1. Misi

Anda melayang dalam keheningan sektor yang belum dipetakan. **Pulsa Matahari** yang sangat besar telah merobek kapal Anda melalui celah, membuat Anda terdampar di bagian alam semesta yang tidak ada di peta bintang mana pun.
Setelah berhari-hari melakukan perbaikan yang melelahkan, Anda akhirnya merasakan deru mesin di bawah kaki Anda. Roket Anda sudah diperbaiki. Anda bahkan berhasil mengamankan uplink jarak jauh ke Mothership. Anda sudah siap untuk berangkat. Anda siap pulang. Namun, saat Anda bersiap untuk menggunakan flash drive, sinyal bahaya menembus suara statis. Sensor Anda mendeteksi lima jejak panas samar yang terperangkap di "The Ravine"—sektor bergerigi yang terpengaruh gravitasi dan tidak dapat dimasuki oleh kapal utama Anda. Mereka adalah sesama penjelajah, korban badai yang sama yang hampir merenggut nyawamu. Anda tidak dapat meninggalkannya.
Anda beralih ke Alpha-Drone Rescue Scout. Kapal kecil yang lincah ini adalah satu-satunya kapal yang mampu melewati dinding sempit The Ravine. Namun, ada masalah: pulsa surya melakukan "Reset Sistem" total pada logika intinya. Sistem kontrol Scout tidak responsif. Pesawat ini dinyalakan, tetapi komputer di dalamnya masih kosong, tidak dapat memproses perintah pilot manual atau jalur penerbangan.
Tantangan
Untuk menyelamatkan para penyintas, Anda harus melewati sirkuit rusak Scout sepenuhnya. Anda memiliki satu opsi terakhir: membuat Agen AI untuk membuat Sinkronisasi Biometrik Neural. Agen ini akan bertindak sebagai jembatan real-time, yang memungkinkan Anda mengontrol Rescue Scout secara manual melalui input biologis Anda sendiri. Anda tidak akan menggunakan joystick atau keyboard; Anda akan menghubungkan niat Anda langsung ke jaringan navigasi kapal.
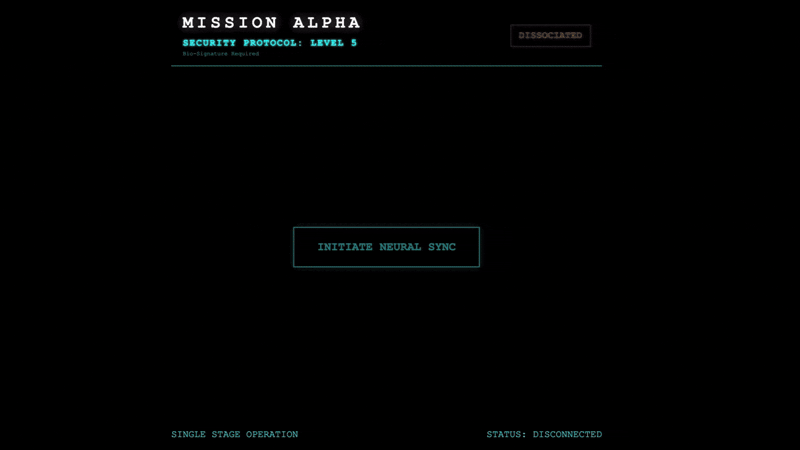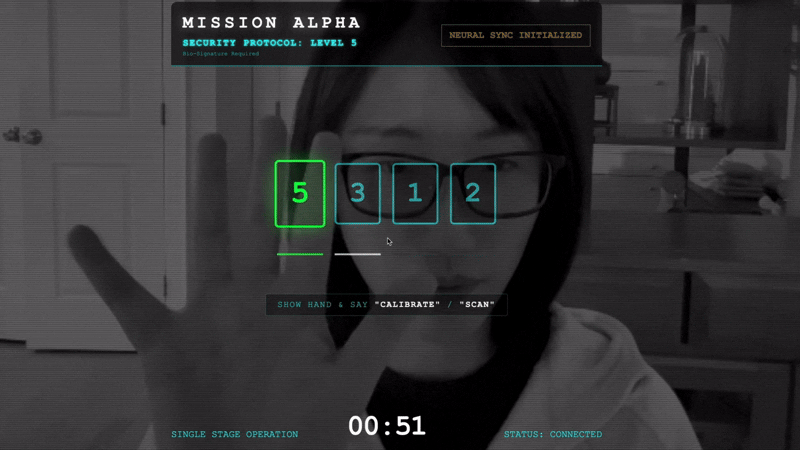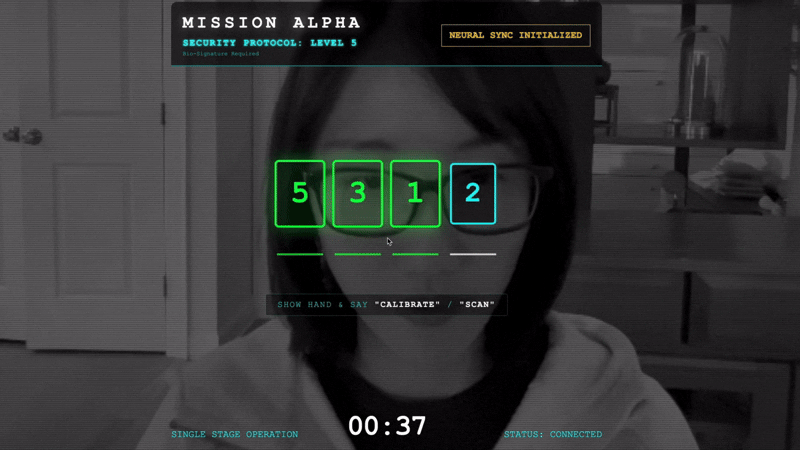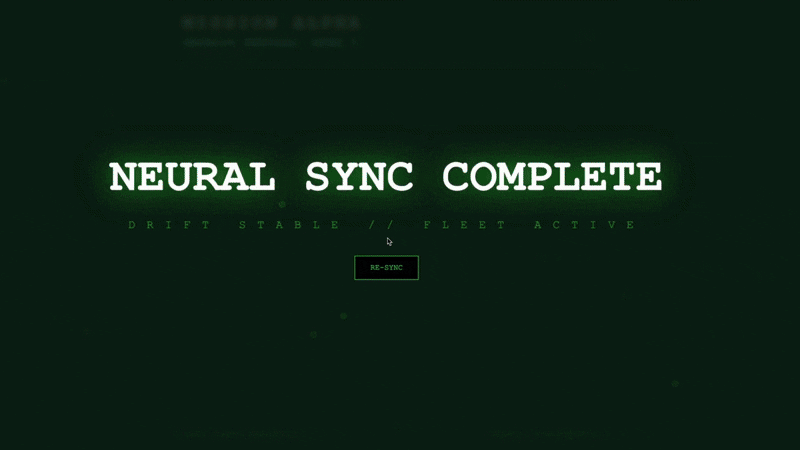
Untuk mengunci tautan, Anda harus melakukan Protokol Sinkronisasi di depan sensor optik Scout. Agen AI harus mengenali tanda tangan biologis Anda melalui handshake real-time yang presisi.
Tujuan Misi Anda:
- Mencetak Neural Core: Menentukan Agen ADK yang dapat mengenali input multimodal.
- Buat Koneksi: Buat pipeline WebSocket dua arah untuk menstreaming data visual dari Scout ke AI.
- Mulai Handshake: Berdiri di depan sensor dan selesaikan urutan jari—tunjukkan 1 hingga 5 secara berurutan.
Jika berhasil, "Sinkronisasi Biometrik" akan diaktifkan. AI akan mengunci link saraf, sehingga Anda memiliki kontrol manual penuh untuk meluncurkan Scout dan membawa pulang para penyintas tersebut.
Yang akan Anda buat
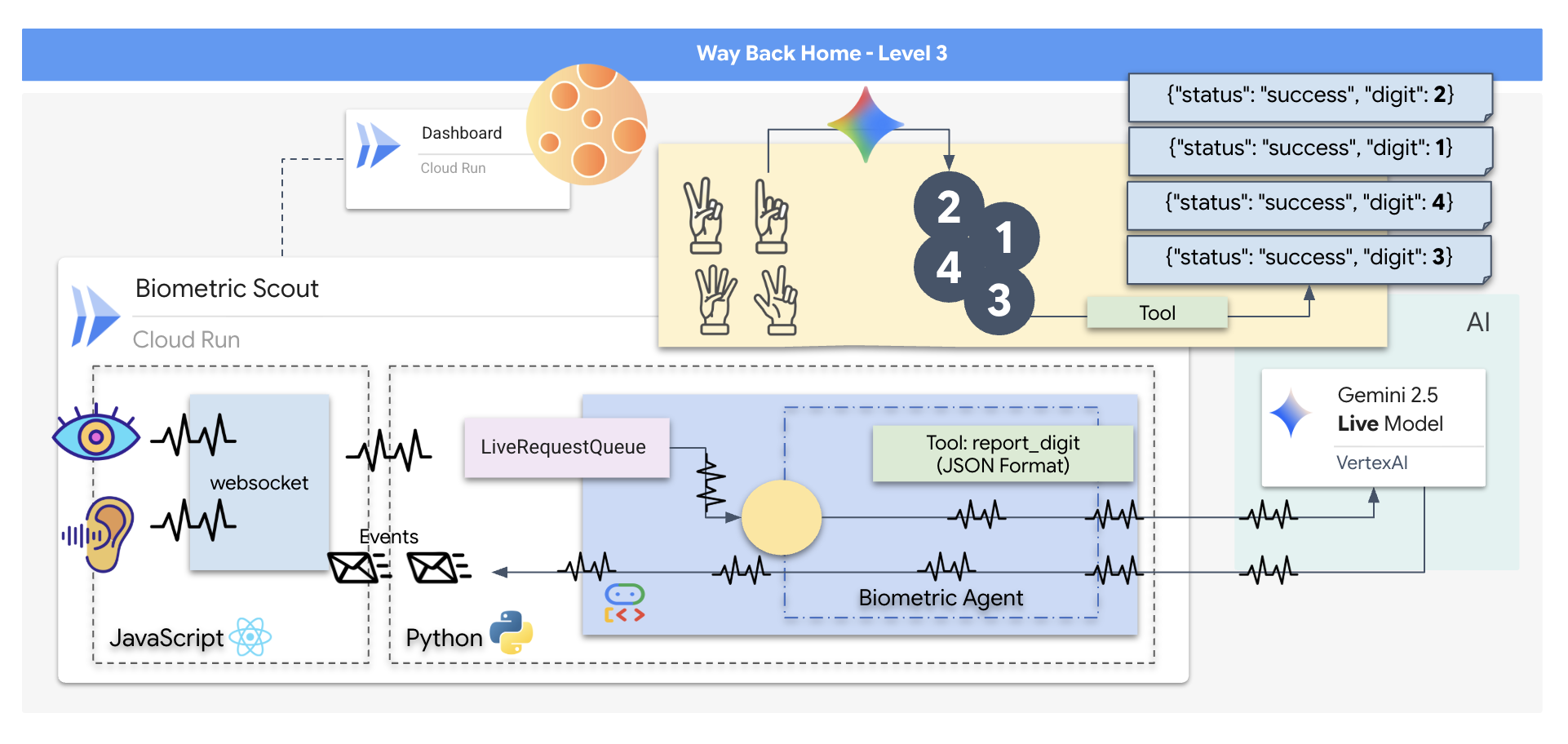
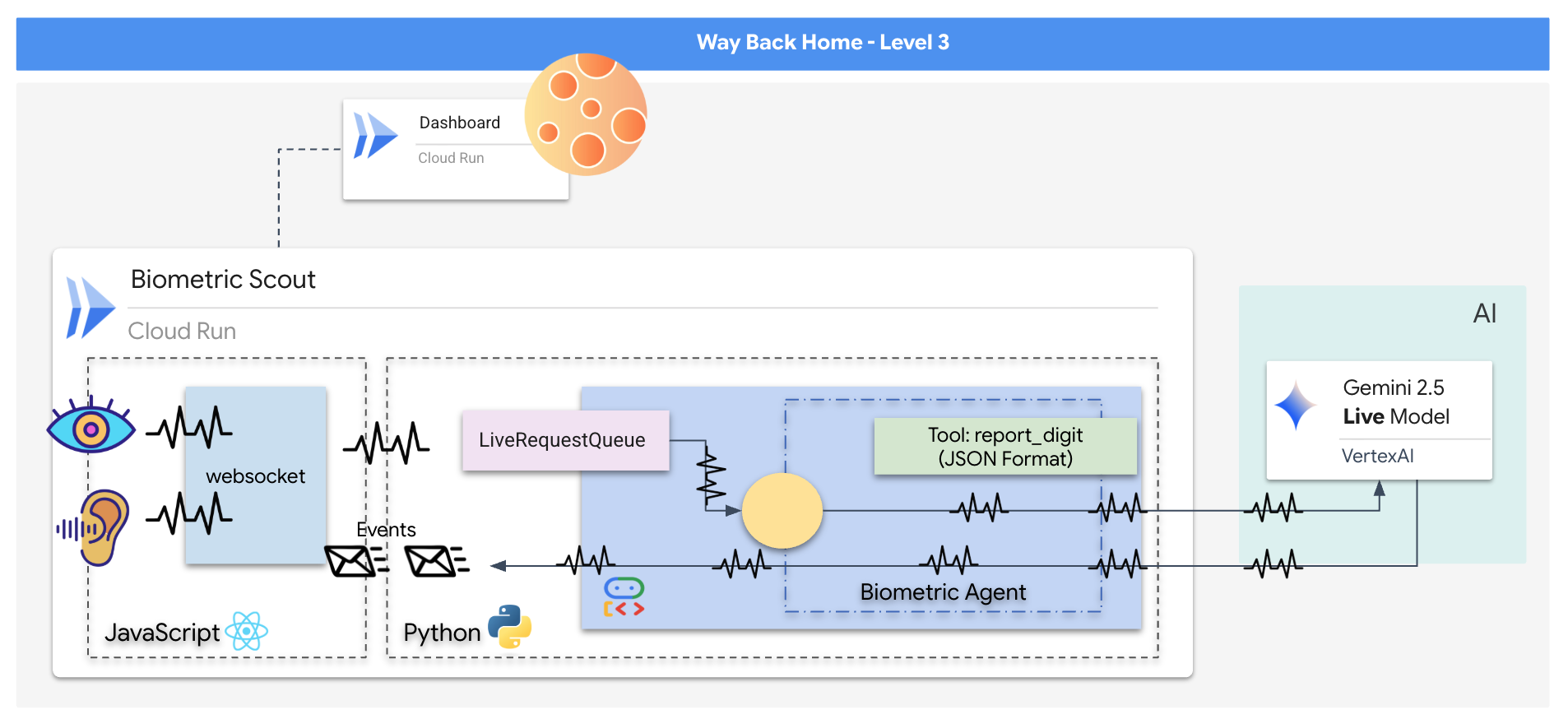
Anda akan membuat aplikasi "Biometric Neural Sync", yaitu sistem real-time berteknologi AI yang berfungsi sebagai antarmuka kontrol untuk drone penyelamat. Sistem ini terdiri dari:
- Frontend React: "Kokpit" kapal Anda, yang merekam video live dari webcam dan audio dari mikrofon Anda.
- Backend Python: Server berperforma tinggi yang dibuat dengan FastAPI, menggunakan Agent Development Kit (ADK) Google untuk mengelola logika dan status LLM.
- Agen AI Multimodal: "Otak" operasi, menggunakan Gemini Live API melalui SDK
google-genaiuntuk memproses dan memahami streaming video dan audio secara bersamaan. - Pipeline WebSocket Dua Arah: "Sistem Saraf" yang membuat koneksi persisten dan berlatensi rendah antara frontend dan AI, sehingga memungkinkan interaksi real-time.
Yang akan Anda pelajari
Teknologi / Konsep | Deskripsi |
Agen AI Backend | Bangun agen AI stateful dengan Python dan FastAPI. Gunakan ADK (Agent Development Kit) Google untuk mengelola petunjuk dan memori, serta SDK |
UI Frontend | Mengembangkan antarmuka pengguna dinamis menggunakan React untuk merekam dan melakukan streaming video dan audio langsung dari browser. |
Komunikasi Real-Time | Menerapkan pipeline WebSocket untuk komunikasi full-duplex latensi rendah, sehingga pengguna dan AI dapat berinteraksi secara bersamaan. |
AI multimodal | Manfaatkan Gemini Live API untuk memproses dan memahami streaming video dan audio serentak, sehingga memungkinkan AI "melihat" dan "mendengar" secara bersamaan. |
Panggilan Alat | Aktifkan AI untuk menjalankan fungsi Python tertentu sebagai respons terhadap pemicu visual, sehingga menjembatani kesenjangan antara kecerdasan model dan tindakan di dunia nyata. |
Deployment Full-Stack | Masukkan seluruh aplikasi (frontend React dan backend Python) ke dalam container dengan Docker dan deploy sebagai layanan serverless yang skalabel di Google Cloud Run. |
2. Menyiapkan Lingkungan Anda
Mengakses Cloud Shell
Pertama, kita akan membuka Cloud Shell, yang merupakan terminal berbasis browser dengan Google Cloud SDK dan alat penting lainnya yang sudah diinstal sebelumnya.
👉Klik Activate Cloud Shell di bagian atas konsol Google Cloud (Ikon berbentuk terminal di bagian atas panel Cloud Shell), 
👉Klik tombol "Open Editor" (terlihat seperti folder terbuka dengan pensil). Tindakan ini akan membuka Editor Kode Cloud Shell di jendela. Anda akan melihat file explorer di sisi kiri. 
👉Buka terminal di IDE cloud,
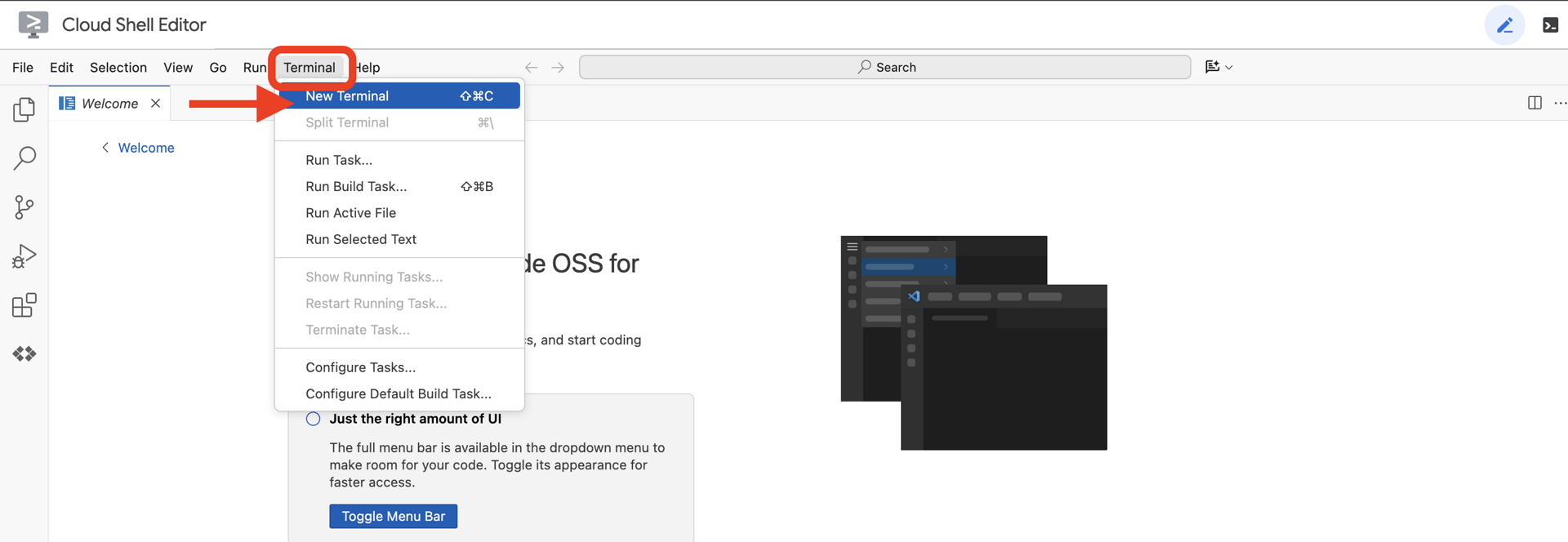
👉💻 Di terminal, verifikasi bahwa Anda sudah diautentikasi dan project disetel ke project ID Anda menggunakan perintah berikut:
gcloud auth list
Anda akan melihat akun Anda tercantum sebagai (ACTIVE).
Prasyarat
ℹ️ Level 0 bersifat Opsional (Tetapi Direkomendasikan)
Anda dapat menyelesaikan misi ini tanpa Level 0, tetapi menyelesaikannya terlebih dahulu akan memberikan pengalaman yang lebih imersif, sehingga Anda dapat melihat suar Anda menyala di peta global saat Anda maju.
Menyiapkan Lingkungan Project
Kembali di terminal, selesaikan konfigurasi dengan menetapkan project aktif dan mengaktifkan layanan Google Cloud yang diperlukan (Cloud Run, Vertex AI, dll.).
👉💻 Di terminal, tetapkan Project ID:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Aktifkan Layanan yang Diperlukan:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
Menginstal Dependensi
👉💻 Buka Level dan instal paket Python yang diperlukan:
cd $HOME/way-back-home/level_3
uv sync
Ketergantungan utamanya adalah:
Paket | Tujuan |
| Framework web berperforma tinggi untuk streaming SSE dan Stasiun Satelit |
| Server ASGI diperlukan untuk menjalankan aplikasi FastAPI |
| Agent Development Kit yang digunakan untuk membangun Agen Formasi |
| Klien native untuk mengakses model Gemini |
| Dukungan untuk komunikasi dua arah real-time |
| Mengelola variabel lingkungan dan secret konfigurasi |
Verifikasi Penyiapan
Sebelum kita mulai menulis kode, pastikan semua sistem berfungsi dengan baik. Jalankan skrip verifikasi untuk mengaudit Project Google Cloud, API, dan dependensi Python Anda.
👉💻 Jalankan Skrip Verifikasi:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Anda akan melihat serangkaian Centang Hijau (✅).
- Jika Anda melihat Tanda Silang Merah (❌), ikuti perintah perbaikan yang disarankan dalam output (misalnya,
gcloud services enable ...ataupip install ...). - Catatan: Peringatan kuning untuk
.envdapat diterima untuk saat ini; kita akan membuat file tersebut di langkah berikutnya.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Mengalibrasi Comm-Link (WebSocket)
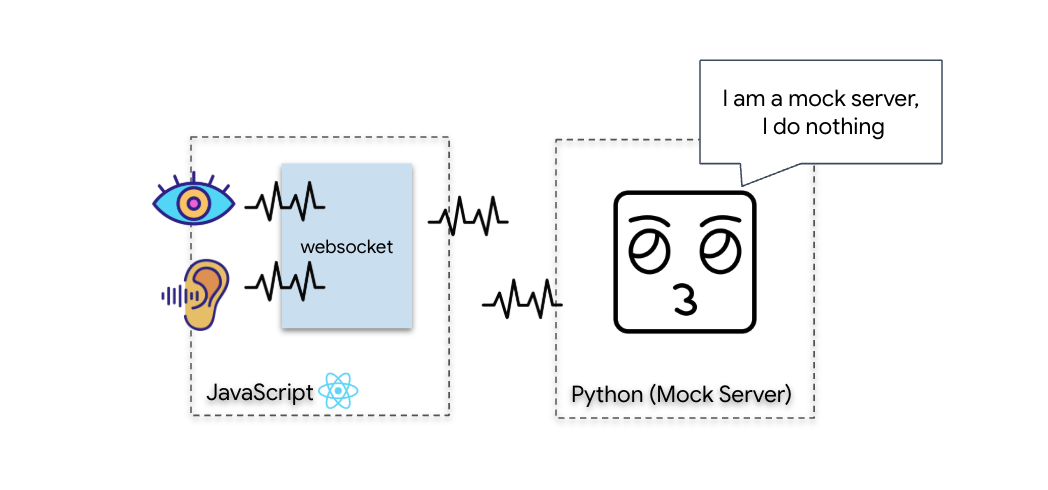
Untuk memulai Sinkronisasi Neural Biometrik, kita perlu memperbarui sistem internal kapal Anda. Tujuan utama kami adalah merekam aliran video dan audio dengan kualitas tinggi dari kokpit Anda. Aliran ini menyediakan komponen penting untuk link saraf: identifikasi visual urutan jari Anda dan frekuensi suara Anda.
Full-Duplex vs. Half-Duplex
Untuk memahami alasan kami memerlukan hal ini untuk Sinkronisasi Neural, Anda harus memahami alur data:
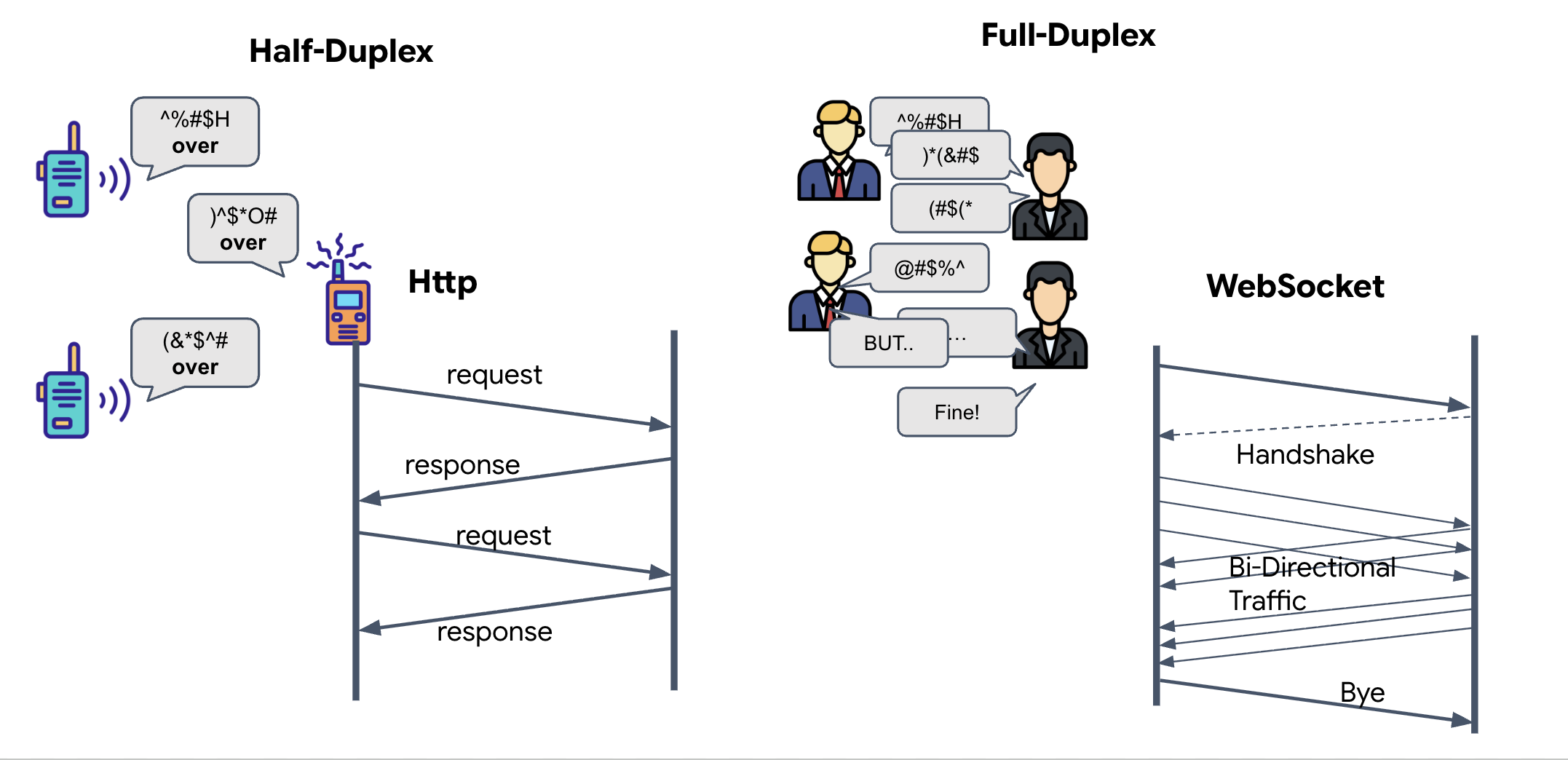
- Half-Duplex (HTTP Standar): Seperti walkie-talkie. Satu orang berbicara, mengatakan "Selesai", lalu orang lain dapat berbicara. Anda tidak dapat mendengarkan dan berbicara secara bersamaan.
- Full-Duplex (WebSocket): Seperti percakapan tatap muka. Data mengalir secara dua arah secara bersamaan. Saat browser Anda mengirimkan frame video dan sampel audio ke AI, AI dapat mengirimkan respons suara dan perintah alat kepada Anda pada saat yang sama.
Alasan Gemini Live memerlukan Full-Duplex: Gemini Live API dirancang untuk "interupsi". Bayangkan Anda menunjukkan urutan jari, dan AI melihat Anda melakukannya dengan salah. Dalam penyiapan HTTP standar, AI harus menunggu Anda selesai mengirim data sebelum dapat memberi tahu Anda untuk berhenti. Dengan WebSockets, AI dapat melihat kesalahan di Frame 1 dan mengirim sinyal "interupsi" yang tiba di kokpit saat Anda masih menggerakkan tangan untuk Frame 2.
Apa itu WebSocket?
Dalam transmisi galaksi standar (HTTP), Anda mengirim permintaan dan menunggu balasan—seperti mengirim kartu pos. Untuk Sinkronisasi Neural, kartu pos terlalu lambat. Kita memerlukan "kabel aktif".
WebSocket dimulai sebagai permintaan web standar (HTTP), tetapi kemudian "diupgrade" menjadi sesuatu yang berbeda.
- Permintaan: Browser Anda mengirim permintaan HTTP standar ke server dengan header khusus:
Upgrade: websocket. Pada dasarnya, Anda mengatakan, "Saya ingin berhenti mengirim kartu pos dan memulai panggilan telepon langsung." - Respons: Jika Agen AI (server) mendukungnya, Agen AI akan mengirimkan respons
HTTP 101 Switching Protocols. - Transformasi: Pada saat ini, koneksi HTTP digantikan oleh protokol WebSocket, tetapi soket TCP/IP yang mendasarinya tetap terbuka. Aturan komunikasi berubah secara instan dari "Permintaan/Respons" menjadi "Streaming Full-Duplex".
Menerapkan Hook WebSocket
Mari kita periksa blok terminal untuk memahami cara aliran data.
👀 Buka $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. Anda akan melihat pengendali peristiwa siklus proses WebSocket standar yang sudah disiapkan. Berikut adalah kerangka sistem komunikasi kita:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
Handler onMessage
Fokus pada blok ws.current.onmessage. Ini adalah penerima. Setiap kali agen "berpikir" atau "berbicara", paket data akan tiba di sini. Saat ini, tidak ada yang dilakukan—paket diambil dan dibatalkan (melalui placeholder //#REPLACE-HANDLE-MSG).
Kita perlu mengisi kekosongan ini dengan logika yang dapat membedakan antara:
- Panggilan Alat (functionCall): AI mengenali sinyal tangan Anda (The "Sync").
- Data Audio (inlineData): Suara AI yang merespons Anda.
👉✏️ Sekarang, di file $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js yang sama, ganti //#REPLACE-HANDLE-MSG dengan logika di bawah untuk menangani aliran data yang masuk:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
Cara Audio dan Video Diubah menjadi Data untuk Transmisi
Untuk mengaktifkan komunikasi real-time melalui internet, audio dan video mentah harus dikonversi ke dalam format yang sesuai untuk transmisi. Hal ini melibatkan pengambilan, encoding, dan pengemasan data sebelum mengirimkannya melalui jaringan.
Transformasi Data Audio
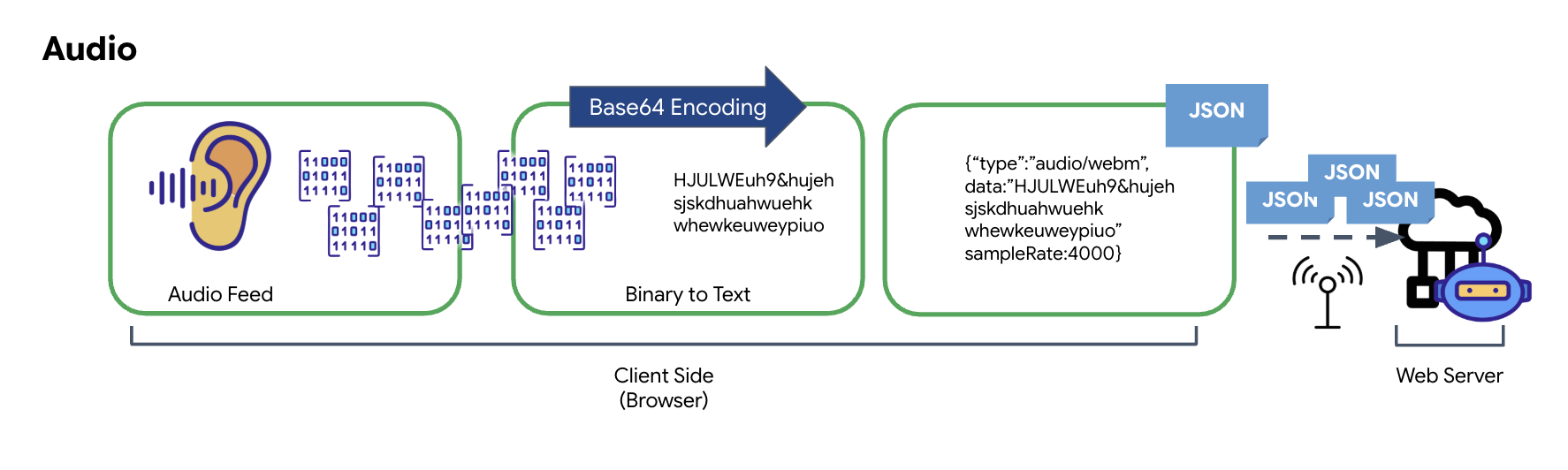
Proses pengubahan audio analog menjadi data digital yang dapat ditransmisikan dimulai dengan merekam gelombang suara menggunakan mikrofon. Audio mentah ini kemudian diproses melalui Web Audio API browser. Karena data mentah ini dalam format biner, data ini tidak kompatibel secara langsung dengan format transmisi berbasis teks seperti JSON. Untuk mengatasinya, setiap segmen audio dienkode menjadi string Base64. Base64 adalah metode yang merepresentasikan data biner dalam format string ASCII, sehingga memastikan integritasnya selama transmisi.
String yang dienkode ini kemudian disematkan dalam objek JSON. Objek ini menyediakan format terstruktur untuk data, biasanya mencakup kolom "type" untuk mengidentifikasinya sebagai audio dan metadata seperti frekuensi sampel audio. Seluruh objek JSON kemudian diserialisasi menjadi string dan dikirim melalui koneksi WebSocket. Pendekatan ini memastikan audio ditransmisikan dengan teratur dan mudah diuraikan.
Transformasi Data Video
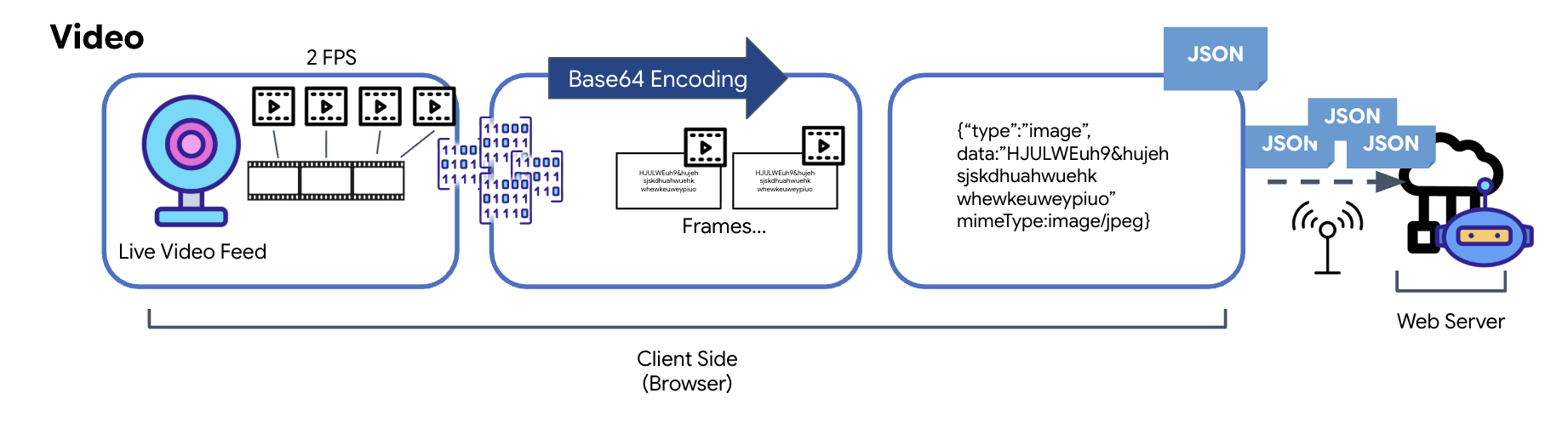
Transmisi video dilakukan melalui teknik pengambilan frame. Alih-alih mengirimkan streaming video berkelanjutan, loop berulang mengambil gambar diam dari feed video langsung pada interval yang ditetapkan, seperti dua frame per detik. Hal ini dilakukan dengan menggambar frame saat ini dari elemen video HTML ke elemen kanvas tersembunyi.
Metode toDataURL kanvas kemudian digunakan untuk mengonversi gambar yang diambil ini menjadi string JPEG berenkode Base64. Metode ini mencakup opsi untuk menentukan kualitas gambar, sehingga memungkinkan kompromi antara kesetiaan gambar dan ukuran file untuk mengoptimalkan performa. Mirip dengan data audio, string Base64 ini kemudian ditempatkan ke dalam objek JSON. Objek ini biasanya diberi label dengan "type" ‘image' dan menyertakan mimeType, seperti ‘image/jpeg'. Paket JSON ini kemudian dikonversi menjadi string dan dikirim melalui WebSocket, sehingga ujung penerima dapat merekonstruksi video dengan menampilkan urutan gambar.
👉✏️ Di file $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js yang sama, ganti //#CAPTURE AUDIO and VIDEO dengan kode berikut untuk merekam input pengguna:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
Setelah disimpan, kokpit akan siap menerjemahkan sinyal digital Agen menjadi pembaruan dasbor visual dan audio.
Pemeriksaan Diagnostik (Uji Loopback)
Kokpit Anda kini sudah aktif. Setiap 500 md, "paket" visual lingkungan Anda dipancarkan. Sebelum terhubung ke Gemini, kita harus memverifikasi bahwa pemancar kapal Anda berfungsi. Kita akan menjalankan "Loopback Test" menggunakan server diagnostik lokal.
👉💻 Pertama, bangun Antarmuka Cockpit dari terminal Anda:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 Selanjutnya, mulai server tiruan:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 Jalankan Protokol Pengujian:
- Membuka Pratinjau: Klik ikon Pratinjau web di toolbar Cloud Shell. Pilih Ubah port, tetapkan ke 8080, lalu klik Ubah dan Pratinjau. Tab browser baru akan terbuka dan menampilkan Antarmuka Cockpit Anda.
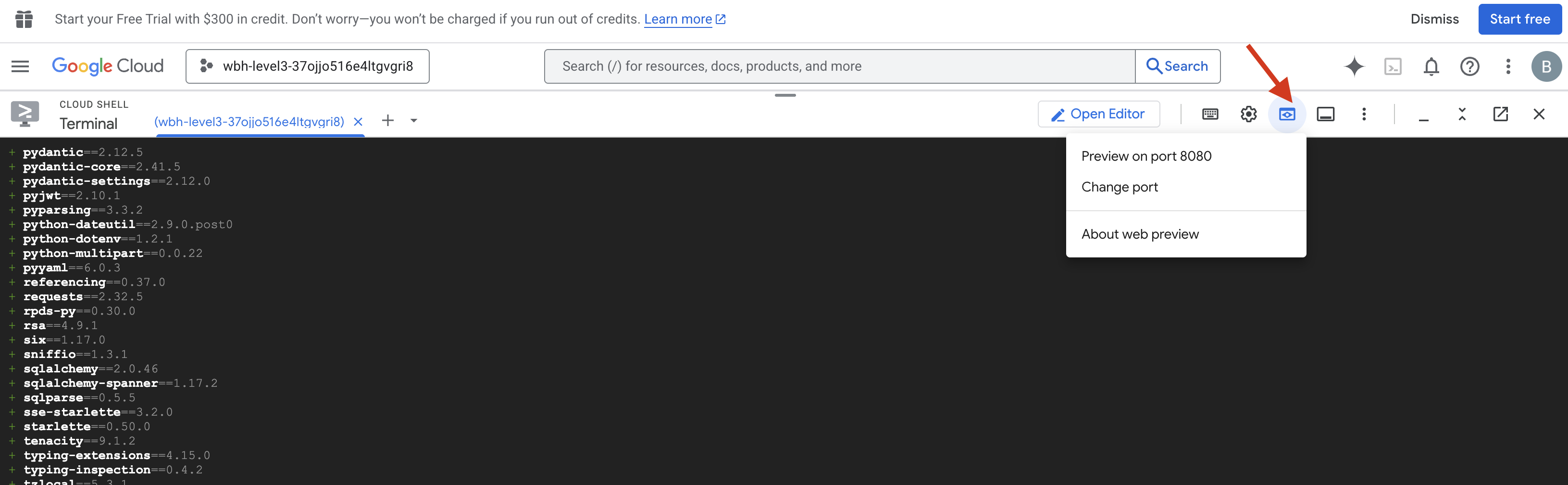
- KRITIS: Saat diminta, Anda HARUS mengizinkan browser mengakses Kamera dan Mikrofon Anda. Tanpa input ini, sinkronisasi saraf tidak dapat dimulai.
- Klik tombol "MULAIKAN SINKRONISASI NEURAL" di UI.
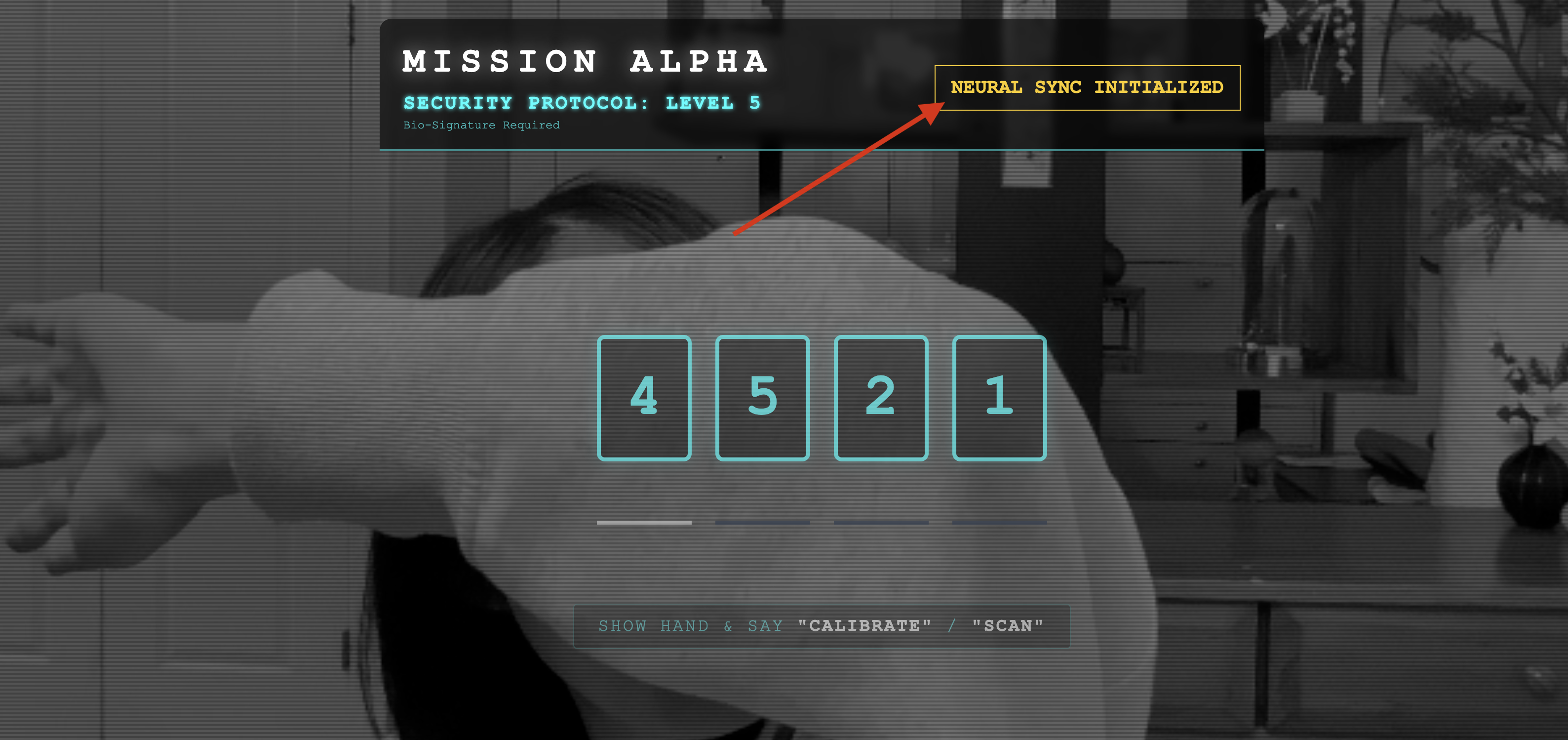
👀 Memverifikasi Indikator Status:
- Pemeriksaan Visual: Buka Konsol Browser Anda. Anda akan melihat
NEURAL SYNC INITIALIZEDdi kanan atas. - Pemeriksaan Audio: Jika pipeline audio dua arah Anda beroperasi sepenuhnya, Anda akan mendengar suara simulasi yang mengonfirmasi: "Sistem terhubung!"
Setelah Anda mendengar konfirmasi audio "System connected!", berarti pengujian berhasil. Tutup tab. Sekarang kita harus mengosongkan frekuensi untuk memberi ruang bagi AI yang sebenarnya.
👉💻 Tekan Ctrl+C di terminal untuk server tiruan dan frontend. Tutup tab browser yang menjalankan UI.
4. Agen Multimodal
Rescue Scout beroperasi, tetapi "otaknya" kosong. Jika Anda menghubungkannya sekarang, dia hanya akan menatap Anda. Ia tidak tahu apa itu "jari". Untuk menyelamatkan para penyintas, Anda harus menanamkan Biometric Neural Protocol ke inti Scout.
Agen Tradisional beroperasi seperti serangkaian penerjemah. Jika Anda berbicara dengan AI lama, model "Speech-to-Text" akan mengubah suara Anda menjadi kata-kata, "Model Bahasa" akan membaca kata-kata tersebut dan mengetik balasan, dan "Text-to-Speech" akan membacakan balasan tersebut kepada Anda. Hal ini menciptakan "kesenjangan latensi"—penundaan yang akan berakibat fatal dalam misi penyelamatan.
Gemini Live API adalah model multimodal native. API ini memproses byte audio mentah dan frame video mentah secara langsung dan bersamaan. Fitur ini "mendengar" getaran suara Anda dan "melihat" piksel gestur tangan Anda dalam arsitektur neural yang sama.
Untuk memanfaatkan kemampuan ini, kita dapat membangun aplikasi dengan menghubungkan kokpit langsung ke Live API mentah. Namun, tujuan kami adalah membangun agen yang dapat digunakan kembali—entitas modular dan tangguh yang lebih cepat dibangun.
Mengapa ADK (Agent Development Kit)?
Google Agent Development Kit (ADK) adalah framework modular untuk mengembangkan dan men-deploy agen AI.
Panggilan LLM standar biasanya stateless; setiap kueri adalah awal yang baru. Agen Langsung, terutama saat diintegrasikan dengan SessionService ADK, memungkinkan sesi percakapan yang kuat dan berjalan lama.
- Persistensi Sesi: Sesi ADK bersifat persisten dan dapat disimpan dalam database (seperti SQL atau Vertex AI), serta tetap ada setelah server dimulai ulang dan koneksi terputus. Artinya, jika pengguna keluar dan terhubung kembali nanti—bahkan beberapa hari kemudian—histori dan konteks percakapan mereka akan dipulihkan sepenuhnya. Sesi Live API sementara dikelola dan diabstraksi oleh ADK.
- Koneksi Ulang Otomatis: Koneksi WebSocket dapat mengalami waktu tunggu habis (misalnya, setelah ~10 menit). ADK menangani koneksi ulang ini secara transparan saat
session_resumptiondiaktifkan diRunConfig. Kode aplikasi Anda tidak perlu mengelola logika koneksi ulang yang rumit, sehingga memastikan pengalaman yang lancar bagi pengguna. - Interaksi Berstatus: Agen mengingat giliran sebelumnya, sehingga memungkinkan pertanyaan lanjutan, klarifikasi, dan dialog multi-giliran yang kompleks di mana konteks sangat penting. Hal ini sangat penting untuk aplikasi seperti dukungan pelanggan, tutorial interaktif, atau skenario kontrol misi yang memerlukan kesinambungan.
Persistensi ini memastikan bahwa interaksi terasa seperti percakapan berkelanjutan dengan entitas cerdas, bukan serangkaian pertanyaan dan jawaban yang terpisah.
Pada dasarnya, "Agen Aktif" dengan streaming dua arah ADK melampaui mekanisme kueri-respons sederhana untuk menawarkan pengalaman percakapan yang benar-benar interaktif, stateful, dan sadar gangguan, sehingga membuat interaksi AI terasa lebih manusiawi dan jauh lebih efektif untuk tugas yang kompleks dan berjalan lama.
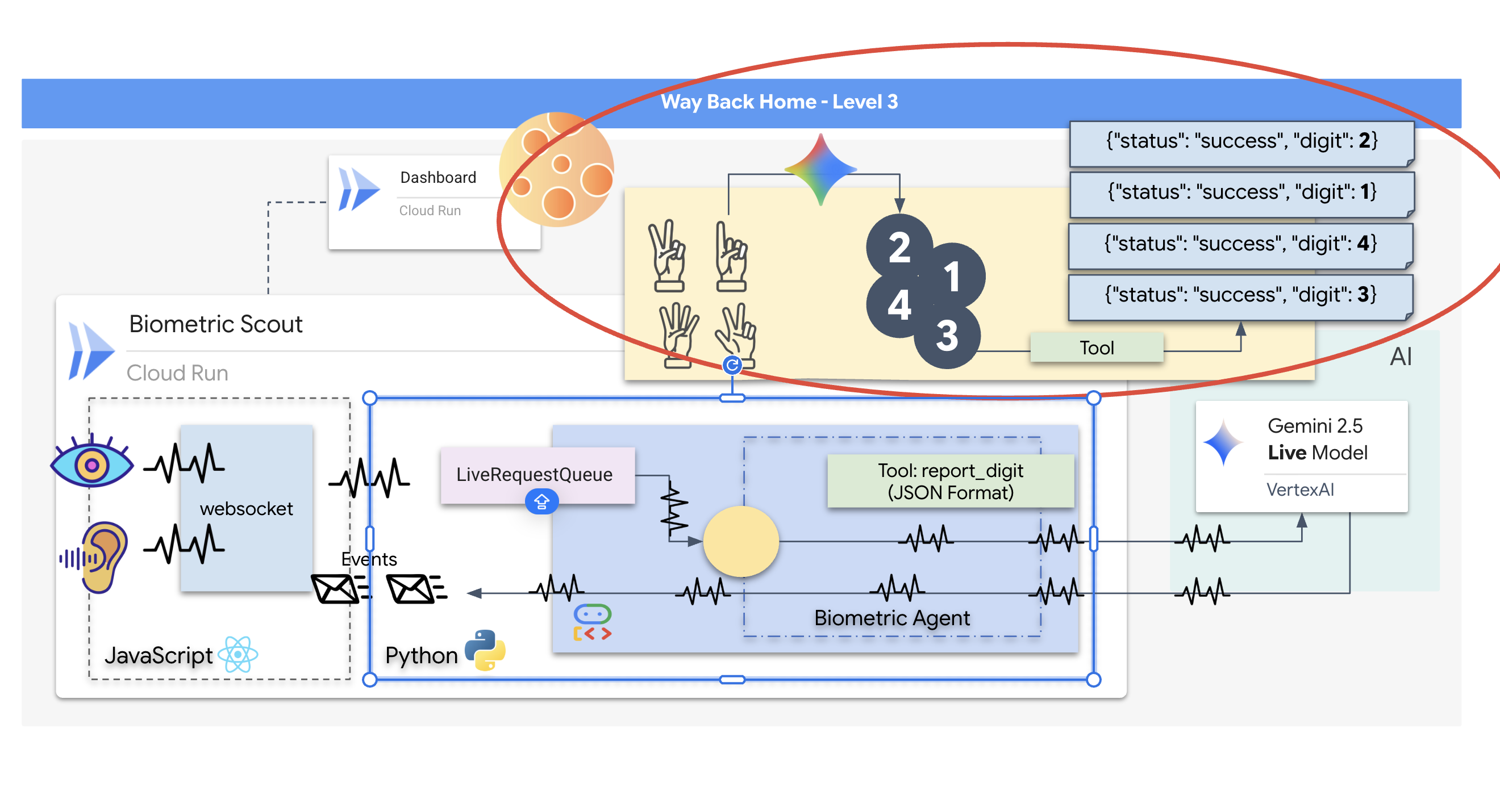
Meminta Agen Langsung
Mendesain perintah untuk agen dua arah real-time memerlukan perubahan pola pikir. Tidak seperti bot chat standar yang menunggu kueri teks statis, Agen Aktif "selalu aktif". Model ini menerima aliran frame audio dan video yang konstan, yang berarti perintah Anda harus bertindak sebagai Skrip Control Loop, bukan hanya definisi kepribadian.
Berikut perbedaan perintah Agen Aktif dengan perintah tradisional:
- Logika Mesin Status: Perintah harus menentukan "Loop Perilaku" (Tunggu → Analisis → Bertindak). Agen memerlukan petunjuk eksplisit tentang kapan harus tetap diam dan kapan harus berinteraksi, sehingga mencegah agen berbicara tanpa henti di tengah suara bising latar belakang yang kosong.
- Kesadaran Multimodal: Agen perlu diberi tahu bahwa ia memiliki "mata". Anda harus secara eksplisit menginstruksikannya untuk menganalisis frame video sebagai bagian dari proses penalarannya.
- Latensi & Singkat: Dalam percakapan suara langsung, paragraf panjang yang penuh prosa terasa tidak alami dan lambat. Perintah ini menekankan keringkasan agar interaksi tetap cepat.
- Arsitektur Mengutamakan Tindakan: Petunjuk memprioritaskan Panggilan Alat daripada ucapan. Kita ingin agen "melakukan" pekerjaan (memindai biometrik) sebelum atau saat agen mengonfirmasi secara lisan, bukan setelah monolog yang panjang.
👉✏️ Buka $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py dan ganti #REPLACE INSTRUCTIONS dengan kode berikut:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
PERHATIAN! Anda tidak terhubung ke LLM standar. Di file yang sama ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py), temukan #REPLACE_MODEL. Kita perlu menargetkan versi pratinjau model ini secara eksplisit untuk mendukung kemampuan audio real-time dengan lebih baik.
👉✏️ Ganti placeholder dengan:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
Agen Anda kini telah ditentukan. Model ini tahu siapa dirinya dan cara berpikir. Selanjutnya, kita memberinya alat untuk bertindak.
Pemanggilan Alat
Live API tidak hanya terbatas pada pertukaran streaming teks, audio, dan video. Model ini mendukung Panggilan Alat secara native. Hal ini mengubah agen dari sekadar lawan bicara pasif menjadi operator aktif.
Selama sesi dua arah langsung, model terus mengevaluasi konteks. Jika LLM mendeteksi kebutuhan untuk melakukan tindakan, baik itu "memeriksa telemetri sensor" atau "membuka kunci pintu yang aman". Fitur ini mengubah percakapan menjadi eksekusi dengan lancar. Agen akan segera memicu fungsi alat tertentu, menunggu hasilnya, dan mengintegrasikan data tersebut kembali ke live stream, tanpa mengganggu alur interaksi.
👉✏️ Di $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py, ganti #REPLACE TOOLS dengan fungsi ini:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ Kemudian, daftarkan dalam definisi Agent dengan mengganti #TOOL CONFIG:
tools=[report_digit],
Simulator adk web
Sebelum menghubungkannya ke kokpit kapal yang kompleks (Frontend React kami), kita harus menguji logika Agen secara terpisah. ADK menyertakan konsol developer bawaan yang disebut adk web yang memungkinkan kami memverifikasi Panggilan Alat sebelum menambahkan kompleksitas jaringan.
👉💻 Di terminal Anda, jalankan:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Klik ikon Web preview di toolbar Cloud Shell. Pilih Ubah port, tetapkan ke 8000, lalu klik Ubah dan Pratinjau.
- Berikan Izin: Izinkan akses ke Kamera dan Mikrofon Anda saat diminta.
- Mulai sesi dengan mengklik ikon kamera.
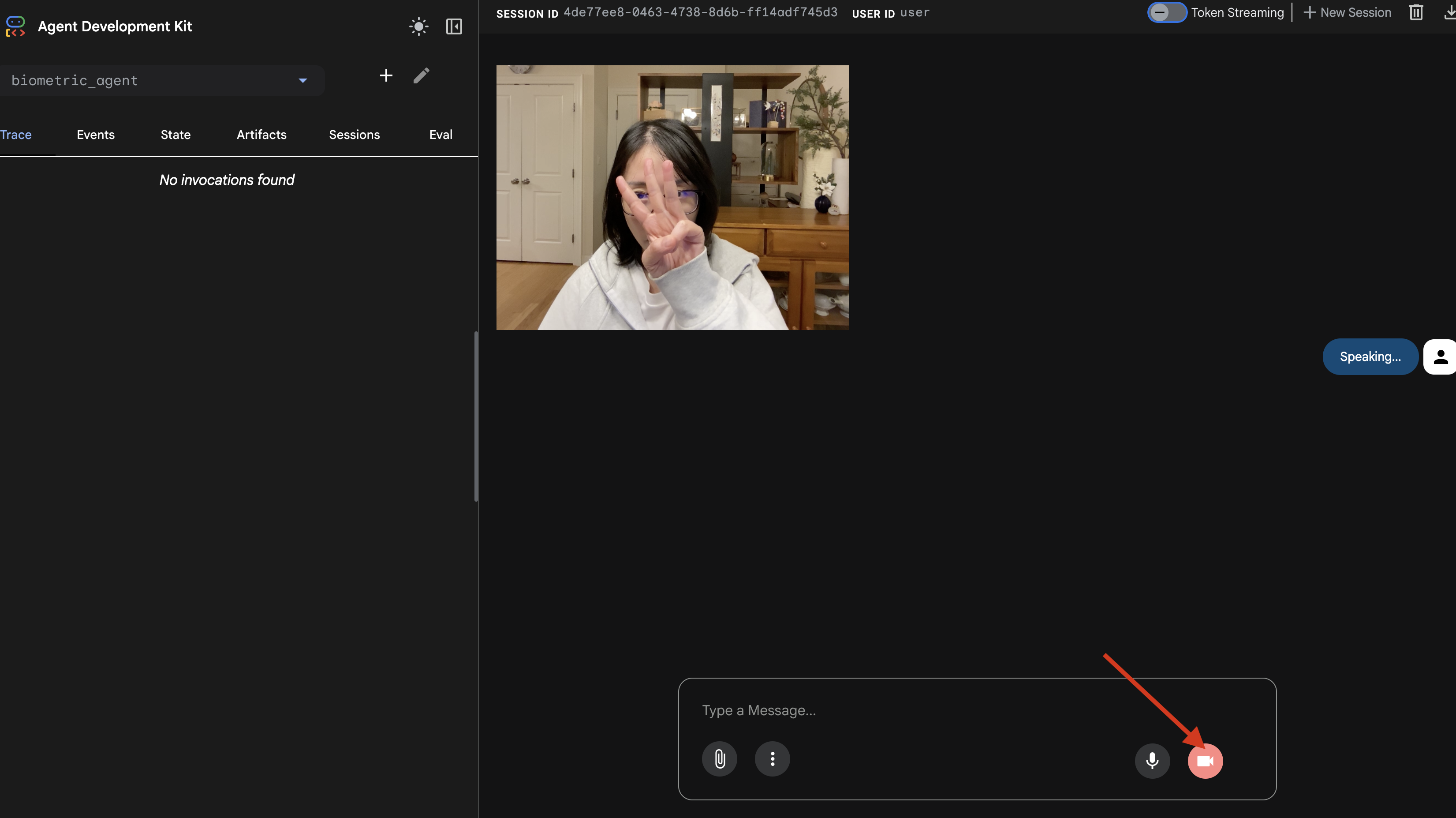
- Tes Visual:
- Angkat 3 jari dengan jelas di depan kamera.
- Ucapkan: "Pindai".
- Verifikasi Berhasil:
- Log: Lihat terminal yang menjalankan perintah
adk web. Anda harus melihat log ini:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- Log: Lihat terminal yang menjalankan perintah
Jika Anda melihat log eksekusi alat, berarti Agen Anda cerdas. Ia bisa melihat, berpikir, dan bertindak. Langkah terakhir adalah menghubungkannya ke kapal utama.
Klik jendela terminal dan tekan Ctrl+C untuk menghentikan simulator adk web.
5. Alur Streaming Dua Arah
Agen berfungsi. Cockpit berfungsi. Sekarang, kita harus menghubungkannya.
Siklus Proses Agen Langsung
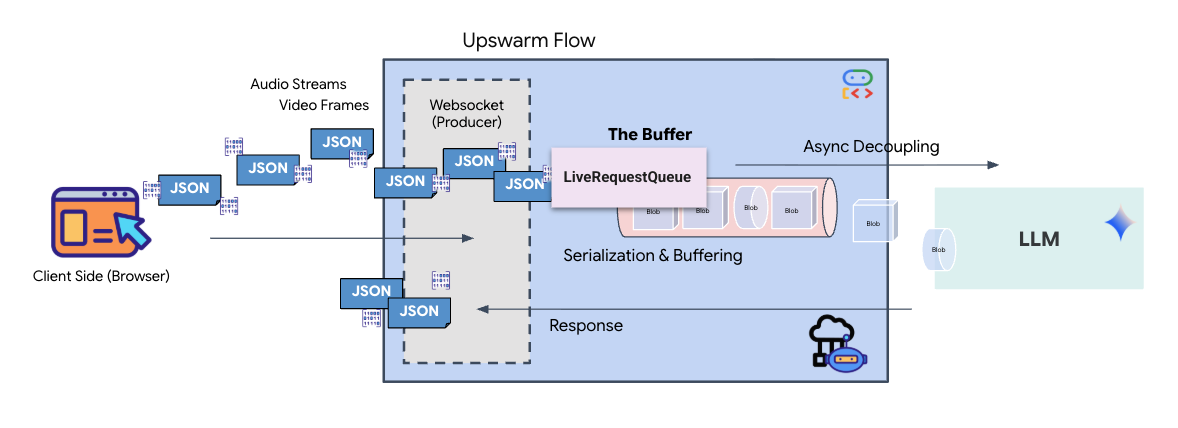
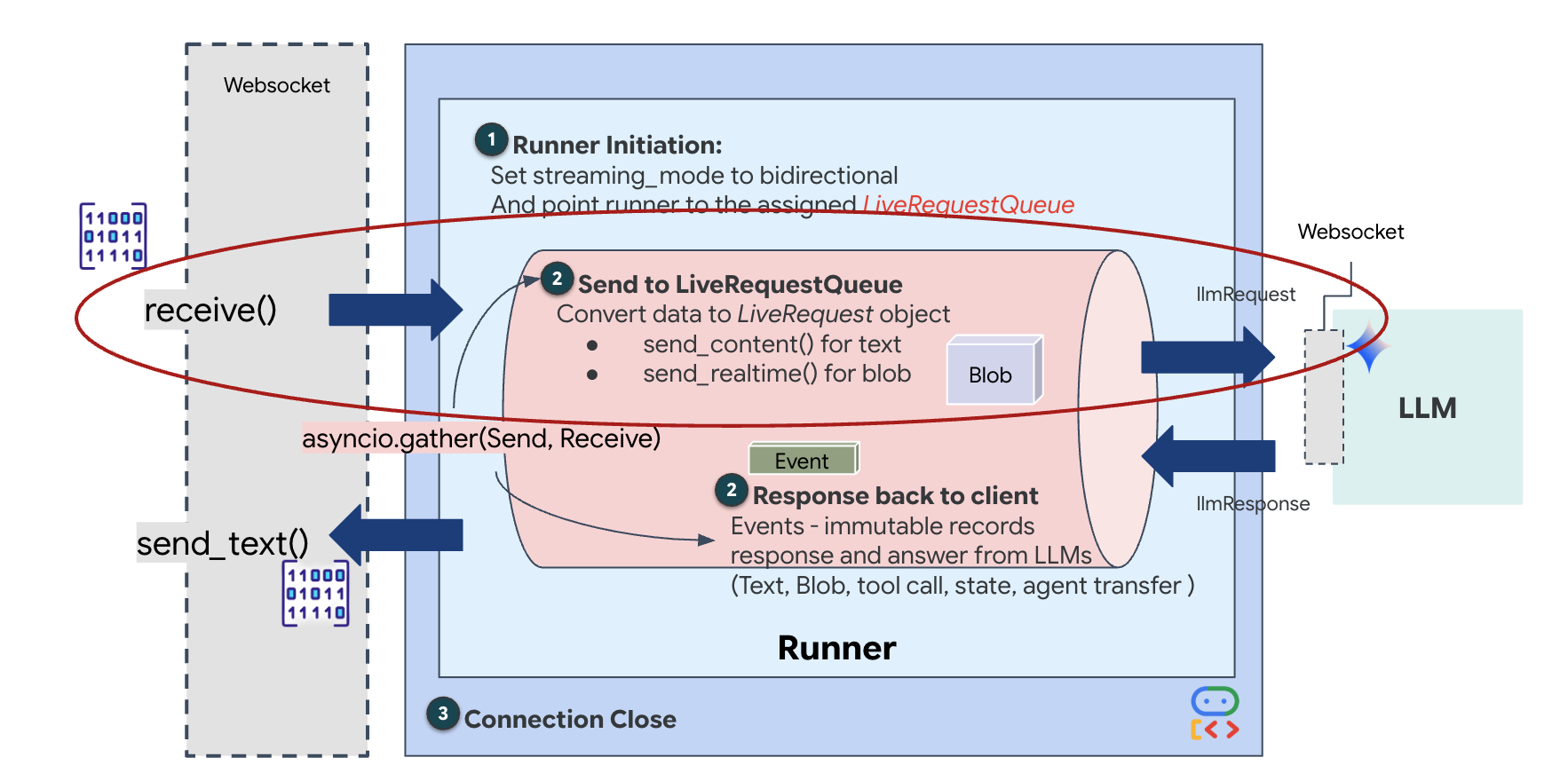
Streaming real-time menimbulkan masalah "ketidakcocokan impedansi". Klien (browser) mengirimkan data secara asinkron dengan kecepatan yang bervariasi—lonjakan jaringan atau input cepat—sementara model memerlukan aliran input yang berurutan dan diatur. ADK Google mengatasi masalah ini dengan menggunakan LiveRequestQueue.
Buffer ini bertindak sebagai buffer First-In-First-Out (FIFO) asinkron yang aman untuk thread. Handler WebSocket bertindak sebagai Produser, yang mengirimkan potongan audio/video mentah ke dalam antrean. Agen ADK bertindak sebagai Konsumen, menarik data dari antrean untuk mengisi jendela konteks model. Pemisahan ini memungkinkan aplikasi terus menerima input pengguna meskipun model sedang menghasilkan respons atau menjalankan alat.
Antrean berfungsi sebagai Multiplexer Multimodal. Di lingkungan nyata, alur upstream terdiri dari jenis data yang berbeda dan bersamaan: byte audio PCM mentah, frame video, petunjuk sistem berbasis teks, dan hasil dari Panggilan Alat asinkron. LiveRequestQueue melinearisasi input yang berbeda-beda ini menjadi satu urutan kronologis. Baik paket berisi keheningan selama milidetik, gambar beresolusi tinggi, atau payload JSON dari kueri database, paket tersebut diserialisasi dalam urutan kedatangan yang tepat, sehingga memastikan model memahami linimasa kausal yang konsisten.
Arsitektur ini memungkinkan Kontrol Non-Pemblokiran. Karena lapisan penyerapan (Produser) dipisahkan dari lapisan pemrosesan (Konsumen), sistem tetap responsif meskipun selama inferensi model yang mahal secara komputasi. Jika pengguna menyela dengan perintah "Berhenti!" saat Agen menjalankan alat, sinyal audio tersebut akan langsung dimasukkan ke dalam antrean. Loop peristiwa yang mendasarinya memproses sinyal prioritas ini secara langsung, sehingga sistem dapat menghentikan pembuatan atau memutar tugas tanpa membekukan UI atau menghilangkan paket.
👉💻 Di $HOME/way-back-home/level_3/backend/app/main.py, temukan komentar #REPLACE_RUNNER_CONFIG dan ganti dengan kode berikut untuk mengaktifkan sistem:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
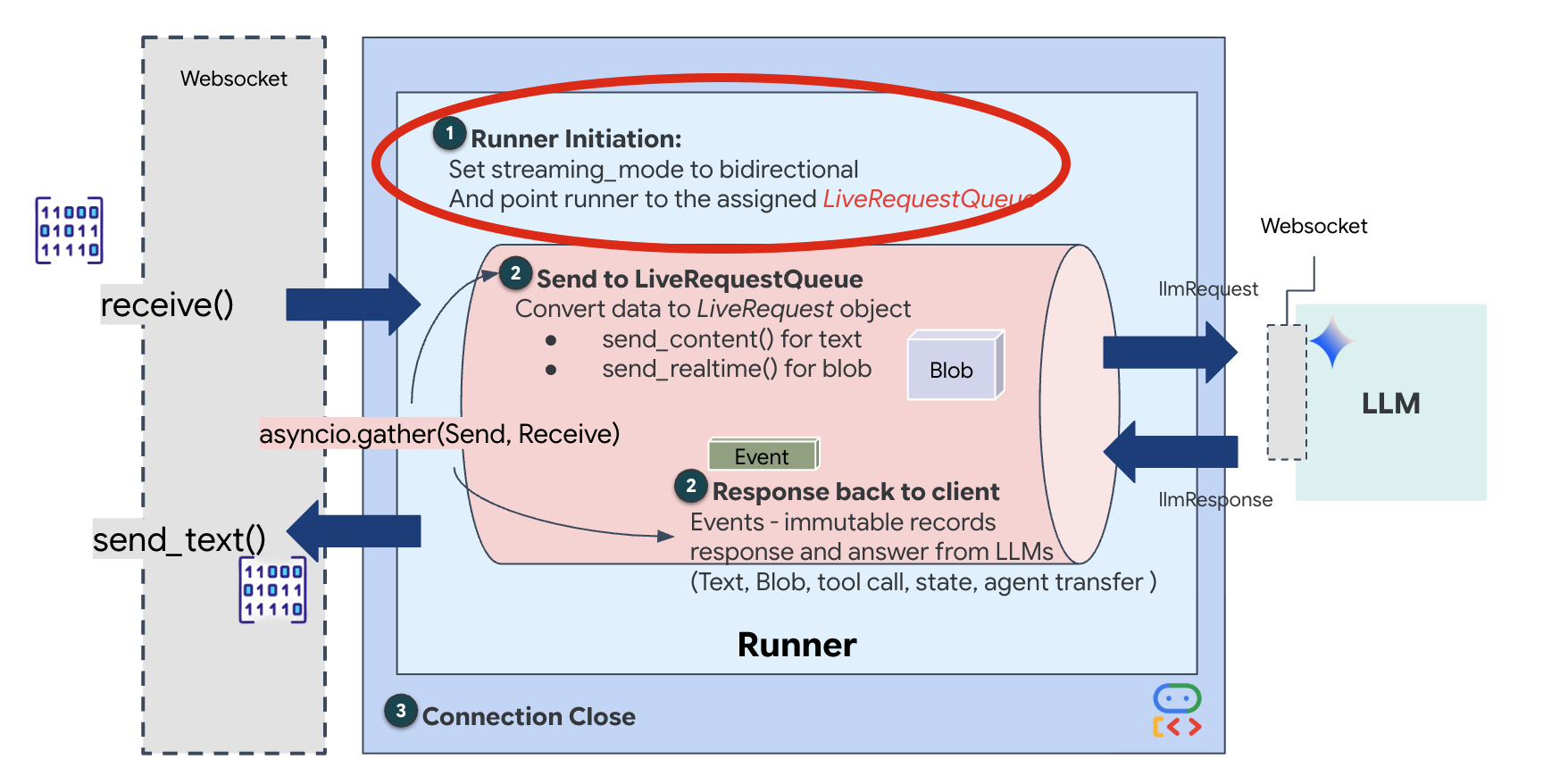
Saat koneksi WebSocket baru dibuka, kita perlu mengonfigurasi cara interaksi AI. Di sinilah kita menentukan "Aturan Interaksi".
👉✏️ Di $HOME/way-back-home/level_3/backend/app/main.py, di dalam fungsi async def websocket_endpoint, ganti komentar #REPLACE_SESSION_INIT dengan kode di bawah:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
Konfigurasi Run
StreamingMode.BIDI: Setelan ini menetapkan koneksi menjadi dua arah. Tidak seperti AI "berbasis giliran" (Anda berbicara, berhenti, lalu AI berbicara), BIDI memungkinkan percakapan "dupleks penuh" yang realistis. Anda dapat menghentikan AI, dan AI dapat berbicara saat Anda bergerak.AudioTranscriptionConfig: Meskipun model "mendengar" audio mentah, kami (developer) perlu melihat log. Konfigurasi ini memberi tahu Gemini: "Proses audio, tetapi juga kirim kembali transkrip teks dari apa yang Anda dengar agar kami dapat men-debug."
Logika Eksekusi Setelah Runner membuat sesi, Runner akan menyerahkan kontrol ke logika eksekusi, yang mengandalkan LiveRequestQueue. Ini adalah komponen paling penting untuk interaksi real-time. Loop ini memungkinkan agen membuat respons suara saat antrean terus menerima frame video baru dari pengguna, sehingga "Sinkronisasi Neural" tidak pernah terganggu.
👉✏️ Di $HOME/way-back-home/level_3/backend/app/main.py, ganti #REPLACE_LIVE_REQUEST untuk menentukan tugas upstream yang mengirim data ke LiveRequestQueue:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
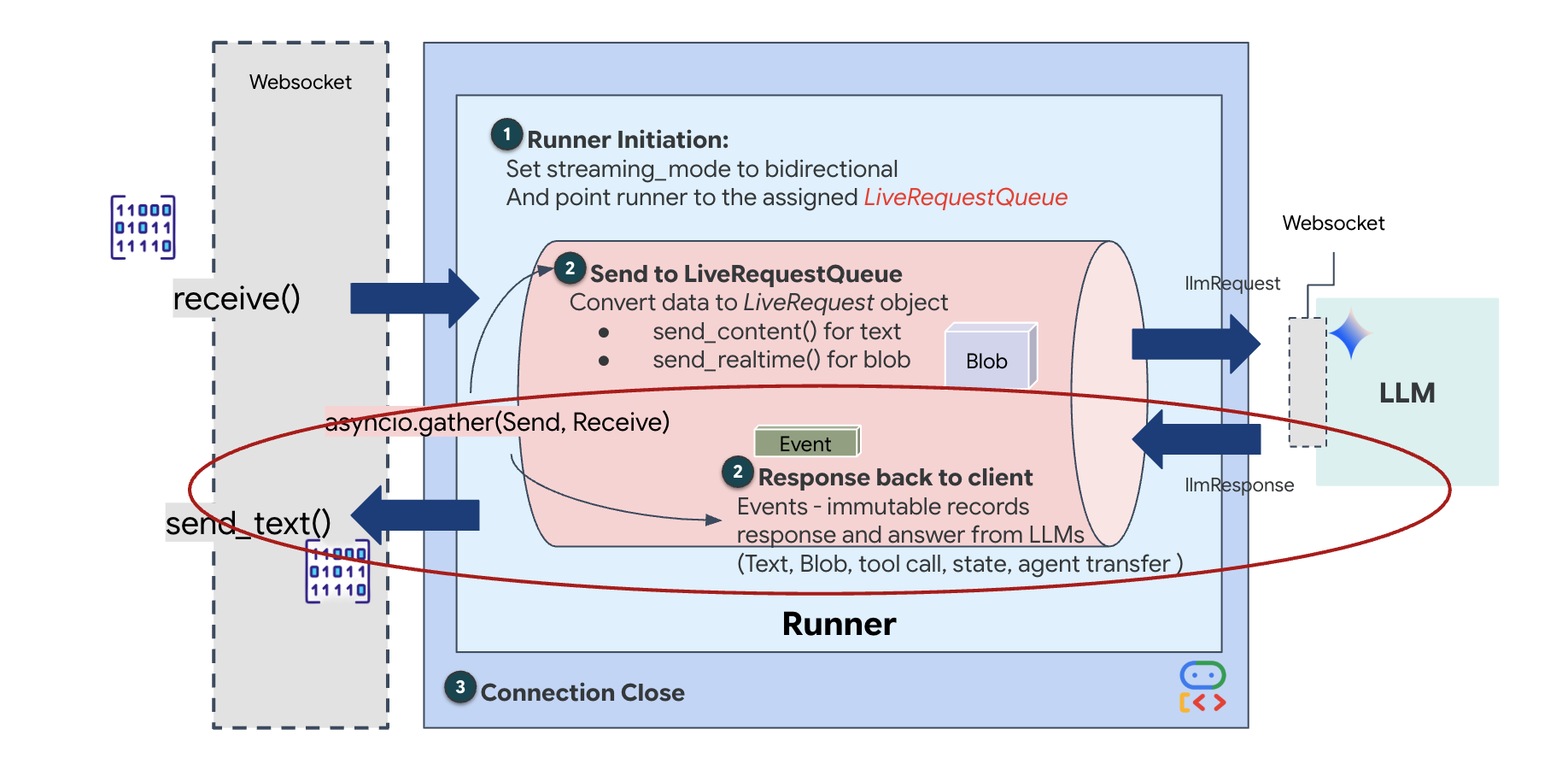
Terakhir, kita perlu menangani respons AI. Ini menggunakan runner.run_live(), yang merupakan generator peristiwa yang menghasilkan peristiwa (Audio, Teks, atau Panggilan Alat) saat terjadi.
👉✏️ Di $HOME/way-back-home/level_3/backend/app/main.py, ganti #REPLACE_SORT_RESPONSE untuk menentukan tugas hilir dan pengelola serentak:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
Perhatikan baris await asyncio.gather(upstream_task(), downstream_task()). Inilah inti dari Full-Duplex. Kami menjalankan tugas mendengarkan (hulu) dan tugas berbicara (hilir) pada waktu yang sama persis. Hal ini memastikan "Neural Link" memungkinkan gangguan dan aliran data simultan.
Backend Anda kini telah sepenuhnya dikodekan. "Otak" (ADK) terhubung ke "Tubuh" (WebSocket).
Eksekusi Bio-Sync
Kodenya sudah selesai. Sistemnya berwarna hijau. Saatnya meluncurkan penyelamatan.
- 👉💻 Mulai Backend:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 Luncurkan Frontend:
- Klik ikon Web preview di toolbar Cloud Shell. Pilih Ubah port, tetapkan ke 8080, lalu klik Ubah dan Pratinjau.
- 👉 Jalankan Protokol:
- Klik "MULAIKAN SINKRONISASI NEURAL".
- Kalibrasi: Pastikan kamera melihat tangan Anda dengan jelas di latar belakang.
- Sinkronisasi: Perhatikan Kode Keamanan yang ditampilkan di layar (misalnya, 3, lalu 2, lalu 5).
- Cocokkan Sinyal: Saat angka muncul, angkat jari dengan jumlah yang sama persis dengan angka tersebut.
- Pegang dengan Stabil: Pastikan tangan Anda terlihat hingga AI mengonfirmasi "Pencocokan biometrik".
- Adaptasi: Kode bersifat acak. Segera beralih ke angka berikutnya yang ditampilkan hingga urutan selesai.

- Saat Anda mencocokkan angka terakhir dalam urutan acak, "Sinkronisasi Biometrik" akan selesai. Link neural akan terkunci. Anda memiliki kontrol manual. Mesin Scout akan menderu, menyelam ke The Ravine untuk membawa para penyintas pulang.
👉💻 Tekan Ctrl+C di terminal backend untuk keluar.
6. Men-deploy ke Produksi (Opsional)
Anda telah berhasil menguji biometrik secara lokal. Sekarang, kita harus mengupload inti saraf Agen ke mainframe kapal (Cloud Run) agar dapat beroperasi secara independen dari konsol lokal Anda.
👉💻 Jalankan perintah berikut di terminal Cloud Shell. Tindakan ini akan membuat Dockerfile multi-tahap yang lengkap di direktori backend Anda.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 Buka direktori backend dan kemas aplikasi ke dalam image container.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 Deploy layanan ke Cloud Run. Kita akan menyisipkan variabel lingkungan yang diperlukan—khususnya konfigurasi Gemini—langsung ke perintah peluncuran.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
Setelah perintah selesai, Anda akan melihat URL Layanan (misalnya, https://biometric-scout-...run.app). Aplikasi kini aktif di cloud.
👉 Buka halaman Google Cloud Run dan pilih layanan biometric-scout dari daftar. 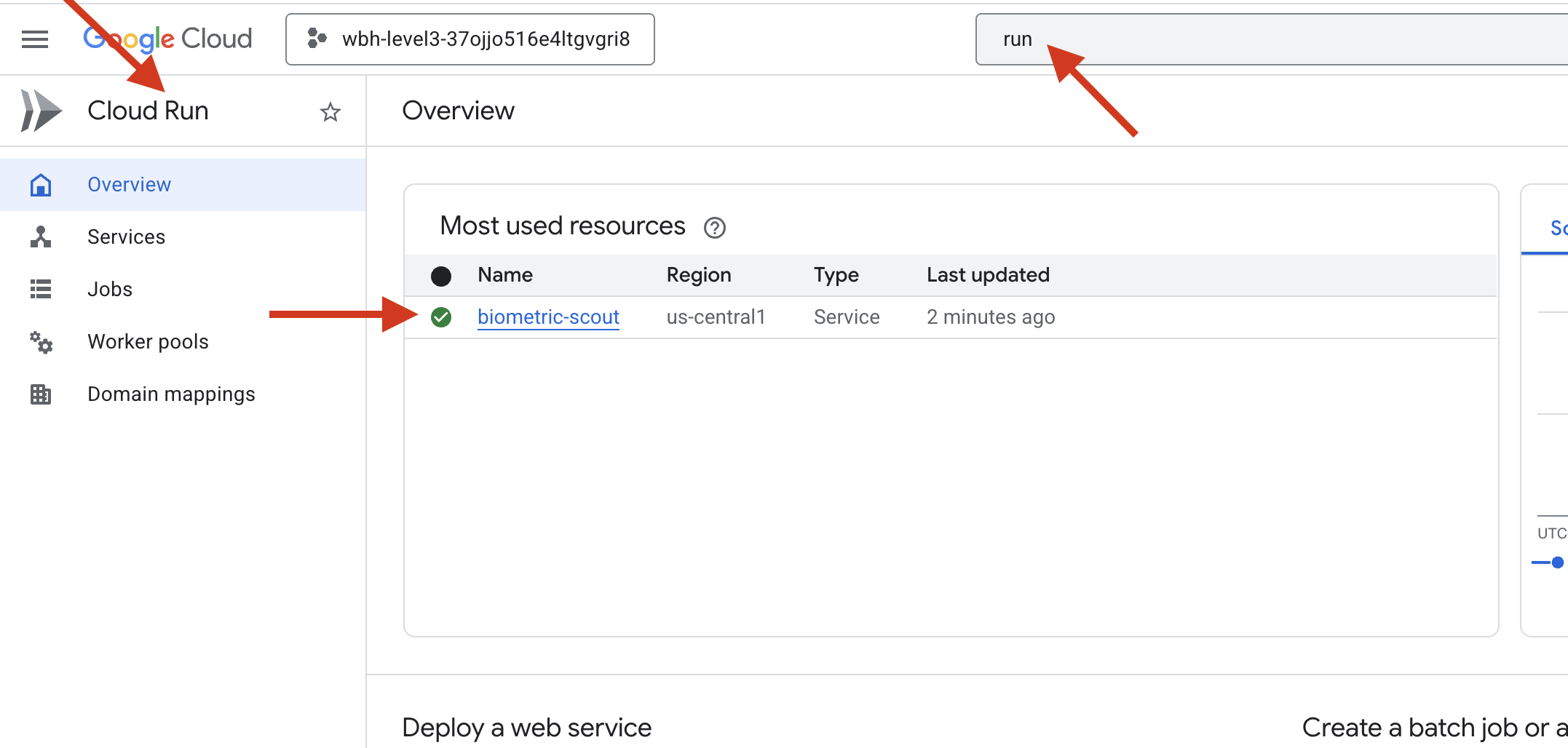
👉 Cari URL Publik yang ditampilkan di bagian atas halaman Detail layanan. 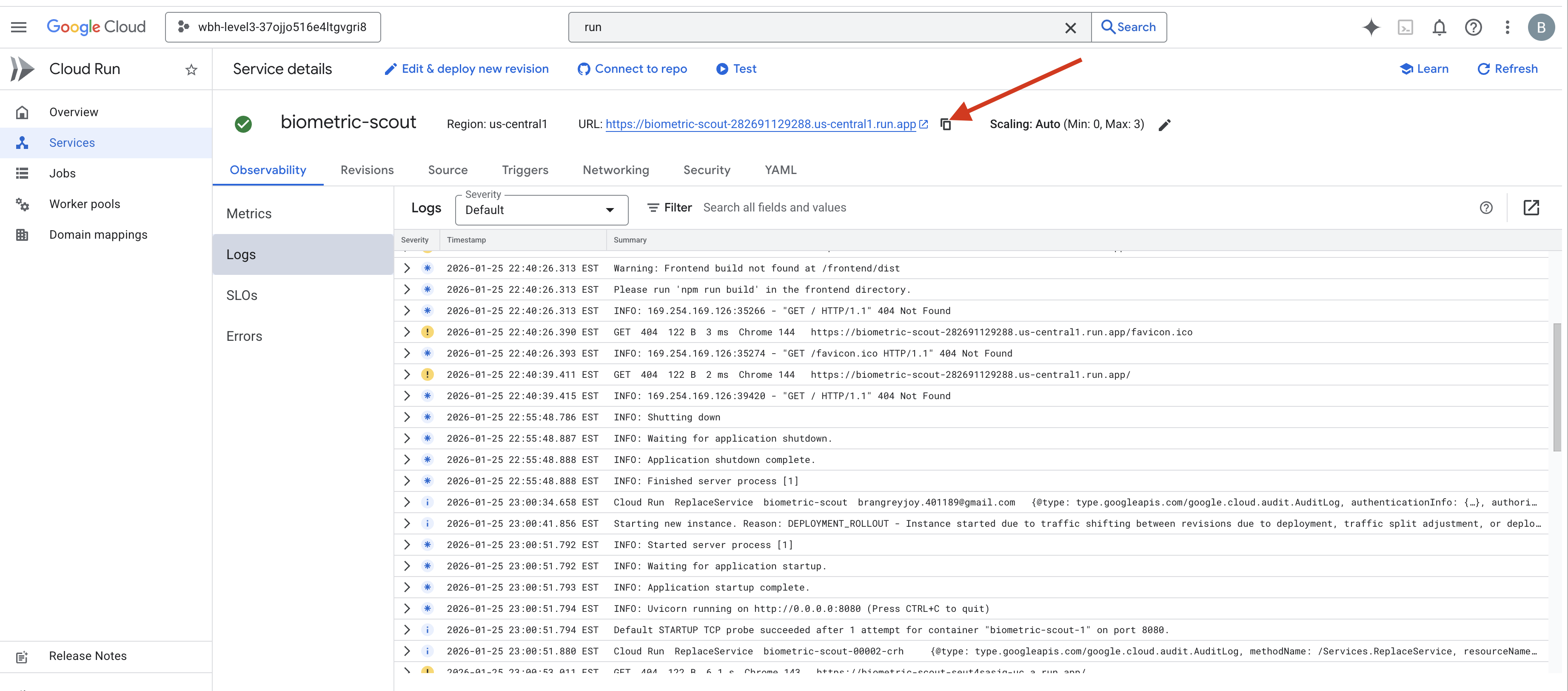
Coba lakukan Bio-Sync di lingkungan ini, apakah juga berfungsi?
Saat jari kelima Anda direntangkan, AI akan mengunci urutan. Layar berkedip hijau: "Biometric Neural Sync: ESTABLISHED".
Dengan satu pikiran, kamu menyelamkan Scout ke dalam kegelapan, mengaitkan diri ke pod yang terdampar, dan menariknya keluar tepat sebelum robekan gravitasi runtuh.

Pintu kedap udara terbuka dengan suara mendesis, dan di sana ada lima orang yang masih hidup dan bernapas. Mereka tersandung di dek, babak belur tetapi masih hidup, akhirnya aman berkat Anda.
Berkat Anda, link neural disinkronkan dan para penyintas diselamatkan.
Jika Anda berpartisipasi dalam Level 0, jangan lupa untuk memeriksa progres Anda dalam misi kembali ke rumah!