
1. 概要
生成 AI アプリケーションの構築を急ぐあまり、最も重要な要素である安全性 を忘れがちです。
人事 chatbot を構築するとします。「"私の給与はいくらですか?"」や「"私のチームのパフォーマンスはどうですか?"」などの質問に回答できるようにしたいと考えています。
- 一般社員のアリス が質問した場合は、自分のデータのみが表示されるようにします。
- マネージャーのボブ が質問した場合は、チームのデータが表示されるようにします。
問題
ほとんどの RAG(検索拡張生成)アーキテクチャは、これをアプリケーション レイヤで処理しようとします。 チャンクを取得した後にフィルタするか、LLM が「適切に動作する」ことを前提としています。 これは脆弱です。アプリのロジックが失敗すると、データが漏洩します。
ソリューション
セキュリティをデータベース レイヤ にプッシュします。AlloyDB で PostgreSQL の行レベルのセキュリティ(RLS) を使用することで、AI が何を要求しても、ユーザーが表示を許可されていないデータをデータベースが物理的に返さないようにします。
このガイドでは、「プライベート ボルト」を構築します。これは、ログインしているユーザーに基づいて回答を動的に変更する安全な人事アシスタントです。
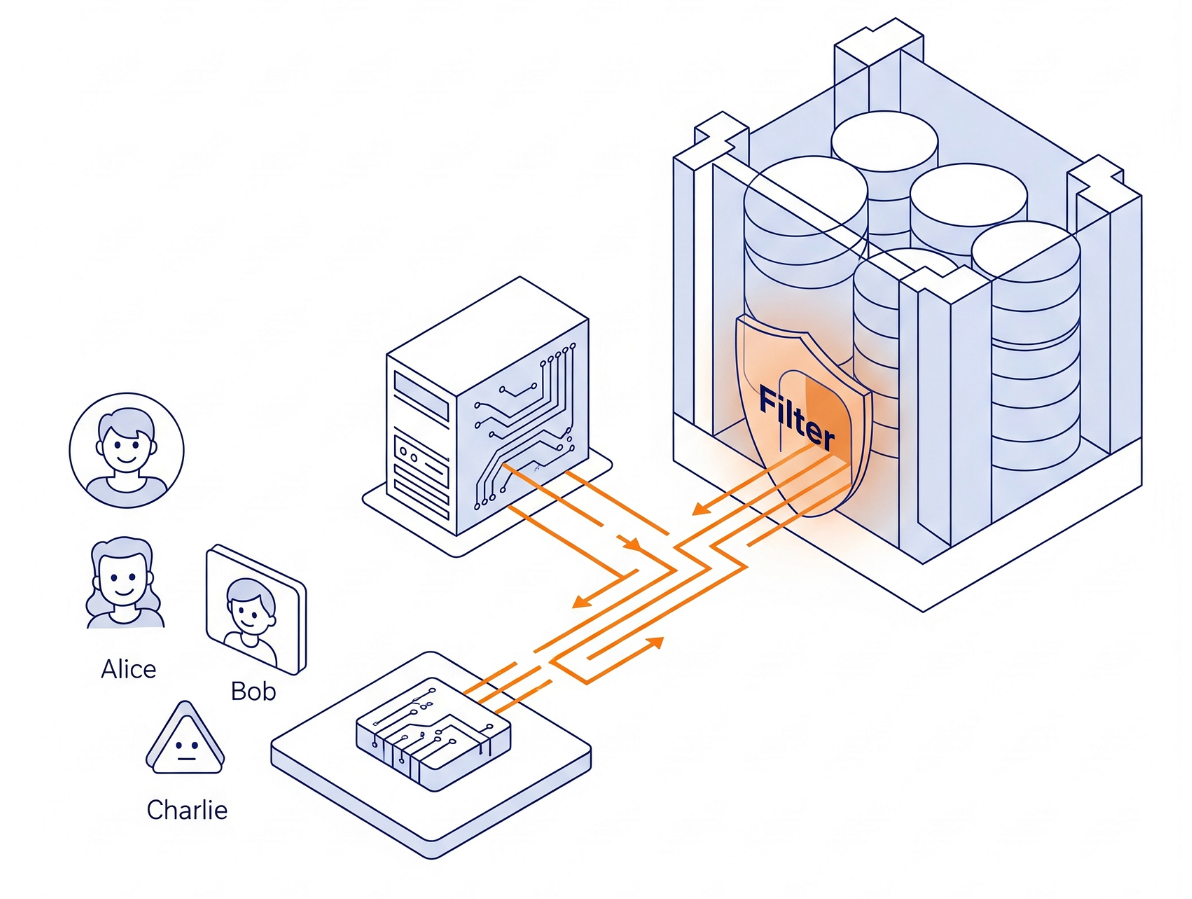
アーキテクチャ
Python で複雑な権限ロジックを構築するのではなく、データベース エンジン自体を使用します。
- インターフェース: ログインをシミュレートするシンプルな Streamlit アプリ。
- ブレイン: AlloyDB AI(PostgreSQL 互換)。
- メカニズム: トランザクションの開始時にセッション変数(
app.active_user)を設定します。データベース ポリシーは、user_rolesテーブル(ID プロバイダとして機能)を自動的にチェックして行をフィルタします。
作成するアプリの概要
安全な人事アシスタント アプリケーション。アプリケーション ロジックに依存してセンシティブ データをフィルタするのではなく、AlloyDB データベース エンジンに直接行レベルのセキュリティ(RLS)を実装します。これにより、AI モデルが「ハルシネーション」したり、不正なデータにアクセスしようとしたりしても、データベースが物理的に返さないようにします。
学習内容
学習内容:
- RLS のスキーマを設計する方法(データと ID を分離)。
- PostgreSQL ポリシー(
CREATE POLICY)を作成する方法。 FORCE ROW LEVEL SECURITYを使用して「テーブル オーナー」の除外をバイパスする方法。- ユーザーの「コンテキスト切り替え」を実行する Python アプリを構築する方法。
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法については、こちらをご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/zero-trust-agents-with-alloydb/img/91567e2f55467574.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にします。リンクに沿って API を有効にします。
または、gcloud コマンドを使用することもできます。gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
注意点とトラブルシューティング
「ゴースト プロジェクト」 シンドローム |
|
**課金** のバリケード | プロジェクトを有効にしましたが、請求先アカウントを忘れていました。AlloyDB は高性能エンジンです。「ガソリン タンク」(課金)が空の場合、起動しません。 |
API の伝播 の遅延 | [API を有効にする] をクリックしましたが、コマンドラインに |
割り当て の問題 | 新しいトライアル アカウントを使用している場合は、AlloyDB インスタンスのリージョン割り当てに達している可能性があります。 |
3. データベースの設定
このラボでは、テストデータのデータベースとして AlloyDB を使用します。データベースやログなどのすべてのリソースを保持するためにクラスタを使用します。 各クラスタには、データへのアクセス ポイントを提供するプライマリ インスタンスがあります。 テーブルには実際のデータが格納されます。
テストデータセットが読み込まれる AlloyDB クラスタ、インスタンス、テーブルを作成しましょう。
- ボタンをクリックするか、以下のリンクを Google Cloud コンソール ユーザーがログインしているブラウザにコピーします。
- この手順が完了すると、リポジトリがローカルの Cloud Shell エディタにクローンされ、プロジェクト フォルダから次のコマンドを実行できるようになります(プロジェクト ディレクトリにいることを確認することが重要です)。
sh run.sh
- UI を使用します(ターミナルでリンクをクリックするか、ターミナルで [ウェブでプレビュー] リンクをクリックします)。
- プロジェクト ID、クラスタ名、インスタンス名の詳細を入力して開始します。
- ログがスクロールしている間にコーヒーを飲みましょう。ログがどのように舞台裏で処理されているかについては、こちらをご覧ください。10 ~ 15 分ほどかかることがあります。
注意点とトラブルシューティング
「忍耐」の問題 | データベース クラスタは大規模なインフラストラクチャです。ページを更新したり、Cloud Shell セッションを強制終了したりすると、「スタックしている」ように見えるため、部分的にプロビジョニングされ、手動で介入しないと削除できない「ゴースト」インスタンスが作成される可能性があります。 |
リージョンの不一致 |
|
ゾンビ クラスタ | 以前にクラスタに同じ名前を使用して削除しなかった場合、スクリプトでクラスタ名がすでに存在すると表示されることがあります。クラスタ名はプロジェクト内で一意にする必要があります。 |
Cloud Shell のタイムアウト | コーヒー ブレイクに 30 分かかると、Cloud Shell がスリープ状態になり、 |
4. スキーマのプロビジョニング
このステップでは、次の内容について説明します。
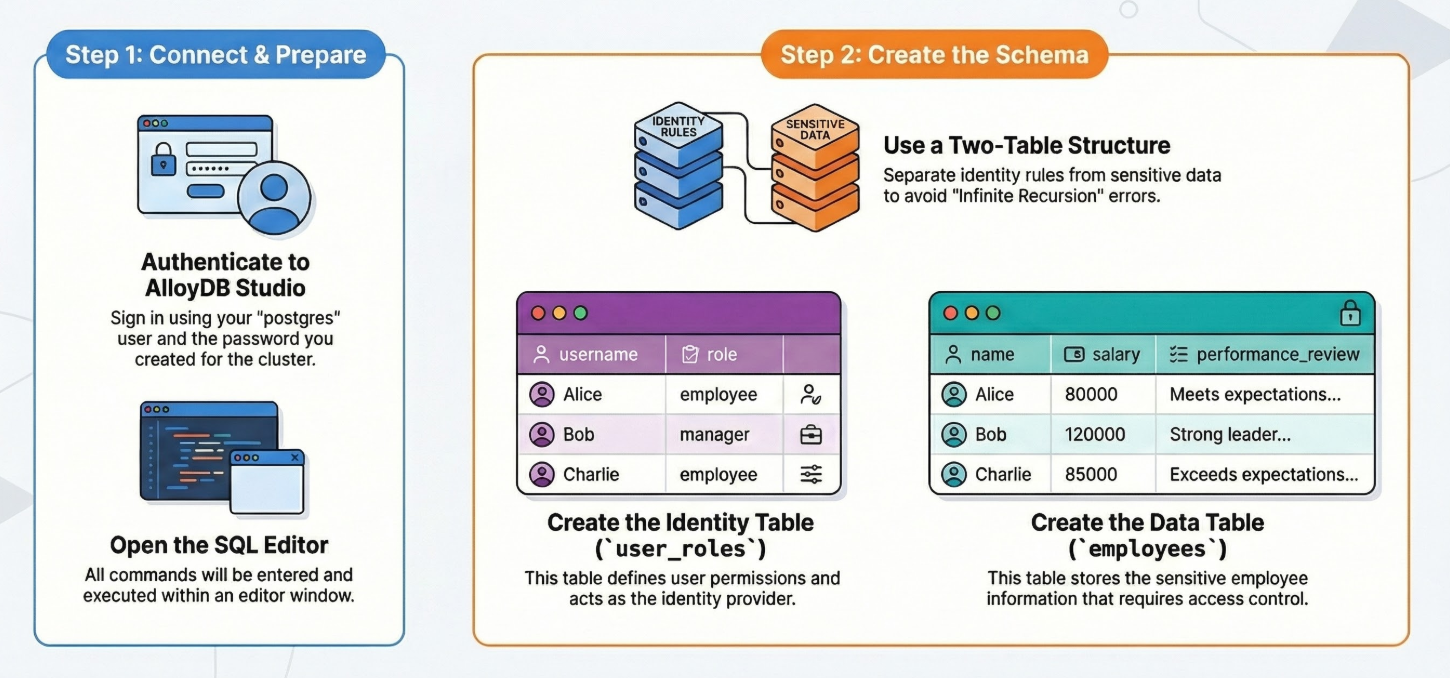
詳細な手順は次のとおりです。
AlloyDB クラスタとインスタンスが実行されたら、AlloyDB Studio SQL エディタに移動して AI 拡張機能を有効にし、スキーマをプロビジョニングします。
インスタンスの作成が完了するまで待つ必要がある場合があります。 完了したら、クラスタの作成時に作成した認証情報を使用して AlloyDB にログインします。 PostgreSQL の認証には次のデータを使用します。
- ユーザー名: "
postgres" - データベース: "
postgres" - パスワード: "
alloydb"(作成時に設定した値)
AlloyDB Studio に正常に認証されると、エディタに SQL コマンドが入力されます。 最後のウィンドウの右側にあるプラス記号を使用して、複数のエディタ ウィンドウを追加できます。
必要に応じて [実行]、[フォーマット]、[クリア] オプションを使用して、エディタ ウィンドウに AlloyDB のコマンドを入力します。
テーブルを作成する
機密データ(従業員)用のテーブルと、ID ルール(user_roles)用のテーブルの 2 つが必要です。ポリシーで「無限再帰」エラーを回避するには、これらを分離することが重要です。
AlloyDB Studio で次の DDL ステートメントを使用してテーブルを作成できます。
-- 1. Create User Roles (The Identity Provider)
CREATE TABLE user_roles (
username TEXT PRIMARY KEY,
role TEXT -- 'employee', 'manager', 'admin'
);
INSERT INTO user_roles (username, role) VALUES
('Alice', 'employee'),
('Bob', 'manager'),
('Charlie', 'employee');
-- 2. Create the Data Table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name TEXT,
salary INTEGER,
performance_review TEXT
);
INSERT INTO employees (name, salary, performance_review) VALUES
('Alice', 80000, 'Alice meets expectations but needs to improve punctuality.'),
('Bob', 120000, 'Bob is a strong leader. Team morale is high.'),
('Charlie', 85000, 'Charlie exceeds expectations. Ready for promotion.');
注意点とトラブルシューティング
employee テーブル内でロールを定義しているときに無限再帰が検出されました | 失敗する理由: ポリシーで「employee テーブルをチェックして、自分がマネージャーかどうかを確認する」と指定すると、データベースはテーブルにクエリを実行してポリシーを確認し、ポリシーを再度トリガーする必要があります。結果: 無限再帰が検出されました。修正: 常に別のルックアップ テーブル(user_roles)を保持するか、ロールに実際のデータベース ユーザーを使用します。 |
データを確認します。
SELECT count(*) FROM employees;
-- Output: 3
5. セキュリティを有効にして適用する
シールドをオンにします。また、Python コードが接続に使用する汎用的な「アプリユーザー」も作成します。
AlloyDB クエリエディタから次の SQL ステートメントを実行します。
-- 1. Activate RLS
ALTER TABLE employees ENABLE ROW LEVEL SECURITY;
-- 2. CRITICAL: Force RLS for Table Owners
ALTER TABLE employees FORCE ROW LEVEL SECURITY;
-- 3. Create the Application User
DO
$do$
BEGIN
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'app_user') THEN
CREATE ROLE app_user LOGIN PASSWORD 'password';
END IF;
END
$do$;
-- 4. Grant Access
GRANT SELECT ON employees TO app_user;
GRANT SELECT ON user_roles TO app_user;
注意点とトラブルシューティング
postgres(スーパーユーザー)としてテストすると、すべてのデータが表示されます。 | 失敗する理由: デフォルトでは、RLS はテーブル オーナーまたはスーパーユーザーには適用されません。すべてのポリシーをバイパスします。トラブルシューティング: ポリシーが "破損している" (すべて許可されている)ように見える場合は、 |
6. アクセス ポリシーを作成する
後でアプリケーション コードから設定するセッション変数(app.active_user)を使用して、2 つのルールを定義します。
AlloyDB クエリエディタから次の SQL ステートメントを実行します。
-- Policy 1: Self-View
-- Users can see rows where their name matches the session variable
CREATE POLICY "view_own_data" ON employees
FOR SELECT
USING (name = current_setting('app.active_user', true));
-- Policy 2: Manager-View
-- Managers can see ALL rows.
CREATE POLICY "manager_view_all" ON employees
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM user_roles
WHERE username = current_setting('app.active_user', true)
AND role = 'manager'
)
);
注意点とトラブルシューティング
app.active_user の代わりに current_user を使用しています。 | 問題: Current_user は、データベース ロール(app_user など)を返す予約済みの SQL キーワードです。アプリケーション ユーザー(アリスなど)が必要です。修正: 常に app.variable_name などのカスタム Namespace を使用します。 |
| 問題: 変数が設定されていない場合、クエリがエラーでクラッシュします。修正: current_setting('...', true) はクラッシュする代わりに NULL を返すため、安全に 0 行が返されます。 |
7. 「カメレオン」アプリを構築する
Python と Streamlit を使用して、アプリケーション ロジックをシミュレートします。
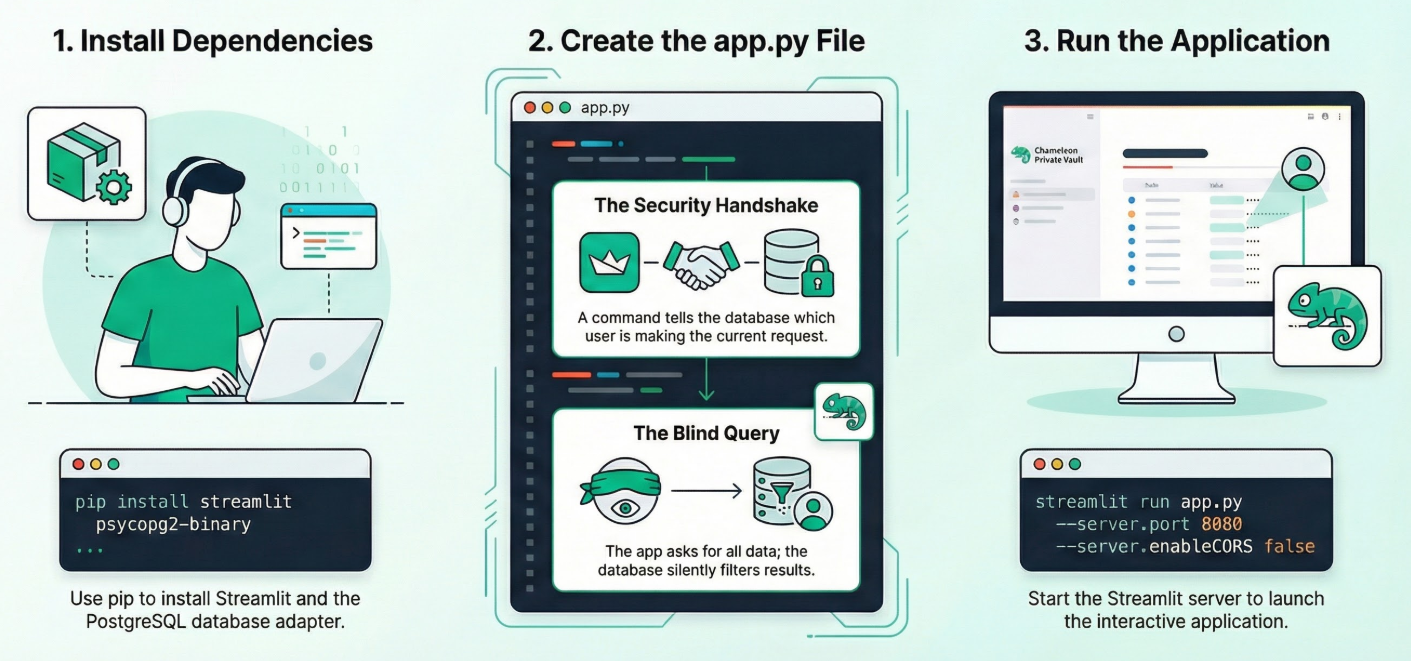
エディタモードで Cloud Shell ターミナルを開き、ルートフォルダまたはこのアプリケーションを作成するディレクトリに移動します。新しいフォルダを作成します。
1. 依存関係をインストールします。
Cloud Shell ターミナルで、新しいプロジェクト ディレクトリ内から 次のコマンドを実行します。
pip install streamlit psycopg2-binary
**2. app.py を作成します。
app.py という名前の新しいファイルを作成し、リポジトリ ファイルからコンテンツをコピーします。
import streamlit as st
import psycopg2
# CONFIGURATION (Replace with your IP)
DB_HOST = "10.x.x.x"
DB_NAME = "postgres"
DB_USER = "postgres"
DB_PASS = "alloydb"
def get_db_connection():
return psycopg2.connect(
host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASS
)
def query_database(user_name):
conn = get_db_connection()
try:
with conn.cursor() as cur:
# THE SECURITY HANDSHAKE
# We tell the database: "For this transaction, I am acting as..."
cur.execute(f"SET app.active_user = '{user_name}';")
# THE BLIND QUERY
# We ask for EVERYTHING. The database silently filters it.
cur.execute("SELECT name, role, salary, performance_review FROM employees;")
return cur.fetchall()
finally:
conn.close()
# UI
st.title("🛡️ The Private Vault")
user = st.sidebar.radio("Act as User:", ["Alice", "Bob", "Charlie", "Eve"])
if st.button("Access Data"):
results = query_database(user)
if not results:
st.error("🚫 Access Denied.")
else:
st.success(f"Viewing data as {user}")
for row in results:
st.write(row)
3. アプリを実行します。
Cloud Shell ターミナルで、新しいプロジェクト ディレクトリ内から 次のコマンドを実行します。
streamlit run app.py --server.port 8080 --server.enableCORS false
注意点とトラブルシューティング
接続プーリング。 | リスク: 接続プールを使用すると、セッション変数 SET app.active_user が接続に保持され、その接続を取得した次のユーザーに「リーク」する可能性があります。修正:本番環境では、接続をプールに戻すときに常に RESET app.active_user または DISCARD ALL を使用します。 |
Cloud Shell の画面が空白です。 | 修正: ポート 8080 の [ウェブでプレビュー] ボタンを使用します。ターミナルで localhost リンクをクリックしないでください。 |
8. ゼロトラストを確認する
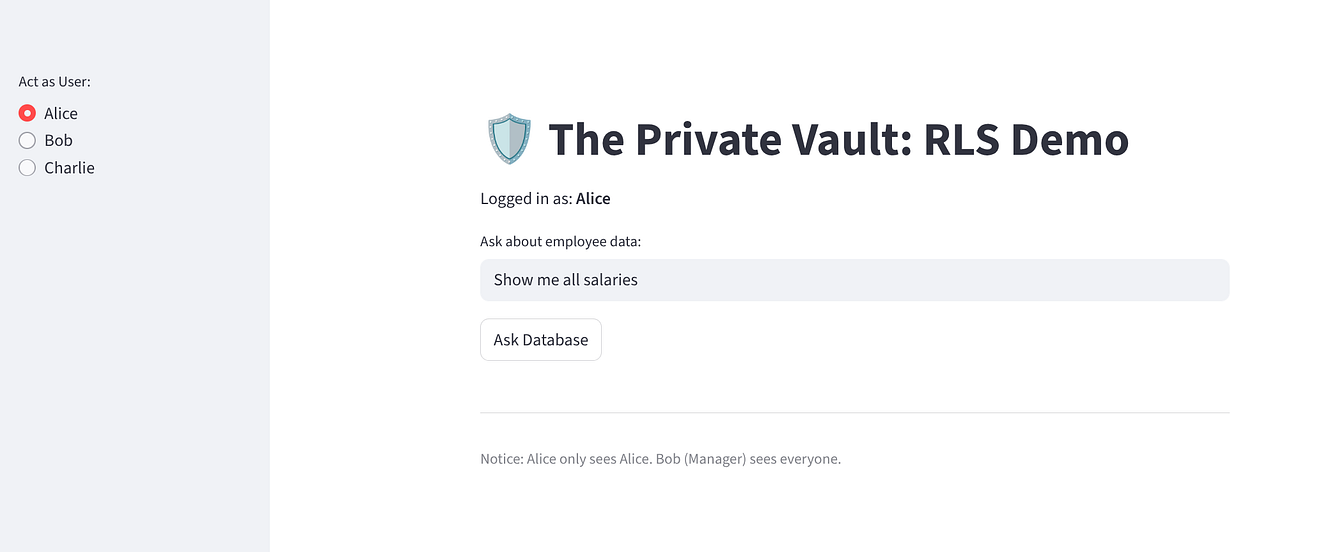
アプリを試して、ゼロトラストの実装を確認します。
[アリス] を選択します。1 行(自分自身)が表示されます。
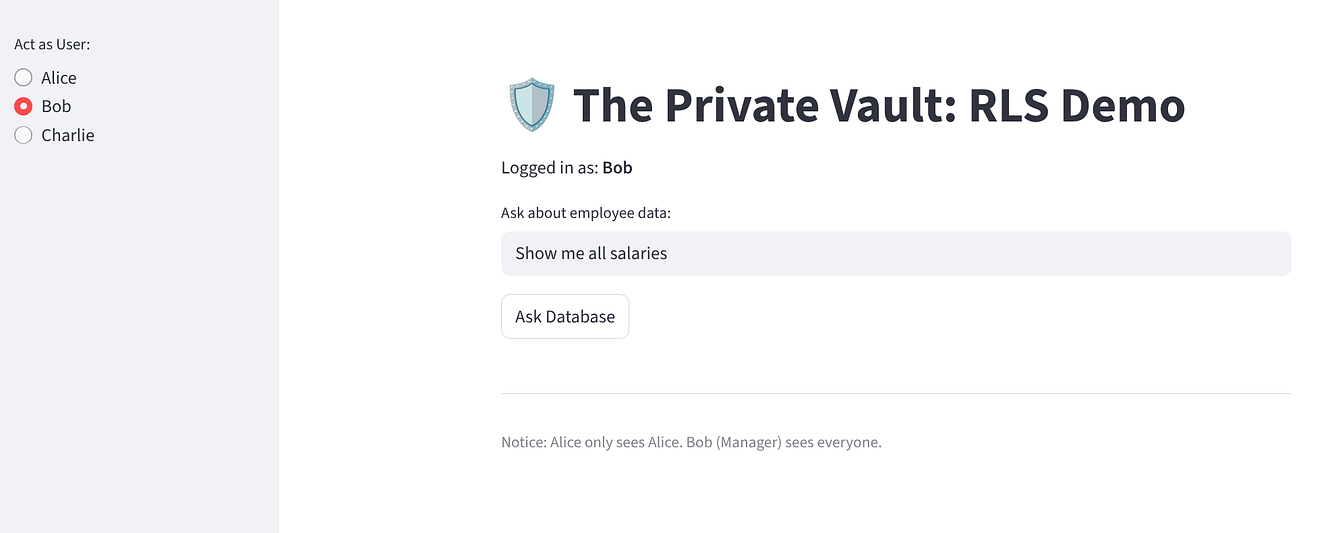
[ボブ] を選択します。3 行(全員)が表示されます。
AI エージェントにとって重要な理由
モデルをこのデータベースに接続するとします。ユーザーがモデルに「すべてのパフォーマンス レビューを要約する」と質問すると、SELECT performance_review FROM employees が生成されます。
- RLS なし: モデルはすべてのユーザーの非公開レビューを取得し、アリスに漏洩します。
- RLS あり: モデルはまったく同じクエリを実行しますが、データベースはアリスのレビューのみを返します。
これがゼロトラスト AI です。モデルがデータをフィルタすることを信頼するのではなく、データベースにデータを非表示にするように強制します。
本番環境への移行
ここで説明するアーキテクチャは本番環境レベルですが、具体的な実装は学習のために簡略化されています。実際のエンタープライズ環境に安全にデプロイするには、次の拡張機能を実装する必要があります。
- 実際の認証: [ID スイッチャー] プルダウンを、Google Identity Platform、Okta、Auth0 などの堅牢な ID プロバイダ(IDP)に置き換えます。アプリケーションは、データベース セッション変数を設定する前に、ユーザーのトークンを確認して ID を安全に抽出する必要があります。これにより、ユーザーが ID をスプーフィングできないようにします。
- 接続プーリングの安全性: 接続プールを使用する場合、セッション変数が正しく処理されないと、異なるユーザー リクエスト間で保持されることがあります。ユーザー間のデータ漏洩を防ぐため、接続をプールに戻すときに、アプリケーションがセッション変数をリセット(RESET app.active_user など)するか、接続状態をクリアするようにします。
- シークレット管理: データベース認証情報をハードコードすることはセキュリティ リスクです。Google Secret Manager などの専用のシークレット管理サービスを使用して、データベースのパスワードと接続文字列を保存し、実行時に安全に取得します。
9. クリーンアップ
このラボが完了したら、alloyDB クラスタとインスタンスを削除してください。
クラスタとそのインスタンスがクリーンアップされます。
10. 完了
これで完了です。セキュリティをデータレイヤにプッシュできました。Python コードに print(all_salaries) を試すバグがあったとしても、データベースはアリスに何も返しません。
次のステップ
- 独自のデータセットで試してください。
- AlloyDB AI のドキュメントをご覧ください。
- その他のワークショップについては、Code Vipassana のウェブサイトをご覧ください。