
1. Introduzione
Testare le applicazioni web può essere un compito noioso. I test tradizionali dell'interfaccia utente spesso sembrano una battaglia costante contro la fragilità. Ti ritrovi a scrivere script complessi, a gestire selettori CSS e XPath fragili e a fare salti mortali solo per verificare un semplice flusso utente.
E se potessi semplicemente dire a un agente cosa testare in linguaggio naturale e lui lo facesse?

In questo codelab, esploreremo come utilizzare Gemini CLI e strumenti multimodali come BrowserMCP. Vedrai come creare ed eseguire test dell'UI automatizzati utilizzando il linguaggio naturale. Tieni presente che questo codelab non richiede alcuna conoscenza preliminare di framework e strumenti di test dell'interfaccia utente.
Obiettivi didattici
- Che cos'è il Model Context Protocol (MCP) e perché è rivoluzionario.
- In che modo BrowserMCP consente agli agenti AI di controllare i browser web.
- Come eseguire test automatici dell'UI da Gemini CLI.
- Comprendere le competenze degli agenti e i relativi vantaggi.
- Insegnare a un agente a utilizzare Playwright con una skill.
- Sfruttare insieme l'MCP e la competenza di Google Chrome DevTools.
- Una rapida occhiata al subagente del browser Antigravity.
- Altri casi d'uso per il controllo del browser.
Attività previste
- Configura l'ambiente di sviluppo.
- Esplora un'applicazione demo che deve essere testata.
- Utilizza Gemini CLI per interagire con l'applicazione tramite BrowserMCP.
- Insegna al tuo agente come utilizzare Playwright con una skill dell'agente.
2. Prerequisiti
Prima di passare alle cose interessanti, assicuriamoci che tu abbia tutto ciò che ti serve.
Questo codelab utilizza Gemini CLI, strumenti MCP, competenze dell'agente e un'applicazione demo React.
Strumenti
Questo lab presuppone che tu disponga già di:
- Browser Chrome
- Nodejs
- Gemini CLI
- Git
Per utilizzare Gemini CLI, devi autenticarti con Google. Esistono diversi modi per farlo, ma ti consigliamo di utilizzare semplicemente l'opzione "Accedi con Google". Questa opzione offre una generosa quota senza costi di utilizzo di Gemini e non richiede un progetto Google Cloud. Se utilizzi questa opzione quando segui il codelab, non ci saranno costi. Se hai già una chiave API Gemini, puoi utilizzarla.
Le istruzioni presuppongono che tu stia lavorando in un ambiente Linux (o WSL) o macOS. Se utilizzi Windows (come me), puoi seguire la procedura utilizzando WSL.
(Tieni presente che
BrowserMCP non funzionerà da Google Cloud Shell
, perché si connetterà solo a un browser locale in esecuzione sulla stessa macchina.)
Configura l'ambiente di sviluppo
Ho creato un repository demo su GitHub. Include un'applicazione di esempio che possiamo utilizzare per i nostri test dell'interfaccia utente. Clonalo eseguendo questo comando dal terminale locale:
git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing
Esiste un file Makefile per semplificare la configurazione dell'ambiente per avviare l'app demo. Eseguiamolo per inizializzare l'ambiente:
make install # Or if you don't have make npm install --prefix demo-app
3. La nostra applicazione demo
L'app che stiamo testando oggi è The Dazbo Omni-Dash, una dashboard futuristica con tema scuro per la gestione della telemetria di sicurezza. (Sì, è stato codificato in base alle vibrazioni!)
Perché questa app?
È progettato per fornire una superficie di test realistica con:
- Autenticazione simulata: un flusso di accesso che richiede credenziali specifiche.
- Contenuti dinamici: schede di telemetria e log di sicurezza che simulano dati in tempo reale.
- Stati interattivi: menu di navigazione e input dei moduli che cambiano in base all'azione dell'utente.
- Tecnologia moderna: creato con React e Vite per un'esperienza veloce e reattiva.
Avvio dell'app
Per avviare l'applicazione, esegui:
make dev # Or if you don't have make npm run dev --prefix demo-app
Il server di sviluppo dovrebbe avviarsi molto rapidamente e l'app sarà disponibile all'indirizzo http://localhost:5173.

Possiamo semplicemente fare clic sul link per aprire l'applicazione nel browser. Lascia in esecuzione questo processo nel terminale. Eseguiremo i comandi del terminale successivi in una sessione del terminale separata.
4. La sfida del test dell'interfaccia utente
I test dell'interfaccia utente tradizionali sono notoriamente difficili da eseguire correttamente e ancora più difficili da mantenere. I punti dolenti più comuni includono:
- Test "instabilità": test che vengono superati un minuto e non superati il minuto successivo a causa di problemi di sincronizzazione, condizioni di competizione o caricamento lento degli asset.
- Selettori fragili: si basano su strutture DOM specifiche (ad esempio div > div > button) che si interrompono con la minima modifica della UI, il che comporta una manutenzione costante degli script.
- Curva di apprendimento elevata: gli sviluppatori devono padroneggiare linguaggi specifici del dominio e peculiarità specifiche del framework (Cypress, Selenium, Playwright) solo per automatizzare un clic di base.
- Parità dell'ambiente: difficoltà a replicare gli stati delle applicazioni e sovraccarico di pulizia dei dati di test.

Abbiamo bisogno di un test che si concentri sull'intento piuttosto che sull'implementazione.
5. MCP to the Rescue
Il Model Context Protocol (MCP) è uno standard aperto che consente a modelli e agenti AI di interagire con strumenti, API e dati esterni. Consideralo come l'adattatore universale che consente a modelli e agenti di trovare ed eseguire gli strumenti a cui hanno accesso.
Tradizionalmente, l'integrazione di modelli linguistici di grandi dimensioni (LLM) con dati e strumenti esterni richiedeva agli sviluppatori di scrivere connessioni API personalizzate e hardcoded per ogni nuova origine dati, creando un problema di integrazione "M x N" insostenibile in cui ogni nuovo modello e strumento moltiplica l'onere di manutenzione. Il Model Context Protocol (MCP) risolve questo problema eliminando la necessità di scrivere codice specifico per orchestrare queste funzionalità. Invece di codificare esplicitamente flussi di esecuzione complessi, gli sviluppatori possono fare affidamento sull'LLM per interpretare le richieste in linguaggio naturale di un utente e ragionare dinamicamente su quali strumenti utilizzare al volo.
Quando un utente emette un comando in linguaggio naturale (ad esempio "Vai a localhost:5173, accedi come "admin" e fai clic sul pulsante Invia"), l'LLM rileva le funzionalità disponibili e genera una richiesta strutturata per richiamare uno strumento specifico. Il client MCP funge da traduttore, indirizzando questa richiesta al server MCP designato, che esegue l'azione o recupera i dati e restituisce il contesto al modello. In questo modo, l'AI può agire in modo autonomo senza che lo sviluppatore debba codificare in modo rigido il percorso di esecuzione specifico.
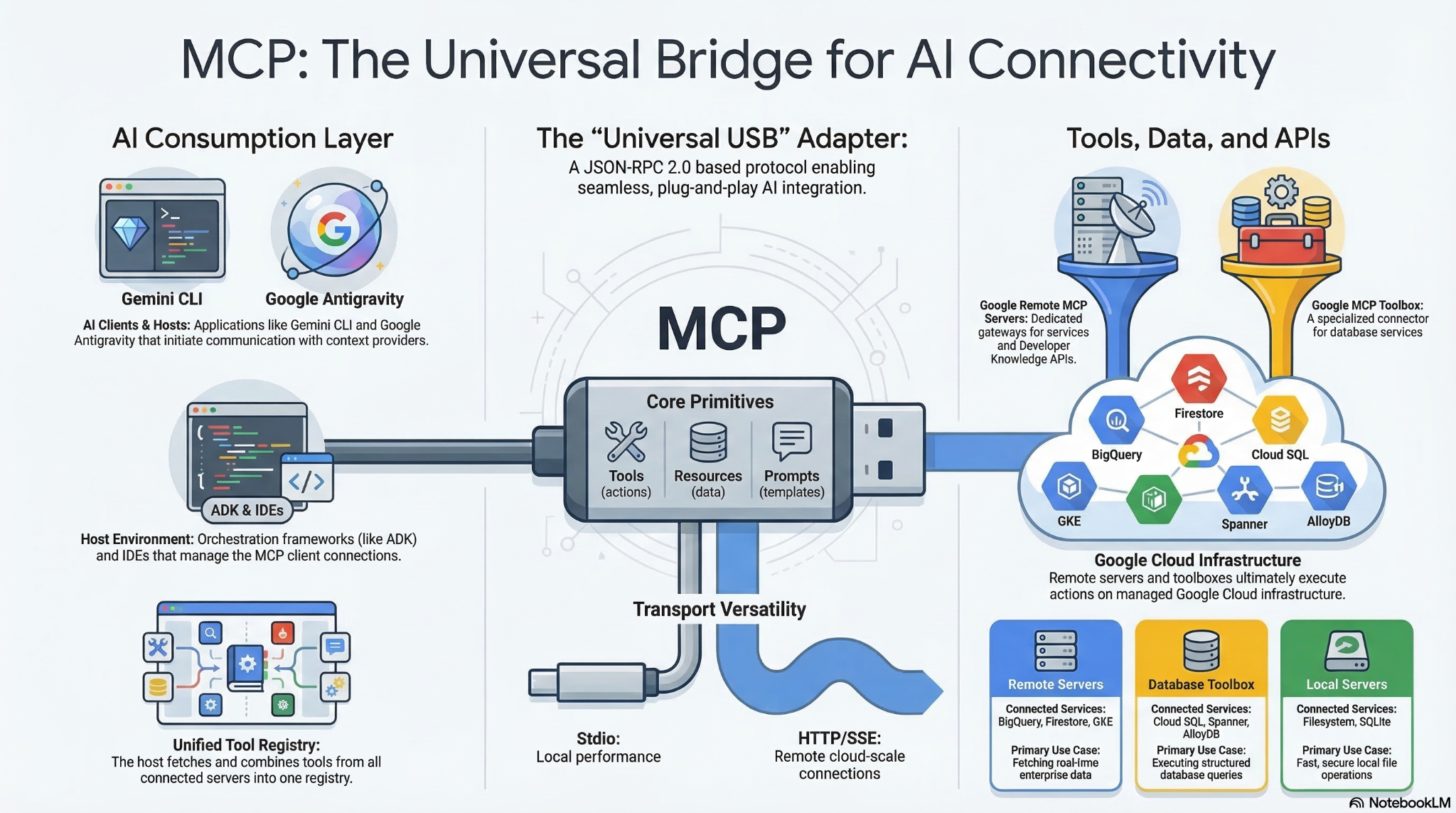
Poiché MCP crea uno standard universale, spesso descritto come "USB-C per le applicazioni di AI", sblocca un'enorme riutilizzabilità pronta all'uso. Gli sviluppatori possono creare un server MCP una sola volta e qualsiasi host AI compatibile con MCP può connettersi immediatamente, eliminando il problema di integrazione M x N. Non devi più creare ponti API personalizzati per ogni piattaforma. Puoi invece sfruttare l'ecosistema di server MCP open source predefiniti per servizi comuni come GitHub, Slack, database e così via, collegandoli direttamente ai tuoi workflow degli agenti. Questa architettura modulare plug-and-play garantisce che, se in un secondo momento cambi provider LLM o esegui l'upgrade degli strumenti, l'infrastruttura di integrazione principale rimanga completamente invariata.
6. Automazione con BrowserMCP
Che cos'è BrowserMCP?
Questo è il primo strumento che utilizzeremo oggi. BrowserMCP è un server MCP che fornisce agli agenti AI gli "occhi" e le "mani" necessari per interagire con un browser web. In breve, imita l'interazione umana con un browser. È open source e puoi dare un'occhiata al repository GitHub qui. Consulta la documentazione principale di BrowserMCP qui.

Ecco alcune delle sue funzionalità:
- Può navigare verso gli URL.
- Può ispezionare il DOM.
- Può fare clic sui pulsanti e digitare testo nei moduli.
- Può trascinare e rilasciare.
- Può leggere i log della console del browser.
- È veloce: l'automazione avviene localmente sulla tua macchina.
Installazione di Browser MCP
Per utilizzare BrowserMCP, devi fare due cose:
- Installa l'estensione BrowserMCP in Chrome (o in qualsiasi browser basato su Chromium).
- Configura il server MCP per l'agente.
Per installare l'estensione, segui le istruzioni riportate qui. L'operazione richiede solo pochi secondi. Una volta installata, fai clic su "Connetti" nell'estensione per consentire all'agente di controllare la scheda corrente. Ovviamente, vuoi che la scheda corrente sia quella in cui è in esecuzione l'applicazione demo.
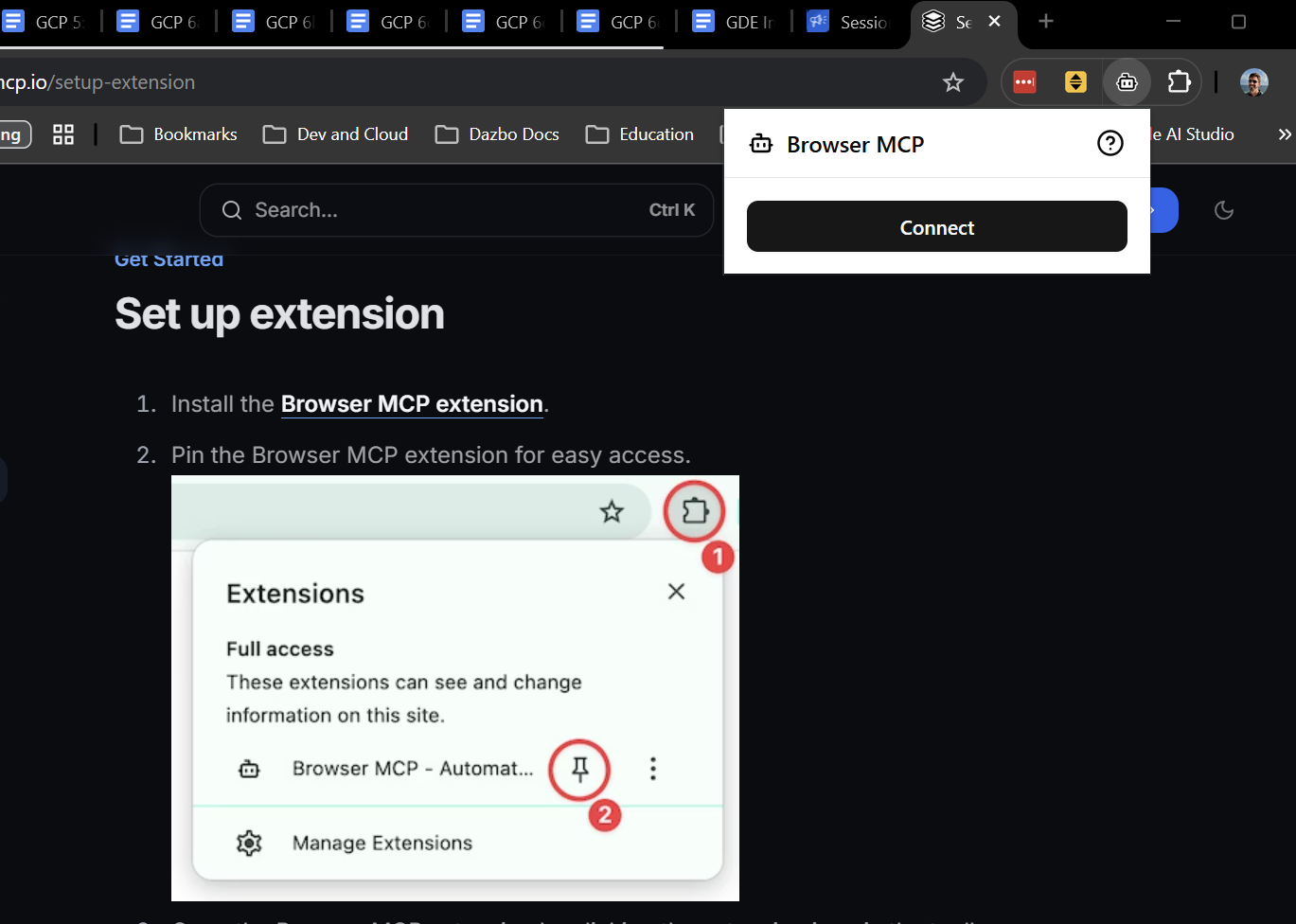
A questo punto, dobbiamo aggiungere il server BrowserMCP effettivo al client. In Gemini CLI è semplicissimo. Basta installare l'estensione:
gemini extensions install https://github.com/derailed-dash/browsermcp-ext
Test con BrowserMCP
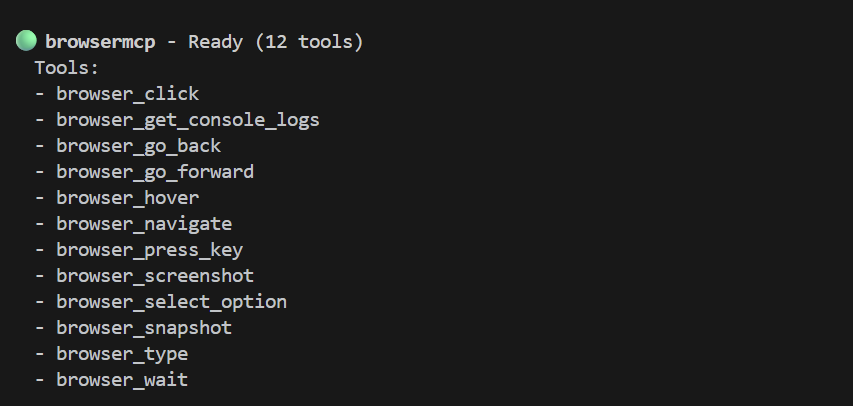
Ora la magia. Innanzitutto, avviamo Gemini CLI (eseguendo gemini) in una nuova sessione del terminale. Ricorda che l'applicazione demo è in esecuzione nella sessione di terminale iniziale. In Gemini CLI, esegui /mcp per verificare che sia installato correttamente. Dovresti visualizzare un elenco di strumenti, come questo:
Se non hai avviato la domanda dimostrativa in precedenza, avviala ora:
make dev
Dobbiamo aprire l'app nel browser Chrome e connettere l'estensione BrowserMCP in quella scheda. Segui il link del comando run. Poi fai clic sull'icona dell'estensione BrowserMCP e su "Connetti".
Ora possiamo utilizzare Gemini CLI per eseguire un test. Copia e incolla questo prompt in Gemini CLI:
Using BrowserMCP, connect to the application at http://localhost:5173. If the application is not showing a login screen, first logout. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Gemini CLI potrebbe prima verificare che l'applicazione demo sia in esecuzione sulla porta specificata. Ti verrà chiesto di confermare le azioni che lo strumento prevede di intraprendere:
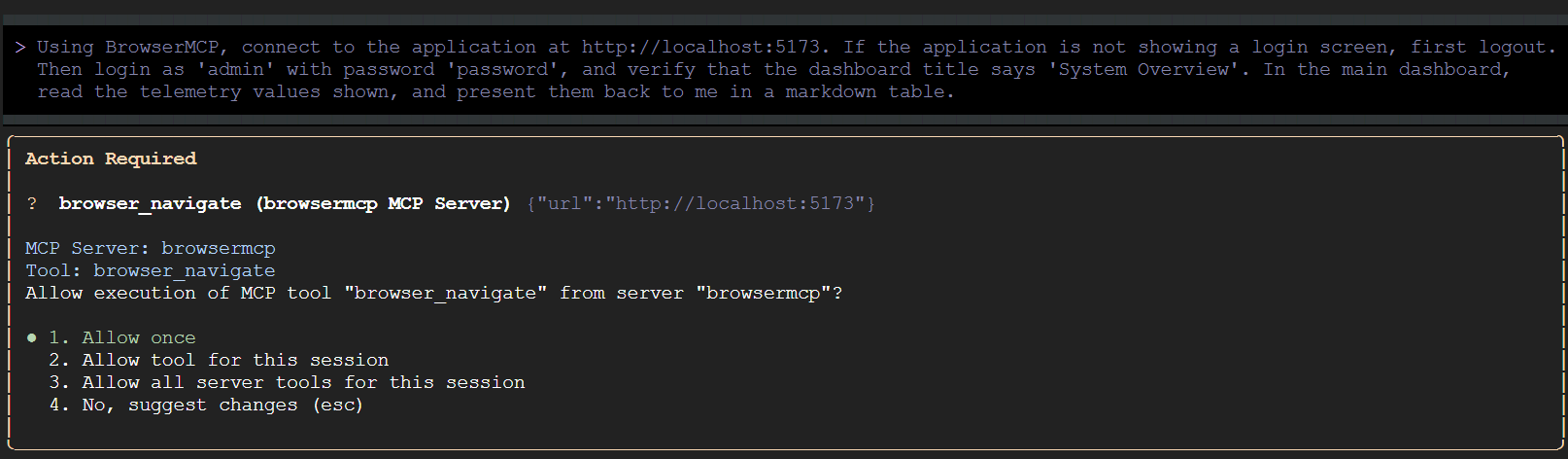
Consente a Gemini CLI di eseguire tutti gli strumenti BrowserMCP per questa sessione. Poi torna al browser e guarda le interazioni automatizzate.
Alcuni aspetti da notare in merito al prompt riportato sopra:
- Iniziamo chiedendo all'agente di disconnettersi, se l'applicazione è già connessa. Tieni presente che non è necessario indicare all'agente di fare clic su un testo specifico come "Esci dal gateway". È abbastanza intelligente da capire su cosa fare clic.
- Dopo aver eseguito l'accesso e il rendering della pagina principale, l'agente acquisisce le informazioni di telemetria. Anche in questo caso, non è necessario indicare all'agente di cercare in riquadri specifici o di trovare corrispondenze con parole specifiche. Pertanto, se in futuro dovessimo estendere o modificare le informazioni mostrate in questa pagina, il prompt continuerà a funzionare e l'output verrà comunque acquisito nella nostra tabella in formato Markdown.
Figo, vero?
Per il momento abbiamo terminato con BrowserMCP, quindi disconnettilo nel browser.
7. Automazione con Skills e Playwright
Limitazioni di BrowserMCP
BrowserMCP è un ottimo strumento, ma presenta alcune limitazioni. Ad esempio:
- Richiede una sessione del browser esistente, con l'estensione BrowserMCP connessa. Non vengono generate nuove sessioni.
- Non supporta i browser non Chromium.
- Richiede l'esecuzione di un processo del browser separato sulla stessa macchina su cui è in esecuzione il server MCP.
- Non è in grado di funzionare con il file system locale. Ad esempio, non può creare file locali per le prove degli screenshot o scaricare e archiviare file dall'applicazione web, ad esempio PDF scaricabili.
- È non deterministico. Tenterà di eseguire le azioni che gli chiedi, ma lo stato locale, ad esempio un popup inaspettato, potrebbe interrompere l'interazione.
- Non supporta l'operazione"headless", il che significa che non può essere eseguito in una pipeline CI/CD senza una finestra del browser reale.
Playwright
Playwright è uno strumento molto più sofisticato. Si tratta di un framework di test e automazione del browser open source consolidato. Può fare molte cose che BrowserMCP non può fare, inclusi tutti i punti che ho menzionato sopra.
È molto più adatta all'esecuzione di scenari di test complessi, affidabili e ripetibili. È particolarmente adatta per lavorare con sessioni di lunga durata o per eseguire più sessioni indipendenti in parallelo.
Tuttavia, questa funzionalità aggiuntiva comporta una curva di apprendimento molto più ripida.
Competenze
Fortunatamente, non dobbiamo imparare a utilizzare Playwright direttamente. In alternativa, possiamo utilizzare una competenza dell'agente.

Quindi, che cos'è esattamente una competenza dell'agente? Consideralo come un pacchetto compatto di competenze di dominio che puoi consegnare al tuo agente AI quando deve fare qualcosa di specifico. Contiene istruzioni, best practice e a volte anche script di assistenza personalizzati per un'attività specifica.
Ecco la parte davvero intelligente: la divulgazione progressiva. Anziché inserire ogni possibile documentazione API e regola del framework di test nel prompt di sistema iniziale del LLM, che consuma la finestra contestuale e i token a una velocità impressionante, l'agente legge la skill solo quando ne ha effettivamente bisogno. Mantiene il contesto di base semplice e conciso, recuperando le istruzioni dettagliate appena in tempo. E sì, una skill può assolutamente includere istruzioni su come utilizzare server MCP specifici per portare a termine il lavoro.
Pensa alla scena di Matrix: l'agente guarda un problema, si rende conto di dover conoscere Playwright, scarica la competenza e improvvisamente: "Conosco il kung fu". Giraffa. Esperto istantaneo.
Se vuoi saperne di più sulle competenze, consulta le seguenti risorse:
- Tutorial : Guida introduttiva alle competenze Google Antigravity
- Codelab: creazione di competenze Google Antigravity
Perché le competenze sono perfette per Playwright
Utilizzare una skill qui è un'ottima scelta. Playwright è incredibilmente potente, ma la sua sintassi può essere complicata. Se forniamo all'agente una competenza Playwright, non dobbiamo preoccuparci che il nostro LLM allucini una sintassi obsoleta o scriva selettori fragili. Stiamo fornendo un playbook autorevole e curato su come utilizzare correttamente Playwright.
Utilizzerò l'interfaccia a riga di comando Playwright e la relativa competenza.
Con questo approccio installiamo Playwright CLI localmente, quindi forniamo all'agente le conoscenze necessarie per utilizzarlo. Per evitare qualsiasi confusione: non sto installando alcun server Playwright MCP.
Installazione in corso…
Innanzitutto, installiamo la CLI open source Microsoft Playwright. Se non l'hai ancora fatto, esci da Gemini CLI digitando /quit``. Poi, nel terminale:
# Pre-req: nodejs installed npm install -g @playwright/cli@latest # Install Playwright CLI globally npm install @playwright/test # Install Playwright test framework npx playwright install-deps # Install dependencies npx playwright install chromium chrome # Install browser binaries in Linux / WSL
Ora aggiungiamo la skill. Questo comando scaricherà la sottocartella delle skill direttamente da GitHub nella cartella delle skill di Gemini:
mkdir -p ~/.gemini/skills npx degit microsoft/playwright-cli/skills/playwright-cli ~/.gemini/skills/playwright-cli
Ora possiamo testarlo.
# Launch Playwright CLI with visible browser playwright-cli open https://playwright.dev --headed
Dovrebbe essere generata una sessione del browser, aperta all'URL specificato.
Voglio anche che Gemini possa utilizzare Playwright in modalità "con intestazione", ovvero con un'interfaccia utente visibile. ma la skill non dice a Gemini come farlo. Ho aggiunto queste righe a ~/.gemini/skills/playwright-cli/SKILL.md nella sezione Core:
# Add the following under the "playwright-cli open" command # Run in headed mode so we can see the browser playwright-cli open https://playwright.dev --headed
Test con Playwright
Come prima, dobbiamo avviare l'applicazione (se non è già in esecuzione). Esegui questa operazione dalla sessione del terminale iniziale:
make dev
Poi, nell'altra sessione del terminale, disattiviamo temporaneamente BrowserMCP in modo che l'agente non si confonda su quali strumenti utilizzare. Riavvia Gemini CLI, quindi esegui:
/mcp disable browsermcp
Ora chiederemo a Gemini di navigare nella nostra applicazione con Playwright. A differenza di BrowserMCP, non è necessario avviare prima il browser. Playwright lo farà per noi con un processo locale.
Inserisci questo prompt in Gemini CLI:
Using Playwright, connect to the application at http://localhost:5173. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Come sempre, Gemini CLI chiederà l'autorizzazione prima di eseguire qualsiasi strumento.
Quali sono le differenze?
- Non è stato necessario avviare prima il browser.
- Non è stato necessario avviare e connettere un'estensione del browser.
- Non è necessario chiedere all'agente di disconnettersi prima. Il test viene istanziato da una sessione "pulita".
- Possiamo acquisire screenshot e salvarli come file locali.
Poco dopo dovresti vedere un file dashboard.png nella cartella output.
Tieni presente che vedrai l'esecuzione delle chiamate di strumenti in Gemini CLI, ma non vedrai la UI del browser. Questo perché Playwright viene eseguito in "modalità headless" per impostazione predefinita.
Se esegui di nuovo il comando con questo prompt modificato, potrai visualizzare anche la UI:
Using Playwright, connect to the application at http://localhost:5173 in **headed** mode, and keep the browser open when you're done. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown and record them. Then wait 3 seconds, read them again. Now present the data back to me in a markdown table.
A breve, l'output di Gemini CLI dovrebbe avere un aspetto simile al seguente:
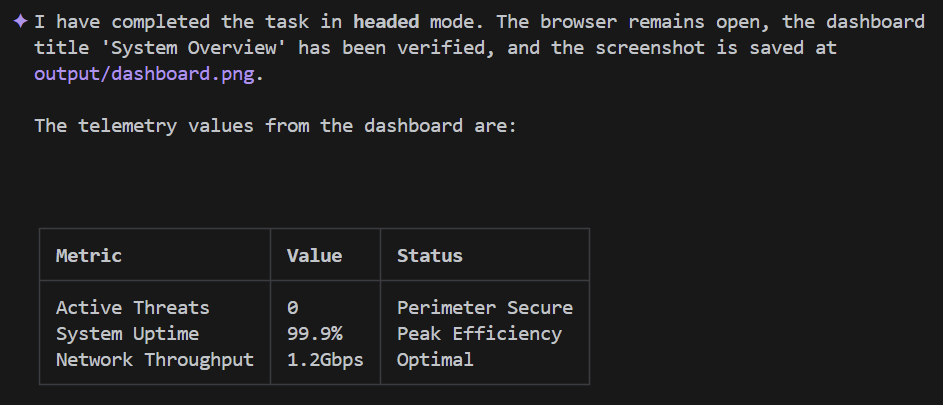
Non è stato fantastico?
8. Ma aspetta, c'è anche Chrome DevTools MCP!
Chrome DevTools è un insieme di strumenti per sviluppatori web integrati nel browser Chrome, pensati per lo sviluppo e il debug web. Esiste da molto tempo. Sai, la console con cui puoi interagire quando apri Altri strumenti -> Strumenti per sviluppatori in Chrome.
Ora, però, ha un proprio server MCP, che non esisteva quando l'anno scorso è stata presa in considerazione l'automazione del browser da Gemini CLI. Ora, però, puoi fare tutto ciò che puoi fare con BrowserMCP e la maggior parte delle cose che puoi fare con Playwright, senza installare nulla nel browser e senza installare una CLI locale.
Proviamo.
Al momento, abbiamo verificato che funziona in Google Cloud Shell. Per questa parte, utilizziamo Google Cloud Shell nella console Google Cloud.
Apri la console e una sessione di Cloud Shell. A questo punto:
# Clone the sample app - like we did before git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing # Build the application - like we did before make install # Install the Chrome DevTools MCP server Gemini CLI Extension gemini extensions install https://github.com/ChromeDevTools/chrome-devtools-mcp
Ora dobbiamo installare un eseguibile di Chrome in Cloud Shell:
# Get the latest executable for Ubuntu wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb # Install it sudo apt install ./google-chrome-stable_current_amd64.deb -y # Check it and get the executable path which google-chrome # Cleanup rm google-chrome-stable_current_amd64.deb
Un ultimo passaggio: dobbiamo comunicare al server MCP di Chrome DevTools dove trovare l'eseguibile di Chrome. Per farlo, possiamo impostare l'opzione executable-path nella configurazione del server MCP e renderla headless. A questo scopo, modifichiamo il file ~/.gemini/extensions/chrome-devtools-mcp/gemini-extension.json:
{
"name": "chrome-devtools-mcp",
"version": "latest",
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest",
"--executable-path=/usr/bin/google-chrome",
"--headless"
]
}
}
}
Bene. Dovremmo essere pronti. Avvia gemini da Cloud Shell e verifica che il server MCP sia in esecuzione utilizzando il comando /mcp list, come prima.
Infine, siamo pronti a testarlo con un prompt.
Facciamo qualcosa di diverso. Questa volta, diremo a Gemini CLI di avviare l'applicazione demo e di connettersi:
Launch my demo application with `make dev`. Then, using Chrome DevTools MCP, connect to the application at the exposed localhost URL. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Come di consueto, ti verrà chiesto di consentire l'esecuzione del server MCP. Ma noterai anche che tenta di attivare un'abilità. Esatto: questa estensione contiene sia il server MCP sia una skill che guida l'agente su come utilizzare al meglio il server MCP. Bene!
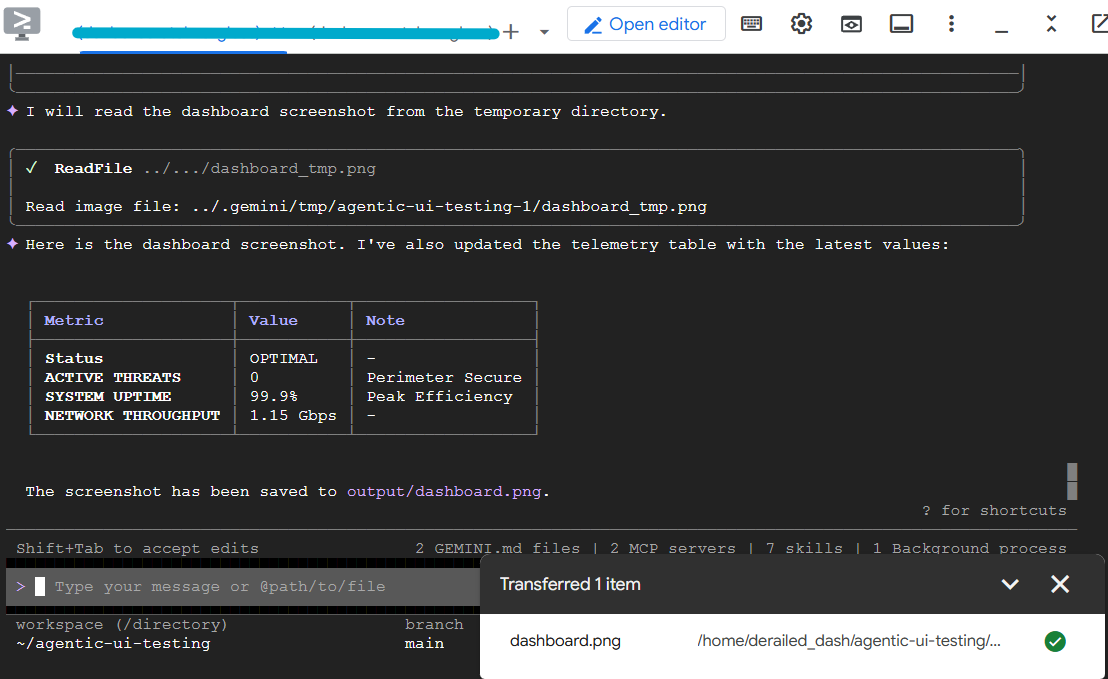
Alcuni secondi dopo, Gemini CLI dovrebbe presentare i risultati nella tabella e salvare lo screenshot. Puoi scaricare lo screenshot da Cloud Shell per verificare che sia corretto.
9. Puoi farlo in Antigravity Out of the Box.
Google Antigravity include Browser Subagent, che offre funzionalità simili a Playwright CLI. Quando chiedi a Gemini in Antigravity di avviare un URL in modo interattivo, questo subagente viene avviato automaticamente.
Questo subagente prende il tuo obiettivo di alto livello (ad es. "Controlla se il modulo di accesso funziona"), analizza visivamente il layout della pagina tramite screenshot e il DOM e determina autonomamente i clic e le sequenze di tasti. Si tratta essenzialmente di un'AI visiva e multimodale che naviga sul web proprio come farebbe un essere umano. E sai qual è la cosa migliore? Registra automaticamente video e acquisisce screenshot di tutto ciò che fa, salvandoli direttamente nell'area di lavoro locale come prova visiva di ciò che ha realizzato. Antigravity chiama queste prove visive artefatti.
Nota per gli utenti di WSL: far funzionare l'agente browser in Antigravity è un po' complicato. Sono riuscito a farlo funzionare, ma trovo che il subagente sia incoerente e inaffidabile in questo ambiente. Questo è uno dei motivi per cui adoro la CLI di Playwright.
10. Altri casi d'uso per l'automazione del browser
L'automazione del browser non serve solo ad assicurarsi che il pulsante di accesso funzioni prima di un deployment di venerdì pomeriggio. Quando ti rendi conto che puoi collegare un LLM direttamente a un browser, si apre un mondo completamente nuovo di progetti autonomi e creati internamente.
Se stai creando i tuoi agenti AI, ecco alcuni modi in cui puoi utilizzare strumenti come BrowserMCP o Playwright CLI per svolgere il lavoro più pesante:
- L'assistente di ricerca personale: immagina di indicare al tuo agente un URL specifico e di chiedergli di fare ricerche su un argomento, ma il sito richiede l'accesso e la navigazione in menu complessi. Anziché scrivere uno scraper web personalizzato che smetterà di funzionare la settimana successiva, puoi semplicemente chiedere all'agente di accedere, navigare fino ai dati e riassumerli per te.
- L'integratore"Swivel-Chair": tutti abbiamo quei sistemi intranet legacy che non hanno API. Sai quali sono: quelle in cui devi copiare manualmente i dati dal sistema A e incollarli in un modulo del sistema B. Un agente con l'automazione del browser può fungere da collante universale, leggendo lo schermo del sistema legacy e compilando il modulo nel nuovo sistema.
- Triage e correzione automatizzati: hai ricevuto un avviso P1 dal tuo sistema di monitoraggio alle 3 del mattino? L'agente potrebbe aprire automaticamente l'URL della dashboard specifica, leggere i grafici o i log (utilizzando le sue funzionalità di visione multimodale) e pubblicare un riepilogo direttamente nel tuo canale Slack, facendoti risparmiare minuti preziosi durante un incidente.
Il bello di questo approccio è che non sei più limitato dalle API disponibili. Se un essere umano può farlo in un browser, può farlo anche il tuo agente.
11. Conclusione
Complimenti! Hai appena creato ed eseguito test dell'interfaccia utente automatizzati e robusti semplicemente dicendo a un agente AI cosa volevi che facesse in inglese semplice. Nessun selettore CSS fragile, nessun script di configurazione complesso.
Hai imparato:
- Il test dell'interfaccia utente non deve essere doloroso: concentrandoci sull'intento del test anziché sull'implementazione fragile del DOM, possiamo ridurre notevolmente il sovraccarico di manutenzione.
- Il Model Context Protocol (MCP) offre agli agenti un accesso universale plug-and-play a strumenti, dati e ambienti.
- BrowserMCP è uno strumento incredibile per integrare funzionalità agentiche nelle sessioni Chrome locali esistenti.
- Skills e Playwright CLI offrono un nuovo livello di test di automazione ripetibili e deterministici, il tutto basato sulla divulgazione progressiva.
- Browser Subagent di Antigravity fa un ulteriore passo avanti introducendo la navigazione autonoma e multimodale e la registrazione degli artefatti fin da subito.
Ora vai e automatizza le attività noiose.
Useful Links
Se vuoi approfondire gli strumenti e i concetti che abbiamo trattato oggi, consulta queste risorse:
Repo Code
- Il repository GitHub agentic-ui-testing. Aggiungi una stella al repository se hai trovato utile questo codelab.
Strumenti e framework principali
- Repository GitHub di BrowserMCP
- Documentazione BrowserMCP
- Estensione Gemini CLI BrowserMCP: aggiungi una stella al repository se hai trovato utile questo codelab.
- Playwright
- Google AI Studio
- Chrome DevTools
- Chrome DevTools MCP
Concetti e competenze agentiche
- Tutorial: Guida introduttiva alle competenze Google Antigravity
- Codelab: Guida introduttiva alle skill Antigravity
- Blog originale di Dazbo: Creating an Automated UI Test in Seconds
Altro