
۱. مقدمه
در این آزمایشگاه کد، یاد خواهید گرفت که چگونه از تجزیهگر فرم هوش مصنوعی سند برای تجزیه یک فرم دستنویس با پایتون استفاده کنید.
ما از یک فرم ساده پذیرش پزشکی به عنوان مثال استفاده خواهیم کرد، اما این روش با هر فرم عمومی پشتیبانی شده توسط DocAI کار خواهد کرد.
پیشنیازها
این آزمایشگاه کد بر اساس محتوای ارائه شده در سایر آزمایشگاههای کد هوش مصنوعی اسناد ساخته شده است.
توصیه میشود قبل از ادامه، Codelabs زیر را تکمیل کنید.
آنچه یاد خواهید گرفت
- نحوه تجزیه و استخراج دادهها از یک فرم اسکن شده با استفاده از تجزیهکننده فرم هوش مصنوعی سند.
آنچه نیاز دارید
نظرسنجی
چگونه از این آموزش استفاده خواهید کرد؟
تجربه خود را با پایتون چگونه ارزیابی میکنید؟
تجربه خود را در استفاده از خدمات ابری گوگل چگونه ارزیابی میکنید؟
۲. تنظیمات و الزامات
این آزمایشگاه کد فرض میکند که شما مراحل راهاندازی Document AI ذکر شده در آزمایشگاه کد Document AI OCR را تکمیل کردهاید.
لطفا قبل از ادامه مراحل زیر را انجام دهید:
همچنین باید Pandas ، یک کتابخانه تحلیل داده متنباز برای پایتون، را نصب کنید.
pip3 install --upgrade pandas
۳. ایجاد یک پردازنده تجزیهکننده فرم
ابتدا باید یک نمونه پردازشگر Form Parser ایجاد کنید تا در پلتفرم هوش مصنوعی سند برای این آموزش استفاده شود.
- در کنسول، به نمای کلی پلتفرم هوش مصنوعی اسناد بروید
- روی ایجاد پردازنده کلیک کنید و تجزیهگر فرم را انتخاب کنید

- نام پردازنده را مشخص کنید و منطقه خود را از لیست انتخاب کنید.
- برای ایجاد پردازنده خود، روی ایجاد کلیک کنید
- شناسه پردازنده خود را کپی کنید. بعداً باید از آن در کد خود استفاده کنید.
پردازنده تست در کنسول ابری
شما میتوانید با آپلود یک سند، پردازنده خود را در کنسول آزمایش کنید. روی آپلود سند کلیک کنید و یک فرم برای تجزیه انتخاب کنید. اگر فرم نمونهای برای استفاده ندارید، میتوانید آن را دانلود و استفاده کنید.

خروجی شما باید به این شکل باشد: 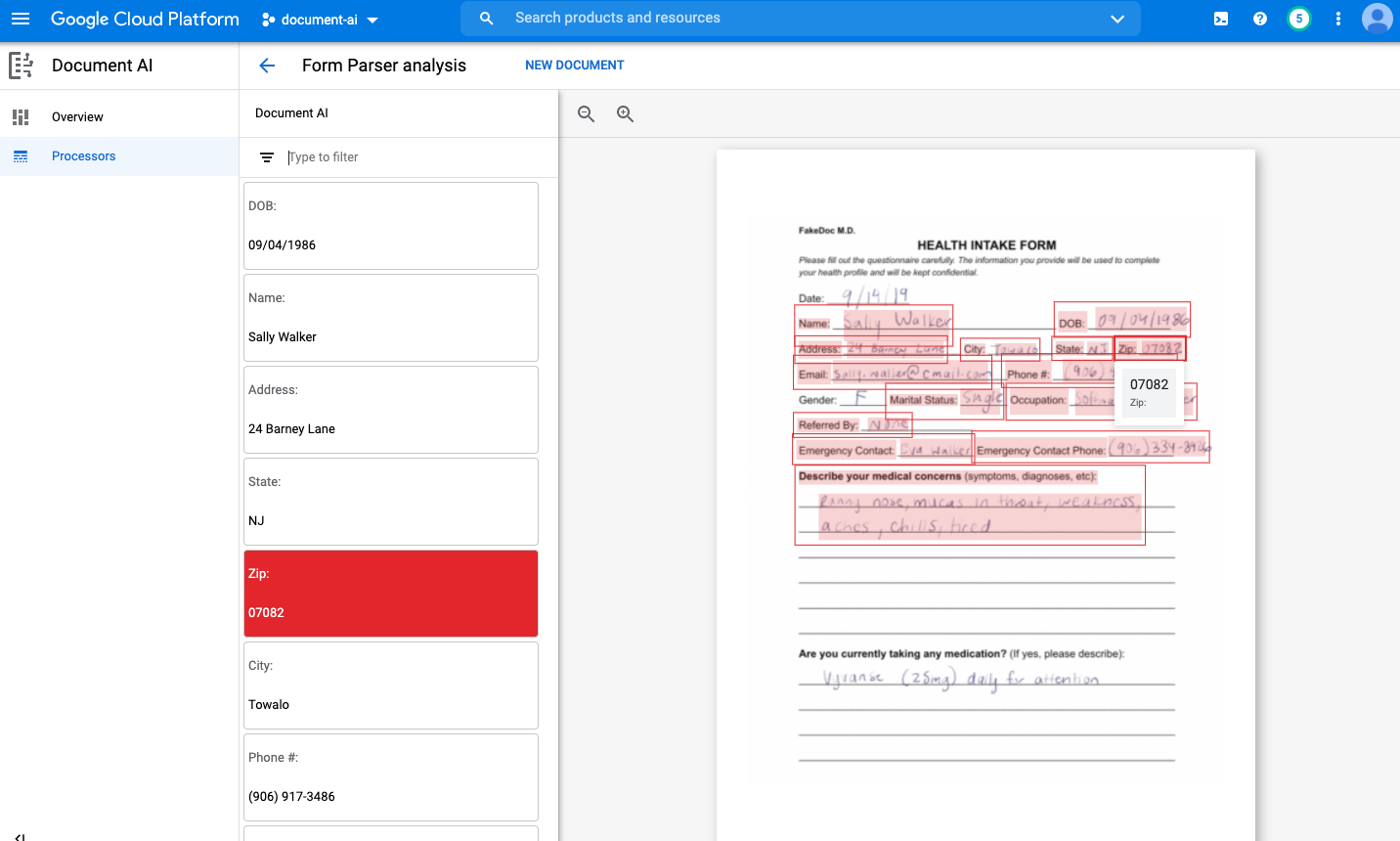
۴. فرم نمونه را دانلود کنید
ما یک سند نمونه داریم که شامل یک فرم ساده پذیرش پزشکی است.
میتوانید فایل PDF را با استفاده از لینک زیر دانلود کنید. سپس آن را در نمونه Cloud Shell آپلود کنید .
روش دیگر، دانلود آن از مخزن ذخیرهسازی ابری عمومی گوگل با استفاده از gsutil است.
gsutil cp gs://cloud-samples-data/documentai/codelabs/form-parser/intake-form.pdf .
با استفاده از دستور زیر، تأیید کنید که فایل در Cloud Shell شما دانلود شده است:
ls -ltr intake-form.pdf
۵. استخراج جفتهای کلید/مقدار فرم
در این مرحله، شما از API پردازش آنلاین برای فراخوانی پردازنده تجزیهگر فرم که قبلاً ایجاد کردهاید، استفاده خواهید کرد. سپس، جفتهای کلید-مقدار موجود در سند را استخراج خواهید کرد.
پردازش آنلاین برای ارسال یک سند واحد و انتظار برای پاسخ است. همچنین میتوانید در صورت تمایل به ارسال چندین فایل یا اگر حجم فایل از حداکثر تعداد صفحات پردازش آنلاین بیشتر است، از پردازش دستهای استفاده کنید. میتوانید نحوه انجام این کار را در OCR Codelab مرور کنید.
کد لازم برای ایجاد درخواست پردازش، برای هر نوع پردازندهای، به جز شناسه پردازنده، یکسان است.
شیء پاسخ Document شامل فهرستی از صفحات سند ورودی است.
هر شیء page شامل فهرستی از فیلدهای فرم و مکان آنها در متن است.
کد زیر در هر صفحه تکرار میشود و هر کلید، مقدار و امتیاز اطمینان را استخراج میکند. این دادههای ساختاریافته میتوانند به راحتی در پایگاههای داده ذخیره شوند یا در برنامههای دیگر استفاده شوند.
یک فایل به نام form_parser.py ایجاد کنید و از کد زیر استفاده کنید.
form_parser.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def trim_text(text: str):
"""
Remove extra space characters from text (blank, newline, tab, etc.)
"""
return text.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "intake-form.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
names = []
name_confidence = []
values = []
value_confidence = []
for page in document.pages:
for field in page.form_fields:
# Get the extracted field names
names.append(trim_text(field.field_name.text_anchor.content))
# Confidence - How "sure" the Model is that the text is correct
name_confidence.append(field.field_name.confidence)
values.append(trim_text(field.field_value.text_anchor.content))
value_confidence.append(field.field_value.confidence)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
{
"Field Name": names,
"Field Name Confidence": name_confidence,
"Field Value": values,
"Field Value Confidence": value_confidence,
}
)
print(df)
اکنون کد خود را اجرا کنید و باید متن استخراج شده و چاپ شده در کنسول خود را ببینید.
اگر از سند نمونه ما استفاده میکنید، باید خروجی زیر را مشاهده کنید:
$ python3 form_parser.py
Field Name Field Name Confidence Field Value Field Value Confidence
0 Phone #: 0.999982 (906) 917-3486 0.999982
1 Emergency Contact: 0.999972 Eva Walker 0.999972
2 Marital Status: 0.999951 Single 0.999951
3 Gender: 0.999933 F 0.999933
4 Occupation: 0.999914 Software Engineer 0.999914
5 Referred By: 0.999862 None 0.999862
6 Date: 0.999858 9/14/19 0.999858
7 DOB: 0.999716 09/04/1986 0.999716
8 Address: 0.999147 24 Barney Lane 0.999147
9 City: 0.997718 Towaco 0.997718
10 Name: 0.997345 Sally Walker 0.997345
11 State: 0.996944 NJ 0.996944
...
۶. تجزیه جداول
تجزیهکننده فرم همچنین قادر به استخراج دادهها از جداول درون اسناد است. در این مرحله، یک سند نمونه جدید دانلود کرده و دادهها را از جدول استخراج میکنیم. از آنجایی که دادهها را در Pandas بارگذاری میکنیم، این دادهها میتوانند با یک فراخوانی متد واحد، به صورت یک فایل CSV و بسیاری از فرمتهای دیگر خروجی داده شوند.
فرم نمونه را به همراه جداول دانلود کنید
ما یک سند نمونه داریم که شامل یک فرم نمونه و یک جدول است.
میتوانید فایل PDF را با استفاده از لینک زیر دانلود کنید. سپس آن را در نمونه Cloud Shell آپلود کنید .
روش دیگر، دانلود آن از مخزن ذخیرهسازی ابری عمومی گوگل با استفاده از gsutil است.
gsutil cp gs://cloud-samples-data/documentai/codelabs/form-parser/form_with_tables.pdf .
با استفاده از دستور زیر، تأیید کنید که فایل در Cloud Shell شما دانلود شده است:
ls -ltr form_with_tables.pdf
استخراج دادههای جدول
درخواست پردازش برای دادههای جدول دقیقاً مشابه استخراج جفتهای کلید-مقدار است. تفاوت در این است که دادهها را از کدام فیلدها در پاسخ استخراج میکنیم. دادههای جدول در فیلد pages[].tables[] ذخیره میشوند.
این مثال اطلاعات مربوط به هر جدول و صفحه را از سطرهای سربرگ و سطرهای بدنه جدول استخراج میکند، سپس جدول را چاپ کرده و آن را به عنوان یک فایل CSV ذخیره میکند.
یک فایل به نام table_parsing.py ایجاد کنید و از کد زیر استفاده کنید.
table_parsing.py
# type: ignore[1]
"""
Uses Document AI online processing to call a form parser processor
Extracts the tables and data in the document.
"""
from os.path import splitext
from typing import List, Sequence
import pandas as pd
from google.cloud import documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def get_table_data(
rows: Sequence[documentai.Document.Page.Table.TableRow], text: str
) -> List[List[str]]:
"""
Get Text data from table rows
"""
all_values: List[List[str]] = []
for row in rows:
current_row_values: List[str] = []
for cell in row.cells:
current_row_values.append(
text_anchor_to_text(cell.layout.text_anchor, text)
)
all_values.append(current_row_values)
return all_values
def text_anchor_to_text(text_anchor: documentai.Document.TextAnchor, text: str) -> str:
"""
Document AI identifies table data by their offsets in the entirety of the
document's text. This function converts offsets to a string.
"""
response = ""
# If a text segment spans several lines, it will
# be stored in different text segments.
for segment in text_anchor.text_segments:
start_index = int(segment.start_index)
end_index = int(segment.end_index)
response += text[start_index:end_index]
return response.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # Create processor before running sample
# The local file in your current working directory
FILE_PATH = "form_with_tables.pdf"
# Refer to https://cloud.google.com/document-ai/docs/file-types
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
header_row_values: List[List[str]] = []
body_row_values: List[List[str]] = []
# Input Filename without extension
output_file_prefix = splitext(FILE_PATH)[0]
for page in document.pages:
for index, table in enumerate(page.tables):
header_row_values = get_table_data(table.header_rows, document.text)
body_row_values = get_table_data(table.body_rows, document.text)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
data=body_row_values,
columns=pd.MultiIndex.from_arrays(header_row_values),
)
print(f"Page {page.page_number} - Table {index}")
print(df)
# Save each table as a CSV file
output_filename = f"{output_file_prefix}_pg{page.page_number}_tb{index}.csv"
df.to_csv(output_filename, index=False)
اکنون کد خود را اجرا کنید و باید متن استخراج شده و چاپ شده در کنسول خود را ببینید.
اگر از سند نمونه ما استفاده میکنید، باید خروجی زیر را مشاهده کنید:
$ python3 table_parsing.py
Page 1 - Table 0
Item Description
0 Item 1 Description 1
1 Item 2 Description 2
2 Item 3 Description 3
Page 1 - Table 1
Form Number: 12345678
0 Form Date: 2020/10/01
1 Name: First Last
2 Address: 123 Fake St
همچنین باید دو فایل CSV جدید در دایرکتوری که کد را از آن اجرا میکنید، داشته باشید.
$ ls form_with_tables_pg1_tb0.csv form_with_tables_pg1_tb1.csv table_parsing.py
۷. تبریک
تبریک میگوییم، شما با موفقیت از API هوش مصنوعی اسناد برای استخراج دادهها از یک فرم دستنویس استفاده کردید. ما شما را تشویق میکنیم که با اسناد فرمهای دیگر آزمایش کنید.
تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این آموزش:
- در کنسول ابری، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژه خود را انتخاب کنید و سپس روی حذف کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن (Shut down) کلیک کنید.
اطلاعات بیشتر
با این Codelabs های بعدی، به یادگیری در مورد هوش مصنوعی اسناد ادامه دهید.
- پردازندههای تخصصی با هوش مصنوعی اسناد (پایتون)
- مدیریت پردازندههای هوش مصنوعی اسناد با پایتون
- هوش مصنوعی سند: انسان در حلقه
منابع
مجوز
این اثر تحت مجوز عمومی Creative Commons Attribution 2.0 منتشر شده است.