
۱. 📖 مقدمه
این کدلب نحوه طراحی یک تعامل ابزار چندوجهی را در کیت توسعه عامل (ADK) نشان میدهد. این یک جریان خاص است که در آن میخواهید عامل به فایل آپلود شده به عنوان ورودی به یک ابزار مراجعه کند و همچنین محتوای فایل تولید شده توسط پاسخ ابزار را نیز درک کند. از این رو تعاملی مانند آنچه در تصویر زیر نشان داده شده است، امکانپذیر است. در این آموزش، ما قصد داریم عاملی را توسعه دهیم که قادر است به کاربر کمک کند تا عکس بهتری را برای نمایش محصول خود ویرایش کند.
از طریق codelab، شما یک رویکرد گام به گام به شرح زیر را به کار خواهید گرفت:
- آمادهسازی پروژه گوگل کلود
- راهاندازی دایرکتوری کاری برای محیط کدنویسی
- مقداردهی اولیه عامل با استفاده از ADK
- ابزاری طراحی کنید که بتوان از آن برای ویرایش عکس با استفاده از Gemini 2.5 Flash Image استفاده کرد.
- یک تابع فراخوانی برای مدیریت آپلود تصویر کاربر، ذخیره آن به عنوان تصویر مصنوعی و اضافه کردن آن به عنوان متن به عامل طراحی کنید.
- یک تابع فراخوانی برای مدیریت تصویر تولید شده توسط پاسخ ابزار طراحی کنید، آن را به عنوان مصنوع ذخیره کنید و به عنوان متن به عامل اضافه کنید.
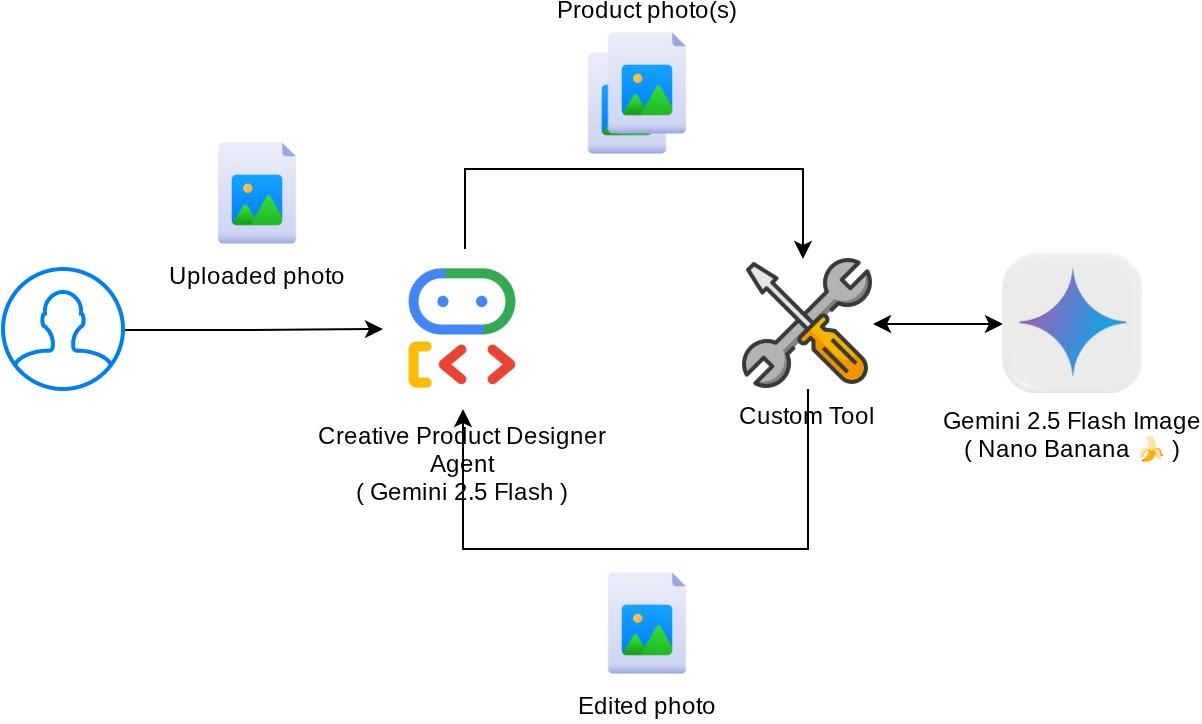
نمای کلی معماری
تعامل کلی در این آزمایشگاه کد در نمودار زیر نشان داده شده است.
پیشنیازها
- کار راحت با پایتون
- (اختیاری) آزمایشگاههای کد بنیادی درباره کیت توسعه عامل (ADK)
آنچه یاد خواهید گرفت
- نحوه استفاده از زمینه فراخوانی برای دسترسی به سرویس مصنوعات
- نحوه طراحی ابزار با انتشار مناسب دادههای چندوجهی
- نحوه تغییر درخواست عامل llm برای افزودن زمینه مصنوع از طریق before_model_callback
- نحوه ویرایش تصویر با استفاده از Gemini 2.5 Flash Image
آنچه نیاز دارید
- مرورگر وب کروم
- یک حساب جیمیل
- یک پروژه ابری با حساب صورتحساب فعال
این آزمایشگاه کد که برای توسعهدهندگان در تمام سطوح (از جمله مبتدیان) طراحی شده است، در برنامه نمونه خود از پایتون استفاده میکند. با این حال، برای درک مفاهیم ارائه شده، دانش پایتون لازم نیست.
۲. 🚀 آمادهسازی مقدمات توسعه کارگاه
Step 1: Select Active Project in the Cloud Console
در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید (به بخش بالا سمت چپ کنسول خود مراجعه کنید)

روی آن کلیک کنید، و لیستی از تمام پروژههای خود را مانند این مثال مشاهده خواهید کرد،
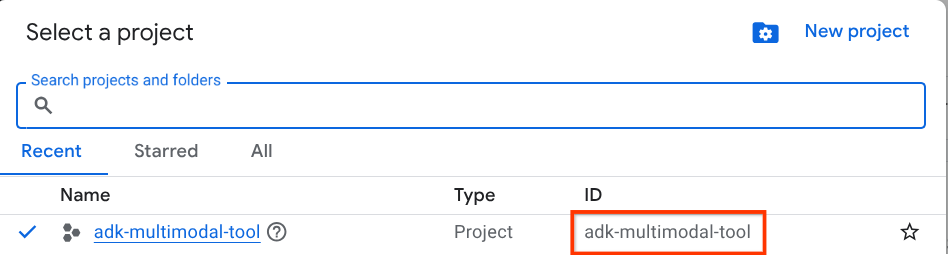
مقداری که با کادر قرمز مشخص شده است، شناسه پروژه (PROJECT ID) است و این مقدار در طول آموزش استفاده خواهد شد.
Make sure that billing is enabled for your Cloud project. To check this, click on the burger icon ☰ on your top left bar which shows the Navigation Menu and find the Billing menu

اگر عبارت «حساب پرداخت آزمایشی پلتفرم ابری گوگل» را زیر عنوان «پرداخت / بررسی اجمالی » ( قسمت بالا سمت چپ کنسول ابری خود ) مشاهده کردید، پروژه شما آماده استفاده برای این آموزش است. در غیر این صورت، به ابتدای این آموزش برگردید و حساب پرداخت آزمایشی را فعال کنید.
مرحله ۲: آشنایی با Cloud Shell
شما در بیشتر بخشهای آموزش از Cloud Shell استفاده خواهید کرد، روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید. اگر از شما درخواست تأیید کرد، روی Authorize کلیک کنید.
Once connected to Cloud Shell, we will need to check whether the shell ( or terminal ) is already authenticated with our account
gcloud auth list
If you see your personal gmail like below example output, all is good
Credentialed Accounts
ACTIVE: *
ACCOUNT: alvinprayuda@gmail.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
اگر اینطور نیست، مرورگر خود را رفرش کنید و مطمئن شوید که در صورت درخواست، روی «مجوز» کلیک میکنید (ممکن است به دلیل مشکل اتصال، قطع شود).
در مرحله بعد، باید بررسی کنیم که آیا پوسته از قبل با شناسه پروژه صحیحی که دارید پیکربندی شده است یا خیر، اگر مقداری را داخل () قبل از نماد $ در ترمینال مشاهده کردید (در تصویر زیر، مقدار "adk-multimodal-tool" است)، این مقدار پروژه پیکربندی شده برای جلسه پوسته فعال شما را نشان میدهد.

If the shown value is already correct , you can skip the next command . However if it's not correct or missing, run the following command
gcloud config set project <YOUR_PROJECT_ID>
Then, clone the template working directory for this codelab from Github, run the following command. It will create the working directory in the adk-multimodal-tool directory
git clone https://github.com/alphinside/adk-mcp-multimodal.git adk-multimodal-tool
مرحله 3: آشنایی با ویرایشگر Cloud Shell و دایرکتوری کاری برنامه نصب
Now, we can set up our code editor to do some coding stuff. We will use the Cloud Shell Editor for this
Click on the Open Editor button, this will open a Cloud Shell Editor 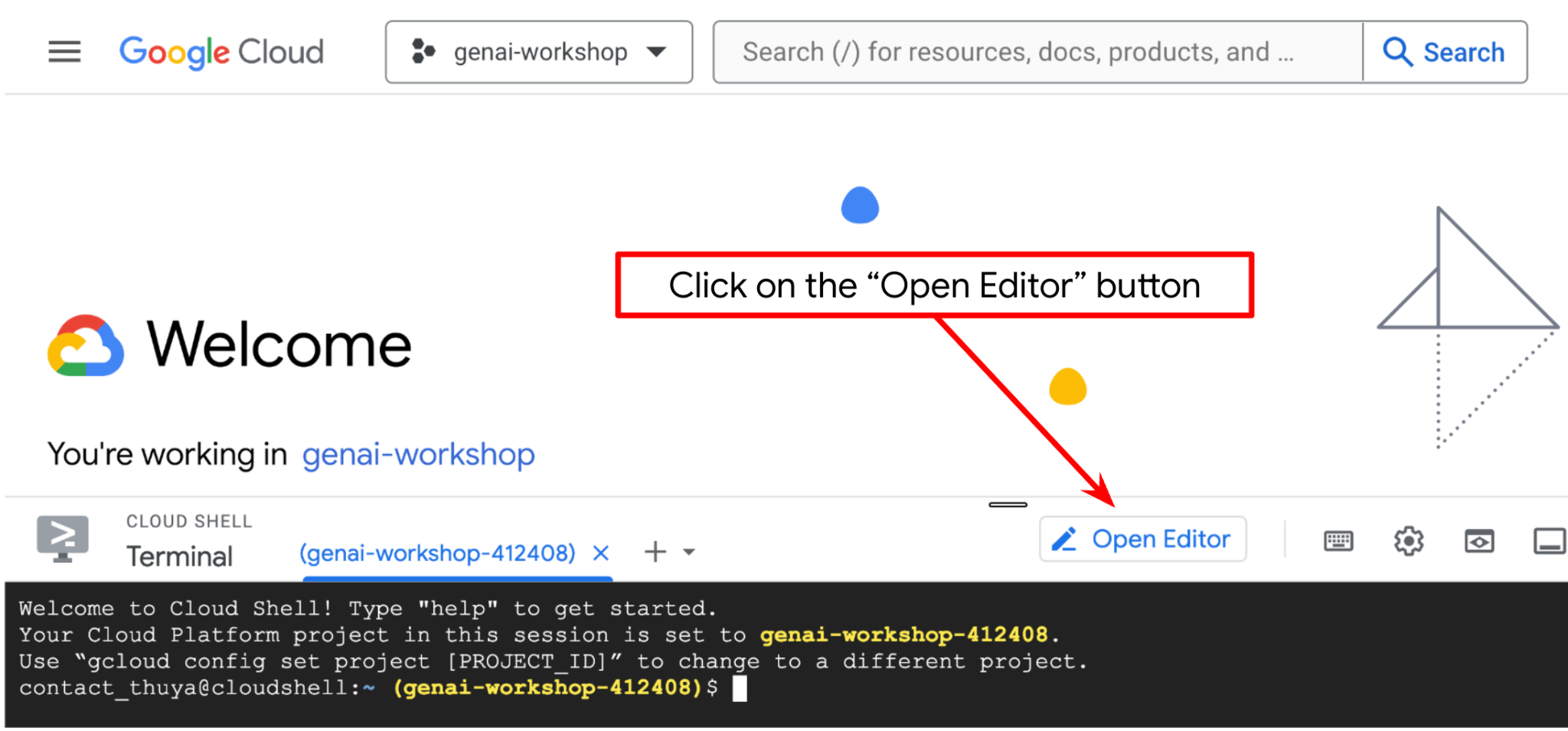
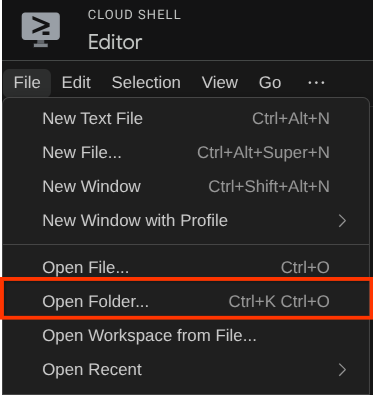
پس از آن، به بخش بالای ویرایشگر Cloud Shell بروید و روی File->Open Folder کلیک کنید، پوشه نام کاربری خود را پیدا کنید و پوشه adk-multimodal-tool را پیدا کنید و سپس روی دکمه OK کلیک کنید. این کار پوشه انتخاب شده را به عنوان پوشه اصلی کار تبدیل میکند. در این مثال، نام کاربری alvinprayuda است، از این رو مسیر پوشه در زیر نشان داده شده است.
Now, your Cloud Shell Editor working directory should look like this ( inside adk-multimodal-tool )
حالا، ترمینال ویرایشگر را باز کنید. میتوانید این کار را با کلیک روی ترمینال -> ترمینال جدید در نوار منو انجام دهید، یا از Ctrl + Shift + C استفاده کنید، این کار یک پنجره ترمینال در قسمت پایین مرورگر باز میکند.

ترمینال فعال فعلی شما باید در دایرکتوری کاری adk-multimodal-tool باشد. ما در این آزمایشگاه کد از پایتون ۳.۱۲ استفاده خواهیم کرد و از uv python project manager برای سادهسازی نیاز به ایجاد و مدیریت نسخه پایتون و محیط مجازی استفاده خواهیم کرد. این بسته uv از قبل روی Cloud Shell نصب شده است.
این دستور را اجرا کنید تا وابستگیهای مورد نیاز برای محیط مجازی در دایرکتوری .venv نصب شود.
uv sync --frozen
Check the pyproject.toml to see the declared dependencies for this tutorial which are google-adk, and python-dotenv .
Now, we will need to enable the required APIs via the command shown below. This could take a while.
gcloud services enable aiplatform.googleapis.com
در صورت اجرای موفقیتآمیز دستور، باید پیامی مشابه آنچه در زیر نشان داده شده است را مشاهده کنید:
Operation "operations/..." finished successfully.
۳. 🚀 مقداردهی اولیه ADK Agent
In this step, we will initialize our agent using the ADK CLI, run the following command
uv run adk create product_photo_editor \
--model gemini-2.5-flash \
--project your-project-id \
--region us-central1
This command will help you to quickly provide the required structure for your agent shown below:
product_photo_editor/ ├── __init__.py ├── .env ├── agent.py
After that, let's prepare our product photo editor agent. First, copy the prompt.py that is already included in the repository to the agent directory you previously created
cp prompt.py product_photo_editor/prompt.py
Then, open the product_photo_editor/agent.py and modify the content with the following code
from google.adk.agents.llm_agent import Agent
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos. Perfect for improving photos of handmade
goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
)
Now, you will have your base photo editor agent which you can already chit chat with to ask for suggestions for your photos. You can try interacting with it using this command
uv run adk web --port 8080
It will spawn output like the following example, means that we can already access the web interface
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Now, to check it you can Ctrl + Click on the URL or click the Web Preview button on the top area of your Cloud Shell Editor and select Preview on port 8080
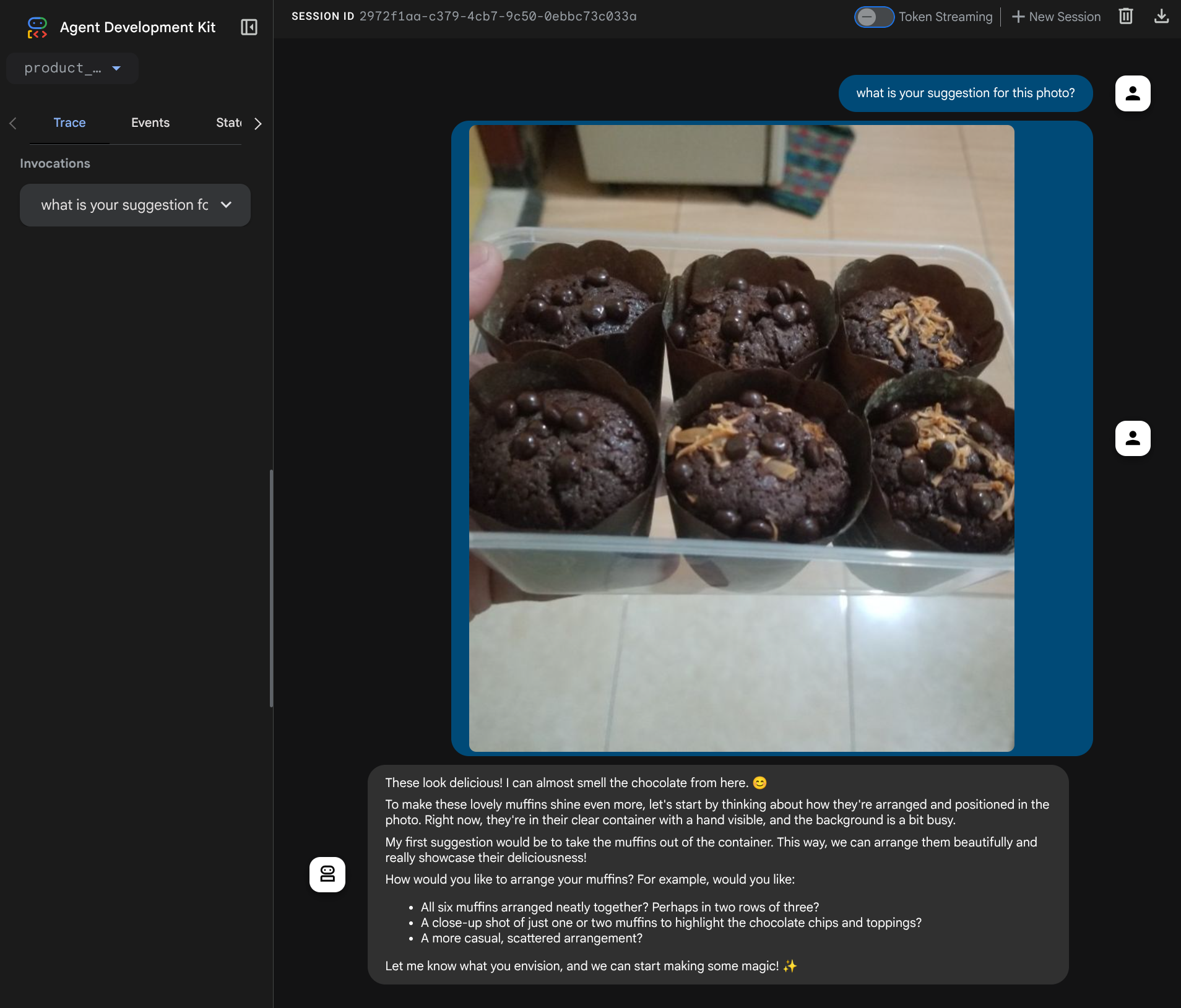
صفحه وب زیر را مشاهده خواهید کرد که در آن میتوانید عوامل موجود را از طریق دکمه کشویی بالا سمت چپ انتخاب کنید (در مورد ما باید product_photo_editor باشد) و با ربات تعامل داشته باشید. تصویر زیر را در رابط چت آپلود کنید و سوالات زیر را بپرسید.
what is your suggestion for this photo?

You will see similar interaction like shown below
You already can ask for some suggestions, however currently it cannot do the editing for you. Let's go to the next step, equipping the agent with the editing tools.
4. 🚀 LLM Request Context Modification - User Uploaded Image
ما میخواهیم عامل ما در انتخاب تصویر آپلود شدهای که میخواهد ویرایش کند، انعطافپذیر باشد. با این حال، ابزارهای LLM معمولاً طوری طراحی شدهاند که پارامترهای نوع داده سادهای مانند str یا int را بپذیرند. این یک نوع داده بسیار متفاوت برای دادههای چندوجهی است که معمولاً به عنوان نوع داده بایت در نظر گرفته میشود، از این رو برای مدیریت این دادهها به استراتژیای شامل مفهوم Artifacts نیاز خواهیم داشت. بنابراین، به جای ارائه دادههای کامل بایت در پارامتر tools، ابزاری را طراحی خواهیم کرد که نام شناسه artifact را بپذیرد.
این استراتژی شامل ۲ مرحله خواهد بود:
- درخواست LLM را طوری تغییر دهید که هر فایل آپلود شده با یک شناسه مصنوع مرتبط باشد و این را به عنوان زمینه به LLM اضافه کنید
- ابزاری را طراحی کنید که شناسههای مصنوع را به عنوان پارامترهای ورودی بپذیرد
بیایید مرحله اول را انجام دهیم، برای تغییر درخواست LLM، از ویژگی ADK Callback استفاده خواهیم کرد. به طور خاص، before_model_callback را اضافه خواهیم کرد تا درست قبل از اینکه عامل، context را به LLM ارسال کند، فعال شود. میتوانید تصویر را در تصویر زیر مشاهده کنید. 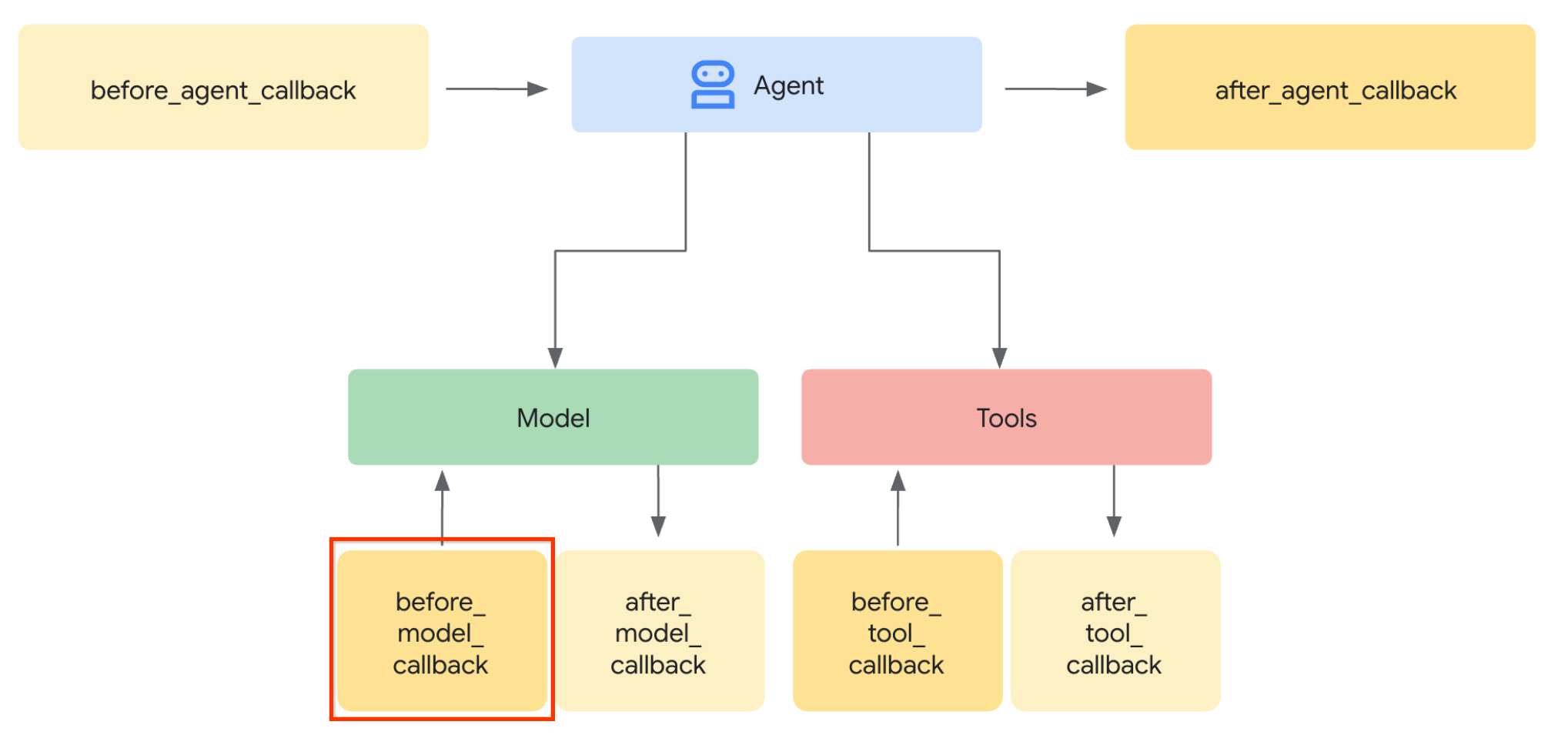
To do this, first create a new file product_photo_editor/model_callbacks.py using the following command
touch product_photo_editor/model_callbacks.py
Then, copy the following code to the file
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
The before_model_modifier function do these following things:
- به متغیر
llm_request.contentsدسترسی پیدا کنید و محتوا را تکرار کنید - بررسی کنید که آیا بخش مورد نظر شامل inline_data (فایل/تصویر آپلود شده) است یا خیر، در صورت وجود، دادههای درونخطی را پردازش کنید.
- شناسه سازنده برای inline_data ، در این مثال ما از ترکیب نام فایل + داده برای ایجاد یک شناسه هش محتوا استفاده میکنیم.
- بررسی کنید که آیا شناسه مصنوع از قبل وجود دارد یا خیر، در غیر این صورت، مصنوع را با استفاده از شناسه مصنوع ذخیره کنید.
- این بخش را طوری تغییر دهید که شامل یک اعلان متنی باشد که زمینهای در مورد شناسه مصنوع دادههای درونخطی زیر ارائه دهد.
پس از آن، فایل product_photo_editor/agent.py را تغییر دهید تا عامل به callback مجهز شود.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
before_model_callback=before_model_modifier,
)
حالا میتوانیم دوباره با عامل تعامل داشته باشیم
uv run adk web --port 8080
و دوباره سعی کنید فایل را آپلود کنید و چت کنید، میتوانیم بررسی کنیم که آیا با موفقیت زمینه درخواست LLM را تغییر دادهایم یا خیر.
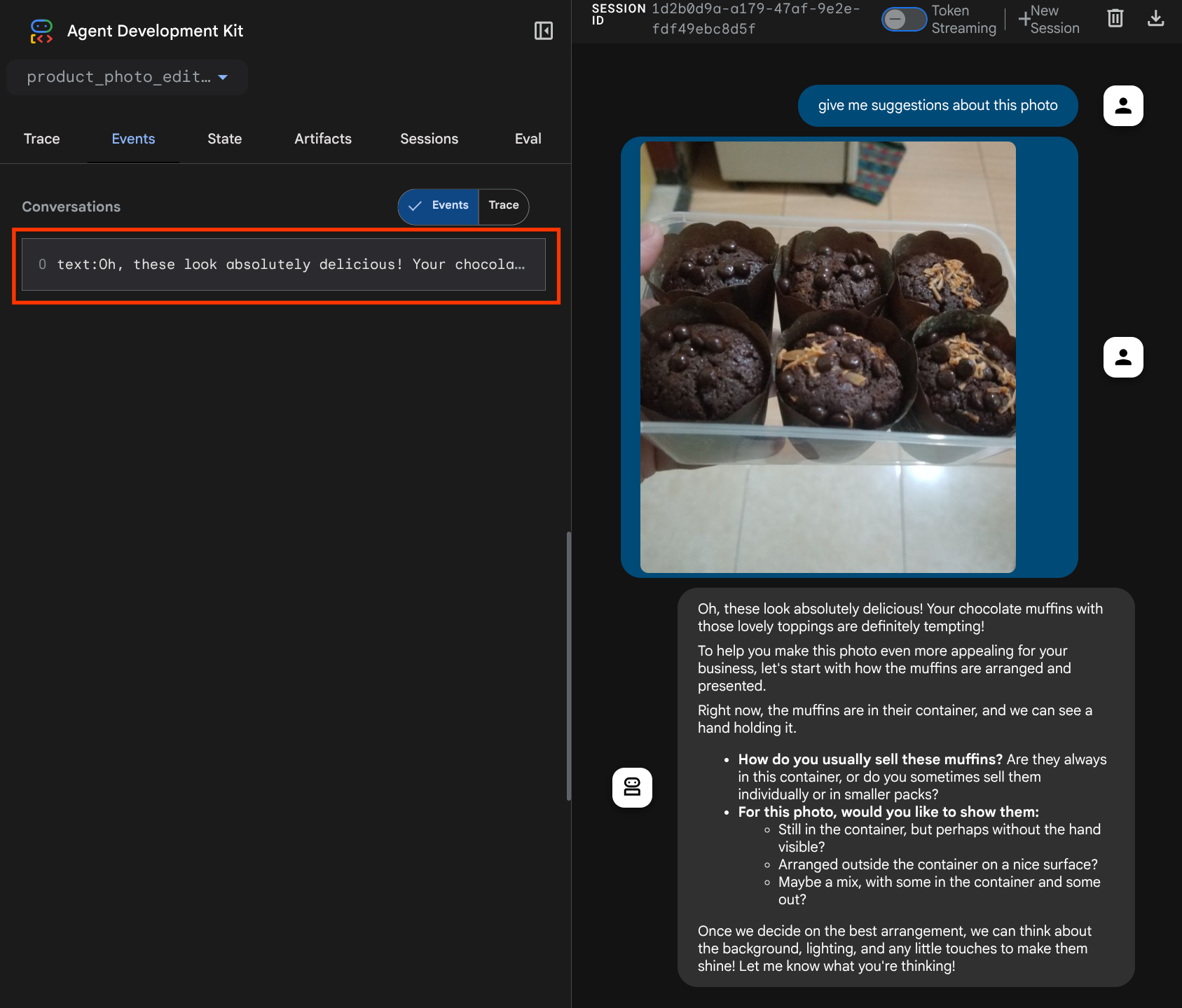
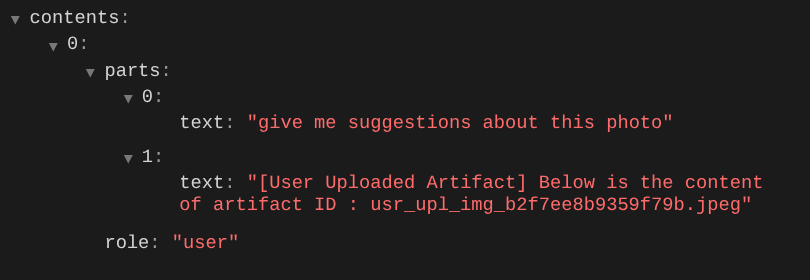
این یکی از راههایی است که میتوانیم به LLM در مورد توالی و شناسایی دادههای چندوجهی اطلاع دهیم. حالا بیایید ابزاری بسازیم که از این اطلاعات استفاده کند.
۵. 🚀 تعامل ابزار چندوجهی
اکنون میتوانیم ابزاری آماده کنیم که شناسه مصنوع را نیز به عنوان پارامتر ورودی خود مشخص میکند. دستور زیر را برای ایجاد فایل جدید product_photo_editor/custom_tools.py اجرا کنید.
touch product_photo_editor/custom_tools.py
سپس، کد زیر را در فایل product_photo_editor/custom_tools.py کپی کنید.
# product_photo_editor/custom_tools.py
from google import genai
from dotenv import load_dotenv
import os
from google.adk.tools import ToolContext
import logging
load_dotenv()
client = genai.Client(
vertexai=True,
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
)
async def edit_product_asset(
tool_context: ToolContext,
change_description: str,
image_artifact_ids: list = [],
) -> dict[str, str]:
"""Modify an existing product photo or combine multiple product photos.
This tool lets you make changes to product photos. You can:
- Edit a single photo (change background, lighting, colors, etc.)
- Combine multiple products into one photo (arrange them side by side, create bundles, etc.)
**IMPORTANT**:
- Make ONE type of change per tool call (background OR lighting OR props OR arrangement)
- For complex edits, chain multiple tool calls together
- BE AS DETAILED AS POSSIBLE in the change_description for best results!
Args:
change_description: What do you want to do? BE VERY DETAILED AND SPECIFIC!
**The more details you provide, the better the result.**
Focus on ONE type of change, but describe it thoroughly.
For BACKGROUND changes:
- "change background to soft pure white with subtle gradient from top to bottom, clean and minimal aesthetic"
- "replace background with rustic dark wood table surface with natural grain texture visible, warm brown tones"
For ADDING PROPS:
- "add fresh pink roses and eucalyptus leaves arranged naturally around the product on the left and right sides,
with some petals scattered in front"
- "add fresh basil leaves and cherry tomatoes scattered around the product naturally"
For LIGHTING changes:
- "add soft natural window light coming from the left side at 45 degree angle, creating gentle shadows on the
right side, warm morning atmosphere"
- "increase brightness with soft diffused studio lighting from above, eliminating harsh shadows"
For ARRANGEMENT/POSITIONING:
- "reposition product to be perfectly centered in frame with equal space on all sides"
- "arrange these three products in a horizontal line, evenly spaced with 2 inches between each"
Note: When combining multiple products, you can include background/lighting in the initial arrangement since it's
one cohesive setup
image_artifact_ids: List of image IDs to edit or combine.
- For single image: provide a list with one item (e.g., ["product.png"])
- For multiple images: provide a list with multiple items (e.g., ["product1.png", "product2.png"])
Use multiple images to combine products into one photo.
Returns:
dict with keys:
- 'tool_response_artifact_id': Artifact ID for the edited image
- 'tool_input_artifact_ids': Comma-separated list of input artifact IDs
- 'edit_prompt': The full edit prompt used
- 'status': Success or error status
- 'message': Additional information or error details
"""
try:
# Validate input
if not image_artifact_ids:
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": "No images provided. Please provide image_artifact_ids as a list.",
}
# Load all images
image_artifacts = []
for img_id in image_artifact_ids:
artifact = await tool_context.load_artifact(filename=img_id)
if artifact is None:
logging.error(f"Artifact {img_id} not found")
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": "",
"edit_prompt": change_description,
"message": f"Artifact {img_id} not found",
}
image_artifacts.append(artifact)
# Build edit prompt
if len(image_artifacts) > 1:
full_edit_prompt = (
f"{change_description}. "
f"Combine these {len(image_artifacts)} product images together. "
"IMPORTANT: Preserve each product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
else:
full_edit_prompt = (
f"{change_description}. "
"IMPORTANT: Preserve the product's original appearance, shape, color, and design as faithfully as possible. "
"Only modify for aesthetic enhancements (lighting, background, composition) or viewing angle adjustments. "
"Do not alter the core product features, branding, or characteristics."
)
# Build contents list: all images followed by the prompt
contents = image_artifacts + [full_edit_prompt]
response = await client.aio.models.generate_content(
model="gemini-2.5-flash-image",
contents=contents,
config=genai.types.GenerateContentConfig(
response_modalities=["Image"]
),
)
artifact_id = ""
logging.info("Gemini Flash Image: response.candidates: ", response.candidates)
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
artifact_id = f"edited_img_{tool_context.function_call_id}.png"
await tool_context.save_artifact(filename=artifact_id, artifact=part)
input_ids_str = ", ".join(image_artifact_ids)
return {
"status": "success",
"tool_response_artifact_id": artifact_id,
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": full_edit_prompt,
"message": f"Image edited successfully using {len(image_artifacts)} input image(s)",
}
except Exception as e:
logging.error(e)
input_ids_str = ", ".join(image_artifact_ids) if image_artifact_ids else ""
return {
"status": "error",
"tool_response_artifact_id": "",
"tool_input_artifact_ids": input_ids_str,
"edit_prompt": change_description,
"message": f"Error editing image: {str(e)}",
}
کد ابزار کارهای زیر را انجام میدهد:
- مستندات ابزار، بهترین شیوههای فراخوانی ابزار را به تفصیل شرح میدهد.
- اعتبارسنجی کنید که لیست image_artifact_ids خالی نباشد.
- Load all image artifacts from tool_context using the provided artifact IDs
- ساخت ویرایش سریع: دستورالعملهایی را برای ترکیب (چند تصویر) یا ویرایش (تک تصویر) به صورت حرفهای اضافه کنید
- مدل تصویر فلش Gemini 2.5 را با خروجی فقط تصویر فراخوانی کنید و تصویر تولید شده را استخراج کنید
- تصویر ویرایششده را به عنوان یک مصنوع جدید ذخیره کنید
- پاسخ ساختاریافتهای شامل موارد زیر را برمیگرداند: وضعیت، شناسه مصنوع خروجی، شناسههای ورودی، اعلان کامل و پیام
در نهایت، میتوانیم عامل خود را به این ابزار مجهز کنیم. محتوای product_photo_editor/agent.py را به کد زیر تغییر دهید.
from google.adk.agents.llm_agent import Agent
from product_photo_editor.custom_tools import edit_product_asset
from product_photo_editor.model_callbacks import before_model_modifier
from product_photo_editor.prompt import AGENT_INSTRUCTION
root_agent = Agent(
model="gemini-2.5-flash",
name="product_photo_editor",
description="""A friendly product photo editor assistant that helps small business
owners edit and enhance their product photos for online stores, social media, and
marketing. Perfect for improving photos of handmade goods, food products, crafts, and small retail items""",
instruction=AGENT_INSTRUCTION,
tools=[
edit_product_asset,
],
before_model_callback=before_model_modifier,
)
حالا، نماینده ما ۸۰٪ آماده است تا به ما در ویرایش عکس کمک کند، بیایید سعی کنیم با آن تعامل داشته باشیم.
uv run adk web --port 8080
و بیایید تصویر زیر را دوباره با اعلان متفاوتی امتحان کنیم:
put these muffins in a white plate aesthetically
ممکن است تعاملی مانند این را ببینید و در نهایت ببینید که نماینده برای شما ویرایش عکس انجام میدهد.
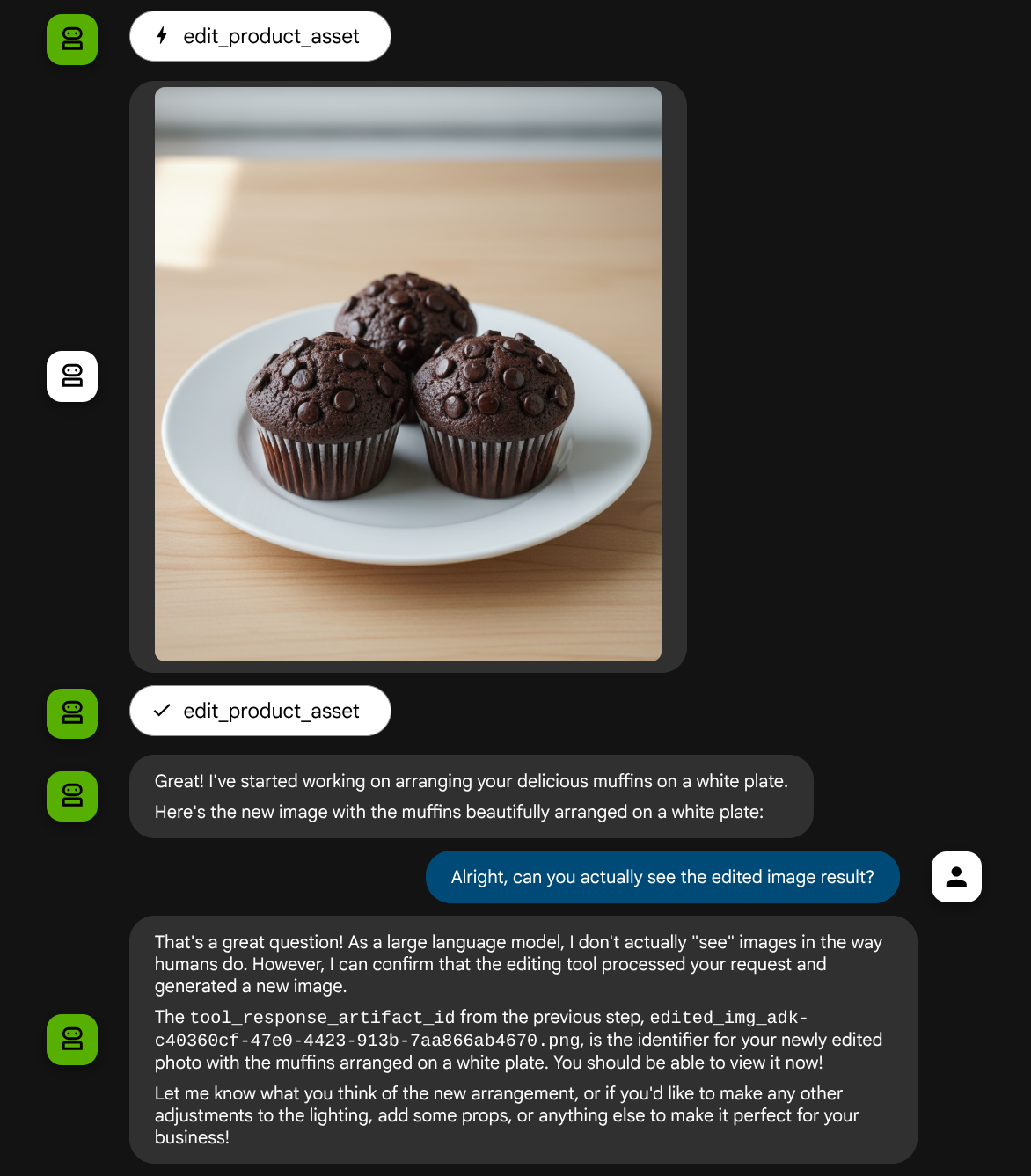
وقتی جزئیات فراخوانی تابع را بررسی میکنید، شناسه مصنوع تصویر آپلود شده توسط کاربر ارائه میشود.
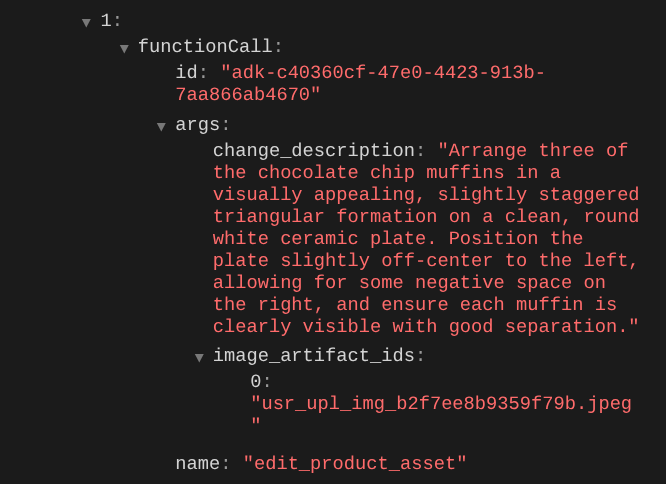
اکنون، عامل میتواند به شما کمک کند تا به طور مداوم عکس را ذره ذره بهبود دهید. همچنین میتواند از عکس ویرایش شده برای دستورالعمل ویرایش بعدی استفاده کند، زیرا ما شناسه مصنوع را در پاسخ ابزار ارائه میدهیم.
با این حال، در وضعیت فعلی، همانطور که در مثال بالا میبینید، عامل نمیتواند نتیجه تصویر ویرایش شده را ببیند و درک کند . دلیل این امر این است که پاسخی که ابزار به عامل میدهد فقط شناسه مصنوع است و نه خود محتوای بایتها، و متأسفانه نمیتوانیم محتوای بایتها را مستقیماً درون پاسخ ابزار قرار دهیم، این کار باعث ایجاد خطا میشود. بنابراین، باید یک شاخه منطقی دیگر درون تابع فراخوانی داشته باشیم تا محتوای بایت را به عنوان دادههای درونخطی از نتیجه پاسخ ابزار اضافه کنیم.
۶. 🚀 اصلاح زمینه درخواست LLM - تصویر پاسخ تابع
بیایید تابع فراخوانی before_model_modifier خود را طوری تغییر دهیم که دادههای بایتی تصویر ویرایششده را پس از پاسخ ابزار اضافه کند تا عامل ما نتیجه را بهطور کامل درک کند.
فایل product_photo_editor/model_callbacks.py را باز کنید و محتوای آن را به صورت زیر تغییر دهید:
# product_photo_editor/model_callbacks.py
from google.adk.agents.callback_context import CallbackContext
from google.adk.models import LlmResponse, LlmRequest
from google.genai.types import Part
import hashlib
from typing import List
async def before_model_modifier(
callback_context: CallbackContext, llm_request: LlmRequest
) -> LlmResponse | None:
"""Modify LLM request to include artifact references for images."""
for content in llm_request.contents:
if not content.parts:
continue
modified_parts = []
for idx, part in enumerate(content.parts):
# Handle user-uploaded inline images
if part.inline_data:
processed_parts = await _process_inline_data_part(
part, callback_context
)
# Handle function response parts for image generation/editing
elif part.function_response:
if part.function_response.name in [
"edit_product_asset",
]:
processed_parts = await _process_function_response_part(
part, callback_context
)
else:
processed_parts = [part]
# Default: keep part as-is
else:
processed_parts = [part]
modified_parts.extend(processed_parts)
content.parts = modified_parts
async def _process_inline_data_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process inline data parts (user-uploaded images).
Returns:
List of parts including artifact marker and the image.
"""
artifact_id = _generate_artifact_id(part)
# Save artifact if it doesn't exist
if artifact_id not in await callback_context.list_artifacts():
await callback_context.save_artifact(filename=artifact_id, artifact=part)
return [
Part(
text=f"[User Uploaded Artifact] Below is the content of artifact ID : {artifact_id}"
),
part,
]
def _generate_artifact_id(part: Part) -> str:
"""Generate a unique artifact ID for user uploaded image.
Returns:
Hash-based artifact ID with proper file extension.
"""
filename = part.inline_data.display_name or "uploaded_image"
image_data = part.inline_data.data
# Combine filename and image data for hash
hash_input = filename.encode("utf-8") + image_data
content_hash = hashlib.sha256(hash_input).hexdigest()[:16]
# Extract file extension from mime type
mime_type = part.inline_data.mime_type
extension = mime_type.split("/")[-1]
return f"usr_upl_img_{content_hash}.{extension}"
async def _process_function_response_part(
part: Part, callback_context: CallbackContext
) -> List[Part]:
"""Process function response parts and append artifacts.
Returns:
List of parts including the original function response and artifact.
"""
artifact_id = part.function_response.response.get("tool_response_artifact_id")
if not artifact_id:
return [part]
artifact = await callback_context.load_artifact(filename=artifact_id)
return [
part, # Original function response
Part(
text=f"[Tool Response Artifact] Below is the content of artifact ID : {artifact_id}"
),
artifact,
]
در کد اصلاحشدهی بالا، قابلیتهای زیر را اضافه میکنیم:
- بررسی کنید که آیا یک قطعه ، پاسخ تابع است یا خیر و آیا در فهرست نام ابزار ما وجود دارد تا امکان تغییر محتوا فراهم شود.
- اگر شناسهی مصنوع از پاسخ ابزار وجود دارد، محتوای مصنوع را بارگذاری کن
- محتوا را طوری تغییر دهید که شامل دادههای تصویر ویرایششده از پاسخ ابزار باشد.
اکنون میتوانیم بررسی کنیم که آیا عامل تصویر ویرایش شده را از پاسخ ابزار به طور کامل درک میکند یا خیر.
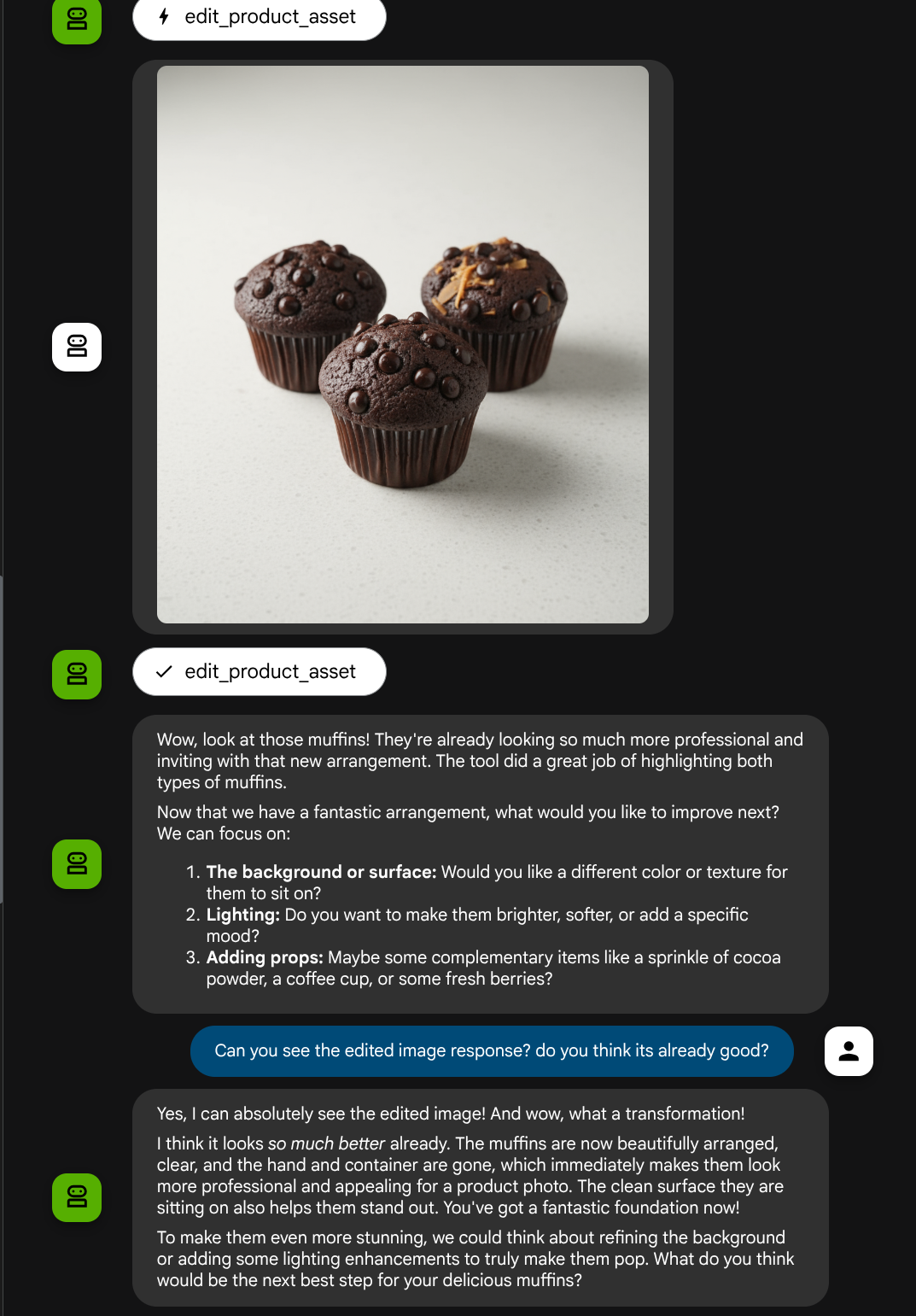
عالی است، حالا ما یک عامل داریم که از جریان تعامل چندوجهی با ابزار سفارشی خودمان پشتیبانی میکند.
حالا میتوانید با یک جریان پیچیدهتر با عامل تعامل کنید، مثلاً برای بهبود عکس، یک آیتم جدید (یخ لاته) اضافه کنید.

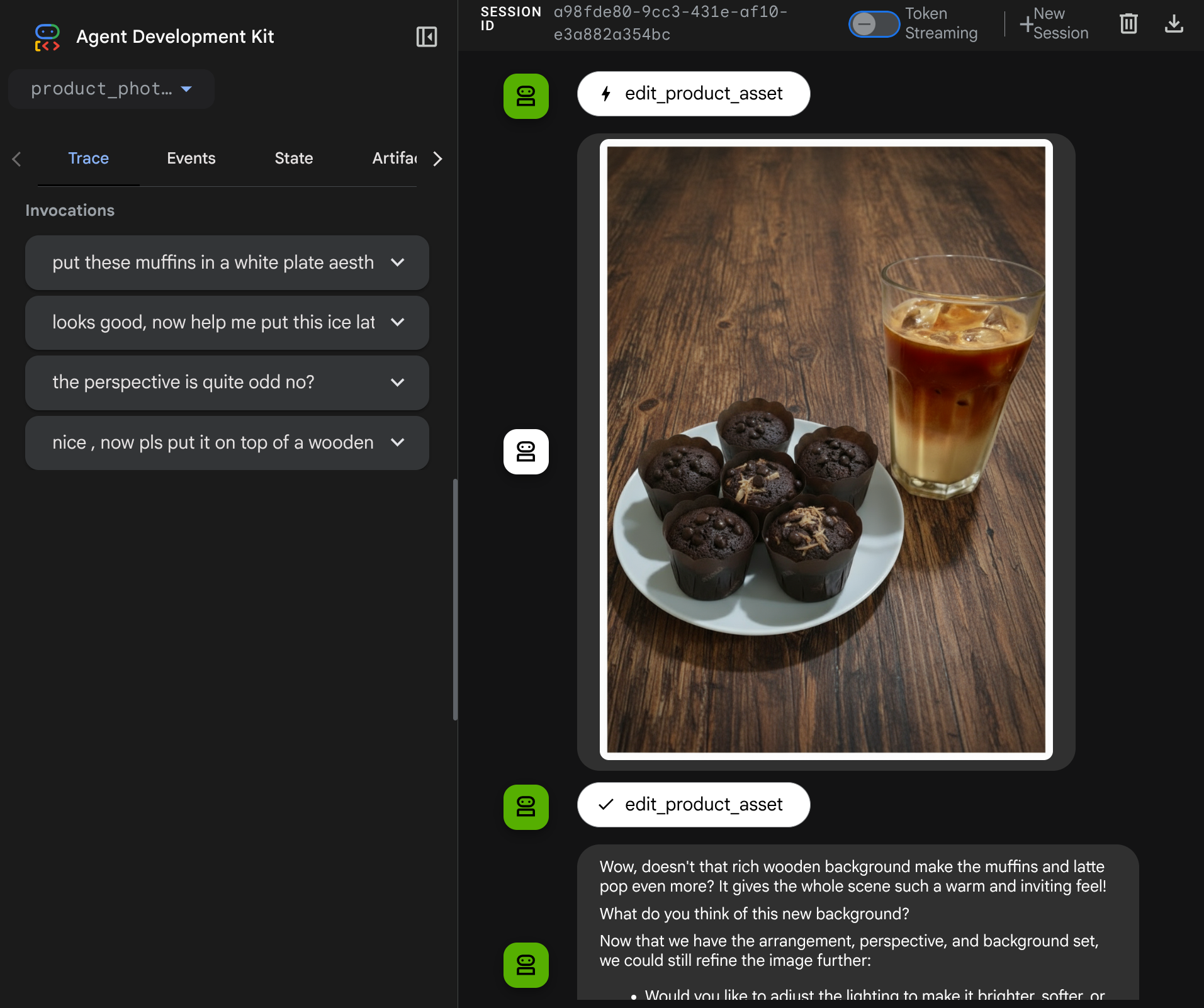
7. ⭐ Summary
حالا بیایید دوباره به کارهایی که در طول این آزمایش کد انجام دادهایم نگاهی بیندازیم، نکات کلیدی این آموزش این است:
- مدیریت دادههای چندوجهی: استراتژی مدیریت دادههای چندوجهی (مانند تصاویر) در جریان زمینه LLM را با استفاده از سرویس Artifacts مربوط به ADK به جای ارسال مستقیم دادههای خام بایتی از طریق آرگومانها یا پاسخهای ابزار، آموختم.
- کاربرد
before_model_callback: ازbefore_model_callbackبرای رهگیری و تغییرLlmRequestقبل از ارسال به LLM استفاده شده است. ما روی جریان زیر ضربه زدهایم:
- بارگذاریهای کاربر: منطقی پیادهسازی شده برای شناسایی دادههای درونخطی بارگذاریشده توسط کاربر، ذخیره آن به عنوان یک مصنوع منحصر به فرد شناساییشده (مثلاً
usr_upl_img_...) و تزریق متن به متن اعلان با ارجاع به شناسه مصنوع، که به LLM امکان میدهد فایل صحیح را برای استفاده از ابزار انتخاب کند. - پاسخهای ابزار: منطقی پیادهسازی شده برای شناسایی پاسخهای خاص تابع ابزار که مصنوعات (مثلاً تصاویر ویرایششده) تولید میکنند، بارگذاری مصنوع تازه ذخیرهشده (مثلاً،
edited_img_...) و تزریق مرجع شناسه مصنوع و محتوای تصویر مستقیماً به جریان زمینه.
- طراحی ابزار سفارشی: یک ابزار پایتون سفارشی (
edit_product_asset) ایجاد شده است که یک لیستimage_artifact_ids(شناسههای رشتهای) را میپذیرد و ازToolContextبرای بازیابی دادههای واقعی تصویر از سرویس Artifacts استفاده میکند. - ادغام مدل تولید تصویر: مدل تصویر فلش Gemini 2.5 را در ابزار سفارشی ادغام کرده تا ویرایش تصویر را بر اساس توضیحات متنی دقیق انجام دهد.
- تعامل چندوجهی مداوم: تضمین میکند که عامل میتواند با درک نتایج فراخوانیهای ابزار خود (تصویر ویرایششده) و استفاده از آن خروجی به عنوان ورودی برای دستورالعملهای بعدی، یک جلسه ویرایش مداوم را حفظ کند.
8. ➡️ Next Challenge
تبریک میگویم که بخش اول از تعامل ابزار چندوجهی ADK را به پایان رساندید. در این آموزش، ما بر تعامل ابزارهای سفارشی تمرکز میکنیم. اکنون آمادهاید تا به مرحله بعدی در مورد نحوه تعامل با مجموعه ابزارهای چندوجهی MCP بروید. به آزمایشگاه بعدی بروید.
9. 🧹 Clean up
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این codelab، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.