
1. Introducción
Los modelos de IA generativa son razonadores potentes, pero carecen de contexto institucional. Si un ejecutivo le pregunta a un agente de IA: "¿Cuáles son nuestros ingresos del primer trimestre?", el agente podría encontrar docenas de tablas llamadas "ingresos" en tu data lake. Algunas son informes financieros rigurosos, otras son estimaciones de marketing en tiempo real y es probable que muchas sean zonas de pruebas obsoletas.
Sin una base explícita, un agente de IA seleccionará una tabla en función de la similitud simple del nombre, lo que generará respuestas "convincentemente incorrectas" derivadas de datos no verificados.
Este codelab es parte de una serie de dos partes que explora cómo crear un agente de IA con reconocimiento de la administración.
En esta primera parte, crearás una base de datos. Configurarás un data lake realista y "desordenado" en BigQuery, aplicarás etiquetas de metadatos rígidas (aspectos de Knowledge Catalog) para diferenciar los datos válidos del ruido y usarás la CLI de Antigravity (AGY) para probar de forma local si el agente sigue estrictamente tus reglas de administración de datos.
Puedes leer la segunda parte de esta serie, que abarca cómo implementar el prototipo de agente local en una aplicación web segura de nivel empresarial con el Protocolo de contexto del modelo (MCP) y Cloud Run. 👉 Lee la Parte 2
Qué aprenderás
- Implementar un data lake realista de varios niveles con una secuencia de comandos de configuración
- Diseñar y registrar plantillas de metadatos personalizados (tipos de aspectos) en Knowledge Catalog para distinguir los productos de datos oficiales de las tablas de zonas de pruebas sin procesar
- Verificar las reglas de administración de datos de forma local con la CLI de AGY antes de escribir cualquier código de aplicación
Requisitos
- Un proyecto de Google Cloud con facturación habilitada.
- Acceso a Google Cloud Shell (la CLI de AGY está preinstalada en Cloud Shell)
- Conocimientos básicos de BigQuery y Knowledge Catalog
Conceptos clave
- Knowledge Catalog: Es el servicio unificado de administración de metadatos. Lo usamos para enriquecer los metadatos técnicos (esquemas) con contexto empresarial (administración).
- Tipo de aspecto: Es una plantilla de metadatos estructurada. A diferencia de las etiquetas de texto libre, los aspectos aplican un tipo fuerte (enums, booleanos), lo que los hace confiables para que las máquinas los evalúen.
2. Configuración y requisitos
Inicie Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En la consola de Google Cloud, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
Inicializa el entorno
Abre Cloud Shell y configura las variables de tu proyecto para asegurarte de que todos los comandos apunten a la infraestructura correcta.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Habilita las APIs
Habilita los servicios de Google Cloud necesarios para ejecutar la siguiente instrucción.
gcloud services enable \
bigquery.googleapis.com \
dataplex.googleapis.com
Clona el repositorio
Obtén el código de infraestructura y las secuencias de comandos de automatización del repositorio de GitHub. Para ahorrar espacio en disco en Cloud Shell, solo descargaremos la carpeta específica necesaria para este lab.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
Compila el data lake "desordenado"
Los entornos de datos del mundo real rara vez están limpios. Para simular la realidad, necesitamos una combinación de data marts "oficiales" y tablas de "zonas de pruebas" no confiables.
Usaremos una secuencia de comandos de configuración para implementar los conjuntos de datos y las tablas de BigQuery.
- Haz que la secuencia de comandos de configuración sea ejecutable y ejecútala. Esto creará tres conjuntos de datos de BigQuery (
finance_mart,marketing_prod,analyst_sandbox) y propagará sus tablas con datos de muestra.
chmod +x ./setup_bq_tables.sh
./setup_bq_tables.sh
Punto de control: Ahora tienes un data lake completamente propagado, pero sin administración. Para una IA, todas las tablas se ven exactamente iguales.
3. Crea la plantilla de administración de datos (tipo de aspecto)
Ahora, definiremos algunas reglas de administración de datos. En Knowledge Catalog, esto se hace creando un tipo de aspecto, que es una plantilla de metadatos reutilizable y de tipo fuerte.
Registraremos esta plantilla con la CLI de gcloud para que puedas ver cómo se define.
Inspecciona el esquema de aspecto
Genera el contenido de aspect_template.json para ver la definición del esquema.
cat aspect_template.json
Te mostrará la siguiente estructura JSON:
{
"name": "OfficialDataProductSpec",
"type": "record",
"recordFields": [
{
"name": "product_tier",
"type": "enum",
"enumValues": [
{ "name": "GOLD_CRITICAL", "index": 1 },
{ "name": "SILVER_STANDARD", "index": 2 },
{ "name": "BRONZE_ADHOC", "index": 3 }
],
...
},
{
"name": "is_certified",
"type": "bool",
...
}
]
}
Observa cómo este esquema aplica tipos de datos estrictos, como enum para el nivel de criticidad (GOLD_CRITICAL, SILVER_STANDARD, BRONZE_ADHOC) y un bool para is_certified. Esto garantiza que los metadatos permanezcan estructurados y legibles por máquina.
Registra el tipo de aspecto
Ejecuta el siguiente comando gcloud para registrar esta plantilla en tu registro de Knowledge Catalog.
gcloud dataplex aspect-types create official-data-product-spec \
--location="${REGION}" \
--project="${PROJECT_ID}" \
--description="Defines the comprehensive profile of a data product for governance agents." \
--display-name="Official Data Product Spec" \
--metadata-template-file-name="aspect_template.json"
4. Aplica la administración
Este es el paso de ingeniería fundamental. Actualmente, las tablas finance_mart.fin_monthly_closing_internal y analyst_sandbox.tmp_data_dump_v2_final_real se ven idénticas a un LLM. Son solo objetos con columnas.
Como ingeniero de administración, debes adjuntar un aspecto (una etiqueta de metadatos certificada) a estas tablas para diferenciarlas. En una empresa real, automatizarías esto a través de canalizaciones de CI/CD. Simularemos esa automatización con secuencias de comandos.
Genera cargas útiles de administración
Las claves de aspecto de Knowledge Catalog deben ser únicas a nivel global (con el prefijo de tu ID del proyecto). La secuencia de comandos ./generate_payloads.sh generará de forma dinámica los archivos de metadatos YAML.
chmod +x ./generate_payloads.sh
./generate_payloads.sh
Resultado:
Esto crea una carpeta "./aspect_payloads" que contiene 4 archivos YAML, que definen las situaciones de administración (Gold/Internal, Gold/Public, Silver/Realtime, Bronze/Sandbox).
Aplica aspectos con la CLI
Antes de ejecutar la secuencia de comandos, veamos lo que realmente aplicamos para desmitificar el proceso. Ejecuta el siguiente comando para ver la estructura de la carga útil de finanzas internas:
cat aspect_payloads/fin_internal.yaml
Te mostrará el siguiente contenido.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
Observa cómo este YAML define de forma explícita el contexto empresarial, como configurar la marca is_certified: true y asignar el nivel GOLD_CRITICAL. Esto le da al LLM reglas claras y estructuradas para evaluar en lugar de solo adivinar en función de los nombres de las tablas.
Ahora, ejecuta la secuencia de comandos de la aplicación. Esto itera a través de las tablas de BigQuery y ejecuta el comando gcloud dataplex entries update para adjuntar estos metadatos rígidos.
chmod +x ./apply_governance.sh
./apply_governance.sh
Verificación (opcional)
Antes de continuar, verifica que los metadatos se hayan aplicado correctamente en la consola.
- Abre la página Knowledge Catalog en la consola de Google Cloud. Si no ves "Knowledge Catalog" en el menú de navegación de la izquierda, usa la barra de búsqueda en la parte superior de la ventana de la consola de Google Cloud, escribe "Knowledge Catalog" y selecciona el resultado en "Resultados principales" o "Productos y páginas".
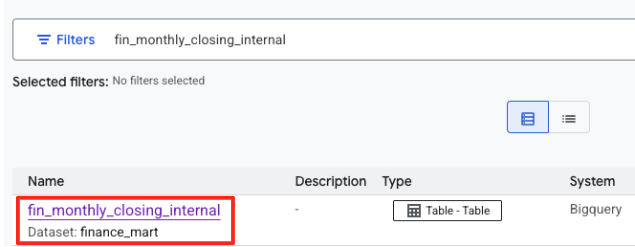
- Busca
fin_monthly_closing_internal. Deberías ver la tabla de BigQuery en los resultados. Haz clic en el nombre de la tabla para ingresar a su página de detalles.
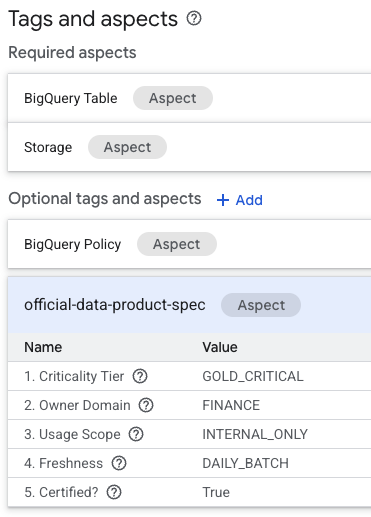
- En la página de detalles de la tabla, busca la sección "Etiquetas y aspectos opcionales" que se encuentra en la parte inferior.
- Encontrarás el aspecto
official-data-product-spec. Confirma que los valores coincidan con la situación "Gold Internal" que aplicamos.
Ahora confirmaste que las tablas de BigQuery técnicamente idénticas (fin_monthly_closing_internal y tmp_data_dump_v2_final_real) se diferencian lógicamente por metadatos legibles por máquina.
5. Configura y crea un prototipo del agente
Antes de compilar una aplicación (que haremos en la Parte 2), verificaremos nuestra lógica de administración de datos de forma local. Debemos instalar el complemento de Knowledge Catalog y configurar la habilidad del agente.
Instalar la extensión
En Cloud Shell, instala el complemento de Knowledge Catalog. Te pedirá confirmación y los detalles de configuración.
export DATAPLEX_PROJECT="${PROJECT_ID}"
agy plugin install https://github.com/gemini-cli-extensions/dataplex
Inspecciona la habilidad del agente
La habilidad del agente es un archivo de definición estático y reutilizable que se encuentra en .agents/skills/knowledge_catalog_governance/SKILL.md. Contiene la lógica que traduce las reglas humanas abstractas (p.ej., "Necesito datos seguros") en búsquedas técnicas estrictas.
Inspecciona el archivo para comprender el algoritmo que le enseñamos a la IA:
cat .agents/skills/knowledge_catalog_governance/SKILL.md
Ten en cuenta que le indica de forma explícita al modelo que siga un bucle estricto de Fase 1 (verificación de metadatos) y Fase 2 (ejecución de consultas). El modelo debe descubrir y verificar los metadatos antes de construir cualquier SQL.
Inicia el agente y prueba las situaciones
Inicia la sesión de la CLI de AGY. Descubrirá y cargará automáticamente la habilidad del directorio .agents/skills.
agy
Nota: Es posible que veas que se cargan varios archivos de contexto. Esto es normal. La CLI carga la habilidad local para las reglas específicas de este proyecto, además de las instrucciones predeterminadas para el complemento de Knowledge Catalog.
Verifica la instalación
Escribe /mcp para confirmar que el complemento de Knowledge Catalog esté activo. Deberías ver knowledge-catalog en la lista como un complemento activo con sus herramientas disponibles.
/mcp
Resultado esperado:
MCP Servers
...
> ✓ knowledge-catalog Tools: search_entries, lookup_context, lookup_entry
Situaciones de prueba (creación de prototipos)
Pega las siguientes instrucciones en la sesión del agente en ejecución una por una para verificar que cumpla con tus reglas.
- Situación A (certificar los datos del CFO):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
Resultado esperado: El agente descubre automáticamente tu proyecto y región activos desde sus herramientas, consulta fin_monthly_closing_internal porque coincide semánticamente con GOLD_CRITICAL (preciso) y INTERNAL_ONLY (reunión de la junta) en su aspecto, y lo recomienda.
- Situación B (divulgación pública):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
Resultado esperado: El agente debe omitir la tabla interna mensual y seleccionar estrictamente fin_quarterly_public_report porque es el único activo etiquetado como EXTERNAL_READY.
- Situación C (necesidades operativas):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Resultado esperado: El agente selecciona mkt_realtime_campaign_performance porque identifica la frecuencia de actualización REALTIME_STREAMING y le da prioridad sobre el nivel GOLD_CRITICAL de los datos financieros.
- Situación D (experimentación en la zona de pruebas):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
Resultado esperado: El agente selecciona tmp_data_dump_v2_final_real porque coincide semánticamente con BRONZE_ADHOC (datos sin procesar) y is_certified: false (entorno de zona de pruebas) en su aspecto.
(Para salir de la sesión de AGY, escribe /exit o /quit)
6. ¡Felicitaciones! Próximos pasos
Creaste correctamente una base de datos administrada y demostraste que una IA puede seguir estrictamente tus reglas de metadatos con un prototipo de CLI local.
Ahora, llegaste a un punto de control. Elige el siguiente paso:
Opción A: Quiero continuar con la Parte 2 ahora mismo.
Si estás listo para convertir este prototipo local en una aplicación web segura de nivel de producción con el Protocolo de contexto del modelo (MCP) y Cloud Run:
👉 Vínculo al codelab de la Parte 2
Opción B: Haré la Parte 2 más tarde o solo quería completar la Parte 1.
Si quieres detenerte por hoy y evitar los costos de la nube, debes limpiar tus recursos.
¡No te preocupes! En la Parte 2, proporcionaremos una "secuencia de comandos de acceso rápido" que volverá a compilar por completo este entorno de la Parte 1 en solo 2 minutos para que puedas retomar exactamente donde lo dejaste.
👉 Continúa a la sección de limpieza.
7. Realiza una limpieza (solo para la opción B)
Si quieres detenerte aquí, destruye los recursos para evitar que se generen cargos.
Destruye el data lake
Si estás en la sesión de la CLI de AGY, sal de la sesión presionando Ctrl+C dos veces o escribiendo /quit. Luego, ejecuta los siguientes comandos:
chmod +x ./cleanup_data_lake.sh
./cleanup_data_lake.sh
Desinstala el complemento de la CLI de AGY y quita los archivos locales
agy plugin uninstall dataplex
cd ~
rm -rf ~/devrel-demos