
1. 개요
1부 에서는 Knowledge Catalog 및 DataScan을 사용하여 혼란스럽고 비정형 PDF를 BigQuery의 깔끔하고 지능적인 정형 테이블로 변환했습니다. 이제 강력한 데이터 웨어하우스가 있습니다. 2부 에서는 AlloyDB를 트랜잭션 백본으로 설정하고 BigQuery 테이블을 통합하여 단일 바이트를 복제하지 않고 통합 데이터 레이어를 만들었습니다.
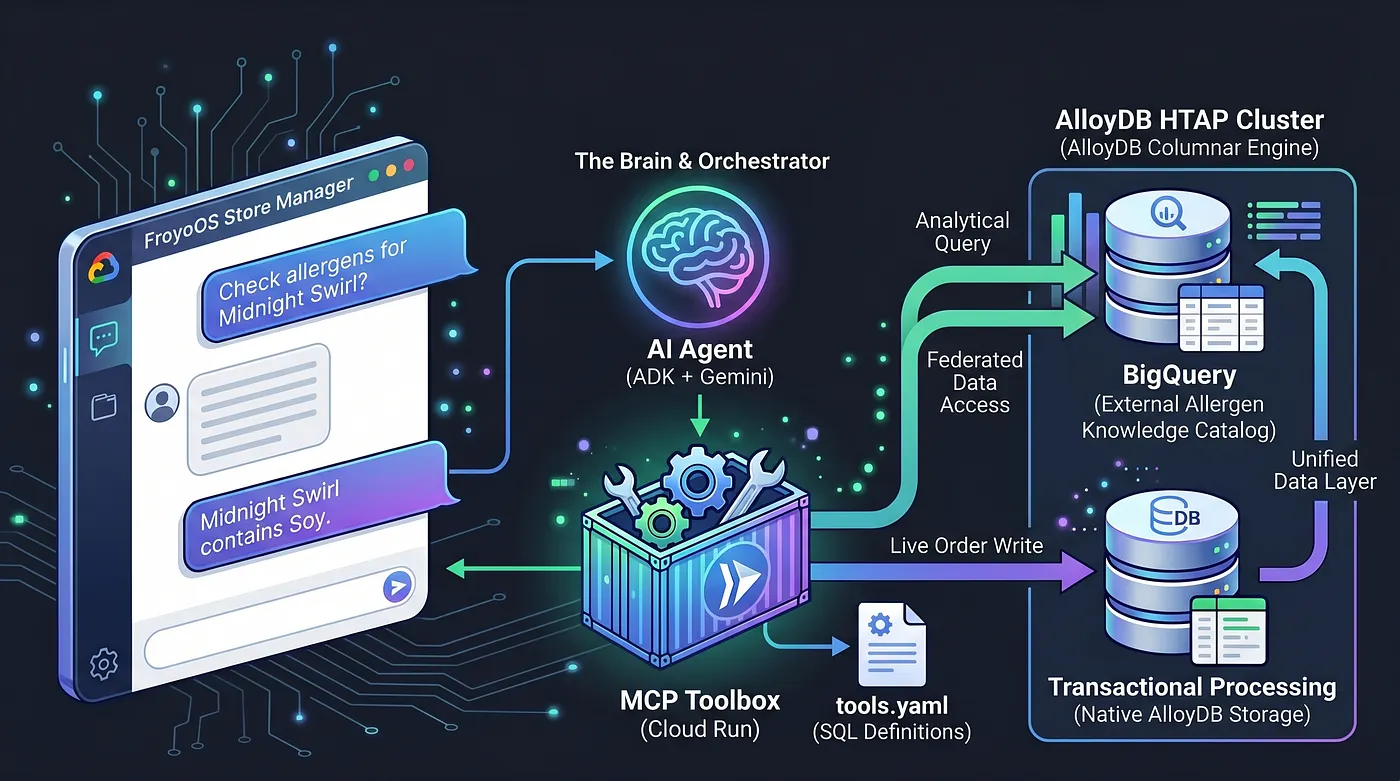
오늘은 브레인을 빌드합니다. 이 데이터 레이어 위에 앉아 질문에 답변하고, 알레르기 유발 물질을 확인하고, 실시간 주문을 처리하는 다중 에이전트 애플리케이션인 'FroyoOS Store Manager'를 만들고 있습니다.
과제: AI를 에이전트에서 분리
데이터베이스와 통신해야 하는 AI 에이전트를 빌드할 때 가장 일반적인 안티패턴은 데이터와 AI 로직을 Python 애플리케이션에 직접 적용하는 것입니다. 이렇게 하면 데이터 아키텍처가 확장됨에 따라 앱이 취약하고 안전하지 않으며 유지보수가 매우 어려워집니다.
이 문제를 해결하기 위해 모델 컨텍스트 프로토콜 (MCP) 도구 상자를 사용하고 있습니다. MCP 도구 상자는 통합 데이터 추상화 레이어 역할을 합니다. 간단한 tools.yaml 파일에서 데이터베이스 작업을 선언적으로 정의합니다. 이 도구 상자를 Google Cloud Run의 보안 서버리스 엔드포인트로 배포합니다. AI 에이전트는 이 엔드포인트에 연결하고 'place_order' 도구를 실행합니다.
HTAP의 이점
에이전트 빌드를 시작하기 전에 이 게시물의 제목에서 HTAP (하이브리드 트랜잭션/분석 처리)를 구체적으로 언급하는 이유를 알아보겠습니다.
기존 아키텍처에서 AI 에이전트가 실시간 사용자 주문 (트랜잭션 OLTP 워크로드)을 처리하고 수천 개의 복잡한 재료 매핑 (분석 OLAP 워크로드)을 상호 참조해야 하는 경우 Python 애플리케이션은 완전히 다른 두 데이터베이스에 대한 연결을 관리해야 합니다. 이로 인해 심각한 지연 시간, 보안 오버헤드, 취약한 상태 관리가 발생합니다.
BigQuery 데이터 웨어하우스를 PostgreSQL에 직접 기본적으로 통합하여 AlloyDB를 HTAP 강자로 만들었습니다. 이 HTAP 아키텍처 덕분에 오늘날 AI 에이전트는 하나의 데이터베이스 엔드포인트와만 통신하면 됩니다. 데이터를 복제하지 않고도 live_orders 테이블에 실시간 트랜잭션을 삽입하고 통합된 BigQuery froyo_data 데이터 세트에 대해 강력한 분석 스캔을 실행할 수 있습니다. 이 엔진을 AI에 노출하는 방법을 알아보겠습니다.
이제 만들어 보겠습니다.
학습할 내용
- 버튼 클릭으로 AlloyDB 클러스터, 인스턴스, 네트워킹을 설정하는 방법
- 통합을 준비하기 위해 확장 프로그램을 설정하는 방법
- BigQuery에서 AlloyDB로 통합을 설정하는 방법
- 테스트하기
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있어야 하므로 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요 .
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화 를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었고 프로젝트가 프로젝트 ID로 설정되어 있는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 인증하려는 경우
gcloud auth login
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API를 사용 설정합니다. 필요한 모든 API를 사용 설정하려면 이 명령어를 실행합니다.
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
주의사항 및 문제 해결
'고스트 프로젝트' 증후군 |
|
결제 장애물 | 프로젝트를 사용 설정했지만 결제 계정을 잊었습니다. AlloyDB는 고성능 엔진입니다. '가스 탱크'(결제)가 비어 있으면 시작되지 않습니다. |
API 전파 지연 | 'API 사용 설정'을 클릭했지만 명령줄에 여전히 |
할당량 늪 | 새 체험판 계정을 사용하는 경우 AlloyDB 인스턴스의 리전 할당량에 도달할 수 있습니다. |
3. 데이터 준비
비정형 PDF에서 추출한 정형 데이터가 BigQuery에서 사용 가능하고 BigQuery 데이터의 AlloyDB 통합도 설정 및 테스트되었는지 확인합니다. 이 단계를 완료하지 않은 경우 여기 및 여기에서 1부와 2부의 간단한 단계를 각각 실행하는 것이 좋습니다.
참고:
이 Codelab을 사용해 보려면 여기에 설명된 에이전트 시스템에 AlloyDB 오케스트레이션이 필요하므로 2부의 정리 단계 (클러스터 및 인스턴스 삭제 단계)를 실행해서는 안 됩니다.
2부에서 이미 만든 이 데이터 외에도 AlloyDB 인스턴스에 테이블을 하나 더 만들어야 합니다. 링크를 사용하여 AlloyDB Studio로 이동합니다.
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
다른 클러스터를 사용하는 경우 위의 링크에서 클러스터 이름을 변경합니다.
AlloyDB Studio의 새 쿼리 편집기 탭에서 다음 문을 실행합니다.
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
이렇게 하면 데이터베이스에 live_orders 테이블이 생성됩니다.
4. 추상화 정의 (tools.yaml)
먼저 데이터베이스 작업을 공식적으로 등록합니다. 트랜잭션 및 분석 데이터 (BigQuery 통합의 분석 데이터)가 모두 포함된 AlloyDB와 에이전트가 상호작용하는 방식을 정의하는 tools.yaml 파일을 만듭니다.
- Cloud Shell 터미널 로 이동합니다. 편집기 모드로 전환합니다.
- 루트 디렉터리에 새 폴더 "froyo-agent"를 만듭니다.
- 폴더 내에서 tools.yaml 파일을 만들고 다음 콘텐츠를 붙여넣습니다. (프로젝트, 클러스터, 인스턴스, 비밀번호에 해당하는 값으로 대체)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
에이전트 기능은 알레르기 유발 물질 확인 및 주문의 두 가지 도구로 제한했습니다.
5. Cloud Run에 도구 상자 배포
애플리케이션에서 이 도구 상자를 사용할 수 있도록 gcloud CLI를 사용하여 안전하게 배포합니다. 이렇게 하면 추상화 레이어 엔드포인트가 생성됩니다.
- Cloud Shell 터미널로 전환하고 다음 명령어를 실행하여 작업 디렉터리로 이동합니다.
cd froyo-agent
- 'tools-froyo'라는 보안 비밀에 tools.yaml을 저장합니다.
gcloud secrets create tools-froyo --data-file=tools.yaml
- MCP 도구 상자 컨테이너를 Cloud Run에 배포합니다.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
2부 Codelab에서 구성한 값과 다른 값을 사용한 경우 '네트워크' 및 '서브넷' 값을 바꿔야 합니다.
- 결과 Cloud Run URL (예: https://toolbox-froyo-xxx.run.app)을 기록해 둡니다.
이 배포된 MCP 도구 상자 엔드포인트는 에이전트 구성 단계에서 사용됩니다.
6. 에이전트 백엔드 (app.py)
데이터베이스가 추상화되면 Python 코드는 오케스트레이션과 추론에만 집중할 수 있습니다.
Flask와 함께 에이전트 개발 키트 (ADK) 를 사용하고 있습니다. ADK는 엔터프라이즈급 세션 메모리 (InMemorySessionService)를 제공하므로 에이전트가 대화의 컨텍스트를 기억합니다. ToolboxSyncClient 와 기본적으로 통합되어 Cloud Run 에서 도구를 원활하게 가져옵니다.
app.py는 다음과 같습니다.
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
간단한 Python Flask 앱은 ADK 에이전트를 도구 상자에 정의된 도구에 연결합니다. 이 도구는 AlloyDB (및 BigQuery 통합 데이터)와 상호작용하고 사용자에게 응답합니다.
Cloud Shell 편집기에서 이 프로젝트를 가져오려면 Cloud Shell 터미널에서 다음 명령어를 실행하여 에이전트의 저장소를 클론하면 됩니다.
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
다음과 같은 프로젝트 구조가 표시됩니다.
결제 계정 없이 데이터를 계속 체험해 보는 단계는 다음과 같습니다.
- 편의를 위해 다음 데이터 파일이 저장소에서 제공됩니다.
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
이 파일은 app.py와 동일한 폴더에 있어야 합니다.
B. 동일한 경로에 있는 app-nobill.py 라는 Python 파일
- 프로젝트 루트 폴더에 app-nobill.py라는 파일이 있습니다.
- 이 파일은 데이터가 파일에서 제공되므로 이러한 데이터 소스에 명시적으로 연결할 필요 없이 동일한 앱 환경을 만들도록 설계되었습니다.
- 실습에 언급된 다른 모든 파일도 이 버전에서 그대로 유지되어야 합니다 (app.py 파일을 실행할 필요는 없음).
7. UI 및 앱 실행
Store Manager에게 적절한 환경을 제공하기 위해 실시간 제품 카탈로그 사이드바와 대화형 채팅 인터페이스가 포함된 세련된 글래스모픽 UI (templates/index.html)를 만들었습니다.
저장소 파일에서 index.html을 찾을 수 있습니다.
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
애플리케이션을 실행하기 전에 requirements.txt 파일에 다음 콘텐츠와 함께 종속 항목이 있는지 확인합니다.
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
.env 파일이 채워져 있습니다.
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
GOOGLE_API_KEY를 가져오는 방법
이 블로그의 안내에 따라 Google API 키를 설정합니다.
MCP_TOOLBOX_SERVER_URL을 가져오는 방법
이 Codelab의 이전 단계에서 이를 설정하고 배포된 MCP 도구 상자 엔드포인트를 복사했습니다. MCP_TOOLBOX_SERVER_URL 환경 변수에 해당 링크를 사용합니다.
앱 실행:
Cloud Shell 터미널에서 프로젝트 폴더에 있는지 확인하고 다음 명령어를 하나씩 실행합니다.
프로젝트 루트 폴더로 이동합니다.
cd froyo-data
종속 항목을 설치합니다.
pip install -r requirements.txt
Python 파일 실행:
python app.py
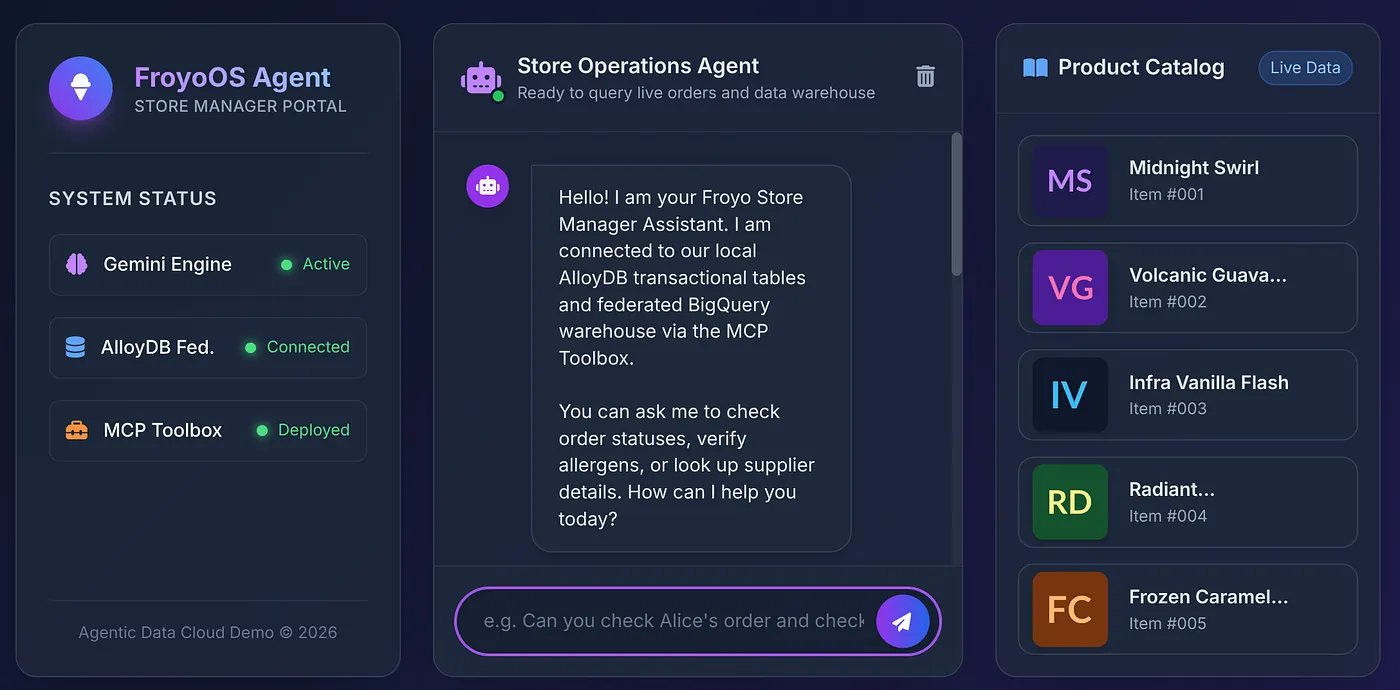
터미널에 표시되는 링크를 클릭하거나 http://localhost:8080을 엽니다.
8. 얼티미트 테스트
카탈로그에서 제품을 클릭하여 에이전트에게 질문해 보겠습니다.
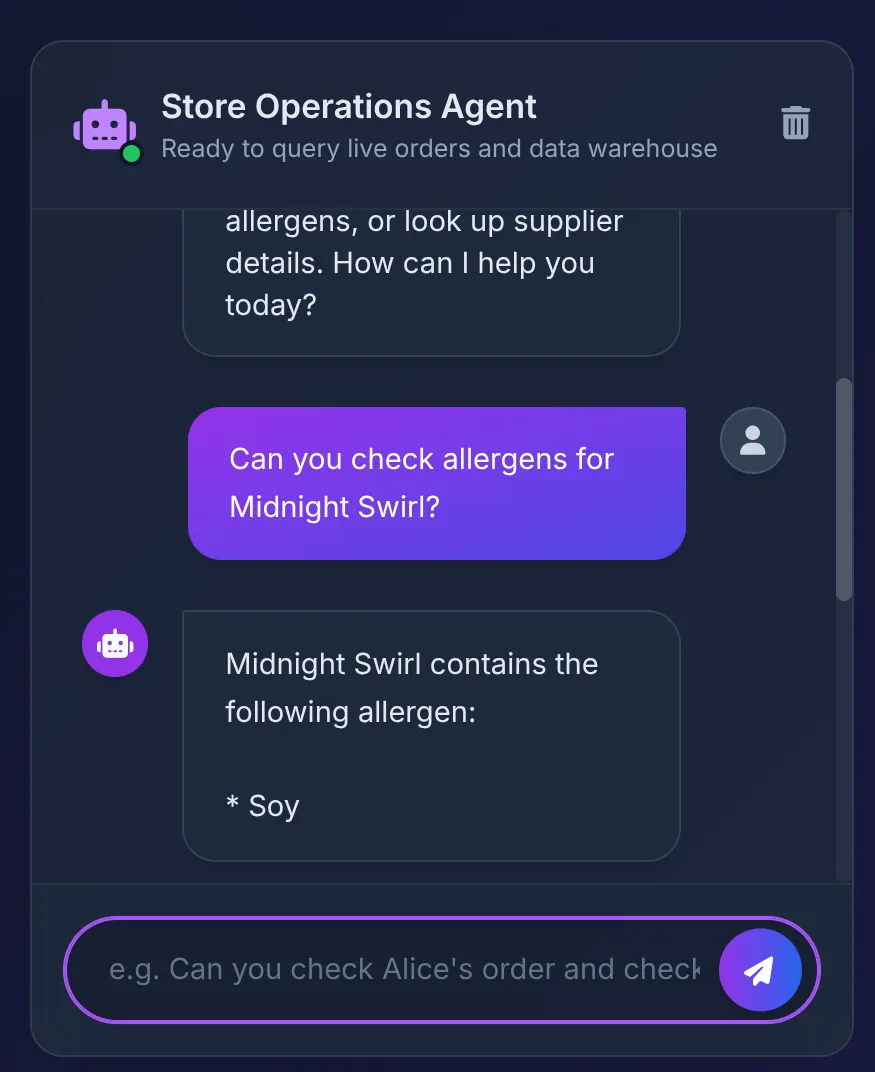
Does Midnight Swirl have any allergens?
다음과 같은 응답이 표시됩니다.
비하인드 스토리:
- ADK 에이전트는 프롬프트를 수신하고 check_allergens 도구를 사용하기로 결정합니다.
- Cloud Run에서 MCP 도구 상자를 안전하게 호출합니다.
- 도구 상자는 AlloyDB에서 쿼리를 실행합니다. 이 쿼리는 BigQuery에 즉시 통합되어 1부에서 빌드한 복잡한 관계를 스캔합니다.
- 데이터베이스는 'Soy'를 반환합니다. 에이전트는 이를 UI에 깔끔하게 요약합니다.
다음으로 다음과 같이 말합니다.
Order 2 Midnight Swirl for Alice.
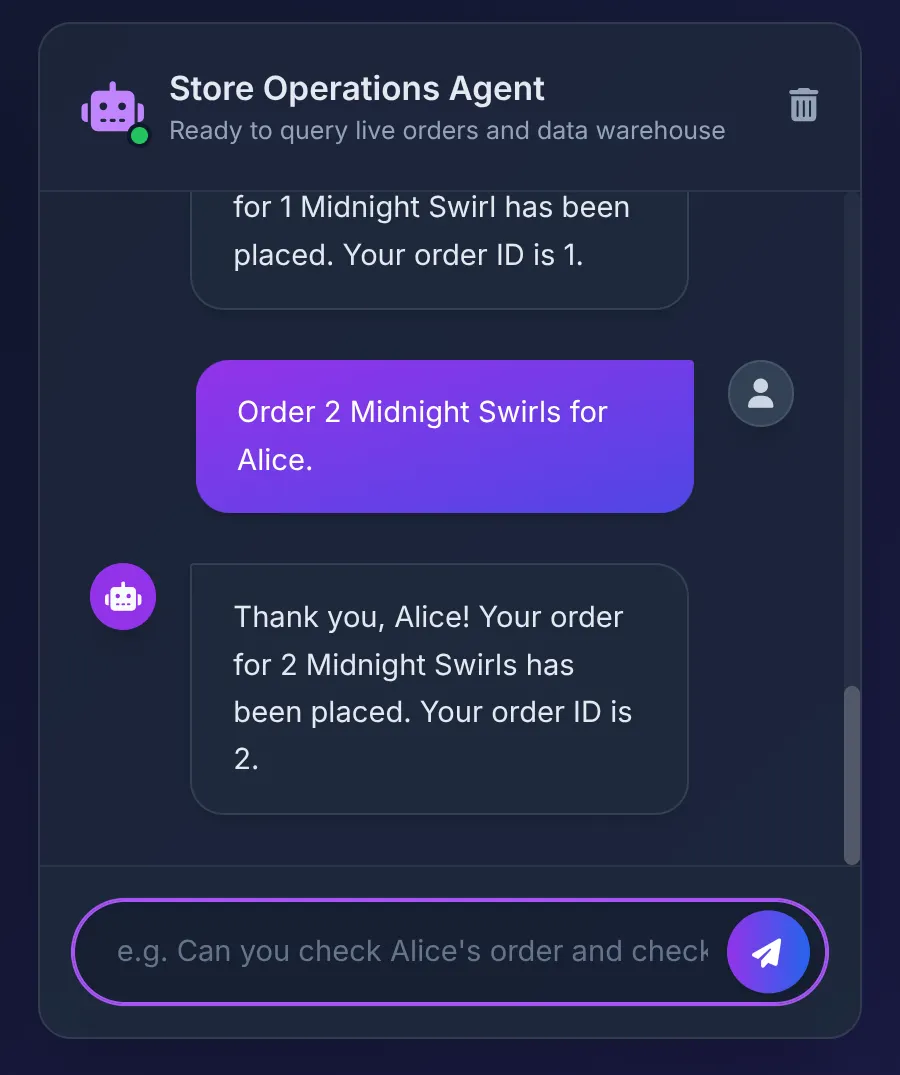
에이전트는 'Midnight Swirl' 문자열을 도구 상자에 전달합니다. 기본 SQL은 BigQuery를 통해 문자열을 정수 ID로 동적으로 확인하고, AlloyDB에 실시간 주문을 삽입하고, 트랜잭션을 확인합니다.
코드 저장소
9. 정리
이 실습이 완료되면 AlloyDB 클러스터와 인스턴스를 삭제해야 합니다.
클러스터와 인스턴스가 정리됩니다.
10. 에이전트 빌드를 축하드립니다.
지금까지 완료한 작업을 생각해 보세요.
잘 오케스트레이션된 에이전트 시스템은 데이터베이스용 MCP 도구 상자와만 상호작용합니다. 이 백엔드는 도구 호출과 애플리케이션의 AI 로직에 대한 데이터를 처리하여 흐름을 단순하게 유지합니다.
- 트랜잭션 앱 (AlloyDB에서 실행)은 빠르고 동시 사용자 세션을 처리할 수 있습니다.
- 공급업체 세부정보 또는 복잡한 재료 매핑과 같은 강력한 분석 데이터 또는 과거 컨텍스트가 필요한 경우 BigQuery froyo_dataschema를 쿼리합니다.
- ETL이 없습니다. 데이터 파이프라인이 중단되지 않습니다. 동기화되지 않은 데이터베이스가 없습니다. 한 번 저장 (BQ)하고 필요한 곳에서 컴퓨팅합니다.
이제 분석 및 트랜잭션 에이전트와 데이터 기반이 모두 완료되었으므로 다음 파트로 이동해 보겠습니다.
다음 단계
에이전트는 해피 경로에서 완벽하게 작동합니다. 4부에서는 에이전트 시스템의 유효성, 근거, 성능을 엄격하게 테스트하기 위해 에이전트 평가 파이프라인을 빌드합니다. 시작 세션에서 뵙겠습니다.