
程式碼研究室簡介
1. 簡介
在這個程式碼研究室中,您將會瞭解如何搭配 Java HBase 用戶端使用 Cloud Bigtable。
你將瞭解如何
- 避免結構定義設計的常見錯誤
- 匯入序列檔案中的資料
- 查詢資料
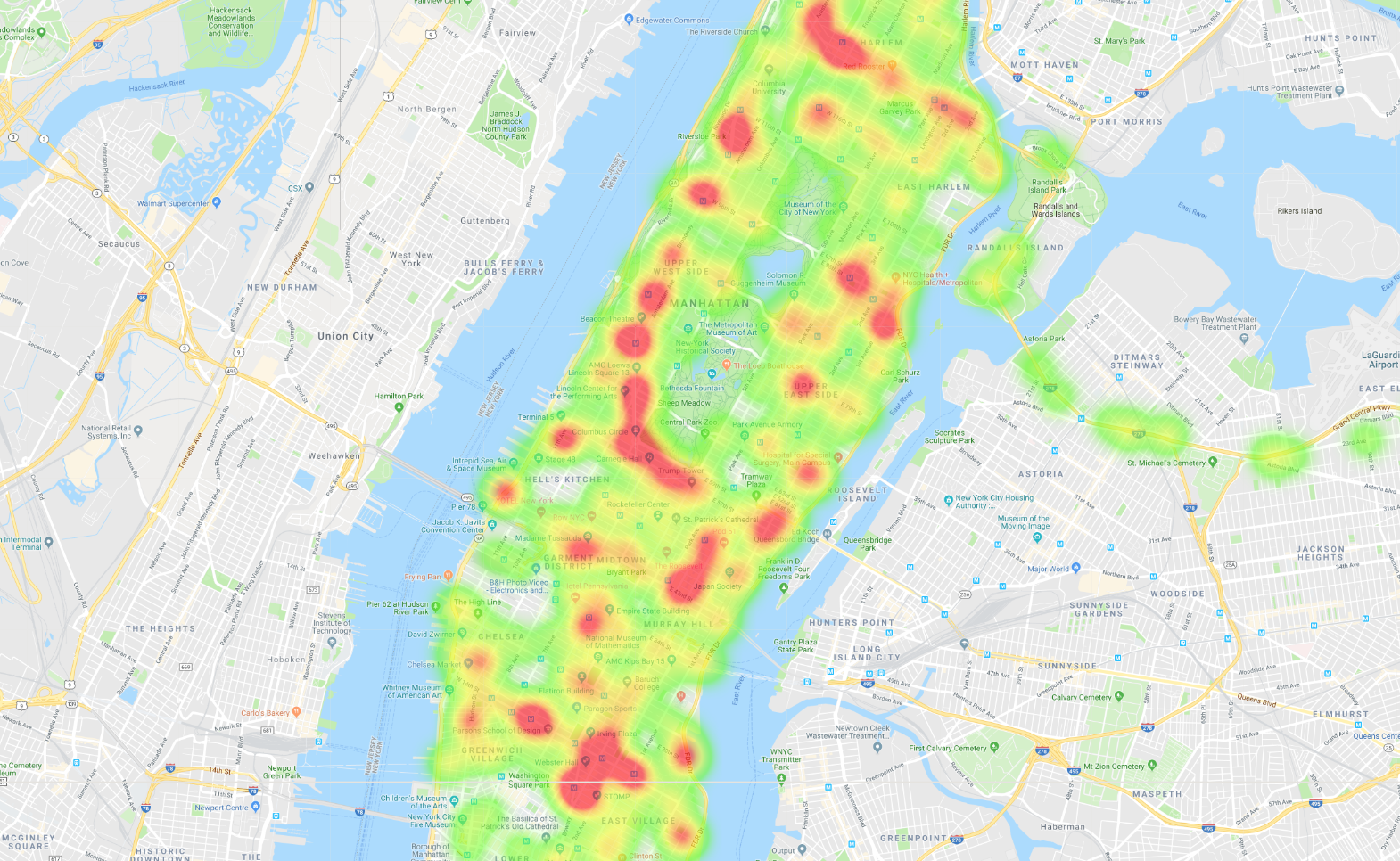
完成後,您會看到好幾張顯示紐約市公車資料的地圖。舉例來說,您能夠建立曼哈頓的公車行程熱視圖:
您對 Google Cloud Platform 使用經驗的評價如何?
您會如何使用這個教學課程?
3. 結構定義設計
如要讓 Cloud Bigtable 發揮最佳效能,在設計結構定義時,請務必審慎考量。Cloud Bigtable 中的資料是以字母順序自動排序,因此,如果設計良好的結構定義,查詢相關資料就會非常有效率。Cloud Bigtable 允許使用「點查詢」(按資料列索引鍵進行查詢) 或是傳回一連串連續資料列的「資料列範圍掃描」來執行查詢。然而,如果您的結構定義未妥善考量,可能會發現自己重複查詢多個資料列,或者執行整個資料表掃描作業,這會非常緩慢。
規劃查詢
我們的資料含有各種資訊,但在本程式碼研究室中,您將使用公車的位置和目的地。
取得這些資訊後,您可以執行查詢:
- 取得特定時段上一輛公車的位置。
- 取得公車路線或特定公車的每日資料。
- 在地圖上找出長方形的所有公車。
- 取得所有公車的目前位置 (如果你是即時擷取這項資料)。
這組查詢無法順利全部一起完成。舉例來說,如果您是依時間排序,則必須先掃描完整的資料表,才能根據位置執行掃描。您必須依據您最常執行的查詢排定優先順序。
在本程式碼研究室中,您的重點是最佳化及執行下列查詢:
- 取得特定車輛一小時以上的位置。
- 取得整條公車路線在一小時內的位置。
- 取得曼哈頓中所有公車的地點資訊。
- 快速取得曼哈頓所有公車的最新地點。
- 取得整個公車路線的當月位置。
- 取得搭乘特定目的地超過一小時的整條公車路線。
設計資料列索引鍵
在本程式碼研究室中,您將使用靜態資料集,但會設計擴充性的結構定義。您設計的結構定義可讓您將更多公車資料串流至資料表,並維持良好成效。
以下是建議的資料列索引鍵結構定義:
[公車公司/公車/時間戳記,四捨五入為小時/車輛 ID]。每個資料列都有一個小時的資料,每個儲存格則含有多個加上時間戳記的資料版本。
在本程式碼研究室中,您將使用一個資料欄系列來簡化作業。以下是資料形式的範例。依資料列索引鍵排序資料。
資料列索引鍵 | cf:VehicleLocation.Latitude | cf:VehicleLocation.Longitude | ... |
MTA/M86-SBS/1496275200000/NYCT_5824 | 40.781212 @20:52:54.0040.776163 @20:43:19.0040.778714 @20:33:46.00 | -73.961942 @20:52:54.00-73.946949 @20:43:19.00-73.953731 @20:33:46.00 | ... |
MTA/M86-SBS/1496275200000/NYCT_5840 | 40.780664 @20:13:51.0040.788416 @20:03:40.00 | -73.958357 @20:13:51.00 -73.976748 @20:03:40.00 | ... |
MTA/M86-SBS/1496275200000/NYCT_5867 | 40.780281 @20:51:45.0040.779961 @20:43:15.0040.788416 @20:33:44.00 | -73.946890 @20:51:45.00-73.959465 @20:43:15.00-73.976748 @20:33:44.00 | ... |
… | … | … | ... |
4. 建立執行個體、資料表和系列
接下來,請建立 Cloud Bigtable 資料表。
首先,請建立新專案。使用內建的 Cloud Shell,只要按一下「啟用 Cloud Shell」即可開啟。

請設定下列環境變數,方便複製及貼上程式碼研究室指令:
INSTANCE_ID="bus-instance" CLUSTER_ID="bus-cluster" TABLE_ID="bus-data" CLUSTER_NUM_NODES=3 CLUSTER_ZONE="us-central1-c"
Cloud Shell 隨附您將在本程式碼研究室中使用的工具,包括 gcloud 指令列工具、cbt 指令列介面和 Maven。
執行下列指令,啟用 Cloud Bigtable API。
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
執行下列指令以建立執行個體:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
建立執行個體後,請填入 cbt 設定檔,然後執行下列指令,建立資料表和資料欄系列:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
5. 匯入資料
請按照下列步驟從 gs://cloud-bigtable-public-datasets/bus-data 匯入本程式碼研究室的一組序列檔案:
執行下列指令來啟用 Cloud Dataflow API。
gcloud services enable dataflow.googleapis.com
執行下列指令來匯入資料表。
NUM_WORKERS=$(expr 3 \* $CLUSTER_NUM_NODES) gcloud beta dataflow jobs run import-bus-data-$(date +%s) \ --gcs-location gs://dataflow-templates/latest/GCS_SequenceFile_to_Cloud_Bigtable \ --num-workers=$NUM_WORKERS --max-workers=$NUM_WORKERS \ --parameters bigtableProject=$GOOGLE_CLOUD_PROJECT,bigtableInstanceId=$INSTANCE_ID,bigtableTableId=$TABLE_ID,sourcePattern=gs://cloud-bigtable-public-datasets/bus-data/*
監控匯入作業
您可以在 Cloud Dataflow UI 中監控工作。另外,您也可以透過監控 UI 查看 Cloud Bigtable 執行個體的負載。整個匯入作業大約需要 5 分鐘。
6. 取得程式碼
git clone https://github.com/googlecodelabs/cbt-intro-java.git cd cbt-intro-java
執行下列指令,變更為 Java 11:
sudo update-java-alternatives -s java-1.11.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
7. 執行查詢
您要執行的第一個查詢是簡單的資料列查詢。你會在 2017 年 6 月 1 日上午 12:00 到 1:00,看到 M86-SBS 線的公車資料。目前公車路線上有 ID 為 NYCT_5824 的車輛。
掌握以上資訊,並瞭解結構定義設計 (公車公司/公車/時間戳記四捨五入至小時/車輛 ID ) 之後,即可推測資料列索引鍵為:
MTA/M86-SBS/1496275200000/NYCT_5824
BusQueries.java
private static final byte[] COLUMN_FAMILY_NAME = Bytes.toBytes("cf");
private static final byte[] LAT_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Latitude");
private static final byte[] LONG_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Longitude");
String rowKey = "MTA/M86-SBS/1496275200000/NYCT_5824";
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
結果應包含該小時內的公車最新位置。但您想要查看所有位置,所以請設定 get 要求的版本數量上限。
BusQueries.java
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
在 Cloud Shell 中執行下列指令,取得該公車每小時的經緯度清單:
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=lookupVehicleInGivenHour
您可以複製經緯度,然後貼到 MapMaker 應用程式中,以視覺化的方式呈現結果。有幾個層之後,系統會指示您建立一個免費帳戶。您可以建立帳戶,也可以刪除現有的圖層。如果你只是想跟著操作,這個程式碼研究室會提供每個步驟的視覺化效果。以下是第一項查詢的結果:

8. 執行掃描
現在,我們來看看該時段的公車資料。掃描碼看起來與 get code 很相似。為掃描器提供起始位置,然後表明您希望掃描器在該小時內僅有 M86-SBS 公車的資料列,並以時間戳記 1496275200000 表示。
BusQueries.java
Scan scan;
scan = new Scan();
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME)
.withStartRow(Bytes.toBytes("MTA/M86-SBS/1496275200000"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/1496275200000"));
ResultScanner scanner = table.getScanner(scan);
執行下列指令取得結果。
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanBusLineInGivenHour

Google 地圖製作工具應用程式可以一次顯示多份清單,方便您查看自己執行的第一個查詢中有哪些公車。

這項查詢還有很有趣的修改方式,就是查看 M86-SBS 公車路線整個月的資料,方法非常簡單。請移除起始列和前置碼篩選器中的時間戳記,取得結果。
BusQueries.java
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
// Optionally, reduce the results to receive one version per column
// since there are so many data points.
scan.setMaxVersions(1);
執行下列指令取得結果。(結果將很長)。
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanEntireBusLine
只要將結果複製到 MapMaker,即可查看公車路線的熱視圖。橘色的 blob 表示停靠站,亮紅色的 blob 是路線的起點和終點。

9. 套用篩選器
接下來,您將篩選往東和往西的公車,然後分別建立熱視圖。
BusQueries.java
Scan scan;
ResultScanner scanner;
scan = new Scan();
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Yorkville East End AV"));
scan.setMaxVersions(1)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
scan.setFilter(valueFilter);
scanner = table.getScanner(scan);
執行下列指令,取得往東的公車結果。
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingEast
如要取得往西的公車,請變更 valueFilter 中的字串:
BusQueries.java
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Westside West End AV"));
執行下列指令,取得往西的公車結果。
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingWest
往東的公車

往西的公車

比較兩張熱視圖後,您就能看到路線差異,以及配置差異。資料的解釋之一是,在朝西的路上,公車的行駛速度變多了,特別是在進入大安森林公園時。而往東的公車則不會出現許多煙霧點。
10. 執行多範圍掃描
在最後一個查詢中,如果您需要某個區域的許多公車線,就會解決這個情況:
BusQueries.java
private static final String[] MANHATTAN_BUS_LINES = {"M1","M2","M3",...
Scan scan;
ResultScanner scanner;
List<RowRange> ranges = new ArrayList<>();
for (String busLine : MANHATTAN_BUS_LINES) {
ranges.add(
new RowRange(
Bytes.toBytes("MTA/" + busLine + "/1496275200000"), true,
Bytes.toBytes("MTA/" + busLine + "/1496275200001"), false));
}
Filter filter = new MultiRowRangeFilter(ranges);
scan = new Scan();
scan.setFilter(filter);
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M")).setRowPrefixFilter(Bytes.toBytes("MTA/M"));
scanner = table.getScanner(scan);
執行下列指令取得結果。
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanManhattanBusesInGivenHour
11. 完成
清除所用資源,以免產生費用
如要避免系統向您的 Google Cloud Platform 帳戶收取這個程式碼研究室所用資源的費用,請刪除執行個體。
gcloud bigtable instances delete $INSTANCE_ID
涵蓋內容
- 結構定義設計
- 設定執行個體、資料表和系列
- 匯入 Dataflow 的序列檔案
- 使用查詢、掃描、含有篩選器的掃描和多範圍掃描作業進行查詢
後續步驟
- 如要進一步瞭解 Cloud Bigtable,請參閱說明文件。
- 自行試用其他 Google Cloud Platform 功能。歡迎參考我們的教學課程。
- 瞭解如何使用 OpenTSDB 整合監控時間序列資料