
1. บทนำ
แล็บนี้มุ่งเน้นการใช้งานและการติดตั้งใช้งานบริการตัวแทนไคลเอ็นต์ คุณจะใช้ Agent Development Kit (ADK) เพื่อสร้าง AI Agent ที่ใช้เครื่องมือระยะไกล เช่น เซิร์ฟเวอร์ MCP ที่สร้างในแล็บ 1 หลักการออกแบบที่สำคัญซึ่งแสดงให้เห็นคือการแยกความกังวล โดยมีเลเยอร์การให้เหตุผลที่แตกต่างกัน (Agent) ซึ่งสื่อสารกับเลเยอร์เครื่องมือที่แตกต่างกัน (เซิร์ฟเวอร์ MCP) ผ่าน API ที่ปลอดภัย
ในแล็บ 1 คุณได้สร้างเซิร์ฟเวอร์ MCP ที่ให้ข้อมูลเกี่ยวกับสัตว์ในสวนสัตว์สมมติแก่ LLM เช่น เมื่อใช้ Gemini CLI ในแล็บนี้ เราจะสร้างเอเจนต์ไกด์นำเที่ยวสำหรับสวนสัตว์สมมติ เอเจนต์จะใช้เซิร์ฟเวอร์ MCP เดียวกันจากแล็บ 1 เพื่อเข้าถึงรายละเอียดเกี่ยวกับสัตว์ในสวนสัตว์ และใช้ Wikipedia เพื่อสร้างประสบการณ์ไกด์นำเที่ยวที่ดีที่สุด

สุดท้าย เราจะติดตั้งใช้งาน Agent ไกด์นำเที่ยวใน Google Cloud Run เพื่อให้ผู้เข้าชมสวนสัตว์ทุกคนเข้าถึงได้แทนที่จะเรียกใช้ในเครื่องเท่านั้น
ข้อกำหนดเบื้องต้น
- เซิร์ฟเวอร์ MCP ที่ทำงานใน Cloud Run หรือ URL ของบริการที่เชื่อมโยง
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
สิ่งที่คุณจะได้เรียนรู้
- วิธีจัดโครงสร้างโปรเจ็กต์ Python สำหรับการติดตั้งใช้งาน ADK
- วิธีติดตั้งใช้งานเอเจนต์ที่ใช้เครื่องมือด้วย google-adk
- วิธีเชื่อมต่อเอเจนต์กับเซิร์ฟเวอร์ MCP ระยะไกลสำหรับชุดเครื่องมือ
- วิธีติดตั้งใช้งานแอปพลิเคชัน Python เป็นคอนเทนเนอร์แบบ Serverless ใน Cloud Run
- วิธีกำหนดค่าการตรวจสอบสิทธิ์จากบริการหนึ่งไปยังอีกบริการหนึ่งอย่างปลอดภัยโดยใช้บทบาท IAM
- วิธีลบทรัพยากรระบบคลาวด์เพื่อหลีกเลี่ยงค่าใช้จ่ายในอนาคต
สิ่งที่คุณต้องมี
- บัญชี Google Cloud และโปรเจ็กต์ Google Cloud
- เว็บเบราว์เซอร์ เช่น Chrome
2. ทำไมจึงควรติดตั้งใช้งานใน Cloud Run
Cloud Run เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการโฮสต์ Agent ADK เนื่องจากเป็นแพลตฟอร์มแบบ Serverless ซึ่งหมายความว่าคุณสามารถมุ่งเน้นไปที่โค้ดและไม่ต้องจัดการโครงสร้างพื้นฐาน เราจะจัดการงานด้านการปฏิบัติการให้คุณ
โดยจะทำงานเหมือนร้านค้าชั่วคราว ซึ่งจะเปิดและใช้ทรัพยากรเมื่อมีลูกค้า (คำขอ) เข้ามาเท่านั้น เมื่อไม่มีลูกค้า ร้านค้าจะปิดตัวลงโดยสมบูรณ์ และคุณไม่ต้องจ่ายเงินสำหรับร้านค้าที่ว่างเปล่า
ฟีเจอร์หลัก
เรียกใช้คอนเทนเนอร์ได้ทุกที่
- คุณนำคอนเทนเนอร์ (อิมเมจ Docker) ที่มีแอปของคุณอยู่ภายในมา
- Cloud Run จะเรียกใช้ในโครงสร้างพื้นฐานของ Google
- ไม่ต้องกังวลเรื่องการแพตช์ระบบปฏิบัติการ การตั้งค่า VM หรือการปรับขนาด
การปรับขนาดอัตโนมัติ:
- หากมีผู้ใช้แอป 0 คน → มีอินสแตนซ์ที่ทำงาน 0 รายการ (ลดขนาดลงเหลือ 0 อินสแตนซ์ ซึ่งคุ้มค่า)
- หากมีคำขอ 1,000 รายการเข้ามา ระบบจะหมุนเวียนสำเนาตามจำนวนที่จำเป็น
ไม่เก็บสถานะโดยค่าเริ่มต้น:
- คำขอแต่ละรายการอาจไปที่อินสแตนซ์ที่แตกต่างกัน
- หากต้องการจัดเก็บสถานะ ให้ใช้บริการภายนอก เช่น Cloud SQL, Firestore หรือ Memorystore
รองรับภาษาหรือเฟรมเวิร์กใดก็ได้
- ตราบใดที่แอปพลิเคชันทำงานในคอนเทนเนอร์ Linux Cloud Run ก็ไม่สนใจว่าจะเป็น Python, Go, Node.js, Java หรือ .Net
จ่ายเงินตามการใช้งานจริง:
- การเรียกเก็บเงินตามคำขอ: เรียกเก็บเงินต่อคำขอ + เวลาในการคำนวณ (ต่ำสุด 100 มิลลิวินาที)
- การเรียกเก็บเงินตามอินสแตนซ์: เรียกเก็บเงินตลอดอายุการใช้งานของอินสแตนซ์ (ไม่มีค่าธรรมเนียมต่อคำขอ)
3. ก่อนเริ่มต้น
การตั้งค่าสภาพแวดล้อมแบบเรียนรู้ด้วยตนเอง
- ลงชื่อเข้าใช้ คอนโซล Google Cloud แล้วสร้างโปรเจ็กต์ใหม่หรือใช้โปรเจ็กต์ที่มีอยู่ซ้ำ หากยังไม่มีบัญชี Gmail หรือ Google Workspace คุณต้องสร้างบัญชี

- ชื่อโปรเจ็กต์คือชื่อที่แสดงสำหรับผู้เข้าร่วมโปรเจ็กต์นี้ ซึ่งเป็นสตริงอักขระที่ Google APIs ไม่ได้ใช้ คุณอัปเดตได้ทุกเมื่อ
- รหัสโปรเจ็กต์จะไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมดและเปลี่ยนแปลงไม่ได้ (เปลี่ยนไม่ได้หลังจากตั้งค่าแล้ว) Cloud Console จะสร้างสตริงที่ไม่ซ้ำกันโดยอัตโนมัติ ซึ่งโดยปกติแล้วคุณไม่จำเป็นต้องสนใจว่าสตริงนั้นคืออะไร ใน Codelab ส่วนใหญ่ คุณจะต้องอ้างอิงรหัสโปรเจ็กต์ (โดยทั่วไปจะระบุเป็น
PROJECT_ID) หากไม่ชอบรหัสที่สร้างขึ้น คุณอาจสร้างรหัสแบบสุ่มอีกรหัสหนึ่งได้ หรือคุณอาจลองใช้ชื่อของคุณเองและดูว่ามีชื่อนั้นหรือไม่ คุณจะเปลี่ยนแปลงรหัสนี้หลังจากขั้นตอนนี้ไม่ได้ และรหัสจะคงอยู่ตลอดระยะเวลาของโปรเจ็กต์ - โปรดทราบว่ายังมีค่าที่ 3 ซึ่งคือหมายเลขโปรเจ็กต์ที่ API บางตัวใช้ ดูข้อมูลเพิ่มเติมเกี่ยวกับค่าทั้ง 3 นี้ได้ในเอกสารประกอบ
- จากนั้นคุณจะต้องเปิดใช้การเรียกเก็บเงินใน Cloud Console เพื่อใช้ทรัพยากร/API ของ Cloud การทำตาม Codelab นี้จะไม่เสียค่าใช้จ่ายมากนัก หรืออาจไม่เสียเลย หากต้องการปิดทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินนอกเหนือจากบทแนะนำนี้ คุณสามารถลบทรัพยากรที่สร้างขึ้นหรือลบโปรเจ็กต์ได้ ผู้ใช้ Google Cloud รายใหม่มีสิทธิ์เข้าร่วมโปรแกรมช่วงทดลองใช้ฟรีมูลค่า$300 USD
เริ่มต้น Cloud Shell
- ไปที่ Cloud Shell Editor
- หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิก Terminal
- คลิก Terminal ใหม่
- ในเทอร์มินัล ให้ตั้งค่าโปรเจ็กต์ด้วยคำสั่งนี้ หากทำแล็บ 1 เสร็จแล้ว ให้ตรวจสอบว่าคุณใช้รหัสโปรเจ็กต์เดียวกัน
gcloud config set project [YOUR-PROJECT-ID]gcloud projects list | awk '/PROJECT_ID/{print $2}' - หากได้รับแจ้งให้ให้สิทธิ์ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
- คุณควรเห็นข้อความต่อไปนี้
Updated property [core/project].
WARNINGและระบบขอให้คุณDo you want to continue (Y/n)?แสดงว่าคุณอาจป้อนรหัสโปรเจ็กต์ไม่ถูกต้อง กดnกดEnterแล้วลองเรียกใช้คำสั่งgcloud config set projectอีกครั้ง
4. ตั้งค่าสภาพแวดล้อม
เปิดใช้ API และตั้งค่าตัวแปรสภาพแวดล้อม
เปิดใช้บริการที่จำเป็นทั้งหมด
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
ผลลัพธ์ที่คาดหวัง
Operation "operations/acat.p2-[GUID]" finished successfully.
สร้างไดเรกทอรีโปรเจ็กต์
คำสั่งนี้จะสร้างโฟลเดอร์หลักสำหรับห้องทดลองสำหรับซอร์สโค้ดของเอเจนต์
cd && mkdir zoo_guide_agent && cd zoo_guide_agent
สร้างไฟล์ requirements.txt ไฟล์นี้แสดงรายการไลบรารี Python ที่เอเจนต์ของคุณต้องการ คำสั่งต่อไปนี้จะสร้างและป้อนข้อมูลในไฟล์
cloudshell edit requirements.txt
google-adk==1.14.0
langchain-community==0.3.27
wikipedia==1.4.0
ตั้งค่าตัวแปรสำหรับรหัสโปรเจ็กต์ หมายเลขโปรเจ็กต์ปัจจุบัน และสร้างบัญชีบริการเฉพาะสำหรับโปรเจ็กต์ ซึ่งเป็นวิธีที่เสถียรกว่าในการเรียกใช้คำสั่งเหล่านี้
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_NAME=lab2-cr-service
export SERVICE_ACCOUNT="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${SA_NAME} \
--display-name="Service Account for lab 2 "
สร้างและเปิดไฟล์ .env เพื่อตรวจสอบสิทธิ์ตัวแทนในไดเรกทอรี zoo_guide_agent
cloudshell edit .env
คำสั่งแก้ไขของ Cloud Shell จะเปิดไฟล์ .env ในโปรแกรมแก้ไขเหนือเทอร์มินัล ป้อนข้อมูลต่อไปนี้ในไฟล์ .env แล้วกลับไปที่เทอร์มินัล
MODEL="gemini-2.5-flash"
เพิ่ม URL ของเซิร์ฟเวอร์ MCP หากทำแล็บ 1 เสร็จแล้ว ให้ทำตามขั้นตอนต่อไปนี้เพื่อใช้เซิร์ฟเวอร์ MCP ที่คุณสร้างในแล็บ 1
ให้สิทธิ์บัญชีบริการของเอเจนต์ในการใช้ Gemini บน Vertex AI และเรียกใช้เซิร์ฟเวอร์ MCP ระยะไกลโดยทำดังนี้
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/run.invoker"
บันทึก URL ของเซิร์ฟเวอร์ MCP จาก Lab 1 ลงในตัวแปรสภาพแวดล้อม
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
หากคุณใช้ลิงก์เซิร์ฟเวอร์ MCP สาธารณะ ให้เรียกใช้คำสั่งต่อไปนี้และแทนที่ PROJECT_NUMBER ด้วยสิ่งที่ได้รับ
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
5. สร้างเวิร์กโฟลว์ของ Agent
สร้างไฟล์ init.py
สร้างไฟล์ init.py ไฟล์นี้จะบอก Python ว่าไดเรกทอรี zoo_guide_agent เป็นแพ็กเกจ
cloudshell edit __init__.py
คำสั่งก่อนหน้าจะเปิดตัวแก้ไขโค้ด เพิ่มโค้ดต่อไปนี้ลงใน __init__.py
from . import agent
สร้างไฟล์ main agent.py
สร้างไฟล์ agent.py หลัก คำสั่งนี้จะสร้างไฟล์ Python และวางโค้ดทั้งหมดสำหรับระบบแบบหลายเอเจนต์
cloudshell edit agent.py
การนำเข้าและการตั้งค่าเริ่มต้น
บล็อกแรกนี้จะนำเข้าไลบรารีที่จำเป็นทั้งหมดจาก ADK และ Google Cloud นอกจากนี้ ยังตั้งค่าการบันทึกและโหลดตัวแปรสภาพแวดล้อมจากไฟล์ .env ซึ่งมีความสำคัญอย่างยิ่งต่อการเข้าถึง URL ของโมเดลและเซิร์ฟเวอร์
เพิ่มโค้ดต่อไปนี้ลงในไฟล์ agent.py
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StreamableHTTPConnectionParams
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
การกำหนดเครื่องมือ (ความสามารถของเอเจนต์)

ประสิทธิภาพของเอเจนต์ขึ้นอยู่กับเครื่องมือที่ใช้ได้ ในส่วนนี้ เราจะกำหนดความสามารถทั้งหมดที่เอเจนต์ของเราจะมี ซึ่งรวมถึงฟังก์ชันที่กำหนดเองเพื่อบันทึกข้อมูล เครื่องมือ MCP ที่เชื่อมต่อกับเซิร์ฟเวอร์ MCP ที่ปลอดภัยของเรา รวมถึงเครื่องมือ Wikipedia
เพิ่มโค้ดต่อไปนี้ที่ด้านล่างของ agent.py
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the MCP Tool to connect to the Zoo MCP server
mcp_server_url = os.getenv("MCP_SERVER_URL")
if not mcp_server_url:
raise ValueError("The environment variable MCP_SERVER_URL is not set.")
def get_id_token():
"""Get an ID token to authenticate with the MCP server."""
target_url = os.getenv("MCP_SERVER_URL")
audience = target_url.split('/mcp/')[0]
request = google.auth.transport.requests.Request()
id_token = google.oauth2.id_token.fetch_id_token(request, audience)
return id_token
"""
# Use this code if you are using the public MCP Server and comment out the code below defining mcp_tools
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url
)
)
"""
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url,
headers={
"Authorization": f"Bearer {get_id_token()}",
},
),
)
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
คำอธิบายเครื่องมือทั้ง 3
add_prompt_to_state📝
เครื่องมือนี้จะจดจำสิ่งที่ผู้เข้าชมสวนสัตว์ถาม เมื่อผู้เข้าชมถามว่า "สิงโตอยู่ที่ไหน" เครื่องมือนี้จะบันทึกคำถามนั้นลงในหน่วยความจำของตัวแทน เพื่อให้ตัวแทนอื่นๆ ในเวิร์กโฟลว์รู้ว่าต้องค้นหาอะไร
วิธี: เป็นฟังก์ชัน Python ที่เขียนพรอมต์ของผู้เข้าชมลงในพจนานุกรม tool_context.state ที่แชร์ บริบทของเครื่องมือนี้แสดงถึงหน่วยความจำระยะสั้นของเอเจนต์สำหรับการสนทนาครั้งเดียว ตัวแทนรายหนึ่งบันทึกข้อมูลลงในสถานะ ตัวแทนรายถัดไปในเวิร์กโฟลว์จะอ่านข้อมูลนั้นได้
MCPToolset🦁
ใช้เพื่อเชื่อมต่อเอเจนต์ไกด์นำเที่ยวกับเซิร์ฟเวอร์ MCP ของสวนสัตว์ที่สร้างขึ้นใน Lab 1 เซิร์ฟเวอร์นี้มีเครื่องมือพิเศษสำหรับค้นหาข้อมูลเฉพาะเกี่ยวกับสัตว์ เช่น ชื่อ อายุ และกรง
วิธี: เชื่อมต่อกับ URL ของเซิร์ฟเวอร์ส่วนตัวของสวนสัตว์อย่างปลอดภัย โดยใช้ get_id_token เพื่อรับ "บัตรคีย์" (โทเค็นรหัสบัญชีบริการ) ที่ปลอดภัยโดยอัตโนมัติเพื่อพิสูจน์ตัวตนและรับสิทธิ์เข้าถึง
LangchainTool🌍
ซึ่งจะช่วยให้เอเจนต์ไกด์นำเที่ยวมีความรู้ทั่วไปเกี่ยวกับโลก เมื่อผู้เข้าชมถามคำถามที่ไม่ได้อยู่ในฐานข้อมูลของสวนสัตว์ เช่น "สิงโตกินอะไรในป่า" เครื่องมือนี้จะช่วยให้ตัวแทนค้นหาคำตอบใน Wikipedia ได้
วิธี: ทำหน้าที่เป็นอะแดปเตอร์ที่ช่วยให้เอเจนต์ของเราใช้เครื่องมือ WikipediaQueryRun ที่สร้างไว้ล่วงหน้าจากคลัง LangChain ได้
แหล่งข้อมูล
การกำหนด Agent ผู้เชี่ยวชาญ

จากนั้นเราจะกำหนดตัวแทนนักวิจัยและตัวแทนจัดรูปแบบคำตอบ เอเจนต์นักวิจัยคือ "สมอง" ของการทำงานของเรา เอเจนต์นี้จะรับพรอมต์ของผู้ใช้จาก State ที่แชร์ ตรวจสอบเครื่องมือที่มีประสิทธิภาพ (เครื่องมือเซิร์ฟเวอร์ MCP ของ Zoo และเครื่องมือ Wikipedia) และตัดสินใจว่าจะใช้เครื่องมือใดเพื่อค้นหาคำตอบ
บทบาทของเอเจนต์ตัวจัดรูปแบบการตอบกลับคือการนำเสนอ โดยไม่ได้ใช้เครื่องมือใดๆ เพื่อค้นหาข้อมูลใหม่ แต่จะใช้ข้อมูลดิบที่รวบรวมโดยตัวแทน Researcher (ส่งผ่านทาง State) และใช้ทักษะด้านภาษาของ LLM เพื่อเปลี่ยนข้อมูลดังกล่าวให้เป็นการตอบกลับแบบสนทนาที่เป็นมิตร
เพิ่มโค้ดต่อไปนี้ที่ด้านล่างของ agent.py
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{{ PROMPT }}
""",
tools=[
mcp_tools,
wikipedia_tool
],
output_key="RESEARCH_DATA" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{{ RESEARCH_DATA }}
"""
)
Agent เวิร์กโฟลว์
เอเจนต์เวิร์กโฟลว์จะทำหน้าที่เป็นผู้จัดการ "แบ็กออฟฟิศ" สำหรับทัวร์ชมสวนสัตว์ โดยจะรับคำขอการวิจัยและตรวจสอบว่าเอเจนต์ 2 รายที่เรากำหนดไว้ข้างต้นทำงานตามลำดับที่ถูกต้อง นั่นคือ ค้นคว้าก่อน แล้วจึงจัดรูปแบบ ซึ่งจะสร้างกระบวนการที่คาดการณ์ได้และเชื่อถือได้ในการตอบคำถามของผู้เข้าชม
วิธีการ: เป็นSequentialAgent ซึ่งเป็นเอเจนต์ประเภทพิเศษที่ไม่คิดเอง หน้าที่ของมันมีเพียงการเรียกใช้รายการ sub_agents (ผู้ค้นคว้าและผู้จัดรูปแบบ) ตามลำดับที่กำหนด โดยจะส่งต่อหน่วยความจำที่แชร์จากหนึ่งไปยังอีกหนึ่งโดยอัตโนมัติ
เพิ่มบล็อกโค้ดนี้ที่ด้านล่างของ agent.py
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
ประกอบเวิร์กโฟลว์หลัก 
เอเจนต์นี้ได้รับการกำหนดให้เป็น root_agent ซึ่งเฟรมเวิร์ก ADK ใช้เป็นจุดเริ่มต้นสำหรับการสนทนาใหม่ทั้งหมด โดยมีบทบาทหลักในการประสานงานกระบวนการโดยรวม โดยจะทำหน้าที่เป็นตัวควบคุมเริ่มต้นที่จัดการการสนทนาในรอบแรก
เพิ่มบล็อกโค้ดสุดท้ายนี้ที่ด้านล่างของ agent.py
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
ไฟล์ agent.py ของคุณเสร็จสมบูรณ์แล้ว การสร้างในลักษณะนี้จะช่วยให้คุณเห็นว่าคอมโพเนนต์แต่ละอย่าง ไม่ว่าจะเป็นเครื่องมือ เอเจนต์ของผู้ปฏิบัติงาน และเอเจนต์ของผู้จัดการ มีบทบาทเฉพาะในการสร้างระบบอัจฉริยะขั้นสุดท้ายอย่างไร ขั้นตอนถัดไปคือการติดตั้งใช้งาน
6. ติดตั้งใช้งาน Agent โดยใช้ ADK CLI
เมื่อโค้ดในเครื่องพร้อมและโปรเจ็กต์ที่อยู่ในระบบคลาวด์ของ Google Cloud เตรียมพร้อมแล้ว ก็ถึงเวลาทำให้ Agent ใช้งานได้ คุณจะใช้คำสั่ง adk deploy cloud_run ซึ่งเป็นเครื่องมือที่สะดวกสบายซึ่งจะทำให้เวิร์กโฟลว์การติดตั้งใช้งานทั้งหมดเป็นอัตโนมัติ คำสั่งเดียวนี้จะแพ็กเกจโค้ด สร้างอิมเมจคอนเทนเนอร์ พุชไปยัง Artifact Registry และเปิดใช้บริการใน Cloud Run ทำให้เข้าถึงได้บนเว็บ
ติดตั้งใช้งาน
เรียกใช้คำสั่งต่อไปนี้เพื่อติดตั้งใช้งานเอเจนต์ คำสั่ง uvx ช่วยให้คุณเรียกใช้เครื่องมือบรรทัดคำสั่งที่เผยแพร่เป็นแพ็กเกจ Python ได้โดยไม่ต้องติดตั้งเครื่องมือเหล่านั้นทั่วโลก
# Run the deployment command
uvx --from google-adk==1.14.0 \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=us-west1 \
--service_name=zoo-tour-guide \
--with_ui \
. \
-- \
--labels=dev-tutorial=codelab-adk \
--service-account=$SERVICE_ACCOUNT
ยอมรับพรอมต์
ระบบอาจแจ้งให้คุณดำเนินการดังนี้
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
พิมพ์ Y แล้วกด Enter
ระบบอาจแจ้งให้คุณดำเนินการดังนี้
Allow unauthenticated invocations to [your-service-name] (y/N)?.
สำหรับ Lab นี้ เราต้องการอนุญาตการเรียกใช้ที่ไม่ผ่านการตรวจสอบสิทธิ์เพื่อให้ทดสอบได้ง่าย ให้พิมพ์ y แล้วกด Enter
รับลิงก์การติดตั้งใช้งาน
เมื่อดำเนินการสำเร็จแล้ว คำสั่งจะแสดง URL ของบริการ Cloud Run ที่ใช้งาน (จะมีลักษณะคล้าย https://zoo-tour-guide-123456789.us-west1.run.app) คัดลอก URL นี้สำหรับงานถัดไป
7. ทดสอบ Agent ที่ทําให้ใช้งานได้
เมื่อตัวแทนพร้อมใช้งานใน Cloud Run แล้ว คุณจะทำการทดสอบเพื่อยืนยันว่าการติดตั้งใช้งานสำเร็จและตัวแทนทำงานได้ตามที่คาดไว้ คุณจะใช้ URL ของบริการสาธารณะ (เช่น https://zoo-tour-guide-123456789.us-west1.run.app/) เพื่อเข้าถึงอินเทอร์เฟซเว็บของ ADK และโต้ตอบกับตัวแทน
เปิด URL ของบริการ Cloud Run สาธารณะในเว็บเบราว์เซอร์ เนื่องจากคุณใช้ --with_ui flag คุณจึงควรเห็น UI ของนักพัฒนาแอป ADK
เปิดToken Streamingที่ด้านขวาบน
ตอนนี้คุณโต้ตอบกับตัวแทนของสวนสัตว์ได้แล้ว
พิมพ์ hello แล้วกด Enter เพื่อเริ่มการสนทนาใหม่
สังเกตผลลัพธ์ ตัวแทนควรตอบกลับอย่างรวดเร็วด้วยคำทักทาย
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
ถามคำถามตัวแทน เช่น
Where can I find the polar bears in the zoo and what is their diet?
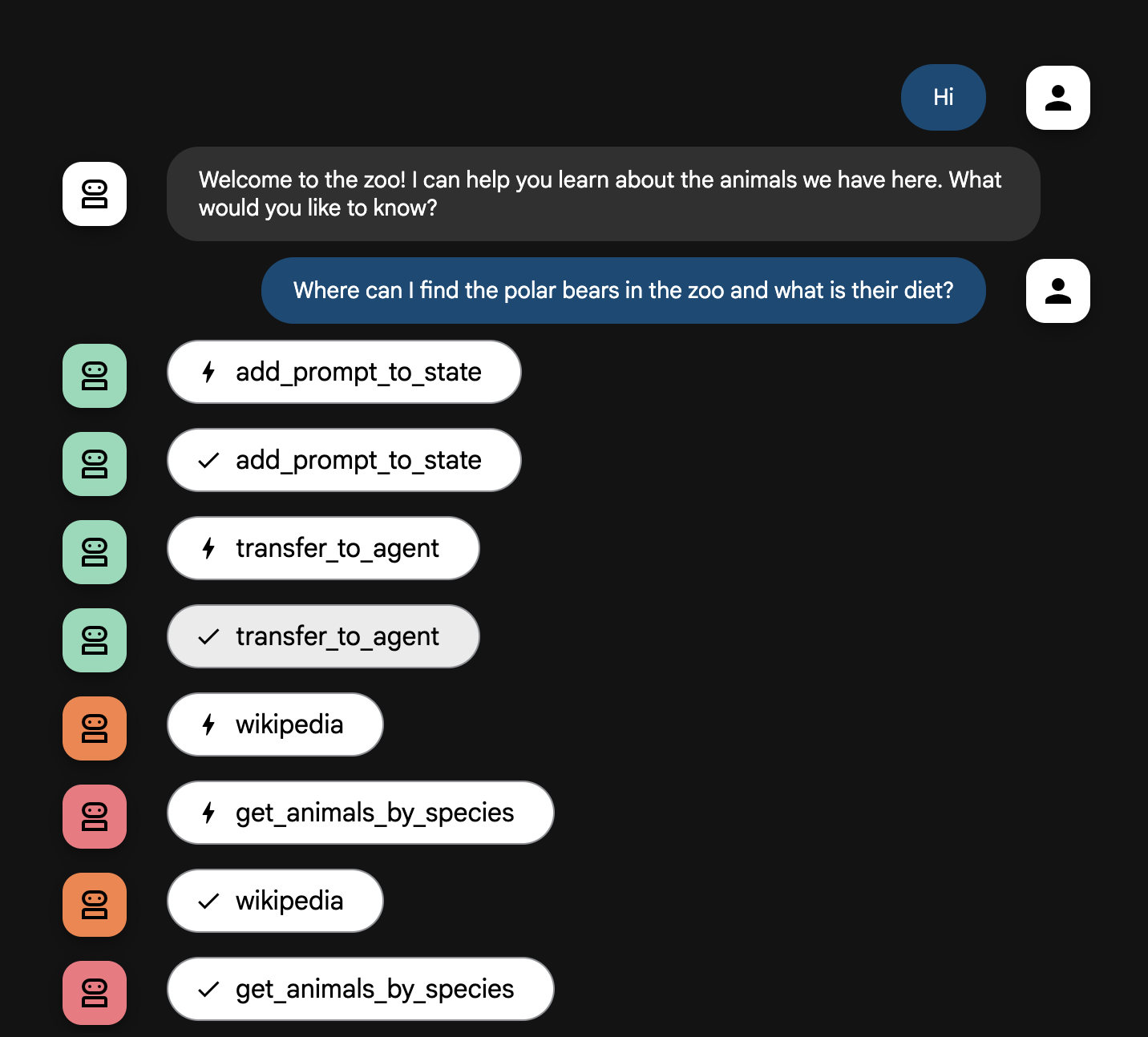

คำอธิบายโฟลว์ของ Agent
ระบบของคุณจะทำงานเป็นทีมอัจฉริยะแบบหลายเอเจนต์ กระบวนการนี้ได้รับการจัดการตามลำดับที่ชัดเจนเพื่อให้มั่นใจว่าการไหลจากคำถามของผู้ใช้ไปจนถึงคำตอบสุดท้ายแบบละเอียดจะเป็นไปอย่างราบรื่นและมีประสิทธิภาพ
1. The Zoo Greeter (The Welcome Desk)
กระบวนการทั้งหมดเริ่มต้นด้วยตัวแทนต้อนรับ
หน้าที่: เริ่มการสนทนา คำสั่งของฟังก์ชันนี้คือทักทายผู้ใช้และถามว่าต้องการเรียนรู้เกี่ยวกับสัตว์ชนิดใด
เครื่องมือของ Greeter: เมื่อผู้ใช้ตอบกลับ Greeter จะใช้เครื่องมือ add_prompt_to_state เพื่อบันทึกคำพูดที่ผู้ใช้พูด (เช่น "เล่าเรื่องสิงโตให้ฟังหน่อย") และบันทึกลงในหน่วยความจำของระบบ
การส่งต่อ: หลังจากบันทึกพรอมต์แล้ว ระบบจะส่งต่อการควบคุมไปยัง Agent ย่อย ซึ่งก็คือ tour_guide_workflow ทันที
2. นักวิจัยที่ครอบคลุม (นักวิจัยขั้นสูง)
นี่คือขั้นตอนแรกในเวิร์กโฟลว์หลักและเป็น "หัวใจ" ของการดำเนินการ ตอนนี้คุณมีตัวแทนที่มีทักษะสูงเพียงคนเดียวที่เข้าถึงข้อมูลทั้งหมดที่มีได้ แทนที่จะมีทีมขนาดใหญ่
หน้าที่: วิเคราะห์คำถามของผู้ใช้และวางแผนอย่างชาญฉลาด โดยจะใช้ความสามารถในการใช้เครื่องมือที่มีประสิทธิภาพของโมเดลภาษาเพื่อพิจารณาว่าจำเป็นต้องทำสิ่งต่อไปนี้หรือไม่
- ข้อมูลภายในจากบันทึกของสวนสัตว์ (ผ่านเซิร์ฟเวอร์ MCP)
- ความรู้ทั่วไปจากเว็บ (ผ่าน Wikipedia API)
- หรือทั้งสองอย่างสำหรับคำถามที่ซับซ้อน
การดำเนินการ: ดำเนินการเครื่องมือที่จำเป็นเพื่อรวบรวมข้อมูลดิบที่จำเป็นทั้งหมด ตัวอย่างเช่น หากมีคนถามว่า "สิงโตของเราอายุเท่าไหร่และกินอะไรในป่า" ระบบจะเรียกเซิร์ฟเวอร์ MCP เพื่อดูอายุและเรียกเครื่องมือ Wikipedia เพื่อดูข้อมูลอาหาร
3. ตัวจัดรูปแบบการตอบกลับ (ผู้นำเสนอ)
เมื่อ Comprehensive Researcher รวบรวมข้อเท็จจริงทั้งหมดแล้ว นี่คือเอเจนต์สุดท้ายที่จะเรียกใช้
หน้าที่: ทำหน้าที่เป็นเสียงที่เป็นมิตรของไกด์นำเที่ยวสวนสัตว์ โดยจะใช้ข้อมูลดิบ (ซึ่งอาจมาจากแหล่งข้อมูลใดแหล่งข้อมูลหนึ่งหรือทั้ง 2 แหล่ง) และปรับแต่งข้อมูล
การทำงาน: สังเคราะห์ข้อมูลทั้งหมดเป็นคำตอบเดียวที่สอดคล้องและน่าสนใจ โดยจะแสดงข้อมูลสวนสัตว์ที่เฉพาะเจาะจงก่อน แล้วจึงเพิ่มข้อเท็จจริงทั่วไปที่น่าสนใจตามคำสั่ง
ผลลัพธ์สุดท้าย: ข้อความที่เอเจนต์นี้สร้างขึ้นคือคำตอบที่สมบูรณ์และมีรายละเอียดซึ่งผู้ใช้จะเห็นในหน้าต่างแชท
หากสนใจเรียนรู้เพิ่มเติมเกี่ยวกับการสร้าง Agent โปรดดูแหล่งข้อมูลต่อไปนี้
8. ล้างข้อมูลในสภาพแวดล้อม
gcloud run services delete zoo-tour-guide --region=us-west1 --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=us-west1 --quiet
9. ขอแสดงความยินดี
ขอแสดงความยินดีที่ทำ Codelab นี้เสร็จสมบูรณ์
สิ่งที่เราได้พูดถึง
- วิธีจัดโครงสร้างโปรเจ็กต์ Python เพื่อการติดตั้งใช้งานด้วยอินเทอร์เฟซบรรทัดคำสั่ง ADK
- วิธีใช้เวิร์กโฟลว์แบบหลายเอเจนต์โดยใช้ SequentialAgent และ ParallelAgent
- วิธีเชื่อมต่อกับเซิร์ฟเวอร์ MCP ระยะไกลโดยใช้ MCPToolset เพื่อใช้เครื่องมือของเซิร์ฟเวอร์
- วิธีเพิ่มข้อมูลภายในโดยการผสานรวมเครื่องมือภายนอก เช่น Wikipedia API
- วิธีทำให้ Agent ใช้งานได้เป็นคอนเทนเนอร์แบบ Serverless ใน Cloud Run โดยใช้คำสั่ง adk deploy