
1. 概览
在争先构建生成式 AI 应用时,我们往往会忘记最重要的组件:安全 。
假设您要构建一个人力资源聊天机器人。您希望它回答“我的工资是多少?”或“我的团队表现如何?”等问题。
- 如果 Alice (普通员工)提问,她应该只能看到自己的数据。
- 如果 Bob (经理)提问,他应该看到其团队的数据。
问题
大多数 RAG(检索增强生成)架构都尝试在 应用层 处理此问题。它们会在检索到数据块 后 对其进行过滤,或者依赖于 LLM 的“行为”。这种做法很脆弱。如果应用逻辑失败,数据就会泄露。
解决方案
将安全性下推到数据库层 。通过在 AlloyDB 中使用 PostgreSQL 行级安全性 (RLS) ,我们确保数据库 实际拒绝 返回用户无权查看的数据,无论 AI 请求什么数据。
在本指南中,我们将构建“私人保险库”:一个安全的人力资源助理,它会根据登录的用户动态更改答案。
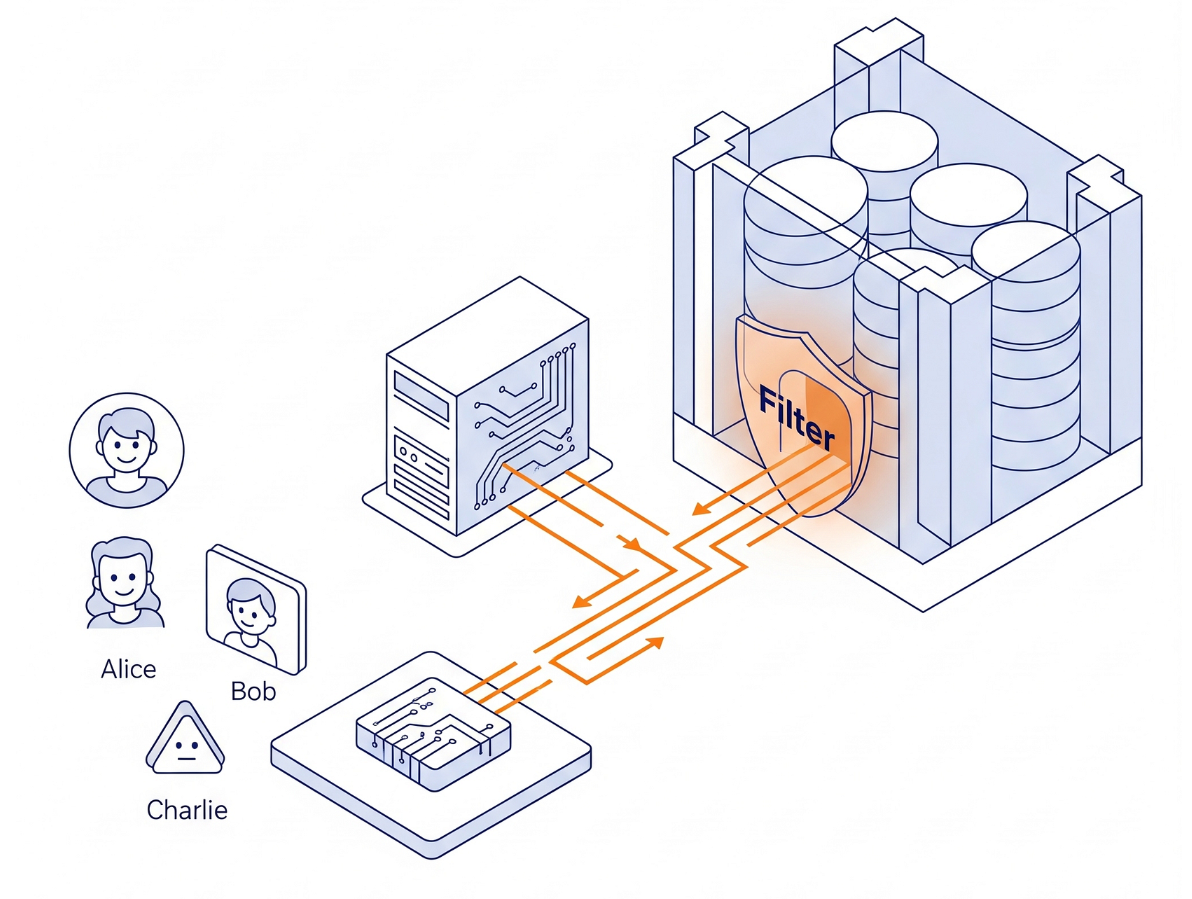
架构
我们不会在 Python 中构建复杂的权限逻辑,而是使用数据库引擎本身。
- 界面 :一个模拟登录的简单 Streamlit 应用。
- 大脑 :AlloyDB AI(与 PostgreSQL 兼容)。
- 机制 :我们在每项事务开始时设置会话变量 (
app.active_user)。数据库政策会自动检查user_roles表(充当我们的身份提供方)以过滤行。
构建内容
一个安全的人力资源助理应用。您将直接在 AlloyDB 数据库引擎中实现行级安全性 (RLS),而不是依赖于应用逻辑来过滤敏感数据。这样可确保,即使 AI 模型“产生幻觉”或尝试访问未经授权的数据,数据库也会实际拒绝返回这些数据。
学习内容
您会了解到以下内容:
- 如何为 RLS 设计架构(将数据与身份分开)。
- 如何编写 PostgreSQL 政策 (
CREATE POLICY)。 - 如何使用
FORCE ROW LEVEL SECURITY绕过“表所有者”豁免。 - 如何构建一个为用户执行“上下文切换”的 Python 应用。
要求
2. 准备工作
创建项目
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何 检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,它是在 Google Cloud 中运行的命令行环境。点击 Google Cloud 控制台顶部的激活 Cloud Shell 。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
- 启用必需的 API:点击 链接 并启用 API。
或者,您也可以使用 gcloud 命令执行此操作。如需了解 gcloud 命令和用法,请参阅 文档。
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
注意事项和问题排查
“幽灵项目” 综合征 | 您运行了 |
结算 障碍 | 您启用了项目,但忘记了结算账号。AlloyDB 是高性能引擎;如果“油箱”(结算)为空,它将无法启动。 |
API 传播 延迟 | 您点击了“启用 API”,但命令行仍然显示 |
配额 陷阱 | 如果您使用的是全新的试用账号,则可能会达到 AlloyDB 实例的区域配额。如果 |
3. 数据库设置
在本实验中,我们将使用 AlloyDB 作为测试数据的数据库。它使用 集群 来保存所有资源,例如数据库和日志。 每个集群都有一个 主实例 ,用于提供对数据的接入点。表将保存实际数据。
让我们创建一个 AlloyDB 集群、实例和表,以便加载测试数据集。
- 点击该按钮,或将以下链接复制到您已登录 Google Cloud 控制台用户的浏览器中。
- 完成此步骤后,代码库将克隆到本地 Cloud Shell 编辑器,您将能够从项目文件夹中运行以下命令(请务必确保您位于项目目录中):
sh run.sh
- 现在,使用界面(点击终端中的链接或点击终端中的“在网页上预览”链接)。
- 输入项目 ID、集群和实例名称的详细信息,即可开始。
- 在日志滚动时,您可以去喝杯咖啡,并在此处了解其在后台执行此操作的方式。这可能需要大约 10-15 分钟。
注意事项和问题排查
“耐心”问题 | 数据库集群是重型基础架构。如果您刷新页面或终止 Cloud Shell 会话,因为它“看起来卡住了”,您最终可能会得到一个“幽灵”实例,该实例已部分预配,并且无法在没有手动干预的情况下删除。 |
区域不匹配 | 如果您在 |
僵尸集群 | 如果您之前对集群使用了相同的名称,但没有删除该集群,脚本可能会显示集群名称已存在。集群名称在项目中必须是唯一的。 |
Cloud Shell 超时 | 如果您的咖啡休息时间为 30 分钟,Cloud Shell 可能会进入休眠状态并断开 |
4. 架构预配
在此步骤中,我们将介绍以下内容:
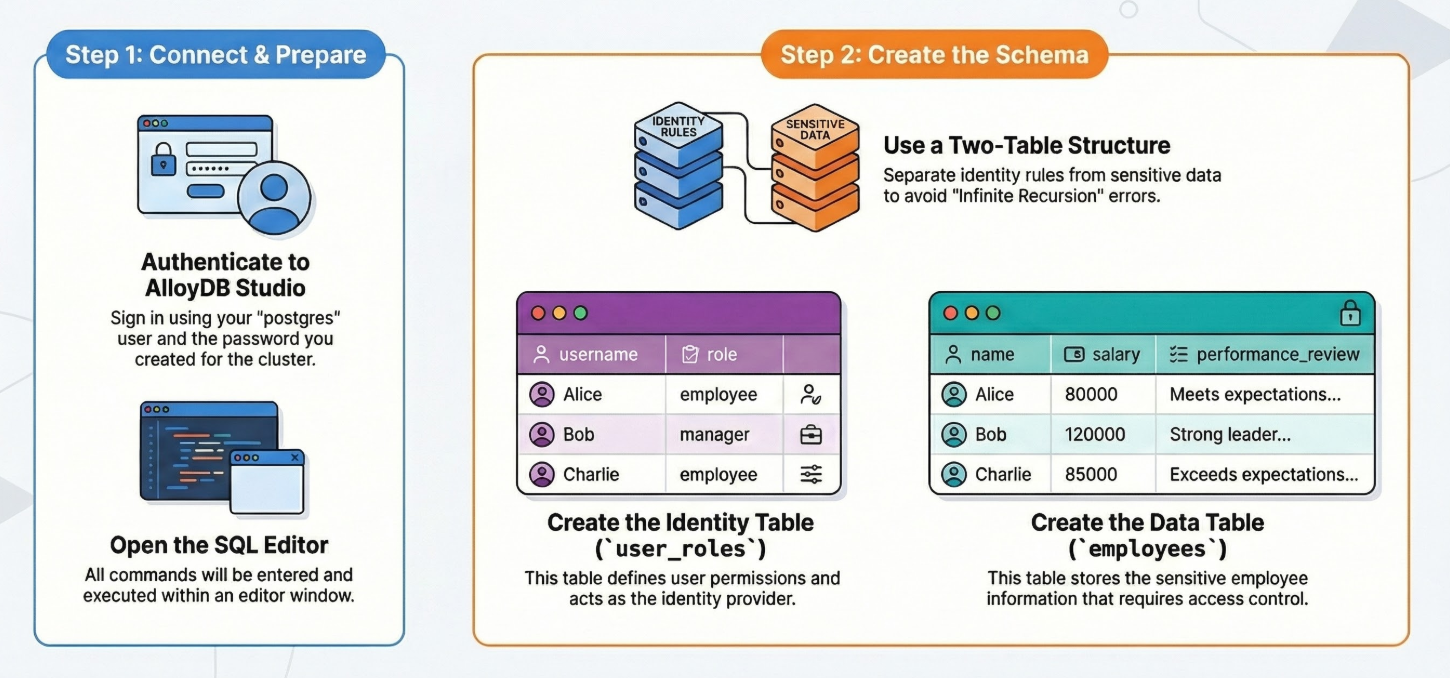
以下是详细的分步操作:
AlloyDB 集群和实例运行后,请前往 AlloyDB Studio SQL 编辑器以启用 AI 扩展程序并预配架构。
您可能需要等待实例创建完成。 完成后,使用您在创建集群时创建的凭据登录 AlloyDB。 使用以下数据向 PostgreSQL 进行身份验证:
- 用户名:“
postgres” - 数据库:“
postgres” - 密码:“
alloydb”(或您在创建时设置的任何密码)
成功通过身份验证并进入 AlloyDB Studio 后,在编辑器中输入 SQL 命令。 您可以使用最后一个窗口右侧的加号添加多个编辑器窗口。
您将在编辑器窗口中输入 AlloyDB 的命令,并根据需要使用“运行”“格式”和“清除”选项。
创建表
我们需要两个表:一个用于敏感数据(员工),另一个用于身份规则 (user_roles)。将它们分开对于避免政策中的“无限递归”错误至关重要。
您可以在 AlloyDB Studio 中使用以下 DDL 语句创建表:
-- 1. Create User Roles (The Identity Provider)
CREATE TABLE user_roles (
username TEXT PRIMARY KEY,
role TEXT -- 'employee', 'manager', 'admin'
);
INSERT INTO user_roles (username, role) VALUES
('Alice', 'employee'),
('Bob', 'manager'),
('Charlie', 'employee');
-- 2. Create the Data Table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name TEXT,
salary INTEGER,
performance_review TEXT
);
INSERT INTO employees (name, salary, performance_review) VALUES
('Alice', 80000, 'Alice meets expectations but needs to improve punctuality.'),
('Bob', 120000, 'Bob is a strong leader. Team morale is high.'),
('Charlie', 85000, 'Charlie exceeds expectations. Ready for promotion.');
注意事项和问题排查
在员工表中定义角色时检测到无限递归 | 失败原因:如果您的政策显示“检查员工表以查看我是否是经理”,则数据库必须查询该表以检查该政策,这会再次触发该政策。结果:检测到无限递归。修复方法:始终保留单独的对照表 (user_roles),或使用实际的数据库用户作为角色。 |
验证数据:
SELECT count(*) FROM employees;
-- Output: 3
5. 启用和强制执行安全性
现在,我们打开防护盾。我们还将创建一个通用“应用用户”,我们的 Python 代码将使用该用户进行连接。
从 AlloyDB 查询编辑器运行以下 SQL 语句:
-- 1. Activate RLS
ALTER TABLE employees ENABLE ROW LEVEL SECURITY;
-- 2. CRITICAL: Force RLS for Table Owners
ALTER TABLE employees FORCE ROW LEVEL SECURITY;
-- 3. Create the Application User
DO
$do$
BEGIN
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'app_user') THEN
CREATE ROLE app_user LOGIN PASSWORD 'password';
END IF;
END
$do$;
-- 4. Grant Access
GRANT SELECT ON employees TO app_user;
GRANT SELECT ON user_roles TO app_user;
注意事项和问题排查
以 postgres(超级用户)身份进行测试,并查看所有数据。 | 失败原因: 默认情况下,RLS 不适用于表所有者或超级用户。他们会绕过所有政策。问题排查: 如果您的政策看起来“损坏”(允许所有内容),请检查您是否以 |
6. 创建访问权限政策
我们将使用会话变量 (app.active_user) 定义两个规则,稍后我们将从应用代码中设置该变量。
从 AlloyDB 查询编辑器运行以下 SQL 语句:
-- Policy 1: Self-View
-- Users can see rows where their name matches the session variable
CREATE POLICY "view_own_data" ON employees
FOR SELECT
USING (name = current_setting('app.active_user', true));
-- Policy 2: Manager-View
-- Managers can see ALL rows.
CREATE POLICY "manager_view_all" ON employees
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM user_roles
WHERE username = current_setting('app.active_user', true)
AND role = 'manager'
)
);
注意事项和问题排查
使用 current_user 而不是 app.active_user。 | 问题: Current_user 是一个保留的 SQL 关键字,用于返回数据库角色(例如 app_user)。我们需要应用用户(例如 Alice)。修复方法:始终使用自定义命名空间,例如 app.variable_name。 |
忘记 | 问题: 如果未设置变量,查询会崩溃并显示错误。修复方法: current_setting('...', true) 会返回 NULL 而不是崩溃,这会安全地导致返回 0 行。 |
7. 构建“变色龙”应用
我们将使用 Python 和 Streamlit 来模拟应用逻辑。
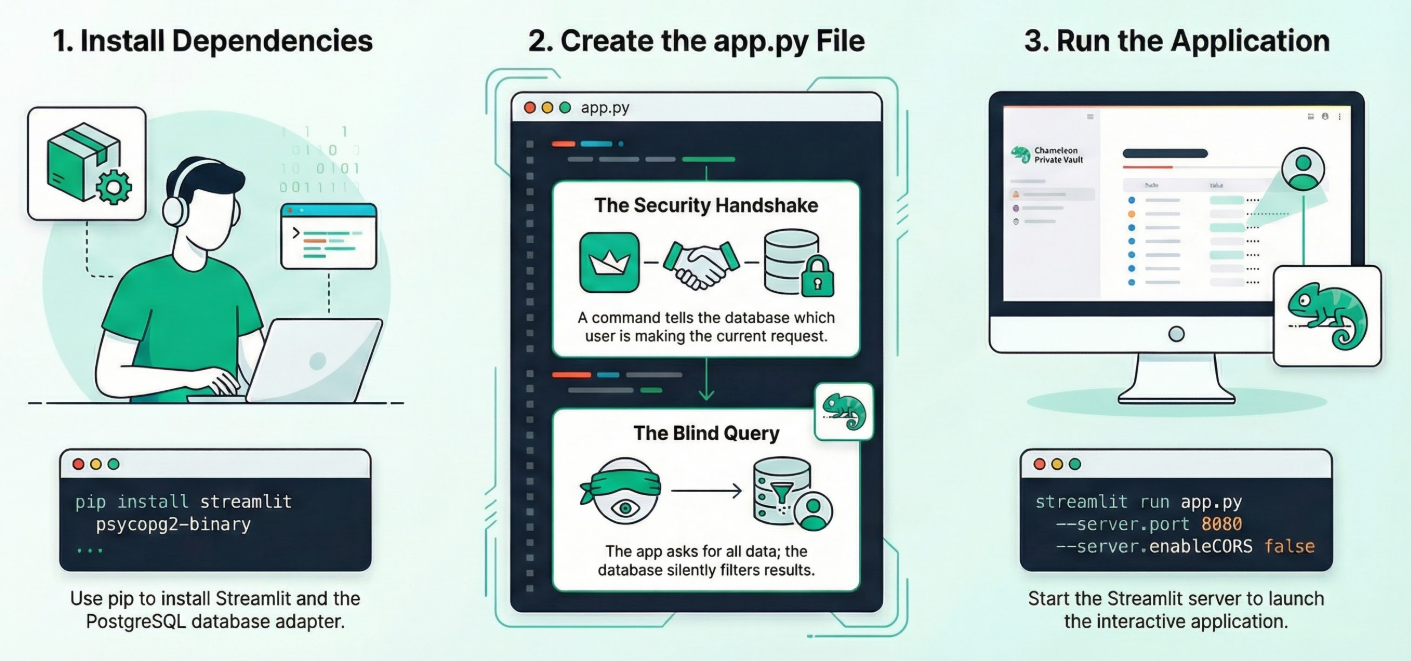
在编辑器模式下打开 Cloud Shell 终端,导航到根文件夹或要创建此应用的目录。创建新文件夹。
1. 安装依赖项:
在 Cloud Shell 终端中运行以下命令:在新的项目目录中
pip install streamlit psycopg2-binary
**2. 创建 app.py:
创建一个名为 app.py 的新文件,然后从 代码库文件 中复制内容。
import streamlit as st
import psycopg2
# CONFIGURATION (Replace with your IP)
DB_HOST = "10.x.x.x"
DB_NAME = "postgres"
DB_USER = "postgres"
DB_PASS = "alloydb"
def get_db_connection():
return psycopg2.connect(
host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASS
)
def query_database(user_name):
conn = get_db_connection()
try:
with conn.cursor() as cur:
# THE SECURITY HANDSHAKE
# We tell the database: "For this transaction, I am acting as..."
cur.execute(f"SET app.active_user = '{user_name}';")
# THE BLIND QUERY
# We ask for EVERYTHING. The database silently filters it.
cur.execute("SELECT name, role, salary, performance_review FROM employees;")
return cur.fetchall()
finally:
conn.close()
# UI
st.title("🛡️ The Private Vault")
user = st.sidebar.radio("Act as User:", ["Alice", "Bob", "Charlie", "Eve"])
if st.button("Access Data"):
results = query_database(user)
if not results:
st.error("🚫 Access Denied.")
else:
st.success(f"Viewing data as {user}")
for row in results:
st.write(row)
3. 运行应用:
在 Cloud Shell 终端中运行以下命令:在新的项目目录中
streamlit run app.py --server.port 8080 --server.enableCORS false
注意事项和问题排查
连接池。 | 风险:如果您使用连接池,会话变量 SET app.active_user 可能会在连接中保留,并“泄露”给获取该连接的下一个用户。修复方法:在生产环境中,将连接返回到池时,请始终使用 RESET app.active_user 或 DISCARD ALL。 |
Cloud Shell 中的空白屏幕。 | 修复方法: 使用端口 8080 上的“网页预览”按钮。请勿点击终端中的 localhost 链接。 |
8. 验证零信任
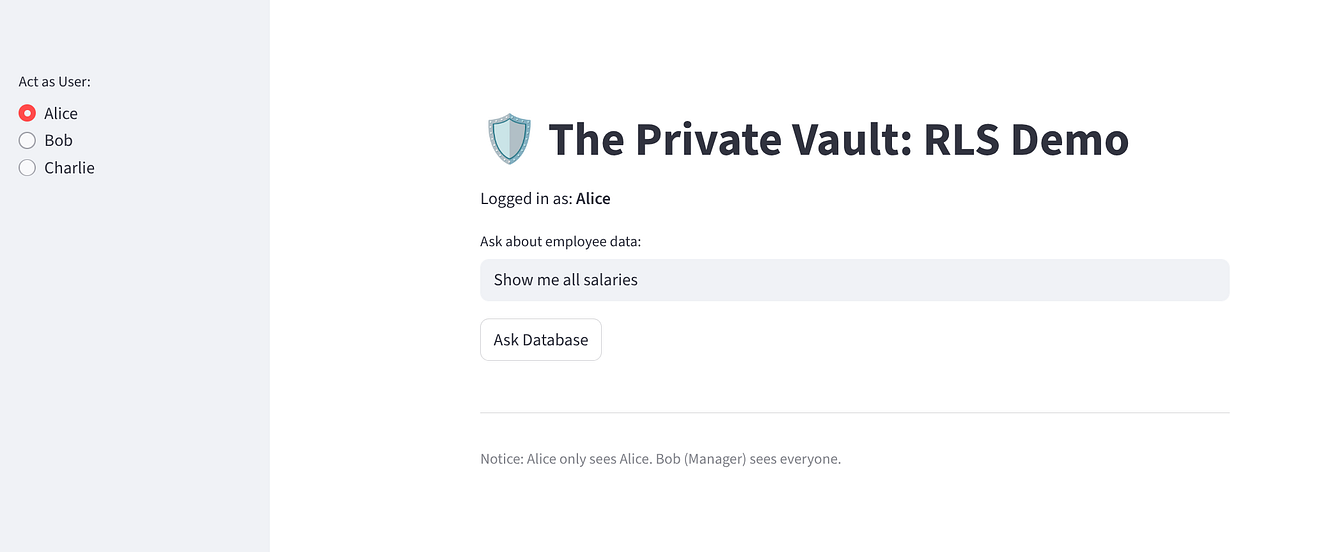
尝试使用该应用,以确保零信任架构已实现:
选择 “Alice”:她应该看到 1 行(她自己)。
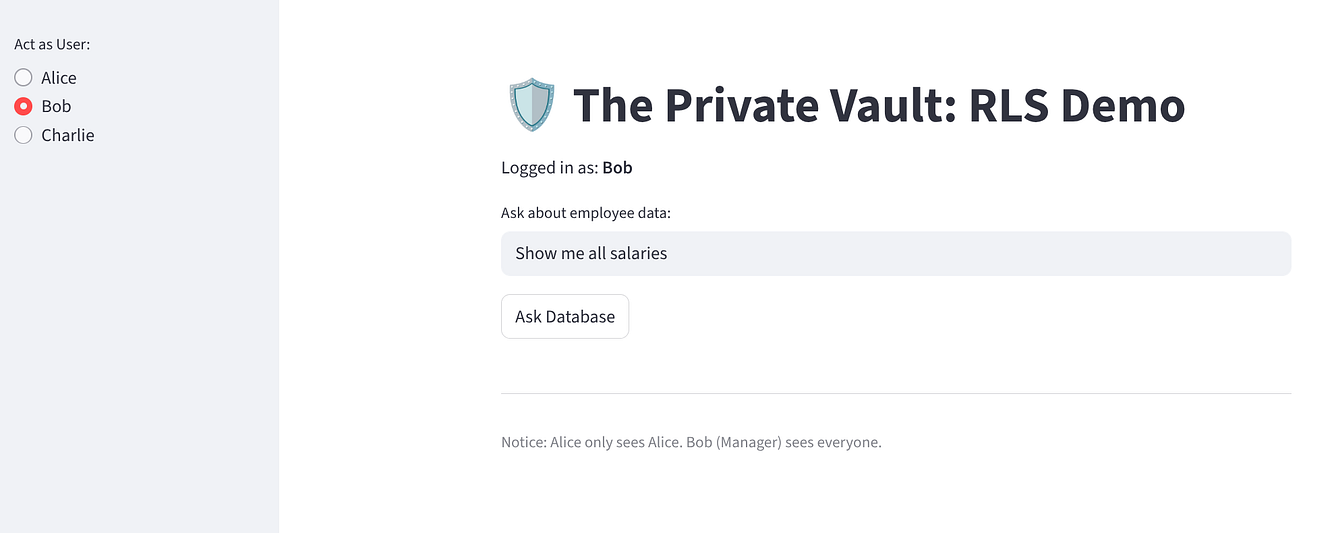
选择 “Bob”:他应该看到 3 行(所有人)。
为什么这对 AI 智能体很重要
假设您将模型连接到此数据库。如果用户向您的模型询问:“总结所有绩效考核”,它将生成 SELECT performance_review FROM employees。
- 没有 RLS:您的模型会检索所有人的私人考核,并将其泄露给 Alice。
- 有 RLS:您的模型运行完全相同的查询,但数据库仅返回 Alice 的考核。
这就是零信任 AI。您不信任模型来过滤数据;您强制数据库隐藏数据。
投入生产环境
此处演示的架构是生产级架构,但具体实现经过简化,以便于学习。如需在真实的企业环境中安全部署此架构,您应实现以下增强功能:
- 真实身份验证: 将“身份切换器”下拉列表替换为可靠的身份提供方 (IDP),例如 Google Identity Platform、Okta 或 Auth0。您的应用应验证用户的令牌并安全地提取其身份,然后再设置数据库会话变量,确保用户无法伪造其身份。
- 连接池安全性: 使用连接池时,如果处理不当,会话变量有时可能会在不同的用户请求之间保留。确保您的应用在将连接返回到池时重置会话变量(例如 RESET app.active_user)或清除连接状态,以防止用户之间的数据泄露。
- 密钥管理: 对数据库凭据进行硬编码存在安全风险。使用专用密钥管理服务(例如 Google Secret Manager)在运行时安全地存储和检索数据库密码和连接字符串。
9. 清理
完成此实验后,请务必删除 alloyDB 集群和实例。
它应该会清理集群及其实例。
10. 恭喜
恭喜!您已成功将安全性下推到数据层。即使您的 Python 代码存在尝试 print(all_salaries) 的 bug,数据库也不会向 Alice 返回任何内容。
后续步骤
- 使用您自己的数据集尝试此操作。
- 探索 AlloyDB AI 文档。
- 如需了解更多讲座,请访问 Code Vipassana 网站。