
১. সংক্ষিপ্ত বিবরণ
এই টিউটোরিয়ালটি টেনসরফ্লো ২.২ এর জন্য হালনাগাদ করা হয়েছে!

এই কোডল্যাবে, আপনি শিখবেন কীভাবে হাতে লেখা সংখ্যা শনাক্তকারী একটি নিউরাল নেটওয়ার্ক তৈরি ও প্রশিক্ষণ দিতে হয়। এই প্রক্রিয়ার মধ্যে, ৯৯% নির্ভুলতা অর্জনের জন্য আপনার নিউরাল নেটওয়ার্ককে উন্নত করার পাশাপাশি, আপনি সেইসব কৌশলও আবিষ্কার করবেন যা ডিপ লার্নিং পেশাদাররা তাদের মডেলগুলোকে দক্ষতার সাথে প্রশিক্ষণ দিতে ব্যবহার করেন।
এই কোডল্যাবটিতে MNIST ডেটাসেট ব্যবহার করা হয়েছে, যা ৬০,০০০ লেবেলযুক্ত সংখ্যার একটি সংগ্রহ এবং যা প্রায় দুই দশক ধরে প্রজন্মের পর প্রজন্ম পিএইচডি গবেষকদের ব্যস্ত রেখেছে। আপনি ১০০ লাইনেরও কম পাইথন / টেনসরফ্লো কোড ব্যবহার করে সমস্যাটি সমাধান করবেন।
আপনি যা শিখবেন
- নিউরাল নেটওয়ার্ক কী এবং এটিকে কীভাবে প্রশিক্ষণ দিতে হয়
- tf.keras ব্যবহার করে কীভাবে একটি সাধারণ ১-স্তর বিশিষ্ট নিউরাল নেটওয়ার্ক তৈরি করা যায়
- কীভাবে আরও স্তর যুক্ত করবেন
- শেখার হারের সময়সূচী কীভাবে সেট আপ করবেন
- কনভোলিউশনাল নিউরাল নেটওয়ার্ক কীভাবে তৈরি করবেন
- রেগুলারাইজেশন কৌশল কীভাবে ব্যবহার করবেন: ড্রপআউট, ব্যাচ নর্মালাইজেশন
- ওভারফিটিং কী?
আপনার যা যা লাগবে
শুধু একটি ব্রাউজার। এই কর্মশালাটি সম্পূর্ণভাবে গুগল কোলাবোরেটরি দিয়ে চালানো যেতে পারে।
প্রতিক্রিয়া
এই ল্যাবে কোনো ত্রুটি দেখলে বা এটির কোনো উন্নতি প্রয়োজন বলে মনে করলে অনুগ্রহ করে আমাদের জানান। আমরা গিটহাব ইস্যুর [ ফিডব্যাক লিঙ্ক ] মাধ্যমে মতামত গ্রহণ করি।
২. গুগল কোলাবোরেটরি কুইক স্টার্ট
এই ল্যাবটি গুগল কোলাবোরেটরি ব্যবহার করে এবং এর জন্য আপনার পক্ষ থেকে কোনো সেটআপের প্রয়োজন নেই। আপনি এটি একটি ক্রোমবুক থেকে চালাতে পারেন। অনুগ্রহ করে নিচের ফাইলটি খুলুন এবং কোলাব নোটবুকের সাথে পরিচিত হওয়ার জন্য সেলগুলো এক্সিকিউট করুন।

নিচে অতিরিক্ত নির্দেশনা দেওয়া হলো:
একটি জিপিইউ ব্যাকএন্ড নির্বাচন করুন

Colab মেনুতে, Runtime > Change runtime type নির্বাচন করুন এবং তারপর GPU নির্বাচন করুন। প্রথমবার চালানোর সময় রানটাইমের সাথে সংযোগ স্বয়ংক্রিয়ভাবে হয়ে যাবে, অথবা আপনি উপরের-ডান কোণায় থাকা 'Connect' বোতামটি ব্যবহার করতে পারেন।
নোটবুক সম্পাদন
একটি সেলে ক্লিক করে Shift-ENTER ব্যবহার করে সেলগুলো এক এক করে চালান। এছাড়াও, আপনি Runtime > Run all ব্যবহার করে সম্পূর্ণ নোটবুকটি চালাতে পারেন।
সূচিপত্র

সব নোটবুকেই একটি সূচিপত্র থাকে। বামদিকের কালো তীরচিহ্নটি ব্যবহার করে আপনি সেটি খুলতে পারেন।
লুকানো কোষ

কিছু সেলে শুধুমাত্র তাদের শিরোনাম দেখা যাবে। এটি কোলাব-এর একটি নোটবুক বৈশিষ্ট্য। ভেতরের কোড দেখার জন্য আপনি এগুলোর উপর ডাবল ক্লিক করতে পারেন, কিন্তু তা সাধারণত খুব একটা আকর্ষণীয় হয় না। এগুলো সাধারণত সাপোর্ট বা ভিজ্যুয়ালাইজেশন ফাংশন। ভেতরের ফাংশনগুলো সংজ্ঞায়িত করার জন্য আপনাকে এই সেলগুলো রান করতে হবে।
৩. একটি নিউরাল নেটওয়ার্ককে প্রশিক্ষণ দিন
আমরা প্রথমে একটি নিউরাল নেটওয়ার্কের প্রশিক্ষণ দেখব। অনুগ্রহ করে নিচের নোটবুকটি খুলুন এবং সমস্ত সেলগুলো দেখুন। আপাতত কোডের দিকে মনোযোগ দেবেন না, আমরা পরে এটি ব্যাখ্যা করা শুরু করব।
নোটবুকটি চালানোর সময় ভিজ্যুয়ালাইজেশনগুলোর উপর মনোযোগ দিন। ব্যাখ্যার জন্য নিচে দেখুন।
প্রশিক্ষণ ডেটা
আমাদের কাছে হাতে লেখা সংখ্যার একটি ডেটাসেট আছে, যেগুলোকে লেবেল করা হয়েছে, যাতে আমরা জানতে পারি প্রতিটি ছবি কীসের প্রতিনিধিত্ব করে, অর্থাৎ ০ থেকে ৯-এর মধ্যে একটি সংখ্যা। নোটবুকটিতে আপনি এর একটি অংশ দেখতে পাবেন:

আমরা যে নিউরাল নেটওয়ার্কটি তৈরি করব, সেটি হাতে লেখা সংখ্যাগুলোকে তাদের ১০টি শ্রেণিতে (০, ..., ৯) ভাগ করে। এটি এমন কিছু অভ্যন্তরীণ প্যারামিটারের উপর ভিত্তি করে এই কাজটি করে, যেগুলোর একটি সঠিক মান থাকা প্রয়োজন যাতে শ্রেণিবিন্যাসটি ভালোভাবে কাজ করে। এই "সঠিক মান" একটি প্রশিক্ষণ প্রক্রিয়ার মাধ্যমে শেখা হয়, যার জন্য ছবি এবং সংশ্লিষ্ট সঠিক উত্তরসহ একটি "লেবেলযুক্ত ডেটাসেট" প্রয়োজন।
আমরা কীভাবে জানব যে প্রশিক্ষিত নিউরাল নেটওয়ার্কটি ভালো কাজ করছে কি না? নেটওয়ার্কটি পরীক্ষা করার জন্য ট্রেনিং ডেটাসেট ব্যবহার করাটা হবে প্রতারণা। এটি ট্রেনিং চলাকালীন ইতোমধ্যেই সেই ডেটাসেটটি একাধিকবার দেখেছে এবং এতে এটি নিশ্চিতভাবেই খুব ভালো পারফর্ম করে। নেটওয়ার্কটির 'বাস্তব-জগতের' পারফরম্যান্স মূল্যায়ন করার জন্য আমাদের আরেকটি লেবেলযুক্ত ডেটাসেট প্রয়োজন, যা ট্রেনিং চলাকালীন কখনও দেখা হয়নি। একে ' ভ্যালিডেশন ডেটাসেট ' বলা হয়।
প্রশিক্ষণ
প্রশিক্ষণ যত এগোতে থাকে, একবারে এক ব্যাচ প্রশিক্ষণ ডেটা যোগ করার মাধ্যমে মডেলের অভ্যন্তরীণ প্যারামিটারগুলো আপডেট হতে থাকে এবং মডেলটি হাতে লেখা সংখ্যা শনাক্ত করার ক্ষেত্রে আরও দক্ষ হয়ে ওঠে। আপনি এটি প্রশিক্ষণ গ্রাফে দেখতে পারেন:

ডানদিকে, 'সঠিকতা' হলো সঠিকভাবে শনাক্ত করা সংখ্যাগুলোর শতাংশ। প্রশিক্ষণ যত এগোয়, এটি তত বাড়ে, যা একটি ভালো লক্ষণ।
বাম দিকে, আমরা 'লস' দেখতে পাচ্ছি। ট্রেনিং পরিচালনা করার জন্য, আমরা একটি 'লস' ফাংশন নির্ধারণ করব, যা নির্দেশ করে সিস্টেমটি সংখ্যাগুলোকে কতটা খারাপভাবে শনাক্ত করছে, এবং এটিকে সর্বনিম্ন করার চেষ্টা করব। আপনি এখানে দেখতে পাচ্ছেন যে, ট্রেনিং যত এগোচ্ছে, ট্রেনিং এবং ভ্যালিডেশন উভয় ডেটার ক্ষেত্রেই লস কমে যাচ্ছে: এটি একটি ভালো লক্ষণ। এর মানে হলো নিউরাল নেটওয়ার্কটি শিখছে।
এক্স-অক্ষটি 'ইপক' বা সম্পূর্ণ ডেটাসেটের মধ্য দিয়ে পুনরাবৃত্তির সংখ্যা নির্দেশ করে।
ভবিষ্যদ্বাণী
মডেলটি প্রশিক্ষিত হয়ে গেলে, আমরা এটি ব্যবহার করে হাতে লেখা সংখ্যা শনাক্ত করতে পারি। পরবর্তী ভিজ্যুয়ালাইজেশনটি দেখায় যে এটি স্থানীয় ফন্ট থেকে রেন্ডার করা কয়েকটি সংখ্যার (প্রথম লাইন) উপর এবং তারপর ভ্যালিডেশন ডেটাসেটের ১০,০০০ সংখ্যার উপর কতটা ভালো কাজ করে। প্রতিটি সংখ্যার নিচে পূর্বাভাসিত শ্রেণিটি দেখানো হয়েছে, ভুল হলে তা লাল রঙে দেখানো হয়।

যেমনটা দেখতে পাচ্ছেন, এই প্রাথমিক মডেলটি খুব একটা ভালো নয়, কিন্তু তা সত্ত্বেও এটি কিছু সংখ্যা সঠিকভাবে শনাক্ত করতে পারে। এর চূড়ান্ত যাচাইকরণ নির্ভুলতা প্রায় ৯০%, যা আমাদের শুরু করা সরল মডেলটির জন্য খুব একটা খারাপ নয়, কিন্তু এর মানে হলো এটি ১০,০০০ সংখ্যার মধ্যে ১,০০০টি যাচাইকরণ সংখ্যা শনাক্ত করতে ব্যর্থ হয়। এই সংখ্যাটি প্রদর্শনের ক্ষমতার চেয়ে অনেক বেশি, আর একারণেই মনে হচ্ছে সব উত্তরই ভুল (লাল)।
টেনসর
ডেটা ম্যাট্রিক্সে সংরক্ষণ করা হয়। একটি ২৮x২৮ পিক্সেলের গ্রেস্কেল ছবি একটি ২৮x২৮ দ্বি-মাত্রিক ম্যাট্রিক্সে এঁটে যায়। কিন্তু একটি রঙিন ছবির জন্য আমাদের আরও বেশি মাত্রার প্রয়োজন হয়। প্রতি পিক্সেলে ৩টি রঙের মান (লাল, সবুজ, নীল) থাকে, তাই [২৮, ২৮, ৩] মাত্রার একটি ত্রি-মাত্রিক টেবিলের প্রয়োজন হবে। এবং ১২৮টি রঙিন ছবির একটি ব্যাচ সংরক্ষণ করার জন্য [১২৮, ২৮, ২৮, ৩] মাত্রার একটি চতুর্মাত্রিক টেবিলের প্রয়োজন হয়।
এই বহুমাত্রিক সারণিগুলোকে 'টেন্সর' বলা হয় এবং এদের মাত্রাগুলোর তালিকাই হলো এদের 'আকৃতি' ।
৪. [তথ্য]: নিউরাল নেটওয়ার্ক ১০১
সংক্ষেপে
পরবর্তী অনুচ্ছেদে বোল্ড করা সমস্ত পরিভাষা যদি আপনার আগে থেকেই জানা থাকে, তাহলে আপনি পরবর্তী অনুশীলনীতে যেতে পারেন। আর আপনি যদি ডিপ লার্নিং সবে শুরু করে থাকেন, তাহলে আপনাকে স্বাগতম, এবং অনুগ্রহ করে পড়তে থাকুন।

ধারাবাহিকভাবে স্তর দিয়ে তৈরি মডেলের জন্য কেরাস সিকোয়েনশিয়াল এপিআই (Sequential API) প্রদান করে। উদাহরণস্বরূপ, তিনটি ডেন্স লেয়ার ব্যবহার করে একটি ইমেজ ক্লাসিফায়ার কেরাসে এভাবে লেখা যেতে পারে:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )

একটি একক ঘন স্তর
MNIST ডেটাসেটের হাতে লেখা সংখ্যাগুলো হলো ২৮x২৮ পিক্সেলের গ্রেস্কেল ছবি। এগুলোকে শ্রেণীবদ্ধ করার সবচেয়ে সহজ উপায় হলো ২৮x২৮=৭৮৪টি পিক্সেলকে একটি ১-স্তর বিশিষ্ট নিউরাল নেটওয়ার্কের ইনপুট হিসেবে ব্যবহার করা।

একটি নিউরাল নেটওয়ার্কের প্রতিটি "নিউরন" তার সমস্ত ইনপুটের একটি ওয়েটেড সাম (weighted sum) করে, এর সাথে "বায়াস" (bias) নামক একটি ধ্রুবক যোগ করে এবং তারপর ফলাফলটিকে কোনো একটি নন-লিনিয়ার "অ্যাক্টিভেশন ফাংশন"-এর মধ্য দিয়ে পাঠায়। এই "ওয়েট" (weights) এবং "বায়াস" (biases) হলো এমন প্যারামিটার যা ট্রেনিংয়ের মাধ্যমে নির্ধারণ করা হয়। শুরুতে এগুলোকে র্যান্ডম মান দিয়ে ইনিশিয়ালাইজ করা হয়।
উপরের ছবিটি ১০টি আউটপুট নিউরন সহ একটি ১-স্তর বিশিষ্ট নিউরাল নেটওয়ার্ককে উপস্থাপন করে, কারণ আমরা সংখ্যাগুলোকে ১০টি শ্রেণিতে (০ থেকে ৯) শ্রেণিবদ্ধ করতে চাই।
ম্যাট্রিক্স গুণনের সাথে
একাধিক চিত্র প্রক্রিয়াকরণকারী একটি নিউরাল নেটওয়ার্ক লেয়ারকে কীভাবে ম্যাট্রিক্স গুণনের মাধ্যমে উপস্থাপন করা যায়, তা এখানে দেখানো হলো:

ওয়েটস ম্যাট্রিক্স W-এর ওয়েটগুলোর প্রথম কলাম ব্যবহার করে, আমরা প্রথম ছবির সমস্ত পিক্সেলের ওয়েটেড সাম গণনা করি। এই সামটি প্রথম নিউরনের সাথে সঙ্গতিপূর্ণ। ওয়েটগুলোর দ্বিতীয় কলাম ব্যবহার করে, আমরা দ্বিতীয় নিউরনের জন্য একই কাজ করি এবং এভাবে ১০ম নিউরন পর্যন্ত চলতে থাকে। এরপর আমরা বাকি ৯৯টি ছবির জন্য এই প্রক্রিয়াটি পুনরাবৃত্তি করতে পারি। যদি আমরা আমাদের ১০০টি ছবি ধারণকারী ম্যাট্রিক্সটিকে X বলি, তবে ১০০টি ছবির উপর গণনা করা আমাদের ১০টি নিউরনের সমস্ত ওয়েটেড সাম হলো কেবল XW, যা একটি ম্যাট্রিক্স গুণন।
এখন প্রতিটি নিউরনকে তার বায়াস (একটি ধ্রুবক) যোগ করতে হবে। যেহেতু আমাদের ১০টি নিউরন আছে, তাই আমাদের ১০টি বায়াস ধ্রুবক রয়েছে। আমরা এই ১০টি মানের ভেক্টরটিকে ‘b’ বলব। এটি পূর্বে গণনা করা ম্যাট্রিক্সের প্রতিটি সারির সাথে যোগ করতে হবে। ‘ব্রডকাস্টিং’ নামক একটি বিশেষ কৌশলের মাধ্যমে আমরা এটিকে একটি সাধারণ যোগ চিহ্ন দিয়ে লিখব।
অবশেষে আমরা একটি অ্যাক্টিভেশন ফাংশন প্রয়োগ করি, যেমন 'সফটম্যাক্স' (যা নিচে ব্যাখ্যা করা হয়েছে) এবং ১০০টি ছবির উপর প্রয়োগ করা একটি ১-স্তর বিশিষ্ট নিউরাল নেটওয়ার্কের সূত্রটি পাই:

কেরাসে
কেরাসের মতো উচ্চ-স্তরের নিউরাল নেটওয়ার্ক লাইব্রেরি ব্যবহার করলে আমাদের এই সূত্রটি প্রয়োগ করার প্রয়োজন হবে না। তবে, এটা বোঝা গুরুত্বপূর্ণ যে একটি নিউরাল নেটওয়ার্ক লেয়ার হলো কেবল কিছু গুণ এবং যোগের সমষ্টি। কেরাসে, একটি ডেন্স লেয়ার এভাবে লেখা হবে:
tf.keras.layers.Dense(10, activation='softmax')
গভীরে যান
নিউরাল নেটওয়ার্কের স্তরগুলোকে শৃঙ্খলিত করা খুবই সহজ। প্রথম স্তরটি পিক্সেলগুলোর ভারযুক্ত যোগফল গণনা করে। পরবর্তী স্তরগুলো পূর্ববর্তী স্তরগুলোর আউটপুটগুলোর ভারযুক্ত যোগফল গণনা করে।

নিউরনের সংখ্যা ছাড়া একমাত্র পার্থক্য হবে অ্যাক্টিভেশন ফাংশনের নির্বাচন।
অ্যাক্টিভেশন ফাংশন: relu, softmax এবং sigmoid
সাধারণত শেষ লেয়ারটি ছাড়া বাকি সব লেয়ারের জন্য 'relu' অ্যাক্টিভেশন ফাংশন ব্যবহার করা হয়। একটি ক্লাসিফায়ারের শেষ লেয়ারে 'softmax' অ্যাক্টিভেশন ব্যবহৃত হয়।

আবার, একটি 'নিউরন' তার সমস্ত ইনপুটের একটি ভারযুক্ত যোগফল গণনা করে, এর সাথে 'বায়াস' নামক একটি মান যোগ করে এবং ফলাফলটিকে অ্যাক্টিভেশন ফাংশনের মধ্য দিয়ে প্রেরণ করে।
সবচেয়ে জনপ্রিয় অ্যাক্টিভেশন ফাংশনটিকে "RELU" বা রেক্টিফাইড লিনিয়ার ইউনিট বলা হয়। এটি একটি খুব সহজ ফাংশন, যেমনটি আপনি উপরের গ্রাফটিতে দেখতে পাচ্ছেন।
নিউরাল নেটওয়ার্কে প্রচলিত অ্যাক্টিভেশন ফাংশন ছিল 'সিগময়েড' , কিন্তু দেখা গেছে যে 'রেলু'-র কনভার্জেন্স বৈশিষ্ট্য প্রায় সবখানেই ভালো এবং এখন এটিই বেশি পছন্দ করা হয়।

শ্রেণীকরণের জন্য সফটম্যাক্স সক্রিয়করণ
আমাদের নিউরাল নেটওয়ার্কের শেষ স্তরে ১০টি নিউরন রয়েছে, কারণ আমরা হাতে লেখা সংখ্যাগুলোকে ১০টি শ্রেণিতে (০,..৯) ভাগ করতে চাই। এর আউটপুট হিসেবে ০ থেকে ১-এর মধ্যে ১০টি সংখ্যা থাকবে, যা ওই সংখ্যাটির ০, ১, ২ ইত্যাদি হওয়ার সম্ভাবনাকে নির্দেশ করবে। এর জন্য, শেষ স্তরে আমরা 'সফটম্যাক্স' নামক একটি অ্যাক্টিভেশন ফাংশন ব্যবহার করব।
একটি ভেক্টরের উপর সফটম্যাক্স প্রয়োগ করা হয় এর প্রতিটি উপাদানের এক্সপোনেনশিয়াল নিয়ে এবং তারপর ভেক্টরটিকে নর্মালাইজ করে, সাধারণত এটিকে এর "L1" নর্ম (অর্থাৎ পরম মানগুলোর যোগফল) দিয়ে ভাগ করে, যাতে নর্মালাইজড মানগুলোর যোগফল ১ হয় এবং সেগুলোকে সম্ভাবনা হিসেবে ব্যাখ্যা করা যায়।
অ্যাক্টিভেশনের আগে, শেষ লেয়ারের আউটপুটকে কখনও কখনও "লজিটস" বলা হয়। যদি এই ভেক্টরটি L = [L0, L1, L2, L3, L4, L5, L6, L7, L8, L9] হয়, তাহলে:


ক্রস-এনট্রপি হ্রাস
এখন যেহেতু আমাদের নিউরাল নেটওয়ার্ক ইনপুট ছবিগুলো থেকে পূর্বাভাস তৈরি করছে, আমাদের পরিমাপ করতে হবে সেগুলো কতটা ভালো, অর্থাৎ নেটওয়ার্ক যা বলছে এবং সঠিক উত্তরের (যাকে প্রায়শই 'লেবেল' বলা হয়) মধ্যেকার পার্থক্য। মনে রাখবেন যে ডেটাসেটের সমস্ত ছবির জন্যই আমাদের কাছে সঠিক লেবেল রয়েছে।
যেকোনো দূরত্বই কাজ করবে, কিন্তু ক্লাসিফিকেশন সমস্যার জন্য তথাকথিত 'ক্রস-এন্ট্রপি দূরত্ব' সবচেয়ে কার্যকর । আমরা একে আমাদের এরর বা 'লস' ফাংশন বলব:

গ্রেডিয়েন্ট অবতরণ
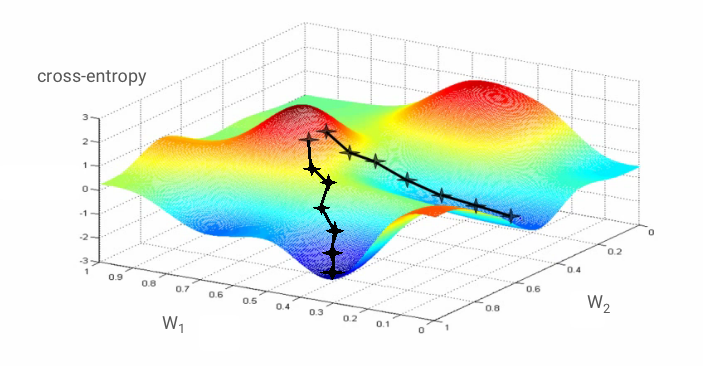
নিউরাল নেটওয়ার্ককে "প্রশিক্ষণ" দেওয়ার অর্থ হলো, প্রশিক্ষণ চিত্র এবং লেবেল ব্যবহার করে ওয়েট ও বায়াস এমনভাবে সমন্বয় করা, যাতে ক্রস-এন্ট্রপি লস ফাংশনটি সর্বনিম্ন হয়। এটি যেভাবে কাজ করে তা নিচে দেওয়া হলো।
ক্রস-এন্ট্রপি হলো ট্রেনিং ইমেজের ওয়েট, বায়াস, পিক্সেল এবং এর জ্ঞাত ক্লাসের একটি ফাংশন।
যদি আমরা সমস্ত ওয়েট এবং বায়াসের সাপেক্ষে ক্রস-এন্ট্রপির আংশিক ডেরিভেটিভ গণনা করি, তাহলে আমরা একটি "গ্রেডিয়েন্ট" পাই, যা একটি নির্দিষ্ট ইমেজ, লেবেল এবং ওয়েট ও বায়াসের বর্তমান মানের জন্য গণনা করা হয়। মনে রাখবেন যে আমাদের লক্ষ লক্ষ ওয়েট এবং বায়াস থাকতে পারে, তাই গ্রেডিয়েন্ট গণনা করা অনেক বড় কাজ বলে মনে হতে পারে। সৌভাগ্যবশত, টেনসরফ্লো আমাদের জন্য এটি করে দেয়। একটি গ্রেডিয়েন্টের গাণিতিক বৈশিষ্ট্য হলো এটি "উপরের দিকে" নির্দেশ করে। যেহেতু আমরা সেখানে যেতে চাই যেখানে ক্রস-এন্ট্রপি কম, তাই আমরা বিপরীত দিকে যাই। আমরা গ্রেডিয়েন্টের একটি ভগ্নাংশ দ্বারা ওয়েট এবং বায়াস আপডেট করি। এরপর আমরা একটি ট্রেনিং লুপের মধ্যে ট্রেনিং ইমেজ এবং লেবেলের পরবর্তী ব্যাচগুলো ব্যবহার করে একই কাজ বারবার করতে থাকি। আশা করা যায়, এটি এমন একটি জায়গায় পৌঁছাবে যেখানে ক্রস-এন্ট্রপি সর্বনিম্ন হবে, যদিও এই সর্বনিম্ন মানটি যে অনন্য হবে তার কোনো নিশ্চয়তা নেই।
মিনি-ব্যাচিং এবং গতি
আপনি শুধুমাত্র একটি উদাহরণ চিত্রের উপর আপনার গ্রেডিয়েন্ট গণনা করতে পারেন এবং অবিলম্বে ওয়েট ও বায়াস আপডেট করতে পারেন, কিন্তু উদাহরণস্বরূপ, ১২৮টি চিত্রের একটি ব্যাচের উপর এটি করলে এমন একটি গ্রেডিয়েন্ট পাওয়া যায় যা বিভিন্ন উদাহরণ চিত্র দ্বারা আরোপিত সীমাবদ্ধতাগুলিকে আরও ভালোভাবে উপস্থাপন করে এবং তাই সমাধানের দিকে দ্রুত অভিসারী হওয়ার সম্ভাবনা থাকে। মিনি-ব্যাচের আকার একটি পরিবর্তনযোগ্য প্যারামিটার।
এই কৌশলটি, যাকে কখনও কখনও 'স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট' বলা হয়, এর আরও একটি বাস্তবসম্মত সুবিধা রয়েছে: ব্যাচ পদ্ধতিতে কাজ করার অর্থ হলো আরও বড় ম্যাট্রিক্স নিয়ে কাজ করা, এবং এগুলো সাধারণত GPU ও TPU-তে অপ্টিমাইজ করা সহজ হয়।
তবে অভিসরণ প্রক্রিয়াটি তখনও কিছুটা বিশৃঙ্খল হতে পারে এবং গ্রেডিয়েন্ট ভেক্টরের সব উপাদান শূন্য হলে এটি থেমেও যেতে পারে। তার মানে কি আমরা একটি সর্বনিম্ন বিন্দু খুঁজে পেয়েছি? সবসময় না। একটি গ্রেডিয়েন্ট উপাংশ সর্বনিম্ন বা সর্বোচ্চ বিন্দুতেও শূন্য হতে পারে। লক্ষ লক্ষ উপাদানবিশিষ্ট একটি গ্রেডিয়েন্ট ভেক্টরের ক্ষেত্রে, যদি সবগুলোই শূন্য হয়, তবে প্রতিটি শূন্যই একটি সর্বনিম্ন বিন্দুর সাথে এবং কোনোটিই সর্বোচ্চ বিন্দুর সাথে সম্পর্কিত না হওয়ার সম্ভাবনা খুবই কম। বহু-মাত্রিক পরিসরে স্যাডল পয়েন্ট বেশ সাধারণ এবং আমরা সেখানে থেমে যেতে চাই না।

উদাহরণ: একটি স্যাডল পয়েন্ট। এর গ্রেডিয়েন্ট ০, কিন্তু এটি সব দিকেই সর্বনিম্ন নয়। (ছবির স্বত্ব উইকিমিডিয়া: নিকোগুয়ারোর নিজস্ব কাজ, সিসি বাই ৩.০ )
এর সমাধান হলো অপ্টিমাইজেশন অ্যালগরিদমে কিছুটা গতি যোগ করা, যাতে এটি না থেমে স্যাডল পয়েন্টগুলো অতিক্রম করতে পারে।
শব্দকোষ
ব্যাচ বা মিনি-ব্যাচ : প্রশিক্ষণ সর্বদা প্রশিক্ষণ ডেটা এবং লেবেলের ব্যাচের উপর সঞ্চালিত হয়। এটি অ্যালগরিদমকে অভিসৃত হতে সাহায্য করে। "ব্যাচ" ডাইমেনশনটি সাধারণত ডেটা টেনসরের প্রথম ডাইমেনশন হয়। উদাহরণস্বরূপ, [100, 192, 192, 3] আকারের একটি টেনসরে 192x192 পিক্সেলের 100টি ছবি থাকে, যেখানে প্রতি পিক্সেলে তিনটি মান (RGB) থাকে।
ক্রস-এন্ট্রপি লস : একটি বিশেষ লস ফাংশন যা প্রায়শই ক্লাসিফায়ারে ব্যবহৃত হয়।
ঘন স্তর : নিউরনের এমন একটি স্তর যেখানে প্রতিটি নিউরন পূর্ববর্তী স্তরের সমস্ত নিউরনের সাথে সংযুক্ত থাকে।
ফিচার : একটি নিউরাল নেটওয়ার্কের ইনপুটগুলোকে কখনও কখনও "ফিচার" বলা হয়। একটি ডেটাসেটের কোন অংশগুলো (বা অংশগুলোর সংমিশ্রণ) একটি নিউরাল নেটওয়ার্কে ইনপুট হিসেবে দিলে ভালো প্রেডিকশন পাওয়া যাবে, তা বের করার কৌশলকে "ফিচার ইঞ্জিনিয়ারিং" বলা হয়।
লেবেল : সুপারভাইজড ক্লাসিফিকেশন সমস্যায় 'ক্লাস' বা সঠিক উত্তরের অপর নাম।
লার্নিং রেট : গ্রেডিয়েন্টের সেই ভগ্নাংশ, যার দ্বারা ট্রেনিং লুপের প্রতিটি ইটারেশনে ওয়েট এবং বায়াস আপডেট করা হয়।
লজিটস : অ্যাক্টিভেশন ফাংশন প্রয়োগ করার আগে নিউরনের একটি স্তরের আউটপুটকে "লজিটস" বলা হয়। এই পরিভাষাটি "লজিস্টিক ফাংশন" বা "সিগময়েড ফাংশন" থেকে এসেছে, যা একসময় সবচেয়ে জনপ্রিয় অ্যাক্টিভেশন ফাংশন ছিল। "লজিস্টিক ফাংশনের আগে নিউরনের আউটপুট" কথাটিকে সংক্ষেপে "লজিটস" বলা হতো।
লস (loss) : নিউরাল নেটওয়ার্কের আউটপুটগুলোকে সঠিক উত্তরের সাথে তুলনা করার জন্য ব্যবহৃত এরর ফাংশন।
নিউরন : এর ইনপুটগুলোর ভারযুক্ত যোগফল গণনা করে, একটি বায়াস যোগ করে এবং ফলাফলটিকে একটি অ্যাক্টিভেশন ফাংশনের মাধ্যমে প্রেরণ করে।
ওয়ান-হট এনকোডিং : ৫টির মধ্যে ৩ নম্বর ক্লাসকে ৫টি উপাদানের একটি ভেক্টর হিসেবে এনকোড করা হয়, যেখানে ৩য় উপাদানটি (১) ছাড়া বাকি সব উপাদান শূন্য থাকে।
relu : রেক্টিফাইড লিনিয়ার ইউনিট। নিউরনের জন্য একটি জনপ্রিয় অ্যাক্টিভেশন ফাংশন।
সিগময়েড : আরেকটি অ্যাক্টিভেশন ফাংশন যা একসময় জনপ্রিয় ছিল এবং বিশেষ ক্ষেত্রে এখনও কাজে লাগে।
সফটম্যাক্স : একটি বিশেষ অ্যাক্টিভেশন ফাংশন যা একটি ভেক্টরের উপর কাজ করে, এর বৃহত্তম উপাদান এবং অন্য সব উপাদানের মধ্যে পার্থক্য বাড়িয়ে দেয় এবং ভেক্টরটিকে এমনভাবে স্বাভাবিক করে যাতে এর যোগফল ১ হয়, ফলে এটিকে সম্ভাবনার ভেক্টর হিসেবে ব্যাখ্যা করা যায়। ক্লাসিফায়ারের শেষ ধাপ হিসেবে এটি ব্যবহৃত হয়।
টেনসর : একটি "টেনসর" হলো ম্যাট্রিক্সের মতো, কিন্তু এর মাত্রা সংখ্যা ইচ্ছামত হতে পারে। ১-মাত্রার টেনসর হলো একটি ভেক্টর। ২-মাত্রার টেনসর হলো একটি ম্যাট্রিক্স। এছাড়াও ৩, ৪, ৫ বা তার বেশি মাত্রার টেনসরও থাকতে পারে।
৫. চলুন কোডটি দেখা যাক।
আবার স্টাডি নোটবুকে ফিরে যাই এবং এবার কোডটা পড়া যাক।
চলুন এই নোটবুকের সমস্ত সেলগুলো দেখে নেওয়া যাক।
কোষ "প্যারামিটার"
এখানে ব্যাচ সাইজ, ট্রেনিং এপোকের সংখ্যা এবং ডেটা ফাইলের অবস্থান নির্ধারণ করা হয়। ডেটা ফাইলগুলো একটি গুগল ক্লাউড স্টোরেজ (GCS) বাকেটে হোস্ট করা থাকে, যে কারণে সেগুলোর অ্যাড্রেস gs:// দিয়ে শুরু হয়।
সেল "আমদানি"
এখানে ভিজ্যুয়ালাইজেশনের জন্য টেনসরফ্লো এবং ম্যাটপ্লটলিব সহ সমস্ত প্রয়োজনীয় পাইথন লাইব্রেরি ইম্পোর্ট করা হয়েছে।
সেল " ভিজ্যুয়ালাইজেশন ইউটিলিটি [আমাকে চালান]****"
এই সেলে গুরুত্বহীন ভিজ্যুয়ালাইজেশন কোড রয়েছে। এটি ডিফল্টরূপে সংকুচিত থাকে, কিন্তু আপনার সময় হলে এর উপর ডাবল-ক্লিক করে আপনি এটি খুলতে এবং কোডটি দেখতে পারেন।
সেল " tf.data.Dataset: ফাইল পার্স করা এবং প্রশিক্ষণ ও যাচাইকরণ ডেটাসেট প্রস্তুত করা "
এই সেলটি ডেটা ফাইলগুলো থেকে MNIST ডেটাসেট লোড করার জন্য tf.data.Dataset API ব্যবহার করেছে। এই সেলটিতে খুব বেশি সময় ব্যয় করার প্রয়োজন নেই। আপনি যদি tf.data.Dataset API সম্পর্কে আগ্রহী হন, তবে এখানে একটি টিউটোরিয়াল রয়েছে যা এটি ব্যাখ্যা করে: TPU-speed data pipelines । আপাতত, মূল বিষয়গুলো হলো:
MNIST ডেটাসেটের ছবি এবং লেবেল (সঠিক উত্তর) ৪টি ফাইলে নির্দিষ্ট দৈর্ঘ্যের রেকর্ড হিসেবে সংরক্ষিত আছে। নির্দিষ্ট ফিক্সড রেকর্ড ফাংশনটি ব্যবহার করে ফাইলগুলো লোড করা যায়:
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16)
এখন আমাদের কাছে ইমেজ বাইটের একটি ডেটাসেট আছে। এগুলোকে ডিকোড করে ইমেজে পরিণত করতে হবে। এই কাজটি করার জন্য আমরা একটি ফাংশন নির্ধারণ করি। ইমেজটি কম্প্রেস করা নেই, তাই ফাংশনটির কোনো কিছু ডিকোড করার প্রয়োজন হয় না ( decode_raw ফাংশনটি মূলত কিছুই করে না)। এরপর ইমেজটিকে ০ থেকে ১-এর মধ্যে ফ্লোটিং পয়েন্ট ভ্যালুতে রূপান্তর করা হয়। আমরা এখানে এটিকে একটি ২ডি ইমেজ হিসেবে রিসেপ করতে পারতাম, কিন্তু আসলে আমরা এটিকে ২৮*২৮ আকারের একটি ফ্ল্যাট পিক্সেল অ্যারে হিসেবেই রাখি, কারণ আমাদের প্রাথমিক ডেন্স লেয়ারটি এটাই প্রত্যাশা করে।
def read_image(tf_bytestring):
image = tf.io.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image
আমরা .map ব্যবহার করে ডেটাসেটে এই ফাংশনটি প্রয়োগ করি এবং ছবিগুলোর একটি ডেটাসেট পাই:
imagedataset = imagedataset.map(read_image, num_parallel_calls=16)
আমরা লেবেলগুলোর জন্যও একই ধরনের পড়া ও ডিকোডিং করি এবং ছবি ও লেবেলগুলোকে একসাথে .zip করি:
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))
এখন আমাদের কাছে (ছবি, লেবেল) জোড়ার একটি ডেটাসেট আছে। আমাদের মডেল এটাই আশা করে। আমরা এখনও এটিকে ট্রেনিং ফাংশনে ব্যবহার করার জন্য পুরোপুরি প্রস্তুত নই।
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
tf.data.Dataset API-তে ডেটাসেট প্রস্তুত করার জন্য প্রয়োজনীয় সকল ইউটিলিটি ফাংশন রয়েছে:
.cache ডেটাসেটটিকে র্যামে ক্যাশ করে। এটি একটি খুব ছোট ডেটাসেট, তাই এটি কাজ করবে। .shuffle এটিকে ৫০০০ উপাদানের একটি বাফার দিয়ে শাফেল করে। ট্রেনিং ডেটা যেন ভালোভাবে শাফেল করা হয়, তা গুরুত্বপূর্ণ। .repeat ডেটাসেটটিকে লুপ করে। আমরা এটির উপর একাধিকবার (একাধিক ইপক) ট্রেনিং করাবো। .batch একাধিক ইমেজ এবং লেবেলকে একত্রিত করে একটি মিনি-ব্যাচ তৈরি করে। সবশেষে, যখন বর্তমান ব্যাচটি জিপিইউ-তে ট্রেনিং হতে থাকে, তখন .prefetch সিপিইউ ব্যবহার করে পরবর্তী ব্যাচ প্রস্তুত করতে পারে।
ভ্যালিডেশন ডেটাসেটটিও একইভাবে প্রস্তুত করা হয়। আমরা এখন একটি মডেল নির্ধারণ করতে এবং এই ডেটাসেটটি ব্যবহার করে সেটিকে প্রশিক্ষণ দিতে প্রস্তুত।
কোষ "কেরাস মডেল"
আমাদের সমস্ত মডেলই লেয়ারের একটি সরল অনুক্রম হবে, তাই আমরা সেগুলি তৈরি করতে tf.keras.Sequential স্টাইল ব্যবহার করতে পারি। প্রাথমিকভাবে এখানে, এটি একটি একক ডেন্স লেয়ার। এতে ১০টি নিউরন আছে কারণ আমরা হাতে লেখা সংখ্যাগুলোকে ১০টি শ্রেণিতে শ্রেণিবদ্ধ করছি। এটি 'সফটম্যাক্স' অ্যাক্টিভেশন ব্যবহার করে, কারণ এটি একটি ক্লাসিফায়ারের শেষ লেয়ার।
একটি কেরাস মডেলকে তার ইনপুটগুলোর আকৃতিও জানতে হয়। এটি নির্ধারণ করতে tf.keras.layers.Input ব্যবহার করা যেতে পারে। এখানে, ইনপুট ভেক্টরগুলো হলো ২৮*২৮ দৈর্ঘ্যের পিক্সেল মানের ফ্ল্যাট ভেক্টর।
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1)
Keras-এ model.compile ফাংশন ব্যবহার করে মডেলটি কনফিগার করা হয়। এখানে আমরা বেসিক অপটিমাইজার 'sgd' (Stochastic Gradient Descent) ব্যবহার করেছি। একটি ক্লাসিফিকেশন মডেলের জন্য একটি ক্রস-এন্ট্রপি লস ফাংশন প্রয়োজন, যা Keras-এ 'categorical_crossentropy' নামে পরিচিত। সবশেষে, আমরা মডেলটিকে 'accuracy' মেট্রিকটি গণনা করতে বলি, যা হলো সঠিকভাবে ক্লাসিফাই করা ছবির শতাংশ।
কেরাসে model.summary() নামে একটি চমৎকার ইউটিলিটি রয়েছে যা আপনার তৈরি করা মডেলের বিস্তারিত তথ্য প্রিন্ট করে। আপনার সদয় প্রশিক্ষক PlotTraining ইউটিলিটিটি (যা 'visualization utilities' সেলে সংজ্ঞায়িত) যোগ করেছেন, যা ট্রেনিং চলাকালীন বিভিন্ন ট্রেনিং কার্ভ প্রদর্শন করবে।
সেল "মডেলটি প্রশিক্ষণ ও যাচাই করুন"
এখানেই model.fit কল করে এবং ট্রেনিং ও ভ্যালিডেশন উভয় ডেটাসেট পাস করে ট্রেনিং সম্পন্ন করা হয়। ডিফল্টভাবে, Keras প্রতিটি ইপোকের শেষে এক দফা ভ্যালিডেশন চালায়।
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])
কেরাসে, কলব্যাক ব্যবহার করে ট্রেনিং চলাকালীন কাস্টম আচরণ যোগ করা সম্ভব। এই ওয়ার্কশপের জন্য এভাবেই ডায়নামিকভাবে আপডেট হওয়া ট্রেনিং প্লটটি বাস্তবায়ন করা হয়েছিল।
কোষ "ভবিষ্যদ্বাণী কল্পনা করুন"
মডেলটি প্রশিক্ষিত হয়ে গেলে, আমরা model.predict() কল করে এর থেকে প্রেডিকশন পেতে পারি:
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)
এখানে আমরা পরীক্ষা হিসেবে স্থানীয় ফন্ট থেকে রেন্ডার করা এক সেট মুদ্রিত সংখ্যা প্রস্তুত করেছি। মনে রাখবেন যে নিউরাল নেটওয়ার্ক তার চূড়ান্ত 'সফটম্যাক্স' থেকে ১০টি সম্ভাবনার একটি ভেক্টর ফেরত দেয়। লেবেলটি পেতে হলে, আমাদের খুঁজে বের করতে হবে কোন সম্ভাবনাটি সর্বোচ্চ। নামপাই লাইব্রেরির np.argmax এই কাজটি করে থাকে।
axis=1 প্যারামিটারটির কেন প্রয়োজন, তা বোঝার জন্য অনুগ্রহ করে মনে রাখবেন যে আমরা ১২৮টি ছবির একটি ব্যাচ প্রসেস করেছি এবং সেই কারণে মডেলটি ১২৮টি সম্ভাবনার ভেক্টর রিটার্ন করে। আউটপুট টেনসরের আকৃতি হলো [১২৮, ১০]। আমরা প্রতিটি ছবির জন্য রিটার্ন করা ১০টি সম্ভাবনার মধ্যে argmax গণনা করছি, এজন্যই axis=1 (প্রথম অক্ষটি হলো ০)।
এই সাধারণ মডেলটি ইতিমধ্যেই ৯০% সংখ্যা শনাক্ত করতে পারে। মন্দ নয়, কিন্তু আপনি এখন এটিকে উল্লেখযোগ্যভাবে উন্নত করবেন।

৬. স্তর যোগ করা

শনাক্তকরণের নির্ভুলতা বাড়ানোর জন্য আমরা নিউরাল নেটওয়ার্কে আরও স্তর যুক্ত করব।

আমরা শেষ লেয়ারে অ্যাক্টিভেশন ফাংশন হিসেবে সফটম্যাক্স রাখি, কারণ ক্লাসিফিকেশনের জন্য এটিই সবচেয়ে ভালো কাজ করে। তবে, মধ্যবর্তী লেয়ারগুলোতে আমরা সবচেয়ে ক্লাসিক্যাল অ্যাক্টিভেশন ফাংশন, অর্থাৎ সিগময়েড ব্যবহার করব।
উদাহরণস্বরূপ, আপনার মডেলটি দেখতে এইরকম হতে পারে (কমাগুলো দিতে ভুলবেন না, tf.keras.Sequential কমা দিয়ে আলাদা করা লেয়ারের একটি তালিকা গ্রহণ করে):
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])
আপনার মডেলের 'সারাংশ' দেখুন। এতে এখন অন্তত ১০ গুণ বেশি প্যারামিটার আছে। এটি ১০ গুণ ভালো হওয়ার কথা! কিন্তু কোনো এক কারণে তা হচ্ছে না...

ক্ষতির পরিমাণও যেন আকাশছোঁয়া হয়ে গেছে। কিছু একটা ঠিক নেই।
৭. গভীর নেটওয়ার্কের জন্য বিশেষ যত্ন
আপনি এইমাত্র ৮০ ও ৯০-এর দশকে ডিজাইন করা নিউরাল নেটওয়ার্কগুলোর অভিজ্ঞতা লাভ করলেন। এতে অবাক হওয়ার কিছু নেই যে, তারা এই ধারণাটি পরিত্যাগ করে তথাকথিত "এআই উইন্টার"-এর সূচনা করেছিল। প্রকৃতপক্ষে, আপনি যত স্তর যোগ করবেন, নিউরাল নেটওয়ার্কগুলোর কনভার্জ করতে ততই বেশি সমস্যার সম্মুখীন হতে হবে।
দেখা গেছে যে, অনেকগুলো স্তরবিশিষ্ট (আজকাল ২০, ৫০, এমনকি ১০০টি) ডিপ নিউরাল নেটওয়ার্কও বেশ ভালোভাবে কাজ করতে পারে, যদি সেগুলোকে কনভার্জ করানোর জন্য কয়েকটি জটিল গাণিতিক কৌশল প্রয়োগ করা হয়। এই সহজ কৌশলগুলোর আবিষ্কারই হলো ২০১০-এর দশকে ডিপ লার্নিং-এর পুনরুজ্জীবনের অন্যতম কারণ।
RELU সক্রিয়করণ

সিগময়েড অ্যাক্টিভেশন ফাংশনটি আসলে ডিপ নেটওয়ার্কের ক্ষেত্রে বেশ সমস্যাজনক। এটি সমস্ত মানকে ০ এবং ১-এর মধ্যে সংকুচিত করে ফেলে এবং বারবার এমনটা করলে নিউরনের আউটপুট ও তাদের গ্রেডিয়েন্ট সম্পূর্ণরূপে অদৃশ্য হয়ে যেতে পারে। ঐতিহাসিক কারণে এর উল্লেখ করা হয়েছিল, কিন্তু আধুনিক নেটওয়ার্কগুলো RELU (Rectified Linear Unit) ব্যবহার করে, যা দেখতে এইরকম:

অন্যদিকে, RELU-এর ডেরিভেটিভ অন্তত এর ডান দিকে ১ হয়। RELU অ্যাক্টিভেশনের মাধ্যমে, কিছু নিউরন থেকে আসা গ্রেডিয়েন্ট শূন্য হলেও, সবসময়ই অন্য নিউরন থাকবে যা একটি স্পষ্ট অশূন্য গ্রেডিয়েন্ট দেবে এবং প্রশিক্ষণ একটি ভালো গতিতে চলতে পারে।
একটি উন্নততর অপ্টিমাইজার
এখানকার মতো অত্যন্ত উচ্চ-মাত্রিক স্পেসে—যেখানে প্রায় ১০ হাজার ওয়েট এবং বায়াস রয়েছে—‘স্যাডল পয়েন্ট’ প্রায়শই দেখা যায়। এগুলো এমন কিছু পয়েন্ট যা লোকাল মিনিমা নয়, কিন্তু যেখানে গ্রেডিয়েন্ট শূন্য থাকে এবং গ্রেডিয়েন্ট ডিসেন্ট অপটিমাইজার সেখানেই আটকে যায়। টেনসরফ্লো-তে বিভিন্ন ধরনের অপটিমাইজার রয়েছে, যার মধ্যে কিছু নির্দিষ্ট জড়তার সাথে কাজ করে এবং নিরাপদে স্যাডল পয়েন্টগুলো অতিক্রম করে যায়।
এলোমেলো প্রারম্ভিকীকরণ
প্রশিক্ষণের আগে ওয়েট বায়াস ইনিশিয়ালাইজ করার কৌশলটি নিজেই একটি গবেষণার বিষয়, এবং এই বিষয়ে অসংখ্য গবেষণাপত্র প্রকাশিত হয়েছে। আপনি এখানে Keras-এ উপলব্ধ সমস্ত ইনিশিয়ালাইজার দেখে নিতে পারেন। সৌভাগ্যবশত, Keras ডিফল্টভাবে সঠিক কাজটি করে এবং 'glorot_uniform' ইনিশিয়ালাইজারটি ব্যবহার করে, যা প্রায় সব ক্ষেত্রেই সেরা।
আপনার করার কিছুই নেই, কারণ কেরাস ইতিমধ্যেই সঠিক কাজটি করে।
NaN ???
ক্রস-এন্ট্রপির সূত্রে একটি লগারিদম রয়েছে এবং log(0) একটি সংখ্যা নয় (NaN, যাকে আপনি সাংখ্যিক ক্র্যাশও বলতে পারেন)। ক্রস-এন্ট্রপির ইনপুট কি ০ হতে পারে? ইনপুটটি সফটম্যাক্স থেকে আসে, যা মূলত একটি এক্সপোনেনশিয়াল এবং এক্সপোনেনশিয়াল কখনো শূন্য হয় না। সুতরাং আমরা নিরাপদ!
সত্যিই? গণিতের সুন্দর জগতে আমরা নিরাপদ থাকতাম, কিন্তু কম্পিউটারের জগতে, float32 ফরম্যাটে প্রকাশিত exp(-150) হলো একেবারে শূন্য এবং এর ফলে ক্রস-এন্ট্রপি ক্র্যাশ করে।
সৌভাগ্যবশত, এখানেও আপনার কিছু করার নেই, কারণ Keras এই বিষয়টি সামলে নেয় এবং সাংখ্যিক স্থিতিশীলতা নিশ্চিত করতে ও সেই ভয়ংকর NaN (ন্যান) এড়াতে অত্যন্ত সতর্কতার সাথে সফটম্যাক্স এবং তারপরে ক্রস-এন্ট্রপি গণনা করে।
সাফল্য?

আপনার নির্ভুলতা এখন ৯৭%-এ পৌঁছানো উচিত। এই কর্মশালার লক্ষ্য হলো ৯৯%-এর চেয়ে উল্লেখযোগ্যভাবে বেশি অর্জন করা, তাই চলুন আমরা এগিয়ে যাই।
আপনি যদি আটকে যান, তাহলে এই মুহূর্তে সমাধানটি হলো:
৮. লার্নিং রেট হ্রাস
আমরা কি আরও দ্রুত প্রশিক্ষণ দেওয়ার চেষ্টা করতে পারি? অ্যাডাম অপটিমাইজারের ডিফল্ট লার্নিং রেট হলো ০.০০১। চলুন এটি বাড়িয়ে দেখি।
আরও দ্রুত গেলেও খুব একটা লাভ হচ্ছে বলে মনে হচ্ছে না, আর এই সব শোরগোল কিসের?

ট্রেনিং কার্ভগুলো খুবই নয়েজি এবং ভ্যালিডেশন কার্ভ দুটোর দিকেই দেখুন: ওগুলো লাফিয়ে লাফিয়ে উঠছে আর নামছে। এর মানে হলো, আমরা খুব দ্রুত এগোচ্ছি। আমরা আমাদের আগের গতিতে ফিরে যেতে পারি, কিন্তু এর চেয়েও ভালো একটি উপায় আছে।

এর ভালো সমাধান হলো দ্রুত শুরু করা এবং ধীরে ধীরে লার্নিং রেট কমিয়ে আনা। Keras-এ, আপনি tf.keras.callbacks.LearningRateScheduler কলব্যাক ব্যবহার করে এটি করতে পারেন।
কপি-পেস্ট করার জন্য দরকারি কোড:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)
আপনার তৈরি করা lr_decay_callback টি ব্যবহার করতে ভুলবেন না। model.fit এর কলব্যাক তালিকায় এটি যোগ করুন:
model.fit(..., callbacks=[plot_training, lr_decay_callback])
এই সামান্য পরিবর্তনের প্রভাব দর্শনীয়। আপনি দেখতে পাচ্ছেন যে বেশিরভাগ নয়েজ দূর হয়ে গেছে এবং পরীক্ষার নির্ভুলতা এখন ধারাবাহিকভাবে ৯৮%-এর উপরে রয়েছে।

৯. ড্রপআউট, ওভারফিটিং
মডেলটি এখন বেশ ভালোভাবে মিলে যাচ্ছে বলে মনে হচ্ছে। চলুন আরও গভীরে যাওয়ার চেষ্টা করি।
এটা কি সাহায্য করে?

আসলে তা নয়, অ্যাকুরেসি এখনও ৯৮%-এ আটকে আছে এবং ভ্যালিডেশন লসের দিকে তাকান। এটা তো বাড়ছে! লার্নিং অ্যালগরিদম শুধুমাত্র ট্রেনিং ডেটার উপর কাজ করে এবং সেই অনুযায়ী ট্রেনিং লস অপটিমাইজ করে। এটি কখনও ভ্যালিডেশন ডেটা দেখে না, তাই এতে অবাক হওয়ার কিছু নেই যে কিছুক্ষণ পর এর কাজের আর ভ্যালিডেশন লসের উপর কোনো প্রভাব থাকে না, যার ফলে এটি কমা বন্ধ করে দেয় এবং কখনও কখনও আবার বেড়েও যায়।
এটি আপনার মডেলের বাস্তব-জগতের শনাক্তকরণ ক্ষমতাকে তাৎক্ষণিকভাবে প্রভাবিত করে না, কিন্তু এটি আপনাকে অনেকগুলো পুনরাবৃত্তি চালাতে বাধা দেবে এবং সাধারণত এটি একটি লক্ষণ যে প্রশিক্ষণটি আর ইতিবাচক প্রভাব ফেলছে না।

এই অসামঞ্জস্যকে সাধারণত 'ওভারফিটিং' বলা হয় এবং এটি দেখা গেলে আপনি 'ড্রপআউট' নামক একটি রেগুলারাইজেশন কৌশল প্রয়োগ করে দেখতে পারেন। ড্রপআউট কৌশলটি প্রতিটি ট্রেনিং ইটারেশনে র্যান্ডম নিউরন বাদ দেয়।
এটা কি কাজ করেছে?

নয়েজ আবার ফিরে এসেছে (ড্রপআউটের কার্যপ্রণালী বিবেচনা করলে যা অপ্রত্যাশিত নয়)। ভ্যালিডেশন লস আর ধীরে ধীরে বাড়ছে বলে মনে হচ্ছে না, কিন্তু ড্রপআউট ছাড়া অবস্থার চেয়ে এটি সামগ্রিকভাবে বেশি। এবং ভ্যালিডেশন অ্যাকুরেসি কিছুটা কমে গেছে। এটি বেশ হতাশাজনক একটি ফলাফল।
মনে হচ্ছে ড্রপআউট সঠিক সমাধান ছিল না, অথবা হয়তো "ওভারফিটিং" আরও জটিল একটি ধারণা এবং এর কিছু কারণ শুধু "ড্রপআউট" দিয়ে সমাধানযোগ্য নয়?
"ওভারফিটিং" কী? ওভারফিটিং ঘটে যখন একটি নিউরাল নেটওয়ার্ক "ভুলভাবে" শেখে; এমনভাবে শেখে যা প্রশিক্ষণের উদাহরণগুলোর জন্য ঠিকঠাক কাজ করলেও বাস্তব ডেটার ক্ষেত্রে ততটা ভালো কাজ করে না। ড্রপআউটের মতো কিছু রেগুলারাইজেশন কৌশল রয়েছে যা নেটওয়ার্কটিকে আরও ভালোভাবে শিখতে বাধ্য করতে পারে, কিন্তু ওভারফিটিংয়ের মূল কারণও আরও গভীরে নিহিত।

বেসিক ওভারফিটিং ঘটে যখন একটি নিউরাল নেটওয়ার্কের নির্দিষ্ট সমস্যার জন্য প্রয়োজনের তুলনায় অনেক বেশি ডিগ্রি অফ ফ্রিডম থাকে। কল্পনা করুন, আমাদের এত বেশি নিউরন আছে যে নেটওয়ার্কটি আমাদের সমস্ত ট্রেনিং ইমেজ সেগুলিতে সংরক্ষণ করতে পারে এবং তারপর প্যাটার্ন ম্যাচিংয়ের মাধ্যমে সেগুলিকে শনাক্ত করতে পারে। এটি বাস্তব ডেটার ক্ষেত্রে পুরোপুরি ব্যর্থ হবে। একটি নিউরাল নেটওয়ার্ককে কিছুটা সীমাবদ্ধ রাখতে হবে, যাতে এটি ট্রেনিংয়ের সময় যা শেখে তা সাধারণীকরণ করতে বাধ্য হয়।
আপনার কাছে যদি খুব কম ট্রেনিং ডেটা থাকে, তাহলে একটি ছোট নেটওয়ার্কও তা মুখস্থ করে ফেলতে পারে এবং আপনি 'ওভারফিটিং' দেখতে পাবেন। সাধারণভাবে বলতে গেলে, নিউরাল নেটওয়ার্ককে প্রশিক্ষণ দেওয়ার জন্য সবসময় প্রচুর ডেটার প্রয়োজন হয়।
অবশেষে, যদি আপনি সবকিছু নিয়ম মেনে করে থাকেন, নেটওয়ার্কের বিভিন্ন আকার নিয়ে পরীক্ষা-নিরীক্ষা করে এর স্বাধীনতার মাত্রা সীমিত রেখেছেন, ড্রপআউট প্রয়োগ করেছেন এবং প্রচুর ডেটার উপর প্রশিক্ষণ দিয়েছেন, তারপরেও আপনি এমন একটি পারফরম্যান্স স্তরে আটকে থাকতে পারেন যা কোনোভাবেই উন্নত করা সম্ভব বলে মনে হয় না। এর মানে হলো, আপনার নিউরাল নেটওয়ার্কটি তার বর্তমান অবস্থায় আপনার ডেটা থেকে আরও তথ্য আহরণ করতে সক্ষম নয়, যেমনটি আমাদের এই ক্ষেত্রে ঘটেছে।
মনে আছে আমরা কীভাবে আমাদের ছবিগুলোকে একটিমাত্র ভেক্টরে পরিণত করে ব্যবহার করছিলাম? সেটা একটা খুবই বাজে বুদ্ধি ছিল। হাতে লেখা সংখ্যাগুলো বিভিন্ন আকৃতি দিয়ে তৈরি হয় এবং পিক্সেলগুলোকে ফ্ল্যাট করার সময় আমরা সেই আকৃতির তথ্যগুলো বাদ দিয়ে দিয়েছিলাম। তবে, এমন এক ধরনের নিউরাল নেটওয়ার্ক আছে যা এই আকৃতির তথ্যকে কাজে লাগাতে পারে: কনভোলিউশনাল নেটওয়ার্ক। চলুন, সেগুলোই চেষ্টা করে দেখা যাক।
আপনি যদি আটকে যান, তাহলে এই মুহূর্তে সমাধানটি হলো:
১০. [তথ্য] কনভোলিউশনাল নেটওয়ার্ক
সংক্ষেপে
পরবর্তী অনুচ্ছেদে বোল্ড করা সমস্ত পরিভাষা যদি আপনার আগে থেকেই জানা থাকে, তাহলে আপনি পরবর্তী অনুশীলনীতে যেতে পারেন। আর যদি আপনি কনভোলিউশনাল নিউরাল নেটওয়ার্ক নিয়ে সবেমাত্র কাজ শুরু করে থাকেন, তাহলে অনুগ্রহ করে পড়তে থাকুন।

উদাহরণ: প্রতিটি 4x4x3=48টি শিখনীয় ওয়েট দিয়ে তৈরি দুটি পরপর ফিল্টার ব্যবহার করে একটি ছবিকে ফিল্টার করা।
কেরাসে একটি সাধারণ কনভল্যুশনাল নিউরাল নেটওয়ার্ক দেখতে এইরকম:
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
একটি কনভোলিউশনাল নেটওয়ার্কের একটি লেয়ারে, একটি "নিউরন" ছবির শুধুমাত্র একটি ছোট অঞ্চলের উপর তার ঠিক উপরের পিক্সেলগুলোর ওয়েটেড সাম (weighted sum) করে। এটি একটি বায়াস (bias) যোগ করে এবং যোগফলটিকে একটি অ্যাক্টিভেশন ফাংশনের মধ্যে দিয়ে পাঠায়, ঠিক যেমনটি একটি সাধারণ ডেন্স লেয়ারের নিউরন করে থাকে। এরপর এই প্রক্রিয়াটি একই ওয়েটগুলো ব্যবহার করে পুরো ছবি জুড়ে পুনরাবৃত্তি করা হয়। মনে রাখবেন যে ডেন্স লেয়ারগুলোতে প্রতিটি নিউরনের নিজস্ব ওয়েট থাকত। এখানে, ওয়েটের একটিমাত্র "প্যাচ" ছবির উপর দিয়ে উভয় দিকে স্লাইড করে (একটি "কনভোলিউশন")। আউটপুটে ছবিতে যতগুলো পিক্সেল আছে ততগুলোই ভ্যালু থাকে (যদিও প্রান্তগুলোতে কিছু প্যাডিং প্রয়োজন হয়)। এটি একটি ফিল্টারিং প্রক্রিয়া। উপরের চিত্রে, এটি 4x4x3=48টি ওয়েটের একটি ফিল্টার ব্যবহার করে।
তবে, ৪৮টি ওয়েট যথেষ্ট হবে না। আরও বেশি স্বাধীনতা যোগ করার জন্য, আমরা নতুন এক সেট ওয়েট ব্যবহার করে একই প্রক্রিয়াটির পুনরাবৃত্তি করি। এর ফলে নতুন এক সেট ফিল্টার আউটপুট তৈরি হয়। ইনপুট ইমেজের R, G, B চ্যানেলের সাথে সাদৃশ্য রেখে, আমরা একে আউটপুটের একটি 'চ্যানেল' বলতে পারি।

একটি নতুন ডাইমেনশন যোগ করে দুই (বা ততোধিক) সেট ওয়েটকে একটি টেনসর হিসেবে যোগ করা যায়। এটি আমাদের একটি কনভোলিউশনাল লেয়ারের ওয়েট টেনসরের সাধারণ আকৃতি প্রদান করে। যেহেতু ইনপুট এবং আউটপুট চ্যানেলের সংখ্যা হলো প্যারামিটার, তাই আমরা কনভোলিউশনাল লেয়ারগুলোকে স্ট্যাকিং এবং চেইনিং শুরু করতে পারি।

উদাহরণ: একটি কনভল্যুশনাল নিউরাল নেটওয়ার্ক ডেটার ‘কিউব’গুলোকে ডেটার অন্য ‘কিউব’-এ রূপান্তরিত করে।
স্ট্রাইডেড কনভোলিউশন, ম্যাক্স পুলিং
২ বা ৩ স্ট্রাইড ব্যবহার করে কনভোলিউশন করার মাধ্যমে আমরা প্রাপ্ত ডেটা কিউবটিকে এর আনুভূমিক দিকেও সংকুচিত করতে পারি। এটি করার দুটি প্রচলিত উপায় রয়েছে:
- স্ট্রাইডেড কনভোলিউশন: উপরেরটির মতো একটি স্লাইডিং ফিল্টার কিন্তু স্ট্রাইড >1 সহ।
- ম্যাক্স পুলিং: একটি স্লাইডিং উইন্ডো যা ম্যাক্স অপারেশন প্রয়োগ করে (সাধারণত ২x২ প্যাচের উপর, প্রতি ২ পিক্সেল পর পর পুনরাবৃত্তি করা হয়)।

উদাহরণস্বরূপ: কম্পিউটিং উইন্ডোকে ৩ পিক্সেল স্লাইড করলে আউটপুট মানের সংখ্যা কমে যায়। স্ট্রাইডেড কনভোলিউশন বা ম্যাক্স পুলিং (২ স্ট্রাইডে স্লাইড করা একটি ২x২ উইন্ডোতে ম্যাক্স অপারেশন) হলো ডেটা কিউবকে আনুভূমিক দিকে সংকুচিত করার একটি উপায়।
The final layer
After the last convolutional layer, the data is in the form of a "cube". There are two ways of feeding it through the final dense layer.
The first one is to flatten the cube of data into a vector and then feed it to the softmax layer. Sometimes, you can even add a dense layer before the softmax layer. This tends to be expensive in terms of the number of weights. A dense layer at the end of a convolutional network can contain more than half the weights of the whole neural network.
Instead of using an expensive dense layer, we can also split the incoming data "cube" into as many parts as we have classes, average their values and feed these through a softmax activation function. This way of building the classification head costs 0 weights. In Keras, there is a layer for this: tf.keras.layers.GlobalAveragePooling2D() .

Jump to the next section to build a convolutional network for the problem at hand.
11. A convolutional network
Let us build a convolutional network for handwritten digit recognition. We will use three convolutional layers at the top, our traditional softmax readout layer at the bottom and connect them with one fully-connected layer:

Notice that the second and third convolutional layers have a stride of two which explains why they bring the number of output values down from 28x28 to 14x14 and then 7x7.
Let's write the Keras code.
Special attention is needed before the first convolutional layer. Indeed, it expects a 3D 'cube' of data but our dataset has so far been set up for dense layers and all the pixels of the images are flattened into a vector. We need to reshape them back into 28x28x1 images (1 channel for grayscale images):
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))
You can use this line instead of the tf.keras.layers.Input layer you had up to now.
In Keras, the syntax for a 'relu'-activated convolutional layer is:

tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')
For a strided convolution, you would write:
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)
To flatten a cube of data into a vector so that it can be consumed by a dense layer:
tf.keras.layers.Flatten()
And for dense layer, the syntax has not changed:
tf.keras.layers.Dense(200, activation='relu')
Did your model break the 99% accuracy barrier? Pretty close... but look at the validation loss curve. Does this ring a bell?

Also look at the predictions. For the first time, you should see that most of the 10,000 test digits are now correctly recognized. Only about 4½ rows of misdetections remain (about 110 digits out of 10,000)

If you are stuck, here is the solution at this point:
12. Dropout again
The previous training exhibits clear signs of overfitting (and still falls short of 99% accuracy). Should we try dropout again?
How did it go this time?

It looks like dropout has worked this time. The validation loss is not creeping up anymore and the final accuracy should be way above 99%. Congratulations!
The first time we tried to apply dropout, we thought we had an overfitting problem, when in fact the problem was in the architecture of the neural network. We could not go further without convolutional layers and there is nothing dropout could do about that.
This time, it does look like overfitting was the cause of the problem and dropout actually helped. Remember, there are many things that can cause a disconnect between the training and validation loss curves, with the validation loss creeping up. Overfitting (too many degrees of freedom, used badly by the network) is only one of them. If your dataset is too small or the architecture of your neural network is not adequate, you might see a similar behavior on the loss curves, but dropout will not help.
13. Batch normalization

Finally, let's try to add batch normalization.
That's the theory, in practice, just remember a couple of rules:
Let's play by the book for now and add a batch norm layer on each neural network layer but the last. Do not add it to the last "softmax" layer. It would not be useful there.
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),
How is the accuracy now?

With a little bit of tweaking (BATCH_SIZE=64, learning rate decay parameter 0.666, dropout rate on dense layer 0.3) and a bit of luck, you can get to 99.5%. The learning rate and dropout adjustments were done following the "best practices" for using batch norm:
- Batch norm helps neural networks converge and usually allows you to train faster.
- Batch norm is a regularizer. You can usually decrease the amount of dropout you use, or even not use dropout at all.
The solution notebook has a 99.5% training run:
14. Train in the cloud on powerful hardware: AI Platform

You will find a cloud-ready version of the code in the mlengine folder on GitHub , along with instructions for running it on Google Cloud AI Platform . Before you can run this part, you will have to create a Google Cloud account and enable billing. The resources necessary to complete the lab should be less than a couple of dollars (assuming 1h of training time on one GPU). To prepare your account:
- Create a Google Cloud Platform project ( http://cloud.google.com/console ).
- Enable billing.
- Install the GCP command line tools ( GCP SDK here ).
- Create a Google Cloud Storage bucket (put in the region
us-central1). It will be used to stage the training code and store your trained model. - Enable the necessary APIs and request the necessary quotas (run the training command once and you should get error messages telling you what to enable).
১৫. অভিনন্দন!
You have built your first neural network and trained it all the way to 99% accuracy. The techniques learned along the way are not specific to the MNIST dataset, actually they are widely used when working with neural networks. As a parting gift, here is the "cliff's notes" card for the lab, in cartoon version. You can use it to remember what you have learned:

পরবর্তী পদক্ষেপ
- After fully-connected and convolutional networks, you should have a look at recurrent neural networks .
- To run your training or inference in the cloud on a distributed infrastructure, Google Cloud provides AI Platform .
- Finally, we love feedback. Please tell us if you see something amiss in this lab or if you think it should be improved. We handle feedback through GitHub issues [ feedback link ].

|
|
 The author: Martin GörnerTwitter:
The author: Martin GörnerTwitter: 
All cartoon images in this lab copyright: alexpokusay / 123RF stock photos