
1. 總覽

開發人員可透過 Text-to-Speech API 生成類似人類的語音。這項 API 會將文字轉換為 WAV、MP3 或 Ogg Opus 等音訊格式。此外,這項服務也支援語音合成標記語言 (SSML) 輸入內容,可指定停頓點、數字、日期與時間格式設定,以及其他發音指示。
在本教學課程中,您將著重於使用 Python 搭配 Text-to-Speech API。
課程內容
- 如何設定環境
- 如何列出支援的語言
- 如何列出可用語音
- 如何從文字合成音訊
軟硬體需求
問卷調查
您會如何使用本教學課程?
你對 Python 的使用體驗如何?
你對 Google Cloud 服務的體驗滿意嗎?
2. 設定和需求條件
自修實驗室環境設定
- 登入 Google Cloud 控制台,然後建立新專案或重複使用現有專案。如果沒有 Gmail 或 Google Workspace 帳戶,請先建立帳戶。



- 專案名稱是這個專案參與者的顯示名稱。這是 Google API 未使用的字元字串。你隨時可以更新。
- 專案 ID 在所有 Google Cloud 專案中都是不重複的,而且設定後即無法變更。Cloud 控制台會自動產生專屬字串,通常您不需要在意該字串為何。在大多數程式碼研究室中,您需要參照專案 ID (通常標示為
PROJECT_ID)。如果您不喜歡產生的 ID,可以產生另一個隨機 ID。你也可以嘗試使用自己的名稱,看看是否可用。完成這個步驟後就無法變更,且專案期間會維持不變。 - 請注意,有些 API 會使用第三個值,也就是「專案編號」。如要進一步瞭解這三種值,請參閱說明文件。
- 接著,您需要在 Cloud 控制台中啟用帳單,才能使用 Cloud 資源/API。完成這個程式碼研究室的費用不高,甚至可能完全免費。如要關閉資源,避免在本教學課程結束後繼續產生費用,請刪除您建立的資源或專案。Google Cloud 新使用者可參加價值$300 美元的免費試用計畫。
啟動 Cloud Shell
雖然您可以透過筆電遠端操作 Google Cloud,但在本程式碼研究室中,您將使用 Cloud Shell,這是 Cloud 中執行的指令列環境。
啟用 Cloud Shell
- 在 Cloud 控制台,點選「啟用 Cloud Shell」 圖示
 。
。

如果您是首次啟動 Cloud Shell,系統會顯示中繼畫面,說明這個指令列環境。如果出現中繼畫面,請按一下「繼續」。
佈建並連至 Cloud Shell 預計只需要幾分鐘。

這部虛擬機器已載入所有必要的開發工具,並提供永久的 5 GB 主目錄,而且可在 Google Cloud 運作,大幅提升網路效能並強化驗證功能。本程式碼研究室幾乎所有工作都可在瀏覽器上完成。
連至 Cloud Shell 後,您應該會看到驗證已完成,專案也已設為獲派的專案 ID。
- 在 Cloud Shell 中執行下列指令,確認您已通過驗證:
gcloud auth list
指令輸出
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- 在 Cloud Shell 中執行下列指令,確認 gcloud 指令知道您的專案:
gcloud config list project
指令輸出
[core] project = <PROJECT_ID>
如未設定,請輸入下列指令手動設定專案:
gcloud config set project <PROJECT_ID>
指令輸出
Updated property [core/project].
3. 環境設定
如要開始使用 Text-to-Speech API,請先在 Cloud Shell 中執行下列指令,啟用 API:
gcloud services enable texttospeech.googleapis.com
畫面應如下所示:
Operation "operations/..." finished successfully.
現在您可以使用 Text-to-Speech API 了!
前往主目錄:
cd ~
建立 Python 虛擬環境,隔離依附元件:
virtualenv venv-texttospeech
啟動虛擬環境:
source venv-texttospeech/bin/activate
安裝 IPython 和 Text-to-Speech API 用戶端程式庫:
pip install ipython google-cloud-texttospeech
畫面應如下所示:
... Installing collected packages: ..., ipython, google-cloud-texttospeech Successfully installed ... google-cloud-texttospeech-2.16.3 ...
現在,您可以使用 Text-to-Speech API 用戶端程式庫了!
在接下來的步驟中,您會使用名為 IPython 的互動式 Python 解譯器,這個解譯器已在先前的步驟中安裝。在 Cloud Shell 中執行 ipython,啟動工作階段:
ipython
畫面應如下所示:
Python 3.9.2 (default, Feb 28 2021, 17:03:44) Type 'copyright', 'credits' or 'license' for more information IPython 8.18.1 -- An enhanced Interactive Python. Type '?' for help. In [1]:
您已準備好發出第一個要求,並列出支援的語言...
4. 列出支援的語言
本節會列出所有支援的語言。
將下列程式碼複製到 IPython 工作階段:
from typing import Sequence
import google.cloud.texttospeech as tts
def unique_languages_from_voices(voices: Sequence[tts.Voice]):
language_set = set()
for voice in voices:
for language_code in voice.language_codes:
language_set.add(language_code)
return language_set
def list_languages():
client = tts.TextToSpeechClient()
response = client.list_voices()
languages = unique_languages_from_voices(response.voices)
print(f" Languages: {len(languages)} ".center(60, "-"))
for i, language in enumerate(sorted(languages)):
print(f"{language:>10}", end="\n" if i % 5 == 4 else "")
請花點時間研究程式碼,瞭解如何使用 list_voices 用戶端程式庫方法建構支援語言清單。
呼叫函式:
list_languages()
您應該會看到下列 (或更多) 清單:
---------------------- Languages: 58 -----------------------
af-ZA am-ET ar-XA bg-BG bn-IN
ca-ES cmn-CN cmn-TW cs-CZ da-DK
de-DE el-GR en-AU en-GB en-IN
en-US es-ES es-US eu-ES fi-FI
fil-PH fr-CA fr-FR gl-ES gu-IN
he-IL hi-IN hu-HU id-ID is-IS
it-IT ja-JP kn-IN ko-KR lt-LT
lv-LV ml-IN mr-IN ms-MY nb-NO
nl-BE nl-NL pa-IN pl-PL pt-BR
pt-PT ro-RO ru-RU sk-SK sr-RS
sv-SE ta-IN te-IN th-TH tr-TR
uk-UA vi-VN yue-HK
清單會顯示 58 種語言和方言,例如:
- 中文和臺灣華語
- 澳洲、英國、印度和美國的英文,
- 加拿大和法國的法文,
- 巴西和葡萄牙的葡萄牙文。
這份清單會隨著新語音推出而擴增。
摘要
這個步驟可讓你列出支援的語言。
5. 列出可用語音
本節會列出不同語言可用的語音。
將下列程式碼複製到 IPython 工作階段:
import google.cloud.texttospeech as tts
def list_voices(language_code=None):
client = tts.TextToSpeechClient()
response = client.list_voices(language_code=language_code)
voices = sorted(response.voices, key=lambda voice: voice.name)
print(f" Voices: {len(voices)} ".center(60, "-"))
for voice in voices:
languages = ", ".join(voice.language_codes)
name = voice.name
gender = tts.SsmlVoiceGender(voice.ssml_gender).name
rate = voice.natural_sample_rate_hertz
print(f"{languages:<8} | {name:<24} | {gender:<8} | {rate:,} Hz")
請花點時間研究程式碼,瞭解如何使用用戶端程式庫方法 list_voices(language_code) 列出特定語言適用的語音。
現在,請取得可用的德文語音清單:
list_voices("de")
畫面應如下所示:
------------------------ Voices: 20 ------------------------ de-DE | de-DE-Neural2-A | FEMALE | 24,000 Hz de-DE | de-DE-Neural2-B | MALE | 24,000 Hz ... de-DE | de-DE-Standard-A | FEMALE | 24,000 Hz de-DE | de-DE-Standard-B | MALE | 24,000 Hz ... de-DE | de-DE-Studio-B | MALE | 24,000 Hz de-DE | de-DE-Studio-C | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-A | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-B | MALE | 24,000 Hz ...
提供多種男女聲音,以及標準、WaveNet、Neural2 和 Studio 聲音:
- 標準語音是由訊號處理演算法生成。
- WaveNet、Neural2 和 Studio 語音是由機器學習模型合成,音質較高,聽起來更自然。
現在,請取得可用的英文語音清單:
list_voices("en")
您應該會看到如下內容:
------------------------ Voices: 90 ------------------------ en-AU | en-AU-Neural2-A | FEMALE | 24,000 Hz ... en-AU | en-AU-Wavenet-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Neural2-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Wavenet-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Standard-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Wavenet-A | FEMALE | 24,000 Hz ... en-US | en-US-Neural2-A | MALE | 24,000 Hz ... en-US | en-US-News-K | FEMALE | 24,000 Hz ... en-US | en-US-Standard-A | MALE | 24,000 Hz ... en-US | en-US-Studio-M | MALE | 24,000 Hz ... en-US | en-US-Wavenet-A | MALE | 24,000 Hz ...
除了提供多種不同性別和音質的聲音外,還支援多種口音,包括澳洲、英國、印度和美國英語。
請花點時間列出偏好語言和變體 (或所有語言和變體) 適用的語音:
list_voices("fr")
list_voices("pt")
list_voices()
摘要
這個步驟可讓您列出可用的語音。進一步瞭解支援的語音和語言。
6. 從文字合成音訊
您可以使用 Text-to-Speech API 將字串轉換為音訊資料。您可以透過各種方式設定語音合成的輸出,包括選取不重複的語音或調節輸出的音調、音量、說話速度和取樣率。
將下列程式碼複製到 IPython 工作階段:
import google.cloud.texttospeech as tts
def text_to_wav(voice_name: str, text: str):
language_code = "-".join(voice_name.split("-")[:2])
text_input = tts.SynthesisInput(text=text)
voice_params = tts.VoiceSelectionParams(
language_code=language_code, name=voice_name
)
audio_config = tts.AudioConfig(audio_encoding=tts.AudioEncoding.LINEAR16)
client = tts.TextToSpeechClient()
response = client.synthesize_speech(
input=text_input,
voice=voice_params,
audio_config=audio_config,
)
filename = f"{voice_name}.wav"
with open(filename, "wb") as out:
out.write(response.audio_content)
print(f'Generated speech saved to "{filename}"')
請花點時間研究程式碼,瞭解如何使用 synthesize_speech 用戶端程式庫方法產生音訊資料,並儲存為 wav 檔案。
現在,你可以用幾種不同的口音生成句子:
text_to_wav("en-AU-Neural2-A", "What is the temperature in Sydney?")
text_to_wav("en-GB-Neural2-B", "What is the temperature in London?")
text_to_wav("en-IN-Wavenet-C", "What is the temperature in Delhi?")
text_to_wav("en-US-Studio-O", "What is the temperature in New York?")
text_to_wav("fr-FR-Neural2-A", "Quelle est la température à Paris ?")
text_to_wav("fr-CA-Neural2-B", "Quelle est la température à Montréal ?")
畫面應如下所示:
Generated speech saved to "en-AU-Neural2-A.wav" Generated speech saved to "en-GB-Neural2-B.wav" Generated speech saved to "en-IN-Wavenet-C.wav" Generated speech saved to "en-US-Studio-O.wav" Generated speech saved to "fr-FR-Neural2-A.wav" Generated speech saved to "fr-CA-Neural2-B.wav"
如要一次下載所有產生的檔案,可以在 Python 環境中使用下列 Cloud Shell 指令:
!cloudshell download *.wav
驗證完成後,瀏覽器就會下載檔案:
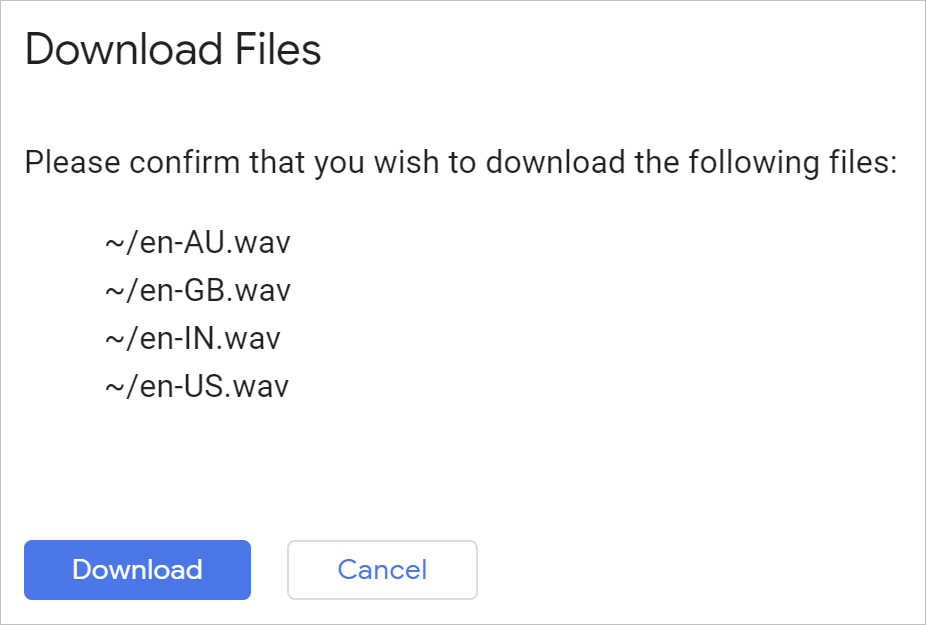

開啟每個檔案並聆聽結果。
摘要
在本步驟中,您已使用 Text-to-Speech API 將句子轉換為音訊 wav 檔案。進一步瞭解如何建立語音音訊檔案。
7. 恭喜!
您已學會如何使用 Python 產生近似人類的語音,並瞭解如何使用 Text-to-Speech API!
清除所用資源
如要清除開發環境,請在 Cloud Shell 中執行下列指令:
- 如果仍在 IPython 工作階段中,請返回 Shell:
exit - 停止使用 Python 虛擬環境:
deactivate - 刪除虛擬環境資料夾:
cd ~ ; rm -rf ./venv-texttospeech
如要刪除 Google Cloud 專案,請在 Cloud Shell 中執行下列操作:
- 擷取目前的專案 ID:
PROJECT_ID=$(gcloud config get-value core/project) - 確認這是要刪除的專案:
echo $PROJECT_ID - 刪除專案:
gcloud projects delete $PROJECT_ID
瞭解詳情
- 在瀏覽器中測試試用版:https://cloud.google.com/text-to-speech
- Text-to-Speech 說明文件:https://cloud.google.com/text-to-speech/docs
- Google Cloud 上的 Python:https://cloud.google.com/python
- Python 適用的 Cloud 用戶端程式庫:https://github.com/googleapis/google-cloud-python
授權
這項內容採用的授權為 Creative Commons 姓名標示 2.0 通用授權。