
1. Przegląd
W pośpiechu związanym z tworzeniem aplikacji opartych na generatywnej AI często zapominamy o najważniejszym elemencie: bezpieczeństwie.
Wyobraź sobie, że tworzysz czatbota HR. Chcesz, aby odpowiadał na pytania takie jak „Ile zarabiam?” lub „Jak radzi sobie mój zespół?”.
- Jeśli zapyta Alicja (zwykły pracownik), powinna zobaczyć tylko swoje dane.
- Jeśli Bob (menedżer) zapyta, powinien zobaczyć dane swojego zespołu.
Problem
Większość architektur RAG (Retrieval Augmented Generation) próbuje sobie z tym poradzić w warstwie aplikacji. Filtrują one fragmenty po ich pobraniu lub polegają na „zachowaniu” modelu LLM. To jest delikatne. Jeśli logika aplikacji zawiedzie, dane wyciekną.
Rozwiązanie
Przenieś zabezpieczenia do warstwy bazy danych. Dzięki zastosowaniu w AlloyDB funkcji bezpieczeństwa na poziomie wiersza (RLS) w PostgreSQL zapewniamy, że baza danych fizycznie odmawia zwrócenia danych, do których użytkownik nie ma dostępu – niezależnie od tego, o co poprosi AI.
W tym przewodniku stworzymy „Prywatny skarbiec”: bezpiecznego asystenta HR, który dynamicznie zmienia odpowiedzi w zależności od tego, kto jest zalogowany.
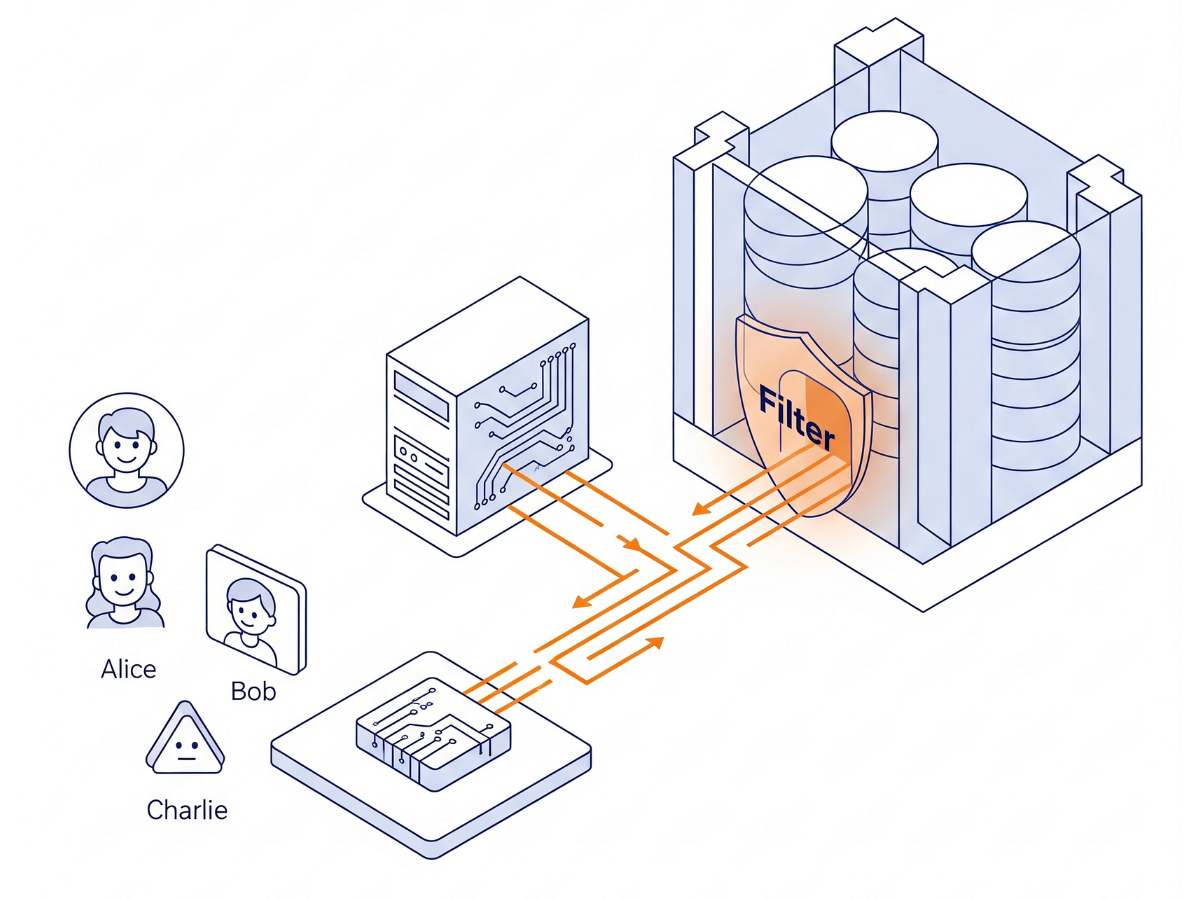
Architektura
Nie tworzymy w Pythonie złożonej logiki uprawnień. Używamy samego silnika bazy danych.
- Interfejs: prosta aplikacja Streamlit symulująca logowanie.
- Mózg: AlloyDB AI (zgodny z PostgreSQL).
- Mechanizm: na początku każdej transakcji ustawiamy zmienną sesji (
app.active_user). Zasady bazy danych automatycznie sprawdzają tabelęuser_roles(pełniącą rolę dostawcy tożsamości), aby filtrować wiersze.
Co utworzysz
bezpieczną aplikację Asystent HR, Zamiast polegać na logice aplikacji w zakresie filtrowania danych wrażliwych, możesz wdrożyć zabezpieczenia na poziomie wiersza (RLS) bezpośrednio w silniku bazy danych AlloyDB. Dzięki temu nawet jeśli model AI „halucynuje” lub próbuje uzyskać dostęp do nieautoryzowanych danych, baza danych fizycznie odmówi ich zwrócenia.
Czego się nauczysz
Dowiesz się:
- Jak zaprojektować schemat na potrzeby RLS (oddzielenie danych od tożsamości).
- Jak pisać zasady PostgreSQL (
CREATE POLICY). - Jak ominąć wyłączenie „Właściciel tabeli” za pomocą
FORCE ROW LEVEL SECURITY. - Jak utworzyć aplikację w Pythonie, która wykonuje „przełączanie kontekstu” dla użytkowników.
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: kliknij link i włącz interfejsy API.
Możesz też użyć polecenia gcloud. Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Pułapki i rozwiązywanie problemów
Syndrom „projektu widma” | Uruchomiono polecenie |
Bariera rozliczeniowa | Projekt został włączony, ale zapomniano o koncie rozliczeniowym. AlloyDB to wydajny mechanizm, który nie uruchomi się, jeśli „zbiornik paliwa” (płatności) jest pusty. |
Opóźnienie propagacji interfejsu API | Kliknięto „Włącz interfejsy API”, ale w wierszu poleceń nadal widnieje znak |
Limit Quags | Jeśli korzystasz z nowego konta próbnego, możesz osiągnąć regionalny limit instancji AlloyDB. Jeśli |
3. Konfiguracja bazy danych
W tym module użyjemy AlloyDB jako bazy danych do przechowywania danych testowych. Używa klastrów do przechowywania wszystkich zasobów, takich jak bazy danych i logi. Każdy klaster ma instancję główną, która zapewnia punkt dostępu do danych. Tabele będą zawierać rzeczywiste dane.
Utwórzmy klaster, instancję i tabelę AlloyDB, do których zostanie załadowany testowy zbiór danych.
- Kliknij przycisk lub skopiuj poniższy link do przeglądarki, w której zalogowany jest użytkownik konsoli Google Cloud.
- Po wykonaniu tego kroku repozytorium zostanie sklonowane do lokalnego edytora Cloud Shell i będziesz mieć możliwość uruchomienia poniższego polecenia z folderu projektu (ważne jest, aby upewnić się, że jesteś w katalogu projektu):
sh run.sh
- Teraz użyj interfejsu (kliknij link w terminalu lub link „Podgląd w internecie” w terminalu).
- Aby rozpocząć, wpisz szczegóły identyfikatora projektu, klastra i nazw instancji.
- Idź po kawę, podczas gdy dzienniki będą się przewijać. Tutaj możesz przeczytać, jak to działa za kulisami. Może to potrwać około 10–15 minut.
Pułapki i rozwiązywanie problemów
Problem z „cierpliwością” | Klastry baz danych to rozbudowana infrastruktura. Jeśli odświeżysz stronę lub zakończysz sesję Cloud Shell, ponieważ „utknęła”, możesz skończyć z „duchem” instancji, która jest częściowo udostępniona i nie można jej usunąć bez ręcznej interwencji. |
Niezgodny region | Jeśli interfejsy API zostały włączone w regionie |
Zombie Clusters | Jeśli nazwa klastra była już wcześniej używana i nie została usunięta, skrypt może wyświetlić komunikat, że nazwa klastra już istnieje. Nazwy klastrów muszą być unikalne w projekcie. |
Limit czasu Cloud Shell | Jeśli przerwa na kawę trwa 30 minut, Cloud Shell może przejść w stan uśpienia i odłączyć proces |
4. Provisioning schematu
W tym kroku omówimy te kwestie:
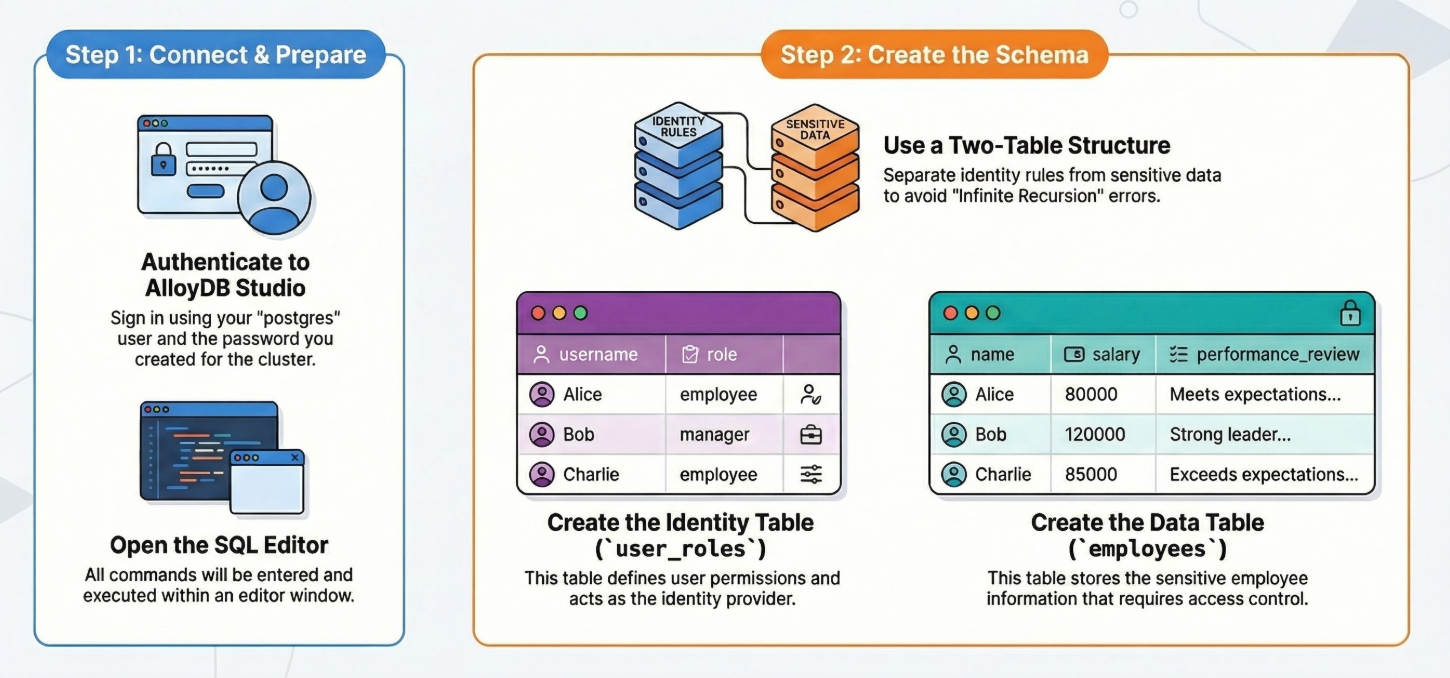
Aby to zrobić:
Gdy klaster i instancja AlloyDB będą działać, przejdź do edytora SQL w AlloyDB Studio, aby włączyć rozszerzenia AI i udostępnić schemat.
Może być konieczne poczekanie na zakończenie tworzenia instancji. Gdy to zrobisz, zaloguj się w AlloyDB przy użyciu danych logowania utworzonych podczas tworzenia klastra. Do uwierzytelniania w PostgreSQL użyj tych danych:
- Nazwa użytkownika: „
postgres” - Baza danych: „
postgres” - Hasło: „
alloydb” (lub inne hasło ustawione podczas tworzenia)
Po pomyślnym uwierzytelnieniu w AlloyDB Studio polecenia SQL są wpisywane w Edytorze. Możesz dodać wiele okien Edytora, klikając znak plusa po prawej stronie ostatniego okna.
Polecenia dla AlloyDB będziesz wpisywać w oknach edytora, w razie potrzeby korzystając z opcji Uruchom, Formatuj i Wyczyść.
Tworzenie tabeli
Potrzebujemy 2 tabel: jednej z danymi wrażliwymi (pracownicy) i jednej z regułami tożsamości (role_użytkowników). Rozdzielenie tych elementów jest kluczowe, aby uniknąć błędów „Infinite Recursion” w zasadach.
Tabelę możesz utworzyć za pomocą instrukcji DDL poniżej w AlloyDB Studio:
-- 1. Create User Roles (The Identity Provider)
CREATE TABLE user_roles (
username TEXT PRIMARY KEY,
role TEXT -- 'employee', 'manager', 'admin'
);
INSERT INTO user_roles (username, role) VALUES
('Alice', 'employee'),
('Bob', 'manager'),
('Charlie', 'employee');
-- 2. Create the Data Table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name TEXT,
salary INTEGER,
performance_review TEXT
);
INSERT INTO employees (name, salary, performance_review) VALUES
('Alice', 80000, 'Alice meets expectations but needs to improve punctuality.'),
('Bob', 120000, 'Bob is a strong leader. Team morale is high.'),
('Charlie', 85000, 'Charlie exceeds expectations. Ready for promotion.');
Pułapki i rozwiązywanie problemów
Wykryto nieskończoną rekurencję podczas definiowania ról w tabeli pracowników | Przyczyna błędu: jeśli zasada brzmi „Sprawdź w tabeli pracowników, czy jestem menedżerem”, baza danych musi wysłać zapytanie do tabeli, aby sprawdzić zasadę, co ponownie ją wywołuje.Wynik: wykryto nieskończoną rekurencję.Rozwiązanie: zawsze używaj oddzielnej tabeli przeglądowej (user_roles) lub rzeczywistych użytkowników bazy danych do określania ról. |
Sprawdź dane:
SELECT count(*) FROM employees;
-- Output: 3
5. Włączanie i wymuszanie zabezpieczeń
Teraz włączamy osłony. Utworzymy też ogólnego „Użytkownika aplikacji”, którego nasz kod Pythona będzie używać do łączenia się.
Uruchom poniższą instrukcję SQL w edytorze zapytań AlloyDB:
-- 1. Activate RLS
ALTER TABLE employees ENABLE ROW LEVEL SECURITY;
-- 2. CRITICAL: Force RLS for Table Owners
ALTER TABLE employees FORCE ROW LEVEL SECURITY;
-- 3. Create the Application User
DO
$do$
BEGIN
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'app_user') THEN
CREATE ROLE app_user LOGIN PASSWORD 'password';
END IF;
END
$do$;
-- 4. Grant Access
GRANT SELECT ON employees TO app_user;
GRANT SELECT ON user_roles TO app_user;
Pułapki i rozwiązywanie problemów
Testowanie jako postgres (superużytkownik) i wyświetlanie wszystkich danych. | Przyczyna błędu: domyślnie RLS nie ma zastosowania do właściciela tabeli ani superużytkowników. Omijają one wszystkie zasady.Rozwiązywanie problemów: jeśli Twoje zasady wydają się „zepsute” (umożliwiają wszystko), sprawdź, czy jesteś zalogowany(-a) jako |
6. Tworzenie zasad dostępu
Zdefiniujemy 2 reguły za pomocą zmiennej sesji (app.active_user), którą ustawimy później w kodzie aplikacji.
Uruchom poniższą instrukcję SQL w edytorze zapytań AlloyDB:
-- Policy 1: Self-View
-- Users can see rows where their name matches the session variable
CREATE POLICY "view_own_data" ON employees
FOR SELECT
USING (name = current_setting('app.active_user', true));
-- Policy 2: Manager-View
-- Managers can see ALL rows.
CREATE POLICY "manager_view_all" ON employees
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM user_roles
WHERE username = current_setting('app.active_user', true)
AND role = 'manager'
)
);
Pułapki i rozwiązywanie problemów
Używanie zmiennej current_user zamiast app.active_user. | Problem: current_user to zarezerwowane słowo kluczowe SQL, które zwraca rolę bazy danych (np. app_user). Potrzebujemy użytkownika aplikacji (np.Alicja).Poprawka: zawsze używaj niestandardowej przestrzeni nazw, np. app.nazwa_zmiennej. |
Zapomnienie parametru | Problem: jeśli zmienna nie jest ustawiona, zapytanie ulega awarii i wyświetla się błąd.Rozwiązanie: funkcja current_setting('...', true) zwraca wartość NULL zamiast powodować awarię, co bezpiecznie skutkuje zwróceniem 0 wierszy. |
7. Tworzenie aplikacji „Chameleon”
Do symulacji logiki aplikacji użyjemy Pythona i Streamlit.
Otwórz terminal Cloud Shell w trybie edytora, przejdź do folderu głównego lub do katalogu, w którym chcesz utworzyć tę aplikację. Utwórz nowy folder.
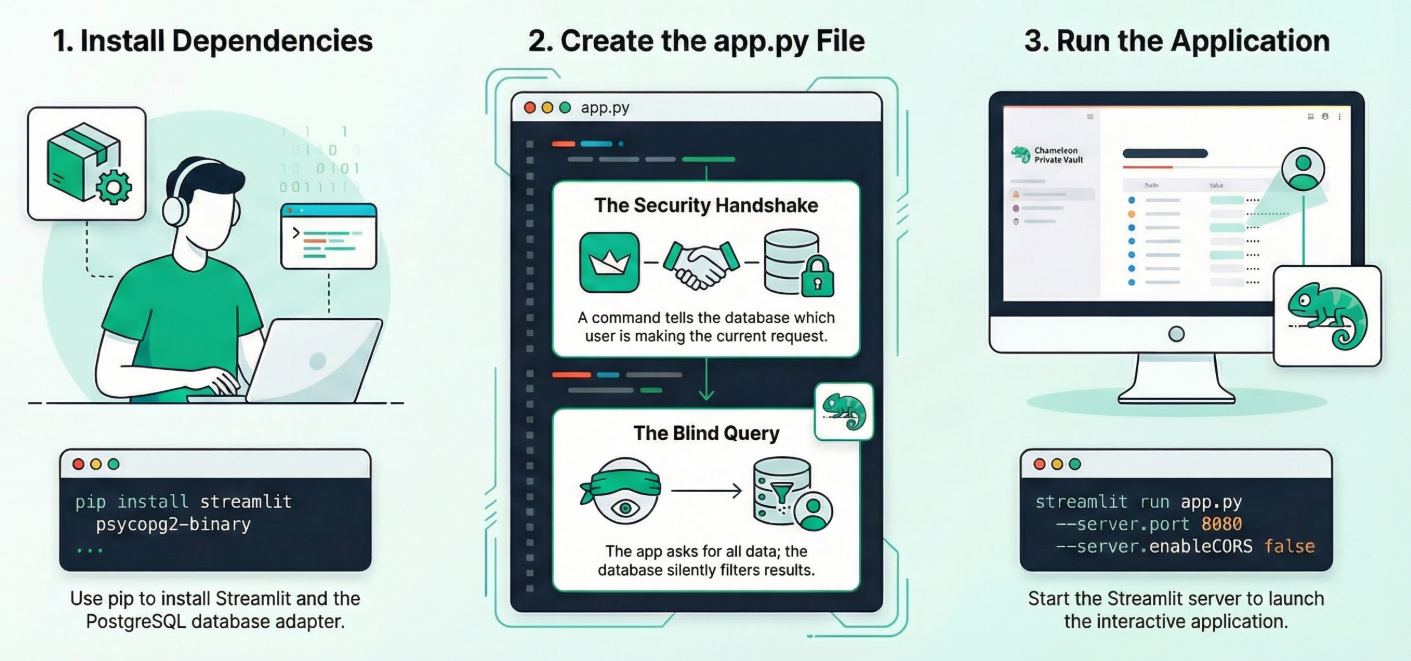
1. Zainstaluj zależności:
Uruchom to polecenie w terminalu Cloud Shell w katalogu nowego projektu:
pip install streamlit psycopg2-binary
2. Utwórz plik app.py:
Utwórz nowy plik o nazwie app.py i skopiuj do niego zawartość z pliku repozytorium.
import streamlit as st
import psycopg2
# CONFIGURATION (Replace with your IP)
DB_HOST = "10.x.x.x"
DB_NAME = "postgres"
DB_USER = "postgres"
DB_PASS = "alloydb"
def get_db_connection():
return psycopg2.connect(
host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASS
)
def query_database(user_name):
conn = get_db_connection()
try:
with conn.cursor() as cur:
# THE SECURITY HANDSHAKE
# We tell the database: "For this transaction, I am acting as..."
cur.execute(f"SET app.active_user = '{user_name}';")
# THE BLIND QUERY
# We ask for EVERYTHING. The database silently filters it.
cur.execute("SELECT name, role, salary, performance_review FROM employees;")
return cur.fetchall()
finally:
conn.close()
# UI
st.title("🛡️ The Private Vault")
user = st.sidebar.radio("Act as User:", ["Alice", "Bob", "Charlie", "Eve"])
if st.button("Access Data"):
results = query_database(user)
if not results:
st.error("🚫 Access Denied.")
else:
st.success(f"Viewing data as {user}")
for row in results:
st.write(row)
3. Uruchom aplikację:
Uruchom to polecenie w terminalu Cloud Shell w katalogu nowego projektu:
streamlit run app.py --server.port 8080 --server.enableCORS false
Pułapki i rozwiązywanie problemów
Agregacja połączeń. | Ryzyko: jeśli używasz puli połączeń, zmienna sesji SET app.active_user może być zachowywana w połączeniu i „wyciekać” do następnego użytkownika, który skorzysta z tego połączenia.Rozwiązanie: w środowisku produkcyjnym zawsze używaj polecenia RESET app.active_user lub DISCARD ALL, gdy zwracasz połączenie do puli. |
Pusty ekran w Cloud Shell. | Rozwiązanie: użyj przycisku „Podgląd w przeglądarce” na porcie 8080. Nie klikaj linku localhost w terminalu. |
8. Weryfikacja modelu „zero zaufania”
Wypróbuj aplikację, aby sprawdzić, czy wdrożenie modelu „zero zaufania” przebiegło prawidłowo:
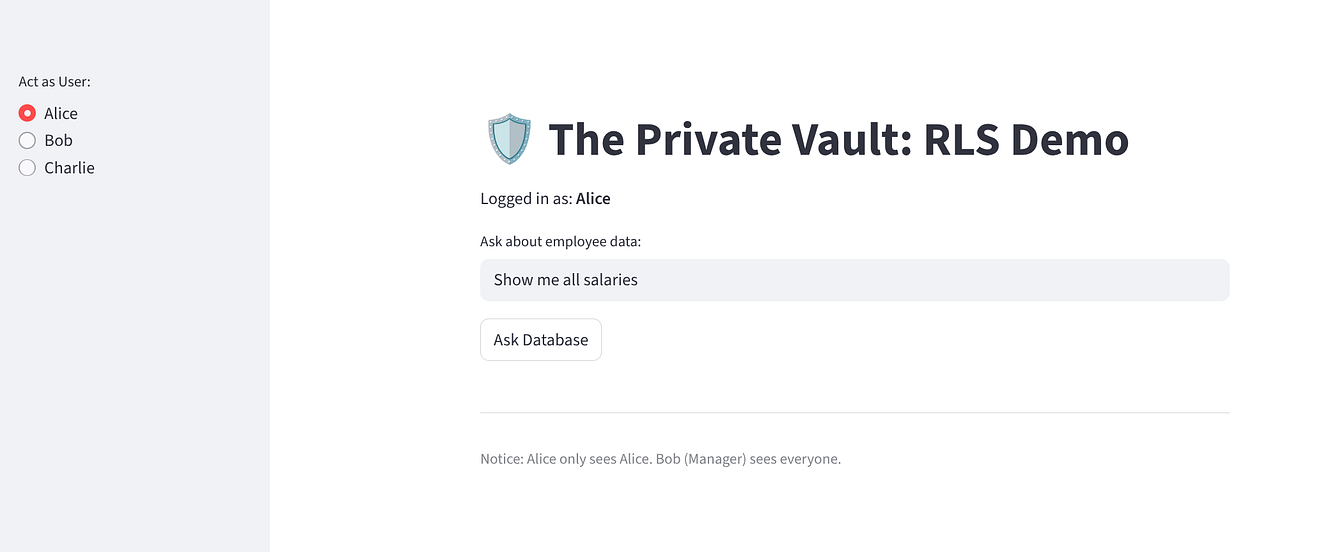
Wybierz „Alice”: powinna zobaczyć 1 wiersz (swoje dane).
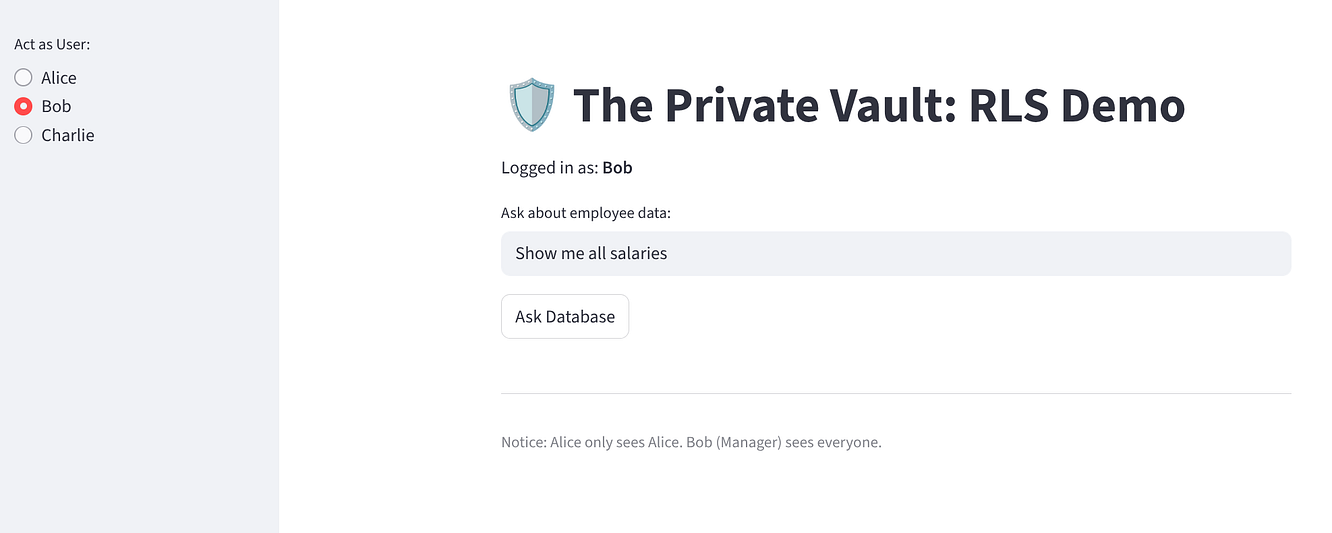
Wybierz „Bob”: powinien zobaczyć 3 wiersze (Wszyscy).
Dlaczego jest to ważne w przypadku agentów AI
Wyobraź sobie, że łączysz swój model z tą bazą danych. Jeśli użytkownik zapyta model: „Podsumuj wszystkie oceny wyników”, wygeneruje on zapytanie SELECT performance_review FROM employees.
- Bez RLS: model pobiera prywatne opinie wszystkich użytkowników i ujawnia je Alicji.
- W przypadku RLS: model uruchamia dokładnie to samo zapytanie, ale baza danych zwraca tylko opinię Alicji.
To jest AI oparta na modelu „zero zaufania”. Nie ufasz modelowi, że odfiltruje dane, więc wymuszasz na bazie danych ich ukrycie.
Wdrażanie w środowisku produkcyjnym
Przedstawiona tu architektura jest przeznaczona do użytku produkcyjnego, ale konkretne wdrożenie zostało uproszczone na potrzeby szkolenia. Aby bezpiecznie wdrożyć to rozwiązanie w prawdziwym środowisku firmowym, należy wprowadzić te ulepszenia:
- Prawdziwe uwierzytelnianie: zastąp menu „Przełącznik tożsamości” solidnym dostawcą tożsamości, takim jak Google Identity Platform, Okta lub Auth0. Aplikacja powinna zweryfikować token użytkownika i bezpiecznie wyodrębnić jego tożsamość przed ustawieniem zmiennej sesji bazy danych, aby użytkownicy nie mogli podszywać się pod inne osoby.
- Bezpieczeństwo puli połączeń: podczas korzystania z puli połączeń zmienne sesji mogą czasami utrzymywać się w różnych żądaniach użytkowników, jeśli nie są prawidłowo obsługiwane. Aby zapobiec wyciekowi danych między użytkownikami, upewnij się, że aplikacja resetuje zmienną sesji (np. RESET app.active_user) lub czyści stan połączenia, gdy zwraca połączenie do puli.
- Zarządzanie danymi tajnymi: zakodowanie na stałe danych logowania do bazy danych stwarza zagrożenie dla bezpieczeństwa. Używaj specjalnej usługi zarządzania kluczami tajnymi, takiej jak Google Secret Manager, do bezpiecznego przechowywania i pobierania haseł do bazy danych oraz ciągów połączenia w czasie działania.
9. Czyszczenie danych
Po ukończeniu tego modułu nie zapomnij usunąć klastra i instancji AlloyDB.
Powinien on zwalniać miejsce w klastrze wraz z jego instancjami.
10. Gratulacje
Gratulacje! Udało Ci się przenieść zabezpieczenia do warstwy danych. Nawet jeśli w kodzie w języku Python wystąpił błąd, który spowodował próbę print(all_salaries), baza danych nie zwróci Alicji żadnych informacji.
Następne kroki
- Wypróbuj to na własnym zbiorze danych.
- Zapoznaj się z dokumentacją AlloyDB AI.
- Więcej warsztatów znajdziesz na stronie Code Vipassana.