
1. Einführung
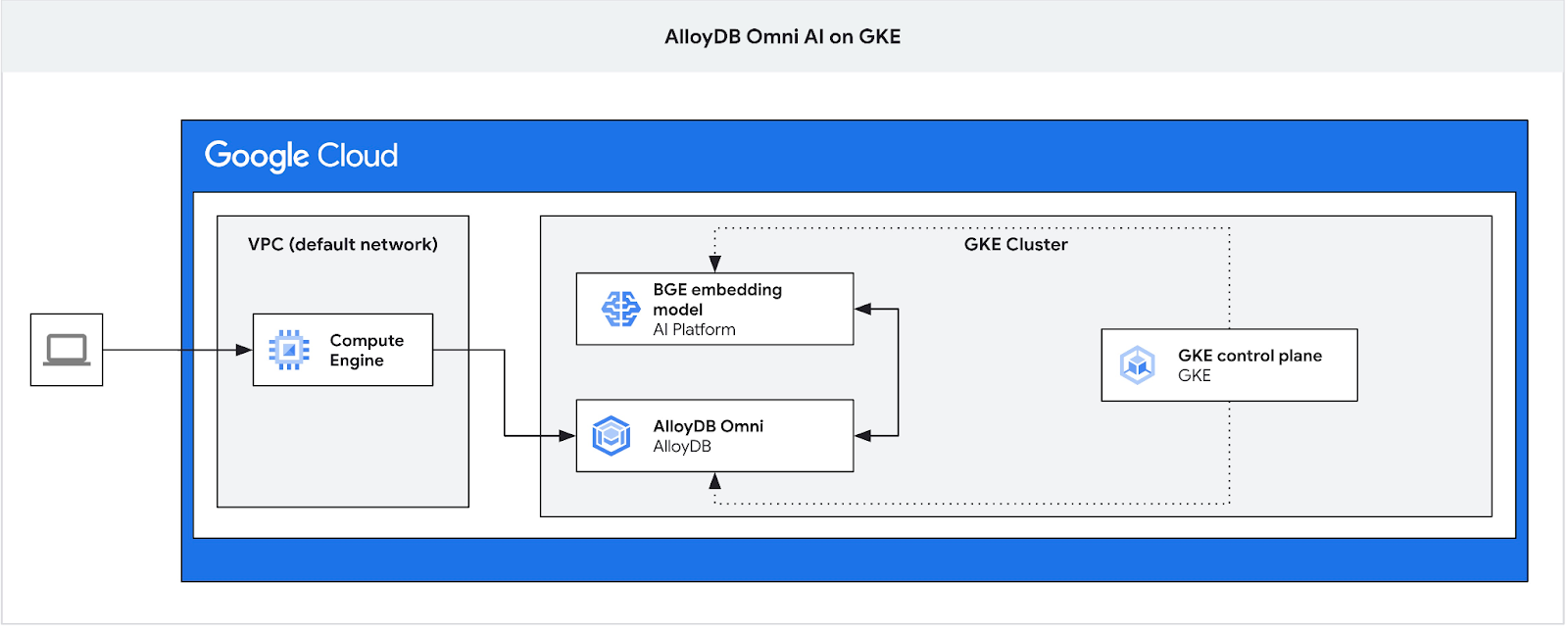
In diesem Codelab erfahren Sie, wie Sie AlloyDB Omni in der GKE bereitstellen und mit einem offenen Einbettungsmodell verwenden, das im selben Kubernetes-Cluster bereitgestellt ist. Die Bereitstellung eines Modells neben der Datenbankinstanz im selben GKE-Cluster reduziert die Latenz und die Abhängigkeiten von Drittanbieterdiensten. Außerdem kann es durch Sicherheitsanforderungen erforderlich sein, wenn die Daten die Organisation nicht verlassen dürfen und die Nutzung von Drittanbieterdiensten nicht zulässig ist.
Voraussetzungen
- Grundkenntnisse in Google Cloud und der Google Cloud Console
- Grundkenntnisse in der Befehlszeile und Cloud Shell
Lerninhalte
- AlloyDB Omni in einem Google Kubernetes-Cluster bereitstellen
- Verbindung zu AlloyDB Omni herstellen
- Daten in AlloyDB Omni laden
- Offenes Embedding-Modell in GKE bereitstellen
- Einbettungsmodell in AlloyDB Omni registrieren
- Einbettungen für die semantische Suche generieren
- Generierte Einbettungen für die semantische Suche in AlloyDB Omni verwenden
- Vektorindexe in AlloyDB erstellen und verwenden
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome, der die Google Cloud Console und die Cloud Shell unterstützt
2. Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

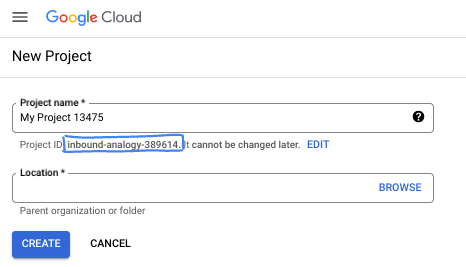
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie es mit einem eigenen Namen versuchen und sehen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/-APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um Kosten zu vermeiden, die über diese Anleitung hinausgehen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am kostenlosen Testzeitraum mit einem Guthaben von 300$ teilnehmen.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:

Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Hinweis
API aktivieren
Ausgabe:
Prüfen Sie in Cloud Shell, ob Ihre Projekt-ID eingerichtet ist:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Wenn sie nicht in der Cloud Shell-Konfiguration definiert ist, richten Sie sie mit den folgenden Befehlen ein.
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Aktivieren Sie alle erforderlichen Dienste:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Erwartete Ausgabe
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB Omni in GKE bereitstellen
Wenn Sie AlloyDB Omni in GKE bereitstellen möchten, müssen Sie einen Kubernetes-Cluster vorbereiten, der den in den Anforderungen für den AlloyDB Omni-Operator aufgeführten Anforderungen entspricht.
GKE-Cluster erstellen
Wir müssen einen GKE-Standardcluster mit einer Poolkonfiguration bereitstellen, die für die Bereitstellung eines Pods mit einer AlloyDB Omni-Instanz ausreicht. Für Omni benötigen wir mindestens 2 CPUs und 8 GB RAM, mit etwas Spielraum für Operator- und Monitoring-Dienste.
Richten Sie die Umgebungsvariablen für Ihre Bereitstellung ein.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Anschließend erstellen wir den GKE-Standardcluster mit gcloud.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Erwartete Konsolenausgabe:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Cluster vorbereiten
Wir müssen erforderliche Komponenten wie den Cert-Manager-Dienst installieren. Wir können die Schritte in der Dokumentation zur Installation von cert-manager ausführen.
Wir verwenden das Kubernetes-Befehlszeilentool kubectl, das bereits in Cloud Shell installiert ist. Bevor wir das Tool verwenden können, müssen wir Anmeldedaten für unseren Cluster abrufen.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Jetzt können wir kubectl verwenden, um cert-manager zu installieren:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml
Erwartete Konsolenausgabe(redigiert):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
AlloyDB Omni installieren
Der AlloyDB Omni-Operator kann mit dem Helm-Dienstprogramm installiert werden.
Führen Sie den folgenden Befehl aus, um den AlloyDB Omni-Operator zu installieren:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Erwartete Konsolenausgabe(redigiert):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
Nachdem der AlloyDB Omni-Operator installiert wurde, können wir mit der Bereitstellung unseres Datenbankclusters fortfahren.
Hier ist ein Beispiel für ein Bereitstellungsmanifest mit aktiviertem Parameter „googleMLExtension“ und einem internen (privaten) Load Balancer:
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
Der Secret-Wert für das Passwort ist eine Base64-Darstellung des Passworts „VeryStrongPassword“. Die zuverlässigere Methode besteht darin, den Passwortwert mit Google Secret Manager zu speichern. Weitere Informationen finden Sie in der Dokumentation.
Speichern Sie das Manifest als my-omni.yaml, um es im nächsten Schritt anzuwenden. Wenn Sie sich in Cloud Shell befinden, können Sie den Editor verwenden. Klicken Sie dazu oben rechts im Terminal auf die Schaltfläche „Editor öffnen“.
Nachdem Sie die Datei unter dem Namen my-omni.yaml gespeichert haben, kehren Sie zum Terminal zurück, indem Sie auf die Schaltfläche „Terminal öffnen“ klicken.
Wenden Sie das Manifest my-omni.yaml mit dem kubectl-Tool auf den Cluster an:
kubectl apply -f my-omni.yaml
Erwartete Konsolenausgabe:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
Prüfen Sie den Status Ihres my-omni-Clusters mit dem kubectl-Tool:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Während der Bereitstellung durchläuft der Cluster verschiedene Phasen und sollte schließlich den Status DBClusterReady erreichen.
Erwartete Konsolenausgabe:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
Verbindung zu AlloyDB Omni herstellen
Verbindung über Kubernetes-Pod herstellen
Wenn der Cluster bereit ist, können wir die PostgreSQL-Clientbinärdateien im Pod der AlloyDB Omni-Instanz verwenden. Wir ermitteln die Pod-ID und verwenden dann „kubectl“, um eine direkte Verbindung zum Pod herzustellen und die Clientsoftware auszuführen. Das Passwort ist „VeryStrongPassword“, wie im Hash in „my-omni.yaml“ festgelegt:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Beispiel für die Konsolenausgabe:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. KI-Modell in GKE bereitstellen
Um die AlloyDB Omni-KI-Integration mit lokalen Modellen zu testen, müssen wir ein Modell im Cluster bereitstellen.
Knotenpool für das Modell erstellen
Damit wir das Modell ausführen können, müssen wir einen Knotenpool für die Inferenz vorbereiten. Aus Leistungssicht ist ein Pool mit Grafikbeschleunigern mit einer Knotenkonfiguration wie „g2-standard-8“ mit L4-Nvidia-Beschleuniger am besten geeignet.
Erstellen Sie den Knotenpool mit dem L4-Beschleuniger:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create gpupool \
--accelerator type=nvidia-l4,count=1,gpu-driver-version=latest \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=g2-standard-8 \
--num-nodes=1
Erwartete Ausgabe
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create gpupool \
> --accelerator type=nvidia-l4,count=1,gpu-driver-version=latest \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=g2-standard-8 \
> --num-nodes=1
Note: Machines with GPUs have certain limitations which may affect your workflow. Learn more at https://cloud.google.com/kubernetes-engine/docs/how-to/gpus
Note: Starting in GKE 1.30.1-gke.115600, if you don't specify a driver version, GKE installs the default GPU driver for your node's GKE version.
Creating node pool gpupool...done.
Created [https://container.googleapis.com/v1/projects/student-test-001/zones/us-central1/clusters/alloydb-ai-gke/nodePools/gpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
gpupool g2-standard-8 100 1.31.4-gke.1183000
Bereitstellungsmanifest vorbereiten
Um das Modell bereitzustellen, müssen wir ein Bereitstellungsmanifest vorbereiten.
Wir verwenden das BGE Base v1.5-Einbettungsmodell von Hugging Face. Die Modellkarte finden Sie hier. Zum Bereitstellen des Modells können wir die bereits vorbereiteten Anleitungen von Hugging Face und das Bereitstellungspaket von GitHub verwenden.
Paket klonen
git clone https://github.com/huggingface/Google-Cloud-Containers
Bearbeiten Sie das Manifest, indem Sie den Wert cloud.google.com/gke-accelerator durch nvidia-l4 ersetzen und den Ressourcen Limits hinzufügen.
vi Google-Cloud-Containers/examples/gke/tei-deployment/gpu-config/deployment.yaml
Hier ist ein korrigiertes Manifest.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Snowflake--snowflake-arctic-embed-m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cu122.1-4.ubuntu2204:latest
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
env:
- name: MODEL_ID
value: Snowflake/snowflake-arctic-embed-m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
volumeMounts:
- mountPath: /dev/shm
name: dshm
- mountPath: /data
name: data
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 1Gi
- name: data
emptyDir: {}
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
Modell bereitstellen
Wir müssen ein Dienstkonto und einen Namespace für die Bereitstellung vorbereiten.
Erstellen Sie einen Kubernetes-Namespace namens hf-gke-namespace.
export NAMESPACE=hf-gke-namespace
kubectl create namespace $NAMESPACE
Kubernetes-Dienstkonto erstellen
export SERVICE_ACCOUNT=hf-gke-service-account
kubectl create serviceaccount $SERVICE_ACCOUNT --namespace $NAMESPACE
Modell bereitstellen
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/gpu-config
Deployments prüfen
kubectl get pods
Modelldienst überprüfen
kubectl get service tei-service
Es sollte der ausgeführte Diensttyp ClusterIP angezeigt werden.
Beispielausgabe:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
Die CLUSTER-IP für den Dienst wird als Endpunktadresse verwendet. Das Modelleinbettungsmodell kann über den URI http://34.118.233.48:8080/embed antworten. Sie wird später verwendet, wenn Sie das Modell in AlloyDB Omni registrieren.
Wir können es testen, indem wir es mit dem Befehl „kubectl port-forward“ verfügbar machen.
kubectl port-forward service/tei-service 8080:8080
Die Portweiterleitung wird in einer Cloud Shell-Sitzung ausgeführt. Wir benötigen eine weitere Sitzung, um sie zu testen.
Öffnen Sie oben über das Pluszeichen (+) einen weiteren Cloud Shell-Tab.
Führen Sie einen curl-Befehl in der neuen Shell-Sitzung aus.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Es sollte ein Vektor-Array wie in der folgenden Beispielausgabe (redigiert) zurückgegeben werden:
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
6. Modell in AlloyDB Omni registrieren
Um zu testen, wie AlloyDB Omni mit dem bereitgestellten Modell funktioniert, müssen wir eine Datenbank erstellen und das Modell registrieren.
Datenbank erstellen
Erstellen Sie eine GCE-VM als Jump-Box, stellen Sie von Ihrer Client-VM aus eine Verbindung zu AlloyDB Omni her und erstellen Sie eine Datenbank.
Wir benötigen die Jumpbox, da der externe GKE-Load Balancer für Omni Ihnen über private IP-Adressierung Zugriff aus der VPC ermöglicht, aber keine Verbindung von außerhalb der VPC zulässt. Sie ist im Allgemeinen sicherer und Ihre Datenbankinstanz ist nicht dem Internet ausgesetzt. Bitte prüfen Sie das Diagramm auf Klarheit.
Führen Sie Folgendes aus, um eine VM in der Cloud Shell-Sitzung zu erstellen:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
So finden Sie die IP-Adresse des AlloyDB Omni-Endpunkts mit kubectl in Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Notieren Sie sich den PRIMARYENDPOINT. Hier ein Beispiel:
Ergebnis:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
Die IP-Adresse 10.131.0.33 wird in unseren Beispielen verwendet, um eine Verbindung zur AlloyDB Omni-Instanz herzustellen.
Mit gcloud eine Verbindung zur VM herstellen:
gcloud compute ssh instance-1 --zone=$ZONE
Folgen Sie der Anleitung, wenn Sie zur Generierung eines SSH-Schlüssels aufgefordert werden. Weitere Informationen zur SSH-Verbindung finden Sie in der Dokumentation.
Installieren Sie in der SSH-Sitzung zur VM den PostgreSQL-Client:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Exportieren Sie die IP-Adresse des AlloyDB Omni-Load-Balancers wie im folgenden Beispiel (ersetzen Sie IP durch die IP-Adresse Ihres Load-Balancers):
export INSTANCE_IP=10.131.0.33
Stellen Sie eine Verbindung zu AlloyDB Omni her. Das Passwort ist „VeryStrongPassword“, wie im Hash in „my-omni.yaml“ festgelegt:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Führen Sie in der eingerichteten psql-Sitzung Folgendes aus:
create database demo;
Beenden Sie die Sitzung und stellen Sie eine Verbindung zur Datenbankdemo her. Alternativ können Sie in derselben Sitzung einfach „\c demo“ ausführen.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Transformationsfunktionen erstellen
Für Einbettungsmodelle von Drittanbietern müssen wir Transformationsfunktionen erstellen, die die Ein- und Ausgabe in das Format bringen, das vom Modell und unseren internen Funktionen erwartet wird.
Hier ist die Transformationsfunktion, die die Eingabe verarbeitet:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Führen Sie den bereitgestellten Code aus, während Sie mit der Demodatenbank verbunden sind, wie in der Beispielausgabe gezeigt:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
Und hier ist die Ausgabefunktion, die die Antwort des Modells in das Array mit reellen Zahlen umwandelt:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Führen Sie den Befehl in derselben Sitzung aus:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Modell registrieren
Jetzt können wir das Modell in der Datenbank registrieren.
Hier ist der Prozeduraufruf zum Registrieren des Modells mit dem Namen bge-base-1.5. Ersetzen Sie die IP-Adresse 34.118.233.48 durch die IP-Adresse Ihres Modelldienstes (die Ausgabe von kubectl get service tei-service):
CALL
google_ml.create_model(
model_id => 'bge-base-1.5',
model_request_url => 'http://34.118.233.48:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Führen Sie den bereitgestellten Code aus, während Sie mit der Demodatenbank verbunden sind:
demo=# CALL
google_ml.create_model(
model_id => 'bge-base-1.5',
model_request_url => 'http://34.118.233.48:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Wir können das Registermodell mit der folgenden Testabfrage testen, die ein Array mit reellen Zahlen zurückgeben sollte.
select google_ml.embedding('bge-base-1.5','What is AlloyDB Omni?');
7. Modell in AlloyDB Omni testen
Daten laden
Um zu testen, wie AlloyDB Omni mit dem bereitgestellten Modell funktioniert, müssen wir einige Daten laden. Ich habe dieselben Daten wie in einem der anderen Codelabs für die Vektorsuche in AlloyDB verwendet.
Eine Möglichkeit zum Laden der Daten besteht darin, das Google Cloud SDK und die PostgreSQL-Clientsoftware zu verwenden. Wir können dieselbe Client-VM verwenden, die zum Erstellen der demo-Datenbank verwendet wurde. Das Google Cloud SDK sollte dort bereits installiert sein, wenn Sie die Standardwerte für das VM-Image verwendet haben. Wenn Sie ein benutzerdefiniertes Bild ohne Google SDK verwendet haben, können Sie es gemäß der Dokumentation hinzufügen.
Exportieren Sie die IP-Adresse des AlloyDB Omni-Load-Balancers wie im folgenden Beispiel (ersetzen Sie IP durch die IP-Adresse Ihres Load-Balancers):
export INSTANCE_IP=10.131.0.33
Stellen Sie eine Verbindung zur Datenbank her und aktivieren Sie die pgvector-Erweiterung.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
In der psql-Sitzung:
CREATE EXTENSION IF NOT EXISTS vector;
Beenden Sie die psql-Sitzung und führen Sie in der Befehlszeilensitzung Befehle aus, um die Daten in die Demodatenbank zu laden.
Tabellen erstellen:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Erwartete Konsolenausgabe:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Hier ist die Liste der erstellten Tabellen:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Ausgabe:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
Laden Sie Daten in die Tabelle cymbal_products:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Erwartete Konsolenausgabe:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
Hier sehen Sie ein Beispiel für einige Zeilen aus der Tabelle cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Ausgabe:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
Laden Sie Daten in die Tabelle cymbal_inventory:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Erwartete Konsolenausgabe:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
Hier sehen Sie ein Beispiel für einige Zeilen aus der Tabelle cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Ausgabe:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
Laden Sie Daten in die Tabelle cymbal_stores:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Erwartete Konsolenausgabe:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
Hier sehen Sie ein Beispiel für einige Zeilen aus der Tabelle cymbal_stores.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Ausgabe:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Einbettungen erstellen
Stellen Sie mit psql eine Verbindung zur Demodatenbank her und erstellen Sie Einbettungen für die Produkte, die in der Tabelle „cymbal_products“ beschrieben sind, basierend auf Produktnamen und ‑beschreibungen.
Stellen Sie eine Verbindung zur Demodatenbank her:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Wir verwenden eine „cymbal_embedding“-Tabelle mit Spalteneinbettung zum Speichern unserer Einbettungen und die Produktbeschreibung als Texteingabe für die Funktion.
Aktivieren Sie das Timing für Ihre Abfragen, um sie später mit Remote-Modellen zu vergleichen:
\timing
Führen Sie die Abfrage aus, um die Einbettungen zu erstellen:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('bge-base-1.5',product_description)::vector FROM cymbal_products;
Erwartete Konsolenausgabe:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('bge-base-1.5',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 11069.762 ms (00:11.070)
demo=#
In diesem Beispiel hat das Erstellen von Einbettungen für 941 Datensätze etwa 11 Sekunden gedauert.
Testabfragen ausführen
Stellen Sie mit psql eine Verbindung zur Demodatenbank her und aktivieren Sie die Zeitmessung, um die Ausführungszeit für unsere Abfragen zu messen, wie wir es beim Erstellen von Einbettungen getan haben.
Wir suchen die fünf besten Produkte, die einer Anfrage wie „Welche Obstbäume wachsen hier gut?“ entsprechen, und verwenden die Kosinus-Distanz als Algorithmus für die Vektorsuche.
Führen Sie in der psql-Sitzung Folgendes aus:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('bge-base-1.5','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Erwartete Konsolenausgabe:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('bge-base-1.5','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.22753925487632942
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.23497374266229387
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.24215884459965364
California Redwood | This is a beautiful redwood tree that can grow to be over 300 feet tall. It is a | 1000.00 | 93230 | 0.24564130578287147
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.24846117929767153
(5 rows)
Time: 28.724 ms
demo=#
Die Abfrage wurde in 28 ms ausgeführt und hat eine Liste von Bäumen aus der Tabelle „cymbal_products“ zurückgegeben, die der Anfrage entsprechen und für die im Geschäft mit der Nummer 1583 Inventar verfügbar ist.
ANN-Index erstellen
Bei einem kleinen Datensatz ist es einfach, die genaue Suche zu verwenden, bei der alle Einbettungen gescannt werden. Wenn die Daten jedoch wachsen, steigen auch die Lade- und Reaktionszeiten. Sie können die Leistung verbessern, indem Sie Indizes für Ihre Einbettungsdaten erstellen. Hier sehen Sie ein Beispiel dafür, wie Sie das mit dem Google ScaNN-Index für Vektordaten tun können.
Stellen Sie die Verbindung zur Demodatenbank wieder her, wenn sie unterbrochen wurde:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Aktivieren Sie die Erweiterung „alloydb_scann“:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Index erstellen:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Führen Sie dieselbe Abfrage wie zuvor aus und vergleichen Sie die Ergebnisse:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('bge-base-1.5','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.22753925487632942
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.23497374266229387
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.24215884459965364
California Redwood | This is a beautiful redwood tree that can grow to be over 300 feet tall. It is a | 1000.00 | 93230 | 0.24564130578287147
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.2533482837690365
(5 rows)
Time: 14.665 ms
demo=#
Die Ausführungszeit der Abfrage hat sich leicht verkürzt. Bei größeren Datasets wäre diese Verbesserung deutlicher zu sehen. Die Ergebnisse sind sehr ähnlich. Nur Cherry wurde durch Fremont Cottonwood ersetzt.
Probieren Sie andere Anfragen aus und lesen Sie in der Dokumentation mehr über die Auswahl von Vektorindexen.
AlloyDB Omni bietet noch mehr Funktionen und Labs.
8. Umgebung bereinigen
Jetzt können wir unseren GKE-Cluster mit AlloyDB Omni und einem KI-Modell löschen.
GKE-Cluster löschen
Führen Sie in Cloud Shell Folgendes aus:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Erwartete Konsolenausgabe:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
VM löschen
Führen Sie in Cloud Shell Folgendes aus:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Erwartete Konsolenausgabe:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Wenn Sie für dieses Codelab ein neues Projekt erstellt haben, können Sie stattdessen das gesamte Projekt löschen: https://console.cloud.google.com/cloud-resource-manager
9. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs.
Behandelte Themen
- AlloyDB Omni in einem Google Kubernetes-Cluster bereitstellen
- Verbindung zu AlloyDB Omni herstellen
- Daten in AlloyDB Omni laden
- Offenes Embedding-Modell in GKE bereitstellen
- Einbettungsmodell in AlloyDB Omni registrieren
- Einbettungen für die semantische Suche generieren
- Generierte Einbettungen für die semantische Suche in AlloyDB Omni verwenden
- Vektorindexe in AlloyDB erstellen und verwenden
Weitere Informationen zum Arbeiten mit KI in AlloyDB Omni finden Sie in der Dokumentation.
10. Umfrage
Ausgabe: