
About this codelab
1. Introduction
BigQuery is Google's fully managed, low-cost analytics database. With BigQuery, you can query terabytes of data without needing a database administrator or any infrastructure to manage. BigQuery uses familiar SQL and a pay-only-for-what-you-use charging model. BigQuery allows you to focus on analyzing data to find meaningful insights.
In this codelab, you'll see how to query the GitHub public dataset, one of many available public datasets available in BigQuery.
What you'll learn
- How to use BigQuery
- How to write a query to gain insight into a large dataset
What you'll need
2. Get set up
Enable BigQuery
If you don't already have a Google Account (Gmail or Google Apps), you must create one.
- Sign-in to Google Cloud Platform console ( console.cloud.google.com) and navigate to BigQuery. You can also open the BigQuery web UI directly by entering the following URL in your browser.
https://console.cloud.google.com/bigquery
- Accept the terms of service.
- Before you can use BigQuery, you must create a project. Follow the prompts to create your new project.
Choose a project name and make note of the project ID.

The project ID is a unique name across all Google Cloud projects. It will be referred to later in this codelab as PROJECT_ID.
This codelab uses BigQuery resources withing the BigQuery sandbox limits. A billing account is not required. If you later want to remove the sandbox limits, you can add a billing account by signing up for the Google Cloud Platform free trial.
3. Preview GitHub data
Open the GitHub dataset in the BigQuery web UI.
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
Get a quick preview of how the data looks.
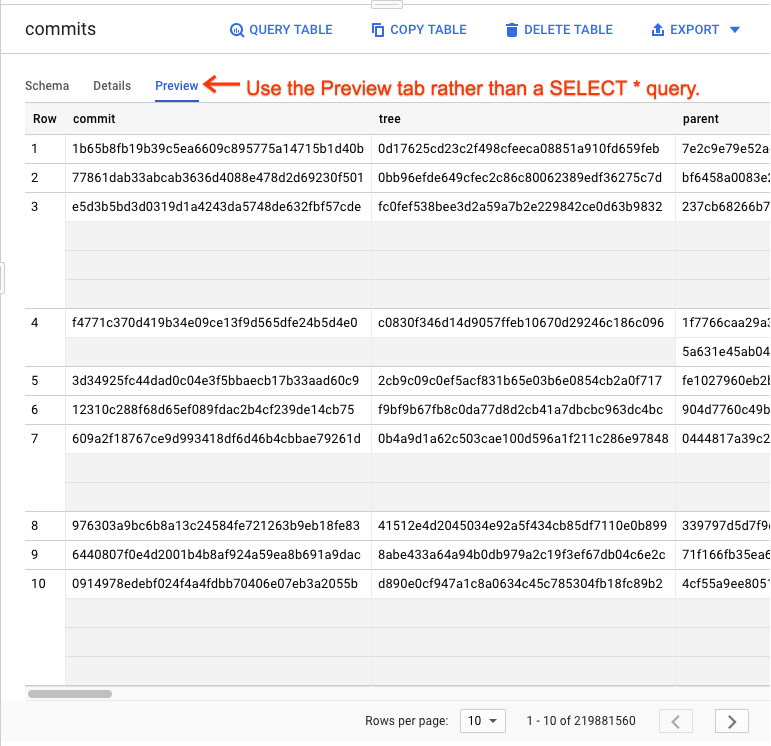
4. Query GitHub data
Open the query editor.
Enter the following query to find the most common commit messages in the GitHub public dataset:
SELECT subject AS subject,
COUNT(*) AS num_duplicates
FROM `bigquery-public-data.github_repos.sample_commits`
GROUP BY subject
ORDER BY num_duplicates DESC
LIMIT 100
Given that the GitHub dataset is large, it helps to use a smaller sample dataset while experimenting to save on costs. Use the bytes processed below the editor to estimate the query cost.
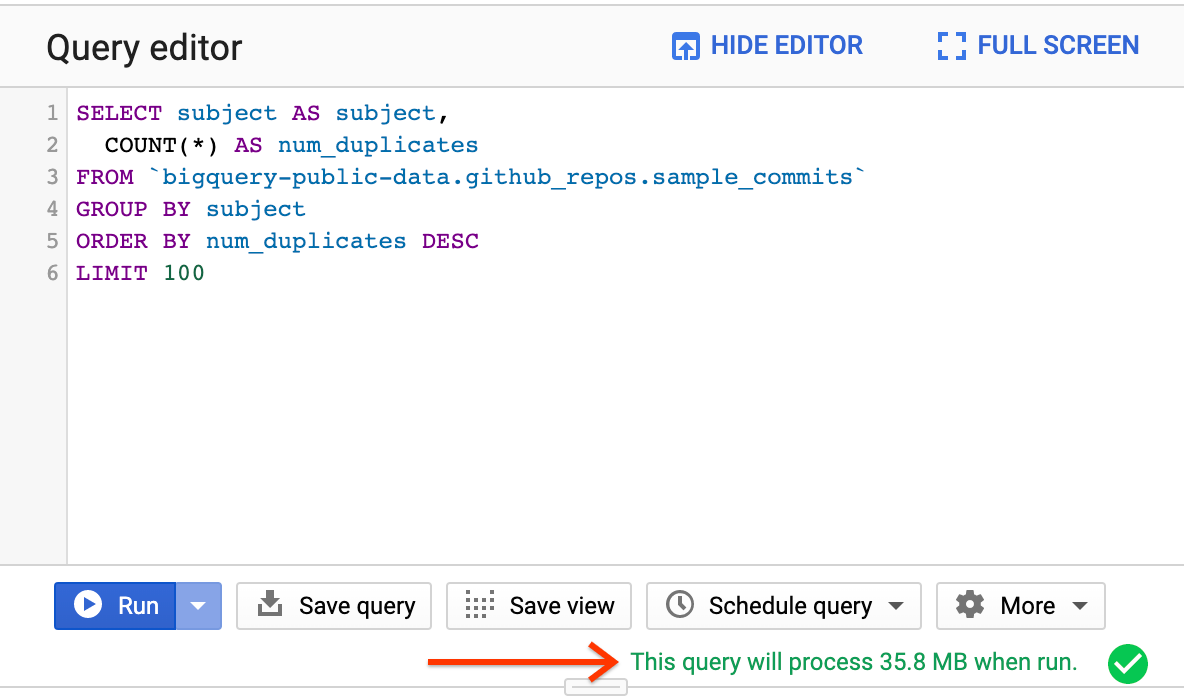
Click the Run button.
In a few seconds, the result will be listed in the bottom, and it'll tell you how much data was processed and how long it took.
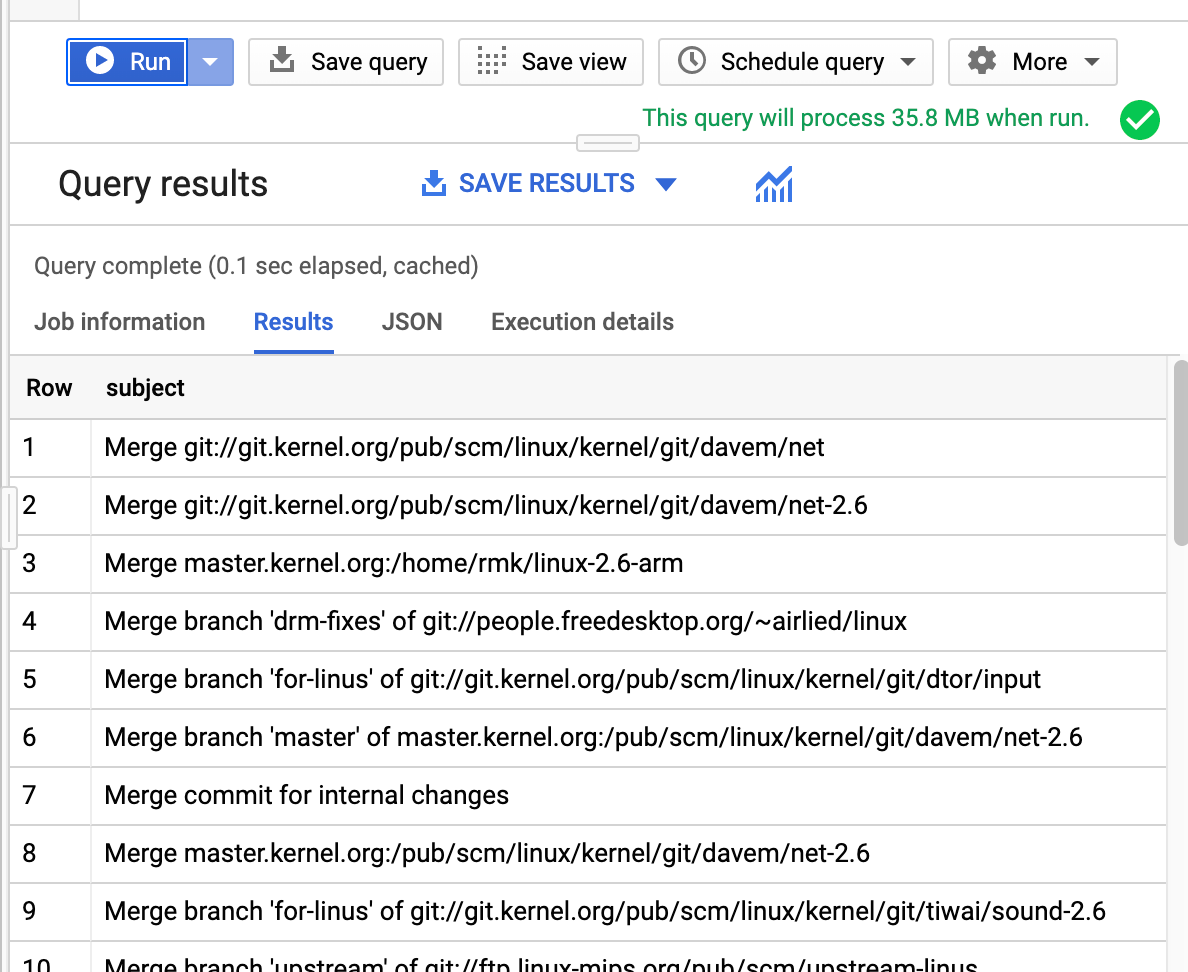
Even though the sample_commits table is 2.49 GB, the query only processed 35.8 MB. BigQuery only processes the bytes from the columns used in the query, so the total amount of data processed can be significantly less than the table size. With clustering and partitioning, the amount of data processed can be reduced even further.
5. More public data
Now try querying another dataset, such as one of the other public datasets.
For example, the following query finds popular deprecated or unmaintained projects in the Libraries.io public dataset that are still used as a dependency in other projects:
SELECT
name,
dependent_projects_count,
language,
status
FROM
`bigquery-public-data.libraries_io.projects_with_repository_fields`
WHERE status IN ('Deprecated', 'Unmaintained')
ORDER BY dependent_projects_count DESC
LIMIT 100
Other organizations have also made their data publicly available in BigQuery. For example, Github's GH Archive dataset can be used to analyze public events on GitHub, such as pull requests, repository stars, and opened issues. The Python Software Foundation's PyPI dataset can be used to analyze download requests for Python packages.
6. Congratulations!
You used BigQuery and SQL to query the GitHub public dataset. You have the power to query petabyte-scale datasets!
What you covered
- Using SQL syntax to query GitHub commit records
- Writing a query to gain insight into a large dataset
Learn more
- Learn SQL with Kaggle's Intro to SQL.
- Explore BigQuery documentation.
- See how others use the GitHub dataset in this blog post.
- Explore weather data, crime data, and more in TIL with BigQuery.
- Learn to load data into BigQuery by using the BigQuery command-line tool.
- Check out the BigQuery subreddit to learn how others use BigQuery today.