
1. Einführung
Das Testen von Webanwendungen kann mühsam sein. Herkömmliche UI-Tests fühlen sich oft wie ein ständiger Kampf gegen die Fragilität an. Sie schreiben komplexe Skripts, verwalten anfällige CSS- und XPath-Selektoren und müssen sich anstrengen, um einen einfachen User Flow zu überprüfen.
Was aber, wenn Sie einem Kundenservicemitarbeiter einfach in natürlicher Sprache sagen könnten, was er testen soll, und er es dann einfach tut?

In diesem Codelab erfahren Sie, wie Sie die Gemini CLI und multimodale Tools wie BrowserMCP verwenden. Sie erfahren, wie Sie automatisierte UI-Tests in natürlicher Sprache erstellen und ausführen. Für dieses Codelab sind keine Vorkenntnisse zu UI-Test-Frameworks und ‑Tools erforderlich.
Lerninhalte
- Was das Model Context Protocol (MCP) ist und warum es ein Gamechanger ist.
- Wie KI-Agents mit BrowserMCP Webbrowser steuern können.
- Automatisierte UI-Tests über die Gemini CLI ausführen
- Agent Skills und ihre Vorteile verstehen
- Einem Agent beibringen, Playwright mit einem Skill zu verwenden
- MCP und Skill der Google Chrome-Entwicklertools gemeinsam nutzen
- Kurzer Überblick über den Antigravity Browser-Unteragenten.
- Weitere Anwendungsfälle für die Browsersteuerung.
Aufgaben
- Richten Sie Ihre Entwicklungsumgebung ein.
- Eine Demoanwendung ansehen, die getestet werden muss.
- Mit der Gemini CLI über BrowserMCP mit der Anwendung interagieren
- Agent beibringen, wie Playwright mit einem Agent-Skill verwendet wird
2. Vorbereitung
Bevor wir uns die coolen Funktionen ansehen, solltest du prüfen, ob du alles hast, was du brauchst.
In diesem Codelab werden die Gemini CLI, MCP-Tools, Agent-Fähigkeiten und eine React-Demoanwendung verwendet.
Tools
In diesem Lab wird Folgendes vorausgesetzt:
- Chrome-Browser
- Node.js
- Gemini CLI
- Git
Wenn Sie die Gemini CLI verwenden möchten, müssen Sie sich bei Google authentifizieren. Dafür gibt es mehrere Möglichkeiten. Wir empfehlen jedoch, einfach die Option Über Google anmelden zu verwenden. Diese Option bietet ein großzügiges kostenloses Kontingent für die Gemini API und erfordert kein Google Cloud-Projekt. Wenn Sie diese Option im Codelab verwenden, fallen keine Kosten an. Wenn Sie bereits einen Gemini API-Schlüssel haben, können Sie diesen verwenden.
Bei der Anleitung wird davon ausgegangen, dass Sie in einer Linux- (oder WSL-) oder macOS-Umgebung arbeiten. Wenn Sie Windows verwenden (wie ich), können Sie WSL verwenden.
Hinweis:
BrowserMCP funktioniert nicht in Google Cloud Shell
, da nur eine Verbindung zu einem lokalen Browser auf demselben Computer hergestellt wird.
Entwicklungsumgebung einrichten
Ich habe ein Demo-Repository auf GitHub erstellt. Sie enthält eine Beispielanwendung, die wir für unsere UI-Tests verwenden können. Klonen Sie es, indem Sie den folgenden Befehl in Ihrem lokalen Terminal ausführen:
git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing
Es gibt ein Makefile, mit dem Sie die Umgebung zum Starten der Demo-App ganz einfach einrichten können. Führen Sie es aus, um die Umgebung zu initialisieren:
make install # Or if you don't have make npm install --prefix demo-app
3. Unsere Demoanwendung
Die App, die wir heute testen, ist The Dazbo Omni-Dash – ein futuristisches, dunkles Dashboard zur Verwaltung von Sicherheitstelemetriedaten. (Ja, es wurde Vibe Coding verwendet!)
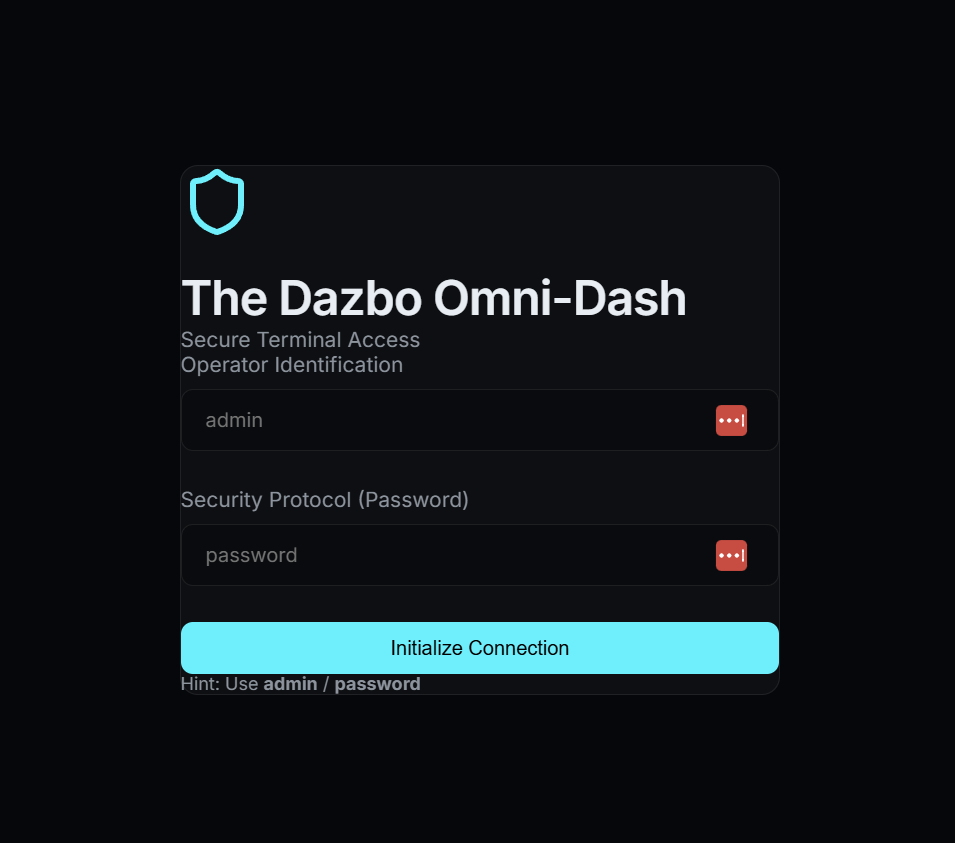
Warum diese App?
Sie wurde entwickelt, um eine realistische Testumgebung zu bieten, mit:
- Mock-Authentifizierung: Ein Anmeldevorgang, für den bestimmte Anmeldedaten erforderlich sind.
- Dynamische Inhalte: Telemetriekarten und Sicherheitslogs, die Echtzeitdaten simulieren.
- Interaktive Status: Navigationsmenüs und Formulareingaben, die sich je nach Nutzeraktion ändern.
- Moderne Technologie: Die Benutzeroberfläche basiert auf React und Vite und bietet eine schnelle, reaktionsfähige Umgebung.
App starten
Führen Sie zum Starten der Anwendung einfach Folgendes aus:
make dev # Or if you don't have make npm run dev --prefix demo-app
Der Entwicklungsserver sollte sehr schnell gestartet werden und die App ist unter http://localhost:5173 verfügbar.

Wir können einfach auf den Link klicken, um die Anwendung in unserem Browser zu öffnen. Lassen Sie diesen Prozess einfach in Ihrem Terminal laufen. Wir führen die nachfolgenden Terminalbefehle in einer separaten Terminalsitzung aus.
4. Herausforderungen beim UI-Testen
Herkömmliche UI-Tests sind bekanntermaßen schwierig durchzuführen und noch schwieriger zu warten. Häufige Probleme:
- Test „Instabilität“: Tests, die aufgrund von Zeitproblemen, Race Conditions oder langsam ladenden Assets in einer Minute bestanden und in der nächsten fehlgeschlagen sind.
- Anfällige Selektoren: Es wird auf bestimmte DOM-Strukturen (z. B. div > div > button) gesetzt, die bei der geringsten Änderung der Benutzeroberfläche nicht mehr funktionieren und zu einer ständigen Scriptwartung führen.
- Hohe Lernkurve: Entwickler müssen komplexe domainspezifische Sprachen und frameworkspezifische Besonderheiten (Cypress, Selenium, Playwright) beherrschen, um einen einfachen Klick zu automatisieren.
- Umgebungsparität: Schwierigkeiten beim Replizieren von Anwendungsstatus und der Aufwand beim Bereinigen von Testdaten.

Wir brauchen eine Testmethode, die sich auf die Intention und nicht auf die Implementierung konzentriert.
5. MCP als Retter in der Not
Das Model Context Protocol (MCP) ist ein offener Standard, der es KI-Modellen und ‑Agents ermöglicht, mit externen Tools, APIs und Daten zu interagieren. Stellen Sie sich das als universellen Adapter vor, mit dem Modelle und Agenten die Tools finden und ausführen können, auf die sie Zugriff haben.
Bisher mussten Entwickler für jede neue Datenquelle benutzerdefinierte, fest codierte API-Verbindungen schreiben, um Large Language Models (LLMs) in externe Daten und Tools einzubinden. Das führte zu einem nicht nachhaltigen „M x N“-Integrationsproblem, bei dem jede neue Datenquelle den Wartungsaufwand vervielfachte. Das Model Context Protocol (MCP) löst dieses Problem, da kein spezifischer Code zum Orchestrieren dieser Funktionen erforderlich ist. Anstatt komplexe Ausführungsabläufe explizit zu codieren, können sich Entwickler darauf verlassen, dass das LLM die Anfragen von Nutzern in natürlicher Sprache interpretiert und dynamisch entscheidet, welche Tools verwendet werden sollen.
Wenn ein Nutzer einen Befehl in natürlicher Sprache eingibt (z. B. „Rufe localhost:5173 auf, melde dich als ‚admin‘ an und klicke auf die Schaltfläche ‚Senden‘“), ermittelt das LLM die verfügbaren Funktionen und generiert eine strukturierte Anfrage zum Aufrufen eines bestimmten Tools. Der MCP-Client fungiert als Übersetzer und leitet diese Anfrage an den entsprechenden MCP-Server weiter, der die Aktion ausführt oder die Daten abruft und den Kontext an das Modell zurückgibt. So kann die KI autonom agieren, ohne dass der Entwickler den spezifischen Ausführungspfad fest codieren muss.
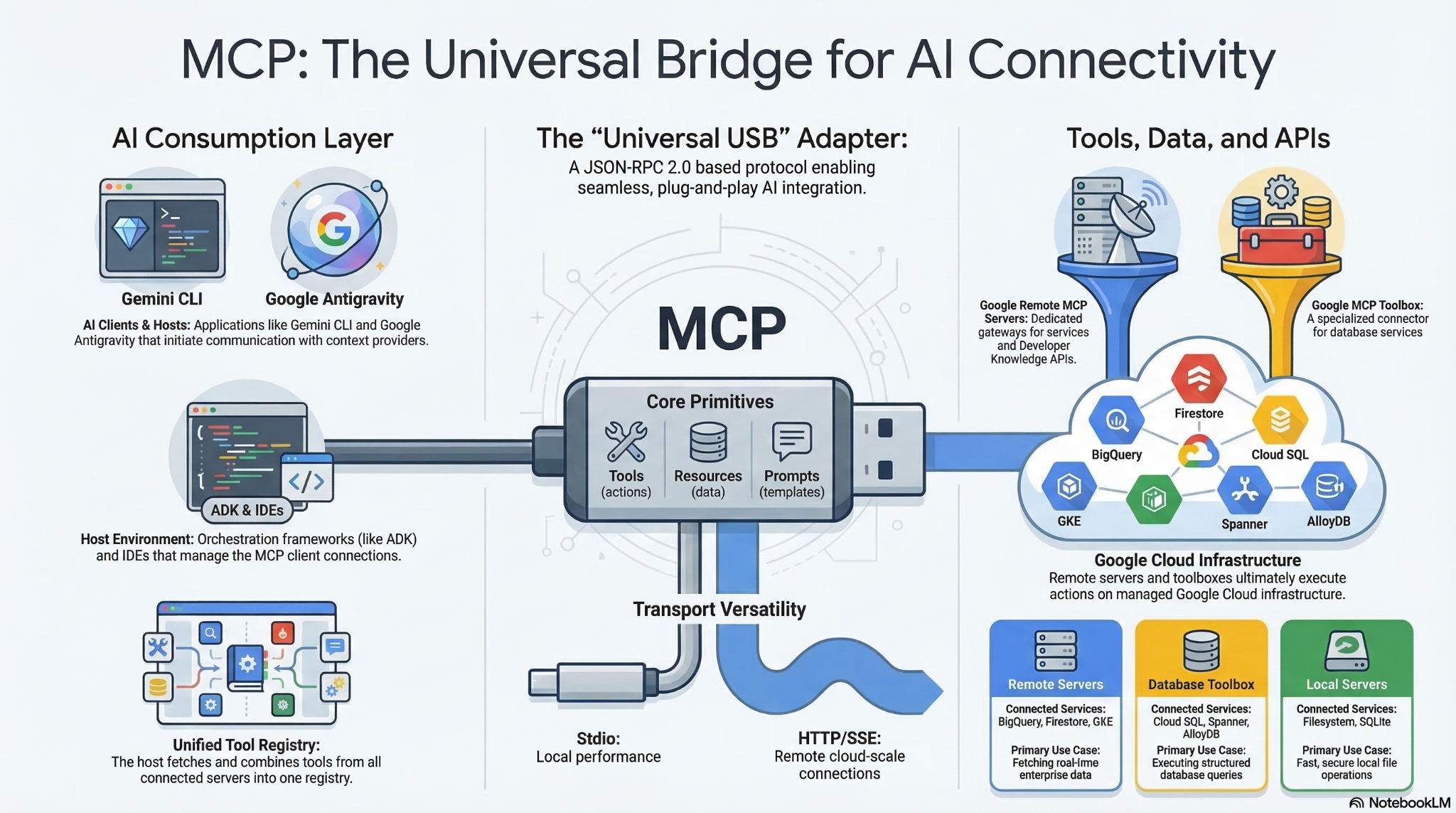
Da MCP einen universellen Standard schafft, der oft als „USB-C für KI-Anwendungen“ bezeichnet wird, ermöglicht er eine enorme Reusability out-of-the-box. Entwickler können einen MCP-Server einmal erstellen und jeder MCP-kompatible KI-Host kann sofort eine Verbindung zu ihm herstellen. So wird das M × N-Integrationsproblem vermieden. Sie müssen nicht mehr für jede Plattform benutzerdefinierte API-Bridges erstellen. Stattdessen können Sie das Ökosystem der vorgefertigten Open-Source-MCP-Server für gängige Dienste wie GitHub, Slack und Datenbanken nutzen und sie direkt in Ihre Agent-Workflows einbinden. Diese modulare Plug-and-Play-Architektur sorgt dafür, dass Ihre Kernintegrationsinfrastruktur völlig unverändert bleibt, wenn Sie später den LLM-Anbieter wechseln oder Ihre Tools aktualisieren.
6. Automatisierung mit BrowserMCP
Was ist BrowserMCP?
Das ist das erste Tool, das wir uns heute ansehen. BrowserMCP ist ein MCP-Server, der KI-Agenten die „Augen“ und „Hände“ gibt, die sie für die Interaktion mit einem Webbrowser benötigen. Kurz gesagt, wird die menschliche Interaktion mit einem Browser nachgeahmt. Die App ist Open Source. Das GitHub-Repository finden Sie hier. Hauptdokumentation zu BrowserMCP

Hier einige Funktionen:
- Es kann zu URLs navigieren.
- Es kann das DOM untersuchen.
- Es kann auf Schaltflächen klicken und Text in Formulare eingeben.
- Sie können Elemente per Drag-and-drop verschieben.
- Sie kann Browserkonsolen-Logs lesen.
- Schnell: Die Automatisierung erfolgt lokal auf Ihrem Computer.
Browser-MCP installieren
Für die Verwendung von BrowserMCP sind zwei Schritte erforderlich:
- Installieren Sie die BrowserMCP-Erweiterung in Chrome oder einem anderen Chromium-basierten Browser.
- Konfigurieren Sie den MCP-Server für Ihren KI-Agenten.
Folgen Sie einfach dieser Anleitung, um die Erweiterung zu installieren. Das dauert nur wenige Sekunden. Nach der Installation klicken Sie in der Erweiterung auf „Verbinden“, damit Ihr aktueller Tab von Ihrem Agent gesteuert werden kann. Der aktuelle Tab sollte natürlich der Tab sein, auf dem die Demoanwendung ausgeführt wird.
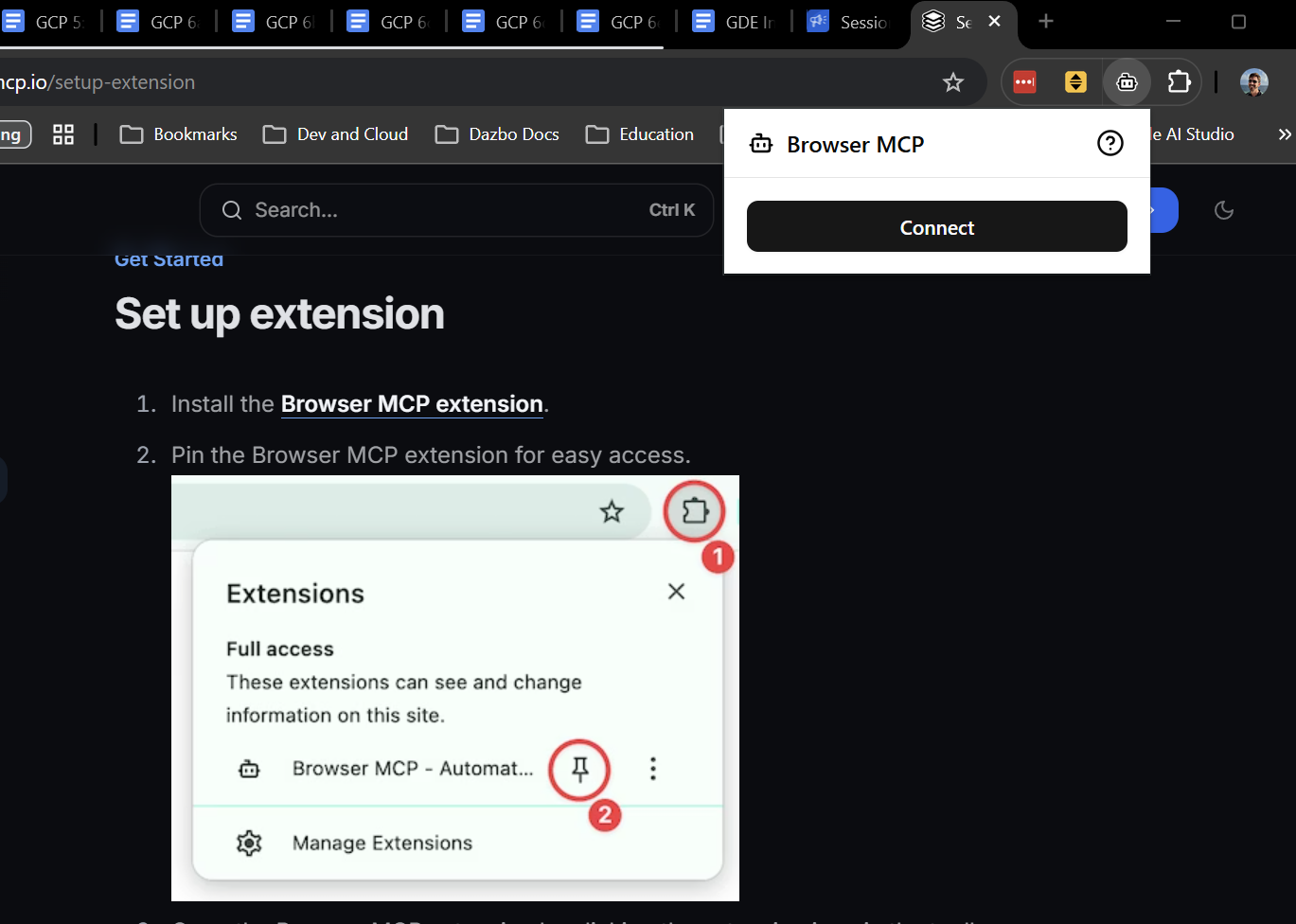
Als Nächstes müssen wir den BrowserMCP-Server in Ihren Client einfügen. In der Gemini CLI ist das ganz einfach. Installieren Sie einfach die Erweiterung:
gemini extensions install https://github.com/derailed-dash/browsermcp-ext
Mit BrowserMCP testen
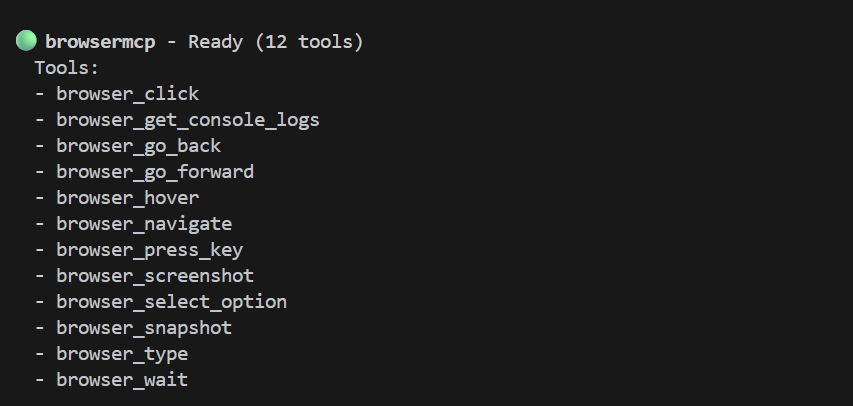
Jetzt kommt der magische Teil. Starten wir zuerst die Gemini CLI (mit gemini) in einer neuen Terminalsitzung. Die Demoanwendung wird in der ursprünglichen Terminalsitzung ausgeführt. Führen Sie in der Gemini CLI /mcp aus, um zu prüfen, ob sie richtig installiert ist. Sie sollten eine Liste mit Tools sehen, die in etwa so aussieht:
Wenn Sie die Demoanwendung noch nicht gestartet haben, starten Sie sie jetzt:
make dev
Wir müssen die App in unserem Chrome-Browser öffnen und die BrowserMCP-Erweiterung auf diesem Tab verbinden. Folgen Sie dem Link aus dem run-Befehl. Klicken Sie dann auf das Symbol der BrowserMCP-Erweiterung und auf „Verbinden“.
Jetzt können wir die Gemini CLI verwenden, um einen Test auszuführen. Kopieren Sie diesen Prompt und fügen Sie ihn in die Gemini CLI ein:
Using BrowserMCP, connect to the application at http://localhost:5173. If the application is not showing a login screen, first logout. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Die Gemini CLI prüft möglicherweise zuerst, ob die Demoanwendung auf dem angegebenen Port ausgeführt wird. Anschließend werden Sie aufgefordert, die geplanten Tool-Aktionen zu bestätigen:
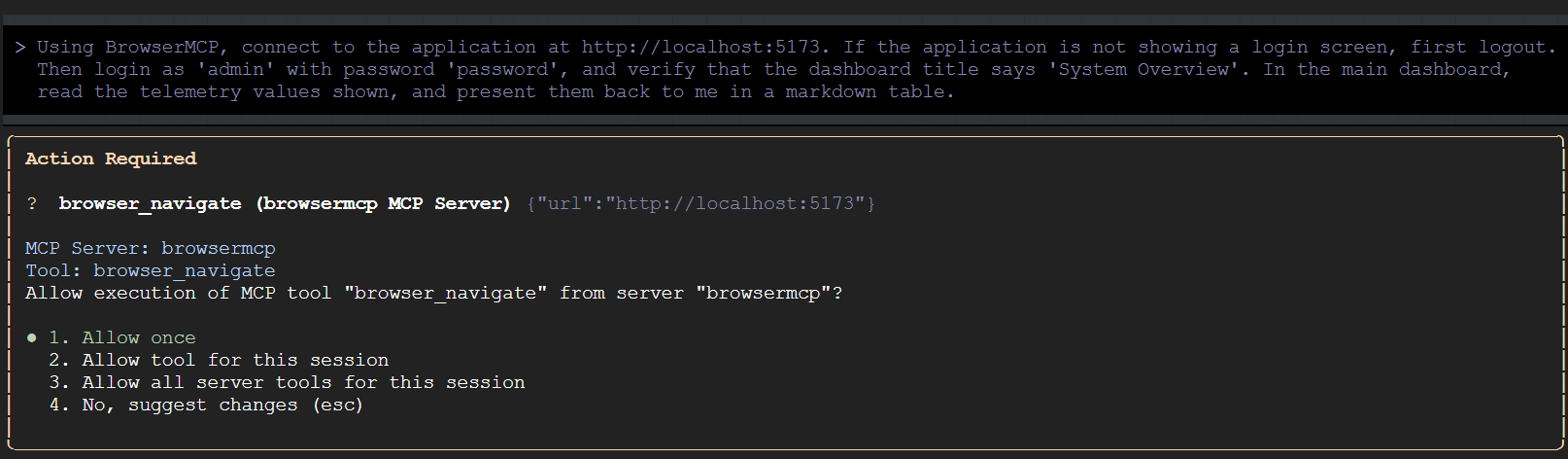
Gemini CLI erlauben, alle BrowserMCP-Tools für diese Sitzung auszuführen. Kehren Sie dann zum Browser zurück und sehen Sie sich die automatisierten Interaktionen an.
Einige Hinweise zum obigen Prompt:
- Zuerst weisen wir den Agent an, sich abzumelden, wenn die Anwendung bereits angemeldet ist. Wir müssen dem Agenten nicht sagen, dass er auf bestimmten Text wie „Exit Gateway“ klicken soll. Die KI ist intelligent genug, um zu wissen, was angeklickt werden muss.
- Nachdem sich der Agent angemeldet und die Hauptseite gerendert hat, erfasst er die Telemetrieinformationen. Auch hier müssen wir dem Agent nicht sagen, dass er in bestimmten Kacheln suchen oder bestimmte Wörter abgleichen soll. Wenn wir die auf dieser Seite angezeigten Informationen später erweitern oder ändern, funktioniert dieser Prompt weiterhin und die Ausgabe wird weiterhin in unserer Markdown-Tabelle erfasst.
Cool, oder?
Wir sind mit BrowserMCP fertig. Trennen Sie die Verbindung in Ihrem Browser.
7. Automatisierung mit Skills und Playwright
Einschränkungen von BrowserMCP
BrowserMCP ist zwar ein tolles Tool, hat aber einige Einschränkungen. Beispiel:
- Dazu ist eine vorhandene Browsersitzung erforderlich, in der die BrowserMCP-Erweiterung verbunden ist. Es werden keine neuen Sitzungen gestartet.
- Nicht-Chromium-Browser werden nicht unterstützt.
- Dazu muss ein separater Browserprozess auf demselben Computer ausgeführt werden, auf dem auch der MCP-Server ausgeführt wird.
- Es kann nicht mit dem lokalen Dateisystem arbeiten. Es kann beispielsweise keine lokalen Dateien für Screenshots erstellen oder Dateien aus der Webanwendung herunterladen und speichern, z. B. herunterladbare PDFs.
- Sie ist nicht deterministisch. Es wird versucht, die von Ihnen angegebenen Aktionen auszuführen. Der lokale Status, z. B. ein unerwartetes Pop-up, kann die Interaktion jedoch unterbrechen.
- „Headless“-Betrieb wird nicht unterstützt. Das bedeutet, dass die Ausführung in einer CI/CD-Pipeline ohne echtes Browserfenster nicht möglich ist.
Playwright
Playwright ist ein viel komplexeres Tool. Es ist ein etabliertes Open-Source-Framework für die Browserautomatisierung und ‑tests. Es kann vieles, was BrowserMCP nicht kann, einschließlich aller oben genannten Punkte.
Es eignet sich viel besser für die Ausführung komplexer, zuverlässiger und wiederholbarer Testszenarien. Sie eignet sich besonders gut für die Arbeit mit lang andauernden Sitzungen oder für die parallele Ausführung mehrerer unabhängiger Sitzungen.
Diese zusätzliche Funktion ist jedoch mit einer viel steileren Lernkurve verbunden.
Kompetenzen
Glücklicherweise müssen wir nicht direkt lernen, wie man Playwright verwendet. Stattdessen können wir eine Agenten-Skill verwenden.

Was genau ist also eine Agent-Kompetenz? Stellen Sie sich das als ein eng gepacktes Bündel von Fachwissen vor, das Sie Ihrem KI‑Agenten übergeben können, wenn er etwas Bestimmtes tun soll. Sie enthält Anleitungen, Best Practices und manchmal sogar Hilfsskripts, die auf eine bestimmte Aufgabe zugeschnitten sind.
Das wirklich Clevere daran ist die progressive Offenlegung. Anstatt jede erdenkliche API-Dokumentation und jede Regel für das Testframework in den ursprünglichen Systemprompt des LLM zu packen – was das Kontextfenster beansprucht und Token verschwendet – liest der Agent den Skill nur, wenn er ihn tatsächlich benötigt. So bleibt der Kontext der Baseline schlank und die detaillierte Anleitung wird erst bei Bedarf abgerufen. Ja, ein Skill kann durchaus Anweisungen enthalten, wie bestimmte MCP-Server genutzt werden können, um die Aufgabe zu erledigen.
Stellen Sie sich das wie in der Szene aus dem Film „Matrix“ vor: Der Agent sieht sich ein Problem an, stellt fest, dass er Playwright kennen muss, lädt die Skill herunter und plötzlich: „Ich kann Kung-Fu.“ Zack! Sofort zum Experten werden
Weitere Informationen zu Skills:
- Tutorial : Erste Schritte mit Google Antigravity-Skills
- Codelab: Skill-Authoring für Google Antigravity
Warum sind Skills perfekt für Playwright?
Hier ist es eine gute Idee, einen Skill zu verwenden. Playwright ist ein sehr leistungsstarkes Tool, aber die Syntax kann schwierig sein. Wenn wir dem Agenten eine Playwright-Fähigkeit geben, müssen wir uns keine Sorgen machen, dass das LLM veraltete Syntax halluziniert oder instabile Selektoren schreibt. Wir stellen ein kuratiertes, maßgebliches Playbook zur Verfügung, in dem genau beschrieben wird, wie Playwright richtig verwendet wird.
Ich werde die Playwright-CLI und den zugehörigen Skill verwenden.
Bei diesem Ansatz installieren wir die Playwright CLI lokal und geben unserem Agenten dann das Wissen, das er für die Verwendung benötigt. Zur Vermeidung von Missverständnissen: Ich installiere keinen Playwright-MCP-Server.
Installation läuft
Installieren wir zuerst die Open-Source-Befehlszeile von Microsoft Playwright. Beenden Sie die Gemini CLI mit dem Befehl /quit``. Führen Sie dann in Ihrem Terminal folgende Schritte aus:
# Pre-req: nodejs installed npm install -g @playwright/cli@latest # Install Playwright CLI globally npm install @playwright/test # Install Playwright test framework npx playwright install-deps # Install dependencies npx playwright install chromium chrome # Install browser binaries in Linux / WSL
Jetzt fügen wir die Kompetenz hinzu. Mit diesem Befehl wird der Unterordner für den Skill direkt von GitHub in unseren Gemini-Skills-Ordner heruntergeladen:
mkdir -p ~/.gemini/skills npx degit microsoft/playwright-cli/skills/playwright-cli ~/.gemini/skills/playwright-cli
Jetzt können wir es testen.
# Launch Playwright CLI with visible browser playwright-cli open https://playwright.dev --headed
Dadurch sollte eine Browsersitzung mit der angegebenen URL geöffnet werden.
Ich möchte auch, dass Gemini Playwright im „headed“-Modus verwenden kann, also mit einer sichtbaren Benutzeroberfläche. Der Skill sagt Gemini aber nicht, wie das geht. Ich habe diese Zeilen also in ~/.gemini/skills/playwright-cli/SKILL.md im Abschnitt Core hinzugefügt:
# Add the following under the "playwright-cli open" command # Run in headed mode so we can see the browser playwright-cli open https://playwright.dev --headed
Mit Playwright testen
Wie zuvor müssen wir die Anwendung starten, falls sie noch nicht ausgeführt wird. Führen Sie die folgenden Schritte in der ursprünglichen Terminalsitzung aus:
make dev
Deaktivieren wir dann in der anderen Terminalsitzung BrowserMCP vorübergehend, damit der Agent nicht verwirrt ist, welche Tools er verwenden soll. Starten Sie die Gemini CLI neu und führen Sie dann Folgendes aus:
/mcp disable browsermcp
Jetzt bitten wir Gemini, mit Playwright zu unserer Anwendung zu navigieren. Anders als bei BrowserMCP müssen wir den Browser jedoch nicht zuerst starten. Playwright übernimmt das für uns mit einem lokalen Prozess.
Geben Sie diesen Prompt in die Gemini CLI ein:
Using Playwright, connect to the application at http://localhost:5173. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Wie immer fragt die Gemini CLI um Erlaubnis, bevor sie Tools ausführt.
Was ist hier anders?
- Wir mussten den Browser nicht erst starten.
- Wir mussten keine Browsererweiterung starten und verbinden.
- Wir müssen dem Agent nicht zuerst sagen, dass er sich abmelden soll. Der Test wird in einer „sauberen“ Sitzung instanziiert.
- Wir können Screenshots erstellen und als lokale Dateien speichern.
Kurz darauf sollte im Ordner output eine Datei mit dem Namen dashboard.png angezeigt werden.
Die Tool-Aufrufe werden in der Gemini CLI ausgeführt, die Browser-Benutzeroberfläche wird jedoch nicht angezeigt. Das liegt daran, dass Playwright standardmäßig im „Headless-Modus“ ausgeführt wird.
Wenn Sie den Vorgang mit diesem geänderten Prompt noch einmal ausführen, sehen Sie auch die Benutzeroberfläche:
Using Playwright, connect to the application at http://localhost:5173 in **headed** mode, and keep the browser open when you're done. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown and record them. Then wait 3 seconds, read them again. Now present the data back to me in a markdown table.
Die Gemini CLI-Ausgabe sollte in Kürze in etwa so aussehen:
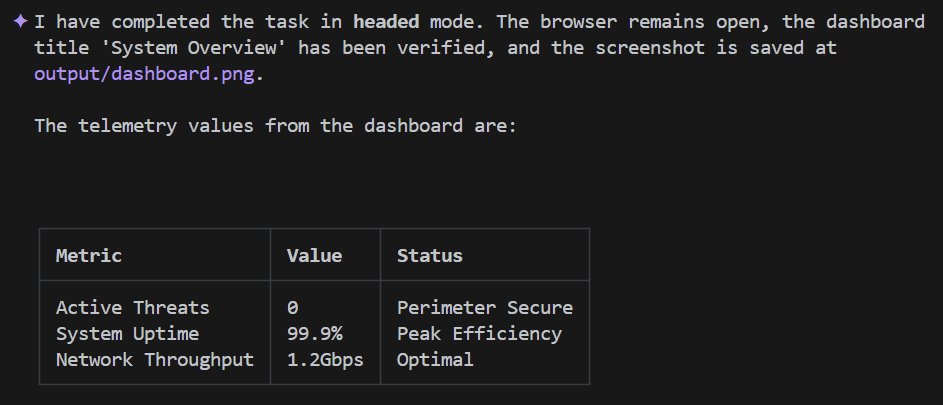
Wie toll war das denn?
8. Aber es gibt auch das MCP der Chrome-Entwicklertools!
Die Chrome-Entwicklertools sind eine Reihe von Webentwicklertools, die in den Chrome-Browser integriert sind und für die Webentwicklung und das Debugging vorgesehen sind. Es gibt sie schon lange. Sie wissen schon – die Konsole, mit der Sie interagieren können, wenn Sie in Chrome „Weitere Tools“ > „Entwicklertools“ öffnen.
Jetzt hat sie aber einen eigenen MCP-Server, den es letztes Jahr noch nicht gab, als wir die Browserautomatisierung über die Gemini CLI in Betracht gezogen haben. Jetzt können Sie jedoch alles, was Sie mit BrowserMCP tun können, und die meisten Dinge, die Sie mit Playwright tun können, ohne etwas in Ihrem Browser oder eine lokale CLI zu installieren.
Probieren wir es aus!
Derzeit haben wir nur die Funktion in Google Cloud Shell validiert. Für diesen Teil verwenden wir Google Cloud Shell in der Google Cloud Console.
Öffnen Sie die Console und eine Cloud Shell-Sitzung. Sie haben folgende Möglichkeiten:
# Clone the sample app - like we did before git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing # Build the application - like we did before make install # Install the Chrome DevTools MCP server Gemini CLI Extension gemini extensions install https://github.com/ChromeDevTools/chrome-devtools-mcp
Jetzt müssen wir eine ausführbare Chrome-Datei in Cloud Shell installieren:
# Get the latest executable for Ubuntu wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb # Install it sudo apt install ./google-chrome-stable_current_amd64.deb -y # Check it and get the executable path which google-chrome # Cleanup rm google-chrome-stable_current_amd64.deb
Ein letzter Schritt: Wir müssen dem Chrome-Entwicklertools-MCP-Server mitteilen, wo sich die ausführbare Chrome-Datei befindet. Dazu müssen wir die Option executable-path in der MCP-Serverkonfiguration auf headless setzen. Dazu bearbeiten wir die Datei ~/.gemini/extensions/chrome-devtools-mcp/gemini-extension.json:
{
"name": "chrome-devtools-mcp",
"version": "latest",
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest",
"--executable-path=/usr/bin/google-chrome",
"--headless"
]
}
}
}
Sehr gut! Wir sollten jetzt bereit sein. Starten Sie gemini über die Cloud Shell und prüfen Sie mit dem Befehl /mcp list wie zuvor, ob der MCP-Server ausgeführt wird.
Jetzt können wir den Prompt testen.
Lass uns das ein bisschen anders machen. Dieses Mal weisen wir Gemini CLI an, die Demoanwendung zu starten und eine Verbindung zu ihr herzustellen:
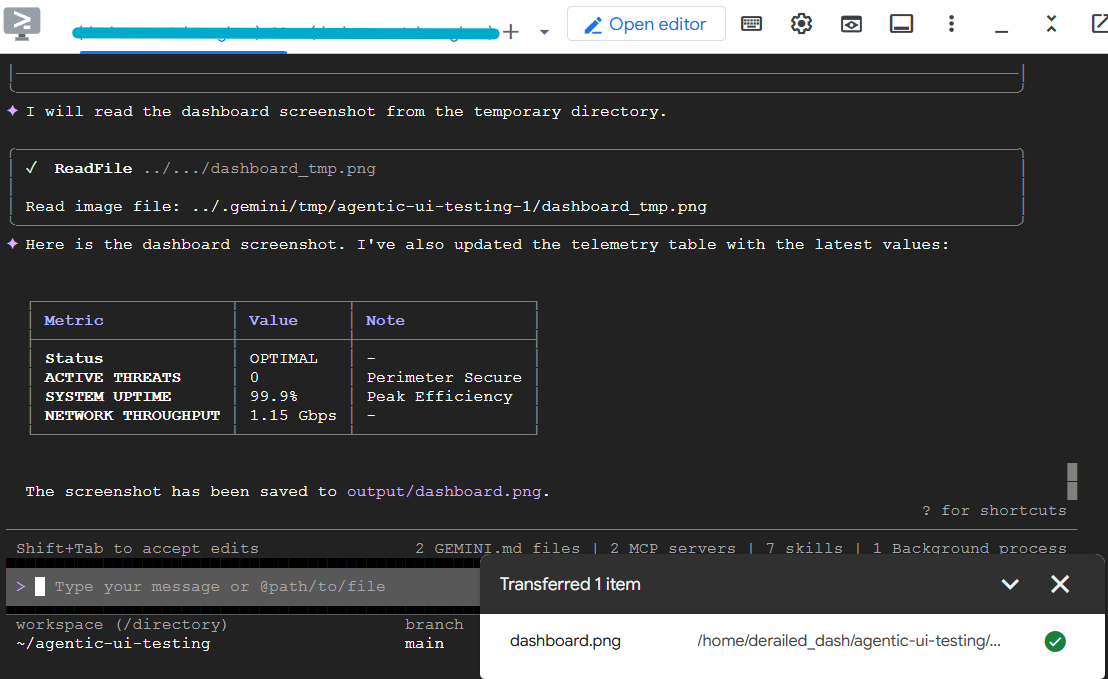
Launch my demo application with `make dev`. Then, using Chrome DevTools MCP, connect to the application at the exposed localhost URL. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Wie gewohnt werden Sie aufgefordert, die Ausführung des MCP-Servers zuzulassen. Sie werden aber auch feststellen, dass versucht wird, einen Skill zu aktivieren. Genau: Diese Erweiterung enthält sowohl den MCP-Server als auch eine Skill, die den Agenten anleitet, wie er den MCP-Server am besten verwendet. Sehr gut!
Einige Sekunden später sollte Gemini CLI die Ergebnisse in der Tabelle präsentieren und den Screenshot gespeichert haben. Sie können den Screenshot in Cloud Shell herunterladen, um zu prüfen, ob er in Ordnung ist.
9. Das ist mit Antigravity sofort möglich.
Google Antigravity enthält den Browser-Unteragenten, der ähnliche Funktionen wie die Playwright-CLI bietet. Wenn Sie Gemini in Antigravity bitten, eine URL interaktiv zu erstellen, wird dieser Subagent automatisch erstellt.
Dieser Unteragent nimmt Ihr übergeordnetes Ziel (z.B. „Prüfen, ob das Anmeldeformular funktioniert“), analysiert das Seitenlayout visuell anhand von Screenshots und des DOM und ermittelt die Klicks und Tasteneingaben selbst. Es handelt sich im Grunde um eine visuelle, multimodale KI, die das Web wie ein Mensch durchsucht. Und das Beste: Es nimmt automatisch Videos auf und macht Screenshots von allem, was es tut, und speichert sie direkt in Ihrem lokalen Arbeitsbereich als visuellen Beweis für das, was es erreicht hat. Antigravity bezeichnet diese visuellen Beweise als Artefakte.
Hinweis für WSL-Nutzer: Es ist etwas schwierig, den Browser-Agent in Antigravity zum Laufen zu bringen. Ich habe es geschafft, es zum Laufen zu bringen, aber ich finde den untergeordneten Agenten in dieser Umgebung inkonsistent und unzuverlässig. Das ist einer der Gründe, warum ich die Playwright-Befehlszeile so mag.
10. Weitere Anwendungsfälle für die Browserautomatisierung
Bei der Browserautomatisierung geht es nicht nur darum, sicherzustellen, dass die Anmeldeschaltfläche vor einer Bereitstellung am Freitagnachmittag funktioniert. Sobald Sie feststellen, dass Sie ein LLM direkt mit einem Browser verbinden können, eröffnet sich eine ganz neue Welt von selbst entwickelten, agentenbasierten Projekten.
Wenn Sie eigene KI-Agenten entwickeln, können Sie Tools wie BrowserMCP oder die Playwright-CLI auf folgende Weise nutzen, um die Hauptarbeit zu erledigen:
- Der persönliche Recherche-Assistent: Stellen Sie sich vor, Sie weisen Ihren Agenten auf eine bestimmte URL hin und bitten ihn, ein Thema zu recherchieren. Für die Website ist jedoch eine Anmeldung erforderlich und es müssen komplexe Menüs durchlaufen werden. Anstatt einen benutzerdefinierten Web-Scraper zu schreiben, der nächste Woche nicht mehr funktioniert, weisen Sie Ihren KI-Agenten einfach an, sich anzumelden, zu den Daten zu navigieren und sie für Sie zusammenzufassen.
- Der „Drehstuhl“-Integrator: Wir alle haben diese alten Intranetsysteme, die keine APIs haben. Sie kennen das sicher: Sie müssen Daten manuell aus System A kopieren und in ein Formular in System B einfügen. Ein Agent mit Browserautomatisierung kann als universeller Klebstoff fungieren, indem er den Bildschirm des alten Systems liest und das Formular im neuen System ausfüllt.
- Automatisierte Priorisierung und Fehlerbehebung: Sie haben um 3 Uhr morgens eine P1-Benachrichtigung von Ihrem Überwachungssystem erhalten? Ihr Agent kann automatisch die spezifische Dashboard-URL öffnen, die Grafiken oder Logs lesen (mithilfe seiner multimodalen Vision-Funktionen) und eine Zusammenfassung direkt in Ihrem Slack-Channel posten. So sparen Sie wertvolle Zeit während eines Vorfalls.
Der Vorteil dieses Ansatzes ist, dass Sie nicht mehr durch die verfügbaren APIs eingeschränkt sind. Wenn ein Mensch es in einem Browser tun kann, kann es auch Ihr Agent.
11. Fazit
Glückwunsch! Sie haben gerade automatisierte, robuste UI-Tests erstellt und ausgeführt, indem Sie einem KI-Agenten in natürlicher Sprache mitgeteilt haben, was er tun soll. Keine anfälligen CSS-Selektoren, keine komplexen Einrichtungs-Scripts.
Sie haben Folgendes gelernt:
- UI-Tests müssen nicht mühsam sein: Wenn wir uns auf die Absicht des Tests und nicht auf die fragile DOM-Implementierung konzentrieren, können wir den Wartungsaufwand erheblich reduzieren.
- Das Model Context Protocol (MCP) bietet Ihren Agenten universellen Plug-and-Play-Zugriff auf Tools, Daten und Umgebungen.
- BrowserMCP ist ein hervorragendes Tool, um Agent-Funktionen in Ihre lokalen, bestehenden Chrome-Sitzungen zu integrieren.
- Mit Skills und der Playwright-CLI können Sie wiederholbare, deterministische Automatisierungstests auf einem neuen Niveau durchführen – alles basierend auf Progressive Disclosure.
- Der Browser-Subagent von Antigravity geht noch einen Schritt weiter und bietet von Anfang an autonome, multimodale Navigation und Artefaktaufzeichnung.
Jetzt können Sie loslegen und die langweiligen Aufgaben automatisieren.
Useful Links
Wenn Sie sich genauer mit den Tools und Konzepten befassen möchten, die wir heute behandelt haben, finden Sie hier weitere Informationen:
Repo-Code
- GitHub-Repository für Agentic UI Testing – Bitte geben Sie dem Repository einen Stern, wenn Sie dieses Codelab hilfreich fanden.
Core-Tools und ‑Frameworks
- BrowserMCP GitHub-Repository
- BrowserMCP-Dokumentation
- BrowserMCP Gemini CLI-Erweiterung: Wenn Sie dieses Codelab hilfreich fanden, geben Sie dem Repository bitte einen Stern.
- Playwright
- Google AI Studio
- Chrome-Entwicklertools
- Chrome-Entwicklertools – MCP
Agentische Konzepte und Fähigkeiten
- Tutorial: Erste Schritte mit Google Antigravity-Skills
- Codelab: Erste Schritte mit Antigravity-Skills
- Originalblog von Dazbo: Creating an Automated UI Test in Seconds
Sonstiges