
۱. مرور کلی
هوش مصنوعی اسناد چیست؟
هوش مصنوعی اسناد، یک راهکار درک اسناد است که دادههای بدون ساختار (مانند اسناد، ایمیلها، فاکتورها، فرمها و غیره) را دریافت کرده و درک، تجزیه و تحلیل و استفاده از دادهها را آسانتر میکند. این API از طریق طبقهبندی محتوا، استخراج موجودیت، جستجوی پیشرفته و موارد دیگر، ساختار ایجاد میکند.
در این آزمایشگاه، شما یاد خواهید گرفت که چگونه با استفاده از API هوش مصنوعی اسناد (Document AI API) در پایتون، تشخیص نوری کاراکتر را انجام دهید.
ما از یک فایل PDF از رمان کلاسیک "وینی پو" نوشتهی ای.ای. میلن استفاده خواهیم کرد که اخیراً در ایالات متحده به مالکیت عمومی درآمده است. این فایل توسط گوگل بوکز اسکن و دیجیتالی شده است.
آنچه یاد خواهید گرفت
- نحوه فعال کردن API هوش مصنوعی اسناد
- نحوه احراز هویت درخواستهای API
- نحوه نصب کتابخانه کلاینت برای پایتون
- نحوه استفاده از API های پردازش آنلاین و دسته ای
- نحوه تجزیه متن از یک فایل PDF
آنچه نیاز دارید
نظرسنجی
چگونه از این آموزش استفاده خواهید کرد؟
تجربه خود را با پایتون چگونه ارزیابی میکنید؟
تجربه خود را در استفاده از خدمات ابری گوگل چگونه ارزیابی میکنید؟
۲. تنظیمات و الزامات
تنظیم محیط خودتنظیم
- وارد Cloud Console شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. (اگر از قبل حساب Gmail یا Google Workspace ندارید، باید یکی ایجاد کنید .)


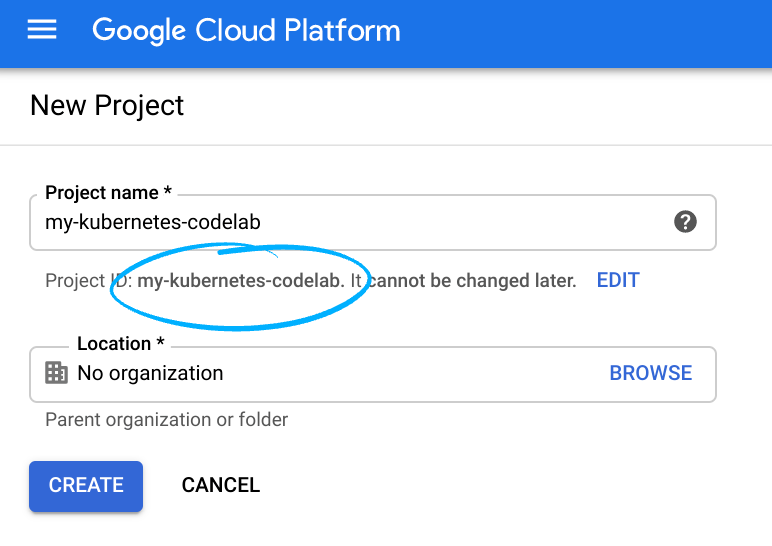
شناسه پروژه، یک نام منحصر به فرد در تمام پروژههای Google Cloud، را به خاطر بسپارید. (شناسه پروژه بالا قبلاً گرفته شده و برای شما کار نخواهد کرد، متاسفیم!). شما باید این شناسه را بعداً به عنوان PROJECT_ID ارائه دهید.
- در مرحله بعد، برای استفاده از منابع گوگل کلود، باید پرداخت صورتحساب را در Cloud Console فعال کنید .
حتماً دستورالعملهای بخش «پاکسازی» را دنبال کنید. این بخش به شما توصیه میکند که چگونه منابع را خاموش کنید تا پس از این آموزش، متحمل هزینه نشوید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
در حالی که میتوانید با استفاده از گوگل کلود، گوگل کلود را از راه دور و از طریق لپتاپ خود مدیریت کنید، این آزمایشگاه کد از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده میکند.
فعال کردن پوسته ابری
- از کنسول ابری، روی فعال کردن پوسته ابری کلیک کنید


اگر قبلاً Cloud Shell را شروع نکردهاید، یک صفحه میانی (در پایین صفحه) به شما نمایش داده میشود که توضیح میدهد چیست. در این صورت، روی ادامه کلیک کنید (و دیگر هرگز آن را نخواهید دید). آن صفحه یکبار مصرف به این شکل است:

آمادهسازی و اتصال به Cloud Shell فقط چند لحظه طول میکشد.

Cloud Shell دسترسی ترمینال به یک ماشین مجازی میزبانی شده در فضای ابری را برای شما فراهم میکند. این ماشین مجازی شامل تمام ابزارهای توسعه مورد نیاز شما است. این ماشین یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و در فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی افزایش میدهد. بخش عمدهای از کار شما در این آزمایشگاه کد، اگر نگوییم همه، را میتوان به سادگی با یک مرورگر انجام داد.
پس از اتصال به Cloud Shell، باید ببینید که از قبل احراز هویت شدهاید و پروژه از قبل روی شناسه پروژه شما تنظیم شده است.
- برای تأیید احراز هویت، دستور زیر را در Cloud Shell اجرا کنید:
gcloud auth list
خروجی دستور
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
خروجی دستور
[core] project = <PROJECT_ID>
اگر اینطور نیست، میتوانید با این دستور آن را تنظیم کنید:
gcloud config set project <PROJECT_ID>
خروجی دستور
Updated property [core/project].
۳. فعال کردن API هوش مصنوعی اسناد
قبل از اینکه بتوانید از Document AI استفاده کنید، باید API را فعال کنید. میتوانید این کار را با استفاده از رابط خط فرمان gcloud یا کنسول ابری انجام دهید.
از رابط خط فرمان gcloud استفاده کنید
- اگر از Cloud Shell استفاده نمیکنید، مراحل نصب
gcloudCLI را روی دستگاه محلی خود دنبال کنید. - APIها را میتوان با استفاده از دستورات
gcloudزیر فعال کرد.
gcloud services enable documentai.googleapis.com storage.googleapis.com
شما باید چیزی شبیه به این را ببینید:
Operation "operations/..." finished successfully.
استفاده از کنسول ابری
کنسول ابری را در مرورگر خود باز کنید.
- با استفاده از نوار جستجو در بالای کنسول، عبارت «Document AI API» را جستجو کنید، سپس برای استفاده از API در پروژه Google Cloud خود، روی فعالسازی کلیک کنید.

- مرحله قبل را برای API ذخیرهسازی ابری گوگل تکرار کنید.
حالا میتوانید از هوش مصنوعی اسناد استفاده کنید!
۴. یک پردازنده ایجاد و آزمایش کنید
ابتدا باید یک نمونه از پردازنده OCR سند ایجاد کنید که استخراج را انجام دهد. این کار را میتوان با استفاده از کنسول ابری یا API مدیریت پردازنده انجام داد.
کنسول ابری
- در کنسول، به نمای کلی پلتفرم هوش مصنوعی اسناد بروید

- روی «کاوش پردازندهها» کلیک کنید و «OCR سند» را انتخاب کنید
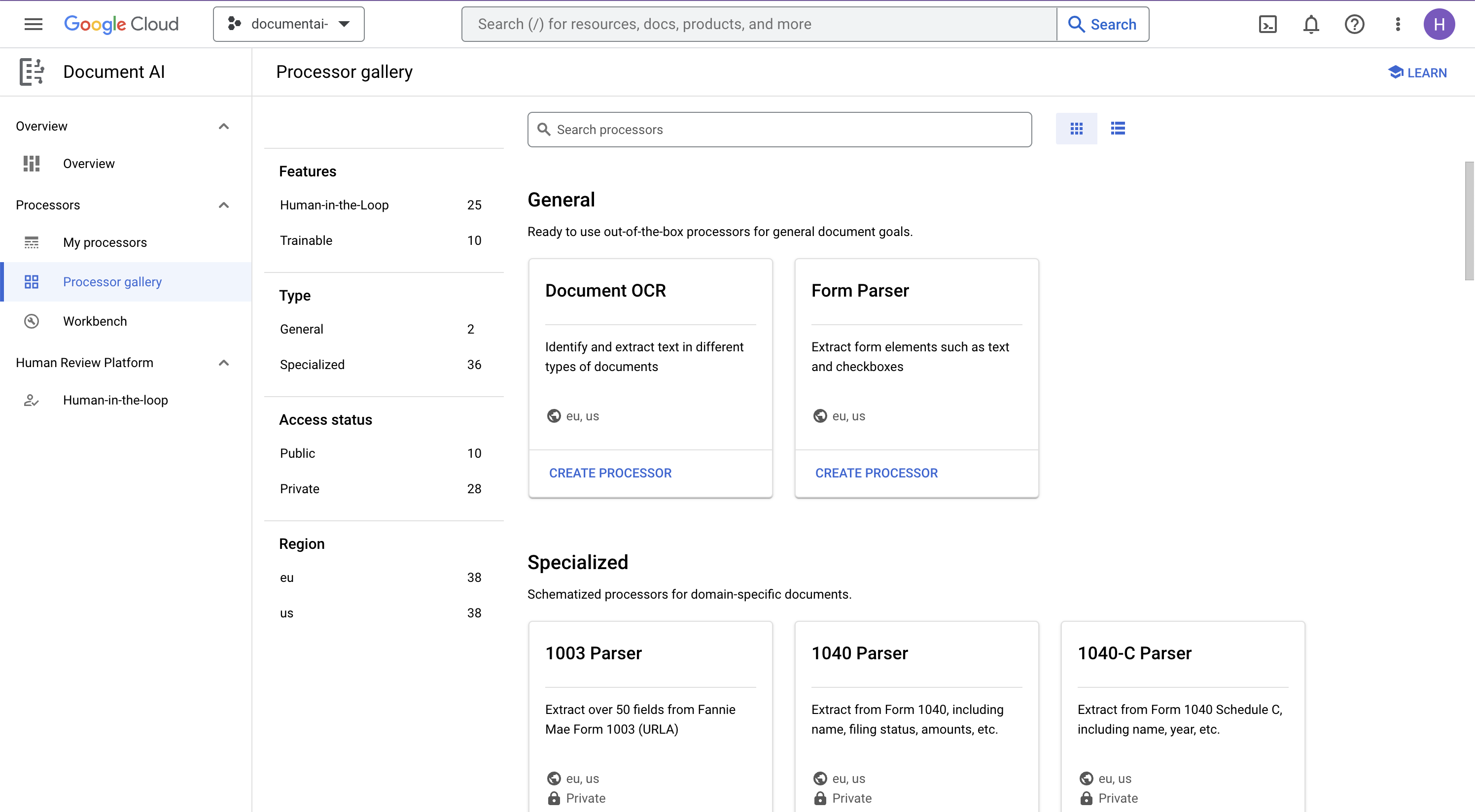
- نام آن را
codelab-ocr(یا هر چیز دیگری که به خاطر دارید) بگذارید و نزدیکترین ناحیه را در لیست انتخاب کنید. - برای ایجاد پردازنده خود، روی ایجاد کلیک کنید
- شناسه پردازنده خود را کپی کنید. بعداً باید از آن در کد خود استفاده کنید.

شما میتوانید با آپلود یک سند، پردازنده خود را در کنسول آزمایش کنید. روی آپلود سند آزمایشی کلیک کنید و سندی را برای تجزیه انتخاب کنید.
شما میتوانید فایل PDF زیر را که شامل ۳ صفحه اول رمان ما است، دانلود کنید.

خروجی شما باید به این شکل باشد: 
کتابخانه کلاینت پایتون
برای یادگیری نحوه مدیریت پردازندههای هوش مصنوعی اسناد با کتابخانه کلاینت پایتون، این codelab را دنبال کنید:
۵. درخواستهای API را تأیید اعتبار کنید
برای ارسال درخواست به API مربوط به Document AI، باید از یک حساب کاربری سرویس (Service Account) استفاده کنید. یک حساب کاربری سرویس متعلق به پروژه شماست و توسط کتابخانه کلاینت پایتون برای ارسال درخواستهای API استفاده میشود. مانند هر حساب کاربری دیگر، یک حساب کاربری سرویس با یک آدرس ایمیل نمایش داده میشود. در این بخش، شما از Cloud SDK برای ایجاد یک حساب کاربری سرویس استفاده خواهید کرد و سپس اعتبارنامههایی را که برای تأیید اعتبار به عنوان حساب کاربری سرویس نیاز دارید، ایجاد خواهید کرد.
ابتدا، Cloud Shell را باز کنید و یک متغیر محیطی با PROJECT_ID خود تنظیم کنید که در طول این codelab از آن استفاده خواهید کرد:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
در مرحله بعد، با استفاده از دستور زیر، یک حساب کاربری سرویس جدید برای دسترسی به Document AI API ایجاد کنید:
gcloud iam service-accounts create my-docai-sa \
--display-name "my-docai-service-account"
در مرحله بعد، به حساب کاربری سرویس خود مجوزهای دسترسی به هوش مصنوعی اسناد و فضای ذخیرهسازی ابری را در پروژه خود بدهید.
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member="serviceAccount:my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--role="roles/documentai.admin"
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member="serviceAccount:my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member="serviceAccount:my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--role="roles/serviceusage.serviceUsageConsumer"
در مرحله بعد، اعتبارنامههایی ایجاد کنید که کد پایتون شما برای ورود به حساب کاربری سرویس جدیدتان از آنها استفاده کند. این اعتبارنامهها را ایجاد کرده و با استفاده از دستور زیر، آن را به عنوان یک فایل JSON ~/key.json ذخیره کنید:
gcloud iam service-accounts keys create ~/key.json \
--iam-account my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
در نهایت، متغیر محیطی GOOGLE_APPLICATION_CREDENTIALS را که توسط کتابخانه برای یافتن اعتبارنامههای شما استفاده میشود، تنظیم کنید. برای مطالعه بیشتر در مورد این نوع احراز هویت، به راهنما مراجعه کنید. متغیر محیطی باید با استفاده از دستور زیر، روی مسیر کامل فایل JSON اعتبارنامههایی که ایجاد کردهاید، تنظیم شود:
export GOOGLE_APPLICATION_CREDENTIALS="/path/to/key.json"
۶. کتابخانه کلاینت را نصب کنید
کتابخانههای کلاینت پایتون را برای Document AI، Cloud Storage و Document AI Toolbox نصب کنید:
pip3 install --upgrade google-cloud-documentai
pip3 install --upgrade google-cloud-storage
pip3 install --upgrade google-cloud-documentai-toolbox
شما باید چیزی شبیه به این را ببینید:
... Installing collected packages: google-cloud-documentai Successfully installed google-cloud-documentai-2.15.0 . . Installing collected packages: google-cloud-storage Successfully installed google-cloud-storage-2.9.0 . . Installing collected packages: google-cloud-documentai-toolbox Successfully installed google-cloud-documentai-toolbox-0.6.0a0
حالا، شما آماده استفاده از API هوش مصنوعی اسناد هستید!
۷. نمونه PDF را دانلود کنید
ما یک سند نمونه داریم که شامل ۳ صفحه اول رمان است.
میتوانید فایل PDF را با استفاده از لینک زیر دانلود کنید. سپس آن را در نمونه cloudshell آپلود کنید .
همچنین میتوانید با استفاده از gsutil آن را از مخزن ذخیرهسازی ابری عمومی گوگل ما دانلود کنید.
gsutil cp gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh_3_Pages.pdf .
۸. درخواست پردازش آنلاین ارسال کنید
در این مرحله، شما ۳ صفحه اول رمان را با استفاده از API پردازش آنلاین (همزمان) پردازش خواهید کرد. این روش برای اسناد کوچکتری که به صورت محلی ذخیره میشوند، مناسبتر است. برای اطلاع از حداکثر صفحات و حجم فایل برای هر نوع پردازنده ، لیست کامل پردازندهها را بررسی کنید.
با استفاده از ویرایشگر Cloud Shell یا یک ویرایشگر متن در دستگاه محلی خود، فایلی به نام online_processing.py ایجاد کنید و از کد زیر در آن استفاده کنید.
YOUR_PROJECT_ID ، YOUR_PROJECT_LOCATION ، YOUR_PROCESSOR_ID و FILE_PATH را با مقادیر مناسب برای محیط خود جایگزین کنید.
پردازش آنلاین.py
from google.api_core.client_options import ClientOptions
from google.cloud import documentai
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "Winnie_the_Pooh_3_Pages.pdf"
# Refer to https://cloud.google.com/document-ai/docs/file-types
# for supported file types
MIME_TYPE = "application/pdf"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Read the file into memory
with open(FILE_PATH, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=image_content, mime_type=MIME_TYPE)
# Configure the process request
request = documentai.ProcessRequest(name=RESOURCE_NAME, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = docai_client.process_document(request=request)
document_object = result.document
print("Document processing complete.")
print(f"Text: {document_object.text}")
کد را اجرا کنید، که متن را استخراج کرده و در کنسول چاپ میکند.
اگر از سند نمونه ما استفاده میکنید، باید خروجی زیر را مشاهده کنید:
Document processing complete. Text: CHAPTER I IN WHICH We Are Introduced to Winnie-the-Pooh and Some Bees, and the Stories Begin Here is Edward Bear, coming downstairs now, bump, bump, bump, on the back of his head, behind Christopher Robin. It is, as far as he knows, the only way of coming downstairs, but sometimes he feels that there really is another way, if only he could stop bumping for a moment and think of it. And then he feels that perhaps there isn't. Anyhow, here he is at the bottom, and ready to be introduced to you. Winnie-the-Pooh. When I first heard his name, I said, just as you are going to say, "But I thought he was a boy?" "So did I," said Christopher Robin. "Then you can't call him Winnie?" "I don't." "But you said " ... Digitized by Google
۹. درخواست پردازش دستهای ایجاد کنید
حالا فرض کنید میخواهید کل رمان را از روی متن بخوانید.
- پردازش آنلاین محدودیتهایی در تعداد صفحات و اندازه فایل ارسالی دارد و فقط امکان ارسال یک فایل سند را در هر فراخوانی API فراهم میکند.
- پردازش دستهای امکان پردازش فایلهای بزرگتر/متعدد را به روشی ناهمزمان فراهم میکند.
در این مرحله، کل رمان «وینی پو» را با API پردازش دستهای هوش مصنوعی اسناد پردازش میکنیم و متن را در یک سطل ذخیرهسازی ابری گوگل (Google Cloud Storage Bucket) خروجی میدهیم.
پردازش دستهای از عملیات طولانی مدت (Long Running Operations) برای مدیریت درخواستها به صورت غیرهمزمان استفاده میکند، بنابراین ما باید درخواست را ایجاد کنیم و خروجی را به روشی متفاوت از پردازش آنلاین بازیابی کنیم. با این حال، خروجی چه با استفاده از پردازش آنلاین و چه با استفاده از پردازش دستهای، در همان قالب شیء Document object) خواهد بود.
این مرحله نحوه ارائه اسناد خاص برای پردازش توسط هوش مصنوعی اسناد را نشان میدهد. مرحله بعدی نحوه پردازش کل فهرست اسناد را نشان خواهد داد.
آپلود فایل PDF در فضای ذخیرهسازی ابری
متد batch_process_documents() در حال حاضر فایلها را از فضای ذخیرهسازی ابری گوگل میپذیرد. برای اطلاعات بیشتر در مورد ساختار شیء، میتوانید به documentai_v1.types.BatchProcessRequest مراجعه کنید.
برای این مثال، میتوانید فایل را مستقیماً از سطل نمونه ما بخوانید.
همچنین میتوانید با استفاده از gsutil فایل را در سطل خود کپی کنید ...
gsutil cp gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh.pdf gs://YOUR_BUCKET_NAME/
... یا میتوانید فایل نمونه رمان را از لینک زیر دانلود کرده و در سطل خودتان آپلود کنید .
همچنین برای ذخیره خروجی API به یک GCS Bucket نیاز خواهید داشت.
برای یادگیری نحوه ایجاد سطلهای ذخیرهسازی، میتوانید مستندات ذخیرهسازی ابری را دنبال کنید.
استفاده از متد batch_process_documents()
یک فایل به نام batch_processing.py ایجاد کنید و از کد زیر استفاده کنید.
مقادیر YOUR_PROJECT_ID ، YOUR_PROCESSOR_LOCATION ، YOUR_PROCESSOR_ID ، YOUR_INPUT_URI و YOUR_OUTPUT_URI را با مقادیر مناسب برای محیط خود جایگزین کنید.
مطمئن شوید که YOUR_INPUT_URI مستقیماً به فایل pdf اشاره میکند، برای مثال: gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh.pdf .
پردازش دستهای.py
"""
Makes a Batch Processing Request to Document AI
"""
import re
from google.api_core.client_options import ClientOptions
from google.api_core.exceptions import InternalServerError
from google.api_core.exceptions import RetryError
from google.cloud import documentai
from google.cloud import storage
# TODO(developer): Fill these variables before running the sample.
project_id = "YOUR_PROJECT_ID"
location = "YOUR_PROCESSOR_LOCATION" # Format is "us" or "eu"
processor_id = "YOUR_PROCESSOR_ID" # Create processor before running sample
gcs_output_uri = "YOUR_OUTPUT_URI" # Must end with a trailing slash `/`. Format: gs://bucket/directory/subdirectory/
processor_version_id = (
"YOUR_PROCESSOR_VERSION_ID" # Optional. Example: pretrained-ocr-v1.0-2020-09-23
)
# TODO(developer): If `gcs_input_uri` is a single file, `mime_type` must be specified.
gcs_input_uri = "YOUR_INPUT_URI" # Format: `gs://bucket/directory/file.pdf` or `gs://bucket/directory/`
input_mime_type = "application/pdf"
field_mask = "text,entities,pages.pageNumber" # Optional. The fields to return in the Document object.
def batch_process_documents(
project_id: str,
location: str,
processor_id: str,
gcs_input_uri: str,
gcs_output_uri: str,
processor_version_id: str = None,
input_mime_type: str = None,
field_mask: str = None,
timeout: int = 400,
):
# You must set the api_endpoint if you use a location other than "us".
opts = ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com")
client = documentai.DocumentProcessorServiceClient(client_options=opts)
if not gcs_input_uri.endswith("/") and "." in gcs_input_uri:
# Specify specific GCS URIs to process individual documents
gcs_document = documentai.GcsDocument(
gcs_uri=gcs_input_uri, mime_type=input_mime_type
)
# Load GCS Input URI into a List of document files
gcs_documents = documentai.GcsDocuments(documents=[gcs_document])
input_config = documentai.BatchDocumentsInputConfig(gcs_documents=gcs_documents)
else:
# Specify a GCS URI Prefix to process an entire directory
gcs_prefix = documentai.GcsPrefix(gcs_uri_prefix=gcs_input_uri)
input_config = documentai.BatchDocumentsInputConfig(gcs_prefix=gcs_prefix)
# Cloud Storage URI for the Output Directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=gcs_output_uri, field_mask=field_mask
)
# Where to write results
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
if processor_version_id:
# The full resource name of the processor version, e.g.:
# projects/{project_id}/locations/{location}/processors/{processor_id}/processorVersions/{processor_version_id}
name = client.processor_version_path(
project_id, location, processor_id, processor_version_id
)
else:
# The full resource name of the processor, e.g.:
# projects/{project_id}/locations/{location}/processors/{processor_id}
name = client.processor_path(project_id, location, processor_id)
request = documentai.BatchProcessRequest(
name=name,
input_documents=input_config,
document_output_config=output_config,
)
# BatchProcess returns a Long Running Operation (LRO)
operation = client.batch_process_documents(request)
# Continually polls the operation until it is complete.
# This could take some time for larger files
# Format: projects/{project_id}/locations/{location}/operations/{operation_id}
try:
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result(timeout=timeout)
# Catch exception when operation doesn"t finish before timeout
except (RetryError, InternalServerError) as e:
print(e.message)
# NOTE: Can also use callbacks for asynchronous processing
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
# Once the operation is complete,
# get output document information from operation metadata
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
storage_client = storage.Client()
print("Output files:")
# One process per Input Document
for process in list(metadata.individual_process_statuses):
# output_gcs_destination format: gs://BUCKET/PREFIX/OPERATION_NUMBER/INPUT_FILE_NUMBER/
# The Cloud Storage API requires the bucket name and URI prefix separately
matches = re.match(r"gs://(.*?)/(.*)", process.output_gcs_destination)
if not matches:
print(
"Could not parse output GCS destination:",
process.output_gcs_destination,
)
continue
output_bucket, output_prefix = matches.groups()
# Get List of Document Objects from the Output Bucket
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# Document AI may output multiple JSON files per source file
for blob in output_blobs:
# Document AI should only output JSON files to GCS
if blob.content_type != "application/json":
print(
f"Skipping non-supported file: {blob.name} - Mimetype: {blob.content_type}"
)
continue
# Download JSON File as bytes object and convert to Document Object
print(f"Fetching {blob.name}")
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
# For a full list of Document object attributes, please reference this page:
# https://cloud.google.com/python/docs/reference/documentai/latest/google.cloud.documentai_v1.types.Document
# Read the text recognition output from the processor
print("The document contains the following text:")
print(document.text)
if __name__ == "__main__":
batch_process_documents(
project_id=project_id,
location=location,
processor_id=processor_id,
gcs_input_uri=gcs_input_uri,
gcs_output_uri=gcs_output_uri,
input_mime_type=input_mime_type,
field_mask=field_mask,
)
کد را اجرا کنید، و باید متن کامل رمان را که در کنسول شما استخراج و چاپ شده است، ببینید.
ممکن است تکمیل این مرحله کمی طول بکشد زیرا فایل بسیار بزرگتر از مثال قبلی است. (وای، بیخیال...)
با این حال، با API پردازش دستهای، یک شناسه عملیات دریافت خواهید کرد که میتواند برای دریافت خروجی از GCS پس از اتمام کار استفاده شود.
خروجی شما باید چیزی شبیه به این باشد:
Waiting for operation projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_NUMBER to complete... Document processing complete. Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-0.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-1.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-10.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-11.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-12.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-13.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-14.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-15.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-16.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-17.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-18.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-2.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-3.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-4.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-5.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-6.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-7.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-8.json Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh-9.json This is a reproduction of a library book that was digitized by Google as part of an ongoing effort to preserve the information in books and make it universally accessible. TM Google books https://books.google.com ..... He nodded and went out ... and in a moment I heard Winnie-the-Pooh -bump, bump, bump-go-ing up the stairs behind him. Digitized by Google
۱۰. درخواست پردازش دستهای برای یک دایرکتوری ایجاد کنید
گاهی اوقات، ممکن است بخواهید کل یک دایرکتوری از اسناد را پردازش کنید، بدون اینکه هر سند را به صورت جداگانه فهرست کنید. متد batch_process_documents() از ورودی لیستی از اسناد خاص یا مسیر دایرکتوری پشتیبانی میکند.
این مرحله نحوه پردازش یک دایرکتوری کامل از فایلهای سند را نشان میدهد. بیشتر کد مانند مرحله قبل عمل میکند، تنها تفاوت در URI ارسالی GCS با BatchProcessRequest است.
ما در سطل نمونه خود یک دایرکتوری داریم که شامل چندین صفحه از رمان در فایلهای جداگانه است.
-
gs://cloud-samples-data/documentai/codelabs/ocr/multi-document/
میتوانید فایلها را مستقیماً بخوانید یا آنها را در فضای ذخیرهسازی ابری خود کپی کنید.
کد مرحله قبل را دوباره اجرا کنید و YOUR_INPUT_URI با یک دایرکتوری در Cloud Storage جایگزین کنید.
کد را اجرا کنید، و باید متن استخراج شده از تمام فایلهای سند موجود در دایرکتوری Cloud Storage را مشاهده کنید.
خروجی شما باید چیزی شبیه به این باشد:
Waiting for operation projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_NUMBER to complete... Document processing complete. Fetching docai-output/OPERATION_NUMBER/0/Winnie_the_Pooh_Page_0-0.json Fetching docai-output/OPERATION_NUMBER/1/Winnie_the_Pooh_Page_1-0.json Fetching docai-output/OPERATION_NUMBER/2/Winnie_the_Pooh_Page_10-0.json Fetching docai-output/OPERATION_NUMBER/3/Winnie_the_Pooh_Page_12-0.json Fetching docai-output/OPERATION_NUMBER/4/Winnie_the_Pooh_Page_16-0.json Fetching docai-output/OPERATION_NUMBER/5/Winnie_the_Pooh_Page_7-0.json Introduction (I₂ F YOU happen to have read another book about Christopher Robin, you may remember th CHAPTER I IN WHICH We Are Introduced to Winnie-the-Pooh and Some Bees, and the Stories Begin HERE is 10 WINNIE-THE-POOH "I wonder if you've got such a thing as a balloon about you?" "A balloon?" "Yes, 12 WINNIE-THE-POOH and you took your gun with you, just in case, as you always did, and Winnie-the-P 16 WINNIE-THE-POOH this song, and one bee sat down on the nose of the cloud for a moment, and then g WE ARE INTRODUCED 7 "Oh, help!" said Pooh, as he dropped ten feet on the branch below him. "If only
۱۱. مدیریت پاسخ پردازش دستهای با جعبه ابزار هوش مصنوعی اسناد
پردازش دستهای به دلیل ادغام با فضای ذخیرهسازی ابری، به چند مرحله نیاز دارد. خروجی Document همچنین میتواند بسته به اندازه سند ورودی، به چندین فایل .json تقسیم شود.
جعبه ابزار پایتون Document AI Toolbox برای سادهسازی پسپردازش و سایر وظایف رایج با Document AI ایجاد شده است. این کتابخانه قرار است مکمل کتابخانه کلاینت Document AI باشد، نه جایگزین آن. برای مشخصات کامل به مستندات مرجع مراجعه کنید.
این مرحله نحوه ایجاد یک درخواست پردازش دستهای و بازیابی خروجی با استفاده از جعبه ابزار هوش مصنوعی سند (Document AI Toolbox) را نشان میدهد.
ابزار پردازش دستهای.py
"""
Makes a Batch Processing Request to Document AI using Document AI Toolbox
"""
from google.api_core.client_options import ClientOptions
from google.cloud import documentai
from google.cloud import documentai_toolbox
# TODO(developer): Fill these variables before running the sample.
project_id = "YOUR_PROJECT_ID"
location = "YOUR_PROCESSOR_LOCATION" # Format is "us" or "eu"
processor_id = "YOUR_PROCESSOR_ID" # Create processor before running sample
gcs_output_uri = "YOUR_OUTPUT_URI" # Must end with a trailing slash `/`. Format: gs://bucket/directory/subdirectory/
processor_version_id = (
"YOUR_PROCESSOR_VERSION_ID" # Optional. Example: pretrained-ocr-v1.0-2020-09-23
)
# TODO(developer): If `gcs_input_uri` is a single file, `mime_type` must be specified.
gcs_input_uri = "YOUR_INPUT_URI" # Format: `gs://bucket/directory/file.pdf`` or `gs://bucket/directory/``
input_mime_type = "application/pdf"
field_mask = "text,entities,pages.pageNumber" # Optional. The fields to return in the Document object.
def batch_process_toolbox(
project_id: str,
location: str,
processor_id: str,
gcs_input_uri: str,
gcs_output_uri: str,
processor_version_id: str = None,
input_mime_type: str = None,
field_mask: str = None,
):
# You must set the api_endpoint if you use a location other than "us".
opts = ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com")
client = documentai.DocumentProcessorServiceClient(client_options=opts)
if not gcs_input_uri.endswith("/") and "." in gcs_input_uri:
# Specify specific GCS URIs to process individual documents
gcs_document = documentai.GcsDocument(
gcs_uri=gcs_input_uri, mime_type=input_mime_type
)
# Load GCS Input URI into a List of document files
gcs_documents = documentai.GcsDocuments(documents=[gcs_document])
input_config = documentai.BatchDocumentsInputConfig(gcs_documents=gcs_documents)
else:
# Specify a GCS URI Prefix to process an entire directory
gcs_prefix = documentai.GcsPrefix(gcs_uri_prefix=gcs_input_uri)
input_config = documentai.BatchDocumentsInputConfig(gcs_prefix=gcs_prefix)
# Cloud Storage URI for the Output Directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=gcs_output_uri, field_mask=field_mask
)
# Where to write results
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
if processor_version_id:
# The full resource name of the processor version, e.g.:
# projects/{project_id}/locations/{location}/processors/{processor_id}/processorVersions/{processor_version_id}
name = client.processor_version_path(
project_id, location, processor_id, processor_version_id
)
else:
# The full resource name of the processor, e.g.:
# projects/{project_id}/locations/{location}/processors/{processor_id}
name = client.processor_path(project_id, location, processor_id)
request = documentai.BatchProcessRequest(
name=name,
input_documents=input_config,
document_output_config=output_config,
)
# BatchProcess returns a Long Running Operation (LRO)
operation = client.batch_process_documents(request)
# Operation Name Format: projects/{project_id}/locations/{location}/operations/{operation_id}
documents = documentai_toolbox.document.Document.from_batch_process_operation(
location=location, operation_name=operation.operation.name
)
for document in documents:
# Read the text recognition output from the processor
print("The document contains the following text:")
# Truncated at 100 characters for brevity
print(document.text[:100])
if __name__ == "__main__":
batch_process_toolbox(
project_id=project_id,
location=location,
processor_id=processor_id,
gcs_input_uri=gcs_input_uri,
gcs_output_uri=gcs_output_uri,
input_mime_type=input_mime_type,
field_mask=field_mask,
)
۱۲. تبریک
شما با موفقیت از هوش مصنوعی اسناد برای استخراج متن از یک رمان با استفاده از پردازش آنلاین، پردازش دستهای و جعبه ابزار هوش مصنوعی اسناد استفاده کردهاید.
ما شما را تشویق میکنیم که با اسناد دیگر آزمایش کنید و پردازندههای دیگر موجود در پلتفرم را بررسی کنید.
تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این آموزش:
- در کنسول ابری، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژه خود را انتخاب کنید و سپس روی حذف کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن (Shut down) کلیک کنید.
اطلاعات بیشتر
با این Codelabs های بعدی، به یادگیری در مورد هوش مصنوعی اسناد ادامه دهید.
- تجزیه فرم با هوش مصنوعی اسناد (پایتون)
- پردازندههای تخصصی با هوش مصنوعی اسناد (پایتون)
- مدیریت پردازندههای هوش مصنوعی اسناد با پایتون
- هوش مصنوعی سند: انسان در حلقه
منابع
- آینده اسناد - لیست پخش یوتیوب
- مستندسازی هوش مصنوعی
- کتابخانه کلاینت پایتون برای مستندسازی هوش مصنوعی
- مخزن نمونههای هوش مصنوعی اسناد
مجوز
این اثر تحت مجوز عمومی Creative Commons Attribution 2.0 منتشر شده است.