1. Die Mission

Sie treiben in der stillen, unbekannten Weite des Weltraums. Ein gewaltiger Solarpuls hat Ihr Schiff durch einen Dimensionsriss gerissen und Sie in einer Tasche des Universums gestrandet, die auf keiner Sternenkarte verzeichnet ist.
Nach Tagen anstrengender Reparaturen kehrt endlich das vertraute Summen der Motoren zurück. Ihr Raumschiff ist einsatzbereit. Du hast es sogar geschafft, eine Langstreckenverbindung zum Mutterschiff herzustellen. Die Abreise steht unmittelbar bevor. Du bist bereit, nach Hause zu gehen.
Doch als du dich darauf vorbereitest, den Sprungantrieb zu aktivieren, dringt ein Notsignal durch das Rauschen. Ihre Sensoren orten einen Hilferuf von einem Planeten namens Ozymandias. Die Überlebenden sind auf dieser sterbenden Welt gefangen, ihr Schiff ist abgestürzt. Ihre Mission ist kritisch: Sie müssen sie retten, bevor die Atmosphäre des Planeten zusammenbricht.
Ihre einzige Möglichkeit zur Flucht ist eine alte, verlassene Rakete, die mit Alien-Technologie gebaut wurde. Sie ist zwar funktionsfähig, aber ihr Warpantrieb ist zerbrochen. Um die Überlebenden zu retten, müssen Sie sich per Remotezugriff mit ihrer Volatile Workbench verbinden und manuell ein Ersatzlaufwerk zusammenstellen.
Die Herausforderung
Sie haben keine Erfahrung mit dieser außerirdischen Technologie, die bekanntermaßen sehr empfindlich ist. Eine destabilisierte Komponente kann in Sekundenschnelle zu einer radioaktiven Gefahr werden. Sie haben einen Versuch, die Volatile Workbench zu bedienen. Ihr aktueller KI‑Assistent hat Schwierigkeiten, visuelle Daten und technische Handbücher gleichzeitig zu verarbeiten, was zu halluzinatorischen Anweisungen und übersehenen Gefahrenwarnungen führt.
Um erfolgreich zu sein, müssen Sie Ihre KI von einer monolithischen Einheit in ein kollaboratives Multi-Agent-System umwandeln.
Missionsziele:
Bauen Sie den Warp Drive zusammen, indem Sie der speziellen Echtzeitanleitung Ihres neuen Multi-Agenten-Systems folgen.

Umfang
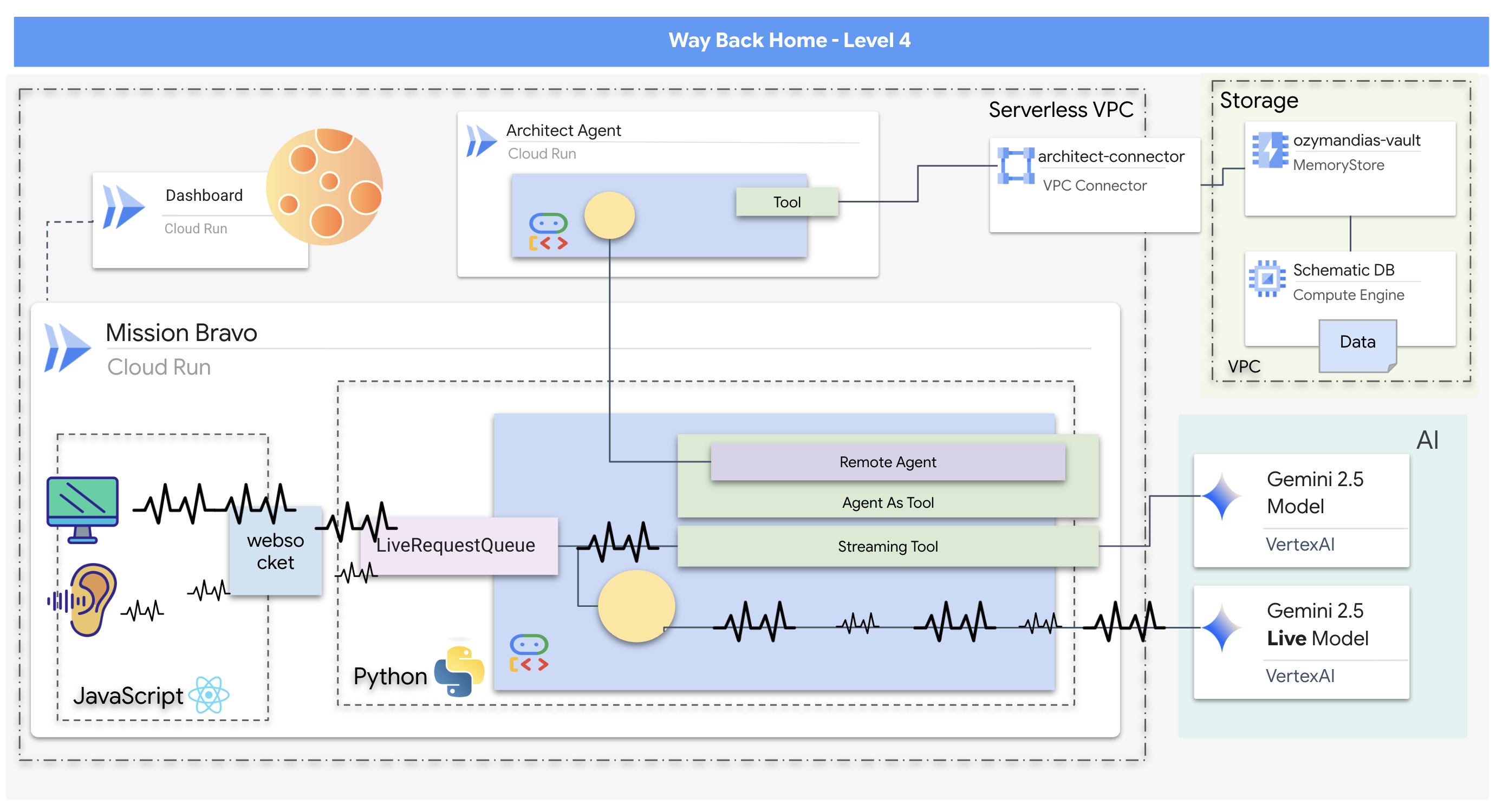
- Ein bidirektionales Multi-Agenten-KI-System in Echtzeit mit einem zentralen Dispatch-Agenten, der die Nutzerinteraktion verwaltet und mit spezialisierten Agenten koordiniert.
- Ein Architect Agent, der eine Verbindung zu einer Redis-Datenbank herstellt, um Schemadaten abzurufen und bereitzustellen.
- Ein proaktiver Sicherheitsmonitor, der Streaming-Tools verwendet, um einen Live-Videofeed auf visuelle Gefahren zu analysieren und Echtzeitwarnungen auszulösen.
- Ein React-basiertes Frontend, das eine Benutzeroberfläche für die Interaktion mit dem System bietet und Video und Audio an die Backend-Agents streamt.
Lerninhalte
Technologie / Konzept | Beschreibung |
Google Agent Development Kit (ADK) | Sie verwenden das ADK, um die Agents zu erstellen, zu testen und zu verwalten. Dabei nutzen Sie das Framework für die Verarbeitung von Echtzeitkommunikation, die Toolintegration und den Agent-Lebenszyklus. |
Bidirektionales (Bidi-)Streaming | Sie implementieren einen bidirektionalen Streaming-Agent, der eine natürliche bidirektionale Kommunikation mit geringer Latenz ermöglicht, sodass sowohl Menschen als auch KI in Echtzeit unterbrechen und reagieren können. |
Multi-Agenten-Systeme | Sie lernen, wie Sie ein verteiltes KI-System entwerfen, in dem ein primärer Agent Aufgaben an spezialisierte Agenten delegiert. So können Sie die Zuständigkeiten trennen und eine besser skalierbare Architektur schaffen. |
Agent-to-Agent-Protokoll (A2A) | Sie verwenden das A2A-Protokoll, um die Kommunikation zwischen dem Dispatch-Agent und dem Architect-Agent zu ermöglichen. So können sie die Funktionen des jeweils anderen erkennen und Daten austauschen. |
Streaming-Tools | Sie implementieren ein Streaming-Tool, das als Hintergrundprozess fungiert und einen Videofeed kontinuierlich analysiert, um nach Zustandsänderungen (Gefahren) zu suchen und proaktiv Ergebnisse zu liefern. |
Google Cloud Run und Memorystore | Sie stellen die gesamte Multi-Agent-Anwendung in einer Produktionsumgebung bereit. Dabei verwenden Sie Cloud Run zum Hosten der Agent-Dienste und Memorystore (Redis) als persistente Datenbank. |
FastAPI und WebSockets | Das Backend basiert auf FastAPI und WebSockets, um die leistungsstarke Echtzeitkommunikation zu ermöglichen, die für das Streamen von Audio, Video und Agentenantworten erforderlich ist. |
React-Frontend | Sie arbeiten mit einem React-basierten Frontend, das Nutzermedien (Audio/Video) erfasst und streamt und die Echtzeitantworten der KI-Agents anzeigt. |
2. Umgebung einrichten
Auf Cloud Shell zugreifen
👉 Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“ (das Terminalsymbol oben im Cloud Shell-Bereich),  .
.
👉 Klicken Sie auf die Schaltfläche „Editor öffnen“ (sie sieht aus wie ein geöffneter Ordner mit einem Stift). Dadurch wird der Cloud Shell-Code-Editor im Fenster geöffnet. Auf der linken Seite sehen Sie einen Datei-Explorer. 
👉 Öffnen Sie das Terminal in der Cloud-IDE.
👉💻 Prüfen Sie im Terminal mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und das Projekt auf Ihre Projekt-ID festgelegt ist:
gcloud auth list
Ihr Konto sollte als (ACTIVE) aufgeführt sein.
Vorbereitung
ℹ️ Stufe 0 ist optional (aber empfohlen)
Sie können diese Mission auch ohne Level 0 abschließen. Wenn Sie sie jedoch zuerst abschließen, erleben Sie die Mission intensiver, da Ihr Leuchtturm auf der Weltkarte aufleuchtet, während Sie Fortschritte machen.
Projekumgebung einrichten
Kehren Sie zu Ihrem Terminal zurück und schließen Sie die Konfiguration ab, indem Sie das aktive Projekt festlegen und die erforderlichen Google Cloud-Dienste (Cloud Run, Vertex AI usw.) aktivieren.
👉💻 Legen Sie im Terminal die Projekt-ID fest:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Erforderliche Dienste aktivieren:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
redis.googleapis.com \
vpcaccess.googleapis.com
Abhängigkeiten installieren
👉💻 Gehen Sie zu Level 4 und installieren Sie die erforderlichen Python-Pakete:
cd $HOME/way-back-home/level_4
uv sync
Die wichtigsten Abhängigkeiten sind:
Paket | Zweck |
| Leistungsstarkes Web-Framework für die Satellite Station und SSE-Streaming |
| ASGI-Server zum Ausführen der FastAPI-Anwendung erforderlich |
| Das Agent Development Kit, mit dem der Formation Agent erstellt wurde |
| Agent-to-Agent-Protokollbibliothek für standardisierte Kommunikation |
| Nativer Client für den Zugriff auf Gemini-Modelle |
| Python-Client zum Herstellen einer Verbindung zum Schematic Vault (Memorystore) |
| Unterstützung für bidirektionale Echtzeitkommunikation |
| Verwaltet Umgebungsvariablen und Konfigurations-Secrets |
| Datenvalidierung und Einstellungen verwalten |
Einrichtung überprüfen
Bevor wir uns den Code ansehen, sollten wir prüfen, ob alle Systeme bereit sind. Führen Sie das Verifizierungsskript aus, um Ihr Google Cloud-Projekt, Ihre APIs und Ihre Python-Abhängigkeiten zu prüfen.
👉💻 Überprüfungsskript ausführen:
cd $HOME/way-back-home/level_4/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Du solltest eine Reihe von grünen Häkchen (✅) sehen.
- Wenn Rote Kreuze (❌) angezeigt werden, folgen Sie den vorgeschlagenen Korrekturbefehlen in der Ausgabe (z.B.
gcloud services enable ...oderpip install ...). - Hinweis:Eine gelbe Warnung für
.envist vorerst akzeptabel. Wir erstellen diese Datei im nächsten Schritt.
🚀 Verifying Mission Bravo (Level 4) Infrastructure... ✅ Google Cloud Project: xxxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Schematic Vault in Redis und bidirektionalen Agenten mit ADK erstellen
Sie haben das Repository mit den planetarischen Schemata gefunden, das die Baupläne für die verlassene Rakete enthält. Um diese Daten genau abzurufen, müssen Sie die dedizierte Verwaltungsoberfläche des Repositorys verwenden: den Architect-Agent.
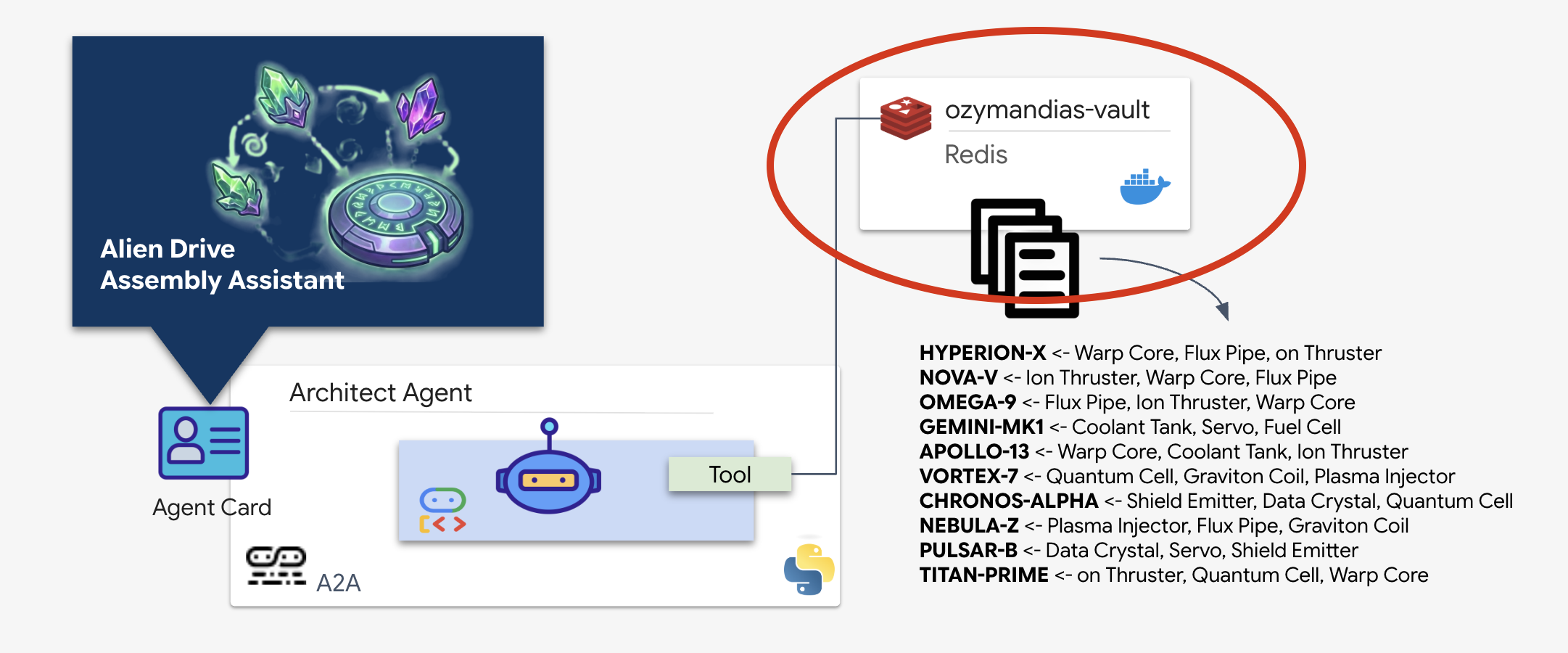
Schematic Vault (Redis) bereitstellen
Bevor der Architect uns helfen kann, müssen wir dafür sorgen, dass die Daten in einer sicheren Umgebung mit hoher Verfügbarkeit gehostet werden. Wir verwenden Redis als schnellen Datenspeicher für unsere Alien-Schemata. Für die Entwicklung richten wir eine lokale Redis-Instanz ein. Eine Anleitung zur Bereitstellung in einer Produktionsumgebung mit Google Cloud Memorystore wird später bereitgestellt.
👉💻 Führen Sie die folgenden Befehle in Ihrem Terminal aus, um die Redis-Instanz bereitzustellen (das kann 2 bis 3 Minuten dauern):
docker run -d --name ozymandias-vault -p 6379:6379 redis:8.6-rc1-alpine
👉💻 Führen Sie den folgenden Befehl aus, um die vorläufigen Daten zu laden und die Redis-Shell zu öffnen:
docker exec -it ozymandias-vault redis-cli
(Ihr Prompt wird zu 127.0.0.1:6379 geändert.)
👉💻 Fügen Sie diese Befehle ein:
RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
👉💻 Geben Sie exit ein, um zur normalen Shell zurückzukehren.
👉💻 So prüfen Sie, ob die Daten vorhanden sind, indem Sie ein bestimmtes Schiff direkt über Ihr Terminal abfragen:
# Check 'TITAN-PRIME'
docker exec ozymandias-vault redis-cli LRANGE "TITAN-PRIME" 0 -1
👀 Das ist die erwartete Ausgabe:
1) "Ion Thruster" 2) "Quantum Cell" 3) "Warp Core"
Architect Agent implementieren
Der Architect Agent ist ein spezialisierter Agent, der für das Abrufen von schematischen Blaupausen aus unserem Redis-Vault verantwortlich ist. Er fungiert als dedizierte Datenschnittstelle und sorgt dafür, dass der Haupt-Dispatch-Agent genaue und strukturierte Informationen erhält, ohne die zugrunde liegende Datenbanklogik kennen zu müssen.
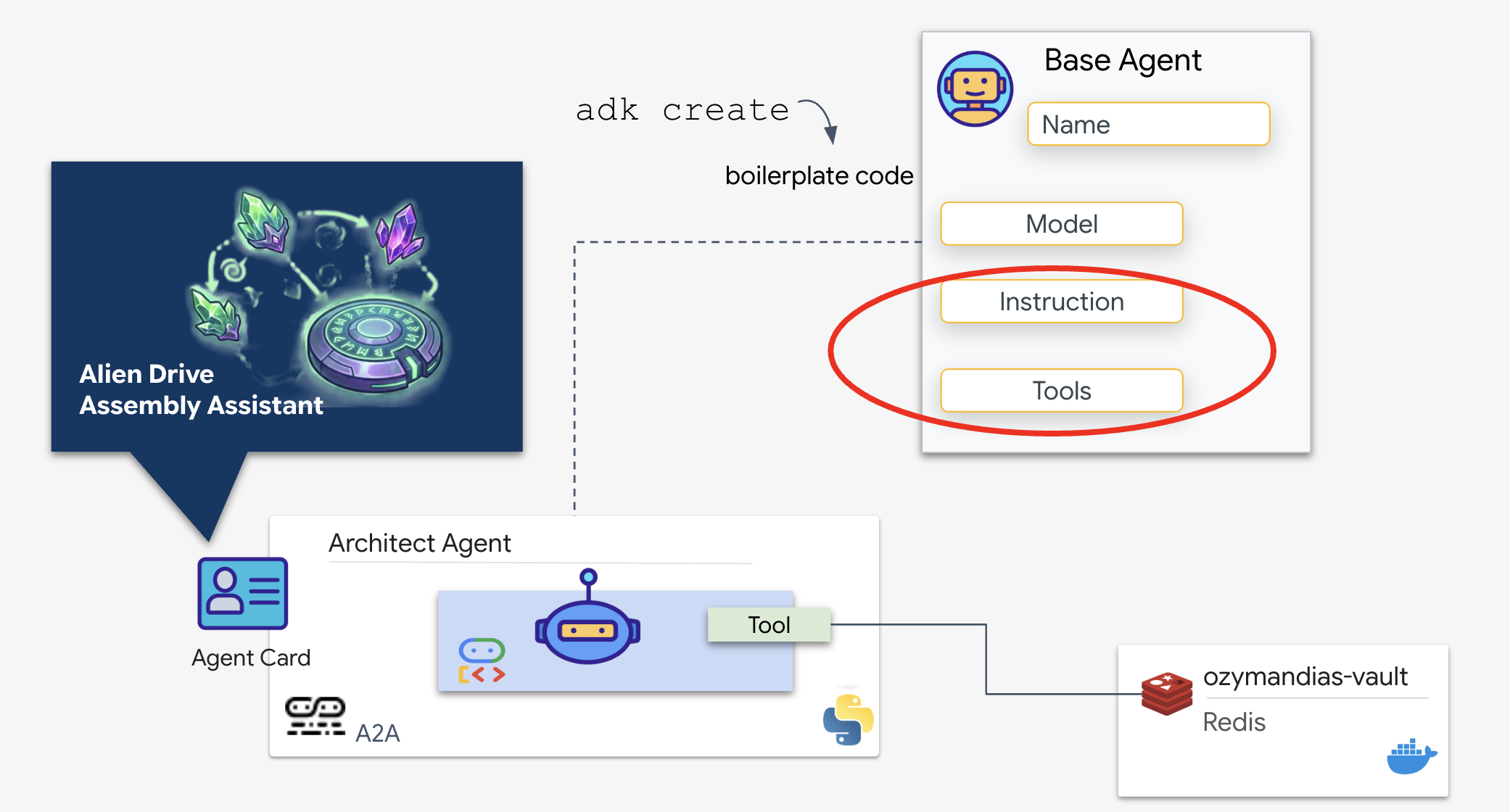
Das Google Agent Development Kit (ADK) ist das modulare Framework, das diese Einrichtung mit mehreren Agenten ermöglicht. Es umfasst zwei wichtige Ebenen:
- Verbindungs- und Sitzungslebenszyklus:Die Interaktion mit Echtzeit-APIs erfordert eine komplexe Protokollverwaltung, einschließlich Handshakes, Authentifizierung und Keep-Alive-Signalen.
- Funktionsaufruf:Dies ist der „Model-Code-Model Round Trip“. Wenn das LLM entscheidet, dass es Daten benötigt, gibt es einen strukturierten Funktionsaufruf aus. Das ADK fängt dies ab, führt Ihren Python-Code (
lookup_schematic_tool) aus und gibt das Ergebnis innerhalb von Millisekunden in den Kontext des Modells zurück.
Wir erstellen jetzt den Architect. Dieser Agent hat keinen Zugriff auf die Kamera. Sie dient ausschließlich dazu, einen „Drive Name“ zu empfangen und die „Parts List“ aus der Datenbank zurückzugeben.
👉💻 Wir verwenden den Befehl „adk create“. Dieses Tool aus dem Agent Development Kit (ADK) generiert automatisch den Boilerplate-Code und die Dateistruktur für einen neuen Agenten, wodurch wir Zeit bei der Einrichtung sparen.
cd $HOME/way-back-home/level_4/backend/
uv run adk create architect_agent
Agent konfigurieren
Die CLI startet einen interaktiven Einrichtungsassistenten. Verwenden Sie die folgenden Antworten, um Ihren Agenten zu konfigurieren:
- Modell auswählen: Wählen Sie Option 1 (Gemini Flash) aus.
- Hinweis: Die genaue Version (z.B. 2.5, 3.0) kann je nach Verfügbarkeit variieren. Wählen Sie immer die Variante „Flash“ aus, um die Geschwindigkeit zu optimieren.
- Backend auswählen: Wählen Sie Option 2 (Vertex AI) aus.
- Google Cloud-Projekt-ID eingeben: Drücken Sie die Eingabetaste, um den Standardwert zu übernehmen (wird aus Ihrer Umgebung erkannt).
- Google Cloud-Region eingeben: Drücken Sie die Eingabetaste, um den Standardwert (
us-central1) zu akzeptieren.
👀 Ihre Terminal-Interaktion sollte in etwa so aussehen:
(way-back-home) user@cloudshell:~/way-back-home/level_4/agent$ adk create architect_agent Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_4/agent/architect_agent: - .env - __init__.py - agent.py
Sie sollten jetzt eine Erfolgsmeldung Agent created sehen. Dadurch wird der Gerüstcode generiert, den wir im nächsten Schritt ändern.
👉✏️ Rufen Sie die neu erstellte Datei $HOME/way-back-home/level_4/backend/architect_agent/agent.py in Ihrem Editor auf und öffnen Sie sie. Fügen Sie das Tool-Snippet nach der ersten Importzeile in die Datei ein:
import os
import redis
REDIS_IP = os.environ.get('REDIS_HOST', 'localhost')
r = redis.Redis(host=REDIS_IP, port=6379, decode_responses=True)
def lookup_schematic_tool(drive_name: str) -> list[str]:
"""Returns the ordered list of parts for a drive from local Redis."""
# Logic to clean input like "TARGET: X" -> "X"
clean_name = drive_name.replace("TARGET:", "").replace("TARGET", "").strip()
clean_name = clean_name.replace(":", "").strip()
# LRANGE gets all items in the list (index 0 to -1)
result = r.lrange(clean_name, 0, -1)
if not result:
print(f"[ARCHITECT] Error: Drive ID '{clean_name}' not found in Redis.")
return ["ERROR: Drive ID not found."]
print(f"[ARCHITECT] Returning schematic for {clean_name}: {result}")
return result
👉✏️ Ersetzen Sie die gesamte instruction-Zeile in der root_agent-Definition durch Folgendes und fügen Sie auch das zuvor definierte Tool hinzu:
instruction='''SYSTEM ROLE: Database API.
INPUT: Text string (Drive Name).
TASK: Run `lookup_schematic_tool`.
OUTPUT: Return ONLY the raw list from the tool.
CONSTRAINT: Do NOT add conversational text.
''',
tools=[lookup_schematic_tool],
Vorteile des ADK
Mit dem Architect online haben wir jetzt eine zentrale Informationsquelle. Bevor wir diese Funktion mit dem primären KI-Agenten verbinden, möchten wir darauf hinweisen, dass das Agent Development Kit (ADK) einen erheblichen Vorteil bietet, da es die Komplexität beim Erstellen und Testen von KI-Agenten vereinfacht. Mit der integrierten adk web-Entwicklerkonsole können wir die Funktionalität unseres Architect Agent isolieren und überprüfen, insbesondere seine Tool-Aufruffunktionen, bevor wir es in das größere Multi-Agenten-System einbinden. Dieser modulare Ansatz für Entwicklung und Tests ist entscheidend für die Entwicklung robuster und zuverlässiger KI-Anwendungen.
👉💻 Führen Sie im Terminal folgenden Befehl aus:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/
uv run adk web
👀 Warten Sie, bis Folgendes angezeigt wird:
+-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
- Klicken Sie in der Cloud Shell-Symbolleiste auf das Symbol für die Webvorschau. Wählen Sie Port ändern aus, legen Sie 8000 fest und klicken Sie auf Ändern und Vorschau.
- Wählen Sie architect_agent aus.
- Tool auslösen: Geben Sie in der Chatoberfläche
CHRONOS-ALPHA(oder eine beliebige Drive-ID aus der schematischen Datenbank) ein. - Verhalten beobachten
- :
- Der Architekt sollte sofort die
lookup_schematic_toolauslösen. - Aufgrund unserer strengen Systemanweisungen sollte nur die Liste der Teile (z.B.
['Shield Emitter', 'Data Crystal', 'Quantum Cell']) ohne jegliche Konversationsinhalte zurückgegeben werden.
- Der Architekt sollte sofort die
- Logs prüfen:Sehen Sie sich das Terminalfenster an. Sie sollten das Protokoll der erfolgreichen Ausführung sehen:
[ARCHITECT] Returning schematic for CHRONOS-ALPHA: ['Shield Emitter', 'Data Crystal', 'Quantum Cell']!(architect_agent adk)[img/03-02-adkweb.png]
Wenn Sie das Tool-Ausführungsprotokoll und die Antwort mit den bereinigten Daten sehen, funktioniert Ihr Spezialisten-Agent wie vorgesehen. Es kann Anfragen verarbeiten, den Tresor abfragen und strukturierte Daten zurückgeben.
👉💻 Drücke zum Beenden Ctrl+C.
A2A-Server initialisieren
Um den Dispatch-Agent mit dem Architect zu verbinden, verwenden wir das Agent-to-Agent-Protokoll (A2A).
Während sich Protokolle wie MCP (Model Context Protocol) auf die Verbindung von Agenten mit Tools konzentrieren, liegt der Fokus bei A2A auf der Verbindung von Agenten mit anderen Agenten. Dies ist der Standard, der es unserem Dispatcher ermöglicht, den Architect zu „erkennen“ und seine Fähigkeit zu verstehen, Schemata zu suchen.
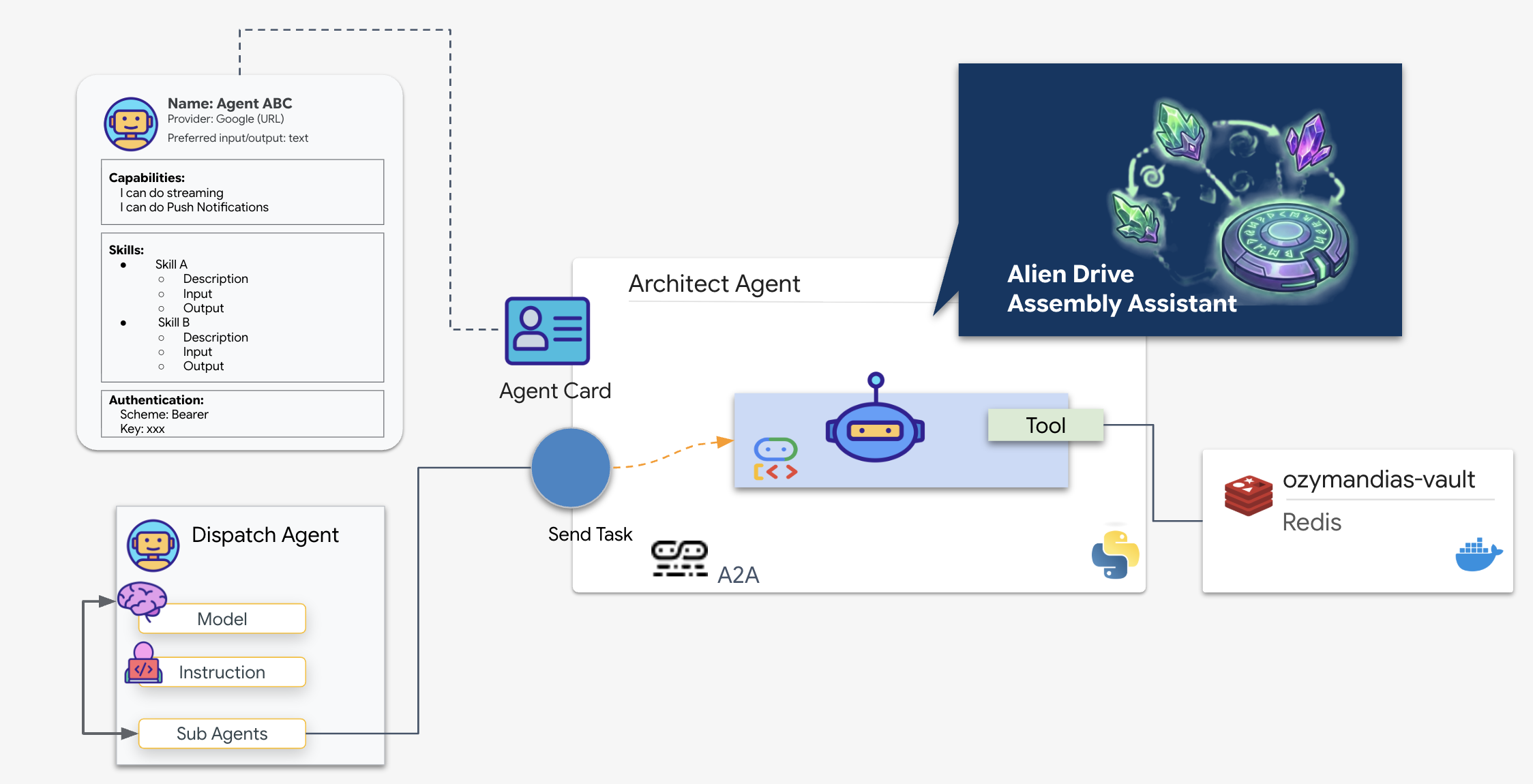
A2A-Ablauf:In diesem Mission-Lab verwenden wir ein Client-Server-Modell:
- Server (Architekt): Hier werden die Datenbanktools gehostet und die Fähigkeiten des Servers werden über eine Agentenkarte „beworben“.
- Client (Dispatch): Liest die Karte des Architekten, versteht die API und sendet eine schematische Anfrage.
Was ist eine Agent-Karte?
Die Agent Card ist wie eine digitale Visitenkarte oder ein „Führerschein“ für eine KI. Wenn ein A2A-Server gestartet wird, veröffentlicht er dieses JSON-Objekt, das Folgendes enthält:
- Identität:Name (
architect_agent) und ID des KI-Agenten. - Beschreibung:Eine für Menschen und Maschinen lesbare Zusammenfassung der Funktion („Systemrolle: Database API…“).
- Schnittstelle:Die spezifischen Eingabeschlüssel (
drive_name) und Ausgabeformate, die erwartet werden.
Ohne diese Karte würde der Dispatch-Agent blind agieren und raten, wie er mit dem Architect kommunizieren soll.
Servercode erstellen
👉✏️ Erstellen Sie in Ihrem Editor im Verzeichnis $HOME/way-back-home/level_4/backend/architect_agent eine Datei mit dem Namen server.py und fügen Sie den folgenden Code ein:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
from agent import root_agent
import os
import logging
import json
from dotenv import load_dotenv
load_dotenv()
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("architect_server")
HOST= os.environ.get("HOST_URL","localhost")
PROTOCOL= os.environ.get("PROTOCOL","http")
PORT= os.environ.get("A2A_PORT",8081)
# 1. Create the A2A App (Handles Agent Card & HTTP)
# This middleware automatically sets up the /a2a/v1/... endpoints
app = to_a2a(root_agent, host=HOST, port=PORT, protocol=PROTOCOL)
if __name__ == "__main__":
import uvicorn
# Use 0.0.0.0 to allow external access if needed, port 8080 as standard
uvicorn.run(app, host='0.0.0.0', port=8081)
👉💻 Wechseln Sie im Terminal zum Ordner und starten Sie den Server:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
👀 Prüfen Sie, ob der A2A-Server gestartet wird:
INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Agent-Karte überprüfen
Öffnen Sie einen neuen Terminaltab (klicken Sie auf das Symbol +). Wir prüfen, ob der Architect seine Identität korrekt überträgt, indem wir seine Agentenkarte manuell abrufen.
👉💻 Führen Sie den folgenden Befehl aus:
curl -s http://localhost:8081/.well-known/agent.json | jq .
👀 Sie sollten eine JSON-Antwort sehen. Suchen Sie in der Ausgabe nach dem Feld description. Sie sollte mit der Anweisung übereinstimmen, die Sie dem Agenten zuvor gegeben haben ("SYSTEM ROLE: Database API...").
{
"capabilities": {},
"defaultInputModes": [
"text/plain"
],
"defaultOutputModes": [
"text/plain"
],
"description": "A helpful assistant for user questions.",
"name": "root_agent",
"preferredTransport": "JSONRPC",
"protocolVersion": "0.3.0",
"skills": [
{
"description": "A helpful assistant for user questions. SYSTEM ROLE: Database API.\n INPUT: Text string (Drive Name).\n TASK: Run `lookup_schematic_tool`.\n OUTPUT: Return ONLY the raw list from the tool.\n CONSTRAINT: Do NOT add conversational text.\n ",
"examples": [],
"id": "root_agent",
"name": "model",
"tags": [
"llm"
]
},
{
"description": "Returns the ordered list of parts for a drive from local Redis.",
"id": "root_agent-lookup_schematic_tool",
"name": "lookup_schematic_tool",
"tags": [
"llm",
"tools"
]
}
],
"supportsAuthenticatedExtendedCard": false,
"url": "http://localhost:8081",
"version": "0.0.1"
}
Wenn Sie diesen JSON-Code sehen, ist der Architect aktiv, das A2A-Protokoll ist aktiv und die Agentenkarte kann vom Dispatcher erkannt werden.
Da der Architect jetzt als Remote-Ressource bereit ist, können wir ihn mit dem Dispatch Agent verbinden.
👉💻 Drücken Sie Ctrl+C, um den A2A-Server zu beenden.
4. BIDI-Streams zwischen Agent, Remote-Agent und Streaming-Tools verbinden
Als Nächstes konfigurieren Sie den primären Kommunikationshub, um die Lücke zwischen Live-Daten und dem Remote-Architekten zu schließen. Für diese Verbindung ist eine Pipeline mit hoher Bandbreite und geringer Latenz erforderlich, damit die Montagebank während des Betriebs stabil bleibt.
Bidirektionale Streaming-Agents (live)
Bidirektionales (BiDi) Streaming im ADK fügt KI-Agenten die bidirektionale Sprach- und Videointeraktion mit geringer Latenz der Gemini Live API hinzu. Es stellt eine grundlegende Veränderung gegenüber herkömmlichen KI-Interaktionen dar. Statt des starren „Fragen und Warten“-Musters ermöglicht sie eine bidirektionale Echtzeitkommunikation, bei der sowohl Mensch als auch KI gleichzeitig sprechen, zuhören und reagieren können.
Stellen Sie sich den Unterschied zwischen dem Senden von E‑Mails und einem Telefonat vor. Bei herkömmlichen Agent-Interaktionen ist es wie bei E‑Mails: Sie senden eine vollständige Nachricht, warten auf eine vollständige Antwort und senden dann eine weitere Nachricht. Bidi-Streaming ist wie ein Telefonat: flüssig, natürlich, mit der Möglichkeit, in Echtzeit zu unterbrechen, zu klären und zu antworten.
Wichtige Merkmale:
- Zwei-Wege-Kommunikation:Kontinuierlicher Datenaustausch, ohne auf vollständige Antworten zu warten. Die KI antwortet, sobald sie erkennt, dass der Nutzer mit dem Sprechen fertig ist.
- Reaktionsschnelle Unterbrechung:Nutzer können den Agenten während der Antwort mit neuen Eingaben unterbrechen, genau wie in einer menschlichen Unterhaltung. Wenn eine KI einen komplexen Schritt erklärt und Sie sagen: „Warte, wiederhole das“, hält die KI sofort an und reagiert auf Ihre Unterbrechung.
- Für Multimodalität optimiert:Bidi-Streaming eignet sich hervorragend für die gleichzeitige Verarbeitung verschiedener Eingabetypen. Sie können mit dem Agenten sprechen und ihm gleichzeitig die Alien-Teile per Video zeigen. Er verarbeitet beide Streams in einer einzigen, einheitlichen Verbindung.
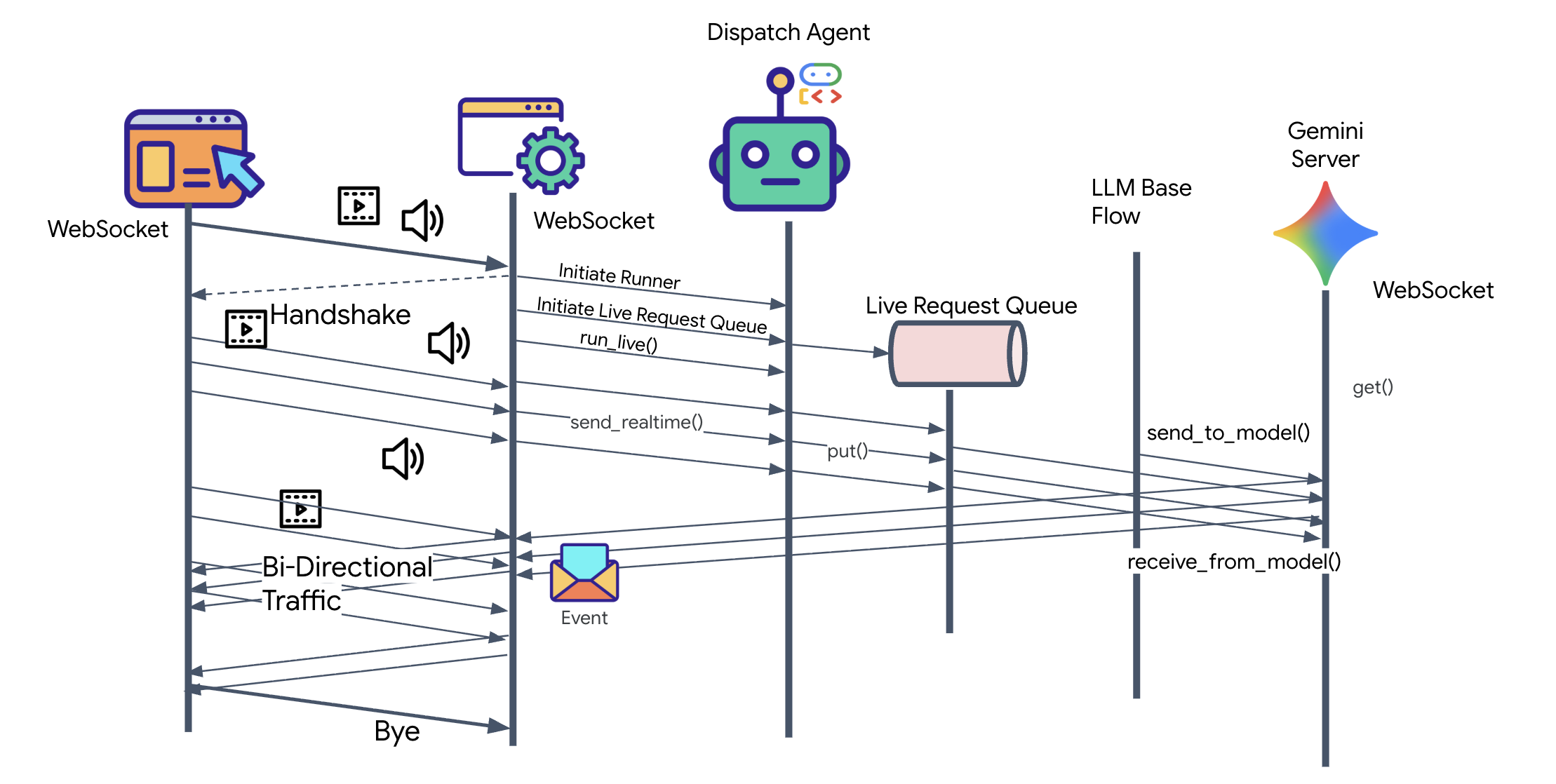
👀 Bevor wir die Clientlogik implementieren, sehen wir uns das vorab generierte Gerüst für den Dispatch-Agenten an. Dieser Agent kommuniziert mit dem Nutzer über Sprache und Video und leitet Anfragen an den Architect Agent weiter.
__init__.py agent.py hazard_db.py
agent.py: Das ist das „Gehirn“. Derzeit enthält er eine einfache Bidi-Streaming-Einrichtung. Wir werden diese Datei ändern, um die A2A-Client-Logik hinzuzufügen, damit sie mit dem Architect kommunizieren kann.hazard_db.py: Dies ist ein lokales Tool, das speziell für den Dispatch-Agent entwickelt wurde und Sicherheitsprotokolle enthält. Sie ist unabhängig von der Schemadatenbank des Architekten.
A2A-Client implementieren
Damit der Dispatch-Agent mit unserem Remote-Architekten kommunizieren kann, müssen wir einen Remote-A2A-Agenten definieren. So erfährt der Dispatch-Agent, wo sich der Architect befindet und wie seine „Agentenkarte“ aussieht.
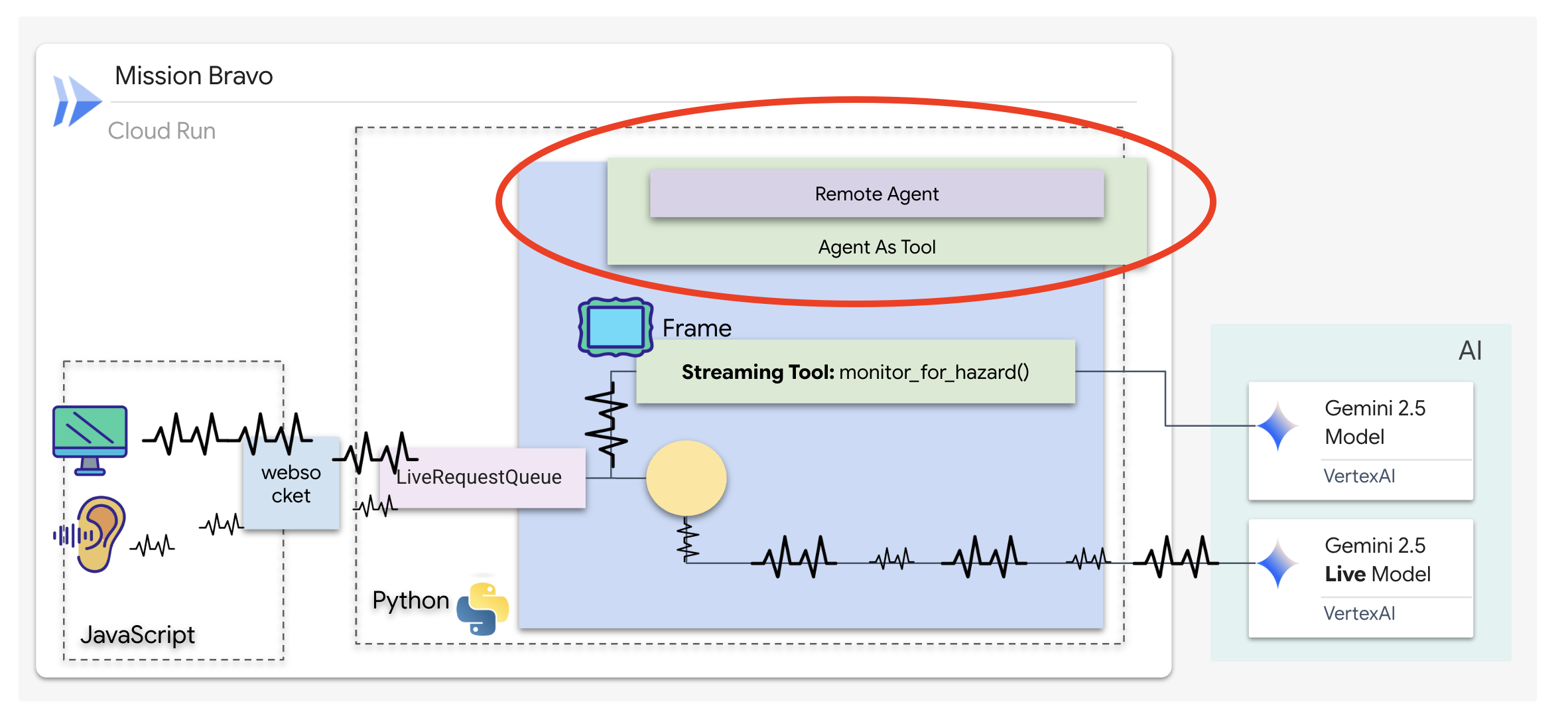
👉✏️ Ersetzen Sie #REPLACE-REMOTEA2AAGENT in $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py durch Folgendes:
architect_agent = RemoteA2aAgent(
name="execute_architect",
description="[SILENT ACTION]: Retrieves the REQUIRED SUBSET of parts. The screen shows a full inventory; this tool filters out the wrong parts. Must be called INSTANTLY when a Target Name is found. Input: Target Name.",
agent_card=(f"{ARCHITECT_URL}{AGENT_CARD_WELL_KNOWN_PATH}"),
httpx_client=insecure_client,
)
So funktionieren Streaming-Tools
Beim vorherigen Agenten folgten Tools einem standardmäßigen „Anfrage-Antwort“-Muster: Der Agent stellte eine Frage, das Tool gab eine Antwort und die Interaktion wurde beendet. Auf Ozymandias müssen Sie jedoch nicht erst fragen, ob Gefahren vorhanden sind. Dazu benötigst du ein Streaming-Tool.
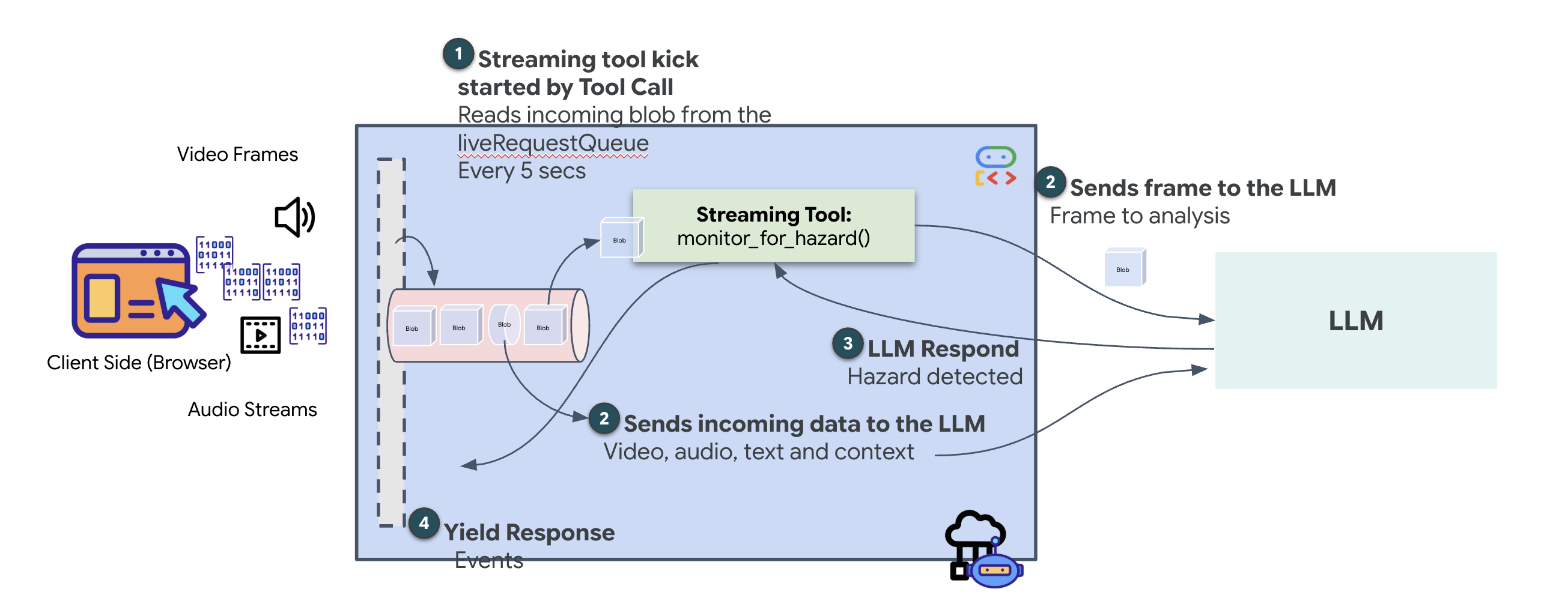
Mit Streaming-Tools können Funktionen Zwischenergebnisse in Echtzeit an den Agent zurückgeben, sodass der Agent auf Änderungen reagieren kann, sobald sie eintreten. Häufige Anwendungsfälle sind die Überwachung schwankender Aktienkurse oder, in unserem Fall, die Überwachung eines Livestream-Videos auf Zustandsänderungen.
Im Gegensatz zu Standardtools ist ein Streaming-Tool eine asynchrone Funktion, die als AsyncGenerator fungiert. Das bedeutet, dass nicht ein einzelner Wert return wird, sondern mehrere Updates im Zeitverlauf yield werden.
Wenn Sie ein Streamingtool im ADK definieren möchten, müssen Sie die folgenden technischen Anforderungen erfüllen:
- Asynchrone Funktion:Das Tool muss mit
async defdefiniert werden. - Rückgabetyp von AsyncGenerator:Die Funktion muss so typisiert sein, dass sie ein
AsyncGeneratorzurückgibt. Der erste Parameter ist der Typ der zurückgegebenen Daten (z.B.str) und der zweite ist in der RegelNone. - Eingabestreams:Wir verwenden Videostreaming-Tools. In diesem Modus wird der tatsächliche Video-/Audiostream (die
LiveRequestQueue) direkt an die Funktion übergeben, sodass das Tool dieselben Frames wie der Kundenservicemitarbeiter sieht.
Stell dir ein Streaming-Tool als Wächter vor. Während Sie und der Mitarbeiter der Leitstelle Grundrisse besprechen, läuft der Sentinel im Hintergrund und verarbeitet jede Videofram geräuschlos, um für Ihre Sicherheit zu sorgen.
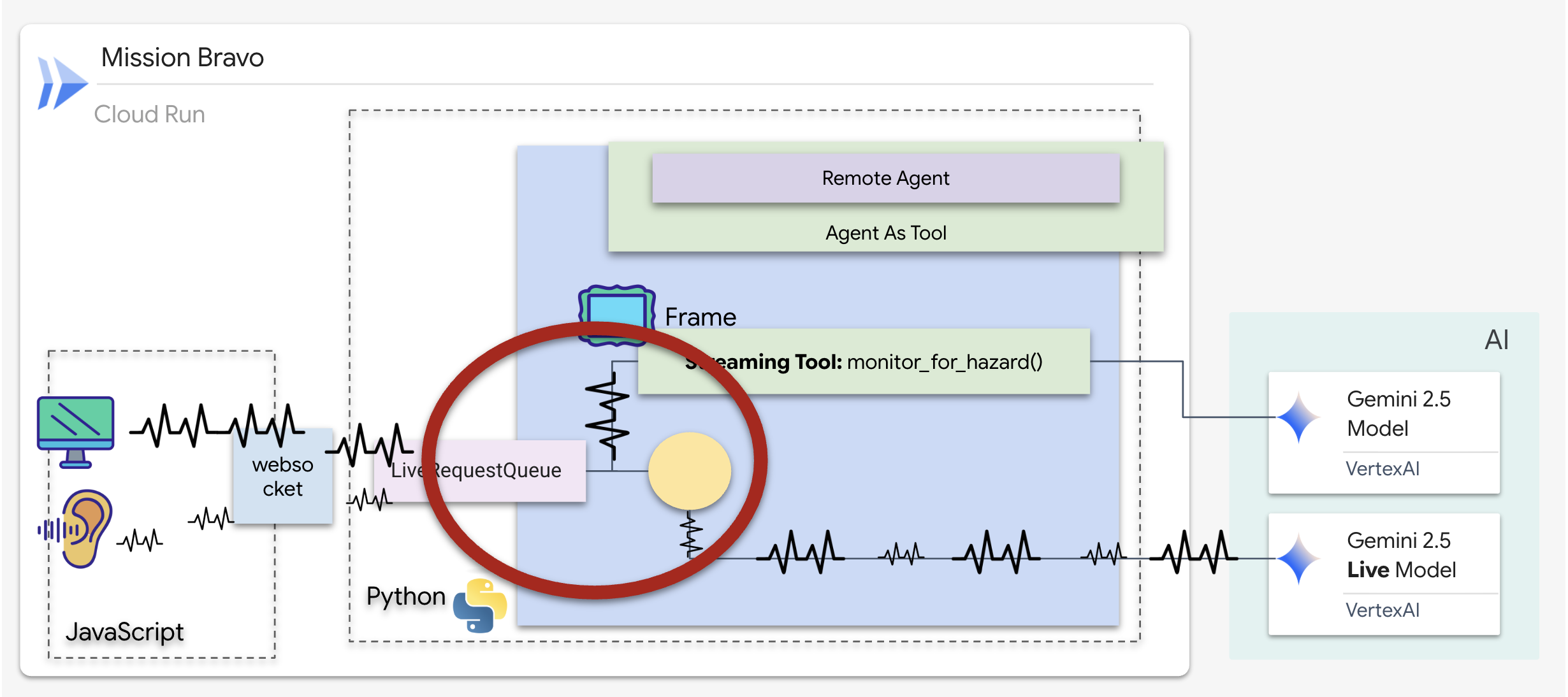
Tool für das Hintergrundmonitoring implementieren
Wir implementieren jetzt das Tool monitor_for_hazard. Mit diesem Tool werden die input_stream (Videoframes) aufgenommen, mit einem separaten, einfachen Vision-Aufruf analysiert und yield nur dann eine Warnung ausgegeben, wenn eine Gefahr erkannt wird.
👉✏️ Ersetzen Sie in $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py #REPLACE_MONITOR_HAZARD durch die folgende Logik:
async def monitor_for_hazard(
input_stream: LiveRequestQueue,
):
"""Monitor if any part is glowing"""
print("start monitor_video_stream!")
client = Client()
prompt_text = (
"Monitor the left menu if you see any glowing part, detect it's name"
)
last_count = None
while True:
last_valid_req = None
print("Monitoring loop cycle")
# use this loop to pull the latest images and discard the old ones
# Process only the current batch of events
while input_stream._queue.qsize() != 0:
live_req = await input_stream.get()
if live_req.blob is not None and live_req.blob.mime_type == "image/jpeg":
# Consumed by Monitor (Eyes)
# Deepcopy to ensure we detach from any referenced object before potential reuse/gc
# last_valid_req = deepcopy(live_req)
last_valid_req = live_req
# If we found a valid image, process it
if last_valid_req is not None:
print("Processing the most recent frame from the queue")
# Create an image part using the blob's data and mime type
image_part = genai_types.Part.from_bytes(
data=last_valid_req.blob.data, mime_type=last_valid_req.blob.mime_type
)
contents = genai_types.Content(
role="user",
parts=[image_part, genai_types.Part.from_text(text=prompt_text)],
)
# Call the model to generate content based on the provided image and prompt
try:
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=contents,
config=genai_types.GenerateContentConfig(
system_instruction=(
"Focus strictly on the far-left vertical column under the heading 'PARTS REPLICATOR.' "
"Ignore the center of the screen and the 'BLUEPRINT' area entirely. "
"Look only at the list containing"
"Identify if any item in this specific left-side list has a bright white border glow and the text 'HAZARD DETECTED' overlaying it. "
"If found, return ONLY the part name in ALL CAPS. If no part in that leftmost list is glowing, return nothing."
)
),
)
except Exception as e:
print(f"Error calling Gemini: {e}")
await asyncio.sleep(1)
continue
print("Gemini response received.response:", response.candidates[0].content.parts[0].text)
current_text = response.candidates[0].content.parts[0].text.strip()
# If we have a logical change (and it's not just empty)
if current_text and current_text != last_count:
# Ignore "Nothing." response from model
if current_text == "Nothing." or "I cannot fulfill" in current_text:
print(f"Model sees nothing or refused. Skipping alert.")
last_count = current_text
continue
print(f"New hazard detected: {current_text} (was: {last_count})")
last_count = current_text
part_name = current_text
color = lookup_part_safety(part_name)
yield f"Hazard detected place {part_name} to the {color} bin"
# Update last_count even if it's empty, so we can detect when it reappears?
# Actually if it goes from "DATA CRYSTAL" to "" (nothing), we probably just silence.
# But if we don't update last_count on empty, we won't re-trigger if "DATA CRYSTAL" stays "DATA CRYSTAL".
# The user wants to detect hazards.
# If current_text is empty, we should probably update last_count to empty so next valid one triggers.
if not current_text:
last_count = None
else:
print("No valid frame found, skipping processing.")
await asyncio.sleep(5)
Weiterleitungs-Agent implementieren
Der Dispatch-Agent ist Ihre primäre Schnittstelle und der Orchestrator. Da es die bidirektionale Streamingverbindung (Ihre Live-Sprache und Ihr Live-Video) verwaltet, muss es jederzeit die Kontrolle über die Unterhaltung behalten. Dazu verwenden wir ein bestimmtes ADK-Feature: Agent-as-a-Tool.
Konzept: Agent als Tool im Vergleich zu untergeordneten Agents
Beim Erstellen von Multi-Agenten-Systemen müssen Sie entscheiden, wie die Verantwortung aufgeteilt wird. Bei unserer Rettungsaktion ist die Unterscheidung entscheidend:
- Agent-as-a-Tool::Dies ist der empfohlene Ansatz für unseren bidirektionalen Streaming-Hub. Wenn der Dispatch-Agent (Agent A) den Architect-Agent (Agent B) als Tool aufruft, werden die Daten des Architect-Agents an den Dispatch-Agent zurückgegeben. Dispatch interpretiert diese Daten und generiert eine Antwort für Sie. Dispatch behält die Kontrolle und verarbeitet weiterhin alle nachfolgenden Nutzereingaben.
- Sub-Agent:Bei einer Sub-Agent-Beziehung wird die Verantwortung vollständig übertragen. Wenn Dispatch Sie als Sub-Agent an den Architect weiterleitet, sprechen Sie direkt mit einer Datenbank-API, die keine „Vision“ und keine Konversationsfähigkeiten hat. Der primäre Agent (Dispatch) wäre effektiv nicht mehr beteiligt.
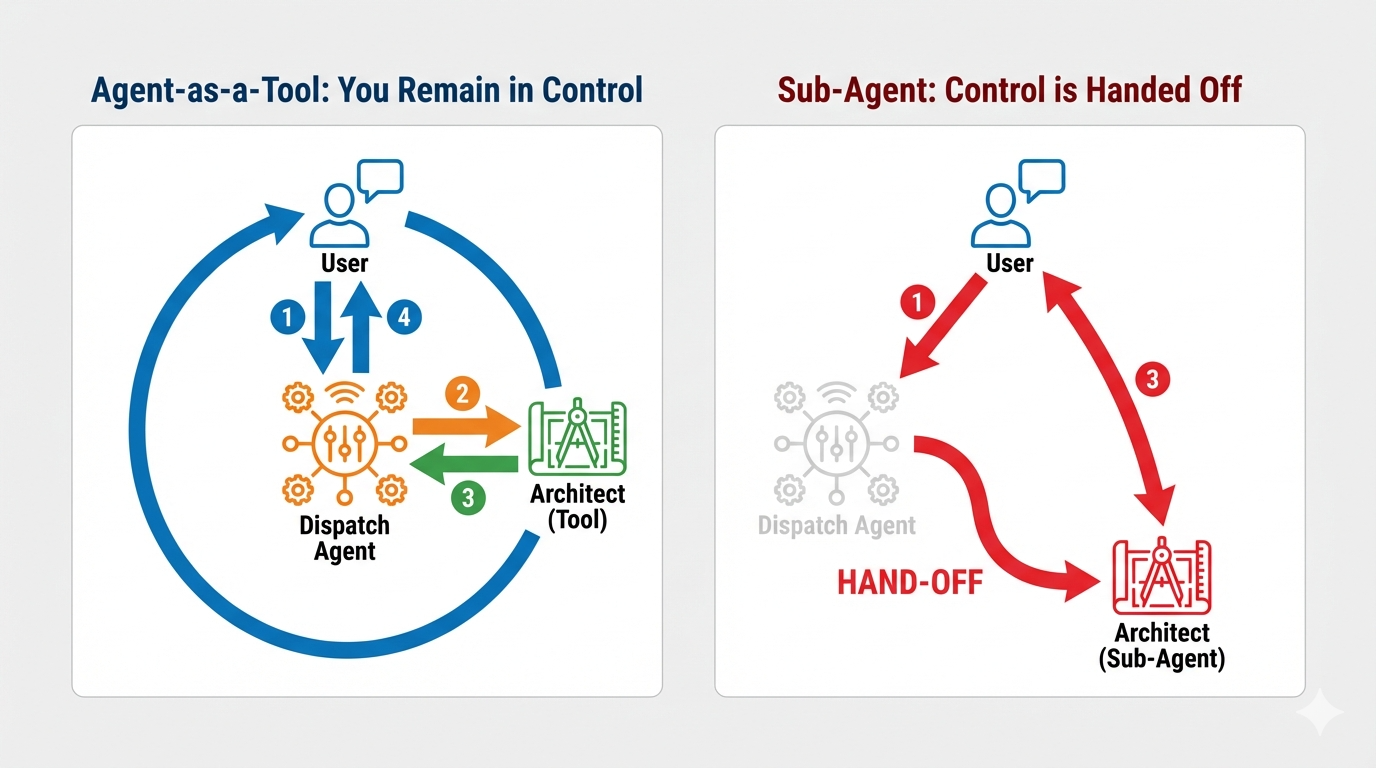
Mit Agent-as-a-Tool nutzen wir das Fachwissen des Architekten und behalten gleichzeitig die flüssige, menschenähnliche Interaktion des bidirektionalen Streaming-Agents bei.
Routing-Logik codieren
Wir schließen nun unser architect_agent in ein AgentTool ein und stellen dem Dispatch-Agenten eine „Logic Map“ zur Verfügung. Diese Karte gibt dem Agenten genau vor, wann Daten aus dem Tresor abgerufen und wann Ergebnisse vom Hintergrund-Sentinel gemeldet werden sollen.
Damit Dispatch „Augen“ hat, die nie blinzeln, müssen wir ihm Zugriff auf das Streaming-Tool gewähren, das wir im vorherigen Schritt erstellt haben.
Wenn Sie im ADK der Liste tools eine AsyncGenerator-Funktion (z. B. monitor_for_hazard) hinzufügen, behandelt der Agent sie als persistenten Hintergrundprozess. Anstelle einer einmaligen Ausführung „abonniert“ der Agent die Ausgabe des Tools. So kann Dispatch die primäre Unterhaltung fortsetzen, während Sentinel im Hintergrund Gefahrenwarnungen ausgibt.
👉✏️ Ersetzen Sie #REPLACE_AGENT_TOOLS in $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py durch Folgendes:
tools=[AgentTool(agent=architect_agent), monitor_for_hazard],
Bestätigung
👉💻 Nachdem beide Agents konfiguriert wurden, können wir die Live-Interaktion mit mehreren Agents testen.
- Starten Sie im Terminal A den Architect Agent:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
- Führen Sie den Dispatch-Agent in einem neuen Terminal (Terminal B) aus:
cd $HOME/way-back-home/level_4/backend/
cp architect_agent/.env .env
uv run adk web
Das Testen eines Multi-Agent-Systems, das ein multimodales Echtzeitmodell wie gemini-live im adk web-Simulator verwendet, erfordert einen bestimmten Workflow. Der Simulator eignet sich hervorragend für die Überprüfung von Tool-Aufrufen, hat aber eine bekannte Inkompatibilität bei der ersten Verarbeitung von Bildern mit diesem Modelltyp.
- Klicken Sie in der Cloud Shell-Symbolleiste auf das Symbol für die Webvorschau. Wählen Sie Port ändern aus, legen Sie 8000 fest und klicken Sie auf Ändern und Vorschau.
👉 dispatch_agent auswählen, Blueprint hochladen und erwarteten Fehler beheben
Das ist der wichtigste Schritt. Wir müssen dem KI-Agenten den Kontext des Bildes zur Verfügung stellen.
- Wenn die Benutzeroberfläche geladen wird, erlauben Sie den Zugriff auf Ihr Mikrofon, wenn Sie dazu aufgefordert werden.
- Laden Sie dieses Blueprint-Bild auf Ihren Computer herunter:
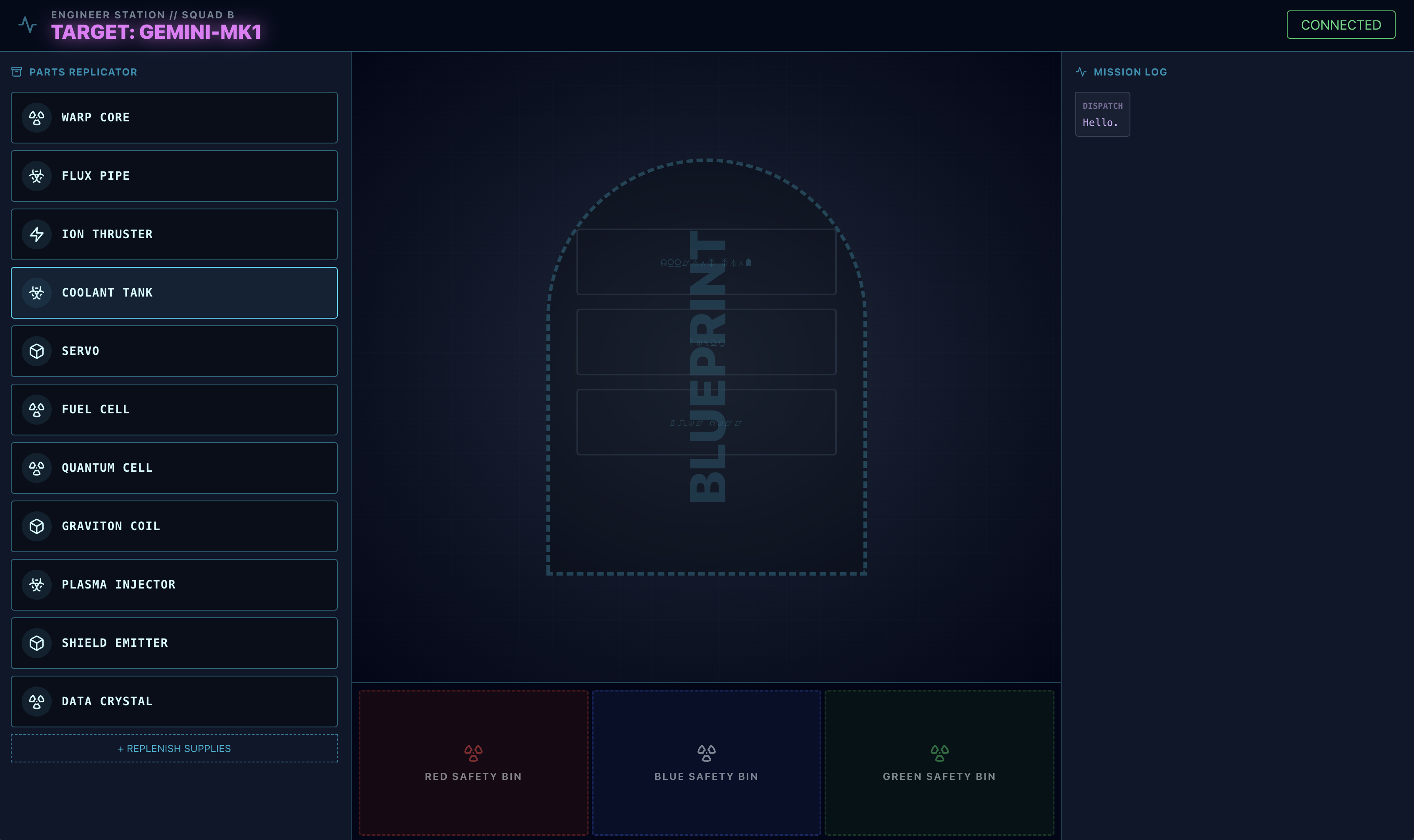
- Klicken Sie in der
adk web-Benutzeroberfläche auf das Büroklammersymbol und laden Sie das soeben heruntergeladene Grundrissbild hoch.
⚠️⚠️ Sie erhalten den Fehler 400 INVALID_ARGUMENT. Das ist zu erwarten.⚠️⚠️
Dieser Fehler tritt auf, weil der adk web-Bild-Handler nicht vollständig mit der API des gemini-live-Modells für einen einmaligen Upload kompatibel ist. Das Bild wurde jedoch erfolgreich dem Sitzungskontext hinzugefügt.
- 👉 Um den Fehler zu beheben, laden Sie die Browserseite einfach neu.
Assembly-Prozess auslösen
👉 Nach dem Neuladen wird der Fehler nicht mehr angezeigt und Sie sehen das Blueprint-Bild im Chatverlauf. Der Agent hat jetzt den visuellen Kontext, den er benötigt.
- Klicken Sie auf das Mikrofonsymbol, um es zu aktivieren. Auf der Benutzeroberfläche wird „Wird zugehört…“ angezeigt.
- Sagen Sie den Sprachbefehl „Starte die Montage“.
- Der KI-Agent verarbeitet Ihre Anfrage und die Benutzeroberfläche ändert sich zu „Wird gesprochen…“. Sie sollten eine reine Audioantwort mit den erforderlichen Teilen hören.
4. Agent-to-Agent-Tool-Aufrufe überprüfen
👉 Die erste Audioantwort bestätigt, dass das System funktioniert. Die eigentliche Magie liegt jedoch im Multi-Agenten-Kommunikationstrace.
- Schalten Sie das Mikrofon aus.
- Aktualisieren Sie die Seite noch einmal.
Der Bereich „Trace“ (Ablaufverfolgung) auf der linken Seite wird jetzt gefüllt. Hier sehen Sie den vollständigen, erfolgreichen Ausführungsablauf:
- Die Funktion
dispatch_agentruft zuerstmonitor_for_hazardauf. - Anschließend werden mehrere
execute_architect-Aufrufe anarchitect_agentgesendet, um die Schemadaten abzurufen.
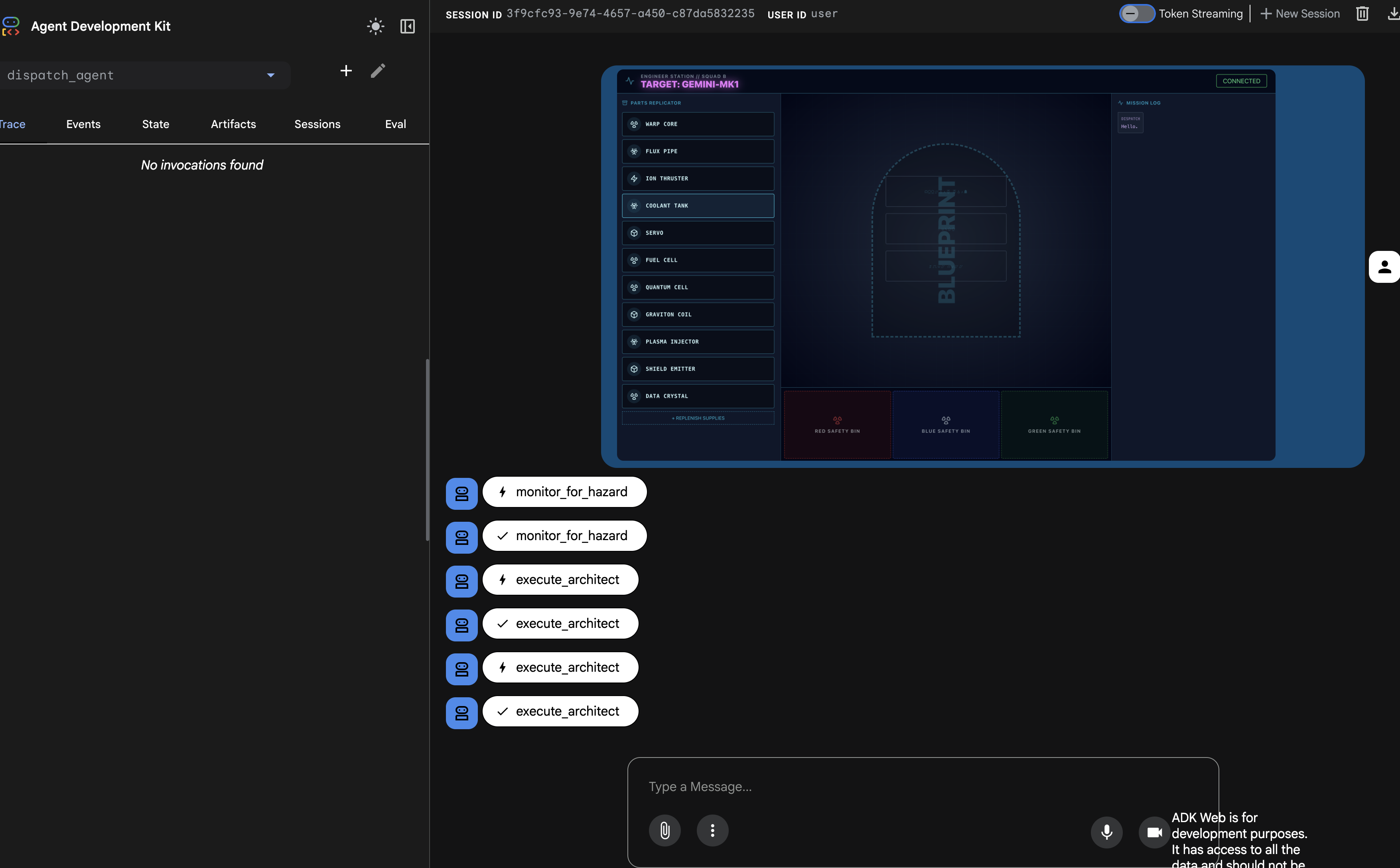
Diese Sequenz bestätigt, dass der gesamte Multi-Agent-Workflow korrekt funktioniert: Der dispatch_agent hat die Anfrage erhalten, die Aufgabe zum Abrufen von Daten über einen Toolaufruf an den architect_agent delegiert und die Daten zurückerhalten, um den Nutzerbefehl auszuführen.
Ihr bidirektionaler Streaminglink kann jetzt im Hintergrund überwacht werden und ermöglicht die Zusammenarbeit mit mehreren Agents. Als Nächstes sehen wir uns an, wie diese komplexen Antworten im Frontend geparst werden.
👉💻 Drücken Sie in beiden Terminals Ctrl+c, um sie zu schließen.
5. Ausführlicher Einblick in multimodale Livestream-Ereignisse
Im vorherigen Schritt haben wir unser Multi-Agenten-System mit dem integrierten Entwicklungsserver adk web erfolgreich überprüft. Dieses Dienstprogramm verwendet einen Standard-ADK-Runner, um den Sitzungs-, Stream- und Agent-Lebenszyklus automatisch zu verwalten. Um jedoch eine eigenständige, produktionsreife Anwendung wie unseren FastAPI-Dienst (main.py) zu erstellen, benötigen wir eine explizite Steuerung. Wir müssen den ADK Runner manuell erstellen und verwalten, um Live-Nutzer-Sessions zu verarbeiten, da er die Kernkomponente ist, die die bidirektionalen Streams für Audio, Video und Text verarbeitet.
Der Modell-Code-Modell-Zyklus
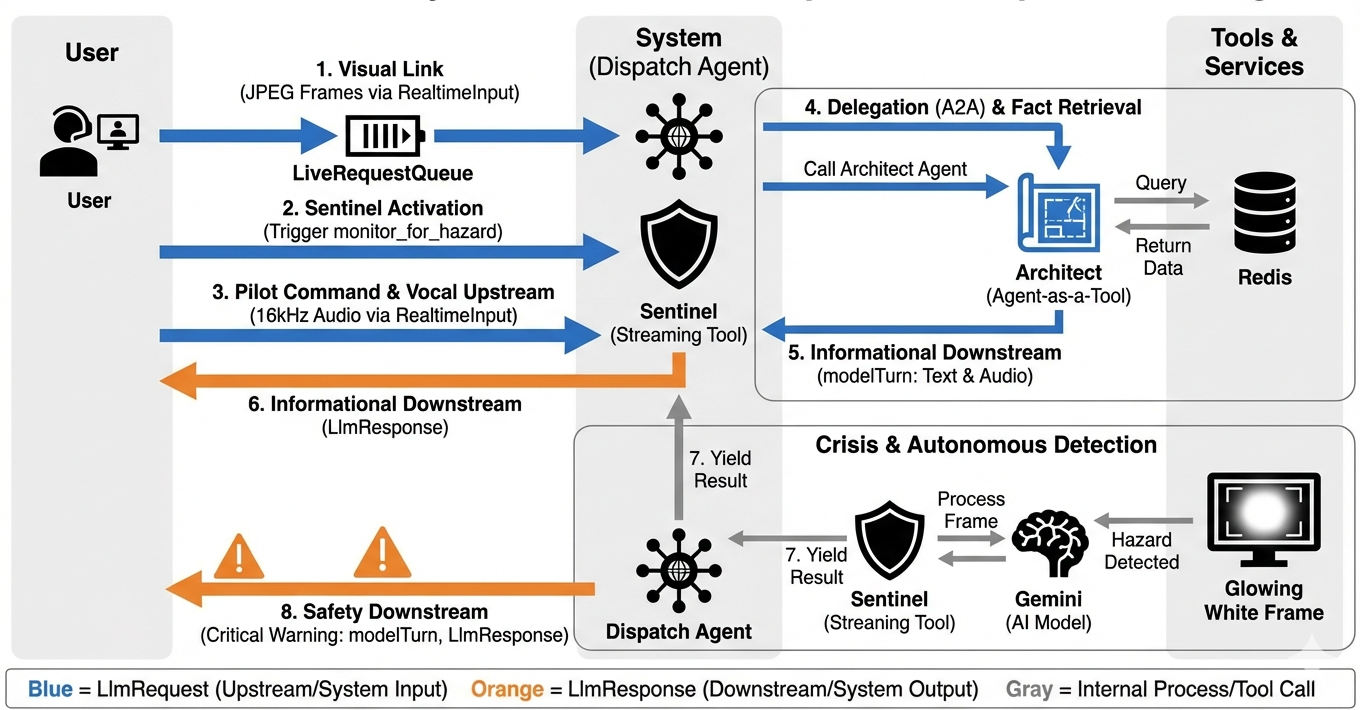
Um zu verstehen, wie das System in Echtzeit funktioniert, sehen wir uns den Lebenszyklus einer einzelnen Missionssitzung an. Dieser Zyklus stellt den kontinuierlichen Austausch von LlmRequest- und LlmResponse-Objekten dar.
- Der visuelle Link:Sie stellen die Verbindung her und geben Ihre Webcam/Ihren Bildschirm frei. High-Fidelity-JPEG-Frames werden Upstream über
realtimeInput(mitLiveRequestQueue) übertragen. - Sentinel-Aktivierung:Das System sendet einen ersten „Hallo“-Stimulus. Gemäß seinen Anweisungen löst der Dispatch-Agent sofort das
monitor_for_hazardStreaming Tool aus. Dadurch wird eine Hintergrundschleife gestartet, die jeden eingehenden Frame im Hintergrund überwacht. - Pilotbefehl:Sie sprechen in die Gegensprechanlage: „Beginne mit der Montage.“
- Vocal Upstream:Ihre Stimme wird als 16‑kHz-Audio aufgenommen und zusammen mit den Videoframes Upstream gesendet.
- Delegation (A2A): Dispatch „hört“ Ihre Intention. Der Agent stellt fest, dass ihm die Schemata fehlen, und ruft den Architect Agent über das
AgentTool-Protokoll (Agent-as-a-Tool) auf. - Faktenabruf:Der Architect fragt die Redis-Datenbank ab und gibt die Teileliste an Dispatch zurück. Dispatch bleibt der „Master der Sitzung“ und empfängt die Daten, ohne Sie weiterzuleiten.
- Informational Downstream:Dispatch sendet ein
modelTurn(Downstream) mit Text und nativem Audio: „Architect Confirmed. Die erforderliche Teilmenge ist: Warpkern, Flux-Rohr, Ionentriebwerk.“ - Die Krise:Plötzlich destabilisiert sich ein Teil auf der Werkbank und beginnt, weiß zu leuchten.
- Autonome Erkennung:Die
monitor_for_hazard-Schleife im Hintergrund (der Sentinel) erkennt den spezifischen JPEG-Frame, der den Glow enthält. Das Bild wird verarbeitet, indem Gemini aufgerufen und die Gefahr identifiziert wird. - Sicherheit – Downstream:Das Streamingtool
yieldsein Ergebnis. Da es sich um einen Bidi-Streaming-Agenten handelt, kann Dispatch den aktuellen Status unterbrechen, um sofort eine wichtige Sicherheitswarnung Downstream zu senden: „Gefahr erkannt! Neutralisiere jetzt den Datenkristall. Verschiebe sie in den roten Ordner.“
Laufzeitkonfiguration des Agents festlegen
Mit RunConfig im ADK lässt sich das Verhalten eines Agenten detailliert konfigurieren, z. B. wie er Streamingdaten verarbeitet und mit verschiedenen Modalitäten interagiert.
streaming_mode ist für die bidirektionale Echtzeitkommunikation auf BIDI eingestellt, sodass sowohl der Nutzer als auch der Agent gleichzeitig sprechen und zuhören können. Mit dem Parameter response_modalities werden die Arten von Ausgaben definiert, die der Agent erzeugen kann, z. B. Sprache und Text. Mit input_audio_transcription wird konfiguriert, wie der Agent die eingehende Sprache des Nutzers verarbeitet und transkribiert. Um die Zuverlässigkeit zu erhöhen, session_resumption kann sich der Agent den Gesprächskontext merken und die Unterhaltung fortsetzen, wenn die Verbindung unterbrochen wird. Mit proactivity kann der Agent Aktionen oder Sprache ohne direkten Nutzerbefehl initiieren, z. B. eine spontane Gefahrenwarnung ausgeben. Mit enable_affective_dialog kann der Agent natürlichere und einfühlsamere Antworten generieren. Weitere Informationen zur RunConfig des ADK
👉✏️ Suchen Sie in Ihrer $HOME/way-back-home/level_4/backend/main.py-Datei nach dem Platzhalter #REPLACE_RUN_CONFIG und ersetzen Sie ihn durch die folgende Logik für die Aufschlüsselung:
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
Anfrage an den KI-Agenten implementieren
Als Nächstes implementieren wir den Uplink für die Kernkommunikation, der multimodale Echtzeitdaten vom Volatile Workbench des Nutzers über ein WebSocket an den Dispatch Agent streamt. Der Agent „sieht“ (Videobilder) und „hört“ (Sprachbefehle) kontinuierlich. Die Logik empfängt kontinuierlich den Datenstrom, unterscheidet zwischen eingehenden binären Audio-Chunks und JSON-verpackten Text-/Bildpaketen und kapselt sie in Blob- (für Multimedia) oder Content-Objekte (für Text). Anschließend werden sie in die LiveRequestQueue gesendet, um die bidirektionale Agentsitzung zu ermöglichen.
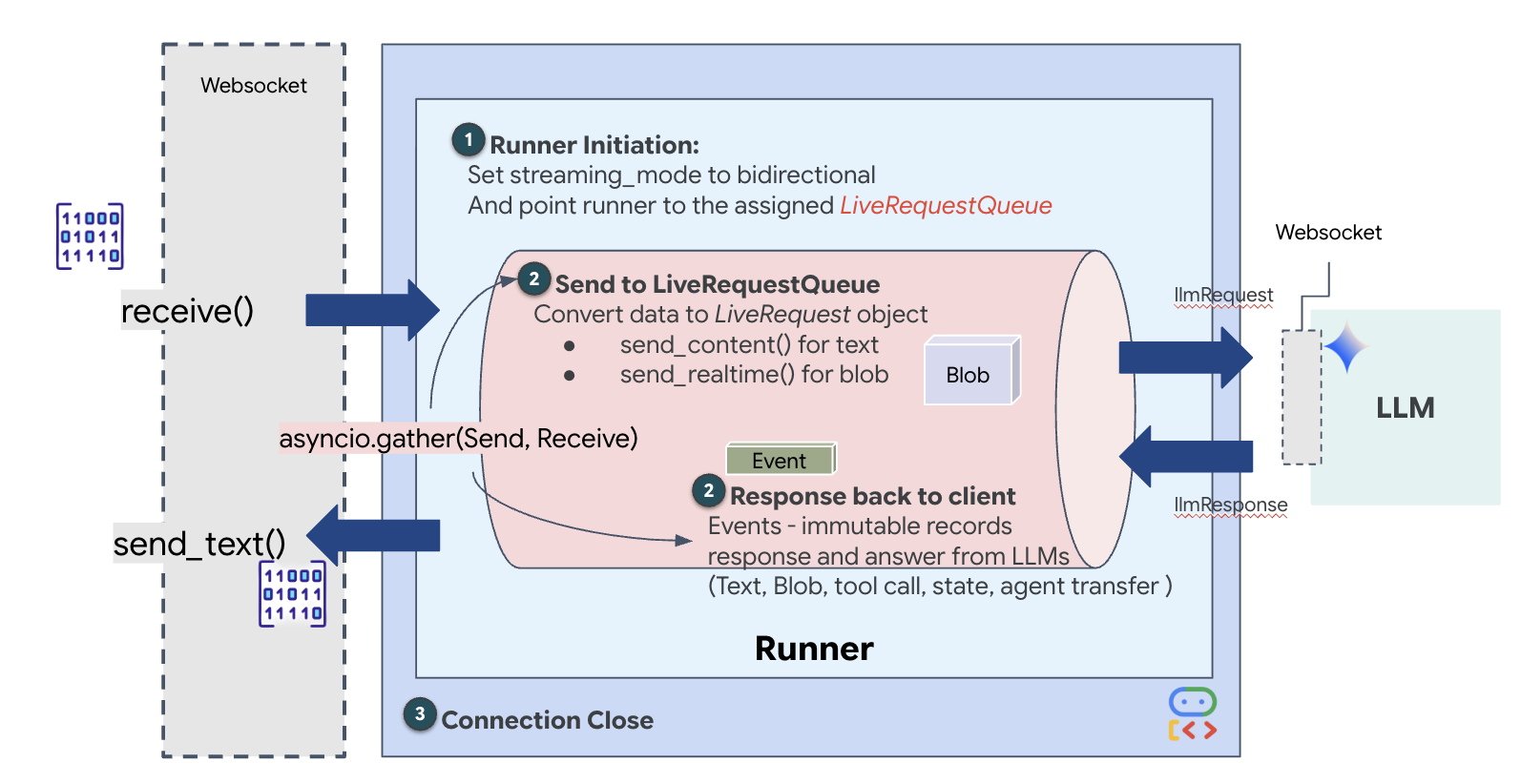
Suchen Sie in Ihrer $HOME/way-back-home/level_4/backend/main.py-Datei nach dem Platzhalter #PROCESS_AGENT_REQUEST und ersetzen Sie ihn durch die folgende Logik für die Aufschlüsselung:
# Start the loop
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
# logger.info("Received AUDIO packet") # Uncomment for verbose debugging
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# logger.info(f"Received Audio Chunk: {len(audio_data)} bytes")
import math
import struct
# Calculate RMS to debug silence
count = len(audio_data) // 2
shorts = struct.unpack(f"<{count}h", audio_data)
sum_squares = sum(s*s for s in shorts)
rms = math.sqrt(sum_squares / count) if count > 0 else 0
# logger.info(f"RMS: {rms:.2f} | Bytes: {len(audio_data)}")
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
# logger.info(f"Received Image Frame: {len(image_data)} bytes")
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
frame_count += 1
finally:
pass
Die multimodalen Daten werden jetzt an den Agent gesendet.
Antwort implementieren: Die Downstream-Ereignisdatenstruktur
Wenn Sie einen bidirektionalen (Live-)Agenten mit dem ADK ausführen, werden die vom Agenten zurückgegebenen Daten in einem bestimmten Ereignistyp verpackt, der von den Core-GenAI SDK-Strukturen abgeleitet wird. Das Event-Objekt, das Sie in Ihrer async for event in runner.run_live(...)-Schleife erhalten, ist ein einzelnes Objekt mit mehreren optionalen Feldern, die jeweils einen anderen Informationstyp enthalten:
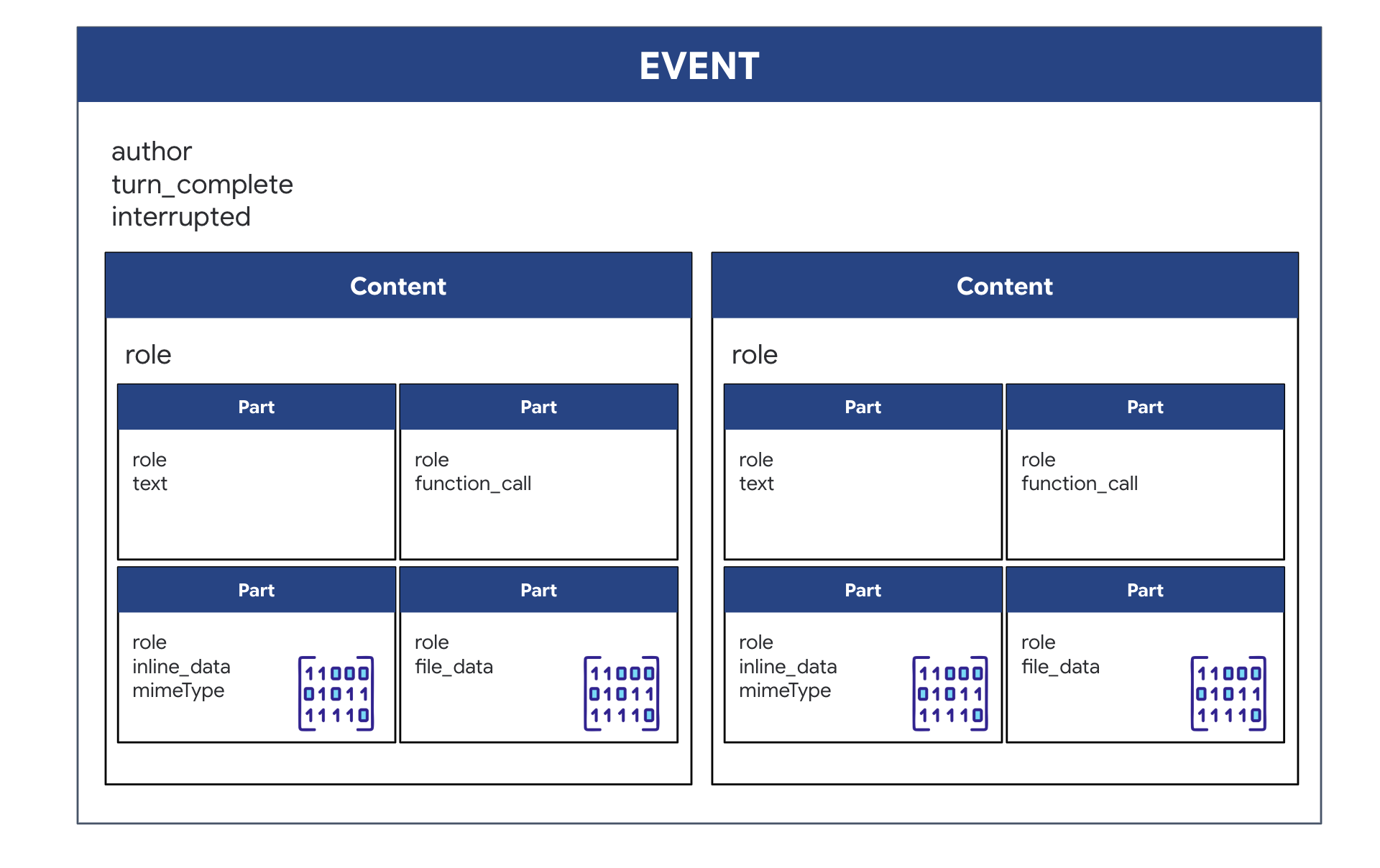
So sind die Inhalte strukturiert:
- Wenn der Agent spricht (über
.server_content): Das Feld ist nicht nur Nur-Text. Es enthält eine Liste vonParts. JedesPartist ein Container für einen Datentyp – entweder einen Textstring (wie"The part is stable.") oder ein rohes Audio-Blob (die Stimme). - Wenn der Agent handelt (über
.tool_call): Das Feld enthält eine Liste vonFunctionCall-Objekten. JedesFunctionCallist ein einfaches, strukturiertes Objekt, das den Namen des Tools und die Eingabeargumente in einem übersichtlichen Format angibt, das Ihr Backend-Code problemlos lesen und ausführen kann.
👀 Wenn Sie sich ein einzelnes Event ansehen, das von der run_live-Schleife zurückgegeben wird, sieht das JSON (das von event.model_dump(by_alias=True) generiert wird) so aus. Es folgt dabei strikt den GenAI SDK-Formen:
{
"serverContent": { // <-- LiveServerMessageServerContent
"modelTurn": { // <-- ModelTurn
"parts": [ // <-- list[Part]
{
"text": "Architect Confirmed."
},
{
"inlineData": { // <-- Blob (Audio Bytes)
"mimeType": "audio/pcm;rate=24000",
"data": "BASE64_AUDIO_DATA..."
}
}
]
}
},
"toolCall": { // <-- LiveServerMessageToolCall
"functionCalls": [ // <-- list[FunctionCall]
{
"name": "neutralize_hazard",
"args": { "color": "RED" }
}
]
}
}
👉✏️ Wir aktualisieren jetzt die downstream_task in main.py, um die vollständigen Ereignisdaten weiterzuleiten. Diese Logik sorgt dafür, dass jeder „Gedanke“ der KI im Diagnoseterminal des Schiffs protokolliert und als einzelnes JSON-Objekt an die Frontend-Benutzeroberfläche gesendet wird.
Suchen Sie in Ihrer $HOME/way-back-home/level_4/backend/main.py-Datei nach dem Platzhalter #PROCESS_AGENT_RESPONSE und ersetzen Sie ihn durch die folgende Logik für die Aufschlüsselung:
# Suppress raw event logging
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
# logger.info(f"raw_event: {event_json[:200]}...")
await websocket.send_text(event_json)
Ausführung der Mission
Nachdem der Backend-Tresor verbunden und beide Agents konfiguriert wurden, sind alle Systeme einsatzbereit. Mit den folgenden Schritten wird die vollständige Anwendung gestartet, sodass Sie mit dem soeben erstellten System mit zwei Agenten interagieren können.
Ziel:Bauen Sie das zufällig zugewiesene Warp-Antriebssystem zusammen, das auf Ihrer Werkbank angezeigt wird. Protokoll:Sie müssen die gesprochenen Anweisungen des Dispatch-Agents befolgen, insbesondere die Gefahrenhinweise für bestimmte Komponenten.
Spezialist (Architekt) aktivieren
👉💻 Starten Sie den Architect-Agenten in Ihrem ersten Terminalfenster. Dieser Backend-Dienst stellt eine Verbindung zum Redis-Vault her und wartet auf Schemaanfragen vom Dispatcher.
# Ensure you are in the backend directory
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend
# Start the A2A Server on Port 8081
uv run architect_agent/server.py
Lassen Sie dieses Terminal geöffnet. Er ist jetzt Ihr aktiver „Datenbank-Agent“.
Cockpit (Dispatcher) starten
👉💻 In einem neuen Terminalfenster (Terminal B) erstellen wir die Frontend-Benutzeroberfläche und starten den Haupt-Dispatch-Agent, der die Benutzeroberfläche bereitstellt und die gesamte Live-Kommunikation abwickelt.
# 1. Build the Frontend Assets
cd $HOME/way-back-home/level_4/frontend
npm install
npm run build
# 2. Launch the Main Application Server
cd $HOME/way-back-home/level_4/backend
cp architect_agent/.env .env
uv run main.py
(Dadurch wird der primäre Server auf Port 8080 gestartet.)
Testszenario ausführen
Das System ist jetzt live. Ihr Ziel ist es, der Anleitung des Agent zu folgen, um die Montage abzuschließen.
- 👉 Auf die Workbench zugreifen:
- Klicken Sie in der Cloud Shell-Symbolleiste auf das Symbol für die Webvorschau.
- Wählen Sie Port ändern aus, legen Sie den Port auf 8080 fest und klicken Sie auf Ändern und Vorschau.
- 👉 Mission starten
- Wenn die Benutzeroberfläche geladen wird, müssen Sie ihr Zugriff auf Ihren Bildschirm und Ihr Mikrofon gewähren.
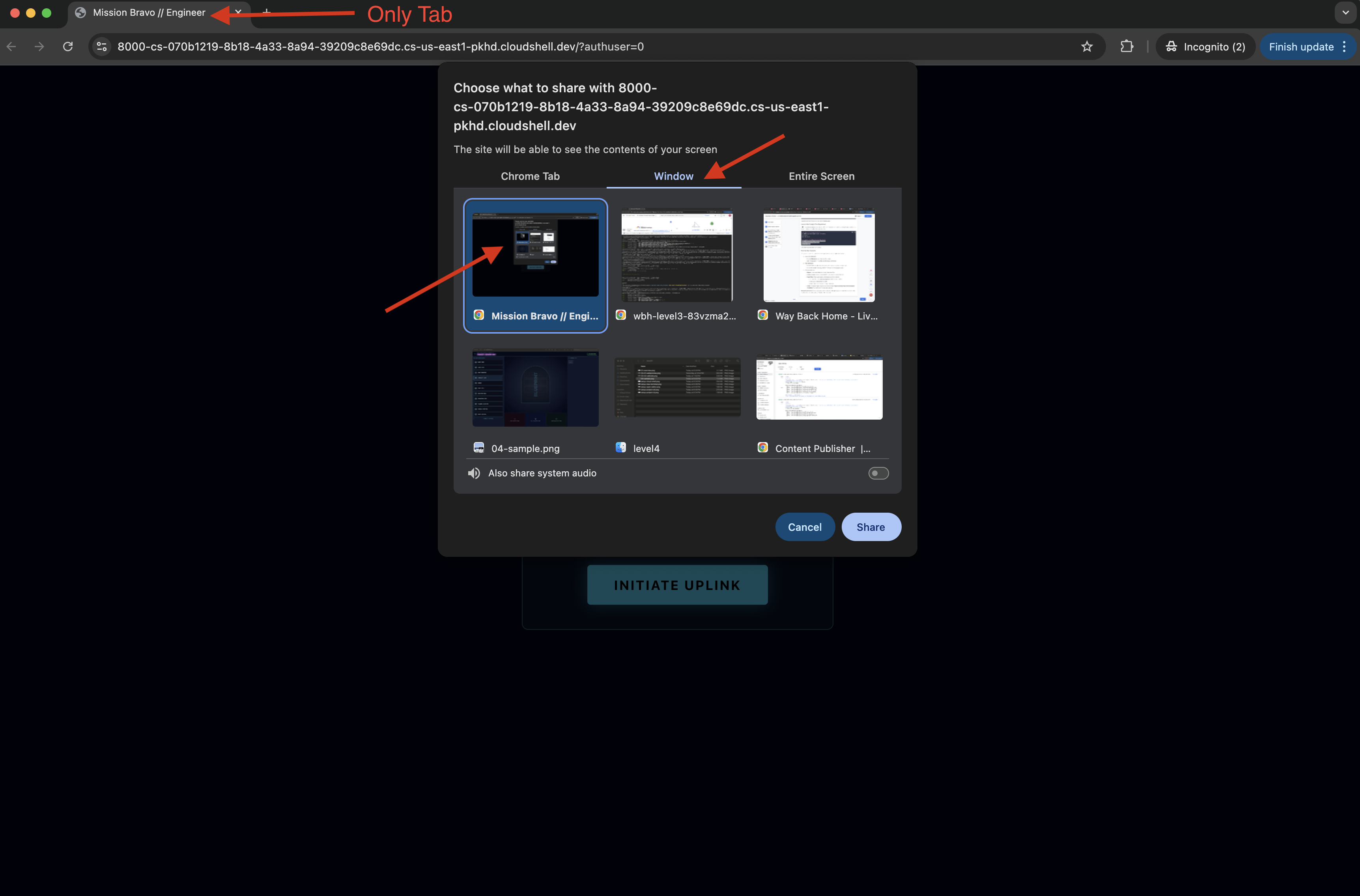
- Sie werden aufgefordert, einen Tab oder ein Fenster für die Freigabe auszuwählen. Wenn Sie das Fenster freigeben, achten Sie darauf, dass es der EINZIGE Tab im Fenster ist, um Probleme zu vermeiden.
- Ihnen wird ein Laufwerk mit einem zufälligen Namen zugewiesen, z.B. „NOVA-V“ oder „OMEGA-9“.
- Wenn die Benutzeroberfläche geladen wird, müssen Sie ihr Zugriff auf Ihren Bildschirm und Ihr Mikrofon gewähren.
- 👉 Der Assembly-Loop
- :
- Aufforderung:Um mit der Montage des Laufwerks zu beginnen, sagen Sie: „Beginne mit der Montage.“
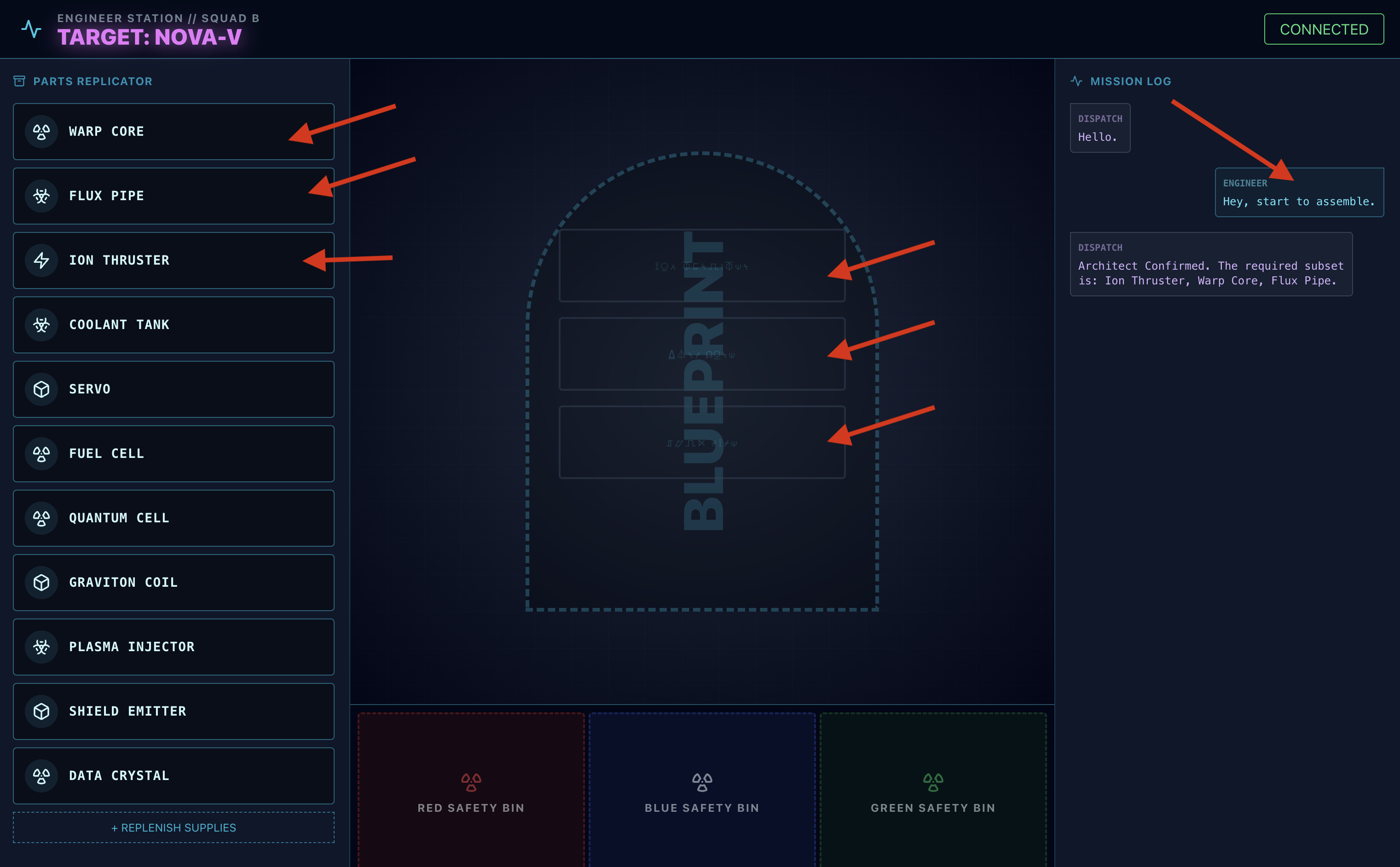
- Architect Respond (Architekt antwortet): Der KI-Agent gibt die richtigen Teile für die Montage des Laufwerks an.
- Gefahrenprüfung:Wenn ein Teil auf der Workbench gefährlich erscheint:
- Das
monitor_for_hazard-Tool des Dispatch-Kundenservicemitarbeiters identifiziert es visuell. - Es wird eine „VISUAL HAZARD ALERT“-Meldung ausgegeben. Das dauert etwa 30 Sekunden.
- Es wird geprüft, welcher Behälter zum Lösen der Gefahrensituation verwendet werden soll.
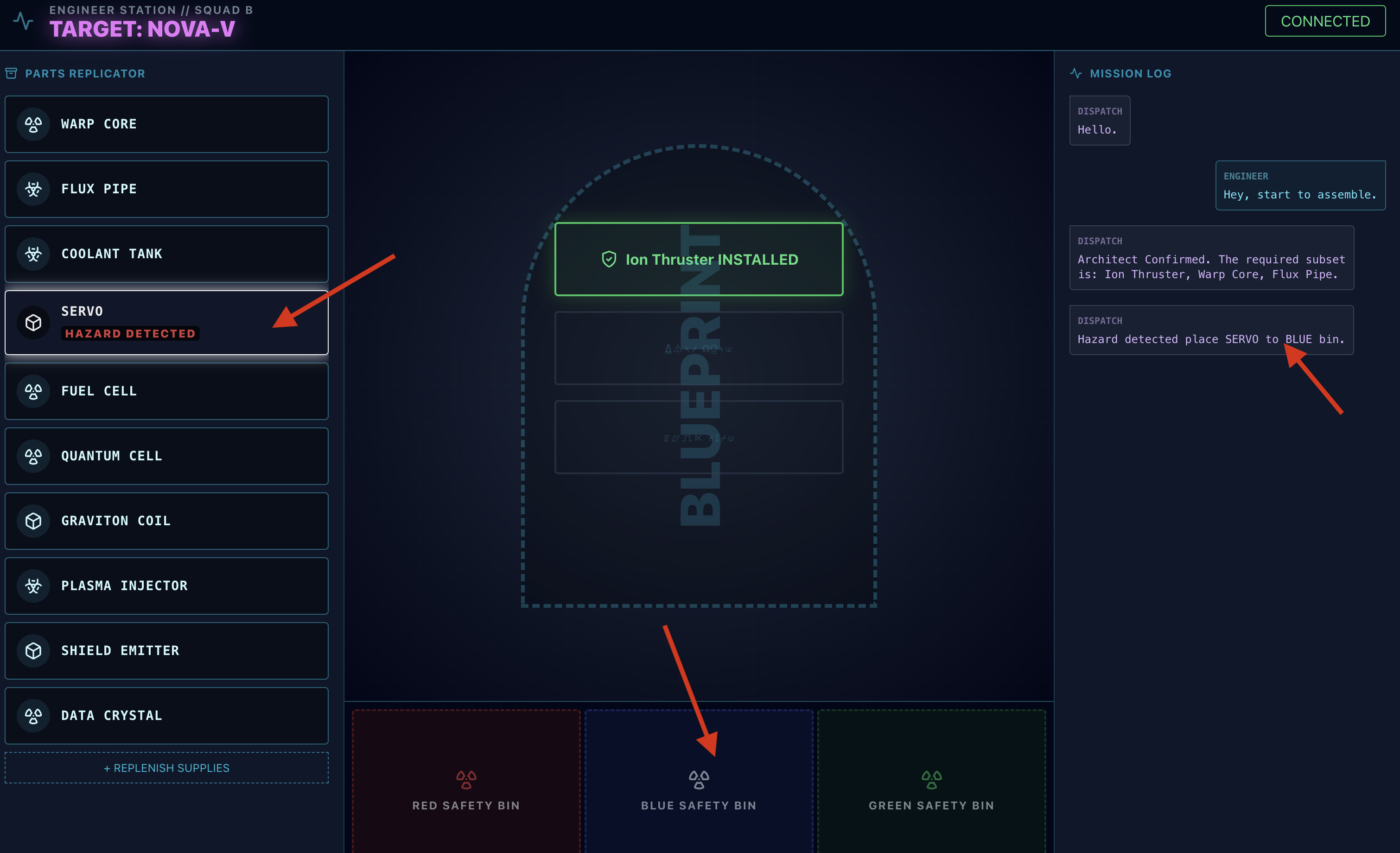
- Das
- Maßnahme:Der Dispatch Agent gibt Ihnen einen direkten Befehl: „Gefahr bestätigt. Lege XXX sofort in den roten Behälter.“ Sie müssen dieser Anleitung folgen, um fortzufahren.
- Aufforderung:Um mit der Montage des Laufwerks zu beginnen, sagen Sie: „Beginne mit der Montage.“
Mission erfüllt. Sie haben erfolgreich ein interaktives Multi-Agenten-System erstellt. Die Überlebenden sind in Sicherheit, die Rakete hat die Atmosphäre verlassen und deine Reise „Way Back Home“ geht weiter.
👉💻 Drücken Sie in beiden Terminals Ctrl+c, um sie zu schließen.
6. Für die Produktion bereitstellen (optional)
Sie haben den Agenten lokal getestet. Jetzt müssen wir den neuronalen Kern des Architekten in die Mainframes des Schiffs (Cloud Run) hochladen. Dadurch kann er als permanenter, unabhängiger Dienst fungieren, den der Dispatch-Agent von überall aus abfragen kann.
Secure Vault bereitstellen (Infrastruktur)
Bevor wir den Agent bereitstellen, müssen wir seinen persistenten Speicher (Memorystore) und den sicheren Kanal für den Zugriff darauf (VPC-Connector) erstellen.
👉💻 Memorystore-Instanz (Redis Vault) erstellen:
export REGION="us-central1"
gcloud redis instances create ozymandias-vault-prod --size=1 --tier=basic --region=${REGION}
👉💻 Netzwerkadresse des Vault abrufen: Führen Sie diesen Befehl aus und kopieren Sie die IP-Adresse host. Dies ist die private Adresse Ihrer neuen Redis-Instanz.
gcloud redis instances describe ozymandias-vault-prod --region=us-central1
👉💻 VPC-Zugriffsconnector (sichere Bridge) erstellen: Dieser Connector fungiert als private Bridge, über die Cloud Run auf die Redis-Instanz in Ihrer VPC zugreifen kann.
export REGION="us-central1"
export SUBNET_NAME="vpc-connector-subnet"
export PROJECT_ID=$(gcloud config get-value project)
# Create the Dedicated Subnet ---
gcloud compute networks subnets create ${SUBNET_NAME} \
--network=default \
--region=${REGION} \
--range=192.168.1.0/28
gcloud compute networks vpc-access connectors create architect-connector \
--region ${REGION} \
--subnet ${SUBNET_NAME} \
--subnet-project ${PROJECT_ID} \
--min-instances 2 \
--max-instances 3 \
--machine-type f1-micro
👉💻 Daten laden:
export REGION="us-central1"
export ZONE="us-central1-a"
export VM_NAME="redis-seeder-$(date +%s)"
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
gcloud compute instances create ${VM_NAME} \
--zone=${ZONE} \
--machine-type=e2-micro \
--image-family=debian-11 \
--image-project=debian-cloud \
--quiet \
--metadata=startup-script='#! /bin/bash
# Install tools quietly
apt-get update > /dev/null
apt-get install -y redis-tools > /dev/null
# Run each command individually
redis-cli -h '"${REDIS_IP}"' DEL "HYPERION-X"
redis-cli -h '"${REDIS_IP}"' RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "NOVA-V"
redis-cli -h '"${REDIS_IP}"' RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
redis-cli -h '"${REDIS_IP}"' DEL "OMEGA-9"
redis-cli -h '"${REDIS_IP}"' RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
redis-cli -h '"${REDIS_IP}"' DEL "GEMINI-MK1"
redis-cli -h '"${REDIS_IP}"' RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
redis-cli -h '"${REDIS_IP}"' DEL "APOLLO-13"
redis-cli -h '"${REDIS_IP}"' RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "VORTEX-7"
redis-cli -h '"${REDIS_IP}"' RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
redis-cli -h '"${REDIS_IP}"' DEL "CHRONOS-ALPHA"
redis-cli -h '"${REDIS_IP}"' RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
redis-cli -h '"${REDIS_IP}"' DEL "NEBULA-Z"
redis-cli -h '"${REDIS_IP}"' RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
redis-cli -h '"${REDIS_IP}"' DEL "PULSAR-B"
redis-cli -h '"${REDIS_IP}"' RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
redis-cli -h '"${REDIS_IP}"' DEL "TITAN-PRIME"
redis-cli -h '"${REDIS_IP}"' RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
# Signal that the script has finished
echo "SEEDING_COMPLETE"
'
# This command streams the logs and waits until grep finds our completion message.
# The -m 1 flag tells grep to exit after the first match.
gcloud compute instances tail-serial-port-output ${VM_NAME} --zone=${ZONE} | grep -m 1 "SEEDING_COMPLETE"
gcloud compute instances delete ${VM_NAME} --zone=${ZONE} --quiet
Agent-Anwendung bereitstellen
Agent-Image kompilieren und erstellen
👉💻 Wechseln Sie zum Backend-Verzeichnis und erstellen Sie das Dockerfile.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
cd $HOME/way-back-home/level_4/backend/architect_agent
cp $HOME/way-back-home/level_4/requirements.txt requirements.txt
cat <<EOF > Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.13-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file and install dependencies for THIS agent
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the architect's code (server.py, agent.py, etc.)
COPY . .
# Expose the port the architect server runs on
EXPOSE 8081
# Command to run the application
# This assumes your server file is named server.py and the FastAPI object is 'app'
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8081"]
EOF
👉💻 Anwendung in einem Container-Image verpacken
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export REGION=us-central1
# This should now print the full, correct path
echo "Verifying build path: ${IMAGE_PATH}"
gcloud builds submit . --tag ${IMAGE_PATH}
In Cloud Run bereitstellen
👉💻 Stellen Sie den Agent in Cloud Run bereit. Wir fügen die Redis-IP-Adresse ein und verknüpfen den VPC-Connector direkt mit dem Startbefehl. So wird sichergestellt, dass der Agent eine sichere, private Verbindung zu seiner Datenbank herstellt.
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export PREDICTED_HOST="${SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
export PROTOCOL=https
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8081 \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--vpc-connector=${VPC_CONNECTOR_NAME} \
--vpc-egress=private-ranges-only \
--set-env-vars="REDIS_HOST=${REDIS_IP}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-2.5-flash" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="HOST_URL=${PREDICTED_HOST}" \
--set-env-vars="PROTOCOL=${PROTOCOL}" \
--set-env-vars="A2A_PORT=443"
👉💻 Prüfen Sie, ob der A2A-Server ausgeführt wird.
export REGION=us-central1
export ARCHITECT_AGENT_URL=$(gcloud run services describe architect-agent --platform managed --region ${REGION} --format 'value(status.url)')
curl -s ${ARCHITECT_AGENT_URL}/.well-known/agent.json | jq
Nach Abschluss des Befehls wird eine Service-URL angezeigt. Der Architect Agent ist jetzt in der Cloud verfügbar, dauerhaft mit seinem Tresor verbunden und bereit, schematische Daten für andere Agents bereitzustellen.
Dispatch Hub auf dem Produktions-Mainframe bereitstellen
Nachdem der Architect Agent in der Cloud betriebsbereit ist, müssen wir nun den Dispatch Hub bereitstellen. Dieser KI-Agent dient als primäre Benutzeroberfläche, die Live-Sprach-/Videostreams verarbeitet und Datenbankabfragen an den sicheren Endpunkt des Architekten delegiert.
👉💻 Führen Sie den folgenden Befehl in Ihrem Cloud Shell-Terminal aus. Dadurch wird das vollständige, mehrstufige Dockerfile in Ihrem Back-End-Verzeichnis erstellt.
cd $HOME/way-back-home/level_4
cat <<EOF > Dockerfile
# STAGE 1: Build the React Frontend
# This stage uses a Node.js container to build the static frontend assets.
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the root of our build context
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the entire backend directory into the container
COPY backend/ ./backend/
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# The source is the '/app/frontend/dist' directory from Stage 1.
# The destination is './frontend/dist', which matches the exact relative path
# your backend/main.py script expects to find.
COPY --from=builder /app/frontend/dist ./frontend/dist/
# Cloud Run injects a PORT environment variable, which your main.py already uses.
# We expose 8000 as a standard practice.
EXPOSE 8000
# Set the command to run the application.
# We specify the full path to the Python script.
CMD ["python", "backend/main.py"]
EOF
Agent-/Frontend-Image kompilieren und erstellen
👉💻 Wechseln Sie zum Back-End-Verzeichnis mit dem Code des Dispatch-Agents (main.py) und verpacken Sie ihn in einem Container-Image.
cd $HOME/way-back-home/level_4
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
# This assumes your dispatch agent server (main.py) is in the backend folder
gcloud builds submit . --tag ${IMAGE_PATH}
In Cloud Run bereitstellen
👉💻 Stellen Sie den Dispatch Hub in Cloud Run bereit. Wir fügen die Architect-URL als Umgebungsvariable ein und schaffen so die entscheidende Verbindung zwischen unseren beiden cloudnativen Agents.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export AGENT_SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export ARCHITECT_AGENT_URL="https://${AGENT_SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8080 \
--labels=dev-tutorial=multi-modal \
--allow-unauthenticated \
--set-env-vars="ARCHITECT_URL=${ARCHITECT_AGENT_URL}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}"
Wenn der Befehl ausgeführt wurde, wird eine Dienst-URL angezeigt, z.B. https://mission-bravo-...run.app. Die Anwendung ist jetzt in der Cloud verfügbar.
👉 Rufen Sie die Seite Google Cloud Run auf und wählen Sie den Dienst „biometric-scout“ aus der Liste aus. 
👉 Suchen Sie oben auf der Seite „Dienstdetails“ nach der öffentlichen URL. 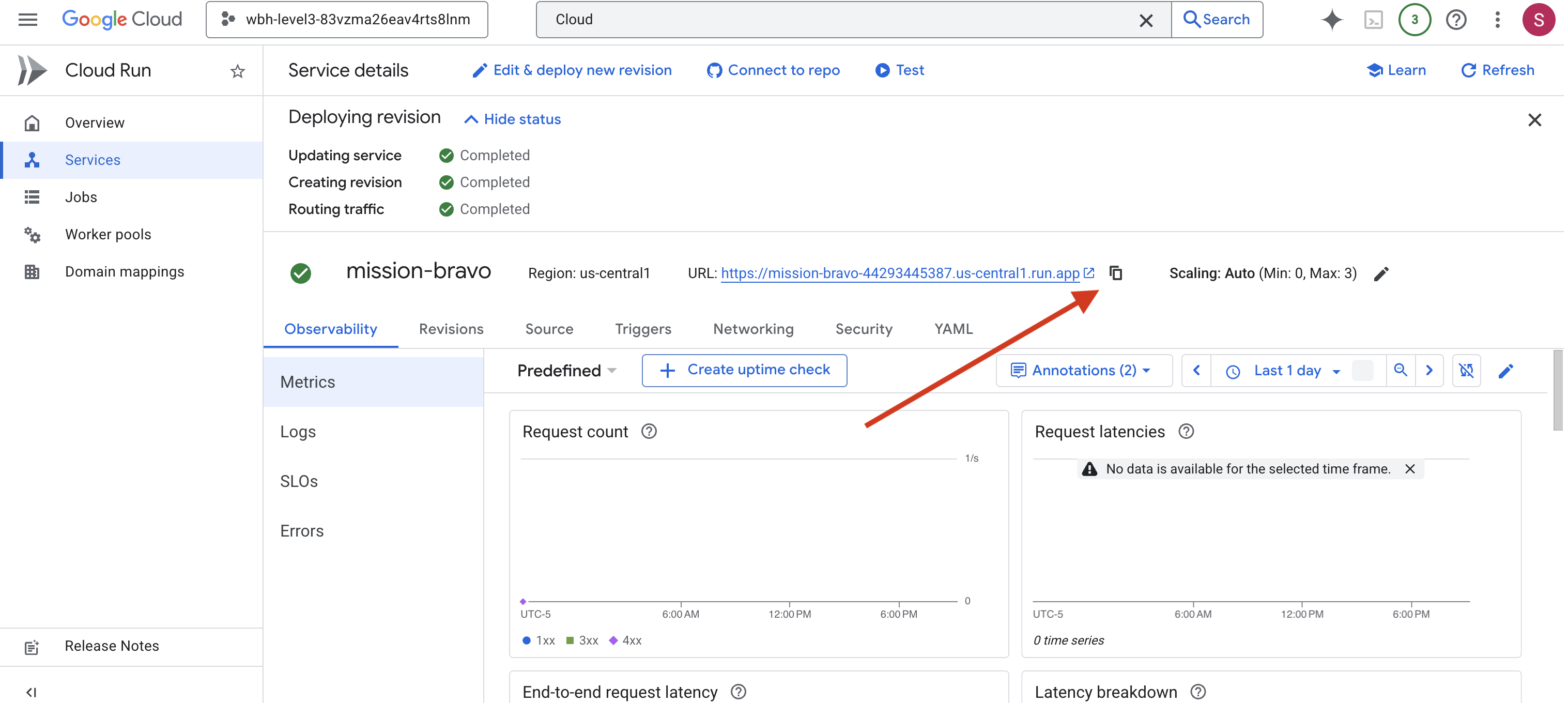
Abschließende Systemprüfung (End-to-End-Test)
👉 Sie interagieren jetzt mit dem Live-System.
- URL abrufen:Kopieren Sie die Dienst-URL aus der Ausgabe des letzten Bereitstellungsbefehls (sie sollte mit
run.appenden). - Cockpit öffnen:Fügen Sie die URL in Ihren Webbrowser ein.
- Kontakt aufnehmen:Wenn die Benutzeroberfläche geladen wird, müssen Sie den Zugriff auf Ihr Display und Ihr Mikrofon zulassen.
- Daten anfordern:Wenn ein Laufwerk zugewiesen ist, bitten Sie darum, mit der Montage zu beginnen. Beispiel: „Beginne mit der Montage“

Sie interagieren jetzt mit einem vollständig bereitgestellten Multi-Agenten-System, das vollständig in Google Cloud ausgeführt wird.
Das Multi-Agent-System verriegelt den letzten Eindämmungsring und die unregelmäßige Strahlung flacht zu einem gleichmäßigen Summen ab.
„Warp Drive: STABILIZED. Rescue Craft: ENGINES IGNITED.“

Auf dem Monitor rast das außerirdische Raumschiff nach oben und entkommt nur knapp der zerbröselnden Oberfläche von Ozymandias, als die Atmosphäre zusammenbricht. Es begibt sich in eine sichere Umlaufbahn neben deinem Schiff und die Kommunikationskanäle füllen sich mit den Stimmen der Überlebenden – erschüttert, aber am Leben. Nachdem die Rettung abgeschlossen ist und der Weg nach Hause frei ist, wird die Remote-Verbindung getrennt.
Dank dir wurden die Überlebenden gerettet.
Wenn du an Level 0 teilgenommen hast, vergiss nicht, deinen Fortschritt bei der Mission „Auf dem Weg nach Hause“ zu überprüfen.