۱. ماموریت

شما در سکوت یک بخش ناشناخته سرگردان هستید. یک **پالس خورشیدی** عظیم، کشتی شما را از شکافی دریده و شما را در گوشهای از کیهان که در هیچ نمودار ستارهای وجود ندارد، تنها گذاشته است.
بعد از روزها تعمیرات طاقتفرسا، بالاخره صدای موتورها را زیر پایتان حس میکنید. سفینه فضاییتان درست شده است. حتی موفق شدهاید یک ارتباط بلندبرد با سفینه مادر برقرار کنید. آماده حرکت هستید. آماده رفتن به خانه هستید. اما همین که آماده میشوید تا سیستم پرش را فعال کنید، یک سیگنال اضطراری از میان امواج عبور میکند. حسگرهای شما پنج علامت حرارتی ضعیف را که در "دره" گیر افتادهاند، دریافت میکنند - یک بخش ناهموار و دارای انحراف گرانشی که سفینه اصلی شما هرگز نمیتواند وارد آن شود. اینها کاوشگران همکار شما هستند، بازماندگان همان طوفانی که نزدیک بود شما را نابود کند. نمیتوانید آنها را پشت سر بگذارید.
شما به سراغ آلفا-درون نجات اسکات خود میروید. این کشتی کوچک و چابک، تنها کشتیای است که قادر به پیمایش دیوارهای باریک دره است. اما مشکلی وجود دارد: پالس خورشیدی یک "تنظیم مجدد سیستم" کامل را در منطق اصلی خود انجام داده است. سیستمهای کنترل اسکات پاسخگو نیستند. روشن است، اما کامپیوتر داخلی آن کاملاً خالی است و قادر به پردازش دستورات دستی خلبان یا مسیرهای پرواز نیست.
چالش
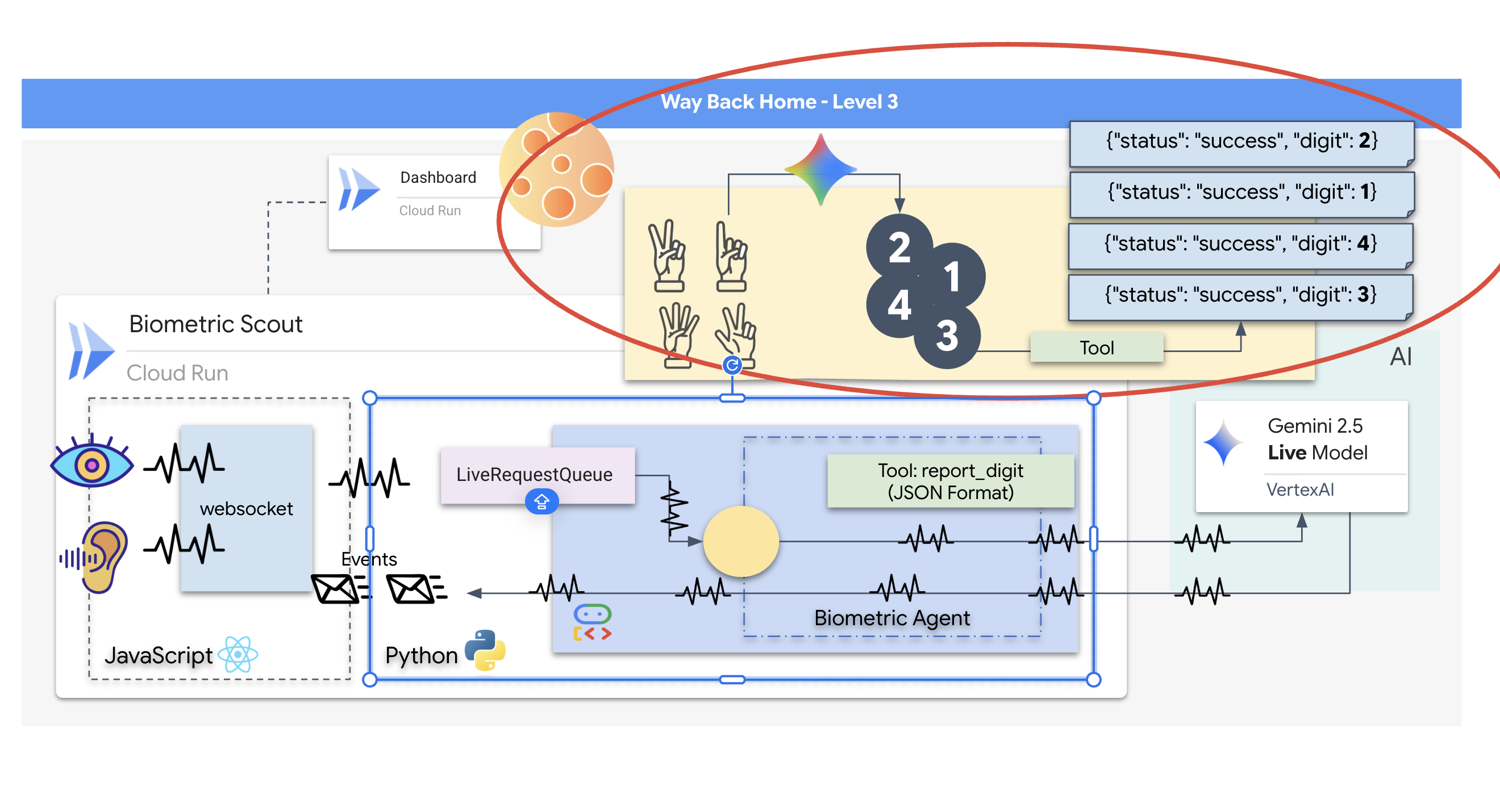
برای نجات بازماندگان، باید مدارهای آسیبدیدهی Scout را بهطور کامل دور بزنید. شما یک گزینهی ناامیدکننده دارید: یک عامل هوش مصنوعی بسازید تا یک همگامسازی عصبی بیومتریک برقرار کند. این عامل بهعنوان یک پل بلادرنگ عمل میکند و به شما امکان میدهد Rescue Scout را بهصورت دستی از طریق ورودیهای بیولوژیکی خود کنترل کنید. شما از جویاستیک یا صفحهکلید استفاده نخواهید کرد؛ شما مستقیماً قصد خود را به شبکهی ناوبری کشتی متصل خواهید کرد.
برای قفل کردن لینک، باید پروتکل همگامسازی را در مقابل حسگرهای نوری Scout اجرا کنید. عامل هوش مصنوعی باید امضای بیولوژیکی شما را از طریق یک دست دادن دقیق و بلادرنگ تشخیص دهد.
اهداف ماموریت شما:
- هسته عصبی را چاپ کنید: یک عامل ADK تعریف کنید که قادر به تشخیص ورودیهای چندوجهی باشد.
- ایجاد اتصال: یک خط لوله WebSocket دو طرفه بسازید تا دادههای بصری را از Scout به هوش مصنوعی منتقل کند.
- شروع دست دادن: روبروی حسگر بایستید و توالی انگشتان خود را کامل کنید - به ترتیب از ۱ تا ۵.
در صورت موفقیت، «همگامسازی بیومتریک» فعال میشود. هوش مصنوعی، پیوند عصبی را قفل میکند و به شما کنترل دستی کامل برای پرتاب اسکات و بازگرداندن بازماندگان به خانه را میدهد.
آنچه خواهید ساخت
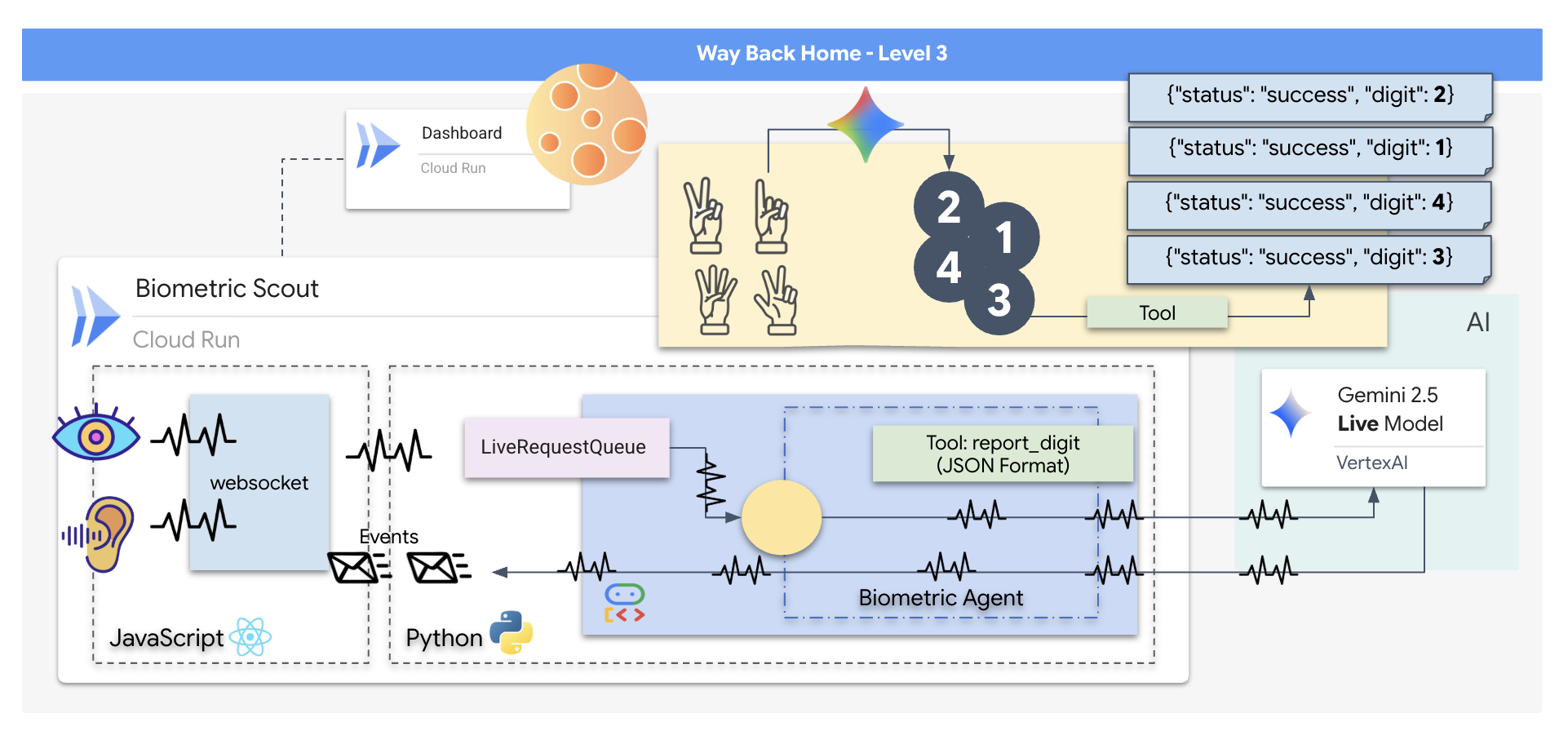
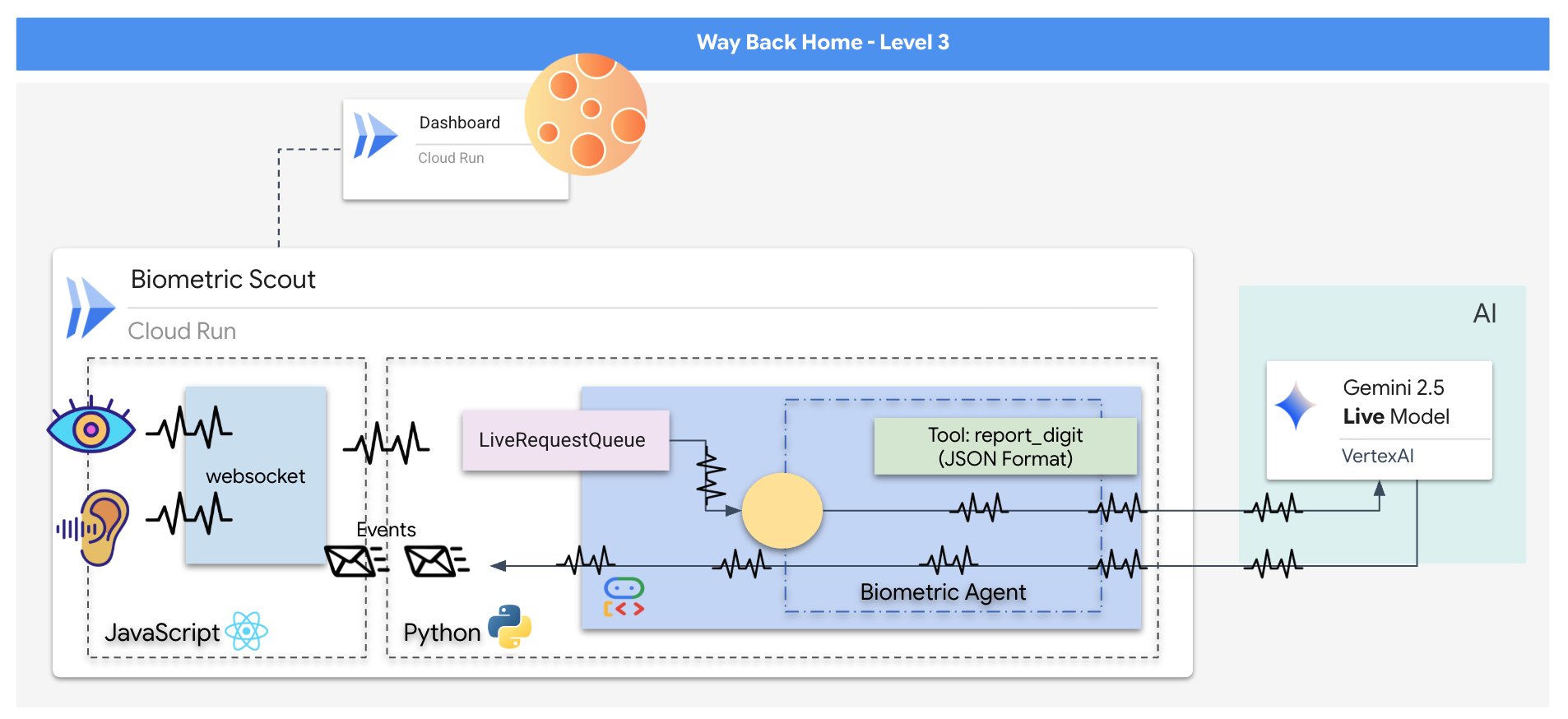
شما یک برنامه "همگامسازی عصبی بیومتریک" خواهید ساخت، یک سیستم مبتنی بر هوش مصنوعی بلادرنگ که به عنوان رابط کنترل برای یک پهپاد نجات عمل میکند. این سیستم شامل موارد زیر است:
- یک رابط کاربری React: «کابین خلبان» کشتی شما که ویدیوی زنده را از وبکم و صدا را از میکروفون شما ضبط میکند.
- یک بکاند پایتون: یک سرور با کارایی بالا که با FastAPI ساخته شده و از کیت توسعه عامل (ADK) گوگل برای مدیریت منطق و وضعیت LLM استفاده میکند.
- یک عامل هوش مصنوعی چندوجهی: «مغز» عملیات، که از رابط برنامهنویسی Gemini Live از طریق
google-genaiSDK برای پردازش و درک همزمان جریانهای ویدیویی و صوتی استفاده میکند. - یک خط لوله وب سوکت دو طرفه: "سیستم عصبی" که یک اتصال پایدار و با تأخیر کم بین رابط کاربری و هوش مصنوعی ایجاد میکند و امکان تعامل در لحظه را فراهم میکند.
آنچه یاد خواهید گرفت
فناوری / مفهوم | توضیحات |
عامل هوش مصنوعی بکاند | با پایتون و FastAPI یک عامل هوش مصنوعی stateful بسازید. از ADK (کیت توسعه عامل) گوگل برای مدیریت دستورالعملها و حافظه و از |
رابط کاربری فرانتاند | با استفاده از React یک رابط کاربری پویا برای ضبط و پخش زنده ویدیو و صدا مستقیماً از مرورگر توسعه دهید. |
ارتباط بلادرنگ | یک خط لوله WebSocket را برای ارتباط کاملاً دوطرفه و با تأخیر کم پیادهسازی کنید، که به کاربر و هوش مصنوعی اجازه میدهد همزمان با هم تعامل داشته باشند. |
هوش مصنوعی چندوجهی | از رابط برنامهنویسی نرمافزار Gemini Live برای پردازش و درک جریانهای همزمان ویدیو و صدا استفاده کنید و هوش مصنوعی را قادر سازید تا همزمان «ببیند» و «بشنود». |
فراخوانی ابزار | هوش مصنوعی را قادر میسازد تا توابع خاص پایتون را در پاسخ به محرکهای بصری اجرا کند و شکاف بین هوش مدل و عمل در دنیای واقعی را پر کند. |
استقرار کامل (Full-Stack) | کل برنامه (ظاهر React و باطن Python) را با Docker کانتینرایز کنید و آن را به عنوان یک سرویس مقیاسپذیر و بدون سرور در Google Cloud Run مستقر کنید. |
۲. محیط خود را آماده کنید
دسترسی به پوسته ابری
ابتدا، Cloud Shell را باز میکنیم که یک ترمینال مبتنی بر مرورگر است و Google Cloud SDK و سایر ابزارهای ضروری از پیش نصب شده روی آن قرار دارند.
👉 روی فعال کردن پوسته ابری (Activate Cloud Shell) در بالای کنسول گوگل کلود کلیک کنید (این آیکون به شکل ترمینال در بالای پنل پوسته ابری قرار دارد)، 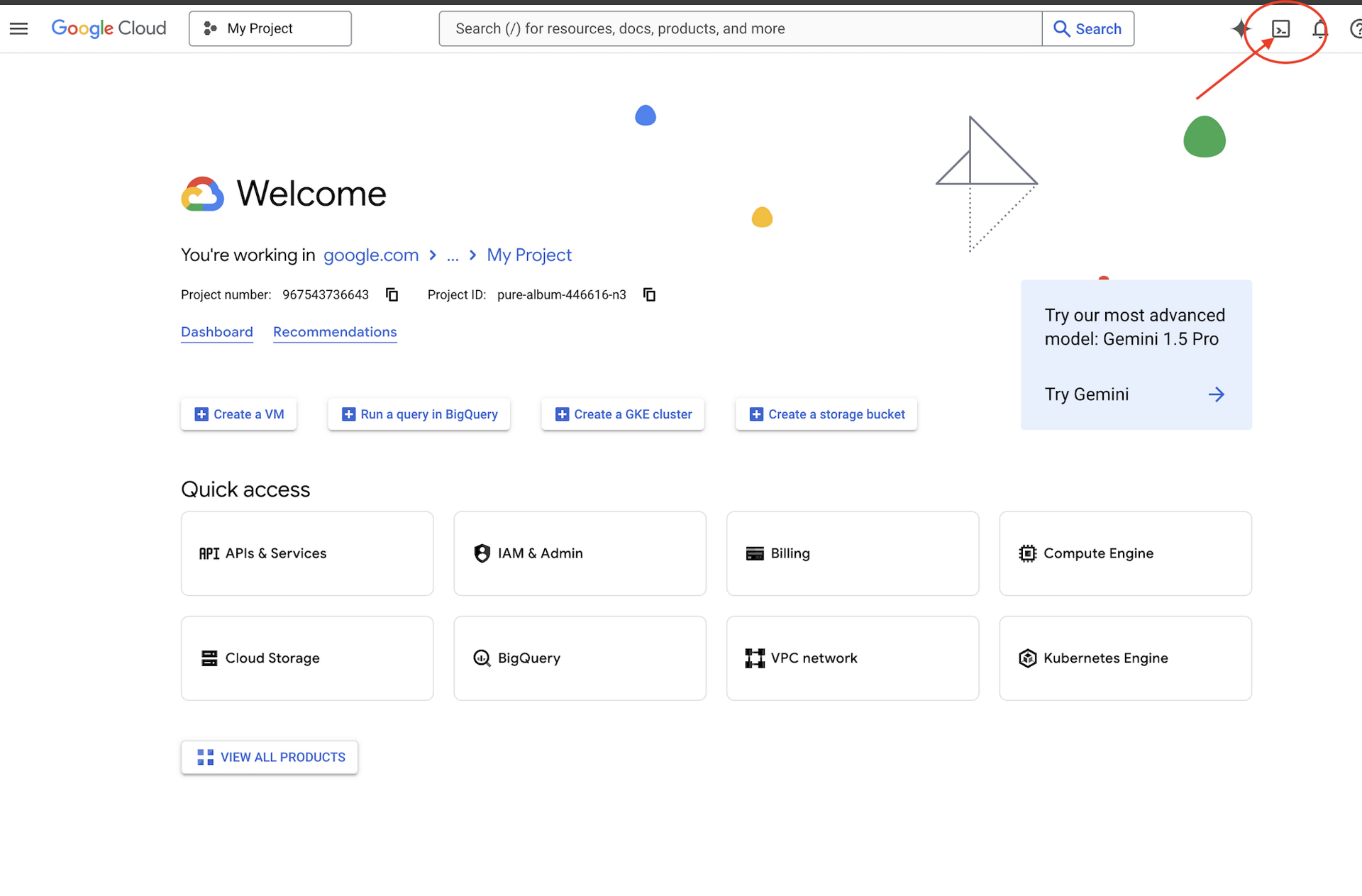
👉 روی دکمهی «باز کردن ویرایشگر» کلیک کنید (شبیه یک پوشهی باز شده با مداد است). با این کار ویرایشگر کد Cloud Shell در پنجره باز میشود. یک فایل اکسپلورر در سمت چپ خواهید دید. 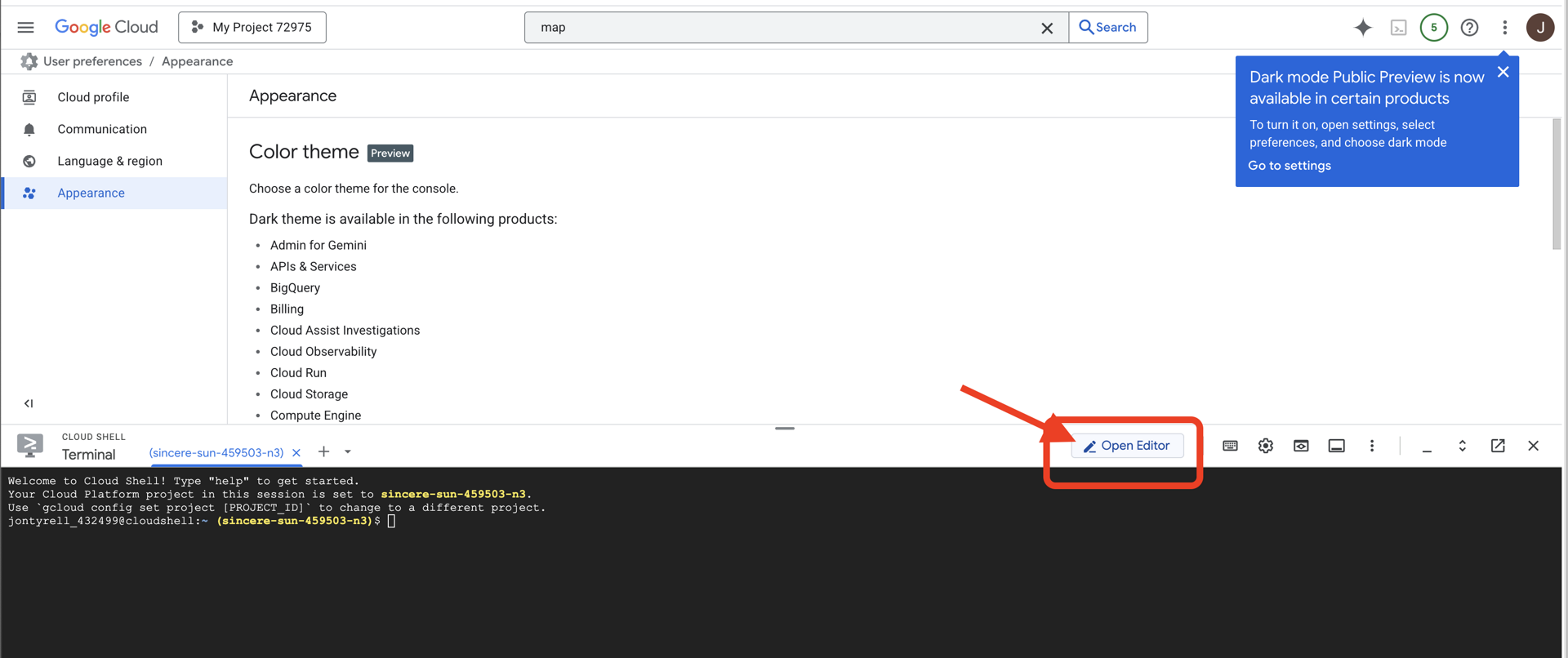
👉 ترمینال را در محیط توسعه ابری (cloud IDE) باز کنید،
👉💻 در ترمینال، با استفاده از دستور زیر تأیید کنید که از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است:
gcloud auth list
باید حساب خود را به عنوان (ACTIVE) مشاهده کنید.
پیشنیازها
ℹ️ سطح ۰ اختیاری است (اما توصیه میشود)
شما میتوانید این ماموریت را بدون سطح ۰ انجام دهید، اما تمام کردن آن در ابتدا تجربهای فراگیرتر ارائه میدهد و به شما این امکان را میدهد که با پیشرفت خود، چراغ راهنمای خود را روی نقشه جهانی ببینید.
راهاندازی محیط پروژه
به ترمینال خود برگردید، با تنظیم پروژه فعال و فعال کردن سرویسهای مورد نیاز Google Cloud (Cloud Run، Vertex AI و غیره) پیکربندی را نهایی کنید.
👉💻 در ترمینال خود، شناسه پروژه را تنظیم کنید:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 فعال کردن سرویسهای مورد نیاز:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
نصب وابستگیها
👉💻 به بخش Level بروید و بستههای پایتون مورد نیاز را نصب کنید:
cd $HOME/way-back-home/level_3
uv sync
وابستگیهای کلیدی عبارتند از:
بسته | هدف |
| چارچوب وب با کارایی بالا برای ایستگاه ماهوارهای و استریم SSE |
| سرور ASGI برای اجرای برنامه FastAPI مورد نیاز است |
| کیت توسعه عامل مورد استفاده برای ساخت عامل سازند |
| کلاینت بومی برای دسترسی به مدلهای Gemini |
| پشتیبانی از ارتباط دو طرفه بلادرنگ |
| متغیرهای محیطی و اسرار پیکربندی را مدیریت میکند |
تأیید تنظیمات
قبل از اینکه وارد کد شویم، بیایید مطمئن شویم که همه سیستمها سبز هستند. اسکریپت تأیید را اجرا کنید تا پروژه Google Cloud، APIها و وابستگیهای پایتون خود را بررسی کنید.
👉💻 اسکریپت تأیید را اجرا کنید:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 شما باید یک سری علامت سبز (✅) ببینید.
- اگر علامت صلیب قرمز (❌) را مشاهده کردید، دستورات اصلاحی پیشنهادی در خروجی را دنبال کنید (مثلاً
gcloud services enable ...یاpip install ...). - نکته: فعلاً اخطار زرد برای
.env قابل قبول است؛ آن فایل را در مرحله بعدی ایجاد خواهیم کرد.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
۳. کالیبره کردن Comm-Link (WebSockets)
برای شروع همگامسازی عصبی بیومتریک، باید سیستمهای داخلی کشتی شما را بهروزرسانی کنیم. هدف اصلی ما ضبط یک جریان ویدیویی و صوتی با کیفیت بالا از کابین خلبان شماست. این جریان اجزای ضروری برای پیوند عصبی را فراهم میکند: شناسایی بصری توالی انگشتان شما و فرکانس صوتی صدای شما.
تمام دوبلکس در مقابل نیمه دوبلکس
برای درک اینکه چرا به این مورد برای همگامسازی عصبی نیاز داریم، باید جریان دادهها را درک کنید:
- نیمه دوطرفه (HTTP استاندارد): مانند یک واکی تاکی. یک نفر صحبت میکند، میگوید «تمام شد» و سپس شخص دیگر میتواند صحبت کند. شما نمیتوانید همزمان هم گوش دهید و هم صحبت کنید.
- دوطرفه کامل (WebSocket): مانند یک مکالمه رو در رو. دادهها به طور همزمان در هر دو جهت جریان مییابند. در حالی که مرورگر شما فریمهای ویدیویی و نمونههای صوتی را به هوش مصنوعی ارسال میکند، هوش مصنوعی میتواند پاسخهای صوتی و دستورات ابزار را دقیقاً همزمان به شما ارسال کند.
چرا Gemini Live به Full-Duplex نیاز دارد: API Gemini Live برای "وقفه" طراحی شده است. تصور کنید که شما دنباله انگشت را نشان میدهید و هوش مصنوعی میبیند که شما آن را اشتباه انجام میدهید. در یک تنظیم استاندارد HTTP، هوش مصنوعی باید منتظر بماند تا ارسال دادههای شما تمام شود تا بتواند به شما بگوید که متوقف شوید. با WebSockets، هوش مصنوعی میتواند در فریم ۱ اشتباهی را ببیند و یک سیگنال "وقفه" ارسال کند که در حالی که شما هنوز دست خود را برای فریم ۲ حرکت میدهید، به کابین خلبان شما میرسد.
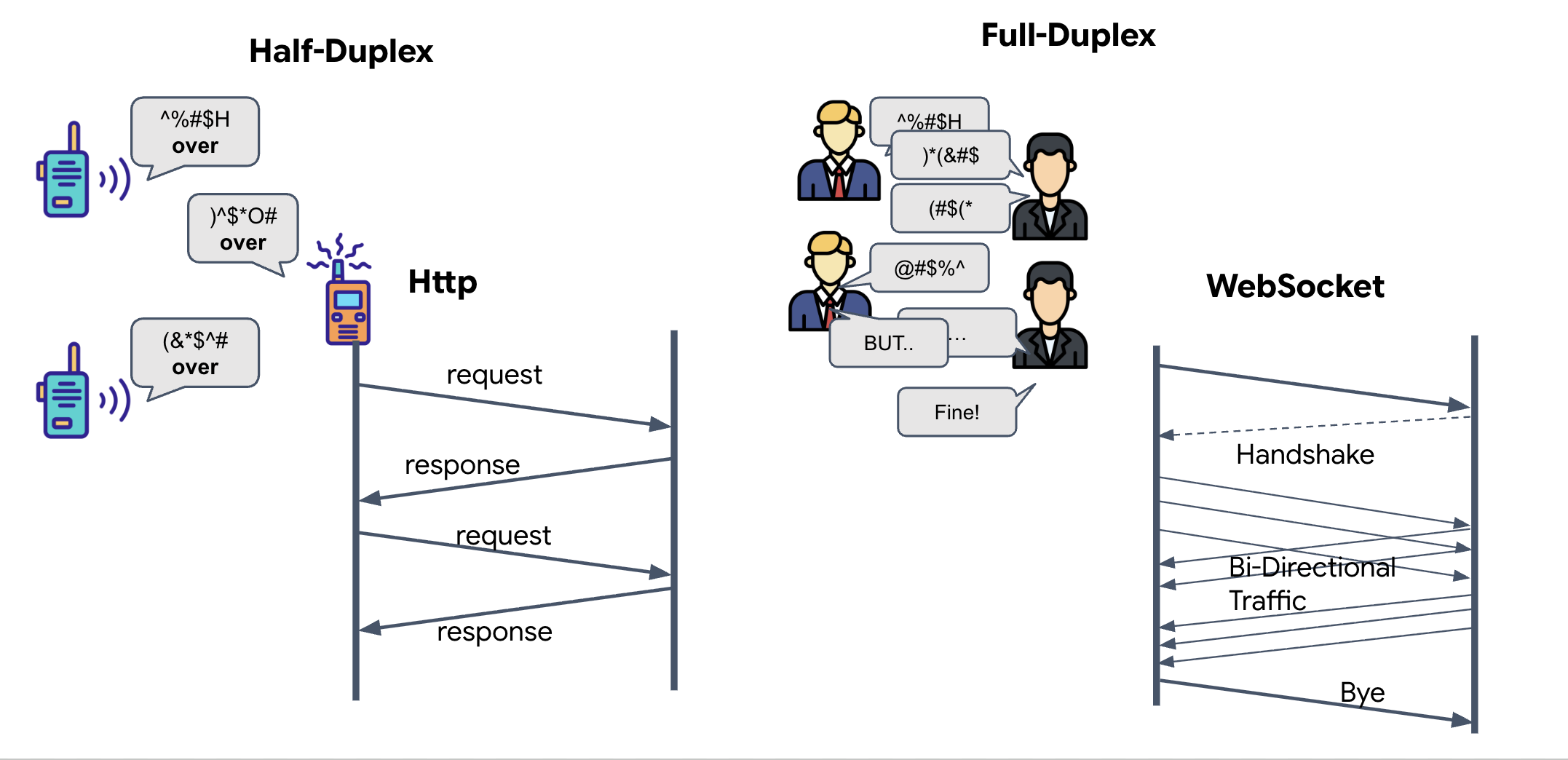
وبساکت چیست؟
در یک انتقال کهکشانی استاندارد (HTTP)، شما یک درخواست ارسال میکنید و منتظر پاسخ میمانید - مانند ارسال کارت پستال. برای یک همگامسازی عصبی ، کارت پستالها خیلی کند هستند. ما به یک "سیم زنده" نیاز داریم.
وبسوکتها به عنوان یک درخواست وب استاندارد (HTTP) شروع میشوند، اما سپس به چیزی متفاوت «ارتقاء» مییابند.
- درخواست: مرورگر شما یک درخواست HTTP استاندارد با یک هدر خاص به نام
Upgrade: websocketبه سرور ارسال میکند. این درخواست اساساً میگوید: «میخواهم ارسال کارت پستال را متوقف کنم و یک تماس تلفنی زنده برقرار کنم.» - پاسخ: اگر عامل هوش مصنوعی (سرور) از این پشتیبانی کند، یک پاسخ
HTTP 101 Switching Protocolsارسال میکند. - تحول: در این لحظه، اتصال HTTP با پروتکل WebSocket جایگزین میشود، اما سوکت TCP/IP زیرین باز میماند. قوانین ارتباط فوراً از "درخواست/پاسخ" به "جریان کامل دوطرفه" تغییر میکند.
پیادهسازی هوک WebSocket
بیایید بلوک ترمینال را بررسی کنیم تا نحوه جریان دادهها را درک کنیم.
👀 $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js را باز کنید. خواهید دید که کنترلکنندههای رویداد چرخه عمر استاندارد WebSocket از قبل تنظیم شدهاند. این اسکلت سیستم ارتباطی ما است:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
کنترلکنندهی onMessage
روی بلوک ws.current.onmessage تمرکز کنید. این بلوک گیرنده است. هر بار که عامل "فکر میکند" یا "صحبت میکند"، یک بسته داده به اینجا میرسد. در حال حاضر، هیچ کاری انجام نمیدهد - بسته را میگیرد و آن را رها میکند (از طریق placeholder //#REPLACE-HANDLE-MSG ).
ما باید این خلأ را با منطقی پر کنیم که بتواند بین موارد زیر تمایز قائل شود:
- فراخوانی ابزار (فراخوان عملکرد): هوش مصنوعی سیگنالهای دست شما را تشخیص میدهد ("همگامسازی").
- دادههای صوتی (inlineData): صدای هوش مصنوعی که به شما پاسخ میدهد.
👉✏️ اکنون، در همان فایل $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js ، عبارت //#REPLACE-HANDLE-MSG را با منطق زیر جایگزین کنید تا جریان ورودی را مدیریت کنید:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
چگونه صدا و تصویر برای انتقال به داده تبدیل میشوند
برای فعال کردن ارتباط بلادرنگ از طریق اینترنت، صدا و تصویر خام باید به فرمتی مناسب برای انتقال تبدیل شوند. این شامل ضبط، رمزگذاری و بستهبندی دادهها قبل از ارسال آنها از طریق شبکه است.
تبدیل دادههای صوتی
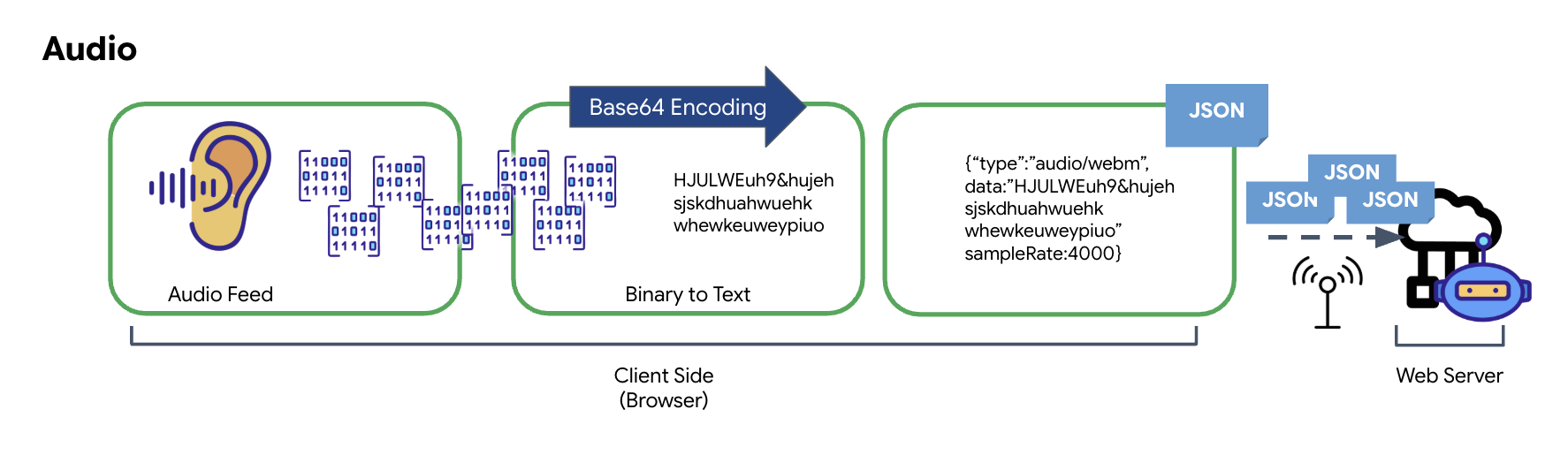
فرآیند تبدیل صدای آنالوگ به دادههای دیجیتال قابل انتقال با ضبط امواج صوتی با استفاده از میکروفون آغاز میشود. این صدای خام سپس از طریق رابط برنامهنویسی کاربردی وب صوتی مرورگر پردازش میشود. از آنجا که این دادههای خام در قالب دودویی هستند، مستقیماً با قالبهای انتقال مبتنی بر متن مانند JSON سازگار نیستند. برای حل این مشکل، هر بخش از صدا در یک رشته Base64 کدگذاری میشود. Base64 روشی است که دادههای دودویی را در قالب رشته ASCII نمایش میدهد و یکپارچگی آن را در حین انتقال تضمین میکند.
این رشته کدگذاری شده سپس در یک شیء JSON جاسازی میشود. این شیء یک قالب ساختاریافته برای دادهها فراهم میکند که معمولاً شامل یک فیلد "نوع" برای شناسایی آن به عنوان صدا و ابردادههایی مانند نرخ نمونهبرداری صدا است. سپس کل شیء JSON به یک رشته سریالی شده و از طریق یک اتصال WebSocket ارسال میشود. این رویکرد تضمین میکند که صدا به شیوهای سازمانیافته و به راحتی قابل تجزیه و تحلیل منتقل میشود.
تبدیل دادههای ویدیویی
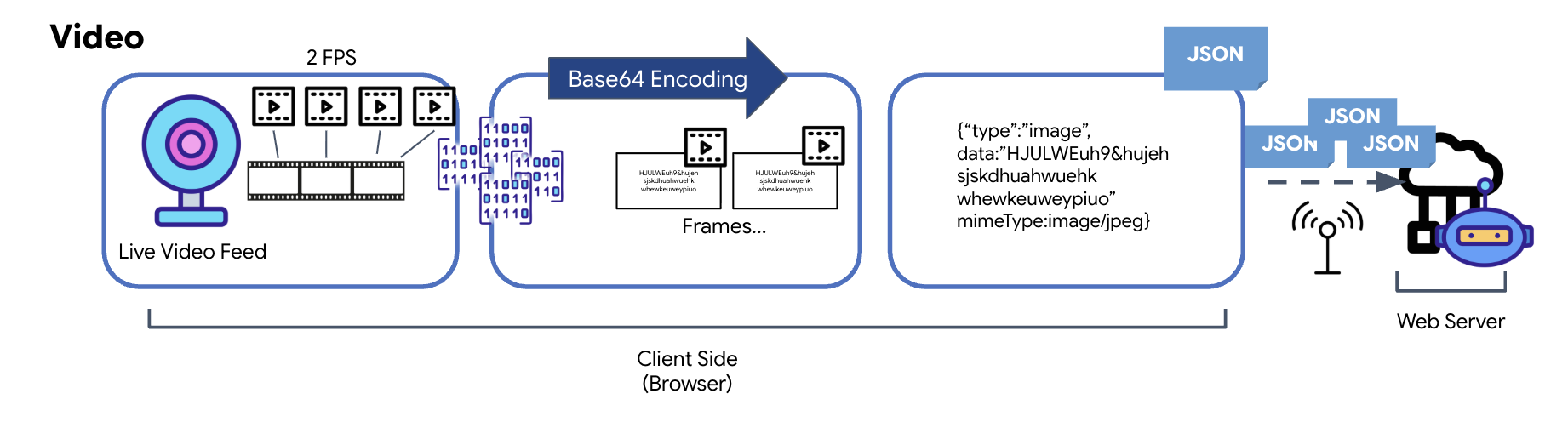
انتقال ویدیو از طریق تکنیک ضبط فریم انجام میشود. به جای ارسال یک جریان ویدیویی مداوم، یک حلقه تکرارشونده تصاویر ثابت را از فید ویدیوی زنده در یک فاصله زمانی مشخص، مانند دو فریم در ثانیه، ضبط میکند. این کار با ترسیم فریم فعلی از یک عنصر ویدیوی HTML روی یک عنصر پنهان canvas انجام میشود.
سپس از متد toDataURL در canvas برای تبدیل این تصویر گرفته شده به یک رشته JPEG کدگذاری شده با Base64 استفاده میشود. این متد شامل گزینهای برای تعیین کیفیت تصویر است که امکان ایجاد تعادل بین کیفیت تصویر و اندازه فایل را برای بهینهسازی عملکرد فراهم میکند. مشابه دادههای صوتی، این رشته Base64 سپس در یک شیء JSON قرار میگیرد. این شیء معمولاً با "نوع" 'image' برچسبگذاری میشود و شامل mimeType مانند 'image/jpeg' است. سپس این بسته JSON به یک رشته تبدیل شده و از طریق WebSocket ارسال میشود و به گیرنده اجازه میدهد تا با نمایش توالی تصاویر، ویدیو را بازسازی کند.
👉✏️ در همان فایل $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js ، برای دریافت ورودی کاربر //#CAPTURE AUDIO and VIDEO را با دستور زیر جایگزین کنید:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
پس از ذخیره شدن، کابین خلبان آماده خواهد بود تا سیگنالهای دیجیتال مامور را به بهروزرسانیهای بصری داشبورد و صدا تبدیل کند.
بررسی تشخیصی (تست حلقه برگشتی)
کابین خلبان شما اکنون فعال است. هر ۵۰۰ میلیثانیه، یک «بسته» تصویری از محیط اطراف شما ارسال میشود. قبل از اتصال به جمینی، باید تأیید کنیم که فرستنده کشتی شما کار میکند. ما با استفاده از یک سرور تشخیصی محلی، یک «آزمایش حلقهوار» اجرا خواهیم کرد.
👉💻 ابتدا رابط کاربری Cockpit را از ترمینال خود بسازید:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 سپس، سرور آزمایشی را اجرا کنید:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 اجرای پروتکل تست:
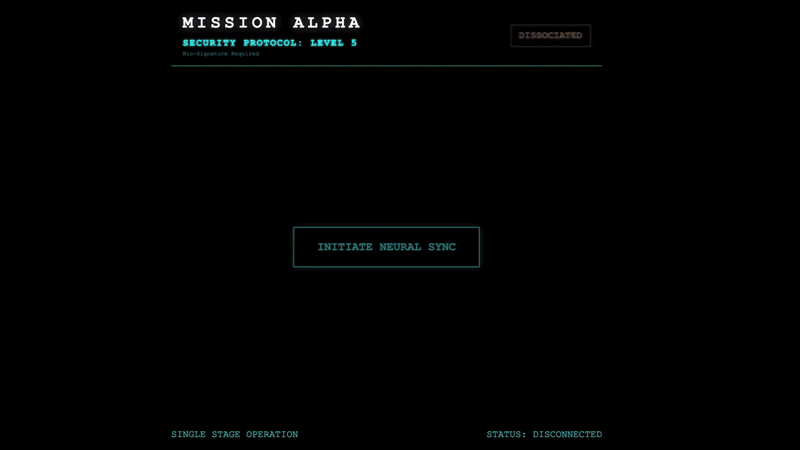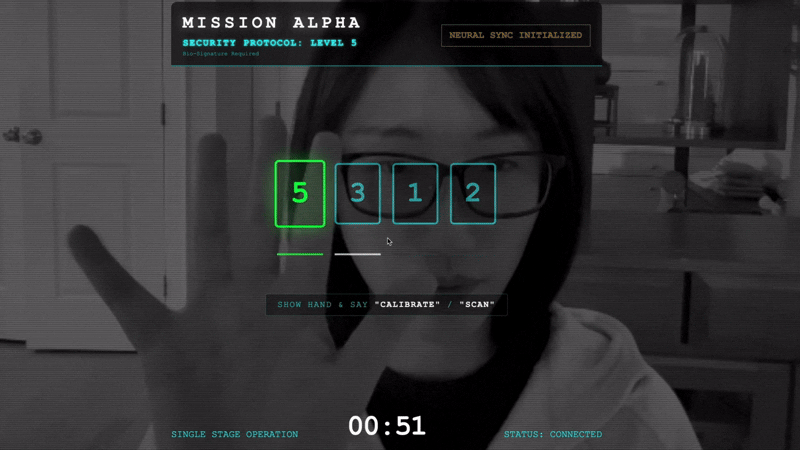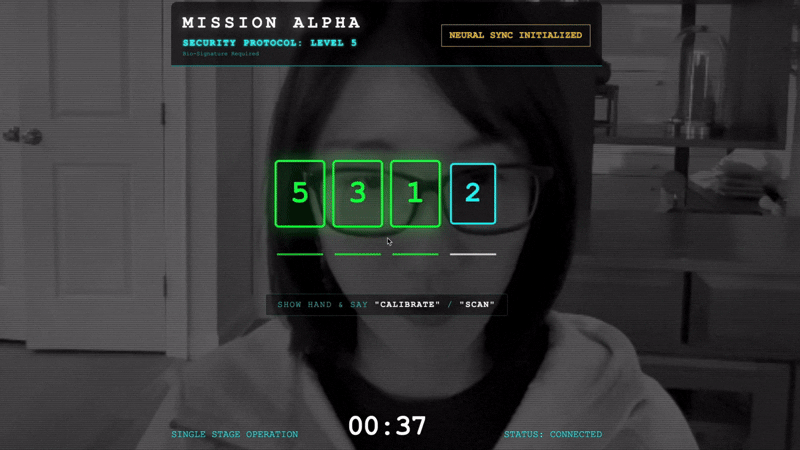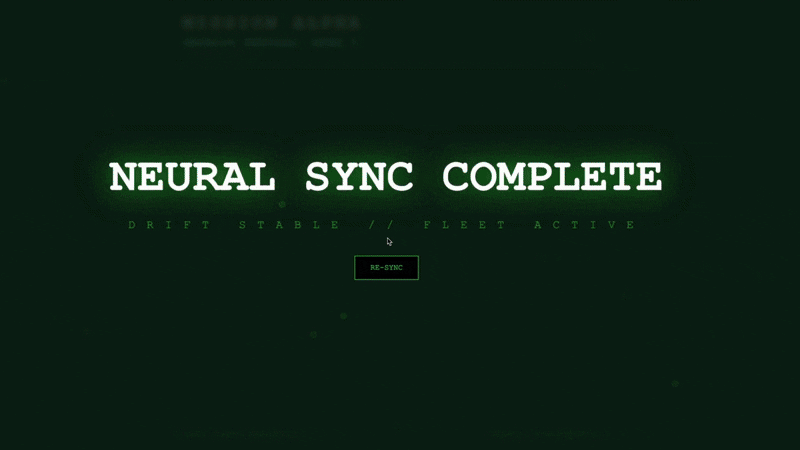
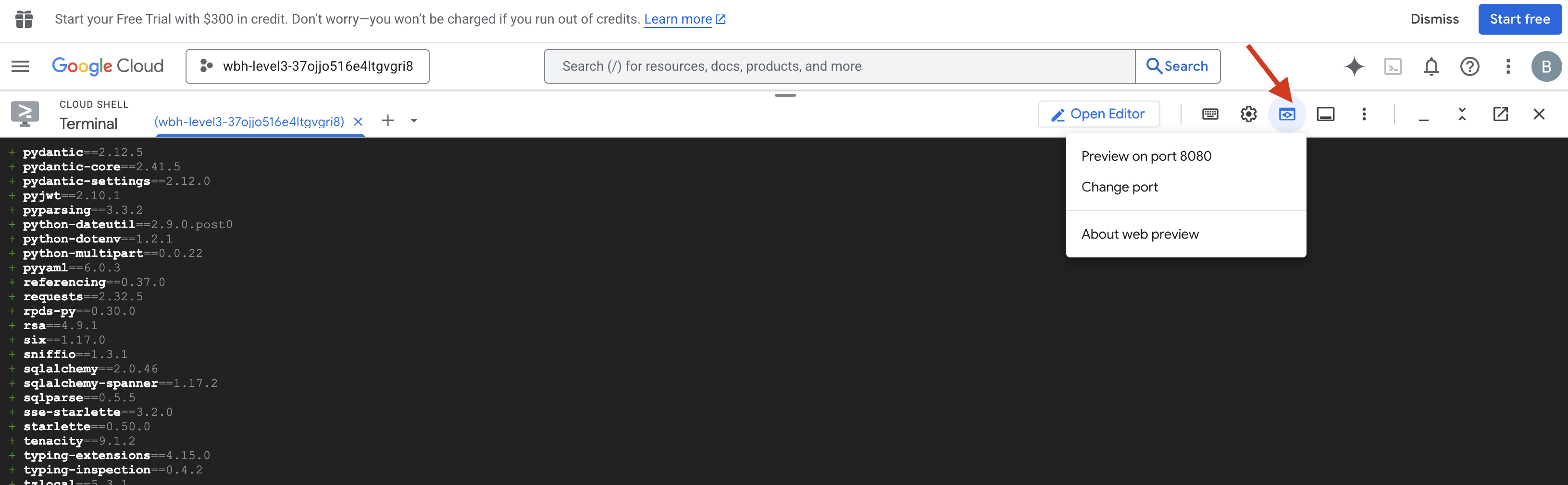
- پیشنمایش را باز کنید: روی نماد پیشنمایش وب در نوار ابزار Cloud Shell کلیک کنید. تغییر پورت را انتخاب کنید، آن را روی ۸۰۸۰ تنظیم کنید و روی تغییر و پیشنمایش کلیک کنید. یک برگه مرورگر جدید باز میشود که رابط کاربری Cockpit شما را نشان میدهد.
- نکته مهم: در صورت درخواست، باید به مرورگر اجازه دهید به دوربین و میکروفون شما دسترسی داشته باشد. بدون این ورودیها، همگامسازی عصبی نمیتواند آغاز شود.
- روی دکمهی «آغاز همگامسازی عصبی» در رابط کاربری کلیک کنید.
👀 تأیید شاخصهای وضعیت:
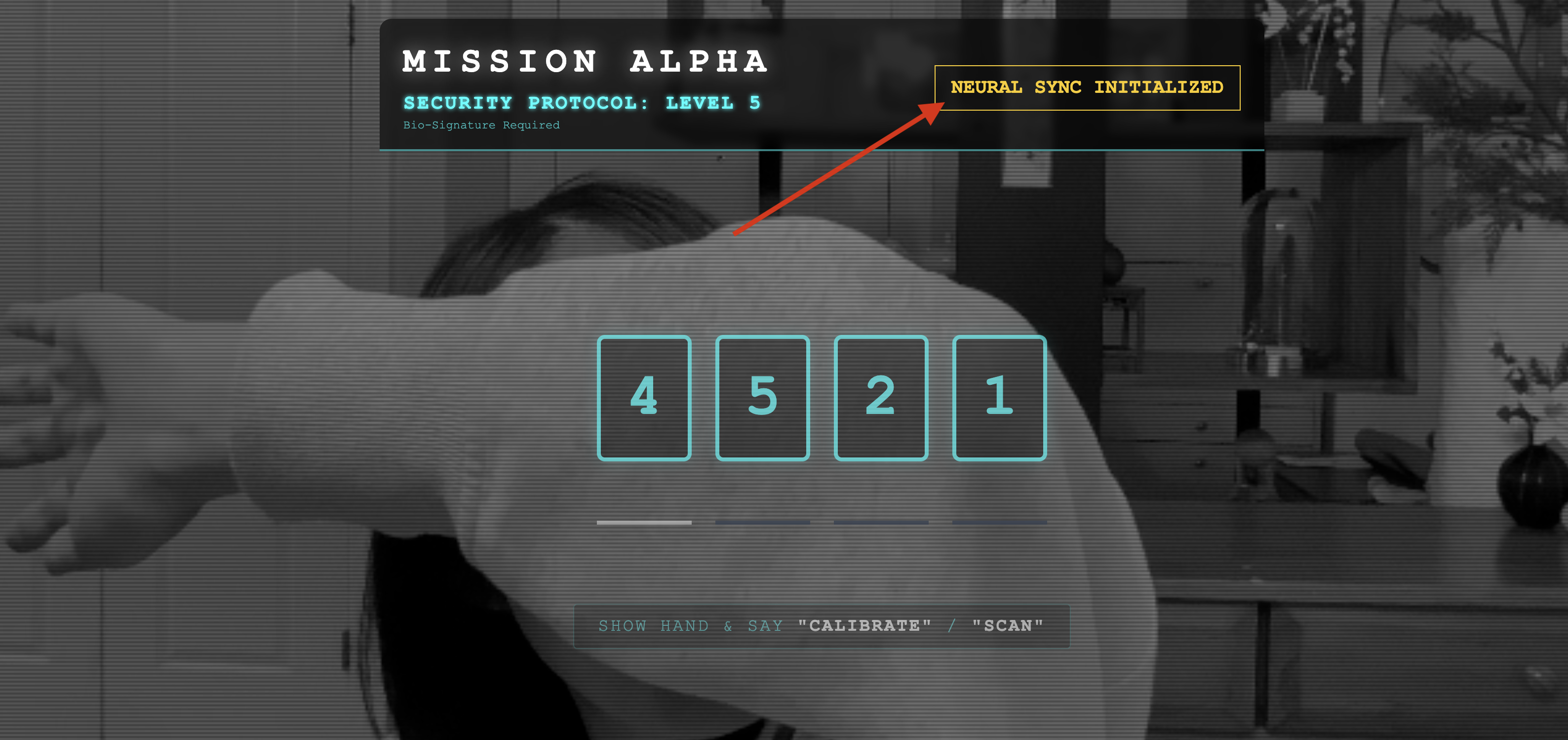
- بررسی بصری: کنسول مرورگر خود را باز کنید. باید
NEURAL SYNC INITIALIZEDدر بالا سمت راست ببینید. - بررسی صدا: اگر خط لوله صوتی دو طرفه شما کاملاً عملیاتی باشد، یک صدای شبیهسازی شده را خواهید شنید که تأیید میکند: « سیستم متصل شد! »
به محض اینکه صدای تایید «سیستم متصل شد!» را شنیدید، آزمایش با موفقیت انجام شده است. تب را ببندید. اکنون باید فرکانس را پاک کنیم تا جا برای هوش مصنوعی واقعی باز شود.
👉💻 در ترمینالها، هم برای سرور آزمایشی و هم برای رابط کاربری، Ctrl+C را فشار دهید. هنگام اجرای رابط کاربری، تب مرورگر را ببندید.
۴. عامل چندوجهی
ربات پیشاهنگ نجات عملیاتی است، اما «ذهنش» خالی است. اگر الان وصل شوید، فقط به شما خیره میشود. نمیداند «انگشت» چیست. برای نجات بازماندگان، باید پروتکل عصبی بیومتریک را روی هسته پیشاهنگ حک کنید.
عامل سنتی مانند مجموعهای از مترجمان عمل میکند. اگر با یک هوش مصنوعی قدیمی صحبت کنید، یک مدل «گفتار به متن» صدای شما را به کلمات تبدیل میکند، یک «مدل زبان» آن کلمات را میخواند و پاسخی تایپ میکند و یک مدل «متن به گفتار» در نهایت آن پاسخ را برای شما میخواند. این یک «شکاف تأخیر» ایجاد میکند - تأخیری که در یک مأموریت نجات کشنده خواهد بود.
رابط برنامهنویسی نرمافزار Gemini Live یک مدل چندوجهی بومی است. این رابط، بایتهای صوتی خام و فریمهای ویدیویی خام را مستقیماً و همزمان پردازش میکند. این رابط، لرزش صدای شما را «میشنود» و پیکسلهای حرکات دست شما را در همان معماری عصبی «میبیند».
برای مهار این قدرت، میتوانیم برنامه را با اتصال مستقیم کابین خلبان به API زنده خام بسازیم. با این حال، هدف ما ساخت یک عامل قابل استفاده مجدد است - یک نهاد ماژولار و قوی که ساخت آن سریعتر باشد.
چرا ADK (کیت توسعه عامل)؟
کیت توسعه عامل گوگل (ADK) یک چارچوب ماژولار برای توسعه و استقرار عاملهای هوش مصنوعی است.
فراخوانیهای استاندارد LLM معمولاً بدون وضعیت هستند؛ هر پرسوجو یک شروع تازه است. عاملهای زنده، بهویژه هنگامی که با SessionService متعلق به ADK ادغام میشوند، امکان جلسات مکالمهای قوی و طولانیمدت را فراهم میکنند.
- پایداری جلسه: جلسات ADK پایدار هستند و میتوانند در پایگاههای داده (مانند SQL یا Vertex AI) ذخیره شوند و از راهاندازی مجدد و قطع اتصال سرور جان سالم به در ببرند. این بدان معناست که اگر کاربری بعداً - حتی چند روز بعد - اتصال را قطع و دوباره وصل کند، تاریخچه و متن مکالمه او به طور کامل بازیابی میشود. جلسه API زنده زودگذر توسط ADK مدیریت و خلاصه میشود.
- اتصال مجدد خودکار: اتصالات WebSocket میتوانند منقضی شوند (مثلاً بعد از حدود ۱۰ دقیقه). ADK این اتصالهای مجدد را به صورت شفاف مدیریت میکند، زمانی که
session_resumptionدرRunConfigفعال باشد. کد برنامه شما نیازی به مدیریت منطق اتصال مجدد پیچیده ندارد و یک تجربه یکپارچه را برای کاربر تضمین میکند. - تعاملات مبتنی بر وضعیت: عامل، نوبتهای قبلی را به خاطر میسپارد و امکان پرسشهای بعدی، توضیحات و گفتگوهای پیچیده چند نوبتی را در مواردی که زمینه بسیار مهم است، فراهم میکند. این امر برای برنامههایی مانند پشتیبانی مشتری، آموزشهای تعاملی یا سناریوهای کنترل ماموریت که در آنها تداوم ضروری است، اساسی است.
این تداوم تضمین میکند که تعامل، به جای مجموعهای از پرسش و پاسخهای مجزا، مانند یک گفتگوی مداوم با یک نهاد هوشمند به نظر برسد.
در اصل، یک «عامل زنده» با ADK Bidi-streaming فراتر از یک مکانیسم سادهی پرسوجو-پاسخ حرکت میکند تا یک تجربهی مکالمهای واقعاً تعاملی، حالتمند و آگاه از وقفه ارائه دهد، که باعث میشود تعاملات هوش مصنوعی، انسانیتر و برای وظایف پیچیده و طولانیمدت، بهطور قابلتوجهی قدرتمندتر به نظر برسند.
درخواست برای یک عامل زنده
طراحی یک دستورالعمل برای یک عامل دوطرفه و بلادرنگ، نیازمند تغییر در طرز فکر است. برخلاف یک ربات چت استاندارد که منتظر یک پرسوجوی متنی ثابت میماند، یک عامل زنده «همیشه روشن» است. این ربات جریان ثابتی از فریمهای صوتی و تصویری را دریافت میکند، به این معنی که دستورالعمل شما باید به عنوان یک اسکریپت حلقه کنترل عمل کند، نه فقط یک تعریف شخصیت.
در اینجا تفاوت یک اعلان نماینده زنده با یک اعلان سنتی آمده است:
- منطق ماشین حالت: اعلان باید یک «حلقه رفتار» (Wait → Analyze → Act) تعریف کند. این حلقه به دستورالعملهای صریح در مورد زمان سکوت و زمان مشارکت نیاز دارد تا از پرحرفی عامل در نویز پسزمینه جلوگیری شود.
- آگاهی چندوجهی: باید به عامل گفته شود که «چشم» دارد. شما باید به صراحت به آن دستور دهید که فریمهای ویدیویی را به عنوان بخشی از فرآیند استدلال خود تجزیه و تحلیل کند.
- تأخیر و اختصار: در یک مکالمه صوتی زنده، پاراگرافهای طولانی و پر از نثر، غیرطبیعی و کند به نظر میرسند. این دستور، اختصار را الزامی میکند تا تعامل سریع بماند.
- معماری عمل-اول: دستورالعملها فراخوانی ابزار را بر گفتار اولویت میدهند. ما میخواهیم عامل قبل یا در حین تأیید شفاهی، کار را «انجام» دهد (اسکن بیومتریک)، نه پس از یک مونولوگ طولانی.
👉✏️ $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py را باز کنید و #REPLACE INSTRUCTIONS با موارد زیر جایگزین کنید:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
توجه! شما به یک LLM استاندارد متصل نمیشوید. در همان فایل ( $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py )، #REPLACE_MODEL را پیدا کنید. ما باید به طور صریح نسخه پیشنمایش این مدل را هدف قرار دهیم تا از قابلیتهای صوتی بلادرنگ بهتر پشتیبانی کند.
👉✏️ عبارت زیر را جایگزین کنید:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
عامل شما اکنون تعریف شده است. او میداند کیست و چگونه باید فکر کند. در مرحله بعد، ما به آن ابزار لازم برای عمل را میدهیم.
فراخوانی ابزار
رابط برنامهنویسی زنده (Live API) فقط به تبادل متن، صدا و جریانهای ویدیویی محدود نمیشود. این رابط به صورت بومی از فراخوانی ابزار (Tool Calling) پشتیبانی میکند. این قابلیت، عاملها را از یک مکالمهگر غیرفعال به یک اپراتور فعال تبدیل میکند.
در طول یک جلسه زنده و دو طرفه، مدل دائماً زمینه را ارزیابی میکند. اگر LLM نیاز به انجام عملی را تشخیص دهد، چه "بررسی تلهمتری حسگر" باشد و چه "باز کردن قفل یک درب امن". به طور یکپارچه از مکالمه به اجرا تغییر جهت میدهد. عامل بلافاصله عملکرد ابزار خاص را فعال میکند، منتظر نتیجه میماند و آن دادهها را دوباره در جریان زنده ادغام میکند، همه این کارها بدون ایجاد اختلال در جریان تعامل انجام میشود.
👉✏️ در $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py ، تابع #REPLACE TOOLS را با این تابع جایگزین کنید:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ سپس، با جایگزینی #TOOL CONFIG ، آن را در تعریف Agent ثبت کنید:
tools=[report_digit],
شبیهساز adk web
قبل از اتصال این به کابین خلبان پیچیده کشتی (React Frontend ما)، باید منطق Agent را به صورت جداگانه آزمایش کنیم. ADK شامل یک کنسول توسعهدهنده داخلی به نام adk web است که به ما امکان میدهد قبل از اضافه کردن پیچیدگی شبکه، فراخوانی ابزار (Tool Calling) را تأیید کنیم.
👉💻 در ترمینال خود، دستور زیر را اجرا کنید:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- روی نماد پیشنمایش وب در نوار ابزار Cloud Shell کلیک کنید. گزینه Change port را انتخاب کنید، آن را روی ۸۰۰۰ تنظیم کنید و روی Change and Preview کلیک کنید.
- اعطای مجوزها: در صورت درخواست، به دوربین و میکروفون خود اجازه دسترسی بدهید .
- جلسه را با کلیک روی نماد دوربین شروع کنید.
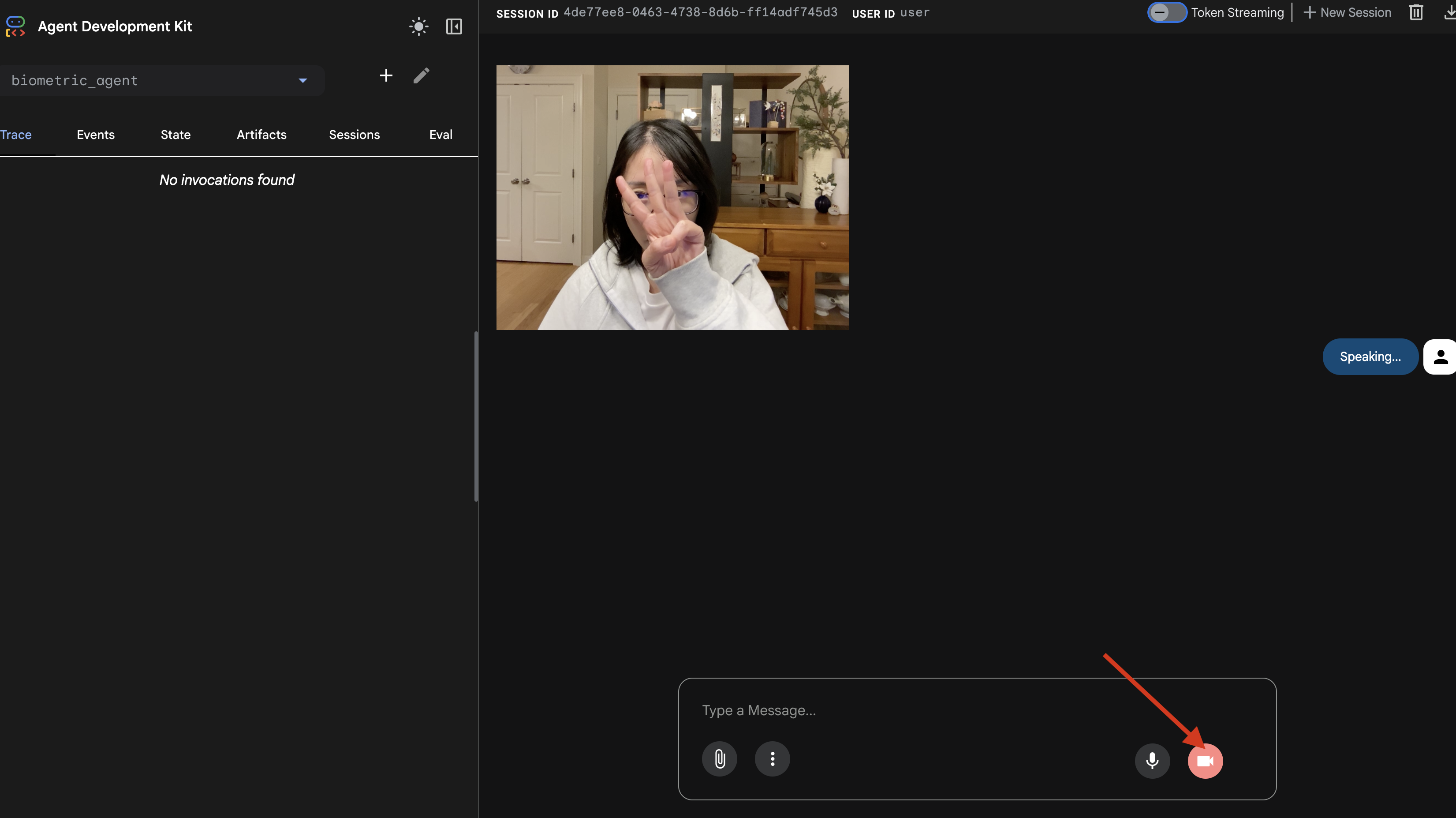
- تست بصری:
- سه انگشت خود را به وضوح جلوی دوربین نگه دارید.
- بگو: «اسکن کن.»
- تأیید موفقیت:
- گزارشها: به ترمینالی که دستور
adk webرا اجرا میکند نگاه کنید. باید این گزارش را ببینید:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- گزارشها: به ترمینالی که دستور
اگر گزارش اجرای ابزار را میبینید، عامل شما هوشمند است. میتواند ببیند، فکر کند و عمل کند. مرحله آخر اتصال آن به کشتی اصلی است.
روی پنجره ترمینال کلیک کنید و Ctrl+C را فشار دهید تا شبیهساز adk web متوقف شود.
۵. جریان دو جهته
مامور کار میکند. کابین خلبان کار میکند. حالا باید آنها را به هم وصل کنیم.
چرخه حیات عامل زنده
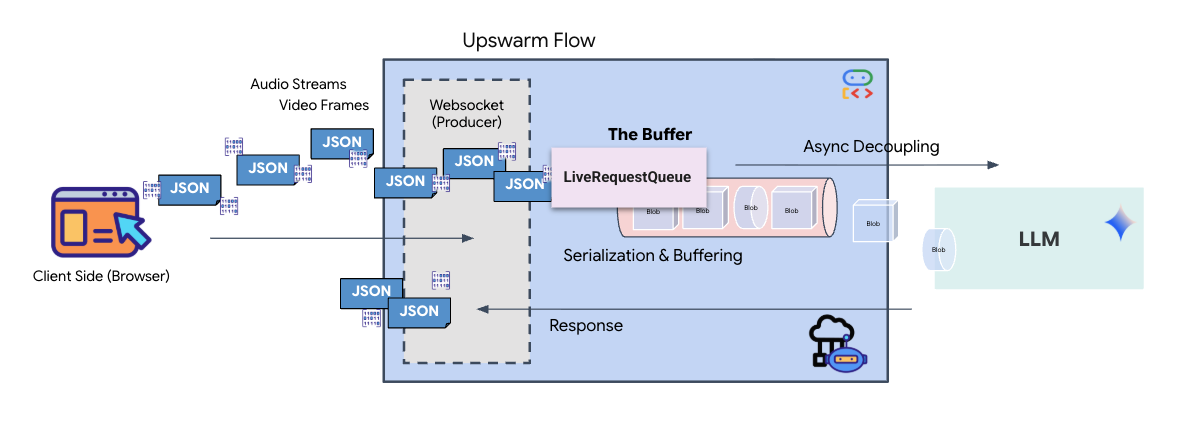
استریمینگ بلادرنگ، مشکل «عدم تطابق امپدانس» را ایجاد میکند. کلاینت (مرورگر) دادهها را به صورت ناهمزمان با نرخهای متغیر - انفجارهای شبکه یا ورودیهای سریع - ارسال میکند، در حالی که مدل به یک جریان ورودی منظم و ترتیبی نیاز دارد. Google ADK این مشکل را با استفاده از LiveRequestQueue حل میکند.
این به عنوان یک بافر FIFO (اولین ورودی-اولین خروجی) ناهمزمان و بدون نیاز به نخ عمل میکند. کنترلکنندهی WebSocket به عنوان تولیدکننده عمل میکند و قطعات خام صوتی/تصویری را به صف ارسال میکند. عامل ADK به عنوان مصرفکننده عمل میکند و دادهها را از صف دریافت میکند تا پنجرهی زمینهی مدل را تغذیه کند. این جداسازی به برنامه اجازه میدهد تا حتی در حالی که مدل در حال تولید پاسخ یا اجرای یک ابزار است، به دریافت ورودی کاربر ادامه دهد.
صف به عنوان یک مالتیپلکسر چندوجهی عمل میکند. در یک محیط واقعی، جریان بالادستی شامل انواع دادههای متمایز و همزمان است: بایتهای صوتی خام PCM، فریمهای ویدیویی، دستورالعملهای سیستم مبتنی بر متن و نتایج حاصل از فراخوانیهای ابزار ناهمزمان. LiveRequestQueue این ورودیهای متفاوت را به یک توالی زمانی واحد خطی میکند. چه بسته حاوی یک میلیثانیه سکوت، یک تصویر با وضوح بالا یا یک بار داده JSON از یک پرسوجوی پایگاه داده باشد، به ترتیب دقیق ورود سریالسازی میشود و تضمین میکند که مدل یک جدول زمانی علّی و سازگار را درک میکند.
این معماری، کنترل غیر مسدودکننده (Non-Blocking Control ) را فعال میکند. از آنجا که لایه مصرف (تولیدکننده) از لایه پردازش (مصرفکننده) جدا شده است، سیستم حتی در طول استنتاج مدل با محاسبات سنگین، پاسخگو باقی میماند. اگر کاربری در حالی که عامل در حال اجرای ابزاری است، با دستور "Stop!" کار را متوقف کند، آن سیگنال صوتی فوراً در صف قرار میگیرد. حلقه رویداد اساسی، این سیگنال اولویت را فوراً پردازش میکند و به سیستم اجازه میدهد بدون اینکه رابط کاربری قفل شود یا بستهها از بین بروند، وظایف تولید یا چرخش را متوقف کند.
👉💻 در $HOME/way-back-home/level_3/backend/app/main.py ، کامنت #REPLACE_RUNNER_CONFIG را پیدا کنید و آن را با کد زیر جایگزین کنید تا سیستم آنلاین شود:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
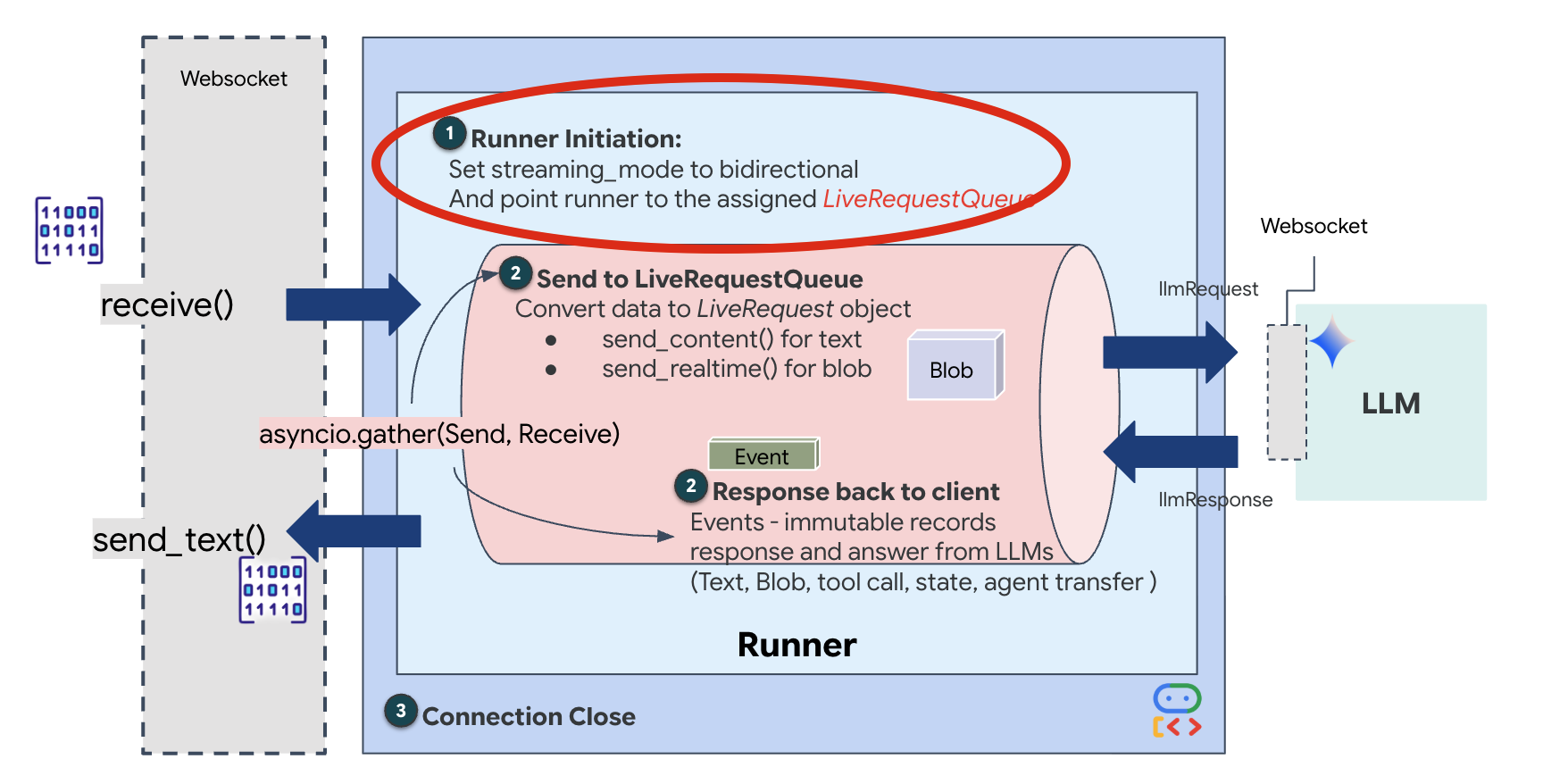
وقتی یک اتصال WebSocket جدید باز میشود، باید نحوه تعامل هوش مصنوعی را پیکربندی کنیم. اینجاست که «قوانین تعامل» را تعریف میکنیم.
👉✏️ در $HOME/way-back-home/level_3/backend/app/main.py ، درون تابع async def websocket_endpoint ، کد زیر را جایگزین کامنت #REPLACE_SESSION_INIT کنید:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
پیکربندی اجرا
-
StreamingMode.BIDI: این گزینه اتصال را به صورت دو طرفه تنظیم میکند. برخلاف هوش مصنوعی "نوبتی" (که در آن صحبت میکنید، متوقف میشوید و سپس صحبت میکند)، BIDI امکان مکالمه "کاملاً دوطرفه" واقعگرایانه را فراهم میکند. شما میتوانید هوش مصنوعی را قطع کنید و هوش مصنوعی میتواند در حین حرکت شما صحبت کند. -
AudioTranscriptionConfig: اگرچه مدل صدای خام را "میشنود"، ما (توسعهدهندگان) باید گزارشها را ببینیم. این پیکربندی به Gemini میگوید: "صدا را پردازش کن، اما یک متن از آنچه شنیدهای را نیز برای ما ارسال کن تا بتوانیم اشکالزدایی کنیم."
منطق اجرا هنگامی که Runner جلسه را برقرار کرد، کنترل را به منطق اجرا واگذار میکند که به LiveRequestQueue متکی است. این مهمترین جزء برای تعامل در زمان واقعی است. این حلقه به عامل اجازه میدهد تا در حالی که صف همچنان فریمهای ویدیویی جدید را از کاربر میپذیرد، پاسخ صوتی تولید کند و تضمین کند که "همگامسازی عصبی" هرگز قطع نمیشود.
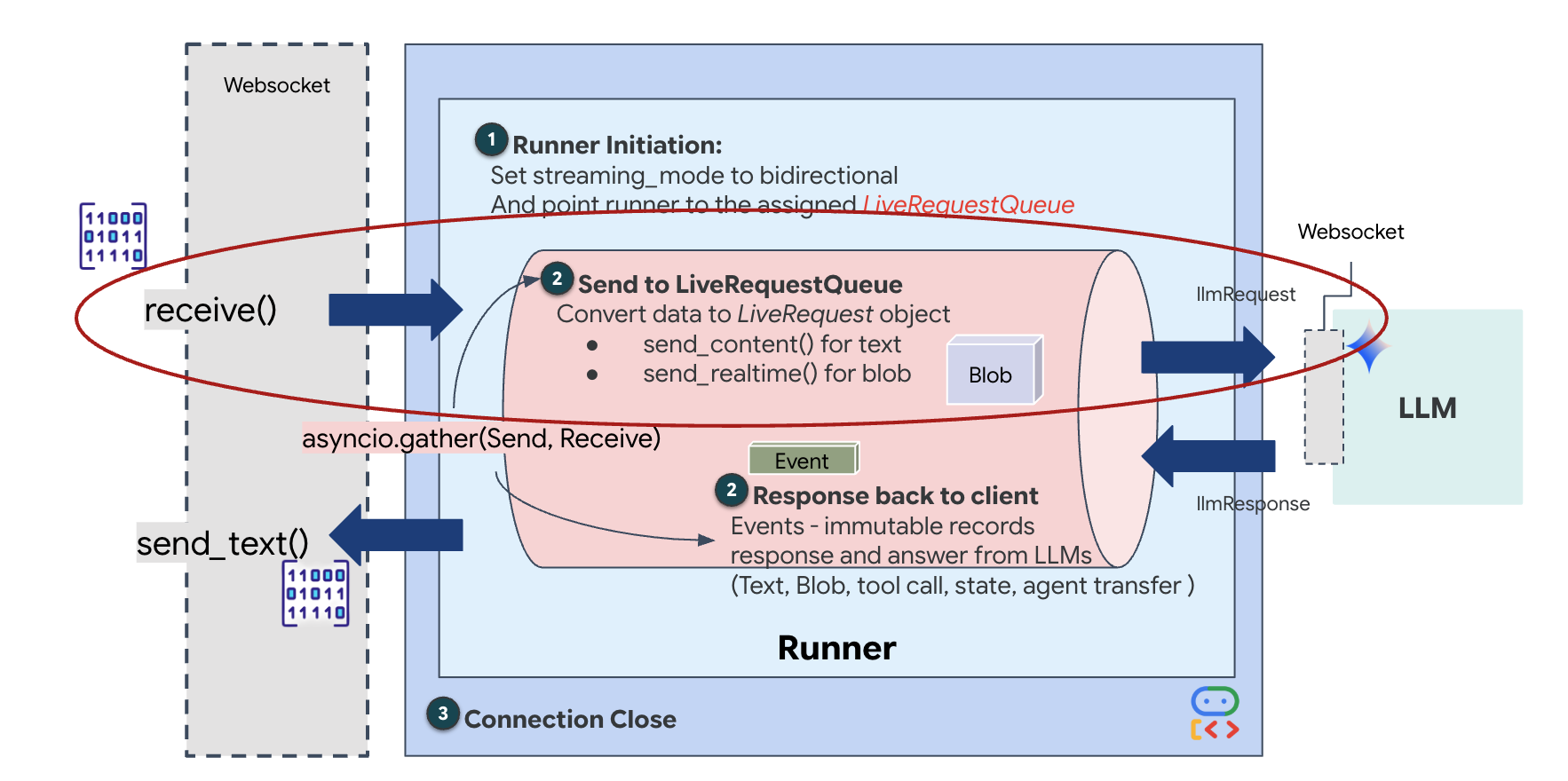
👉✏️ در $HOME/way-back-home/level_3/backend/app/main.py ، #REPLACE_LIVE_REQUEST را برای تعریف وظیفه بالادستی که دادهها را به LiveRequestQueue ارسال میکند، جایگزین کنید:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
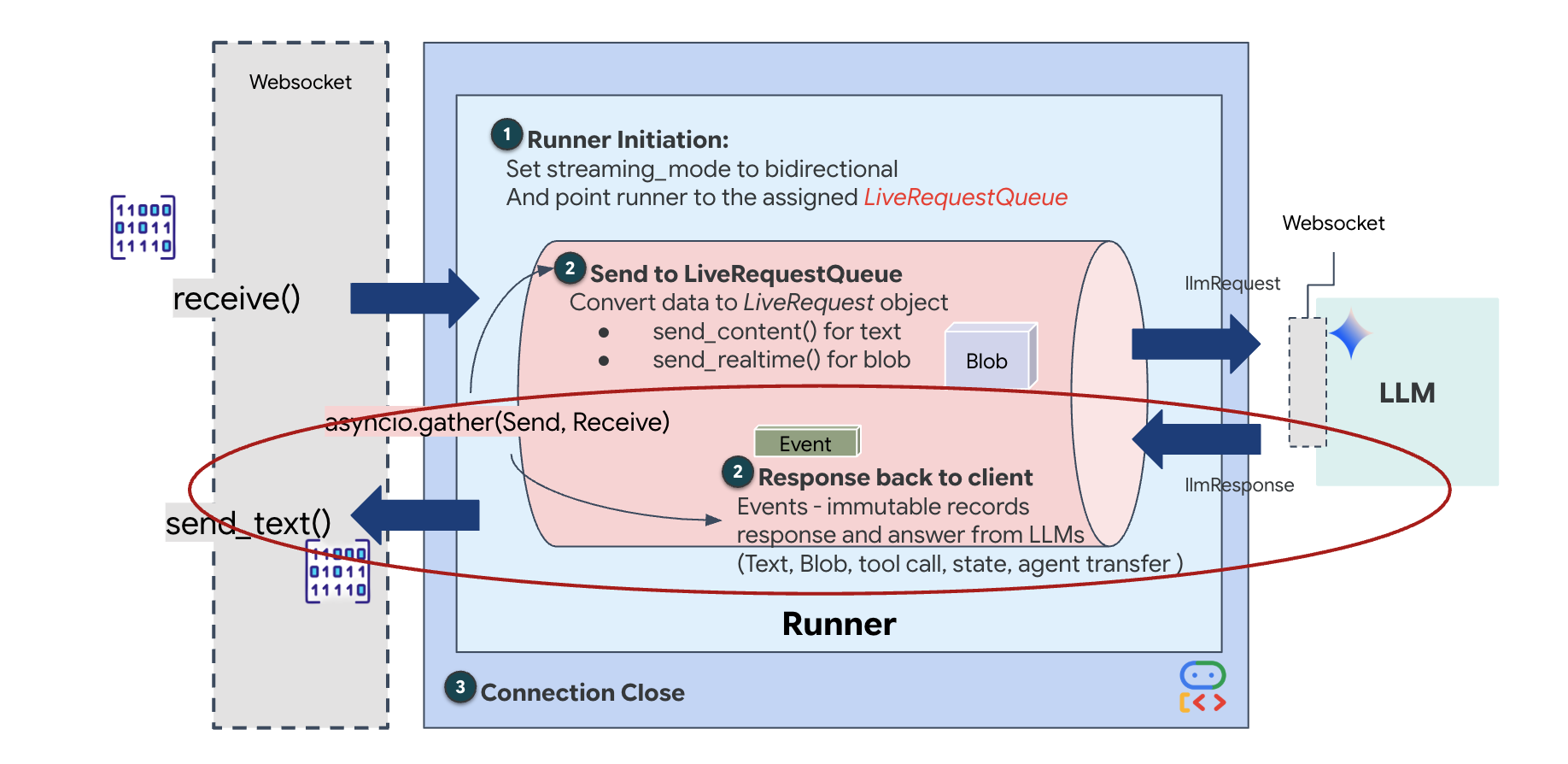
در نهایت، باید پاسخهای هوش مصنوعی را مدیریت کنیم. برای این کار runner.run_live() استفاده میشود که یک تولیدکننده رویداد است و رویدادها (صدا، متن یا فراخوانی ابزار) را در حین وقوع نمایش میدهد.
👉✏️ در $HOME/way-back-home/level_3/backend/app/main.py ، #REPLACE_SORT_RESPONSE را برای تعریف وظیفهی پاییندستی و مدیر همزمانی جایگزین کنید:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
به خط await asyncio.gather(upstream_task(), downstream_task()) توجه کنید. این اساس Full-Duplex است. ما وظیفه شنیداری (بالادستی) و وظیفه گفتاری (پایینی) را دقیقاً همزمان اجرا میکنیم. این تضمین میکند که "پیوند عصبی" امکان وقفه و جریان همزمان دادهها را فراهم میکند.
اکنون بخش مدیریت شما به طور کامل کدنویسی شده است. "مغز" (ADK) به "بدنه" (WebSocket) متصل شده است.
اجرای همگامسازی زیستی
کد کامل شد. سیستمها سبز شدند. وقت شروع عملیات نجات است.
- 👉💻 شروع بخش مدیریت:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 رابط کاربری (Frontend) را راهاندازی کنید:
- روی نماد پیشنمایش وب در نوار ابزار Cloud Shell کلیک کنید. تغییر پورت را انتخاب کنید، آن را روی ۸۰۸۰ تنظیم کنید و روی تغییر و پیشنمایش کلیک کنید.
- 👉 اجرای پروتکل:
- روی «آغاز همگامسازی عصبی» کلیک کنید.
- کالیبره کردن: مطمئن شوید که دوربین دست شما را به وضوح در مقابل پسزمینه میبیند.
- همگامسازی: به کد امنیتی نمایش داده شده روی صفحه توجه کنید (مثلاً ۳، سپس ۲، و سپس ۵).
- علامت را مطابقت دهید: وقتی عددی ظاهر میشود، دقیقاً به همان تعداد انگشت، انگشت خود را بالا نگه دارید.
- ثابت نگه دارید: دست خود را تا زمانی که هوش مصنوعی «تطابق بیومتریک» را تأیید کند، قابل مشاهده نگه دارید.
- تطبیق: کد تصادفی است. فوراً به عدد بعدی نشان داده شده بروید تا توالی کامل شود.

- همانطور که عدد نهایی را در دنباله تصادفی مطابقت میدهید، "همگامسازی بیومتریک" کامل میشود. پیوند عصبی قفل میشود. شما کنترل دستی دارید. موتورهای Scout غرش میکنند و به درون دره شیرجه میزنند تا بازماندگان را به خانه برگردانند.
👉💻 برای خروج، در ترمینال بخش مدیریت، Ctrl+C را فشار دهید.
۶. استقرار در محیط عملیاتی (اختیاری)
شما با موفقیت بیومتریکها را به صورت محلی آزمایش کردهاید. اکنون، باید هسته عصبی عامل را روی رایانههای اصلی کشتی (Cloud Run) آپلود کنیم تا بتواند مستقل از کنسول محلی شما عمل کند.
👉💻 دستور زیر را در ترمینال Cloud Shell خود اجرا کنید. این دستور، یک Dockerfile کامل و چند مرحلهای را در دایرکتوری backend شما ایجاد میکند.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 به دایرکتوری backend بروید و برنامه را در یک تصویر کانتینر پکیج کنید.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 سرویس را روی Cloud Run مستقر کنید. ما متغیرهای محیطی لازم - به ویژه پیکربندی Gemini - را مستقیماً به دستور راهاندازی تزریق خواهیم کرد.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
پس از اتمام دستور، یک URL سرویس (مثلاً https://biometric-scout-...run.app ) مشاهده خواهید کرد. اکنون برنامه در فضای ابری فعال است.
👉 به صفحه Google Cloud Run بروید و سرویس biometric-scout را از لیست انتخاب کنید. 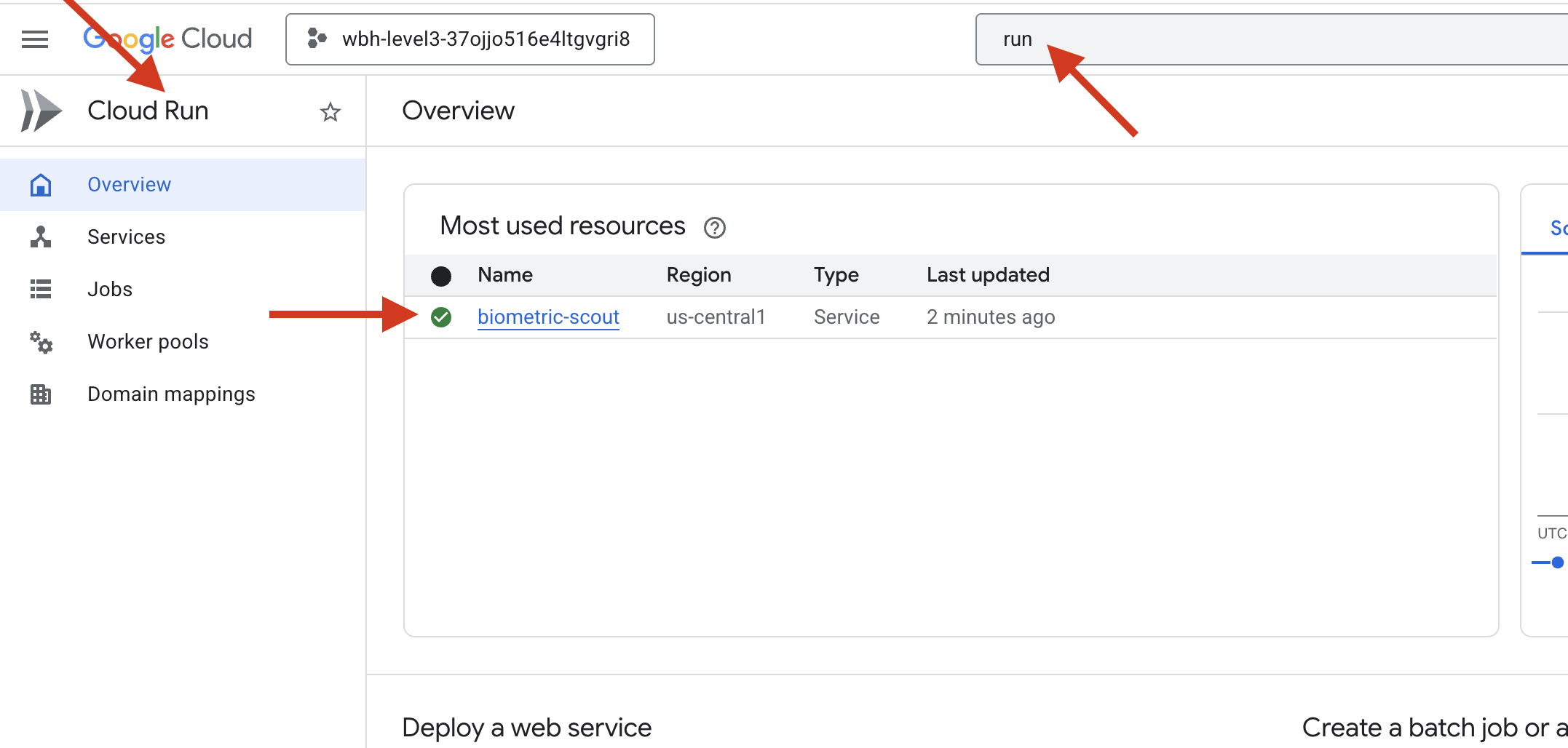
👉 آدرس عمومی (Public URL) نمایش داده شده در بالای صفحه جزئیات سرویس را پیدا کنید. 
سعی کنید در این محیط Bio-Sync انجام دهید، آیا این هم جواب میدهد؟
همزمان با باز کردن انگشت پنجم شما، هوش مصنوعی توالی را قفل میکند. صفحه نمایش به رنگ سبز چشمک میزند: «همگامسازی عصبی بیومتریک: برقرار شد.»
با یک فکر، اسکات را به درون تاریکی فرو میبرید، به غلاف به گل نشسته میچسبید و درست قبل از اینکه پارگی ناشی از جاذبه فرو بریزد، آن را بیرون میکشید.

دریچه هوا با صدای هیس باز میشود و آنها آنجا هستند - پنج بازمانده زنده و در حال نفس کشیدن. آنها به آرامی روی عرشه میافتند، آسیب دیده اما زنده، و بالاخره به خاطر شما در امان هستند.
به لطف شما، ارتباط عصبی هماهنگ شد و بازماندگان نجات یافتند.
اگر در سطح ۰ شرکت کردهاید، فراموش نکنید که در ماموریت بازگشت به خانه، پیشرفت خود را بررسی کنید!