
1. Wprowadzenie
Google Antigravity to oparta na agentach platforma dla programistów, która została zaprojektowana, aby ułatwić Ci programowanie w erze agentów. Antigravity to centralne centrum dowodzenia agentów AI, które zapewnia ujednoliconą platformę do uruchamiania, monitorowania i koordynowania ich działań.
W tym ćwiczeniu najpierw poznamy umiejętności agentów, czyli lekki, otwarty format rozszerzania możliwości agentów AI o specjalistyczną wiedzę i przepływy pracy. Dowiesz się, czym są umiejętności agenta, jakie są ich zalety i jak są tworzone. Następnie utworzysz wiele umiejętności agenta, od formatowania Git, przez generator szablonów, po szkielet kodu narzędzia i inne, które można wykorzystać w Antigravity.
Wymagania wstępne:
- Antigravity jest zainstalowany i skonfigurowany.
- Podstawowa wiedza o Google Antigravity. Zalecamy ukończenie ćwiczenia Pierwsze kroki z Google Antigravity.
2. Dlaczego umiejętności
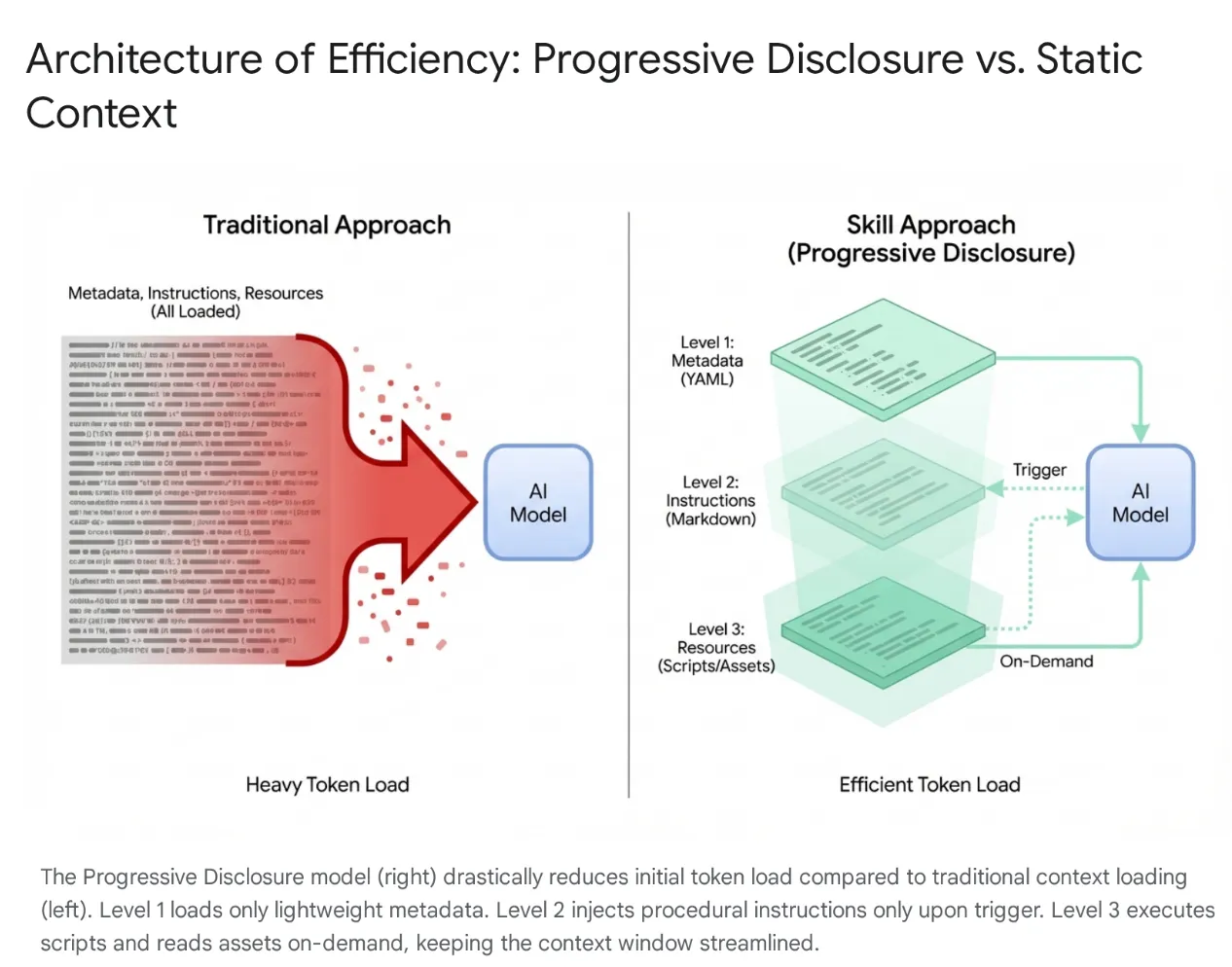
Nowoczesne agenty AI ewoluowały od prostych słuchaczy do złożonych systemów wnioskowania, które integrują się z lokalnymi systemami plików i narzędziami zewnętrznymi (za pomocą serwerów MCP). Jednak bezkrytyczne ładowanie agenta całymi bazami kodu i setkami narzędzi prowadzi do nasycenia kontekstu i „przeładowania narzędziami”. Nawet w przypadku dużych okien kontekstowych umieszczanie w aktywnej pamięci 40–50 tys. tokenów nieużywanych narzędzi powoduje duże opóźnienia, marnotrawstwo środków i „psucie się kontekstu”, w którym model jest zdezorientowany przez nieistotne dane.
Rozwiązanie: umiejętności agenta
Aby rozwiązać ten problem, firma Anthropic wprowadziła umiejętności agenta, zmieniając architekturę z monolitycznego wczytywania kontekstu na stopniowe ujawnianie informacji. Zamiast zmuszać model do „zapamiętywania” każdego konkretnego przepływu pracy (np. migracji baz danych lub audytów bezpieczeństwa) na początku sesji, te funkcje są pakowane w modułowe, wykrywalne jednostki.
Jak to działa
Model jest początkowo udostępniany tylko w formie uproszczonego „menu” metadanych. Wczytuje on rozbudowaną wiedzę proceduralną (instrukcje i skrypty) tylko wtedy, gdy intencja użytkownika jest zgodna z umiejętnością. Dzięki temu programista, który chce refaktoryzować oprogramowanie pośredniczące uwierzytelniania, uzyskuje kontekst bezpieczeństwa bez wczytywania niezwiązanych potoków CSS, co sprawia, że kontekst jest prosty, szybki i opłacalny.
3. Umiejętności agenta i Antigravity
W ekosystemie Antigravity umiejętności działają jako specjalistyczne moduły szkoleniowe, które wypełniają lukę między modelami ogólnymi a konkretnym kontekstem. Umożliwiają one „wyposażenie” agenta w określony zestaw instrukcji i protokołów, takich jak standardy migracji baz danych czy kontrole bezpieczeństwa, tylko wtedy, gdy zostanie zgłoszone odpowiednie żądanie. Dzięki dynamicznemu wczytywaniu tych protokołów wykonawczych umiejętności skutecznie przekształcają AI z ogólnego programisty w specjalistę, który ściśle przestrzega skodyfikowanych sprawdzonych metod i standardów bezpieczeństwa organizacji.
Czym jest umiejętność w Antigravity?
W kontekście Google Antigravity umiejętność to pakiet oparty na katalogu, który zawiera plik definicji (SKILL.md) i opcjonalne zasoby pomocnicze (skrypty, odwołania, szablony).
Jest to mechanizm rozszerzania możliwości na żądanie.
- Na żądanie: w przeciwieństwie do prompta systemowego (który jest zawsze wczytywany) umiejętność jest wczytywana do kontekstu agenta tylko wtedy, gdy agent uzna, że jest ona istotna dla bieżącego żądania użytkownika. Optymalizuje to okno kontekstu i zapobiega rozpraszaniu agenta przez nieistotne instrukcje. W przypadku dużych projektów z dziesiątkami narzędzi selektywne wczytywanie ma kluczowe znaczenie dla wydajności i dokładności rozumowania.
- Rozszerzenie możliwości: umiejętności mogą nie tylko wydawać polecenia, ale też je wykonywać. Dzięki pakietom skryptów w językach Python lub powłoce bash umiejętność może wykonywać złożone, wieloetapowe działania na komputerze lokalnym lub w sieciach zewnętrznych bez konieczności ręcznego uruchamiania poleceń przez użytkownika. Spowoduje to przekształcenie agenta z generatora tekstu w użytkownika narzędzi.
Umiejętności a ekosystem (narzędzia, reguły i przepływy pracy)
Protokół Model Context Protocol (MCP) pełni funkcję „rąk” agenta – zapewnia trwałe połączenia z zewnętrznymi systemami, takimi jak GitHub czy PostgreSQL – a umiejętności działają jak „mózg”, który nimi kieruje.
MCP zarządza infrastrukturą stanową, a umiejętności to lekkie, efemeryczne definicje zadań, które zawierają metodologię korzystania z tych narzędzi. To podejście bezserwerowe umożliwia agentom wykonywanie zadań ad hoc (takich jak generowanie dzienników zmian lub migracji) bez obciążenia operacyjnego związanego z uruchamianiem trwałych procesów. Kontekst jest wczytywany tylko wtedy, gdy zadanie jest aktywne, i zwalniany natychmiast po jego zakończeniu.
Umiejętności są wywoływane przez agenta: model automatycznie wykrywa intencje użytkownika i dynamicznie udostępnia odpowiednie umiejętności. Ta architektura umożliwia zaawansowane komponowanie. Na przykład globalna reguła może wymuszać używanie umiejętności „Bezpieczna migracja” podczas zmian w bazie danych, a pojedynczy przepływ pracy może koordynować wiele umiejętności, aby utworzyć niezawodny potok wdrażania.
4. Tworzenie umiejętności
Tworzenie umiejętności w Antigravity wymaga zachowania określonej struktury katalogów i formatu pliku. Ta standaryzacja zapewnia przenośność umiejętności oraz możliwość ich niezawodnego parsowania i wykonywania przez agenta. Projekt jest celowo prosty i opiera się na powszechnie znanych formatach, takich jak Markdown i YAML, co obniża próg wejścia dla deweloperów, którzy chcą rozszerzyć możliwości swojego środowiska IDE.
Struktura katalogu
Typowy katalog umiejętności wygląda tak:
my-skill/
├── SKILL.md # The definition file
├── scripts/ # [Optional] Python, Bash, or Node scripts
├── run.py
└── util.sh
├── references/ # [Optional] Documentation or templates
└── api-docs.md
└── assets/ # [Optional] Static assets (images, logos)
Ta struktura skutecznie rozdziela poszczególne obszary. Logika (scripts) jest oddzielona od instrukcji (SKILL.md) i wiedzy (references), co odzwierciedla standardowe praktyki inżynierii oprogramowania.
Plik definicji SKILL.md
Plik SKILL.md to mózg umiejętności. Informuje ona agenta, czym jest umiejętność, kiedy należy jej używać i jak ją wykorzystać.
Składa się z 2 części:
- YAML Frontmatter
- Treść w formacie Markdown.
YAML Frontmatter
Jest to warstwa metadanych. Jest to jedyna część umiejętności indeksowana przez router wysokiego poziomu agenta. Gdy użytkownik wyśle prompt, agent dopasuje go semantycznie do pól opisu wszystkich dostępnych umiejętności.
---
name: database-inspector
description: Use this skill when the user asks to query the database, check table schemas, or inspect user data in the local PostgreSQL instance.
---
Kluczowe pola:
- name: ten element nie jest obowiązkowy. Musi być niepowtarzalna w danym zakresie. Małe litery, dozwolone łączniki (np.
postgres-query,pr-reviewer). Jeśli nie podasz tej wartości, domyślnie zostanie użyta nazwa katalogu. - description: to pole jest obowiązkowe i najważniejsze. Pełni funkcję „frazy wywołującej”. Musi być wystarczająco opisowy, aby model LLM mógł rozpoznać trafność semantyczną. Nie wystarczy ogólny opis, np. „Narzędzia do baz danych”. Dokładny opis, np. „Wykonuje zapytania SQL tylko do odczytu w lokalnej bazie danych PostgreSQL, aby pobrać dane użytkownika lub transakcji. Użyj tego do debugowania stanów danych" zapewnia prawidłowe rozpoznanie umiejętności.
Treść w formacie Markdown
Treść zawiera instrukcje. Jest to „tworzenie promptów” zapisane w pliku. Gdy umiejętność jest aktywowana, te treści są wstrzykiwane do okna kontekstu agenta.
Treść powinna zawierać:
- Cel: jasne określenie, co umożliwia dana umiejętność.
- Instrukcje: logika krok po kroku.
- Przykłady: przykłady danych wejściowych i wyjściowych, które pomagają modelowi osiągać lepsze wyniki.
- Ograniczenia: reguły „Nie” (np. „Nie uruchamiaj zapytań DELETE”).
Przykładowa treść pliku SKILL.md:
Database Inspector
Goal
To safely query the local database and provide insights on the current data state.
Instructions
- Analyze the user's natural language request to understand the data need.
- Formulate a valid SQL query.
- CRITICAL: Only SELECT statements are allowed.
- Use the script scripts/query_runner.py to execute the SQL.
- Command: python scripts/query_runner.py "SELECT * FROM..."
- Present the results in a Markdown table.
Constraints
- Never output raw user passwords or API keys.
- If the query returns > 50 rows, summarize the data instead of listing it all.
Integracja skryptu
Jedną z najważniejszych funkcji umiejętności jest możliwość delegowania wykonywania zadań do skryptów. Umożliwia to agentowi wykonywanie działań, które są trudne lub niemożliwe do wykonania bezpośrednio przez LLM (takich jak wykonywanie kodu binarnego, złożone obliczenia matematyczne czy interakcje z systemami starszego typu).
Skrypty są umieszczane w podkatalogu scripts/. SKILL.md odwołuje się do nich za pomocą ścieżki względnej.
5. Umiejętności tworzenia
Celem tej sekcji jest tworzenie umiejętności, które można zintegrować z Antigravity i stopniowo prezentować różne funkcje, takie jak zasoby czy skrypty.
Umiejętności możesz pobrać z repozytorium GitHub: https://github.com/rominirani/antigravity-skills.
Zanim dowiemy się, jak powstały poszczególne umiejętności, zobaczmy, jak je skonfigurować i udostępnić w pakiecie produktów Antigravity. Poniższe foldery są aktualne w momencie publikacji tego modułu.
Korzystanie z Antigravity lub Antigravity CLI
Umiejętności można zdefiniować w 2 zakresach, co pozwala na określenie umiejętności związanych z projektem i umiejętności użytkownika, czyli umiejętności globalnych:
- Zakres globalny (
~/.gemini/config/skills/): dostępny we wszystkich usługach Antigravity (Antigravity, Antigravity IDE, Antigravity CLI) i projektach. Te umiejętności są dostępne we wszystkich projektach na urządzeniu użytkownika. Jest to odpowiednie w przypadku ogólnych narzędzi, takich jak „Format JSON”, „Generate UUIDs”, „Review Code Style” czy integracja z osobistymi narzędziami zwiększającymi produktywność. - Zakres projektu lub obszaru roboczego (
<project-root>/.agents/skills/): ta opcja sprawi, że umiejętność będzie dostępna tylko w określonym projekcie. Jest to idealne rozwiązanie w przypadku skryptów związanych z konkretnym projektem, takich jak wdrażanie w określonym środowisku, zarządzanie bazą danych aplikacji czy generowanie powtarzalnego kodu dla zastrzeżonych platform.
Instalowanie umiejętności w Antigravity lub Antigravity CLI
W tym samouczku wystarczy wykonać te czynności (możesz też zrobić to po swojemu):
Krok 1. Wykonaj git clone repozytorium https://github.com/rominirani/antigravity-skills.
Krok 2. W zależności od tego, czy używasz Antigravity czy Antigravity CLI, przejdź do folderu antigravity-skills/skills_tutorial.
Krok 3. Znajdziesz zestaw umiejętności podzielonych na odpowiednie foldery. Skopiuj te 4 foldery:
git-commit-formatterlicense-header-adderdatabase-schema-validatorjson-to-pydantic
do folderu docelowych umiejętności dla produktu (w zakresie projektu lub globalnym).
Krok 4. Jeśli używasz Antigravity lub Antigravity CLI , skopiuj go do <project-root>/.agents/skills/ (zakres projektu).
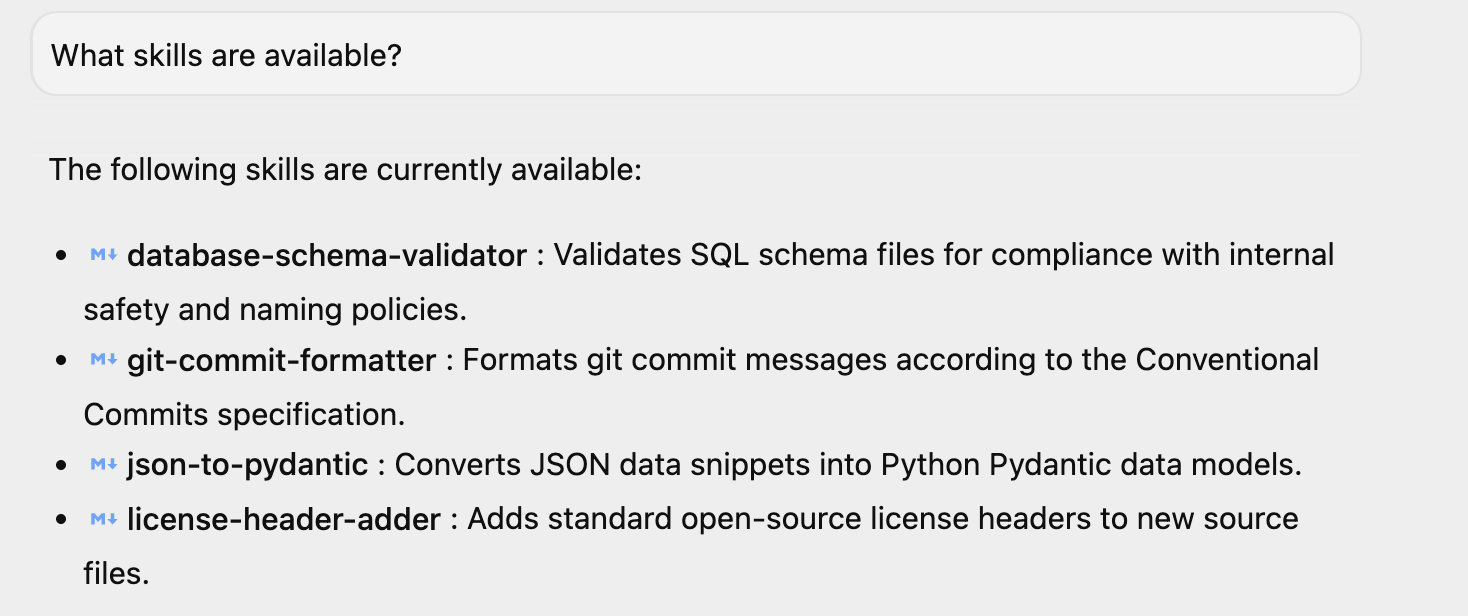
Jeśli masz uruchomioną Antigravity, możesz zadać proste pytanie „Jakie umiejętności są dostępne?”, a ona odpowie na nie. Możesz tam zobaczyć 4 umiejętności. Możesz też mieć dodatkowe umiejętności, jeśli zostały one zainstalowane w Twoim środowisku.
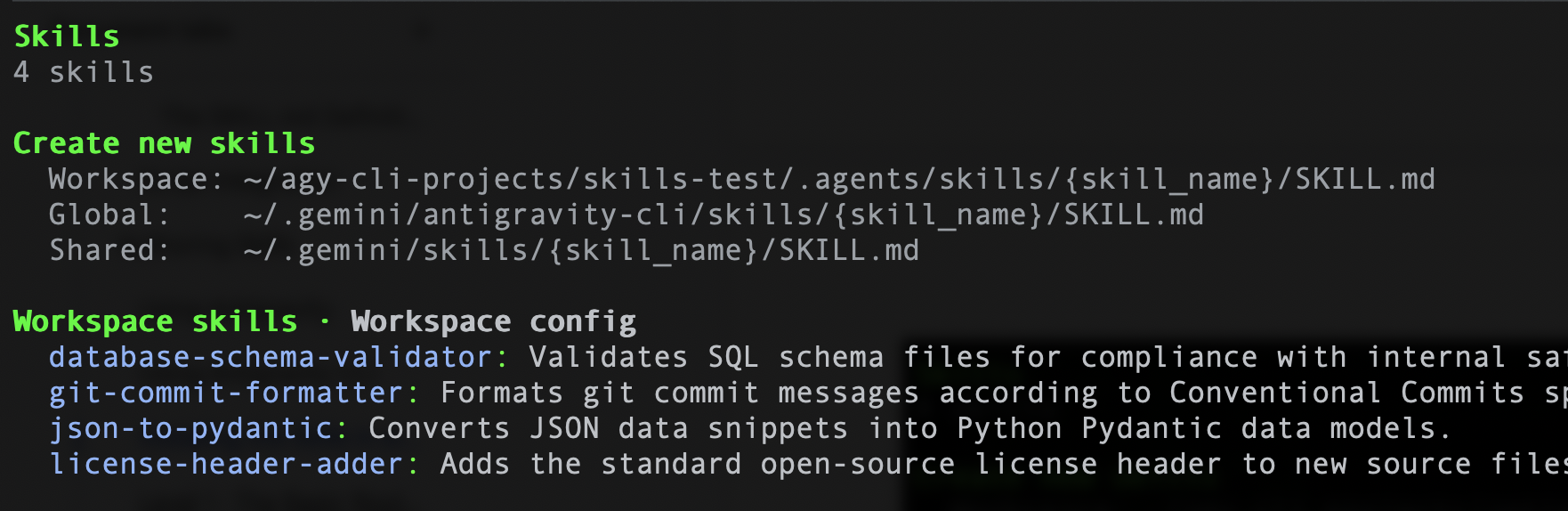
Podobnie, jeśli używasz interfejsu Antigravity CLI, możesz wpisać to polecenie: /skills. Powinno ono wyświetlić 4 umiejętności. Przykładowy kod:
Wiemy już, jak skonfigurować umiejętności. Przyjrzyjmy się teraz każdej z nich i zobaczmy, jak zostały utworzone. Możesz też użyć tych szablonów do tworzenia własnych umiejętności.
Poziom 1. Podstawowy router ( git-commit-formatter)
Można to uznać za „Hello World” w przypadku umiejętności.
Deweloperzy często piszą leniwe komunikaty o zatwierdzeniu, np. „wip”, „fix bug”, „updates”. Ręczne wymuszanie „Conventional Commits” jest żmudne i często zapominane. Wdróżmy umiejętność, która wymusza stosowanie specyfikacji Conventional Commits. Wystarczy, że poinstruujemy agenta w zakresie zasad, a będzie on mógł egzekwować ich przestrzeganie.
git-commit-formatter/
└── SKILL.md (Instructions only)
Plik SKILL.md jest widoczny poniżej:
---
name: git-commit-formatter
description: Formats git commit messages according to Conventional Commits specification. Use this when the user asks to commit changes or write a commit message.
---
Git Commit Formatter Skill
When writing a git commit message, you MUST follow the Conventional Commits specification.
Format
`<type>[optional scope]: <description>`
Allowed Types
- **feat**: A new feature
- **fix**: A bug fix
- **docs**: Documentation only changes
- **style**: Changes that do not affect the meaning of the code (white-space, formatting, etc)
- **refactor**: A code change that neither fixes a bug nor adds a feature
- **perf**: A code change that improves performance
- **test**: Adding missing tests or correcting existing tests
- **chore**: Changes to the build process or auxiliary tools and libraries such as documentation generation
Instructions
1. Analyze the changes to determine the primary `type`.
2. Identify the `scope` if applicable (e.g., specific component or file).
3. Write a concise `description` in an imperative mood (e.g., "add feature" not "added feature").
4. If there are breaking changes, add a footer starting with `BREAKING CHANGE:`.
Example
`feat(auth): implement login with google`
Jak uruchomić ten przykład w Antigravity
Poniższe kroki zakładają, że masz na komputerze lokalnym zainstalowany i prawidłowo skonfigurowany system Git.
Jeśli masz już uruchomione narzędzie Antigravity lub Antigravity CLI, wykonaj te czynności:
Krok 1. Skonfiguruj testowe repozytorium Git
Poproś agenta o skonfigurowanie czystego, odizolowanego katalogu do testowania operacji Git.
Twój prompt:
Create a folder named git_test in the workspace, initialize a git repository inside it, and create an initial file auth.py with def login(): pass. Stage this file and make an initial commit.
Agent utworzy katalog, zainicjuje repozytorium, przygotuje plik i zatwierdzi go za pomocą komunikatu takiego jak „initial commit”.
Krok 2. Wprowadź zmianę w kodzie
Poproś agenta o zmodyfikowanie kodu, aby można było zatwierdzić zmianę.
Twój prompt:
In the git_test folder, modify auth.py to add Google Login functionality.
Agent zmodyfikuje plik, aby dodać nową funkcję, przygotowując go do fazy zatwierdzania.
Krok 3. Przygotuj i zatwierdź zmiany
Wywołaj git-commit-formatter umiejętność, prosząc agenta o zebranie zmian i utworzenie zatwierdzenia.
Twój prompt:
Stage the changes in the git_test folder and commit them. Make sure to format the commit message using the Conventional Commits skill.
Agent uruchomi polecenie git add auth.py, przeanalizuje różnicę, aby stwierdzić, że do modułu auth dodano nową funkcję, i sformułuje komunikat zatwierdzenia zgodny z konwencją, np. feat(auth): implement google login, a następnie uruchomi polecenie git commit.
Krok 4. Sprawdź dziennik Git
Poproś pracownika pomocy o pobranie historii Git, aby sprawdzić, czy sformatowane zatwierdzenie zostało zarejestrowane.
Twój prompt:
Show me the git log in the git_test folder.
Agent uruchomi polecenie git log -n 5 i zwróci dane wyjściowe z sformatowanym komunikatem zatwierdzenia.
Poziom 2. Wykorzystanie komponentów (license-header-adder)
To jest wzorzec „Odwołanie”.
Każdy plik źródłowy w projekcie firmowym może wymagać nagłówka licencji Apache 2.0 o długości 20 wierszy. Umieszczanie tego tekstu statycznego bezpośrednio w prompcie (lub SKILL.md) jest nieefektywne. Za każdym razem, gdy umiejętność jest indeksowana, zużywa tokeny, a model może „halucynować” błędy w tekście prawnym. Dobrym rozwiązaniem jest przeniesienie tekstu statycznego do pliku tekstowego w folderze resources/. Umiejętność instruuje agenta, aby odczytywał ten plik tylko w razie potrzeby.
Pliki znajdziesz w folderze license-header-adder w katalogu skills.
license-header-adder/
├── SKILL.md
└── resources/
└── HEADER_TEMPLATE.txt (The heavy text)
Plik SKILL.md jest widoczny poniżej:
---
name: license-header-adder
description: Adds the standard open-source license header to new source files. Use involves creating new code files that require copyright attribution.
---
# License Header Adder Skill
This skill ensures that all new source files have the correct copyright header.
## Instructions
1. **Read the Template**:
First, read the content of the header template file located at `resources/HEADER_TEMPLATE.txt`.
2. **Prepend to File**:
When creating a new file (e.g., `.py`, `.java`, `.js`, `.ts`, `.go`), prepend the `target_file` content with the template content.
3. **Modify Comment Syntax**:
- For C-style languages (Java, JS, TS, C++), keep the `/* ... */` block as is.
- For Python, Shell, or YAML, convert the block to use `#` comments.
- For HTML/XML, use `<!-- ... -->`.
Jak uruchomić ten przykład w Antigravity
Jeśli masz już uruchomione narzędzie Antigravity lub Antigravity CLI, wykonaj te czynności:
Krok 1. Utwórz plik Pythona z przykładowym kodem
Twój prompt:
Create a new file my_script.py with the following python code:
def hello():
print("Hello, World!")
Co się stało (wyjaśnienie): agent wywołał narzędzie do zapisywania plików (write_to_file), aby utworzyć nowy plik o nazwie my_script.py bezpośrednio w aktywnym katalogu obszaru roboczego i zapisać w nim podstawową funkcję Pythona. Dodatkowo prompt wywołał umiejętność license-header-adder. Agent odnalazł i odczytał plik szablonu licencji (HEADER_TEMPLATE.txt), zmienił styl komentarzy z blokowych komentarzy w stylu C (/* … */) na komentarze w stylu Pythona (#) i dodał go na początku pliku za pomocą narzędzia replace_file_content.
Krok 2. Sprawdź zawartość pliku
Sprawdź plik my_script.py. U góry będzie zawierać nagłówek licencji.
Poziom 3. Uczenie się na przykładach (json-to-pydantic)
Wzorzec „Few-Shot”.
Konwertowanie luźnych danych (np. odpowiedzi interfejsu JSON API) na ścisły kod (np. modele Pydantic) wymaga podjęcia wielu decyzji. Jak powinniśmy nazywać zajęcia? Czy powinniśmy używać Optional? snake_case czy camelCase? Wypisanie tych 50 reguł w języku angielskim jest żmudne i podatne na błędy.
Modele LLM to silniki dopasowywania wzorców.
Tworzenie umiejętności na podstawie wzorcowego przykładu (Input –> Output) jest często skuteczniejsze niż obszerne instrukcje.
Otwórz folder json-to-pydantic/ zawierający pliki umiejętności, jak pokazano poniżej:
json-to-pydantic/
├── SKILL.md
└── examples/
├── input_data.json (The Before State)
└── output_model.py (The After State)
Plik SKILL.md jest widoczny poniżej:
---
name: json-to-pydantic
description: Converts JSON data snippets into Python Pydantic data models.
---
# JSON to Pydantic Skill
This skill helps convert raw JSON data or API responses into structured, strongly-typed Python classes using Pydantic.
Instructions
1. **Analyze the Input**: Look at the JSON object provided by the user.
2. **Infer Types**:
- `string` -> `str`
- `number` -> `int` or `float`
- `boolean` -> `bool`
- `array` -> `List[Type]`
- `null` -> `Optional[Type]`
- Nested Objects -> Create a separate sub-class.
3. **Follow the Example**:
Review `examples/` to see how to structure the output code. notice how nested dictionaries like `preferences` are extracted into their own class.
- Input: `examples/input_data.json`
- Output: `examples/output_model.py`
Style Guidelines
- Use `PascalCase` for class names.
- Use type hints (`List`, `Optional`) from `typing` module.
- If a field can be missing or null, default it to `None`.
W folderze /examples znajduje się plik JSON i plik wyjściowy , czyli plik Pythona. Oba te rodzaje znajdziesz poniżej:
input_data.json
{
"user_id": 12345,
"username": "jdoe_88",
"is_active": true,
"preferences": {
"theme": "dark",
"notifications": [
"email",
"push"
]
},
"last_login": "2024-03-15T10:30:00Z",
"meta_tags": null
}
output_model.py
from pydantic import BaseModel, Field
from typing import List, Optional
class Preferences(BaseModel):
theme: str
notifications: List[str]
class User(BaseModel):
user_id: int
username: str
is_active: bool
preferences: Preferences
last_login: Optional[str] = None
meta_tags: Optional[List[str]] = None
Jak uruchomić ten przykład w Antigravity
Jeśli masz już uruchomione narzędzie Antigravity lub Antigravity CLI, wykonaj te czynności:
Krok 1. Utwórz plik JSON z danymi przykładowymi
Poproś agenta o utworzenie nowego pliku product.json zawierającego nieprzetworzony ładunek JSON.
Twój prompt:
Create a new file product.json with the following JSON:
{
"product": "Widget",
"cost": 10.99,
"stock": null
}
Krok 2. Skonwertuj JSON na model Pydantic
Wywołaj funkcję json-to-pydantic, aby przekonwertować dane JSON na uporządkowaną klasę Pydantic.
Twój prompt:
Convert the JSON in product.json to a Pydantic model and save it to product_model.py.
Krok 3. Sprawdź dane wyjściowe
Sprawdź plik product_model.py. Będzie on zawierać ukończony model Pydantic.
Poziom 4. Logika proceduralna (database-schema-validator)
Jest to wzorzec „Korzystanie z narzędzi”.
Jeśli zapytasz LLM „Czy ten schemat jest bezpieczny?”, może odpowiedzieć, że wszystko jest w porządku, nawet jeśli brakuje kluczowego klucza podstawowego, ponieważ kod SQL wygląda poprawnie.
Przekażmy to sprawdzenie do deterministycznego skryptu. Nasza database-schema-validator umiejętność przekieruje agenta do uruchomienia napisanego przez nas skryptu w Pythonie. Skrypt podaje prawdę w formie binarnej (prawda/fałsz).
database-schema-validator/
├── SKILL.md
└── scripts/
└── validate_schema.py (The Validator)
Plik SKILL.md jest widoczny poniżej:
---
name: database-schema-validator
description: Validates SQL schema files for compliance with internal safety and naming policies.
---
# Database Schema Validator Skill
This skill ensures that all SQL files provided by the user comply with our strict database standards.
Policies Enforced
1. **Safety**: No `DROP TABLE` statements.
2. **Naming**: All tables must use `snake_case`.
3. **Structure**: Every table must have an `id` column as PRIMARY KEY.
Instructions
1. **Do not read the file manually** to check for errors. The rules are complex and easily missed by eye.
2. **Run the Validation Script**:
Use the `run_command` tool to execute the python script provided in the `scripts/` folder against the user's file.
`python scripts/validate_schema.py <path_to_user_file>`
3. **Interpret Output**:
- If the script returns **exit code 0**: Tell the user the schema looks good.
- If the script returns **exit code 1**: Report the specific error messages printed by the script to the user and suggest fixes.
Plik validate_schema.py jest widoczny poniżej:
import sys
import re
def validate_schema(filename):
"""
Validates a SQL schema file against internal policy:
1. Table names must be snake_case.
2. Every table must have a primary key named 'id'.
3. No 'DROP TABLE' statements allowed (safety).
"""
try:
with open(filename, 'r') as f:
content = f.read()
lines = content.split('\n')
errors = []
# Check 1: No DROP TABLE
if re.search(r'DROP TABLE', content, re.IGNORECASE):
errors.append("ERROR: 'DROP TABLE' statements are forbidden.")
# Check 2 & 3: CREATE TABLE checks
table_defs = re.finditer(r'CREATE TABLE\s+(?P<name>\w+)\s*\((?P<body>.*?)\);', content, re.DOTALL | re.IGNORECASE)
for match in table_defs:
table_name = match.group('name')
body = match.group('body')
# Snake case check
if not re.match(r'^[a-z][a-z0-9_]*$', table_name):
errors.append(f"ERROR: Table '{table_name}' must be snake_case.")
# Primary key check
if not re.search(r'\bid\b.*PRIMARY KEY', body, re.IGNORECASE):
errors.append(f"ERROR: Table '{table_name}' is missing a primary key named 'id'.")
if errors:
for err in errors:
print(err)
sys.exit(1)
else:
print("Schema validation passed.")
sys.exit(0)
except FileNotFoundError:
print(f"Error: File '{filename}' not found.")
sys.exit(1)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python validate_schema.py <schema_file>")
sys.exit(1)
validate_schema(sys.argv[1])
Jak uruchomić ten przykład w Antigravity
Jeśli masz już uruchomione narzędzie Antigravity lub Antigravity CLI, wykonaj te czynności:
Krok 1. Utwórz plik JSON z danymi przykładowymi
Poproś agenta o utworzenie nowego pliku bad_schema.sql zawierającego wiele naruszeń zasad.
Twój prompt:
Create a new file bad_schema.sql with the following SQL:
DROP TABLE IF EXISTS legacy_users;
CREATE TABLE userProfile (
id INT PRIMARY KEY,
bio TEXT
);
CREATE TABLE posts (
title TEXT,
content TEXT,
created_at TIMESTAMP
);
CREATE TABLE comments (
id INT PRIMARY KEY,
post_id INT,
body TEXT
);
Powyższy plik schematu narusza wszystkie 3 zasady: używa zabronionego polecenia DROP TABLE, używa camelCase w nazwie tabeli userProfile i zapomina o kluczu podstawowym id w tabeli posts.
Krok 2. Sprawdź poprawność schematu SQL
Uruchom database-schema-validator, aby sprawdzić plik za pomocą skryptu weryfikującego w Pythonie.
Twój prompt:
Validate bad_schema.sql using the database-schema-validator skill.
Krok 3. Sprawdź dane wyjściowe
Agent zgłosi błąd i wyświetli w czacie konkretne błędy znalezione przez skrypt. Przykładowe dane wyjściowe są pokazane poniżej:
Suggested Fixes:
Remove the line DROP TABLE IF EXISTS legacy_users; as dropping tables is forbidden by safety policy.
Rename the table userProfile to use snake_case (e.g., user_profile).
Add a primary key column named id to the posts table definition.
6. Zestaw narzędzi dla programistów (umiejętności interfejsu wiersza poleceń agentów)
Wzorzec „Działanie i cykl życia”.
Tworzenie agentów AI obejmuje powtarzalne zadania związane z cyklem życia: tworzenie plików szablonowych, konfigurowanie lokalnych środowisk wykonawczych, uruchamianie testowych promptów i uruchamianie interaktywnych środowisk testowych.
Zamiast zmuszać asystenta kodowania do zgadywania struktur katalogów lub pisania od zera konfiguracji agenta, umiejętności interfejsu CLI agentów pakują tę wiedzę o cyklu życia w konkretne umiejętności agenta.
Umiejętności interfejsu wiersza poleceń agenta (CLI) zapewniają uproszczoną, zorientowaną na programistów automatyzację bezpośrednio w terminalu, wypełniając lukę między surowym kodem a autonomicznym wykonywaniem. Pakiet Agent Development Kit (ADK) koncentruje się na platformie programowej, udostępniając pakiety SDK, interfejsy API i plany strukturalne do tworzenia agentów AI i zarządzania nimi, a umiejętności interfejsu Agent CLI zapewniają możliwości operacyjne. Umożliwia programistom tworzenie szkieletów, testowanie i wdrażanie agentów lokalnie z szybkim uzyskiwaniem informacji zwrotnych, całkowicie pomijając duże obciążenie interfejsu.
Opcjonalnie, po zmapowaniu na Google Cloud umiejętności interfejsu wiersza poleceń agenta działają jako bezpośrednie połączenie z infrastrukturą klasy korporacyjnej. Zamiast klikać w konsolach, możesz używać poleceń interfejsu CLI, aby błyskawicznie pakować przepływy pracy agenta, zarządzać uprawnieniami dostępu i wdrażać je w ekosystemach Google Cloud (takich jak Vertex AI czy Cloud Run). Dzięki temu złożone zadania związane z architekturą chmury stają się prostymi, powtarzalnymi poleceniami terminala, co znacznie ułatwia integrację autonomicznych agentów z dotychczasowymi potokami wdrażania CI/CD.
Instalacja
Sprawdź, czy masz zainstalowane Python 3.11+, Node.js i menedżera pakietów uv. Następnie uruchom w terminalu polecenie konfiguracji:
uvx google-agents-cli setup
To polecenie instaluje plik binarny agents-cli i rejestruje jego specjalistyczne umiejętności w zakresie tworzenia szkieletów i oceny w środowisku asystenta programowania.
Uwaga: umiejętności zostaną zainstalowane w folderze ~/.agents/skills, który jest widoczny dla Antigravity. Jeśli chcesz zobaczyć te umiejętności w interfejsie Antigravity CLI, musisz przenieść je do folderu ~/.gemini/antigravity-cli/skills (zakres globalny).
Aby sprawdzić, czy umiejętności zostały wczytane w Antigravity, wystarczy zapytać, które umiejętności są dostępne. Poniżej znajduje się przykładowa odpowiedź dotycząca zainstalowanych właśnie umiejętności interfejsu CLI agenta.

Szczegółowy przewodnik
Po zakończeniu procesu uvx google-agents-cli setup możesz uruchomić agenta AI, wchodzić z nim w interakcje i go testować w całości na swoim komputerze.
Krok 1. Utwórz szkielet nowego projektu agenta i go zainicjuj
Uruchom polecenie tworzenia, aby wygenerować standardowy układ. Po utworzeniu projektu musisz zainstalować jego zależności, zanim uruchomisz jakiekolwiek zadania wykonawcze.
# 1. Create a lightweight prototype project structure
agents-cli create weather-assistant --prototype --yes
# 2. Move into the directory and install required ADK dependencies
cd weather-assistant
agents-cli install
Co się dzieje w tle: tworzone jest czyste miejsce pracy z app/agent.py (kodem głównym), pyproject.toml (metadanymi pakietu) i agents-cli-manifest.yaml (śledzeniem projektu).
Krok 2. Uruchom lokalne zapytanie testowe
Przeprowadź szybki test przedstawiciela bezpośrednio w wierszu poleceń. Jeśli nie używasz domyślnego uwierzytelniania aplikacji (ADC) Google Cloud, upewnij się, że masz wyeksportowane GEMINI_API_KEY w terminalu. Klucz interfejsu Gemini API możesz uzyskać tutaj. Gdy uzyskasz klucz, wyeksportuj go w terminalu za pomocą tego polecenia:
export GEMINI_API_KEY="YOUR_GEMINI_API_KEY"
Wpisz w terminalu to polecenie:
agents-cli run "How are you?"
Co się dzieje za kulisami: interfejs CLI inicjuje cykl życia pakietu Agent Development Kit (ADK) w całości w pamięci terminala. Bezpiecznie przekierowuje prompt za pomocą lokalnych danych logowania i zapisuje odpowiedź z transmisji na żywo bezpośrednio w wierszu poleceń.
Krok 3. Uruchom interaktywny symulator internetowy
Uruchom wbudowane, lokalne środowisko testowe w przeglądarce, aby wizualnie wchodzić w interakcje z agentem.
agents-cli playground
Co się dzieje w tle: interfejs CLI uruchamia serwer interfejsu internetowego ADK, zwykle dostępny pod adresem http://localhost:8080 lub alternatywnym adresem http://127.0.0.1:8000, z funkcją szybkiego ponownego wczytywania. W interfejsie internetowym wybierz aplikację w menu Wybierz aplikację u góry i skorzystaj z agenta w interfejsie konwersacyjnym po prawej stronie aplikacji internetowej.
7. Instalowanie umiejętności agenta za pomocą npx skills
npx skills to narzędzie wiersza poleceń opracowane przez Vercel Labs, które działa jako menedżer pakietów dla agentów AI (takich jak Antigravity, Claude Code, GitHub Copilot, Cursor i Cline). Jest to interfejs wiersza poleceń dla otwartego ekosystemu umiejętności agenta.
Jeśli chcesz pobrać i zainstalować umiejętności agenta za pomocą pakietu npx skills, pamiętaj, że zostaną one umieszczone w folderze ~/.agents/skills. W artykule wspomniano, że narzędzia takie jak Antigravity będą pobierać umiejętności z tego folderu. Pamiętaj jednak, że w momencie pisania tego artykułu Antigravity pobiera umiejętności z tego folderu, ale interfejs wiersza poleceń Antigravity nie. Jak wspomnieliśmy wcześniej, musisz skopiować te umiejętności zainstalowane w folderze ~/.agents/skills do zakresu projektu lub globalnego dla folderów umiejętności w interfejsie wiersza poleceń Antigravity, czyli:
- Zakres projektu: znajduje się w
<project-root>/.agent/skills/. - Zakres globalny: lokalizacja:
~/.gemini/antigravity-cli/skills/.
8. Gratulacje
Gratulacje! Udało Ci się użyć Google Antigravity do utworzenia pierwszej umiejętności agenta, skonfigurowania jej i dodania do niej niestandardowych funkcji.
Udało Ci się też skonfigurować zestaw umiejętności agenta w zakresie projektu i globalnym, dzięki czemu powstały dostosowane narzędzia.
Możesz teraz pozwolić Antigravity na wykonanie ciężkiej pracy przy Twoich projektach i pisać kod po swojemu.
Zdobywanie plakietki Kaggle 5-Day AI Agents
Czy ten moduł został ukończony w ramach 5-Day AI Agents: Intensive Vibe Coding Course with Google w Kaggle? Odbierz odznakę za ukończenie: zdobądź odznakę za 5-dniowy kurs o agentach AI.
9. Dokumentacja
- Codelab : pierwsze kroki z Google Antigravity
- Oficjalna strona : https://antigravity.google/
- Dokumentacja: https://antigravity.google/docs
- Pobierz : https://antigravity.google/download
- Dokumentacja umiejętności Antigravity: https://antigravity.google/docs/skills