1. A missão

Você está à deriva no silêncio de um setor desconhecido. Um enorme **Pulso Solar** rasgou sua nave por uma fenda, deixando você preso em um bolsão do universo que não existe em nenhum mapa estelar.
Depois de dias de consertos exaustivos, você finalmente sente o zumbido dos motores sob seus pés. Sua nave espacial foi consertada. Você até conseguiu proteger um uplink de longo alcance para a nave-mãe. Você está liberado para decolar. Você está pronto para ir para casa. Mas, enquanto você se prepara para acionar o drive de salto, um sinal de socorro atravessa a estática. Seus sensores detectam cinco assinaturas de calor fracas presas em "O Ravina", um setor irregular e distorcido pela gravidade em que sua nave principal nunca pode entrar. São outros exploradores, sobreviventes da mesma tempestade que quase te levou. Não é possível deixá-los para trás.
Você recorre ao seu Alpha-Drone Rescue Scout. Essa embarcação pequena e ágil é a única capaz de navegar pelas paredes estreitas do Ravine. Mas há um problema: o pulso solar executou uma "redefinição de sistema" total na lógica principal. Os sistemas de controle do Scout não respondem. Ele está ligado, mas o computador de bordo está em branco, sem capacidade de processar comandos de piloto manual ou trajetos de voo.
O desafio
Para salvar os sobreviventes, você precisa desviar completamente dos circuitos danificados do Scout. Você tem uma opção desesperada: criar um agente de IA para estabelecer uma sincronização neural biométrica. Esse agente vai atuar como uma ponte em tempo real, permitindo que você controle o Rescue Scout manualmente usando suas próprias entradas biológicas. Você não vai usar um joystick ou um teclado. Sua intenção será conectada diretamente à rede de navegação da nave.
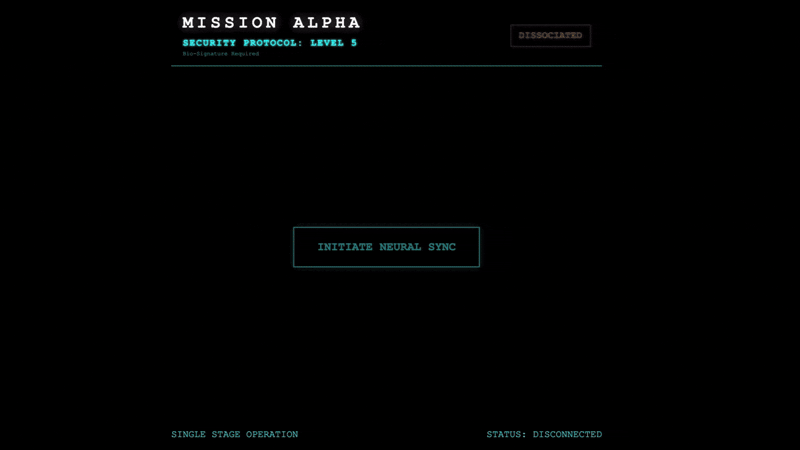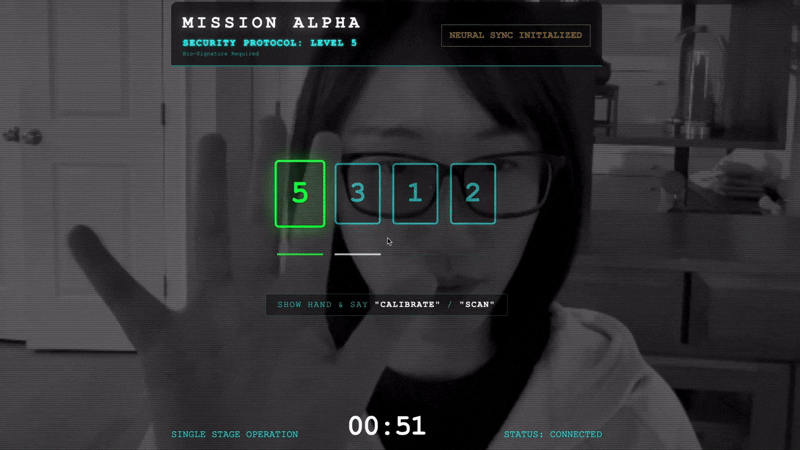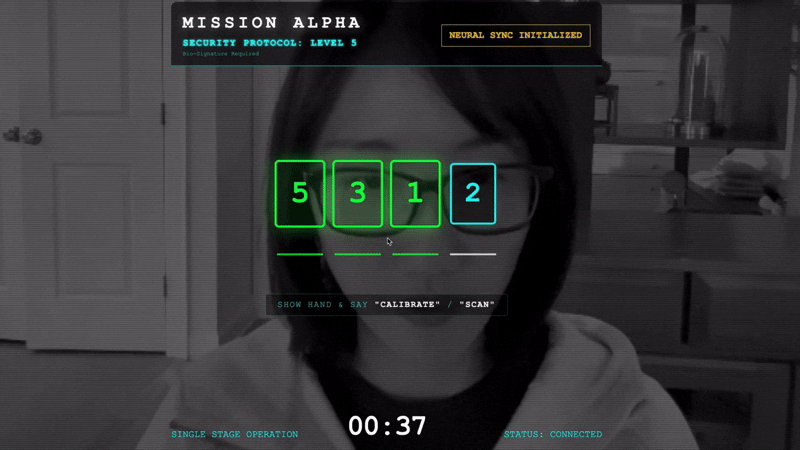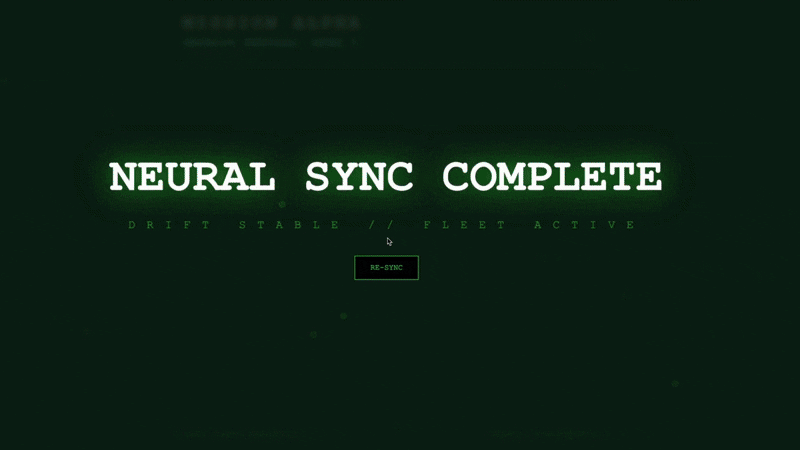
Para bloquear o link, execute o Protocolo de sincronização na frente dos sensores ópticos do Scout. O agente de IA precisa reconhecer sua assinatura biológica por um handshake preciso e em tempo real.
Objetivos da missão:
- Imprimir o Neural Core:defina um agente do ADK capaz de reconhecer entradas multimodais.
- Estabelecer a conexão:crie um pipeline WebSocket bidirecional para transmitir dados visuais do Scout para a IA.
- Inicie o aperto de mão:fique em frente ao sensor e complete a sequência de dedos, mostrando de 1 a 5 em ordem.
Se for bem-sucedida, a "Sincronização biométrica" será ativada. A IA vai bloquear o link neural, a você controle manual total para lançar o Scout e trazer os sobreviventes para casa.
O que você criará
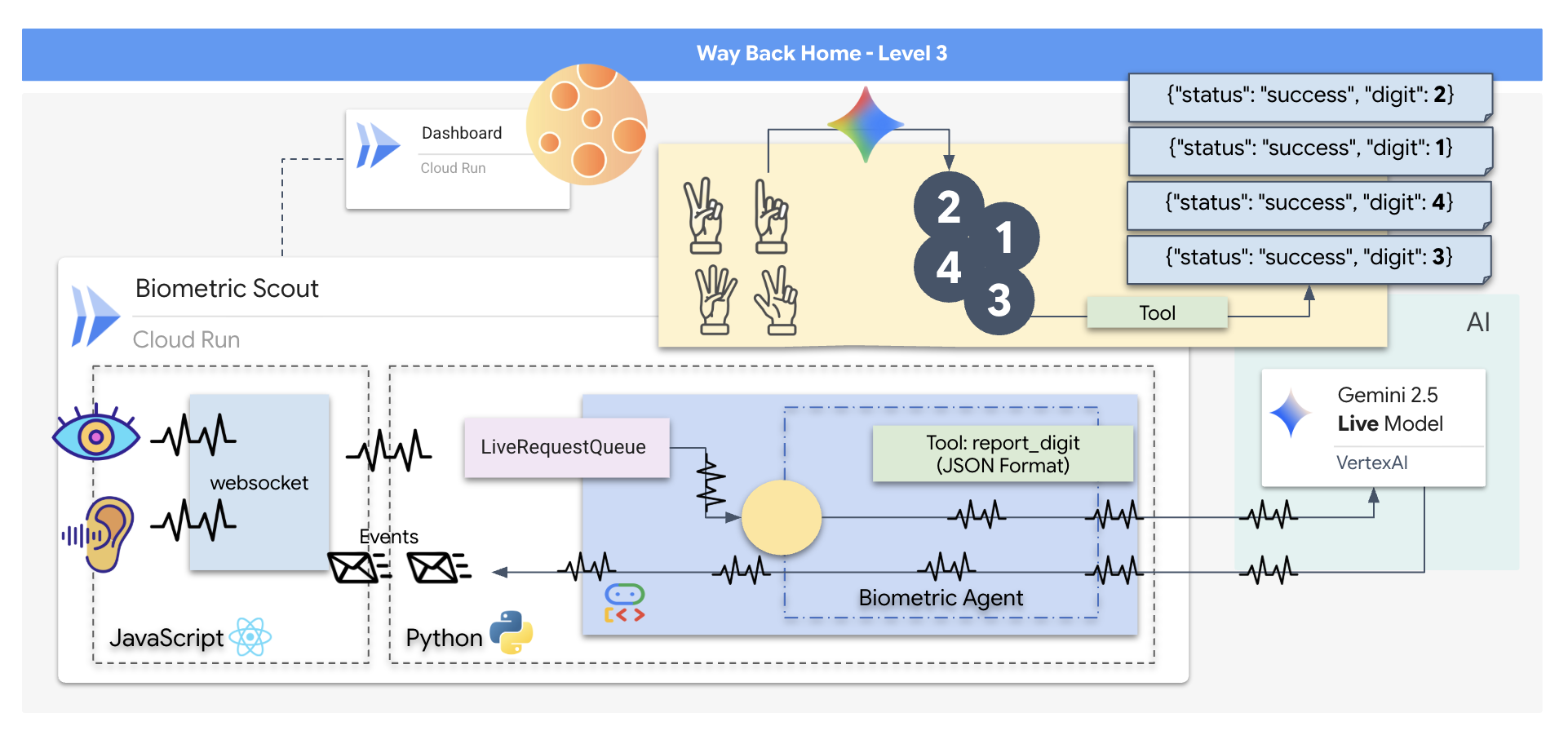
Você vai criar um aplicativo de "Sincronização Neural Biométrica", um sistema em tempo real com tecnologia de IA que atua como interface de controle de um drone de resgate. Esse sistema consiste em:
- Um front-end React:o "cockpit" da sua nave, que captura vídeo ao vivo da webcam e áudio do microfone.
- Um back-end em Python:um servidor de alta performance criado com FastAPI, usando o Kit de Desenvolvimento de Agente (ADK) do Google para gerenciar a lógica e o estado do LLM.
- Um agente de IA multimodal:o "cérebro" da operação, usando a API Gemini Live pelo SDK
google-genaipara processar e entender streams de vídeo e áudio simultaneamente. - Um pipeline WebSocket bidirecional:o "sistema nervoso" que cria uma conexão persistente de baixa latência entre o front-end e a IA, permitindo a interação em tempo real.
O que você vai aprender
Tecnologia / Conceito | Descrição |
Agente de IA de back-end | Crie um agente de IA com estado usando Python e FastAPI. Use o ADK (Kit de Desenvolvimento de Agente) do Google para gerenciar instruções e memória, e o SDK |
Interface de front-end | Desenvolva uma interface do usuário dinâmica usando o React para capturar e transmitir vídeo e áudio ao vivo diretamente do navegador. |
Comunicação em tempo real | Implemente um pipeline WebSocket para comunicação full-duplex de baixa latência, permitindo que o usuário e a IA interajam simultaneamente. |
IA multimodal | Use a API Gemini Live para processar e entender streams de vídeo e áudio simultâneos, permitindo que a IA "veja" e "ouça" ao mesmo tempo. |
Chamadas de ferramentas | Permite que a IA execute funções específicas do Python em resposta a gatilhos visuais, diminuindo a distância entre a inteligência do modelo e a ação no mundo real. |
Implantação full-stack | Conteinerize todo o aplicativo (front-end do React e back-end do Python) com o Docker e implante-o como um serviço escalonável e sem servidor no Google Cloud Run. |
2. Configuração de seu ambiente
Acessar o Cloud Shell
Primeiro, vamos abrir o Cloud Shell, que é um terminal baseado em navegador com o SDK Google Cloud e outras ferramentas essenciais pré-instaladas.
👉Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud. É o ícone em formato de terminal na parte de cima do painel do Cloud Shell. 
👉Clique no botão "Abrir editor" (parece uma pasta aberta com um lápis). Isso vai abrir o editor de código do Cloud Shell na janela. Um explorador de arquivos vai aparecer no lado esquerdo. 
👉Abra o terminal no IDE da nuvem.
👉💻 No terminal, verifique se você já está autenticado e se o projeto está definido como seu ID do projeto usando o seguinte comando:
gcloud auth list
Sua conta vai aparecer como (ACTIVE).
Pré-requisitos
ℹ️ O nível 0 é opcional (mas recomendado)
É possível concluir essa missão sem o nível 0, mas terminar esse nível primeiro oferece uma experiência mais imersiva, permitindo que você veja seu farol acender no mapa global à medida que avança.
Configurar o ambiente do projeto
De volta ao terminal, conclua a configuração definindo o projeto ativo e ativando os serviços necessários do Google Cloud (Cloud Run, Vertex AI etc.).
👉💻 No terminal, defina o ID do projeto:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Ative os serviços obrigatórios:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
Instalar dependências
👉💻 Acesse o nível e instale os pacotes Python necessários:
cd $HOME/way-back-home/level_3
uv sync
As principais dependências são:
Pacote | Finalidade |
| Framework da Web de alto desempenho para a estação de satélite e streaming SSE. |
| Servidor ASGI necessário para executar o aplicativo FastAPI |
| O Kit de Desenvolvimento de Agente usado para criar o Agente de formação |
| Cliente nativo para acessar modelos do Gemini. |
| Suporte para comunicação bidirecional em tempo real |
| Gerencia variáveis de ambiente e secrets de configuração. |
Verificar configuração
Antes de começar a codificar, vamos verificar se todos os sistemas estão funcionando. Execute o script de verificação para auditar seu projeto do Google Cloud, APIs e dependências do Python.
👉💻 Execute o script de verificação:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Uma série de marcas de seleção verdes (✅) vai aparecer.
- Se você vir cruzes vermelhas (❌), siga os comandos de correção sugeridos na saída (por exemplo,
gcloud services enable ...oupip install ...). - Observação:um aviso amarelo para
.envé aceitável por enquanto. Vamos criar esse arquivo na próxima etapa.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Calibrando o Comm-Link (WebSockets)
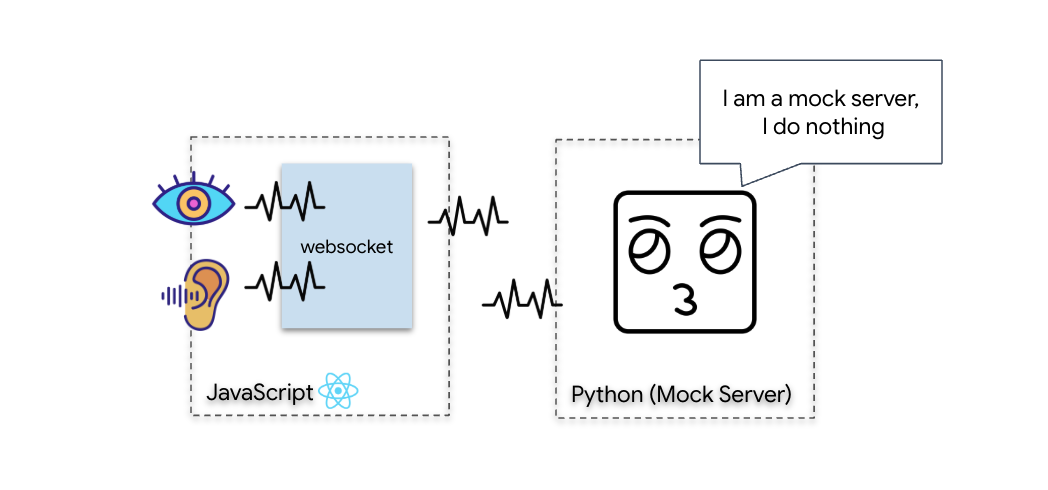
Para iniciar a sincronização neural biométrica, precisamos atualizar os sistemas internos da sua nave. Nosso objetivo principal é capturar um stream de vídeo e áudio de alta fidelidade da sua cabine. Esse fluxo fornece os componentes essenciais para o link neural: a identificação visual das sequências de dedos e a frequência sonora da sua voz.
Full-duplex x half-duplex
Para entender por que precisamos disso para a sincronização neural, você precisa entender o fluxo de dados:
- Half-Duplex (HTTP padrão): como um walkie-talkie. Uma pessoa fala, diz "Câmbio" e a outra pode falar. Não é possível ouvir e falar ao mesmo tempo.
- Full-duplex (WebSocket): como uma conversa presencial. Os dados fluem nas duas direções simultaneamente. Enquanto o navegador envia frames de vídeo e amostras de áudio para cima para a IA, ela pode enviar respostas de voz e comandos de ferramentas para baixo para você ao mesmo tempo.
Por que o Gemini Live precisa de full-duplex:a API Gemini Live foi projetada para interrupção. Imagine que você está mostrando a sequência de dedos e a IA percebe que você está fazendo errado. Em uma configuração HTTP padrão, a IA precisaria esperar você terminar de enviar os dados antes de pedir para parar. Com os WebSockets, a IA pode identificar um erro no Frame 1 e enviar um sinal de "interrupção" que chega ao cockpit enquanto você ainda está movendo a mão para o Frame 2.
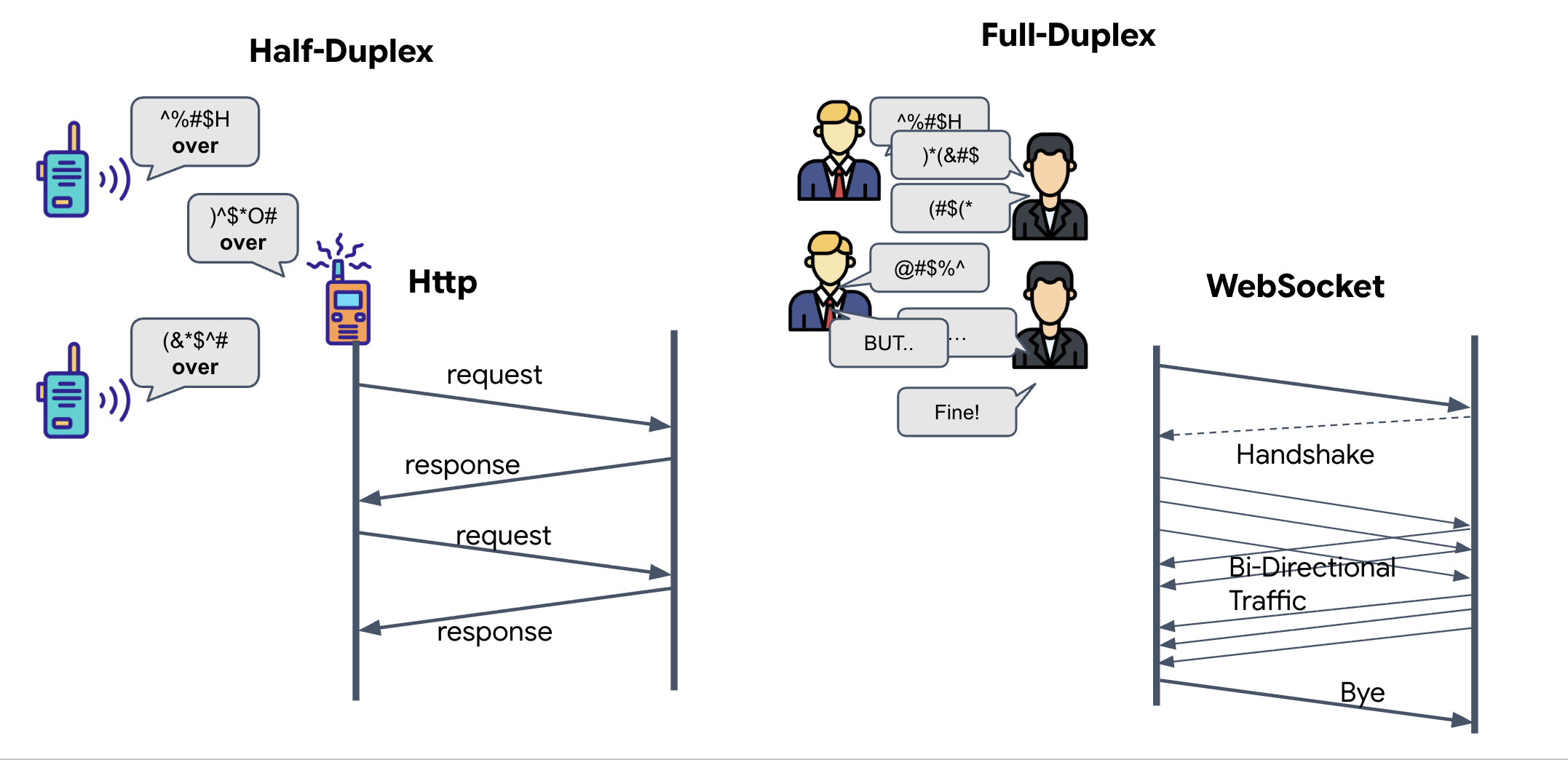
O que é um WebSocket?
Em uma transmissão galáctica padrão (HTTP), você envia uma solicitação e aguarda uma resposta, como enviar um cartão-postal. Para uma sincronização neural, os cartões postais são muito lentos. Precisamos de um "fio desencapado".
Os WebSockets começam como uma solicitação da Web padrão (HTTP), mas depois são "atualizados" para algo diferente.
- A solicitação:seu navegador envia uma solicitação HTTP padrão ao servidor com um cabeçalho especial:
Upgrade: websocket. É como dizer: "Quero parar de enviar cartões postais e começar uma ligação telefônica." - A resposta:se o agente de IA (o servidor) oferecer suporte a isso, ele vai enviar uma resposta
HTTP 101 Switching Protocols. - A transformação:neste momento, a conexão HTTP é substituída pelo protocolo WebSocket, mas o soquete TCP/IP subjacente permanece aberto. As regras de comunicação mudam instantaneamente de "Solicitação/Resposta" para "Streaming full-duplex".
Implementar o hook do WebSocket
Vamos inspecionar o bloco do conector para entender como os dados fluem.
👀 Abra $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. Os manipuladores de eventos de ciclo de vida padrão do WebSocket já estarão configurados. Este é o esqueleto do nosso sistema de comunicação:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
O gerenciador onMessage
Concentre-se no bloco ws.current.onmessage. Este é o destinatário. Toda vez que o agente "pensa" ou "fala", um pacote de dados chega aqui. No momento, ele não faz nada: captura e descarta o pacote (usando o marcador de posição //#REPLACE-HANDLE-MSG).
Precisamos preencher essa lacuna com uma lógica que possa distinguir entre:
- Chamadas de ferramenta (functionCall): a IA reconhece seus gestos com as mãos (a "Sincronização").
- Dados de áudio (inlineData): a voz da IA respondendo a você.
👉✏️ Agora, no mesmo arquivo $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, substitua //#REPLACE-HANDLE-MSG pela lógica abaixo para processar o fluxo de entrada:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
Como o áudio e o vídeo são transformados em dados para transmissão
Para ativar a comunicação em tempo real pela Internet, o áudio e o vídeo brutos precisam ser convertidos em um formato adequado para transmissão. Isso envolve capturar, codificar e empacotar os dados antes de enviá-los por uma rede.
Transformação de dados de áudio
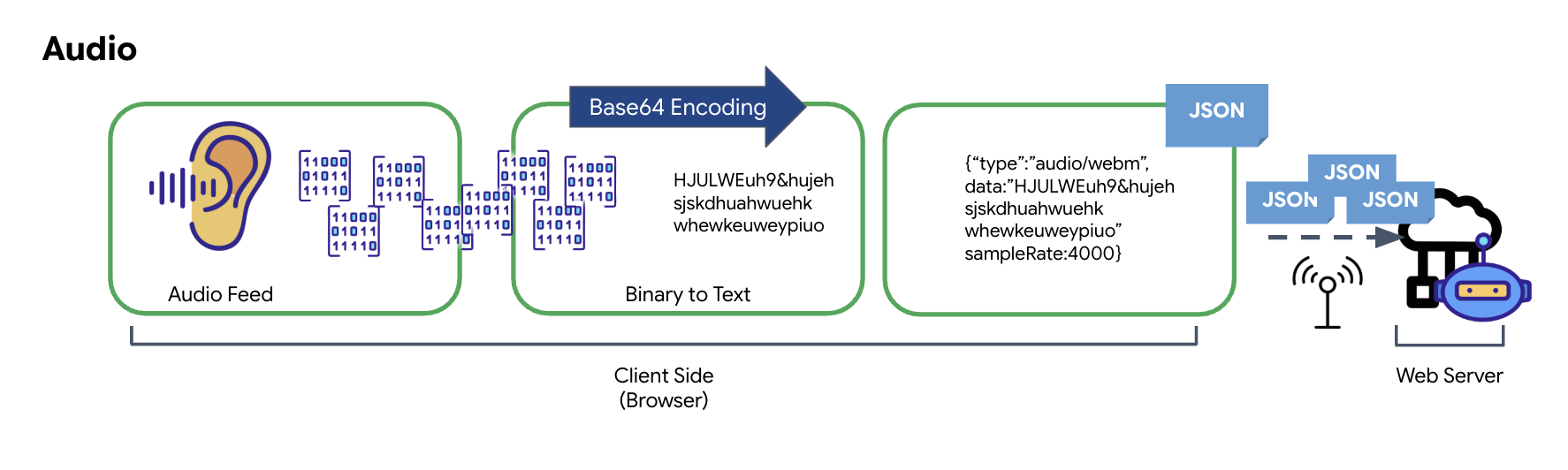
O processo de conversão de áudio analógico em dados digitais transmissíveis começa com a captura das ondas sonoras usando um microfone. Em seguida, esse áudio bruto é processado pela API Web Audio do navegador. Como esses dados brutos estão em formato binário, eles não são diretamente compatíveis com formatos de transmissão baseados em texto, como JSON. Para resolver isso, cada segmento de áudio é codificado em uma string Base64. O Base64 é um método que representa dados binários em um formato de string ASCII, garantindo a integridade deles durante a transmissão.
Essa string codificada é incorporada a um objeto JSON. Esse objeto fornece um formato estruturado para os dados, geralmente incluindo um campo "type" para identificá-lo como áudio e metadados, como a taxa de amostragem do áudio. Todo o objeto JSON é serializado em uma string e enviado por uma conexão WebSocket. Essa abordagem garante que o áudio seja transmitido de maneira bem organizada e fácil de analisar.
Transformação de dados de vídeo
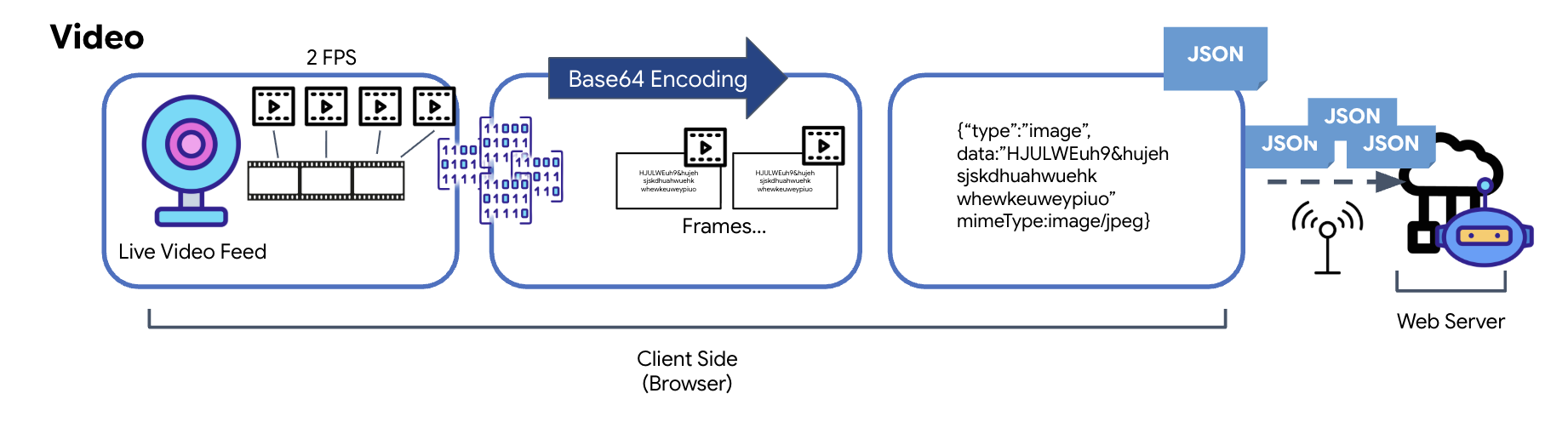
A transmissão de vídeo é feita com uma técnica de captura de frames. Em vez de enviar um fluxo de vídeo contínuo, um loop recorrente captura imagens estáticas do feed de vídeo ao vivo em um intervalo definido, como dois frames por segundo. Isso é feito desenhando o frame atual de um elemento de vídeo HTML em um elemento de tela oculto.
O método toDataURL da tela é usado para converter essa imagem capturada em uma string JPEG codificada em Base64. Esse método inclui uma opção para especificar a qualidade da imagem, permitindo uma troca entre fidelidade da imagem e tamanho do arquivo para otimizar o desempenho. Assim como os dados de áudio, essa string Base64 é colocada em um objeto JSON. Normalmente, esse objeto é rotulado com um "tipo" de "image" e inclui o mimeType, como "image/jpeg". Esse pacote JSON é convertido em uma string e enviado pelo WebSocket, permitindo que a extremidade receptora reconstrua o vídeo mostrando a sequência de imagens.
👉✏️ No mesmo arquivo $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, substitua //#CAPTURE AUDIO and VIDEO pelo seguinte para capturar a entrada do usuário:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
Depois de salvo, o cockpit estará pronto para traduzir os sinais digitais do agente em atualizações visuais do painel e áudio.
Verificação de diagnóstico (teste de loopback)
Seu cockpit já está disponível. A cada 500 ms, um "pacote" visual do seu entorno é transmitido. Antes de se conectar ao Gemini, precisamos verificar se o transmissor da sua nave está funcionando. Vamos executar um "Teste de loopback" usando um servidor de diagnóstico local.
👉💻 Primeiro, crie a interface do Cockpit no terminal:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 Em seguida, inicie o servidor simulado:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 Execute o protocolo de teste:
- Abra a prévia:clique no ícone Visualização da Web na barra de ferramentas do Cloud Shell. Selecione Alterar porta, defina como 8080 e clique em Alterar e visualizar. Uma nova guia do navegador será aberta mostrando a interface do Cockpit.
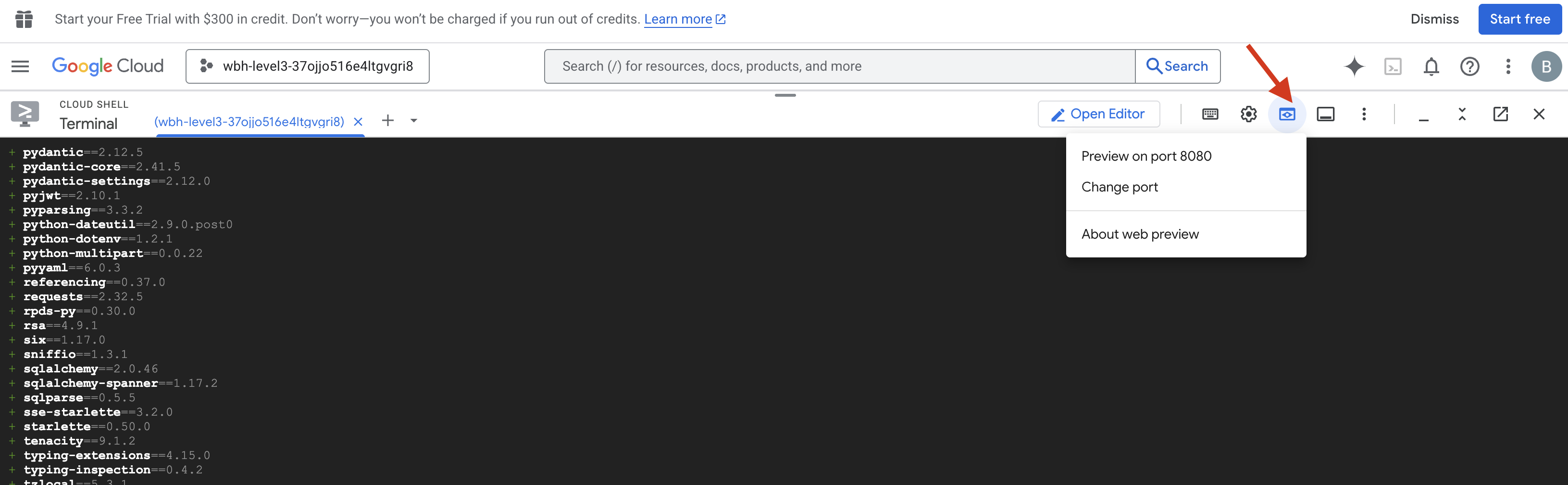
- CRÍTICO:quando solicitado, PERMITA que o navegador acesse sua câmera e seu microfone. Sem essas entradas, a sincronização neural não pode ser iniciada.
- Clique no botão INICIAR SINCRONIZAÇÃO NEURAL na interface.
👀 Verifique os indicadores de status:
- Verificação visual:abra o console do navegador. Você vai encontrar
NEURAL SYNC INITIALIZEDno canto superior direito. - Teste de áudio:se o pipeline de áudio bidirecional estiver totalmente operacional, você vai ouvir uma voz simulada confirmar: "Sistema conectado!"
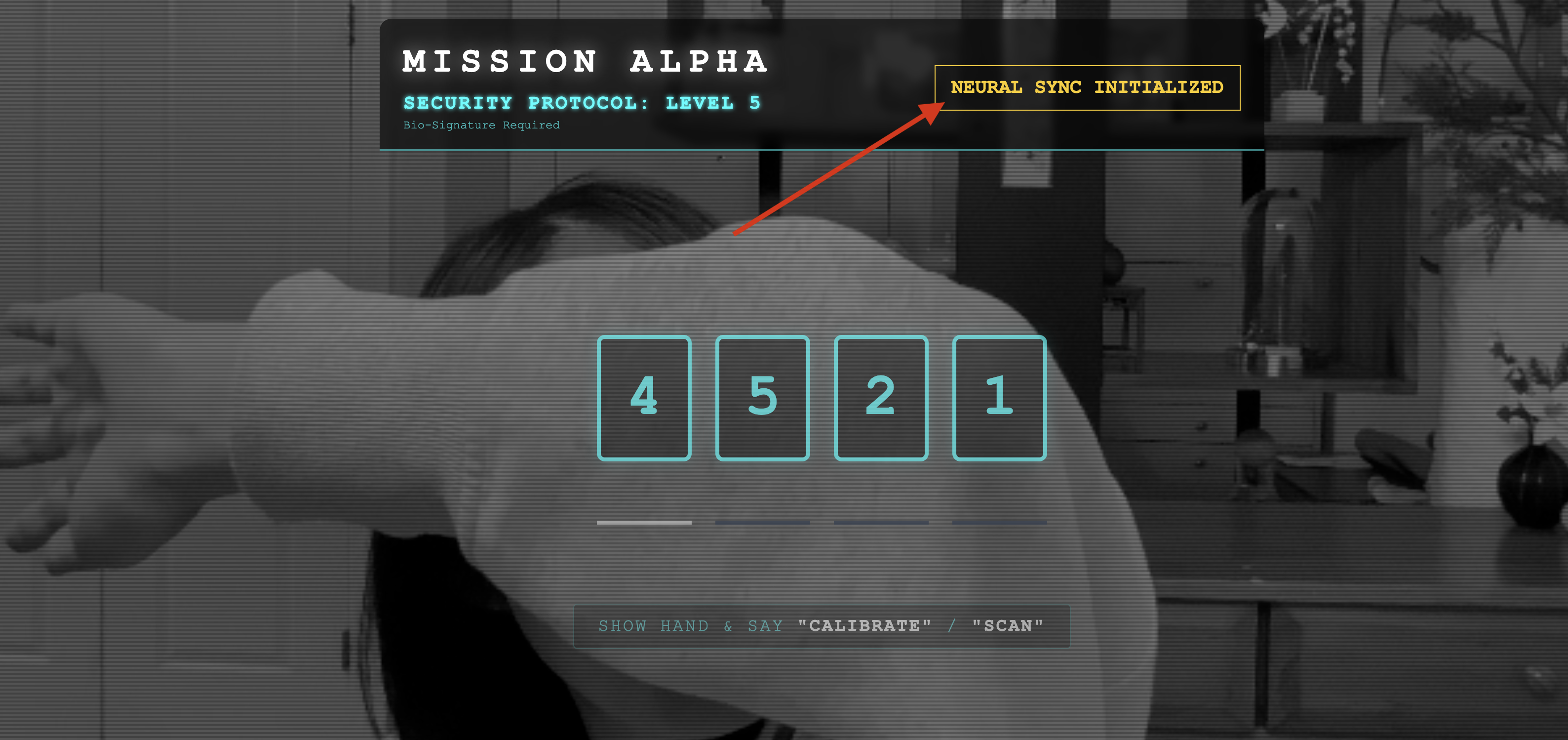
Depois de ouvir a confirmação de áudio "Sistema conectado!", o teste foi concluído com sucesso. Feche a guia. Agora precisamos limpar a frequência para abrir espaço para a IA real.
👉💻 Pressione Ctrl+C nos terminais para o servidor simulado e o front-end. Feche a guia do navegador que está executando a interface.
4. O agente multimodal
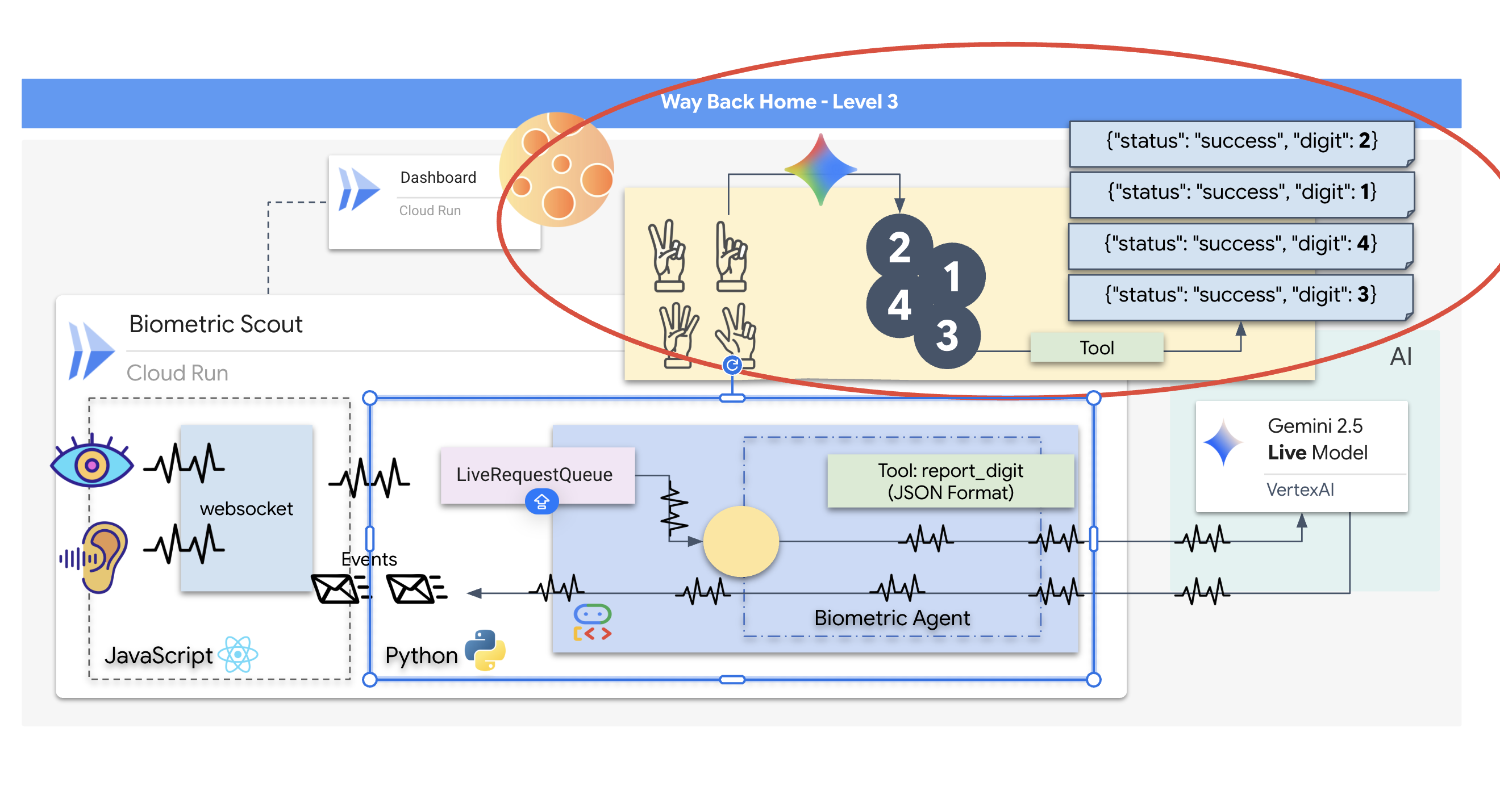
O Rescue Scout está operacional, mas a "mente" dele está em branco. Se você se conectar agora, ele vai ficar olhando para você. Ele não sabe o que é um "dedo". Para salvar os sobreviventes, você precisa gravar o Protocolo Neural Biométrico no núcleo do Scout.
O agente tradicional funciona como uma série de tradutores. Se você falar com uma IA da velha guarda, um modelo de "conversão de voz em texto" transforma sua voz em palavras, um "modelo de linguagem" lê essas palavras e digita uma resposta, e um modelo de "conversão de texto em voz" lê essa resposta para você. Isso cria uma "lacuna de latência", um atraso que seria fatal em uma missão de resgate.
A API Gemini Live é um modelo multimodal nativo. Ele processa bytes de áudio e frames de vídeo brutos diretamente e ao mesmo tempo. Ele "ouve" a vibração da sua voz e "vê" os pixels dos seus gestos com as mãos na mesma arquitetura neural.
Para aproveitar esse poder, podemos criar o aplicativo conectando o cockpit diretamente à API Live bruta. No entanto, nosso objetivo é criar um agente reutilizável, uma entidade modular e robusta que seja mais rápida de criar.
Por que usar o ADK (Kit de Desenvolvimento de Agente)?
O Kit de Desenvolvimento de Agente (ADK) do Google é um framework modular para desenvolver e implantar agentes de IA.
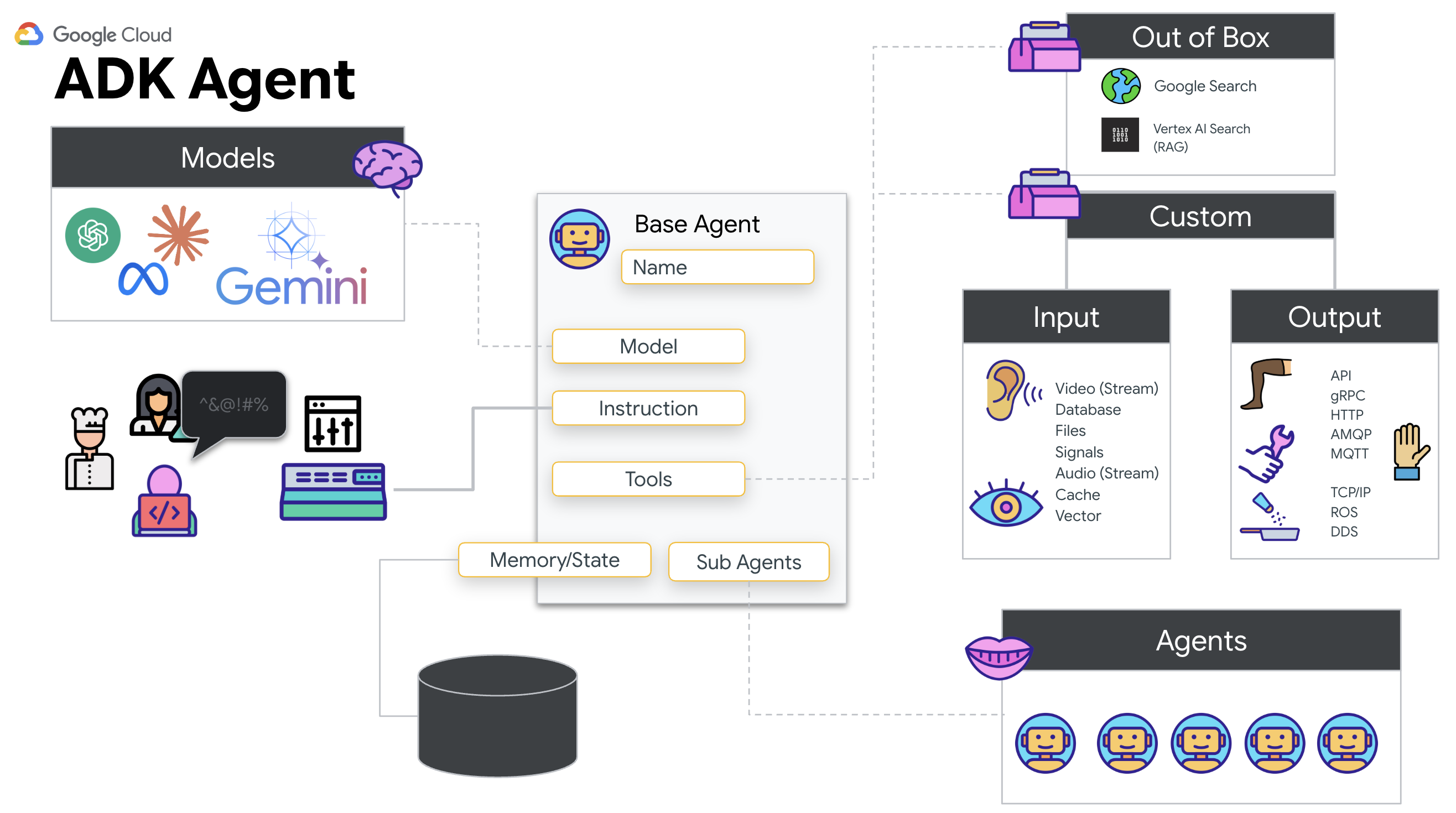
As chamadas padrão de LLM geralmente não têm estado. Cada consulta é um novo começo. Os atendentes humanos, principalmente quando integrados ao SessionService do ADK, permitem sessões de conversa robustas e de longa duração.
- Persistência de sessão:as sessões do ADK são persistentes e podem ser armazenadas em bancos de dados (como SQL ou Vertex AI), sobrevivendo a reinicializações e desconexões do servidor. Isso significa que, se um usuário se desconectar e se reconectar depois, mesmo dias depois, o histórico e o contexto da conversa serão totalmente restaurados. A sessão efêmera da API Live é gerenciada e abstraída pelo ADK.
- Reconexão automática:as conexões WebSocket podem expirar, por exemplo, após cerca de 10 minutos. O ADK processa essas reconexões de forma transparente quando o
session_resumptionestá ativado noRunConfig. O código do aplicativo não precisa gerenciar uma lógica de reconexão complexa, garantindo uma experiência perfeita para o usuário. - Interações com estado:o agente lembra das interações anteriores, permitindo perguntas de acompanhamento, esclarecimentos e diálogos complexos com várias interações em que o contexto é fundamental. Isso é fundamental para aplicativos como suporte ao cliente, tutoriais interativos ou cenários de controle de missão em que a continuidade é essencial.
Essa persistência garante que a interação pareça uma conversa contínua com uma entidade inteligente, em vez de uma série de perguntas e respostas isoladas.
Em essência, um "agente ativo" com ADK Bidi-streaming vai além de um simples mecanismo de consulta-resposta para oferecer uma experiência de conversa verdadeiramente interativa, com estado e sensível a interrupções, tornando as interações de IA mais humanas e significativamente mais poderosas para tarefas complexas e de longa duração.
Solicitar um atendente
Criar um comando para um agente bidirecional em tempo real exige uma mudança de mentalidade. Ao contrário de um chatbot padrão que aguarda uma consulta de texto estático, um atendente está "sempre ativado". Ele recebe um fluxo constante de frames de áudio e vídeo, o que significa que seu comando precisa agir como um script de loop de controle, em vez de apenas uma definição de personalidade.
Confira a diferença entre um comando de agente ativo e um tradicional:
- Lógica da máquina de estado:o comando precisa definir um "loop de comportamento" (esperar → analisar → agir). Ele precisa de instruções explícitas sobre quando ficar em silêncio e quando interagir, evitando que o agente fale sem parar sobre um ruído de fundo vazio.
- Percepção multimodal:o agente precisa ser informado de que tem "olhos". Você precisa instruir explicitamente o modelo a analisar frames de vídeo como parte do processo de raciocínio.
- Latência e brevidade:em uma conversa por voz ao vivo, parágrafos longos e pesados parecem lentos e não naturais. O comando exige brevidade para manter a interação dinâmica.
- Arquitetura de ação em primeiro lugar:as instruções priorizam a chamada de função em vez da fala. Queremos que o agente "faça" o trabalho (leia a biometria) antes ou enquanto confirma verbalmente, não depois de um longo monólogo.
👉✏️ Abra $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py e substitua #REPLACE INSTRUCTIONS pelo seguinte:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
OBSERVAÇÃO! Você não está se conectando a um LLM padrão. No mesmo arquivo ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py), localize #REPLACE_MODEL. Precisamos segmentar explicitamente a versão de prévia desse modelo para oferecer melhor suporte aos recursos de áudio em tempo real.
👉✏️ Substitua o marcador de posição por:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
Seu agente foi definido. Ela sabe quem é e como pensar. Em seguida, damos a ele as ferramentas para agir.
Chamadas de ferramentas
A API Live não se limita apenas à troca de fluxos de texto, áudio e vídeo. Ele oferece suporte nativo à chamada de ferramenta. Isso transforma os agentes de um interlocutor passivo em um operador ativo.
Durante uma sessão bidirecional ao vivo, o modelo avalia constantemente o contexto. Se o LLM detectar a necessidade de realizar uma ação, seja "verificar a telemetria do sensor" ou "destrancar uma porta segura". Ela muda da conversa para a execução sem problemas. O agente aciona a função de ferramenta específica imediatamente, aguarda o resultado e integra esses dados de volta ao fluxo de dados em tempo real, tudo sem interromper o fluxo da interação.
👉✏️ Em $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py, substitua #REPLACE TOOLS por esta função:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ Em seguida, registre-o na definição Agent substituindo #TOOL CONFIG:
tools=[report_digit],
O simulador adk web
Antes de conectar isso ao cockpit complexo da nave (nosso front-end React), vamos testar a lógica do agente isoladamente. O ADK inclui um console de desenvolvedor integrado chamado adk web, que permite verificar a chamada de função antes de adicionar complexidade à rede.
👉💻 No terminal, execute:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Clique no ícone Visualização da Web na barra de ferramentas do Cloud Shell. Selecione Alterar porta, defina como 8000 e clique em Alterar e visualizar.
- Conceda permissões: Permita o acesso à câmera e ao microfone quando solicitado.
- Clique no ícone de câmera para iniciar a sessão.
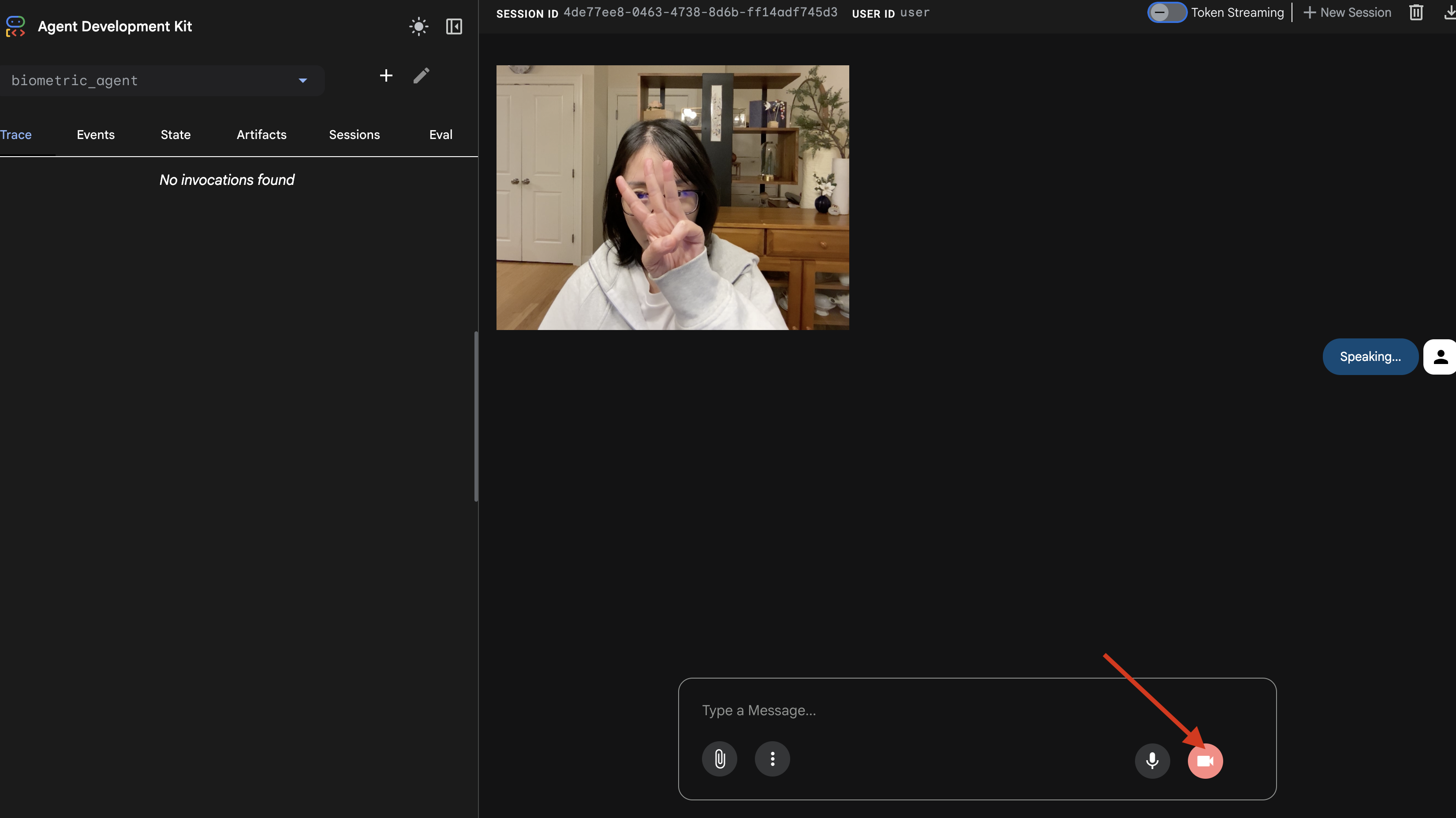
- O teste visual:
- Levante três dedos na frente da câmera.
- Diga "Digitalizar".
- Verificar sucesso:
- Registros:consulte o terminal que executa o comando
adk web. Você precisa ver este registro:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- Registros:consulte o terminal que executa o comando
Se você vir o registro de execução da ferramenta, seu agente é inteligente. Ele pode ver, pensar e agir. A etapa final é conectá-lo à nave principal.
Clique na janela do terminal e pressione Ctrl+C para interromper o simulador adk web.
5. Fluxo de streaming bidirecional
O agente funciona. O Cockpit funciona. Agora, precisamos conectá-los.
O ciclo de vida do agente em tempo real
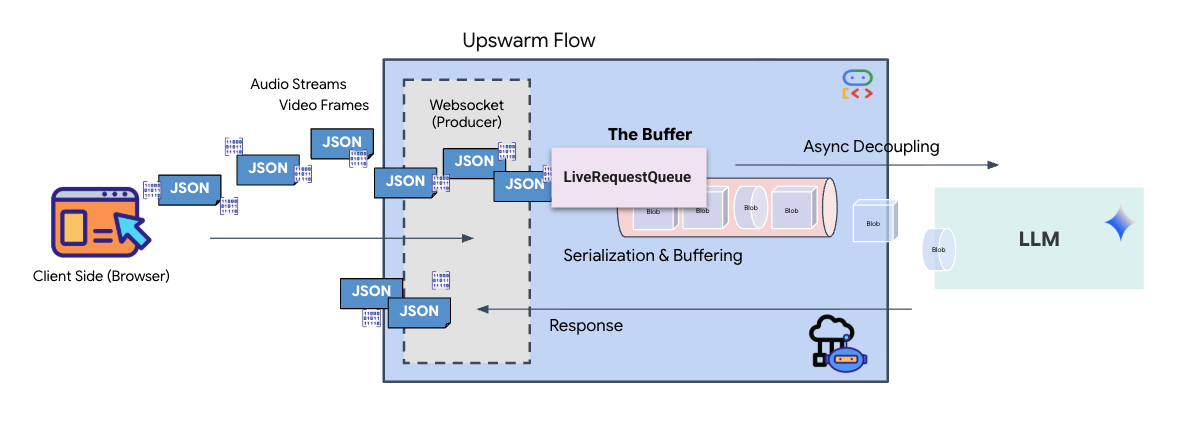
O streaming em tempo real apresenta um problema de "incompatibilidade de impedância". O cliente (navegador) envia dados de forma assíncrona em taxas variáveis (picos de rede ou entradas rápidas), enquanto o modelo exige um fluxo de entrada regulamentado e sequencial. O ADK do Google resolve isso usando o LiveRequestQueue.
Ele funciona como um buffer assíncrono e thread-safe de "primeiro a entrar, primeiro a sair" (PEPS). O manipulador do WebSocket atua como o produtor, enviando partes de áudio/vídeo bruto para a fila. O agente do ADK atua como o consumidor, extraindo dados da fila para alimentar a janela de contexto do modelo. Esse desacoplamento permite que o aplicativo continue recebendo entradas do usuário mesmo enquanto o modelo gera uma resposta ou executa uma ferramenta.
A fila serve como um multiplexador multimodal. Em um ambiente real, o fluxo upstream consiste em tipos de dados distintos e simultâneos: bytes de áudio PCM brutos, frames de vídeo, instruções do sistema baseadas em texto e os resultados de chamadas de função assíncronas. O LiveRequestQueue lineariza essas entradas diferentes em uma única sequência cronológica. Se o pacote contém um milissegundo de silêncio, uma imagem de alta resolução ou um payload JSON de uma consulta de banco de dados, ele é serializado na ordem exata de chegada, garantindo que o modelo perceba uma linha do tempo consistente e causal.
Essa arquitetura permite o controle sem bloqueio. Como a camada de ingestão (produtor) é separada da camada de processamento (consumidor), o sistema permanece responsivo mesmo durante a inferência de modelos computacionalmente cara. Se um usuário interromper com um comando "Pare!" enquanto o Agente estiver executando uma ferramenta, esse sinal de áudio será enfileirado instantaneamente. O loop de eventos subjacente processa esse indicador de prioridade imediatamente, permitindo que o sistema interrompa a geração ou gire as tarefas sem que a interface congele ou descarte pacotes.
👉💻 Em $HOME/way-back-home/level_3/backend/app/main.py, encontre o comentário #REPLACE_RUNNER_CONFIG e substitua-o pelo código a seguir para colocar o sistema on-line:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
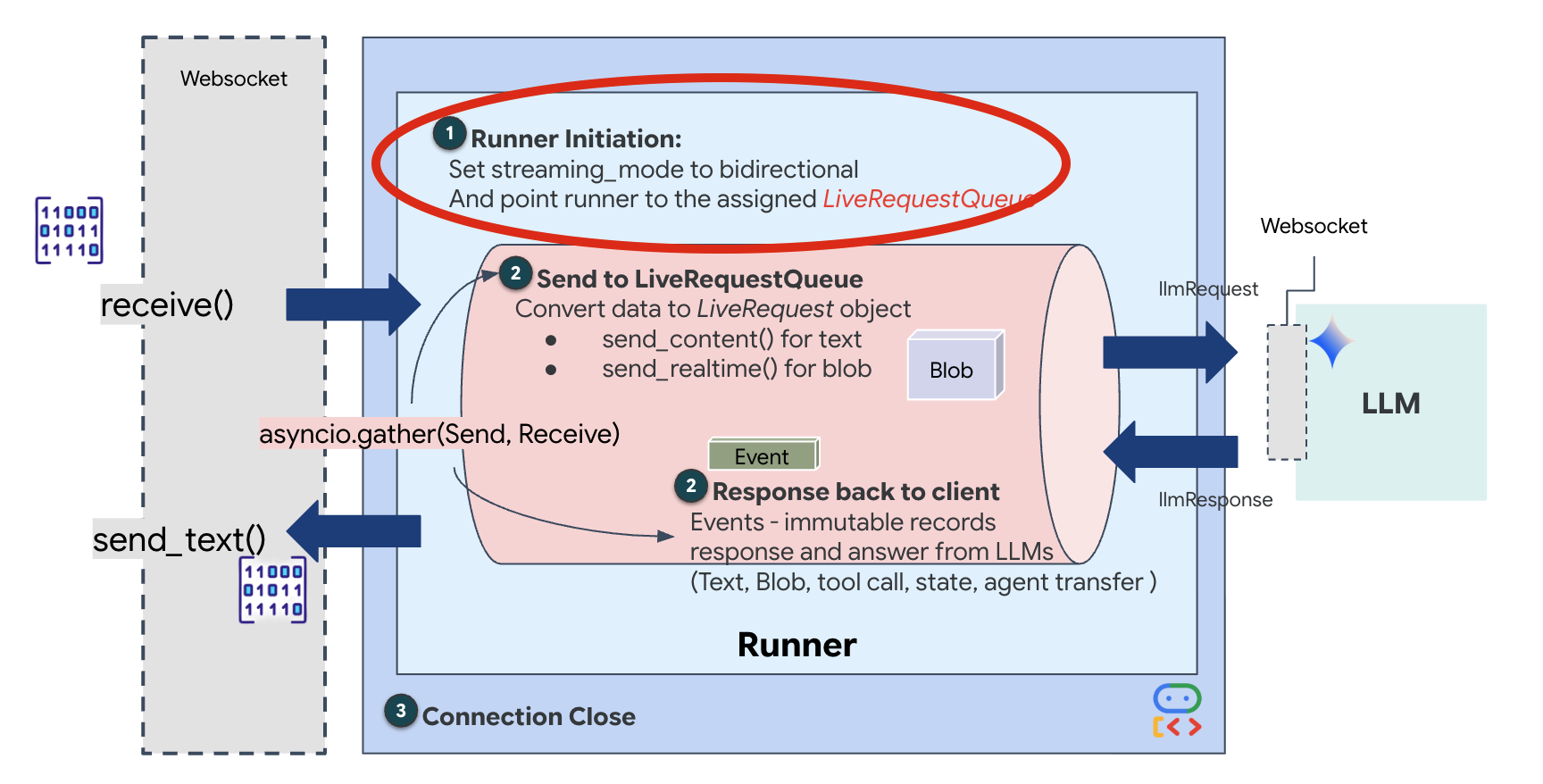
Quando uma nova conexão WebSocket é aberta, precisamos configurar como a IA interage. É aqui que definimos as "Regras de engajamento".
👉✏️ Em $HOME/way-back-home/level_3/backend/app/main.py, dentro da função async def websocket_endpoint, substitua o comentário #REPLACE_SESSION_INIT pelo código abaixo:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
A configuração de execução
StreamingMode.BIDI: define a conexão como bidirecional. Ao contrário da IA "baseada em turnos" (em que você fala, para e depois ela fala), o BIDI permite uma conversa realista "full-duplex". Você pode interromper a IA, e ela pode falar enquanto você se move.AudioTranscriptionConfig: mesmo que o modelo "ouça" áudio bruto, nós (os desenvolvedores) precisamos ver os registros. Essa configuração diz ao Gemini: "Processe o áudio, mas também envie uma transcrição de texto do que você ouviu para que possamos depurar".
A lógica de execução: depois que o Runner estabelece a sessão, ele transfere o controle para a lógica de execução, que depende do LiveRequestQueue. Esse é o componente mais importante para a interação em tempo real. O loop permite que o agente gere uma resposta de voz enquanto a fila continua aceitando novos frames de vídeo do usuário, garantindo que a "Sincronia neural" nunca seja interrompida.
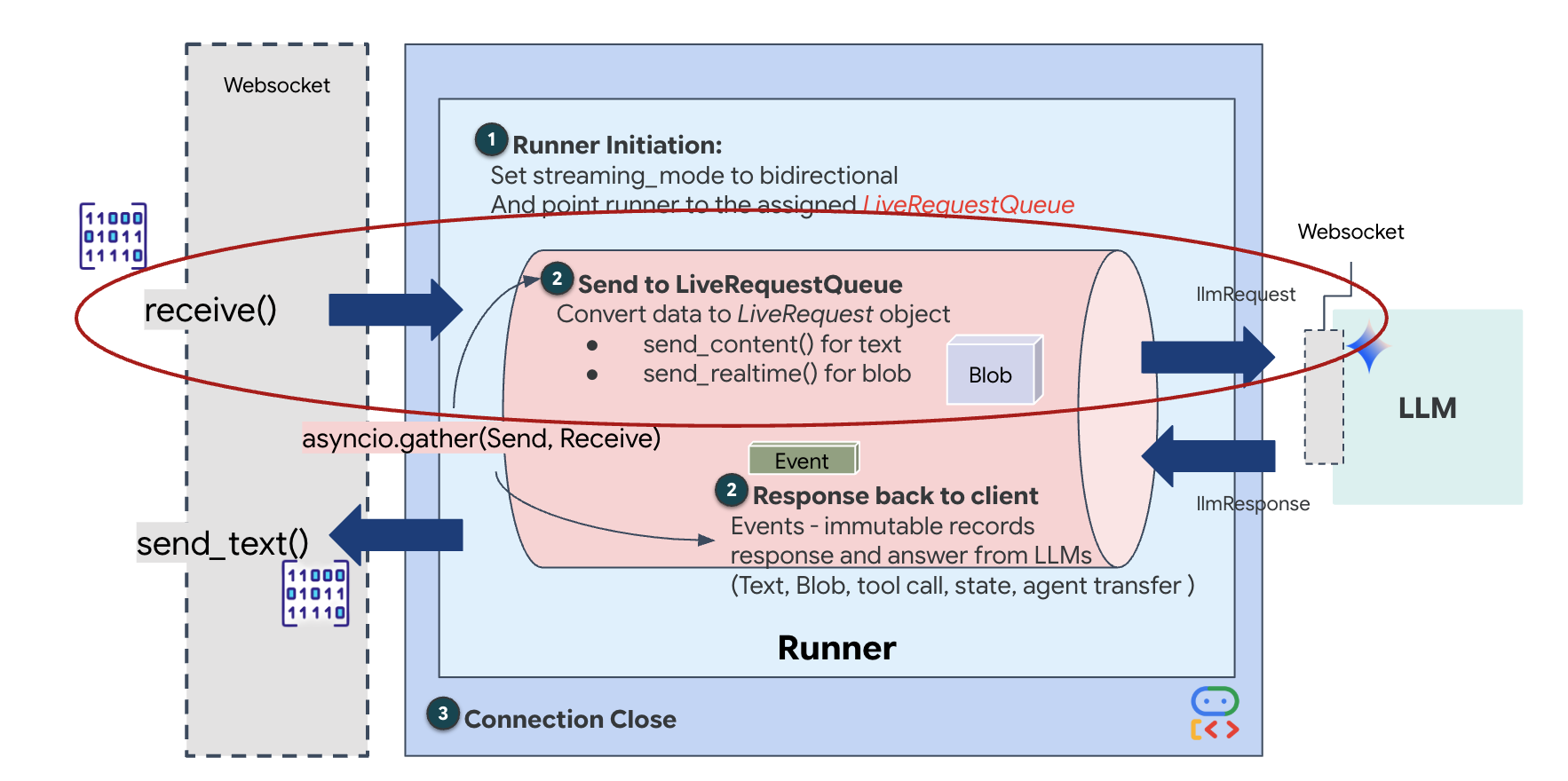
👉✏️ Em $HOME/way-back-home/level_3/backend/app/main.py, substitua #REPLACE_LIVE_REQUEST para definir a tarefa upstream que envia dados para o LiveRequestQueue:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
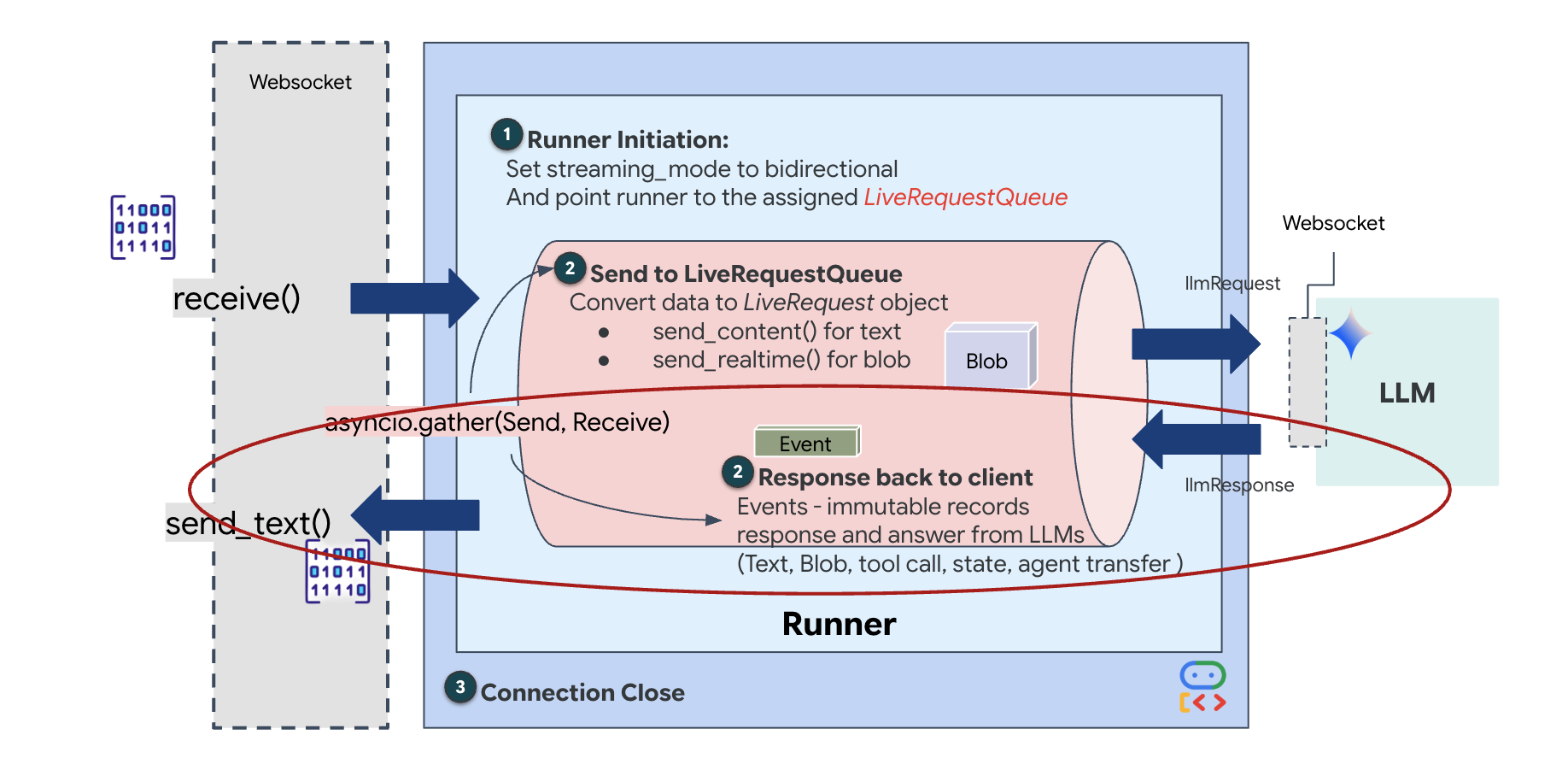
Por fim, precisamos processar as respostas da IA. Isso usa runner.run_live(), que é um gerador de eventos que gera eventos (áudio, texto ou chamadas de função) à medida que eles acontecem.
👉✏️ Em $HOME/way-back-home/level_3/backend/app/main.py, substitua #REPLACE_SORT_RESPONSE para definir a tarefa downstream e o gerenciador de simultaneidade:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
Observe a linha await asyncio.gather(upstream_task(), downstream_task()). Essa é a essência do Full-Duplex. Executamos a tarefa de escuta (upstream) e a tarefa de fala (downstream) exatamente ao mesmo tempo. Isso garante que a "Neural Link" permita interrupção e fluxo de dados simultâneo.
Seu back-end agora está totalmente codificado. O "cérebro" (ADK) está conectado ao "corpo" (WebSocket).
Execução de Bio-Sync
O código está completo. Os sistemas estão verdes. É hora de iniciar o resgate.
- 👉💻 Inicie o back-end:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 Inicie o front-end:
- Clique no ícone Visualização da Web na barra de ferramentas do Cloud Shell. Selecione Alterar porta, defina como 8080 e clique em Alterar e visualizar.
- 👉 Execute o protocolo:
- Clique em INICIAR SINCRONIZAÇÃO NEURAL.
- Calibrar:confira se a câmera consegue ver sua mão com clareza em relação ao plano de fundo.
- A sincronização:assista o código de segurança exibido na tela (por exemplo, 3, depois 2 e depois 5).
- Combine o sinal:quando um número aparecer, levante exatamente essa quantidade de dedos.
- Segure firme:mantenha a mão visível até que a IA confirme a "Correspondência biométrica".
- Adaptar:o código é aleatório. Mude imediatamente para o próximo número mostrado até que a sequência seja concluída.

- Quando você corresponder ao número final na sequência aleatória, a "Sincronização biométrica" será concluída. O link neural será bloqueado. Você tem controle manual. Os motores do Scout vão ganhar vida, mergulhando no Ravine para levar os sobreviventes para casa.
👉💻 Pressione Ctrl+C no terminal de back-end para sair.
6. Implantar na produção (opcional)
Você testou a biometria localmente. Agora, precisamos fazer upload do núcleo neural do agente para os mainframes da nave (Cloud Run) para que ele possa operar de forma independente do seu console local.
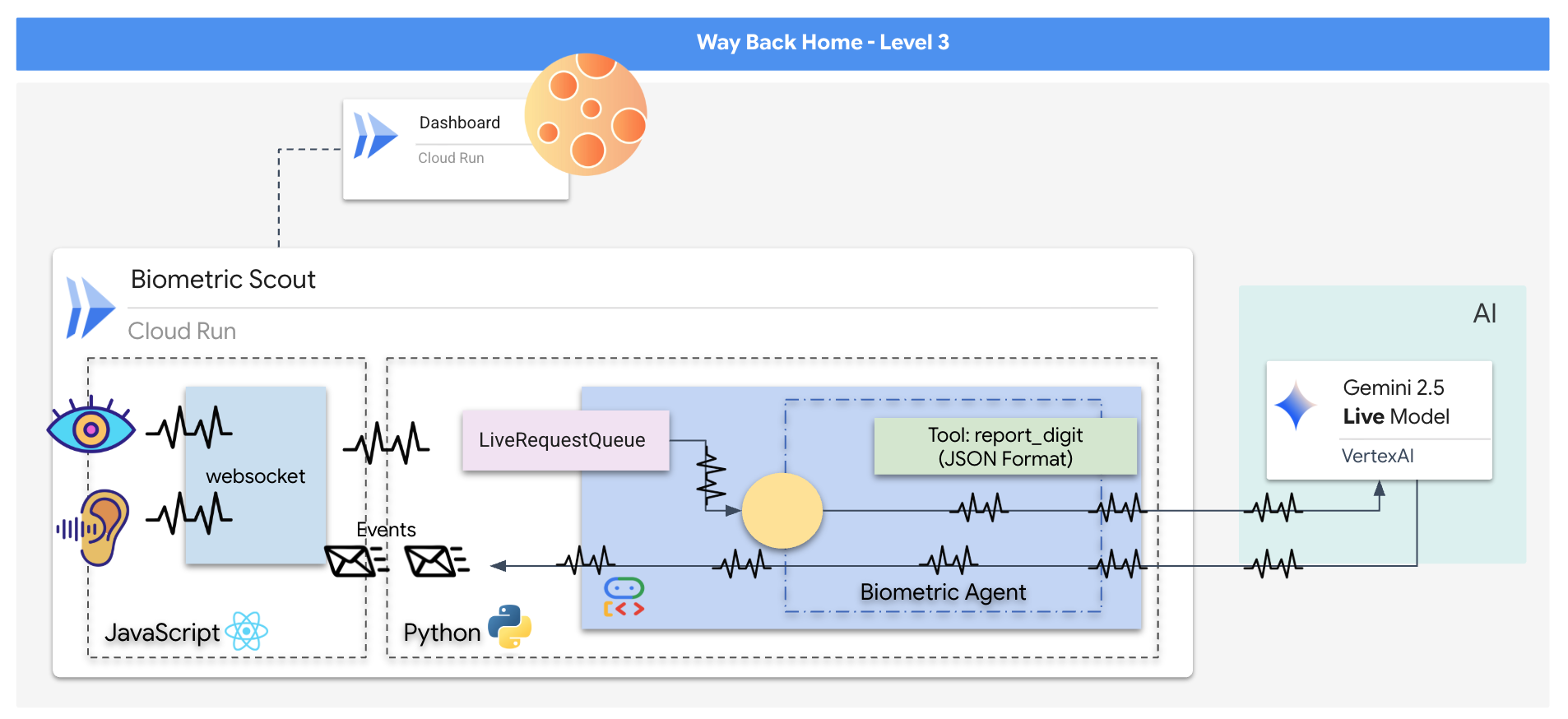
👉💻 Execute o comando a seguir no terminal do Cloud Shell. Isso vai criar o Dockerfile completo de vários estágios no diretório de back-end.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 Navegue até o diretório de back-end e empacote o aplicativo em uma imagem do contêiner.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 Implante o serviço no Cloud Run. Vamos injetar as variáveis de ambiente necessárias, especificamente a configuração do Gemini, diretamente no comando de inicialização.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
Quando o comando terminar, você vai ver um URL de serviço (por exemplo, https://biometric-scout-...run.app). O aplicativo agora está ativo na nuvem.
👉 Acesse a página Google Cloud Run e selecione o serviço biometric-scout na lista. 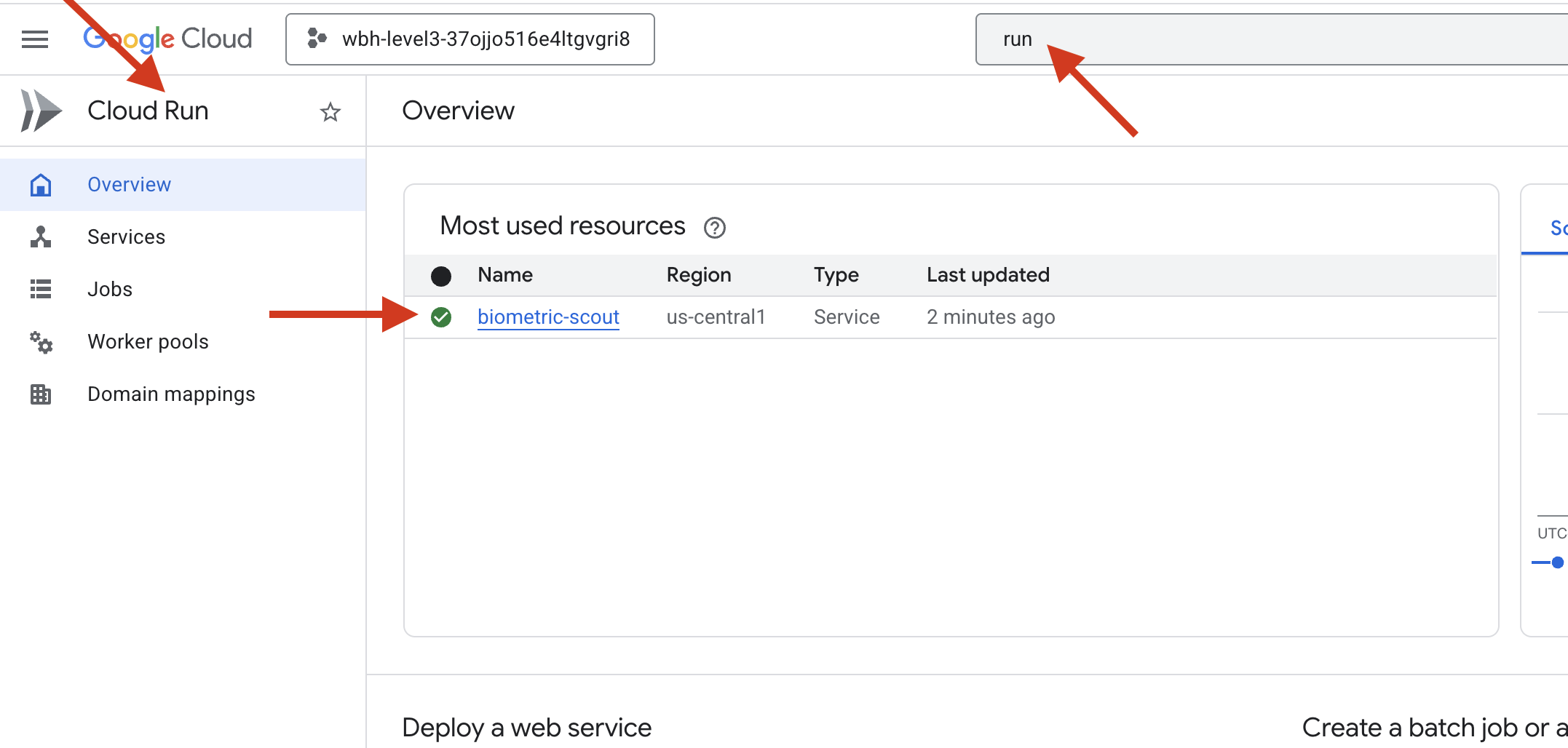
👉 Localize o URL público exibido na parte de cima da página de detalhes do serviço. 
Tente fazer a Bio-Sync nesse ambiente. Ela também funciona?
À medida que o quinto dedo se estende, a IA bloqueia a sequência. A tela pisca em verde: "Sincronização neural biométrica: ESTABELECIDA".
Com um único pensamento, você mergulha o Batedor na escuridão, se prende ao pod encalhado e o puxa para fora pouco antes do colapso da gravidade.

A escotilha se abre com um chiado, e lá estão eles: cinco sobreviventes vivos e respirando. Eles tropeçam no convés, machucados, mas vivos, finalmente seguros por sua causa.
Graças a você, o link neural foi sincronizado e os sobreviventes foram resgatados.
Se você participou do nível 0, não se esqueça de verificar seu progresso a caminho da missão de volta para casa!