
1. Visão geral
Na pressa de criar aplicativos de IA generativa, muitas vezes esquecemos o componente mais importante: a segurança.
Imagine criar um chatbot de RH. Você quer que ele responda a perguntas como "Qual é meu salário?" ou "Como está o desempenho da minha equipe?"
- Se Alice (uma funcionária comum) perguntar, ela só vai ver os dados dela.
- Se Bob (um gerente) perguntar, ele vai ver os dados da equipe.
O problema
A maioria das arquiteturas de RAG (geração aumentada de recuperação) tenta lidar com isso na camada de aplicativo. Eles filtram os trechos depois de recuperá-los ou confiam no LLM para "se comportar". Isso é frágil. Se a lógica do app falhar, os dados vão vazar.
A solução
Envie a segurança para a camada de banco de dados. Ao usar a segurança no nível da linha (RLS) do PostgreSQL no AlloyDB, garantimos que o banco de dados se recuse fisicamente a retornar dados que o usuário não tem permissão para ver, não importa o que a IA peça.
Neste guia, vamos criar "O cofre privado": um assistente de RH seguro que muda dinamicamente as respostas com base em quem está conectado.
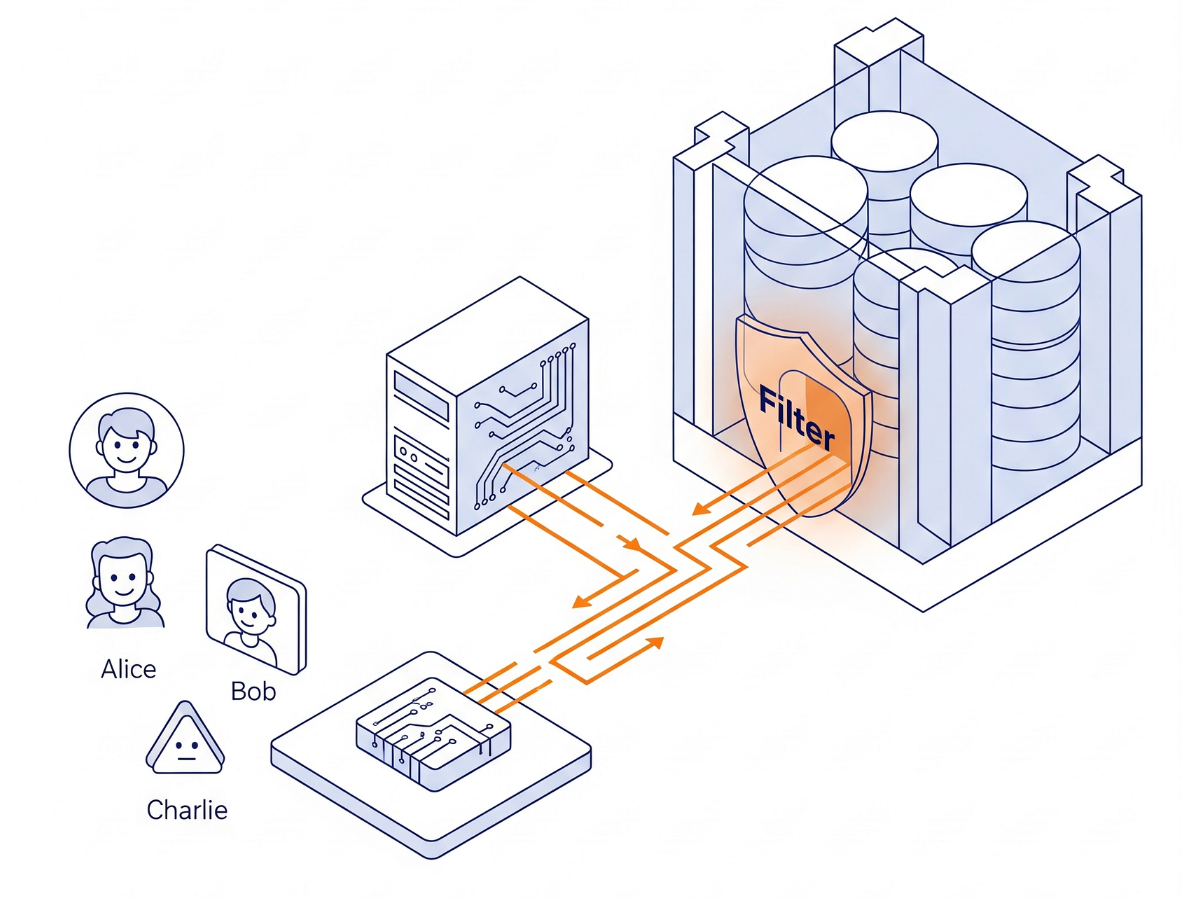
A arquitetura
Não estamos criando uma lógica de permissão complexa em Python. Estamos usando o próprio mecanismo de banco de dados.
- A interface:um app Streamlit simples que simula um login.
- O cérebro:AlloyDB AI (compatível com PostgreSQL).
- O mecanismo:definimos uma variável de sessão (
app.active_user) no início de cada transação. As políticas de banco de dados verificam automaticamente uma tabelauser_roles(que funciona como nosso provedor de identidade) para filtrar as linhas.
O que você vai criar
Um aplicativo de assistente de RH seguro. Em vez de depender da lógica do aplicativo para filtrar dados sensíveis, você vai implementar a segurança no nível da linha (RLS, na sigla em inglês) diretamente no mecanismo de banco de dados do AlloyDB. Isso garante que, mesmo que o modelo de IA "alucine" ou tente acessar dados não autorizados, o banco de dados se recusará fisicamente a retorná-los.
O que você vai aprender
Você vai aprender:
- Como projetar um esquema para RLS (separando dados e identidade).
- Como escrever políticas do PostgreSQL (
CREATE POLICY). - Como ignorar a isenção de "Proprietário da tabela" usando
FORCE ROW LEVEL SECURITY. - Como criar um app Python que realiza "troca de contexto" para os usuários.
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com o ID do seu projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: siga o link e ative as APIs.
Como alternativa, use o comando gcloud. Consulte a documentação para ver o uso e os comandos gcloud.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Problemas e solução de problemas
A síndrome do projeto fantasma | Você executou |
A barricada de faturamento | Você ativou o projeto, mas esqueceu a conta de faturamento. O AlloyDB é um mecanismo de alto desempenho. Ele não vai iniciar se o "tanque de combustível" (faturamento) estiver vazio. |
Atraso na propagação da API | Você clicou em "Ativar APIs", mas a linha de comando ainda mostra |
Quags de cota | Se você estiver usando uma conta de teste nova, poderá atingir uma cota regional para instâncias do AlloyDB. Se |
3. Configuração do banco de dados
Neste laboratório, vamos usar o AlloyDB como banco de dados para os dados de teste. Ele usa clusters para armazenar todos os recursos, como bancos de dados e registros. Cada cluster tem uma instância principal que fornece um ponto de acesso aos dados. As tabelas vão conter os dados reais.
Vamos criar um cluster, uma instância e uma tabela do AlloyDB em que o conjunto de dados de teste será carregado.
- Clique no botão ou copie o link abaixo para o navegador em que o usuário do console do Google Cloud está conectado.
- Depois que essa etapa for concluída, o repositório será clonado no editor local do Cloud Shell, e você poderá executar o comando abaixo na pasta do projeto. É importante verificar se você está no diretório do projeto:
sh run.sh
- Agora use a interface (clique no link no terminal ou no link "visualizar na Web" no terminal).
- Insira os detalhes do ID do projeto, do cluster e dos nomes das instâncias para começar.
- Tome um café enquanto os registros rolam e leia aqui como isso é feito nos bastidores. Isso pode levar de 10 a 15 minutos.
Problemas e solução de problemas
O problema da "paciência" | Os clusters de banco de dados são uma infraestrutura pesada. Se você atualizar a página ou encerrar a sessão do Cloud Shell porque ela "parece travada", poderá acabar com uma instância "fantasma" parcialmente provisionada e impossível de excluir sem intervenção manual. |
Incompatibilidade de região | Se você ativou as APIs em |
Clusters zumbis | Se você usou o mesmo nome para um cluster e não o excluiu, o script pode informar que o nome do cluster já existe. Os nomes de cluster precisam ser exclusivos em um projeto. |
Tempo limite do Cloud Shell | Se o intervalo para o café durar 30 minutos, o Cloud Shell poderá entrar em modo de espera e desconectar o processo |
4. Provisionamento de esquema
Nesta etapa, vamos abordar o seguinte:
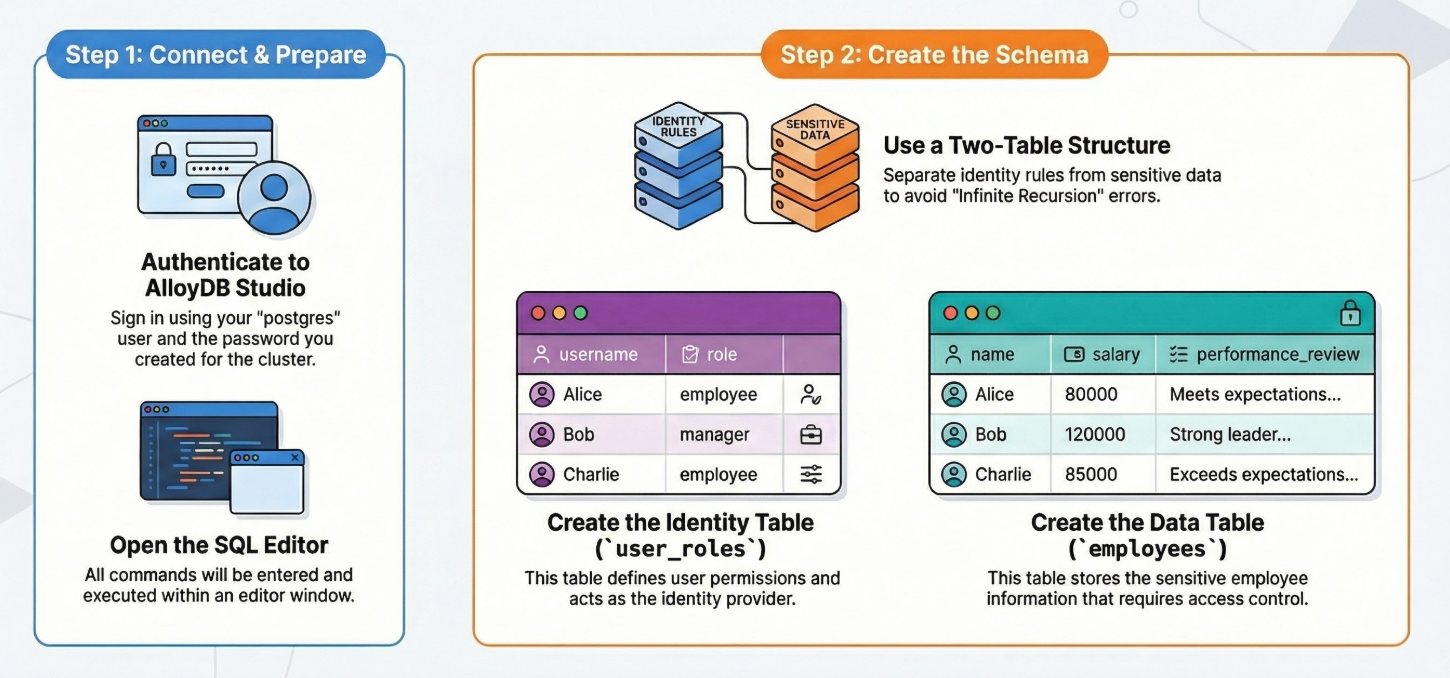
Confira as etapas detalhadas:
Depois que o cluster e a instância do AlloyDB estiverem em execução, acesse o editor de SQL do AlloyDB Studio para ativar as extensões de IA e provisionar o esquema.
Talvez seja necessário aguardar a conclusão da criação da instância. Depois disso, faça login no AlloyDB usando as credenciais criadas ao criar o cluster. Use os seguintes dados para autenticar no PostgreSQL:
- Nome de usuário : "
postgres" - Banco de dados : "
postgres" - Senha : "
alloydb" (ou o que você definiu no momento da criação)
Depois de se autenticar no AlloyDB Studio, os comandos SQL são inseridos no editor. É possível adicionar várias janelas do Editor usando o sinal de mais à direita da última janela.
Você vai inserir comandos para o AlloyDB nas janelas do editor, usando as opções "Executar", "Formatar" e "Limpar" conforme necessário.
Criar uma tabela
Precisamos de duas tabelas: uma para os dados sensíveis (funcionários) e outra para as regras de identidade (user_roles). É fundamental separá-los para evitar erros de "recursão infinita" nas políticas.
É possível criar uma tabela usando a instrução DDL abaixo no AlloyDB Studio:
-- 1. Create User Roles (The Identity Provider)
CREATE TABLE user_roles (
username TEXT PRIMARY KEY,
role TEXT -- 'employee', 'manager', 'admin'
);
INSERT INTO user_roles (username, role) VALUES
('Alice', 'employee'),
('Bob', 'manager'),
('Charlie', 'employee');
-- 2. Create the Data Table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name TEXT,
salary INTEGER,
performance_review TEXT
);
INSERT INTO employees (name, salary, performance_review) VALUES
('Alice', 80000, 'Alice meets expectations but needs to improve punctuality.'),
('Bob', 120000, 'Bob is a strong leader. Team morale is high.'),
('Charlie', 85000, 'Charlie exceeds expectations. Ready for promotion.');
Problemas e solução de problemas
Recursão infinita detectada ao definir papéis na tabela de funcionários | Por que isso acontece: se a política diz "Verifique a tabela de funcionários para saber se sou um gerente", o banco de dados precisa consultar a tabela para verificar a política, o que a aciona novamente.Resultado: recursão infinita detectada.Correção: sempre mantenha uma tabela de consulta separada (user_roles) ou use usuários reais do banco de dados para funções. |
Verifique os dados:
SELECT count(*) FROM employees;
-- Output: 3
5. Ativar e aplicar segurança
Agora vamos ativar os escudos. Também vamos criar um "usuário do app" genérico que nosso código Python vai usar para se conectar.
Execute a instrução SQL abaixo no editor de consultas do AlloyDB:
-- 1. Activate RLS
ALTER TABLE employees ENABLE ROW LEVEL SECURITY;
-- 2. CRITICAL: Force RLS for Table Owners
ALTER TABLE employees FORCE ROW LEVEL SECURITY;
-- 3. Create the Application User
DO
$do$
BEGIN
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'app_user') THEN
CREATE ROLE app_user LOGIN PASSWORD 'password';
END IF;
END
$do$;
-- 4. Grant Access
GRANT SELECT ON employees TO app_user;
GRANT SELECT ON user_roles TO app_user;
Problemas e solução de problemas
Teste como postgres (superusuário) e veja todos os dados. | Por que isso falha : por padrão, a RLS não se aplica ao proprietário da tabela nem a superusuários. Elas ignoram todas as políticas.Solução de problemas:se as políticas parecerem "quebradas" (permitindo tudo), verifique se você fez login como |
6. Criar as políticas de acesso
Vamos definir duas regras usando uma variável de sessão (app.active_user) que será definida posteriormente no código do aplicativo.
Execute a instrução SQL abaixo no editor de consultas do AlloyDB:
-- Policy 1: Self-View
-- Users can see rows where their name matches the session variable
CREATE POLICY "view_own_data" ON employees
FOR SELECT
USING (name = current_setting('app.active_user', true));
-- Policy 2: Manager-View
-- Managers can see ALL rows.
CREATE POLICY "manager_view_all" ON employees
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM user_roles
WHERE username = current_setting('app.active_user', true)
AND role = 'manager'
)
);
Problemas e solução de problemas
Usar current_user em vez de app.active_user. | Problema : "current_user" é uma palavra-chave reservada do SQL que retorna a função do banco de dados (por exemplo, "app_user"). Precisamos do usuário do aplicativo (por exemplo, Alice).Correção: sempre use um namespace personalizado, como app.variable_name. |
Esquecer o parâmetro | Problema:se a variável não estiver definida, a consulta falhará com um erro.Correção:current_setting('...', true) retorna NULL em vez de falhar, o que resulta em 0 linhas retornadas. |
7. Criar o app "Chameleon"
Vamos usar Python e Streamlit para simular a lógica do aplicativo.
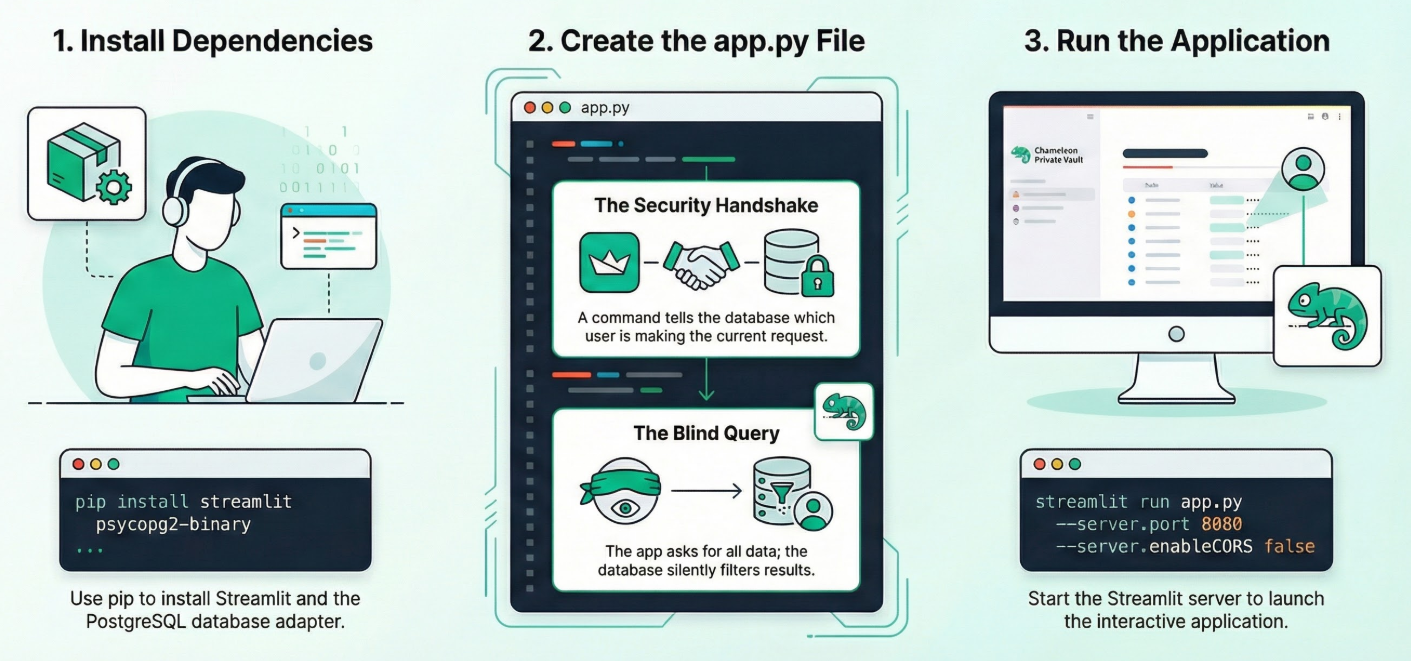
Abra o terminal do Cloud Shell no modo Editor, navegue até a pasta raiz ou o diretório em que você quer criar o aplicativo. Criar uma nova pasta.
1. Instalar dependências:
Execute o seguinte comando no terminal do Cloud Shell no diretório do novo projeto:
pip install streamlit psycopg2-binary
2. Crie app.py:
Crie um arquivo chamado app.py e copie o conteúdo do arquivo do repositório.
import streamlit as st
import psycopg2
# CONFIGURATION (Replace with your IP)
DB_HOST = "10.x.x.x"
DB_NAME = "postgres"
DB_USER = "postgres"
DB_PASS = "alloydb"
def get_db_connection():
return psycopg2.connect(
host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASS
)
def query_database(user_name):
conn = get_db_connection()
try:
with conn.cursor() as cur:
# THE SECURITY HANDSHAKE
# We tell the database: "For this transaction, I am acting as..."
cur.execute(f"SET app.active_user = '{user_name}';")
# THE BLIND QUERY
# We ask for EVERYTHING. The database silently filters it.
cur.execute("SELECT name, role, salary, performance_review FROM employees;")
return cur.fetchall()
finally:
conn.close()
# UI
st.title("🛡️ The Private Vault")
user = st.sidebar.radio("Act as User:", ["Alice", "Bob", "Charlie", "Eve"])
if st.button("Access Data"):
results = query_database(user)
if not results:
st.error("🚫 Access Denied.")
else:
st.success(f"Viewing data as {user}")
for row in results:
st.write(row)
3. Execute o app:
Execute o seguinte comando no terminal do Cloud Shell no diretório do novo projeto:
streamlit run app.py --server.port 8080 --server.enableCORS false
Problemas e solução de problemas
Pooling de conexão. | Risco: se você usar um pool de conexões, a variável de sessão SET app.active_user poderá persistir na conexão e "vazar" para o próximo usuário que usar essa conexão.Correção:em produção, sempre use RESET app.active_user ou DISCARD ALL ao retornar uma conexão para o pool. |
Tela em branco no Cloud Shell. | Correção : use o botão "Visualização da Web" na porta 8080. Não clique no link localhost no terminal. |
8. Verificar a confiança zero
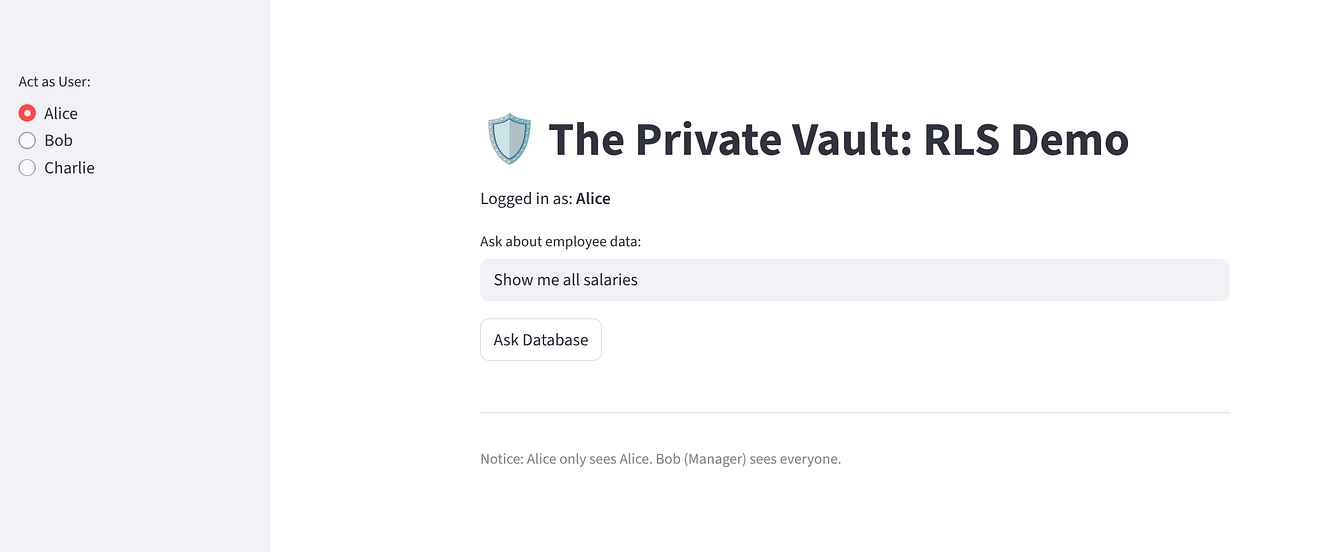
Teste o app para garantir a implementação da confiança zero:
Selecione Alice: ela vai ver uma linha (ela mesma).
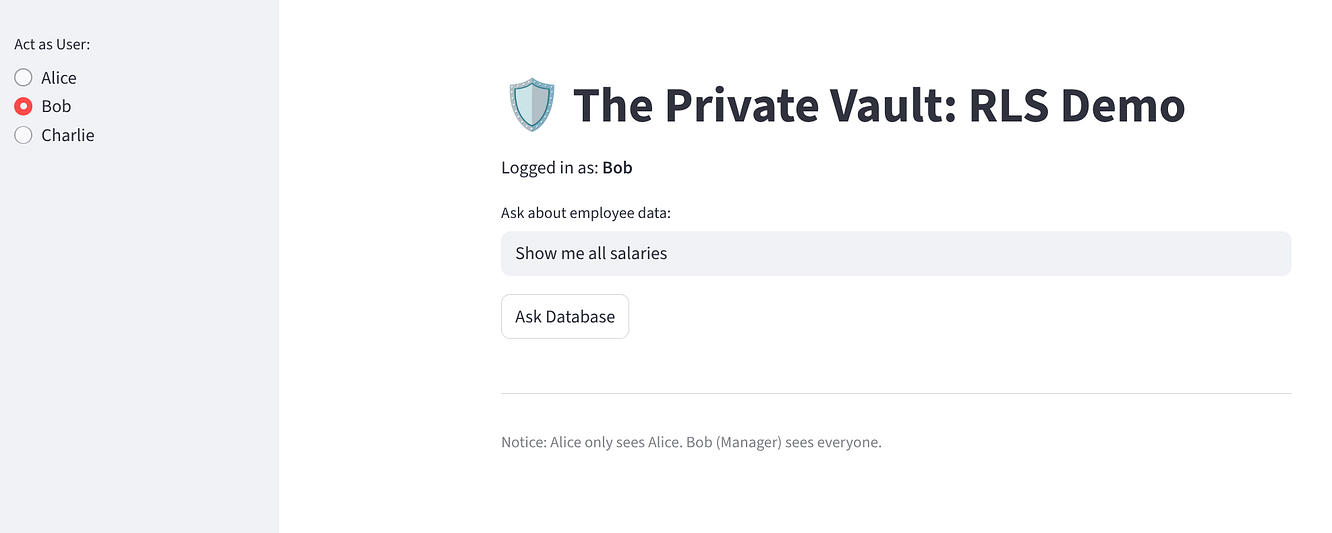
Selecione "Bob": ele vai ver três linhas (Todos).
Por que isso é importante para os agentes de IA
Imagine conectar seu modelo a esse banco de dados. Se um usuário perguntar ao modelo: "Resuma todas as avaliações de desempenho", ele vai gerar SELECT performance_review FROM employees.
- Sem RLS: seu modelo recupera as avaliações particulares de todos e as vaza para Alice.
- Com RLS: seu modelo executa exatamente a mesma consulta, mas o banco de dados retorna apenas a avaliação de Alice.
Essa é a IA de confiança zero. Você não confia no modelo para filtrar dados, então força o banco de dados a ocultá-los.
Como levar isso para a produção
A arquitetura demonstrada aqui é de nível de produção, mas a implementação específica é simplificada para aprendizado. Para fazer uma implantação segura em um ambiente empresarial real, implemente as seguintes melhorias:
- Autenticação real:substitua o menu suspenso "Troca de identidade" por um provedor de identidade (IdP) robusto, como o Google Identity Platform, o Okta ou o Auth0. Seu aplicativo precisa verificar o token do usuário e extrair a identidade dele com segurança antes de definir a variável de sessão do banco de dados, garantindo que os usuários não possam falsificar a identidade.
- Segurança do pooling de conexões:ao usar pools de conexões, as variáveis de sessão podem persistir em diferentes solicitações de usuários se não forem processadas corretamente. Verifique se o aplicativo redefine a variável de sessão (por exemplo, RESET app.active_user) ou limpa o estado da conexão ao retornar uma conexão para o pool para evitar vazamento de dados entre usuários.
- Gerenciamento de secrets:codificar credenciais de banco de dados é um risco de segurança. Use um serviço dedicado de gerenciamento de secrets, como o Google Secret Manager, para armazenar e recuperar senhas e strings de conexão do banco de dados com segurança no ambiente de execução.
9. Limpar
Depois de concluir este laboratório, não se esqueça de excluir o cluster e a instância do AlloyDB.
Ele vai limpar o cluster e as instâncias dele.
10. Parabéns
Parabéns! Você transferiu a segurança para a camada de dados. Mesmo que o código Python tivesse um bug que tentasse print(all_salaries), o banco de dados não retornaria nada para Alice.
Próximas etapas
- Faça um teste com seu próprio conjunto de dados.
- Confira a documentação da IA do AlloyDB.
- Confira mais workshops no site Code Vipassana (em inglês).