
1. 總覽
在第 1 部分中,我們已使用 Knowledge Catalog 和 DataScan,成功將混亂的非結構化 PDF 轉換為 BigQuery 中乾淨、智慧且結構化的表格。現在我們有穩固的資料倉儲。在第 2 部分中,我們將 AlloyDB 設為交易式主幹,並將 BigQuery 資料表聯合到其中,建立統一的資料層,完全不需複製任何位元組。
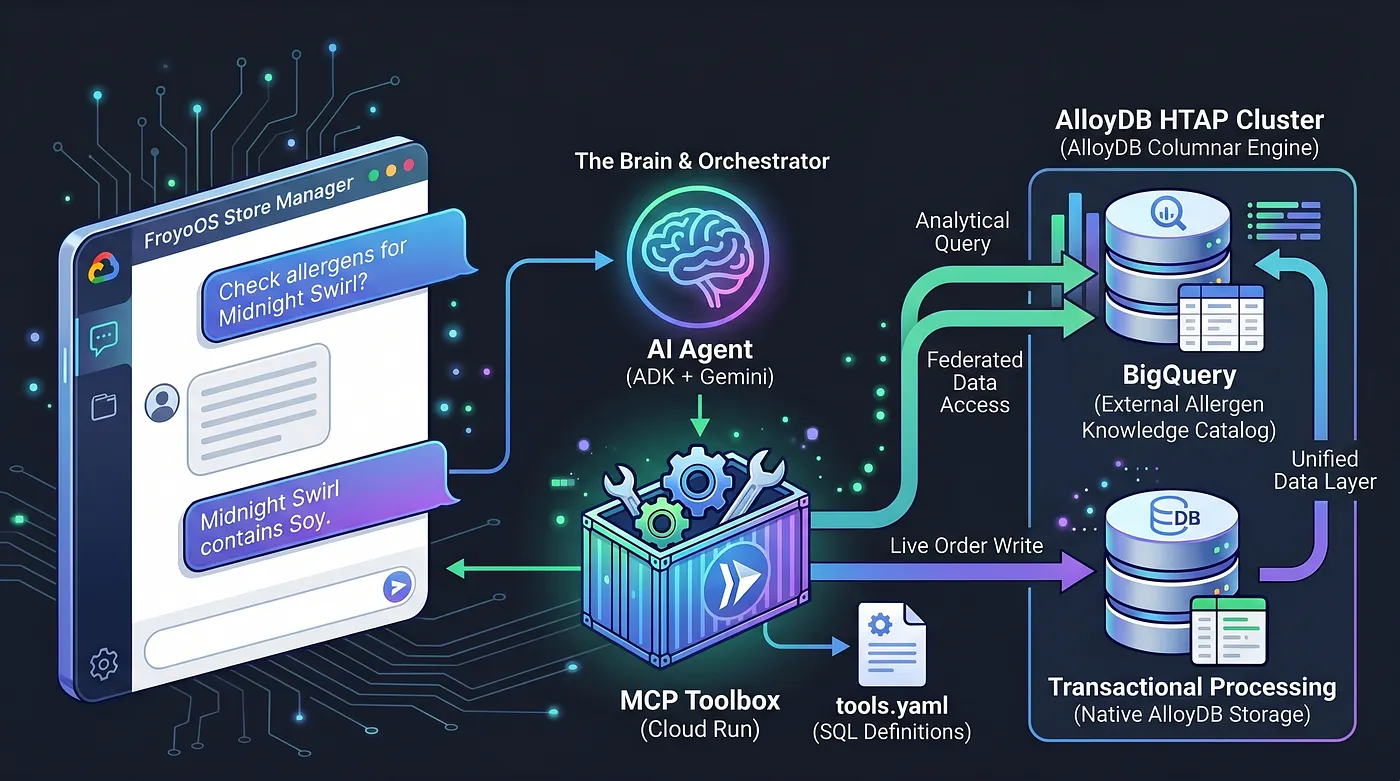
今天我們要建構大腦。我們正在建立「FroyoOS 商店管理員」多代理應用程式,這個應用程式會位於資料層上方,負責回答問題、檢查過敏原,以及處理即時訂單。
挑戰:將 AI 與代理程式分離
建構需要與資料庫互動的 AI 代理時,最常見的反模式是直接將資料和 AI 邏輯強制導入 Python 應用程式。隨著資料架構擴大,這會導致應用程式變得脆弱、不安全,且難以維護。
為解決這個問題,我們使用 Model Context Protocol (MCP) Toolbox。MCP Toolbox 是統一的資料抽象層,我們會在簡單的 tools.yaml 檔案中,以宣告方式定義資料庫作業。我們會在 Google Cloud Run 上,將這個工具箱部署為安全的無伺服器端點。我們的 AI 代理程式只要連線至這個端點,然後說「執行『place_order』工具」即可。
HTAP 的強大功能
開始建構代理程式之前,我們先來談談為什麼這篇文章的標題特別提到 HTAP (混合型交易/分析處理)。
在傳統架構中,如果 AI 代理程式需要處理即時使用者訂單 (交易型 OLTP 工作負載),並交叉比對數千個複雜的食材對應 (分析型 OLAP 工作負載),Python 應用程式就必須同時管理與兩個完全不同資料庫的連線。這會造成嚴重延遲、安全負擔,以及脆弱的狀態管理。
我們將 BigQuery 資料倉儲直接聯合至 PostgreSQL,讓 AlloyDB 成為 HTAP 強大工具。由於採用這種 HTAP 架構,我們的 AI 代理程式目前只需要與一個資料庫端點通訊。這樣一來,您就能將即時交易插入 live_orders 資料表,並對聯合 BigQuery froyo_data 資料集執行大量分析掃描,完全不必複製任何位元組的資料。接下來看看如何向 AI 公開這個引擎。
讓我們開始建構吧!
課程內容
- 如何按一下按鈕,即可設定 AlloyDB 叢集、執行個體和網路
- 如何設定擴充功能,為同盟做好準備
- 如何從 BigQuery 設定身分聯盟至 AlloyDB
- 立即測試
需求條件
2. 事前準備
建立專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
- 您將使用 Cloud Shell,這是 Google Cloud 中執行的指令列環境。按一下 Google Cloud 控制台頂端的「啟用 Cloud Shell」。

- 連至 Cloud Shell 後,請使用下列指令確認驗證已完成,專案也已設為獲派的專案 ID:
gcloud auth list
- 在 Cloud Shell 中執行下列指令,確認 gcloud 指令已瞭解您的專案。
gcloud config list project
- 如要驗證
gcloud auth login
- 如果未設定專案,請使用下列指令設定:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 啟用必要的 API:執行下列指令,啟用所有必要的 API:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
常見錯誤與疑難排解
「幽靈專案」 症候群 | 您執行了 |
帳單 路障 | 您已啟用專案,但忘記帳單帳戶。AlloyDB 是高效能引擎,如果「油箱」(帳單) 空了,就無法啟動。 |
API 傳播 延遲 | 您點選了「啟用 API」,但指令列仍顯示 |
配額 Quags | 如果您使用全新的試用帳戶,可能會達到 AlloyDB 執行個體的區域配額。如果 |
3. 準備資料
請確認從非結構化 PDF 擷取的結構化資料位於 BigQuery 中,並已建立及測試 BigQuery 資料的 AlloyDB 聯盟。如果尚未完成這些步驟,請前往這裡和這裡,分別執行第 1 部分和第 2 部分的簡單步驟。
注意:
如果您要嘗試這個程式碼研究室,請勿執行第 2 部分的清理步驟 (刪除叢集和執行個體步驟),因為我們需要 AlloyDB 編排來示範代理程式系統。
除了在第 2 部分中建立的資料外,我們還需要在 AlloyDB 執行個體中建立一個額外資料表。使用下列連結前往 AlloyDB Studio:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
如果使用其他叢集,請變更上方連結中的叢集名稱。
在 AlloyDB Studio 的新查詢編輯器分頁中,執行下列陳述式:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
這應該會在資料庫中建立 live_orders 資料表。
4. 定義抽象化 (tools.yaml)
首先,我們正式註冊資料庫作業。我們建立 tools.yaml 檔案,定義代理程式與 AlloyDB 的互動方式,AlloyDB 包含交易和分析資料 (來自 BigQuery 聯盟的分析資料)。
- 前往 Cloud Shell 終端機。切換至「編輯器」模式。
- 在根目錄中建立新資料夾:「froyo-agent」
- 在資料夾中建立 tools.yaml 檔案,並貼上下列內容 (請將專案、叢集、執行個體和密碼替換成您自己的值):
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
我們將代理程式功能限制為 2 項工具:檢查過敏原和下單。
5. 將 Toolbox 部署至 Cloud Run
如要讓應用程式使用這個工具箱,請使用 gcloud CLI 安全地部署工具箱。這會建立我們的抽象層端點。
- 切換至 Cloud Shell 終端機,然後執行下列指令,前往工作目錄:
cd froyo-agent
- 將 tools.yaml 儲存為名為「tools-froyo」的密鑰:
gcloud secrets create tools-froyo --data-file=tools.yaml
- 將 MCP Toolbox 容器部署至 Cloud Run
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
如果您使用的「網路」和「子網路」值與第 2 部分 Codelab 中設定的值不同,請務必加以替換。
- 記下產生的 Cloud Run 網址 (例如 https://toolbox-froyo-xxx.run.app)。
我們會在代理程式設定步驟中使用這個已部署的 MCP Toolbox 端點。
6. 代理後端 (app.py)
由於資料庫已抽象化,我們的 Python 程式碼可以完全專注於協調和推理。
我們使用 Agent Development Kit (ADK) 和 Flask。ADK 提供企業級工作階段記憶體 (InMemorySessionService),因此代理程式會記住對話內容。並與 ToolboxSyncClient 原生整合,可從 Cloud Run 順暢提取工具。
以下是 app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
簡單的 Python Flask 應用程式會將 ADK 代理程式連結至工具箱中定義的工具,這些工具會與 AlloyDB (以及 BigQuery 聯邦資料) 互動,並回應使用者。
如要在 Cloud Shell 編輯器中取得這個專案,請在 Cloud Shell 終端機執行下列指令,複製代理的存放區:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
您應該會看到下列專案結構:
如要繼續使用資料,但不要帳單帳戶,請按照下列步驟操作:
- 為方便起見,存放區提供下列資料檔案:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
這些檔案應與 app.py 位於同一資料夾。
B. 名為 app-nobill.py 的 Python 檔案,位於相同路徑
- 專案根資料夾中有名為 app-nobill.py 的檔案
- 這個檔案的設計目的是建立相同的應用程式體驗,但不需要明確連線至這些資料來源,因為資料已在檔案中提供。
- 本版本也應包含實驗室中提及的所有其他檔案 (只是不需要執行 app.py 檔案)
7. 使用者介面和執行應用程式
為了提供合適的體驗給商店管理員,我們建立了簡潔的玻璃擬態 UI (templates/index.html),其中包含即時產品目錄側欄和互動式聊天介面。
您可以在存放區檔案中找到 index.html,路徑如下:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
執行應用程式前,請確認 requirements.txt 檔案中包含下列內容:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
並填入 .env 檔案:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
如何取得 GOOGLE_API_KEY?
請按照這篇網誌文章的操作說明設定 Google API 金鑰。
如何取得 MCP_TOOLBOX_SERVER_URL?
我們已在本程式碼研究室的上一個步驟中完成這項設定,您也複製了已部署的 MCP Toolbox 端點。在 MCP_TOOLBOX_SERVER_URL 環境變數中使用該連結。
執行應用程式:
在 Cloud Shell 終端機中,確認您位於專案資料夾,然後依序執行下列指令:
前往專案根資料夾:
cd froyo-data
安裝依附元件:
pip install -r requirements.txt
執行 Python 檔案:
python app.py
點按終端機中顯示的連結,或開啟 http://localhost:8080!
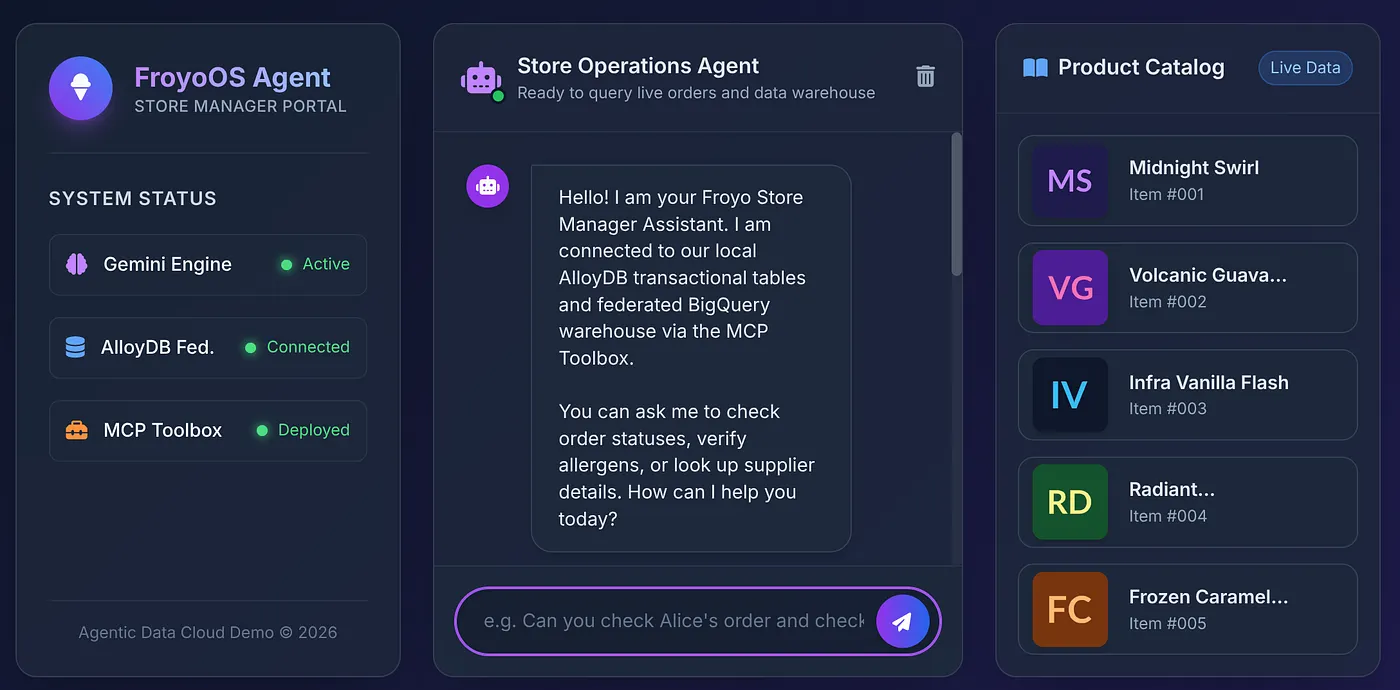
8. 終極測試
現在點選目錄中的產品,向服務專員提問:
Does Midnight Swirl have any allergens?
畫面上應會顯示下列回應內容:
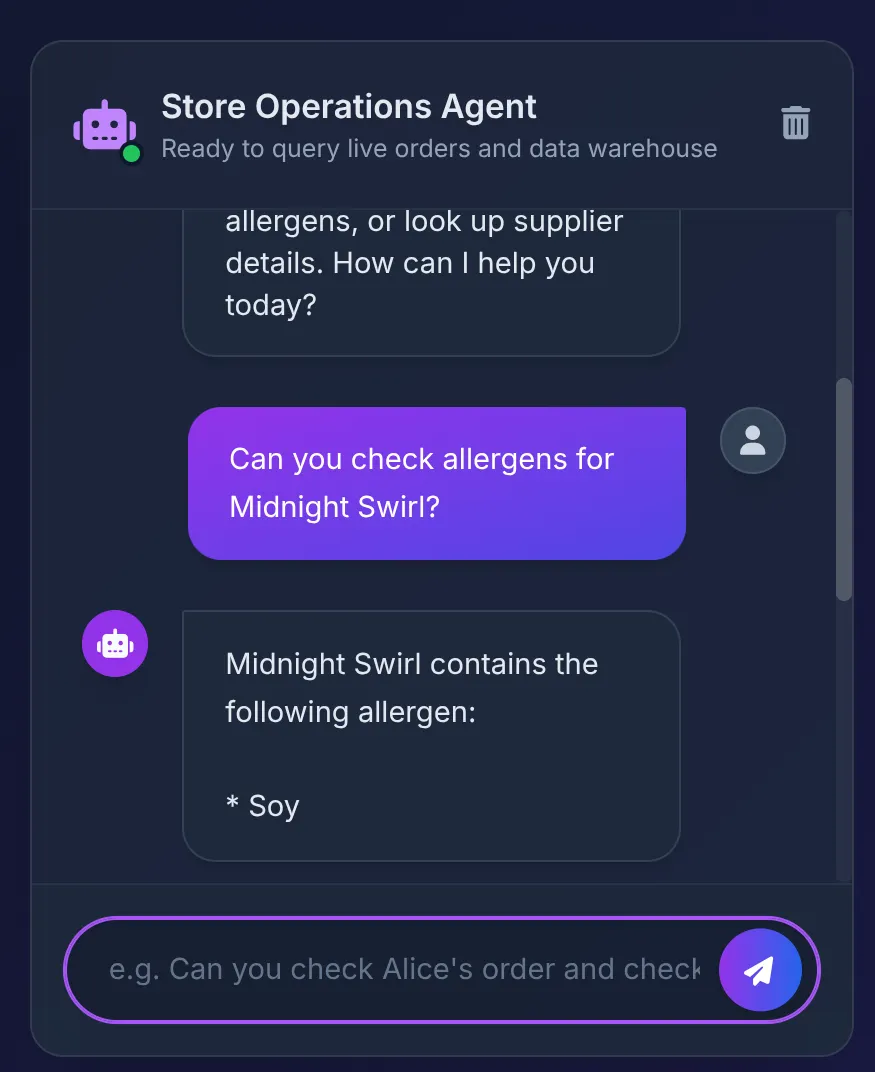
幕後花絮:
- ADK 代理收到提示後,決定使用 check_allergens 工具。
- 安全地呼叫 Cloud Run 上的 MCP Toolbox。
- Toolbox 會在 AlloyDB 中執行查詢,並立即聯合至 BigQuery,掃描我們在第 1 部分中建立的複雜關係。
- 資料庫會傳回「Soy」,而 Agent 會在 UI 中簡要匯總這項資訊。
接著,我們說:
Order 2 Midnight Swirl for Alice.
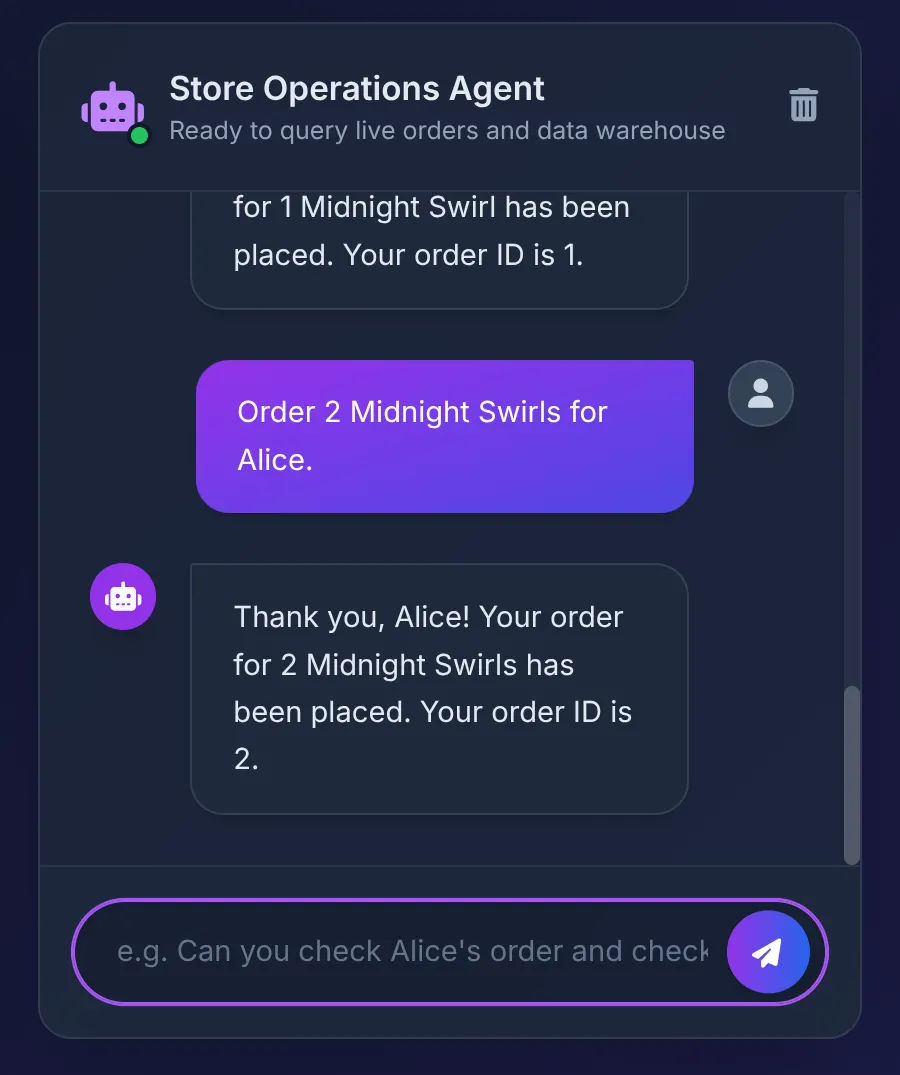
代理程式會將「Midnight Swirl」字串傳遞至工具箱。基礎 SQL 會透過 BigQuery 將字串動態解析為整數 ID,將即時訂單插入 AlloyDB,並確認交易。
程式碼存放區
9. 清理
完成本實驗室後,請務必刪除 AlloyDB 叢集和執行個體。
這項作業應會清理叢集及其執行個體。
10. 恭喜您獲得 Agent!
請回想我們剛才完成的作業:
我們精心設計的代理系統只會與資料庫的 MCP Toolbox 互動。這項作業會在幕後處理工具呼叫和應用程式的 AI 邏輯資料,讓流程保持簡單:
- 我們的交易應用程式 (在 AlloyDB 上執行) 可處理快速的並行使用者工作階段。
- 需要大量分析資料或歷來脈絡 (例如供應商詳細資料或複雜的成分對應) 時,就會查詢 BigQuery froyo_dataschema。
- 零 ETL。沒有資料管道中斷。沒有不同步的資料庫。我們在 BQ 中儲存一次,並在需要時進行運算。
現在我們已完成代理程式和資料基礎 (包括分析和交易資料),接下來要進入下一個部分。
後續步驟
我們的代理程式在順利的情況下運作良好,在第 4 部分中,我們將建構代理評估管道,嚴格測試代理系統的有效性、根據事實程度和效能。到時見!