
1. Panoramica
Nella fretta di creare applicazioni di AI generativa, spesso dimentichiamo il componente più critico: la sicurezza.
Immagina di creare un chatbot per le risorse umane. Vuoi che risponda a domande come "Qual è il mio stipendio?" o "Come sta andando il mio team?"
- Se la richiesta viene effettuata da Alice (una dipendente regolare), dovrebbe visualizzare solo i suoi dati.
- Se Bob (un manager) lo chiede, dovrebbe visualizzare i dati del suo team.
Il problema
La maggior parte delle architetture RAG (Retrieval-Augmented Generation) tenta di gestire questo problema nel livello applicazione. Filtrano i chunk dopo averli recuperati oppure si affidano al comportamento dell'LLM. Questo è fragile. Se la logica dell'app non funziona, i dati vengono divulgati.
La soluzione
Trasferisci la sicurezza al livello del database. Utilizzando la sicurezza a livello di riga (RLS) di PostgreSQL in AlloyDB, ci assicuriamo che il database si rifiuti fisicamente di restituire i dati che l'utente non è autorizzato a visualizzare, indipendentemente da ciò che chiede l'AI.
In questa guida, creeremo "The Private Vault": un assistente HR sicuro che cambia dinamicamente le risposte in base all'utente che ha eseguito l'accesso.
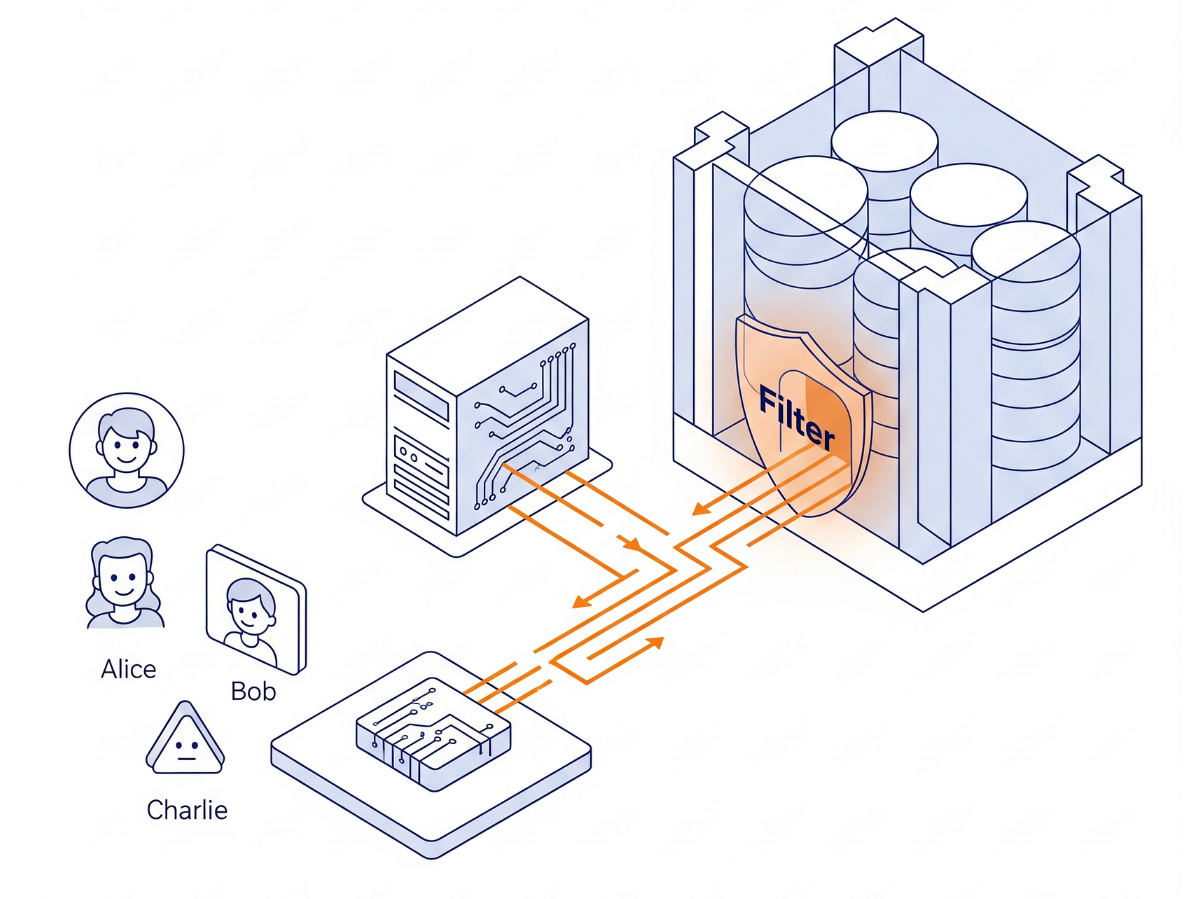
L'architettura
Non stiamo creando una logica di autorizzazione complessa in Python. Stiamo utilizzando il motore del database stesso.
- L'interfaccia:una semplice app Streamlit che simula un accesso.
- Il cervello:AlloyDB AI (compatibile con PostgreSQL).
- Il meccanismo:impostiamo una variabile di sessione (
app.active_user) all'inizio di ogni transazione. I criteri del database controllano automaticamente una tabellauser_roles(che funge da Identity Provider) per filtrare le righe.
Cosa creerai
Un'applicazione di assistente HR sicura. Anziché fare affidamento sulla logica dell'applicazione per filtrare i dati sensibili, implementerai la sicurezza a livello di riga (RLS) direttamente nel motore del database AlloyDB. In questo modo, anche se il modello di AI "allucina" o tenta di accedere a dati non autorizzati, il database si rifiuterà fisicamente di restituirli.
Obiettivi didattici
Scoprirai:
- Come progettare uno schema per RLS (separazione di dati e identità).
- Come scrivere criteri PostgreSQL (
CREATE POLICY). - Come ignorare l'esenzione "Proprietario tabella" utilizzando
FORCE ROW LEVEL SECURITY. - Come creare un'app Python che esegue il "cambio di contesto" per gli utenti.
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: segui il link e abilita le API.
In alternativa, puoi utilizzare il comando gcloud. Consulta la documentazione per i comandi e l'utilizzo di gcloud.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Aspetti da considerare e risoluzione dei problemi
La sindrome del "progetto fantasma" | Hai eseguito |
La barriera di fatturazione | Hai attivato il progetto, ma hai dimenticato l'account di fatturazione. AlloyDB è un motore ad alte prestazioni; non si avvia se il "serbatoio" (fatturazione) è vuoto. |
Ritardo di propagazione dell'API | Hai fatto clic su "Abilita API", ma la riga di comando indica ancora |
Quota Quags | Se utilizzi un account di prova nuovo di zecca, potresti raggiungere una quota regionale per le istanze AlloyDB. Se |
3. Configurazione del database
In questo lab utilizzeremo AlloyDB come database per i dati di test. Utilizza i cluster per contenere tutte le risorse, come database e log. Ogni cluster ha un'istanza primaria che fornisce un punto di accesso ai dati. Le tabelle conterranno i dati effettivi.
Creiamo un cluster, un'istanza e una tabella AlloyDB in cui verrà caricato il set di dati di test.
- Fai clic sul pulsante o copia il link riportato di seguito nel browser in cui hai eseguito l'accesso all'utente della console Google Cloud.
- Una volta completato questo passaggio, il repository verrà clonato nell'editor Cloud Shell locale e potrai eseguire il comando riportato di seguito dalla cartella del progetto (è importante assicurarsi di trovarsi nella directory del progetto):
sh run.sh
- Ora utilizza la UI (facendo clic sul link nel terminale o sul link "Anteprima sul web" nel terminale).
- Inserisci i tuoi dati per l'ID progetto, il cluster e i nomi delle istanze per iniziare.
- Prendi un caffè mentre scorrono i log e leggi qui come funziona dietro le quinte. L'operazione potrebbe richiedere circa 10-15 minuti.
Aspetti da considerare e risoluzione dei problemi
Il problema della "pazienza" | I cluster di database sono un'infrastruttura pesante. Se aggiorni la pagina o termini la sessione Cloud Shell perché "sembra bloccata", potresti ritrovarti con un'istanza "fantasma" di cui è stato eseguito il provisioning parziale e impossibile da eliminare senza un intervento manuale. |
Regione non corrispondente | Se hai abilitato le API in |
Cluster di zombie | Se in precedenza hai utilizzato lo stesso nome per un cluster e non lo hai eliminato, lo script potrebbe indicare che il nome del cluster esiste già. I nomi dei cluster devono essere univoci all'interno di un progetto. |
Timeout di Cloud Shell | Se la pausa caffè dura 30 minuti, Cloud Shell potrebbe entrare in modalità di sospensione e disconnettere il processo |
4. Provisioning dello schema
In questo passaggio, tratteremo i seguenti argomenti:
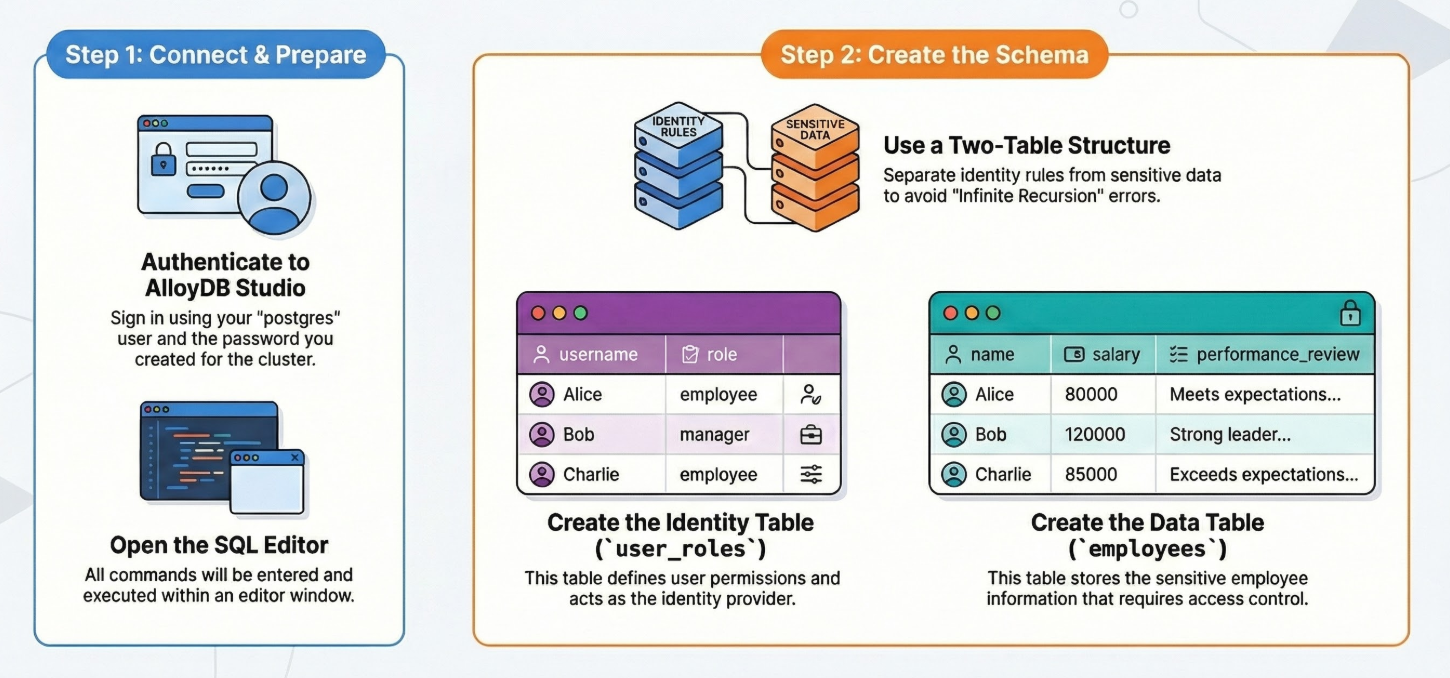
Ecco le azioni dettagliate passo passo:
Una volta che il cluster e l'istanza AlloyDB sono in esecuzione, vai all'editor SQL di AlloyDB Studio per attivare le estensioni AI e eseguire il provisioning dello schema.
Potrebbe essere necessario attendere il completamento della creazione dell'istanza. Una volta creato, accedi ad AlloyDB utilizzando le credenziali che hai creato durante la creazione del cluster. Utilizza i seguenti dati per l'autenticazione a PostgreSQL:
- Nome utente : "
postgres" - Database : "
postgres" - Password : "
alloydb" (o qualsiasi altra password impostata al momento della creazione)
Una volta eseguita l'autenticazione in AlloyDB Studio, i comandi SQL vengono inseriti nell'editor. Puoi aggiungere più finestre dell'editor utilizzando il segno più a destra dell'ultima finestra.
Inserirai i comandi per AlloyDB nelle finestre dell'editor, utilizzando le opzioni Esegui, Formatta e Cancella in base alle esigenze.
Creare una tabella
Abbiamo bisogno di due tabelle: una per i dati sensibili (dipendenti) e una per le regole di identità (user_roles). La separazione è fondamentale per evitare errori di "ricorsione infinita" nelle policy.
Puoi creare una tabella utilizzando l'istruzione DDL riportata di seguito in AlloyDB Studio:
-- 1. Create User Roles (The Identity Provider)
CREATE TABLE user_roles (
username TEXT PRIMARY KEY,
role TEXT -- 'employee', 'manager', 'admin'
);
INSERT INTO user_roles (username, role) VALUES
('Alice', 'employee'),
('Bob', 'manager'),
('Charlie', 'employee');
-- 2. Create the Data Table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name TEXT,
salary INTEGER,
performance_review TEXT
);
INSERT INTO employees (name, salary, performance_review) VALUES
('Alice', 80000, 'Alice meets expectations but needs to improve punctuality.'),
('Bob', 120000, 'Bob is a strong leader. Team morale is high.'),
('Charlie', 85000, 'Charlie exceeds expectations. Ready for promotion.');
Aspetti da considerare e risoluzione dei problemi
Ricorsione infinita rilevata durante la definizione dei ruoli all'interno della tabella dei dipendenti | Perché non funziona: se la tua norma indica "Controlla la tabella dei dipendenti per vedere se sono un manager", il database deve eseguire una query sulla tabella per controllare la norma, il che la attiva di nuovo.Risultato: è stata rilevata una ricorsione infinita.Soluzione: mantieni sempre una tabella di ricerca separata (user_roles) o utilizza utenti del database effettivi per i ruoli. |
Verifica i dati:
SELECT count(*) FROM employees;
-- Output: 3
5. Abilitare e applicare la sicurezza
Ora attiviamo gli scudi. Creeremo anche un "Utente app" generico che il nostro codice Python utilizzerà per connettersi.
Esegui la seguente istruzione SQL dall'editor di query AlloyDB:
-- 1. Activate RLS
ALTER TABLE employees ENABLE ROW LEVEL SECURITY;
-- 2. CRITICAL: Force RLS for Table Owners
ALTER TABLE employees FORCE ROW LEVEL SECURITY;
-- 3. Create the Application User
DO
$do$
BEGIN
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'app_user') THEN
CREATE ROLE app_user LOGIN PASSWORD 'password';
END IF;
END
$do$;
-- 4. Grant Access
GRANT SELECT ON employees TO app_user;
GRANT SELECT ON user_roles TO app_user;
Aspetti da considerare e risoluzione dei problemi
Test come postgres (superutente) e visualizzazione di tutti i dati. | Motivo dell'errore: per impostazione predefinita, RLS non si applica al proprietario della tabella o ai superuser. Ignorano tutte le norme.Risoluzione dei problemi: se le tue norme sembrano "non funzionare" (consentono tutto), controlla di aver eseguito l'accesso come |
6. Crea le policy di accesso
Definiremo due regole utilizzando una variabile di sessione (app.active_user) che imposteremo in un secondo momento dal codice dell'applicazione.
Esegui la seguente istruzione SQL dall'editor di query AlloyDB:
-- Policy 1: Self-View
-- Users can see rows where their name matches the session variable
CREATE POLICY "view_own_data" ON employees
FOR SELECT
USING (name = current_setting('app.active_user', true));
-- Policy 2: Manager-View
-- Managers can see ALL rows.
CREATE POLICY "manager_view_all" ON employees
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM user_roles
WHERE username = current_setting('app.active_user', true)
AND role = 'manager'
)
);
Aspetti da considerare e risoluzione dei problemi
Utilizzo di current_user anziché app.active_user. | Problema: Current_user è una parola chiave SQL riservata che restituisce il ruolo del database (ad es. app_user). Abbiamo bisogno dell'utente dell'applicazione (ad es. Alice).Correzione: utilizza sempre uno spazio dei nomi personalizzato come app.variable_name. |
Dimenticare il parametro | Problema:se la variabile non è impostata, la query genera un errore irreversibile.Correzione:current_setting('...', true) restituisce NULL anziché generare un errore irreversibile, il che comporta in modo sicuro la restituzione di 0 righe. |
7. Crea l'app "Chamaleon"
Utilizzeremo Python e Streamlit per simulare la logica dell'applicazione.
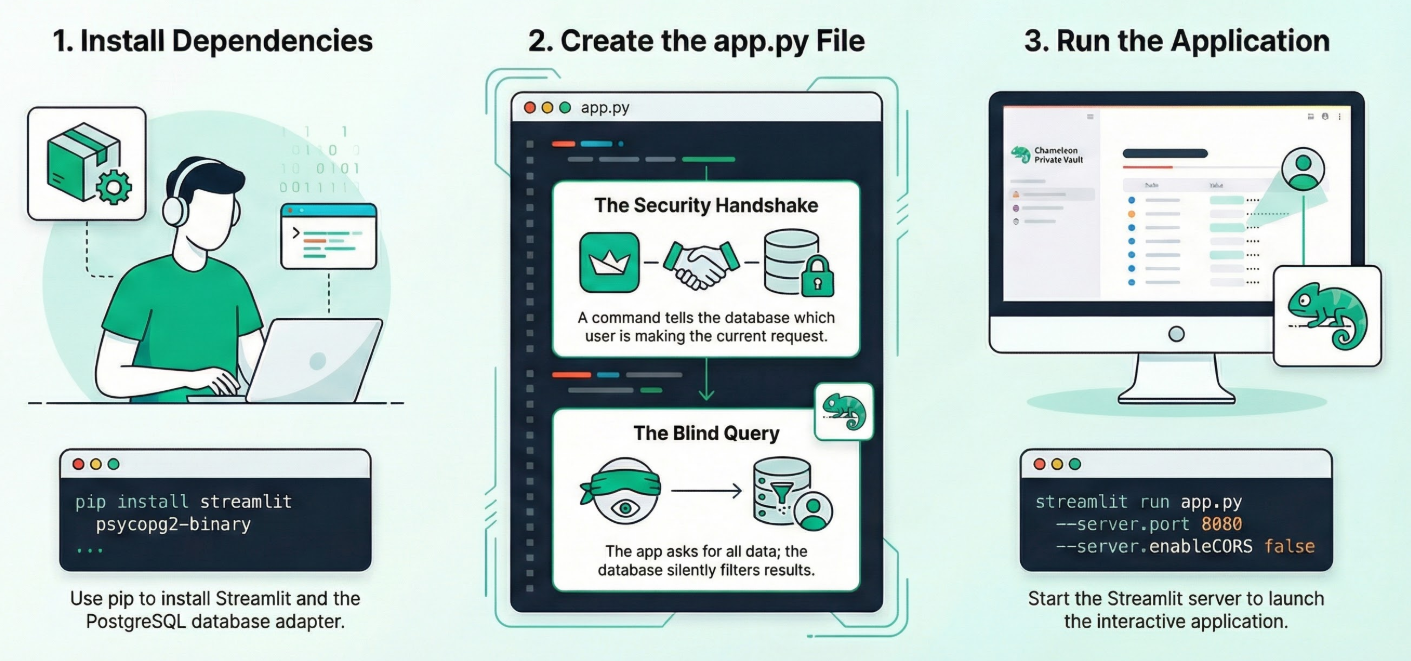
Apri il terminale di Cloud Shell in modalità Editor, vai alla cartella principale o alla directory in cui vuoi creare questa applicazione. Crea una nuova cartella.
1. Installa le dipendenze:
Esegui questo comando nel terminale Cloud Shell dall'interno della nuova directory del progetto:
pip install streamlit psycopg2-binary
2. Crea app.py:
Crea un nuovo file denominato app.py e copia i contenuti dal file del repository.
import streamlit as st
import psycopg2
# CONFIGURATION (Replace with your IP)
DB_HOST = "10.x.x.x"
DB_NAME = "postgres"
DB_USER = "postgres"
DB_PASS = "alloydb"
def get_db_connection():
return psycopg2.connect(
host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASS
)
def query_database(user_name):
conn = get_db_connection()
try:
with conn.cursor() as cur:
# THE SECURITY HANDSHAKE
# We tell the database: "For this transaction, I am acting as..."
cur.execute(f"SET app.active_user = '{user_name}';")
# THE BLIND QUERY
# We ask for EVERYTHING. The database silently filters it.
cur.execute("SELECT name, role, salary, performance_review FROM employees;")
return cur.fetchall()
finally:
conn.close()
# UI
st.title("🛡️ The Private Vault")
user = st.sidebar.radio("Act as User:", ["Alice", "Bob", "Charlie", "Eve"])
if st.button("Access Data"):
results = query_database(user)
if not results:
st.error("🚫 Access Denied.")
else:
st.success(f"Viewing data as {user}")
for row in results:
st.write(row)
3. Esegui l'app:
Esegui questo comando nel terminale Cloud Shell dall'interno della nuova directory del progetto:
streamlit run app.py --server.port 8080 --server.enableCORS false
Aspetti da considerare e risoluzione dei problemi
Pool di connessioni. | Rischio: se utilizzi un pool di connessioni, la variabile di sessione SET app.active_user potrebbe persistere nella connessione e "trapelare" all'utente successivo che acquisisce la connessione.Correzione:in produzione, utilizza sempre RESET app.active_user o DISCARD ALL quando restituisci una connessione al pool. |
Schermo vuoto in Cloud Shell. | Correzione : utilizza il pulsante "Anteprima web" sulla porta 8080. Non fare clic sul link localhost nel terminale. |
8. Verifica Zero Trust
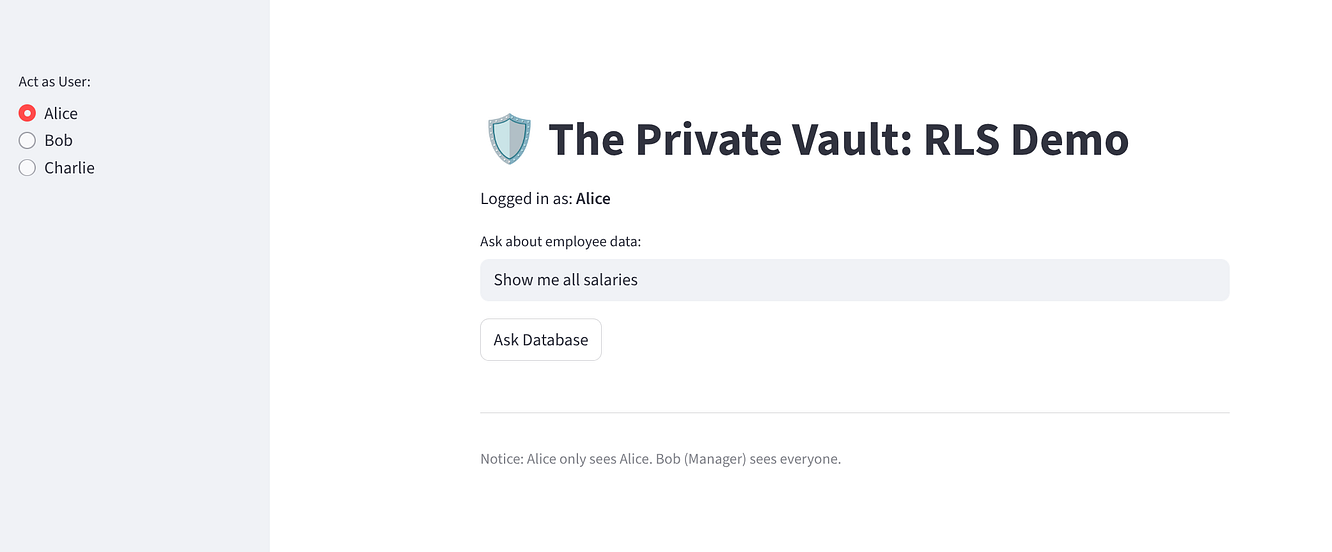
Prova l'app per assicurarti l'implementazione di Zero Trust:
Seleziona "Alice": dovrebbe visualizzare una riga (se stessa).
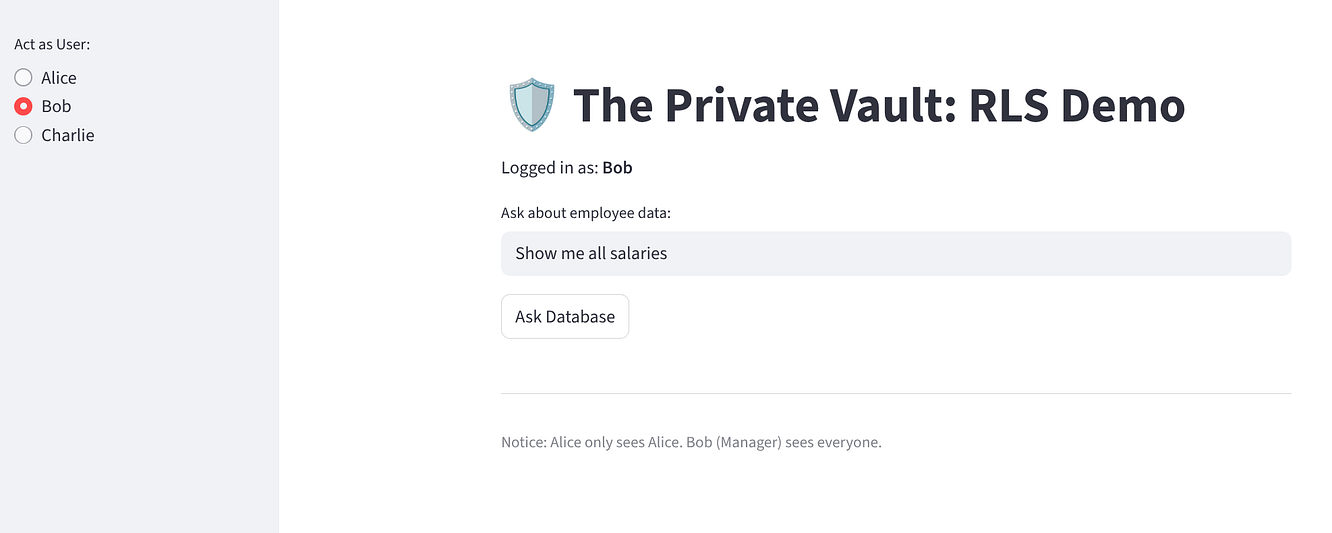
Seleziona "Bob": dovrebbe visualizzare 3 righe (Tutti).
Perché è importante per gli AI Agent
Immagina di connettere il tuo modello a questo database. Se un utente chiede al tuo modello: "Riepiloga tutte le valutazioni del rendimento", verrà generato SELECT performance_review FROM employees.
- Senza RLS: il modello recupera le recensioni private di tutti e le mostra ad Alice.
- Con RLS: il modello esegue esattamente la stessa query, ma il database restituisce solo la recensione di Alice.
Si tratta di Zero-Trust AI. Non ti fidi del modello per filtrare i dati, quindi forzi il database a nasconderli.
Trasferimento in produzione
L'architettura mostrata qui è di livello di produzione, ma l'implementazione specifica è semplificata per l'apprendimento. Per eseguire il deployment in modo sicuro in un ambiente aziendale reale, devi implementare i seguenti miglioramenti:
- Autenticazione reale: sostituisci il menu a discesa "Cambio identità" con un provider di identità (IdP) solido come Google Identity Platform, Okta o Auth0. La tua applicazione deve verificare il token dell'utente ed estrarre la sua identità in modo sicuro prima di impostare la variabile di sessione del database, assicurandosi che gli utenti non possano falsificare la propria identità.
- Sicurezza del pool di connessioni:quando si utilizzano i pool di connessioni, le variabili di sessione possono a volte persistere in diverse richieste degli utenti se non vengono gestite correttamente. Assicurati che l'applicazione reimposti la variabile di sessione (ad es. RESET app.active_user) o cancelli lo stato della connessione quando restituisce una connessione al pool per impedire la perdita di dati tra gli utenti.
- Gestione dei secret:l'hardcoding delle credenziali del database è un rischio per la sicurezza. Utilizza un servizio di gestione dei secret dedicato come Google Secret Manager per archiviare e recuperare in modo sicuro le password e le stringhe di connessione del database in fase di runtime.
9. Esegui la pulizia
Al termine di questo lab, non dimenticare di eliminare il cluster e l'istanza AlloyDB.
Dovrebbe liberare spazio nel cluster insieme alle relative istanze.
10. Complimenti
Complimenti! Hai eseguito il push della sicurezza fino al livello dei dati. Anche se il codice Python avesse un bug che tentava di print(all_salaries), il database non restituirebbe nulla ad Alice.
Passaggi successivi
- Prova con il tuo set di dati.
- Esplora la documentazione di AlloyDB AI.
- Visita il sito web di Code Vipassana per altri workshop.