
1. Descripción general
En la prisa por crear aplicaciones basadas en IA generativa, a menudo olvidamos el componente más importante: la seguridad.
Imagina que estás creando un chatbot de RR.HH. Quieres que responda preguntas como "¿Cuál es mi salario?" o "¿Cómo se desempeña mi equipo?"
- Si Alice (una empleada normal) pregunta, solo debería ver sus datos.
- Si Bob (un administrador) pregunta, debería ver los datos de su equipo.
El problema
La mayoría de las arquitecturas de RAG (generación mejorada por recuperación) intentan controlar esto en la capa de aplicación. Filtran fragmentos después de recuperarlos o confían en que el LLM se “comporte”. Es frágil. Si falla la lógica de la app, se filtran datos.
La solución
Envía la seguridad a la capa de la base de datos. Con la seguridad a nivel de las filas (RLS) de PostgreSQL en AlloyDB, nos aseguramos de que la base de datos se niegue físicamente a devolver datos que el usuario no tiene permiso para ver, sin importar lo que solicite la IA.
En esta guía, crearemos "La bóveda privada": Un asistente de RR.HH. seguro que cambia sus respuestas de forma dinámica según quién haya accedido.
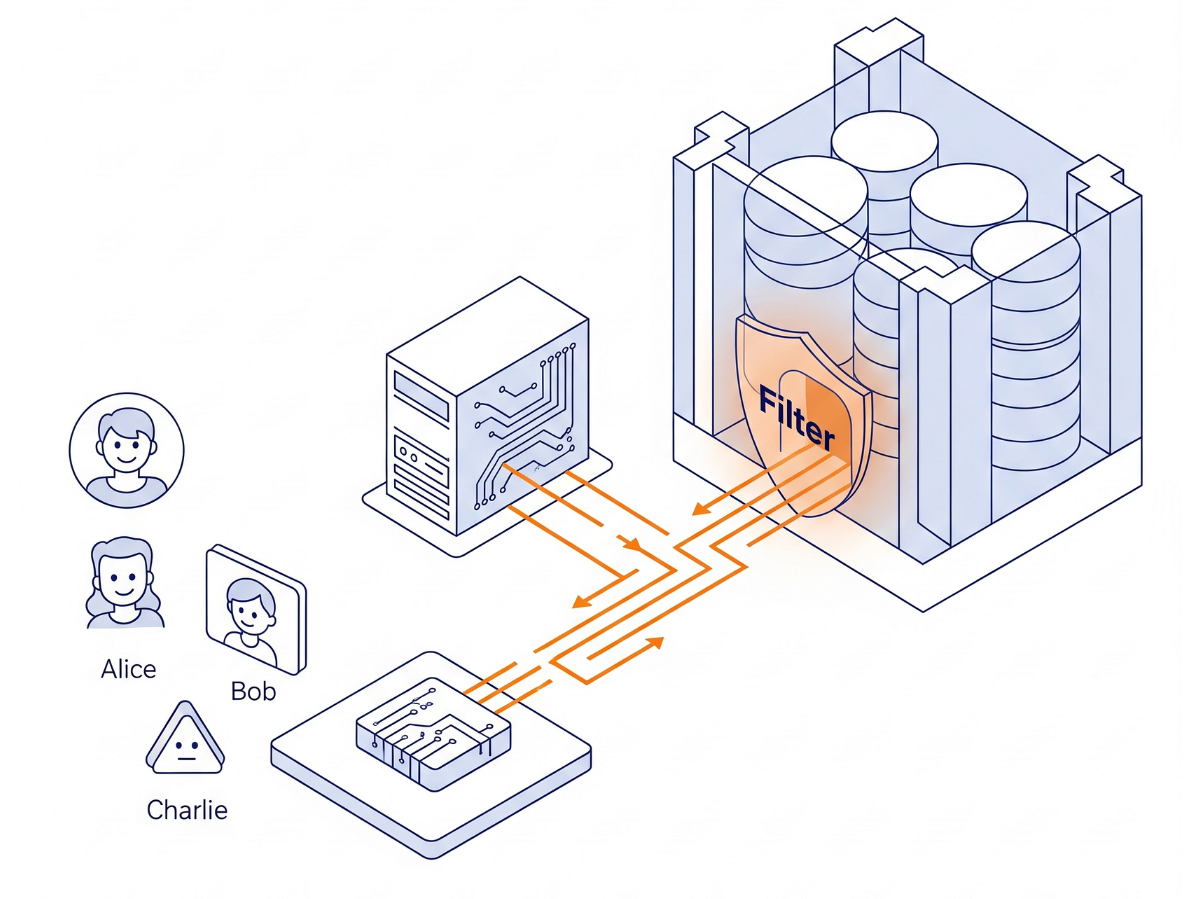
La arquitectura
No estamos creando una lógica de permisos compleja en Python. Estamos usando el motor de base de datos en sí.
- La interfaz: Una app de Streamlit simple que simula un acceso.
- El cerebro: AlloyDB AI (compatible con PostgreSQL)
- El mecanismo: Establecemos una variable de sesión (
app.active_user) al comienzo de cada transacción. Las políticas de la base de datos verifican automáticamente una tablauser_roles(que actúa como nuestro proveedor de identidad) para filtrar las filas.
Qué compilarás
Una aplicación segura de asistente de RR.HH. En lugar de depender de la lógica de la aplicación para filtrar los datos sensibles, implementarás la seguridad a nivel de la fila (RLS) directamente en el motor de la base de datos de AlloyDB. Esto garantiza que, incluso si tu modelo de IA "alucina" o intenta acceder a datos no autorizados, la base de datos se negará físicamente a devolverlos.
Qué aprenderás
Aprenderás a hacer lo siguiente:
- Cómo diseñar un esquema para la RLS (separación de datos y de identidad)
- Cómo escribir políticas de PostgreSQL (
CREATE POLICY) - Cómo omitir la exención de "Propietario de la tabla" con
FORCE ROW LEVEL SECURITY - Cómo compilar una app de Python que realice un "cambio de contexto" para los usuarios
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias: Sigue el vínculo y habilita las APIs.
Como alternativa, puedes usar el comando de gcloud para esto. Consulta la documentación para ver los comandos y el uso de gcloud.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Problemas potenciales y solución de problemas
El "Proyecto Fantasma" : Síndrome | Ejecutaste |
La barricada de facturación | Habilitaste el proyecto, pero olvidaste la cuenta de facturación. AlloyDB es un motor de alto rendimiento que no se iniciará si el "tanque de combustible" (facturación) está vacío. |
Desfase de la propagación de la API | Hiciste clic en "Habilitar APIs", pero la línea de comandos aún dice |
Cuota de Quags | Si usas una cuenta de prueba nueva, es posible que alcances una cuota regional para las instancias de AlloyDB. Si falla |
3. Configuración de la base de datos
En este lab, usaremos AlloyDB como la base de datos para los datos de prueba. Utiliza clústeres para contener todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas contendrán los datos reales.
Creemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de prueba.
- Haz clic en el botón o copia el siguiente vínculo en el navegador en el que accediste como usuario a la consola de Google Cloud.
- Una vez que se complete este paso, el repo se clonará en tu editor local de Cloud Shell y podrás ejecutar el siguiente comando desde la carpeta del proyecto (es importante que te asegures de estar en el directorio del proyecto):
sh run.sh
- Ahora usa la IU (haz clic en el vínculo de la terminal o en el vínculo "preview on web" de la terminal).
- Ingresa los detalles del ID del proyecto, el clúster y los nombres de las instancias para comenzar.
- Ve a tomar un café mientras se desplazan los registros. Aquí puedes leer cómo se hace esto en segundo plano. Esto puede tardar entre 10 y 15 minutos.
Problemas potenciales y solución de problemas
El problema de la "paciencia" | Los clústeres de bases de datos son una infraestructura pesada. Si actualizas la página o finalizas la sesión de Cloud Shell porque "parece que se detuvo", es posible que termines con una instancia "fantasma" que se aprovisionó parcialmente y que es imposible borrar sin intervención manual. |
Región no coincidente | Si habilitaste tus APIs en |
Clústeres de zombis | Si antes usaste el mismo nombre para un clúster y no lo borraste, es posible que la secuencia de comandos indique que el nombre del clúster ya existe. Los nombres de los clústeres deben ser únicos dentro de un proyecto. |
Tiempo de espera de Cloud Shell | Si tu descanso para tomar café dura 30 minutos, es posible que Cloud Shell entre en modo de suspensión y desconecte el proceso |
4. Aprovisionamiento de esquemas
En este paso, abordaremos lo siguiente:
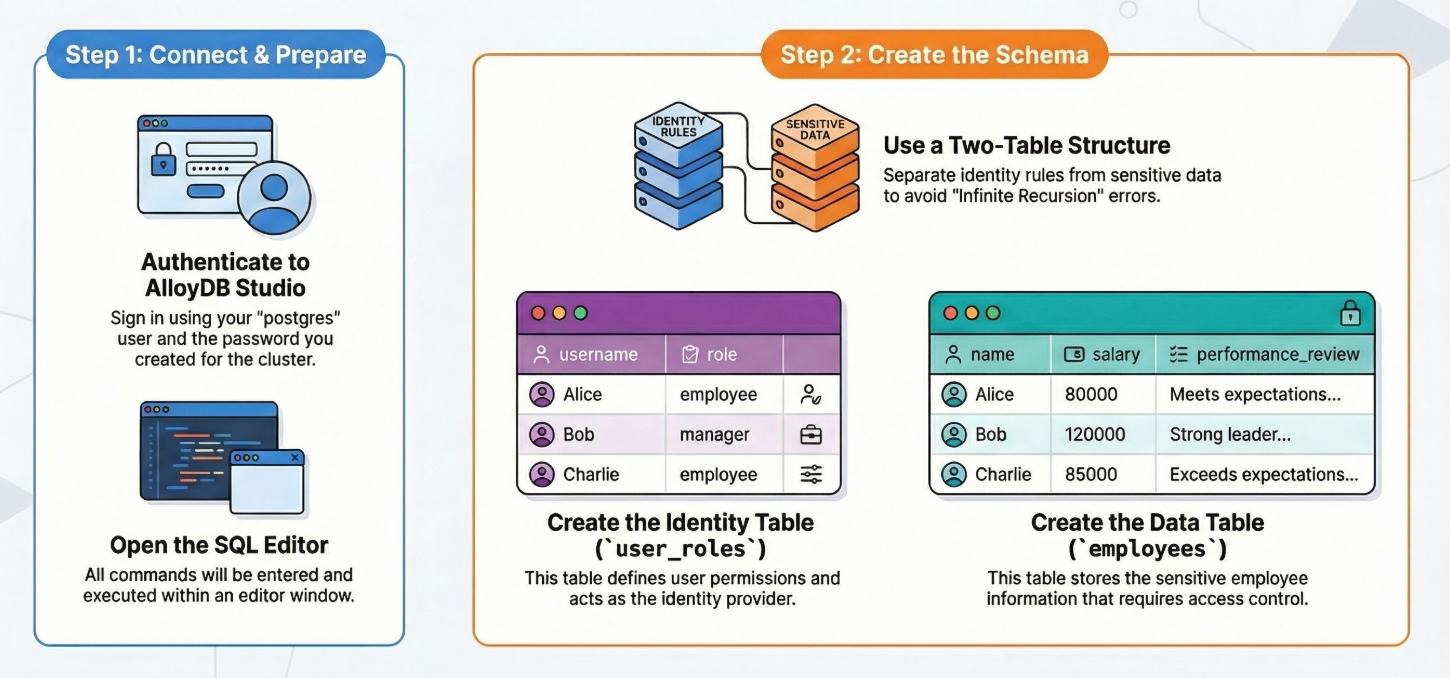
Estas son las acciones detalladas paso a paso:
Una vez que tengas en funcionamiento tu clúster y tu instancia de AlloyDB, dirígete al editor de SQL de AlloyDB Studio para habilitar las extensiones de IA y aprovisionar el esquema.
Es posible que debas esperar a que termine de crearse la instancia. Una vez que lo hagas, accede a AlloyDB con las credenciales que creaste cuando creaste el clúster. Usa los siguientes datos para autenticarte en PostgreSQL:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña : "
alloydb" (o la que hayas configurado en el momento de la creación)
Una vez que te autentiques correctamente en AlloyDB Studio, ingresa los comandos SQL en el editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la última ventana.
Ingresarás comandos para AlloyDB en ventanas del editor, y usarás las opciones Ejecutar, Formatear y Borrar según sea necesario.
Crea una tabla
Necesitamos dos tablas: una para los datos sensibles (empleados) y otra para las reglas de identidad (user_roles). Es fundamental separarlos para evitar errores de "recursión infinita" en las políticas.
Puedes crear una tabla con la siguiente instrucción DDL en AlloyDB Studio:
-- 1. Create User Roles (The Identity Provider)
CREATE TABLE user_roles (
username TEXT PRIMARY KEY,
role TEXT -- 'employee', 'manager', 'admin'
);
INSERT INTO user_roles (username, role) VALUES
('Alice', 'employee'),
('Bob', 'manager'),
('Charlie', 'employee');
-- 2. Create the Data Table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name TEXT,
salary INTEGER,
performance_review TEXT
);
INSERT INTO employees (name, salary, performance_review) VALUES
('Alice', 80000, 'Alice meets expectations but needs to improve punctuality.'),
('Bob', 120000, 'Bob is a strong leader. Team morale is high.'),
('Charlie', 85000, 'Charlie exceeds expectations. Ready for promotion.');
Problemas potenciales y solución de problemas
Se detectó una recursión infinita mientras se definían roles dentro de la tabla de empleados | Por qué falla: Si tu política dice "Consulta la tabla de empleados para ver si soy gerente", la base de datos debe consultar la tabla para verificar la política, lo que vuelve a activar la política.Resultado: Se detectó una recursión infinita.Solución: Siempre mantén una tabla de búsqueda separada (user_roles) o usa usuarios de la base de datos reales para los roles. |
Verifica los datos:
SELECT count(*) FROM employees;
-- Output: 3
5. Habilita y aplica la seguridad
Ahora activaremos los escudos. También crearemos un "Usuario de la app" genérico que nuestro código de Python usará para conectarse.
Ejecuta la siguiente instrucción de SQL desde el editor de consultas de AlloyDB:
-- 1. Activate RLS
ALTER TABLE employees ENABLE ROW LEVEL SECURITY;
-- 2. CRITICAL: Force RLS for Table Owners
ALTER TABLE employees FORCE ROW LEVEL SECURITY;
-- 3. Create the Application User
DO
$do$
BEGIN
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'app_user') THEN
CREATE ROLE app_user LOGIN PASSWORD 'password';
END IF;
END
$do$;
-- 4. Grant Access
GRANT SELECT ON employees TO app_user;
GRANT SELECT ON user_roles TO app_user;
Problemas potenciales y solución de problemas
Pruebas como postgres (superusuario) y visualización de todos los datos. | Por qué falla: De forma predeterminada, la RLS no se aplica al propietario de la tabla ni a los superusuarios. Eluden todas las políticas.Solución de problemas: Si tus políticas parecen "rotas" (permiten todo), verifica si accediste como |
6. Crea las políticas de acceso
Definiremos dos reglas con una variable de sesión (app.active_user) que estableceremos más adelante desde el código de nuestra aplicación.
Ejecuta la siguiente instrucción de SQL desde el editor de consultas de AlloyDB:
-- Policy 1: Self-View
-- Users can see rows where their name matches the session variable
CREATE POLICY "view_own_data" ON employees
FOR SELECT
USING (name = current_setting('app.active_user', true));
-- Policy 2: Manager-View
-- Managers can see ALL rows.
CREATE POLICY "manager_view_all" ON employees
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM user_roles
WHERE username = current_setting('app.active_user', true)
AND role = 'manager'
)
);
Problemas potenciales y solución de problemas
Usar current_user en lugar de app.active_user | Problema: Current_user es una palabra clave reservada de SQL que devuelve el rol de la base de datos (p.ej., app_user). Necesitamos el usuario de la aplicación (p.ej., Alice).Corrección: Siempre usa un espacio de nombres personalizado, como app.variable_name. |
Olvidar el parámetro | Problema: Si no se configura la variable, la consulta falla con un error.Solución: current_setting('...', true) devuelve NULL en lugar de fallar, lo que genera de forma segura que se devuelvan 0 filas. |
7. Compila la app "Chameleon"
Usaremos Python y Streamlit para simular la lógica de la aplicación.
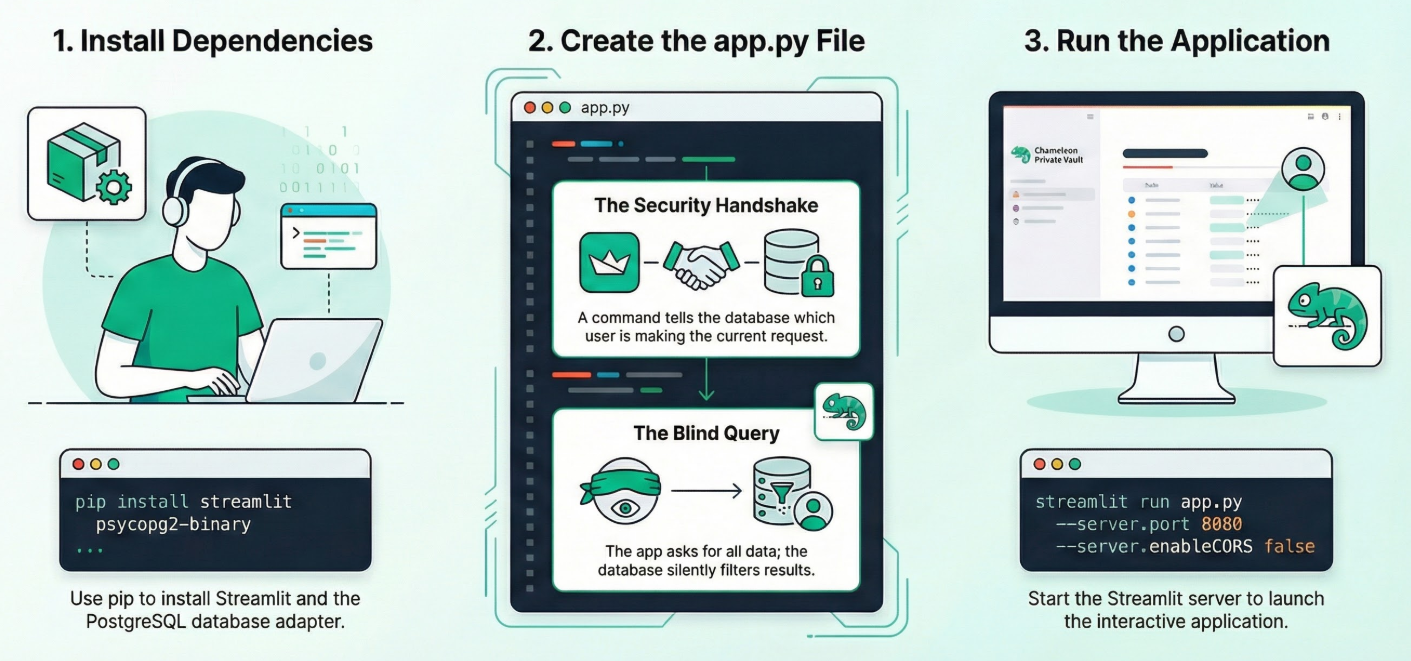
Abre la terminal de Cloud Shell en modo Editor, navega a tu carpeta raíz o al directorio en el que deseas crear esta aplicación. Crear una carpeta nueva.
1. Instala las dependencias:
Ejecuta el siguiente comando en la terminal de Cloud Shell desde el directorio de tu nuevo proyecto:
pip install streamlit psycopg2-binary
2. Crea app.py:
Crea un archivo nuevo llamado app.py y copia el contenido del archivo del repo.
import streamlit as st
import psycopg2
# CONFIGURATION (Replace with your IP)
DB_HOST = "10.x.x.x"
DB_NAME = "postgres"
DB_USER = "postgres"
DB_PASS = "alloydb"
def get_db_connection():
return psycopg2.connect(
host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASS
)
def query_database(user_name):
conn = get_db_connection()
try:
with conn.cursor() as cur:
# THE SECURITY HANDSHAKE
# We tell the database: "For this transaction, I am acting as..."
cur.execute(f"SET app.active_user = '{user_name}';")
# THE BLIND QUERY
# We ask for EVERYTHING. The database silently filters it.
cur.execute("SELECT name, role, salary, performance_review FROM employees;")
return cur.fetchall()
finally:
conn.close()
# UI
st.title("🛡️ The Private Vault")
user = st.sidebar.radio("Act as User:", ["Alice", "Bob", "Charlie", "Eve"])
if st.button("Access Data"):
results = query_database(user)
if not results:
st.error("🚫 Access Denied.")
else:
st.success(f"Viewing data as {user}")
for row in results:
st.write(row)
3. Ejecuta la app:
Ejecuta el siguiente comando en la terminal de Cloud Shell desde el directorio de tu nuevo proyecto:
streamlit run app.py --server.port 8080 --server.enableCORS false
Problemas potenciales y solución de problemas
Agrupación de conexiones | Riesgo: Si usas un grupo de conexiones, la variable de sesión SET app.active_user podría persistir en la conexión y “filtrarse” al siguiente usuario que tome esa conexión.Solución: En producción, siempre usa RESET app.active_user o DISCARD ALL cuando devuelvas una conexión al grupo. |
Pantalla en blanco en Cloud Shell. | Solución: Usa el botón "Vista previa en la Web" en el puerto 8080. No hagas clic en el vínculo localhost de la terminal. |
8. Verifica la confianza cero
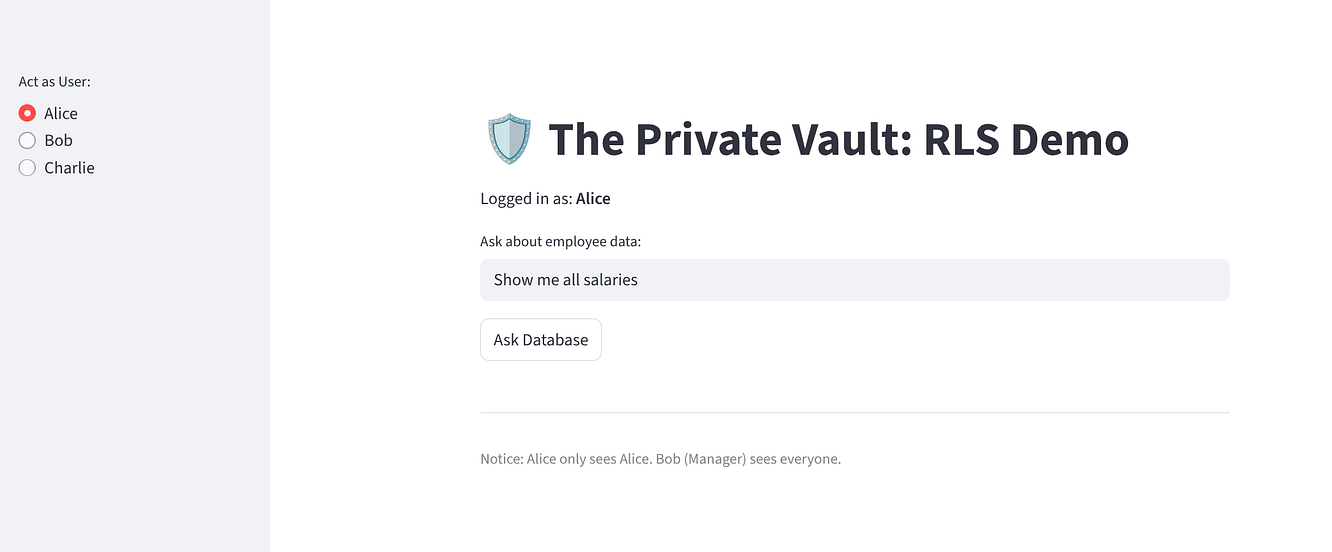
Prueba la app para asegurarte de que se implementó la confianza cero:
Selecciona "Alice": Debería ver 1 fila (ella misma).
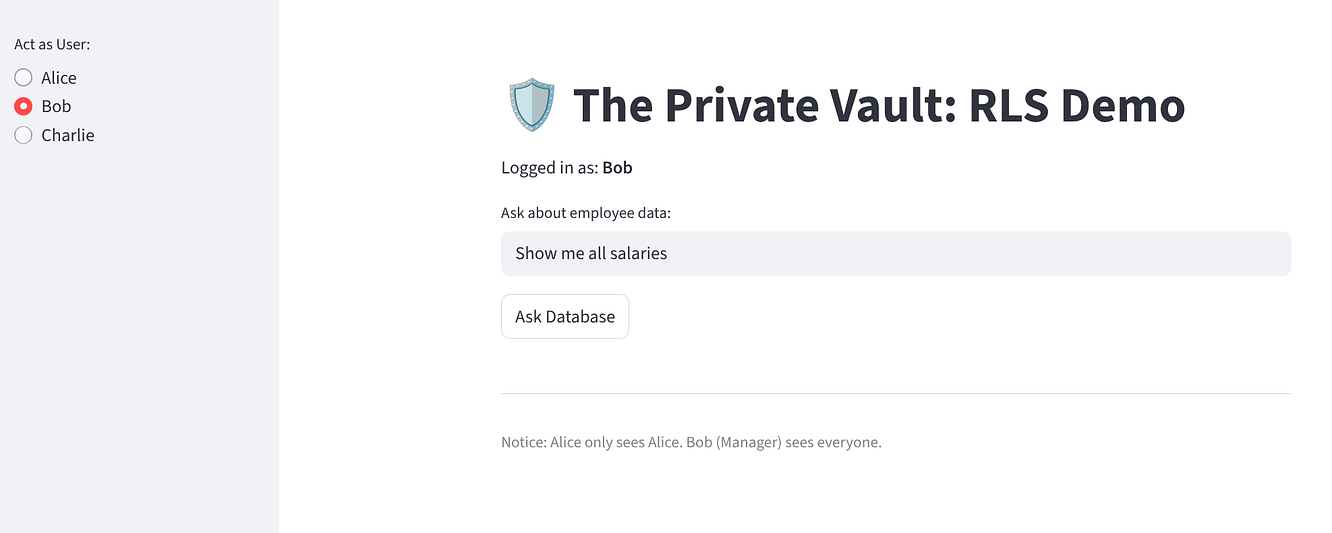
Selecciona "Bob": Debería ver 3 filas (Todos).
Por qué esto es importante para los agentes de IA
Imagina que conectas tu modelo a esta base de datos. Si un usuario le pregunta a tu modelo: "Resume todas las revisiones de rendimiento", se generará SELECT performance_review FROM employees.
- Sin RLS: Tu modelo recupera las opiniones privadas de todos y se las filtra a Alicia.
- Con RLS: Tu modelo ejecuta exactamente la misma consulta, pero la base de datos solo devuelve la opinión de Alice.
Esta es la IA de confianza cero. No confías en el modelo para filtrar los datos, sino que obligas a la base de datos a ocultarlos.
Lanzamiento en producción
La arquitectura que se muestra aquí es apta para la producción, pero la implementación específica se simplificó para facilitar el aprendizaje. Para implementar esto de forma segura en un entorno empresarial real, debes implementar las siguientes mejoras:
- Autenticación real: Reemplaza el menú desplegable "Identity Switcher" por un proveedor de identidad (IDP) sólido, como Google Identity Platform, Okta o Auth0. Tu aplicación debe verificar el token del usuario y extraer su identidad de forma segura antes de configurar la variable de sesión de la base de datos, lo que garantiza que los usuarios no puedan suplantar su identidad.
- Seguridad de la agrupación de conexiones: Cuando se usan grupos de conexiones, las variables de sesión a veces pueden persistir en diferentes solicitudes de usuarios si no se controlan correctamente. Asegúrate de que tu aplicación restablezca la variable de sesión (p.ej., RESET app.active_user) o borre el estado de conexión cuando devuelva una conexión al grupo para evitar la filtración de datos entre usuarios.
- Administración de secretos: Codificar de forma rígida las credenciales de la base de datos es un riesgo de seguridad. Usa un servicio de administración de secretos dedicado, como Google Secret Manager, para almacenar y recuperar de forma segura tus contraseñas de bases de datos y cadenas de conexión durante el tiempo de ejecución.
9. Limpia
Cuando termines este lab, no olvides borrar el clúster y la instancia de AlloyDB.
Debería limpiar el clúster junto con sus instancias.
10. Felicitaciones
¡Felicitaciones! Enviaste correctamente la seguridad a la capa de datos. Incluso si tu código de Python tuviera un error que intentara print(all_salaries), la base de datos no devolvería nada a Alice.
Próximos pasos
- Prueba esto con tu propio conjunto de datos.
- Explora la documentación de AlloyDB AI.
- Consulta el sitio web de Code Vipassana para ver más talleres.