
1. Wprowadzenie
Testowanie aplikacji internetowych może być uciążliwe. Tradycyjne testowanie interfejsu często przypomina ciągłą walkę z niestabilnością. Piszesz złożone skrypty, zarządzasz niestabilnymi selektorami CSS i XPath oraz wykonujesz skomplikowane czynności, aby zweryfikować prosty przepływ użytkownika.
A gdyby tak po prostu powiedzieć agentowi, co ma przetestować, w języku naturalnym, a on by to zrobił?

W tym ćwiczeniu dowiesz się, jak korzystać z interfejsu wiersza poleceń Gemini i narzędzi multimodalnych, takich jak BrowserMCP. Dowiesz się, jak tworzyć i uruchamiać zautomatyzowane testy interfejsu przy użyciu języka naturalnego. Pamiętaj, że to ćwiczenie nie wymaga wcześniejszej znajomości platform i narzędzi do testowania interfejsu.
Czego się nauczysz
- Czym jest protokół Model Context Protocol (MCP) i dlaczego jest to przełomowa technologia.
- Jak BrowserMCP umożliwia agentom AI sterowanie przeglądarkami.
- Jak uruchamiać automatyczne testy UI z interfejsu wiersza poleceń Gemini.
- Poznaj umiejętności agentów i ich zalety.
- Uczenie agenta korzystania z Playwright za pomocą umiejętności.
- Korzystanie z MCP i umiejętności w Narzędziach deweloperskich w Chrome.
- Szybki podgląd subagenta przeglądarki Antigravity.
- Inne przypadki użycia sterowania przeglądarką.
Co zrobisz
- Skonfiguruj środowisko programistyczne.
- Zapoznaj się z aplikacją demonstracyjną, która wymaga przetestowania.
- Użyj interfejsu wiersza poleceń Gemini, aby wchodzić w interakcje z aplikacją za pomocą BrowserMCP.
- Naucz agenta, jak korzystać z Playwright, za pomocą umiejętności agenta.
2. Wymagania wstępne
Zanim przejdziemy do ciekawych rzeczy, upewnijmy się, że masz wszystko, czego potrzebujesz.
W tym ćwiczeniu wykorzystujemy interfejs wiersza poleceń Gemini, narzędzia MCP, umiejętności agenta i aplikację demonstracyjną w React.
Narzędzia
W tym module zakładamy, że masz już:
- Przeglądarka Chrome
- Nodejs
- Interfejs wiersza poleceń Gemini
- Git
Aby korzystać z interfejsu wiersza poleceń Gemini, musisz uwierzytelnić się w Google. Możesz to zrobić na kilka sposobów, ale zalecamy użycie opcji „Zaloguj się przez Google”. Ta opcja obejmuje duży bezpłatny limit wykorzystania Gemini i nie wymaga projektu w chmurze Google Cloud. Jeśli użyjesz tej opcji podczas wykonywania ćwiczeń z samouczka, nie poniesiesz żadnych kosztów. (Jeśli masz już klucz interfejsu Gemini API, możesz go użyć).
Instrukcje zakładają, że pracujesz w środowisku Linux (lub WSL) albo macOS. Jeśli używasz systemu Windows (tak jak ja), możesz skorzystać z WSL.
(Pamiętaj, że
BrowserMCP nie będzie działać w Google Cloud Shell
, ponieważ połączy się tylko z lokalną przeglądarką działającą na tym samym komputerze).
Konfigurowanie środowiska programistycznego
Mam utworzone repozytorium demonstracyjne w GitHubie. Zawiera przykładową aplikację, której możemy użyć do testowania interfejsu. Sklonuj go, uruchamiając to polecenie w terminalu lokalnym:
git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing
Jest tam plik Makefile, który ułatwia skonfigurowanie środowiska do uruchomienia aplikacji demonstracyjnej. Uruchommy go, aby zainicjować nasze środowisko:
make install # Or if you don't have make npm install --prefix demo-app
3. Nasza aplikacja demonstracyjna
Testowana dziś aplikacja to Dazbo Omni-Dash – futurystyczny panel w ciemnej kolorystyce do zarządzania danymi telemetrycznymi dotyczącymi bezpieczeństwa. (Tak, został zakodowany w ten sposób).
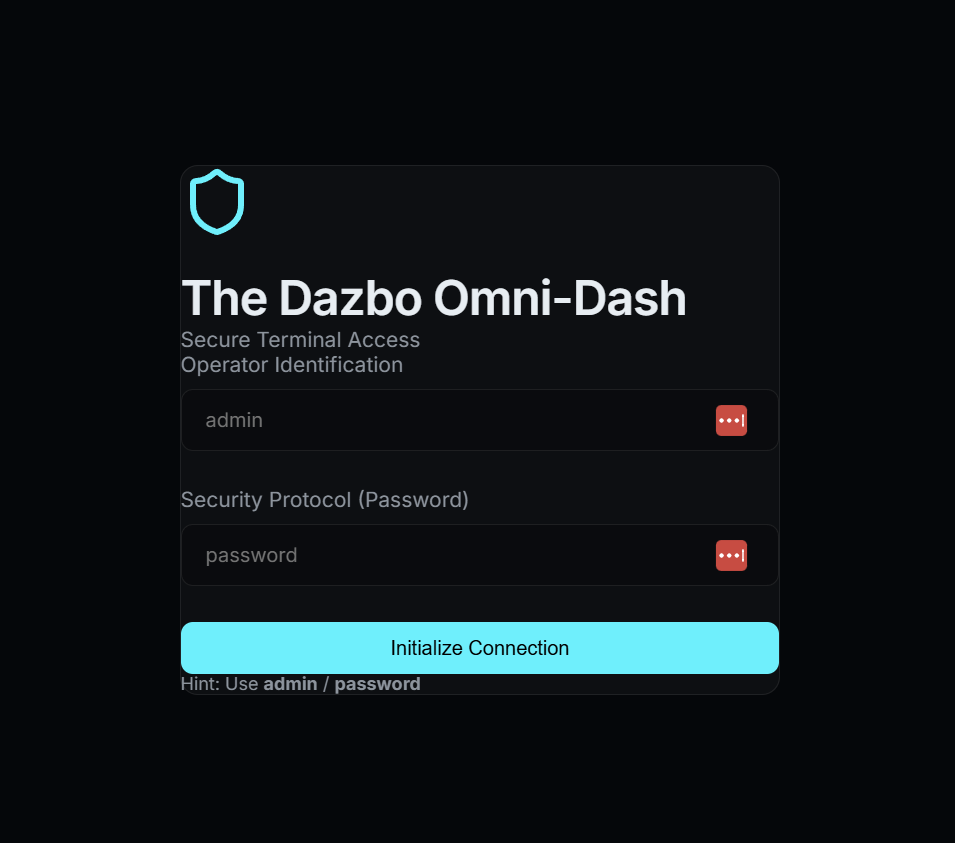
Dlaczego ta aplikacja?
Został on zaprojektowany tak, aby zapewnić realistyczną powierzchnię testową dzięki:
- Uwierzytelnianie próbne: proces logowania wymagający określonych danych logowania.
- Treści dynamiczne: karty telemetryczne i dzienniki zabezpieczeń, które symulują dane w czasie rzeczywistym.
- Stany interaktywne: menu nawigacyjne i pola formularza, które zmieniają się w zależności od działania użytkownika.
- Nowoczesna technologia: aplikacja została stworzona w technologii React i Vite, co zapewnia szybkie działanie i krótki czas reakcji.
Uruchamianie aplikacji
Aby uruchomić aplikację, wpisz:
make dev # Or if you don't have make npm run dev --prefix demo-app
Serwer deweloperski powinien uruchomić się bardzo szybko, a aplikacja będzie dostępna pod adresem http://localhost:5173.

Wystarczy kliknąć link, aby otworzyć aplikację w przeglądarce. Po prostu pozostaw ten proces uruchomiony w terminalu. Kolejne polecenia terminala wykonamy w osobnej sesji terminala.
4. Wyzwania związane z testowaniem interfejsu
Tradycyjne testowanie interfejsu użytkownika jest bardzo trudne do przeprowadzenia i utrzymania. Typowe problemy to:
- Test „niestabilności”: testy, które w jednej minucie kończą się powodzeniem, a w następnej niepowodzeniem z powodu problemów z czasem, warunków wyścigu lub wolno wczytujących się zasobów.
- Kruche selektory: poleganie na konkretnych strukturach DOM (np. div > div > button), które ulegają uszkodzeniu przy najmniejszej zmianie interfejsu, co prowadzi do ciągłej konserwacji skryptu.
- Wysoka krzywa uczenia się: wymaga od deweloperów opanowania złożonych języków specyficznych dla domeny i osobliwości związanych z platformą (Cypress, Selenium, Playwright) tylko po to, aby zautomatyzować podstawowe kliknięcie.
- Spójność środowiska: zmaganie się z trudnymi do odtworzenia stanami aplikacji i kosztami oczyszczania danych testowych.

Potrzebujemy sposobu testowania, który skupia się na intencji, a nie na implementacji.
5. MCP na ratunek
Model Context Protocol (MCP) to otwarty standard, który umożliwia modelom i agentom AI interakcję z zewnętrznymi narzędziami, interfejsami API i danymi. Można go porównać do uniwersalnego adaptera, który umożliwia modelom i agentom znajdowanie i wykonywanie narzędzi, do których mają dostęp.
Tradycyjnie integracja dużych modeli językowych (LLM) z zewnętrznymi danymi i narzędziami wymagała od deweloperów pisania niestandardowych, zakodowanych na stałe połączeń API dla każdego nowego źródła danych, co stwarzało problem integracji „M x N”, w którym każdy nowy model i narzędzie zwiększały obciążenie związane z konserwacją. Model Context Protocol (MCP) rozwiązuje ten problem, eliminując konieczność pisania specjalnego kodu do koordynowania tych funkcji. Zamiast jawnie kodować złożone przepływy pracy, deweloperzy mogą polegać na LLM, który interpretuje żądania użytkownika w języku naturalnym i dynamicznie określa, których narzędzi użyć.
Gdy użytkownik wyda polecenie w języku naturalnym (np. „Przejdź do localhost:5173, zaloguj się jako „admin” i kliknij przycisk Prześlij”), LLM wykryje dostępne funkcje i wygeneruje uporządkowane żądanie wywołania konkretnego narzędzia. Klient MCP działa jako tłumacz, przekazując to żądanie do wyznaczonego serwera MCP, który wykonuje działanie lub pobiera dane i zwraca kontekst do modelu. Dzięki temu AI może działać autonomicznie bez konieczności zakodowania przez programistę konkretnej ścieżki wykonania.
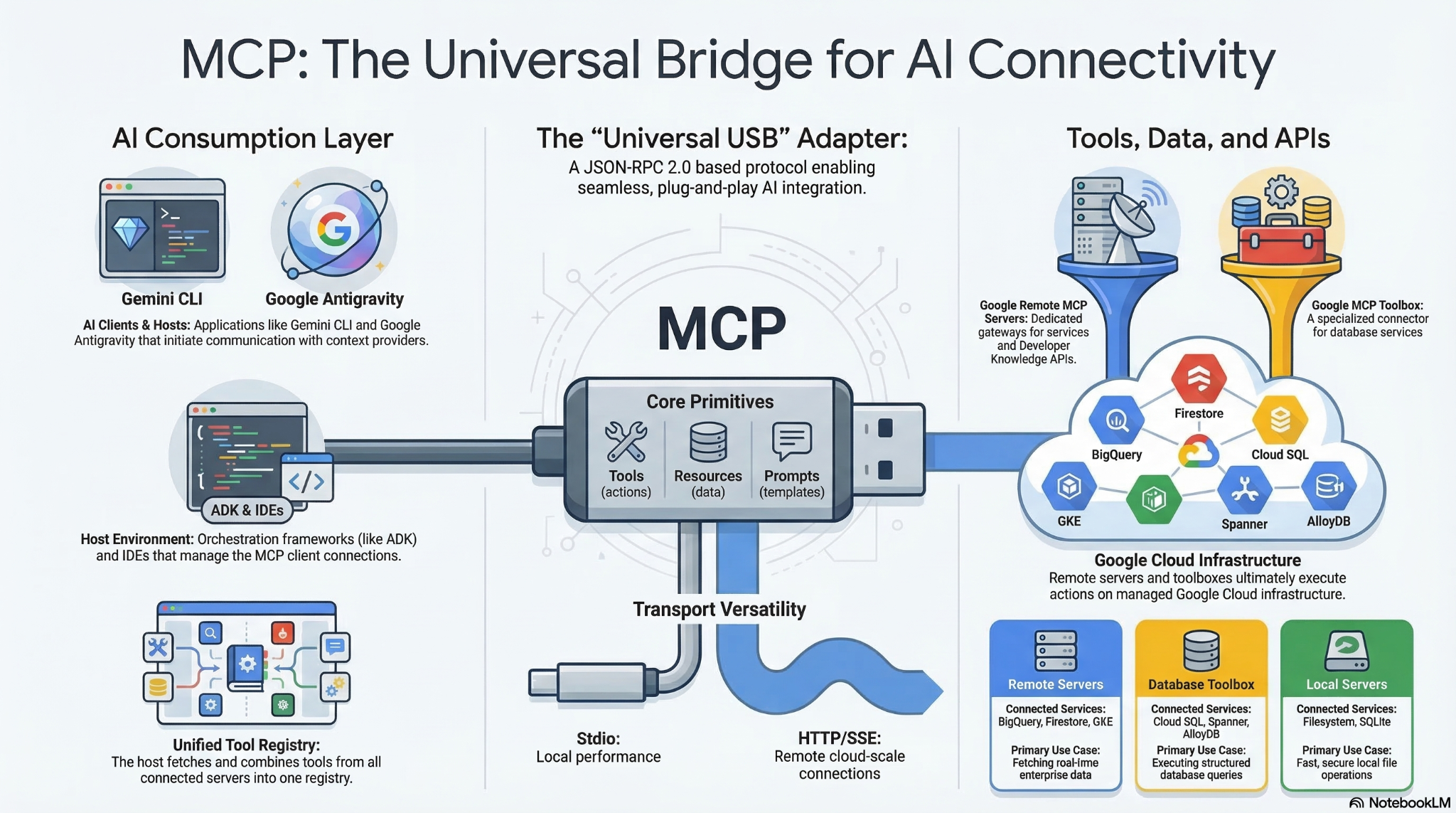
MCP tworzy uniwersalny standard, często określany jako „USB-C dla aplikacji AI”, co umożliwia natychmiastowe ponowne wykorzystanie. Deweloperzy mogą zbudować serwer MCP tylko raz, a każdy prezenter AI zgodny z MCP może się z nim natychmiast połączyć, eliminując problem integracji M x N. Nie musisz już tworzyć niestandardowych pomostów API dla każdej platformy. Zamiast tego możesz korzystać z ekosystemu gotowych serwerów MCP open source dla popularnych usług, takich jak GitHub, Slack czy bazy danych, i podłączać je bezpośrednio do przepływów pracy opartych na agentach. Ta modułowa architektura typu plug-and-play sprawia, że jeśli później zmienisz dostawcę LLM lub ulepszysz narzędzia, podstawowa infrastruktura integracji pozostanie całkowicie niezmieniona.
6. Automatyzacja za pomocą BrowserMCP
Co to jest BrowserMCP?
To pierwsze narzędzie, z którego dziś skorzystamy. BrowserMCP to serwer MCP, który zapewnia agentom AI „oczy” i „ręce” potrzebne do interakcji z przeglądarką. W skrócie: naśladuje interakcje człowieka z przeglądarką. Jest to projekt open source, a repozytorium GitHub znajdziesz tutaj. Główną dokumentację BrowserMCP znajdziesz tutaj.

Oto niektóre z jej możliwości:
- Może otwierać adresy URL.
- Może sprawdzać DOM.
- Może klikać przyciski i wpisywać tekst w formularzach.
- Możesz przeciągać i upuścić.
- Może odczytywać dzienniki konsoli przeglądarki.
- Jest szybki: automatyzacja odbywa się lokalnie na Twoim komputerze.
Instalowanie Browser MCP
Aby używać BrowserMCP, musisz wykonać 2 czynności:
- Zainstaluj rozszerzenie BrowserMCP w Chrome (lub w dowolnej przeglądarce opartej na Chromium).
- Skonfiguruj serwer MCP dla agenta.
Aby zainstalować rozszerzenie, postępuj zgodnie z instrukcjami podanymi tutaj. Zajmie to tylko kilka sekund. Po zainstalowaniu rozszerzenia kliknij „Połącz”, aby zezwolić agentowi na sterowanie bieżącą kartą. (Oczywiście chcesz, aby bieżąca karta była tą, na której działa aplikacja demonstracyjna).
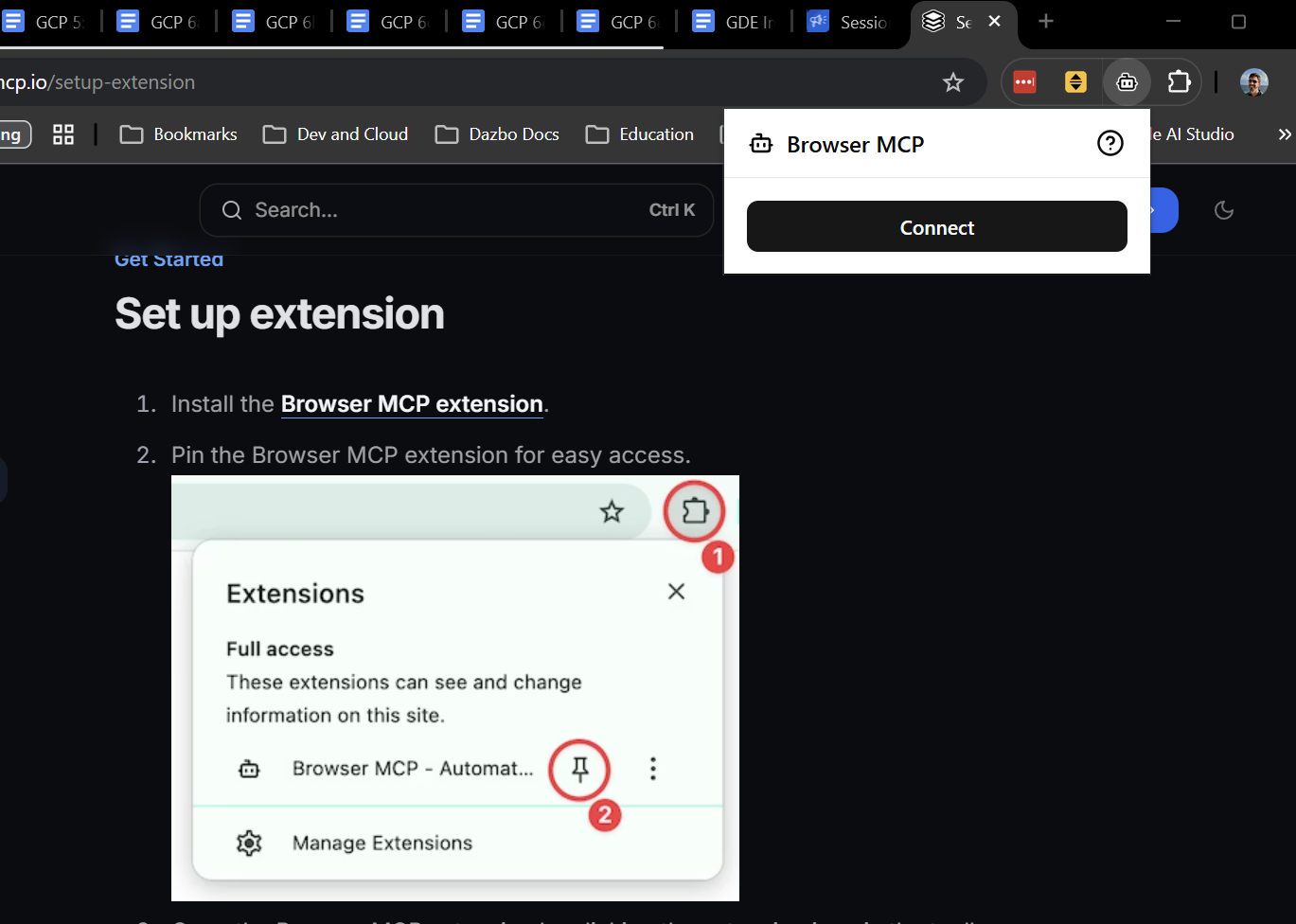
Następnie musimy dodać rzeczywisty serwer BrowserMCP do klienta. W interfejsie wiersza poleceń Gemini jest to bardzo proste. Wystarczy zainstalować rozszerzenie:
gemini extensions install https://github.com/derailed-dash/browsermcp-ext
Testowanie za pomocą BrowserMCP
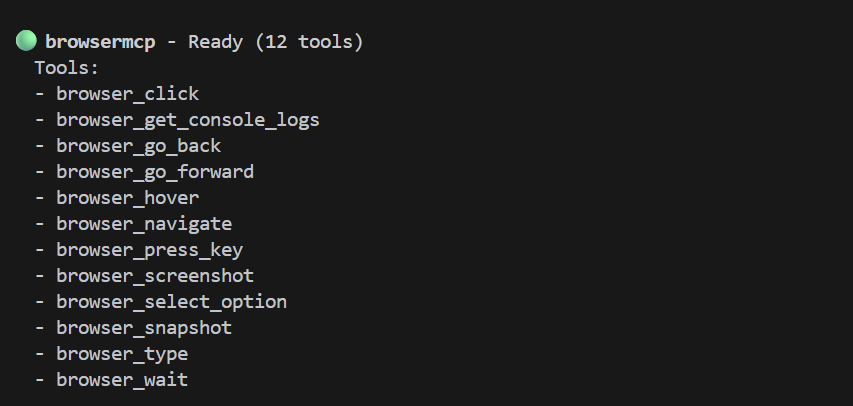
A teraz magia. Najpierw uruchom interfejs wiersza poleceń Gemini (uruchamiając gemini) w nowej sesji terminala. (Pamiętaj, że aplikacja demonstracyjna jest uruchomiona w naszej początkowej sesji terminala). W interfejsie wiersza poleceń Gemini uruchom polecenie /mcp, aby sprawdzić, czy został on prawidłowo zainstalowany. Powinna się wyświetlić lista narzędzi, np. taka:
Jeśli nie została jeszcze uruchomiona, uruchom teraz aplikację demonstracyjną:
make dev
Musimy otworzyć aplikację w przeglądarce Chrome i połączyć rozszerzenie BrowserMCP na tej karcie. Kliknij link z polecenia run. Następnie kliknij ikonę rozszerzenia BrowserMCP i wybierz „Połącz”.
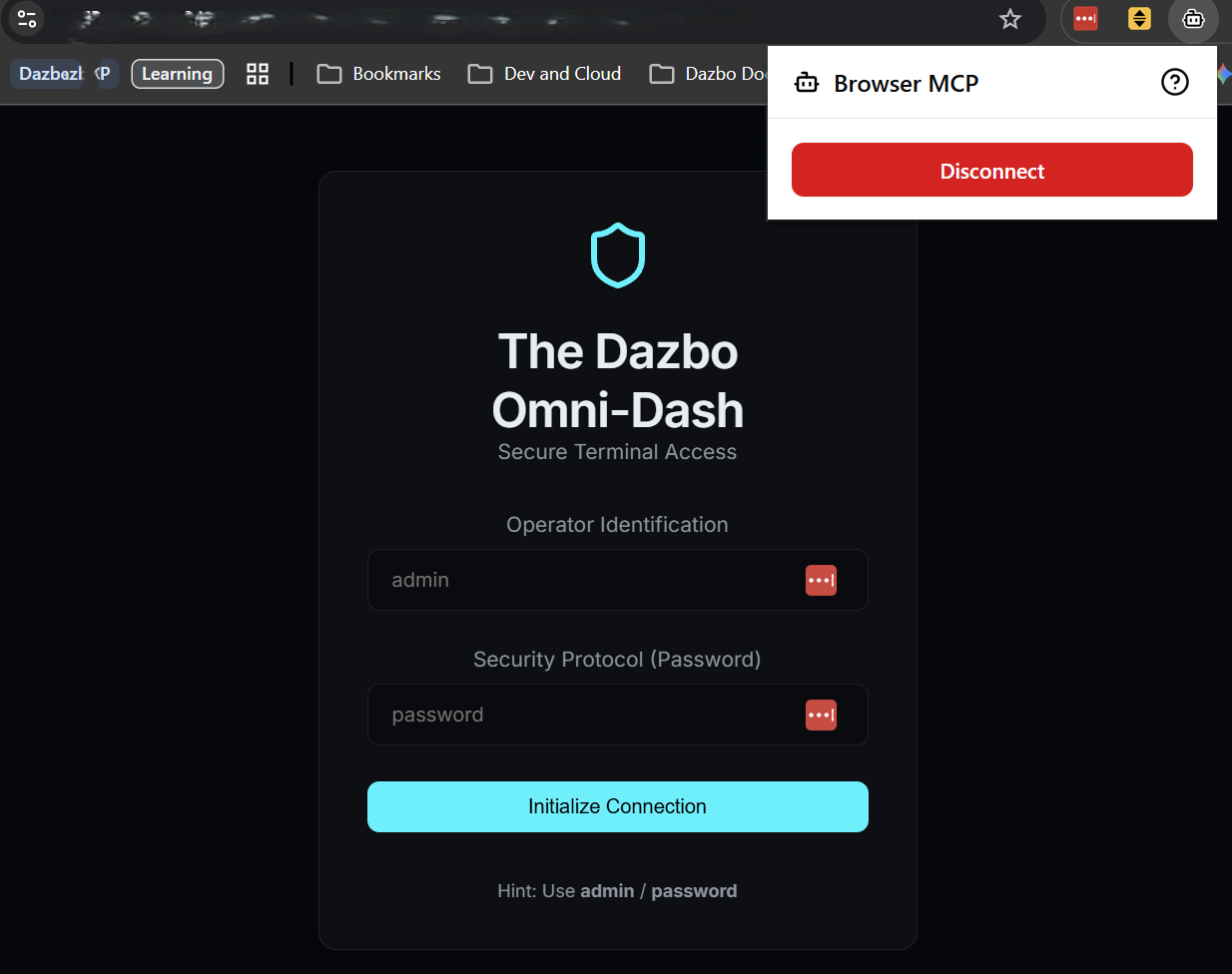
Teraz możemy użyć interfejsu wiersza poleceń Gemini, aby uruchomić test. Skopiuj ten prompt i wklej go w interfejsie wiersza poleceń Gemini:
Using BrowserMCP, connect to the application at http://localhost:5173. If the application is not showing a login screen, first logout. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Interfejs wiersza poleceń Gemini może najpierw sprawdzić, czy aplikacja demonstracyjna działa na określonym porcie. Następnie poprosi Cię o potwierdzenie działań, które planuje wykonać:
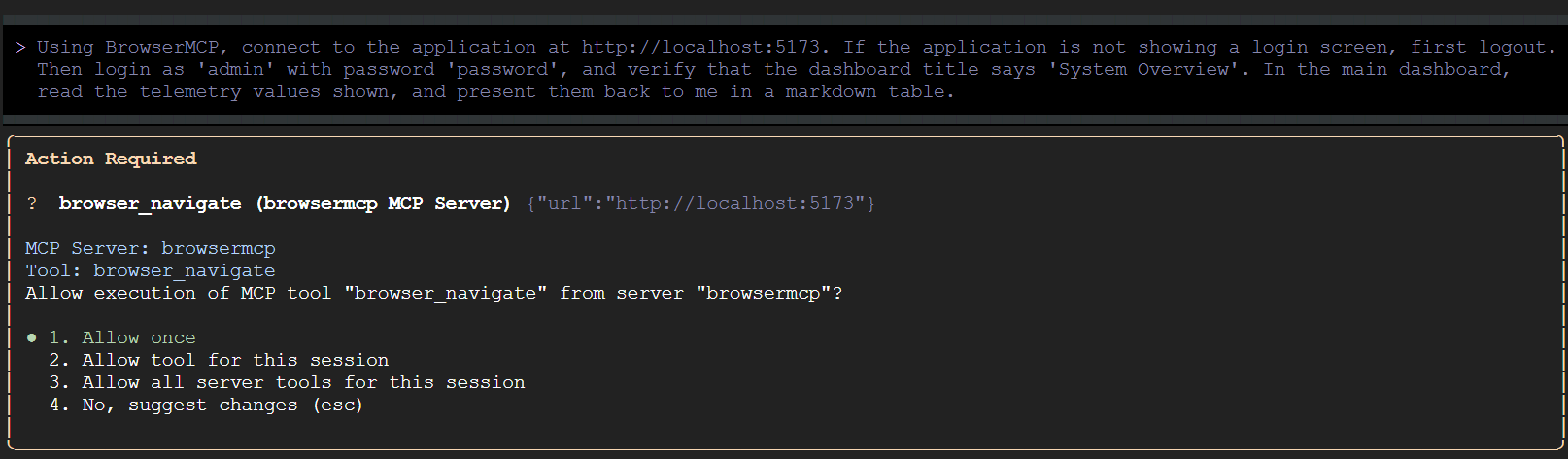
Zezwól interfejsowi wiersza poleceń Gemini na uruchamianie wszystkich narzędzi BrowserMCP w tej sesji. Następnie wróć do przeglądarki i obserwuj automatyczne interakcje.
Kilka uwag na temat powyższego prompta:
- Najpierw informujemy agenta, aby się wylogował, jeśli aplikacja jest już zalogowana. Pamiętaj, że nie musimy mówić agentowi, aby kliknął konkretny tekst, np. „Wyjdź z bramy”. Jest na tyle inteligentny, że wie, co kliknąć.
- Po zalogowaniu się i wyrenderowaniu strony głównej agent rejestruje informacje telemetryczne. Ponownie nie musimy mówić agentowi, aby szukał w określonych kafelkach lub dopasowywał konkretne słowa. Jeśli później rozszerzymy lub zmienimy informacje wyświetlane na tej stronie, ten prompt nadal będzie działać, a wynik będzie nadal rejestrowany w naszej tabeli Markdown.
Fajnie, prawda?
Na razie kończymy pracę z BrowserMCP, więc odłącz go w przeglądarce.
7. Automatyzacja za pomocą umiejętności i Playwright
Ograniczenia BrowserMCP
BrowserMCP to świetne rozwiązanie, ale ma kilka ograniczeń. Na przykład:
- Wymaga to istniejącej sesji przeglądarki z połączonym rozszerzeniem BrowserMCP. (Nie powoduje to rozpoczęcia nowych sesji).
- Nie obsługuje przeglądarek innych niż Chromium.
- Wymaga uruchomienia osobnego procesu przeglądarki na tym samym komputerze, na którym działa serwer MCP.
- Nie może współpracować z lokalnym systemem plików. Nie może na przykład tworzyć plików lokalnych z dowodami w postaci zrzutów ekranu ani pobierać i przechowywać plików z aplikacji internetowej, takich jak pliki PDF do pobrania.
- Nie jest deterministyczny. Będzie próbować wykonywać działania, o które go poprosisz, ale stan lokalny, np. nieoczekiwane wyskakujące okienko, może przerwać interakcję.
- Nie obsługuje działania „headless”, co oznacza, że nie może działać w potoku CI/CD bez prawdziwego okna przeglądarki.
Playwright
Playwright to znacznie bardziej zaawansowane narzędzie. Jest to sprawdzona platforma open source do automatyzacji i testowania przeglądarek. Może robić wiele rzeczy, których nie potrafi BrowserMCP, w tym wszystkie wymienione powyżej.
Znacznie lepiej nadaje się do przeprowadzania złożonych, niezawodnych i powtarzalnych scenariuszy testowych. Szczególnie dobrze sprawdza się w przypadku długotrwałych sesji lub równoległego prowadzenia wielu niezależnych sesji.
Jednak ta dodatkowa funkcja wiąże się z dużo bardziej stromą krzywą uczenia się.
Umiejętności
Na szczęście nie musimy uczyć się bezpośrednio korzystania z Playwright. Zamiast tego możemy użyć umiejętności agenta.

Czym dokładnie jest umiejętność agenta? Możesz to sobie wyobrazić jako ściśle powiązany pakiet wiedzy specjalistycznej, który możesz przekazać agentowi AI, gdy musi on wykonać określone zadanie. Zawiera instrukcje, sprawdzone metody, a czasami nawet skrypty pomocnicze dostosowane do konkretnego zadania.
Najciekawsza jest tu zasada stopniowego ujawniania informacji. Zamiast umieszczać w początkowym promcie systemowym LLM wszystkie możliwe dokumenty API i reguły platformy testowej, co zużywa okno kontekstowe i szybko wyczerpuje tokeny, agent odczytuje umiejętność tylko wtedy, gdy jest mu potrzebna. Dzięki temu kontekst podstawowy jest prosty i zwięzły, a szczegółowe instrukcje są pobierane w odpowiednim momencie. Tak, umiejętność może zawierać instrukcje, jak wykorzystać konkretne serwery MCP do wykonania zadania.
Wyobraź sobie scenę z filmu „Matrix”: agent patrzy na problem, zdaje sobie sprawę, że musi znać Playwright, pobiera umiejętność i nagle mówi: „Znam kung-fu”. Na wysięgniku Błyskawiczna wiedza ekspercka.
Jeśli chcesz dowiedzieć się więcej o umiejętnościach, zapoznaj się z tymi materiałami:
- Samouczek : pierwsze kroki z umiejętnościami Google Antigravity
- Ćwiczenia z programowania: tworzenie umiejętności dla Google Antigravity
Dlaczego umiejętności są idealne dla Playwright
Użycie umiejętności w tym miejscu to świetny wybór. Playwright jest niezwykle potężnym narzędziem, ale jego składnia może być skomplikowana. Dzięki nadaniu agentowi umiejętności Playwright nie musimy się martwić, że LLM będzie halucynować przestarzałą składnię lub pisać niestabilne selektory. Dostarczamy mu wyselekcjonowany, wiarygodny przewodnik, który dokładnie wyjaśnia, jak prawidłowo korzystać z Playwright.
Będę korzystać z interfejsu wiersza poleceń Playwright i powiązanych z nim umiejętności.
W tym podejściu instalujemy interfejs wiersza poleceń Playwright lokalnie, a następnie przekazujemy agentowi wiedzę potrzebną do korzystania z niego. Aby uniknąć nieporozumień: nie instaluję żadnego serwera MCP Playwright.
Instalowanie
Najpierw zainstalujmy interfejs wiersza poleceń Microsoft Playwright o otwartym kodzie źródłowym. Jeśli nie zostało to zrobione wcześniej, zamknij interfejs wiersza poleceń Gemini, wpisując /quit``. Następnie w terminalu:
# Pre-req: nodejs installed npm install -g @playwright/cli@latest # Install Playwright CLI globally npm install @playwright/test # Install Playwright test framework npx playwright install-deps # Install dependencies npx playwright install chromium chrome # Install browser binaries in Linux / WSL
Teraz dodajmy umiejętność. To polecenie pobierze podfolder umiejętności bezpośrednio z GitHuba do folderu umiejętności Gemini:
mkdir -p ~/.gemini/skills npx degit microsoft/playwright-cli/skills/playwright-cli ~/.gemini/skills/playwright-cli
Teraz możemy go przetestować.
# Launch Playwright CLI with visible browser playwright-cli open https://playwright.dev --headed
Powinno to spowodować uruchomienie sesji przeglądarki otwartej pod określonym adresem URL.
Chcę też, aby Gemini mógł używać Playwright w trybie „z interfejsem”, czyli z widocznym interfejsem. Ale ta umiejętność nie mówi Gemini, jak to zrobić. Dlatego w sekcji Core dodałem te wiersze do pliku ~/.gemini/skills/playwright-cli/SKILL.md:
# Add the following under the "playwright-cli open" command # Run in headed mode so we can see the browser playwright-cli open https://playwright.dev --headed
Testowanie za pomocą Playwright
Podobnie jak wcześniej musimy uruchomić aplikację (jeśli nie jest jeszcze uruchomiona). W początkowej sesji terminala wykonaj te czynności:
make dev
Następnie w drugiej sesji terminala tymczasowo wyłączmy BrowserMCP, aby agent nie miał problemu z wyborem narzędzi. Uruchom ponownie interfejs wiersza poleceń Gemini, a następnie uruchom to polecenie:
/mcp disable browsermcp
Teraz poprosimy Gemini o przejście do naszej aplikacji za pomocą Playwright. W przeciwieństwie do BrowserMCP nie musimy jednak najpierw uruchamiać przeglądarki. Playwright zrobi to za nas w ramach lokalnego procesu.
Wpisz ten prompt w interfejsie wiersza poleceń Gemini:
Using Playwright, connect to the application at http://localhost:5173. Then login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
(Jak zawsze, interfejs wiersza poleceń Gemini poprosi o zezwolenie przed uruchomieniem narzędzi).
Co się zmieniło?
- Nie musieliśmy najpierw uruchamiać przeglądarki.
- Nie musieliśmy uruchamiać rozszerzenia przeglądarki ani się z nim łączyć.
- Nie musimy najpierw prosić agenta o wylogowanie się. Test jest przeprowadzany w ramach „czystej” sesji.
- Możemy robić zrzuty ekranu i zapisywać je jako pliki lokalne.
Wkrótce w folderze output powinien pojawić się plik dashboard.png.
Pamiętaj, że wywołania narzędzi będą wykonywane w interfejsie wiersza poleceń Gemini, ale nie zobaczysz interfejsu przeglądarki. Dzieje się tak, ponieważ Playwright domyślnie działa w „trybie bez interfejsu graficznego”.
Jeśli jednak ponownie uruchomisz go z tym zmienionym promptem, zobaczysz też interfejs:
Using Playwright, connect to the application at http://localhost:5173 in **headed** mode, and keep the browser open when you're done. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown and record them. Then wait 3 seconds, read them again. Now present the data back to me in a markdown table.
Dane wyjściowe interfejsu wiersza poleceń Gemini powinny wyglądać mniej więcej tak:
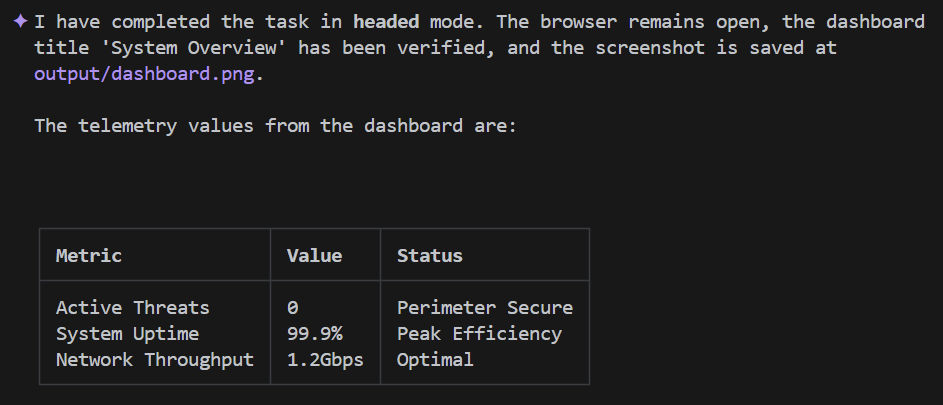
Jakie to było niesamowite?
8. Ale to nie wszystko, jest jeszcze MCP w Narzędziach deweloperskich w Chrome!
Narzędzia deweloperskie w Chrome to zestaw narzędzi dla programistów stron internetowych wbudowany w przeglądarkę Chrome, przeznaczony do tworzenia i debugowania stron internetowych. Istnieje od dawna. Chodzi o konsolę, z którą możesz wchodzić w interakcje, gdy w Chrome otworzysz Więcej narzędzi –> Narzędzia dla deweloperów.
Teraz ma jednak własny serwer MCP, który nie istniał, gdy w zeszłym roku rozważaliśmy automatyzację przeglądarki za pomocą interfejsu wiersza poleceń Gemini. Teraz możesz robić wszystko, co jest możliwe w przypadku BrowserMCP, i większość rzeczy, które możesz robić w przypadku Playwright, bez instalowania niczego w przeglądarce i bez instalowania lokalnego interfejsu wiersza poleceń.
Spróbujmy!
Obecnie potwierdziliśmy, że działa w Google Cloud Shell. W tej części użyjemy Google Cloud Shell w konsoli Google Cloud.
Otwórz konsolę i sesję Cloud Shell. Następnie:
# Clone the sample app - like we did before git clone https://github.com/derailed-dash/agentic-ui-testing cd agentic-ui-testing # Build the application - like we did before make install # Install the Chrome DevTools MCP server Gemini CLI Extension gemini extensions install https://github.com/ChromeDevTools/chrome-devtools-mcp
Teraz musimy zainstalować plik wykonywalny Chrome w Cloud Shell:
# Get the latest executable for Ubuntu wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb # Install it sudo apt install ./google-chrome-stable_current_amd64.deb -y # Check it and get the executable path which google-chrome # Cleanup rm google-chrome-stable_current_amd64.deb
Ostatni krok: musimy poinformować serwer MCP Narzędzi deweloperskich w Chrome, gdzie znajduje się plik wykonywalny Chrome. Możemy to zrobić, ustawiając w konfiguracji serwera MCP opcję executable-path na headless. Aby to zrobić, edytujemy plik ~/.gemini/extensions/chrome-devtools-mcp/gemini-extension.json:
{
"name": "chrome-devtools-mcp",
"version": "latest",
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest",
"--executable-path=/usr/bin/google-chrome",
"--headless"
]
}
}
}
Świetnie. Wszystko powinno być w porządku. Uruchom gemini w Cloud Shell i sprawdź, czy serwer MCP działa, używając polecenia /mcp list, tak jak wcześniej.
Na koniec możemy przetestować go za pomocą prompta.
Zróbmy to trochę inaczej. Tym razem polecimy interfejsowi wiersza poleceń Gemini uruchomić aplikację demonstracyjną i się z nią połączyć:
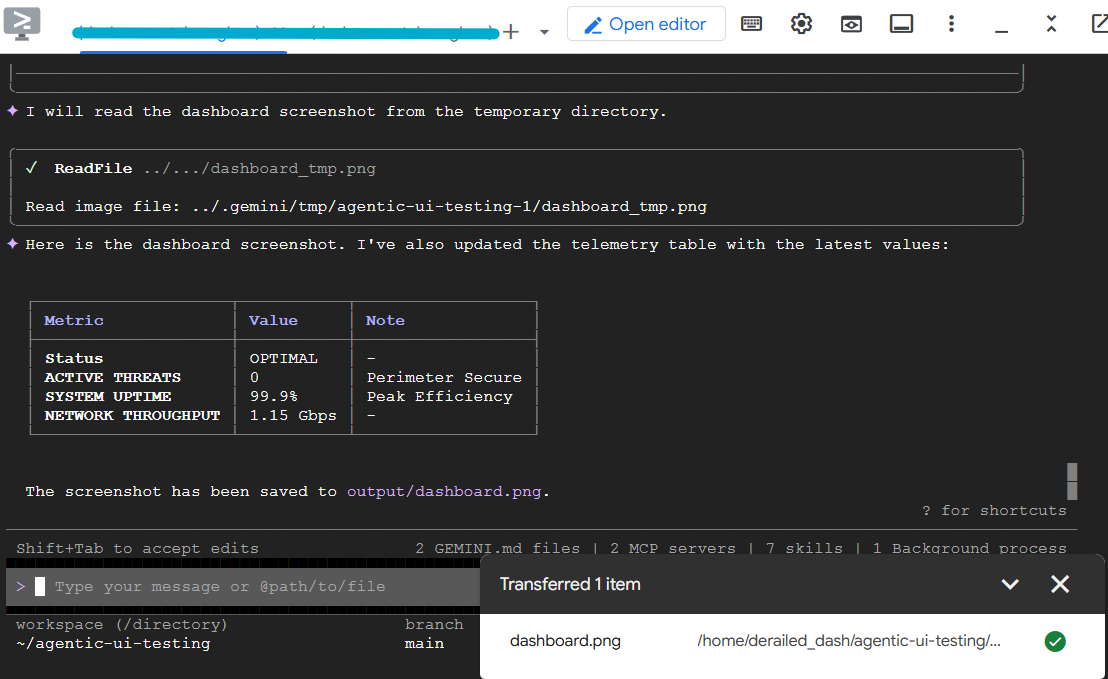
Launch my demo application with `make dev`. Then, using Chrome DevTools MCP, connect to the application at the exposed localhost URL. Login as 'admin' with password 'password', and verify that the dashboard title says 'System Overview'. Take a screenshot of the dashboard and save it to output/dashboard.png. In the main dashboard, read the telemetry values shown, and present them back to me in a markdown table.
Jak zwykle pojawi się prośba o zezwolenie na uruchomienie serwera MCP. Zauważysz jednak, że próbuje też aktywować umiejętność. Tak, to prawda: to rozszerzenie zawiera zarówno serwer MCP, jak i umiejętność, która podpowiada agentowi, jak najlepiej korzystać z serwera MCP. Super!
Po kilku sekundach interfejs wiersza poleceń Gemini powinien wyświetlić wyniki w tabeli i zapisać zrzut ekranu. Możesz pobrać zrzut ekranu z Cloud Shell, aby sprawdzić, czy wygląda prawidłowo.
9. You Can Do This in Antigravity Out of the Box!
Google Antigravity zawiera podagenta przeglądarki, który oferuje podobne funkcje jak interfejs wiersza poleceń Playwright. Gdy zapytasz Gemini w Antigravity o interaktywne uruchomienie adresu URL, automatycznie uruchomi on tego subagenta.
Ten podagent przyjmuje Twój ogólny cel (np. „Sprawdź, czy formularz logowania działa”), wizualnie analizuje układ strony za pomocą zrzutów ekranu i DOM oraz samodzielnie określa kliknięcia i naciśnięcia klawiszy. To w zasadzie wizualna, multimodalna AI, która porusza się po internecie tak jak człowiek. A co najlepsze, Automatycznie nagrywa filmy i robi zrzuty ekranu wszystkiego, co robi, i zapisuje je bezpośrednio w lokalnym obszarze roboczym jako wizualne potwierdzenie wykonanych zadań. Antigravity nazywa te dowody wizualne artefaktami.
Uwaga dla użytkowników WSL: uruchomienie agenta przeglądarki w Antigravity jest dość kłopotliwe. Udało mi się go uruchomić, ale w tym środowisku subagent jest niestabilny i niezbyt wiarygodny. To jeden z powodów, dla których uwielbiam interfejs wiersza poleceń Playwright.
10. Inne zastosowania automatyzacji przeglądarki
Automatyzacja przeglądarki nie polega tylko na sprawdzaniu, czy przycisk logowania działa przed wdrożeniem w piątkowe popołudnie. Gdy zdasz sobie sprawę, że możesz połączyć LLM bezpośrednio z przeglądarką, otworzy się przed Tobą zupełnie nowy świat projektów opartych na agentach.
Jeśli tworzysz własnych agentów AI, oto kilka sposobów, w jakie możesz wykorzystać narzędzia takie jak BrowserMCP czy interfejs wiersza poleceń Playwright, aby wykonać za Ciebie najtrudniejsze zadania:
- Osobisty asystent badawczy: wyobraź sobie, że wskazujesz agentowi konkretny adres URL i prosisz go o zbadanie tematu, ale witryna wymaga zalogowania się i przejścia przez złożone menu. Zamiast pisać niestandardowy skrypt do pobierania danych z internetu, który w przyszłym tygodniu może przestać działać, możesz po prostu poprosić agenta o zalogowanie się, przejście do danych i ich podsumowanie.
- Integrator „Swivel-Chair”: wszyscy mamy starsze systemy intranetowe, które nie mają interfejsów API. Chodzi o sytuacje, w których musisz ręcznie skopiować dane z systemu A i wkleić je do formularza w systemie B. Agent z automatyzacją przeglądarki może działać jako uniwersalny łącznik, odczytując ekran starszego systemu i wypełniając formularz w nowym.
- Automatyczne triage i usuwanie problemów: czy o 3 w nocy system monitorowania wysłał Ci alert P1? Agent może automatycznie otwierać adres URL konkretnego panelu, odczytywać wykresy lub dzienniki (korzystając z funkcji widzenia multimodalnego) i publikować podsumowanie bezpośrednio na kanale Slack, co pozwala zaoszczędzić cenny czas podczas incydentu.
Zaletą tego podejścia jest to, że nie musisz już ograniczać się do dostępnych interfejsów API. Jeśli człowiek może to zrobić w przeglądarce, Twój agent też może.
11. Podsumowanie
Gratulacje! Właśnie udało Ci się utworzyć i przeprowadzić automatyczne, niezawodne testy interfejsu, po prostu mówiąc agentowi AI, co ma zrobić, w zwykłym języku. Bez niestabilnych selektorów CSS i złożonych skryptów konfiguracji.
Wiesz już:
- Testowanie interfejsu nie musi być trudne: skupiając się na celu testu, a nie na niestabilnej implementacji DOM, możemy znacznie zmniejszyć nakłady na utrzymanie.
- Protokół kontekstu modelu (MCP) zapewnia agentom uniwersalny dostęp do narzędzi, danych i środowisk typu plug-and-play.
- BrowserMCP to niesamowite narzędzie, które umożliwia korzystanie z funkcji agenta w lokalnych, istniejących sesjach Chrome.
- Umiejętności i interfejs wiersza poleceń Playwright zapewniają nowy poziom powtarzalnego i deterministycznego testowania automatyzacji – wszystko to dzięki progresywnemu ujawnianiu informacji.
- Subagent przeglądarki Antigravity idzie o krok dalej, wprowadzając autonomiczne, multimodalne nagrywanie nawigacji i artefaktów od razu po wyjęciu z pudełka.
A teraz idź i zautomatyzuj nudne czynności!
Useful Links
Jeśli chcesz dowiedzieć się więcej o narzędziach i koncepcjach, które omówiliśmy dzisiaj, zapoznaj się z tymi materiałami:
Kod repozytorium
- Repozytorium GitHub agentic-ui-testing – jeśli to ćwiczenie było dla Ciebie przydatne, oznacz repozytorium gwiazdką.
Podstawowe narzędzia i metodologie
- Repozytorium GitHub BrowserMCP
- Dokumentacja BrowserMCP
- Dodatek do interfejsu wiersza poleceń Gemini BrowserMCP – jeśli ten przewodnik Ci się przydał, dodaj gwiazdkę do repozytorium.
- Playwright
- Google AI Studio
- Narzędzia deweloperskie w Chrome
- Chrome DevTools MCP
Koncepcje i umiejętności agentowe
- Samouczek: pierwsze kroki z umiejętnościami Google Antigravity
- Ćwiczenia z programowania: pierwsze kroki z umiejętnościami Antigravity
- Dazbo's Original Blog: Creating an Automated UI Test in Seconds
Inne