
1. Übersicht
Bei der Entwicklung von Anwendungen mit generativer KI wird die wichtigste Komponente oft vergessen: Sicherheit.
Stellen Sie sich vor, Sie erstellen einen HR-Chatbot. Sie möchten, dass sie Fragen wie Wie hoch ist mein Gehalt? oder Wie schneidet mein Team ab? beantwortet.
- Wenn Anne (eine normale Mitarbeiterin) eine Anfrage stellt, sollte sie nur ihre Daten sehen.
- Wenn Bob (ein Manager) fragt, sollte er die Daten seines Teams sehen.
Das Problem
Die meisten RAG-Architekturen (Retrieval Augmented Generation) versuchen, dies in der Anwendungsschicht zu beheben. Sie filtern Chunks nach dem Abrufen oder verlassen sich darauf, dass das LLM sich „richtig verhält“. Das ist zerbrechlich. Wenn die App-Logik fehlschlägt, kommt es zu Datenlecks.
Die Lösung
Verschieben Sie die Sicherheit auf die Datenbankschicht. Durch die Verwendung von Sicherheit auf Zeilenebene (Row-Level Security, RLS) in AlloyDB stellen wir sicher, dass die Datenbank physisch verweigert, Daten zurückzugeben, die der Nutzer nicht sehen darf – unabhängig davon, was die KI anfordert.
In diesem Leitfaden erstellen wir The Private Vault, einen sicheren HR-Assistenten, der seine Antworten dynamisch an den angemeldeten Nutzer anpasst.
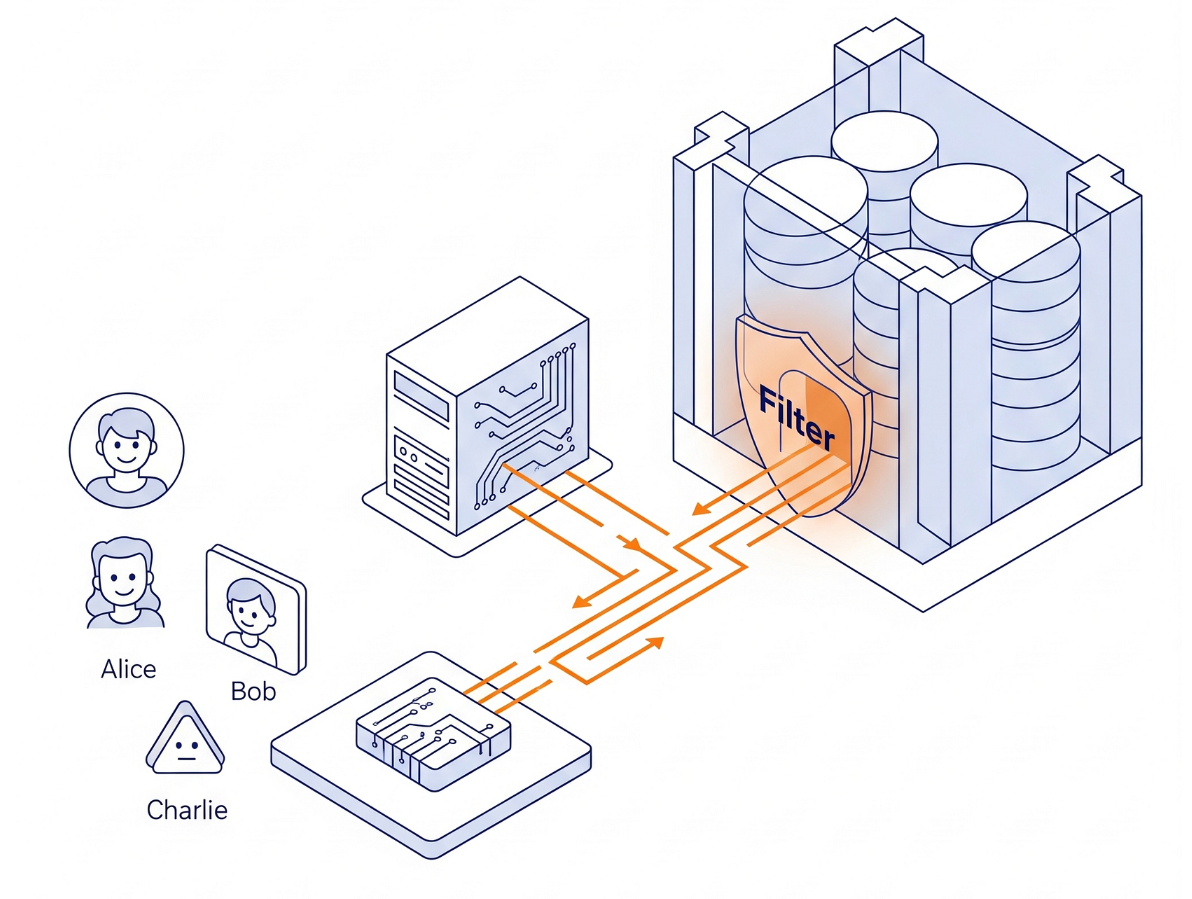
Die Architektur
Wir entwickeln keine komplexe Berechtigungslogik in Python. Wir verwenden das Datenbankmodul selbst.
- Die Schnittstelle:Eine einfache Streamlit-App, die eine Anmeldung simuliert.
- Das Gehirn:AlloyDB AI (PostgreSQL-kompatibel).
- Funktionsweise:Wir legen zu Beginn jeder Transaktion eine Sitzungsvariable (
app.active_user) fest. Die Datenbankrichtlinien prüfen automatisch eineuser_roles-Tabelle (die als unser Identitätsanbieter fungiert), um die Zeilen zu filtern.
Aufgaben
Eine sichere HR Assistant-Anwendung. Anstatt sich auf die Anwendungslogik zum Filtern sensibler Daten zu verlassen, implementieren Sie die Sicherheit auf Zeilenebene (Row-Level Security, RLS) direkt in der AlloyDB-Datenbank-Engine. So wird verhindert, dass Ihr KI-Modell „halluziniert“ oder versucht, auf nicht autorisierte Daten zuzugreifen. Die Datenbank weigert sich dann, die Daten zurückzugeben.
Lerninhalte
Lerninhalte:
- So entwerfen Sie ein Schema für RLS (Trennung von Daten und Identität).
- Informationen zum Schreiben von PostgreSQL-Richtlinien (
CREATE POLICY). - So umgehen Sie die Ausnahme „Tabelleninhaber“ mit
FORCE ROW LEVEL SECURITY. - So erstellen Sie eine Python-App, die für Nutzer „Context Switching“ ausführt.
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Folgen Sie dem Link und aktivieren Sie die APIs.
Alternativ können Sie dazu den gcloud-Befehl verwenden. Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Wichtige Hinweise und Fehlerbehebung
Das „Geisterprojekt“-Syndrom | Sie haben |
Die Abrechnungsbarrikade | Sie haben das Projekt aktiviert, aber das Rechnungskonto vergessen. AlloyDB ist eine leistungsstarke Engine, die nicht startet, wenn der „Benzintank“ (Abrechnung) leer ist. |
Verzögerung bei der API-Weitergabe | Sie haben auf „APIs aktivieren“ geklickt, aber in der Befehlszeile wird weiterhin |
Kontingent – Häufig gestellte Fragen | Wenn Sie ein brandneues Testkonto verwenden, erreichen Sie möglicherweise ein regionales Kontingent für AlloyDB-Instanzen. Wenn |
3. Datenbank einrichten
In diesem Lab verwenden wir AlloyDB als Datenbank für die Testdaten. Darin werden Cluster verwendet, um alle Ressourcen wie Datenbanken und Logs zu speichern. Jeder Cluster hat eine primäre Instanz, die einen Zugriffspunkt auf die Daten bietet. Tabellen enthalten die tatsächlichen Daten.
Erstellen wir einen AlloyDB-Cluster, eine AlloyDB-Instanz und eine AlloyDB-Tabelle, in die das Test-Dataset geladen wird.
- Klicken Sie auf den Button oder kopieren Sie den Link unten in den Browser, in dem der Google Cloud Console-Nutzer angemeldet ist.
- Sobald dieser Schritt abgeschlossen ist, wird das Repository in Ihren lokalen Cloud Shell-Editor geklont und Sie können den folgenden Befehl über den Projektordner ausführen. Achten Sie darauf, dass Sie sich im Projektverzeichnis befinden:
sh run.sh
- Verwenden Sie jetzt die Benutzeroberfläche (klicken Sie auf den Link im Terminal oder auf den Link „Vorschau im Web“ im Terminal).
- Geben Sie die Details für Projekt-ID, Cluster- und Instanznamen ein, um zu beginnen.
- Holen Sie sich einen Kaffee, während die Logs durchlaufen. Hier können Sie nachlesen, wie das im Hintergrund funktioniert. Das kann etwa 10 bis 15 Minuten dauern.
Wichtige Hinweise und Fehlerbehebung
Das Problem mit der Geduld | Datenbankcluster sind eine schwere Infrastruktur. Wenn Sie die Seite aktualisieren oder die Cloud Shell-Sitzung beenden, weil sie „hängt“, kann es passieren, dass eine „Geisterinstanz“ entsteht, die teilweise bereitgestellt wurde und ohne manuellen Eingriff nicht gelöscht werden kann. |
Region stimmt nicht überein | Wenn Sie Ihre APIs in |
Zombie-Cluster | Wenn Sie zuvor denselben Namen für einen Cluster verwendet und ihn nicht gelöscht haben, wird im Skript möglicherweise angezeigt, dass der Clustername bereits vorhanden ist. Cluster-Namen müssen innerhalb eines Projekts eindeutig sein. |
Cloud Shell-Zeitüberschreitung | Wenn Ihre Kaffeepause 30 Minuten dauert, wird Cloud Shell möglicherweise inaktiv und die Verbindung zum |
4. Schemabereitstellung
In diesem Schritt geht es um Folgendes:
Hier finden Sie eine detaillierte Schritt-für-Schritt-Anleitung:
Sobald Ihr AlloyDB-Cluster und Ihre Instanz ausgeführt werden, können Sie im SQL-Editor von AlloyDB Studio die KI-Erweiterungen aktivieren und das Schema bereitstellen.
Möglicherweise müssen Sie warten, bis die Instanz erstellt wurde. Melden Sie sich dann mit den Anmeldedaten in AlloyDB an, die Sie beim Erstellen des Clusters erstellt haben. Verwenden Sie die folgenden Daten für die Authentifizierung bei PostgreSQL:
- Nutzername: „
postgres“ - Datenbank: „
postgres“ - Passwort: „
alloydb“ (oder das Passwort, das Sie bei der Erstellung festgelegt haben)
Nachdem Sie sich erfolgreich in AlloyDB Studio authentifiziert haben, werden SQL-Befehle im Editor eingegeben. Sie können mehrere Editorfenster hinzufügen, indem Sie auf das Pluszeichen rechts neben dem letzten Fenster klicken.
Sie geben Befehle für AlloyDB in Editorfenstern ein und verwenden bei Bedarf die Optionen „Ausführen“, „Formatieren“ und „Löschen“.
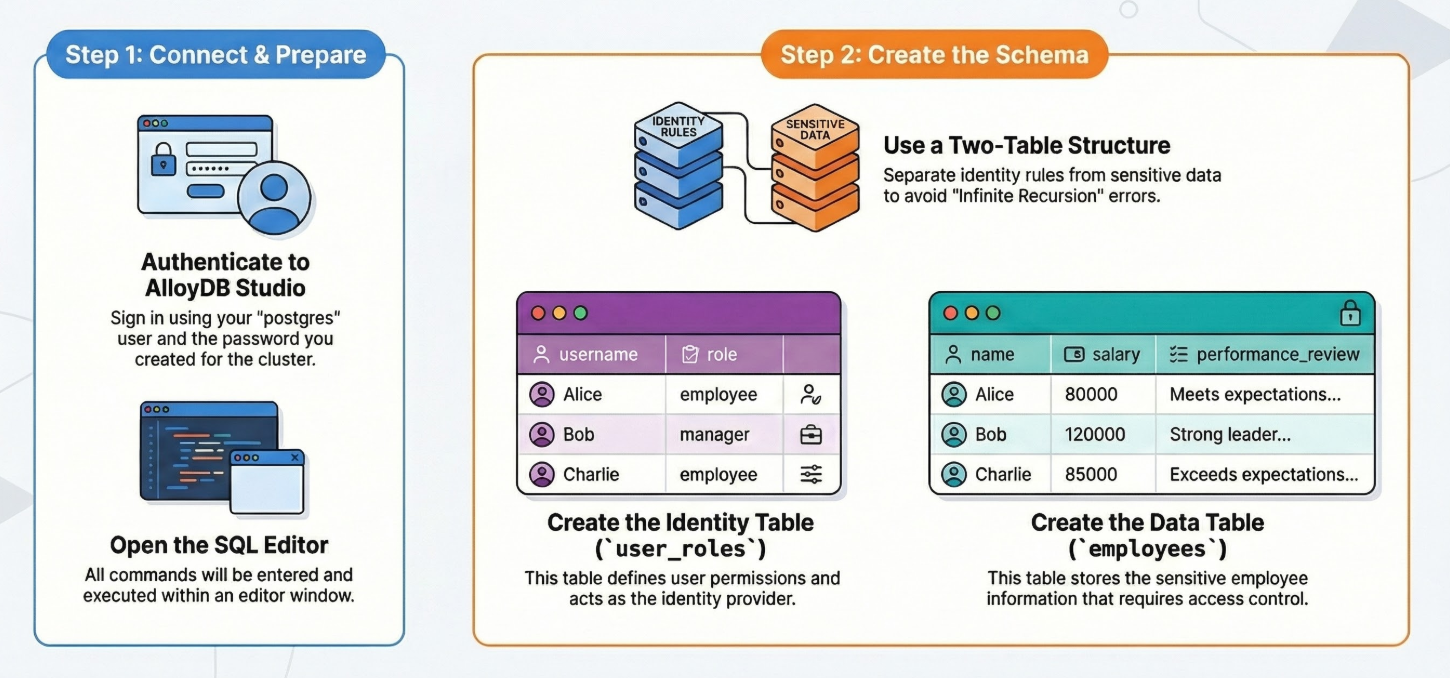
Tabelle erstellen
Wir benötigen zwei Tabellen: eine für die vertraulichen Daten (Mitarbeiter) und eine für die Identitätsregeln (user_roles). Es ist wichtig, sie zu trennen, um Fehler vom Typ „Infinite Recursion“ (Endlose Rekursion) in Richtlinien zu vermeiden.
Sie können eine Tabelle mit der folgenden DDL-Anweisung in AlloyDB Studio erstellen:
-- 1. Create User Roles (The Identity Provider)
CREATE TABLE user_roles (
username TEXT PRIMARY KEY,
role TEXT -- 'employee', 'manager', 'admin'
);
INSERT INTO user_roles (username, role) VALUES
('Alice', 'employee'),
('Bob', 'manager'),
('Charlie', 'employee');
-- 2. Create the Data Table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name TEXT,
salary INTEGER,
performance_review TEXT
);
INSERT INTO employees (name, salary, performance_review) VALUES
('Alice', 80000, 'Alice meets expectations but needs to improve punctuality.'),
('Bob', 120000, 'Bob is a strong leader. Team morale is high.'),
('Charlie', 85000, 'Charlie exceeds expectations. Ready for promotion.');
Wichtige Hinweise und Fehlerbehebung
Beim Definieren von Rollen in der Mitarbeitertabelle wurde eine Endlosschleife erkannt. | Grund für Fehler: Wenn in Ihrer Richtlinie steht: „Prüfe in der Mitarbeitertabelle, ob ich ein Manager bin“, muss die Datenbank die Tabelle abfragen, um die Richtlinie zu prüfen. Dadurch wird die Richtlinie noch einmal ausgelöst. Ergebnis: Es wurde eine Endlosschleife erkannt.Lösung: Verwenden Sie immer eine separate Nachschlagetabelle (user_roles) oder tatsächliche Datenbanknutzer für Rollen. |
Daten überprüfen:
SELECT count(*) FROM employees;
-- Output: 3
5. Sicherheit aktivieren und erzwingen
Jetzt aktivieren wir die Schutzschilde. Außerdem erstellen wir einen generischen „App-Nutzer“, den unser Python-Code für die Verbindung verwendet.
Führen Sie die folgende SQL-Anweisung im AlloyDB-Abfrageeditor aus:
-- 1. Activate RLS
ALTER TABLE employees ENABLE ROW LEVEL SECURITY;
-- 2. CRITICAL: Force RLS for Table Owners
ALTER TABLE employees FORCE ROW LEVEL SECURITY;
-- 3. Create the Application User
DO
$do$
BEGIN
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'app_user') THEN
CREATE ROLE app_user LOGIN PASSWORD 'password';
END IF;
END
$do$;
-- 4. Grant Access
GRANT SELECT ON employees TO app_user;
GRANT SELECT ON user_roles TO app_user;
Wichtige Hinweise und Fehlerbehebung
Testen als postgres (Superuser) und alle Daten ansehen. | Grund für den Fehler : Standardmäßig wird RLS nicht auf den Tabelleninhaber oder Superuser angewendet. Sie umgehen alle Richtlinien.Fehlerbehebung:Wenn Ihre Richtlinien „defekt“ zu sein scheinen (alles ist erlaubt), prüfen Sie, ob Sie als |
6. Zugriffsrichtlinien erstellen
Wir definieren zwei Regeln mit einer Sitzungsvariable (app.active_user), die wir später über unseren Anwendungscode festlegen.
Führen Sie die folgende SQL-Anweisung im AlloyDB-Abfrageeditor aus:
-- Policy 1: Self-View
-- Users can see rows where their name matches the session variable
CREATE POLICY "view_own_data" ON employees
FOR SELECT
USING (name = current_setting('app.active_user', true));
-- Policy 2: Manager-View
-- Managers can see ALL rows.
CREATE POLICY "manager_view_all" ON employees
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM user_roles
WHERE username = current_setting('app.active_user', true)
AND role = 'manager'
)
);
Wichtige Hinweise und Fehlerbehebung
„current_user“ anstelle von „app.active_user“ verwenden | Problem : „current_user“ ist ein reserviertes SQL-Schlüsselwort, das die Datenbankrolle zurückgibt (z.B. „app_user“). Wir benötigen den Anwendungsnutzer (z.B. Alice).Korrektur: Verwenden Sie immer einen benutzerdefinierten Namespace wie app.variable_name. |
Der Parameter | Problem:Wenn die Variable nicht festgelegt ist, stürzt die Abfrage mit einem Fehler ab.Lösung:current_setting('...', true) gibt NULL zurück, anstatt abzustürzen. Das führt sicher dazu, dass 0 Zeilen zurückgegeben werden. |
7. App „Chameleon“ erstellen
Wir verwenden Python und Streamlit, um die Anwendungslogik zu simulieren.
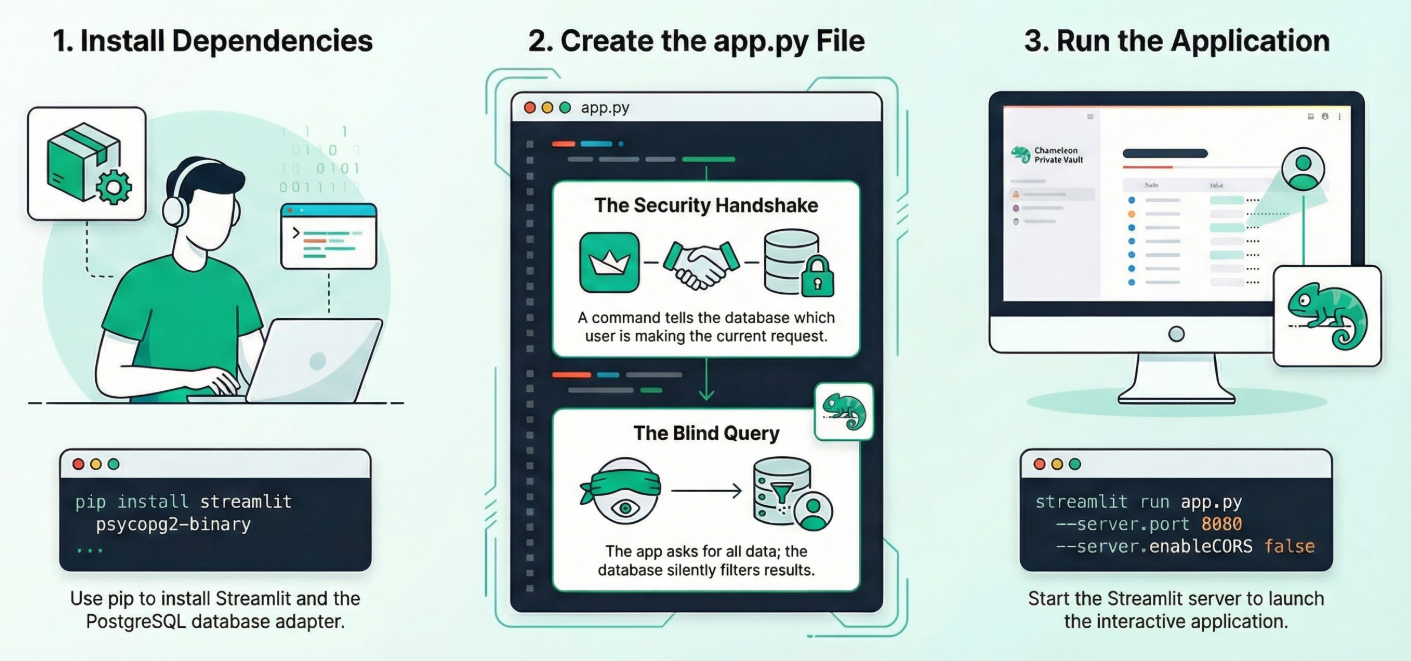
Öffnen Sie das Cloud Shell-Terminal im Editormodus, rufen Sie den Stammordner oder das Verzeichnis auf, in dem Sie diese Anwendung erstellen möchten. Erstellen Sie einen neuen Ordner.
1. Abhängigkeiten installieren:
Führen Sie den folgenden Befehl im Cloud Shell-Terminal in Ihrem neuen Projektverzeichnis aus:
pip install streamlit psycopg2-binary
2. Erstellen Sie app.py:
Erstellen Sie eine neue Datei mit dem Namen app.py und kopieren Sie den Inhalt aus der Repo-Datei.
import streamlit as st
import psycopg2
# CONFIGURATION (Replace with your IP)
DB_HOST = "10.x.x.x"
DB_NAME = "postgres"
DB_USER = "postgres"
DB_PASS = "alloydb"
def get_db_connection():
return psycopg2.connect(
host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASS
)
def query_database(user_name):
conn = get_db_connection()
try:
with conn.cursor() as cur:
# THE SECURITY HANDSHAKE
# We tell the database: "For this transaction, I am acting as..."
cur.execute(f"SET app.active_user = '{user_name}';")
# THE BLIND QUERY
# We ask for EVERYTHING. The database silently filters it.
cur.execute("SELECT name, role, salary, performance_review FROM employees;")
return cur.fetchall()
finally:
conn.close()
# UI
st.title("🛡️ The Private Vault")
user = st.sidebar.radio("Act as User:", ["Alice", "Bob", "Charlie", "Eve"])
if st.button("Access Data"):
results = query_database(user)
if not results:
st.error("🚫 Access Denied.")
else:
st.success(f"Viewing data as {user}")
for row in results:
st.write(row)
3. Führen Sie die App aus:
Führen Sie den folgenden Befehl im Cloud Shell-Terminal in Ihrem neuen Projektverzeichnis aus:
streamlit run app.py --server.port 8080 --server.enableCORS false
Wichtige Hinweise und Fehlerbehebung
Verbindungs-Pooling | Risiko: Wenn Sie einen Verbindungspool verwenden, kann die Sitzungsvariable SET app.active_user in der Verbindung bestehen bleiben und an den nächsten Nutzer „weitergegeben“ werden, der diese Verbindung verwendet.Lösung:Verwenden Sie in der Produktion immer RESET app.active_user oder DISCARD ALL, wenn Sie eine Verbindung an den Pool zurückgeben. |
Leerer Bildschirm in Cloud Shell | Lösung : Verwenden Sie die Schaltfläche „Webvorschau“ auf Port 8080. Klicken Sie nicht auf den Localhost-Link im Terminal. |
8. Zero-Trust-Konzept überprüfen
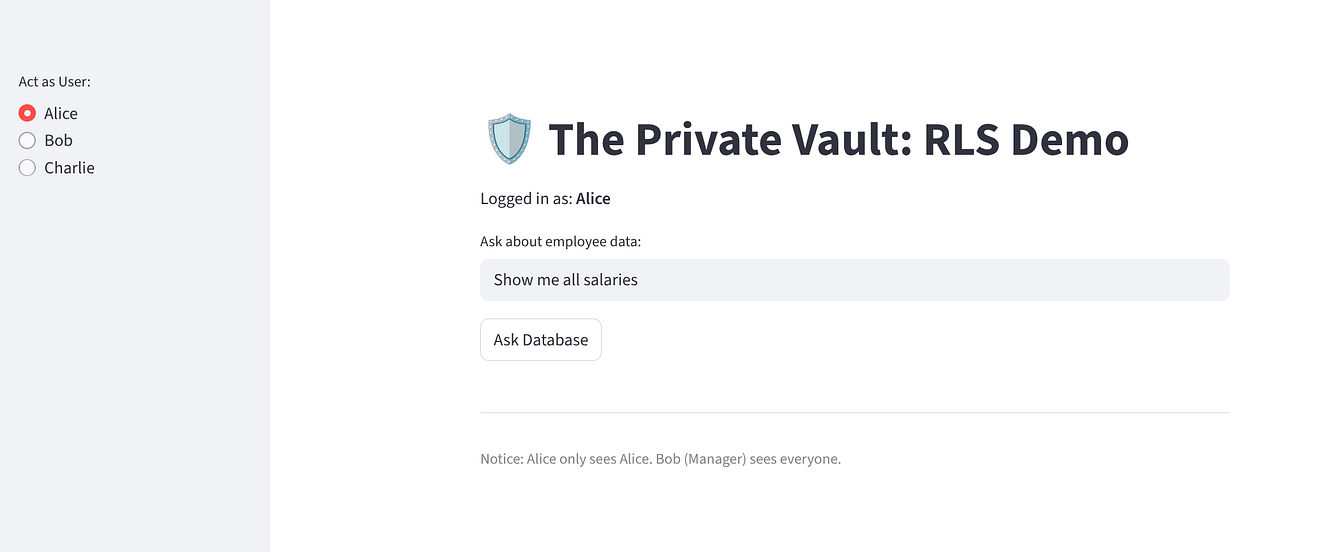
Testen Sie die App, um die Zero-Trust-Implementierung zu überprüfen:
Wählen Sie Alice aus. Sie sollte eine Zeile sehen (sich selbst).
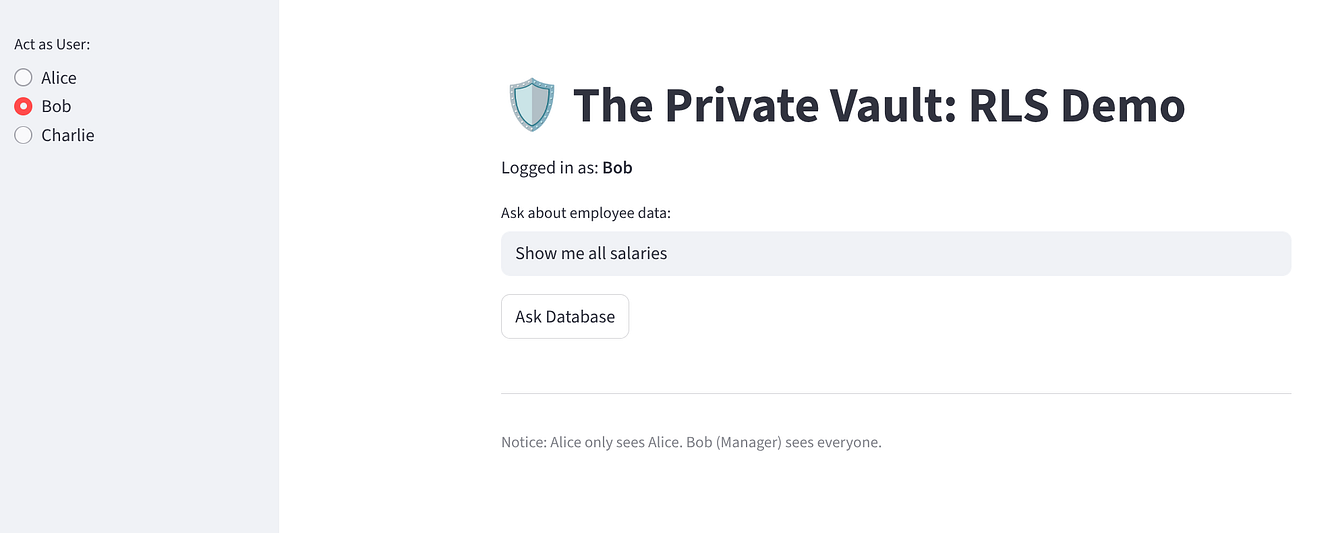
Wählen Sie Bob aus. Er sollte 3 Zeilen sehen („Alle“).
Warum ist das für KI-Agents wichtig?
Stellen Sie sich vor, Sie verbinden Ihr Modell mit dieser Datenbank. Wenn ein Nutzer Ihr Modell fragt: „Fasse alle Leistungsbeurteilungen zusammen“, wird SELECT performance_review FROM employees generiert.
- Ohne RLS: Ihr Modell ruft die privaten Rezensionen aller Nutzer ab und gibt sie an Alice weiter.
- Mit RLS: Ihr Modell führt genau dieselbe Abfrage aus, aber die Datenbank gibt nur die Rezension von Alice zurück.
Das ist Zero-Trust AI. Sie vertrauen dem Modell nicht, Daten zu filtern, sondern zwingen die Datenbank, sie auszublenden.
In der Produktion bereitstellen
Die hier gezeigte Architektur ist für die Produktion geeignet, die spezifische Implementierung ist jedoch vereinfacht, um das Lernen zu erleichtern. Um diese Lösung sicher in einer realen Unternehmensumgebung bereitzustellen, sollten Sie die folgenden Verbesserungen implementieren:
- Echte Authentifizierung:Ersetzen Sie das Drop-down-Menü „Identitätswechsler“ durch einen robusten Identitätsanbieter (Identity Provider, IDP) wie Google Identity Platform, Okta oder Auth0. Ihre Anwendung sollte das Token des Nutzers überprüfen und seine Identität sicher extrahieren, bevor die Datenbank-Sitzungsvariable festgelegt wird. So wird sichergestellt, dass Nutzer ihre Identität nicht fälschen können.
- Sicherheit beim Verbindungs-Pooling:Bei Verwendung von Verbindungspools können Sitzungsvariablen manchmal über verschiedene Nutzeranfragen hinweg bestehen bleiben, wenn sie nicht richtig behandelt werden. Achten Sie darauf, dass Ihre Anwendung die Sitzungsvariable zurücksetzt (z.B. RESET app.active_user) oder den Verbindungsstatus löscht, wenn eine Verbindung an den Pool zurückgegeben wird, um Datenlecks zwischen Nutzern zu verhindern.
- Secret-Verwaltung:Das Hardcoding von Datenbankanmeldedaten stellt ein Sicherheitsrisiko dar. Verwenden Sie einen speziellen Secret-Verwaltungsdienst wie Google Secret Manager, um Ihre Datenbankpasswörter und Verbindungsstrings zur Laufzeit sicher zu speichern und abzurufen.
9. Bereinigen
Vergessen Sie nicht, den AlloyDB-Cluster und die AlloyDB-Instanz zu löschen, wenn Sie dieses Lab abgeschlossen haben.
Dadurch sollte der Cluster zusammen mit seinen Instanzen bereinigt werden.
10. Glückwunsch
Das wars! Sie haben die Sicherheit erfolgreich auf die Datenschicht verlagert. Selbst wenn Ihr Python-Code einen Fehler enthält, der versucht, print(all_salaries), würde die Datenbank nichts an Alice zurückgeben.
Nächste Schritte
- Probieren Sie es mit Ihrem eigenen Dataset aus.
- AlloyDB AI-Dokumentation
- Weitere Workshops finden Sie auf der Code Vipassana-Website.