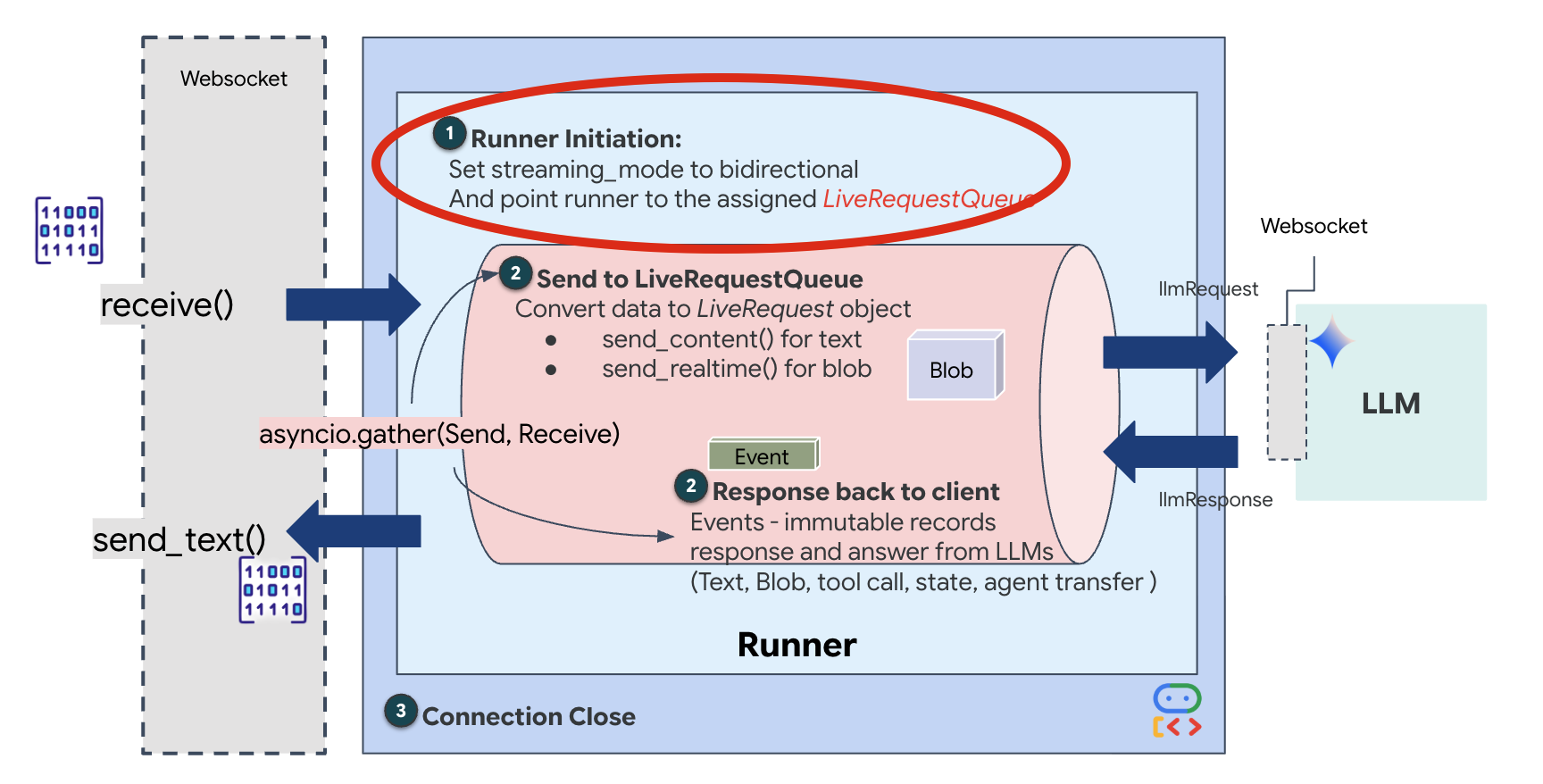
Cuando se abre una nueva conexión de WebSocket, debemos configurar cómo interactúa la IA. Aquí es donde definimos las "Reglas de participación".
👉✏️ En $HOME/way-back-home/level_3/backend/app/main.py, dentro de la función async def websocket_endpoint, reemplaza el comentario #REPLACE_SESSION_INIT por el siguiente código:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
La configuración de ejecución
StreamingMode.BIDI: Esto configura la conexión como bidireccional. A diferencia de la IA "por turnos" (en la que hablas, te detienes y luego habla la IA), BIDI permite una conversación "dúplex completa" realista. Puedes interrumpir a la IA, y esta puede hablar mientras te mueves.AudioTranscriptionConfig: Aunque el modelo "escucha" el audio sin procesar, nosotros (los desarrolladores) necesitamos ver los registros. Esta configuración le indica a Gemini: "Procesa el audio, pero también envía una transcripción de texto de lo que escuchaste para que podamos depurar".
La lógica de ejecución Una vez que el ejecutor establece la sesión, le entrega el control a la lógica de ejecución, que se basa en LiveRequestQueue. Este es el componente más importante para la interacción en tiempo real. El bucle permite que el agente genere una respuesta de voz mientras la cola sigue aceptando nuevos fotogramas de video del usuario, lo que garantiza que la "Sincronización neuronal" nunca se interrumpa.
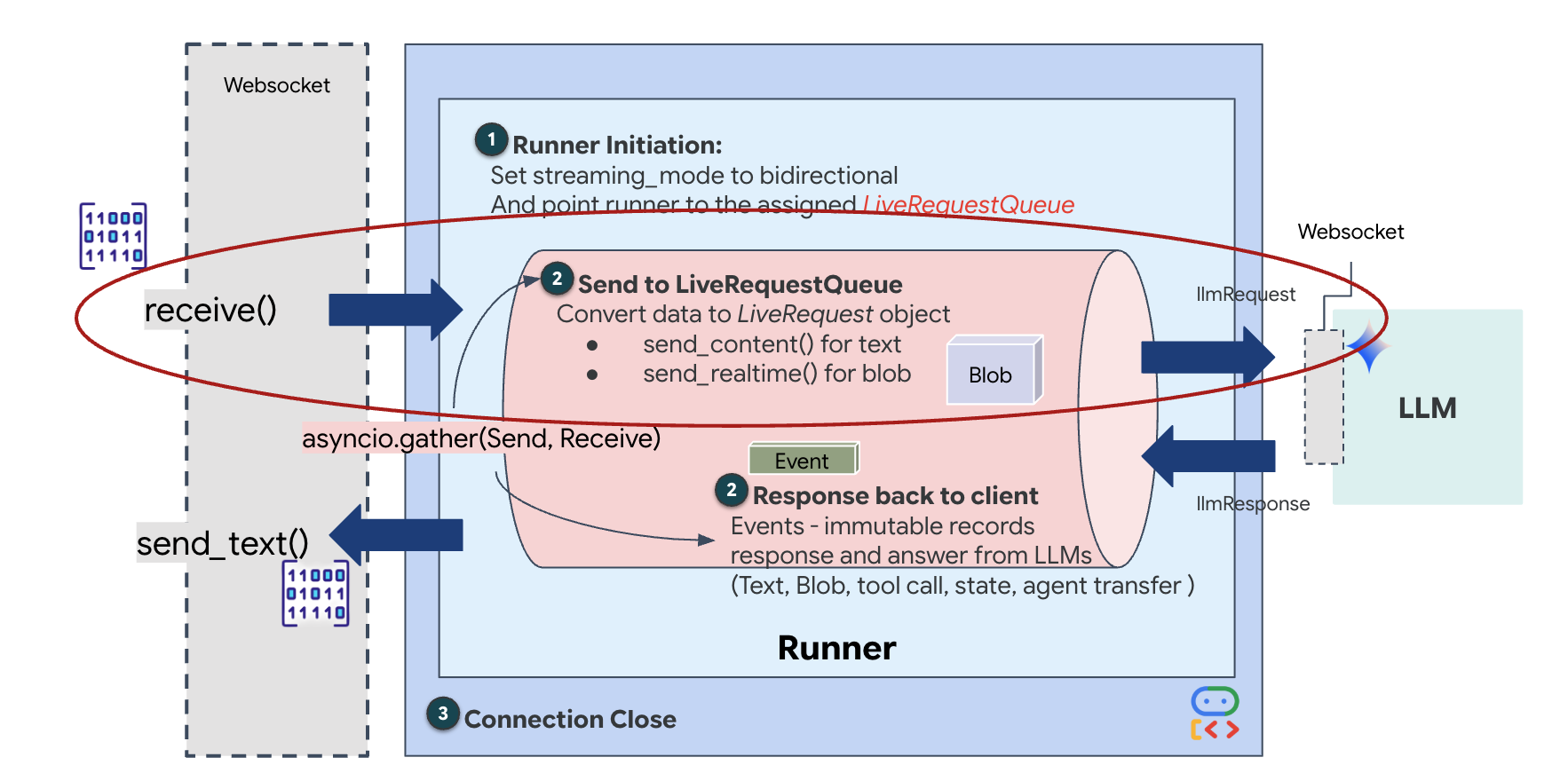
👉✏️ En $HOME/way-back-home/level_3/backend/app/main.py, reemplaza #REPLACE_LIVE_REQUEST para definir la tarea upstream que envía datos a LiveRequestQueue:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
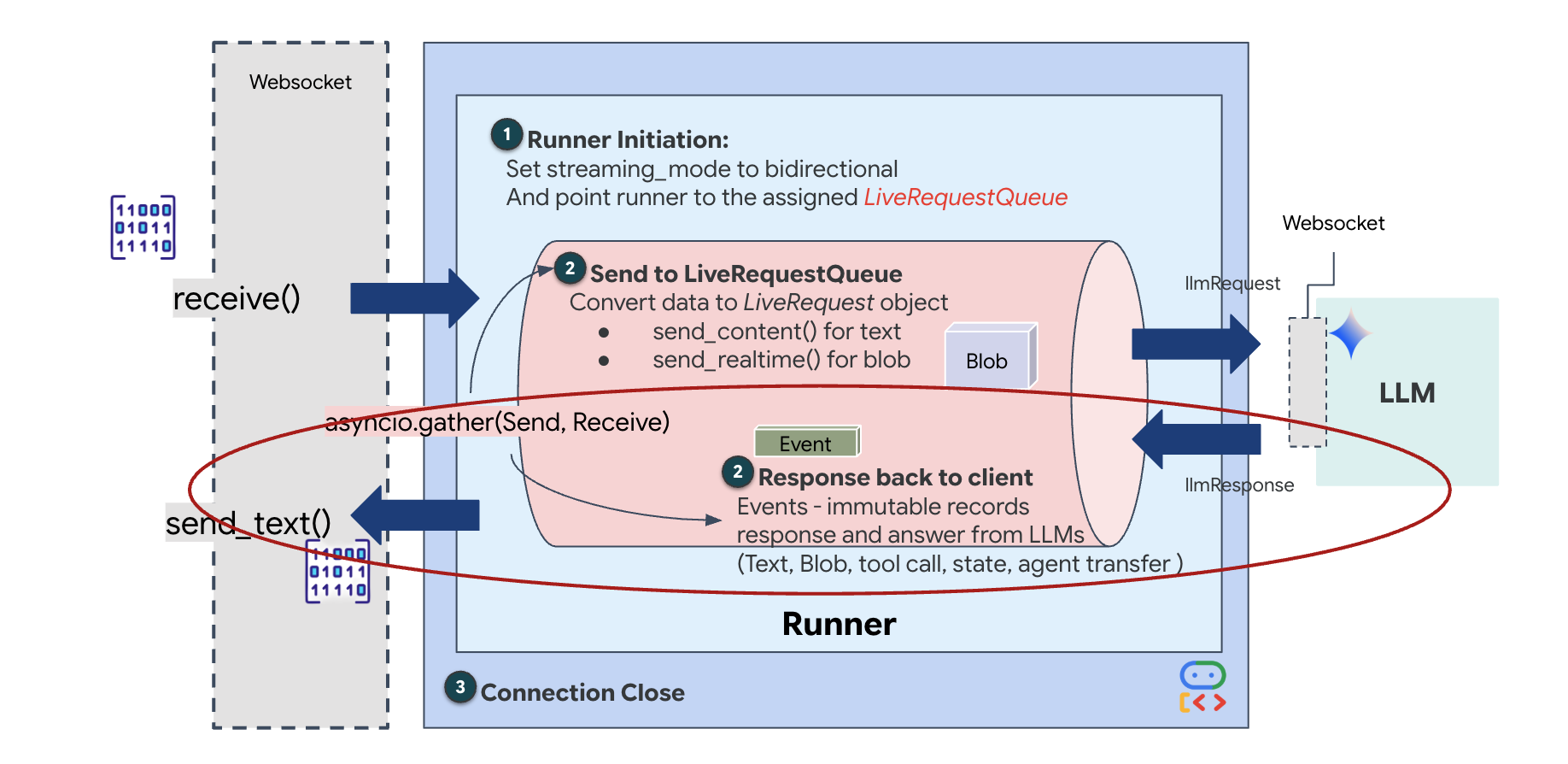
Por último, debemos controlar las respuestas de la IA. Esto usa runner.run_live(), que es un generador de eventos que produce eventos (Audio, Texto o Llamadas a herramientas) a medida que suceden.
👉✏️ En $HOME/way-back-home/level_3/backend/app/main.py, reemplaza #REPLACE_SORT_RESPONSE para definir la tarea posterior y el administrador de simultaneidad:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
Observa la línea await asyncio.gather(upstream_task(), downstream_task()). Esta es la esencia de Full-Duplex. Ejecutamos la tarea de escucha (upstream) y la tarea de habla (downstream) al mismo tiempo. Esto garantiza que la "vinculación neuronal" permita la interrupción y el flujo de datos simultáneo.
Ahora, tu backend está completamente codificado. El "cerebro" (ADK) está conectado al "cuerpo" (WebSocket).
Ejecución de Bio-Sync
El código está completo. Los sistemas son verdes. Es hora de iniciar el rescate.
- 👉💻 Inicia el backend:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 Inicia el frontend:
- Haz clic en el ícono de vista previa en la Web en la barra de herramientas de Cloud Shell. Selecciona Cambiar puerto, configúralo en 8080 y haz clic en Cambiar y obtener vista previa.
- 👉 Ejecuta el protocolo:
- Haz clic en "INICIAR SINCRONIZACIÓN NEURAL".
- Calibrar: Asegúrate de que la cámara vea tu mano con claridad en el fondo.
- La sincronización: Mira el código de seguridad que se muestra en la pantalla (p.ej., 3, luego 2 y, luego, 5).
- Coincide con el número: Cuando aparezca un número, levanta esa cantidad exacta de dedos.
- Mantén la mano firme: Mantén la mano visible hasta que la IA confirme la "Coincidencia biométrica".
- Adaptación: El código es aleatorio. Cambia de inmediato al siguiente número que se muestra hasta que se complete la secuencia.

- Cuando coincida el número final de la secuencia aleatoria, se completará la "Sincronización biométrica". El vínculo neuronal se bloqueará. Tienes control manual. Los motores del Scout rugirán y se sumergirán en The Ravine para llevar a los sobrevivientes a casa.
👉💻 Presiona Ctrl+C en la terminal de backend para salir.
6. Implementa el lanzamiento en producción (opcional)
Probaste correctamente la biometría de forma local. Ahora, debemos subir el núcleo neuronal del agente a los servidores centrales de la nave (Cloud Run) para que pueda operar de forma independiente de tu consola local.
👉💻 Ejecuta el siguiente comando en tu terminal de Cloud Shell. Se creará el Dockerfile completo de varias etapas en tu directorio de backend.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 Navega al directorio de backend y empaqueta la aplicación en una imagen de contenedor.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 Implementa el servicio en Cloud Run. Insertaremos las variables de entorno necesarias, específicamente la configuración de Gemini, directamente en el comando de inicio.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
Una vez que finalice el comando, verás una URL de servicio (p.ej., https://biometric-scout-...run.app). La aplicación ahora está activa en la nube.
👉 Ve a la página Google Cloud Run y selecciona el servicio biometric-scout de la lista. 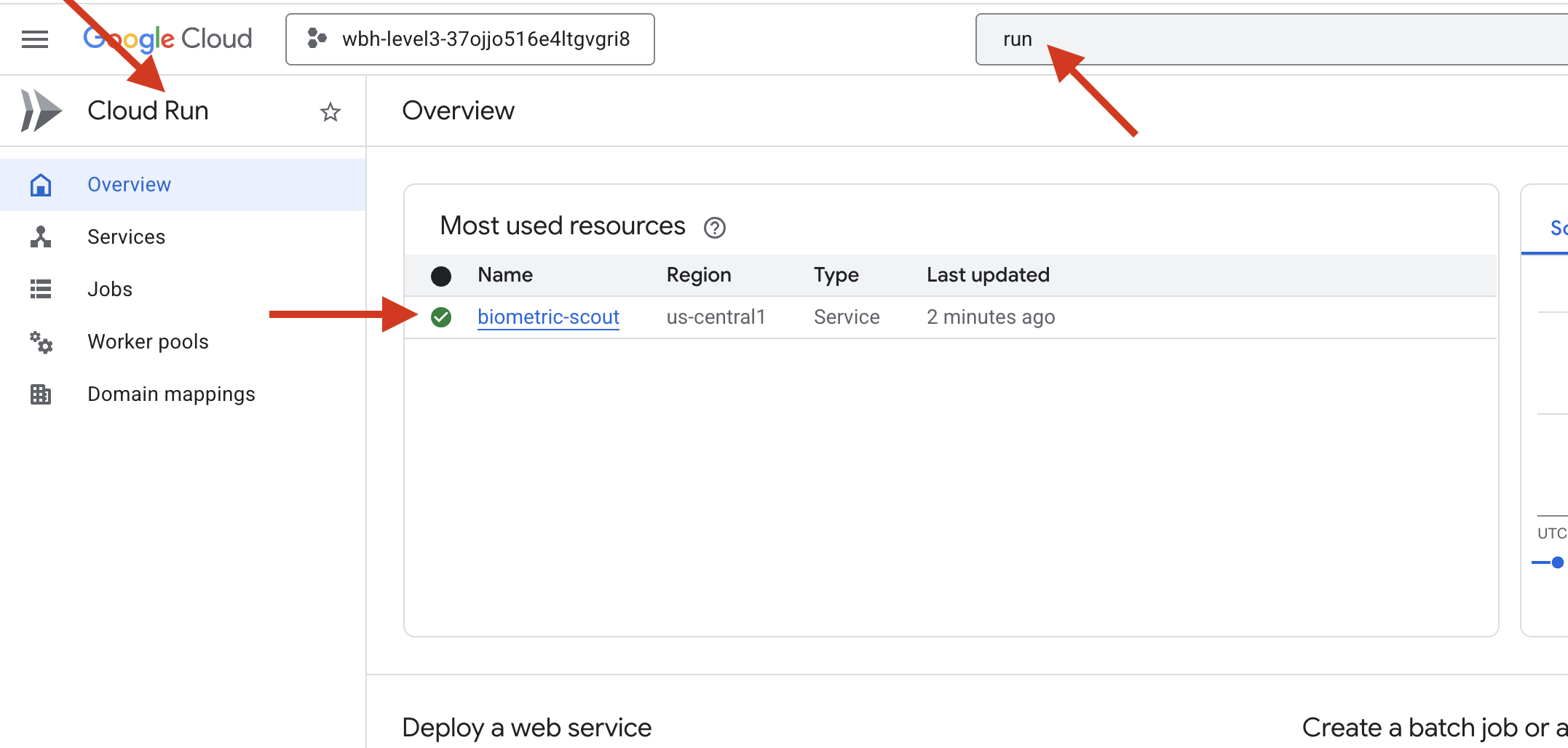
👉 Busca la URL pública que se muestra en la parte superior de la página Detalles del servicio. 
Intenta realizar la sincronización de la biografía en este entorno. ¿También funciona?
Cuando extiendas el quinto dedo, la IA bloqueará la secuencia. La pantalla parpadea en verde: "Sincronización neuronal biométrica: ESTABLECIDA".
Con un solo pensamiento, sumerges al explorador en la oscuridad, te enganchas a la cápsula varada y la sacas justo antes de que se derrumbe la grieta de gravedad.

La esclusa de aire se abre con un siseo, y allí están: cinco sobrevivientes vivos y respirando. Se tambalean en la cubierta, golpeados pero vivos, y a salvo por fin gracias a ti.
Gracias a ti, el vínculo neuronal se sincronizó y se rescató a los sobrevivientes.
Si participaste en el nivel 0, no olvides verificar tu progreso en la misión de regreso a casa.