
1. はじめに
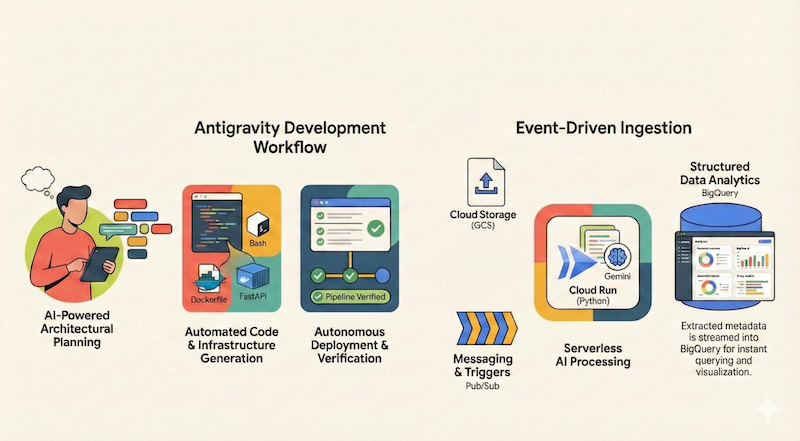
この Codelab では、Google Antigravity を使用して、サーバーレス アプリケーションを設計、構築、Google Cloud にデプロイする方法を学習します。Google Cloud Storage(GCS)からファイルを取り込み、Cloud Run と Gemini を使用して処理し、メタデータを BigQuery にストリーミングするサーバーレスのイベント ドリブン ドキュメント パイプラインを構築します。
学習内容
- 建築計画と設計に Antigravity を使用する方法。
- AI エージェントを使用して、Infrastructure as Code(シェル スクリプト)を生成します。
- Python ベースの Cloud Run サービスをビルドしてデプロイします。
- マルチモーダル ドキュメント分析のために Vertex AI の Gemini を統合します。
- Antigravity の Walkthrough アーティファクトを使用して、エンドツーエンドのパイプラインを確認します。
必要なもの
- Google Antigravity がインストールされている。
- 課金が有効な Google Cloud プロジェクトが用意されていること。
- gcloud CLI がインストールされ、認証されている。
2. アプリの概要
Antigravity を使用してアプリケーションの設計と実装を行う前に、まず、自分で構築するアプリケーションの概要を説明します。
Google Cloud Storage(GCS)からファイルを取り込み、Cloud Run と Gemini を使用して処理し、メタデータを BigQuery にストリーミングする、サーバーレスでイベント ドリブンのドキュメント パイプラインを構築します。
このアプリケーションのアーキテクチャの概要図は次のようになります。
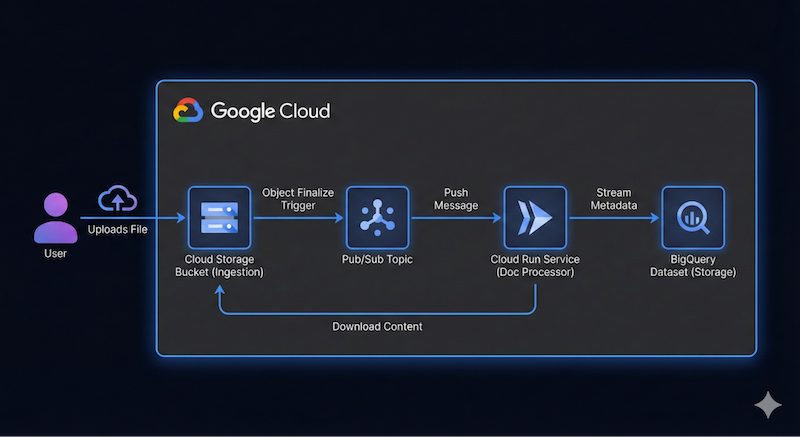
正確である必要はありません。Antigravity を使用すると、アーキテクチャの詳細を把握しながら作業を進めることができます。ただし、何を構築したいかについてアイデアがあると便利です。詳細な情報を提供するほど、アーキテクチャとコードに関する Antigravity の結果が向上します。
3. アーキテクチャを計画する
Antigravity を使用してアーキテクチャの詳細を計画する準備が整いました。
Antigravity は複雑なシステムの計画に優れています。コードをすぐに記述するのではなく、まず大まかなアーキテクチャを定義し、機能の 1 つを使用して Antigravity がリクエストを評価し、もっと聞くをしてから、計画と実装に進むようにします。
Antigravity を起動したことを前提として、この Codelab 用に新しいプロジェクトを作成します。
下の図に示すように、Projects ラボの横にある新しいプロジェクト アイコンをクリックし、New Project をクリックします。

次のように、Add Folder オプションが表示されます。
[Add Folder] ボタンをクリックして、プロジェクトにフォルダを追加します。自分のマシンに google-cloud-serverless-app フォルダを作成し、このプロジェクトに追加しました。
google-cloud-serverless-app ワークスペースで会話が開きます。
画面の左下にあるメイン設定アイコン ⚙️ をクリックして、プロジェクト固有の設定に移動します。以下に示すように、Agent Settings / Security Preset を Default に、Agent Behaviour / Artifact Review Policy を Always Ask に設定します。
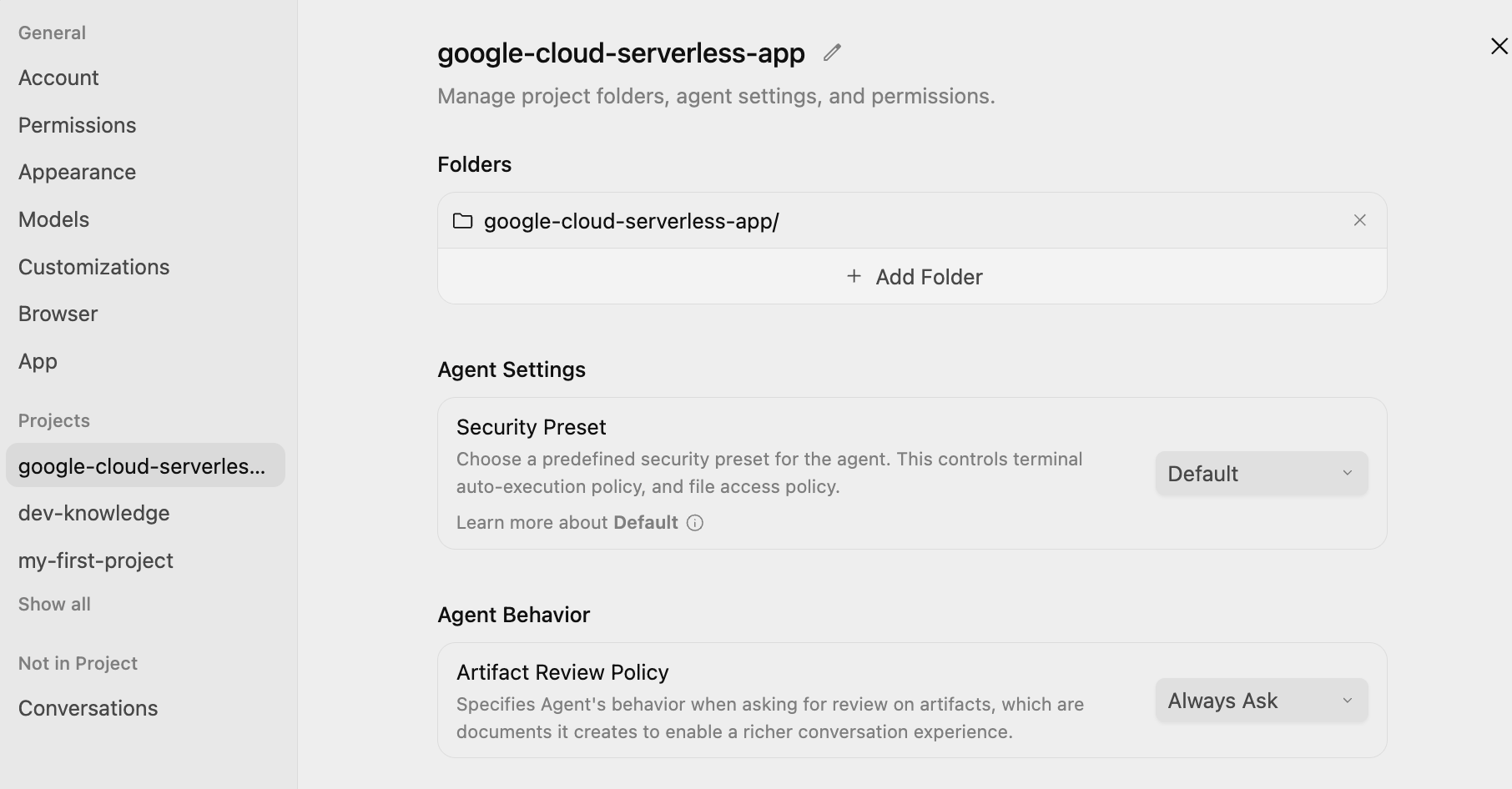
これにより、エージェントが実行する前に、各ステップでプランを確認して承認することができます。
プロンプト
これで、Antigravity に最初のプロンプトを提供する準備が整いました。リクエストを評価するために、スラッシュ コマンド /grill-me を使用します。
「/grill-me」と入力し、次のプロンプトを入力して [送信] ボタンをクリックします。
/grill-me
I want to build a serverless event-driven document processing pipeline on Google Cloud.
Architecture:
- Ingestion: Users upload files to a Cloud Storage bucket.
- Trigger: File uploads trigger a Pub/Sub message.
- Processor: A Python-based Cloud Run service receives the message, processes the file (simulated OCR), and extracts metadata.
- Storage: Stream the metadata (filename, date, tags, word_count) into a BigQuery dataset.
/grill-me コマンドは、一連のフォローアップ質問をします。できるだけ詳しく回答してください。推奨される回答も提案されるため、必要に応じてそれを使用できます。
/grill-me コマンドの実行例を次に示します。
How would you provision and manage the Google Cloud infrastructure resources (Cloud Storage buckets, Pub/Sub topics, BigQuery datasets, Cloud Run service)?
gcloud CLI Setup Script - Shell scripts running gcloud CLI commands to create resources step-by-step
How should the Cloud Storage upload events trigger and reach your Python Cloud Run service?
(Recommended) Native Cloud Storage Pub/Sub Notifications + Pub/Sub Push subscription to Cloud Run (direct, lightweight, standard event-driven approach)
Which Python web framework would you prefer for the Cloud Run processing service?
Flask (with Gunicorn) - Standard, lightweight, and very common for simple Cloud Run services
How should the OCR and metadata extraction logic be implemented in the Cloud Run service?
(Recommended) Full local simulation - If it's a .txt file, read the contents, count words, and extract tags. For other files, generate mock OCR metadata and simulated word count. No external API calls.
Which BigQuery insertion method should the Cloud Run service use to store metadata?
(Recommended) BigQuery table.insert_rows() (Legacy Streaming API) - Extremely simple to code, clean error handling, perfect for simulation and low-to-medium volumes.
How should security/authentication be configured for the Cloud Run service?
Unauthenticated Cloud Run - Allow public requests to the Cloud Run service URL (simpler setup, but insecure for production).
What schema would you like to define for the BigQuery metadata table?
(Recommended) Extended Schema - Include filename, bucket, size, content_type, word_count, tags (as a REPEATED STRING array), ocr_text_preview, and process_timestamp.
How should the Cloud Run service handle processing failures (e.g., file not found, BigQuery write error)?
(Recommended) Fail-Fast with Retry - Log error to standard output (Cloud Logging) and return HTTP 500 to Pub/Sub, so that Pub/Sub automatically retries the message delivery.
What testing tools should we generate to verify the pipeline's functionality?
(Recommended) Both - Include a local test script (sending mock Pub/Sub POST requests to the local Flask server) and a Cloud-integrated test script (uploading a real file to GCS and verifying BigQuery).
Antigravity に次のことを依頼しました。
- リソースをプロビジョニングする簡単な gcloud CLI スクリプト
- ネイティブの Cloud Storage Pub/Sub 通知 + Cloud Run への Pub/Sub Push サブスクリプション
- フレームワークに Flask(Gunicorn を使用)を使用する
- ライブ OCR データの代わりに、データにテキスト ファイルを使用してローカル シミュレーションを行う
- BigQuery table.insert_rows() を使用して BigQuery に行を挿入する
- 未認証の Cloud Run デプロイ
などの推奨オプションを確認します。
実装計画とタスクリスト
Antigravity は、実装計画の生成を開始します。生成された実装計画は、次のようなメッセージで確認できます。
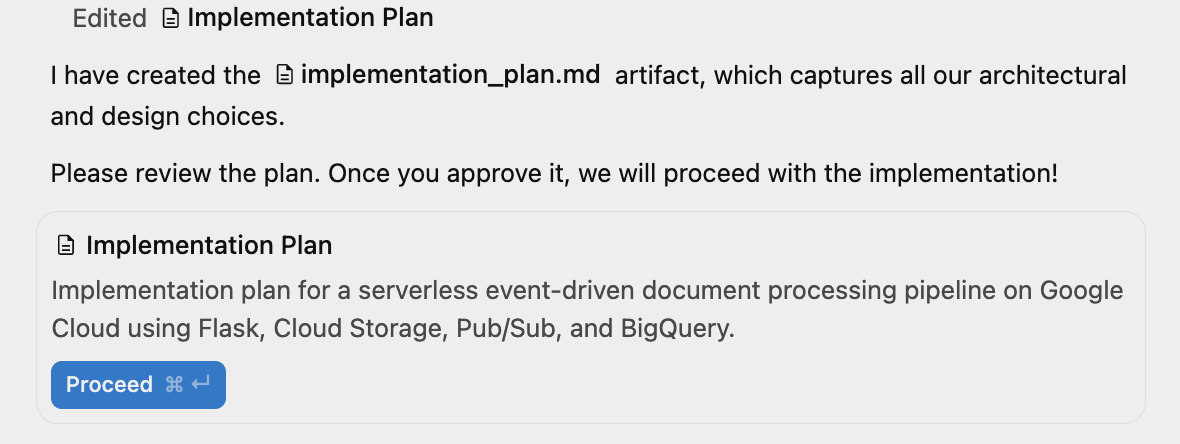
ウィンドウの右上にある [補助ペイン] の切り替えをクリックすると、生成されたアーティファクト(この時点では実装計画のみ)を表示できます。
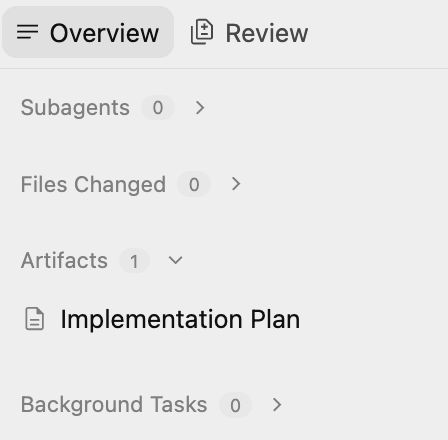
このプランでは、以下について概説します。
- インフラストラクチャ: GCS バケット、Pub/Sub トピック、BigQuery データセット。
- プロセッサ: Python/Flask アプリ、Dockerfile、要件。
- 統合: GCS 通知 → Pub/Sub → Cloud Run。
次のような出力が表示されます。以下は、マシン上の実装計画の一部を示しています。
Event-Driven Document Processing Pipeline Implementation Plan
This implementation plan describes the components and setup scripts required to build a serverless event-driven document processing pipeline on Google Cloud.
User Review Required
Please review the proposed architecture, components, and default configuration. If you agree, please approve the plan so we can proceed with creating the files and implementation.
IMPORTANT
Security Notice: As requested, the Cloud Run service is configured to allow unauthenticated invocations (--allow-unauthenticated) for simpler testing and development.
Error Handling: The service returns an HTTP 500 error code for failures to trigger Pub/Sub retries.
GCP Configuration: The provisioning scripts will use standard environment variables (e.g., GCP_PROJECT, GCP_REGION) that default to the active configuration of your local gcloud CLI.
Proposed Components and Files
The project will be organized as follows:
google-cloud-serverless-app/
├── src/
│ ├── __init__.py
│ ├── app.py # Flask app entrypoint and routes
│ ├── processor.py # Simulated OCR and metadata extraction engine
│ ├── gcs_helper.py # Helper functions to read files from Cloud Storage
│ └── bq_helper.py # Helper functions to write metadata to BigQuery
├── requirements.txt # Python dependencies
├── Dockerfile # Docker configuration for Cloud Run
├── deploy.sh # gcloud CLI provisioning and deployment script
├── test_local.sh # Script to test the Flask app locally with mock Pub/Sub events
├── test_cloud.sh # Script to upload a real file to GCS and query BigQuery
└── README.md # Setup and execution guide
慎重に確認してください。これは、実装に関するフィードバックを提供する機会です。実装計画の任意の部分をクリックして、コメントを追加できます。コメントを追加したら、特に命名、Google Cloud プロジェクト ID、リージョンなど、変更してほしい点について審査をリクエストしてください。
すべて問題ないことを確認したら、Proceed ボタンをクリックして、エージェントに実装プランの続行を許可します。
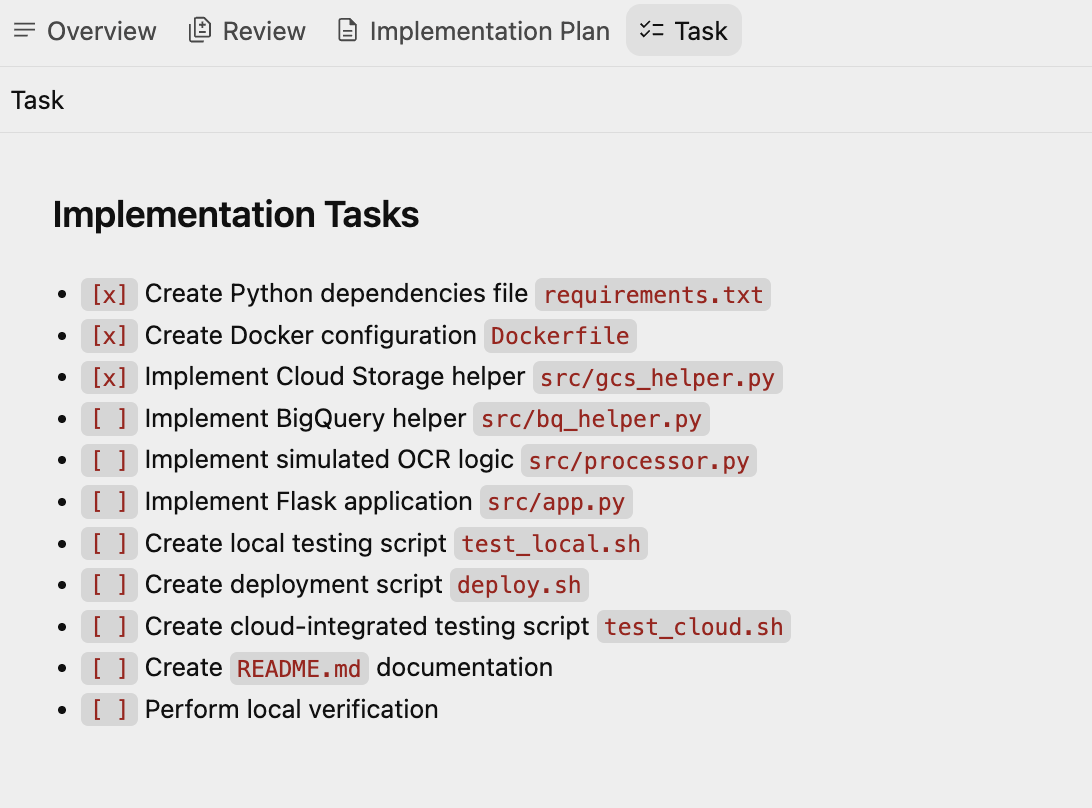
次に、Antigravity によって作成された一連のタスクを含む別のアーティファクト Task Plan の作成に進みます。エージェントはこれらを 1 つずつ実行します。タスクリストの例を以下に示します。
4. アプリケーションを生成する
プランが承認されると、Antigravity はプロビジョニング スクリプトからアプリケーション コードまで、アプリケーションに必要なファイルの生成を開始します。
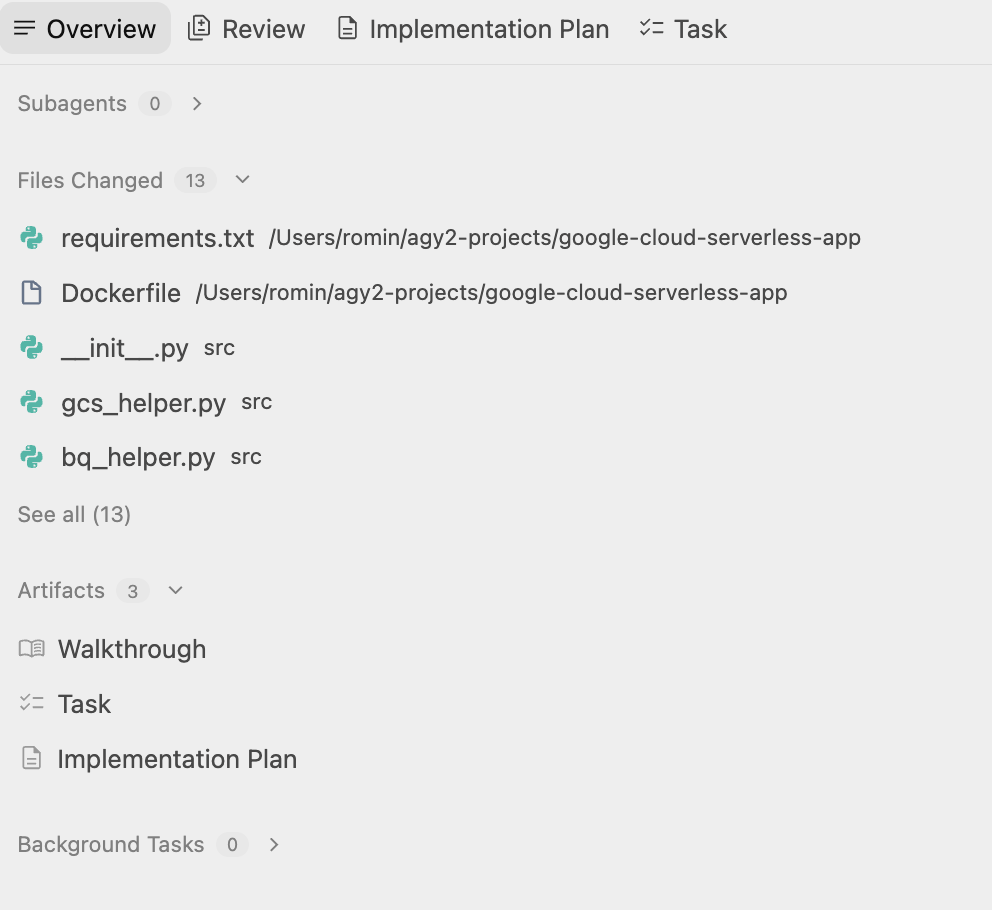
Antigravity はフォルダを作成し、プロジェクトに必要なファイルの作成を開始します。アーティファクトを確認すると、いくつかのファイル(ソースコード、スクリプト ファイルなど)が生成されていることがわかります。
作業が完了すると、その旨が通知され、確認できるチュートリアル ドキュメントが作成されます。ユーザー向けの次のステップが記載されている。サンプルは以下のとおりです。
- パイプラインをデプロイする: GCP CLI にログインしてターゲット プロジェクトを設定したら、
./deploy.shを実行します。 - エンドツーエンド テストを実行する: クラウド統合テスト スクリプトを実行して、ファイルのアップロードが Cloud Run 処理をトリガーし、メタデータを BigQuery にストリーミングすることを確認します。
./test_cloud.sh - クリーンアップ: テストが完了したら、
README.mdクリーンアップ コマンドを参照して、作成したリソースを削除し、課金が発生しないようにします。
deploy.sh または同様の名前のシェル スクリプト ファイルが生成され、リソースの作成が自動化されます。処理できる内容:
- API(
run、pubsub、bigquery、storage)を有効にします。 - Google Cloud Storage バケット(
document-processing-ingest-{project-id})を作成します。 - BigQuery データセットとテーブルの作成(
document_processing.processed_metadata)。 - Pub/Sub トピックと通知を構成する。
5. アプリケーションをデプロイする
./ deploy.sh コマンドを使用して、前述のようにアプリケーションをデプロイしましょう。Antigravity にこの実行を依頼できますが、その前に、gcloud CLI が存在し、Google Cloud プロジェクト用に構成されていることを確認してください。
Antigravity に「deploy.sh を実行して」というプロンプトを送信します。権限を求めるプロンプトが表示されます。入力してください。
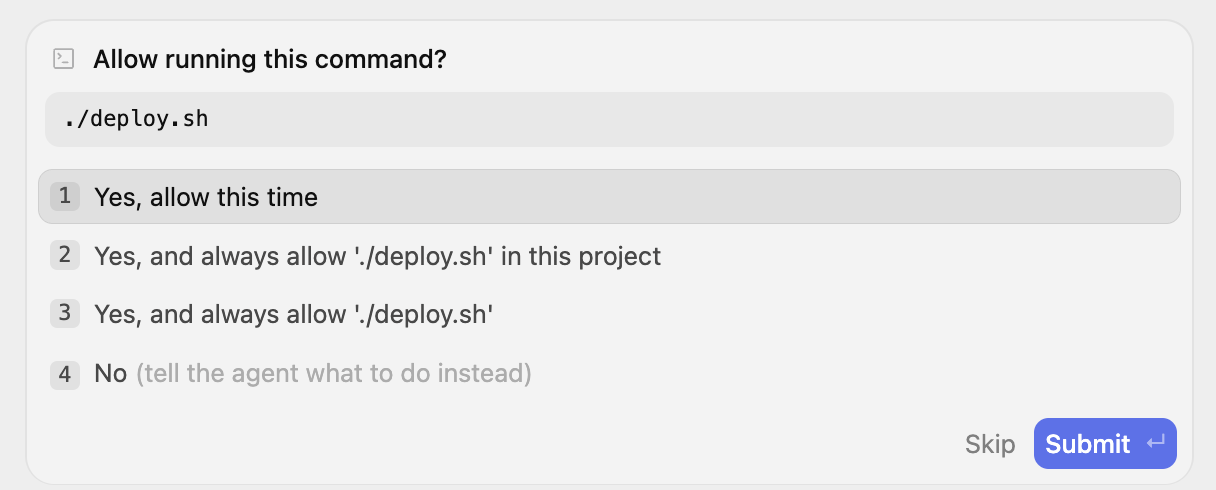
次のメッセージで説明されているように、プロセスはバックグラウンド タスクとして開始されます。
バックグラウンドで ./deploy.sh を実行してデプロイ プロセスを開始しました。実行ログをモニタリングし、デプロイが完了したらすぐに通知します。
6. アプリケーションを確認する
パイプラインがデプロイされると、Antigravity はアプリケーションが実際に動作することを確認します。test_cloud.sh ファイルを実行できるかどうかを尋ねてくるので、許可します。

最終的に、次の情報が返されます。
I have successfully run both ./deploy.sh and ./test_cloud.sh.
The pipeline is fully deployed to your GCP project PROJECT_ID and working end-to-end.
Please refer to the walkthrough.md for full verification details and the query output from BigQuery showing the successfully processed document metadata.
ウォークスルー アーティファクトを開いて結果を確認できます。
Cloud Verification Results
The deployment and end-to-end cloud integration test (./test_cloud.sh) succeeded perfectly!
Resources Created:
GCS Bucket: gs://document-processing-ingest-gcp-experiments-349209
Pub/Sub Topic: document-uploads-topic
Pub/Sub Subscription: document-uploads-sub (pushing to Cloud Run)
Cloud Run Service: document-processor (URL: https://document-processor-ido3ocn3pq-uc.a.run.app)
BigQuery Dataset: document_processing
BigQuery Table: processed_metadata
Integration Test Run: A test file cloud_test_sample.txt was uploaded to the bucket. The pipeline processed the file and streamed the metadata record into BigQuery:
🔍 Querying BigQuery to verify metadata insertion...
<BIQUERY DATA HERE>
The pipeline successfully detected the hashtags #gcp and #serverless as tags, correctly counted the 47 words, generated the OCR preview, and wrote the entry to BigQuery under the schema.
省略可: 手動による確認
Antigravity はすでにアプリケーションを検証していますが、必要に応じて、次の手順に沿って Google Cloud コンソールで、すべてのリソースが作成されていることを手動で確認することもできます。
Cloud Storage
目標: バケットが存在することを確認し、アップロードされたファイルを確認します。
- [Cloud Storage] > [バケット] に移動します。
document-processing-ingest-{project-id}という名前のバケットを見つけます。- バケット名をクリックしてファイルを参照します。
- 確認: アップロードしたファイル(
cloud_test_sample.txtなど)が表示されます。
Pub/Sub
目標: トピックが存在し、プッシュ サブスクリプションがあることを確認します。
- [Pub/Sub] > [トピック] に移動します。
- document-uploads-topic を見つけます。
- トピック ID をクリックします。
- [登録チャンネル] タブまで下にスクロールします。
- 確認: doc-uploads-sub が「Push」配信タイプでリストされていることを確認します。
Cloud Run
目標: サービスのステータスとログを確認します。
- Cloud Run に移動します。
- サービス document-processor をクリックします。
- 確認:
- 健全性: サービスがアクティブであることを示す緑色のチェックマーク。
- ログ: [ログ] タブをクリックします。「Processing file: gs://...」や「Successfully inserted...」などのエントリを探します。
BigQuery
目標: データが実際に保存されていることを検証します。
- [BigQuery] > [SQL ワークスペース] に移動します。
- [エクスプローラ] ペインで、プロジェクト > document_processing データセットを開きます。
- processed_metadata テーブルをクリックします。
- [クエリ] タブをクリックし、SELECT * ステートメントを使用してテーブルからすべての行を取得します。
- 確認: filename、process_timestamp、tags、word_count を含む行が表示されます。
7. アプリケーションを探索する
この時点で、基本的なアプリがプロビジョニングされて実行されています。このアプリケーションをさらに拡張する前に、コードを確認してください。アーティファクトを表示すると、生成されたコードファイルが表示されます。
表示される可能性のあるファイルの概要は次のとおりです。
deploy.sh: すべての Google Cloud リソースをプロビジョニングし、必要な API を有効にするマスター スクリプト。appy.py: パイプラインのメイン エントリ ポイント。この Python アプリは、Pub/Sub プッシュ メッセージを受信するウェブサーバーを作成し、GCS からファイルをダウンロードして「処理」(OCR をシミュレート)し、メタデータを BigQuery にストリーミングします。Dockerfile: アプリをコンテナ イメージにパッケージ化する方法を定義します。requirements.txt: Python 依存関係を一覧表示します。
テストと検証に必要な他のスクリプトやテキスト ファイルも表示されることがあります。
8. アプリケーションを拡張する
これで、基本的なアプリケーションが完成しました。このアプリケーションを繰り返し拡張していくことができます。以下にいくつかのアイデアを示します。
フロントエンドを追加する
処理されたドキュメントを表示するシンプルなウェブ インターフェースを構築します。
次のプロンプトを試してください。Create a simple Streamlit or Flask web application that connects to BigQuery. It should display a table of the processed documents (filename, upload_date, tags, word_count) and allow me to filter the results by tag
実際の AI/ML と統合する
シミュレートされた OCR 処理の代わりに、Gemini モデルを使用して抽出、分類、翻訳を行います。
- ダミーの OCR ロジックを置き換えます。画像や PDF を Gemini に送信して、実際のテキストとデータを抽出します。抽出したテキストを分析して、ドキュメント タイプ(請求書、契約書、履歴書)を分類したり、エンティティ(日付、名前、場所)を抽出したりします。
- ドキュメントの言語を自動的に検出し、保存する前に英語に翻訳します。他の言語を使用することもできます。
ストレージと分析を強化する
バケットにライフサイクル ルールを構成して、古いファイルを Coldline Storage または Archive Storage に移動すると、コストを節約できます。
堅牢性とセキュリティ
アプリの堅牢性とセキュリティを強化できます。
- デッドレター キュー(DLQ): 障害を処理するように Pub/Sub サブスクリプションを更新します。Cloud Run サービスがファイルの処理に 5 回失敗した場合は、メッセージを別の「デッドレター」トピック/バケットに送信して、手動で検査します。
- Secret Manager: アプリで API キーや機密性の高い構成が必要な場合は、文字列をハードコーディングするのではなく、Secret Manager に保存して Cloud Run から安全にアクセスします。
- Eventarc: より柔軟なイベント ルーティングを実現するために、Pub/Sub から Eventarc にアップグレードします。これにより、複雑な監査ログや他の GCP サービス イベントに基づいてトリガーできます。
もちろん、独自のアイデアを思いついて、Antigravity を使用して実装することもできます。
9. まとめ
Google Antigravity を使用して、スケーラブルでサーバーレスの AI 搭載ドキュメント パイプラインを数分で構築できました。具体的には、以下の方法について学習しました。
- AI を使用してアーキテクチャを計画します。
- コード生成からデプロイと検証まで、アプリケーションの生成を行う Antigravity を指示して管理します。
- チュートリアルでデプロイと検証を確認します。
リファレンス ドキュメント
- 公式サイト : https://antigravity.google/
- ドキュメント: https://antigravity.google/docs
- ユースケース : https://antigravity.google/use-cases
- ダウンロード : https://antigravity.google/download