
1. 개요
생성형 AI 애플리케이션을 빌드하는 데 급급하다 보면 가장 중요한 구성요소인 안전을 잊는 경우가 많습니다.
HR 챗봇을 구축한다고 가정해 보겠습니다. '내 급여는 얼마야?' 또는 '우리 팀의 실적은 어때?'와 같은 질문에 대답하도록 하고 싶습니다.
- 앨리스 (일반 직원)가 요청하는 경우 자신의 데이터만 표시되어야 합니다.
- 밥 (관리자)이 요청하면 팀의 데이터가 표시되어야 합니다.
문제
대부분의 RAG (검색 증강 생성) 아키텍처는 애플리케이션 레이어에서 이 문제를 처리하려고 합니다. 청크를 가져온 후에 필터링하거나 LLM이 '작동'하도록 합니다. 이것은 깨지기 쉽습니다. 앱 로직이 실패하면 데이터가 유출됩니다.
해결 방법
보안을 데이터베이스 레이어로 푸시합니다. AlloyDB에서 PostgreSQL 행 수준 보안 (RLS)을 사용하면 AI가 무엇을 요청하든 사용자가 볼 수 없는 데이터를 데이터베이스가 물리적으로 거부합니다.
이 가이드에서는 로그인한 사용자에 따라 답변을 동적으로 변경하는 안전한 HR 어시스턴트인 '비밀 보관함'을 빌드합니다.
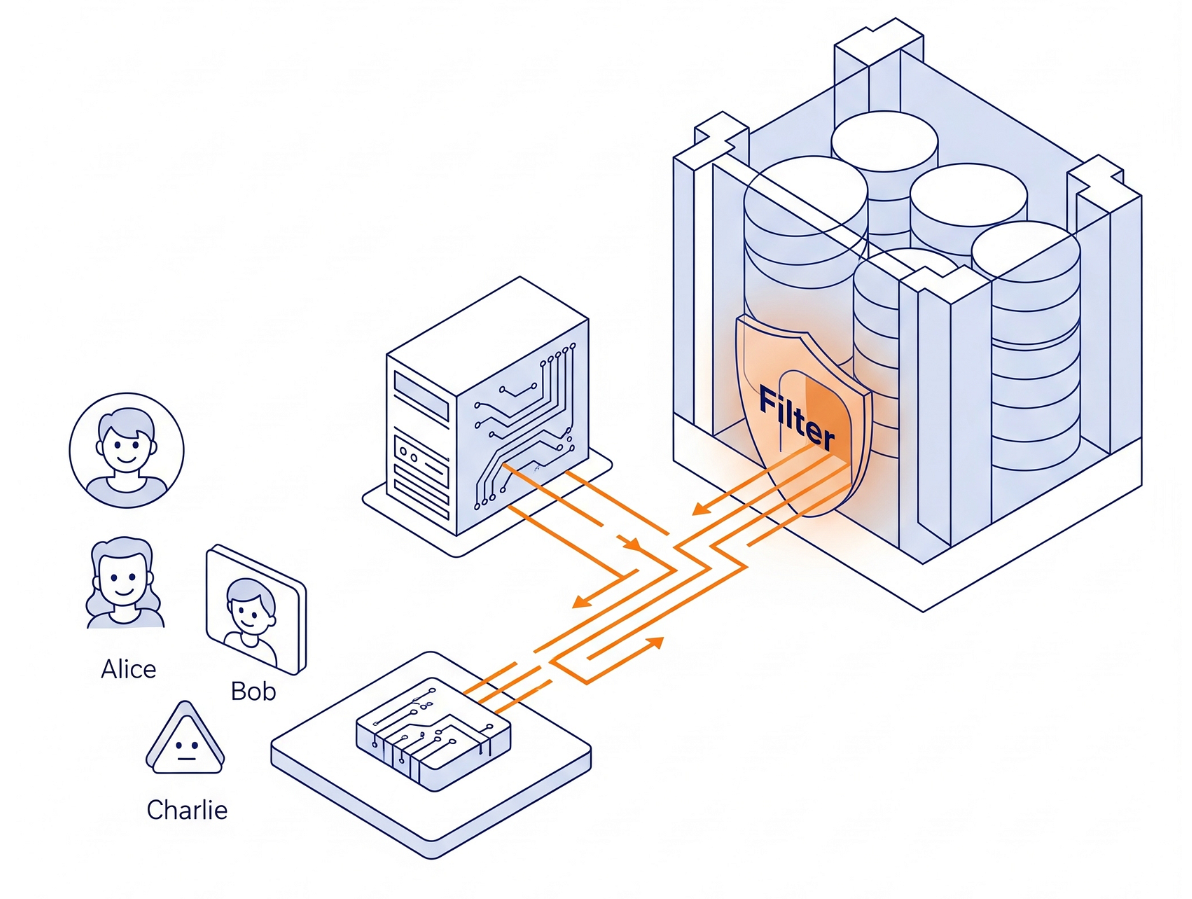
아키텍처
Python으로 복잡한 권한 로직을 빌드하지 않습니다. 데이터베이스 엔진 자체를 사용하고 있습니다.
- 인터페이스: 로그인을 시뮬레이션하는 간단한 Streamlit 앱
- 브레인: AlloyDB AI (PostgreSQL 호환)
- 메커니즘: 모든 거래가 시작될 때 세션 변수 (
app.active_user)가 설정됩니다. 데이터베이스 정책은 ID 공급업체 역할을 하는user_roles테이블을 자동으로 확인하여 행을 필터링합니다.
빌드할 항목
안전한 HR 어시스턴트 애플리케이션 애플리케이션 로직을 사용하여 민감한 데이터를 필터링하는 대신 AlloyDB 데이터베이스 엔진에서 직접 행 수준 보안 (RLS)을 구현합니다. 이렇게 하면 AI 모델이 '환각'을 일으키거나 승인되지 않은 데이터에 액세스하려고 시도하더라도 데이터베이스에서 물리적으로 반환을 거부합니다.
학습할 내용
학습할 내용은
- RLS 스키마를 설계하는 방법 (데이터와 ID 분리)
- PostgreSQL 정책 작성 방법 (
CREATE POLICY) FORCE ROW LEVEL SECURITY를 사용하여 '표 소유자' 예외를 우회하는 방법- 사용자를 위해 '컨텍스트 전환'을 실행하는 Python 앱을 빌드하는 방법
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있어야 하므로 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API 사용 설정: 링크를 따라 API를 사용 설정합니다.
또는 gcloud 명령어를 사용할 수 있습니다. gcloud 명령어 및 사용법은 문서를 참조하세요.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
주의사항 및 문제 해결
'유령 프로젝트' 증후군 |
|
결제 바리케이드 | 프로젝트를 사용 설정했지만 결제 계정을 잊었습니다. AlloyDB는 고성능 엔진이므로 '연료 탱크' (결제)가 비어 있으면 시작되지 않습니다. |
API 전파 지연 | 'API 사용 설정'을 클릭했지만 명령줄에 여전히 |
할당량 문제 | 새 체험판 계정을 사용하는 경우 AlloyDB 인스턴스의 리전별 할당량에 도달할 수 있습니다. |
3. 데이터베이스 설정
이 실습에서는 AlloyDB를 테스트 데이터의 데이터베이스로 사용합니다. 클러스터를 사용하여 데이터베이스, 로그와 같은 모든 리소스를 보유합니다. 각 클러스터에는 데이터에 대한 액세스 포인트를 제공하는 기본 인스턴스가 있습니다. 테이블에는 실제 데이터가 저장됩니다.
테스트 데이터 세트가 로드될 AlloyDB 클러스터, 인스턴스, 테이블을 만들어 보겠습니다.
- 아래 버튼을 클릭하거나 Google Cloud 콘솔 사용자가 로그인한 브라우저에 링크를 복사합니다.
- 이 단계를 완료하면 저장소가 로컬 Cloud Shell 편집기에 복제되며 프로젝트 폴더에서 아래 명령어를 실행할 수 있습니다 (프로젝트 디렉터리에 있는지 확인하는 것이 중요함).
sh run.sh
- 이제 UI를 사용하여 터미널에서 링크를 클릭하거나 터미널에서 '웹에서 미리보기' 링크를 클릭합니다.
- 시작하려면 프로젝트 ID, 클러스터, 인스턴스 이름을 입력하세요.
- 로그가 스크롤되는 동안 커피를 마시세요. 여기에서 백그라운드에서 이 작업이 어떻게 이루어지는지 확인할 수 있습니다. 10~15분 정도 걸릴 수 있습니다.
주의사항 및 문제 해결
'인내심' 문제 | 데이터베이스 클러스터는 무거운 인프라입니다. 페이지를 새로고침하거나 '멈춘 것 같아서' Cloud Shell 세션을 종료하면 부분적으로 프로비저닝되어 수동 개입 없이는 삭제할 수 없는 '고스트' 인스턴스가 생성될 수 있습니다. |
지역 불일치 |
|
좀비 클러스터 | 이전에 클러스터에 동일한 이름을 사용했고 삭제하지 않은 경우 스크립트에서 클러스터 이름이 이미 있다고 표시할 수 있습니다. 클러스터 이름은 프로젝트 내에서 고유해야 합니다. |
Cloud Shell 시간 제한 | 커피를 마시는 데 30분이 걸리면 Cloud Shell이 절전 모드로 전환되어 |
4. 스키마 프로비저닝
이 단계에서는 다음 내용을 다룹니다.
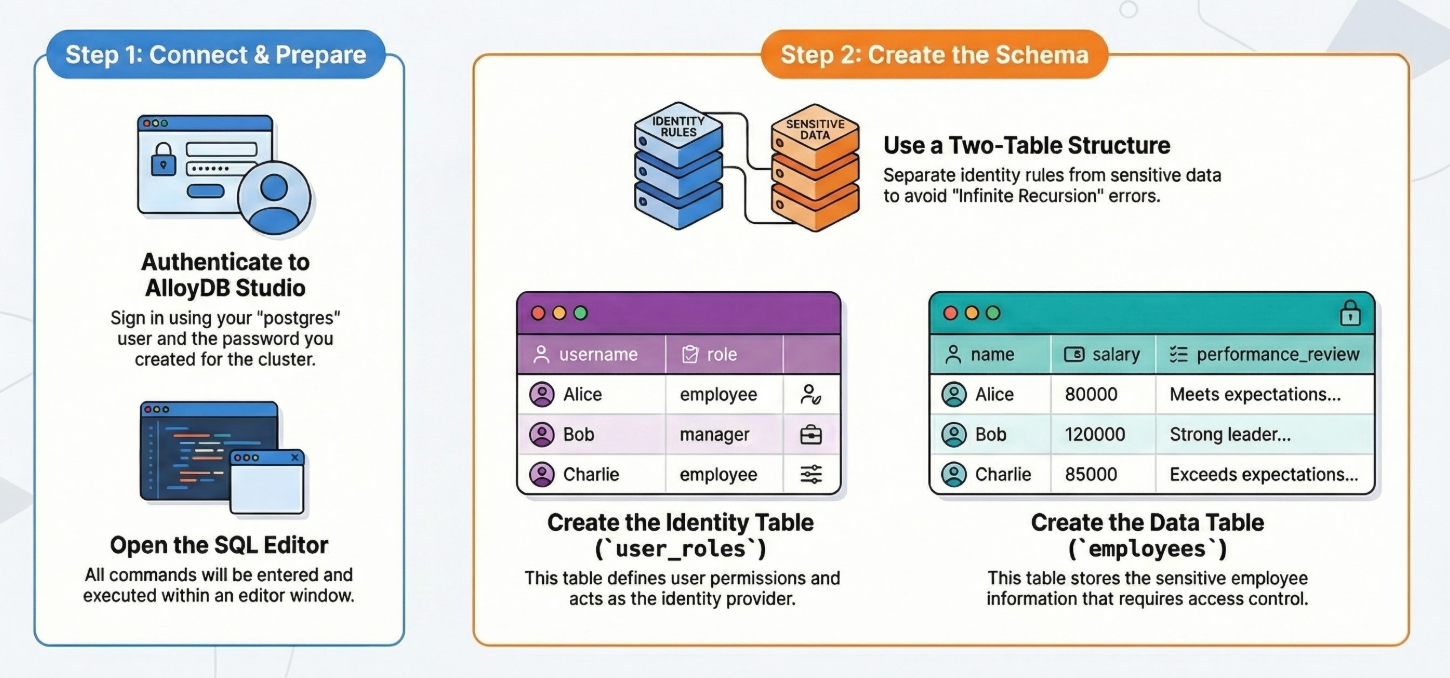
자세한 단계별 작업은 다음과 같습니다.
AlloyDB 클러스터와 인스턴스가 실행되면 AlloyDB Studio SQL 편집기로 이동하여 AI 확장 프로그램을 사용 설정하고 스키마를 프로비저닝합니다.
인스턴스 생성이 완료될 때까지 기다려야 할 수 있습니다. 완료되면 클러스터를 만들 때 만든 사용자 인증 정보를 사용하여 AlloyDB에 로그인합니다. PostgreSQL에 인증하려면 다음 데이터를 사용하세요.
- 사용자 이름 : '
postgres' - 데이터베이스 : '
postgres' - 비밀번호 : '
alloydb' (또는 생성 시 설정한 비밀번호)
AlloyDB Studio에 인증되면 편집기에 SQL 명령어가 입력됩니다. 마지막 창 오른쪽에 있는 더하기 기호를 사용하여 여러 편집기 창을 추가할 수 있습니다.
필요에 따라 실행, 형식 지정, 지우기 옵션을 사용하여 편집기 창에 AlloyDB 명령어를 입력합니다.
테이블 만들기
민감한 정보 (직원)용 테이블과 ID 규칙 (user_roles)용 테이블 두 개가 필요합니다. 정책에서 '무한 재귀' 오류를 방지하려면 이를 분리해야 합니다.
AlloyDB Studio에서 아래 DDL 문을 사용하여 테이블을 만들 수 있습니다.
-- 1. Create User Roles (The Identity Provider)
CREATE TABLE user_roles (
username TEXT PRIMARY KEY,
role TEXT -- 'employee', 'manager', 'admin'
);
INSERT INTO user_roles (username, role) VALUES
('Alice', 'employee'),
('Bob', 'manager'),
('Charlie', 'employee');
-- 2. Create the Data Table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name TEXT,
salary INTEGER,
performance_review TEXT
);
INSERT INTO employees (name, salary, performance_review) VALUES
('Alice', 80000, 'Alice meets expectations but needs to improve punctuality.'),
('Bob', 120000, 'Bob is a strong leader. Team morale is high.'),
('Charlie', 85000, 'Charlie exceeds expectations. Ready for promotion.');
주의사항 및 문제 해결
직원 테이블 내에서 역할을 정의하는 동안 무한 재귀가 감지됨 | 실패 이유: 정책에 '직원 테이블에서 내가 관리자인지 확인해'라고 명시되어 있으면 데이터베이스에서 테이블을 쿼리하여 정책을 확인해야 하므로 정책이 다시 트리거됩니다.결과: 무한 재귀가 감지되었습니다.해결 방법: 항상 별도의 조회 테이블 (user_roles)을 유지하거나 역할에 실제 데이터베이스 사용자를 사용하세요. |
데이터 확인:
SELECT count(*) FROM employees;
-- Output: 3
5. 보안 사용 설정 및 적용
이제 실드를 켭니다. 또한 Python 코드에서 연결하는 데 사용할 일반적인 '앱 사용자'도 만듭니다.
AlloyDB 쿼리 편집기에서 아래 SQL 문을 실행합니다.
-- 1. Activate RLS
ALTER TABLE employees ENABLE ROW LEVEL SECURITY;
-- 2. CRITICAL: Force RLS for Table Owners
ALTER TABLE employees FORCE ROW LEVEL SECURITY;
-- 3. Create the Application User
DO
$do$
BEGIN
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'app_user') THEN
CREATE ROLE app_user LOGIN PASSWORD 'password';
END IF;
END
$do$;
-- 4. Grant Access
GRANT SELECT ON employees TO app_user;
GRANT SELECT ON user_roles TO app_user;
주의사항 및 문제 해결
postgres (슈퍼 사용자)로 테스트하고 모든 데이터를 확인합니다. | 실패하는 이유: 기본적으로 RLS는 테이블 소유자나 수퍼유저에게 적용되지 않습니다. 모든 정책을 우회합니다.문제 해결: 정책이 '손상'된 것 같으면(모든 것이 허용됨) |
6. 액세스 정책 만들기
나중에 애플리케이션 코드에서 설정할 세션 변수 (app.active_user)를 사용하여 두 가지 규칙을 정의합니다.
AlloyDB 쿼리 편집기에서 아래 SQL 문을 실행합니다.
-- Policy 1: Self-View
-- Users can see rows where their name matches the session variable
CREATE POLICY "view_own_data" ON employees
FOR SELECT
USING (name = current_setting('app.active_user', true));
-- Policy 2: Manager-View
-- Managers can see ALL rows.
CREATE POLICY "manager_view_all" ON employees
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM user_roles
WHERE username = current_setting('app.active_user', true)
AND role = 'manager'
)
);
주의사항 및 문제 해결
app.active_user 대신 current_user 사용 | 문제: current_user는 데이터베이스 역할 (예: app_user)을 반환하는 예약된 SQL 키워드입니다. 애플리케이션 사용자 (예: Alice)가 필요합니다.해결 방법: 항상 app.variable_name과 같은 맞춤 네임스페이스를 사용하세요. |
| 문제: 변수가 설정되지 않으면 쿼리가 오류와 함께 비정상 종료됩니다.해결 방법: current_setting('...', true)은 비정상 종료되는 대신 NULL을 반환하므로 안전하게 0개의 행이 반환됩니다. |
7. 'Chameleon' 앱 빌드
Python과 Streamlit을 사용하여 애플리케이션 로직을 시뮬레이션합니다.
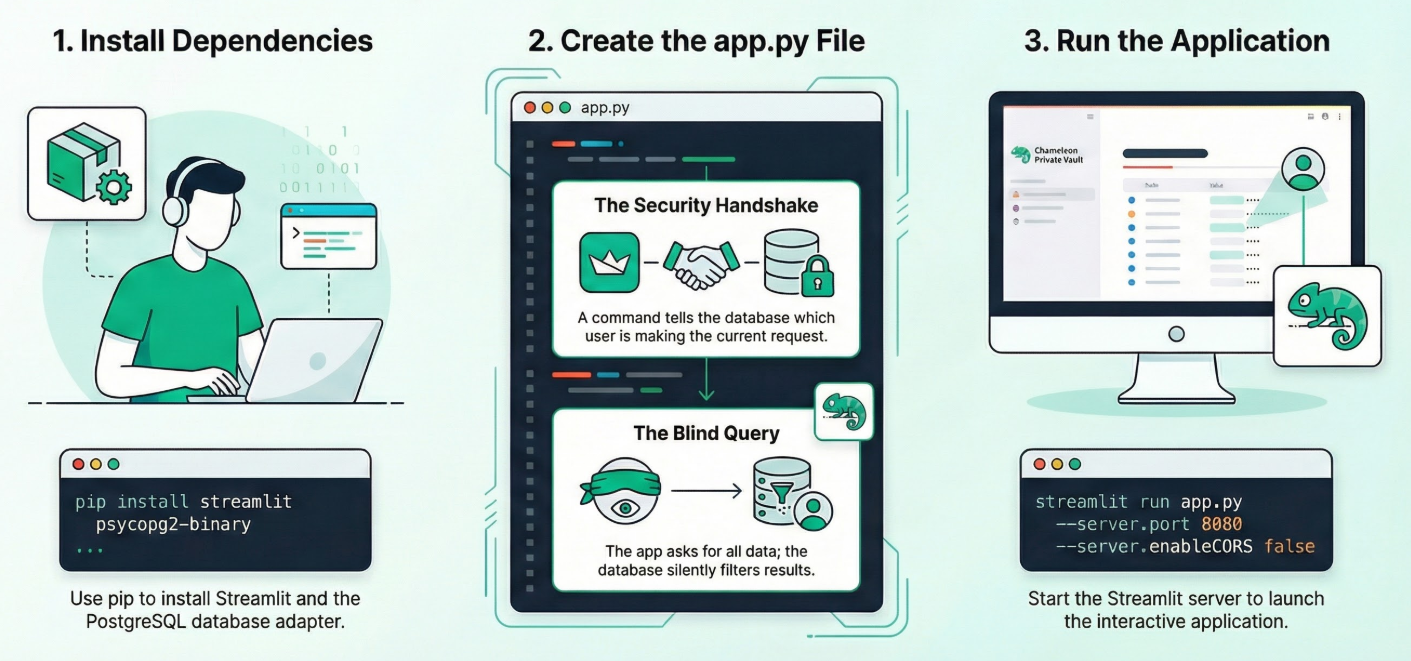
편집기 모드에서 Cloud Shell 터미널을 열고 루트 폴더 또는 이 애플리케이션을 만들려는 디렉터리로 이동합니다. 새 폴더를 만듭니다.
1. 종속 항목 설치:
새 프로젝트 디렉터리 내에서 Cloud Shell 터미널에서 다음 명령어를 실행합니다.
pip install streamlit psycopg2-binary
2. app.py를 만듭니다.
app.py라는 새 파일을 만들고 저장소 파일의 콘텐츠를 복사합니다.
import streamlit as st
import psycopg2
# CONFIGURATION (Replace with your IP)
DB_HOST = "10.x.x.x"
DB_NAME = "postgres"
DB_USER = "postgres"
DB_PASS = "alloydb"
def get_db_connection():
return psycopg2.connect(
host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASS
)
def query_database(user_name):
conn = get_db_connection()
try:
with conn.cursor() as cur:
# THE SECURITY HANDSHAKE
# We tell the database: "For this transaction, I am acting as..."
cur.execute(f"SET app.active_user = '{user_name}';")
# THE BLIND QUERY
# We ask for EVERYTHING. The database silently filters it.
cur.execute("SELECT name, role, salary, performance_review FROM employees;")
return cur.fetchall()
finally:
conn.close()
# UI
st.title("🛡️ The Private Vault")
user = st.sidebar.radio("Act as User:", ["Alice", "Bob", "Charlie", "Eve"])
if st.button("Access Data"):
results = query_database(user)
if not results:
st.error("🚫 Access Denied.")
else:
st.success(f"Viewing data as {user}")
for row in results:
st.write(row)
3. 앱을 실행합니다.
새 프로젝트 디렉터리 내에서 Cloud Shell 터미널에서 다음 명령어를 실행합니다.
streamlit run app.py --server.port 8080 --server.enableCORS false
주의사항 및 문제 해결
연결 풀링 | 위험: 연결 풀을 사용하는 경우 세션 변수 SET app.active_user가 연결에 유지되어 해당 연결을 가져오는 다음 사용자에게 '누출'될 수 있습니다.해결 방법:프로덕션에서는 연결을 풀로 반환할 때 항상 RESET app.active_user 또는 DISCARD ALL을 사용하세요. |
Cloud Shell의 빈 화면 | 해결: 포트 8080에서 '웹 미리보기' 버튼을 사용합니다. 터미널에서 localhost 링크를 클릭하지 마세요. |
8. 제로 트러스트 확인
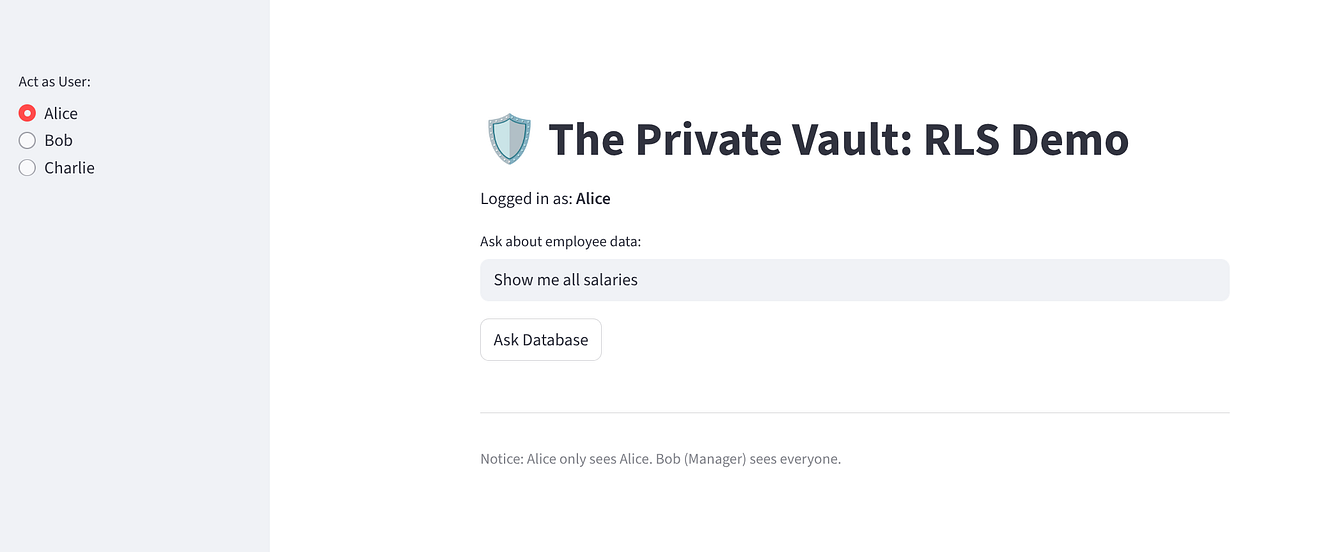
앱을 사용해 제로 트러스트 구현을 확인합니다.
'Alice'를 선택합니다. 행이 1개 (본인) 표시됩니다.
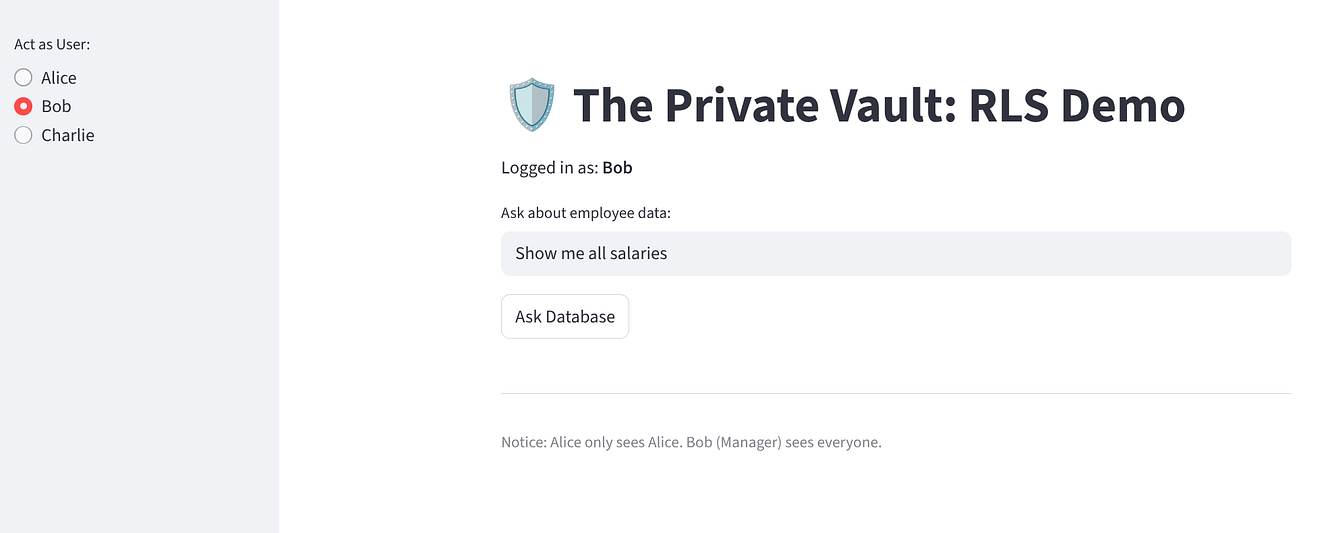
'밥'을 선택합니다. 3개의 행 (모두)이 표시됩니다.
AI 에이전트에게 중요한 이유
모델을 이 데이터베이스에 연결한다고 가정해 보겠습니다. 사용자가 모델에 '모든 실적 검토를 요약해 줘'라고 요청하면 SELECT performance_review FROM employees가 생성됩니다.
- RLS가 없는 경우: 모델이 모든 사용자의 비공개 리뷰를 가져와 Alice에게 유출합니다.
- RLS 사용: 모델은 정확히 동일한 쿼리를 실행하지만 데이터베이스는 Alice의 리뷰만 반환합니다.
이것이 제로 트러스트 AI입니다. 모델이 데이터를 필터링한다고 신뢰하지 않고 데이터베이스가 데이터를 숨기도록 강제합니다.
프로덕션에 적용
여기에 설명된 아키텍처는 프로덕션 등급이지만, 학습을 위해 특정 구현이 간소화되었습니다. 실제 엔터프라이즈 환경에 안전하게 배포하려면 다음 개선사항을 구현해야 합니다.
- 실제 인증: 'ID 전환기' 드롭다운을 Google Identity Platform, Okta, Auth0와 같은 강력한 ID 제공업체 (IDP)로 바꿉니다. 애플리케이션은 데이터베이스 세션 변수를 설정하기 전에 사용자의 토큰을 확인하고 ID를 안전하게 추출하여 사용자가 ID를 스푸핑할 수 없도록 해야 합니다.
- 연결 풀링 안전성: 연결 풀을 사용할 때 세션 변수가 올바르게 처리되지 않으면 서로 다른 사용자 요청 간에 지속될 수 있습니다. 사용자 간 데이터 유출을 방지하려면 애플리케이션이 풀에 연결을 반환할 때 세션 변수 (예: RESET app.active_user)를 재설정하거나 연결 상태를 지워야 합니다.
- Secret 관리: 데이터베이스 사용자 인증 정보를 하드코딩하면 보안 위험이 발생합니다. Google Secret Manager와 같은 전용 보안 비밀 관리 서비스를 사용하여 런타임에 데이터베이스 비밀번호와 연결 문자열을 안전하게 저장하고 검색합니다.
9. 삭제
이 실습을 완료한 후에는 AlloyDB 클러스터와 인스턴스를 삭제해야 합니다.
인스턴스와 함께 클러스터를 정리해야 합니다.
10. 축하합니다
수고하셨습니다. 보안을 데이터 레이어로 푸시했습니다. Python 코드에 print(all_salaries)를 시도하는 버그가 있더라도 데이터베이스는 Alice에게 아무것도 반환하지 않습니다.
다음 단계
- 자체 데이터 세트로 사용해 보세요.
- AlloyDB AI 문서를 살펴봅니다.
- 더 많은 워크숍은 Code Vipassana 웹사이트를 확인하세요.