
1. Giriş
Bu codelab'de, Agent Development Kit (ADK) kullanarak BigQuery'de depolanan verilerle ilgili soruları yanıtlayabilen aracıları nasıl oluşturacağınızı öğreneceksiniz. Ayrıca, Vertex AI'ın GenAI Evaluation hizmetini kullanarak bu aracıları değerlendireceksiniz:
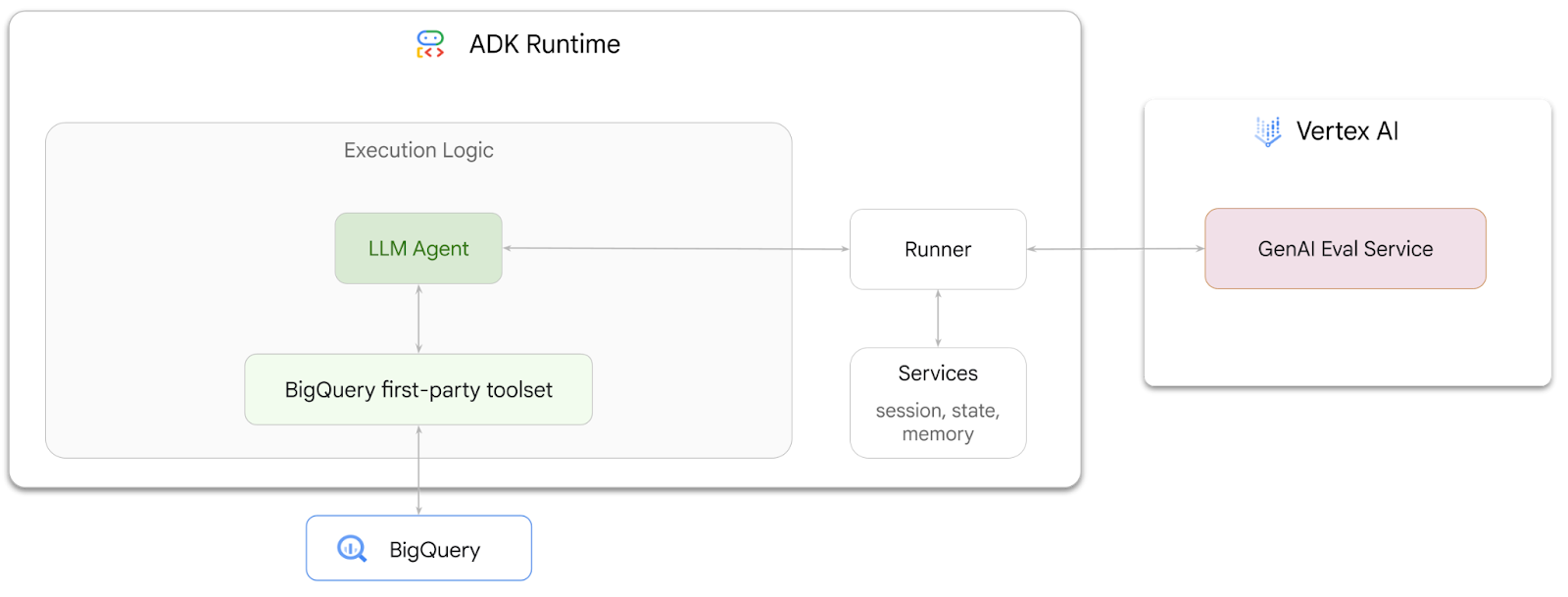
Yapacaklarınız
- ADK'da etkileşimli analiz ajanı oluşturma
- Bu ajanı, BigQuery'de depolanan verilerle etkileşime girebilmesi için ADK'nın BigQuery için birinci taraf araç seti ile donatın.
- Vertex AI GenAI Evaluation Service'i kullanarak temsilciniz için değerlendirme çerçevesi oluşturma
- Bu temsilciyle ilgili değerlendirmeler yapın. Değerlendirmeler, bir dizi altın yanıtla karşılaştırılarak yapılır.
Gerekenler
- Chrome gibi bir web tarayıcısı
- Faturalandırmanın etkin olduğu bir Google Cloud projesi veya
- Gmail hesabı Sonraki bölümde, bu codelab için ücretsiz 5 ABD doları tutarındaki krediyi nasıl kullanacağınız ve yeni bir projeyi nasıl oluşturacağınız gösterilecektir.
Bu codelab, yeni başlayanlar da dahil olmak üzere her seviyeden geliştiriciye yöneliktir. ADK geliştirme için Google Cloud Shell'deki komut satırı arayüzünü ve Python kodunu kullanacaksınız. Python uzmanı olmanız gerekmez ancak kod okuma konusunda temel bilgi sahibi olmanız kavramları anlamanıza yardımcı olur.
2. Başlamadan önce
Google Cloud projesi oluşturma
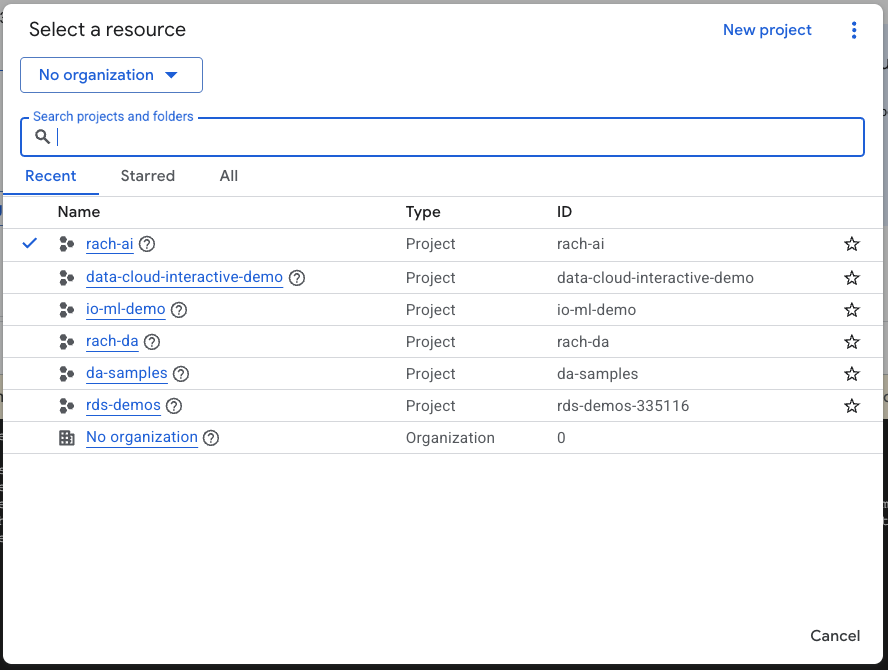
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
Cloud Shell'i başlatma
Cloud Shell, Google Cloud'da çalışan ve gerekli araçların önceden yüklendiği bir komut satırı ortamıdır.
- Google Cloud Console'un üst kısmında Cloud Shell'i etkinleştir'i tıklayın:

- Cloud Shell'e bağlandıktan sonra Cloud Shell'de kimlik doğrulamanızı doğrulamak için şu komutu çalıştırın:
gcloud auth list
- Projenizin gcloud ile kullanılacak şekilde yapılandırıldığını doğrulamak için aşağıdaki komutu çalıştırın:
gcloud config list project
- Projenizi ayarlamak için aşağıdaki komutu kullanın:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API'leri etkinleştir
- Gerekli tüm API'leri ve hizmetleri etkinleştirmek için bu komutu çalıştırın:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- Komut başarıyla yürütüldüğünde aşağıda gösterilene benzer bir mesaj görürsünüz:
Operation "operations/..." finished successfully.
3. Bir BigQuery veri kümesi oluşturma
- BigQuery'de ecommerce adlı yeni bir veri kümesi oluşturmak için Cloud Shell'de aşağıdaki komutu çalıştırın:
bq mk --dataset --location=US ecommerce
BigQuery herkese açık veri kümesi thelook_ecommerce'in statik bir alt kümesi, herkese açık bir Google Cloud Storage paketinde AVRO dosyaları olarak kaydedilir.
- Bu Avro dosyalarını BigQuery'ye tablo olarak yüklemek için Cloud Shell'de şu komutu çalıştırın (events, order_items, products, users, orders):
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
Bu işlem birkaç dakika sürebilir.
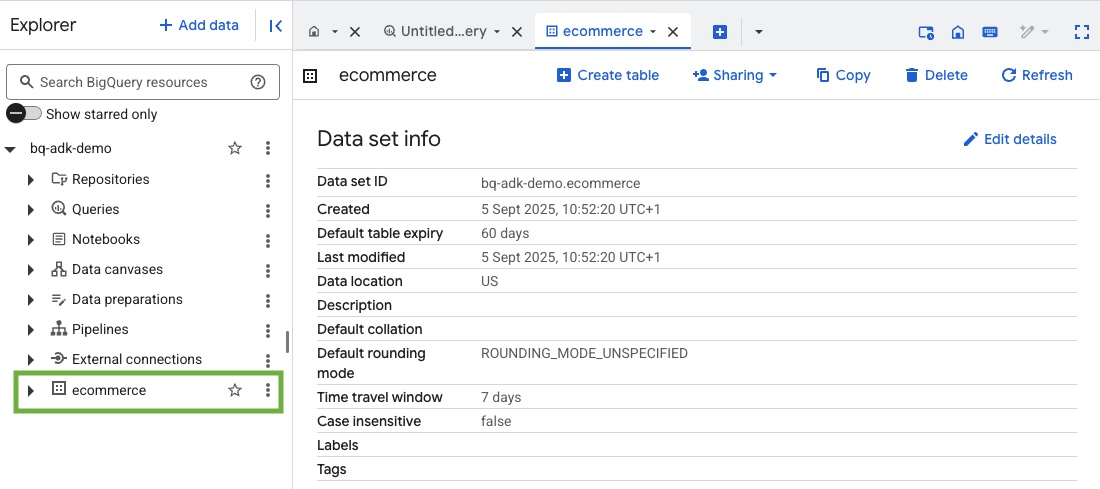
- Google Cloud projenizdeki BigQuery konsolunu ziyaret ederek veri kümesinin ve tabloların oluşturulduğunu doğrulayın:
4. Ortamı ADK aracıları için hazırlama
Cloud Shell'e dönün ve ana dizininizde olduğunuzdan emin olun. Sanal bir Python ortamı oluşturup gerekli paketleri yükleyeceğiz.
- Cloud Shell'de yeni bir terminal sekmesi açın ve bigquery-adk-codelab adlı bir klasör oluşturup bu klasöre gitmek için şu komutu çalıştırın:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- Sanal Python ortamı oluşturun:
python -m venv .venv
- Sanal ortamı etkinleştirin:
source .venv/bin/activate
- Google'ın ADK ve AI-Platform Python paketlerini yükleyin. BigQuery temsilcisini değerlendirmek için yapay zeka platformu ve pandas paketi gerekir:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. ADK uygulaması oluşturma
Şimdi BigQuery temsilcimizi oluşturalım. Bu temsilci, BigQuery'de depolanan verilerle ilgili doğal dil sorularını yanıtlamak için tasarlanmıştır.
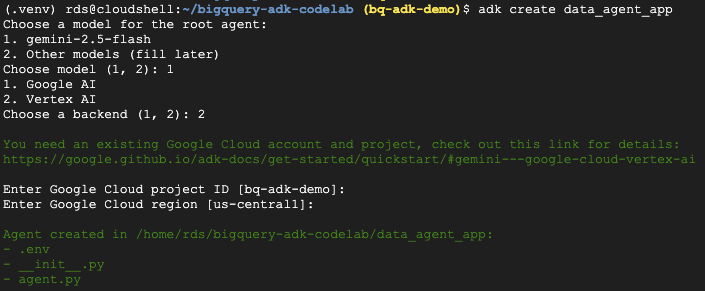
- Gerekli klasör ve dosyaları içeren yeni bir aracı uygulaması oluşturmak için adk create utility command komutunu çalıştırın:
adk create data_agent_app
İstemleri uygulayın:
- Model olarak gemini-2.5-flash'i seçin.
- Arka uç için Vertex AI'ı seçin.
- Varsayılan Google Cloud proje kimliğinizi ve bölgenizi onaylayın.
Aşağıda örnek bir etkileşim gösterilmektedir:
- Cloud Shell Düzenleyici'yi açmak ve yeni oluşturulan klasörleri ve dosyaları görüntülemek için Cloud Shell'de Open Editor (Düzenleyiciyi Aç) düğmesini tıklayın:

Oluşturulan dosyaları not edin:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: Klasörü bir Python modülü olarak işaretler.
- agent.py: İlk aracı tanımını içerir.
- .env: Projenizin ortam değişkenlerini içerir (Bu dosyayı görüntülemek için Görünüm > Gizli Dosyaları Aç/Kapat'ı tıklamanız gerekebilir).
İstemlerden doğru şekilde ayarlanmamış değişkenleri güncelleyin:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. Ajanınızı tanımlayın ve BigQuery araç setini atayın
BigQuery araç setini kullanarak BigQuery ile etkileşim kuran bir ADK aracısı tanımlamak için agent.py dosyasının mevcut içeriğini aşağıdaki kodla değiştirin.
Aracının talimatlarındaki proje kimliğini gerçek proje kimliğinizle güncellemeniz gerekir:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
BigQuery araç seti, meta verileri getirme ve BigQuery verilerinde SQL sorguları yürütme özelliklerine sahip bir aracı sağlar. Araç setini kullanmak için kimlik doğrulamanız gerekir. En yaygın seçenekler arasında geliştirme için Uygulama Varsayılan Kimlik Bilgileri (ADC), aracının belirli bir kullanıcı adına hareket etmesi gerektiğinde kullanılan Etkileşimli OAuth veya güvenli, üretim düzeyinde kimlik doğrulama için Hizmet Hesabı Kimlik Bilgileri yer alır.
Buradan Cloud Shell'e dönüp şu komutu çalıştırarak ajanınızla sohbet edebilirsiniz:
adk web
Web sunucusunun başlatıldığını belirten bir bildirim görmelisiniz:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
Adk web'i başlatmak için sağlanan URL'yi tıklayın. Aracınıza veri kümesiyle ilgili bazı sorular sorabilirsiniz:
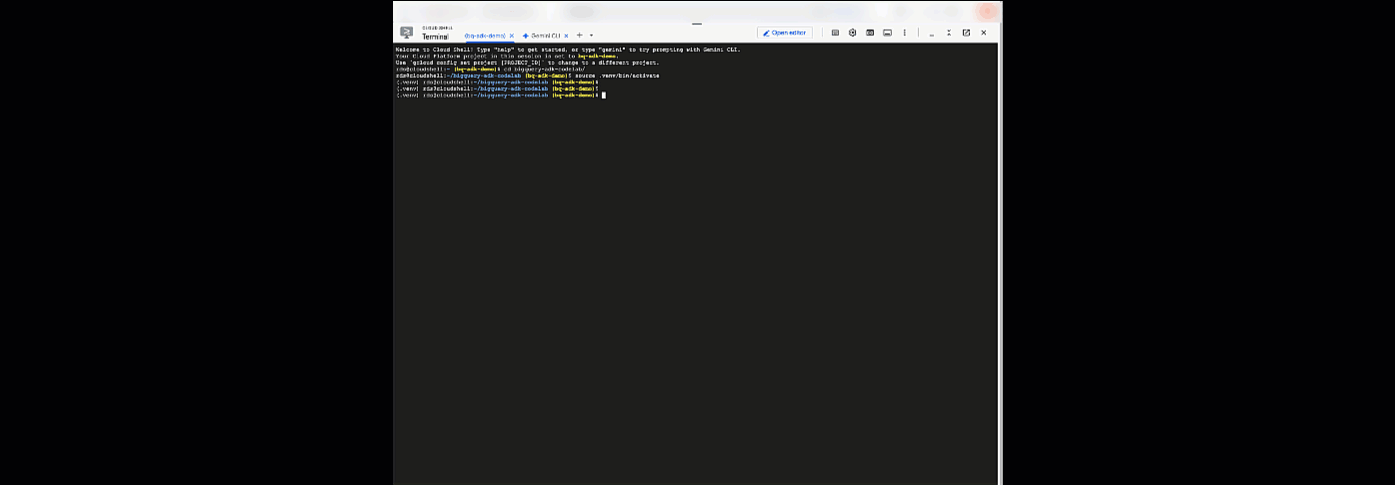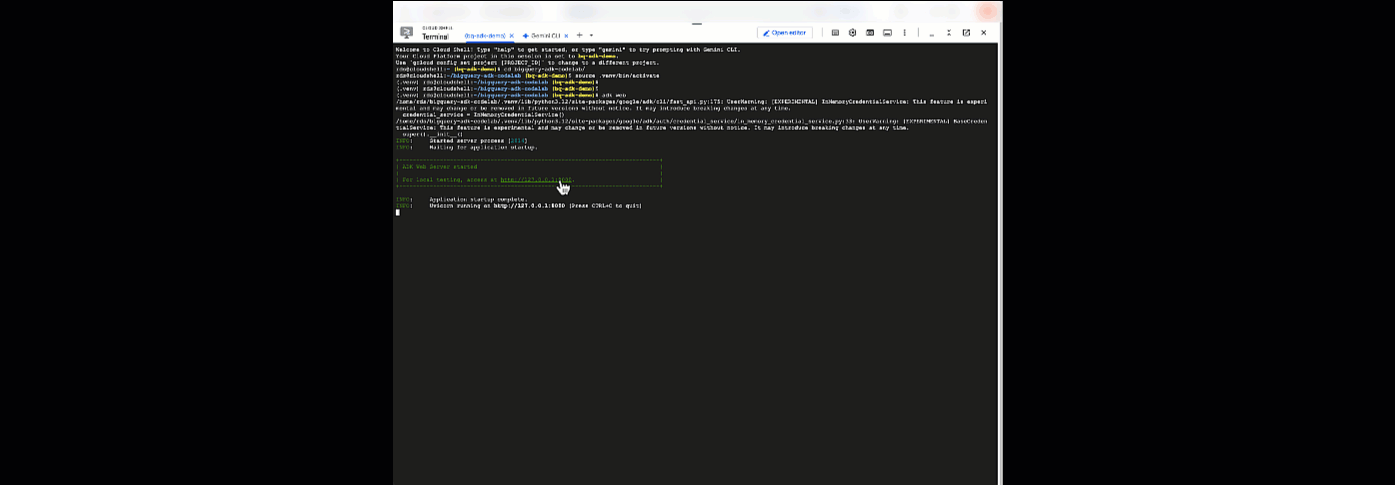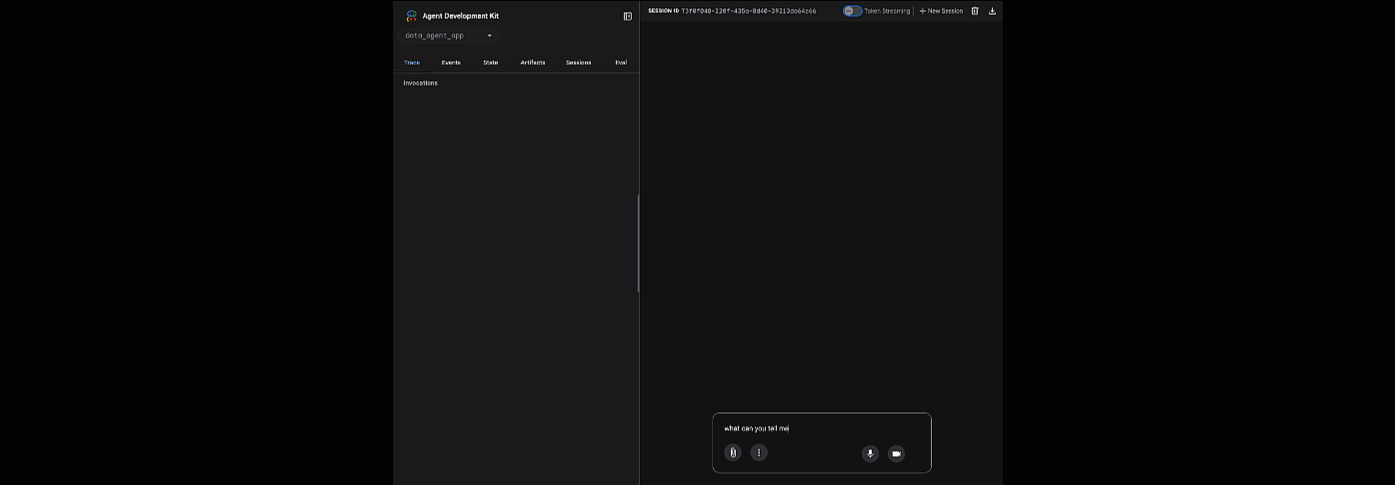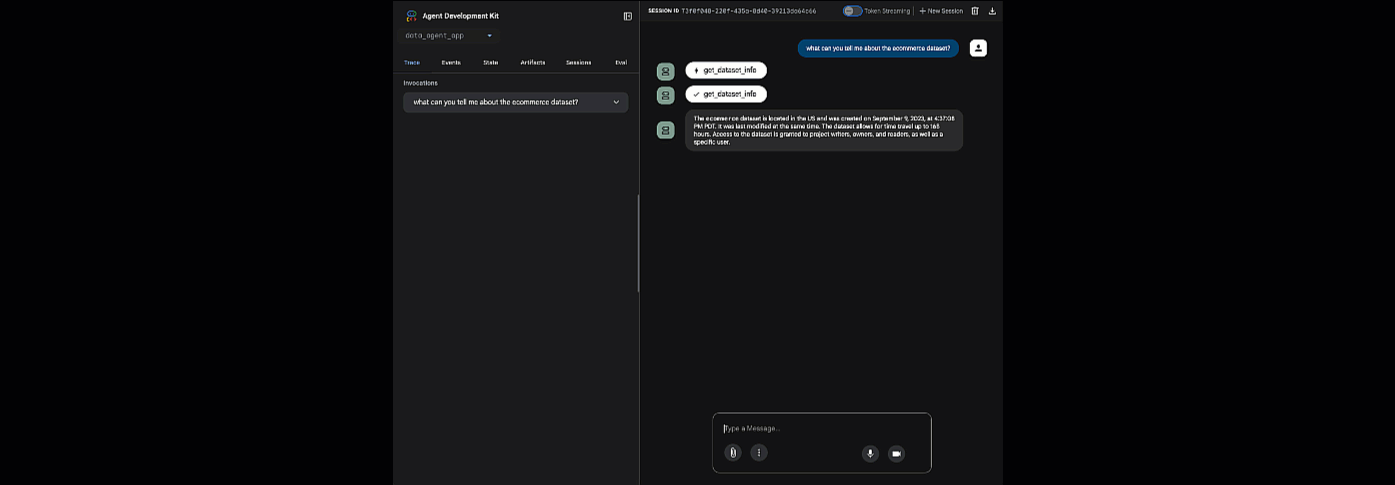
adk web'i kapatın ve web sunucusunu kapatmak için terminalde Ctrl + C tuşlarına basın.
7. Temsilcinizi değerlendirmeye hazırlama
BigQuery aracınızı tanımladığınıza göre artık değerlendirme için çalıştırılabilir hale getirmeniz gerekiyor.
Aşağıdaki kod, bir aracı oluşturarak, oturum çalıştırarak ve son yanıtı almak için etkinlikleri işleyerek görüşme akışını yöneten bir işlevi (run_conversation) tanımlar.
- Cloud Editor'a geri dönün ve bigquery-adk-codelab dizininde
run_agent.pyadlı yeni bir dosya oluşturup aşağıdaki kodu kopyalayıp yapıştırın:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
Aşağıdaki kod, bu çalıştırılabilir işlevi çağırmak ve sonucu döndürmek için yardımcı işlevleri tanımlar. Ayrıca değerlendirme sonuçlarını yazdıran ve kaydeden yardımcı işlevler de içerir:
- bigquery-adk-codelab dizininde
utils.pyadında yeni bir dosya oluşturun ve bu kodu utils.py dosyasına kopyalayıp yapıştırın:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. Değerlendirme veri kümesi oluşturma
Aracınızı değerlendirmek için değerlendirme veri kümesi oluşturmanız, değerlendirme metriklerinizi tanımlamanız ve değerlendirme görevini çalıştırmanız gerekir.
Değerlendirme veri kümesi, bir soru listesi (istemler) ve bunlara karşılık gelen doğru yanıtları (referanslar) içerir. Değerlendirme hizmeti, aracınızın yanıtlarını karşılaştırmak ve doğru olup olmadıklarını belirlemek için bu çiftleri kullanır.
- bigquery-adk-codelab dizininde evaluation_dataset.json adlı yeni bir dosya oluşturun ve aşağıdaki değerlendirme veri kümesini kopyalayıp yapıştırın:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. Değerlendirme metriklerinizi tanımlayın
Artık, aracının BigQuery verilerinizle ilgili soruları yanıtlama becerisini değerlendirmek için 1 ile 5 arasında puan veren iki özel metrik kullanacağız:
- Doğruluk Metriği: Bu metrik, yanıtta sunulan tüm verilerin ve bilgilerin kesin referansla karşılaştırıldığında doğru ve kesin olup olmadığını değerlendirir.
- Eksiksizlik metriği: Bu metrik, yanıtta kullanıcının istediği ve doğru yanıtta yer alan tüm önemli bilgilerin eksiksiz olarak yer alıp almadığını ölçer.
- Son olarak, bigquery-adk-codelab dizininde
evaluate_agent.pyadlı yeni bir dosya oluşturun ve metrik tanımı kodunu evaluate_agent.py dosyasına kopyalayıp yapıştırın:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
Yörünge değerlendirmesi için TrajectorySingleToolUse metriğini de ekledim. Bu metrikler mevcut olduğunda, değerlendirme yanıtına aracı işlevi çağrıları (BigQuery'ye karşı oluşturup yürüttüğü ham SQL dahil) eklenir ve ayrıntılı inceleme yapılmasına olanak tanınır.
TrajectorySingleToolUse metriği, bir aracının belirli bir aracı kullanıp kullanmadığını belirler. Bu durumda, değerlendirme veri kümesindeki her soru için bu aracın çağrılmasını beklediğimizden list_table_ids'yi seçtim. Diğer yörünge metriklerinin aksine bu metrik, değerlendirme veri kümesindeki her soru için beklenen tüm araç çağrılarını ve bağımsız değişkenlerini belirtmenizi gerektirmez.
10. Değerlendirme görevinizi oluşturma
EvalTask, değerlendirme veri kümesini ve özel metrikleri alıp yeni bir değerlendirme denemesi oluşturur.
run_eval işlevi, değerlendirmenin ana motorudur. EvalTask'te döngü oluşturarak veri kümesindeki her soruda aracınızı çalıştırır. Her soru için temsilcinin yanıtını kaydeder ve ardından daha önce tanımladığınız metrikleri kullanarak yanıtı derecelendirir.
Aşağıdaki kodu kopyalayıp evaluate_agent.py dosyasının en altına yapıştırın:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
Sonuçlar özetlenir ve bir JSON dosyasına kaydedilir.
11. Değerlendirmenizi çalıştırma
Artık aracınız, değerlendirme metrikleriniz ve değerlendirme veri kümeniz hazır olduğuna göre değerlendirmeyi çalıştırabilirsiniz.
Cloud Shell'e dönün, bigquery-adk-codelab dizininde olduğunuzdan emin olun ve aşağıdaki komutu kullanarak değerlendirme komut dosyasını çalıştırın:
python evaluate_agent.py
Değerlendirme ilerledikçe şuna benzer bir çıkış görürsünüz:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
Aşağıdakiler gibi hatalarla karşılaşırsanız bu, aracının belirli bir çalıştırma için herhangi bir araç çağırmadığı anlamına gelir. Sonraki adımda aracı davranışını daha ayrıntılı olarak inceleyebilirsiniz.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
Sonuçları yorumlama:
data_agent_app dizinindeki eval_results klasörüne gidin ve bq_agent_eval_results_*.json adlı değerlendirme sonucu dosyasını açın:
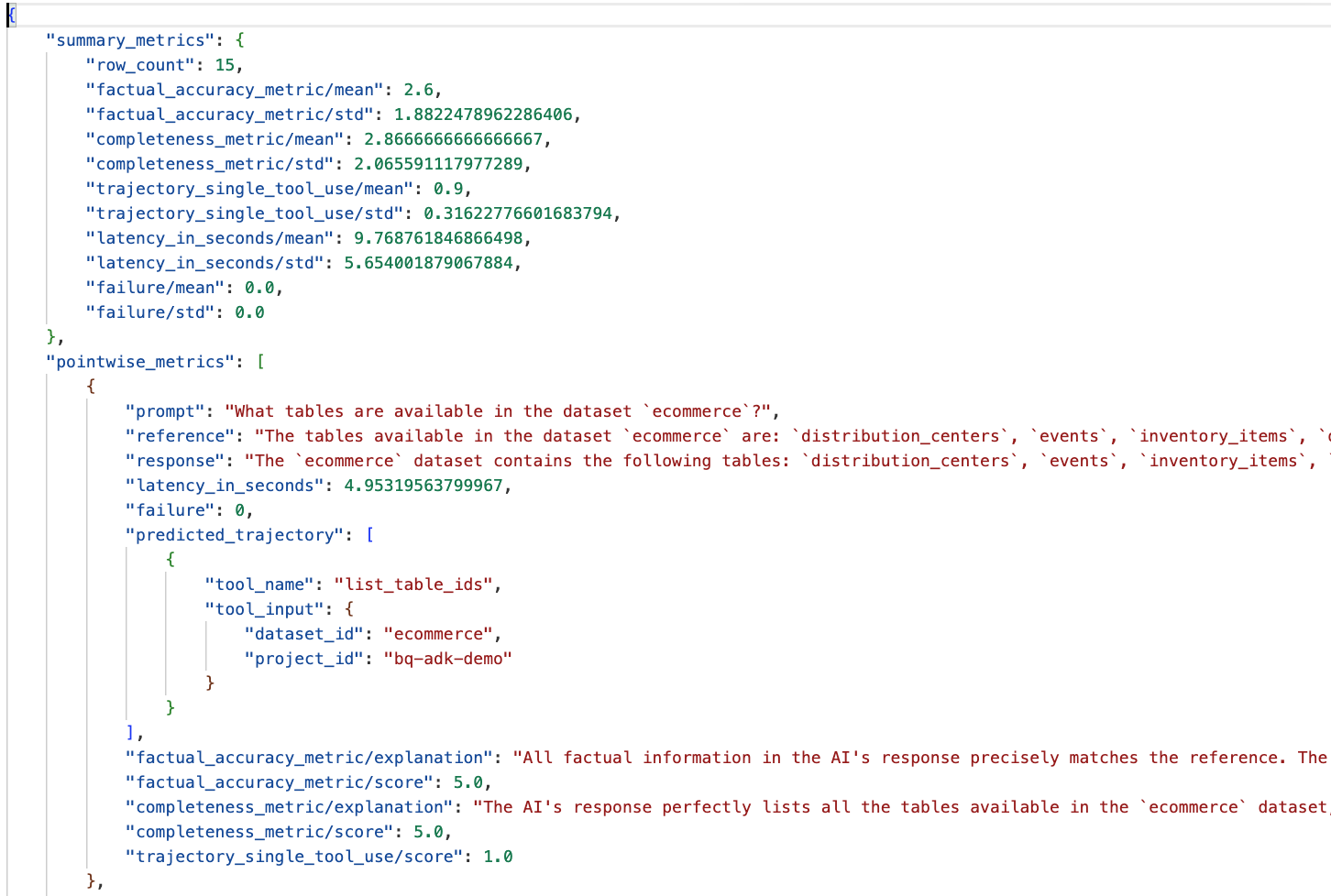
- Özet Metrikler: Aracınızın veri kümesindeki performansının toplu görünümünü sağlar.
- Doğruluk ve Eksiksizlik Noktası Metrikleri: 5'e yakın bir puan, daha yüksek doğruluk ve eksiksizlik anlamına gelir. Her soru için bir puan ve bu puanın neden verildiğine dair yazılı bir açıklama yer alır.
- Tahmini Yörünge: Bu, nihai yanıta ulaşmak için aracılar tarafından kullanılan araç çağrıları listesidir. Bu sayede, temsilci tarafından oluşturulan tüm SQL sorgularını görebiliriz.
Ortalama eksiksizlik ve olgusal doğruluk için ortalama puanın sırasıyla 2,87 ve 2,6 olduğunu görüyoruz.
Sonuçlar çok iyi değil. Ajanımızın soruları yanıtlama becerisini geliştirmeye çalışalım.
12. Ajanınızın değerlendirme sonuçlarını iyileştirme
bigquery-adk-codelab dizinindeki agent.py dosyasına gidin ve aracının modelini ve sistem talimatlarını güncelleyin. <YOUR_PROJECT_ID> kısmını proje kimliğinizle değiştirmeyi unutmayın:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
Şimdi terminale geri dönün ve değerlendirmeyi yeniden çalıştırın:
python evaluate_agent.py
Sonuçların artık çok daha iyi olduğunu göreceksiniz:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
Aracınızı değerlendirmek yinelemeli bir süreçtir. Değerlendirme sonuçlarını daha da iyileştirmek için sistem talimatlarını, model parametrelerini veya BigQuery'deki meta verileri değiştirebilirsiniz. Daha fazla fikir edinmek için bu ipuçlarını ve püf noktalarını inceleyin.
13. Temizleme
Google Cloud hesabınızın sürekli olarak ücretlendirilmesini önlemek için bu atölye çalışması sırasında oluşturduğumuz kaynakları silmeniz önemlidir.
Bu codelab için belirli BigQuery veri kümeleri veya tabloları (ör. e-ticaret veri kümesi) oluşturduysanız bunları silmek isteyebilirsiniz:
bq rm -r $PROJECT_ID:ecommerce
bigquery-adk-codelab dizinini ve içeriğini kaldırmak için:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. Tebrikler
Tebrikler! Agent Development Kit'i (ADK) kullanarak bir BigQuery aracısı oluşturup değerlendirdiniz. Artık BigQuery araçlarıyla ADK aracısı oluşturmayı ve özel değerlendirme metriklerini kullanarak performansını ölçmeyi biliyorsunuz.
Referans belgeler
- Agent Development Kit Documentation (Temsilci Geliştirme Kiti Dokümanları)
- BigQuery belgeleri
- Vertex AI Evaluation Belgeleri
- ADK meets BigQuery Blog Series (ADK meets BigQuery Blog Serisi)