
1. Introduction
In this codelab you will learn how to deploy AlloyDB Omni and use Columnar Engine to improve performance for queries.
Prerequisites
- A basic understanding of the Google Cloud, Console
- Basic skills in command line interface and google shell
What you'll learn
- How to deploy AlloyDB Omni on GCE VM in the Google Cloud
- How to connect to the AlloyDB Omni
- How to load data to AlloyDB Omni
- How to enable Columnar Engine
- How to check Columnar Engine in Automatic mode
- How to populate Columnar Store manually
What you'll need
- A Google Cloud Account and Google Cloud Project
- A web browser such as Chrome
2. Setup and Requirements
Self-paced environment setup
- Sign-in to the Google Cloud Console and create a new project or reuse an existing one. If you don't already have a Gmail or Google Workspace account, you must create one.

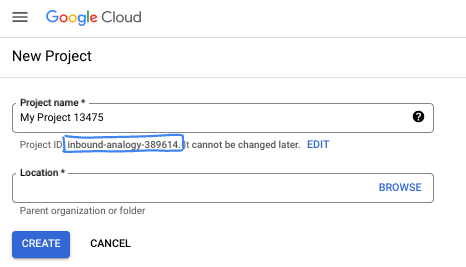
- The Project name is the display name for this project's participants. It is a character string not used by Google APIs. You can always update it.
- The Project ID is unique across all Google Cloud projects and is immutable (cannot be changed after it has been set). The Cloud Console auto-generates a unique string; usually you don't care what it is. In most codelabs, you'll need to reference your Project ID (typically identified as
PROJECT_ID). If you don't like the generated ID, you might generate another random one. Alternatively, you can try your own, and see if it's available. It can't be changed after this step and remains for the duration of the project. - For your information, there is a third value, a Project Number, which some APIs use. Learn more about all three of these values in the documentation.
- Next, you'll need to enable billing in the Cloud Console to use Cloud resources/APIs. Running through this codelab won't cost much, if anything at all. To shut down resources to avoid incurring billing beyond this tutorial, you can delete the resources you created or delete the project. New Google Cloud users are eligible for the $300 USD Free Trial program.
Start Cloud Shell
While Google Cloud can be operated remotely from your laptop, in this codelab you will be using Google Cloud Shell, a command line environment running in the Cloud.
From the Google Cloud Console, click the Cloud Shell icon on the top right toolbar:
It should only take a few moments to provision and connect to the environment. When it is finished, you should see something like this:

This virtual machine is loaded with all the development tools you'll need. It offers a persistent 5GB home directory, and runs on Google Cloud, greatly enhancing network performance and authentication. All of your work in this codelab can be done within a browser. You do not need to install anything.
3. Before you begin
Enable API
Output:
Inside Cloud Shell, make sure that your project ID is setup:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Expected output
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) our active configuration is: [cloudshell-14650] student@cloudshell:~ (test-project-001-402417)$
If it is not defined in the cloud shell configuration set it up using following commands
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Enable all necessary services:
gcloud services enable compute.googleapis.com
Expected output
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Deploy AlloyDB Omni on GCE
To deploy AlloyDB Omni on GCE we need to prepare a virtual machine with compatible configuration and software. Here is an example of how to deploy the AlloyDB Omni on a Debian based VM.
Create a GCE VM
We need to deploy a VM with acceptable configuration for CPU, memory and storage. We are going to use the default Debian image with system disk size increased to 20 Gb to accommodate AlloyDB Omni database files.
We can use the started cloud shell or a terminal with cloud SDK installed
All the steps are also described in the quick start for AlloyDB Omni.
Set up the environment variables for your deployment.
export ZONE=us-central1-a
export MACHINE_TYPE=n2-highmem-2
export DISK_SIZE=20
export MACHINE_NAME=omni01
Then we use gcloud to create the GCE VM.
gcloud compute instances create $MACHINE_NAME \
--project=$(gcloud info --format='value(config.project)') \
--zone=$ZONE --machine-type=$MACHINE_TYPE \
--metadata=enable-os-login=true \
--create-disk=auto-delete=yes,boot=yes,size=$DISK_SIZE,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" \
--format="value(name)"),type=pd-ssd
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ export ZONE=us-central1-a
export MACHINE_TYPE=n2-highmem-2
export DISK_SIZE=20
export MACHINE_NAME=omni01
student@cloudshell:~ (test-project-001-402417)$ gcloud compute instances create $MACHINE_NAME \
--project=$(gcloud info --format='value(config.project)') \
--zone=$ZONE --machine-type=$MACHINE_TYPE \
--metadata=enable-os-login=true \
--create-disk=auto-delete=yes,boot=yes,size=$DISK_SIZE,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" \
--format="value(name)"),type=pd-ssd
Created [https://www.googleapis.com/compute/v1/projects/test-project-001-402417/zones/us-central1-a/instances/omni01].
WARNING: Some requests generated warnings:
- Disk size: '20 GB' is larger than image size: '10 GB'. You might need to resize the root repartition manually if the operating system does not support automatic resizing. See https://cloud.google.com/compute/docs/disks/add-persistent-disk#resize_pd for details.
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: n2-highmem-2
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (test-project-001-402417)$
Install AlloyDB Omni
Connect to the created VM:
gcloud compute ssh omni01 --zone $ZONE
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ gcloud compute ssh omni01 --zone $ZONE Warning: Permanently added 'compute.5615760774496706107' (ECDSA) to the list of known hosts. Linux omni01.us-central1-a.c.gleb-test-short-003-421517.internal 6.1.0-20-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.85-1 (2024-04-11) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@omni01:~$
Run the following command in your connected terminal.
Install docker on the VM:
sudo apt update
sudo apt-get -y install docker.io
Expected console output(redacted):
student@omni01:~$ sudo apt update sudo apt-get -y install docker.io Get:1 file:/etc/apt/mirrors/debian.list Mirrorlist [30 B] Get:5 file:/etc/apt/mirrors/debian-security.list Mirrorlist [39 B] Get:7 https://packages.cloud.google.com/apt google-compute-engine-bookworm-stable InRelease [5146 B] Get:8 https://packages.cloud.google.com/apt cloud-sdk-bookworm InRelease [6406 B] Get:9 https://packages.cloud.google.com/apt google-compute-engine-bookworm-stable/main amd64 Packages [1916 B] Get:2 https://deb.debian.org/debian bookworm InRelease [151 kB] ... Setting up binutils (2.40-2) ... Setting up needrestart (3.6-4+deb12u1) ... Processing triggers for man-db (2.11.2-2) ... Processing triggers for libc-bin (2.36-9+deb12u4) ... student@omni01:~$
Define password for the postgres user:
export PGPASSWORD=<your password>
Create a directory for AlloyDB Omni data. It is an optional but recommended approach. By default the data would be created using the docker ephemeral filesystem layer and everything destroyed when the docker container is deleted. Keeping it separately allows you to manage containers independently from your data and optionally place it to a storage with better IO characteristics
Here is a command creating a directory in the user's home directory where all data will be placed:
mkdir -p $HOME/alloydb-data
Deploy AlloyDB Omni container:
sudo docker run --name my-omni \
-e POSTGRES_PASSWORD=$PGPASSWORD \
-p 5432:5432 \
-v $HOME/alloydb-data:/var/lib/postgresql/data \
-v /dev/shm:/dev/shm \
-d google/alloydbomni
Expected console output(redacted):
student@omni01:~$ export PGPASSWORD=StrongPassword student@omni01:~$ sudo docker run --name my-omni \ -e POSTGRES_PASSWORD=$PGPASSWORD \ -p 5432:5432 \ -v $HOME/alloydb-data:/var/lib/postgresql/data \ -v /dev/shm:/dev/shm \ -d google/alloydbomni Unable to find image 'google/alloydbomni:latest' locally latest: Pulling from google/alloydbomni 71215d55680c: Pull complete ... 2e0ec3fe1804: Pull complete Digest: sha256:d6b155ea4c7363ef99bf45a9dc988ce5467df5ae8cd3c0f269ae9652dd1982a6 Status: Downloaded newer image for google/alloydbomni:latest 56de4ae0018314093c8b048f69a1e9efe67c6c8117f44c8e1dc829a2d4666cd2 student@omni01:~$
Install PostgreSQL client software to the VM (optional - it is expected to be already installed):
sudo apt install -y postgresql-client
Expected console output:
student@omni01:~$ sudo apt install -y postgresql-client Reading package lists... Done Building dependency tree... Done Reading state information... Done postgresql-client is already the newest version (15+248). 0 upgraded, 0 newly installed, 0 to remove and 4 not upgraded.
Connect to the AlloyDB Omni:
psql -h localhost -U postgres
Expected console output:
student@omni01:~$ psql -h localhost -U postgres
WARNING: psql major version 15, server major version 17.
Some psql features might not work.
Type "help" for help.
postgres=#
Disconnect from the AlloyDB Omni:
exit
Expected console output:
postgres=# exit student@omni01:~$
5. Prepare a Test Database
To test the Columnar Engine we need to create a database and fill it with some test data.
Create Database
Connect to the AlloyDB Omni VM and create a database
In the Cloud Shell session execute:
Connect to the AlloyDB Omni VM:
ZONE=us-central1-a
gcloud compute ssh omni01 --zone $ZONE
Expected console output:
student@cloudshell:~ (gleb-test-short-001-416213)$ ZONE=us-central1-a gcloud compute ssh omni01 --zone $ZONE Linux omni01.us-central1-a.c.gleb-test-short-003-421517.internal 6.1.0-20-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.85-1 (2024-04-11) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. Last login: Mon Mar 4 18:17:55 2024 from 35.237.87.44 student@omni01:~$
In the established SSH session execute:
export PGPASSWORD=<your password>
psql -h localhost -U postgres -c "CREATE DATABASE quickstart_db"
Expected console output:
student@omni01:~$ psql -h localhost -U postgres -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@omni01:~$
Create a table with sample data
For our tests we are going to use public data about Insurance Producers Licensed in Iowa. You can find this dataset on the Iowa government website - https://data.iowa.gov/catalog/dataset/669 .
First, we need to create a table.
In the GCE VM execute:
psql -h localhost -U postgres -d quickstart_db -c "DROP TABLE if exists insurance_producers_licensed_in_iowa;
CREATE TABLE insurance_producers_licensed_in_iowa (
npn int8,
last_name text,
first_name text,
address_line_1 text,
city text,
state text,
zip_code int4,
first_active_date timestamp,
expiry_date timestamp,
business_phone text,
email text,
iowa_resident text,
loa_has_crop text,
loa_has_surety text,
loa_has_ah text,
loa_has_life text,
loa_has_variable text,
loa_has_personal_lines text,
loa_has_credit text,
loa_has_excess text,
loa_has_property text,
loa_has_casualty text,
loa_has_reciprocal text,
latitude text,
longitude text,
physical_location text,
address_line_2 text,
address_line_3 text
);"
Expected console output:
otochkin@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "DROP TABLE if exists insurance_producers_licensed_in_iowa;
CREATE TABLE insurance_producers_licensed_in_iowa (
npn int8,
last_name text,
first_name text,
address_line_1 text,
address_line_2 text,
address_line_3 text,
city text,
state text,
zip int4,
firstactivedate timestamp,
expirydate timestamp,
business_phone text,
email text,
physical_location text,
iowaresident text,
loa_has_crop text,
loa_has_surety text,
loa_has_ah text,
loa_has_life text,
loa_has_variable text,
loa_has_personal_lines text,
loa_has_credit text,
loa_has_excess text,
loa_has_property text,
loa_has_casualty text,
loa_has_reciprocal text
);"
NOTICE: table "insurance_producers_licensed_in_iowa" does not exist, skipping
DROP TABLE
CREATE TABLE
otochkin@omni01:~$
Load data to the table.
In the GCE VM execute:
curl -L https://idh-be.iowa.gov/api/v1/datasets/669/rows.csv | sed '$d' | psql -h localhost -U postgres -d quickstart_db -c "\copy insurance_producers_licensed_in_iowa from stdin csv header"
Expected console output:
otochkin@omni01:~$ curl -L https://idh-be.iowa.gov/api/v1/datasets/669/rows.csv | sed '$d' | psql -h localhost -U postgres -d quickstart_db -c "\copy insurance_producers_licensed_in_iowa from stdin csv header"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 48.0M 0 48.0M 0 0 33.9M 0 --:--:-- 0:00:01 --:--:-- 33.9M
COPY 226772
otochkin@omni01:~$
We've loaded 226772 records about insurance producers to our database and can do some testing. The number of rows for you can be different because the dataset is getting updated on a daily basis.
Run Test Queries
Connect to the quickstart_db using psql and enable timing to measure execution time for our queries.
In the GCE VM execute:
psql -h localhost -U postgres -d quickstart_db
Expected console output:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db
psql (15.18 (Debian 15.18-0+deb12u1), server 17.7)
WARNING: psql major version 15, server major version 17.
Some psql features might not work.
Type "help" for help.
quickstart_db=#
In the PSQL session execute:
\timing
Expected console output:
quickstart_db=# \timing Timing is on. quickstart_db=#
Let's find the top 5 cities by number of insurance producers selling Accident and Health insurances and whose license is valid at least for the next 6 months.
In the PSQL session execute:
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Expected console output:
quickstart_db=# SELECT city, count(*)
quickstart_db-# FROM insurance_producers_licensed_in_iowa
quickstart_db-# WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
quickstart_db-# GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 2159
OMAHA | 1527
MIAMI | 1293
KANSAS CITY | 1091
DALLAS | 1000
(5 rows)
Time: 90.492 ms
Run a test query preferably multiple times to get reliable execution time. We can see that the average time to return the result is about 94 ms. In the following steps we are going to enable the AlloyDB Columnar Engine and see if it can improve performance.
Exit from the psql session:
exit
6. Enable Columnar Engine
Now we need to enable the Columnar Engine on our AlloyDB Omni.
Update AlloyDB Omni Parameters
We need to switch the instance parameter "google_columnar_engine.enabled" to "on" for our AlloyDB Omni and it requires restart.
Update the postgresql.conf in the /var/alloydb/config directory and restart the instance.
In the GCE VM execute:
sudo docker exec my-omni /bin/bash -c "echo 'google_columnar_engine.enabled=true' >> /var/lib/postgresql/data/postgresql.conf" && \
sudo docker exec my-omni /bin/bash -c "echo \"shared_preload_libraries='google_columnar_engine,google_job_scheduler,google_db_advisor,google_storage'\" >> /var/lib/postgresql/data/postgresql.conf" && \
sudo docker restart my-omni
Expected console output:
student@omni01:~$ sudo docker exec my-omni /bin/bash -c "echo 'google_columnar_engine.enabled=true' >> /var/lib/postgresql/data/postgresql.conf" && \ > sudo docker exec my-omni /bin/bash -c "echo \"shared_preload_libraries='google_columnar_engine,google_job_scheduler,google_db_advisor,google_storage'\" >> /var/lib/postgresql/data/postgresql.conf" && \ > sudo docker restart my-omni my-omni student@omni01:~$
Verify the Columnar Engine
Connect to the database using psql and verify the columnar engine.
Connect to the AlloyDB Omni database
In the VM SSH session connect to the database:
psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.enabled"
The command should show the enabled columnar engine.
Expected console output:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.enabled" google_columnar_engine.enabled -------------------------------- on (1 row)
7. Performance Comparison
We can now populate the columnar engine store and verify the performance.
Automatic Columnar Store Population
By default the job populating the store runs every hour. We are going to reduce this time to 10 minutes to avoid waiting.
In the GCE VM execute:
sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.auto_columnarization_schedule=\'EVERY 10 MINUTES\' >>/var/lib/postgresql/data/postgresql.conf" && \
sudo docker restart my-omni
And here is the expected output:
sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.auto_columnarization_schedule=\'EVERY 10 MINUTES\' >>/var/lib/postgresql/data/postgresql.conf" && \ > sudo docker restart my-omni my-omni
Verify the settings
In the GCE VM execute:
psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.auto_columnarization_schedule;"
Expected output:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.auto_columnarization_schedule;" google_columnar_engine.auto_columnarization_schedule ------------------------------------------------------ EVERY 10 MINUTES (1 row) student@omni01:~$
Check the objects in the Columnar Store. It should be empty.
In the GCE VM execute:
psql -h localhost -U postgres -d quickstart_db -c "SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;"
Expected output:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;" database_name | schema_name | relation_name | column_name ---------------+-------------+---------------+------------- (0 rows) student@omni01:~$
Connect to the database and run the same query we executed earlier several times.
In the GCE VM execute:
psql -h localhost -U postgres -d quickstart_db
In the PSQL session.
Enable timing
\timing
Run the query a couple of times:
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Expected output:
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 1885
OMAHA | 1656
KANSAS CITY | 1279
AUSTIN | 1254
MIAMI | 1003
(5 rows)
Time: 81.428 ms
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 1885
OMAHA | 1656
KANSAS CITY | 1279
AUSTIN | 1254
MIAMI | 1003
(5 rows)
Time: 82.608 ms
quickstart_db=#
Wait 10 minutes and check if the columns of the insurance_producers_licensed_in_iowa table have been populated into the columnar store.
SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;
Expected output:
quickstart_db=# SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns; database_name | schema_name | relation_name | column_name ---------------+-------------+--------------------------------------+------------- quickstart_db | public | insurance_producers_licensed_in_iowa | city quickstart_db | public | insurance_producers_licensed_in_iowa | expiry_date quickstart_db | public | insurance_producers_licensed_in_iowa | loa_has_ah (3 rows) Time: 0.643 ms
Now we can run the query for the insurance_producers_licensed_in_iowa table again and see if the performance is improved.
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Expected output:
quickstart_db=# SELECT city, count(*)
quickstart_db-# FROM insurance_producers_licensed_in_iowa
quickstart_db-# WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
quickstart_db-# GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 2159
OMAHA | 1527
MIAMI | 1293
KANSAS CITY | 1091
DALLAS | 1000
(5 rows)
Time: 11.757 ms
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 2159
OMAHA | 1527
MIAMI | 1293
KANSAS CITY | 1091
DALLAS | 1000
(5 rows)
Time: 10.839 ms
The execution time has dropped from 82 ms to 11 ms. If you don't see any improvements you can check if the columns have been successfully populated to the columnar store by checking the g_columnar_columns view.
SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
Expected output:
quickstart_db=# SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
relation_name | column_name | column_type | status | size_in_bytes
--------------------------------------+-------------+-------------+--------+---------------
insurance_producers_licensed_in_iowa | city | text | Usable | 637312
insurance_producers_licensed_in_iowa | expiry_date | timestamp | Usable | 228356
insurance_producers_licensed_in_iowa | loa_has_ah | text | Usable | 227608
(3 rows)
Now we can verify if the query execution plan uses the Columnar Engine.
In the PSQL session execute:
EXPLAIN (ANALYZE,SETTINGS,BUFFERS)
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Expected output:
quickstart_db=# EXPLAIN (ANALYZE,SETTINGS,BUFFERS)
quickstart_db-# SELECT city, count(*)
quickstart_db-# FROM insurance_producers_licensed_in_iowa
quickstart_db-# WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
quickstart_db-# GROUP BY city ORDER BY count(*) desc limit 5;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=2398.48..2398.49 rows=5 width=17) (actual time=10.018..10.021 rows=5 loops=1)
-> Sort (cost=2398.48..2411.61 rows=5252 width=17) (actual time=10.017..10.019 rows=5 loops=1)
Sort Key: (count(*)) DESC
Sort Method: top-N heapsort Memory: 25kB
-> HashAggregate (cost=2258.73..2311.25 rows=5252 width=17) (actual time=8.320..9.212 rows=7695 loops=1)
Group Key: city
Batches: 1 Memory Usage: 913kB
-> Append (cost=20.00..1762.13 rows=99320 width=9) (actual time=8.314..8.315 rows=8595 loops=1)
-> Custom Scan (columnar scan) on insurance_producers_licensed_in_iowa (cost=20.00..1758.11 rows=99319 width=9) (actual time=8.311..8.312 rows=8595 loops=1)
Filter: ((loa_has_ah = 'Yes'::text) AND (expiry_date > (now() + '6 mons'::interval)))
Rows Removed by Columnar Filter: 127723
Rows Aggregated by Columnar Scan: 99049
Columnar cache search mode: native
-> Seq Scan on insurance_producers_licensed_in_iowa (cost=0.00..4.02 rows=1 width=9) (never executed)
Filter: ((loa_has_ah = 'Yes'::text) AND (expiry_date > (now() + '6 mons'::interval)))
Planning Time: 0.221 ms
Execution Time: 10.127 ms
(17 rows)
Time: 11.171 ms
And we can see that the "Seq Scan" operation on the business_licenses table segment was never executed and the "Custom Scan (columnar scan)" was used instead. That helped us to improve response time from 82 to 11 ms.
If we want to clear the auto-populated content from the columnar engine we can do it using SQL function google_columnar_engine_reset_recommendation.
In the PSQL session execute:
SELECT google_columnar_engine_reset_recommendation(drop_columns => true);
It will clear the populated columns and you can verify it in the views g_columnar_columns and g_columnar_recommended_columns as it was shown earlier.
SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;
SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
Expected output:
quickstart_db=# SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns; database_name | schema_name | relation_name | column_name ---------------+-------------+---------------+------------- (0 rows) Time: 0.447 ms quickstart_db=# select relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns; relation_name | column_name | column_type | status | size_in_bytes ---------------+-------------+-------------+--------+--------------- (0 rows) Time: 0.556 ms quickstart_db=#
Manual Columnar Store Population
We can add columns to the Columnar Engine Store manually using SQL functions or specify the required entities in the instance flags to load them automatically when the instance starts.
Let's add the same columns as before using google_columnar_engine_add SQL function.
In the PSQL session execute:
SELECT google_columnar_engine_add(relation => 'insurance_producers_licensed_in_iowa', columns => 'city,expiry_date,loa_has_ah');
And we can verify the result using the same g_columnar_columns view:
SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
Expected output:
quickstart_db=# SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
relation_name | column_name | column_type | status | size_in_bytes
--------------------------------------+-------------+-------------+--------+---------------
insurance_producers_licensed_in_iowa | city | text | Usable | 664231
insurance_producers_licensed_in_iowa | expirydate | timestamp | Usable | 212434
insurance_producers_licensed_in_iowa | loa_has_ah | text | Usable | 211734
(3 rows)
Time: 0.692 ms
quickstart_db=#
You can verify that the columnar store is used it by running the same query as before and examining the execution plan:
EXPLAIN (ANALYZE,SETTINGS,BUFFERS)
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Exit the psql session:
exit
If we restart the AlloyDB Omni container we can see that all columnar information is lost.
In the shell session execute:
sudo docker restart my-omni
Wait 5-10 seconds and run:
psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns"
Expected output:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns" relation_name | column_name | column_type | status | size_in_bytes ---------------+-------------+-------------+--------+--------------- (0 rows)
To automatically repopulate the columns during the restart we can add them as database flags to our AlloyDB Omni parameters. We are adding the flag google_columnar_engine.relations=‘quickstart_db.public.insurance_producers_licensed_in_iowa(city,expirydate,loa_has_ah)' and restarting the container.
In the shell session execute:
sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.relations=\'quickstart_db.public.insurance_producers_licensed_in_iowa\(city,expiry_date,loa_has_ah\)\' >>/var/lib/postgresql/data/postgresql.conf" && \
sudo docker restart my-omni
And after that we can see that the columns have been added to the Columnar Store automatically after startup.
Wait 5-10 seconds and run:
psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns"
Expected output:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns"
relation_name | column_name | column_type | status | size_in_bytes
--------------------------------------+-------------+-------------+--------+---------------
insurance_producers_licensed_in_iowa | city | text | Usable | 637312
insurance_producers_licensed_in_iowa | expiry_date | timestamp | Usable | 228356
insurance_producers_licensed_in_iowa | loa_has_ah | text | Usable | 227608
(3 rows)
8. Clean up environment
Now we can destroy our AlloyDB Omni VM
Delete GCE VM
In Cloud Shell execute:
export GCEVM=omni01
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=omni01
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
9. Congratulations
Congratulations for completing the codelab.
What we've covered
- How to deploy AlloyDB Omni on GCE VM in the Google Cloud
- How to connect to the AlloyDB Omni
- How to load data to AlloyDB Omni
- How to enable Columnar Engine
- How to check Columnar Engine in Automatic mode
- How to populate Columnar Store manually
You can read more about working with the Columnar Engine in the documentation.
10. Survey
Output: