
1. Introduction
Tester des applications Web peut être une corvée. Les tests d'UI traditionnels s'apparentent souvent à une lutte constante contre la fragilité. Vous vous retrouvez à écrire des scripts complexes, à gérer des sélecteurs CSS et XPath fragiles, et à faire des pieds et des mains juste pour vérifier un simple parcours utilisateur.
Et si vous pouviez simplement dire à un agent ce qu'il doit tester en langage naturel, et qu'il le fasse tout simplement ?

Dans cet atelier de programmation, nous allons découvrir comment utiliser Gemini CLI et des outils multimodaux comme BrowserMCP. Vous découvrirez comment créer et exécuter des tests d'UI automatisés à l'aide du langage naturel. Notez que cet atelier de programmation ne nécessite aucune connaissance préalable des frameworks et outils de test d'UI.
Au programme
- Qu'est-ce que le protocole MCP (Model Context Protocol) et pourquoi est-il révolutionnaire ?
- Comment BrowserMCP permet aux agents d'IA de contrôler les navigateurs Web.
- Exécuter des tests d'UI automatisés à partir de Gemini CLI
- Comprendre les compétences des agents et leurs avantages.
- Apprendre à un agent à utiliser Playwright avec une compétence.
- Utiliser ensemble le MCP et la compétence des Outils pour les développeurs Google Chrome.
- Aperçu rapide du sous-agent Antigravity Browser.
- Autres cas d'utilisation du contrôle du navigateur.
Objectifs de l'atelier
- Configurez votre environnement de développement.
- Explorez une application de démonstration qui doit être testée.
- Utilisez Gemini CLI pour interagir avec l'application via BrowserMCP.
- Apprenez à votre agent à utiliser Playwright avec une compétence d'agent.
2. Prérequis
Avant de passer aux choses intéressantes, assurez-vous d'avoir tout ce dont vous avez besoin.
Cet atelier de programmation utilise Gemini CLI, des outils MCP, des compétences d'agent et une application de démonstration React.
Outils
Dans cet atelier, nous partons du principe que vous disposez déjà des éléments suivants :
- Navigateur Chrome
- Nodejs
- Gemini CLI
- Git
Pour utiliser Gemini CLI, vous devez vous authentifier auprès de Google. Vous pouvez le faire de plusieurs façons, mais nous vous recommandons d'utiliser simplement l'option Se connecter avec Google. Cette option est associée à un quota sans frais généreux d'utilisation de Gemini et ne nécessite pas de projet Google Cloud. Si vous utilisez cette option en suivant l'atelier de programmation, vous n'aurez aucun frais à payer. (Si vous disposez déjà d'une clé API Gemini, vous pouvez l'utiliser à la place.)
Les instructions supposent que vous travaillez dans un environnement Linux (ou WSL) ou macOS. Si vous utilisez Windows (comme moi), vous pouvez suivre le tutoriel à l'aide de WSL.
(Notez que
BrowserMCP ne fonctionnera pas depuis Google Cloud Shell.
, car il ne se connectera qu'à un navigateur local exécuté sur la même machine.)
Configurer l'environnement de développement
J'ai créé un dépôt de démonstration sur GitHub. Il inclut un exemple d'application que nous pouvons utiliser pour nos tests d'interface utilisateur. Clonez-le en exécutant cette commande depuis votre terminal local :
git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing
Un fichier Makefile vous permet de configurer facilement l'environnement pour lancer l'application de démonstration. Exécutons-le pour initialiser notre environnement :
make install # Or if you don't have make npm install --prefix demo-app
3. Notre application de démonstration
L'application que nous testons aujourd'hui est The Dazbo Omni-Dash, un tableau de bord futuriste à thème sombre permettant de gérer la télémétrie de sécurité. (Oui, il a été codé avec des vibrations !)
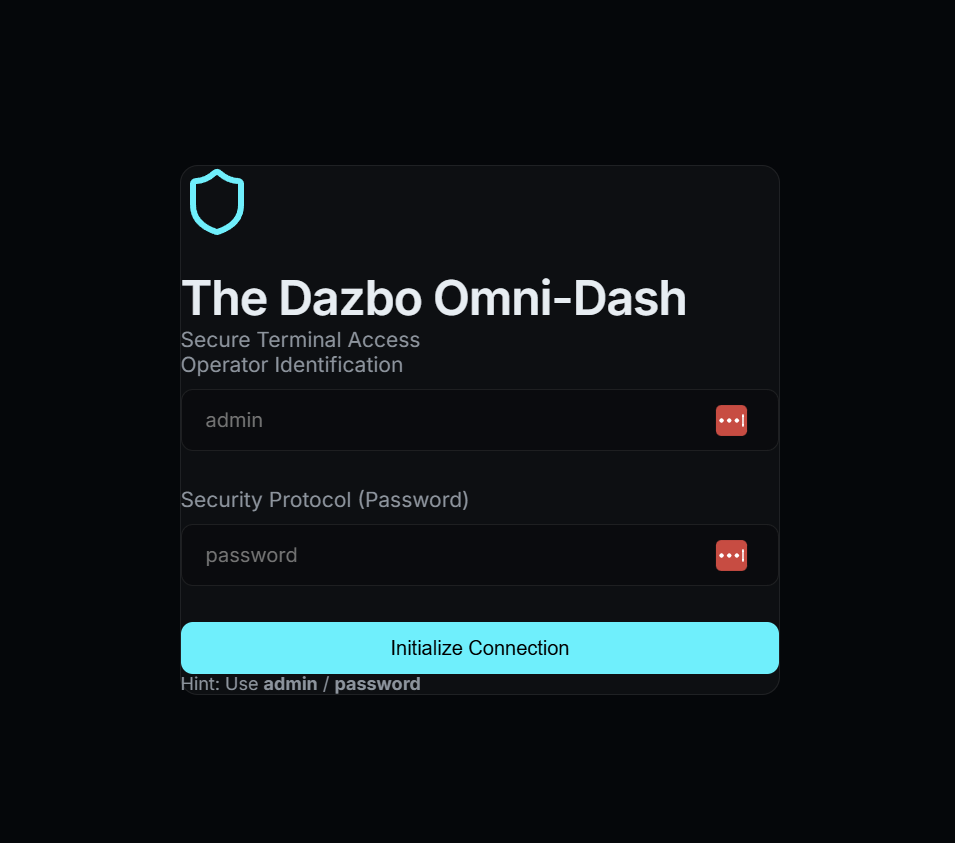
Pourquoi cette application ?
Il est conçu pour fournir une surface de test réaliste avec :
- Authentification fictive : flux de connexion nécessitant des identifiants spécifiques.
- Contenu dynamique : fiches de télémétrie et journaux de sécurité qui simulent des données en temps réel.
- États interactifs : menus de navigation et saisies de formulaire qui changent en fonction de l'action de l'utilisateur.
- Technologie moderne : conçu avec React et Vite pour une expérience rapide et réactive.
Lancer l'application
Pour démarrer l'application, exécutez simplement la commande suivante :
make dev # Or if you don't have make npm run dev --prefix demo-app
Le serveur de développement devrait démarrer très rapidement, et l'application sera disponible à l'adresse http://localhost:5173.

Il nous suffit de cliquer sur le lien pour ouvrir l'application dans notre navigateur. Laissez simplement ce processus s'exécuter dans votre terminal. Nous exécuterons les commandes de terminal suivantes dans une session de terminal distincte.
4. Le défi des tests d'UI
Il est notoire que les tests d'UI traditionnels sont difficiles à mettre en place et encore plus à maintenir. Voici quelques difficultés courantes :
- Test d'irrégularité : tests qui réussissent une minute et échouent la suivante en raison de problèmes de timing, de conditions de concurrence ou d'éléments à chargement lent.
- Sélecteurs fragiles : ils s'appuient sur des structures DOM spécifiques (comme div > div > button) qui se cassent au moindre ajustement de l'UI, ce qui entraîne une maintenance constante des scripts.
- Courbe d'apprentissage élevée : les développeurs doivent maîtriser des langages spécifiques à un domaine et des particularités spécifiques à un framework (Cypress, Selenium, Playwright) juste pour automatiser un clic de base.
- Parité de l'environnement : difficulté à reproduire les états d'application et surcharge liée au nettoyage des données de test.

Nous avons besoin d'une méthode de test axée sur l'intention plutôt que sur l'implémentation.
5. MCP à la rescousse
Le Model Context Protocol (MCP) est une norme ouverte qui permet aux modèles et agents d'IA d'interagir avec des outils, des API et des données externes. Considérez-le comme un adaptateur universel qui permet aux modèles et aux agents de trouver et d'exécuter les outils auxquels ils ont accès.
Traditionnellement, l'intégration de grands modèles de langage (LLM) avec des données et des outils externes nécessitait que les développeurs écrivent des connexions d'API personnalisées et codées en dur pour chaque nouvelle source de données. Cela créait un problème d'intégration "M x N" insoutenable, où chaque nouveau modèle et outil multipliait la charge de maintenance. Le protocole MCP (Model Context Protocol) résout ce problème en supprimant la nécessité d'écrire du code spécifique pour orchestrer ces fonctionnalités. Au lieu de coder explicitement des workflows d'exécution complexes, les développeurs peuvent s'appuyer sur le LLM pour interpréter les requêtes en langage naturel d'un utilisateur et déterminer de manière dynamique les outils à utiliser à la volée.
Lorsqu'un utilisateur émet une commande en langage naturel (par exemple, "Accède à localhost:5173, connecte-toi en tant qu'administrateur et clique sur le bouton "Envoyer""), le LLM découvre les fonctionnalités disponibles et génère une requête structurée pour appeler un outil spécifique. Le client MCP sert de traducteur, en acheminant cette requête vers le serveur MCP désigné, qui exécute l'action ou récupère les données et renvoie le contexte au modèle. L'IA peut ainsi agir de manière autonome sans que le développeur ait à coder en dur le chemin d'exécution spécifique.
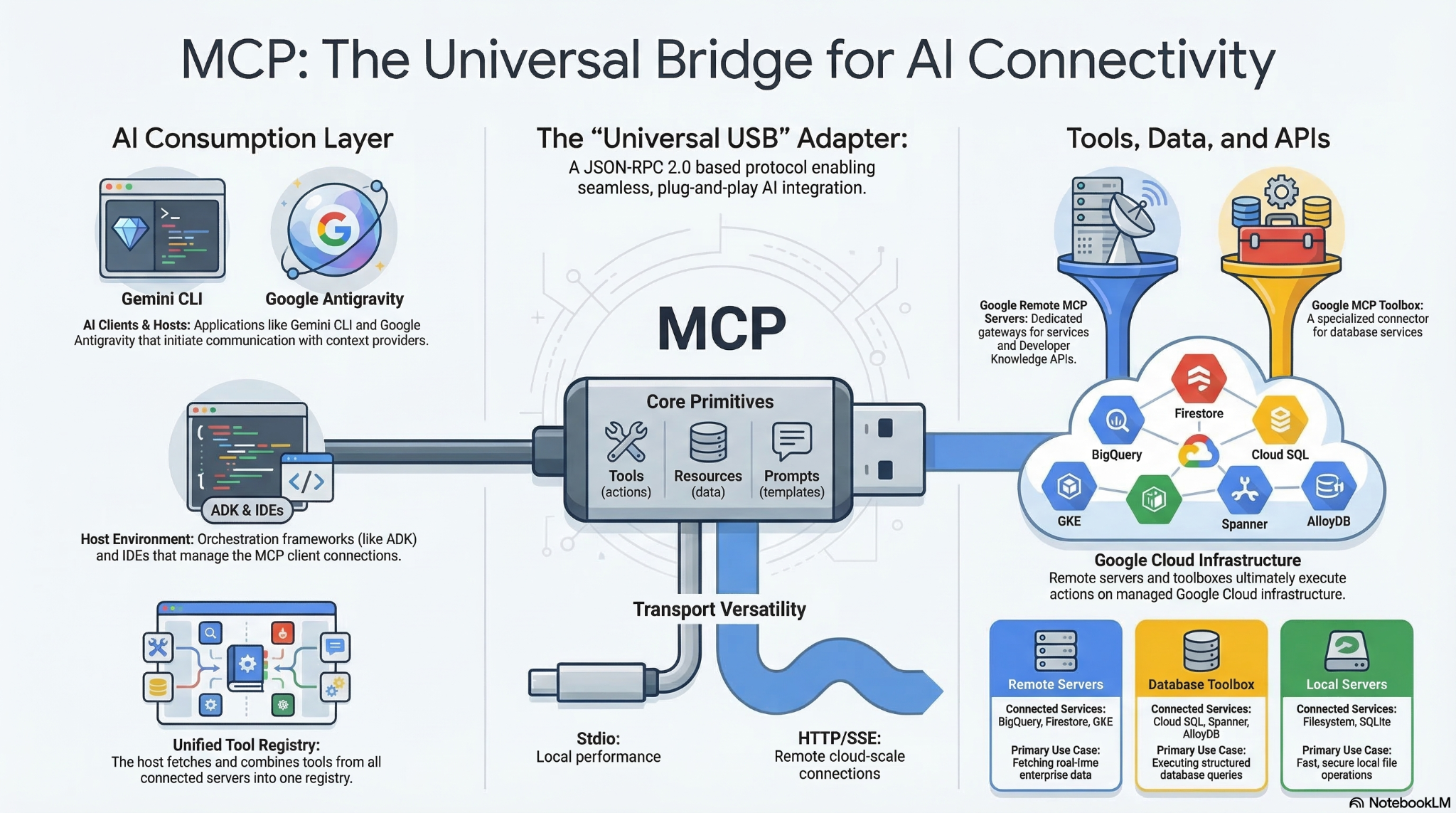
Étant donné que MCP crée une norme universelle (souvent décrite comme l'équivalent de l'USB-C pour les applications d'IA), il permet une réutilisation prête à l'emploi à grande échelle. Les développeurs peuvent créer un serveur MCP une seule fois, et n'importe quel hôte d'IA compatible avec MCP peut s'y connecter instantanément, ce qui élimine le problème d'intégration M x N. Vous n'avez plus besoin de créer des ponts d'API personnalisés pour chaque plate-forme. Vous pouvez plutôt exploiter l'écosystème de serveurs MCP Open Source prédéfinis pour les services courants tels que GitHub, Slack, les bases de données, etc., et les intégrer directement à vos workflows agentiques. Cette architecture modulaire et plug-and-play garantit que votre infrastructure d'intégration de base reste complètement inchangée si vous changez de fournisseur de LLM ou si vous mettez à niveau vos outils ultérieurement.
6. Automatisation avec BrowserMCP
Qu'est-ce que BrowserMCP ?
C'est le premier outil que nous allons utiliser aujourd'hui. BrowserMCP est un serveur MCP qui donne aux agents d'IA les "yeux" et les "mains" dont ils ont besoin pour interagir avec un navigateur Web. En résumé, il imite l'interaction humaine avec un navigateur. Il s'agit d'un projet Open Source. Vous pouvez consulter le dépôt GitHub en cliquant ici. Consultez la documentation principale de BrowserMCP.

Voici quelques-unes de ses fonctionnalités :
- Il peut accéder à des URL.
- Il peut inspecter le DOM.
- Il peut cliquer sur des boutons et saisir du texte dans des formulaires.
- Il peut effectuer des opérations de glisser-déposer.
- Il peut lire les journaux de la console du navigateur.
- C'est rapide : l'automatisation s'effectue localement sur votre ordinateur.
Installer Browser MCP
Pour utiliser BrowserMCP, vous devez effectuer deux opérations :
- Installez l'extension BrowserMCP dans Chrome (ou tout autre navigateur basé sur Chromium).
- Configurez le serveur MCP pour votre agent.
Pour installer l'extension, suivez simplement les instructions ici. Cela ne prend que quelques secondes. Une fois l'extension installée, cliquez sur "Connect" (Connecter) pour autoriser votre agent à contrôler l'onglet actuel. (Évidemment, l'onglet actuel doit être celui où l'application de démonstration est en cours d'exécution.)
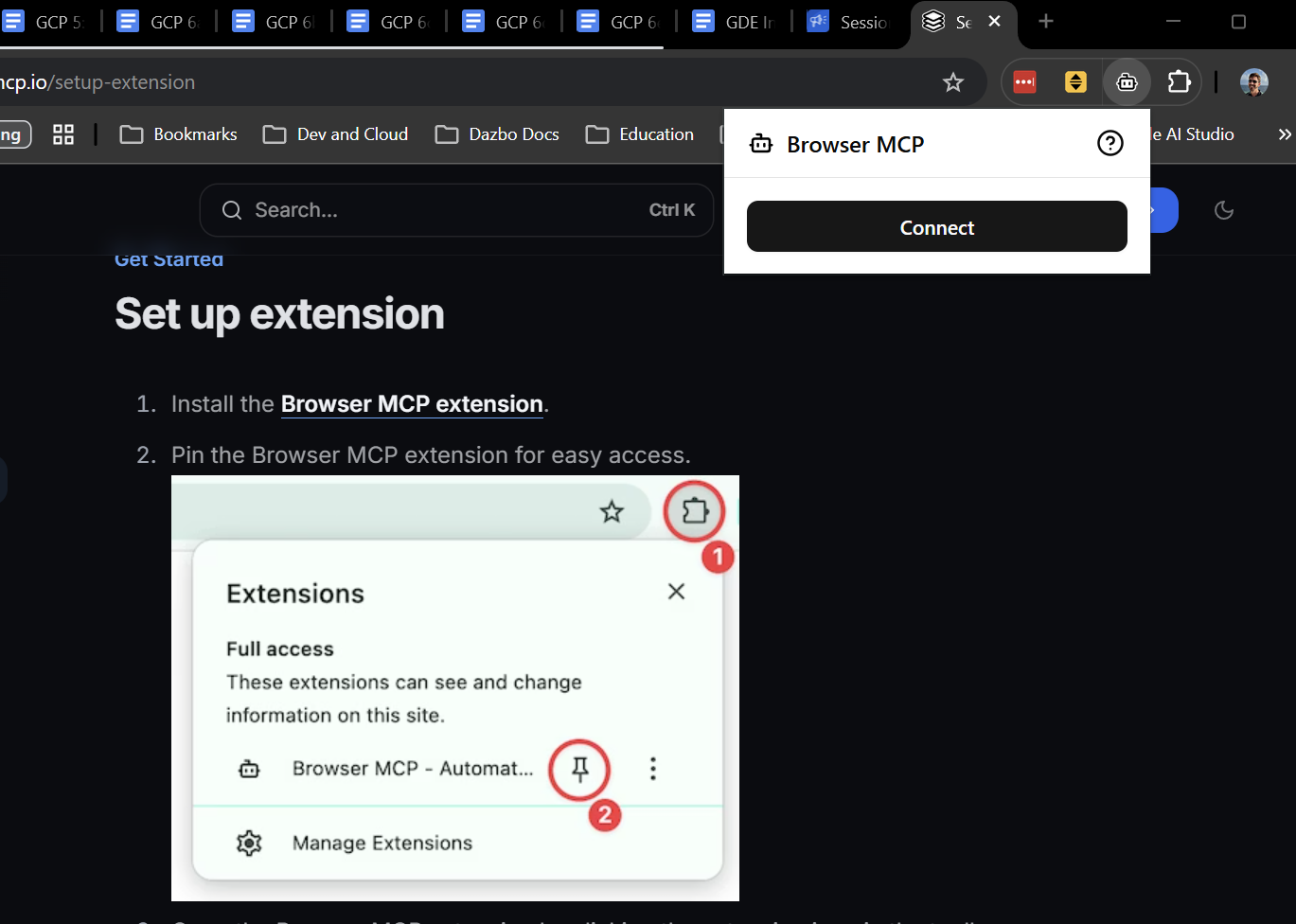
Ensuite, nous devons ajouter le serveur BrowserMCP à votre client. Dans Gemini CLI, c'est très simple. Il vous suffit d'installer l'extension :
gemini extensions install https://github.com/derailed-dash/browsermcp-ext
Tester avec BrowserMCP
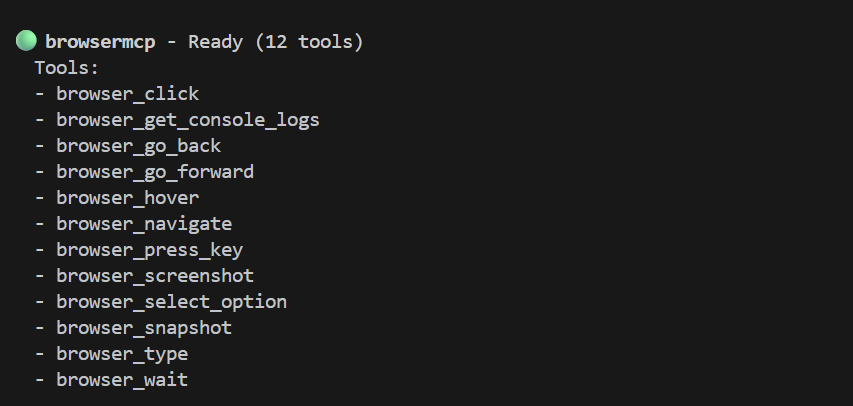
Passons maintenant à la magie. Tout d'abord, lançons Gemini CLI (en exécutant gemini) dans une nouvelle session de terminal. (Rappelons que l'application de démonstration s'exécute dans notre session de terminal initiale.) Dans Gemini CLI, exécutez /mcp pour vérifier que l'outil est correctement installé. Une liste d'outils s'affiche, comme celle-ci :
Si vous n'avez pas démarré l'application de démonstration plus tôt, lancez-la maintenant :
make dev
Nous devons ouvrir l'application dans notre navigateur Chrome et connecter l'extension BrowserMCP dans cet onglet. Suivez le lien de la commande run. Cliquez ensuite sur l'icône de l'extension BrowserMCP, puis sur "Connect" (Connecter).
Nous pouvons maintenant utiliser Gemini CLI pour exécuter un test. Copiez et collez ce prompt dans Gemini CLI :
Using BrowserMCP, connect to the application at http://localhost:5173. If the application is not showing a login screen, first logout. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Gemini CLI peut d'abord vérifier que l'application de démonstration s'exécute sur le port spécifié. Il vous demandera ensuite de confirmer les actions de l'outil qu'il prévoit d'effectuer :
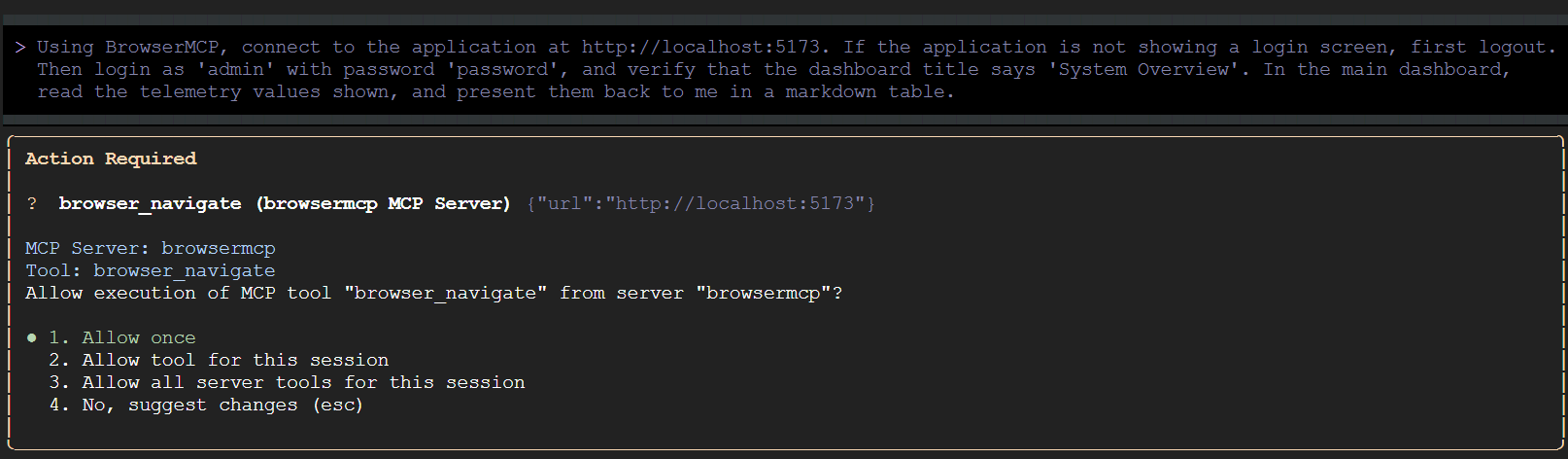
Autorisez Gemini CLI à exécuter tous les outils BrowserMCP pour cette session. Revenez ensuite au navigateur et regardez les interactions automatisées se dérouler.
Voici quelques points à noter concernant la requête ci-dessus :
- Nous commençons par demander à l'agent de se déconnecter si l'application est déjà connectée. Notez que nous n'avons pas besoin de demander à l'agent de cliquer sur un texte spécifique comme "Quitter la passerelle". Il est suffisamment intelligent pour savoir sur quoi cliquer.
- Une fois connecté et la page principale affichée, l'agent capture les informations de télémétrie. Une fois encore, nous n'avons pas besoin de demander à l'agent de rechercher des tuiles spécifiques ou de faire correspondre des mots spécifiques. Par conséquent, si nous devions ultérieurement étendre ou modifier les informations affichées sur cette page, cette requête fonctionnerait toujours et le résultat serait toujours consigné dans notre tableau Markdown.
Pas mal, non ?
Nous en avons terminé avec BrowserMCP pour le moment. Déconnectez-le dans votre navigateur.
7. Automatisation avec Skills et Playwright
Limites de BrowserMCP
BrowserMCP est un excellent outil, mais il présente quelques limites. Exemple :
- Il nécessite une session de navigateur existante, avec l'extension BrowserMCP connectée. (Il ne génère pas de nouvelles sessions.)
- Elle n'est pas compatible avec les navigateurs autres que Chromium.
- Il nécessite l'exécution d'un processus de navigateur distinct sur la même machine que celle sur laquelle le serveur MCP est exécuté.
- Il n'est pas en mesure de fonctionner avec le système de fichiers local. Par exemple, il ne peut pas créer de fichiers locaux pour stocker des captures d'écran ni télécharger et stocker des fichiers depuis l'application Web, comme des PDF téléchargeables.
- Elle est non déterministe. Il tentera d'effectuer les actions que vous lui demandez, mais l'état local, tel qu'un pop-up inattendu, peut interrompre l'interaction.
- Il n'est pas compatible avec le fonctionnement "sans interface graphique", ce qui signifie qu'il ne peut pas s'exécuter dans un pipeline CI/CD sans fenêtre de navigateur réelle.
Playwright
Playwright est un outil beaucoup plus sophistiqué. Il s'agit d'un framework de test et d'automatisation de navigateur Open Source bien établi. Il peut faire beaucoup de choses que BrowserMCP ne peut pas faire, y compris tous les points que j'ai mentionnés ci-dessus.
Il est beaucoup plus adapté à l'exécution de scénarios de test complexes, fiables et reproductibles. Il est particulièrement adapté aux sessions de longue durée ou à l'exécution de plusieurs sessions indépendantes en parallèle.
Mais cette capacité supplémentaire s'accompagne d'une courbe d'apprentissage beaucoup plus abrupte.
Compétences
Heureusement, nous n'avons pas besoin d'apprendre à utiliser Playwright directement. Nous pouvons plutôt utiliser une compétence d'agent.

Qu'est-ce qu'une compétence d'agent ? Considérez-le comme un ensemble d'expertise dans un domaine spécifique que vous pouvez transmettre à votre agent IA lorsqu'il doit effectuer une tâche spécifique. Il contient des instructions, des bonnes pratiques et parfois même des scripts d'aide adaptés à une tâche spécifique.
Voici la partie vraiment astucieuse : la divulgation progressive. Au lieu de bourrer l'invite système initiale du LLM avec toutes les règles de documentation d'API et de framework de test imaginables (ce qui consomme votre fenêtre de contexte et brûle des jetons à tout-va), l'agent ne lit la compétence que lorsqu'il en a réellement besoin. Il maintient le contexte de base simple et efficace, en récupérant les instructions détaillées juste à temps. Et oui, une compétence peut tout à fait inclure des instructions sur la façon d'utiliser des serveurs MCP spécifiques pour accomplir une tâche.
Imaginez la scène dans Matrix : l'agent est confronté à un problème, se rend compte qu'il a besoin de connaître Playwright, télécharge la compétence et, tout à coup, "il sait le kung-fu". Le micro sur perche. Devenez un expert instantanément.
Pour en savoir plus sur les compétences, consultez les ressources suivantes :
- Tutoriel : Premiers pas avec les skills Google Antigravity
- Atelier de programmation : Créer des compétences pour Google Antigravity
Pourquoi les compétences sont idéales pour Playwright
Utiliser une compétence est un excellent choix. Playwright est un outil extrêmement puissant, mais sa syntaxe peut être délicate. En dotant l'agent d'une compétence Playwright, nous n'avons pas à nous soucier de l'hallucination de syntaxe obsolète ou de l'écriture de sélecteurs fragiles par notre LLM. Nous lui fournissons un playbook organisé et faisant autorité sur la façon d'utiliser correctement Playwright.
Je vais utiliser la CLI Playwright et la compétence associée.
Avec cette approche, nous installons Playwright CLI en local, puis nous fournissons à notre agent les connaissances dont il a besoin pour l'utiliser. Pour éviter toute confusion, je ne vais installer aucun serveur MCP Playwright.
Installation
Commençons par installer la CLI Microsoft Playwright Open Source. Si vous ne l'avez pas déjà fait, quittez Gemini CLI en saisissant /quit``. Ensuite, dans votre terminal :
# Pre-req: nodejs installed npm install -g @playwright/cli@latest # Install Playwright CLI globally npm install @playwright/test # Install Playwright test framework npx playwright install-deps # Install dependencies npx playwright install chromium chrome # Install browser binaries in Linux / WSL
Ajoutons maintenant la compétence. Cette commande téléchargera le sous-dossier de compétence directement depuis GitHub dans notre dossier de compétences Gemini :
mkdir -p ~/.gemini/skills npx degit microsoft/playwright-cli/skills/playwright-cli ~/.gemini/skills/playwright-cli
Nous pouvons maintenant le tester.
# Launch Playwright CLI with visible browser playwright-cli open https://playwright.dev --headed
Une session de navigateur doit s'ouvrir sur l'URL spécifiée.
Je souhaite également que Gemini puisse utiliser Playwright en mode "headed", c'est-à-dire avec une interface utilisateur visible. Mais la compétence n'indique pas à Gemini comment faire. J'ai donc ajouté ces lignes à ~/.gemini/skills/playwright-cli/SKILL.md dans la section Core :
# Add the following under the "playwright-cli open" command # Run in headed mode so we can see the browser playwright-cli open https://playwright.dev --headed
Tester avec Playwright
Comme précédemment, nous devons lancer l'application (si elle n'est pas déjà en cours d'exécution). Effectuez cette opération à partir de la session de terminal initiale :
make dev
Ensuite, dans l'autre session de terminal, désactivons temporairement BrowserMCP afin que l'agent ne soit pas confus quant aux outils à utiliser. Relancez Gemini CLI, puis exécutez :
/mcp disable browsermcp
Nous allons maintenant demander à Playwright de naviguer vers notre application avec Gemini. Mais contrairement à BrowserMCP, nous n'avons pas besoin de démarrer le navigateur en premier. Playwright le fera pour nous avec un processus local.
Saisissez le prompt suivant dans Gemini CLI :
Using Playwright, connect to the application at http://localhost:5173. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
(Comme toujours, Gemini CLI vous demandera votre autorisation avant d'exécuter des outils.)
Qu'est-ce qui change ?
- Nous n'avons pas eu besoin de démarrer le navigateur en premier.
- Nous n'avons pas eu besoin de démarrer ni de connecter une extension de navigateur.
- Nous n'avons pas besoin de demander à l'agent de se déconnecter d'abord. Le test est instancié à partir d'une session "propre".
- Nous pouvons faire des captures d'écran et les enregistrer en tant que fichiers locaux.
Peu de temps après, un fichier dashboard.png devrait s'afficher dans le dossier output.
Notez que vous verrez les appels d'outils s'exécuter dans Gemini CLI, mais pas l'interface utilisateur du navigateur. En effet, Playwright s'exécute par défaut en "mode sans affichage".
Mais si vous réexécutez la requête avec cette invite modifiée, vous pourrez également voir l'UI :
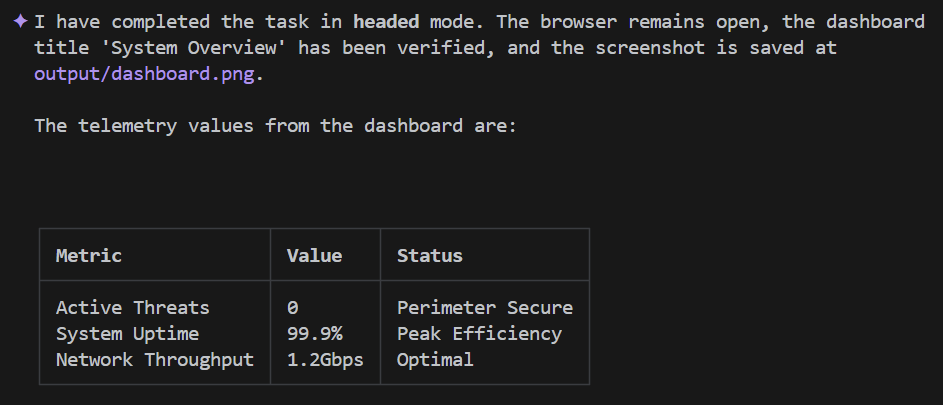
Using Playwright, connect to the application at http://localhost:5173 in **headed** mode, and keep the browser open when you're done. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown and record them. Then wait 3 seconds, read them again. Now present the data back to me in a markdown table.
Le résultat de Gemini CLI devrait ressembler à ceci :
C'était génial, non ?
8. Mais attendez, il y a aussi le MCP des outils pour les développeurs Chrome !
Les outils pour les développeurs Chrome sont un ensemble d'outils pour les développeurs Web intégrés au navigateur Chrome, destinés au développement et au débogage Web. Elle existe depuis longtemps. Vous savez, la console avec laquelle vous pouvez interagir lorsque vous ouvrez Plus d'outils > Outils pour les développeurs dans Chrome.
Mais il dispose désormais de son propre serveur MCP, qui n'existait pas lorsque nous avons envisagé l'automatisation du navigateur à partir de Gemini CLI l'année dernière. Mais désormais, vous pouvez faire tout ce que vous pouvez faire avec BrowserMCP et la plupart des choses que vous pouvez faire avec Playwright, sans rien installer dans votre navigateur ni installer d'interface de ligne de commande locale.
Essayons !
Pour le moment, nous avons vérifié qu'il fonctionnait dans Google Cloud Shell. Pour cette partie, utilisons Google Cloud Shell dans la console Google Cloud.
Ouvrez la console et une session Cloud Shell. Ensuite :
# Clone the sample app - like we did before git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing # Build the application - like we did before make install # Install the Chrome DevTools MCP server Gemini CLI Extension gemini extensions install https://github.com/ChromeDevTools/chrome-devtools-mcp
Nous devons maintenant installer un exécutable Chrome dans Cloud Shell :
# Get the latest executable for Ubuntu wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb # Install it sudo apt install ./google-chrome-stable_current_amd64.deb -y # Check it and get the executable path which google-chrome # Cleanup rm google-chrome-stable_current_amd64.deb
Dernière étape : nous devons indiquer au serveur MCP des outils pour les développeurs Chrome où trouver l'exécutable Chrome. Pour ce faire, définissez l'option executable-path sur headless dans la configuration du serveur MCP. Pour ce faire, modifiez le fichier ~/.gemini/extensions/chrome-devtools-mcp/gemini-extension.json :
{
"name": "chrome-devtools-mcp",
"version": "latest",
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest",
"--executable-path=/usr/bin/google-chrome",
"--headless"
]
}
}
}
Parfait ! Nous devrions être prêts. Lancez gemini depuis Cloud Shell et vérifiez que le serveur MCP est en cours d'exécution à l'aide de la commande /mcp list, comme précédemment.
Enfin, nous sommes prêts à le tester avec un prompt.
Faisons-le un peu différemment. Cette fois, nous allons demander à Gemini CLI de lancer l'application de démonstration et de s'y connecter :
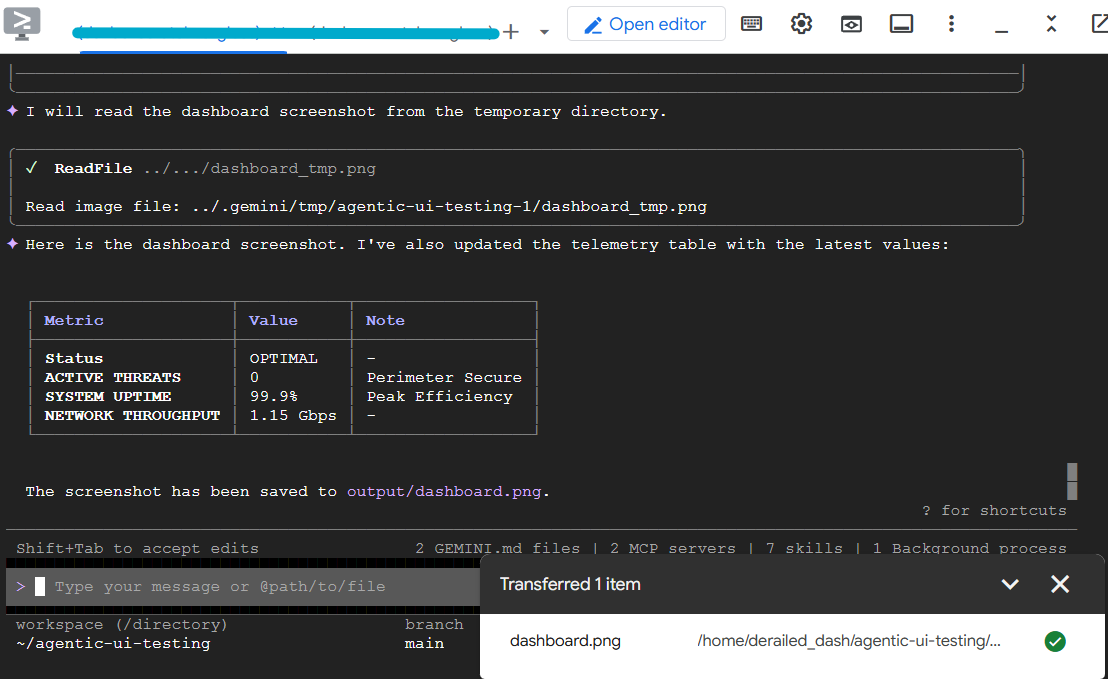
Launch my demo application with `make dev`. Then, using Chrome DevTools MCP, connect to the application at the exposed localhost URL. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Comme d'habitude, vous serez invité à autoriser l'exécution du serveur MCP. Mais vous remarquerez également qu'il essaie d'activer une skill. En effet, cette extension contient à la fois le serveur MCP et une compétence qui guide l'agent sur la meilleure façon d'utiliser le serveur MCP. Bravo !
Quelques secondes plus tard, la Gemini CLI devrait présenter les résultats dans le tableau et avoir enregistré la capture d'écran. Vous pouvez télécharger la capture d'écran depuis Cloud Shell pour vérifier qu'elle est correcte.
9. Vous pouvez le faire dans Antigravity Out of the Box !
Google Antigravity inclut le sous-agent de navigateur, qui offre des fonctionnalités semblables à Playwright CLI. Lorsque vous demandez à Gemini dans Antigravity de générer une URL de manière interactive, ce sous-agent est généré automatiquement.
Ce sous-agent prend votre objectif général (par exemple, "Vérifier si le formulaire de connexion fonctionne"), analyse visuellement la mise en page à l'aide de captures d'écran et du DOM, et détermine lui-même les clics et les frappes au clavier. Il s'agit essentiellement d'une IA multimodale et visuelle qui navigue sur le Web comme le ferait un humain. Cerise sur le gâteau, Il enregistre automatiquement des vidéos et prend des captures d'écran de tout ce qu'il fait, en les enregistrant directement dans votre espace de travail local comme preuve visuelle de ce qu'il a accompli. Antigravity appelle ces preuves visuelles des artefacts.
Remarque pour les utilisateurs de WSL : Faire fonctionner l'agent de navigateur dans Antigravity est un peu compliqué. J'ai réussi à le faire fonctionner, mais je trouve que le sous-agent est incohérent et peu fiable dans cet environnement. C'est l'une des raisons pour lesquelles j'adore Playwright CLI !
10. Autres cas d'utilisation de l'automatisation du navigateur
L'automatisation du navigateur ne consiste pas seulement à s'assurer que votre bouton de connexion fonctionne avant un déploiement le vendredi après-midi. Une fois que vous avez compris que vous pouvez connecter un LLM directement à un navigateur, un tout nouveau monde de projets autonomes et personnalisés s'ouvre à vous.
Si vous créez vos propres agents d'IA, voici quelques façons d'utiliser des outils comme BrowserMCP ou Playwright CLI pour vous faciliter la tâche :
- L'assistant de recherche personnel : imaginez que vous demandiez à votre agent de faire des recherches sur un sujet spécifique à partir d'une URL, mais que le site nécessite de se connecter et de parcourir des menus complexes. Au lieu d'écrire un scraper Web personnalisé qui ne fonctionnera plus la semaine prochaine, il vous suffit de demander à votre agent de se connecter, d'accéder aux données et de les résumer pour vous.
- L'intégrateur "Swivel-Chair" : nous avons tous ces anciens systèmes intranet qui n'ont pas d'API. Vous savez de quoi je parle : vous devez copier manuellement des données du système A et les coller dans un formulaire du système B. Un agent doté de l'automatisation du navigateur peut servir de lien universel, en lisant l'écran de l'ancien système et en remplissant le formulaire dans le nouveau.
- Tri et correction automatisés : vous avez reçu une alerte P1 de votre système de surveillance à 3h du matin ? Votre agent peut ouvrir automatiquement l'URL du tableau de bord spécifique, lire les graphiques ou les journaux (à l'aide de ses capacités de vision multimodale) et publier un récapitulatif directement dans votre canal Slack, ce qui vous fait gagner de précieuses minutes en cas d'incident.
L'avantage de cette approche est que vous n'êtes plus limité par les API disponibles. Si un humain peut le faire dans un navigateur, votre agent le peut aussi.
11. Conclusion
Félicitations ! Vous venez de créer et d'exécuter des tests d'interface utilisateur automatisés et robustes en indiquant simplement à un agent d'IA ce que vous vouliez qu'il fasse en langage courant. Pas de sélecteurs CSS fragiles ni de scripts de configuration complexes.
Vous avez appris à :
- Les tests d'UI ne doivent pas être douloureux : en se concentrant sur l'intention du test plutôt que sur l'implémentation fragile du DOM, nous pouvons réduire considérablement les frais généraux de maintenance.
- Le Model Context Protocol (MCP) offre à vos agents un accès universel et plug-and-play aux outils, aux données et aux environnements.
- BrowserMCP est un outil incroyable qui permet d'intégrer des fonctionnalités d'agent dans vos sessions Chrome locales existantes.
- Les compétences et Playwright CLI offrent un nouveau niveau de tests d'automatisation reproductibles et déterministes, le tout grâce à la divulgation progressive.
- Le sous-agent de navigateur d'Antigravity va encore plus loin en introduisant la navigation autonome et multimodale, ainsi que l'enregistrement d'artefacts prêts à l'emploi.
À vous de jouer ! Automatisez les tâches ennuyeuses.
Useful Links
Si vous souhaitez approfondir les outils et les concepts que nous avons abordés aujourd'hui, consultez les ressources suivantes :
Code du dépôt
- Dépôt GitHub agentic-ui-testing : n'hésitez pas à ajouter une étoile au dépôt si vous avez trouvé cet atelier de programmation utile.
Outils et frameworks principaux
- Dépôt GitHub BrowserMCP
- Documentation BrowserMCP
- Extension BrowserMCP Gemini CLI : n'hésitez pas à ajouter une étoile au dépôt si cet atelier de programmation vous a été utile.
- Playwright
- Google AI Studio
- Outils pour les développeurs Chrome
- Outils pour les développeurs Chrome MCP
Concepts et compétences agentiques
- Tutoriel : Premiers pas avec les skills Google Antigravity
- Atelier de programmation : Premiers pas avec les compétences Antigravity
- Blog d'origine de Dazbo : Créer un test d'interface utilisateur automatisé en quelques secondes
Autre