1. Sứ mệnh

Bạn đang trôi dạt trong sự tĩnh lặng của một khu vực chưa được khám phá. Một **Xung năng lượng mặt trời** cực mạnh đã xé toạc con tàu của bạn qua một vết nứt, khiến bạn mắc kẹt trong một vùng vũ trụ không có trên bất kỳ biểu đồ sao nào.
Sau nhiều ngày sửa chữa vất vả, cuối cùng bạn cũng cảm nhận được tiếng động cơ gầm rú dưới chân. Tàu vũ trụ của bạn đã được sửa chữa. Bạn thậm chí còn tìm được cách liên lạc tầm xa với Tàu mẹ. Bạn đã được phép khởi hành. Bạn đã sẵn sàng về nhà. Nhưng khi bạn chuẩn bị kích hoạt ổ đĩa nhảy, một tín hiệu cấp cứu sẽ xuyên qua tĩnh điện. Các cảm biến của bạn phát hiện thấy 5 dấu hiệu nhiệt mờ bị mắc kẹt trong "Khe nứt" – một khu vực lởm chởm, bị biến dạng do trọng lực mà tàu chính của bạn không bao giờ có thể đi vào. Đây là những người cùng khám phá, những người sống sót sau cơn bão gần như đã cướp đi mạng sống của bạn. Bạn không thể bỏ lại chúng.
Bạn chuyển sang Alpha-Drone Rescue Scout. Con tàu nhỏ, linh hoạt này là chiếc tàu duy nhất có khả năng di chuyển qua những bức tường hẹp của Khe nứt. Nhưng có một vấn đề: xung năng lượng mặt trời đã thực hiện thao tác "Thiết lập lại hệ thống" hoàn toàn đối với logic cốt lõi của nó. Hệ thống điều khiển của Scout không phản hồi. Nó được bật nguồn, nhưng máy tính trên máy bay là một bảng trắng, không thể xử lý các lệnh của phi công hoặc đường bay theo cách thủ công.
Thử thách
Để cứu những người sống sót, bạn phải hoàn toàn bỏ qua các mạch điện bị hỏng của Scout. Bạn có một lựa chọn duy nhất: xây dựng một tác nhân AI để thiết lập Biometric Neural Sync (Đồng bộ hoá sinh trắc học). Đặc vụ này sẽ đóng vai trò là cầu nối theo thời gian thực, cho phép bạn điều khiển Rescue Scout theo cách thủ công thông qua các tín hiệu sinh học của riêng bạn. Bạn sẽ không dùng cần điều khiển hay bàn phím mà sẽ truyền ý định của mình trực tiếp vào mạng lưới điều hướng của con tàu.
Để khoá đường liên kết, bạn phải thực hiện Giao thức đồng bộ hoá trước các cảm biến quang học của Scout. Nhân viên hỗ trợ AI phải nhận ra chữ ký sinh học của bạn thông qua một quy trình bắt tay chính xác theo thời gian thực.
Mục tiêu của nhiệm vụ:
- In dấu ấn lên Neural Core: Xác định một ADK Agent có khả năng nhận dạng dữ liệu đầu vào đa phương thức.
- Thiết lập kết nối: Xây dựng một quy trình WebSocket hai chiều để truyền trực tuyến dữ liệu trực quan từ Scout đến AI.
- Bắt đầu quá trình bắt tay: Đứng trước cảm biến và hoàn thành trình tự ngón tay – lần lượt giơ từ 1 đến 5 ngón tay.
Nếu thành công, tính năng "Đồng bộ hoá dữ liệu sinh trắc học" sẽ hoạt động. AI sẽ khoá mối liên kết thần kinh, giúp bạn có toàn quyền kiểm soát thủ công để phóng Scout và đưa những người sống sót đó về nhà.
Sản phẩm bạn sẽ tạo ra
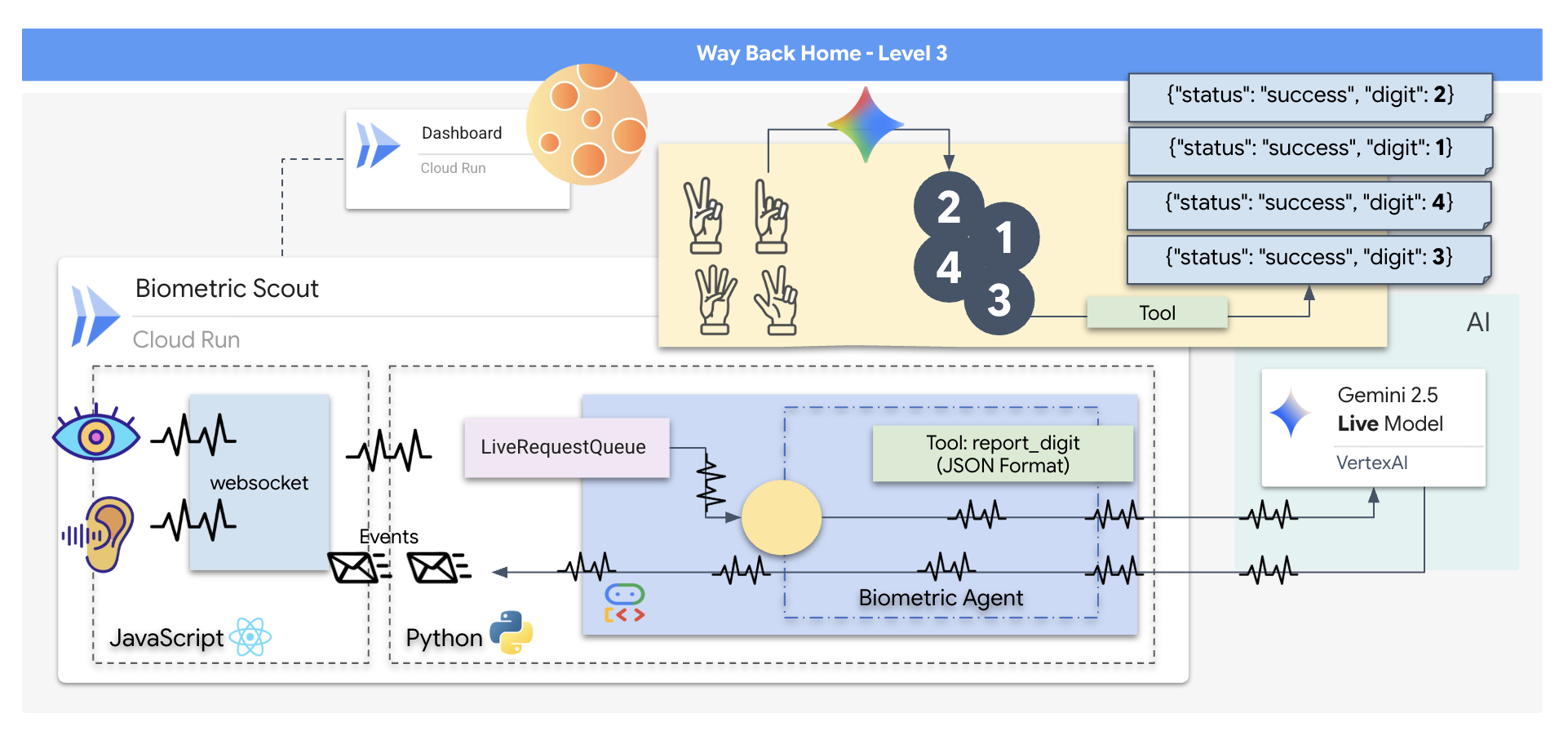
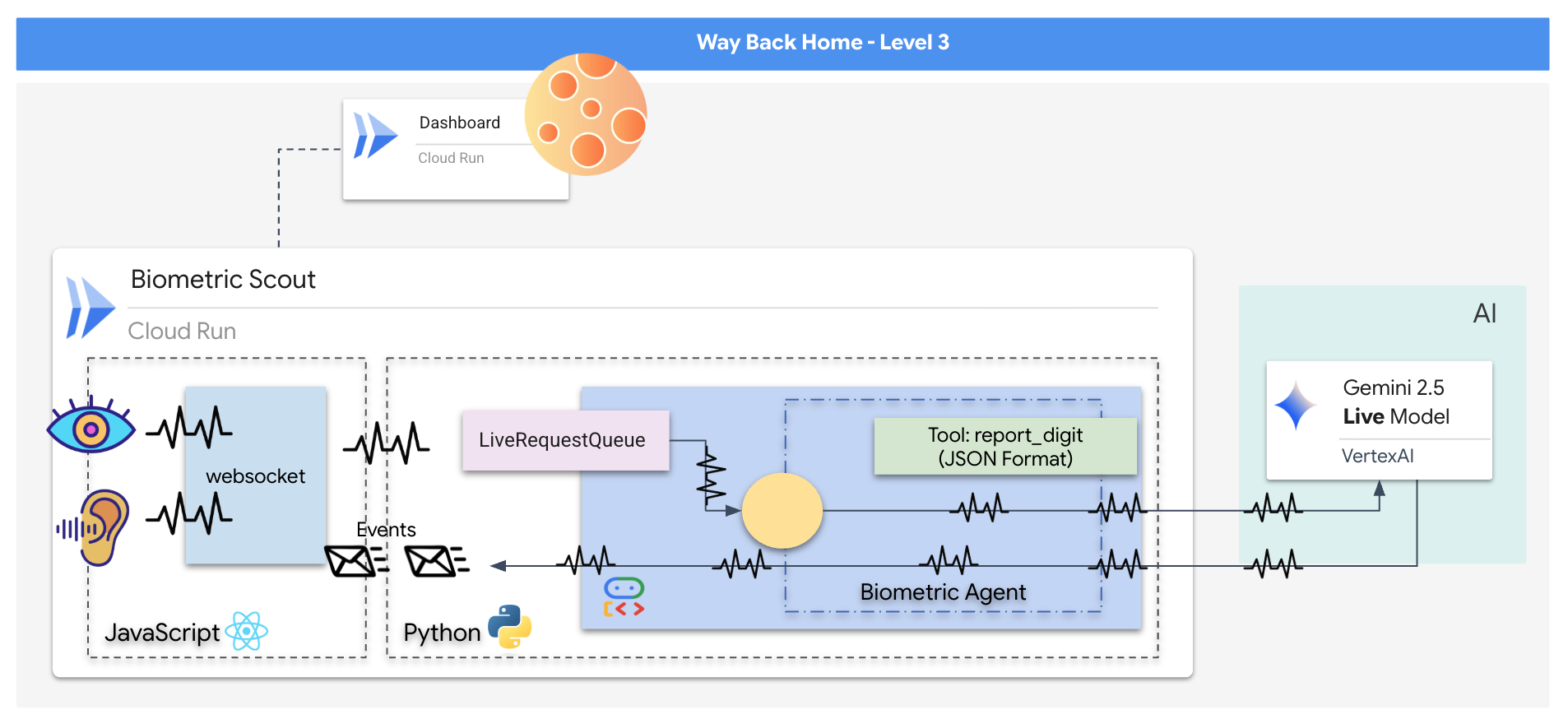
Bạn sẽ tạo một ứng dụng "Biometric Neural Sync" (Đồng bộ hoá sinh trắc học thần kinh), một hệ thống theo thời gian thực dựa trên AI, đóng vai trò là giao diện điều khiển cho một máy bay không người lái cứu hộ. Hệ thống này bao gồm:
- Giao diện người dùng React: "Buồng lái" của con tàu, nơi ghi lại video trực tiếp từ webcam và âm thanh từ micrô.
- Phần phụ trợ Python: Một máy chủ hiệu suất cao được xây dựng bằng FastAPI, sử dụng Bộ công cụ phát triển tác nhân (ADK) của Google để quản lý logic và trạng thái của LLM.
- Một AI Agent đa phương thức: "Bộ não" của hoạt động này, sử dụng Gemini Live API thông qua
google-genaiSDK để xử lý và hiểu đồng thời các luồng video và âm thanh. - Đường ống WebSocket hai chiều: "Hệ thống thần kinh" tạo ra một kết nối liên tục, có độ trễ thấp giữa giao diện người dùng và AI, cho phép tương tác theo thời gian thực.
Kiến thức bạn sẽ học được
Công nghệ / Khái niệm | Mô tả |
Tác nhân AI phụ trợ | Tạo một tác nhân AI có trạng thái bằng Python và FastAPI. Sử dụng ADK (Bộ công cụ phát triển tác nhân) của Google để quản lý hướng dẫn và bộ nhớ, đồng thời sử dụng |
Giao diện người dùng của phần hiển thị | Phát triển giao diện người dùng động bằng React để ghi lại và phát video trực tiếp và âm thanh ngay từ trình duyệt. |
Giao tiếp theo thời gian thực | Triển khai một quy trình WebSocket để giao tiếp song công, có độ trễ thấp, cho phép người dùng và AI tương tác đồng thời. |
AI đa phương thức | Tận dụng Gemini Live API để xử lý và hiểu các luồng video và âm thanh đồng thời, cho phép AI "nhìn" và "nghe" cùng một lúc. |
Gọi công cụ | Cho phép AI thực thi các hàm Python cụ thể để phản hồi các điều kiện kích hoạt trực quan, thu hẹp khoảng cách giữa trí thông minh của mô hình và hành động ngoài đời thực. |
Triển khai Full-Stack | Đóng gói toàn bộ ứng dụng (giao diện người dùng React và phần phụ trợ Python) bằng Docker rồi triển khai ứng dụng đó dưới dạng một dịch vụ có khả năng mở rộng và không máy chủ trên Google Cloud Run. |
2. Thiết lập môi trường
Truy cập Cloud Shell
Trước tiên, chúng ta sẽ mở Cloud Shell. Đây là một cửa sổ dòng lệnh dựa trên trình duyệt có Google Cloud SDK và các công cụ thiết yếu khác được cài đặt sẵn.
👉Nhấp vào biểu tượng Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud (Đây là biểu tượng có hình dạng thiết bị đầu cuối ở đầu ngăn Cloud Shell), 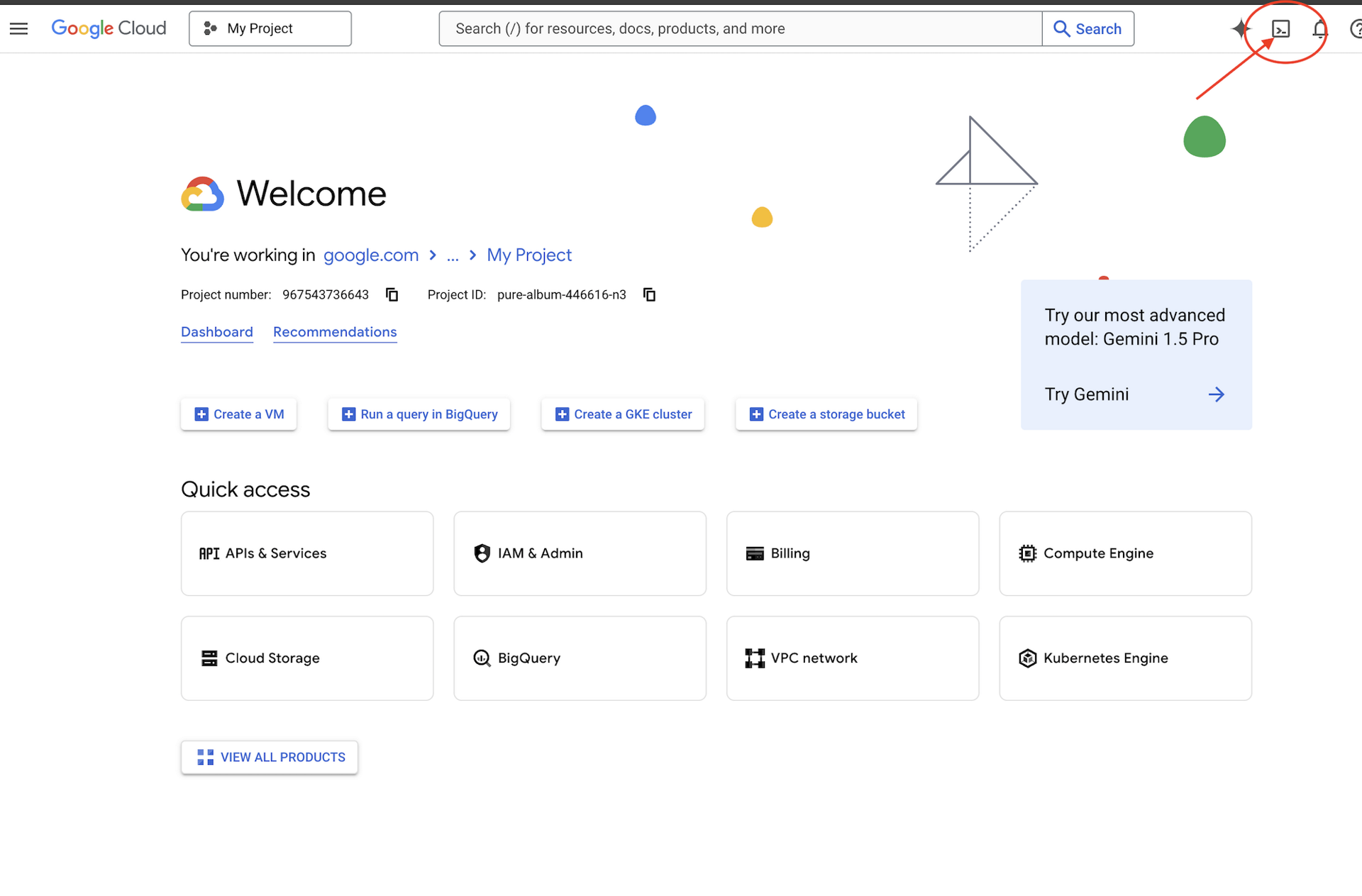
👉Nhấp vào nút "Mở trình chỉnh sửa" (nút này trông giống như một thư mục đang mở có bút chì). Thao tác này sẽ mở Trình chỉnh sửa mã Cloud Shell trong cửa sổ. Bạn sẽ thấy một trình khám phá tệp ở bên trái. 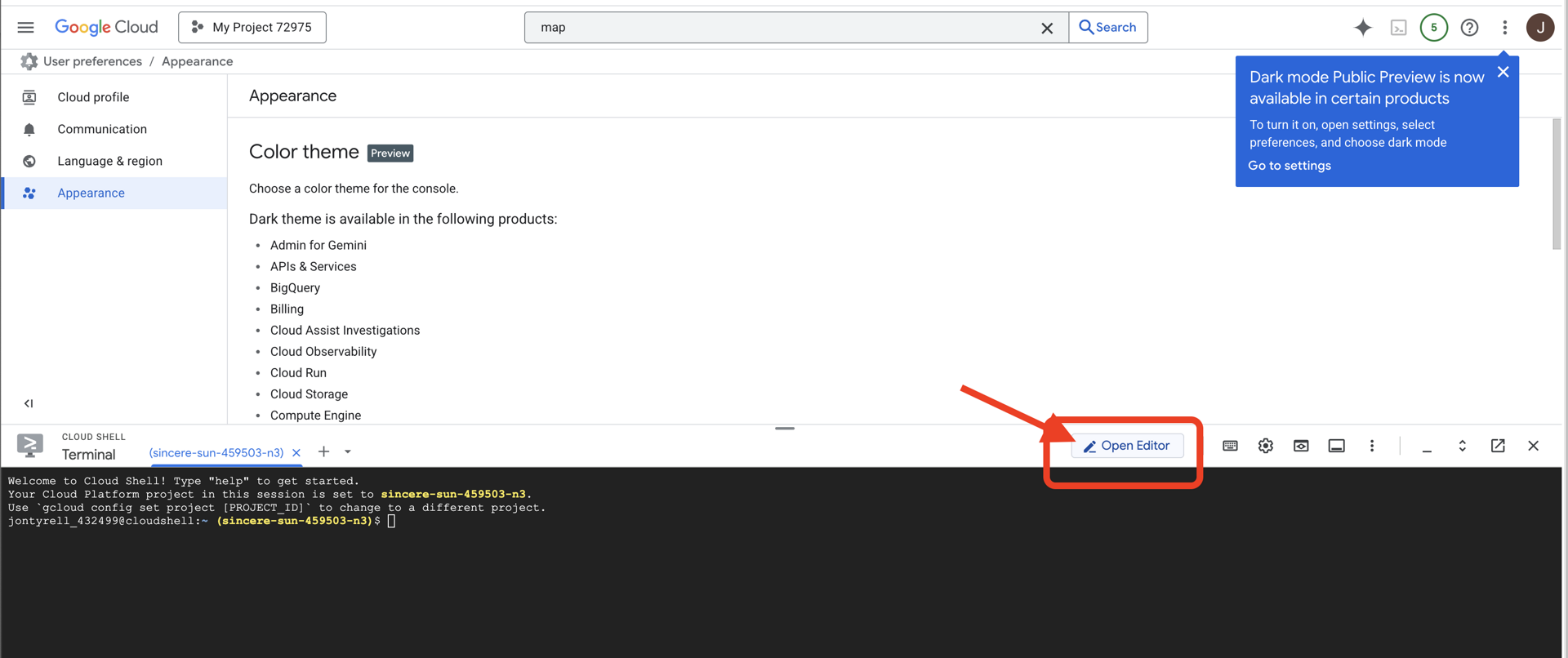
👉Mở cửa sổ dòng lệnh trong IDE trên đám mây,
👉💻 Trong thiết bị đầu cuối, hãy xác minh rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
Bạn sẽ thấy tài khoản của mình được liệt kê là (ACTIVE).
Điều kiện tiên quyết
ℹ️ Cấp 0 là không bắt buộc (nhưng nên dùng)
Bạn có thể hoàn thành nhiệm vụ này mà không cần đạt Cấp 0, nhưng hoàn thành nhiệm vụ này trước sẽ mang đến trải nghiệm sống động hơn, cho phép bạn thấy đèn hiệu của mình sáng lên trên bản đồ toàn cầu khi bạn tiến bộ.
Thiết lập môi trường dự án
Quay lại thiết bị đầu cuối, hoàn tất cấu hình bằng cách đặt dự án đang hoạt động và bật các dịch vụ cần thiết của Google Cloud (Cloud Run, Vertex AI, v.v.).
👉💻 Trong thiết bị đầu cuối, hãy đặt mã dự án:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Bật các dịch vụ bắt buộc:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
Cài đặt các phần phụ thuộc
👉💻 Chuyển đến Level và cài đặt các gói Python bắt buộc:
cd $HOME/way-back-home/level_3
uv sync
Sau đây là các phần phụ thuộc chính:
Gói | Mục đích |
| Khung web hiệu suất cao cho Trạm vệ tinh và hoạt động phát trực tuyến SSE |
| Cần có máy chủ ASGI để chạy ứng dụng FastAPI |
| Bộ công cụ phát triển tác nhân dùng để tạo Tác nhân hình thành |
| Ứng dụng gốc để truy cập vào các mô hình Gemini |
| Hỗ trợ giao tiếp hai chiều theo thời gian thực |
| Quản lý các biến môi trường và bí mật cấu hình |
Xác minh chế độ thiết lập
Trước khi bắt đầu viết mã, hãy đảm bảo rằng tất cả hệ thống đều hoạt động bình thường. Chạy tập lệnh xác minh để kiểm tra Dự án Google Cloud, API và các phần phụ thuộc Python.
👉💻 Chạy tập lệnh xác minh:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Bạn sẽ thấy một loạt Dấu kiểm màu xanh lục (✅).
- Nếu bạn thấy Dấu gạch chéo màu đỏ (❌), hãy làm theo các lệnh sửa lỗi được đề xuất trong đầu ra (ví dụ:
gcloud services enable ...hoặcpip install ...). - Lưu ý: Cảnh báo màu vàng cho
.envhiện có thể chấp nhận được; chúng ta sẽ tạo tệp đó ở bước tiếp theo.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Hiệu chỉnh Comm-Link (WebSocket)
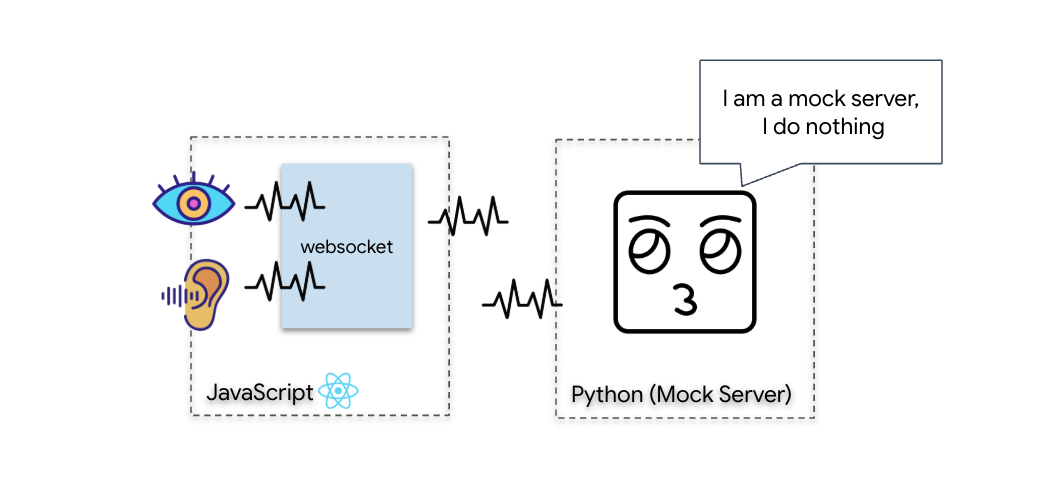
Để bắt đầu quá trình Đồng bộ hoá sinh trắc học thần kinh, chúng ta cần cập nhật hệ thống nội bộ của tàu. Mục tiêu chính của chúng tôi là ghi lại luồng video và luồng âm thanh có độ trung thực cao từ buồng lái của bạn. Luồng dữ liệu này cung cấp các thành phần thiết yếu cho mối liên kết thần kinh: nhận dạng trực quan các chuỗi ngón tay và tần số âm thanh của giọng nói.
Song công hoàn toàn so với bán song công
Để hiểu lý do chúng tôi cần thông tin này cho tính năng Đồng bộ hoá nơ-ron, bạn phải hiểu được quy trình truyền dữ liệu:
- Bán song công (HTTP tiêu chuẩn): Giống như bộ đàm. Một người nói, nói "Hết" rồi người kia có thể nói. Bạn không thể vừa nghe vừa nói cùng một lúc.
- Song công (WebSocket): Tương tự như cuộc trò chuyện trực tiếp. Dữ liệu lưu chuyển đồng thời theo cả hai hướng. Trong khi trình duyệt của bạn đang đẩy các khung hình video và mẫu âm thanh lên AI, thì AI có thể đẩy các câu trả lời bằng giọng nói và lệnh công cụ xuống cho bạn cùng lúc.
Lý do Gemini Live cần chế độ Full-Duplex: Gemini Live API được thiết kế cho "gián đoạn". Hãy tưởng tượng bạn đang thực hiện trình tự ngón tay và AI nhận thấy bạn đang làm sai. Trong chế độ thiết lập HTTP tiêu chuẩn, AI sẽ phải đợi bạn gửi xong dữ liệu rồi mới có thể yêu cầu bạn dừng lại. Với WebSockets, AI có thể phát hiện lỗi ở Khung hình 1 và gửi tín hiệu "gián đoạn" đến buồng lái trong khi bạn vẫn đang di chuyển tay cho Khung hình 2.
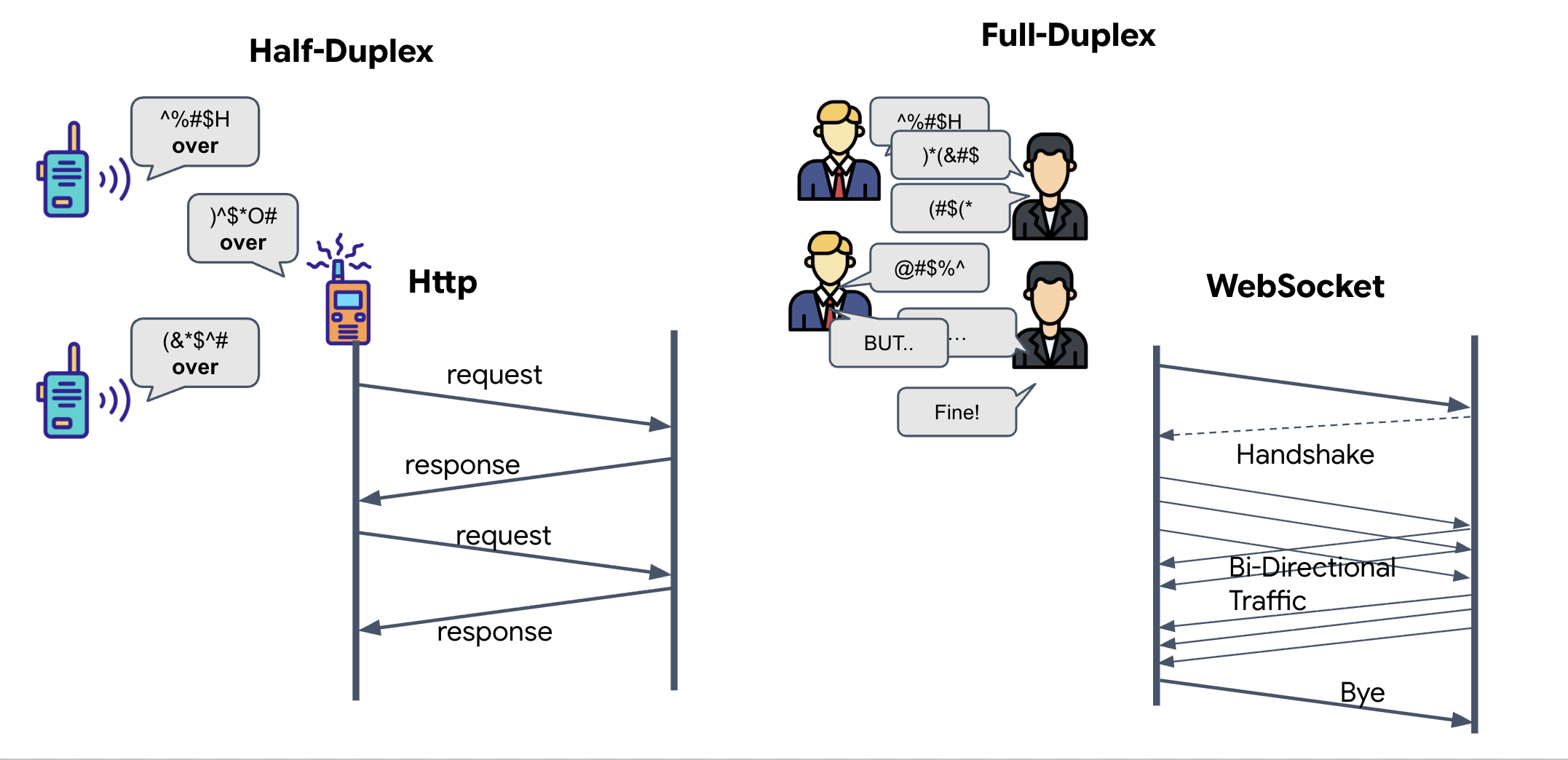
WebSocket là gì?
Trong một quá trình truyền dữ liệu tiêu chuẩn giữa các thiên hà (HTTP), bạn gửi một yêu cầu và đợi phản hồi, giống như gửi một tấm bưu thiếp. Đối với Neural Sync, bưu thiếp quá chậm. Chúng ta cần một "dây điện đang có dòng điện".
WebSocket bắt đầu dưới dạng một yêu cầu web tiêu chuẩn (HTTP), nhưng sau đó "nâng cấp" thành một yêu cầu khác.
- Yêu cầu: Trình duyệt của bạn gửi một yêu cầu HTTP tiêu chuẩn đến máy chủ bằng một tiêu đề đặc biệt:
Upgrade: websocket. Về cơ bản, bạn đang nói "Tôi muốn ngừng gửi bưu thiếp và bắt đầu một cuộc gọi điện thoại trực tiếp". - Phản hồi: Nếu hỗ trợ, thì AI Agent (máy chủ) sẽ gửi lại một phản hồi
HTTP 101 Switching Protocols. - Quá trình chuyển đổi: Tại thời điểm này, kết nối HTTP sẽ được thay thế bằng giao thức WebSocket, nhưng socket TCP/IP cơ bản vẫn mở. Các quy tắc giao tiếp thay đổi ngay lập tức từ "Yêu cầu/Phản hồi" thành "Truyền phát trực tiếp song công toàn phần".
Triển khai lệnh gọi WebSocket
Hãy kiểm tra cầu đấu dây để hiểu cách dữ liệu truyền tải.
👀 Mở $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. Bạn sẽ thấy các trình xử lý sự kiện trong vòng đời WebSocket tiêu chuẩn đã được thiết lập. Đây là cấu trúc cơ bản của hệ thống liên lạc của chúng tôi:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
Trình xử lý onMessage
Tập trung vào khối ws.current.onmessage. Đây là máy thu. Mỗi khi tác nhân "suy nghĩ" hoặc "nói", một gói dữ liệu sẽ đến đây. Hiện tại, nó không làm gì cả – nó bắt gói và thả gói (thông qua phần giữ chỗ //#REPLACE-HANDLE-MSG).
Chúng ta cần điền vào khoảng trống này bằng logic có thể phân biệt giữa:
- Lệnh gọi công cụ (functionCall): AI nhận dạng cử chỉ tay của bạn ("Đồng bộ hoá").
- Dữ liệu âm thanh (inlineData): Giọng nói của AI phản hồi bạn.
👉✏️ Giờ đây, trong cùng một tệp $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, hãy thay thế //#REPLACE-HANDLE-MSG bằng logic bên dưới để xử lý luồng dữ liệu đến:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
Cách chuyển đổi âm thanh và video thành dữ liệu để truyền tải
Để cho phép giao tiếp theo thời gian thực qua Internet, âm thanh và video thô phải được chuyển đổi thành một định dạng phù hợp để truyền tải. Việc này bao gồm thu thập, mã hoá và đóng gói dữ liệu trước khi gửi qua mạng.
Chuyển đổi dữ liệu âm thanh
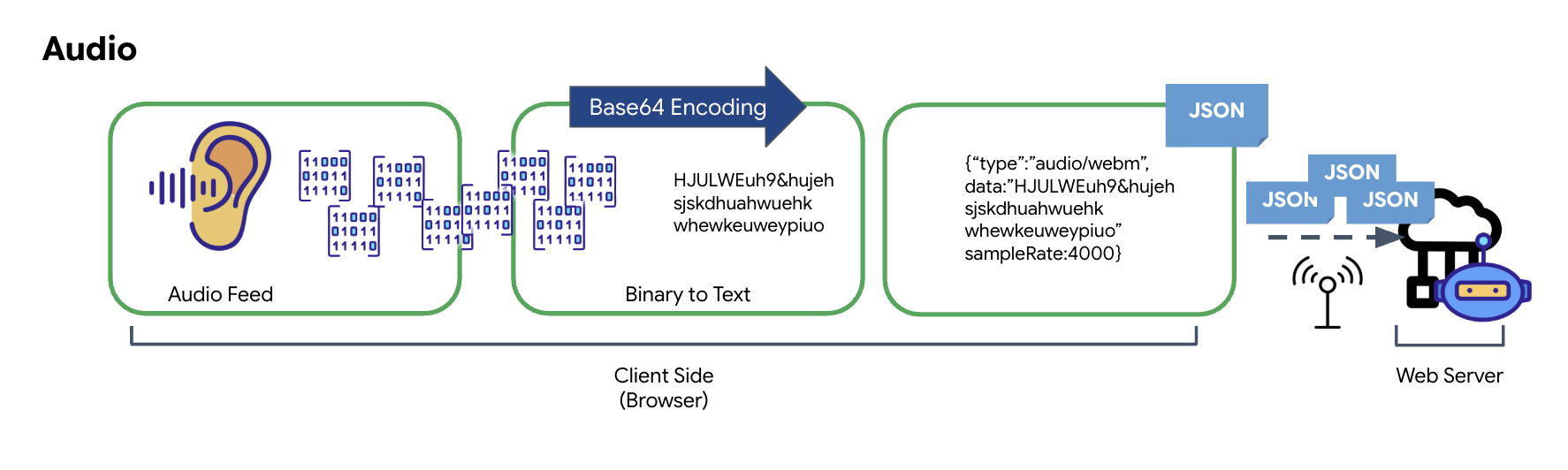
Quá trình chuyển đổi âm thanh tương tự thành dữ liệu kỹ thuật số có thể truyền được bắt đầu bằng việc thu sóng âm bằng micrô. Sau đó, âm thanh thô này sẽ được xử lý thông qua Web Audio API của trình duyệt. Vì dữ liệu thô này ở định dạng nhị phân, nên không tương thích trực tiếp với các định dạng truyền dựa trên văn bản như JSON. Để giải quyết vấn đề này, mỗi đoạn âm thanh sẽ được mã hoá thành một chuỗi Base64. Base64 là một phương thức biểu thị dữ liệu nhị phân ở định dạng chuỗi ASCII, đảm bảo tính toàn vẹn của dữ liệu trong quá trình truyền.
Sau đó, chuỗi được mã hoá này sẽ được nhúng trong một đối tượng JSON. Đối tượng này cung cấp một định dạng có cấu trúc cho dữ liệu, thường bao gồm một trường "type" để xác định đó là âm thanh và siêu dữ liệu, chẳng hạn như tốc độ lấy mẫu của âm thanh. Sau đó, toàn bộ đối tượng JSON sẽ được chuyển đổi tuần tự thành một chuỗi và gửi qua kết nối WebSocket. Phương pháp này đảm bảo âm thanh được truyền theo cách có tổ chức và dễ phân tích.
Chuyển đổi dữ liệu video
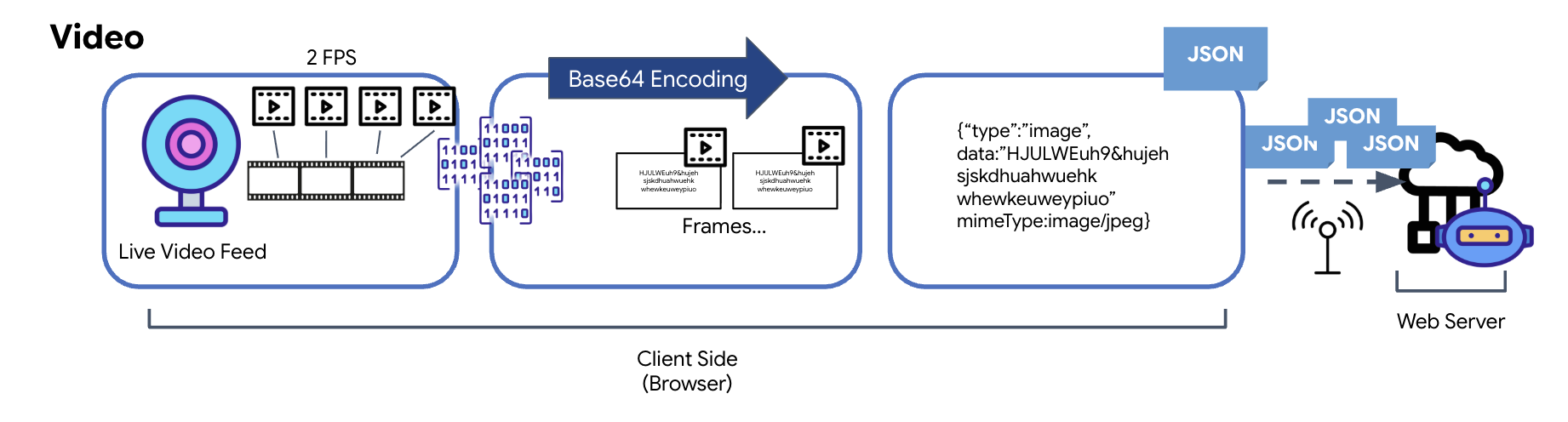
Video được truyền bằng kỹ thuật chụp khung hình. Thay vì gửi một luồng video liên tục, vòng lặp định kỳ sẽ chụp ảnh tĩnh từ nguồn cấp dữ liệu video trực tiếp theo một khoảng thời gian nhất định, chẳng hạn như 2 khung hình mỗi giây. Việc này được thực hiện bằng cách vẽ khung hình hiện tại từ một phần tử video HTML lên một phần tử canvas ẩn.
Sau đó, phương thức toDataURL của canvas được dùng để chuyển đổi hình ảnh đã chụp này thành một chuỗi JPEG được mã hoá Base64. Phương thức này có một lựa chọn để chỉ định chất lượng ảnh, cho phép đánh đổi giữa độ trung thực của hình ảnh và kích thước tệp để tối ưu hoá hiệu suất. Tương tự như dữ liệu âm thanh, chuỗi Base64 này sau đó được đặt vào một đối tượng JSON. Đối tượng này thường được gắn nhãn bằng "type" là "image" và bao gồm mimeType, chẳng hạn như "image/jpeg". Sau đó, gói JSON này sẽ được chuyển đổi thành một chuỗi và gửi qua WebSocket, cho phép đầu nhận dựng lại video bằng cách hiển thị chuỗi hình ảnh.
👉✏️ Trong cùng tệp $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, hãy thay thế //#CAPTURE AUDIO and VIDEO bằng đoạn mã sau để ghi lại hoạt động đầu vào của người dùng:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
Sau khi được lưu, bảng điều khiển sẽ sẵn sàng dịch các tín hiệu kỹ thuật số của Nhân viên thành thông tin cập nhật trực quan trên trang tổng quan và âm thanh.
Kiểm tra chẩn đoán (Kiểm tra vòng lặp)
Khoang lái của bạn hiện đã hoạt động. Cứ 500 mili giây, một "gói" hình ảnh về môi trường xung quanh bạn sẽ được truyền đi. Trước khi kết nối với Gemini, chúng tôi phải xác minh rằng máy phát của tàu đang hoạt động. Chúng tôi sẽ chạy "Kiểm tra vòng lặp" bằng máy chủ chẩn đoán cục bộ.
👉💻 Trước tiên, hãy tạo Giao diện Cockpit từ thiết bị đầu cuối:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 Tiếp theo, hãy khởi động máy chủ mô phỏng:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 Thực hiện Giao thức kiểm thử:
- Mở bản xem trước: Nhấp vào biểu tượng Xem trước trên web trong thanh công cụ Cloud Shell. Chọn Thay đổi cổng, đặt thành 8080 rồi nhấp vào Thay đổi và xem trước. Một thẻ trình duyệt mới sẽ mở ra và cho thấy Giao diện Cockpit.
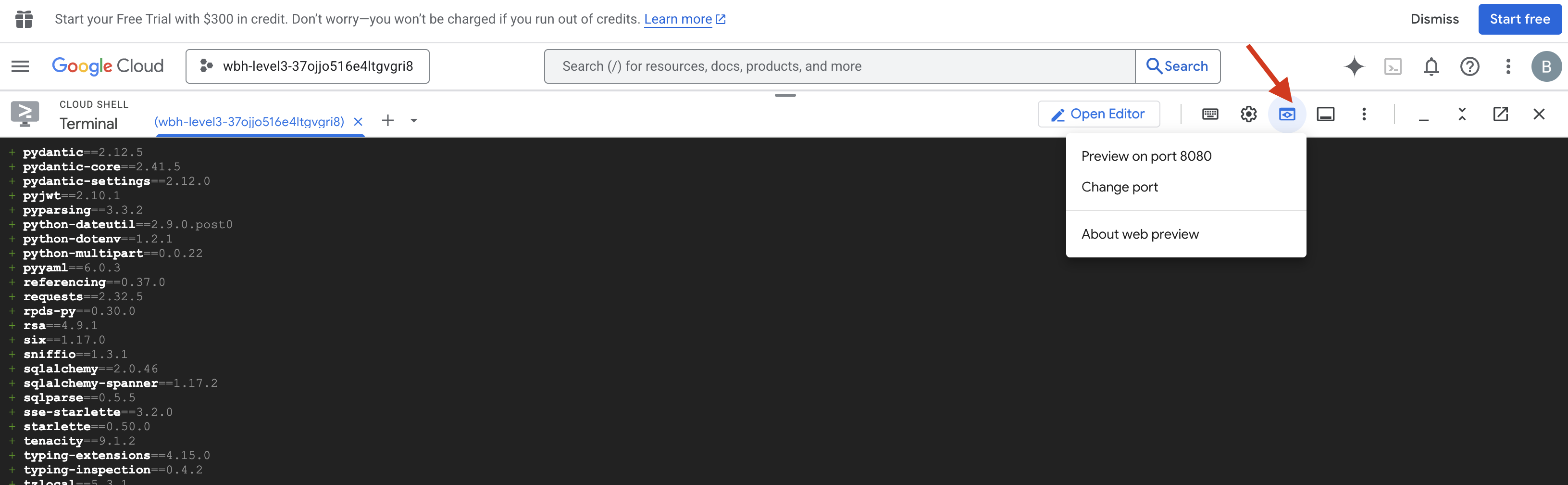
- QUAN TRỌNG: Khi được nhắc, bạn PHẢI cho phép trình duyệt truy cập vào Camera và Micrô. Nếu không có các đầu vào này, tính năng đồng bộ hoá bằng mạng nơ-ron sẽ không thể bắt đầu.
- Nhấp vào nút "INITIATE NEURAL SYNC" (KHỞI TẠO ĐỒNG BỘ HOÁ NEURAL) trong giao diện người dùng.
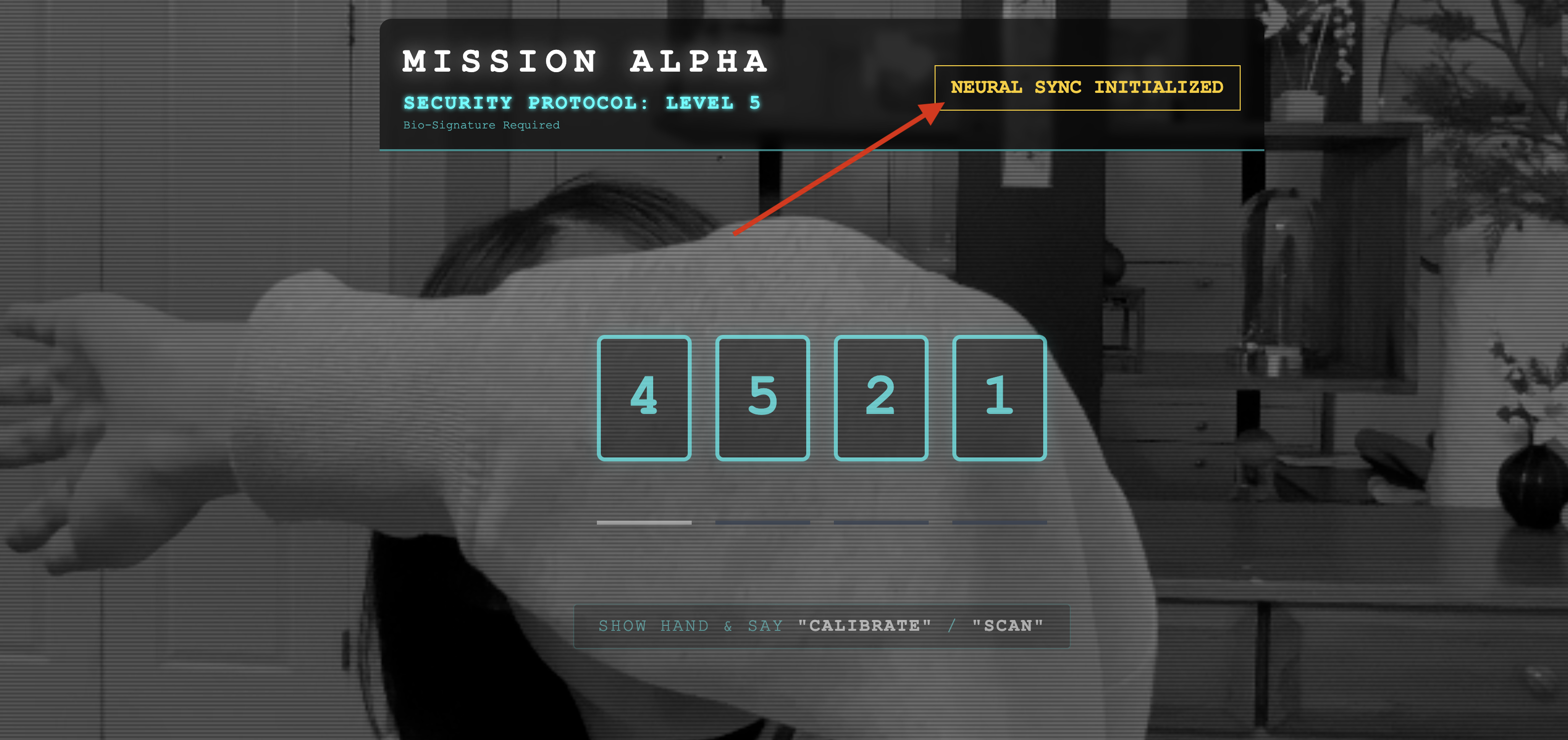
👀 Chỉ báo trạng thái xác minh:
- Kiểm tra bằng mắt: Mở Bảng điều khiển của trình duyệt. Bạn sẽ thấy biểu tượng
NEURAL SYNC INITIALIZEDở trên cùng bên phải. - Kiểm tra âm thanh: Nếu đường truyền âm thanh hai chiều hoạt động bình thường, bạn sẽ nghe thấy một giọng nói mô phỏng xác nhận: "Đã kết nối hệ thống!"
Sau khi bạn nghe thấy thông báo xác nhận bằng âm thanh "Đã kết nối hệ thống!", tức là bạn đã kiểm tra thành công. Đóng thẻ. Giờ đây, chúng ta phải xoá tần số để nhường chỗ cho AI thực sự.
👉💻 Nhấn Ctrl+C trong các thiết bị đầu cuối cho cả máy chủ mô phỏng và giao diện người dùng. Đóng thẻ trình duyệt đang chạy giao diện người dùng.
4. Tác nhân đa phương thức
Rescue Scout đang hoạt động, nhưng "tâm trí" của nó trống rỗng. Nếu bạn kết nối ngay bây giờ, nó sẽ chỉ nhìn chằm chằm vào bạn. Nó không biết "ngón tay" là gì. Để cứu những người sống sót, bạn phải in Giao thức thần kinh sinh trắc học lên lõi của Scout.
Tác nhân truyền thống hoạt động như một loạt người dịch. Nếu bạn nói chuyện với một AI kiểu cũ, mô hình "Chuyển lời nói thành văn bản" sẽ chuyển giọng nói của bạn thành chữ, "Mô hình ngôn ngữ" sẽ đọc những chữ đó và nhập câu trả lời, còn mô hình "Chuyển văn bản thành lời nói" cuối cùng sẽ đọc câu trả lời đó cho bạn. Điều này tạo ra một "khoảng trống về độ trễ" – một độ trễ có thể gây ra hậu quả nghiêm trọng trong nhiệm vụ cứu hộ.
Gemini Live API là một mô hình đa phương thức gốc. Nó xử lý trực tiếp và đồng thời các byte âm thanh thô và khung hình video thô. Công nghệ này "nghe" rung động của giọng nói và "nhìn" các pixel của cử chỉ tay trong cùng một cấu trúc mạng nơ-ron.
Để khai thác sức mạnh này, chúng ta có thể tạo ứng dụng bằng cách kết nối bảng điều khiển trực tiếp với Live API thô. Tuy nhiên, mục tiêu của chúng tôi là xây dựng một tác nhân có thể dùng lại – một thực thể mô-đun, mạnh mẽ và có thể xây dựng nhanh hơn.
Tại sao nên dùng ADK (Bộ công cụ phát triển tác nhân)?
Bộ công cụ phát triển tác nhân (ADK) của Google là một khung mô-đun để phát triển và triển khai các tác nhân AI.
Các lệnh gọi LLM tiêu chuẩn thường không có trạng thái; mỗi truy vấn là một khởi đầu mới. Nhân viên hỗ trợ trực tiếp, đặc biệt là khi được tích hợp với SessionService của ADK, sẽ cho phép các phiên trò chuyện mạnh mẽ, kéo dài.
- Tính liên tục của phiên: Các phiên ADK có tính liên tục và có thể được lưu trữ trong cơ sở dữ liệu (chẳng hạn như SQL hoặc Vertex AI), tồn tại sau khi máy chủ khởi động lại và ngắt kết nối. Điều này có nghĩa là nếu người dùng ngắt kết nối rồi kết nối lại sau đó (ngay cả vài ngày sau), nhật ký trò chuyện và ngữ cảnh của họ sẽ được khôi phục hoàn toàn. Phiên Live API tạm thời do ADK quản lý và trừu tượng hoá.
- Tự động kết nối lại: Các kết nối WebSocket có thể hết thời gian chờ (ví dụ: sau khoảng 10 phút). ADK xử lý các lần kết nối lại này một cách minh bạch khi
session_resumptionđược bật trongRunConfig. Mã xử lý ứng dụng của bạn không cần quản lý logic kết nối lại phức tạp, đảm bảo mang đến trải nghiệm liền mạch cho người dùng. - Tương tác có trạng thái: AI có thể nhớ các lượt tương tác trước đó, cho phép đặt câu hỏi nối tiếp, yêu cầu giải thích và thực hiện các cuộc đối thoại phức tạp gồm nhiều lượt tương tác, trong đó bối cảnh đóng vai trò quan trọng. Đây là yếu tố cơ bản đối với các ứng dụng như hỗ trợ khách hàng, hướng dẫn tương tác hoặc các tình huống kiểm soát nhiệm vụ mà tính liên tục là yếu tố thiết yếu.
Tính năng duy trì này đảm bảo rằng người dùng cảm thấy như đang trò chuyện liên tục với một thực thể thông minh, thay vì chỉ là một loạt câu hỏi và câu trả lời riêng lẻ.
Về cơ bản, "Live Agent" (Nhân viên hỗ trợ trực tiếp) có tính năng truyền dữ liệu hai chiều ADK không chỉ là một cơ chế truy vấn-phản hồi đơn giản mà còn mang đến trải nghiệm đàm thoại thực sự mang tính tương tác, có trạng thái và nhận biết được sự gián đoạn, giúp các hoạt động tương tác với AI trở nên gần gũi hơn và hiệu quả hơn đáng kể đối với các tác vụ phức tạp, kéo dài.
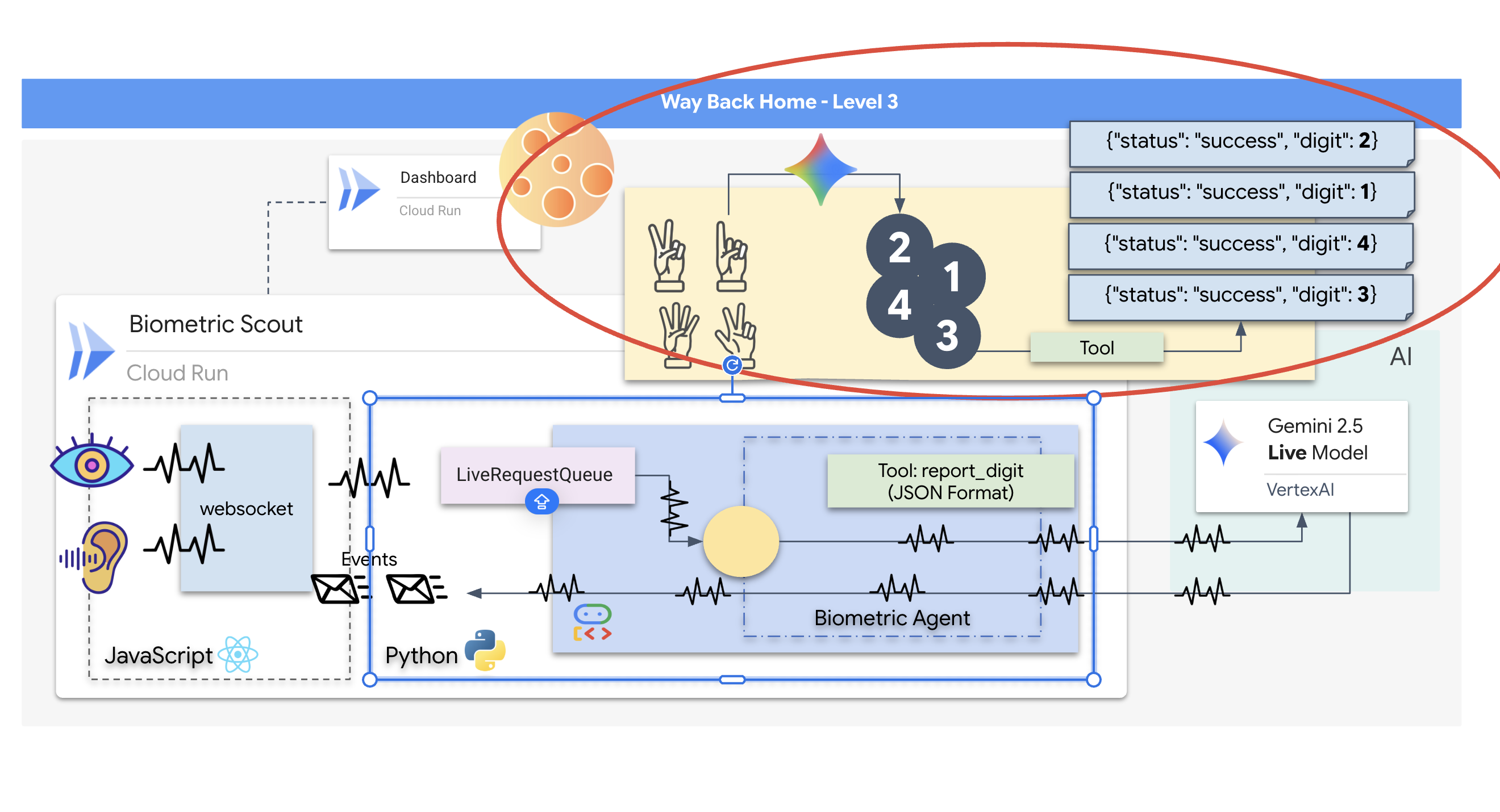
Yêu cầu gặp nhân viên hỗ trợ
Việc thiết kế câu lệnh cho một tác nhân hai chiều theo thời gian thực đòi hỏi bạn phải thay đổi tư duy. Không giống như một chatbot tiêu chuẩn chỉ chờ một câu hỏi bằng văn bản tĩnh, Nhân viên hỗ trợ trực tiếp "luôn bật". Mô hình này nhận được một luồng khung hình âm thanh và video liên tục, tức là câu lệnh của bạn phải đóng vai trò là Tập lệnh vòng lặp kiểm soát chứ không chỉ là định nghĩa về tính cách.
Sau đây là điểm khác biệt giữa câu lệnh dành cho Nhân viên hỗ trợ trực tiếp và câu lệnh truyền thống:
- Logic của máy trạng thái: Câu lệnh phải xác định một "Vòng lặp hành vi" (Chờ → Phân tích → Hành động). Bạn cần đưa ra hướng dẫn rõ ràng về thời điểm giữ im lặng và thời điểm tương tác, ngăn không cho trợ lý nói luyên thuyên khi không có tạp âm.
- Nhận thức đa phương thức: Bạn cần cho biết rằng tác nhân có "mắt". Bạn phải hướng dẫn rõ ràng cho mô hình này phân tích các khung hình video trong quá trình suy luận.
- Độ trễ và tính ngắn gọn: Trong cuộc trò chuyện trực tiếp bằng giọng nói, những đoạn văn dài, nặng nề sẽ tạo cảm giác không tự nhiên và chậm chạp. Câu lệnh này yêu cầu bạn đưa ra câu trả lời ngắn gọn để cuộc trò chuyện diễn ra nhanh chóng.
- Cấu trúc ưu tiên hành động: Các chỉ dẫn ưu tiên Gọi công cụ hơn lời nói. Chúng tôi muốn nhân viên hỗ trợ "thực hiện" công việc (quét dữ liệu sinh trắc học) trước hoặc trong khi xác nhận bằng lời nói, chứ không phải sau một đoạn độc thoại dài.
👉✏️ Mở $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py rồi thay thế #REPLACE INSTRUCTIONS bằng nội dung sau:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
LƯU Ý! Bạn không kết nối với một LLM tiêu chuẩn. Trong cùng một tệp ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py), hãy tìm #REPLACE_MODEL. Chúng ta cần nhắm đến phiên bản xem trước của mô hình này một cách rõ ràng để hỗ trợ tốt hơn các chức năng âm thanh theo thời gian thực.
👉✏️ Thay thế phần giữ chỗ bằng:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
Giờ đây, bạn đã xác định được Nhân viên hỗ trợ. Nó biết mình là ai và cách suy nghĩ. Tiếp theo, chúng ta cung cấp cho nó các công cụ để hành động.
Gọi công cụ
Live API không chỉ giới hạn ở việc trao đổi luồng văn bản, âm thanh và video. Nền tảng này hỗ trợ Lệnh gọi công cụ một cách tự nhiên. Điều này giúp nhân viên hỗ trợ chuyển từ người trò chuyện thụ động thành người điều hành tích cực.
Trong một phiên trực tiếp, hai chiều, mô hình liên tục đánh giá ngữ cảnh. Nếu LLM phát hiện thấy cần thực hiện một hành động, cho dù đó là "kiểm tra dữ liệu đo từ xa của cảm biến" hay "mở khoá cửa bảo mật". Công cụ này chuyển đổi liền mạch từ cuộc trò chuyện sang việc thực thi. Tác nhân sẽ kích hoạt ngay chức năng công cụ cụ thể, chờ kết quả và tích hợp dữ liệu đó trở lại luồng trực tiếp mà không làm gián đoạn quy trình tương tác.
👉✏️ Trong $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py, hãy thay thế #REPLACE TOOLS bằng hàm sau:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ Sau đó, hãy đăng ký trong định nghĩa Agent bằng cách thay thế #TOOL CONFIG:
tools=[report_digit],
Trình mô phỏng adk web
Trước khi kết nối điều này với bảng điều khiển phức tạp của tàu (Giao diện người dùng React của chúng tôi), chúng ta nên kiểm thử logic của Tác nhân một cách riêng biệt. ADK có một bảng điều khiển dành cho nhà phát triển tích hợp có tên là adk web, cho phép chúng tôi xác minh Lệnh gọi công cụ trước khi thêm độ phức tạp của mạng.
👉💻 Trong thiết bị đầu cuối, hãy chạy:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Nhấp vào biểu tượng Xem trước trên web trong thanh công cụ Cloud Shell. Chọn Thay đổi cổng, đặt thành 8000 rồi nhấp vào Thay đổi và xem trước.
- Cấp quyền: Cho phép truy cập vào Camera và Micrô khi được nhắc.
- Bắt đầu phiên bằng cách nhấp vào biểu tượng máy ảnh.
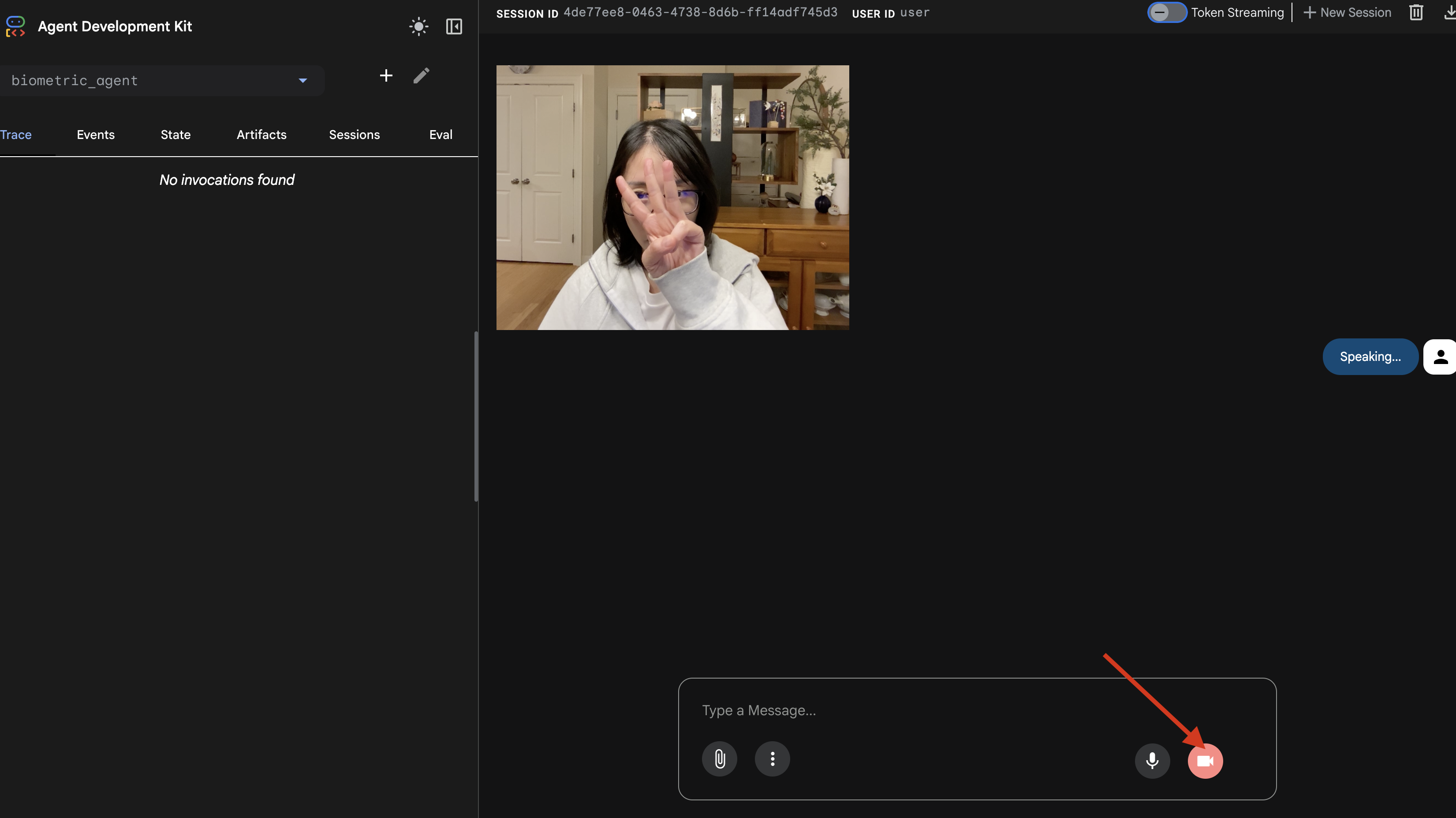
- Thử nghiệm trực quan:
- Giơ 3 ngón tay rõ ràng trước camera.
- Nói: "Quét".
- Xác minh thành công:
- Nhật ký: Xem cửa sổ dòng lệnh đang chạy lệnh
adk web. Bạn phải thấy nhật ký này:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- Nhật ký: Xem cửa sổ dòng lệnh đang chạy lệnh
Nếu bạn thấy nhật ký thực thi công cụ, thì tức là Agent của bạn có khả năng thông minh. Nó có thể nhìn, suy nghĩ và hành động. Bước cuối cùng là kết nối nó với con tàu chính.
Nhấp vào cửa sổ dòng lệnh rồi nhấn Ctrl+C để dừng trình mô phỏng adk web.
5. Luồng truyền trực tuyến hai chiều
Tác nhân hoạt động. Cockpit hoạt động. Giờ chúng ta phải kết nối họ.
Vòng đời của nhân viên hỗ trợ trực tiếp
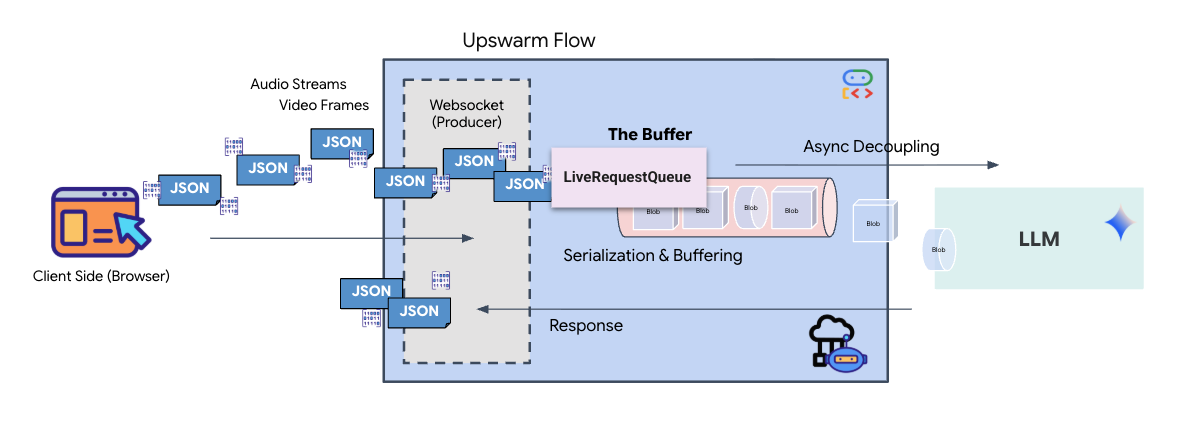
Tính năng phát trực tiếp theo thời gian thực gây ra vấn đề "trở kháng không khớp". Ứng dụng (trình duyệt) đẩy dữ liệu không đồng bộ ở tốc độ thay đổi – các đợt dữ liệu mạng hoặc đầu vào liên tục – trong khi mô hình yêu cầu một luồng đầu vào tuần tự, có quy tắc. Google ADK giải quyết vấn đề này bằng cách sử dụng LiveRequestQueue.
Nó hoạt động như một vùng đệm Vào trước ra trước (FIFO) không đồng bộ và an toàn cho luồng. Trình xử lý WebSocket đóng vai trò là Producer (Nhà sản xuất), đẩy các đoạn âm thanh/video thô vào hàng đợi. ADK Agent đóng vai trò là Consumer, lấy dữ liệu từ hàng đợi để cung cấp cho cửa sổ ngữ cảnh của mô hình. Việc tách rời này cho phép ứng dụng tiếp tục nhận hoạt động đầu vào của người dùng ngay cả khi mô hình đang tạo phản hồi hoặc thực thi một công cụ.
Hàng đợi đóng vai trò là một Bộ ghép kênh đa phương thức. Trong môi trường thực, luồng dữ liệu đầu nguồn bao gồm các loại dữ liệu riêng biệt, đồng thời: byte âm thanh PCM thô, khung hình video, hướng dẫn hệ thống dựa trên văn bản và kết quả từ Lệnh gọi công cụ không đồng bộ. LiveRequestQueue sẽ tuyến tính hoá các dữ liệu đầu vào riêng biệt này thành một chuỗi thời gian duy nhất. Cho dù gói chứa một mili giây im lặng, một hình ảnh có độ phân giải cao hay một tải trọng JSON từ một truy vấn cơ sở dữ liệu, thì gói đó sẽ được chuyển đổi tuần tự theo đúng thứ tự đến, đảm bảo mô hình nhận thấy một dòng thời gian nhất quán và có quan hệ nhân quả.
Cấu trúc này cho phép Non-Blocking Control (Điều khiển không chặn). Vì lớp tiếp nhận (Producer) tách biệt với lớp xử lý (Consumer), nên hệ thống vẫn phản hồi ngay cả trong quá trình suy luận mô hình tốn nhiều tài nguyên tính toán. Nếu người dùng ngắt lời bằng lệnh "Dừng!" trong khi Nhân viên hỗ trợ đang thực thi một công cụ, thì tín hiệu âm thanh đó sẽ được đưa vào hàng đợi ngay lập tức. Vòng lặp sự kiện cơ bản sẽ xử lý ngay tín hiệu ưu tiên này, cho phép hệ thống dừng tạo hoặc xoay vòng các tác vụ mà không làm giao diện người dùng bị treo hoặc giảm gói.
👉💻 Trong $HOME/way-back-home/level_3/backend/app/main.py, hãy tìm nhận xét #REPLACE_RUNNER_CONFIG rồi thay thế bằng đoạn mã sau để đưa hệ thống vào hoạt động:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
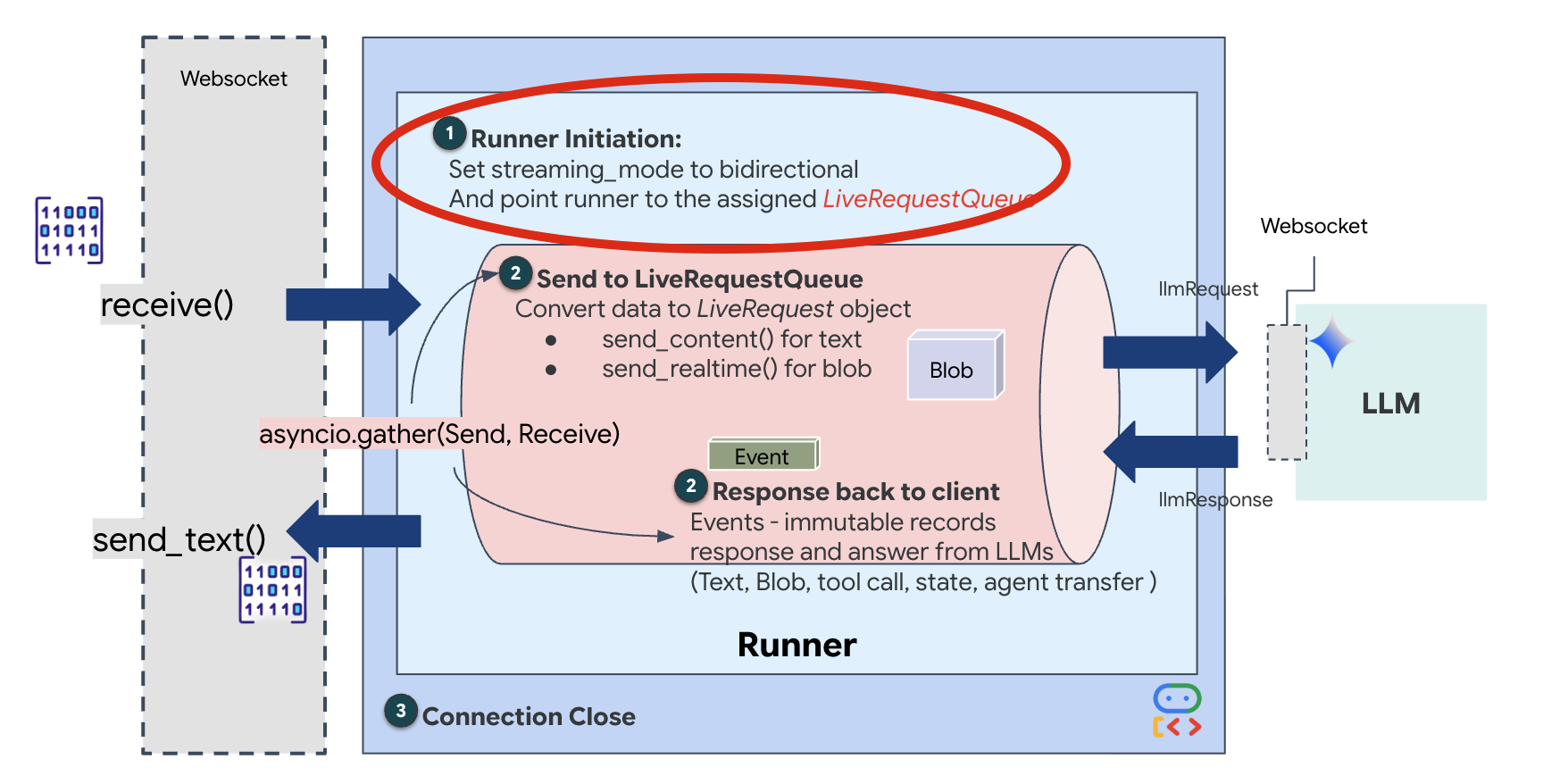
Khi một kết nối WebSocket mới mở ra, chúng ta cần định cấu hình cách AI tương tác. Đây là nơi chúng ta xác định "Quy tắc giao tranh".
👉✏️ Trong $HOME/way-back-home/level_3/backend/app/main.py, bên trong hàm async def websocket_endpoint, hãy thay thế nhận xét #REPLACE_SESSION_INIT bằng mã bên dưới:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
Cấu hình chạy
StreamingMode.BIDI: Thao tác này thiết lập kết nối hai chiều. Không giống như AI "theo lượt" (bạn nói, dừng lại, sau đó AI nói), BIDI cho phép cuộc trò chuyện "song công hoàn toàn" diễn ra chân thực. Bạn có thể ngắt lời AI và AI có thể nói trong khi bạn đang di chuyển.AudioTranscriptionConfig: Mặc dù mô hình "nghe" âm thanh thô, nhưng chúng tôi (nhà phát triển) cần xem nhật ký. Cấu hình này cho Gemini biết: "Xử lý âm thanh, nhưng cũng gửi lại bản chép lời bằng văn bản về những gì bạn nghe được để chúng tôi có thể gỡ lỗi."
Logic thực thi Sau khi Runner thiết lập phiên, Runner sẽ chuyển quyền kiểm soát cho logic thực thi, dựa vào LiveRequestQueue. Đây là thành phần quan trọng nhất để tương tác theo thời gian thực. Vòng lặp này cho phép tác nhân tạo ra một phản hồi bằng giọng nói trong khi hàng đợi tiếp tục chấp nhận các khung hình video mới từ người dùng, đảm bảo "Neural Sync" không bao giờ bị gián đoạn.
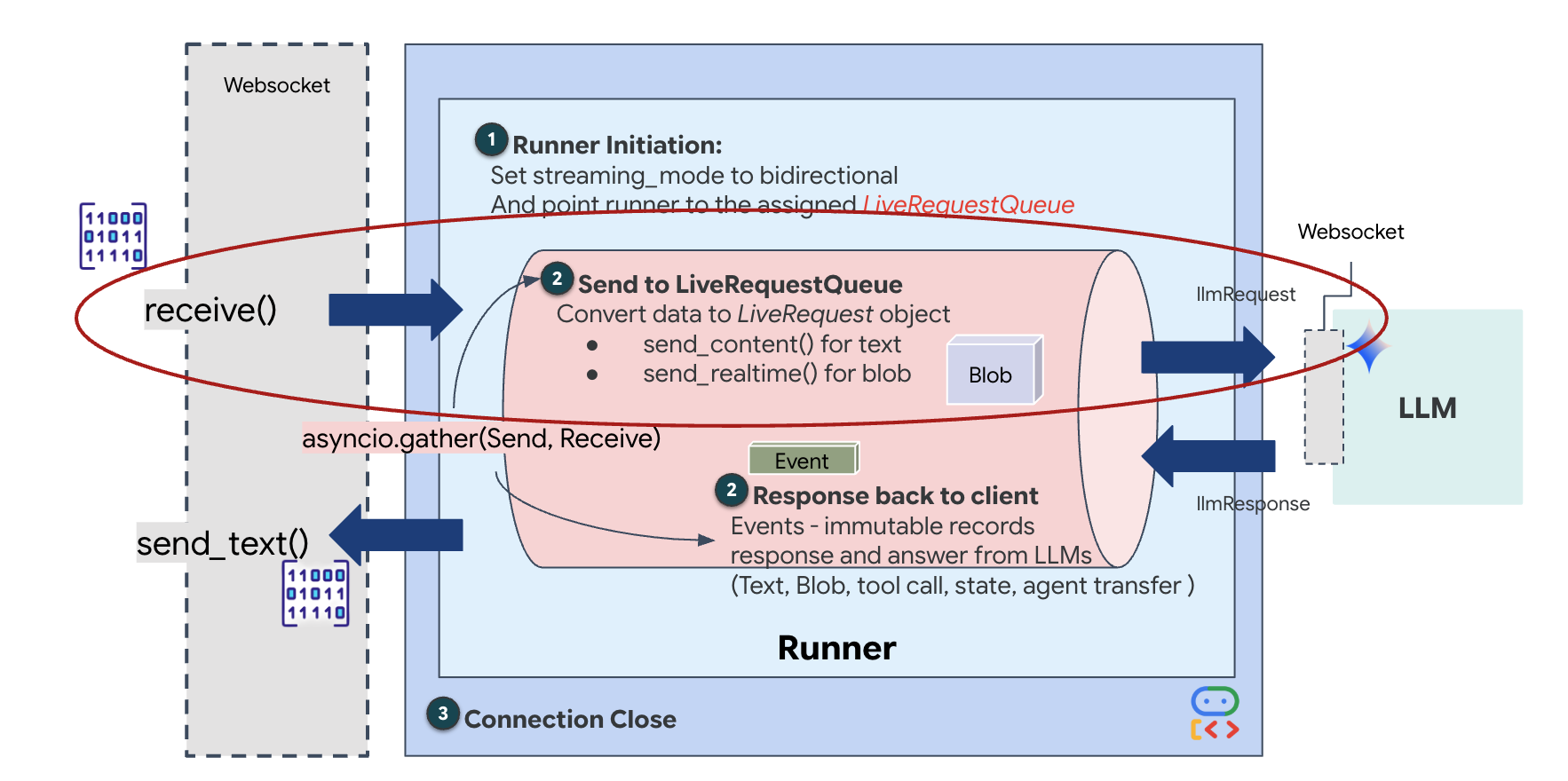
👉✏️ Trong $HOME/way-back-home/level_3/backend/app/main.py, hãy thay thế #REPLACE_LIVE_REQUEST để xác định tác vụ nguồn gửi dữ liệu đến LiveRequestQueue:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
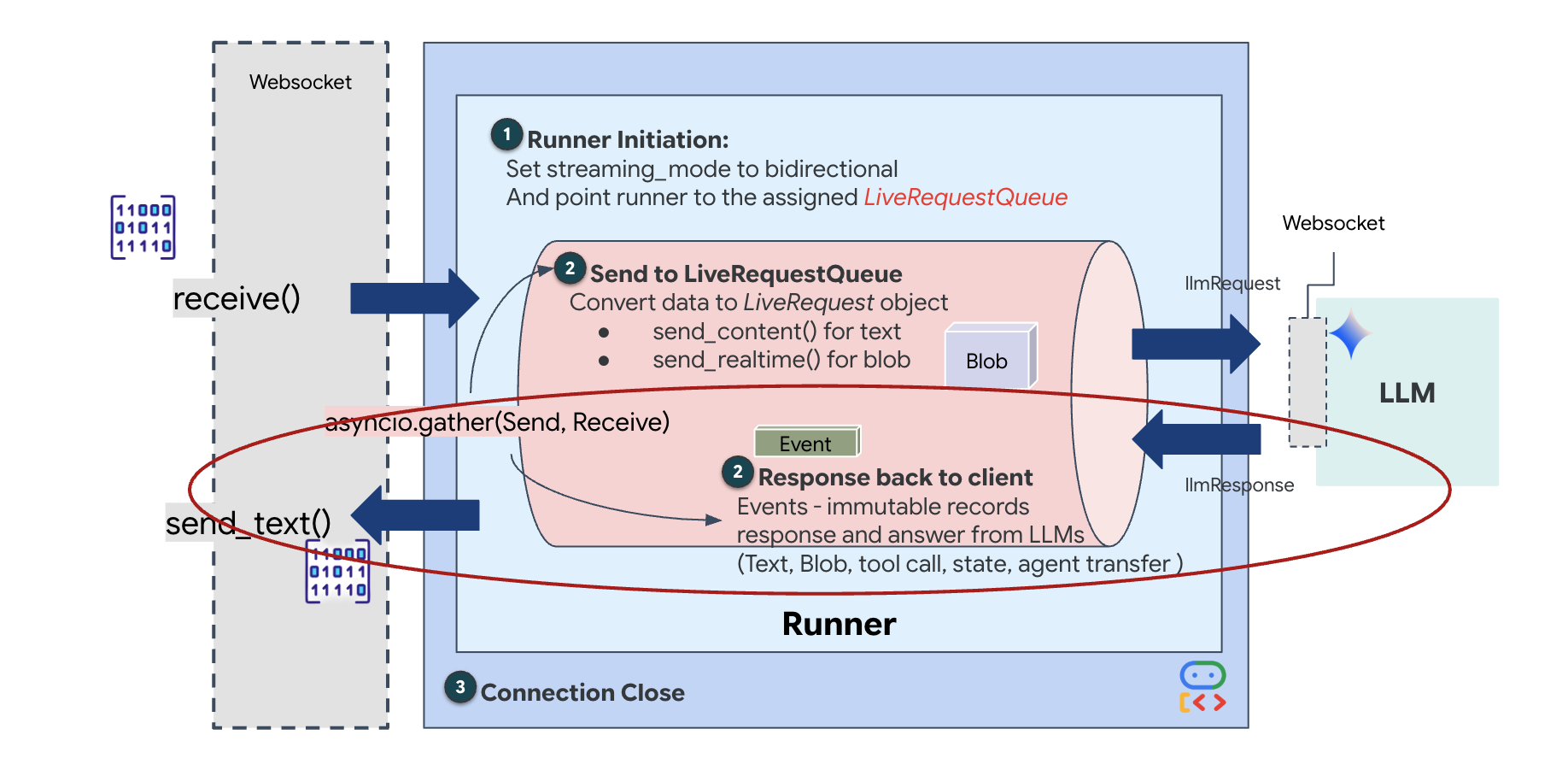
Cuối cùng, chúng ta cần xử lý các câu trả lời của AI. Thao tác này sử dụng runner.run_live(), là một trình tạo sự kiện tạo ra các sự kiện (Âm thanh, Văn bản hoặc Lệnh gọi công cụ) khi chúng xảy ra.
👉✏️ Trong $HOME/way-back-home/level_3/backend/app/main.py, hãy thay thế #REPLACE_SORT_RESPONSE để xác định tác vụ hạ nguồn và trình quản lý đồng thời:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
Hãy lưu ý dòng await asyncio.gather(upstream_task(), downstream_task()). Đây là bản chất của Full-Duplex. Chúng tôi chạy tác vụ nghe (thượng nguồn) và tác vụ nói (hạ nguồn) cùng lúc. Điều này đảm bảo "Neural Link" cho phép gián đoạn và luồng dữ liệu đồng thời.
Phần phụ trợ của bạn hiện đã được mã hoá đầy đủ. "Não" (ADK) được kết nối với "Cơ thể" (WebSocket).
Thực thi Bio-Sync
Mã đã hoàn tất. Các hệ thống đều hoạt động bình thường. Đã đến lúc bắt đầu hoạt động cứu hộ.
- 👉💻 Bắt đầu phần phụ trợ:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 Khởi chạy giao diện người dùng:
- Nhấp vào biểu tượng Xem trước trên web trong thanh công cụ Cloud Shell. Chọn Thay đổi cổng, đặt thành 8080 rồi nhấp vào Thay đổi và xem trước.
- 👉 Thực thi giao thức:
- Nhấp vào "INITIATE NEURAL SYNC" (BẮT ĐẦU ĐỒNG BỘ HOÁ THẦN KINH).
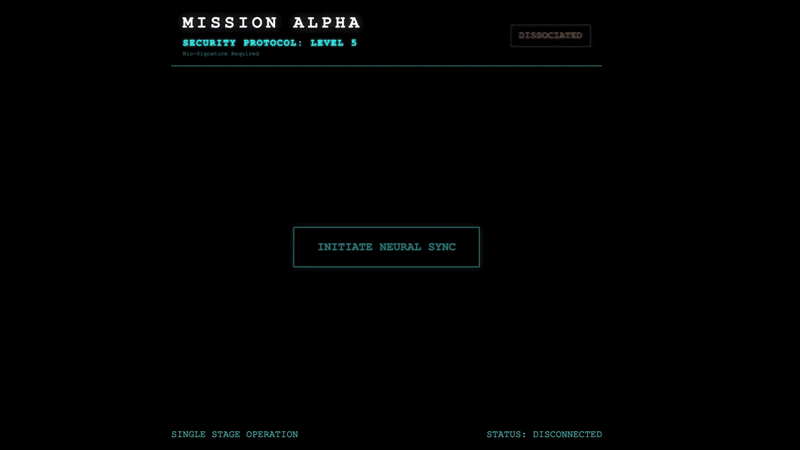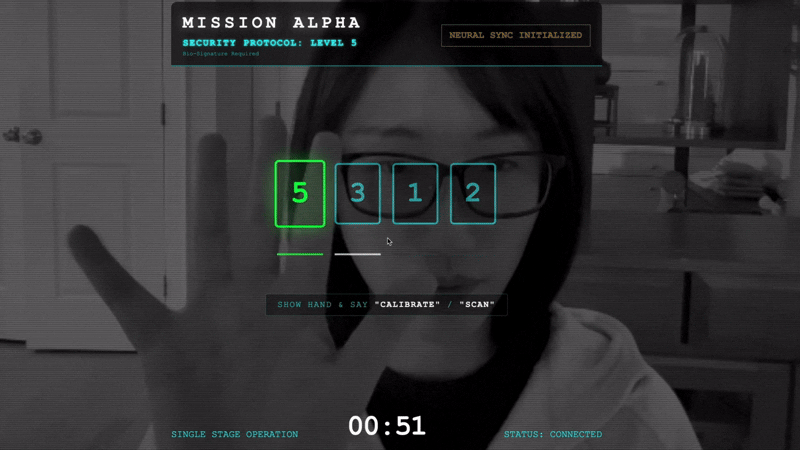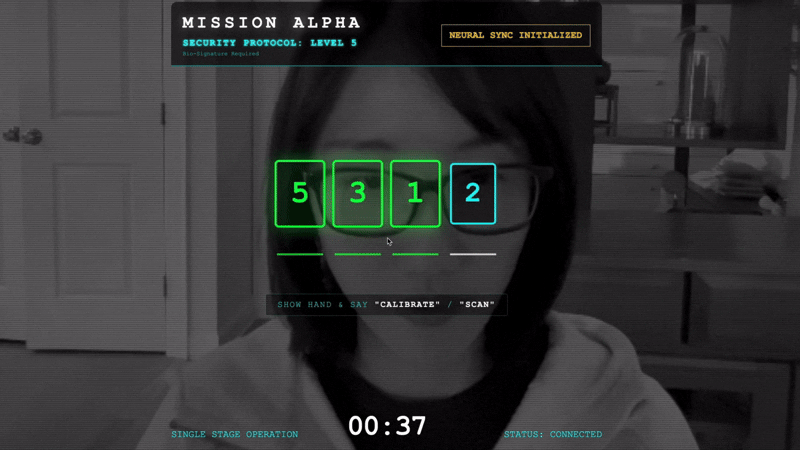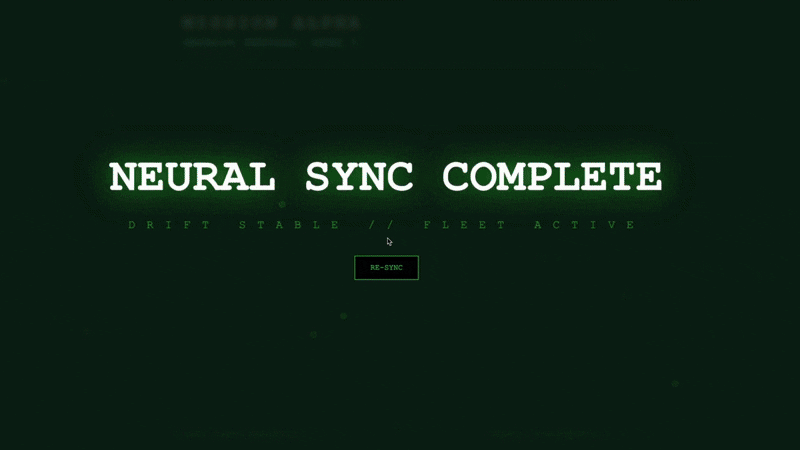
- Điều chỉnh: Đảm bảo camera nhìn thấy rõ bàn tay của bạn trên nền.
- Đồng bộ hoá: Xem Mã bảo mật xuất hiện trên màn hình (ví dụ: 3, sau đó là 2, rồi đến 5).
- So khớp tín hiệu: Khi một số xuất hiện, hãy giơ chính xác số ngón tay đó.
- Giữ chắc: Giữ cho bàn tay của bạn xuất hiện trên màn hình cho đến khi AI xác nhận "Kết quả khớp sinh trắc học".
- Thích ứng: Mã này là ngẫu nhiên. Chuyển ngay sang số tiếp theo xuất hiện cho đến khi hoàn tất chuỗi.

- Khi bạn khớp số cuối cùng trong chuỗi ngẫu nhiên, quá trình "Đồng bộ hoá dữ liệu sinh trắc học" sẽ hoàn tất. Thiết bị liên kết thần kinh sẽ khoá. Bạn có quyền kiểm soát theo cách thủ công. Động cơ của chiếc Scout sẽ gầm rú, lao vào Hẻm núi để đưa những người sống sót về nhà.
👉💻 Nhấn Ctrl+C trong thiết bị đầu cuối phụ trợ để thoát.
6. Triển khai cho kênh phát hành công khai (Không bắt buộc)
Bạn đã kiểm thử thành công dữ liệu sinh trắc học trên thiết bị. Giờ đây, chúng ta phải tải lõi thần kinh của Tác nhân lên các máy tính lớn của tàu (Cloud Run) để nó có thể hoạt động độc lập với bảng điều khiển cục bộ của bạn.
👉💻 Chạy lệnh sau trong cửa sổ dòng lệnh Cloud Shell. Thao tác này sẽ tạo Dockerfile hoàn chỉnh, nhiều giai đoạn trong thư mục phụ trợ của bạn.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 Chuyển đến thư mục phụ trợ và đóng gói ứng dụng vào một hình ảnh vùng chứa.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 Triển khai dịch vụ lên Cloud Run. Chúng ta sẽ chèn các biến môi trường cần thiết (cụ thể là cấu hình Gemini) trực tiếp vào lệnh khởi chạy.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
Sau khi lệnh này hoàn tất, bạn sẽ thấy một URL dịch vụ (ví dụ: https://biometric-scout-...run.app). Giờ đây, ứng dụng đã hoạt động trên đám mây.
👉 Truy cập vào trang Google Cloud Run rồi chọn dịch vụ biometric-scout trong danh sách. 
👉 Tìm URL công khai xuất hiện ở đầu trang thông tin chi tiết Dịch vụ. 
Hãy thử Bio-Sync trong môi trường này, liệu tính năng này có hoạt động không?
Khi ngón tay thứ năm duỗi ra, AI sẽ khoá chuỗi. Màn hình nhấp nháy màu xanh lục: "Biometric Neural Sync: ESTABLISHED" (Đồng bộ hoá sinh trắc học: ĐÃ THIẾT LẬP).
Chỉ với một ý nghĩ, bạn lao chiếc Trinh sát vào bóng tối, bám vào chiếc vỏ bị mắc kẹt và kéo nó ra ngay trước khi vết rách do trọng lực sụp đổ.

Khoang điều áp mở ra, và năm người sống sót đang thở xuất hiện. Họ loạng choạng bước lên boong tàu, bị thương nhưng vẫn còn sống, cuối cùng cũng an toàn nhờ bạn.
Nhờ bạn, mối liên kết thần kinh đã được đồng bộ hoá và những người sống sót đã được giải cứu.
Nếu bạn đã tham gia Cấp độ 0, đừng quên kiểm tra tiến trình của bạn trong nhiệm vụ trên đường về nhà!