
1. Présentation
Dans la précipitation pour créer des applications d'IA générative, nous oublions souvent le composant le plus important : la sécurité.
Imaginez que vous créez un chatbot RH. Vous souhaitez qu'il réponde à des questions comme Quel est mon salaire ? ou Quelles sont les performances de mon équipe ?
- Si Alice (une employée standard) demande à consulter ses données, elle ne devrait voir que les siennes.
- Si Bob (un responsable) pose une question, il devrait voir les données de son équipe.
Le problème
La plupart des architectures RAG (Retrieval Augmented Generation) tentent de gérer cela dans la couche Application. Ils filtrent les blocs après les avoir récupérés ou comptent sur le LLM pour "se comporter correctement". C'est fragile. Si la logique de l'application échoue, les données sont divulguées.
La solution
Transférez la sécurité à la couche de base de données. En utilisant la sécurité au niveau des lignes (RLS) de PostgreSQL dans AlloyDB, nous nous assurons que la base de données refuse physiquement de renvoyer les données que l'utilisateur n'est pas autorisé à consulter, quelle que soit la demande de l'IA.
Dans ce guide, nous allons créer The Private Vault, un assistant RH sécurisé qui modifie dynamiquement ses réponses en fonction de l'utilisateur connecté.
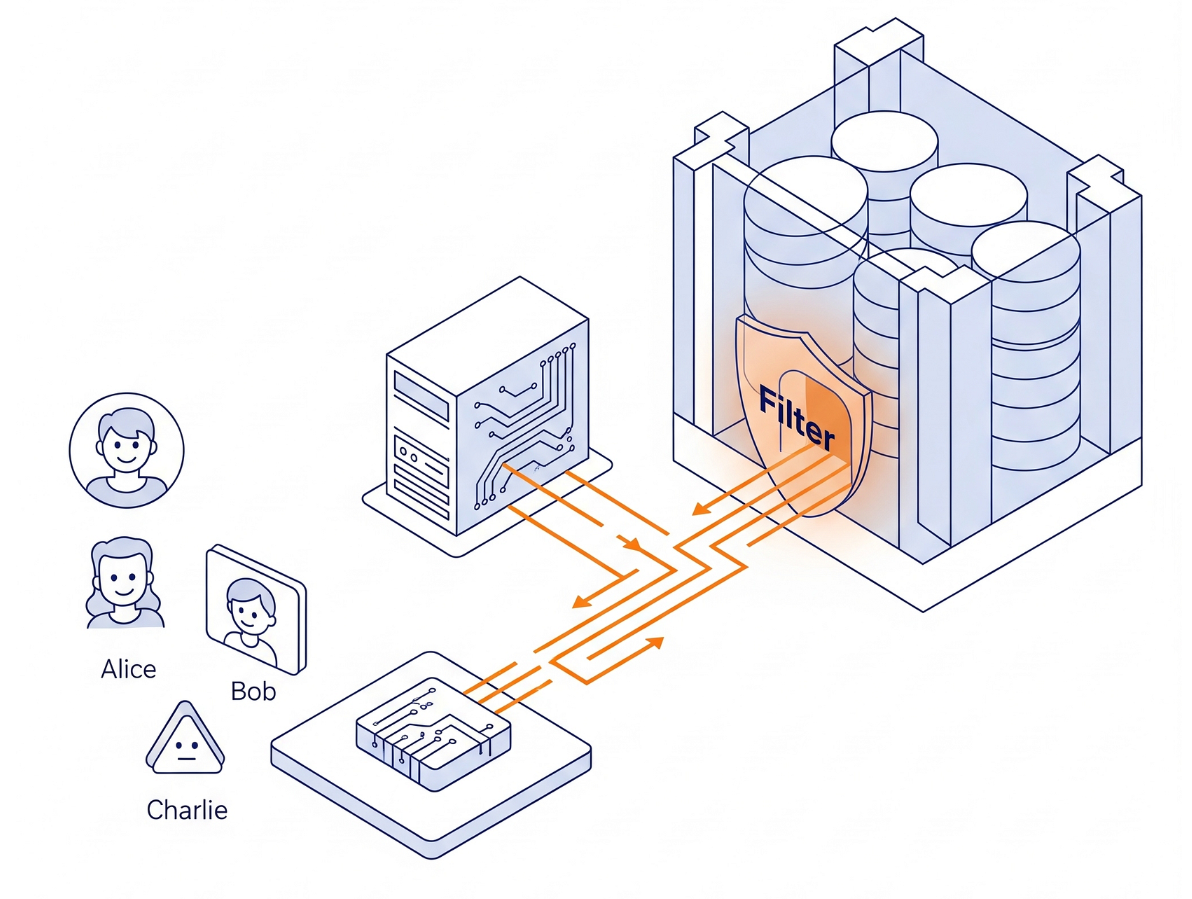
Architecture
Nous ne créons pas de logique d'autorisation complexe en Python. Nous utilisons le moteur de base de données lui-même.
- L'interface : une application Streamlit simple simulant une connexion.
- Le cerveau : AlloyDB AI (compatible avec PostgreSQL).
- Mécanisme : nous définissons une variable de session (
app.active_user) au début de chaque transaction. Les règles de la base de données vérifient automatiquement une tableuser_roles(qui sert de fournisseur d'identité) pour filtrer les lignes.
Ce que vous allez faire
Une application d'assistance RH sécurisée. Au lieu de vous appuyer sur la logique d'application pour filtrer les données sensibles, vous allez implémenter la sécurité au niveau des lignes (RLS, Row-Level Security) directement dans le moteur de base de données AlloyDB. Ainsi, même si votre modèle d'IA "hallucine" ou tente d'accéder à des données non autorisées, la base de données refusera physiquement de les renvoyer.
Points abordés
Vous pourrez découvrir :
- Concevoir un schéma pour la sécurité au niveau des lignes (en séparant les données de l'identité)
- Écrire des règles PostgreSQL (
CREATE POLICY) - Comment contourner l'exemption "Propriétaire de la table" à l'aide de
FORCE ROW LEVEL SECURITY. - Découvrez comment créer une application Python qui effectue un "changement de contexte" pour les utilisateurs.
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : suivez ce lien et activez les API.
Vous pouvez également utiliser la commande gcloud. Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Problèmes et dépannage
Syndrome du projet fantôme | Vous avez exécuté |
Barricade de facturation | Vous avez activé le projet, mais oublié le compte de facturation. AlloyDB est un moteur hautes performances. Il ne démarrera pas si le "réservoir" (la facturation) est vide. |
Décalage de la propagation de l'API | Vous avez cliqué sur "Activer les API", mais la ligne de commande indique toujours |
Quags de quota | Si vous utilisez un tout nouveau compte d'essai, vous pouvez atteindre un quota régional pour les instances AlloyDB. Si |
3. Configuration de la base de données
Dans cet atelier, nous allons utiliser AlloyDB comme base de données pour les données de test. Il utilise des clusters pour stocker toutes les ressources, telles que les bases de données et les journaux. Chaque cluster possède une instance principale qui fournit un point d'accès aux données. Les tables contiennent les données réelles.
Commençons par créer un cluster, une instance et une table AlloyDB dans lesquels l'ensemble de données de test sera chargé.
- Cliquez sur le bouton ou copiez le lien ci-dessous dans le navigateur dans lequel l'utilisateur de la console Google Cloud est connecté.
- Une fois cette étape terminée, le dépôt sera cloné dans votre éditeur Cloud Shell local. Vous pourrez ensuite exécuter la commande ci-dessous à partir du dossier du projet (assurez-vous d'être dans le répertoire du projet) :
sh run.sh
- Utilisez maintenant l'UI (en cliquant sur le lien dans le terminal ou sur le lien "Prévisualiser sur le Web" dans le terminal).
- Saisissez les détails de l'ID de projet, du nom du cluster et du nom de l'instance pour commencer.
- Allez prendre un café pendant que les journaux défilent. Pour en savoir plus sur le fonctionnement en coulisses, cliquez ici. Cette opération peut prendre entre 10 et 15 minutes.
Problèmes et dépannage
Le problème de la patience | Les clusters de bases de données sont une infrastructure lourde. Si vous actualisez la page ou mettez fin à la session Cloud Shell parce qu'elle semble bloquée, vous risquez de vous retrouver avec une instance "fantôme" partiellement provisionnée et impossible à supprimer sans intervention manuelle. |
Région non concordante | Si vous avez activé vos API dans |
Clusters de zombies | Si vous avez déjà utilisé le même nom pour un cluster et que vous ne l'avez pas supprimé, le script peut indiquer que le nom du cluster existe déjà. Les noms de clusters doivent être uniques dans un projet. |
Délai d'inactivité de Cloud Shell | Si votre pause-café dure 30 minutes, Cloud Shell peut se mettre en veille et déconnecter le processus |
4. Provisionnement de schémas
Au cours de cette étape, nous allons aborder les points suivants :
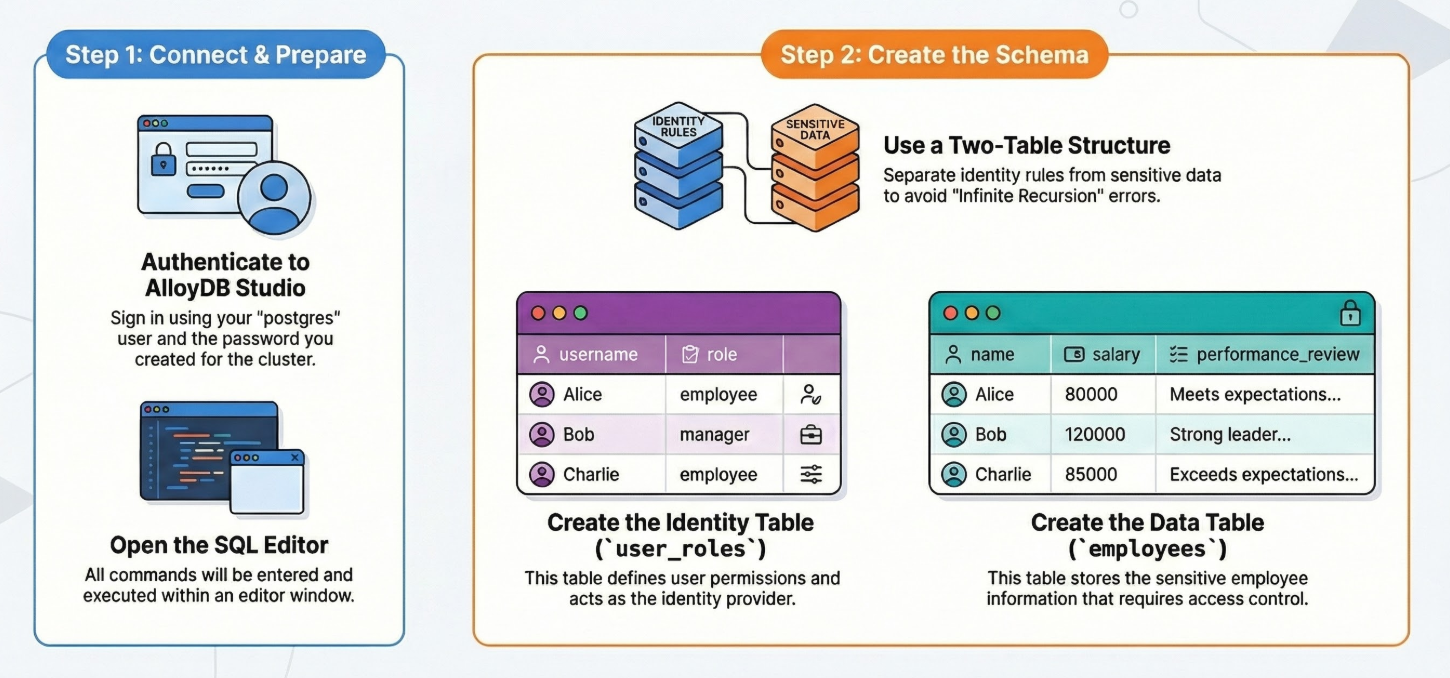
Voici la procédure détaillée :
Une fois votre cluster et votre instance AlloyDB en cours d'exécution, accédez à l'éditeur SQL AlloyDB Studio pour activer les extensions d'IA et provisionner le schéma.
Vous devrez peut-être attendre que votre instance soit créée. Une fois le cluster créé, connectez-vous à AlloyDB à l'aide des identifiants que vous avez créés. Utilisez les données suivantes pour vous authentifier auprès de PostgreSQL :
- Nom d'utilisateur : "
postgres" - Base de données : "
postgres" - Mot de passe : "
alloydb" (ou celui que vous avez défini lors de la création)
Une fois l'authentification réussie dans AlloyDB Studio, les commandes SQL sont saisies dans l'éditeur. Vous pouvez ajouter plusieurs fenêtres de l'éditeur en cliquant sur le signe plus à droite de la dernière fenêtre.
Vous saisirez les commandes pour AlloyDB dans les fenêtres de l'éditeur, en utilisant les options "Exécuter", "Mettre en forme" et "Effacer" selon les besoins.
Créer une table
Nous avons besoin de deux tables : l'une pour les données sensibles (employés) et l'autre pour les règles d'identité (user_roles). Il est essentiel de les séparer pour éviter les erreurs de "récursion infinie" dans les règles.
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans AlloyDB Studio :
-- 1. Create User Roles (The Identity Provider)
CREATE TABLE user_roles (
username TEXT PRIMARY KEY,
role TEXT -- 'employee', 'manager', 'admin'
);
INSERT INTO user_roles (username, role) VALUES
('Alice', 'employee'),
('Bob', 'manager'),
('Charlie', 'employee');
-- 2. Create the Data Table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name TEXT,
salary INTEGER,
performance_review TEXT
);
INSERT INTO employees (name, salary, performance_review) VALUES
('Alice', 80000, 'Alice meets expectations but needs to improve punctuality.'),
('Bob', 120000, 'Bob is a strong leader. Team morale is high.'),
('Charlie', 85000, 'Charlie exceeds expectations. Ready for promotion.');
Problèmes et dépannage
Récursion infinie détectée lors de la définition des rôles dans la table des employés | Pourquoi l'opération échoue : si votre règle indique "Vérifie dans le tableau des employés si je suis un responsable", la base de données doit interroger le tableau pour vérifier la règle, ce qui déclenche à nouveau la règle.Résultat : récursivité infinie détectée.Solution : conservez toujours une table de recherche distincte (user_roles) ou utilisez de vrais utilisateurs de base de données pour les rôles. |
Vérifiez les données :
SELECT count(*) FROM employees;
-- Output: 3
5. Activer et appliquer la sécurité
Nous allons maintenant activer les boucliers. Nous allons également créer un "utilisateur d'application" générique que notre code Python utilisera pour se connecter.
Exécutez l'instruction SQL ci-dessous à partir de l'éditeur de requête AlloyDB :
-- 1. Activate RLS
ALTER TABLE employees ENABLE ROW LEVEL SECURITY;
-- 2. CRITICAL: Force RLS for Table Owners
ALTER TABLE employees FORCE ROW LEVEL SECURITY;
-- 3. Create the Application User
DO
$do$
BEGIN
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'app_user') THEN
CREATE ROLE app_user LOGIN PASSWORD 'password';
END IF;
END
$do$;
-- 4. Grant Access
GRANT SELECT ON employees TO app_user;
GRANT SELECT ON user_roles TO app_user;
Problèmes et dépannage
Test en tant que postgres (super-utilisateur) et affichage de toutes les données. | Pourquoi l'opération échoue : par défaut, RLS ne s'applique pas au propriétaire de la table ni aux super-utilisateurs. Elles contournent toutes les règles.Dépannage : si vos règles semblent "cassées" (tout est autorisé), vérifiez si vous êtes connecté en tant que |
6. Créer les règles d'accès
Nous allons définir deux règles à l'aide d'une variable de session (app.active_user) que nous allons définir ultérieurement à partir du code de notre application.
Exécutez l'instruction SQL ci-dessous à partir de l'éditeur de requête AlloyDB :
-- Policy 1: Self-View
-- Users can see rows where their name matches the session variable
CREATE POLICY "view_own_data" ON employees
FOR SELECT
USING (name = current_setting('app.active_user', true));
-- Policy 2: Manager-View
-- Managers can see ALL rows.
CREATE POLICY "manager_view_all" ON employees
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM user_roles
WHERE username = current_setting('app.active_user', true)
AND role = 'manager'
)
);
Problèmes et dépannage
Utilisation de current_user au lieu de app.active_user. | Problème : current_user est un mot clé SQL réservé qui renvoie le rôle de la base de données (par exemple, app_user). Nous avons besoin de l'utilisateur de l'application (par exemple, Alice). Correction : utilisez toujours un espace de noms personnalisé, comme app.variable_name. |
Oubli du paramètre | Problème : si la variable n'est pas définie, la requête plante et génère une erreur.Solution : current_setting('...', true) renvoie NULL au lieu de planter, ce qui permet de renvoyer 0 ligne de manière sécurisée. |
7. Compiler l'application "Caméléon"
Nous utiliserons Python et Streamlit pour simuler la logique de l'application.
Ouvrez le terminal Cloud Shell en mode Éditeur, puis accédez à votre dossier racine ou au répertoire dans lequel vous souhaitez créer cette application. Créer un dossier.
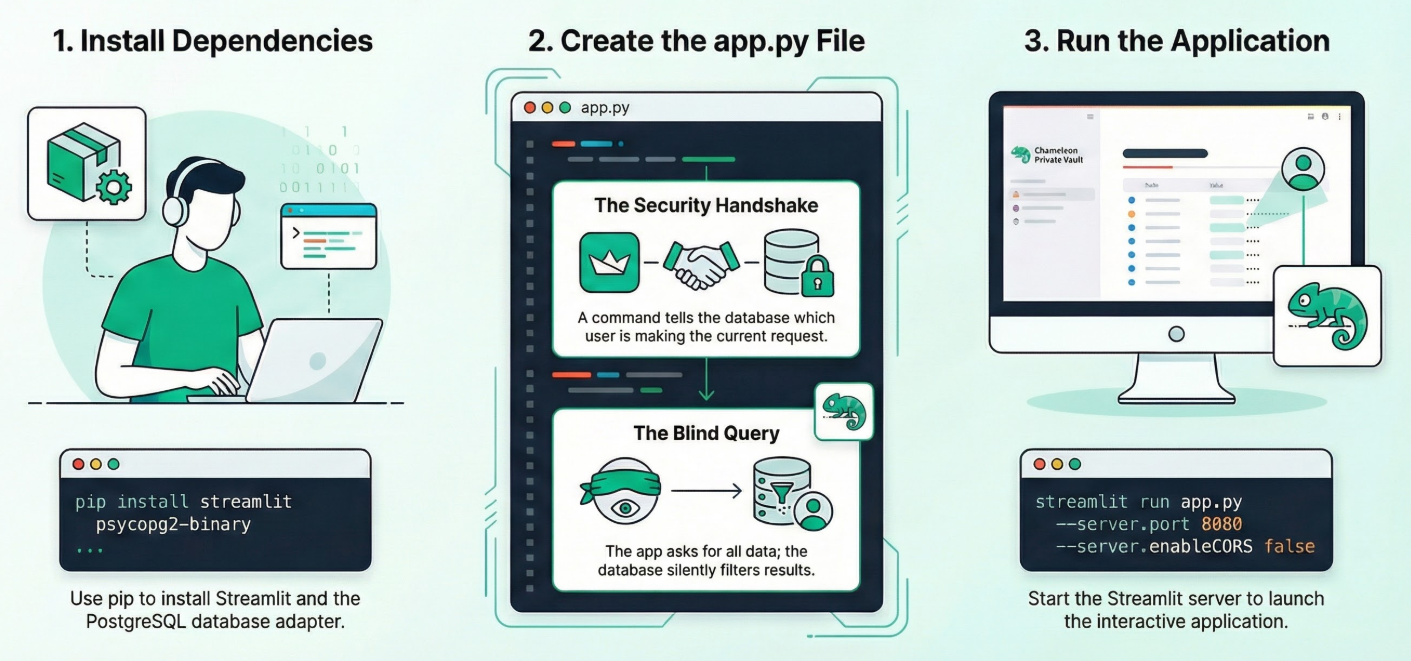
1. Installer les dépendances :
Exécutez la commande suivante dans le terminal Cloud Shell à partir du répertoire de votre nouveau projet :
pip install streamlit psycopg2-binary
2. Créez app.py :
Créez un fichier nommé app.py et copiez-y le contenu du fichier du dépôt.
import streamlit as st
import psycopg2
# CONFIGURATION (Replace with your IP)
DB_HOST = "10.x.x.x"
DB_NAME = "postgres"
DB_USER = "postgres"
DB_PASS = "alloydb"
def get_db_connection():
return psycopg2.connect(
host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASS
)
def query_database(user_name):
conn = get_db_connection()
try:
with conn.cursor() as cur:
# THE SECURITY HANDSHAKE
# We tell the database: "For this transaction, I am acting as..."
cur.execute(f"SET app.active_user = '{user_name}';")
# THE BLIND QUERY
# We ask for EVERYTHING. The database silently filters it.
cur.execute("SELECT name, role, salary, performance_review FROM employees;")
return cur.fetchall()
finally:
conn.close()
# UI
st.title("🛡️ The Private Vault")
user = st.sidebar.radio("Act as User:", ["Alice", "Bob", "Charlie", "Eve"])
if st.button("Access Data"):
results = query_database(user)
if not results:
st.error("🚫 Access Denied.")
else:
st.success(f"Viewing data as {user}")
for row in results:
st.write(row)
3. Exécutez l'application :
Exécutez la commande suivante dans le terminal Cloud Shell à partir du répertoire de votre nouveau projet :
streamlit run app.py --server.port 8080 --server.enableCORS false
Problèmes et dépannage
Regroupement de connexions. | Risque : si vous utilisez un pool de connexions, la variable de session SET app.active_user peut persister sur la connexion et "fuiter" vers le prochain utilisateur qui récupère cette connexion.Solution : en production, utilisez toujours RESET app.active_user ou DISCARD ALL lorsque vous renvoyez une connexion au pool. |
Écran vide dans Cloud Shell. | Correction : utilisez le bouton "Aperçu sur le Web" sur le port 8080. Ne cliquez pas sur le lien localhost dans le terminal. |
8. Valider le modèle zéro confiance
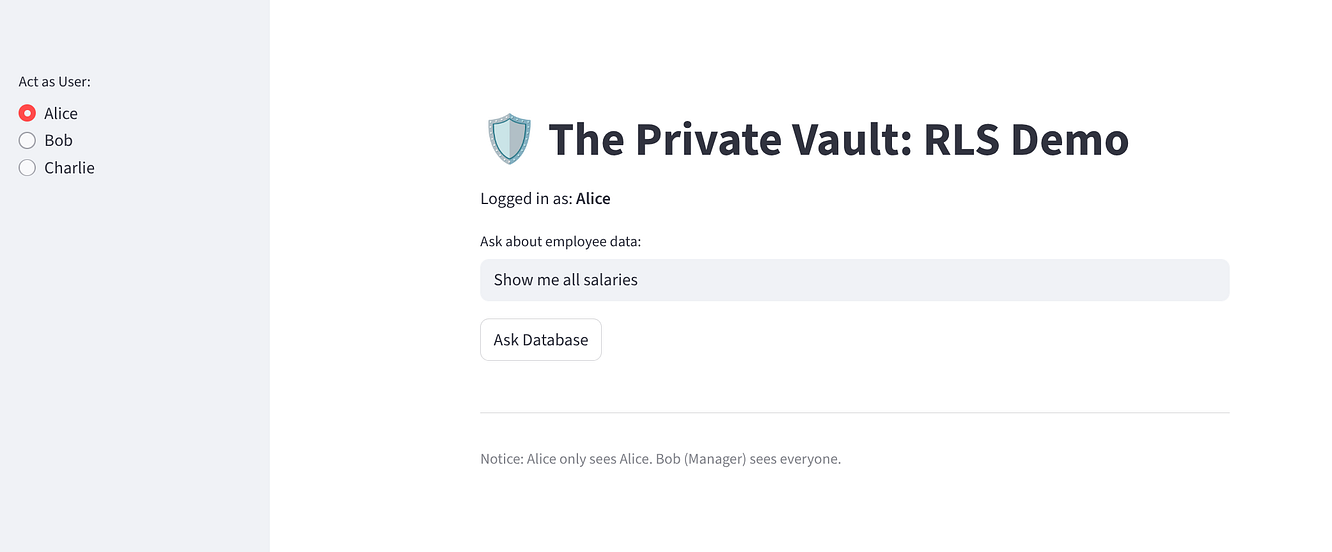
Essayez l'application pour vous assurer que l'implémentation Zero Trust fonctionne :
Sélectionnez Alice. Elle devrait voir une ligne (elle-même).
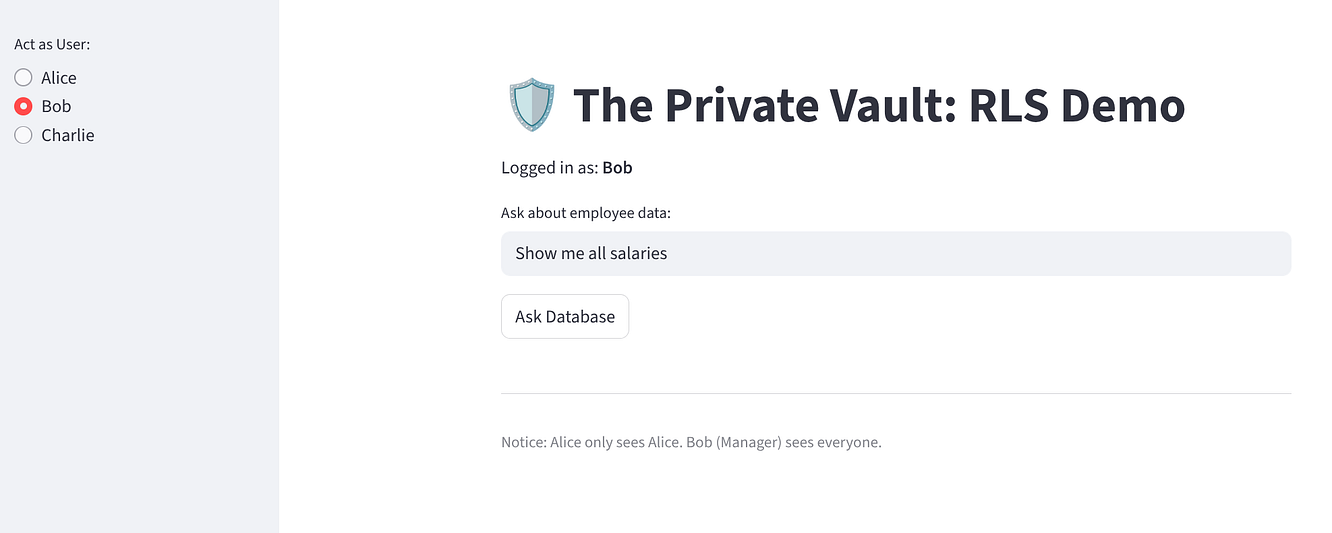
Sélectionnez Bob. Il devrait voir trois lignes ("Tout le monde").
Pourquoi est-ce important pour les agents d'IA ?
Imaginez que vous connectez votre modèle à cette base de données. Si un utilisateur demande à votre modèle : "Résume toutes les évaluations des performances", il générera SELECT performance_review FROM employees.
- Sans RLS : votre modèle récupère les avis privés de tous les utilisateurs et les divulgue à Alice.
- Avec RLS : votre modèle exécute exactement la même requête, mais la base de données ne renvoie que l'avis d'Alice.
Voici l'IA zéro confiance. Vous ne faites pas confiance au modèle pour filtrer les données. Vous forcez la base de données à les masquer.
Passer en production
L'architecture présentée ici est de qualité professionnelle, mais l'implémentation spécifique est simplifiée à des fins pédagogiques. Pour déployer cette solution de manière sécurisée dans un environnement d'entreprise réel, vous devez implémenter les améliorations suivantes :
- Authentification réelle : remplacez le menu déroulant "Identity Switcher" par un fournisseur d'identité (IdP) robuste tel que Google Identity Platform, Okta ou Auth0. Votre application doit valider le jeton de l'utilisateur et extraire son identité de manière sécurisée avant de définir la variable de session de la base de données, afin de s'assurer que les utilisateurs ne peuvent pas usurper leur identité.
- Sécurité du regroupement de connexions : lorsque vous utilisez des pools de connexions, les variables de session peuvent parfois persister pour différentes requêtes utilisateur si elles ne sont pas gérées correctement. Assurez-vous que votre application réinitialise la variable de session (par exemple, RESET app.active_user) ou efface l'état de la connexion lorsqu'elle renvoie une connexion au pool pour éviter toute fuite de données entre les utilisateurs.
- Gestion des secrets : le codage en dur des identifiants de base de données présente un risque pour la sécurité. Utilisez un service de gestion des secrets dédié tel que Google Secret Manager pour stocker et récupérer vos mots de passe de base de données et vos chaînes de connexion de manière sécurisée au moment de l'exécution.
9. Effectuer un nettoyage
Une fois cet atelier terminé, n'oubliez pas de supprimer le cluster et l'instance AlloyDB.
Il devrait nettoyer le cluster ainsi que ses instances.
10. Félicitations
Félicitations ! Vous avez réussi à transférer la sécurité au niveau de la couche de données. Même si votre code Python contenait un bug qui tentait d'effectuer une print(all_salaries), la base de données ne renverrait rien à Alice.
Étapes suivantes
- Essayez avec votre propre ensemble de données.
- Consultez la documentation AlloyDB AI.
- Pour découvrir d'autres ateliers, consultez le site Web Code Vipassana.