
১. সংক্ষিপ্ত বিবরণ
টিপিইউগুলো খুব দ্রুতগামী। ট্রেনিং ডেটার প্রবাহকে অবশ্যই এদের ট্রেনিং গতির সাথে তাল মিলিয়ে চলতে হবে। এই ল্যাবে, আপনি শিখবেন কীভাবে tf.data.Dataset API ব্যবহার করে GCS থেকে ডেটা লোড করে আপনার টিপিইউ-তে ফিড করতে হয়।
এই ল্যাবটি 'Keras on TPU' সিরিজের প্রথম পর্ব। আপনি এগুলো নিম্নলিখিত ক্রমানুসারে অথবা আলাদাভাবে করতে পারেন।
- [এই ল্যাব] টিপিইউ-গতির ডেটা পাইপলাইন: tf.data.Dataset এবং TFRecords
- ট্রান্সফার লার্নিং সহ আপনার প্রথম কেরাস মডেল
- কেরাস এবং টিপিইউ সহ কনভল্যুশনাল নিউরাল নেটওয়ার্ক
- আধুনিক কনভনেট, স্কুইজনেট, এক্সসেপশন, কেরাস এবং টিপিইউ সহ

আপনি যা শিখবেন
- প্রশিক্ষণ ডেটা লোড করতে tf.data.Dataset API ব্যবহার করুন
- GCS থেকে প্রশিক্ষণ ডেটা দক্ষতার সাথে লোড করার জন্য TFRecord ফরম্যাট ব্যবহার করতে
প্রতিক্রিয়া
এই কোড ল্যাবে কোনো ভুল দেখলে, অনুগ্রহ করে আমাদের জানান। GitHub ইস্যুর মাধ্যমে মতামত জানানো যাবে [ মতামত লিঙ্ক ]।
২. গুগল কোলাবোরেটরি কুইক স্টার্ট
এই ল্যাবটি গুগল কোলাবোরেটরি ব্যবহার করে এবং এর জন্য আপনার পক্ষ থেকে কোনো সেটআপের প্রয়োজন নেই। কোলাবোরেটরি হলো শিক্ষামূলক উদ্দেশ্যে ব্যবহৃত একটি অনলাইন নোটবুক প্ল্যাটফর্ম। এটি বিনামূল্যে সিপিইউ, জিপিইউ এবং টিপিইউ প্রশিক্ষণের সুযোগ দেয়।

Colaboratory-র সাথে পরিচিত হওয়ার জন্য আপনি এই নমুনা নোটবুকটি খুলে কয়েকটি সেল চালিয়ে দেখতে পারেন।
একটি টিপিইউ ব্যাকএন্ড নির্বাচন করুন

Colab মেনুতে, Runtime > Change runtime type নির্বাচন করুন এবং তারপর TPU নির্বাচন করুন। এই কোড ল্যাবে আপনি হার্ডওয়্যার-ত্বরিত প্রশিক্ষণের জন্য একটি শক্তিশালী TPU (টেনসর প্রসেসিং ইউনিট) ব্যবহার করবেন। প্রথমবার চালানোর সময় রানটাইমের সাথে সংযোগ স্বয়ংক্রিয়ভাবে হয়ে যাবে, অথবা আপনি উপরের-ডান কোণায় থাকা "Connect" বোতামটি ব্যবহার করতে পারেন।
নোটবুক সম্পাদন

একটি সেলে ক্লিক করে Shift-ENTER ব্যবহার করে সেলগুলো এক এক করে চালান। এছাড়াও, আপনি Runtime > Run all ব্যবহার করে সম্পূর্ণ নোটবুকটি চালাতে পারেন।
সূচিপত্র

সব নোটবুকেই একটি সূচিপত্র থাকে। বামদিকের কালো তীরচিহ্নটি ব্যবহার করে আপনি সেটি খুলতে পারেন।
লুকানো কোষ

কিছু সেলে শুধুমাত্র তাদের শিরোনাম দেখা যাবে। এটি কোলাব-এর একটি নোটবুক বৈশিষ্ট্য। ভেতরের কোড দেখার জন্য আপনি এগুলোর উপর ডাবল ক্লিক করতে পারেন, কিন্তু তা সাধারণত খুব একটা আকর্ষণীয় হয় না। এগুলো সাধারণত সাপোর্ট বা ভিজ্যুয়ালাইজেশন ফাংশন। ভেতরের ফাংশনগুলো সংজ্ঞায়িত করার জন্য আপনাকে এই সেলগুলো রান করতে হবে।
প্রমাণীকরণ

একটি অনুমোদিত অ্যাকাউন্ট দিয়ে প্রমাণীকরণ করলে কোলাব আপনার ব্যক্তিগত গুগল ক্লাউড স্টোরেজ বাকেটগুলো অ্যাক্সেস করতে পারবে। উপরের কোড স্নিপেটটি একটি প্রমাণীকরণ প্রক্রিয়া চালু করবে।
৩. [তথ্য] টেনসর প্রসেসিং ইউনিট (টিপিইউ) কী?
সংক্ষেপে

Keras-এ TPU-তে একটি মডেল প্রশিক্ষণের জন্য কোড (এবং TPU উপলব্ধ না থাকলে GPU বা CPU-তে ফিরে যাওয়ার জন্য):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
আজ আমরা টিপিইউ ব্যবহার করে ইন্টারেক্টিভ গতিতে (প্রতি ট্রেনিং রানে কয়েক মিনিট) একটি ফ্লাওয়ার ক্লাসিফায়ার তৈরি ও অপ্টিমাইজ করব।
টিপিইউ কেন?
আধুনিক জিপিইউগুলো প্রোগ্রামযোগ্য 'কোর'-এর উপর ভিত্তি করে গঠিত, যা একটি অত্যন্ত নমনীয় আর্কিটেকচার এবং এর ফলে এগুলো থ্রিডি রেন্ডারিং, ডিপ লার্নিং, ফিজিক্যাল সিমুলেশন ইত্যাদির মতো বিভিন্ন ধরনের কাজ সামলাতে পারে। অন্যদিকে, টিপিইউগুলো একটি ক্লাসিক ভেক্টর প্রসেসরের সাথে একটি ডেডিকেটেড ম্যাট্রিক্স মাল্টিপ্লাই ইউনিটকে যুক্ত করে এবং নিউরাল নেটওয়ার্কের মতো যেকোনো কাজে পারদর্শী, যেখানে বড় ম্যাট্রিক্সের গুণন প্রাধান্য পায়।

উদাহরণ: একটি ডেন্স নিউরাল নেটওয়ার্ক লেয়ারকে ম্যাট্রিক্স গুণন হিসেবে দেখানো হয়েছে, যেখানে নিউরাল নেটওয়ার্কের মাধ্যমে একবারে আটটি ছবির একটি ব্যাচ প্রসেস করা হয়। এটি যে সত্যিই একটি ছবির সমস্ত পিক্সেল মানের ওয়েটেড সাম (weighted sum) করছে, তা যাচাই করার জন্য অনুগ্রহ করে একটি লাইন x কলাম গুণন প্রক্রিয়াটি চালিয়ে দেখুন। কনভল্যুশনাল লেয়ারগুলোকেও ম্যাট্রিক্স গুণন হিসেবে উপস্থাপন করা যায়, যদিও বিষয়টি কিছুটা বেশি জটিল (এর ব্যাখ্যা এখানে, সেকশন ১-এ দেওয়া আছে )।
হার্ডওয়্যার
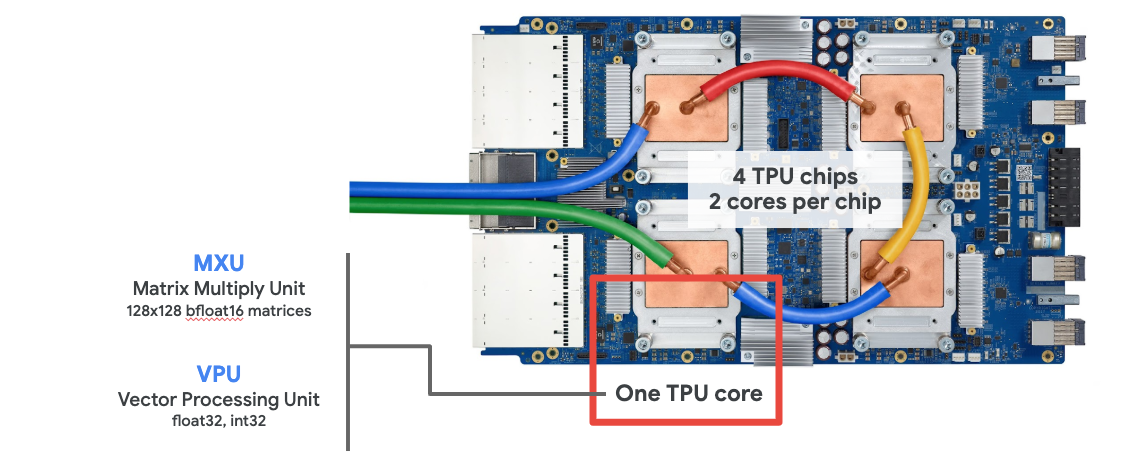
MXU এবং VPU
একটি TPU v2 কোর একটি ম্যাট্রিক্স মাল্টিপ্লাই ইউনিট (MXU) দ্বারা গঠিত, যা ম্যাট্রিক্স গুণন সম্পাদন করে, এবং একটি ভেক্টর প্রসেসিং ইউনিট (VPU) দ্বারা গঠিত, যা অ্যাক্টিভেশন, সফটম্যাক্স ইত্যাদির মতো অন্যান্য সমস্ত কাজ করে। VPU ফ্লোট৩২ এবং ইন্ট৩২ গণনা পরিচালনা করে। অন্যদিকে, MXU একটি মিশ্র প্রিসিশন ১৬-৩২ বিট ফ্লোটিং পয়েন্ট ফরম্যাটে কাজ করে।
মিশ্র প্রিসিশন ফ্লোটিং পয়েন্ট এবং বিফ্লোট১৬
এমএক্সইউ (MXU) বিফ্লোট১৬ (bfloat16) ইনপুট এবং ফ্লোট৩২ (float32) আউটপুট ব্যবহার করে ম্যাট্রিক্স গুণন গণনা করে। মধ্যবর্তী সঞ্চয়নগুলো ফ্লোট৩২ (float32) প্রিসিশনে সম্পাদিত হয়।
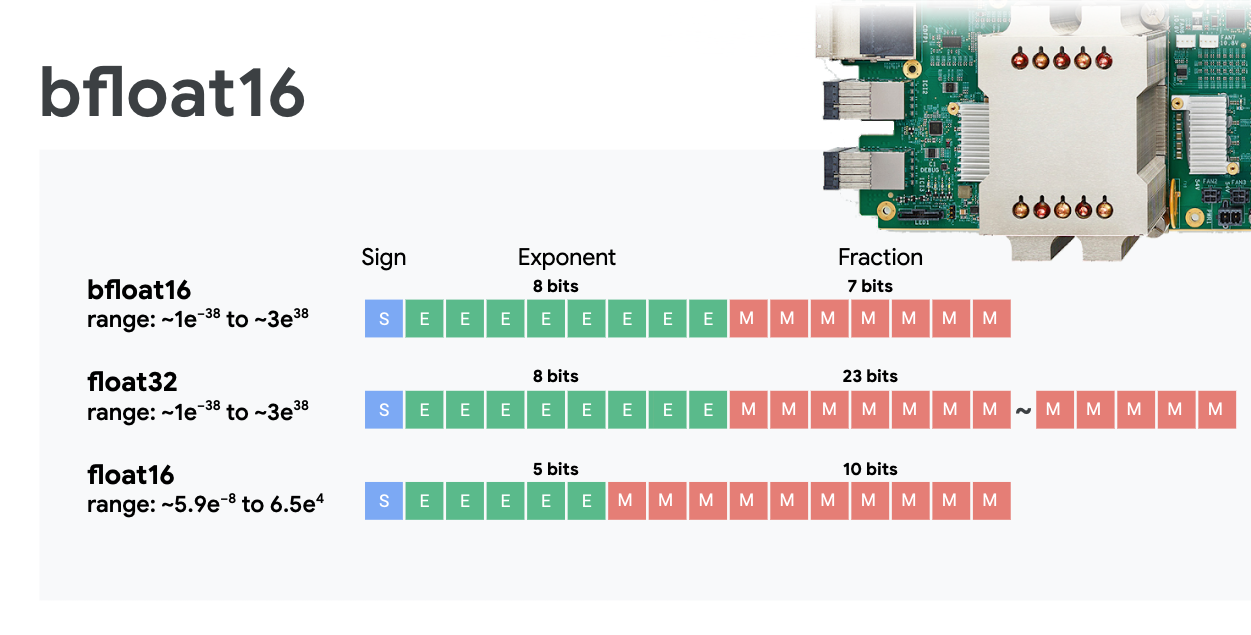
নিউরাল নেটওয়ার্ক প্রশিক্ষণ সাধারণত হ্রাসকৃত ফ্লোটিং পয়েন্ট প্রিসিশনের কারণে সৃষ্ট নয়েজের বিরুদ্ধে প্রতিরোধী। এমনও ক্ষেত্র আছে যেখানে নয়েজ এমনকি অপটিমাইজারকে কনভার্জ করতে সাহায্য করে। গণনার গতি বাড়ানোর জন্য ঐতিহ্যগতভাবে ১৬-বিট ফ্লোটিং পয়েন্ট প্রিসিশন ব্যবহার করা হয়েছে, কিন্তু float16 এবং float32 ফরম্যাটের রেঞ্জ খুব আলাদা। float32 থেকে float16-এ প্রিসিশন কমালে সাধারণত ওভারফ্লো এবং আন্ডারফ্লো হয়। এর সমাধান আছে, কিন্তু float16-কে কার্যকর করতে সাধারণত অতিরিক্ত কাজ করার প্রয়োজন হয়।
এই কারণেই গুগল টিপিইউ-তে বিফ্লোট১৬ (bfloat16) ফরম্যাট চালু করেছে। বিফ্লোট১৬ হলো ফ্লোট৩২-এর একটি সংক্ষিপ্ত রূপ, যার এক্সপোনেন্ট বিট এবং রেঞ্জ হুবহু ফ্লোট৩২-এর সমান। এর সাথে এই বিষয়টিও যুক্ত যে, টিপিইউ-গুলো বিফ্লোট১৬ ইনপুট কিন্তু ফ্লোট৩২ আউটপুট ব্যবহার করে মিক্সড প্রিসিশনে ম্যাট্রিক্স গুণন গণনা করে। এর ফলে, কম প্রিসিশনের কারণে প্রাপ্ত পারফরম্যান্সের সুবিধাগুলো পেতে সাধারণত কোডে কোনো পরিবর্তনের প্রয়োজন হয় না।
সিস্টোলিক অ্যারে
এমএক্সইউ (MXU) তথাকথিত "সিস্টোলিক অ্যারে" আর্কিটেকচার ব্যবহার করে হার্ডওয়্যারে ম্যাট্রিক্স গুণন বাস্তবায়ন করে, যেখানে ডেটা উপাদানগুলো হার্ডওয়্যার কম্পিউটেশন ইউনিটের একটি অ্যারের মধ্য দিয়ে প্রবাহিত হয়। (চিকিৎসাবিজ্ঞানে, "সিস্টোলিক" বলতে হৃৎপিণ্ডের সংকোচন এবং রক্ত প্রবাহকে বোঝায়, এবং এখানে এটি ডেটার প্রবাহকে বোঝায়।)
ম্যাট্রিক্স গুণনের মূল উপাদান হলো একটি ম্যাট্রিক্সের একটি সারি এবং অন্য ম্যাট্রিক্সের একটি কলামের মধ্যে ডট প্রোডাক্ট (এই বিভাগের শীর্ষে থাকা চিত্রটি দেখুন)। Y=X*W ম্যাট্রিক্স গুণনের ক্ষেত্রে, ফলাফলের একটি উপাদান হবে:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
একটি জিপিইউ-তে, এই ডট প্রোডাক্টটি একটি জিপিইউ "কোর"-এ প্রোগ্রাম করা হয় এবং তারপর ফলাফল ম্যাট্রিক্সের প্রতিটি মান একবারে গণনা করার জন্য উপলব্ধ যতগুলো "কোর" আছে, সেগুলোতে এটি চালানো হয়। যদি ফলাফল ম্যাট্রিক্সটি 128x128 আকারের হয়, তবে এর জন্য 128x128=16K "কোর" উপলব্ধ থাকার প্রয়োজন হবে, যা সাধারণত সম্ভব নয়। সবচেয়ে বড় জিপিইউ-গুলোতে প্রায় 4000 কোর থাকে। অন্যদিকে, একটি টিপিইউ তার এমএক্সইউ-এর কম্পিউট ইউনিটগুলোর জন্য ন্যূনতম হার্ডওয়্যার ব্যবহার করে: শুধু bfloat16 x bfloat16 => float32 মাল্টিপ্লাই-অ্যাকুমুলেটর, আর কিছু নয়। এগুলো এতটাই ছোট যে একটি টিপিইউ একটি 128x128 এমএক্সইউ-তে এগুলোর 16K ইমপ্লিমেন্ট করতে পারে এবং এই ম্যাট্রিক্স গুণনটি একবারে প্রক্রিয়া করতে পারে।

উদাহরণ: এমএক্সইউ সিস্টোলিক অ্যারে। এর কম্পিউট এলিমেন্টগুলো হলো মাল্টিপ্লাই-অ্যাকুমুলেটর। একটি ম্যাট্রিক্সের মানগুলো অ্যারেতে লোড করা হয় (লাল বিন্দু)। অন্য ম্যাট্রিক্সের মানগুলো অ্যারের মধ্য দিয়ে প্রবাহিত হয় (ধূসর বিন্দু)। উল্লম্ব রেখাগুলো মানগুলোকে উপরের দিকে সঞ্চারিত করে। আনুভূমিক রেখাগুলো আংশিক যোগফল সঞ্চারিত করে। ব্যবহারকারীর জন্য এটি একটি অনুশীলন হিসেবে রেখে দেওয়া হলো যে, ডেটা অ্যারের মধ্য দিয়ে প্রবাহিত হওয়ার সময় ম্যাট্রিক্স গুণফলের ফলাফলটি ডান দিক থেকে বেরিয়ে আসছে কি না, তা যাচাই করা।
এর পাশাপাশি, যখন একটি MXU-তে ডট প্রোডাক্ট গণনা করা হয়, তখন মধ্যবর্তী যোগফলগুলো কেবল পাশাপাশি থাকা কম্পিউট ইউনিটগুলোর মধ্যে প্রবাহিত হয়। এগুলোকে মেমোরি বা এমনকি কোনো রেজিস্টার ফাইলে সংরক্ষণ বা সেখান থেকে পুনরুদ্ধার করার প্রয়োজন হয় না। এর ফলে, ম্যাট্রিক্স গুণন গণনার ক্ষেত্রে TPU সিস্টোলিক অ্যারে আর্কিটেকচারটি GPU-এর তুলনায় ঘনত্ব ও শক্তির দিক থেকে উল্লেখযোগ্য সুবিধা দেয়, এবং সেই সাথে এর গতিও নগণ্য নয়।
ক্লাউড টিপিইউ
যখন আপনি গুগল ক্লাউড প্ল্যাটফর্মে একটি " ক্লাউড টিপিইউ ভি২" এর জন্য অনুরোধ করেন, তখন আপনি একটি ভার্চুয়াল মেশিন (ভিএম) পান, যেটিতে একটি পিসিআই-সংযুক্ত টিপিইউ বোর্ড থাকে। টিপিইউ বোর্ডটিতে চারটি ডুয়াল-কোর টিপিইউ চিপ থাকে। প্রতিটি টিপিইউ কোরে একটি ভিপিইউ (ভেক্টর প্রসেসিং ইউনিট) এবং একটি ১২৮x১২৮ এমএক্সইউ (ম্যাট্রিক্স মাল্টিপ্লাই ইউনিট) থাকে। এরপর এই "ক্লাউড টিপিইউ" সাধারণত নেটওয়ার্কের মাধ্যমে সেই ভিএম-এর সাথে সংযুক্ত হয়, যেটি এটির জন্য অনুরোধ করেছিল। সুতরাং, সম্পূর্ণ চিত্রটি দেখতে এইরকম:
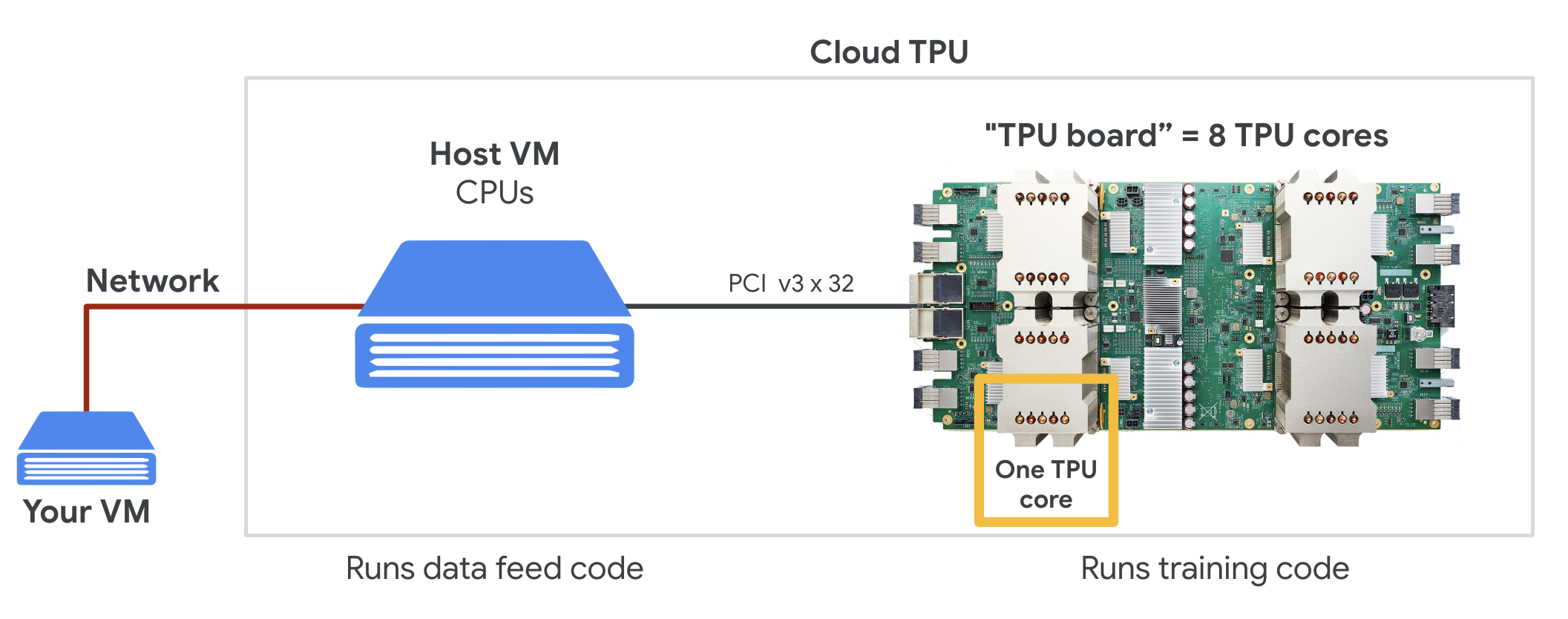
উদাহরণ: নেটওয়ার্ক-সংযুক্ত 'ক্লাউড টিপিইউ' অ্যাক্সেলারেটরসহ আপনার ভিএম। 'ক্লাউড টিপিইউ' নিজেই একটি ভিএম দিয়ে তৈরি, যার সাথে একটি পিসিআই-সংযুক্ত টিপিইউ বোর্ড রয়েছে এবং এতে চারটি ডুয়াল-কোর টিপিইউ চিপ আছে।
টিপিইউ পড
গুগলের ডেটা সেন্টারগুলিতে, টিপিইউ-গুলি একটি হাই-পারফরম্যান্স কম্পিউটিং (এইচপিসি) ইন্টারকানেক্টের সাথে সংযুক্ত থাকে, যা সেগুলিকে একটি বিশাল অ্যাক্সিলারেটর হিসাবে উপস্থাপন করতে পারে। গুগল এগুলিকে 'পড' বলে এবং এগুলিতে সর্বোচ্চ ৫১২টি টিপিইউ ভি২ কোর বা ২০৪৮টি টিপিইউ ভি৩ কোর থাকতে পারে।

উদাহরণ: একটি TPU v3 পড। TPU বোর্ড এবং র্যাকগুলো HPC ইন্টারকানেক্টের মাধ্যমে সংযুক্ত।
প্রশিক্ষণের সময়, অল-রিডিউস অ্যালগরিদম ব্যবহার করে টিপিইউ কোরগুলোর মধ্যে গ্রেডিয়েন্ট বিনিময় করা হয় ( অল-রিডিউস সম্পর্কে এখানে একটি ভালো ব্যাখ্যা রয়েছে )। প্রশিক্ষণাধীন মডেলটি বড় ব্যাচ সাইজে প্রশিক্ষণ নিয়ে হার্ডওয়্যারের সুবিধা নিতে পারে।

দৃষ্টান্ত: গুগল টিপিইউ-এর দ্বি-মাত্রিক টরয়েডাল মেশ এইচপিসি নেটওয়ার্কে অল-রিডিউস অ্যালগরিদম ব্যবহার করে প্রশিক্ষণের সময় গ্রেডিয়েন্টের সিঙ্ক্রোনাইজেশন।
সফটওয়্যারটি
বড় ব্যাচের প্রশিক্ষণ
টিপিইউ-এর জন্য আদর্শ ব্যাচ সাইজ হলো প্রতি টিপিইউ কোরে ১২৮টি ডেটা আইটেম, কিন্তু হার্ডওয়্যারটি প্রতি টিপিইউ কোরে ৮টি ডেটা আইটেম থেকেই ভালো ইউটিলাইজেশন দেখাতে পারে। মনে রাখবেন যে একটি ক্লাউড টিপিইউ-তে ৮টি কোর থাকে।
এই কোড ল্যাবে আমরা কেরাস এপিআই (Keras API) ব্যবহার করব। কেরাসে, আপনার নির্দিষ্ট করা ব্যাচটি হলো পুরো টিপিইউ (TPU)-এর জন্য গ্লোবাল ব্যাচ সাইজ। আপনার ব্যাচগুলো স্বয়ংক্রিয়ভাবে ৮ ভাগে বিভক্ত হয়ে টিপিইউ-এর ৮টি কোরে রান করবে।

অতিরিক্ত পারফরম্যান্স টিপসের জন্য টিপিইউ পারফরম্যান্স গাইড দেখুন। খুব বড় ব্যাচ সাইজের ক্ষেত্রে, কিছু মডেলে বিশেষ যত্নের প্রয়োজন হতে পারে, আরও বিস্তারিত জানতে LARSOptimizer দেখুন।
ভেতরে: XLA
Tensorflow প্রোগ্রামগুলো কম্পিউটেশন গ্রাফ নির্ধারণ করে। TPU সরাসরি পাইথন কোড চালায় না, এটি আপনার Tensorflow প্রোগ্রাম দ্বারা নির্ধারিত কম্পিউটেশন গ্রাফটি চালায়। নেপথ্যে, XLA (অ্যাক্সিলারেটেড লিনিয়ার অ্যালজেব্রা কম্পাইলার) নামক একটি কম্পাইলার Tensorflow-এর কম্পিউটেশন নোডগুলোর গ্রাফকে TPU মেশিন কোডে রূপান্তরিত করে। এই কম্পাইলারটি আপনার কোড এবং মেমরি লেআউটের উপর অনেক উন্নত অপটিমাইজেশনও সম্পাদন করে। TPU-তে কাজ পাঠানোর সাথে সাথে কম্পাইলেশনটি স্বয়ংক্রিয়ভাবে সম্পন্ন হয়। আপনাকে আপনার বিল্ড চেইনে স্পষ্টভাবে XLA অন্তর্ভুক্ত করতে হবে না।

উদাহরণস্বরূপ: TPU-তে চালানোর জন্য, আপনার Tensorflow প্রোগ্রাম দ্বারা সংজ্ঞায়িত কম্পিউটেশন গ্রাফটিকে প্রথমে একটি XLA (অ্যাক্সিলারেটেড লিনিয়ার অ্যালজেব্রা কম্পাইলার) উপস্থাপনায় রূপান্তরিত করা হয়, এবং তারপর XLA দ্বারা কম্পাইল করে TPU মেশিন কোডে পরিণত করা হয়।
কেরাসে টিপিইউ ব্যবহার
Tensorflow 2.1 থেকে Keras API-এর মাধ্যমে TPU সমর্থিত। Keras সাপোর্ট TPU এবং TPU পড-এ কাজ করে। এখানে একটি উদাহরণ দেওয়া হলো যা TPU, GPU এবং CPU-তে কাজ করে:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
এই কোড স্নিপেটে:
-
TPUClusterResolver().connect()নেটওয়ার্কে TPU খুঁজে বের করে। এটি বেশিরভাগ গুগল ক্লাউড সিস্টেমে (AI Platform jobs, Colaboratory, Kubeflow, 'ctpu up' ইউটিলিটির মাধ্যমে তৈরি Deep Learning VM) কোনো প্যারামিটার ছাড়াই কাজ করে। এই সিস্টেমগুলো একটি TPU_NAME এনভায়রনমেন্ট ভেরিয়েবলের মাধ্যমে জানে তাদের TPU কোথায় আছে। আপনি যদি নিজে থেকে একটি TPU তৈরি করেন, তাহলে যে VM থেকে এটি ব্যবহার করছেন সেখানে TPU_NAME এনভায়রনমেন্ট ভেরিয়েবলটি সেট করুন, অথবা সুস্পষ্ট প্যারামিটারসহTPUClusterResolverকল করুন:TPUClusterResolver(tp_uname, zone, project) -
TPUStrategyহলো সেই অংশ যা ডিস্ট্রিবিউশন এবং "অল-রিডিউস" গ্রেডিয়েন্ট সিনক্রোনাইজেশন অ্যালগরিদম বাস্তবায়ন করে। - কৌশলটি একটি স্কোপের মাধ্যমে প্রয়োগ করা হয়। মডেলটিকে অবশ্যই কৌশলের স্কোপ()-এর মধ্যে সংজ্ঞায়িত করতে হবে।
- TPU প্রশিক্ষণের জন্য ইনপুট হিসেবে
tpu_model.fitফাংশনটি একটি tf.data.Dataset অবজেক্ট গ্রহণ করে।
সাধারণ TPU পোর্টিং টাস্ক
- টেনসরফ্লো মডেলে ডেটা লোড করার অনেক উপায় থাকলেও, টিপিইউ-এর জন্য
tf.data.DatasetAPI-এর ব্যবহার আবশ্যক। - টিপিইউগুলো খুব দ্রুতগতির এবং এগুলোতে চলার সময় ডেটা গ্রহণ করা প্রায়শই একটি প্রতিবন্ধকতা হয়ে দাঁড়ায়। ডেটার প্রতিবন্ধকতা শনাক্ত করার জন্য আপনি বিভিন্ন টুল ব্যবহার করতে পারেন এবং টিপিইউ পারফরম্যান্স গাইডে অন্যান্য পারফরম্যান্স টিপসও রয়েছে।
- int8 বা int16 সংখ্যাগুলোকে int32 হিসেবে গণ্য করা হয়। TPU-তে ৩২ বিটের কম বিটে কাজ করার মতো কোনো ইন্টিজার হার্ডওয়্যার নেই।
- কিছু টেনসরফ্লো অপারেশন সমর্থিত নয়। তালিকাটি এখানে দেওয়া আছে । সুখবর হলো, এই সীমাবদ্ধতা শুধুমাত্র ট্রেনিং কোডের ক্ষেত্রে প্রযোজ্য, অর্থাৎ আপনার মডেলের ফরোয়ার্ড এবং ব্যাকওয়ার্ড পাসের ক্ষেত্রে। আপনি আপনার ডেটা ইনপুট পাইপলাইনে সমস্ত টেনসরফ্লো অপারেশন ব্যবহার করতে পারবেন, কারণ এটি সিপিইউ-তে এক্সিকিউট হবে।
-
tf.py_funcটিপিইউ-তে সমর্থিত নয়।
৪. ডেটা লোড করা






আমরা ফুলের ছবির একটি ডেটাসেট নিয়ে কাজ করব। এর লক্ষ্য হলো ছবিগুলোকে ৫টি ফুলের ধরনে ভাগ করতে শেখা। tf.data.Dataset API ব্যবহার করে ডেটা লোড করা হয়। প্রথমে, চলুন API-টি সম্পর্কে জেনে নেওয়া যাক।
হাতে-কলমে
অনুগ্রহ করে নিম্নলিখিত নোটবুকটি খুলুন, সেলগুলো এক্সিকিউট করুন (Shift-ENTER) এবং যেখানেই "WORK REQUIRED" লেবেল দেখবেন, সেখানকার নির্দেশাবলী অনুসরণ করুন।

Fun with tf.data.Dataset (playground).ipynb
অতিরিক্ত তথ্য
'ফুল' ডেটাসেট সম্পর্কে
ডেটা সেটটি ৫টি ফোল্ডারে সাজানো আছে। প্রতিটি ফোল্ডারে এক ধরনের ফুল রয়েছে। ফোল্ডারগুলোর নাম হলো সূর্যমুখী, ডেইজি, ড্যান্ডেলিয়ন, টিউলিপ এবং গোলাপ। ডেটাটি গুগল ক্লাউড স্টোরেজের একটি পাবলিক বাকেটে হোস্ট করা আছে। উদ্ধৃতাংশ:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
tf.data.Dataset কেন?
Keras এবং Tensorflow তাদের সমস্ত প্রশিক্ষণ এবং মূল্যায়ন ফাংশনে ডেটাসেট গ্রহণ করে। একবার আপনি একটি ডেটাসেটে ডেটা লোড করলে, এপিআইটি নিউরাল নেটওয়ার্ক প্রশিক্ষণ ডেটার জন্য উপযোগী সমস্ত সাধারণ কার্যকারিতা প্রদান করে:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
এই আর্টিকেলটিতে আপনি পারফরম্যান্স টিপস এবং ডেটাসেটের সেরা অনুশীলনগুলো খুঁজে পাবেন। রেফারেন্স ডকুমেন্টেশনটি এখানে রয়েছে।
tf.data.Dataset এর প্রাথমিক বিষয়সমূহ
ডেটা সাধারণত একাধিক ফাইলে আসে, এখানে ছবিগুলো। নিম্নলিখিত কমান্ডটি ব্যবহার করে আপনি ফাইলের নামগুলোর একটি ডেটাসেট তৈরি করতে পারেন:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
এরপর আপনি প্রতিটি ফাইলের নামের সাথে একটি ফাংশন "ম্যাপ" করেন, যেটি সাধারণত ফাইলটিকে লোড ও ডিকোড করে মেমরিতে প্রকৃত ডেটাতে রূপান্তর করে:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
একটি ডেটাসেটে পুনরাবৃত্তি করতে:
for data in my_dataset:
print(data)
টাপলের ডেটাসেট
সুপারভাইজড লার্নিং-এ, একটি ট্রেনিং ডেটাসেট সাধারণত ট্রেনিং ডেটা এবং সঠিক উত্তরের জোড়া দিয়ে তৈরি হয়। এটি সম্ভব করার জন্য, ডিকোডিং ফাংশনটি টাপল রিটার্ন করতে পারে। এর ফলে আপনার কাছে টাপলের একটি ডেটাসেট থাকবে এবং আপনি যখন এটিতে ইটারেট করবেন, তখন টাপল রিটার্ন হবে। রিটার্ন করা ভ্যালুগুলো হলো টেনসরফ্লো টেনসর, যা আপনার মডেল ব্যবহারের জন্য প্রস্তুত। র ভ্যালুগুলো দেখার জন্য আপনি এগুলোর উপর .numpy() কল করতে পারেন।
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
উপসংহার: একটি একটি করে ছবি লোড করা ধীরগতির!
আপনি যখন এই ডেটাসেটটি নিয়ে কাজ করবেন, তখন দেখবেন যে প্রতি সেকেন্ডে মাত্র ১-২টির মতো ছবি লোড হচ্ছে। এটা খুবই ধীর! আমরা প্রশিক্ষণের জন্য যে হার্ডওয়্যার অ্যাক্সিলারেটরগুলো ব্যবহার করব, সেগুলো এই হারের চেয়ে অনেক গুণ বেশি গতিতে কাজ করতে পারে। আমরা কীভাবে এটি অর্জন করব তা জানতে পরবর্তী বিভাগে যান।
সমাধান
এই হলো সমাধান নোটবুক। কোথাও আটকে গেলে এটি ব্যবহার করতে পারেন।
Fun with tf.data.Dataset (solution).ipynb
আমরা যা আলোচনা করেছি
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 টাপলের ডেটাসেট
- 😀 ডেটাসেটগুলির মধ্যে পুনরাবৃত্তি করা
অনুগ্রহ করে এক মুহূর্ত সময় নিয়ে মনে মনে এই চেকলিস্টটি একবার দেখে নিন।
৫. দ্রুত ডেটা লোড করা
এই ল্যাবে আমরা যে টেনসর প্রসেসিং ইউনিট (TPU) হার্ডওয়্যার অ্যাক্সিলারেটরগুলো ব্যবহার করব, সেগুলো খুব দ্রুতগতির। প্রায়শই চ্যালেঞ্জটি হলো সেগুলোকে ব্যস্ত রাখার জন্য যথেষ্ট দ্রুত গতিতে ডেটা সরবরাহ করা। গুগল ক্লাউড স্টোরেজ (GCS) খুব উচ্চ থ্রুপুট বজায় রাখতে সক্ষম, কিন্তু সমস্ত ক্লাউড স্টোরেজ সিস্টেমের মতোই, একটি সংযোগ স্থাপন করতে কিছুটা নেটওয়ার্ক আদান-প্রদানের প্রয়োজন হয়। তাই, আমাদের ডেটা হাজার হাজার স্বতন্ত্র ফাইল হিসেবে সংরক্ষণ করা আদর্শ নয়। আমরা সেগুলোকে অল্প সংখ্যক ফাইলে ব্যাচ করব এবং সমান্তরালভাবে একাধিক ফাইল থেকে ডেটা পড়ার জন্য tf.data.Dataset-এর ক্ষমতা ব্যবহার করব।
রিড-থ্রু
যে কোডটি ইমেজ ফাইল লোড করে, সেগুলোকে একটি সাধারণ আকারে রিসাইজ করে এবং তারপর ১৬টি TFRecord ফাইলে সংরক্ষণ করে, তা নিম্নলিখিত নোটবুকে রয়েছে। অনুগ্রহ করে এটি দ্রুত পড়ে নিন। এটি চালানো আবশ্যক নয়, কারণ কোডল্যাবের বাকি অংশের জন্য যথাযথভাবে TFRecord-ফরম্যাট করা ডেটা সরবরাহ করা হবে।
Flower pictures to TFRecords.ipynb
সর্বোত্তম GCS থ্রুপুটের জন্য আদর্শ ডেটা বিন্যাস
TFRecord ফাইল ফরম্যাট
ডেটা সংরক্ষণের জন্য টেনসরফ্লো-এর পছন্দের ফাইল ফরম্যাট হলো প্রোটোবাফ -ভিত্তিক TFRecord ফরম্যাট। অন্যান্য সিরিয়ালাইজেশন ফরম্যাটও কাজ করবে, কিন্তু আপনি সরাসরি TFRecord ফাইল থেকে ডেটাসেট লোড করতে পারেন এভাবে লিখে:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
সর্বোত্তম পারফরম্যান্সের জন্য, একই সাথে একাধিক TFRecord ফাইল থেকে ডেটা পড়ার জন্য নিম্নলিখিত আরও জটিল কোডটি ব্যবহার করার পরামর্শ দেওয়া হচ্ছে। এই কোডটি সমান্তরালভাবে N সংখ্যক ফাইল থেকে ডেটা পড়বে এবং পড়ার গতি বাড়ানোর জন্য ডেটার ক্রম উপেক্ষা করবে।
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
টিএফরেকর্ড চিট শিট
TFRecords-এ তিন ধরনের ডেটা সংরক্ষণ করা যায়: বাইট স্ট্রিং (বাইটের তালিকা), ৬৪-বিট পূর্ণসংখ্যা এবং ৩২-বিট ফ্লোট । এগুলো সর্বদা তালিকা হিসেবে সংরক্ষিত হয় এবং প্রতিটি ডেটা উপাদানের আকার হবে ১। TFRecords-এ ডেটা সংরক্ষণ করার জন্য আপনি নিম্নলিখিত সহায়ক ফাংশনগুলো ব্যবহার করতে পারেন।
বাইট স্ট্রিং লেখা
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
পূর্ণসংখ্যা লেখা
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
লেখা ভেসে ওঠে
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
উপরের হেল্পারগুলো ব্যবহার করে একটি TFRecord লেখা ।
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
TFRecords থেকে ডেটা পড়ার জন্য, আপনাকে প্রথমে আপনার সংরক্ষিত রেকর্ডগুলোর লেআউট ঘোষণা করতে হবে। এই ঘোষণার সময়, আপনি যেকোনো নামযুক্ত ফিল্ডকে একটি নির্দিষ্ট দৈর্ঘ্যের তালিকা বা একটি পরিবর্তনশীল দৈর্ঘ্যের তালিকা হিসাবে অ্যাক্সেস করতে পারেন:
টিএফরেকর্ডস থেকে পড়া
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
দরকারী কোড স্নিপেট:
একক ডেটা উপাদান পড়া
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
নির্দিষ্ট আকারের উপাদানের তালিকা পড়া
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
পরিবর্তনশীল সংখ্যক ডেটা আইটেম পড়া হচ্ছে
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
একটি VarLenFeature একটি স্পার্স ভেক্টর রিটার্ন করে এবং TFRecord ডিকোড করার পর একটি অতিরিক্ত ধাপের প্রয়োজন হয়:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
TFRecords-এ ঐচ্ছিক ফিল্ড রাখাও সম্ভব। কোনো ফিল্ড পড়ার সময় যদি আপনি একটি ডিফল্ট মান নির্দিষ্ট করে দেন, তাহলে ফিল্ডটি অনুপস্থিত থাকলে ত্রুটির পরিবর্তে সেই ডিফল্ট মানটিই ফেরত দেওয়া হয়।
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
আমরা যা আলোচনা করেছি
- 🤔 GCS থেকে দ্রুত অ্যাক্সেসের জন্য ডেটা ফাইল শার্ডিং করা হচ্ছে
- 😓 কিভাবে TFRecords লিখতে হয়। (আপনি কি এরই মধ্যে সিনট্যাক্স ভুলে গেছেন? কোনো সমস্যা নেই, এই পৃষ্ঠাটি একটি চিট শিট হিসেবে বুকমার্ক করে রাখুন)
- 🤔 TFRecordDataset ব্যবহার করে TFRecords থেকে একটি ডেটাসেট লোড করা হচ্ছে
অনুগ্রহ করে এক মুহূর্ত সময় নিয়ে মনে মনে এই চেকলিস্টটি একবার দেখে নিন।
৬. অভিনন্দন!
আপনি এখন একটি টিপিইউ-তে ডেটা সরবরাহ করতে পারেন। অনুগ্রহ করে পরবর্তী ল্যাবে যান।
- [এই ল্যাব] টিপিইউ-গতির ডেটা পাইপলাইন: tf.data.Dataset এবং TFRecords
- ট্রান্সফার লার্নিং সহ আপনার প্রথম কেরাস মডেল
- কেরাস এবং টিপিইউ সহ কনভল্যুশনাল নিউরাল নেটওয়ার্ক
- আধুনিক কনভনেট, স্কুইজনেট, এক্সসেপশন, কেরাস এবং টিপিইউ সহ
বাস্তবে টিপিইউ
ক্লাউড এআই প্ল্যাটফর্মে টিপিইউ এবং জিপিইউ উপলব্ধ আছে:
সবশেষে, আমরা মতামতকে স্বাগত জানাই। এই ল্যাবে কোনো ভুল দেখলে বা এর উন্নতি প্রয়োজন বলে মনে করলে, অনুগ্রহ করে আমাদের জানান। GitHub ইস্যুর মাধ্যমে মতামত দেওয়া যাবে [ মতামত লিঙ্ক ]।

|
|

