
1. Pengantar
Document AI adalah solusi pemahaman dokumen yang mengambil data tidak terstruktur seperti dokumen, email, dan lainnya, kemudian membuat data tersebut lebih mudah dipahami, dianalisis, serta digunakan.
Dengan Document AI Workbench, Anda dapat mencapai akurasi pemrosesan dokumen yang lebih tinggi dengan membuat model yang disesuaikan sepenuhnya menggunakan data pelatihan Anda sendiri.
Di lab ini, Anda akan membuat prosesor Ekstraksi Dokumen Kustom, mengimpor set data, memberi label dokumen contoh, dan melatih prosesor.
Set data dokumen yang digunakan di lab ini berasal dari Set Data W-2 (Formulir Pajak AS) Palsu di Kaggle dengan CC0: Lisensi Domain Publik.
Prasyarat
Codelab ini dibangun berdasarkan konten yang disajikan dalam Codelab Document AI lainnya.
Sebaiknya Anda menyelesaikan Codelab berikut sebelum melanjutkan.
- Pengenalan Karakter Optik (OCR) dengan Document AI (Python)
- Penguraian Formulir dengan Document AI (Python)
- Prosesor Terspesialisasi dengan Document AI (Python)
- Mengelola prosesor Document AI dengan Python
- Document AI: Memerlukan Interaksi Manusia
- Document AI: Melakukan Pelatihan
Yang akan Anda pelajari
- Membuat prosesor Ekstraktor Dokumen Kustom
- Melabeli data pelatihan Document AI menggunakan alat anotasi.
- Melatih versi model baru.
- Evaluasi keakuratan versi model baru.
Yang akan Anda butuhkan
2. Mempersiapkan
Codelab ini akan menganggap Anda telah menyelesaikan langkah-langkah Penyiapan Document AI yang tercantum di Codelab Pengantar.
Harap selesaikan langkah-langkah berikut sebelum melanjutkan:
3. Membuat Prosesor
Anda harus membuat prosesor Ekstraktor Dokumen Kustom terlebih dahulu untuk digunakan di lab ini.
- Di konsol, buka halaman Document AI Overview.
- Klik Create Custom Processor, lalu pilih Custom Document Extractor.
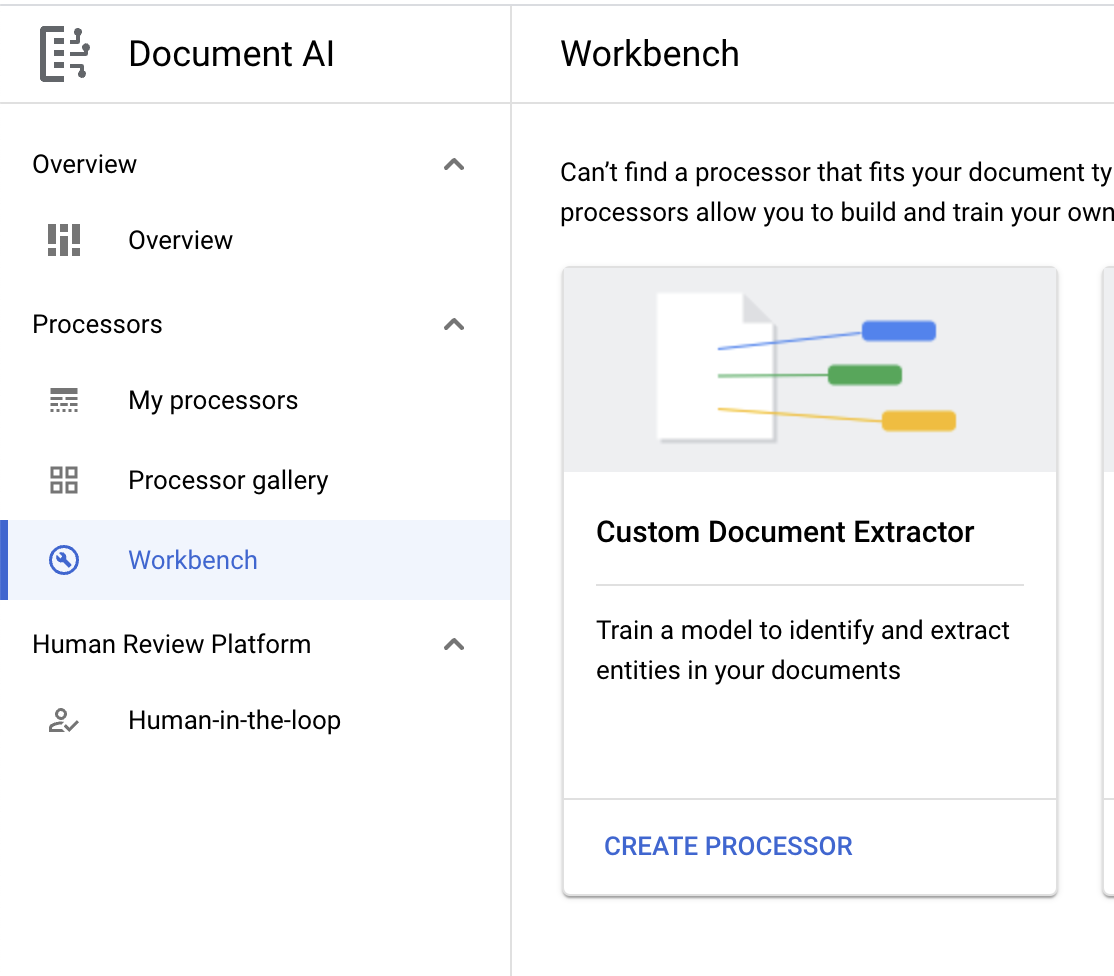
- Beri nama
codelab-custom-extractor(Atau hal lain yang akan Anda ingat) dan pilih region terdekat di daftar.
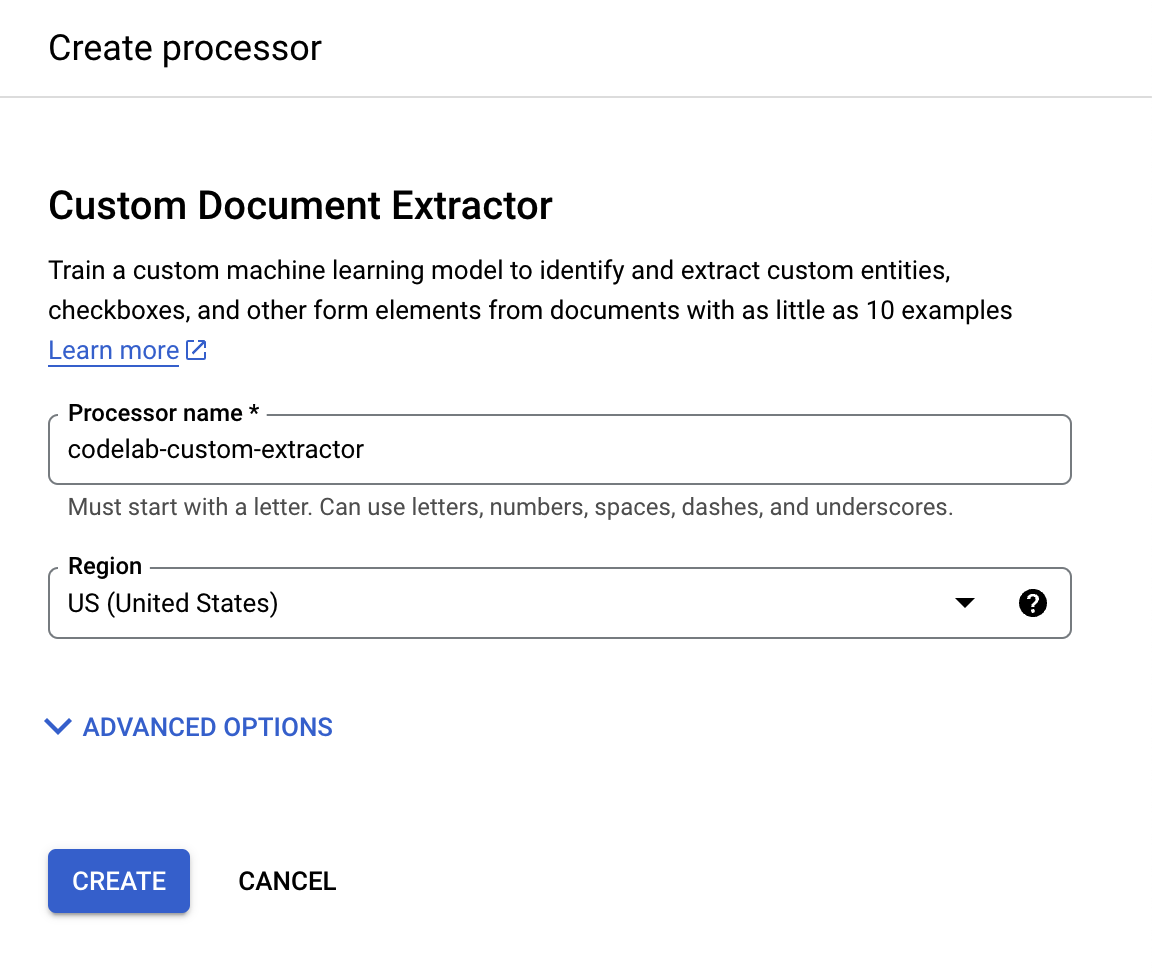
- Klik Create untuk membuat prosesor. Anda kemudian akan melihat halaman Processor Overview.
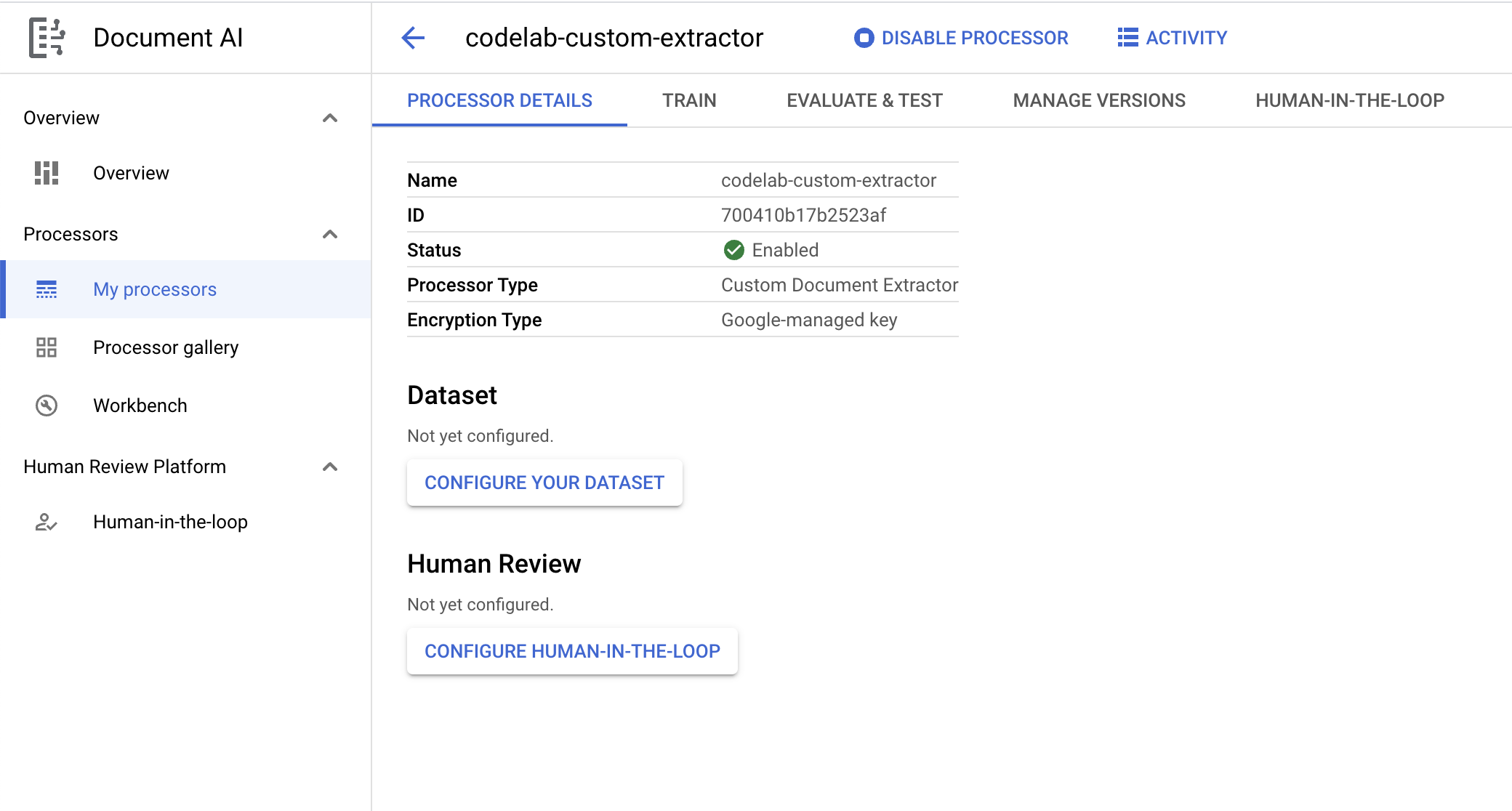
4. Membuat Set Data
Untuk melatih prosesor, kita harus membuat set data dengan data pelatihan dan pengujian untuk membantu prosesor mengidentifikasi entitas yang ingin kita ekstrak.
- Di halaman Processor Overview, klik Configure Your Dataset.
- Anda sekarang akan berada di halaman Configure Dataset. Jika Anda ingin menentukan bucket sendiri untuk menyimpan dokumen dan label pelatihan, klik Tampilkan Opsi Lanjutan. Jika tidak, cukup klik Lanjutkan.
- Tunggu hingga set data dibuat, lalu Anda akan diarahkan ke halaman Training.
5. Mengimpor Dokumen Uji
Sekarang, impor contoh pdf W2 ke dalam kumpulan set data Anda.
- Klik Import Documents
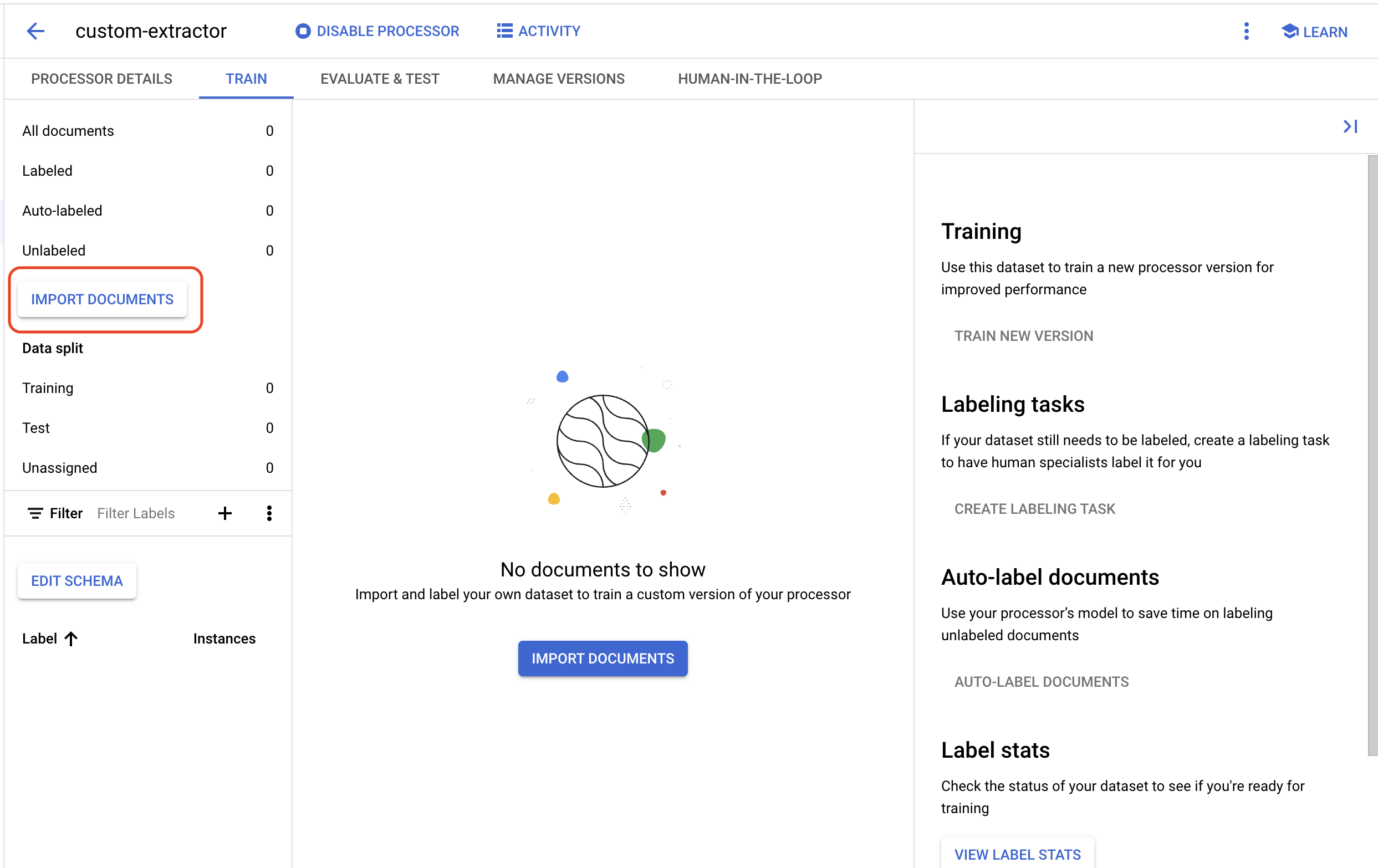
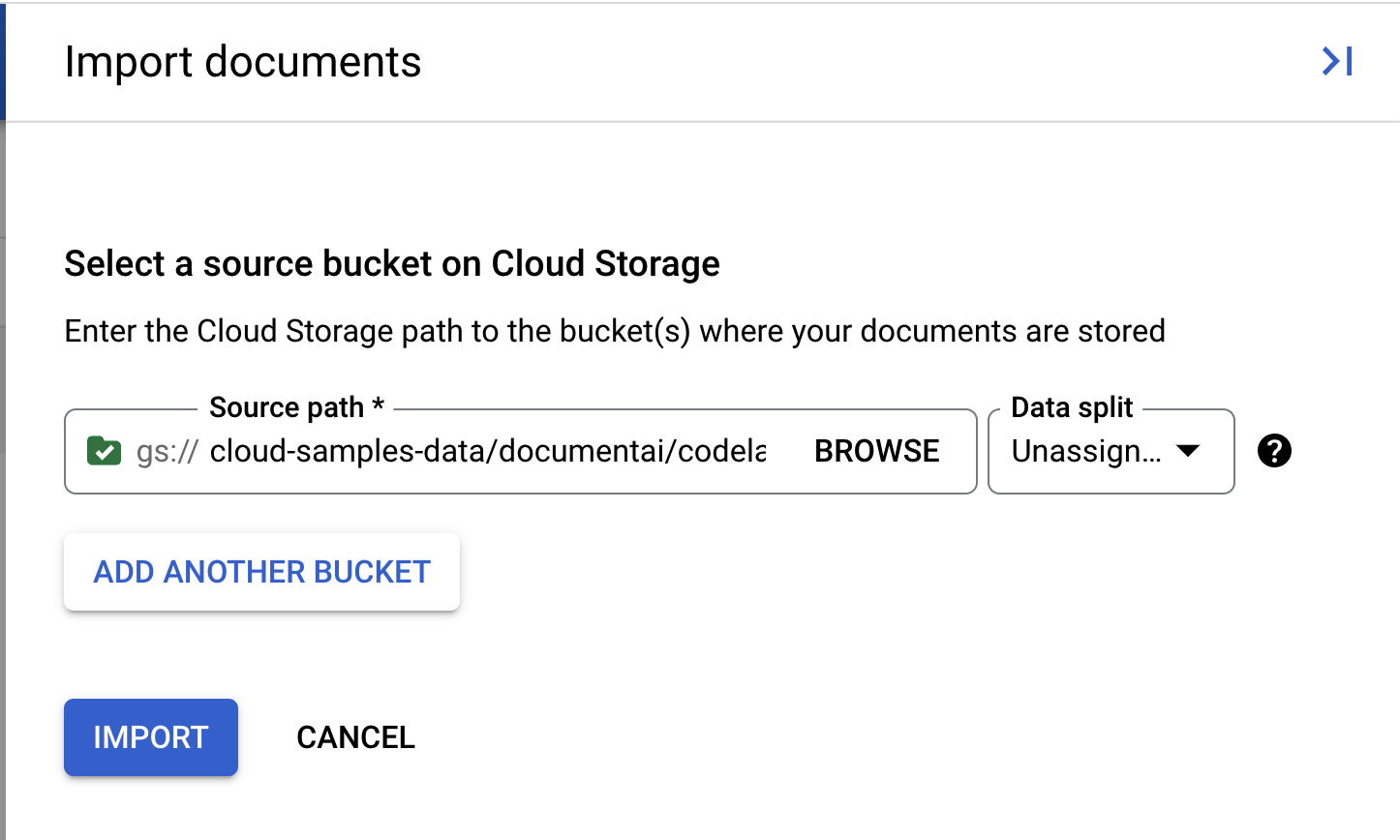
- Kami memiliki PDF sampel untuk Anda gunakan di lab ini. Salin dan tempel link berikut ke kotak Source Path. Biarkan "Data split" sebagai "Unassigned" untuk saat ini. Biarkan semua kotak lainnya tidak dicentang. Klik Import.
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs
- Tunggu hingga dokumen selesai diimpor. Proses ini akan berlangsung kurang dari 1 menit.
- Saat impor selesai, Anda akan melihat Dokumen ini di halaman Training.
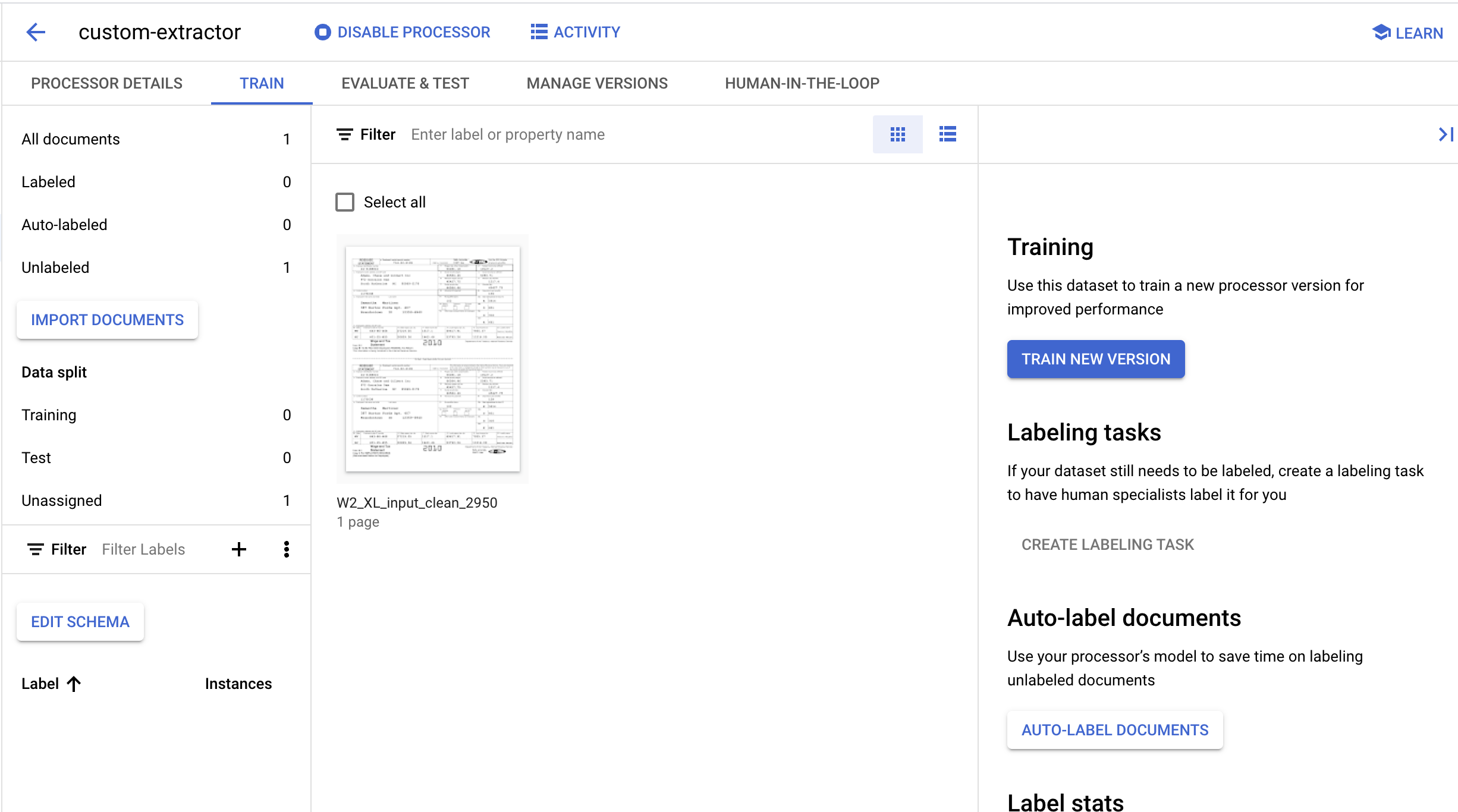
6. Membuat Label
Karena kita membuat jenis prosesor baru, kita perlu membuat label khusus untuk memberi tahu Document AI kolom mana yang ingin kita ekstrak.
- Klik Edit Skema di pojok kiri bawah.
- Anda sekarang seharusnya berada di konsol Schema Management.
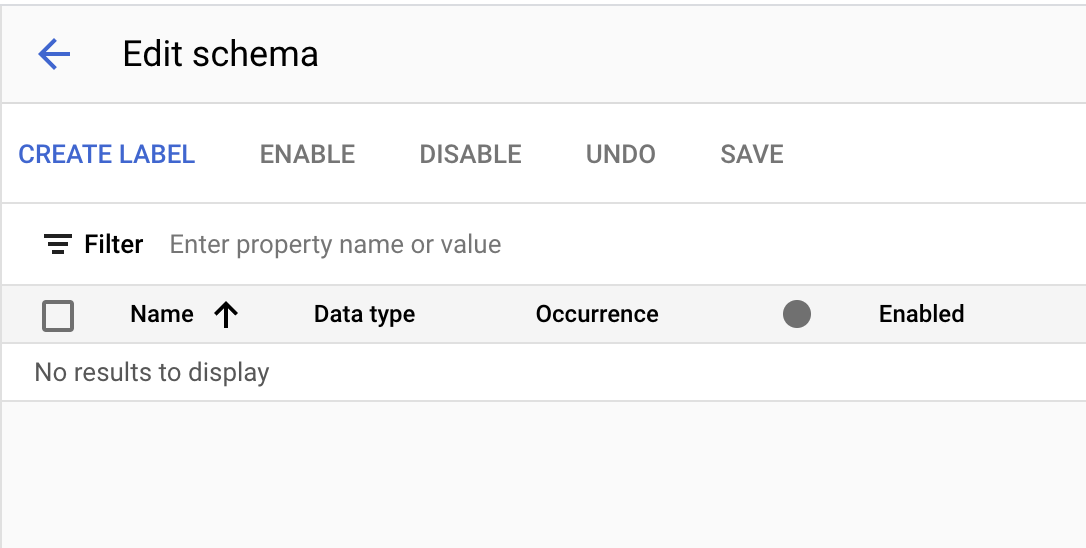
- Buat label berikut menggunakan tombol Buat Label.
Nama | Data Type | Occurrence |
| Number | Required multiple |
| Plain Text | Required multiple |
| Plain Text | Required multiple |
| Address | Required multiple |
| Money | Required multiple |
| Money | Required multiple |
| Money | Required multiple |
| Money | Required multiple |
- Konsol akan terlihat seperti ini setelah selesai. Klik Save setelah selesai.
- Klik panah Kembali untuk kembali ke halaman Pelatihan. Perhatikan bahwa label yang kita buat akan muncul di pojok kiri bawah.
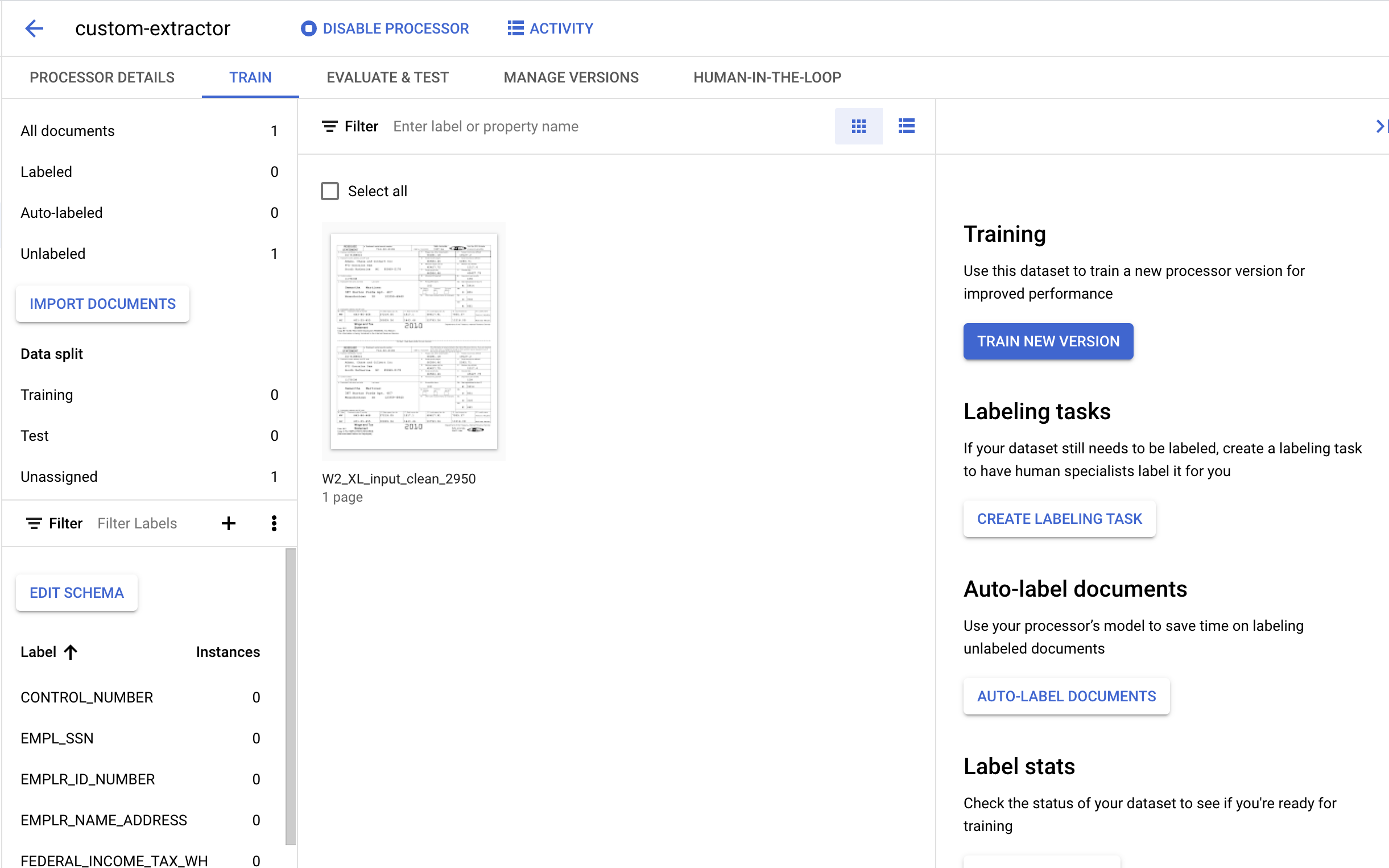
7. Melabeli Dokumen Uji
Selanjutnya, kita akan mengidentifikasi elemen teks dan label untuk entitas yang akan diekstrak. Label-label ini akan digunakan untuk melatih model kita untuk mengurai struktur dokumen khusus ini dan mengidentifikasi jenis yang benar.
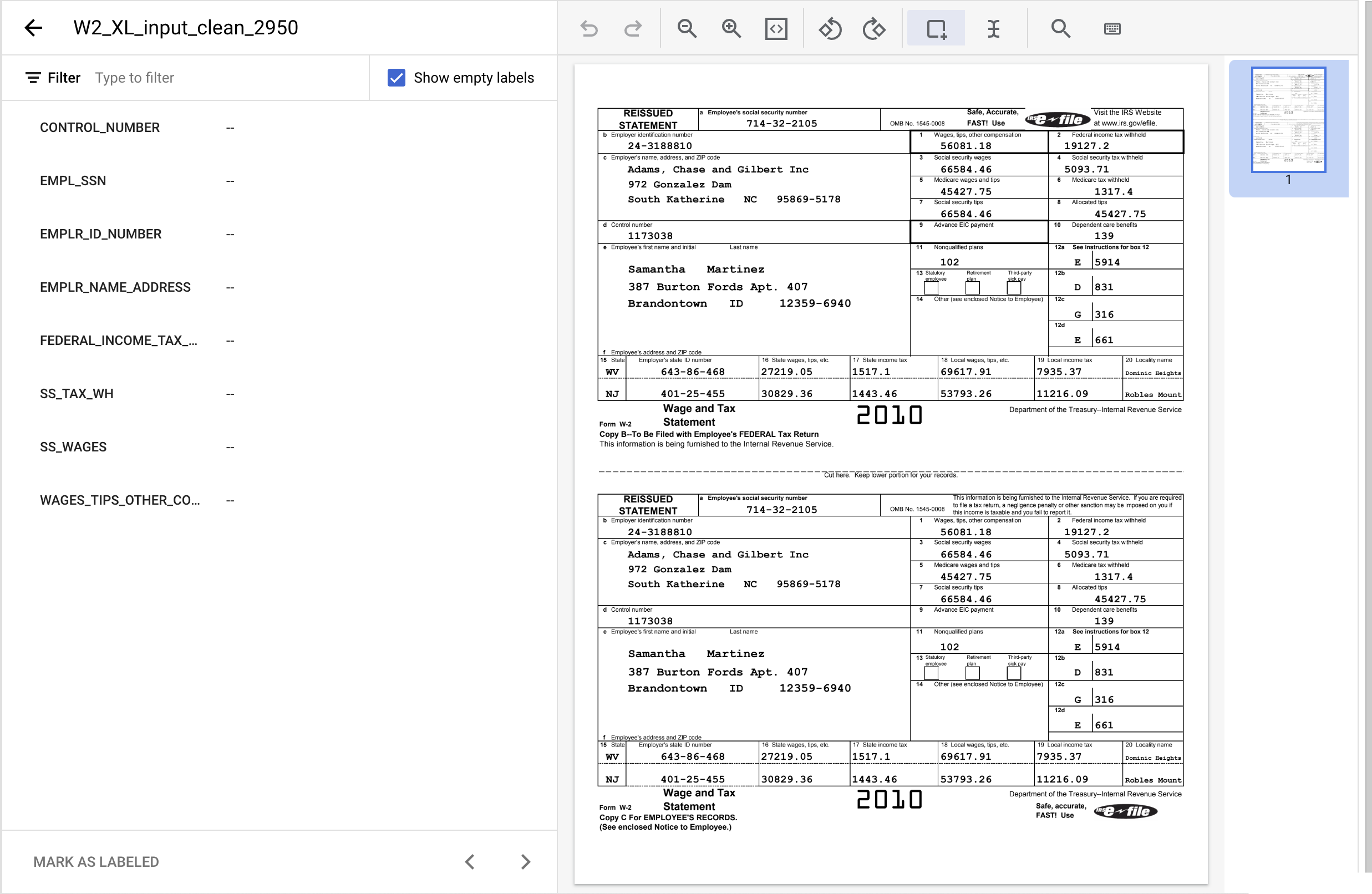
- Klik dua kali pada dokumen yang telah kita impor sebelumnya untuk masuk ke konsol pelabelan. Hasilnya akan terlihat seperti ini.
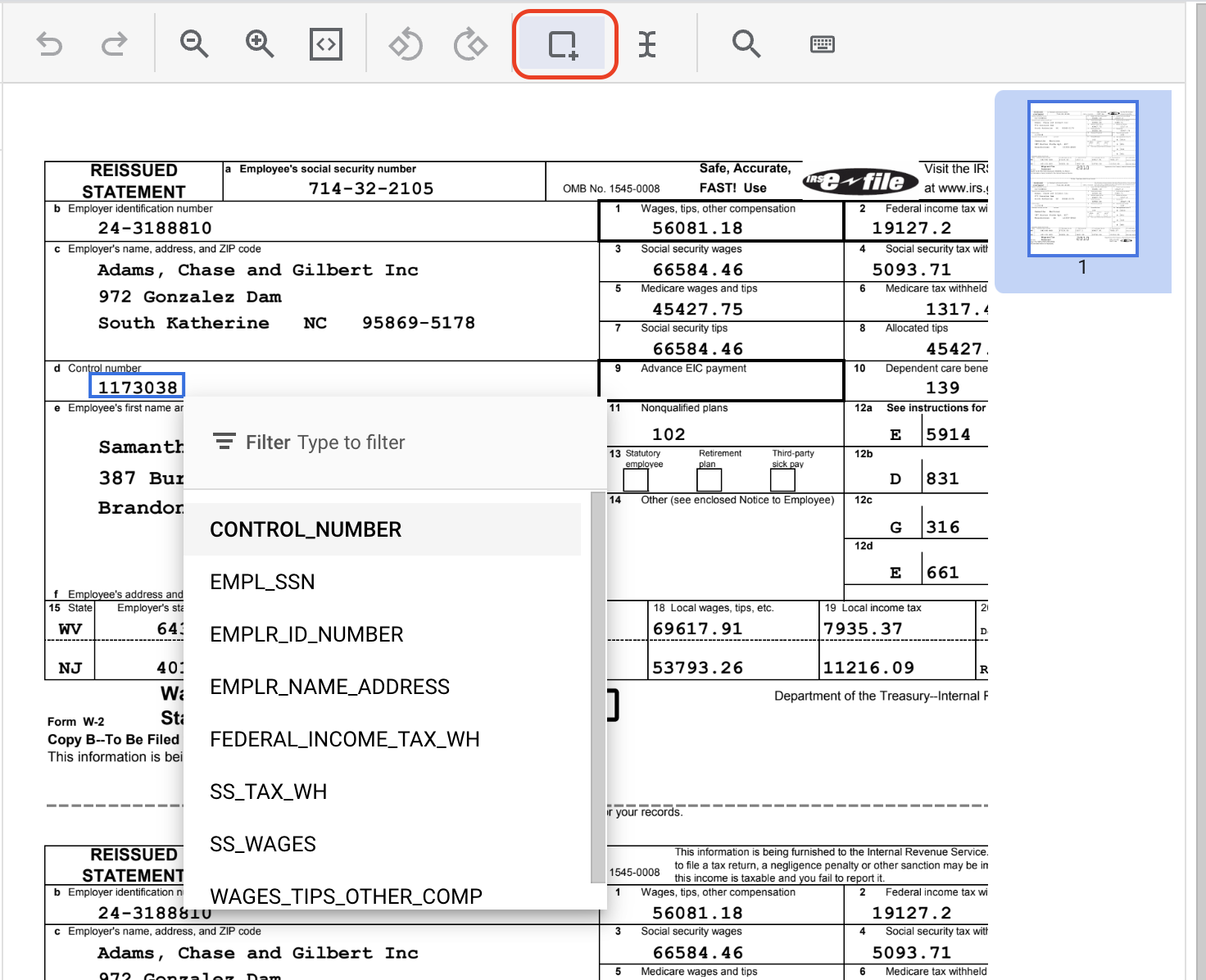
- Klik Alat "Bounding Box", lalu tandai teks "1173038" dan beri label
CONTROL_NUMBER. Anda dapat menggunakan filter teks untuk mencari nama label.
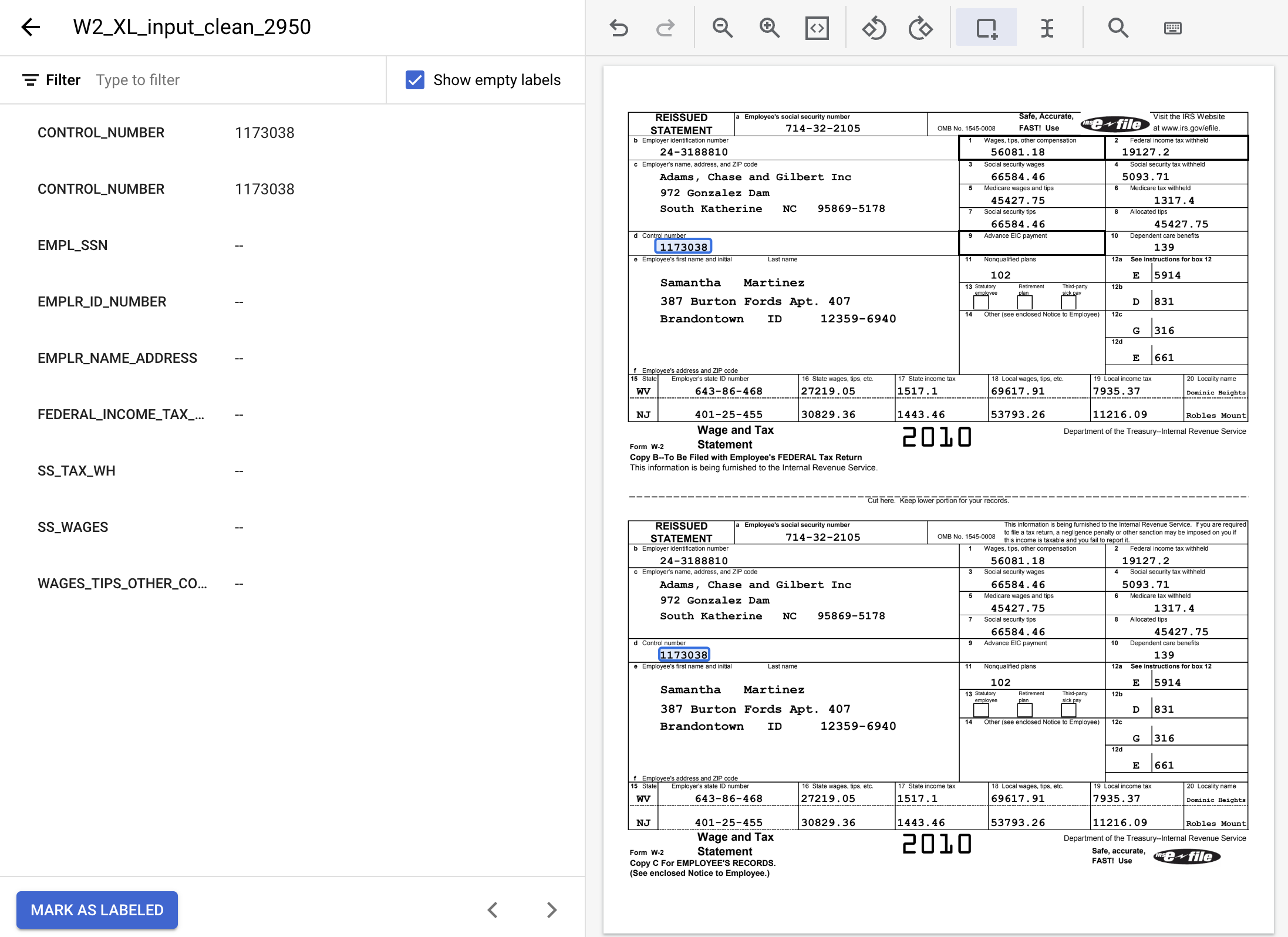
- Selesaikan untuk instance
CONTROL_NUMBERlainnya. Setelah diberi label, hasilnya akan terlihat seperti ini.
- Tandai semua instance nilai teks berikut dan berikan label yang sesuai.
Nama Label | Teks |
| 24-3188810 |
| 19127.2 |
| 5093.71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc 972 Gonzalez Dam South Katherine NC 95869-5178 |
- Dokumen berlabel akan terlihat seperti ini setelah selesai. Perlu diperhatikan bahwa Anda dapat melakukan penyesuaian pada label ini dengan mengklik kotak pembatas di dokumen atau nama/nilai label di menu sebelah kiri. Klik Mark As Labeled setelah Anda selesai memberi label, lalu kembali ke konsol Dataset management.
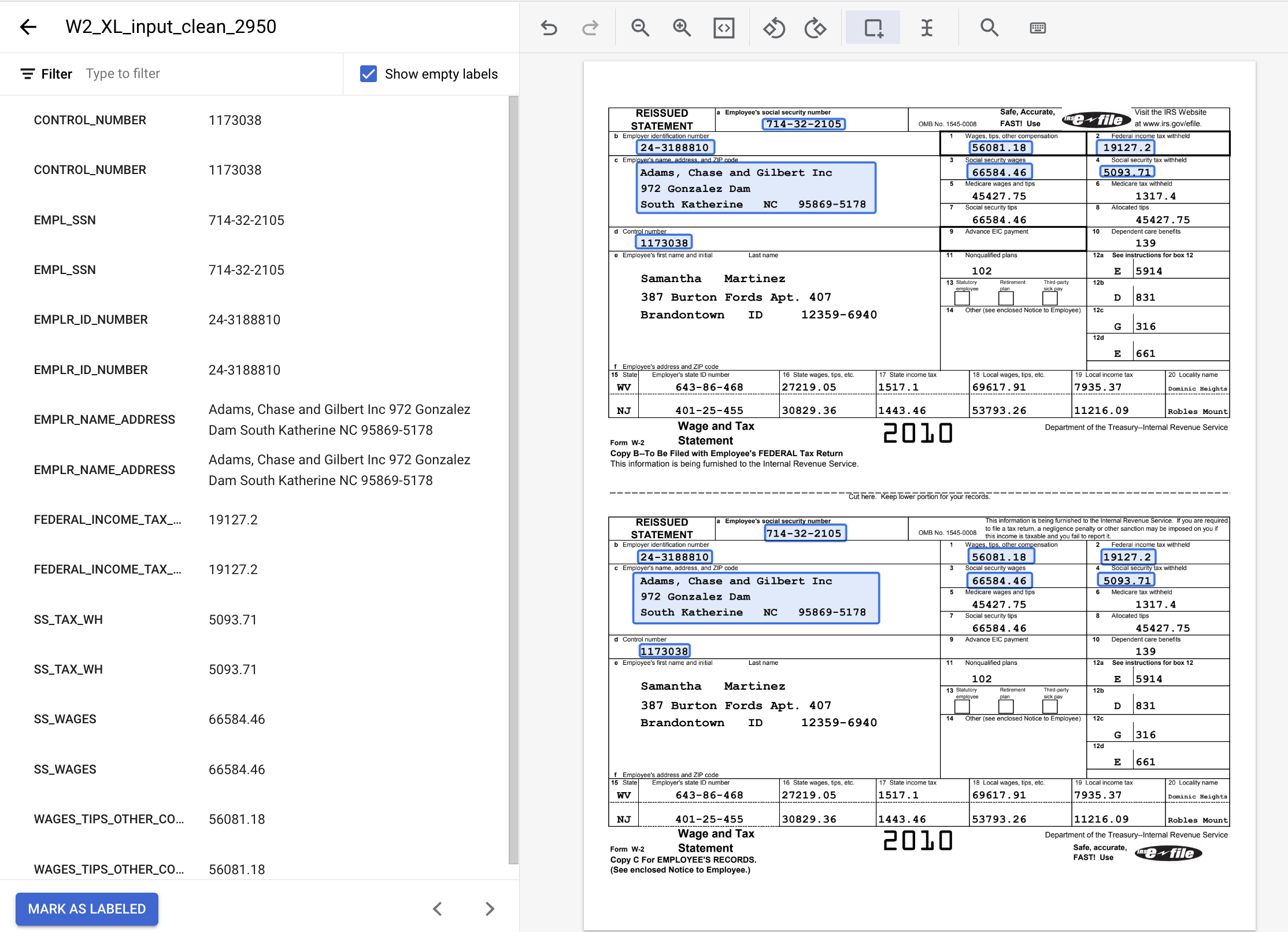
8. Menetapkan Dokumen ke Set Pelatihan
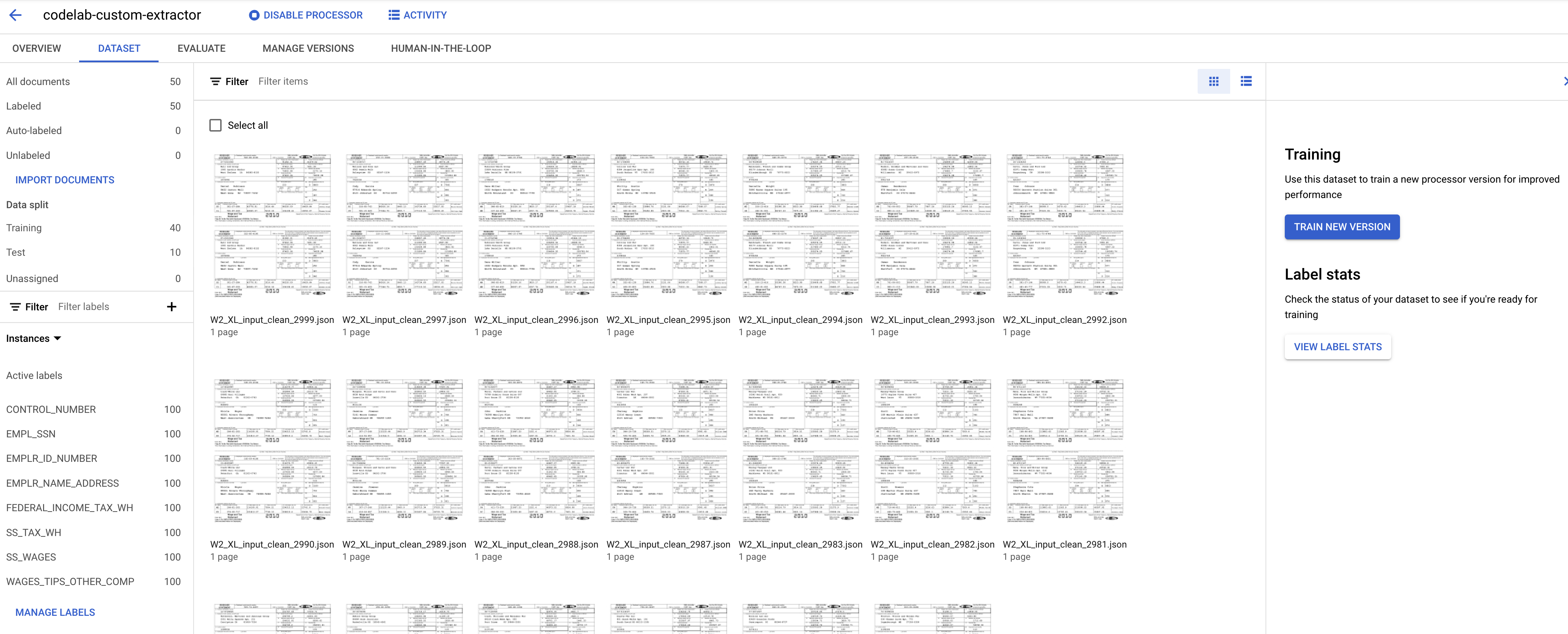
Anda sekarang akan kembali ke konsol Dataset management. Perhatikan bahwa jumlah Dokumen Berlabel dan Tidak Berlabel serta jumlah instance per label telah berubah.
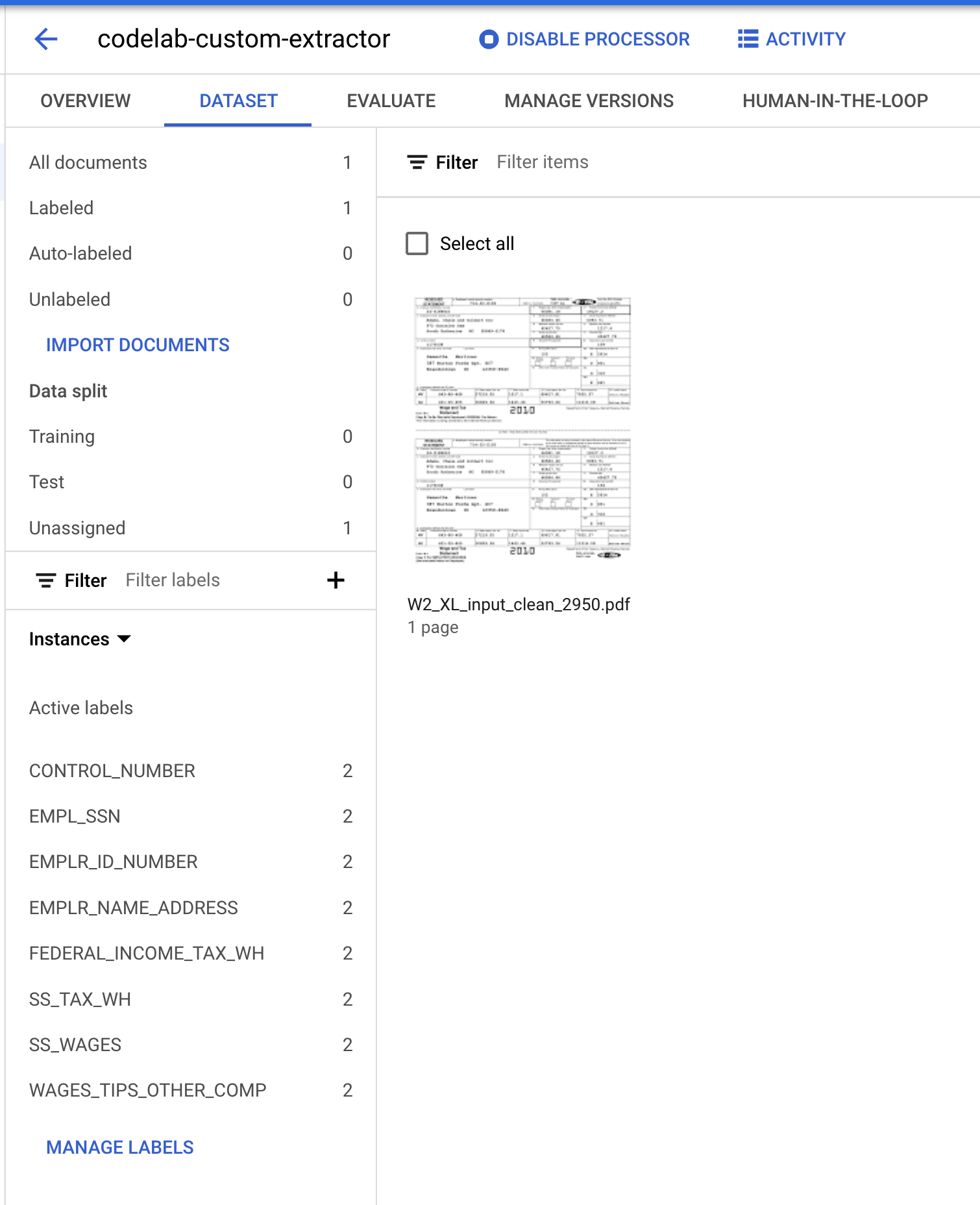
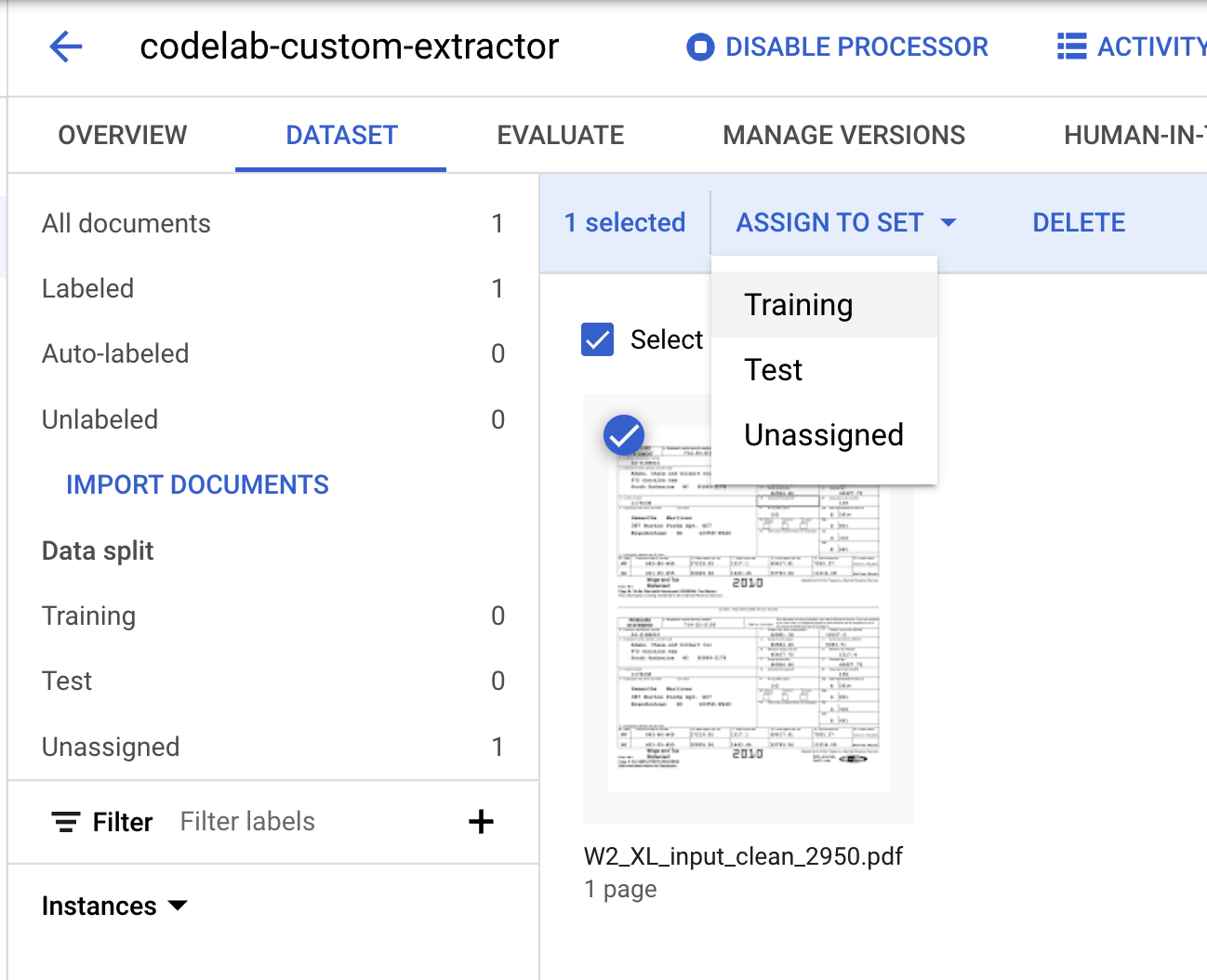
- Kita perlu menetapkan dokumen ini ke set "Pelatihan"/"Training" atau "Uji"/"Test". Klik Document, klik Assign to Set, lalu klik Training.
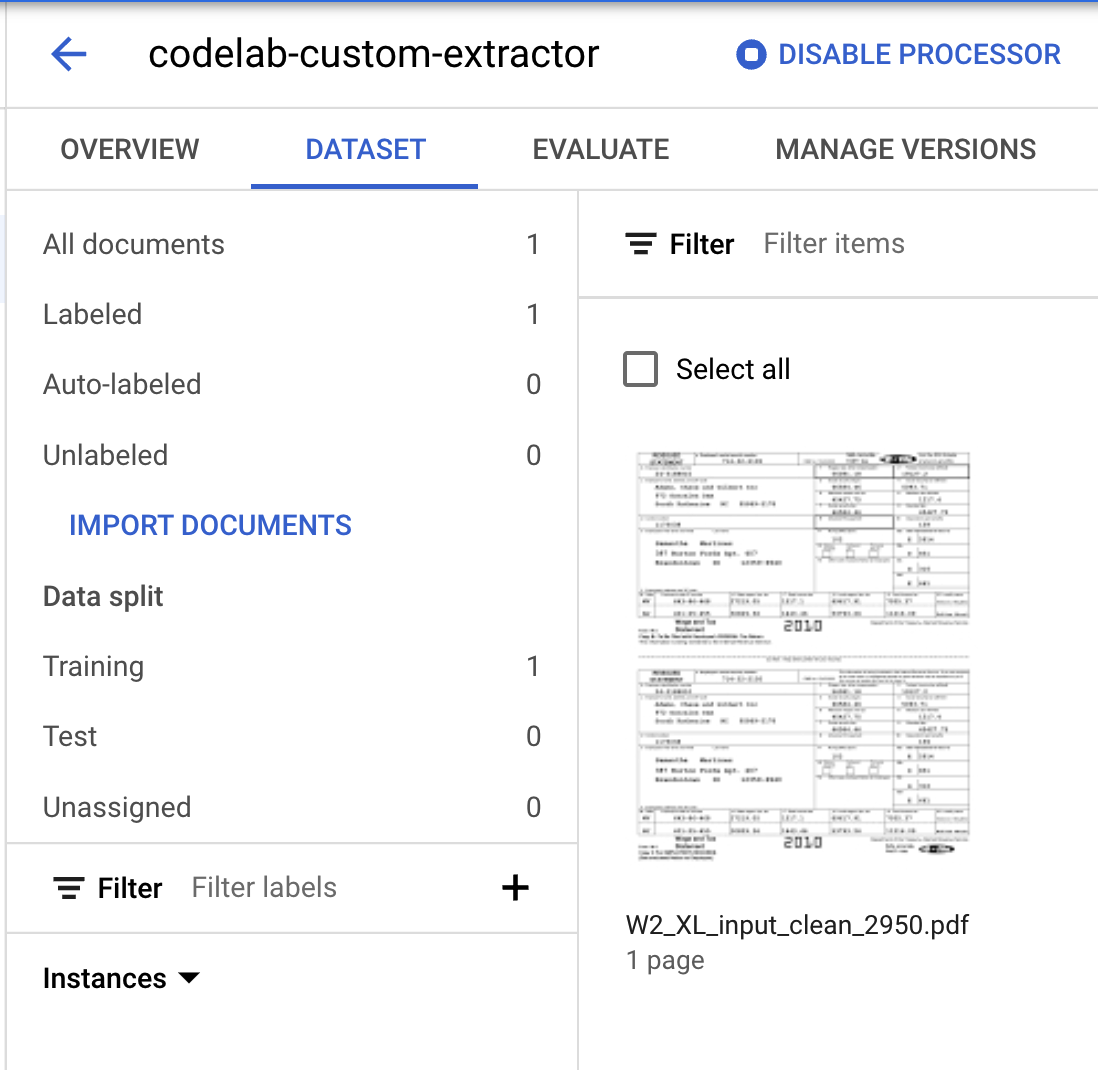
- Perhatikan bahwa angka Data Split telah berubah.
9. Mengimpor Data Pra-Label
Prosesor Kustom Document AI memerlukan minimal 10 dokumen dalam set pelatihan dan pengujian, bersama dengan 10 instance dari setiap label di setiap set.
Anda sebaiknya memiliki minimal 50 dokumen di setiap set dengan 50 instance dari setiap label untuk mendapatkan performa terbaik. Makin banyak data pelatihan, umumnya makin tinggi akurasinya.
Perlu waktu lama untuk melabeli semua dokumen secara manual. Jadi ada beberapa dokumen yang telah diberi label sebelumnya yang dapat Anda impor untuk lab ini.
Anda dapat mengimpor file dokumen yang telah diberi label sebelumnya dalam format Document.json. Ini bisa merupakan hasil dari memanggil prosesor dan memverifikasi keakuratan menggunakan Human in the Loop (HITL).
aside negative
CATATAN: Saat Anda mengimpor data yang sudah diberi label sebelumnya, sangat disarankan untuk meninjau anotasi secara manual sebelum model dilatih.
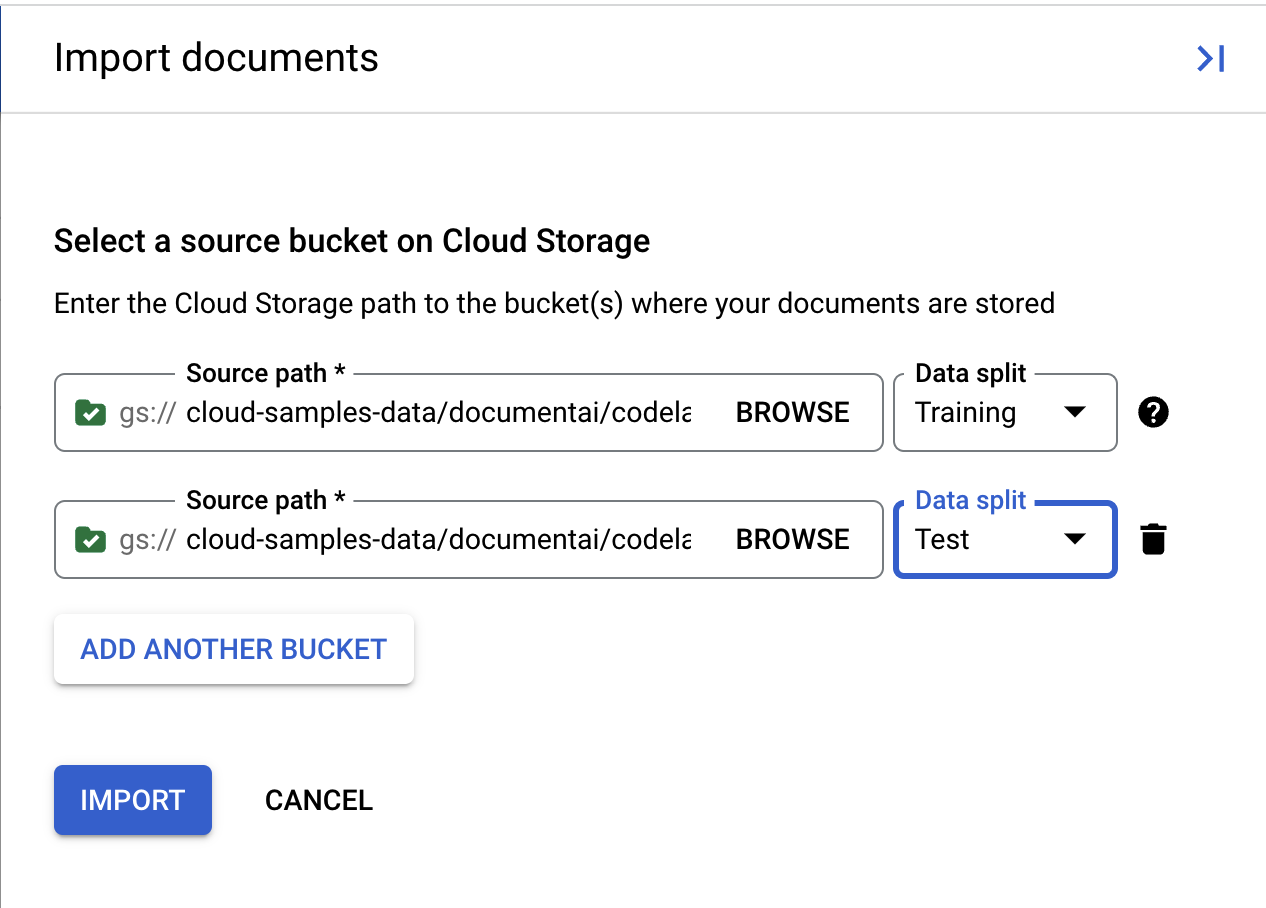
- Klik Import Document.
- Salin/Tempel jalur Cloud Storage berikut dan tetapkan ke set Training.
cloud-samples-data/documentai/codelabs/custom/extractor/training
- Klik Tambahkan Folder Lain. Kemudian Salin/Tempel jalur Cloud Storage berikut dan tetapkan ke set Test.
cloud-samples-data/documentai/codelabs/custom/extractor/test
- Klik Import dan tunggu hingga dokumen selesai diimpor. Prosesnya memakan waktu lebih lama daripada sebelumnya karena ada lebih banyak dokumen yang harus diproses. Proses ini akan memakan waktu sekitar 6 menit. Anda dapat keluar dari halaman ini dan kembali lagi nanti.
- Setelah selesai, Anda akan melihat dokumen di halaman Training.
10. Melatih Model
Sekarang, kita siap untuk mulai melatih Ekstraktor Dokumen Kustom kita.
- Klik Train New Version
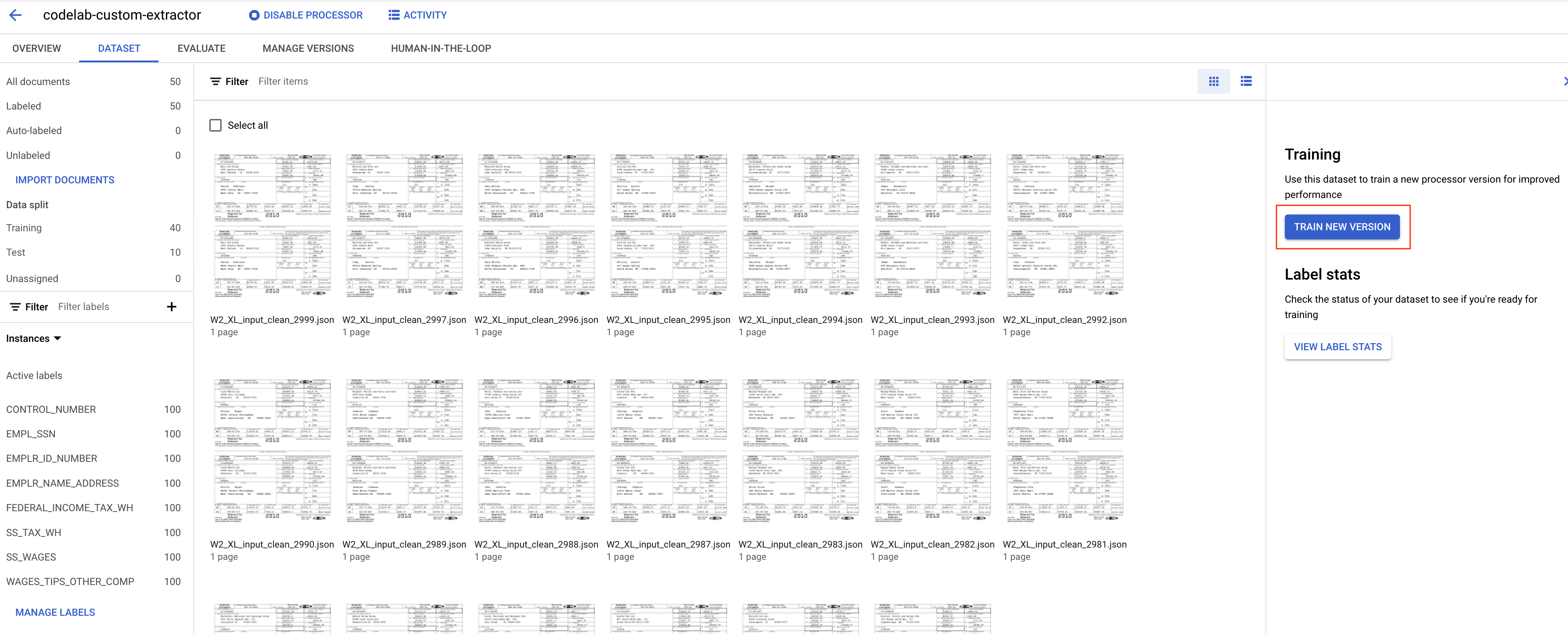
- Beri nama pada versi Anda dengan nama yang mudah diingat, seperti
codelab-custom-1. Untuk "Training Mode", pilih "Train from scratch".
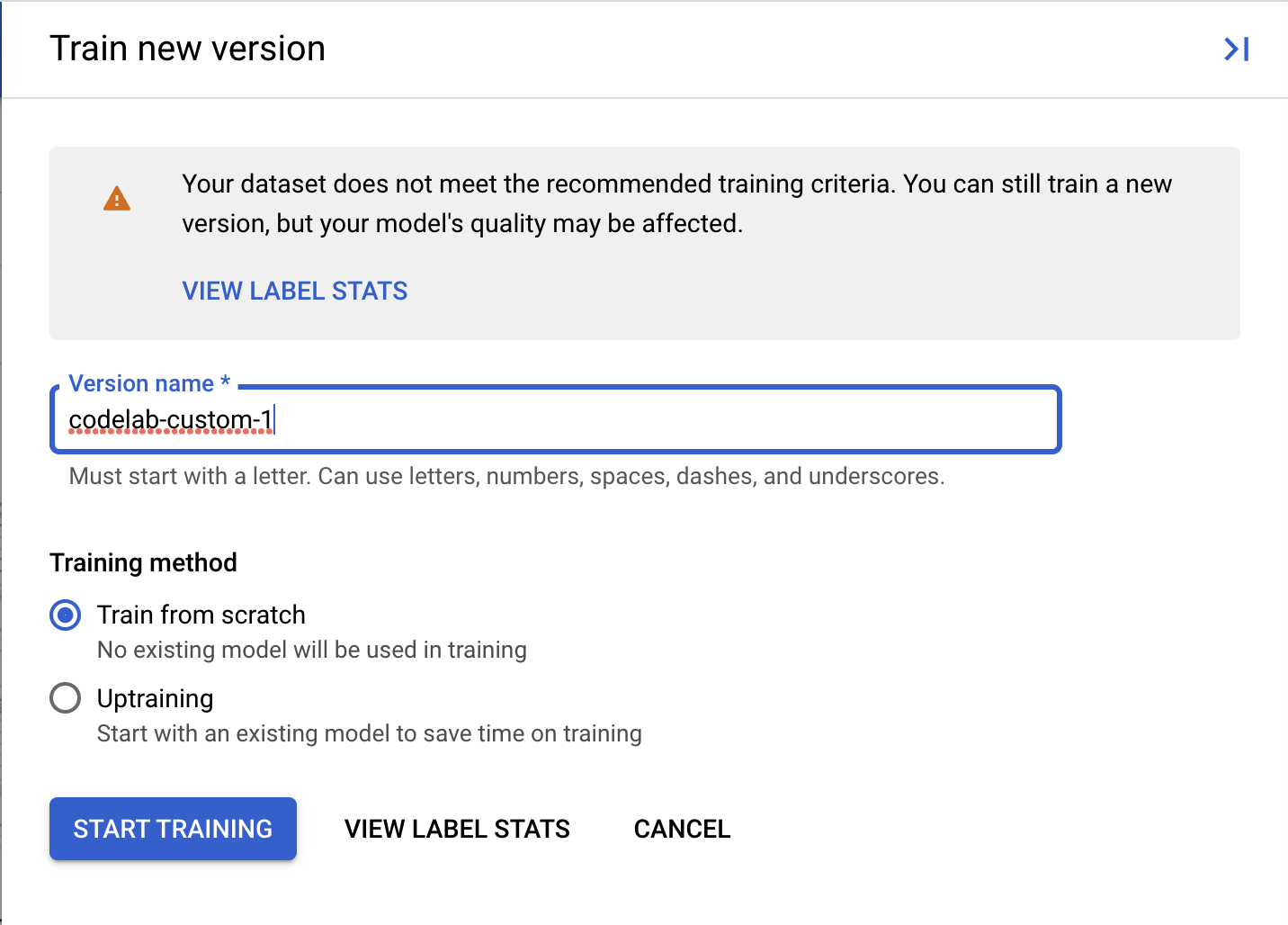
- (Opsional) Anda juga dapat memilih View Label Stats untuk melihat metrik terkait label tersebut di set data Anda.
- Klik Start Training untuk memulai proses Pelatihan. Anda akan diarahkan ke halaman Dataset management. Anda dapat melihat status pelatihan di sisi kanan. Diperlukan waktu beberapa jam untuk menyelesaikan pelatihan. Anda dapat meninggalkan halaman ini dan kembali lagi nanti.
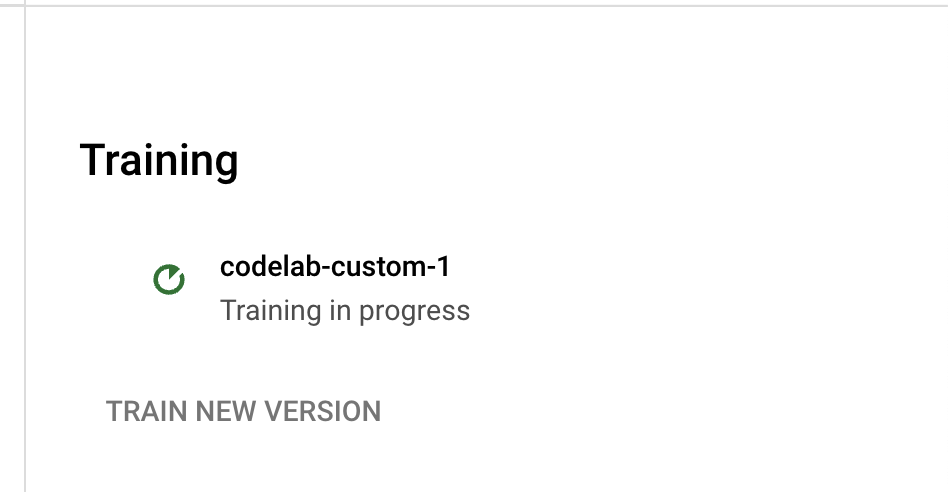
- Jika Anda mengklik nama versi, Anda akan diarahkan ke halaman Manage Version, yang menunjukkan ID Versi dan status Tugas Pelatihan saat ini.
11. Menguji Versi Model Baru
Setelah Tugas Pelatihan selesai (perlu waktu sekitar 1 jam dalam pengujian saya), Anda sekarang dapat menguji versi model baru dan mulai menggunakannya untuk melakukan prediksi.
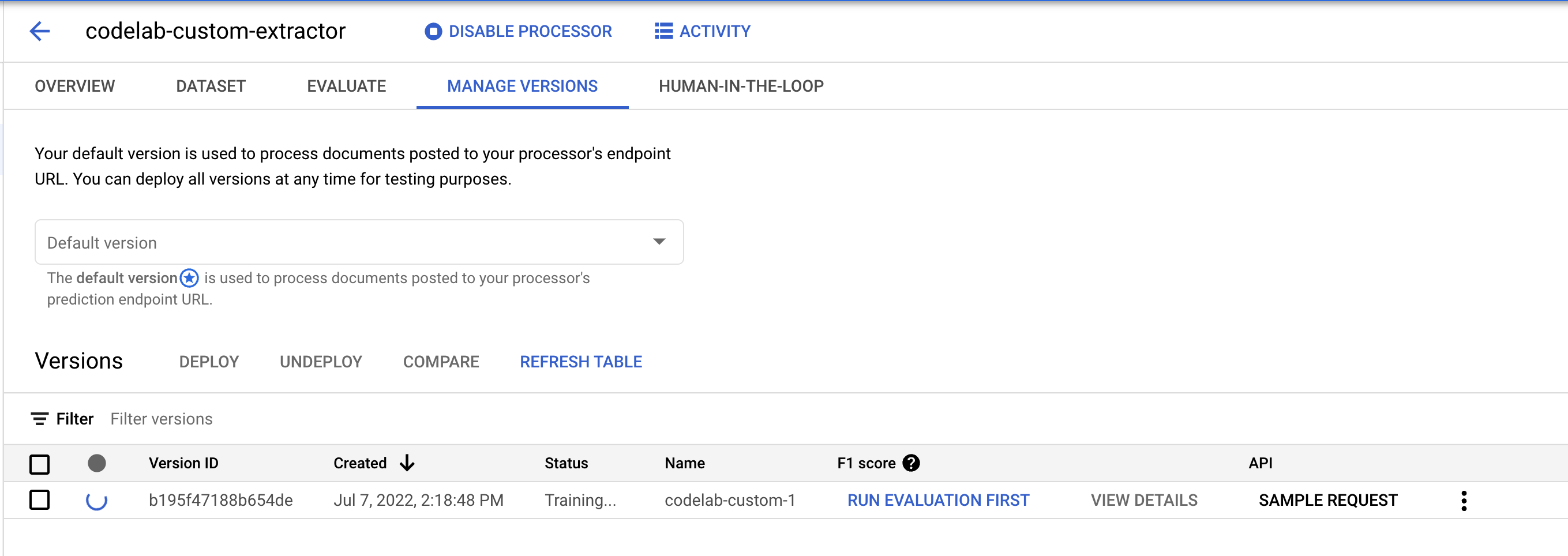
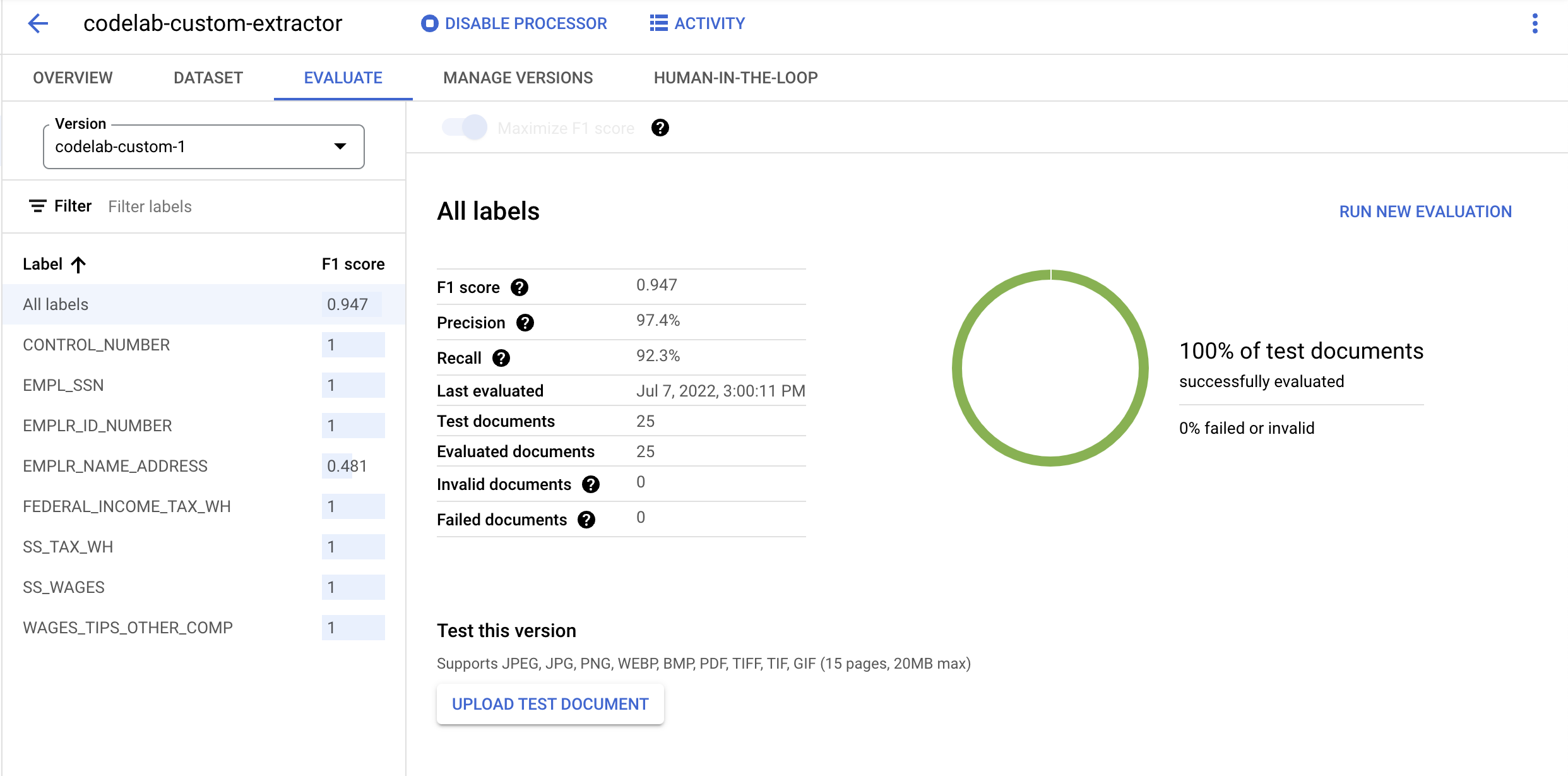
- Buka halaman Manage Versions. Di sini Anda dapat melihat status terkini dan Skor F1.
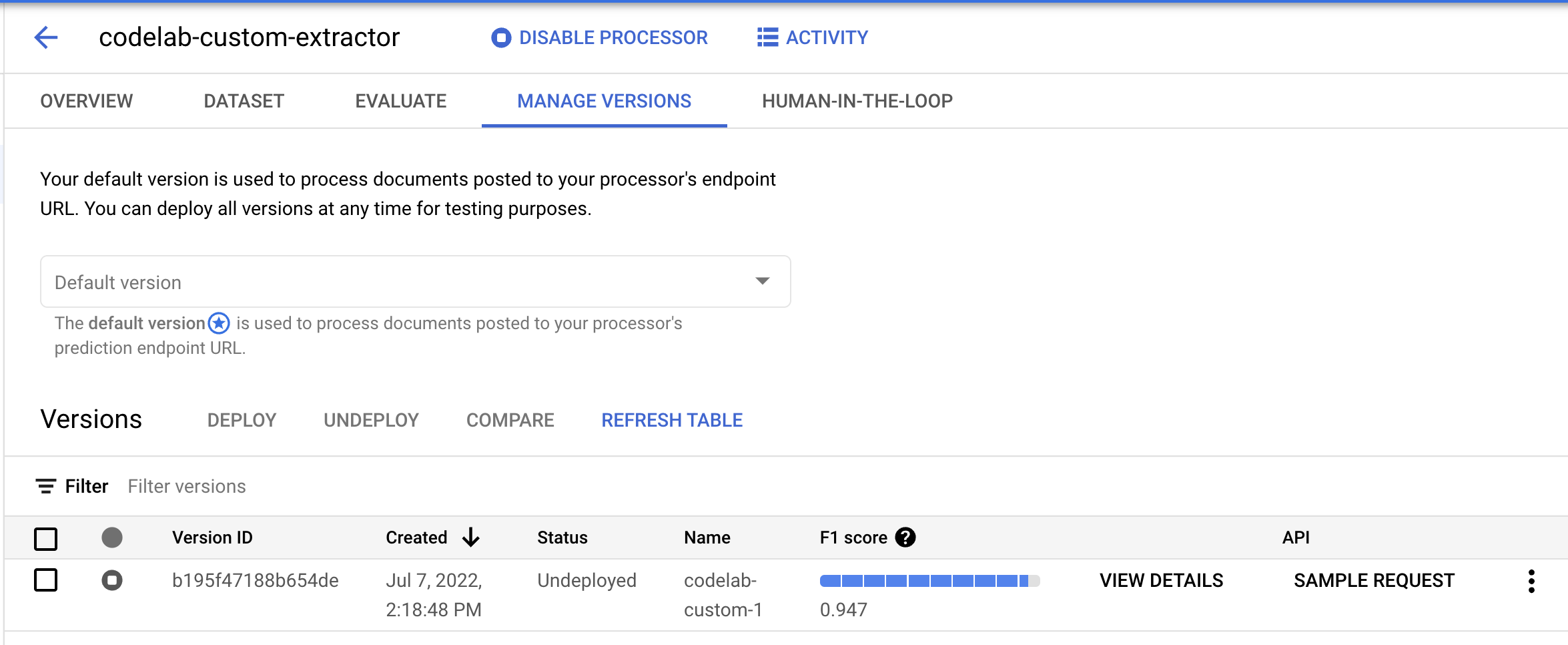
- Kita perlu men-deploy versi model ini sebelum dapat digunakan. Klik titik vertikal di sisi kanan lalu pilih Deploy Version.
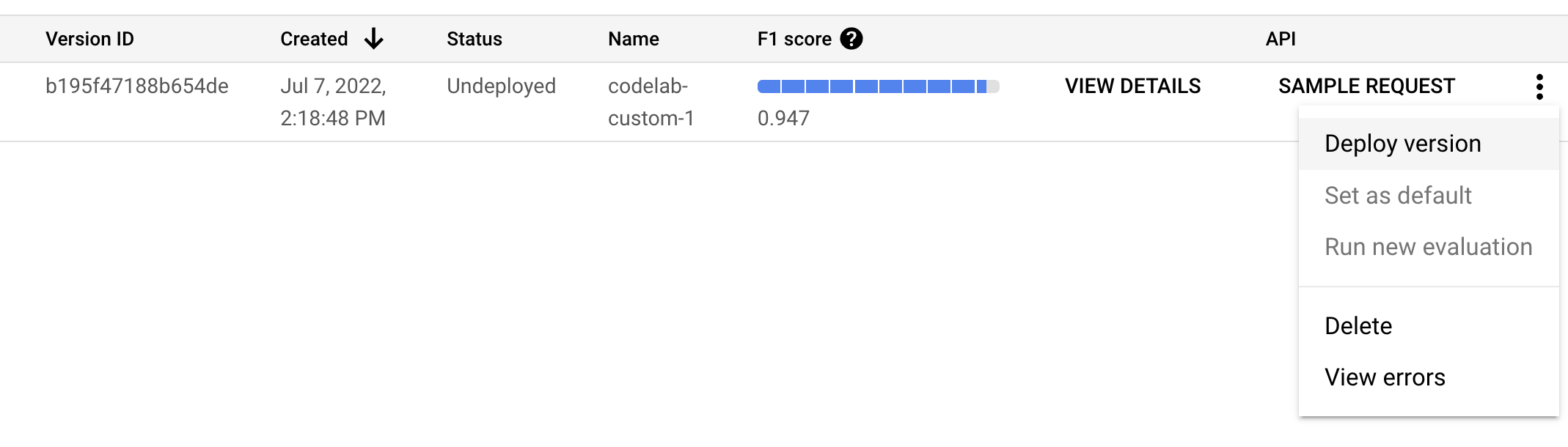
- Pilih Deploy dari jendela pop-up, lalu tunggu hingga versi di-deploy. Prosesnya perlu waktu beberapa menit sampai selesai. Setelah di-deploy, Anda juga dapat menetapkan versi ini sebagai Versi Default.
- Setelah selesai di-deploy, buka Tab Evaluate. Di halaman ini, Anda dapat melihat metrik evaluasi termasuk skor F1, Presisi, dan Recall untuk dokumen lengkap serta masing-masing label. Anda dapat membaca info selengkapnya tentang metrik ini di Dokumentasi AutoML.
- Download file PDF yang link-nya ada di bawah ini. Ini adalah sampel W2 yang tidak disertakan dalam set Pelatihan atau Pengujian.
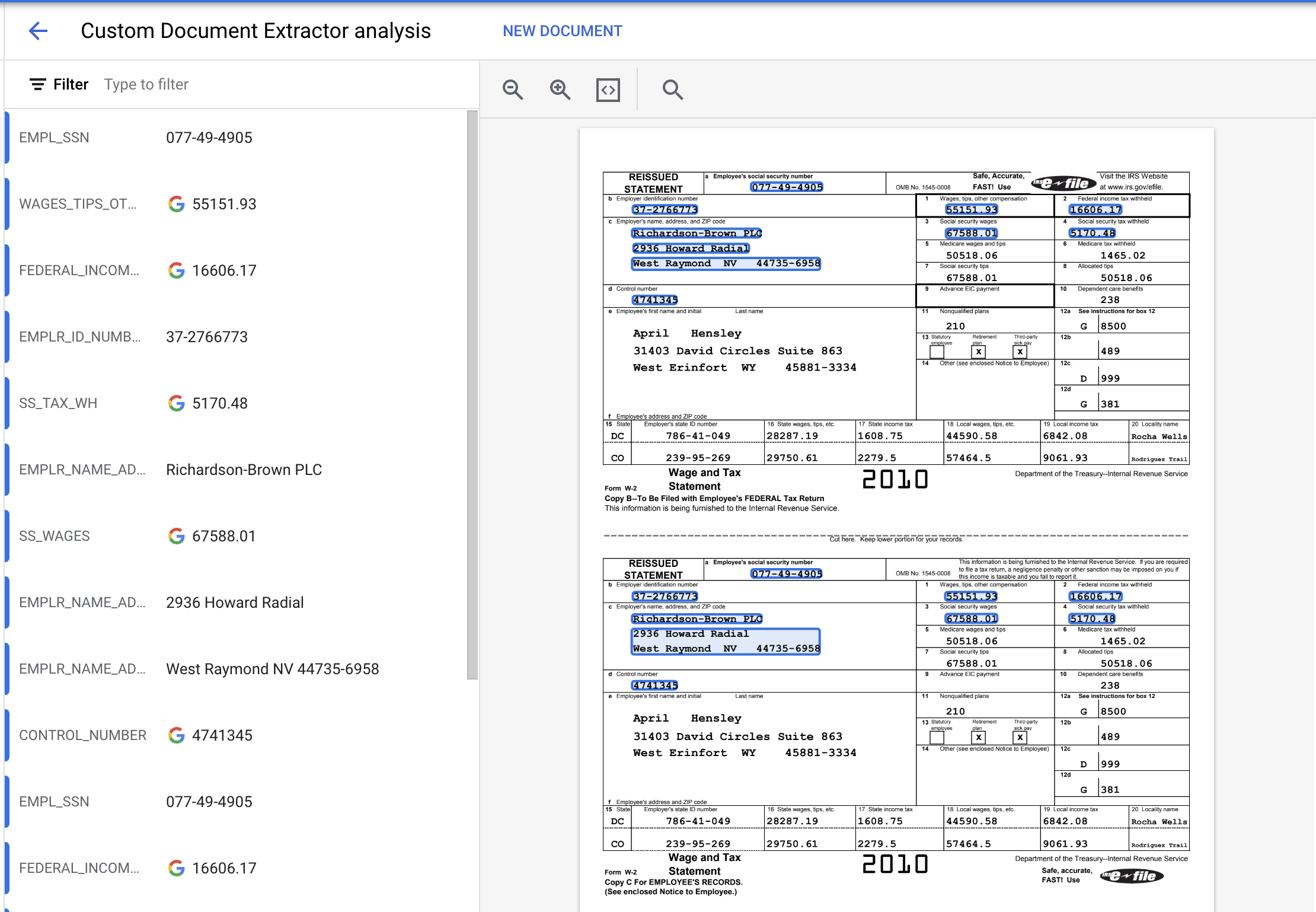
- Klik Upload Test Document dan pilih file PDF.
- Entitas yang diekstrak akan terlihat seperti ini.
12. Opsional: Otomatis melabeli dokumen yang baru diimpor
Setelah menerapkan versi prosesor terlatih, Anda dapat menggunakan Pelabelan otomatis untuk menghemat waktu pelabelan saat mengimpor dokumen baru.
- Di halaman Train, klik Import Document.
- Salin dan tempel jalur berikut. Direktori ini berisi 5 PDF W2 tanpa label. Dari daftar dropdown Data split, pilih Training.
cloud-samples-data/documentai/Custom/W2/AutoLabel - Di bagian Auto-labeling, pilih kotak centang Import with auto-labeling.
- Pilih versi prosesor yang ada untuk melabeli dokumen.
- Contoh:
2af620b2fd4d1fcf
- Klik Import dan tunggu hingga dokumen selesai diimpor. Anda dapat meninggalkan halaman ini dan kembali lagi nanti.
- Setelah selesai, dokumen akan muncul di halaman Train di bagian Auto-labeled.
- Anda tidak dapat menggunakan dokumen berlabel otomatis untuk pelatihan atau pengujian tanpa menandainya sebagai berlabel. Buka bagian Auto-labeled untuk melihat dokumen berlabel otomatis.
- Pilih dokumen pertama untuk masuk ke konsol pelabelan.
- Verifikasikan label, kotak pembatas, dan nilai untuk memastikan semuanya benar. Beri label pada nilai apa pun yang dihilangkan.
- Pilih Mark as labeled setelah selesai.
- Ulangi verifikasi label untuk setiap dokumen yang diberi label otomatis, lalu kembali ke halaman Train untuk menggunakan data tersebut untuk pelatihan.
13. Kesimpulan
Selamat, Anda telah berhasil menggunakan Document AI untuk melatih prosesor Ekstraktor Dokumen Kustom. Anda sekarang dapat menggunakan prosesor ini untuk mengurai dokumen dalam format ini seperti yang Anda lakukan untuk Prosesor Khusus mana pun.
Anda dapat merujuk ke Codelab Prosesor Khusus untuk meninjau cara menangani respons pemrosesan.
Pembersihan
Agar tidak menimbulkan tagihan ke akun Google Cloud Anda untuk resource yang digunakan dalam tutorial ini:
- Di Cloud Console, buka halaman Mengelola resource.
- Dalam daftar project, pilih project Anda lalu klik Hapus.
- Pada dialog, ketik project ID, lalu klik Shut Down untuk menghapus project.
Resource
- Dokumentasi Document AI Workbench
- Masa Depan Dokumen - Playlist YouTube
- Dokumentasi Document AI
- Library Klien Python Document AI
- Sampel Document AI
Lisensi
Karya ini dilisensikan berdasarkan Lisensi Umum Creative Commons Attribution 2.0.